1.本发明涉及与皮肤色素沉着程度有关联显著性的基因多态性标记、包含对其能够进行检测的探针或能够进行扩增的制剂的用于诊断皮肤色素沉着与否的组合物、包含上述用于诊断皮肤类型的色素沉着与否的组合物的用于诊断皮肤类型的色素沉着与否的试剂盒或微阵列、以及利用上述基因多态性标记或标记组合提供关于皮肤色素沉着程度的信息的方法。
背景技术:
2.皮肤色素沉着的变化可能会受到环境因素和年龄、性别和基因变异等因素的影响。最近的许多基因组全长分析研究(gwas)表明,位于与色素沉着的生物学途径功能相关的基因中的基因变异与皮肤色素沉着显著相关。然而,现有的gwas研究大部分以欧洲人为对象进行,而对亚洲人种的研究几乎没有,因此对亚洲人种的皮肤色素沉着相关遗传变异的理解较低。
3.皮肤是人体的最外层,对外部环境做出反应,保护身体免受有害物质的侵害,感受不同的感觉,进行体温调节等各种功能,并且皮肤的适当功能是保护身体免受疾病侵害、保持魅力所必需的。
4.皮肤色素沉着类型分为在没有外部环境刺激的情况下决定皮肤颜色的类型和雀斑及面部色素斑点等刺激性皮肤色素沉着(shekar等人,j invest dermatol.2005,125:1119-1129,del bino等人,int j mol sci.2018;19(9):2668),色素沉着水平因人种和个人而非常不同。为了发掘参与皮肤色素沉着相关特性的遗传因素,以欧洲和美国人口为对象,进行了对包括bnc2、ugt1a8、irf4和pomc在内的多个候选基因的研究(jacobs等人,hum genet.2013,132:147-158,nan等人,int j cancer.2009;125:909-917,praetorius c等人,cell.2013;155:1022-1033)。另外,由于皮肤色素沉着相关特性的遗传复杂性,进行了基因组全长水平分析研究以发现数百或数千个基因座,并且发现mc1r、slc24a5、slc45a2和bnc2等多个基因与皮肤色素沉着相关特性有关。
5.现有的gwas研究大部分以欧洲人为对象进行,而对亚洲人种的研究几乎没有,因此对亚洲人种的皮肤色素沉着相关遗传变异的理解较低,因此如果要发现新的基因变异或确认调节皮肤色素的因果基因,则需要对各种群体进行追加研究。
技术实现要素:
6.技术课题
7.本发明的发明人通过掌握决定个体皮肤特性的遗传特征,构建科学的皮肤分类标准,并以此为依据开发个人定制型有效成分,通过各种产品细分化,为开发不同皮肤特性的定制型化妆品做出贡献,经过不懈的努力的结果,确认了通过筛选与皮肤色素沉着有显著相关关系的特定单核苷酸多态性(snp)标记来诊断色素沉着与否的方法,从而完成了本发明。
8.技术方案
9.本发明的一个目的是提供一种用于诊断皮肤色素沉着与否的单核苷酸多态性(snp)标记。
10.本发明的又一目的是提供一种用于诊断皮肤色素沉着与否的组合物,其包含对用于诊断皮肤色素沉着与否的单核苷酸多态性(snp)标记能够进行检测的探针或能够进行扩增的制剂。
11.本发明的又一目的是提供一种用于诊断皮肤色素沉着与否的试剂盒或微阵列,其包含上述用于诊断皮肤色素沉着与否的组合物。
12.本发明的又一目的是提供一种提供关于皮肤色素沉着与否的信息的方法,其包括确认上述单核苷酸多态性标记的多态性位点的步骤。
13.发明效果
14.可以通过本发明的与皮肤色素沉着程度有关联显著性的基因多态性标记来提供关于个人的皮肤色素沉着程度的信息,此外,可以根据在个人中观察到的基因多态性标记的信息开发能够缓解皮肤色素沉着程度的定制型成分或产品。
具体实施方式
15.本发明所公开的各个说明及实施方式也可以应用于各个其他说明及实施方式。即,本发明所公开的各种要素的所有组合属于本发明的范畴。另外,本发明的范畴不限于下面描述的具体叙述。
16.为了达到本发明的目的,在一个方面中,本发明提供一种用于诊断皮肤色素沉着与否的单核苷酸多态性(snp)标记。
17.在另一个方面中,本发明提供一种用于诊断皮肤色素沉着与否的组合物,其包含对用于诊断皮肤色素沉着与否的单核苷酸多态性(snp)标记能够进行检测的探针或能够进行扩增的制剂。
18.根据上述皮肤色素沉着与否,可以区分个体的皮肤类型。
19.在本发明中,术语“多态性(polymorphism)”是指在一个基因座(locus)上存在两种以上的等位基因(allele)的情况,并且在多态性位点中,根据人的不同,仅单个碱基不同的称为单核苷酸多态性(single nucleotide polymorphism,snp)。优选的多态性标记具有在选定的群体中显示出1%以上、更具体地10%或20%以上的发生频率的两种以上的等位基因。“基因多态性标记”通常是指在同一基因位点(碱基)观察到两种以上的等位基因(allele)的情况,通常取决于个体,存在主要等位基因(major allele)/主要等位基因(major allele)、主要等位基因(major allele)/次要等位基因(minor allele)、次要等位基因(minor allele)/次要等位基因(minor allele)的情况。在本发明中,可以与“多态性标记”混用,并且是指次要等位基因的碱基和碱基位点,或者可以与染色体的数目(number)和碱基位置(baseposition)一起定义,但不限于此。
20.在本发明中,术语“等位基因(allele)”是指存在于同源染色体的同一基因座的一个基因的多种类型。等位基因也用于表示多态性,例如,snp具有两种类型的双等位基因(biallele)。另外,是指染色体的数目和碱基位置相同的两种以上的碱基的组合,上述碱基包括在特定群体的个体中发生频率高的主要等位基因(major allele)和发生频率低于上
述主要等位基因的次要等位基因(minor allele)。
21.具体地,本发明的基因多态性标记与皮肤色素沉着有关联显著性,在两种等位基因(allele)中保留一个以上的次要等位基因(minor allele)时,可以说皮肤色素沉着与具有主要等位基因(major allele)/主要等位基因(major allele)的个体相比具有显著性。即,在主要等位基因(major allele)/次要等位基因(minor allele)、次要等位基因(minor allele)/次要等位基因(minor allele)的情况下,与保留主要等位基因(major allele)/主要等位基因(major allele)的情况相比,可以看出与皮肤色素沉着程度相比,具有高于或低于其程度的皮肤特性。
22.在本发明中,术语“rs_id”是指对从1998年开始积累snp信息的ncbi初期登记的所有snp赋予的独立标识符rs-id。这种表中记载的rs_id是指本发明的多态性标记即snp标记。
23.在本发明中,术语“皮肤类型”是指待测量或诊断的个体的皮肤类型,可以用本发明的snp测量的皮肤类型不受限制地包括,但具体地可以是色素沉着。本发明的单核苷酸多态性标记可以测量准确的皮肤类型,因此还可以提供与有效成分接触的皮肤的变化的皮肤类型的信息,可以提供个人定制型化妆品等,但不限于此。
24.上述皮肤色素沉着还与美白有关,可以包括判断皮肤类型是因色素多而容易晒黑的皮肤还是因色素少而不易晒黑的美白皮肤的用于诊断皮肤类型的美白与否的标记,但不限于此。
25.另外,出于本发明的目的,上述术语“皮肤色素沉着”是指观察到个人的皮肤中部分部位的颜色与整体颜色相比变成黑色或褐色。即,是指整体皮肤中与周围部分的皮肤颜色相比相对较暗的皮肤,测量观察到黑色或褐色的部位的比例的结果,当色素沉着减少时,可以诱导皮肤美白效果。
26.具体地,上述单核苷酸多态性标记可以是选自表1至表3所示的单核苷酸多态性标记中的一种以上的单核苷酸多态性标记。上述表1至表3所示的单核苷酸多态性标记可以判断是否与皮肤色素沉着程度有关联性。
27.本发明的单核苷酸多态性标记的皮肤类型诊断与否通过测量各标记的频率数来判断。上述显著性的特征在于但不限于p-值,例如小于0.05、小于0.01、小于0.001、小于0.0001、小于0.00001、小于0.000001、小于0.0000001、小于0.00000001、或小于0.000000001的p-值(p-value)。具体地,p-值可以小于0.01,更具体地,p-值可以小于0.001,更具体地可以小于0.0001,但不限于此。
28.本发明的单核苷酸多态性(snp)标记可以是选自表1至表3所示的标记中的任一种以上,但不限于此。上述单核苷酸多态性(snp)标记可以是一个以上,并且可以以两个以上、三个以上、四个以上等能够判断色素沉着的个数的组合利用,但不限于此。
29.上述标记可以是snp其本身,或由包括上述snp位置的5-100个连续的dna序列构成的多核苷酸,或由其互补序列构成的多核苷酸,但不限于此。
30.具体地,在一个具体例中,单核苷酸多态性标记可以是选自表1所示的标记中的任一种以上,但不限于此。
31.可以如下说明选自表1所示的标记中的标记。
32.作为一例,当snp id为rs1710447时,chr.position(grch ver.37)记载为"5:
149192846",如果等位基因(allele)公开为a》g,则这表示人类的5号染色体的第149192846个碱基是a或g,并且位于等位基因(allele)的“》”右侧的碱基可意味着主要等位基因(major allele),位于左侧的碱基可意味着次要等位基因(minor allele)。
33.在一个具体例中,选自表1的标记可以由选自由以下多核苷酸;以及其互补多核苷酸组成的组的一个以上的多核苷酸组成,但不限于此:由包含第149192846个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149192846个碱基是a或g(rs17110447);由包含第149191111个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149191111个碱基是c或t(rs4235745);由包含第149195389个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149195389个碱基是t或c(rs251467);由包含第149196682个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196682个碱基是t或g(rs109077);由包含第149200603个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149200603个碱基是t或c(rs32587);由包含第149194923个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149194923个碱基是t或c(rs109075);由包含第149202206个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149202206个碱基是c或g(rs28282);由包含第149194485个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149194485个碱基是c或t(rs251468);由包含第149195603个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149195603个碱基是c或g(rs251466);由包含第149196090个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196090个碱基是a或c(rs251465);由包含第149196234个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196234个碱基是g或c(rs251464);由包含第149205630个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149205630个碱基是g或t(rs32581);由包含第149210848个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149210848个碱基是c或t(rs32579);由包含第149211868个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149211868个碱基是g或a(rs32578);由包含第149209546个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149209546个碱基是c或t(rs32580);由包含第149212430个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149212430个碱基是g或a(rs45520937);由包含第149216304个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149216304个碱基是c或t(rs45543631);由包含第149226633个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149226633个碱基是g或a(rs75739000);由包含第149216256个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149216256个碱基是c或t(rs45588534);由包含第149228648个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149228648个碱基是c或t(rs26124);由包含第149213456个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149213456个碱基是a或g(rs32576);由包含第149204852个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149204852个碱基是c或g
