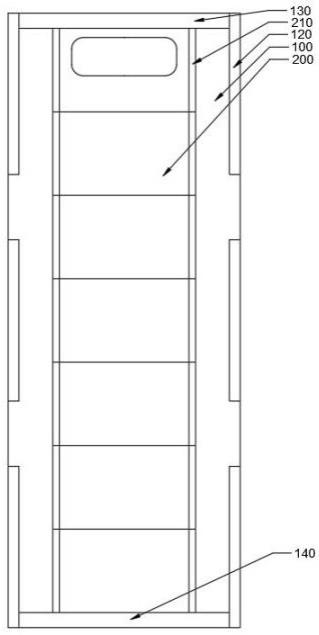
工程化抗her2双特异性蛋白
1.相关申请的交叉引用
2.本技术要求2020年2月19日提交的美国临时申请号62/978,758的优先权,所述临时申请的公开内容出于所有目的特此以引用的方式整体并入。
背景技术:
3.目前,治疗诸如乳腺癌等癌症的脑转移展现令人生畏的临床挑战。在乳腺癌患者中,脑转移的发生率高达50%。临床数据表明her2阳性乳腺癌有转移至脑中的倾向。值得注意的是,抗her2疗法已被证明可用于控制颅外肿瘤,但不能用于控制颅内病变。这些疗法未能控制转移性病变,诸如her2阳性乳腺癌的脑转移,主要归因于治疗剂无法穿过血脑屏障(bbb)并进入脑实质。
技术实现要素:
4.在一方面,本公开提供了一种蛋白质,其包含:
5.(a)第一fc多肽,其在n端融合至fab的fd部分;
6.(b)第二fc多肽,其在n端融合至单链可变片段(scfv),其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
7.(c)轻链多肽,其与(a)中所述的fd部分配对以形成fab,
8.其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。在一些实施方案中,fab结合至人her2的亚结构域ii并且scfv结合至人her2的亚结构域iv。在其他实施方案中,fab结合至人her2的亚结构域iv并且scfv结合至人her2的亚结构域ii。
9.在此蛋白质的一些实施方案中,第二fc多肽通过第一接头融合至scfv。第一接头的长度可以为1至20个氨基酸,例如ggggsggggs(seq id no:118)。
10.在此蛋白质的一些实施方案中,scfv包含通过第二接头连接的v
l
区和vh区。第二接头的长度可以为1至20个氨基酸,例如,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
11.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽特异性结合至转铁蛋白受体(例如,含有本文所述的产生tfr结合位点的序列修饰中的任一种)。在一些实施方案中,第一fc多肽和第二fc多肽各自包含促进异二聚化的修饰。在某些实施方案中,根据eu编号,第一fc多肽包含t366w取代,并且第二fc多肽包含t366s、l368a和y407v取代。在其他实施方案中,根据eu编号,第一fc多肽包含t366s、l368a和y407v取代,并且第二fc多肽包含t366w取代。在一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含降低效应子功能
的修饰。在某些实施方案中,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。
12.在此蛋白质的一些实施方案中,铰链区或其一部分连接至第一fc多肽和/或第二fc多肽的n端。
13.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自由seq id no:131-149组成的组的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在特定实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
14.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
15.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
16.在此蛋白质的其他实施方案中,根据eu编号,第一fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
17.在此蛋白质的一些实施方案中,
18.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:21的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
19.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:20的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、
96%、97%、98%、99%或100%)同一性的序列;或者
20.(iii)(a)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:19的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
21.(iv)(a)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:18的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
22.(v)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:15或17的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
23.(vi)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:14的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
24.(vii)(a)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:13的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
25.(viii)(a)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:11或12的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
26.(ix)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:22的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
27.(x)(a)包含与seq id no:5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:18的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序
列,并且(c)包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
28.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
29.在另一方面,本公开涉及一种蛋白质,其包含:
30.(a)第一fc多肽,其在n端融合至fab的fd部分;
31.(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
32.(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
33.其中所述第一fc多肽和/或所述第二fc多肽在c端融合至scfv,或者
34.其中(a)和/或(b)中的所述fd部分在n端融合至scfv,或者
35.其中所述第一fc多肽或所述第二fc多肽在c端融合至scfv并且(a)或(b)中的所述fd部分在n端融合至scfv,并且
36.其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。在一些实施方案中,第一fc多肽和/或第二fc多肽在c端融合至scfv。在一些实施方案中,(a)和/或(b)中的fd部分在n端融合至scfv。
37.在此蛋白质的一些实施方案中,第一fc多肽或第二fc多肽在c端融合至scfv,并且(a)或(b)中的fd部分在n端融合至scfv。
38.在此蛋白质的一些实施方案中,fab结合至人her2的亚结构域ii并且scfv结合至人her2的亚结构域iv。在其他实施方案中,fab结合至人her2的亚结构域iv并且scfv结合至人her2的亚结构域ii。
39.在此蛋白质的一些实施方案中,融合至第一fc多肽和/或第二fc多肽的scfv包含相同的序列。在其他实施方案中,融合至(a)和/或(b)中的fd部分的scfv包含相同的序列。
40.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽通过第一接头融合至scfv。在一些实施方案中,(a)和/或(b)中的fd部分通过第一接头融合至scfv。在某些实施方案中,第一接头的长度为1至20个氨基酸,例如,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
41.在此蛋白质的一些实施方案中,scfv包含通过第二接头连接的v
l
区和vh区。在一些实施方案中,第二接头的长度为1至20个氨基酸,例如,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
42.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽特异性结合至转铁
蛋白受体(例如,含有本文所述的产生tfr结合位点的序列修饰中的任一种)。在一些实施方案中,第一fc多肽和第二fc多肽各自包含促进异二聚化的修饰。在某些实施方案中,根据eu编号,第一fc多肽包含t366w取代,并且第二fc多肽包含t366s、l368a和y407v取代。在其他实施方案中,根据eu编号,第一fc多肽包含t366s、l368a和y407v取代,并且第二fc多肽包含t366w取代。在一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含降低效应子功能的修饰。在某些实施方案中,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在一些实施方案中,铰链区或其一部分连接至第一fc多肽和/或第二fc多肽的n端。在某些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自由seq id no:131-149组成的组的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在特定实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
43.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
44.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
45.在此蛋白质的其他实施方案中,根据eu编号,第一fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
46.在此蛋白质的一些实施方案中,
47.(i)(a)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
48.(ii)(a)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
49.(iii)(a)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
50.(iv)(a)包含与seq id no:31的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
51.(v)(a)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
52.(vi)(a)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
53.(vii)(a)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
54.(viii)(a)包含与seq id no:37或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
55.(ix)(a)包含与seq id no:37的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,
并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
56.(x)(a)包含与seq id no:157的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
57.在此蛋白质的一些实施方案中,
58.(i)(a)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:31的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
59.(ii)(a)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
60.(iii)(a)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:37或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
61.(iv)(a)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
62.(v)(a)包含与seq id no:33的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:38的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
63.在此蛋白质的一些实施方案中,
64.(i)(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,
91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
65.(ii)(a)包含与seq id no:41的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
66.(iii)(a)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
67.(iv)(a)包含与seq id no:43的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
68.(v)(a)包含与seq id no:45或46的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
69.(vi)(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
70.(vii)(a)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
71.(viii)(a)包含与seq id no:49的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
72.(ix)(a)包含与seq id no:44的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,
并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
73.(x)(a)包含与seq id no:50的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
74.(xi)(a)包含与seq id no:156的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
75.在此蛋白质的一些实施方案中,
76.(i)(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:43的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
77.(ii)(a)包含与seq id no:41的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
78.(iii)(a)包含与seq id no:45的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:49的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
79.(iv)(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
80.(v)(a)包含与seq id no:45的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:50的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
81.(vi)(a)包含与seq id no:46的序列具有至少90%(例如,91%、92%、93%、94%、
95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:156的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
82.在此蛋白质的一些实施方案中,第一fc多肽或第二fc多肽在c端融合至scfv,并且(a)或(b)中的fd部分在n端融合至scfv,并且其中:
83.(i)(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:31的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
84.(ii)(a)包含与seq id no:41的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
85.(iii)(a)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
86.(iv)(a)包含与seq id no:43的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
87.(v)(a)包含与seq id no:45的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:37或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
88.(vi)(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
89.(vii)(a)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性
的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
90.(viii)(a)包含与seq id no:49的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
91.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
92.在另一方面,本公开提供一种蛋白质,其包含:
93.(a)第一fc多肽,其在n端融合至fab的fd部分;
94.(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
95.(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
96.其中一个或两个所述轻链多肽在n端融合至scfv,或者
97.其中一个或两个所述轻链多肽在c端融合至scfv,或者
98.其中第一轻链多肽在n端融合至scfv,并且第二轻链多肽在c端融合至scfv,并且
99.其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。
100.在此蛋白质的一些实施方案中,一个或两个轻链多肽在n端融合至scfv。在一些实施方案中,一个或两个轻链多肽在c端融合至scfv。
101.在此蛋白质的一些实施方案中,第一轻链多肽在n端融合至scfv,并且第二轻链多肽在c端融合至scfv。
102.在此蛋白质的一些实施方案中,fab结合至人her2的亚结构域ii并且scfv结合至人her2的亚结构域iv。在一些实施方案中,fab结合至人her2的亚结构域iv并且scfv结合至人her2的亚结构域ii。
103.在此蛋白质的一些实施方案中,融合至一个或两个轻链多肽的scfv包含相同的序列。
104.在此蛋白质的一些实施方案中,一个或两个轻链多肽通过第一接头融合至scfv。在一些实施方案中,第一接头的长度为1至20个氨基酸,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
105.在此蛋白质的一些实施方案中,scfv包含通过第二接头连接的v
l
区和vh区。在一些实施方案中,第二接头的长度为1至20个氨基酸,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、
ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
106.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽特异性结合至转铁蛋白受体(例如,含有本文所述的产生tfr结合位点的序列修饰中的任一种)。在一些实施方案中,第一fc多肽和第二fc多肽各自包含促进异二聚化的修饰。在某些实施方案中,根据eu编号,第一fc多肽包含t366w取代,并且第二fc多肽包含t366s、l368a和y407v取代。在某些实施方案中,根据eu编号,第一fc多肽包含t366s、l368a和y407v取代,并且第二fc多肽包含t366w取代。在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含降低效应子功能的修饰。在一些实施方案中,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。
107.在此蛋白质的一些实施方案中,铰链区或其一部分连接至第一fc多肽和/或第二fc多肽的n端。
108.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自由seq id no:131-149组成的组的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在特定实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
109.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
110.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
111.在此蛋白质的其他实施方案中,根据eu编号,第一fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
112.在此蛋白质的一些实施方案中,
113.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
114.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