(rs17110586);由包含第149218886个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149218886个碱基是c或a(rs32574);由包含第149215213个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149215213个碱基是c或g(rs32575);由包含第149229822个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149229822个碱基是g或t(rs6579761);由包含第149231519个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149231519个碱基是c或t(rs26122);由包含第149233110个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149233110个碱基是c或a(rs7712296);由包含第149233186个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149233186个碱基是c或t(rs17653703);由包含第149216987个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149216987个碱基是a或g(rs10783180);由包含第149199148个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149199148个碱基是g或a(rs251459);由包含第149231830个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149231830个碱基是a或g(rs26121);由包含第149195125个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149195125个碱基是t或g(rs109076);由包含第149232525个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149232525个碱基是a或g(rs888853);由包含第149197230个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149197230个碱基是t或c(rs251460);由包含第149232308个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149232308个碱基是g或a(rs2341294);由包含第149196329个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196329个碱基是g或a(rs251463);由包含第149230952个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149230952个碱基是a或g(rs1549188);由包含第149230745个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149230745个碱基是t或c(rs1549186);由包含第149230787个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149230787个碱基是c或t(rs1549187);由包含第149231786个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149231786个碱基是g或a(rs1107344);由包含第149234235个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149234235个碱基是c或a(rs393499);由包含第149234236个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149234236个碱基是a或t(rs439598);由包含第149159174个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149159174个碱基是g或a(rs55926576);由包含第149190810个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149190810个碱基是c或t(rs79489540);由包含第149194785个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149194785个碱基是g或a(rs80069564);由包含第149191547个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149191547个碱基是c或t(rs78814834);由包含第149193133个碱基的5-100个连续的dna序列构成的多核苷酸,其中
人类的5号染色体的上述第149193133个碱基是c或t(rs77655035);由包含第149195726个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149195726个碱基是c或t(rs17110463);由包含第149196638个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196638个碱基是c或t(rs4705385);由包含第149196916个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196916个碱基是a或g(rs112183859);由包含第149192166个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149192166个碱基是t或c(rs4705384);由包含第149197747个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149197747个碱基是c或g(rs17600568);由包含第149199467个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149199467个碱基是c或t(rs79435714);由包含第149197609个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149197609个碱基是t或c(rs76390604);由包含第149197815个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149197815个碱基是t或c(rs10491360);由包含第149200932个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149200932个碱基是g或a(rs2003602);由包含第149190799个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149190799个碱基是g或a(rs79694606);由包含第149190248个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149190248个碱基是c或g(rs75548653);由包含第149203782个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149203782个碱基是a或g(rs17653577);由包含第149205992个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149205992个碱基是g或a(rs741582);由包含第149201956个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149201956个碱基是c或g(rs1078325);由包含第149208516个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149208516个碱基是g或t(rs76994147);由包含第149206531个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149206531个碱基是g或a(rs45560442);由包含第149227540个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149227540个碱基是t或c(rs76174857);由包含第149204461个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149204461个碱基是c或t(rs62382344);由包含第149192744个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149192744个碱基是g或t(rs67393352);由包含第149189449个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149189449个碱基是g或c(rs11948432);由包含第149205417个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149205417个碱基是c或a(rs32582);由包含第149196564个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196564个碱基是c或t(rs71586143);由包含第149200402个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149200402个碱基是a或g(rs17462080);由包含第149199656个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149199656个碱基是c或t
(rs7729592);由包含第149196513个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149196513个碱基是a或g(rs251462);由包含第149199889个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149199889个碱基是g或a(rs32589);由包含第149200920个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149200920个碱基是a或g(rs32586);由包含第149202168个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149202168个碱基是a或g(rs32585);由包含第149200043个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149200043个碱基是t或c(rs32588);由包含第149203993个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149203993个碱基是a或g(rs32584);由包含第149187322个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149187322个碱基是g或a(rs73267734);由包含第149204444个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149204444个碱基是c或t(rs32583);由包含第149178996个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149178996个碱基是t或c(rs76861039);由包含第149179725个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149179725个碱基是t或c(rs17461842);由包含第149185923个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149185923个碱基是c或a(rs75321435);由包含第149187212个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149187212个碱基是c或t(rs80262653);由包含第149187640个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149187640个碱基是g或a(rs75294071);由包含第149183256个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149183256个碱基是g或t(rs75465608);由包含第149234701个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149234701个碱基是g或a(rs4705386);由包含第149236008个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149236008个碱基是g或a(rs76295025);由包含第149164366个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149164366个碱基是g或a(rs74340302);由包含第149230730个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149230730个碱基是c或t(rs25846);由包含第149186478个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149186478个碱基是a或t(rs4705383);由包含第149162451个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149162451个碱基是g或a(rs62382308);由包含第149162294个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149162294个碱基是g或a(rs72830233);由包含第149212471个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149212471个碱基是g或a(rs17572019);由包含第149179741个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149179741个碱基是c或a(rs72830248);由包含第149159862个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149159862个碱基是c或g(rs62382307);由包含第149184905个碱基的5-100个连续的dna序列构成的
多核苷酸,其中人类的5号染色体的上述第149184905个碱基是g或t(rs759814);由包含第149159107个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149159107个碱基是a或g(rs56160216);由包含第149211392个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149211392个碱基是c或g(rs13178617);由包含第149182832个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149182832个碱基是g或c(rs55650980);由包含第149208768个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的5号染色体的上述第149208768个碱基是a或g(rs10491361);由包含第16795790个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16795790个碱基是a或c(rs16935073);由包含第16795241个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16795241个碱基是t或c(rs10810635);由包含第16794418个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16794418个碱基是c或a(rs12376135);由包含第16806521个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16806521个碱基是t或c(rs12351269);由包含第16801450个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16801450个碱基是g或t(rs4455968);由包含第16808172个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16808172个碱基是c或g(rs10122901);由包含第16806694个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16806694个碱基是g或c(rs10121347);由包含第16801743个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16801743个碱基是c或a(rs4523356);由包含第16801120个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16801120个碱基是a或c(rs10962609);由包含第16788274个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788274个碱基是a或g(rs12378588);由包含第16788253个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788253个碱基是t或c(rs12341542);由包含第16790074个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16790074个碱基是t或g(rs10115109);由包含第16790968个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16790968个碱基是g或c(rs2183407);由包含第16788363个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788363个碱基是a或g(rs12378598);由包含第16790960个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16790960个碱基是a或g(rs2183406);由包含第16799844个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16799844个碱基是c或t(rs10119811);由包含第16793202个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16793202个碱基是t或c(rs12341168);由包含第16793104个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16793104个碱基是a或g(rs10120562);由包含第16792350个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16792350个碱基是a或c(rs10119731);由包含第16796252个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16796252个碱基是t或g(rs10962601);由包含第16792675个碱
基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16792675个碱基是g或c(rs10125996);由包含第16791865个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16791865个碱基是c或t(rs12380481);由包含第16787767个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16787767个碱基是t或c(rs73410488);由包含第16788327个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788327个碱基是a或g(rs10756814);由包含第16788333个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788333个碱基是t或c(rs74645810);由包含第16788336个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788336个碱基是a或g(rs76233908);由包含第16788308个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788308个碱基是c或t(rs10756813);由包含第16788328个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788328个碱基是g或a(rs76211545);由包含第16815861个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16815861个碱基是a或g(rs10962619);由包含第16825110个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16825110个碱基是c或t(rs7043062);由包含第16789652个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16789652个碱基是t或c(rs4961496);由包含第16795159个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16795159个碱基是a或g(rs10962598);由包含第16812810个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16812810个碱基是t或c(rs10962618);由包含第16789024个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16789024个碱基是t或c(rs10810632);由包含第16789436个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16789436个碱基是a或g(rs6475082);由包含第16820923个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16820923个碱基是c或g(rs10962622);由包含第16795588个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16795588个碱基是a或t(rs16935071);由包含第16795211个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16795211个碱基是g或c(rs57542309);由包含第16824921个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16824921个碱基是c或g(rs10810640);由包含第16788367个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的9号染色体的上述第16788367个碱基是c或t(rs10810631);由包含第119568133个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119568133个碱基是g或a(rs17096846);由包含第119570121个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119570121个碱基是a或t(rs1925258);由包含第119569921个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119569921个碱基是g或a(rs1925257);由包含第119570915个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119570915个碱基是g或t(rs55927713);由包含第119571832个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第
119571832个碱基是g或a(rs17096850);由包含第119572168个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119572168个碱基是c或a(rs4751640);由包含第119547342个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119547342个碱基是c或t(rs4752110);由包含第119561946个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119561946个碱基是c或t(rs61865966);由包含第119570716个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119570716个碱基是c或a(rs28605039);由包含第119563422个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119563422个碱基是t或a(rs61865967);由包含第119544822个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119544822个碱基是a或g(rs7098480);由包含第119544385个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119544385个碱基是c或t(rs9804204);由包含第119547279个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119547279个碱基是g或t(rs2025562);由包含第119544027个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119544027个碱基是g或t(rs10749248);由包含第119545571个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545571个碱基是g或a(rs10749249);由包含第119547081个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119547081个碱基是t或c(rs10749250);由包含第119547669个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119547669个碱基是a或g(rs72829865);由包含第119545287个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545287个碱基是t或g(rs7099175);由包含第119545401个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545401个碱基是g或a(rs10787792);由包含第119545101个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545101个碱基是t或c(rs1925285);由包含第119545375个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545375个碱基是a或t(rs10787791);由包含第119545741个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545741个碱基是t或g(rs4752106);由包含第119545762个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545762个碱基是t或c(rs4752107);由包含第119546979个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119546979个碱基是t或c(rs2025561);由包含第119545238个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119545238个碱基是t或c(rs7098850);由包含第119546034个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119546034个碱基是a或t(rs4752109);由包含第119546496个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119546496个碱基是g或t(rs2031458);由包含第119546323个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119546323个碱基是a或g(rs10787794);由包含第119552651个
碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119552651个碱基是g或a(rs55723754);由包含第119566093个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119566093个碱基是c或t(rs11198114);由包含第119564143个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119564143个碱基是c或t(rs11198112);由包含第119563401个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119563401个碱基是t或c(rs10444110);由包含第119565538个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119565538个碱基是c或a(rs10444039);由包含第119561969个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119561969个碱基是c或t(rs7070575);由包含第119573178个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119573178个碱基是c或t(rs7098111);由包含第119572403个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119572403个碱基是c或t(rs35563099);由包含第119587425个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119587425个碱基是g或a(rs4751641);由包含第119584730个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119584730个碱基是c或t(rs61865972);由包含第119599727个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119599727个碱基是a或g(rs61866015);由包含第119575974个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