115.(iii)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
116.(iv)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
117.在此蛋白质的一些实施方案中,
118.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
119.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,
并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
120.(iii)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
121.(iv)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
122.在此蛋白质的一些实施方案中,
123.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
124.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
125.(iii)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
126.(iv)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至
少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
127.在此蛋白质的一些实施方案中,
128.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
129.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
130.(iii)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
131.(iv)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
132.在此蛋白质的一些实施方案中,
133.(i)(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
134.(ii)(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、
95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
135.(iii)(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
136.(iv)(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
137.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
138.在另一方面,本公开提供一种蛋白质,其包含:
139.(a)第一fc多肽,其在n端融合至fab的fd部分;
140.(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
141.(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
142.其中(a)和(b)中的所述fd部分中的每一个在n端融合至fv片段的vh区或v
l
区,并且
143.其中所述两个轻链多肽中的每一个在n端融合至所述fv片段的vh区或v
l
区中的另一个,并且
144.其中所述vh区和所述v
l
区一起形成所述fv片段,并且
145.其中所述fab结合至人her2的亚结构域ii并且所述fv片段结合至人her2的亚结构域iv,或其中所述fab结合至人her2的亚结构域iv并且所述fv片段结合至人her2的亚结构域ii。
146.在此蛋白质的一些实施方案中,fab结合至人her2的亚结构域ii并且fv片段结合至人her2的亚结构域iv。在一些实施方案中,fab结合至人her2的亚结构域iv并且fv片段结合至人her2的亚结构域ii。
147.在此蛋白质的一些实施方案中,(a)和(b)中的fd部分中的每一个在n端通过第一接头融合至vh区或v
l
区。在一些实施方案中,第一接头的长度为1至20个氨基酸,例如astkgpsvf(seq id no:125)的序列。
148.在此蛋白质的一些实施方案中,两个轻链多肽中的每一个在n端通过第二接头融合至vh区或v
l
区。在一些实施方案中,第二接头的长度为1至20个氨基酸,例如rtvaapsvfi(seq id no:126)的序列。
149.在此蛋白质的一些实施方案中,(a)和(b)中的fd部分中的每一个在n端融合至fv片段的vh区,并且两个轻链多肽中的每一个在n端融合至fv片段的v
l
区。
150.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽特异性结合至转铁蛋白受体(例如,含有本文所述的产生tfr结合位点的序列修饰中的任一种)。在一些实施方案中,第一fc多肽和第二fc多肽各自包含促进异二聚化的修饰。在一些实施方案中,根据eu编号,第一fc多肽包含t366w取代,并且第二fc多肽包含t366s、l368a和y407v取代。在其他实施方案中,根据eu编号,第一fc多肽包含t366s、l368a和y407v取代,并且第二fc多肽包含t366w取代。在一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含降低效应子功能的修饰。在特定实施方案中,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。
151.在此蛋白质的一些实施方案中,铰链区或其一部分连接至第一fc多肽和/或第二fc多肽的n端。
152.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自由seq id no:131-149组成的组的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在特定实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
153.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
154.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
155.在此蛋白质的其他实施方案中,根据eu编号,第一fc多肽包含在位置366处的ser、
在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
156.在此蛋白质的一些实施方案中,
157.(i)第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:58的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:61的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:78的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
158.(ii)第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:59的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:60的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:78的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
159.(iii)第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:63的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:66的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:79的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
160.(iv)第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:64的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:65的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:79的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
161.(v)第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:63的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:67的序列
具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:79的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
162.在此蛋白质的一些实施方案中,
163.(i)第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:68的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:71的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:80的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
164.(ii)第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:69的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:70的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:80的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
165.(iii)第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:73的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:76的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:81的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
166.(iv)第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:74的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:75的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:81的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
167.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在其他实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
168.在另一方面,本公开提供一种蛋白质,其包含:
169.(a)第一fc多肽,其在n端融合至fab的fd部分,并且在c端融合至fv片段的vh区或v
l
区;
170.(b)第二fc多肽,其在n端融合至fab的fd部分,并且在c端融合至(a)中所述的vh区或v
l
区中的另一个,
171.其中所述vh区和所述v
l
区一起形成所述fv片段,并且其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
172.(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
173.其中所述fab结合至人her2的亚结构域ii并且所述fv片段结合至人her2的亚结构域iv,或其中所述fab结合至人her2的亚结构域iv并且所述fv片段结合至人her2的亚结构域ii。在一些实施方案中,fab结合至人her2的亚结构域ii并且fv片段结合至人her2的亚结构域iv。在一些实施方案中,fab结合至人her2的亚结构域iv并且fv片段结合至人her2的亚结构域ii。
174.在此蛋白质的一些实施方案中,第一fc多肽融合至fv片段的vh区,并且第二fc多肽融合至fv片段的v
l
区。在一些实施方案中,第一fc多肽融合至fv片段的v
l
区,并且第二fc多肽融合至fv片段的vh区。在一些实施方案中,第一fc多肽和/或第二fc多肽在c端通过第一接头融合至vh区或v
l
区。
175.在此蛋白质的一些实施方案中,第一接头的长度为1至20个氨基酸,例如,以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
176.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽特异性结合至转铁蛋白受体(例如,含有本文所述的产生tfr结合位点的序列修饰中的任一种)。在一些实施方案中,第一fc多肽和第二fc多肽各自包含促进异二聚化的修饰。在一些实施方案中,根据eu编号,第一fc多肽包含t366w取代,并且第二fc多肽包含t366s、l368a和y407v取代。在其他实施方案中,根据eu编号,第一fc多肽包含t366s、l368a和y407v取代,并且第二fc多肽包含t366w取代。在一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含降低效应子功能的修饰。在某些实施方案中,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。
177.在此蛋白质的一些实施方案中,铰链区或其一部分连接至第一fc多肽和/或第二fc多肽的n端。
178.在此蛋白质的一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自由seq id no:131-149组成的组的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在一些实施方案中,第一fc多肽和/或第二fc多肽独立地包含与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
179.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
180.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234处的ala、
在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
181.在此蛋白质的其他实施方案中,根据eu编号,第一fc多肽包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且根据eu编号,第二fc多肽包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
182.在此蛋白质的一些实施方案中,
183.(i)(a)包含与seq id no:82或83的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:99或100的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
184.(ii)(a)包含与seq id no:84的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:98的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
185.(iii)(a)包含与seq id no:85的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:97的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
186.(iv)(a)包含与seq id no:86或88的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:95或96的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
187.(v)(a)包含与seq id no:89或90的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:105或107
的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
188.(vi)(a)包含与seq id no:91的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:104的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
189.(vii)(a)包含与seq id no:92的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:103的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
190.(viii)(a)包含与seq id no:93的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:102的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
191.(ix)(a)包含与seq id no:82的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:99的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
192.(x)(a)包含与seq id no:82的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:100的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
193.(xi)(a)包含与seq id no:90的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:107的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;或者
194.(xii}(a)包含与seq id no:90的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:158的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
195.在此蛋白质的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在其他实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
196.在本公开的另一方面,本公开提供了一种药物组合物,其包含本文所述的蛋白质中的任一种和药学上可接受的载剂。
197.在本公开的另一方面,本公开提供了一种分离的多核苷酸,其包含编码本文所述的蛋白质的核苷酸序列。
198.在本公开的另一方面,本公开提供了一种载体,其包含先前方面的多核苷酸。
199.在本公开的另一方面,本公开提供了一种宿主细胞,其包含多核苷酸或载体。
200.在本公开的另一方面,本公开提供了一种用于治疗受试者的癌症或治疗受试者的癌症脑转移的方法,所述方法包括向受试者施用治疗有效量的本文所述的蛋白质或含有其的药物组合物。
201.在所述方法的一些实施方案中,蛋白质与化学疗法或放射疗法组合施用。
202.在所述方法的一些实施方案中,癌症是转移性癌症。在一些实施方案中,癌症是乳腺癌。在一些实施方案中,癌症是her2阳性癌症。
附图说明
203.图1a是示出具有“fab-fc多肽/scfv-fc多肽”结构的示例性双特异性蛋白的示意图,其中scfv通过铰链或部分铰链区融合至具有tfr结合位点(星号)和杵突变的fc多肽的n端,而另一个fc多肽具有臼突变。
204.图1b是示出具有“fab-fc多肽/scfv-fc多肽”结构的示例性双特异性蛋白的示意图,其中scfv通过铰链或部分铰链区融合至具有臼突变的fc多肽的n端,而另一个fc多肽具有tfr结合位点(星号)和杵突变。
205.图2a是示出具有“mab/n端或c端scfv在hc上”结构的示例性双特异性蛋白的示意图,其中scfv融合至具有臼突变的fc多肽的c端,而另一个fc多肽具有tfr结合位点(星号)和杵突变。
206.图2b是示出具有“mab/n端或c端scfv在hc上”结构的示例性双特异性蛋白的示意图,其中scfv通过接头融合至fd部分的n端。scfv融合至含有具有臼突变的fc多肽的重链fd部分,而另一个fc多肽具有tfr结合位点(星号)和杵突变。
207.图2c是示出具有“mab/n端或c端scfv在hc上”结构的示例性双特异性蛋白的示意图,其中两个scfv各自通过接头融合至重链fd部分的n端。fc多肽上的tfr结合位点用星号表示。
208.图2d是示出具有“mab/n端或c端scfv在hc上”结构的示例性双特异性蛋白的示意图,其中两个scfv各自通过接头融合至重链fc多肽的c端。fc多肽上的tfr结合位点用星号表示。
209.图3a是示出具有“mab/n端或c端scfv在lc上”结构的示例性双特异性蛋白的示意图,其中scfv通过接头融合至轻链的c端。fc多肽上的tfr结合位点用星号表示。
210.图3b是示出具有“mab/n端或c端scfv在lc上”结构的示例性双特异性蛋白的示意图,其中scfv通过接头融合至轻链的n端。fc多肽上的tfr结合位点用星号表示。
211.图3c是示出具有“mab/n端或c端scfv在lc上”结构的示例性双特异性蛋白的示意图,其中两个scfv各自通过接头融合至轻链的n端。fc多肽上的tfr结合位点用星号表示。
212.图3d是示出具有“mab/n端或c端scfv在lc上”结构的示例性双特异性蛋白的示意图,其中两个scfv各自通过接头融合至轻链的c端。fc多肽上的tfr结合位点用星号表示。
213.图4是示出具有“mab/n端v
h v
l
在hc和lc上”结构的示例性双特异性蛋白的示意图,其中两个vh区各自融合至重链fd部分的n端并且两个v
l
区各自融合至轻链的n端。vh区和v
l
区形成fv片段。fc多肽上的tfr结合位点用星号表示。
214.图5是示出具有“mab/c端v
h v
l
在hc上”结构的示例性双特异性蛋白的示意图,其中vh区融合至具有臼突变的fc多肽的c端并且v
l
区融合至具有tfr结合位点(星号)和杵突变的fc多肽的c端。vh区和v
l
区形成fv片段。
215.图6a和图6b分别示出具有“fab-fc多肽/scfv-fc多肽”结构的双特异性蛋白在bt474和oe19细胞的生长抑制测定中,在第6天和第3天对癌细胞增殖的抑制。