119575974个碱基是c或t(rs1806957);由包含第119576317个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119576317个碱基是g或c(rs555269109);由包含第119576318个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119576318个碱基是g或t(rs532411111);由包含第119576319个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119576319个碱基是c或g(rs4994045);由包含第119584861个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119584861个碱基是a或g(rs6585463);由包含第119562387个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119562387个碱基是c或t(rs12146158);由包含第119572476个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119572476个碱基是c或a(rs74317863);由包含第119577677个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119577677个碱基是g或a(rs34878973);由包含第119601436个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119601436个碱基是t或g(rs7098136);由包含第119575798个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119575798个碱基是c或t(rs12773211);由包含第119601939个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119601939个碱基是g或c(rs7916406);由包含第119602316个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119602316个碱基是g或a(rs61866016);由包含第119602424个碱基的5-100个连续的dna序列构成的多核苷酸,其中
人类的10号染色体的上述第119602424个碱基是g或t(rs61866017);由包含第119601743个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119601743个碱基是g或a(rs12250372);由包含第119586963个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586963个碱基是c或t(rs4752118);由包含第119586186个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586186个碱基是a或t(rs10749252);由包含第119586231个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586231个碱基是c或t(rs7085292);由包含第119586178个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586178个碱基是c或t(rs4752117);由包含第119587158个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119587158个碱基是g或a(rs10749253);由包含第119591330个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119591330个碱基是g或a(rs10886151);由包含第119586980个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586980个碱基是a或g(rs4752119);由包含第119586462个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119586462个碱基是c或a(rs4431946);由包含第119592083个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119592083个碱基是c或t(rs1925264);由包含第119595140个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119595140个碱基是g或a(rs11498896);由包含第119582802个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119582802个碱基是c或t(rs4752116);由包含第119591168个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119591168个碱基是c或a(rs11198135);由包含第119581527个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的10号染色体的上述第119581527个碱基是g或a(rs10886148);由包含第89985940个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89985940个碱基是g或a(rs2228479);由包含第89986760个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89986760个碱基是a或g(rs3212369);由包含第89987201个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89987201个碱基是a或g(rs3212371);由包含第89986608个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89986608个碱基是a或g(rs2228478);由包含第89985177个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89985177个碱基是t或c(rs3212359);由包含第89985441个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89985441个碱基是t或a(rs3212363);由包含第89986025个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89986025个碱基是t或c(rs33932559);由包含第89986154个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89986154个碱基是a或g(rs885479);由包含第89985222个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的16号染色体的上述第89985222个碱基是a或g(rs3212361);由包含第200473658个碱基的5-100个连续的dna序列构成的多核苷
酸,其中人类的2号染色体的上述第200473658个碱基是c或t(rs12693889);由包含第200475044个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200475044个碱基是c或g(rs755276);由包含第200492565个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200492565个碱基是a或g(rs1901150);由包含第200492076个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200492076个碱基是a或c(rs4673381);由包含第200484107个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200484107个碱基是a或g(rs1823487);由包含第200478921个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200478921个碱基是t或g(rs1450566);由包含第200491198个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491198个碱基是g或c(rs62180586);由包含第200491299个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491299个碱基是g或a(rs13419888);由包含第200477380个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200477380个碱基是a或t(rs1450571);由包含第200477504个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200477504个碱基是c或t(rs10563018);由包含第200477506个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200477506个碱基是a或c(rs56112313);由包含第200484696个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200484696个碱基是a或g(rs2034486);由包含第200485100个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200485100个碱基是t或c(rs7591758);由包含第200487486个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200487486个碱基是c或a(rs1868723);由包含第200491726个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491726个碱基是a或c(rs7597643);由包含第200491877个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491877个碱基是a或g(rs4675732);由包含第200484452个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200484452个碱基是t或g(rs2034484);由包含第200491187个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491187个碱基是a或g(rs13394614);由包含第200479539个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200479539个碱基是a或t(rs4675721);由包含第200488306个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200488306个碱基是t或c(rs6435022);由包含第200488785个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200488785个碱基是t或c(rs1450565);由包含第200488905个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200488905个碱基是a或g(rs1450564);由包含第200489109个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200489109个碱基是g或a(rs1450563);由包含第200484657个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200484657个碱基是c或g(rs2167215);由包含第200481019个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200481019个碱基是a或t
(rs1376134);由包含第200486976个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200486976个碱基是t或g(rs983677);由包含第200487539个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200487539个碱基是g或c(rs1868724);由包含第200489964个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200489964个碱基是c或g(rs10206526);由包含第200490260个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200490260个碱基是a或g(rs986750);由包含第200491038个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491038个碱基是a或g(rs12467197);由包含第200482025个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200482025个碱基是a或g(rs6730854);由包含第200482231个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200482231个碱基是g或a(rs6759297);由包含第200482513个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200482513个碱基是c或t(rs1450567);由包含第200480777个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200480777个碱基是t或c(rs1376133);由包含第200481498个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200481498个碱基是c或g(rs2122532);由包含第200481506个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200481506个碱基是a或t(rs2122533);由包含第200495743个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200495743个碱基是a或c(rs4675733);由包含第200482881个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200482881个碱基是a或t(rs4507037);由包含第200499444个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200499444个碱基是g或a(rs12693894);由包含第200499255个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200499255个碱基是t或a(rs12052634);由包含第200491272个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200491272个碱基是a或g(rs13394647);由包含第200474888个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200474888个碱基是c或a(rs768637);由包含第200478354个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200478354个碱基是g或c(rs4675720);由包含第200484686个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200484686个碱基是c或t(rs2034485);由包含第200485648个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200485648个碱基是t或c(rs6743286);由包含第200498327个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200498327个碱基是c或t(rs78394027);由包含第200501964个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200501964个碱基是c或g(rs7562843);由包含第200499206个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200499206个碱基是c或g(rs12053334);由包含第200500431个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200500431个碱基是c或t(rs4624324);由包含第200500296个碱基的5-100个连续的dna
序列构成的多核苷酸,其中人类的2号染色体的上述第200500296个碱基是t或c(rs12477506);由包含第200506846个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200506846个碱基是c或t(rs28890501);由包含第200492529个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200492529个碱基是a或c(rs1901151);由包含第200501467个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200501467个碱基是t或a(rs57791827);由包含第200505203个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200505203个碱基是t或g(rs4673384);由包含第200494912个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200494912个碱基是a或g(rs7609357);由包含第200496036个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200496036个碱基是t或c(rs4673383);由包含第200497907个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200497907个碱基是t或g(rs1450561);由包含第200499399个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200499399个碱基是a或g(rs11691837);由包含第200501134个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200501134个碱基是t或c(rs10191530);由包含第200499157个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200499157个碱基是a或g(rs12053332);由包含第200498080个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200498080个碱基是a或g(rs1450559);由包含第200490231个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200490231个碱基是c或a(rs60315704);由包含第200497975个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200497975个碱基是g或a(rs1450560);由包含第200501827个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200501827个碱基是t或c(rs10194512);由包含第200489315个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200489315个碱基是g或a(rs17590093);由包含第200497286个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200497286个碱基是g或t(rs7578193);由包含第200494182个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200494182个碱基是g或a(rs1450562);由包含第200497711个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200497711个碱基是a或g(rs4675735);由包含第200496814个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200496814个碱基是a或t(rs4675734);由包含第200509555个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200509555个碱基是g或a(rs149819797);由包含第200509556个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200509556个碱基是c或t(rs145839112);由包含第200495510个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200495510个碱基是a或g(rs77833142);由包含第200510641个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的2号染色体的上述第200510641个碱基是a或c(rs78251380);由包含第200510941个碱基的5-100个连续的dna序列构成的多核苷酸,其中
人类的2号染色体的上述第200510941个碱基是t或g(rs80333946);由包含第3548231个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的19号染色体的上述第3548231个碱基是a或g(rs2240751);由包含第3542983个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的19号染色体的上述第3542983个碱基是c或t(rs12608592);由包含第3540539个碱基的5-100个连续的dna序列构成的多核苷酸,其中人类的19号染色体的上述第3540539个碱基是g或c(rs12984831)。上面记载的标记在表1中仅以一部分为例进行了记载,并且在其他位置的染色体上也可以用与上述相同的方法进行选择。
34.在另一个实施例中,与表1一样,可选择表2所示的单核苷酸多态性(snp)标记中的任一个以上,但不限于此。
35.在另一个实施例中,与表1一样,可选择表3所示的单核苷酸多态性(snp)标记中的任一个以上,但不限于此。
36.表2和表3所示的单核苷酸多态性标记可以如上所述进行解释和选择,但不限于此。
37.对于本发明的上述等位基因,在每个个体中染色体的数目(number)相同,其中存在snp的主要等位基因(major allele)和次要等位基因(minor allele),并且随着多态性标记的多态性位点的碱基逐一增加为次要等位基因,主要等位基因可逐一减少,并且随着碱基逐一增加为主要等位基因,次要等位基因可逐一减少。但是,次要等位基因和主要等位基因可增减的范围可以在i)主要等位基因(major allele)/主要等位基因(major allele)、ii)主要等位基因(major allele)/次要等位基因(minor allele)、iii)次要等位基因(minor allele)/次要等位基因(minor allele)的三种类型内,并且在上述三种类型的范围内等位基因可减少或增加,但不限于此。
38.另外,在本发明中,上述标记是随着个体的多态性标记的多态性位点的碱基逐一增加为主要等位基因(major allele),能够判断表型(色素沉着)的增减变化程度的标记。作为一例,在表1所示的标记中,如果个体的5号染色体的第149192846个碱基是次要等位基因a(rs17110447),则效应大小(effect size)为负(-),因此可以判断色素沉着减少,如果个体的9号染色体的第16795241个碱基是次要等位基因c(rs10810635),则效应大小为正( ),因此可以判断色素沉着增加,但不限于此。
39.具体地,当上述单核苷酸多态性标记包含一个以上的作为主要等位基因(major allele)的下述碱基时,可增加色素沉着,但不限于此:
40.人类的9号染色体的第16795790个碱基是a;人类的9号染色体的第16795241个碱基是t;人类的9号染色体的第16794418个碱基是c;人类的9号染色体的第16806521个碱基是t;人类的9号染色体的第16801450个碱基是g;人类的9号染色体的第16808172个碱基是c;人类的9号染色体的第16806694个碱基是g;人类的9号染色体的第16801743个碱基是c;人类的9号染色体的第16801120个碱基是a;人类的9号染色体的第16788274个碱基是a;人类的9号染色体的第16788253个碱基是t;人类的9号染色体的第16790074个碱基是t;人类的9号染色体的第16790968个碱基是g;人类的9号染色体的第16788363个碱基是a;人类的9号染色体的第16790960个碱基是a;人类的9号染色体的第16799844个碱基是c;人类的9号染色体的第16793202个碱基是t;人类的9号染色体的第16793104个碱基是a;人类的9号染色体的第16792350个碱基是a;人类的9号染色体的第16796252个碱基是t;人类的9号染色
体的第16792675个碱基是g;人类的9号染色体的第16791865个碱基是c;人类的9号染色体的第16787767个碱基是t;人类的10号染色体的第119568133个碱基是g;人类的10号染色体的第119570121个碱基是a;人类的10号染色体的第119569921个碱基是g;人类的10号染色体的第119570915个碱基是g;人类的10号染色体的第119571832个碱基是g;人类的10号染色体的第119572168个碱基是c;人类的10号染色体的第119547342个碱基是c;人类的10号染色体的第119561946个碱基是c;人类的10号染色体的第119570716个碱基是c;人类的10号染色体的第119563422个碱基是t;人类的10号染色体的第119544822个碱基是a;人类的10号染色体的第119544385个碱基是c;人类的10号染色体的第119547279个碱基是g;人类的10号染色体的第119544027个碱基是g;人类的10号染色体的第119545571个碱基是g;人类的10号染色体的第119547081个碱基是t;人类的10号染色体的第119547669个碱基是a;人类的10号染色体的第119545287个碱基是t;人类的10号染色体的第119545401个碱基是g;人类的10号染色体的第119545101个碱基是t;人类的10号染色体的第119545375个碱基是a;人类的10号染色体的第119545741个碱基是t;人类的10号染色体的第119545762个碱基是t;人类的10号染色体的第119546979个碱基是t;人类的10号染色体的第119545238个碱基是t;人类的10号染色体的第119546034个碱基是a;人类的10号染色体的第119546496个碱基是g;人类的10号染色体的第119546323个碱基是a;人类的10号染色体的第119552651个碱基是g;人类的10号染色体的第119566093个碱基是c;人类的16号染色体的第89985940个碱基是g;人类的16号染色体的第89986760个碱基是a;人类的16号染色体的第89987201个碱基是a;人类的16号染色体的第89986608个碱基是a;人类的16号染色体的第89985177个碱基是t;人类的16号染色体的第89985441个碱基是t;人类的16号染色体的第89986025个碱基是t;人类的16号染色体的第89986154个碱基是a;人类的16号染色体的第89985222个碱基是a;人类的2号染色体的第200473658个碱基是c;人类的2号染色体的第200475044个碱基是c;人类的2号染色体的第200492565个碱基是a;人类的2号染色体的第200492076个碱基是a;人类的2号染色体的第200484107个碱基是a;人类的2号染色体的第200478921个碱基是t;人类的2号染色体的第200491198个碱基是g;人类的2号染色体的第200491299个碱基是g;人类的2号染色体的第200477380个碱基是a;人类的2号染色体的第200477504个碱基是c;人类的2号染色体的第200477506个碱基是a;人类的2号染色体的第200484696个碱基是a;人类的2号染色体的第200485100个碱基是t;人类的2号染色体的第200487486个碱基是c;人类的2号染色体的第200491726个碱基是a;人类的2号染色体的第200491877个碱基是a;人类的2号染色体的第200484452个碱基是t;人类的2号染色体的第200491187个碱基是a;人类的2号染色体的第200479539个碱基是a;人类的2号染色体的第200488306个碱基是t;人类的2号染色体的第200488785个碱基是t;人类的2号染色体的第200488905个碱基是a;人类的2号染色体的第200489109个碱基是g;人类的2号染色体的第200484657个碱基是c;人类的2号染色体的第200481019个碱基是a;人类的2号染色体的第200486976个碱基是t;人类的2号染色体的第200487539个碱基是g;人类的2号染色体的第200489964个碱基是c;人类的2号染色体的第200490260个碱基是a;人类的2号染色体的第200491038个碱基是a;人类的2号染色体的第200482025个碱基是a;人类的2号染色体的第200482231个碱基是g;人类的2号染色体的第200482513个碱基是c;人类的2号染色体的第200480777个碱基是t;人类的2号染色体的第200481498个碱基是c;人类的2号染色体的第