216.图7是示出c57/bl6小鼠中抗her2双特异性蛋白和抗her2对照的血浆pk曲线的图。
217.图8a是示出静脉内施用抗her2双特异性蛋白或抗her2对照的tfr
mu/hu ki小鼠中的网状红细胞定量的图。
218.图8b是示出tfr
mu/hu ki小鼠中抗her2双特异性蛋白和抗her2对照的血浆pk曲线的图。
219.图8c是示出tfr
mu/hu ki小鼠中抗her2双特异性蛋白和抗her2对照的脑pk曲线的图。
220.图8d是示出tfr
mu/hu ki小鼠中抗her2双特异性蛋白和抗her2对照的脑-血浆浓度百分比的图。
221.图9a-图9f示出在有(图9a-图9c)或没有(图9d-图9f)nrg1的情况下,抗her2双特异性蛋白和抗her2对照对bt474细胞的生长抑制测定。
222.图9g-图9i示出抗her2双特异性蛋白和抗her2对照对oe19细胞的生长抑制测定。
223.图9j-图9l示出抗her2双特异性蛋白和抗her2对照对zr75细胞的生长抑制测定。
具体实施方式
224.i.引言
225.在一方面,提供了可以结合至人her2的亚结构域ii和人her2的亚结构域iv的双特异性蛋白。一般来说,可以在没有轻链错配或转向的情况下生成双特异性蛋白。在一些实施方案中,双特异性蛋白单价结合至人her2的每个靶亚结构域。在一些实施方案中,双特异性蛋白单价结合至人her2的一个靶亚结构域并且二价结合至人her2的另一个靶亚结构域(例如,单价结合至亚结构域ii并且二价结合至亚结构域iv,或者单价结合至亚结构域iv并且二价结合至亚结构域ii)。在一些实施方案中,双特异性蛋白二价结合至人her2的每个靶亚结构域。本文进一步详细描述了双特异性蛋白的各种结构。
226.在一些实施方案中,双特异性蛋白包含结合至人her2的亚结构域ii(或亚结构域iv)的scfv和结合至人her2的亚结构域iv(或亚结构域ii)的fab(参见例如第iii部分中的“fab-fc多肽/scfv-fc多肽”结构)。在一些实施方案中,双特异性蛋白包含一个或多个连接至所述双特异性蛋白的重链n端或c端的scfv,其中所述scfv结合至人her2的亚结构域ii
(或亚结构域iv),并且双特异性蛋白中的fab结合至人her2的亚结构域iv(或亚结构域ii)(参见例如第iii部分中的“mab/n端或c端scfv在hc上”结构)。在一些实施方案中,双特异性蛋白包含一个或多个连接至所述双特异性蛋白的轻链n端或c端的scfv,其中所述scfv结合至人her2的亚结构域ii(或亚结构域iv),并且双特异性蛋白中的fab结合至人her2的亚结构域iv(或亚结构域ii)(参见例如第iii部分中的“mab/n端或c端scfv在hc上mab/n端或c端scfv在lc上”结构)。在一些实施方案中,双特异性蛋白包含连接至重链n端的fv片段的vh区(或v
l
区)和连接至轻链n端的fv片段的v
l
区(或vh区),其中fv片段结合至人her2的亚结构域ii(或亚结构域iv),并且双特异性蛋白中的fab结合至人her2的亚结构域iv(或亚结构域ii)(参见例如,第iii部分中的“mab/n端v
h v
l
在hc和lc上”结构)。在又其他实施方案中,双特异性蛋白包含连接至双特异性蛋白中两条重链中的一个的c端的fv片段的vh区(或v
l
区)和连接至两条重链中的另一个的c端的fv片段的v
l
区(或vh区),其中fv片段结合至人her2的亚结构域ii(或亚结构域iv),并且双特异性蛋白中的fab结合至人her2的亚结构域iv(或亚结构域ii)(参见例如第iii部分中的“mab/c端v
h v
l
在hc上”结构)。
227.先前的疗法未能控制her2阳性乳腺癌的脑转移,主要是因为治疗剂不能穿过血脑屏障(bbb)并进入脑实质。因此,需要可穿过bbb并靶向脑实质中的her2的新治疗剂。我们先前描述了使用转铁蛋白受体(tfr)结合作为使得能够跨脑内皮进行bbb递送的方法,因为tfr的表达在脑内皮细胞中高度表达,并且可以使得能够通过受体介导的转胞吞作用进行bbb递送。有趣的是,tfr在各种癌症中高度表达,包括her2阳性乳腺癌。癌细胞获得tfr表达增加的机制可能与肿瘤细胞增殖和增加的代谢需求(诸如铁摄取)有关。事实上,公共微阵列数据集表明了tfr表达与乳腺癌预后的相关性(miller等人,cancer res.71:6728,2011)。也有一些关于使用tfr作为各种类型癌症的药理学靶标的报道。
228.在一些实施方案中,双特异性蛋白包含一种或多种特异性结合至bbb受体的修饰的fc多肽,例如tfr(即,tfr结合fc多肽)。在一些实施方案中,双特异性蛋白能够穿过bbb转运。在一些实施方案中,与结合至单独her2的其他治疗剂相比,如本文所述的结合至her2和tfr两者的抗her2双特异性蛋白在结合至也表达高水平tfr的her2阳性肿瘤细胞时可提供额外的抗肿瘤益处。具体来说,由于这些蛋白质可同时结合tfr和her2,所以这可增强它们的效力和/或功效。
229.ii.定义
230.除非内容另外明确指出,否则如本文所用,单数形式“一个”、“一种”和“所述”包括多个指代物。因此,例如,对“一种抗体”的提及任选地包括两种或更多种此类分子的组合等等。
231.如本文所用,术语“约”和“大约”在用于修饰以数值或范围指定的量时表示该数值以及本领域技术人员已知的该值的合理偏差,例如
±
20%、
±
10%或
±
5%,在所述值的预期含义内。
232.如本文所用,术语“抗体”是指具有免疫球蛋白折叠的蛋白质,所述蛋白质通过其可变区与抗原特异性结合。该术语涵盖完整的多克隆抗体、完整的单克隆抗体、单链抗体、多特异性抗体诸如双特异性抗体、单特异性抗体、一价抗体、嵌合抗体、人源化抗体和人抗体。如本文所用,术语“抗体”还包括保留抗原结合特异性的抗体片段,包括但不限于fab、f(ab’)2、fv、scfv和二价scfv。抗体可含有分为κ或λ的轻链。抗体可含有分为γ、μ、α、δ或ε的
重链,其分别依次定义免疫球蛋白类别igg、igm、iga、igd和ige。
233.示例性免疫球蛋白(抗体)结构单元包含四聚体。每个四聚体由相同的两对多肽链构成,每一对具有一条“轻”链(约25kd)和一条“重”链(约50-70kd)。每条链的n端限定了主要负责抗原识别的约100至110或更多个氨基酸的可变区。术语“可变轻链”(v
l
)和“可变重链”(vh)分别是指这些轻链和重链。
234.术语“可变区”或“可变结构域”是指抗体重链或轻链中衍生自生殖系可变(v)基因、多样性(d)基因或连接(j)基因(而不是衍生自恒定(cμ和cδ)基因区段)并且赋予抗体结合至抗原的特异性的结构域。通常,抗体可变区包含四个保守的“框架”区,其间散布着三个高变的“互补决定区”。
235.术语“互补决定区”或“cdr”是指每条链中的三个高变区,其中断由轻链和重链可变区建立的四个框架区。cdr主要负责抗体结合至抗原的表位。每条链的cdr通常称为cdr1、cdr2和cdr3,从n端开始顺序编号,并且通常还由特定cdr所定位的链来标识。因此,v
h cdr3或cdr-h3位于其所存在的抗体的重链可变区中,而v
l cdr1或cdr-l1是来自其所存在的抗体的轻链可变区的cdr1。
236.不同轻链或重链的“框架区”或“fr”在物种内相对保守。抗体的框架区,即构成轻链和重链的组合框架区,用于在三维空间中定位和对齐cdr。框架序列可以从包括生殖系抗体基因序列的公共dna数据库或公布的参考文献获得。例如,可以在人和小鼠序列的“vbase2”生殖系可变基因序列数据库中找到人重链和轻链可变区基因的生殖系dna序列。
237.cdr和框架区的氨基酸序列可以使用本领域各种众所周知的定义进行确定,例如,kabat、chothia、国际immunogenetics数据库(imgt)、abm和观察到的抗原接触(“contact”)。在一些实施方案中,根据contact定义确定cdr。参见,maccallum等人,j.mol.biol.262:732-745,1996。在一些实施方案中,通过kabat、chothia和/或contact cdr定义的组合确定cdr。
238.术语“fd部分”是指免疫球蛋白重链的n端部分。通常,fd部分包括重链可变(vh)区和重链恒定(ch1)区。
239.术语“fab”是指由轻链可变区、轻链恒定区、重链可变区和重链ch1恒定区组成的抗原结合片段。
240.术语“单链可变片段”或“scfv”是指由通过肽接头连接在一起的重链可变区和轻链可变区组成的抗原结合片段。scfv缺少恒定区。
241.术语“fv片段”是指由一起形成抗原结合位点的重链可变区和轻链可变区组成的抗原结合片段。
242.术语“表位”是指分子(例如,抗体的cdr)特异性结合的抗原的区域或区,并且可包括几个氨基酸或几个氨基酸的部分,例如5或6或更多个,例如20或更多个氨基酸,或那些氨基酸的部分。在一些情况下,表位包括非蛋白质组分,例如来自碳水化合物、核酸或脂质。在一些情况下,表位是三维部分。因此,例如,在靶标是蛋白质的情况下,表位可包含连续氨基酸(例如,线性表位),或来自蛋白质的不同部分的因蛋白质折叠而邻近的氨基酸(例如,不连续或构象表位)。
243.如本文所用,关于抗体使用的短语“识别表位”意指抗体cdr在所述表位或含有所述表位的抗原的一部分上与抗原相互作用或特异性结合。
[0244]“人源化抗体”是衍生自非人来源(例如,鼠)的嵌合免疫球蛋白,其含有cdr之外的衍生自非人免疫球蛋白的最小序列。一般来说,人源化抗体将包含至少一个(例如,两个)可变结构域,其中cdr区基本上对应于非人免疫球蛋白的那些,并且框架区基本上对应于人免疫球蛋白序列的那些。在一些情况下,人免疫球蛋白的某些框架区残基可以替换为来自非人物种的对应残基,以例如改善特异性、亲和力和/或血清半衰期。人源化抗体还可以包含免疫球蛋白(通常为人免疫球蛋白序列)恒定区(fc)的至少一部分。抗体人源化的方法是本领域中已知的。
[0245]“人抗体”或“完全人抗体”是具有人重链和轻链序列的抗体,其通常衍生自人生殖系基因。在一些实施方案中,抗体通过人细胞,利用人抗体库通过非人动物(例如,基因工程化以表达人抗体序列的转基因小鼠)或通过噬菌体展示平台产生。
[0246]
术语“特异性结合”是指分子(例如,fab、scfv或修饰的fc多肽(或其靶标结合部分))结合至表位或靶标,其中与其与另一表位或非靶标化合物(例如,结构上不同的抗原)的结合相比,其与样品中的所述表位或靶标的结合具有更大的亲和力、更大的亲合力和/或更长的持续时间。在一些实施方案中,特异性结合至表位或靶标的fab、scfv或修饰的fc多肽(或其靶标结合部分)是以比其他表位或非靶标化合物高至少5倍的亲和力结合至所述表位或靶标的fab、scfv或修饰的fc多肽(或其靶标结合部分),例如,至少6倍、7倍、8倍、9倍、10倍、25倍、50倍、100倍、1000倍、10,000倍或更高的亲和力。如本文所用,术语“特异性结合”、“特异性结合至”特定表位或靶标或对于所述特定表位或靶标“具有特异性”可以例如通过对其所结合的表位或靶标具有例如10-4
m或更小,例如10-5
m、10-6
m、10-7
m、10-8
m、10-9
m、10-10
m、10-11
m或10-12
m的平衡解离常数kd的分子表现出来。技术人员将认识到,特异性结合至来自一种物种的靶标的fab或scfv也可特异性结合至该靶标的直系同源物。
[0247]
术语“结合亲和力”在本文用于指两个分子之间,例如fab或scfv与抗原之间,或修饰的fc多肽(或其靶标结合部分)与靶标之间的非共价相互作用的强度。因此,例如,除非上下文另外指出或清楚可知,否则该术语可指fab或scfv与抗原之间或修饰的fc多肽(或其靶标结合部分)与靶标之间的1:1相互作用。结合亲和力可通过测量平衡解离常数(kd)进行量化,所述平衡解离常数(kd)是指解离速率常数(kd,时间-1
)除以缔合速率常数(ka,时间-1
m-1
)。kd可通过测量复合物形成和解离的动力学进行确定,例如使用表面等离子体共振(spr)方法,例如biacore
tm
系统;动力学排除测定诸如以及biolayer干涉法(例如,使用octet平台)。如本文所用,“结合亲和力”不仅包括正式结合亲和力,诸如反映fab或scfv与抗原之间或修饰的fc多肽(或其靶标结合部分)与靶标之间的1:1相互作用的那些,而且还包括计算出的其kd可反映亲合结合的表观亲和力。
[0248]
如本文所用,“转铁蛋白受体”或“tfr”是指转铁蛋白受体蛋白1。人转铁蛋白受体1多肽序列在seq id no:150中列出。还已知来自其他物种的转铁蛋白受体蛋白1序列(例如,黑猩猩,登录号xp_003310238.1;恒河猴,np_001244232.1;狗,np_001003111.1;牛,np_001193506.1;小鼠,np_035768.1;大鼠,np_073203.1;以及鸡,np_990587.1)。术语“转铁蛋白受体”还涵盖示例性参考序列(例如人序列)的等位基因变体,其由转铁蛋白受体蛋白1染色体座位处的基因编码。全长转铁蛋白受体蛋白包括短的n端细胞内区域、跨膜区和大的细胞外结构域。细胞外结构域通过三个结构域表征:蛋白酶样结构域、螺旋结构域和顶端结构
域。
[0249]
如本文所用,术语“fc多肽”是指天然存在的免疫球蛋白重链多肽的c端区域,其通过为结构域形式的ig折叠表征。fc多肽含有恒定区序列,所述恒定区序列包括至少ch2结构域和/或ch3结构域,并且可含有至少部分铰链区,但不含可变区。
[0250]“修饰的fc多肽”是指与野生型免疫球蛋白重链fc多肽序列相比具有至少一个突变,例如取代、缺失或插入,但保留天然fc多肽的总体ig折叠或结构的fc多肽。
[0251]
如本文所用,“fcrn”是指新生儿fc受体。fc多肽与fcrn的结合降低清除率并增加fc多肽的血清半衰期。人fcrn蛋白是异源二聚体,其由与主要组织相容性(mhc)i类蛋白类似的大小为约50kda的蛋白质和大小为约15kda的β2-微球蛋白组成。
[0252]
如本文所用,“fcrn结合位点”是指fc多肽的结合至fcrn的区域。在人igg中,如使用eu索引所编号,fcrn结合位点包括l251、m252、i253、s254、r255、t256、m428、h433、n434、h435和y436。这些位置对应于seq id no:130的位置21至26、198和203至206。
[0253]
如本文所用,“天然fcrn结合位点”是指fc多肽的结合至fcrn的区域,并且所述区域具有与天然存在的fc多肽的结合至fcrn的区域相同的氨基酸序列。
[0254]
如本文所用,术语“ch3结构域”和“ch2结构域”是指免疫球蛋白恒定区结构域多肽。出于本技术的目的,ch3结构域多肽是指如根据eu编号方案所编号的从约位置341至约位置447的氨基酸的区段,并且ch2结构域多肽是指如根据eu编号方案所编号的从约位置231至约位置340的氨基酸的区段并且不包括铰链区序列。根据imgt scientific图表编号(imgt网站),ch2和ch3结构域多肽也可通过imgt(immunogenetics)编号方案进行编号,其中ch2结构域编号为1-110并且ch3结构域编号为1-107。ch2和ch3结构域是免疫球蛋白的fc区的部分。fc区是指如根据eu编号方案所编号的从约位置231至约位置447的氨基酸的区段,但是如本文所用,可以包括抗体的铰链区的至少一部分。例示性的铰链区序列是人igg1铰链序列epkscdkthtcppcp(seq id no:127)。
[0255]
如关于ch3或ch2结构域所用的术语“野生型”、“天然”和“天然存在的”是指具有天然存在的序列的结构域。
[0256]
如本文所用,如关于突变多肽或突变多核苷酸所用的术语“突变”与“变异”可互换使用。相对于给定的野生型ch3或ch2结构域参考序列的变体可以包括天然存在的等位基因变体。“非天然”存在的ch3或ch2结构域是指在自然界的细胞中不存在并且通过天然ch3结构域或ch2结构域多核苷酸或多肽的基因修饰(例如,使用基因工程化技术或诱变技术)产生的变异或突变结构域。“变体”包括相对于野生型包含至少一个氨基酸突变的任何结构域。突变可包括取代、插入和缺失。
[0257]
如关于核酸或蛋白质所用的术语“分离”表示核酸或蛋白质基本上不含在天然状态中与其缔合的其他细胞组分。它优选处于均质状态。纯度和均匀性通常使用分析化学技术诸如电泳(例如,聚丙烯酰胺凝胶电泳)或色谱(例如,高效液相色谱)确定。在一些实施方案中,分离的核酸或蛋白质为至少85%纯、至少90%纯、至少95%纯或至少99%纯。
[0258]
术语“氨基酸”是指天然存在的和合成的氨基酸,以及以类似于天然存在的氨基酸的方式起作用的氨基酸类似物和氨基酸模拟物。天然存在的是由遗传密码编码的那些,以及后期修饰的那些氨基酸,例如,羟基脯氨酸、γ-羧基谷氨酸和o-磷酸丝氨酸。天然存在的α-氨基酸包括但不限于丙氨酸(ala)、半胱氨酸(cys)、天冬氨酸(asp)、谷氨酸(glu)、苯丙
氨酸(phe)、甘氨酸(gly)、组氨酸(his)、异亮氨酸(ile)、精氨酸(arg)、赖氨酸(lys)、亮氨酸(leu)、甲硫氨酸(met)、天冬酰胺(asn)、脯氨酸(pro)、谷氨酰胺(gln)、丝氨酸(ser)、苏氨酸(thr)、缬氨酸(val)、色氨酸(trp)、酪氨酸(tyr)及其组合。天然存在的α-氨基酸的立体异构体包括但不限于d-丙氨酸(d-ala)、d-半胱氨酸(d-cys)、d-天冬氨酸(d-asp)、d-谷氨酸(d-glu)、d-苯丙氨酸(d-phe)、d-组氨酸(d-his)、d-异亮氨酸(d-ile)、d-精氨酸(d-arg)、d-赖氨酸(d-lys)、d-亮氨酸(d-leu)、d-甲硫氨酸(d-met)、d-天冬酰胺(d-asn)、d-脯氨酸(d-pro)、d-谷氨酰胺(d-gln)、d-丝氨酸(d-ser)、d-苏氨酸(d-thr)、d-缬氨酸(d-val)、d-色氨酸(d-trp)、d-酪氨酸(d-tyr)及其组合。“氨基酸类似物”是指与天然存在的氨基酸具有相同的基本化学结构的化合物,即,结合至氢、羧基、氨基和r基团的α碳,例如,高丝氨酸、正亮氨酸、甲硫氨酸亚砜、甲硫氨酸甲基锍。此类类似物具有修饰的r基团(例如,正亮氨酸)或修饰的肽骨架,但保留了与天然存在的氨基酸相同的基本化学结构。“氨基酸模拟物”是指具有不同于氨基酸的一般化学结构的结构、但以类似于天然存在的氨基酸的方式起作用的化合物。氨基酸可在本文中由其通常已知的三字母符号或由iupac-iub生物化学命名委员会推荐的单字母符号来表示。
[0259]
术语“多肽”和“肽”在本文可互换用于指单链形式的氨基酸残基的聚合物。该术语应用于其中一个或多个氨基酸残基是对应的天然存在的氨基酸的人工化学模拟物的氨基酸聚合物,以及天然存在的氨基酸聚合物和非天然存在的氨基酸聚合物。氨基酸聚合物可包含完全l-氨基酸、完全d-氨基酸,或l和d氨基酸的混合物。
[0260]
如本文所用,术语“蛋白质”是指多肽或单链多肽的二聚体(即两个)或多聚体(即三个或更多个)。蛋白质的单链多肽可通过共价键(例如,二硫键)或非共价相互作用接合。
[0261]
如本文所用,术语“接头”是指连接(例如共价连接)两个肽或多肽(例如,在fc多肽与scfv之间)以连接或融合肽或多肽的部分。在一些实施方案中,接头包含化学键联。在一些实施方案中,接头包含长度为一个或多个氨基酸残基的肽。可基于接头的性质,诸如接头的长度、疏水性、柔性、刚性或可切割性来选择用于连接或融合肽或多肽的合适接头。
[0262]
术语“多核苷酸”和“核酸”可互换地指任何长度的核苷酸链,并且包括dna和rna。核苷酸可以是脱氧核糖核苷酸、核糖核苷酸、修饰的核苷酸或碱基和/或它们的类似物,或可以通过dna或rna聚合酶并入链中的任何基质。多核苷酸可包含修饰核苷酸,诸如甲基化核苷酸及其类似物。本文设想的多核苷酸的实例包括单链和双链dna、单链和双链rna,以及具有单链和双链dna和rna的混合物的杂交体分子。
[0263]
术语“保守取代”和“保守突变”是指导致氨基酸被可以分类为具有相似特征的另一氨基酸取代的改变。以此方式定义的保守氨基酸组的类别的实例可以包括:“带电/极性组”,包括glu(谷氨酸或e)、asp(天冬氨酸或d)、asn(天冬酰胺或n)、gln(谷氨酰胺或q)、lys(赖氨酸或k)、arg(精氨酸或r)和his(组氨酸或h);“芳族组”,包括phe(苯丙氨酸或f)、tyr(酪氨酸或y)、trp(色氨酸或w)和(组氨酸或h);以及“脂族组”,包括gly(甘氨酸或g)、ala(丙氨酸或a)、val(缬氨酸或v)、leu(亮氨酸或l)、ile(异亮氨酸或i)、met(甲硫氨酸或m)、ser(丝氨酸或s)、thr(苏氨酸或t)和cys(半胱氨酸或c)。在每个组内,还可以鉴定亚组。例如,带电或极性氨基酸的组可细分为亚组,包括:包括lys、arg和his的“带正电的亚组”;包括glu和asp的“带负电的亚组”;以及包括asn和gln的“极性亚组”。在另一实例中,芳族或环状组可细分为亚组,包括:包括pro、his和trp的“氮环亚组”;以及包括phe和tyr的“苯基亚
组”。在另一进一步实例中,脂族组可细分为亚组,例如,包括val、leu、gly和ala的“脂族非极性亚组”;以及包括met、ser、thr和cys的“脂族弱极性亚组”。保守突变的类别的实例包括以上亚组内的氨基酸的氨基酸取代,诸如但不限于:lys取代arg或反之亦然,使得可以保持正电荷;glu取代asp或反之亦然,使得可以保持负电荷;ser取代thr或反之亦然,使得可以保持游离-oh;以及gln取代asn或反之亦然,使得可以保持游离-nh2。在一些实施方案中,用疏水氨基酸取代例如活性位点中的天然存在的疏水氨基酸,以保持疏水性。
[0264]
在两个或更多个多肽序列的上下文中,术语“同一性”或百分比“同一性”是指当如使用序列比较算法或通过人工比对和目视检查所测量比较和比对在比较窗口或指定区域上的最大对应性时,两个或更多个序列或子序列在特定区域上是相同的或具有特定百分比的相同氨基酸残基(例如,至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%或至少95%或更大)。
[0265]
对于多肽的序列比较,通常一个氨基酸序列充当参考序列,将其与候选序列比较。可以使用本领域技术人员可获得的各种方法进行比对,例如,目视比对或使用利用已知算法的公开可获得的软件,以实现最大比对。此类程序包括blast程序、align、align-2(genentech,south san francisco,calif.)或megalign(dnastar)。用于比对以实现最大对齐的参数可由本领域技术人员确定。出于本技术的目的,对于多肽序列的序列比较,使用了用于利用默认参数对两个蛋白质序列进行比对的blastp算法标准蛋白质blast。
[0266]
当在多肽序列中的给定氨基酸残基的鉴定的上下文中使用时,术语“对应于”、“参考......确定”或“参考......编号”是指在将给定氨基酸序列与参考序列进行最大程度的比对和比较时指定参考序列的残基的位置。因此,例如,当在与seq id no:130最佳比对时残基与seq id no:130中的氨基酸对齐时,修饰fc多肽中的氨基酸残基“对应于”seq id no:130中的氨基酸。与参考序列比对的多肽不必与参考序列具有相同的长度。
[0267]
如本文可互换使用的术语“受试者”、“个体”和“患者”是指哺乳动物,包括但不限于人、非人灵长类动物、啮齿动物(例如,大鼠、小鼠和豚鼠)、兔、牛、猪、马和其他哺乳动物物种。在一个实施方案中,患者为人。
[0268]
本文中术语“治疗(treatment)”、“治疗(treating)”等一般用于意指获得所需药理作用和/或生理作用。“治疗(treating)”或“治疗(treatment)”可指成功治疗或改善神经变性疾病(例如,阿尔茨海默病或本文所述的另一神经变性疾病)的任何指标,包括任何客观或主观参数,诸如消减、缓解、患者生存的改善、生存时间或生存率的增加、症状的减轻或使患者更耐受该疾病、退化或衰退速率的减缓,或患者身心健康的改善。症状的治疗或缓解可以基于客观或主观参数。可以将治疗的效果与未接受治疗的一个个体或一组个体进行比较,或与治疗前或治疗期间不同时间的同一患者进行比较。
[0269]
术语“药学上可接受的赋形剂”是指在生物学或药理学上相容以用于人或动物的非活性药物成分,诸如但不限于缓冲剂、载剂或防腐剂。
[0270]
如本文所用,剂的“治疗量”或“治疗有效量”是治疗受试者的疾病的所述剂(例如本文所述的任何蛋白质)的量。
[0271]
术语“施用”是指将剂、化合物或组合物递送至所需生物作用部位的方法。这些方法包括但不限于局部递送、肠胃外递送、静脉内递送、皮内递送、肌内递送、鞘内递送、结肠递送、直肠递送或腹膜内递送。在一个实施方案中,静脉内施用如本文所述的蛋白质。