200481506个碱基是a;人类的2号染色体的第200495743个碱基是a;人类的2号染色体的第200482881个碱基是a;人类的2号染色体的第200499444个碱基是g;人类的2号染色体的第200499255个碱基是t;人类的2号染色体的第200491272个碱基是a;人类的2号染色体的第200474888个碱基是c;人类的2号染色体的第200478354个碱基是g;人类的2号染色体的第200484686个碱基是c;人类的2号染色体的第200485648个碱基是t;人类的2号染色体的第200498327个碱基是c;人类的2号染色体的第200501964个碱基是c;人类的2号染色体的第200499206个碱基是c;人类的2号染色体的第200500431个碱基是c;人类的2号染色体的第200500296个碱基是t;人类的2号染色体的第200506846个碱基是c;人类的2号染色体的第200492529个碱基是a;人类的2号染色体的第200501467个碱基是t;人类的2号染色体的第200505203个碱基是t;人类的2号染色体的第200494912个碱基是a;人类的2号染色体的第200496036个碱基是t;人类的2号染色体的第200497907个碱基是t;人类的2号染色体的第200499399个碱基是a;人类的2号染色体的第200501134个碱基是t;人类的2号染色体的第200499157个碱基是a;人类的2号染色体的第200498080个碱基是a;人类的2号染色体的第200490231个碱基是c;人类的2号染色体的第200497975个碱基是g;人类的2号染色体的第200501827个碱基是t;人类的2号染色体的第200489315个碱基是g;人类的2号染色体的第200497286个碱基是g;人类的2号染色体的第200494182个碱基是g;人类的2号染色体的第200497711个碱基是a;人类的2号染色体的第200496814个碱基是a;人类的2号染色体的第200509555个碱基是g;人类的2号染色体的第200509556个碱基是c;人类的2号染色体的第200495510个碱基是a;人类的2号染色体的第200510641个碱基是a;以及人类的2号染色体的第200510941个碱基是t。
41.另外,当上述单核苷酸多态性标记包含一个以上的作为主要等位基因(major allele)的下述碱基时,可减少色素沉着,但不限于此:
42.人类的5号染色体的第149192846个碱基是a;人类的5号染色体的第149191111个碱基是c;人类的5号染色体的第149195389个碱基是t;人类的5号染色体的第149196682个碱基是t;人类的5号染色体的第149200603个碱基是t;人类的5号染色体的第149194923个碱基是t;人类的5号染色体的第149202206个碱基是c;人类的5号染色体的第149194485个碱基是c;人类的5号染色体的第149195603个碱基是c;人类的5号染色体的第149196090个碱基是a;人类的5号染色体的第149196234个碱基是g;人类的5号染色体的第149205630个碱基是g;人类的5号染色体的第149210848个碱基是c;人类的5号染色体的第149211868个碱基是g;人类的5号染色体的第149209546个碱基是c;人类的5号染色体的第149212430个碱基是g;人类的5号染色体的第149216304个碱基是c;人类的5号染色体的第149226633个碱基是g;人类的5号染色体的第149216256个碱基是c;人类的5号染色体的第149228648个碱基是c;人类的5号染色体的第149213456个碱基是a;人类的5号染色体的第149204852个碱基是c;人类的5号染色体的第149218886个碱基是c;人类的5号染色体的第149215213个碱基是c;人类的5号染色体的第149229822个碱基是g;人类的5号染色体的第149231519个碱基是c;人类的5号染色体的第149233110个碱基是c;人类的5号染色体的第149233186个碱基是c;人类的5号染色体的第149216987个碱基是a;人类的5号染色体的第149199148个碱基是g;人类的5号染色体的第149231830个碱基是a;人类的5号染色体的第149195125个碱基是t;人类的5号染色体的第149232525个碱基是a;人类的5号染色体的第149197230个
碱基是t;人类的5号染色体的第149232308个碱基是g;人类的5号染色体的第149196329个碱基是g;人类的5号染色体的第149230952个碱基是a;人类的5号染色体的第149230745个碱基是t;人类的5号染色体的第149230787个碱基是c;人类的5号染色体的第149231786个碱基是g;人类的5号染色体的第149234235个碱基是c;人类的5号染色体的第149234236个碱基是a;人类的5号染色体的第149159174个碱基是g;人类的5号染色体的第149190810个碱基是c;人类的5号染色体的第149194785个碱基是g;人类的5号染色体的第149191547个碱基是c;人类的5号染色体的第149193133个碱基是c;人类的5号染色体的第149195726个碱基是c;人类的5号染色体的第149196638个碱基是c;人类的5号染色体的第149196916个碱基是a;人类的5号染色体的第149192166个碱基是t;人类的5号染色体的第149197747个碱基是c;人类的5号染色体的第149199467个碱基是c;人类的5号染色体的第149197609个碱基是t;人类的5号染色体的第149197815个碱基是t;人类的5号染色体的第149200932个碱基是g;人类的5号染色体的第149190799个碱基是g;人类的5号染色体的第149190248个碱基是c;人类的5号染色体的第149203782个碱基是a;人类的5号染色体的第149205992个碱基是g;人类的5号染色体的第149201956个碱基是c;人类的5号染色体的第149208516个碱基是g;人类的5号染色体的第149206531个碱基是g;人类的5号染色体的第149227540个碱基是t;人类的5号染色体的第149204461个碱基是c;人类的5号染色体的第149192744个碱基是g;人类的5号染色体的第149189449个碱基是g;人类的5号染色体的第149205417个碱基是c;人类的5号染色体的第149196564个碱基是c;人类的5号染色体的第149200402个碱基是a;人类的5号染色体的第149199656个碱基是c;人类的5号染色体的第149196513个碱基是a;人类的5号染色体的第149199889个碱基是g;人类的5号染色体的第149200920个碱基是a;人类的5号染色体的第149202168个碱基是a;人类的5号染色体的第149200043个碱基是t;人类的5号染色体的第149203993个碱基是a;人类的5号染色体的第149187322个碱基是g;人类的5号染色体的第149204444个碱基是c;人类的5号染色体的第149178996个碱基是t;人类的5号染色体的第149179725个碱基是t;人类的5号染色体的第149185923个碱基是c;人类的5号染色体的第149187212个碱基是c;人类的5号染色体的第149187640个碱基是g;人类的5号染色体的第149183256个碱基是g;人类的5号染色体的第149234701个碱基是g;人类的5号染色体的第149236008个碱基是g;人类的5号染色体的第149164366个碱基是g;人类的5号染色体的第149230730个碱基是c;人类的5号染色体的第149186478个碱基是a;人类的5号染色体的第149162451个碱基是g;人类的5号染色体的第149162294个碱基是g;人类的5号染色体的第149212471个碱基是g;人类的5号染色体的第149179741个碱基是c;人类的5号染色体的第149159862个碱基是c;人类的5号染色体的第149184905个碱基是g;人类的5号染色体的第149159107个碱基是a;人类的5号染色体的第149211392个碱基是c;人类的5号染色体的第149182832个碱基是g;人类的5号染色体的第149208768个碱基是a;人类的9号染色体的第16788327个碱基是a;人类的9号染色体的第16788333个碱基是t;人类的9号染色体的第16788336个碱基是a;人类的9号染色体的第16788308个碱基是c;人类的9号染色体的第16788328个碱基是g;人类的9号染色体的第16815861个碱基是a;人类的9号染色体的第16825110个碱基是c;人类的9号染色体的第16789652个碱基是t;人类的9号染色体的第16795159个碱基是a;人类的9号染色体的第16812810个碱基是t;人类的9号染色体的第16789024个碱基是t;人类的9号染色体的第16789436个碱基是a;人类
的9号染色体的第16820923个碱基是c;人类的9号染色体的第16795588个碱基是a;人类的9号染色体的第16795211个碱基是g;人类的9号染色体的第16824921个碱基是c;人类的9号染色体的第16788367个碱基是c;人类的10号染色体的第119564143个碱基是c;人类的10号染色体的第119563401个碱基是t;人类的10号染色体的第119565538个碱基是c;人类的10号染色体的第119561969个碱基是c;人类的10号染色体的第119573178个碱基是c;人类的10号染色体的第119572403个碱基是c;人类的10号染色体的第119587425个碱基是g;人类的10号染色体的第119584730个碱基是c;人类的10号染色体的第119599727个碱基是a;人类的10号染色体的第119575974个碱基是c;人类的10号染色体的第119576317个碱基是g;人类的10号染色体的第119576318个碱基是g;人类的10号染色体的第119576319个碱基是c;人类的10号染色体的第119584861个碱基是a;人类的10号染色体的第119562387个碱基是c;人类的10号染色体的第119572476个碱基是c;人类的10号染色体的第119577677个碱基是g;人类的10号染色体的第119601436个碱基是t;人类的10号染色体的第119575798个碱基是c;人类的10号染色体的第119601939个碱基是g;人类的10号染色体的第119602316个碱基是g;人类的10号染色体的第119602424个碱基是g;人类的10号染色体的第119601743个碱基是g;人类的10号染色体的第119586963个碱基是c;人类的10号染色体的第119586186个碱基是a;人类的10号染色体的第119586231个碱基是c;人类的10号染色体的第119586178个碱基是c;人类的10号染色体的第119587158个碱基是g;人类的10号染色体的第119591330个碱基是g;人类的10号染色体的第119586980个碱基是a;人类的10号染色体的第119586462个碱基是c;人类的10号染色体的第119592083个碱基是c;人类的10号染色体的第119595140个碱基是g;人类的10号染色体的第119582802个碱基是c;人类的10号染色体的第119591168个碱基是c;人类的10号染色体的第119581527个碱基是g;人类的19号染色体的第3548231个碱基是a;人类的19号染色体的第3542983个碱基是c;以及人类的19号染色体的第3540539个碱基是g。
43.上述碱基仅以表1为例进行了记载,虽然没有具体记载,但通过表2和表3也可以与上述同样地导出参与色素沉着的标记。
44.另外,在本发明中,上述标记是随着个体的多态性标记的多态性位点的碱基逐一增加为次要等位基因(minor allele),能够判断表型(色素沉着)的增减变化程度的标记。作为一例,在表1所示的标记中,如果个体的5号染色体的第149192846个碱基是次要等位基因g(rs17110447),则效应大小为负(-),因此可以判断色素沉着减少,如果个体的9号染色体的第16795241个碱基是次要等位基因c(rs10810635),则效应大小为正( ),因此可以判断色素沉着增加,但不限于此。
45.具体地,当上述单核苷酸多态性标记包含一个以上的作为次要等位基因(minor allele)的下述碱基时,可增加色素沉着,但不限于此:
46.人类的9号染色体的第16795790个碱基是c;人类的9号染色体的第16795241个碱基是c;人类的9号染色体的第16794418个碱基是a;人类的9号染色体的第16806521个碱基是c;人类的9号染色体的第16801450个碱基是t;人类的9号染色体的第16808172个碱基是g;人类的9号染色体的第16806694个碱基是c;人类的9号染色体的第16801743个碱基是a;人类的9号染色体的第16801120个碱基是c;人类的9号染色体的第16788274个碱基是g;人类的9号染色体的第16788253个碱基是c;人类的9号染色体的第16790074个碱基是g;人类
的9号染色体的第16790968个碱基是c;人类的9号染色体的第16788363个碱基是g;人类的9号染色体的第16790960个碱基是g;人类的9号染色体的第16799844个碱基是t;人类的9号染色体的第16793202个碱基是c;人类的9号染色体的第16793104个碱基是g;人类的9号染色体的第16792350个碱基是c;人类的9号染色体的第16796252个碱基是g;人类的9号染色体的第16792675个碱基是c;人类的9号染色体的第16791865个碱基是t;人类的9号染色体的第16787767个碱基是c;人类的10号染色体的第119568133个碱基是a;人类的10号染色体的第119570121个碱基是t;人类的10号染色体的第119569921个碱基是a;人类的10号染色体的第119570915个碱基是t;人类的10号染色体的第119571832个碱基是a;人类的10号染色体的第119572168个碱基是a;人类的10号染色体的第119547342个碱基是t;人类的10号染色体的第119561946个碱基是t;人类的10号染色体的第119570716个碱基是a;人类的10号染色体的第119563422个碱基是a;人类的10号染色体的第119544822个碱基是g;人类的10号染色体的第119544385个碱基是t;人类的10号染色体的第119547279个碱基是t;人类的10号染色体的第119544027个碱基是t;人类的10号染色体的第119545571个碱基是a;人类的10号染色体的第119547081个碱基是c;人类的10号染色体的第119547669个碱基是g;人类的10号染色体的第119545287个碱基是g;人类的10号染色体的第119545401个碱基是a;人类的10号染色体的第119545101个碱基是c;人类的10号染色体的第119545375个碱基是t;人类的10号染色体的第119545741个碱基是g;人类的10号染色体的第119545762个碱基是c;人类的10号染色体的第119546979个碱基是c;人类的10号染色体的第119545238个碱基是c;人类的10号染色体的第119546034个碱基是t;人类的10号染色体的第119546496个碱基是t;人类的10号染色体的第119546323个碱基是g;人类的10号染色体的第119552651个碱基是a;人类的10号染色体的第119566093个碱基是t;人类的16号染色体的第89985940个碱基是a;人类的16号染色体的第89986760个碱基是g;人类的16号染色体的第89987201个碱基是g;人类的16号染色体的第89986608个碱基是g;人类的16号染色体的第89985177个碱基是c;人类的16号染色体的第89985441个碱基是a;人类的16号染色体的第89986025个碱基是c;人类的16号染色体的第89986154个碱基是g;人类的16号染色体的第89985222个碱基是g;人类的2号染色体的第200473658个碱基是t;人类的2号染色体的第200475044个碱基是g;人类的2号染色体的第200492565个碱基是g;人类的2号染色体的第200492076个碱基是c;人类的2号染色体的第200484107个碱基是g;人类的2号染色体的第200478921个碱基是g;人类的2号染色体的第200491198个碱基是c;人类的2号染色体的第200491299个碱基是a;人类的2号染色体的第200477380个碱基是t;人类的2号染色体的第200477504个碱基是t;人类的2号染色体的第200477506个碱基是c;人类的2号染色体的第200484696个碱基是g;人类的2号染色体的第200485100个碱基是c;人类的2号染色体的第200487486个碱基是a;人类的2号染色体的第200491726个碱基是c;人类的2号染色体的第200491877个碱基是g;人类的2号染色体的第200484452个碱基是g;人类的2号染色体的第200491187个碱基是g;人类的2号染色体的第200479539个碱基是t;人类的2号染色体的第200488306个碱基是c;人类的2号染色体的第200488785个碱基是c;人类的2号染色体的第200488905个碱基是g;人类的2号染色体的第200489109个碱基是a;人类的2号染色体的第200484657个碱基是g;人类的2号染色体的第200481019个碱基是t;人类的2号染色体的第200486976个碱基是g;人类的2号染色体的第200487539个碱基是c;人类的2号染色体的第