[0272]
iii.抗her2双特异性蛋白
[0273]
在一方面,提供了能够特异性结合至人her2的亚结构域ii和人her2的亚结构域iv的双特异性蛋白。在一些实施方案中,双特异性蛋白的一个或两个fc多肽是修饰的fc多肽(例如,经修饰以促进tfr结合和/或增强fc多肽的异二聚化)。
[0274]
fab-fc多肽/scfv-fc多肽
[0275]
在一些实施方案中,双特异性蛋白包含融合至fab的一部分和scfv的fc多肽。这种双特异性蛋白的示意图在图1a和图1b中示出。在一些实施方案中,所述双特异性蛋白包含:
[0276]
(a)第一fc多肽,其在n端融合至fab的fd部分;
[0277]
(b)第二fc多肽,其在n端融合至单链可变片段(scfv),其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
[0278]
(c)轻链多肽,其与(a)中所述的fd部分配对以形成fab,
[0279]
其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。在一些实施方案中,蛋白质中的fab结合至人her2的亚结构域ii并且scfv结合至人her2的亚结构域iv。在其他实施方案中,蛋白质中的fab结合至人her2的亚结构域iv并且scfv结合至人her2的亚结构域ii。
[0280]
fab由fab的fd部分(其融合至第一fc多肽的n端)与轻链配对形成。在一些实施方案中,特异性结合至人her2的亚结构域ii的fab包含与seq id no:108的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。在一些实施方案中,特异性结合至人her2的亚结构域iv的fab包含与seq id no:109的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。
[0281]
在一些实施方案中,双特异性蛋白的第二fc多肽在n端融合至scfv片段。在一些实施方案中,第二fc多肽在n端通过第一接头融合至scfv片段。在一些实施方案中,第一接头的长度为约1至约50个氨基酸,例如约1至约40个、约1至约30个、约1至约25个、约1至约20个、约1至约15个、约1至约10个、约2至约40个、约2至约30个、约2至约20个、约2至约10个、约5至约40个、约5至约30个、约5至约25个、或约5至约20个氨基酸。在一些实施方案中,第一接头的长度为约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45或50个氨基酸。本文进一步详细描述了各种接头。在一些实施方案中,第一接头包含ggggsggggs(seq id no:118)的序列。
[0282]
在一些实施方案中,双特异性蛋白中的scfv包含通过第二接头连接的vh区和v
l
区。在一些实施方案中,scfv中v
l
区和vh区的取向是(n端)-v
l
区-vh区-(c端),其中scfv的c端通过第一接头接合至fc多肽的n端。在其他实施方案中,scfv中v
l
区和vh区的取向是(n端)-vh区-v
l
区-(c端),其中scfv的c端通过第一接头接合至fc多肽的n端。
[0283]
在一些实施方案中,scfv的v
l
区和vh区通过第二接头连接。在一些实施方案中,第二接头的长度为约10至约25个氨基酸,例如约10至约20个、约12至约25个、约12至约20个、约14至约25个,或约14至约20个氨基酸。在一些实施方案中,第二接头的长度为约10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个氨基酸。在一些实施方案中,第二接头包括柔性接头。本文进一步详细描述了各种接头。在一些实施方案中,第二接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;
g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0284]
在一些实施方案中,scfv的v
l
区和vh区两者都含有cys取代。在一些实施方案中,v
l
区和vh区中的cys取代可形成二硫键并且有助于稳定scfv的结构。在一些实施方案中,根据kabat可变结构域编号,scfv在位置vh44和v
l
100中的每一个处包含半胱氨酸。在一些实施方案中,scfv在位置vh44和v
l
100处的半胱氨酸之间包含二硫键。
[0285]
例如,抗her2dii v
l
区在seq id no:110的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2dii v
l
区可具有seq id no:114的序列。在一些实施方案中,抗her2div v
l
区在seq id no:111的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2div v
l
区可具有seq id no:115的序列。
[0286]
例如,抗her2dii vh区在seq id no:108的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2dii vh区可具有seq id no:112的序列。在一些实施方案中,抗her2div vh区在seq id no:109的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2div vh区可具有seq id no:113的序列。
[0287]
在一些实施方案中,在具有结构“fab-fc多肽/scfv-fc多肽”的双特异性蛋白的部分(a)中,第一fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。在一些实施方案中,在具有结构“fab-fc多肽/scfv-fc多肽”的双特异性蛋白的部分(b)中,第二fc多肽在n端通过铰链区或部分铰链区融合至scfv。例示性的铰链区序列是人igg1铰链序列epkscdkthtcppcp(seq id no:127)。部分铰链区是指seq id no:127的序列的一部分,例如,具有dkthtcppcp(seq id no:128)的序列的部分铰链区。
[0288]
在另外的实施方案中,在具有结构“fab-fc多肽/scfv-fc多肽”的双特异性蛋白的部分(b)中,铰链区(例如,seq id no:127)或部分铰链区(例如,seq id no:128)在第二fc多肽的n端融合。在某些实施方案中,当铰链区在第二fc多肽的n端融合时,相对于seq id no:127的序列,所述铰链区可在位置5处含有cys至ser突变。例如,具有cys至ser突变的铰链区可具有epkssdkthtcppcp(seq id no:129)的序列。
[0289]
在具有结构“fab-fc多肽/scfv-fc多肽”的双特异性蛋白中,第一fc多肽和/或第二fc多肽可特异性结合至转铁蛋白受体(例如,tfr结合fc多肽)。本文进一步详细描述了不同的fc多肽及其修饰。在一些实施方案中,第一fc多肽和第二fc多肽可各自包含促进异二聚化的修饰。例如,根据eu编号,第一fc多肽可包含t366w取代,并且第二fc多肽可包含t366s、l368a和y407v取代。在另一实例中,根据eu编号,第一fc多肽可包含t366s、l368a和y407v取代,并且第二fc多肽可包含t366w取代。此外,第一fc多肽和/或第二fc多肽可独立地包含降低效应子功能的修饰。例如,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在具有结构“fab-fc多肽/scfv-fc多肽”的双特异性蛋白的特定实施方案中,根据eu编号,第一fc多肽(或第二fc多肽)是包含t366w取代以及l234a和l235a取代的tfr结合fc多肽,并且根据eu编号,第二fc多肽(或第一fc多肽)包含t366s、l368a和y407v取代。例如,第一fc多肽(或第二fc多肽)可包含与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二fc多肽(或第一fc多肽)可包含与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、
no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。注意,在这两个实例中,scfv部分都含有具有gln至cys取代的抗her2div v
l
区(seq id no:115)和具有gly至cys取代的抗her2div vh区(seq id no:113)。而且在两种构建体中,(b)中的铰链区在位置5处具有cys至ser突变(epkssdkthtcppcp(seq id no:129))。
[0298]
在一些实施方案中,双特异性蛋白包含:
[0299]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0300]
(b)第二fc多肽,其在n端融合至单链可变片段(scfv),所述scfv结合至人her2的亚结构域ii,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0301]
(c)轻链多肽,其与(a)中所述的fd部分配对以形成fab。
[0302]
在一个实例中,(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:15、16或17的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:14的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:13的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:11或12的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0303]
在上述双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
[0304]
在上述双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端的赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0305]
mab/n端或c端scfv在hc上
[0306]
在一些实施方案中,双特异性蛋白包含在每个n端融合至fab的fc多肽,所述fab特异性结合至人her2的亚结构域ii或iv,并且一个或两个fc多肽在c端融合至scfv,所述scfv
特异性结合至人her2的亚结构域ii或iv。在一些实施方案中,双特异性蛋白包含在每个n端融合至fab的fc多肽,所述fab特异性结合至人her2的亚结构域ii或iv,并且一个或两个fab在n端融合至scfv,所述scfv特异性结合至人her2的亚结构域ii或iv。这种双特异性蛋白的示意图在图2a-图2d中示出。在一些实施方案中,双特异性蛋白包含:
[0307]
(a)第一fc多肽,其在n端融合至fab的fd部分;
[0308]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
[0309]
(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab,
[0310]
其中所述第一fc多肽和/或所述第二fc多肽在c端融合至scfv,或者
[0311]
其中(a)和/或(b)中的所述fd部分在n端融合至scfv,或者
[0312]
其中所述第一fc多肽或所述第二fc多肽在c端融合至scfv并且(a)或(b)中的所述fd部分在n端融合至scfv,并且
[0313]
其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。在一些实施方案中,fab结合至人her2的亚结构域ii并且scfv结合至人her2的亚结构域iv。在其他实施方案中,fab结合至人her2的亚结构域iv并且scfv结合至人her2的亚结构域ii。
[0314]
在一些实施方案中,特异性结合至人her2的亚结构域ii的fab包含与seq id no:108的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。在一些实施方案中,特异性结合至人her2的亚结构域iv的fab包含与seq id no:109的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。
[0315]
在某些实施方案中,第一fc多肽和/或第二fc多肽在c端融合至scfv。在特定实施方案中,第一fc多肽或第二fc多肽在c端融合至scfv。在特定实施方案中,第一fc多肽和第二fc多肽中的每一个在c端融合至scfv。在某些实施方案中,(a)和/或(b)中的fd部分在n端融合至scfv。在特定实施方案中,(a)或(b)中的fd部分在n端融合至scfv。在特定实施方案中,(a)和(b)中的fd部分中的每一个在n端融合至scfv。在另外的实施方案中,第一fc多肽或第二fc多肽在c端融合至scfv,并且(a)或(b)中的fd部分在n端融合至scfv。
[0316]
在一些实施方案中,当第一fc多肽和第二fc多肽各自在c端融合至scfv时,两个scfv可包含相同的序列。在一些实施方案中,当(a)中的fd部分和(b)中的fd部分各自在n端融合至scfv时,两个scfv可包含相同的序列。在一些实施方案中,当第一fc多肽或第二fc多肽在c端融合至scfv并且(a)或(b)中的fd部分在n端融合至scfv时,两个scfv可包含相同的序列。
[0317]
在一些实施方案中,第一fc多肽和/或第二fc多肽在c端通过第一接头融合至scfv。在其他实施方案中,(a)中的fd部分和/或(b)中的fd部分在n端通过第一接头融合至scfv。在一些实施方案中,第一接头的长度为约1至约50个氨基酸,例如约1至约40个、约1至约30个、约1至约25个、约1至约20个、约1至约15个、约1至约10个、约2至约40个、约2至约30个、约2至约20个、约2至约10个、约5至约40个、约5至约30个、约5至约25个、或约5至约20个氨基酸。在一些实施方案中,第一接头的长度为约1、2、3、4、5、6、7、8、9、10、11、12、13、14、
15、16、17、18、19、20、21、22、23、24、25、30、35、40、45或50个氨基酸。本文进一步详细描述了各种接头。在某些实施方案中,第一接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0318]
在一些实施方案中,双特异性蛋白中的scfv包含通过第二接头连接的vh区和v
l
区。在一些实施方案中,scfv中v
l
区和vh区的取向是(n端)-v
l
区-vh区-(c端),其中scfv的c端通过第一接头接合至(a)或(b)中的fd部分的n端。在其他实施方案中,scfv中v
l
区和vh区的取向是(n端)-vh区-v
l
区-(c端),其中scfv的c端通过第一接头接合至(a)或(b)中的fd部分的n端。在一些实施方案中,scfv中v
l
区和vh区的取向是(n端)-v
l
区-vh区-(c端),其中scfv的n端通过第一接头接合至第一fc多肽或第二fc多肽的c端。在其他实施方案中,scfv中v
l
区和vh区的取向是(n端)-vh区-v
l
区-(c端),其中scfv的n端通过第一接头接合至第一fc多肽或第二fc多肽的c端。
[0319]
在一些实施方案中,连接scfv中v
l
和vh区的第二接头的长度为约10至约25个氨基酸,例如约10至约20个、约12至约25个、约12至约20个、约14至约25个,或约14至约20个氨基酸。在一些实施方案中,第二接头的长度为约10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个氨基酸。在一些实施方案中,第二接头包括柔性接头。本文进一步详细描述了各种接头。在一些实施方案中,第二接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0320]
在一些实施方案中,scfv的v
l
区和vh区两者都含有cys取代。在一些实施方案中,v
l
区和vh区中的cys取代可形成二硫键并且有助于稳定scfv的结构。在一些实施方案中,根据kabat可变结构域编号,scfv在位置vh44和v
l
100中的每一个处包含半胱氨酸。在一些实施方案中,scfv在位置vh44和v
l
100处的半胱氨酸之间包含二硫键。
[0321]
例如,抗her2dii v
l
区在seq id no:110的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2dii v
l
区可具有seq id no:114的序列。在一些实施方案中,抗her2div v
l
区在seq id no:111的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2div v
l
区可具有seq id no:115的序列。
[0322]
例如,抗her2dii vh区在seq id no:108的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2dii vh区可具有seq id no:112的序列。在一些实施方案中,抗her2div vh区在seq id no:109的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2div vh区可具有seq id no:113的序列。
[0323]
在一些实施方案中,在具有结构“mab/n端或c端scfv在hc上”的双特异性蛋白的部分(a)中,第一fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。在一些实施方案中,在具有结构“mab/n端或c端scfv在hc上”的双特异性蛋白的部分(b)中,第二fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。例示性的铰链区序列是人igg1铰链序列
epkscdkthtcppcp(seq id no:127)。部分铰链区是指seq id no:127的序列的一部分,例如,具有dkthtcppcp(seq id no:128)的序列的部分铰链区。
[0324]
在具有结构“mab/n端或c端scfv在hc上”的双特异性蛋白中,第一fc多肽和/或第二fc多肽可特异性结合至转铁蛋白受体(例如,tfr结合fc多肽)。本文进一步详细描述了不同的fc多肽及其修饰。在一些实施方案中,第一fc多肽和第二fc多肽可各自包含促进异二聚化的修饰。例如,根据eu编号,第一fc多肽可包含t366w取代,并且第二fc多肽可包含t366s、l368a和y407v取代。在另一实例中,根据eu编号,第一fc多肽可包含t366s、l368a和y407v取代,并且第二fc多肽可包含t366w取代。此外,第一fc多肽和/或第二fc多肽可独立地包含降低效应子功能的修饰。例如,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在具有结构“mab/n端或c端scfv在hc上”的双特异性蛋白的特定实施方案中,根据eu编号,第一fc多肽(或第二fc多肽)是包含t366w取代以及l234a和l235a取代的tfr结合fc多肽,并且根据eu编号,第二fc多肽(或第一fc多肽)包含t366s、l368a和y407v取代。例如,第一fc多肽(或第二fc多肽)可包含与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二fc多肽(或第一fc多肽)可包含与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0325]
在某些实施方案中,根据eu编号,第一fc多肽是tfr结合fc多肽并且含有l234a和l235a取代,并且第二fc多肽不包括l234a或l325a取代。在某些实施方案中,根据eu编号,第一fc多肽不包括l234a或l325a取代,并且第二fc多肽是tfr结合fc多肽并且含有l234a和l235a取代。
[0326]
示例性双特异性“mab/n端或c端scfv在hc上”蛋白
[0327]
在一些实施方案中,双特异性蛋白包含:
[0328]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0329]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0330]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0331]
其中第一fc多肽或第二fc多肽在c端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0332]
在双特异性蛋白的一个实例中,(a)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25
的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:31或32的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0333]
在一些实施方案中,双特异性蛋白包含:
[0334]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0335]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0336]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0337]
其中第一fc多肽或第二fc多肽在c端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0338]
在双特异性蛋白的一个实例中,(a)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:37、38或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、
99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0339]
在一些实施方案中,双特异性蛋白包含:
[0340]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0341]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0342]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0343]
其中第一fc多肽和第二fc多肽中的每一个在c端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0344]
在双特异性蛋白的一个实例中,(a)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:31或32的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0345]
在一些实施方案中,双特异性蛋白包含:
[0346]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0347]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0348]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0349]
其中第一fc多肽和第二fc多肽中的每一个在c端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0350]