200489964个碱基是g;人类的2号染色体的第200490260个碱基是g;人类的2号染色体的第200491038个碱基是g;人类的2号染色体的第200482025个碱基是g;人类的2号染色体的第200482231个碱基是a;人类的2号染色体的第200482513个碱基是t;人类的2号染色体的第200480777个碱基是c;人类的2号染色体的第200481498个碱基是g;人类的2号染色体的第200481506个碱基是t;人类的2号染色体的第200495743个碱基是c;人类的2号染色体的第200482881个碱基是t;人类的2号染色体的第200499444个碱基是a;人类的2号染色体的第200499255个碱基是a;人类的2号染色体的第200491272个碱基是g;人类的2号染色体的第200474888个碱基是a;人类的2号染色体的第200478354个碱基是c;人类的2号染色体的第200484686个碱基是t;人类的2号染色体的第200485648个碱基是c;人类的2号染色体的第200498327个碱基是t;人类的2号染色体的第200501964个碱基是g;人类的2号染色体的第200499206个碱基是g;人类的2号染色体的第200500431个碱基是t;人类的2号染色体的第200500296个碱基是c;人类的2号染色体的第200506846个碱基是t;人类的2号染色体的第200492529个碱基是c;人类的2号染色体的第200501467个碱基是a;人类的2号染色体的第200505203个碱基是g;人类的2号染色体的第200494912个碱基是g;人类的2号染色体的第200496036个碱基是c;人类的2号染色体的第200497907个碱基是g;人类的2号染色体的第200499399个碱基是g;人类的2号染色体的第200501134个碱基是c;人类的2号染色体的第200499157个碱基是g;人类的2号染色体的第200498080个碱基是g;人类的2号染色体的第200490231个碱基是a;人类的2号染色体的第200497975个碱基是a;人类的2号染色体的第200501827个碱基是c;人类的2号染色体的第200489315个碱基是a;人类的2号染色体的第200497286个碱基是t;人类的2号染色体的第200494182个碱基是a;人类的2号染色体的第200497711个碱基是g;人类的2号染色体的第200496814个碱基是t;人类的2号染色体的第200509555个碱基是a;人类的2号染色体的第200509556个碱基是t;人类的2号染色体的第200495510个碱基是g;人类的2号染色体的第200510641个碱基是c;以及人类的2号染色体的第200510941个碱基是g。
47.另外,当上述单核苷酸多态性标记包含一个以上的作为次要等位基因(minor allele)的下述碱基时,可减少色素沉着,但不限于此:
48.人类的5号染色体的第149192846个碱基是g;人类的5号染色体的第149191111个碱基是t;人类的5号染色体的第149195389个碱基是c;人类的5号染色体的第149196682个碱基是g;人类的5号染色体的第149200603个碱基是c;人类的5号染色体的第149194923个碱基是c;人类的5号染色体的第149202206个碱基是g;人类的5号染色体的第149194485个碱基是t;人类的5号染色体的第149195603个碱基是g;人类的5号染色体的第149196090个碱基是c;人类的5号染色体的第149196234个碱基是c;人类的5号染色体的第149205630个碱基是t;人类的5号染色体的第149210848个碱基是t;人类的5号染色体的第149211868个碱基是a;人类的5号染色体的第149209546个碱基是t;人类的5号染色体的第149212430个碱基是a;人类的5号染色体的第149216304个碱基是t;人类的5号染色体的第149226633个碱基是a;人类的5号染色体的第149216256个碱基是t;人类的5号染色体的第149228648个碱基是t;人类的5号染色体的第149213456个碱基是g;人类的5号染色体的第149204852个碱基是g;人类的5号染色体的第149218886个碱基是a;人类的5号染色体的第149215213个碱基是g;人类的5号染色体的第149229822个碱基是t;人类的5号染色体的第149231519个
碱基是t;人类的5号染色体的第149233110个碱基是a;人类的5号染色体的第149233186个碱基是t;人类的5号染色体的第149216987个碱基是g;人类的5号染色体的第149199148个碱基是a;人类的5号染色体的第149231830个碱基是g;人类的5号染色体的第149195125个碱基是g;人类的5号染色体的第149232525个碱基是g;人类的5号染色体的第149197230个碱基是c;人类的5号染色体的第149232308个碱基是a;人类的5号染色体的第149196329个碱基是a;人类的5号染色体的第149230952个碱基是g;人类的5号染色体的第149230745个碱基是c;人类的5号染色体的第149230787个碱基是t;人类的5号染色体的第149231786个碱基是a;人类的5号染色体的第149234235个碱基是a;人类的5号染色体的第149234236个碱基是t;人类的5号染色体的第149159174个碱基是a;人类的5号染色体的第149190810个碱基是t;人类的5号染色体的第149194785个碱基是a;人类的5号染色体的第149191547个碱基是t;人类的5号染色体的第149193133个碱基是t;人类的5号染色体的第149195726个碱基是t;人类的5号染色体的第149196638个碱基是t;人类的5号染色体的第149196916个碱基是g;人类的5号染色体的第149192166个碱基是c;人类的5号染色体的第149197747个碱基是g;人类的5号染色体的第149199467个碱基是t;人类的5号染色体的第149197609个碱基是c;人类的5号染色体的第149197815个碱基是c;人类的5号染色体的第149200932个碱基是a;人类的5号染色体的第149190799个碱基是a;人类的5号染色体的第149190248个碱基是g;人类的5号染色体的第149203782个碱基是g;人类的5号染色体的第149205992个碱基是a;人类的5号染色体的第149201956个碱基是g;人类的5号染色体的第149208516个碱基是t;人类的5号染色体的第149206531个碱基是a;人类的5号染色体的第149227540个碱基是c;人类的5号染色体的第149204461个碱基是t;人类的5号染色体的第149192744个碱基是t;人类的5号染色体的第149189449个碱基是c;人类的5号染色体的第149205417个碱基是a;人类的5号染色体的第149196564个碱基是t;人类的5号染色体的第149200402个碱基是g;人类的5号染色体的第149199656个碱基是t;人类的5号染色体的第149196513个碱基是g;人类的5号染色体的第149199889个碱基是a;人类的5号染色体的第149200920个碱基是g;人类的5号染色体的第149202168个碱基是g;人类的5号染色体的第149200043个碱基是c;人类的5号染色体的第149203993个碱基是g;人类的5号染色体的第149187322个碱基是a;人类的5号染色体的第149204444个碱基是t;人类的5号染色体的第149178996个碱基是c;人类的5号染色体的第149179725个碱基是c;人类的5号染色体的第149185923个碱基是a;人类的5号染色体的第149187212个碱基是t;人类的5号染色体的第149187640个碱基是a;人类的5号染色体的第149183256个碱基是t;人类的5号染色体的第149234701个碱基是a;人类的5号染色体的第149236008个碱基是a;人类的5号染色体的第149164366个碱基是a;人类的5号染色体的第149230730个碱基是t;人类的5号染色体的第149186478个碱基是t;人类的5号染色体的第149162451个碱基是a;人类的5号染色体的第149162294个碱基是a;人类的5号染色体的第149212471个碱基是a;人类的5号染色体的第149179741个碱基是a;人类的5号染色体的第149159862个碱基是g;人类的5号染色体的第149184905个碱基是t;人类的5号染色体的第149159107个碱基是g;人类的5号染色体的第149211392个碱基是g;人类的5号染色体的第149182832个碱基是c;人类的5号染色体的第149208768个碱基是g;人类的9号染色体的第16788327个碱基是g;人类的9号染色体的第16788333个碱基是c;人类的9号染色体的第16788336个碱基是g;人类的9号染色体的第16788308个碱基
是t;人类的9号染色体的第16788328个碱基是a;人类的9号染色体的第16815861个碱基是g;人类的9号染色体的第16825110个碱基是t;人类的9号染色体的第16789652个碱基是c;人类的9号染色体的第16795159个碱基是g;人类的9号染色体的第16812810个碱基是c;人类的9号染色体的第16789024个碱基是c;人类的9号染色体的第16789436个碱基是g;人类的9号染色体的第16820923个碱基是g;人类的9号染色体的第16795588个碱基是t;人类的9号染色体的第16795211个碱基是c;人类的9号染色体的第16824921个碱基是g;人类的9号染色体的第16788367个碱基是t;人类的10号染色体的第119564143个碱基是t;人类的10号染色体的第119563401个碱基是c;人类的10号染色体的第119565538个碱基是a;人类的10号染色体的第119561969个碱基是t;人类的10号染色体的第119573178个碱基是t;人类的10号染色体的第119572403个碱基是t;人类的10号染色体的第119587425个碱基是a;人类的10号染色体的第119584730个碱基是t;人类的10号染色体的第119599727个碱基是g;人类的10号染色体的第119575974个碱基是t;人类的10号染色体的第119576317个碱基是c;人类的10号染色体的第119576318个碱基是t;人类的10号染色体的第119576319个碱基是g;人类的10号染色体的第119584861个碱基是g;人类的10号染色体的第119562387个碱基是t;人类的10号染色体的第119572476个碱基是a;人类的10号染色体的第119577677个碱基是a;人类的10号染色体的第119601436个碱基是g;人类的10号染色体的第119575798个碱基是t;人类的10号染色体的第119601939个碱基是c;人类的10号染色体的第119602316个碱基是a;人类的10号染色体的第119602424个碱基是t;人类的10号染色体的第119601743个碱基是a;人类的10号染色体的第119586963个碱基是t;人类的10号染色体的第119586186个碱基是t;人类的10号染色体的第119586231个碱基是t;人类的10号染色体的第119586178个碱基是t;人类的10号染色体的第119587158个碱基是a;人类的10号染色体的第119591330个碱基是a;人类的10号染色体的第119586980个碱基是g;人类的10号染色体的第119586462个碱基是a;人类的10号染色体的第119592083个碱基是t;人类的10号染色体的第119595140个碱基是a;人类的10号染色体的第119582802个碱基是t;人类的10号染色体的第119591168个碱基是a;人类的10号染色体的第119581527个碱基是a;人类的19号染色体的第3548231个碱基是g;人类的19号染色体的第3542983个碱基是t;以及人类的19号染色体的第3540539个碱基是c。
49.上述碱基仅以表1为例进行了记载,虽然没有具体记载,但通过表2和表3也可以与上述同样地导出参与色素沉着的标记。
50.在本发明中,术语“能够检测用于诊断皮肤类型的色素沉着与否的标记的探针”是指通过与上述基因的多态性位点的特异性杂交反应确认从而能够诊断皮肤色素沉着与否的组合物,并且这种基因分析的具体方法没有特别限制,可以根据本发明所属技术领域中已知的所有基因检测方法。
51.在本发明中,术语“能够扩增用于诊断皮肤类型的色素沉着与否的标记的制剂”是指通过扩增确认上述基因的多态性位点从而能够诊断皮肤色素沉着与否的组合物,具体地,是指能够特异性扩增上述用于诊断皮肤类型的色素沉着与否的标记的多核苷酸的引物。
52.用于扩增上述多态性标记的引物是指在适当的缓冲液中在适当的条件(例如,4个不同的核苷三磷酸及dna、rna聚合酶或逆转录酶等聚合酶)以及适当的温度下作为模板-指
导dna合成的起始点可以起作用的单链寡核苷酸。上述引物的适当长度可根据使用目的而有所不同,但通常为15至30个核苷酸。短引物分子通常需要更低的温度以与模板形成稳定的杂交体。引物序列不必与模板完全互补,但必须充分互补至与模板杂交的程度。
53.在本发明中,术语“引物”作为具有短游离3'末端羟基(游离3'羟基,free 3'hydroxyl group)的碱基序列,是指可以与互补模板(template)形成碱基对(base pair)并充当用于模板链复制的起始点的短序列。引物可以在适当的缓冲溶液和温度下在用于聚合反应(即dna聚合酶或逆转录酶)的试剂以及四种不同的核苷三磷酸的存在下引发dna合成。可以通过以下方式预测皮肤类型:通过实施pcr扩增,所需的产物是否产生。pcr条件、正义和反义引物的长度可以以本领域公知的为基础进行变形。
54.本发明的探针或引物可以使用亚磷酰胺(phosphoramidite)固体支持体方法或其他广泛公知的方法化学合成。此类核酸序列还可以利用本领域公知的许多手段来修饰。作为此类修饰的非限制性实例,有甲基化、“加帽(capping)”、用天然核苷酸的一种以上的同系物进行的置换,以及核苷酸之间的修饰,例如,对不带电荷的连接体(例如,磷酸甲酯(methyl phosphonate)、磷酸三酯、氨基磷酸酯(phosphoroamidate)、氨基甲酸酯等)或带电荷的连接体(例如,硫代磷酸酯、二硫代磷酸酯等)的修饰。
55.在另一个方面中,本发明提供一种用于诊断皮肤类型的色素沉着与否的试剂盒,其包含上述用于诊断皮肤色素沉着与否的组合物。上述试剂盒可以是rt-pcr试剂盒或dna芯片试剂盒,但不限于此。