在双特异性蛋白的一个实例中,(a)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:37、38或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,
(b)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0351]
在一些实施方案中,双特异性蛋白包含:
[0352]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0353]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0354]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0355]
其中(a)或(b)中的fd部分在n端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0356]
在双特异性蛋白的一个实例中,(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:41的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:43或44的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0357]
在一些实施方案中,双特异性蛋白包含:
[0358]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0359]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0360]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成
fab,
[0361]
其中(a)或(b)中的fd部分在n端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0362]
在双特异性蛋白的一个实例中,(a)包含与seq id no:45或46的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:49或50的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0363]
在一些实施方案中,双特异性蛋白包含:
[0364]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0365]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0366]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0367]
其中(a)和(b)中的fd部分中的每一个在n端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0368]
在双特异性蛋白的一个实例中,(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:43或44的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:41的序列具有至少90%(例如,
91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0369]
在一些实施方案中,双特异性蛋白包含:
[0370]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0371]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0372]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0373]
其中(a)和(b)中的fd部分中的每一个在n端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0374]
在双特异性蛋白的一个实例中,(a)包含与seq id no:45的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:49或50的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0375]
在一些实施方案中,双特异性蛋白包含:
[0376]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0377]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0378]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0379]
其中第一fc多肽或第二fc多肽在c端融合至scfv,所述scfv结合至人her2的亚结构域iv,并且(a)或(b)中的fd部分在n端融合至所述scfv。
[0380]
在双特异性蛋白的一个实例中,(a)包含与seq id no:40的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:31或32的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或
100%)同一性的序列。在另一实例中,(a)包含与seq id no:41的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:30的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:42的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:29的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:43或44的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:27或28的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0381]
在一些实施方案中,双特异性蛋白包含:
[0382]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0383]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0384]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab,
[0385]
其中第一fc多肽或第二fc多肽在c端融合至scfv,所述scfv结合至人her2的亚结构域ii,并且(a)或(b)中的fd部分在n端融合至所述scfv。
[0386]
在一个实例中,(a)包含与seq id no:45的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:37、38或39的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:47的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:36的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:48的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:35的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另
一实例中,(a)包含与seq id no:49或50的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:33或34的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两个轻链多肽中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0387]
在上述双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
[0388]
在上述双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端的赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0389]
mab/n端或c端scfv在lc上
[0390]
在一些实施方案中,双特异性蛋白包含在n端和/或c端融合至scfv的轻链,所述scfv特异性结合至人her2的亚结构域ii或iv。这种双特异性蛋白的示意图在图3a-图3d中示出。在一些实施方案中,双特异性蛋白包含:
[0391]
(a)第一fc多肽,其在n端融合至fab的fd部分;
[0392]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
[0393]
(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
[0394]
其中一个或两个所述轻链多肽在n端融合至scfv,或者
[0395]
其中一个或两个所述轻链多肽在c端融合至scfv,或者
[0396]
其中第一轻链多肽在n端融合至scfv,并且第二轻链多肽在c端融合至scfv,并且
[0397]
其中所述fab结合至人her2的亚结构域ii并且所述scfv结合至人her2的亚结构域iv,或者其中所述fab结合至人her2的亚结构域iv并且所述scfv结合至人her2的亚结构域ii。
[0398]
在一些实施方案中,特异性结合至人her2的亚结构域ii的fab包含与seq id no:108的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。在一些实施方案中,特异性结合至人her2的亚结构域iv的fab包含与seq id no:109的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。
[0399]
在某些实施方案中,一个或两个轻链多肽在n端融合至scfv。在特定实施方案中,轻链多肽中的一个在n端融合至scfv。在特定实施方案中,两个轻链多肽中的每一个在n端融合至scfv。在某些实施方案中,一个或两个轻链多肽在c端融合至scfv。在特定实施方案中,轻链多肽中的一个在c端融合至scfv。在特定实施方案中,两个轻链多肽中的每一个在c端融合至scfv。在另外的实施方案中,第一轻链多肽在n端融合至scfv,并且第二轻链多肽在c端融合至scfv。
[0400]
在一些实施方案中,当两个轻链多肽各自在c端融合至scfv时,两个scfv可包含相同的序列。在一些实施方案中,当两个轻链多肽各自在n端融合至scfv时,两个scfv可包含相同的序列。
[0401]
在一些实施方案中,一个或两个轻链多肽通过第一接头融合至scfv。在一些实施方案中,第一接头的长度为约1至约50个氨基酸,例如约1至约40个、约1至约30个、约1至约25个、约1至约20个、约1至约15个、约1至约10个、约2至约40个、约2至约30个、约2至约20个、约2至约10个、约5至约40个、约5至约30个、约5至约25个、或约5至约20个氨基酸。在一些实施方案中,第一接头的长度为约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45或50个氨基酸。本文进一步详细描述了各种接头。在某些实施方案中,第一接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0402]
在一些实施方案中,双特异性蛋白中的scfv包含通过第二接头连接的vh区和v
l
区。在一些实施方案中,scfv中v
l
区和vh区的取向是(n端)-v
l
区-vh区-(c端),其中scfv的c端通过第一接头接合至轻链多肽的n端。在其他实施方案中,scfv中v
l
区和vh区的取向是(n端)-vh区-v
l
区-(c端),其中scfv的c端通过第一接头接合至轻链多肽的n端。在一些实施方案中,scfv中v
l
区和vh区的取向是(n端)-v
l
区-vh区-(c端),其中scfv的n端通过第一接头接合至轻链多肽的c端。在其他实施方案中,scfv中v
l
区和vh区的取向是(n端)-vh区-v
l
区-(c端),其中scfv的n端通过第一接头接合至轻链多肽的c端。
[0403]
在一些实施方案中,连接scfv中v
l
和vh区的第二接头的长度为约10至约25个氨基酸,例如约10至约20个、约12至约25个、约12至约20个、约14至约25个,或约14至约20个氨基酸。在一些实施方案中,第二接头的长度为约10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个氨基酸。在一些实施方案中,第二接头包括柔性接头。本文进一步详细描述了各种接头。在一些实施方案中,第二接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0404]
在一些实施方案中,scfv的v
l
区和vh区两者都含有cys取代。在一些实施方案中,v
l
区和vh区中的cys取代可形成二硫键并且有助于稳定scfv的结构。在一些实施方案中,根据kabat可变结构域编号,scfv在位置vh44和v
l
100中的每一个处包含半胱氨酸。在一些实施方案中,scfv在位置vh44和v
l
100处的半胱氨酸之间包含二硫键。
[0405]
例如,抗her2dii v
l
区在seq id no:110的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2dii v
l
区可具有seq id no:114的序列。在一些实施方案中,抗her2div v
l
区在seq id no:111的位置100处可具有gln至cys取代。在特定实施方案中,含有cys取代的抗her2div v
l
区可具有seq id no:115的序列。
[0406]
例如,抗her2dii vh区在seq id no:108的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2dii vh区可具有seq id no:112的序列。在一些实施方案中,抗her2div vh区在seq id no:109的位置44处可具有gly至cys取代。在特定实施方案中,含有cys取代的抗her2div vh区可具有seq id no:113的序列。
[0407]
在一些实施方案中,在具有结构“mab/n端或c端scfv在lc上”的双特异性蛋白的部分(a)中,第一fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。在一些实施方案中,在具有结构“mab/n端或c端scfv在lc上”的双特异性蛋白的部分(b)中,第二fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。例示性的铰链区序列是人igg1铰链序列epkscdkthtcppcp(seq id no:127)。部分铰链区是指seq id no:127的序列的一部分,例如,具有dkthtcppcp(seq id no:128)的序列的部分铰链区。
[0408]
在具有结构“mab/n端或c端scfv在lc上”的双特异性蛋白中,第一fc多肽和/或第二fc多肽可特异性结合至转铁蛋白受体(例如,tfr结合fc多肽)。本文进一步详细描述了不同的fc多肽及其修饰。在一些实施方案中,第一fc多肽和第二fc多肽可各自包含促进异二聚化的修饰。例如,根据eu编号,第一fc多肽可包含t366w取代,并且第二fc多肽可包含t366s、l368a和y407v取代。在另一实例中,根据eu编号,第一fc多肽可包含t366s、l368a和y407v取代,并且第二fc多肽可包含t366w取代。此外,第一fc多肽和/或第二fc多肽可独立地包含降低效应子功能的修饰。例如,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在具有结构“mab/n端或c端scfv在hc上”的双特异性蛋白的特定实施方案中,根据eu编号,第一fc多肽(或第二fc多肽)是包含t366w取代以及l234a和l235a取代的tfr结合fc多肽,并且根据eu编号,第二fc多肽(或第一fc多肽)包含t366s、l368a和y407v取代。例如,第一fc多肽(或第二fc多肽)可包含与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二fc多肽(或第一fc多肽)可包含与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0409]
在某些实施方案中,根据eu编号,第一fc多肽是tfr结合fc多肽并且含有l234a和l235a取代,并且第二fc多肽不包括l234a或l325a取代。在某些实施方案中,根据eu编号,第一fc多肽不包括l234a或l325a取代,并且第二fc多肽是tfr结合fc多肽并且含有l234a和l235a取代。
[0410]
示例性双特异性“mab/n端或c端scfv在lc上”蛋白
[0411]
在一些实施方案中,双特异性蛋白包含:
[0412]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0413]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0414]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0415]
其中所述轻链多肽中的一个在c端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0416]
在双特异性蛋白的一个实例中,(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)
同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0417]
在一些实施方案中,双特异性蛋白包含:
[0418]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0419]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0420]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0421]
其中所述轻链多肽中的一个在c端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0422]
在双特异性蛋白的一个实例中,(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0423]
在一些实施方案中,双特异性蛋白包含:
[0424]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0425]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0426]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0427]
其中所述两个轻链多肽中的每一个在c端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0428]
在一个实例中,(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0429]
在一些实施方案中,双特异性蛋白包含:
[0430]
一些实施方案中,双特异性蛋白包含:
[0431]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0432]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0433]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0434]
其中所述两个轻链多肽中的每一个在c端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0435]
在一个实例中,(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0436]
在一些实施方案中,双特异性蛋白包含:
[0437]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0438]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0448]
在一些实施方案中,双特异性蛋白包含:
[0449]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0450]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0451]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0452]
其中所述两个轻链多肽中的每一个在n端融合至scfv,所述scfv结合至人her2的亚结构域iv。
[0453]
在双特异性蛋白的一个实例中,(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0454]
在一些实施方案中,双特异性蛋白包含:
[0455]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0456]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0457]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0458]
其中所述两个轻链多肽中的每一个在n端融合至scfv,所述scfv结合至人her2的亚结构域ii。
[0459]
在双特异性蛋白的一个实例中,(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、
96%、97%、98%、99%或100%)同一性的序列,并且两个轻链多肽中的每一个在c端融合至scfv,且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0460]
在一些实施方案中,双特异性蛋白包含:
[0461]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0462]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0463]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0464]
其中第一轻链多肽在n端融合至scfv,所述scfv结合至人her2的亚结构域iv,并且第二轻链多肽在c端融合至scfv。
[0465]
在双特异性蛋白的一个实例中,(a)包含与seq id no:1的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:4或5的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:2的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:3的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:55的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:52的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0466]
在一些实施方案中,双特异性蛋白包含:
[0467]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0468]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0469]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0470]
其中第一轻链多肽在n端融合至scfv,所述scfv结合至人her2的亚结构域ii,并且第二轻链多肽在c端融合至scfv。
[0471]
在双特异性蛋白的一个实例中,(a)包含与seq id no:6的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:9或10的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56
或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:7的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:8的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,第一轻链多肽在n端融合至scfv且包含与seq id no:56或57的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二轻链多肽在c端融合至scfv且包含与seq id no:53或54的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0472]
在上述双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
[0473]
在上述双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端的赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0474]
mab/n端v
h v
l
在hc和lc上
[0475]
在一些实施方案中,双特异性蛋白包含在两条重链中的每一个的n端融合的vh区(或v
l
区)和在两条轻链中的每一个的n端融合的v
l
区(或vh区)。这种双特异性蛋白的示意图在图4中示出。在一些实施方案中,双特异性蛋白包含:
[0476]
(a)第一fc多肽,其在n端融合至fab的fd部分;
[0477]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
[0478]
(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
[0479]
其中(a)和(b)中的所述fd部分中的每一个在n端融合至fv片段的vh区或v
l
区,并且
[0480]
其中所述两个轻链多肽中的每一个在n端融合至所述fv片段的vh区或v
l
区中的另一个,并且
[0481]
其中所述vh区和所述v
l
区一起形成所述fv片段,并且
[0482]
其中所述fab结合至人her2的亚结构域ii并且所述fv片段结合至人her2的亚结构域iv,或其中所述fab结合至人her2的亚结构域iv并且所述fv片段结合至人her2的亚结构域ii。
[0483]
在双特异性蛋白的一些实施方案中,(a)和(b)中的fd部分中的每一个在n端融合至fv片段的vh区,并且两个轻链多肽中的每一个在n端融合至fv片段的v
l
区。在其他实施方案中,(a)和(b)中的fd部分中的每一个在n端融合至fv片段的v
l
区,并且两个轻链多肽中的每一个在n端融合至fv片段的vh区。
[0484]
在一些实施方案中,特异性结合至人her2的亚结构域ii的fab包含与seq id no:
108的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。在一些实施方案中,特异性结合至人her2的亚结构域iv的fab包含与seq id no:109的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。
[0485]
在一些实施方案中,第一接头将vh区或v
l
区连接至(a)和(b)中的fd部分中的每一个的n端。在一些实施方案中,第二接头将vh区或v
l
区连接至两个轻链多肽中的每一个的n端。在一些实施方案中,第一接头或第二接头的长度为约1至约50个氨基酸,例如约1至约40个、约1至约30个、约1至约25个、约1至约20个、约1至约15个、约1至约10个、约2至约40个、约2至约30个、约2至约20个、约2至约10个、约5至约40个、约5至约30个、约5至约25个、或约5至约20个氨基酸。在一些实施方案中,第一接头的长度为约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45或50个氨基酸。本文进一步详细描述了各种接头。在某些实施方案中,第一接头包含astkgpsvf(seq id no:125)的序列。在某些实施方案中,第二接头包含rtvaapsvfi(seq id no:126)的序列。
[0486]
在一些实施方案中,在具有结构“mab/n端v
h v
l
在hc和lc上”的双特异性蛋白的部分(a)中,第一fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。在一些实施方案中,在具有结构“mab/n端v
h v
l
在hc和lc上”的双特异性蛋白的部分(b)中,第二fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。例示性的铰链区序列是人igg1铰链序列epkscdkthtcppcp(seq id no:127)。部分铰链区是指seq id no:127的序列的一部分,例如,具有dkthtcppcp(seq id no:128)的序列的部分铰链区。
[0487]
在具有结构“mab/n端v
h v
l
在hc和lc上”的双特异性蛋白中,第一fc多肽和/或第二fc多肽可特异性结合至转铁蛋白受体(例如,tfr结合fc多肽)。本文进一步详细描述了不同的fc多肽及其修饰。在一些实施方案中,第一fc多肽和第二fc多肽可各自包含促进异二聚化的修饰。例如,根据eu编号,第一fc多肽可包含t366w取代,并且第二fc多肽可包含t366s、l368a和y407v取代。在另一实例中,根据eu编号,第一fc多肽可包含t366s、l368a和y407v取代,并且第二fc多肽可包含t366w取代。此外,第一fc多肽和/或第二fc多肽可独立地包含降低效应子功能的修饰。例如,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在具有结构“mab/n端v
h v
l
在hc和lc上”的双特异性蛋白的特定实施方案中,根据eu编号,第一fc多肽(或第二fc多肽)是包含t366w取代以及l234a和l235a取代的tfr结合fc多肽,并且根据eu编号,第二fc多肽(或第一fc多肽)包含t366s、l368a和y407v取代。例如,第一fc多肽(或第二fc多肽)可包含与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二fc多肽(或第一fc多肽)可包含与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0488]
在某些实施方案中,根据eu编号,第一fc多肽是tfr结合fc多肽并且含有l234a和l235a取代,并且第二fc多肽不包括l234a或l325a取代。在某些实施方案中,根据eu编号,第一fc多肽不包括l234a或l325a取代,并且第二fc多肽是tfr结合fc多肽并且含有l234a和l235a取代。
[0489]
示例性双特异性“mab/n端v
h v
l
在hc和lc上”蛋白
[0490]
在一些实施方案中,双特异性蛋白包含:
[0491]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0492]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0493]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0494]
其中(a)和(b)中的fd部分中的每一个在n端融合至fv片段的vh区,所述fv片段结合至人her2的亚结构域iv,并且
[0495]
其中两个轻链多肽中的每一个在n端融合至fv片段中的另一个v
l
区,并且
[0496]
其中vh区和v
l
区一起形成fv片段。
[0497]
在一个实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:58的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:61或62的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:78的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:59的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:60的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:78的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0498]
在一些实施方案中,双特异性蛋白包含:
[0499]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0500]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0501]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0502]
其中(a)和(b)中的fd部分中的每一个在n端融合至fv片段的vh区,所述fv片段结合至人her2的亚结构域ii,并且
[0503]
其中两个轻链多肽中的每一个在n端融合至fv片段中的另一个v
l
区,并且
[0504]
其中vh区和v
l
区一起形成fv片段。
[0505]
在一个实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:63的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:66或67的序列具有至少90%(例如,91%、92%、93%、94%、95%、
96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:79的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,第一多肽,其包含在n端融合至fv片段的vh区的(a)以及与seq id no:64的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的vh区的(b)以及与seq id no:65的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的v
l
区的轻链多肽,并且其各自包含与seq id no:79的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0506]
在一些实施方案中,双特异性蛋白包含:
[0507]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii;
[0508]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成fc二聚体;以及
[0509]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0510]
其中(a)和(b)中的fd部分中的每一个在n端融合至fv片段的v
l
区,所述fv片段结合至人her2的亚结构域iv的,并且
[0511]
其中两个轻链多肽中的每一个在n端融合至fv片段中的另一个vh区,并且
[0512]
其中vh区和v
l
区一起形成fv片段。
[0513]
在一个实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:68的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:71或72的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:80的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:69的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:70的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:80的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0514]
在一些实施方案中,双特异性蛋白包含:
[0515]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv;
[0516]
(b)第二fc多肽,其在n端融合至fab的fd部分,其中第一fc多肽和第二fc多肽形成
fc二聚体;以及
[0517]
(c)两个轻链多肽,其各自与(a)和(b)中所述的fd部分中的每一个配对以形成fab;
[0518]
其中(a)和(b)中的fd部分中的每一个在n端融合至fv片段的v
l
区,所述fv片段结合至人her2的亚结构域ii的,并且
[0519]
其中两个轻链多肽中的每一个在n端融合至fv片段中的另一个vh区,并且
[0520]
其中vh区和v
l
区一起形成fv片段。
[0521]
在一个实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:73的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:76或77的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:81的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,双特异性蛋白包含第一多肽,其包含在n端融合至fv片段的v
l
区的(a)以及与seq id no:74的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;第二多肽,其包含在n端融合至fv片段的v
l
区的(b)以及与seq id no:75的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列;以及第三多肽和第四多肽,其各自包含在n端融合至fv片段的vh区的轻链多肽,并且其各自包含与seq id no:81的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0522]
在上述双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
[0523]
在上述双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端的赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0524]
mab/c端v
h v
l
在hc上
[0525]
在一些实施方案中,双特异性蛋白包含在两个fc多肽中的一个的c端融合的vh区(或v
l
区)和在两个fc多肽中的另一个的c端融合的v
l
区(或vh区)。这种双特异性蛋白的示意图在图5中示出。在一些实施方案中,双特异性蛋白包含:
[0526]
(a)第一fc多肽,其在n端融合至fab的fd部分,并且在c端融合至fv片段的vh区或v
l
区;
[0527]
(b)第二fc多肽,其在n端融合至fab的fd部分,并且在c端融合至(a)中所述的vh区或v
l
区中的另一个,
[0528]
其中所述vh区和所述v
l
区一起形成所述fv片段,并且其中所述第一fc多肽和第二fc多肽形成fc二聚体;以及
[0529]
(c)两个轻链多肽,其各自与(a)和(b)中所述的每个fd部分配对以形成fab;
[0530]
其中所述fab结合至人her2的亚结构域ii并且所述fv片段结合至人her2的亚结构
域iv,或其中所述fab结合至人her2的亚结构域iv并且所述fv片段结合至人her2的亚结构域ii。
[0531]
在双特异性蛋白的一些实施方案中,第一fc多肽融合至fv片段的vh区,并且第二fc多肽融合至fv片段的v
l
区。在一些实施方案中,第一fc多肽融合至fv片段的v
l
区,并且第二fc多肽融合至fv片段的vh区。
[0532]
在一些实施方案中,特异性结合至人her2的亚结构域ii的fab包含与seq id no:108的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。在一些实施方案中,特异性结合至人her2的亚结构域iv的fab包含与seq id no:109的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的vh区。
[0533]
在一些实施方案中,第一接头将vh区或v
l
区连接至fc多肽的c端。在一些实施方案中,第一接头或第二接头的长度为约1至约50个氨基酸,例如约1至约40个、约1至约30个、约1至约25个、约1至约20个、约1至约15个、约1至约10个、约2至约40个、约2至约30个、约2至约20个、约2至约10个、约5至约40个、约5至约30个、约5至约25个、或约5至约20个氨基酸。在一些实施方案中,第一接头的长度为约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45或50个氨基酸。本文进一步详细描述了各种接头。在一些实施方案中,第一接头包含以下序列中的任一种:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0534]
在一些实施方案中,在具有结构“mab/c端v
h v
l
在hc上”的双特异性蛋白的部分(a)中,第一fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。在一些实施方案中,在具有结构“mab/c端v
h v
l
在hc上”的双特异性蛋白的部分(b)中,第二fc多肽在n端通过铰链区或部分铰链区融合至fab的fd部分。例示性的铰链区序列是人igg1铰链序列epkscdkthtcppcp(seq id no:127)。部分铰链区是指seq id no:127的序列的一部分,例如,具有dkthtcppcp(seq id no:128)的序列的部分铰链区。
[0535]
在具有结构“mab/c端v
h v
l
在hc上”的双特异性蛋白中,第一fc多肽和/或第二fc多肽可特异性结合至转铁蛋白受体(例如,tfr结合fc多肽)。本文进一步详细描述了不同的fc多肽及其修饰。在一些实施方案中,第一fc多肽和第二fc多肽可各自包含促进异二聚化的修饰。例如,根据eu编号,第一fc多肽可包含t366w取代,并且第二fc多肽可包含t366s、l368a和y407v取代。在另一实例中,根据eu编号,第一fc多肽可包含t366s、l368a和y407v取代,并且第二fc多肽可包含t366w取代。此外,第一fc多肽和/或第二fc多肽可独立地包含降低效应子功能的修饰。例如,根据eu编号,降低效应子功能的修饰是l234a和l235a取代。在具有结构“mab/n端v
h v
l
在hc上”的双特异性蛋白的特定实施方案中,根据eu编号,第一fc多肽(或第二fc多肽)是包含t366w取代以及l234a和l235a取代的tfr结合fc多肽,并且根据eu编号,第二fc多肽(或第一fc多肽)包含t366s、l368a和y407v取代。例如,第一fc多肽(或第二fc多肽)可包含与seq id no:137的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且第二fc多肽(或第一fc多肽)可包
含与seq id no:133的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0536]
在某些实施方案中,根据eu编号,第一fc多肽是tfr结合fc多肽并且含有l234a和l235a取代,并且第二fc多肽不包括l234a或l325a取代。在某些实施方案中,根据eu编号,第一fc多肽不包括l234a或l325a取代,并且第二fc多肽是tfr结合fc多肽并且含有l234a和l235a取代。
[0537]
示例性双特异性“mab/c端v
h v
l
在hc上”蛋白
[0538]
在一些实施方案中,双特异性蛋白包含:
[0539]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域ii,并且在c端融合至fv片段的vh区,所述fv片段结合至人her2的亚结构域iv;
[0540]
(b)第二fc多肽,其在n端融合至fab的fd部分,并且在c端融合至fv片段的v
l
区。
[0541]
在双特异性蛋白的一个实例中,(a)包含与seq id no:82或83的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:99、100或101的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:84的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:98的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:85的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:97的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:86、87或88的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:95或96的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:25的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0542]
在一些实施方案中,双特异性蛋白包含:
[0543]
(a)第一fc多肽,其在n端融合至fab的fd部分,所述fab结合至人her2的亚结构域iv,并且在c端融合至fv片段的vh区,所述fv片段结合至人her2的亚结构域ii;
[0544]
(b)第二fc多肽,其在n端融合至fab的fd部分,并且在c端融合至fv片段的v
l
区。
[0545]
在双特异性蛋白的一个实例中,(a)包含与seq id no:89或90的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:105、106或107的序列具有至少90%(例如,91%、92%、93%、94%、
95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:91的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:104的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在另一实例中,(a)包含与seq id no:92的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:103的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。在又另一实例中,(a)包含与seq id no:93或94的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,(b)包含与seq id no:102的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列,并且(c)中的两条轻链中的每一个包含与seq id no:26的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0546]
在上述双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽包含在位置234和235处的leu。在一些实施方案中,根据eu编号,第二fc多肽包含在位置234和235处的leu。在某些实施方案中,蛋白质包括下文所述的顺式lala构型。
[0547]
在上述双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端的赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0548]
iv.fc多肽及其修饰
[0549]
在一些方面,本文所述的任何抗her2双特异性蛋白包含fc多肽二聚体,其中所述二聚体中的一个或两个fc多肽含有相对于野生型fc多肽的氨基酸修饰。在一些实施方案中,fc多肽(例如,修饰的fc多肽)中的氨基酸修饰可导致fc多肽二聚体与bbb受体(例如,tfr)的结合,促进二聚体中两个fc多肽的异二聚化、调节效应子功能、延长血清半衰期、影响糖基化和/或降低在人中的免疫原性。在一些实施方案中,双特异性蛋白中存在的fc多肽独立地与对应的野生型fc多肽(例如,人igg1、igg2、igg3或igg4 fc多肽)具有至少约85%、90%、95%、96%、97%、98%或99%的氨基酸序列同一性。修饰的fc多肽(例如,tfr结合fc多肽)的实例和描述可以在例如国际专利公开号wo 2018/152326中找到,所述专利以引用的方式整体并入本文。
[0550]
用于bbb受体结合的fc多肽修饰
[0551]
本文提供了能够跨bbb转运的抗her2双特异性蛋白。这样的蛋白质包含结合至bbb受体的修饰的fc多肽。bbb受体在bbb内皮以及其他细胞和组织类型上表达。在一些实施方案中,bbb受体是tfr。结合至tfr的修饰的fc多肽也称为具有tfr结合位点。
[0552]
在各种fc修饰中指定的氨基酸残基,包括在结合至bbb受体(例如tfr)的修饰fc多
肽中引入的那些氨基酸残基,在本文中使用eu索引编号进行编号。任何fc多肽,例如igg1、igg2、igg3或igg4 fc多肽,可在如本文所述的一个或多个位置具有修饰,例如氨基酸取代。在一些实施方案中,针对bbb受体(例如,tfr)结合活性进行修饰的结构域是人ig ch3结构域,诸如igg1 ch3结构域。ch3结构域可属于任何igg亚型,即来自igg1、igg2、igg3或igg4。在igg1抗体的上下文中,ch3结构域是指根据eu编号方案进行编号的从约位置341至约位置447的氨基酸的区段。
[0553]
在一些实施方案中,特异性结合至tfr的修饰fc多肽结合至tfr的顶端结构域,并且可在不阻断或以其他方式抑制转铁蛋白与tfr的结合的情况下结合至tfr。在一些实施方案中,转铁蛋白与tfr的结合基本上不受抑制。在一些实施方案中,转铁蛋白与tfr的结合的抑制小于约50%(例如,小于约45%、40%、35%、30%、25%、20%、15%、10%或5%)。
[0554]
在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含一个或多个、至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于包括266、267、268、269、270、271、295、297、298和299的氨基酸位置上的至少四个、五个、六个、七个、八个、九个或十个取代。在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于包括274、276、283、285、286、287、288、289和290的氨基酸位置上的至少四个、五个、六个、七个、八个或九个取代。在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于包括268、269、270、271、272、292、293、294、296和300的氨基酸位置上的至少四个、五个、六个、七个、八个、九个或十个取代。在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于包括272、274、276、322、324、326、329、330和331的氨基酸位置上的至少四个、五个、六个、七个、八个或九个取代。在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于包括345、346、347、349、437、438、439和440的氨基酸位置上的至少四个、五个、六个或七个取代。
[0555]
在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个、两个或三个取代;并且在一些实施方案中,根据eu编号方案,包含处于氨基酸位置384、386、387、388、389、390、413、416和421上的至少四个、五个、六个、七个、八个或九个取代。
[0556]
在一些实施方案中,本文所述的双特异性蛋白中存在的bbb受体(例如,tfr)结合fc多肽包含至少一个相对于seq id no:130具有取代的位置,如下所示:在位置384处的leu、tyr、met或val;在位置386处的leu、thr、his或pro;在位置387处的val、pro或酸性氨基酸;在位置388处的芳族氨基酸,例如trp或gly(例如trp);在位置389处的val、ser或ala;在位置413处的酸性氨基酸、ala、ser、leu、thr或pro;在位置416处的thr或酸性氨基酸;或在位置421处的trp、tyr、his或phe。在一些实施方案中,bbb受体(例如,tfr)结合fc多肽可包含保守取代,例如在该集合中的一个或多个位置处的指定氨基酸的相同电荷分组、疏水性分组、侧链环结构分组(例如,芳族氨基酸),或大小分组,和/或极性或非极性分组中的氨基
酸。因此,例如,ile可存在于位置384、386和/或位置413处。在一些实施方案中,在位置387、413和416中的一个、两个或每一个位置处的酸性氨基酸是glu。在其他实施方案中,在位置387、413和416中的一个、两个或每一个处的酸性氨基酸是asp。在一些实施方案中,位置384、386、387、388、389、413、416和421中的两个、三个、四个、五个、六个、七个或者全部八个具有如在本段中所指出的氨基酸取代。
[0557]
在一些实施方案中,在氨基酸位置384、386、387、388、389、390、413、416和/或421处具有修饰的fc多肽包含在位置390处的天然asn。在一些实施方案中,fc多肽在位置390处包含gly、his、gln、leu、lys、val、phe、ser、ala或asp。在一些实施方案中,fc多肽还在包括380、391、392和415的位置处包含一个、两个、三个或四个取代。在一些实施方案中,trp、tyr、leu或gln可存在于位置380处。在一些实施方案中,ser、thr、gln或phe可存在于位置391处。在一些实施方案中,gln、phe或his可存在于位置392处。在一些实施方案中,glu可存在于位置415处。
[0558]
在某些实施方案中,fc多肽包括选自以下的两个、三个、四个、五个、六个、七个、八个、九个或十个位置:在位置380处的trp、leu或glu;在位置384处的tyr或phe;在位置386处的thr;在位置387处的glu;在位置388处的trp;在位置389处的ser、ala、val或asn;在位置390处的ser或asn;在位置413处的thr或ser;在位置415处的glu或ser;在位置416处的glu;和/或在位置421处的phe。在一些实施方案中,fc多肽包含如下的全部十一个位置:在位置380处的trp、leu或glu;在位置384处的tyr或phe;在位置386处的thr;在位置387处的glu;在位置388处的trp;在位置389处的ser、ala、val或asn;在位置390处的ser或asn;在位置413处的thr或ser;在位置415处的glu或ser;在位置416处的glu;和/或在位置421处的phe。
[0559]
在某些实施方案中,bbb受体(例如,tfr)结合fc多肽包含在位置384处的leu或met;在位置386处的leu、his或pro;在位置387处的val;在位置388处的trp;在位置389处的val或ala;在位置413处的pro;在位置416处的thr;和/或在位置421处的trp。在一些实施方案中,fc多肽还包含在位置391处的ser、thr、gln或phe。在一些实施方案中,fc多肽还包含在位置380处的trp、tyr、leu或gln和/或在位置392处的gln、phe或his。在一些实施方案中,trp存在于位置380处和/或gln存在于位置392处。在一些实施方案中,bbb受体(例如,tfr)结合fc多肽在位置380处不具有trp。
[0560]
在其他实施方案中,bbb受体(例如,tfr)结合fc多肽包含在位置384处的tyr;在位置386处的thr;在位置387处的glu或val;在位置388处的trp;在位置389处的ser;在位置413处的ser或thr;在位置416处的glu;和/或在位置421处的phe。在一些实施方案中,bbb受体(例如,tfr)结合fc多肽包含在位置390处的天然asn。在某些实施方案中,fc多肽还包含在位置380处的trp、tyr、leu或gln;和/或在位置415处的glu。在一些实施方案中,fc多肽还包含在位置380处的trp和/或在位置415处的glu。
[0561]
在一些实施方案中,bbb受体(例如,tfr)结合fc多肽包含以下取代中的一个或多个:在位置380处的trp;在位置386处的thr;在位置388处的trp;在位置389处的val;在位置413处的thr或ser;在位置415处的glu;和/或在位置421处的phe。
[0562]
在另外的实施方案中,bbb受体(例如,tfr)结合fc多肽还包含选自以下的一个、两个或三个位置:位置414是lys、arg、gly或pro;位置424是ser、thr、glu或lys;并且位置426是ser、trp或gly。
[0563]
在一些实施方案中,bbb受体(例如,tfr)结合fc多肽具有seq id no:135的序列。在本文所述的双特异性蛋白的一些实施方案中,fc多肽二聚体中的两个fc多肽中的一个可以是具有seq id no:135的序列的bbb受体(例如,tfr)结合fc多肽,而fc多肽二聚体中的另一个fc多肽可具有野生型fc多肽的序列(例如,seq id no:130)。在本文所述的双特异性蛋白的其他实施方案中,fc多肽二聚体中的两个fc多肽可以是具有seq id no:135的序列的bbb受体(例如,tfr)结合fc多肽。
[0564]
在本文所述的双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:135-139的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0565]
在本文所述的双特异性蛋白的一些实施方案中,fc多肽二聚体中的两个fc多肽中的一个可以是bbb受体(例如,tfr)结合fc多肽,根据eu编号,其包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:135的序列具有至少90%同一性的序列,而fc多肽二聚体中的另一个fc多肽可具有野生型fc多肽的序列(例如,seq id no:130)。
[0566]
在本文所述的双特异性蛋白的一些实施方案中,根据eu编号,第一fc多肽和/或第二fc多肽独立地包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ala、在位置413处的thr、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与选自seq id no:140-144的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%、99%或100%)同一性的序列。
[0567]
在本文所述的双特异性蛋白的一些实施方案中,fc多肽二聚体中的两个fc多肽中的一个可以是bbb受体(例如,tfr)结合fc多肽,根据eu编号,其包含在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ala、在位置413处的thr、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:140的序列具有至少90%同一性的序列,而fc多肽二聚体中的另一个fc多肽可具有野生型fc多肽的序列(例如,seq id no:130)。
[0568]
在一些实施方案中,bbb受体(例如,tfr)结合fc多肽具有seq id no:140的序列。在本文所述的双特异性蛋白的一些实施方案中,fc多肽二聚体中的两个fc多肽中的一个可以是具有seq id no:140的序列的bbb受体(例如,tfr)结合fc多肽,而fc多肽二聚体中的另一个fc多肽可具有野生型fc多肽的序列(例如,seq id no:130)。在本文所述的双特异性蛋白的其他实施方案中,fc多肽二聚体中的两个fc多肽可以是具有seq id no:140的序列的bbb受体(例如,tfr)结合fc多肽。
[0569]
在一些实施方案中,bbb受体(例如,tfr)结合fc多肽具有seq id no:145的序列。在本文所述的双特异性蛋白的一些实施方案中,fc多肽二聚体中的两个fc多肽中的一个可以是具有seq id no:145的序列的bbb受体(例如,tfr)结合fc多肽,而fc多肽二聚体中的另一个fc多肽可具有野生型fc多肽的序列(例如,seq id no:130)。在本文所述的双特异性蛋白的其他实施方案中,fc多肽二聚体中的两个fc多肽可以是具有seq id no:145的序列的
bbb受体(例如,tfr)结合fc多肽。
[0570]
用于异二聚化的fc多肽修饰
[0571]
在一些实施方案中,本文所述的任何双特异性蛋白中存在的fc多肽包括杵和臼突变,以促进异源二聚体形成并阻碍同源二聚体形成。一般来说,修饰在第一多肽的界面处引入突出部(“杵”),并且在第二多肽的界面中引入对应的腔穴(“臼”),使得突出部可以定位在腔穴中,以便促进异源二聚体形成,并且从而阻碍同源二聚体形成。突出部通过将第一多肽的界面的小氨基酸侧链替换为更大侧链(例如,酪氨酸或色氨酸)来构造。在第二多肽的界面中通过将大氨基酸侧链替换为更小的氨基酸侧链(例如,丙氨酸或苏氨酸)而产生具有与突出部相同或相似大小的补偿性腔穴。在一些实施方案中,此类另外的突变处于fc多肽中对多肽与bbb受体(例如tfr)的结合没有负面影响的位置上。
[0572]
在用于二聚化的杵和臼方法的一个例示性实施方案中,双特异性蛋白中存在的fc多肽中的一个中的位置366(根据eu编号方案进行编号)包含色氨酸,代替了天然苏氨酸。二聚体中的另一个fc多肽在位置407(根据eu编号方案进行编号)上具有缬氨酸,代替了天然酪氨酸。另一个fc多肽还可包含这样的取代:其中位置366处(根据eu编号方案进行编号)的天然苏氨酸被丝氨酸取代,并且位置368处(根据eu编号方案进行编号)的天然亮氨酸被丙氨酸取代。因此,本文所述的双特异性蛋白的fc多肽中的一个具有t366w杵突变,并且另一个fc多肽具有y407v突变,其通常伴有t366s和l368a臼突变。
[0573]
在一些实施方案中,本文所述的双特异性蛋白中存在的一个或两个fc多肽还可被工程化以含有用于异二聚化的其他修饰,例如,ch3-ch3界面内的天然带电的接触残基的静电工程化或疏水性补丁修饰(patch modification)。
[0574]
例如,在一些实施方案中,本文所述的双特异性蛋白可含有fc多肽二聚体,其一个fc多肽具有t366w杵突变且与seq id no:131的序列具有至少90%(例如,91%、92%、93%、94%、95%、96%、97%、98%或99%)同一性,并且另一个fc多肽具有t366s、l368a和y407v臼突变且与seq id no:133的序列具有至少90%同一性。在某些实施方案中,fc多肽二聚体中的一个或两个fc多肽可以是tfr结合fc多肽。在特定实施方案中,本文所述的双特异性蛋白可含有fc多肽二聚体,所述二聚体具有(i)具有seq id no:133的序列的第一fc多肽和(ii)具有seq id no:136的序列的第二fc多肽。在特定实施方案中,本文所述的双特异性蛋白可含有fc多肽二聚体,所述二聚体具有(i)具有seq id no:133的序列的第一fc多肽和(ii)具有seq id no:141的序列的第二fc多肽。在特定实施方案中,本文所述的双特异性蛋白可含有fc多肽二聚体,所述二聚体具有(i)与seq id no:133的序列具有至少90%同一性的第一fc多肽和(ii)具有seq id no:146的序列的第二fc多肽。
[0575]
用于调节效应子功能的fc多肽修饰
[0576]
在一些实施方案中,本文所述的任何双特异性蛋白中存在的一个或两个fc多肽可包含降低效应子功能(即,在结合至介导效应子功能的在效应细胞上表达的fc受体时诱导某些生物学功能的能力降低)的修饰。抗体效应子功能的实例包括但不限于c1q结合和补体依赖性细胞毒性(cdc)、fc受体结合、抗体依赖性细胞介导的细胞毒性(adcc)、抗体依赖性细胞介导的吞噬作用(adcp)、细胞表面受体(例如b细胞受体)的下调,以及b细胞活化。效应子功能可随抗体类别而变化。例如,天然人igg1和igg3抗体在结合至存在于免疫系统细胞上的适当fc受体时可引发adcc和cdc活性;并且天然人igg1、igg2、igg3和igg4在结合至存
在于免疫细胞上的适当fc受体时可引发adcp功能。
[0577]
在一些实施方案中,本文所述的双特异性蛋白中存在的一个或两个fc多肽可包含减少或消除效应子功能的修饰。根据eu编号方案,降低效应子功能的例示性fc多肽突变包括但不限于ch2结构域中的取代,例如在位置234和235处。例如,在一些实施方案中,一个或两个fc多肽可包含在位置234和235处的丙氨酸残基。因此,一个或两个fc多肽可具有l234a和l235a(在本文中也称为“lala”)取代。
[0578]
调节效应子功能的另外的fc多肽突变包括但不限于以下:位置329可具有其中脯氨酸被甘氨酸、丙氨酸、丝氨酸或精氨酸或大到足以破坏在fc的脯氨酸329与fcγriii的色氨酸残基trp 87和trp 110之间形成的fc/fcγ受体界面的氨基酸残基取代的突变。根据eu编号方案,另外的例示性取代包括s228p、e233p、l235e、n297a、n297d和p331s。还可存在多个取代,例如,根据eu编号方案,人igg1 fc区的l234a和l235a;人igg1 fc区的l234a、l235a和p329g;人igg4 fc区的s228p和l235e;人igg1 fc区的l234a和g237a;人igg1 fc区的l234a、l235a和g237a;人igg2 fc区的v234a和g237a;人igg4 fc区的l235a、g237a和e318a;以及人igg4 fc区的s228p和l236e。在一些实施方案中,一个或两个fc多肽可具有调节adcc的一个或多个氨基酸取代,例如,根据eu编号方案,在位置298、333和/或334处的取代。
[0579]“顺式lala”构型
[0580]
在本文所述的任何双特异性蛋白的一些实施方案中,双特异性蛋白中的两个fc多肽的两个fc多肽中的仅一个(而不是两个fc多肽)被修饰以降低效应子功能并结合tfr。另一个fc多肽不含有tfr结合位点或任何降低效应子功能的修饰。双特异性蛋白中的fc多肽二聚体的两个fc多肽中的仅一个含有tfr结合位点和降低fcγr结合的修饰(例如,lala取代)两者,而另一个fc多肽不含有tfr结合位点或任何降低fcγr结合的修饰,被称为具有顺式lala构型。
[0581]
例如,在一些实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)具有seq id no:137的序列的第一fc多肽,其具有tfr结合位点和lala取代两者,以及杵修饰,和(ii)与seq id no:133的序列具有至少90%同一性的第二fc多肽,其仅具有臼修饰。在一些实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)具有seq id no:142的序列的第一fc多肽,其具有tfr结合位点和lala取代两者,以及杵修饰,和(ii)与seq id no:133的序列具有至少90%同一性的第二fc多肽,其仅具有臼修饰。在一些实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)具有seq id no:147的序列的第一fc多肽,其具有tfr结合位点和lala取代两者,以及杵修饰,和(ii)与seq id no:133的序列具有至少90%同一性的第二fc多肽,其仅具有臼修饰。
[0582]
在特定实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)第一fc多肽,根据eu编号,其包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%同一性的序列,和(ii)第二fc多肽,根据eu编号,其包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%同一性的序列。
[0583]
在特定实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)第一fc多肽,根据eu编号,其包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%同一性的序列,和(ii)第二fc多肽,根据eu编号,其包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ser、在位置413处的ser、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:137的序列具有至少90%的同一性的序列。
[0584]
在特定实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)第一fc多肽,根据eu编号,其包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ala、在位置413处的thr、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:142的序列具有至少90%同一性的序列,和(ii)第二fc多肽,根据eu编号,其包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%同一性的序列。
[0585]
在特定实施方案中,本文所述的双特异性蛋白可含有具有顺式lala构型的fc多肽二聚体,所述二聚体具有(i)第一fc多肽,根据eu编号,其包含在位置366处的ser、在位置368处的ala和在位置407处的val,以及与seq id no:133的序列具有至少90%同一性的序列,和(ii)第二fc多肽,根据eu编号,其包含在位置234处的ala、在位置235处的ala、在位置366处的trp、在位置384处的tyr、在位置386处的thr、在位置387处的glu、在位置388处的trp、在位置389处的ala、在位置413处的thr、在位置415处的glu、在位置416处的glu和在位置421处的phe,以及与seq id no:142的序列具有至少90%的同一性的序列。
[0586]
用于延长血清半衰期的fc多肽修饰
[0587]
在一些实施方案中,可将提高血清半衰期的修饰引入本文所述的任何双特异性蛋白中。例如,在一些实施方案中,如根据eu编号方案进行编号,本文所述的双特异性蛋白中存在的一个或两个fc多肽可包含在位置252处的酪氨酸、在位置254处的苏氨酸和在位置256处的谷氨酸。因此,一个或两个fc多肽可具有m252y、s254t和t256e取代。或者,如根据eu编号方案进行编号,一个或两个fc多肽可具有m428l和n434s取代。或者,一个或两个fc多肽可具有n434s或n434a取代。
[0588]
去除c端赖氨酸残基的fc多肽
[0589]
在本文所述的双特异性蛋白的一些实施方案中,一个或两个fc多肽的c端赖氨酸可去除(例如,根据eu编号,在fc多肽的位置447处的lys残基)。c端赖氨酸残基在许多物种的免疫球蛋白中高度保守,并且可能在蛋白质产生期间被细胞机制完全或部分地去除。在一些实施方案中,去除fc多肽中的c端赖氨酸可改善双特异性蛋白的稳定性。
[0590]
v.接头
[0591]
如本文所述,双特异性蛋白可含有一个或多个接头。接头是指双特异性蛋白中的两个元件之间的键联(即,vh区与v
l
区之间、scfv与fc多肽之间、scfv与fd部分之间、scfv与轻链之间,vh区或v
l
区与fd部分之间,vh区或v
l
区与轻链之间或者vh区或v
l
区与fc多肽之间)。在一些实施方案中,接头可以是肽接头,其可连接双特异性蛋白中的两个元件以提供空间和/或柔性。
[0592]
在一些实施方案中,接头可包括1-100个氨基酸(例如,1-90、1-80、1-70、1-90、1-60、1-50、1-40、1-30、1-20、1-10、1-8、1-6、1-4、5-100、10-100、15-100、20-100、30-100、40-100、50-100、60-100、70-100、80-100、90-100、10-90、10-80、10-70、10-60、10-50、10-40、10-30、10-25、10-20或10-15个氨基酸)。在一些实施方案中,两个fc结构域单体之间的接头是含有1-30个氨基酸(例如,1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个氨基酸)的氨基酸间隔区。接头可含有天然氨基酸、非天然氨基酸或其组合。在一些实施方案中,接头可以是柔性接头,例如,含有诸如gly、asn、ser、thr、ala等氨基酸。此类接头可使用已知参数来设计,并且可以具有任何长度并且含有任何数量的任何长度的重复单元(例如,gly和ser残基的重复单元)。例如,接头可具有重复,诸如两个、三个、四个、五个或更多个ggggs(seq id no:117)、ggsg(seq id no:151)、gsgg(seq id no:152)或sggg(seq id no:153)重复或单一ggggs(seq id no:117)、ggsg(seq id no:151)、gsgg(seq id no:152)或sggg(seq id no:153)。含有gly和ser残基的柔性接头的实例包括但不限于:ggsgggsgggsgggsgggsg(seq id no:116;(ggsg)5)、ggggs(seq id no:117;g4s)、ggggsggggs(seq id no:118;(g4s)2)、ggggsggggsggggs(seq id no:119;(g4s)3)、ggggsggggsgggg(seq id no:120;(g4s)
2-g4)、ggggsggggsgg(seq id no:121)、gggggsggggs(seq id no:122)和gggggsgggggsggggs(seq id no:123)。
[0593]
在一些实施方案中,接头还可含有甘氨酸和丝氨酸以外的氨基酸,例如ggggsepkss(seq id no:124)、astkgpsvf(seq id no:125)或rtvaapsvfi(seq id no:126)。本领域还描述了其他接头的实例,参见例如,chen等人adv.drug deliv rev.65(10):1357-1369,2013。
[0594]
vi.双特异性蛋白的制备
[0595]
为了制备本文所述的双特异性蛋白,可使用本领域已知的许多技术。在一些实施方案中,编码所关注的抗体的重链和轻链的基因可从细胞中(例如从杂交瘤中)克隆。编码单克隆抗体的重链和轻链的基因文库也可从杂交瘤或浆细胞制得。或者,噬菌体或酵母展示技术可用于鉴定特异性结合至所选抗原的抗体和fab片段。
[0596]
可使用任何数量的表达系统产生双特异性蛋白,包括原核和真核表达系统。在一些实施方案中,表达系统是哺乳动物细胞表达系统,诸如杂交瘤,或cho细胞表达系统。许多此类系统可从商业供应商处广泛获得。在一些实施方案中,编码包含双特异性蛋白的多肽的多核苷酸可使用单一载体表达,例如,在双顺反子表达单元中,或在不同启动子的控制下。在其他实施方案中,编码包含双特异性蛋白的多肽的多核苷酸可使用单独的载体表达。
[0597]
在一些方面,本公开提供了分离的核酸,其包含编码包含如本文所述的双特异性蛋白的任何多肽的核酸序列;包含此类核酸的载体;和其中引入了所述核酸的宿主细胞,其用于复制核酸和/或表达双特异性蛋白。
[0598]
在一些实施方案中,多核苷酸(例如,分离的多核苷酸)包含编码包含如本文所公开的双特异性蛋白(例如,如上文第iii部分所述)的多肽的核苷酸序列。在一些实施方案中,多核苷酸包含编码下文非正式序列表中公开的一个或多个氨基酸序列(例如,重链、轻链和/或fc多肽序列)的核苷酸序列。在一些实施方案中,多核苷酸包含编码与下文非正式序列表中公开的序列具有至少85%序列同一性(例如,至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列同一
性)的氨基酸序列的核苷酸序列。在一些实施方案中,如本文所述的多核苷酸可操作地连接至异源核酸,例如异源启动子。
[0599]
含有编码本公开的抗体或其片段的多核苷酸的合适的载体包括克隆载体和表达载体。虽然所选择的克隆载体可根据旨在使用的宿主细胞而变化,但是可用的克隆载体通常具有自我复制的能力,可拥有针对特定限制性内切核酸酶的单一靶标,和/或可携带可用于选择含有载体的克隆的标志物的基因。实例包括质粒和细菌病毒,例如puc18、puc19、bluescript(例如,pbs sk )及其衍生物、mpl8、mpl9、pbr322、pmb9、cole1、pcr1、rp4、噬菌体dna,以及穿梭载体诸如psa3和pat28。这些和许多其他克隆载体可从商业供应商(诸如biorad、strategene和invitrogen)获得。
[0600]
表达载体一般是含有本公开的核酸的可复制多核苷酸构建体。表达载体可在宿主细胞中作为游离体或作为染色体dna的整体部分复制。合适的表达载体包括但不限于质粒、病毒载体(包括腺病毒、腺相关病毒、逆转录病毒),以及任何其他载体。
[0601]
用于克隆或表达如本文所述的多核苷酸或载体的合适的宿主细胞包括原核或真核细胞。在一些实施方案中,宿主细胞是原核细胞。在一些实施方案中,宿主细胞是真核细胞,例如中国仓鼠卵巢(cho)细胞或淋巴细胞。在一些实施方案中,宿主细胞是人细胞,例如人胚胎肾(hek)细胞。
[0602]
在另一方面,提供了制备如本文所述的双特异性蛋白的方法。在一些实施方案中,所述方法包括在适合双特异性蛋白表达的条件下培养如本文所述的宿主细胞(例如,表达如本文所述的多核苷酸或载体的宿主细胞)。在一些实施方案中,随后从宿主细胞(或宿主细胞培养基)中回收双特异性蛋白。在一些实施方案中,对双特异性蛋白进行纯化,例如通过色谱法。
[0603]
vii.治疗方法
[0604]
在一些方面,本文提供了通过向受试者施用治疗有效量的本文所述的任何双特异性蛋白或含有其的药物组合物来治疗受试者的癌症(例如,her2阳性癌症)或治疗癌症(例如,her2阳性癌症)的脑转移的方法。本文还提供了跨内皮对能够结合her2(例如人her2)或其抗原结合片段的抗体可变区进行转胞吞作用的方法。在一些实施方案中,所述方法包括使内皮与包含本文所述的双特异性蛋白的组合物接触。在一些实施方案中,内皮是血脑屏障(bbb)。
[0605]
可根据本文提供的方法治疗的her2阳性癌症的非限制性实例包括her2阳性乳腺癌、卵巢癌、膀胱癌、唾液腺癌、子宫内膜癌、胰腺癌和非小细胞肺癌(nsclc),以及her2阳性胃腺癌和/或her2阳性胃食管接合部腺癌。在一些实施方案中,her2阳性癌症是her2阳性乳腺癌。在一些实施方案中,her2阳性癌症是her2阳性胃腺癌和/或her2阳性胃食管接合部腺癌。在一些实施方案中,her2阳性癌症是转移性癌症。
[0606]
在再其他方面,本文提供了用于治疗癌症(例如,her2阳性癌症)转移的方法。在一些实施方案中,所述方法包括向受试者施用治疗有效量的本文所述的抗her2双特异性蛋白。在一些实施方案中,转移是上述her2阳性癌症的脑转移。在一些实施方案中,转移是her2阳性乳腺癌的脑转移。在一些实施方案中,转移是her2阳性胃腺癌和/或her2阳性胃食管接合部腺癌的脑转移。
[0607]
在一些实施方案中,治疗益处可包括肿瘤生长的减少或减缓、肿瘤大小(例如体
积)的减少、肿瘤细胞活力的降低、转移性病灶数量的减少、癌症(例如her2阳性癌症)的一种或多种体征或症状的改善,和/或患者存活率的增加。在一些实施方案中,肿瘤细胞存活、肿瘤生长、肿瘤大小和/或转移性病灶数量减少至少约10%、20%、30%、40%、50%、60%、70%、80%、90%或更多。
[0608]
在一些实施方案中,抗her2双特异性蛋白拮抗her2活性。在一些实施方案中,her2活性被抑制(例如,抑制至少约10%、20%、30%、40%、50%、60%、70%、80%、90%或更多)。
[0609]
本文所述的抗her2双特异性蛋白的施用途径可以是经口、腹膜内、透皮、皮下、静脉内、肌内、鞘内、吸入、局部、病灶内、直肠、支气管内、鼻腔、透粘膜、肠、眼或耳部递送,或本领域已知的任何其他方法。在一些实施方案中,抗her2双特异性蛋白经口、静脉内或腹膜内施用。
[0610]
viii.药物组合物和试剂盒
[0611]
在其他方面,提供了包含根据本公开的抗her2双特异性蛋白的药物组合物和试剂盒。
[0612]
药物组合物
[0613]
制备用于本公开的制剂的指南可在本领域技术人员已知的任何数量的药物制备和制剂手册中找到。
[0614]
在一些实施方案中,药物组合物包含如本文所述的抗her2双特异性蛋白,并且还包含一种或多种药学上可接受的载剂和/或赋形剂。药学上可接受的载剂包括生理上相容且不干扰或以其他方式抑制活性剂的活性的任何溶剂、分散介质或包衣。
[0615]
在一些实施方案中,可配制双特异性蛋白用于通过注射进行肠胃外施用。通常,用于体内施用的药物组合物是无菌的,例如加热灭菌、蒸汽灭菌、无菌过滤或照射。
[0616]
本文所述的药物组合物的剂量和所需药物浓度可根据设想的特定用途而变化。
[0617]
试剂盒
[0618]
在一些实施方案中,提供了用于治疗癌症(例如,her2阳性癌症)的试剂盒,其包含本文所述的双特异性蛋白。在一些实施方案中,试剂盒还包含一种或多种另外的治疗剂。例如,在一些实施方案中,试剂盒包含如本文所述的双特异性蛋白并且还包含一种或多种用于治疗癌症的另外的治疗剂。在一些实施方案中,试剂盒还包含说明材料,所述说明材料含有用于实践本文所述方法的指导(即,方案)(例如,使用试剂盒施用双特异性蛋白的说明书)。虽然所述说明材料通常包含书面或打印材料,但它们并不限于此。本公开涵盖能够存储此类说明书并且将它们传达给最终用户的任何介质。此类介质包括但不限于电子存储介质(例如,磁盘、磁带、盒式磁带、芯片)、光学介质(例如,cd-rom)等。此类介质可包括提供此类说明材料的互联网网站的网址。
[0619]
ix.实施例
[0620]
将通过具体实施例来更详细地描述本发明。以下实施例仅出于说明目的而提供,且不旨在以任何方式限制本发明。
[0621]
实施例1.双特异性蛋白的产生
[0622]
产生具有如本文所述并且在图1-图5中示出的双特异性蛋白结构的工程化蛋白,以靶向人her2的亚结构域ii和人her2的亚结构域iv。在一些构建体中,fc多肽的c端赖氨酸
被去除。在一些构建体中,将fd部分(vh ch1)克隆至包含编码fc多肽的序列的表达载体中。在一些实施方案中,fc多肽被工程化以具有tfr结合位点。在构建体的一些实施方案中,fc多肽中的一个含有tfr结合位点和“杵”(t366w)突变(例如,seq id no:137),而另一个fc多肽含有“臼”(t366s/l368a/y407v)突变(例如,seq id no:133)。另外,一个或两个fc多肽还含有突变l234a/l235a,其减弱了fcγr结合。
[0623]
将载体与对应的轻链载体一起以1:1:2的杵:臼:轻链的比率共转染至expicho或expi293细胞中。通过将上清液加载在蛋白a柱上,从条件培养基中纯化表达的蛋白。将柱用10个柱体积的pbs(ph 7.4)洗涤。用50mm柠檬酸钠(ph 3.0,含有150mm nacl)洗脱蛋白质,并立即用200mm精氨酸/137mm琥珀酸(ph 5.0)中和。使用200mm精氨酸/137mm琥珀酸(ph 5.0)作为运行缓冲液,通过尺寸排阻色谱(sec)(ge superdex200)进一步纯化蛋白质。通过完整质量lc/ms确认纯化的蛋白质,并且通过sds-page和分析型hplc-sec确认纯度>95%。产生了含有未修饰的人igg1恒定区的抗her2双特异性蛋白。下表1提供抗her2双特异性蛋白和两种对照抗her2抗体的序列。
[0624]
表1
[0625][0626][0627]
实施例2.双特异性蛋白的biacore评估
[0628]
使用biacore t200或biacore 8k,通过spr测量双特异性蛋白的亲和力。biacore
tm
series s cm5传感器芯片固定有用于her2亲和力测量的单克隆小鼠抗人igg(fc)抗体或用于tfr亲和力测量的小鼠抗人fab(来自ge healthcare的人抗体或fab捕获试剂盒)。以30μl/min的流速注射分析物(重组her2细胞外结构域或重组tfr顶端结构域)的连续3倍稀释液。使用针对her2细胞外结构域结合的3分钟缔合和10分钟解离和针对人tfr顶端结构域结合的40秒缔合和3分钟解离来分析每个样品。每次注射后,使用3m mgcl2或50mm甘氨酸(ph 2.0)对芯片进行再生。通过从以相似密度捕获无关igg的流动池中减去ru来校正
结合反应。同时对kon和koff进行拟合的1:1朗格缪尔模型用于动力学分析。构建体“抗her2_div/dii_scfv_1”的kd为2.3nm,构建体“抗her2_div/dii_scfv_2”的kd为1.9nm。这两种构建体描述如下。
[0629]
两种构建体“抗her2_div/dii_scfv_1”和“抗her2_div/dii_scfv_2”都具有“fab-fc多肽/scfv-fc多肽”结构。在构建体“抗her2_div/dii_scfv_1”中,(a)包含seq id no:1的序列(抗her2dii fab通过铰链区融合至具有杵lala的ch3c.35.23.4的n端),(b)包含seq id no:23的序列(抗her2div scfv通过铰链区融合至具有臼突变的fc多肽的n端),并且(c)包含seq id no:25的序列。在构建体“抗her2_div/dii_scfv_2”中,(a)包含seq id no:5的序列(抗her2dii fab通过铰链区融合至具有臼突变的fc多肽的n端),(b)包含seq id no:24的序列(抗her2div scfv通过铰链区融合至具有杵lala的ch3c.35.23.4的n端),并且(c)包含seq id no:25的序列。在两种构建体中,scfv部分都含有在位置100处具有gln至cys取代的抗her2div v
l
区(seq id no:115)和在位置44处具有gly至cys取代的抗her2div vh区(seq id no:113)。而且在两种构建体中,(b)中的铰链区在位置5处具有cys至ser突变(epkssdkthtcppcp(seq id no:129))。
[0630]
下表2进一步示出抗her2双特异性蛋白的her2结合kd和tfr结合kd。
[0631]
表2
[0632] her2结合kd(nm)tfr结合kd(nm)抗her2div对照3.0不适用抗her2dii对照2.9不适用双特异性蛋白#13.0460双特异性蛋白#20.024480双特异性蛋白#30.027450双特异性蛋白#40.019470双特异性蛋白#50.031540双特异性蛋白#60.0074490双特异性蛋白#70.0038350双特异性蛋白#80.0031290双特异性蛋白#90.0033500双特异性蛋白#100.0017520双特异性蛋白#110.0028470双特异性蛋白#120.0006560双特异性蛋白#130.0008600
[0633]
实施例3.共同靶向tfr和her2亚结构域ii和iv
[0634]
许多肿瘤细胞和肿瘤细胞系,诸如bt474和oe19,表达her2和tfr两者。虽然已经充分确定靶向her2亚结构域iv的抗体能够在一些her2
细胞系中抑制肿瘤细胞生长并降低肿瘤细胞活力,但我们试图了解共同靶向her2亚结构域iv和tfr是否会导致增强的细胞杀伤。
[0635]
使用了具有“fab-fc多肽/scfv-fc多肽”结构的两种构建体。构建体“抗her2_div/dii_scfv_1”和构建体“抗her2_div/dii_scfv_2”描述于先前的实施例中。
[0636]
我们首先在对抗her2疗法敏感的her2
肿瘤细胞系bt474的生长抑制测定中比较
了两种构建体和对照单克隆抗her2抗体。将bt474细胞以10,000个细胞/孔铺种在96孔板中过夜,用60μl从166nm(25,000ng/ml)开始的所关注的分子的1:3连续稀释液处理。在第3天补充培养基(rpmi)和药物。在第6天,在50μl生长培养基中使用5μl wst-1试剂(sigma aldrich)测定细胞生长。将板在wst-1试剂存在下孵育4小时,并在440nm处测定吸光度。基于a440nm计算生长抑制/增殖百分比,并且将其归一化至未处理对照。如图6a中所示,抗her2-div和抗her2-dii的组合相对于对照降低了bt474细胞活力,其中最大抑制为约87%。相似地,与抗-her2-div和抗-her2-dii相比,抗-her2_div/dii_scfv_1和抗-her2_div/dii_scfv_2显示出相似的最大生长抑制(图6a)。
[0637]
接下来,我们用对抗her2治疗具有抗性的另一her2
癌细胞系oe19对两种构建体和对照单克隆抗her2抗体进行了比较。如图6b中所示,与bt474不同(其中两种抗her2_div/dii_scfv构建体与抗her2-div和抗her2-dii的组合的最大生长抑制作用之间没有差异),oe19细胞系在抗her2_div/dii_scfv_1和抗her2_div/dii_scfv_2处理时最大抑制为约80%,而细胞对抗her2-div和抗her2-dii的组合的反应最小。这些结果表明,与仅靶向her2亚结构域相比,靶向her2亚结构域iv、her2亚结构域ii和tfr可导致抗her2抗性细胞系中细胞生长抑制增强。值得注意的是,如果细胞系已经对抗her2疗法敏感,则任何增强都可能被掩盖。
[0638]
实施例4.抗her2双特异性蛋白的体内药代动力学性质
[0639]
为了评价在不存在tfr结合的情况下抗her2双特异性蛋白的体内血浆药代动力学,向c57bl/6小鼠静脉内施用10mg/kg的抗her2双特异性蛋白。在单一剂量后30分钟、1天、4天和7天收集血液,处理成血浆,并且在-80℃下储存直至分析。使用抗人igg夹心elisa(图7)并使用适当的给药溶液作为标准品来对血浆中双特异性蛋白的总治疗浓度进行量化。将板用抗人igg包被过夜,然后用洗涤缓冲剂洗涤3次。将标准品和相关稀释样品在室温下搅拌孵育2小时。孵育后,将板用洗涤缓冲剂洗涤3次。将检测抗体稀释在封闭缓冲剂中,并将板在室温下搅拌孵育1小时。在最后3次洗涤后,通过添加tmb底物使板显影并孵育5-10分钟。淬灭反应并使用450nm吸光度(biotek酶标仪)读数。所有抗her2双特异性蛋白的清除率值都在正常igg范围内。
[0640]
实施例5.抗her2双特异性蛋白的体内脑摄取
[0641]
为了评价抗her2双特异性蛋白至脑中的体内摄取,向tfr
mu/hu ki小鼠静脉内施用50mg/kg的抗her2双特异性蛋白。给药后大约24小时,通过心脏穿刺将全血收集至涂有edta的管中,然后用冰冷的pbs灌注动物。使用新鲜全血评价临床血液化学和网状红细胞定量(图8a),并将单独的等分试样处理成血浆。与对照处理的小鼠相比,大多数抗her2双特异性蛋白的网状红细胞值在正常范围内。
[0642]
血浆和新鲜脑在干冰上速冻并储存在-80℃下。使用qiagen tissue lyser ii用带有蛋白酶和磷酸酶抑制剂的10倍体积的pbs中的按组织重量计1%np40缓冲剂对脑进行匀浆;上清液储存在-80℃下。使用夹心elisa定量抗her2双特异性蛋白的血浆(图8b)和脑裂解物(图8c)浓度。血浆浓度表现出预期的tfr介导的药物处置;脑中抗her2双特异性蛋白的脑浓度在大约15nm至52nm范围内,表明这些分子能够结合至血脑屏障上的tfr并被转运至脑中。所得脑-血浆浓度百分比介于大约1-2%之间(图8d),大约比缺少tfr或其他受体介导的转胞吞作用靶向的抗体的预期高十倍。此数据表明并支持如本文所述的具有不同结构
的多种抗her2双特异性蛋白是脑渗透性的。
[0643]
实施例6.抗her2双特异性蛋白的体外生长抑制
[0644]
用对抗her2疗法敏感的各种her2
肿瘤细胞系(bt474(图9a-图9f)、oe19(图9g-图9i)和zr75(图9j-图9l))评价抗her2双特异性蛋白和现有抗her2疗法的体外生长抑制功效。将肿瘤细胞以10,000个细胞/孔铺种在96孔板中过夜,用60μl从166nm(25,000ng/ml)开始的所关注的分子的1:3连续稀释液处理。在第3天补充培养基(rpmi)和药物。对于神经调节蛋白1(nrg1)处理的bt474组(图9d-图9f),将细胞在50ng/ml nrg1存在下孵育。在第6天,在50μl生长培养基中使用5μl wst-1试剂(sigma aldrich)测定细胞生长。将板在wst-1试剂存在下孵育4小时,并在440nm处测定吸光度。基于a440 nm计算生长抑制/增殖百分比,并且将其归一化至未处理对照。下表3进一步示出抗her2双特异性蛋白和抗her2对照在三种不同的her2
细胞系中的生长抑制功效。图9a-图9l和表3示出,总体抗her2双特异性蛋白显示出与具有野生型fc的抗her2div对照和抗her2dii对照等效或优于其的生长抑制。在具有某些抗her2双特异性蛋白的一些细胞系中,与具有野生型fc的抗her2div对照或抗her2dii对照相比,生长抑制降低,这可能是由于在某些构型中对结合位点的竞争。
[0645]
表3
[0646]
[0647][0648]
*nd
–
未测定
[0649]
非正式序列表
[0650]
[0651]
[0652]
[0653]
[0654]
[0655]
[0656]
[0657]
[0658]
[0659]
[0660]
[0661]
[0662]
[0663]
[0664]
[0665]
[0666]
[0667]
[0668]
[0669]
[0670]
[0671]
[0672]
[0673]
[0674]
[0675]
[0676]
[0677]
[0678]
[0679]
[0680]
[0681]
[0682]
[0683]
[0684]
[0685]
[0686]
[0687]
[0688]
[0689]
[0690]
[0691]
[0692]
[0693]
[0694]
[0695]
[0696]
[0697]
[0698]
[0699]
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。