56.本发明的试剂盒通过扩增确认用于诊断皮肤类型的标记即snp多态性标记,或者确认snp多态性标记的表达水平和mrna的表达水平,从而能够诊断皮肤类型。作为一个具体例,在本发明中,用于测量皮肤类型诊断用标记的mrna表达水平的试剂盒可以是包含进行rt-pcr所必需的必要要素的试剂盒。除了对皮肤类型诊断用标记的基因特异的各自的引物对之外,rt-pcr试剂盒还可以包括试管或其他适当的容器、反应缓冲液(ph和镁浓度多样)、脱氧核苷酸(dntps)、taq-聚合酶和逆转录酶等酶、dna酶、rna酶抑制剂、depc-水(depc-water)、无菌水等。另外,可以包括对用作定量对照群的基因特异的引物对。另外,具体地,本发明的试剂盒可以是包含进行dna芯片所必需的必要要素的用于诊断皮肤类型的试剂盒。dna芯片试剂盒通常是将核酸物种以格子型阵列(gridded array)附着于平坦固体支撑板、典型地不大于显微镜用载玻片的玻璃表面的dna芯片试剂盒,并且是核酸均匀排列在芯片表面上以能够在dna芯片上的核酸和芯片表面上处理的溶液中包含的互补核酸之间发生多次杂交(hybridization)反应、从而进行大量并行分析的工具。
57.在另一个方面中,本发明提供一种用于诊断皮肤类型的色素沉着与否的微阵列,其包含上述用于诊断皮肤色素沉着与否的组合物。
58.上述微阵列可以包括dna或rna多核苷酸。除了在探针多核苷酸中包括本发明的多核苷酸之外,上述微阵列由常规微阵列组成。
59.通过将探针多核苷酸固定在基底上来制备微阵列的方法是本领域中公知的。上述探针多核苷酸是指可杂交的多核苷酸,是指能够与核酸的互补链以序列特异性结合的寡核苷酸。本发明的探针是等位基因特异性探针,多态性位点存在于衍生自相同物种的两个成员的核酸片段中,与衍生自一个成员的dna片段杂交,但不与衍生自另一个成员的片段杂交。在这种情况下,杂交条件在等位基因之间的杂交强度上显示显著差异,因此必须足够严
格以与仅等位基因之一杂交。通过这样做,可诱发不同等位基因形式之间的良好杂交差异。本发明的上述探针可以用于通过检测等位基因来诊断皮肤类型的方法等中。上述诊断方法包括基于核酸杂交的检测方法,例如southern印迹杂交(southern blot)等,并且在利用dna芯片的方法中可以提供为预先结合在dna芯片的基底上的形式。上述杂交通常可以在严格的条件,例如1m以下的盐浓度和25℃以上的温度下进行。例如,5x sspe(750mm nacl,50mm磷酸钠,5mm edta,ph 7.4)和25~30℃的条件可适合于等位基因特异性探针杂交。
60.将本发明的与皮肤诊断相关的探针多核苷酸固定在基底上的过程也可以使用这种现有技术容易地制备。另外,核酸在微阵列上的杂交和杂交结果的检测是本领域中公知的。上述检测可以通过以下过程检测杂交结果,例如,用能够产生可检测信号的标记材料(包括荧光材料,例如cy3和cy5等材料)标记核酸试料,然后在微阵列上杂交并检测由上述标记材料产生的信号。
61.在另一个方面中,本发明提供一种提供关于皮肤色素沉着与否的信息的方法,其包括:(a)在从分离自个体的试料中获得的dna中将上述单核苷酸多态性标记的多态性位点扩增或与探针杂交的步骤;以及(b)确认上述(a)步骤的扩增或杂交的多态性位点的碱基的步骤。
62.本发明的术语“个体”是指用于诊断皮肤色素沉着与否的受试者。在上述检测样本中,可以从头发、尿、血液、各种体液、分离的组织、分离的细胞或唾液等试料等中获得dna,但不限于此。
63.上述(a)步骤的基因组(genome)dna获取方法可以使用本领域技术人员已知的任何方法。
64.从上述(a)步骤获得的dna中扩增上述单核苷酸多态性标记的多态性位点或将其与探针杂交的步骤可以使用本领域技术人员已知的任何方法。例如,可以通过pcr扩增靶核酸并将其纯化来获得。此外,可以使用连接酶链反应(lcr)(wu和wallace,genomics 4,560(1989),landegren等,science 241,1077(1988))、转录扩增(transcription amplification)(kwoh等,proc.natl.acad.sci.usa 86,1173(1989))以及自我维持序列复制(guatelli等,proc.natl.acad.sci.usa 87,1874(1990))以及基于核酸的序列扩增(nasba)。
65.在上述方法中,(b)步骤的多态性位点的碱基的确定包括测序分析、通过微阵列(microarray)的杂交,等位基因特异性pcr(allele specific pcr)、动态等位基因杂交技术(动态等位基因特异性杂交,dynamic allele-specifichybridization,dash)、pcr延伸分析、sscp、pcr-rflp分析或taqman技术、snplex平台(applied biosystems)、质谱(例如sequenom的massarray系统)、微测序(mini-sequencing)方法、bio-plex系统(biorad)、ceq和snpstream系统(beckman)、分子反转探针(molecular inversion probe)阵列技术(例如affymetrix genechip)和beadarray technologies(例如illumina goldengate和infinium分析法),但不限于此。通过上述方法或本发明所属技术领域的技术人员可利用的其他方法,可以确认包括微卫星标记(microsatellite)、snp或其他类型的多态性标记在内的多态性标记中的一个以上的等位基因。这种多态性位点的碱基的确定具体地可以通过snp芯片进行。
66.在上述方法中,额外(c)扩增或杂交的多态性位点的碱基包含一个以上的根据上
述单核苷酸多态性标记的作为次要等位基因(minor allele)的碱基时,可以判断色素沉着增加或减少,但不限于此。另外,额外(c)扩增或杂交的多态性位点的碱基包含一个以上的根据上述单核苷酸多态性标记的作为主要等位基因(major allele)的碱基时,可以判断色素沉着增加或减少,但不限于此。
67.在本发明中,术语“snp芯片”是指可以一次性确认数十万个snp的各碱基的dna微阵列之一。
68.taqman方法包括:(1)设计和制造引物和taqman探针以使得能够扩增所需dna片段的步骤;(2)用fam染料和vic染料(applied biosystems)标记不同等位基因的探针的步骤;(3)以上述dna为模板,利用上述引物和探针进行pcr的步骤;(4)上述pcr反应完成后,用核酸分析仪对taqman分析板进行分析和确认的步骤;以及(5)根据上述分析结果确定步骤(1)的多核苷酸的基因型的步骤。
69.在上述中,测序分析可以使用用于确定碱基序列的常规方法,并且可以利用自动化基因分析仪进行。另外,等位基因特异性pcr是指使用包括以snp所在的碱基为3'末端设计的引物的引物组扩增上述snp所在的dna片段的pcr方法。上述方法的原理利用了如下:例如,当特定碱基由a被g取代时,通过设计包含上述a作为3'末端碱基的引物和能够扩增适当大小的dna片段的反向引物来进行pcr反应时,如果上述snp位置的碱基是a,则由于扩增反应正常进行而观察到期望位置的条带,如果上述碱基被g取代,则引物可以与模板dna互补地结合,但由于3'末端不进行互补结合,因此扩增反应无法正常进行。dash可以通过常规方法进行,具体地可以通过prince等人的方法进行。
70.同时,pcr延伸分析通过以下过程实现:首先用引物对扩增包含单核苷酸多态性所在的碱基的dna片段,然后通过去磷酸化使添加到反应中的所有核苷酸失活,并向其中添加snp特异性延伸引物、dntp混合物、双脱氧核苷酸、反应缓冲液和dna聚合酶来进行引物延伸反应。此时,延伸引物以snp所在的碱基的5'方向的直接邻接的碱基为3'末端,dntp混合物中不包含具有与双脱氧核苷酸相同碱基的核酸,并且上述双脱氧核苷酸选自显示snp的碱基类型之一。例如,在用g取代a的情况下,当将dgtp、dctp以及ttp混合物和ddatp添加到反应中时,在发生上述取代的碱基中,引物由dna聚合酶延伸,并且在经过几个碱基后,在a碱基首次出现的位置通过ddatp终止引物延伸反应。如果不发生上述取代,则延伸反应在该位置终止,因此可以通过比较上述延伸的引物的长度来判断显示snp的碱基类型。
71.此时,作为检测方法,当延伸引物或双脱氧核苷酸被荧光标记时,可以通过使用用于确定碱基序列的常规基因分析仪(例如,abi公司的model 3700等)检测荧光来检测上述snp,并且当使用未标记的延伸引物和双脱氧核苷酸时,可以通过利用maldi-tof(基质辅助激光解吸电离飞行时间质谱,matrix assisted laser desorption ionization-time of flight)技术测量分子量来检测上述snp。
72.实施方式
73.在下文中,将通过实施例更详细地说明本发明。这些实施例仅用于示例本发明,并且本发明的范围不应被解释为受这些实施例的限制。
74.试图根据遗传信息从韩国人(女性)中发掘面部皮肤色素沉着程度(数值)出现差异的基因组位点(基因变异)。本发明为了发掘与色素沉着有关的基因组位点(基因变异),使用了能够在不预先筛选候选基因的情况下筛选出基因组全长水平的微阵列基因分型芯
片(microarray genotyping chip)(illumina公司产品)。
75.在本发明中,为了评价色素沉着程度,使用了基于图像的皮肤诊断专业仪器(pie公司janus3),并且为了使可能影响皮肤色素沉着程度(数值)的外部效果最小化,在对年龄和群集主成分数值进行校正后使用。
76.为了确认基因组位点(基因变异)与皮肤色素沉着程度(数值)的关联性,使用线性回归分析对相关显著性和遗传效果进行数值化。
77.实施例1:皮肤的特性分类以及基因采集
78.为了导出能够说明一般皮肤色素沉着程度的基因多态性标记,招募了20~70多岁的健康韩国女性。另外,为了测量皮肤,所有分析对象都用洗面奶或皂洗脸,并在不涂抹任何产品的情况下等待30分钟使得皮肤能够适应测量环境,然后评价皮肤色素沉着程度,在评价中使用了基于图像的皮肤诊断专业仪器(pie公司janus3)(测量和分析根据仪器制造公司的手册进行)。
79.一般个人(拥有主要等位基因(major allele)/主要等位基因(major allele))的皮肤色素沉着程度是指以17,019名在同一基因位点(碱基)观察到两种等位基因的分析对象为对象测量的皮肤色素沉着程度的面部平均,其值是用在分析区域内与周围部分的皮肤颜色相比以相对黑色或褐色观察到的位点的比率导出的。
80.基因采集是通过唾液收集实现的,为了有效的基因采集,所有分析对象从采集前30分钟开始禁止摄取包括水在内的任何食物。
81.上述受试者中
①
妊娠、哺乳期或计划在6个月内怀孕的情况、
②
为了治疗皮肤疾病而使用含有类固醇的皮肤外用剂1个月以上的情况、
③
参加相同试验后未经过6个月的情况、
④
具有敏感性、过敏性皮肤的情况、
⑤
试验部位有痣、痤疮、红斑、毛细血管扩张等皮肤异常的情况、
⑥
试验开始3个月内在试验部位使用相同或相似的化妆品或医药品的情况、
⑦
在试验部位接受或计划在6个月内进行手术(皮肤剥皮术、肉毒杆菌毒素(botox)、其他皮肤护理)的情况、
⑧
患有慢性消耗性疾病的情况(哮喘、糖尿、高血压等)、
⑨
患有特应性皮炎的情况、
⑩
此外根据主试验者的判断,判断为难以试验的情况被排除在受试者之外。
82.实施例2:根据皮肤特性的基因型分析
83.对于从唾液中提取基因进行基因分析,利用qiamp mini prep kit(qiagen)提取人类基因组dna(human genomic dna),其质量通过吸光度(od 260/280)或1.7、浓度50ng/ul,1x tae 1%琼脂糖凝胶(agarose gel)的条带(band)检验确认,并且仅对通过质量的基因进行基因分析。
84.利用illumina公司的微阵列基因分型芯片进行基因分析,具体地,利用同一公司的全球筛选阵列(global screening array)产品对分析受试者的基因进行分析。
85.illumina公司的微阵列基因分型芯片基因分析实验根据提供的手册进行,使用提供的试剂,进行基因组dna扩增(amplification)、dna片段化(fragmentation)、沉淀(precipitation)、杂交(hybridization)、染色(staining)、洗涤(washing)、包被(coating)、扫描(scanning)的过程。
86.实验完成的微阵列基因分型芯片利用iscan control software(illumina)进行扫描,扫描完成后,自动生成idat文件并利用genomestudio(illumina)程序进行数据质量管理(样品检出率(sample call rate)98%,标记检出率(marker call rate)98%)以及基
因信息确认。
87.在本实验中,仅使用基因分析后通过数据质量管理的数据。
88.实施例3:利用不同皮肤类型的基因型分析导出皮肤色素沉着程度关联显著性基因多态性标记
89.为了导出与皮肤色素沉着程度有关联显著性的基因多态性标记,利用分析对象的基因多态性标记进行了线性回归分析,并且为了分析,使用了plink v 1.90和snp&variation suite(golden helix,inc.,博兹曼,蒙大拿州,usa)程序。
90.为了使用通过实验确认的基因多态性标记来确保有关附加基因多态性标记的信息,使用beagle v 5.1程序进行了imputation分析,并且为了进行相关分析,作为标准的参考数据,使用了在国际公开基因组数据数据库(database)1000基因组计划(genomes project)中登记的信息。
91.imputation是一种根据通过实验确保的基因多态性标记信息推断未分析的基因多态性标记信息的统计学技术。
92.为了分析对象基因多态性标记的质量管理,各基因多态性标记仅限于超过次要等位基因频率(minor allele frequency)或0.01以及哈迪-温伯格平衡(hardy-weinberg equilibrium)或0.000001标准而使用。
93.与皮肤色素沉着程度有关联性的基因多态性标记的显著性通过线性回归分析f-statistics进行了评价,其标准设定为p-值(p-value)《0.0001。
94.为了使可能影响皮肤色素沉着程度的外部效果最小化并导出根据遗传信息的效果,可以用年龄或bmi信息或生活习惯(饮酒、吸烟、饮食习惯、睡眠习惯等)的信息校正皮肤色素沉着程度,并用于分析(例如,进行线性回归分析)。
95.导出了很多皮肤色素沉着程度关联显著性基因多态性标记,并且确认了相关基因多态性标记主要位于人类基因组中的第2、5、9、10、16、19号染色体上。
96.与皮肤色素沉着显著相关的snp标记列表示于下表1至表3中。
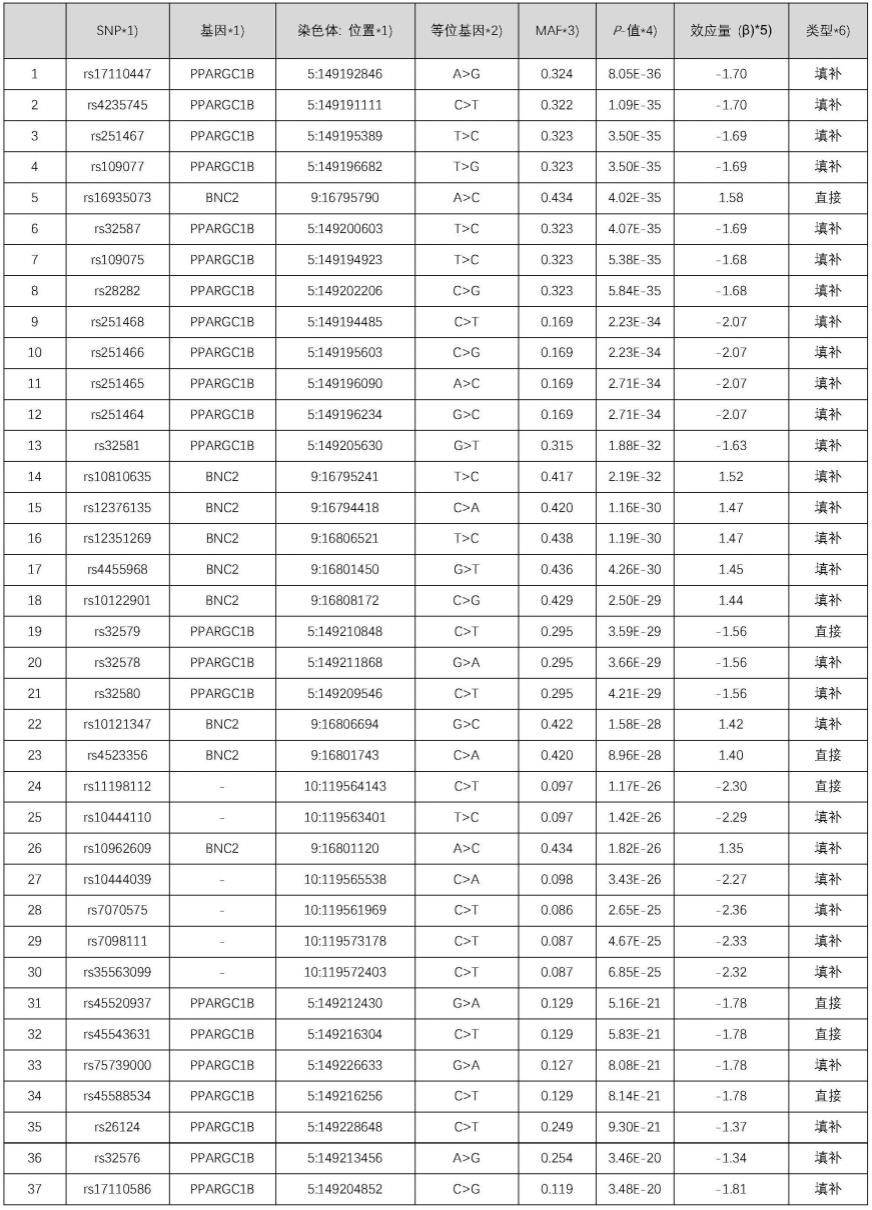
97.[表1]
[0098]
[0099]
[0100]
[0101]
[0102]
[0103]
[0104]
[0105]
[0106]
[0107]
[0108]
[0109]
[0110]
[0111]
[0112]
[0113]
[0114]
[0115]
[0116]
[0117]
[0118]
[0119]
[0120]
[0121][0122]
[表2]
[0123]
[0124]
[0125]
[0126]
[0127]
[0128]
[0129]
[0130]
[0131]
[0132]
[0133]
[0134]
[0135]
[0136]
[0137]
[0138]
[0139]
[0140]
[0141]
[0142]
[0143]
[0144]
[0145]
[0146]
[0147]
[0148]
[0149]
[0150]
[0151]
[0152]
[0153]
[0154]
[0155]
[0156]
[0157]
[0158]
[0159]
[0160]
[0161]
[0162]
[0163]
[0164]
[0165]
[0166]
[0167]
[0168]
[0169]
[0170]
[0171]
[0172]
[0173]
[0174]
[0175]
[0176]
[0177]
[0178]
[0179]
[0180]
[0181]
[0182]
[0183]
[0184]
[0185]
[0186]
[0187]
[0188]
[0189]
[0190]
[0191]
[0192]
[0193]
[0194]
[0195]
[0196]
[0197]
[0198]
[0199]
[0200]
[0201]
[0202]
[0203]
[0204]
[0205]
[0206]
[0207]
[0208]
[0209]
[0210]
[0211][0212]
[表3]
[0213]
[0214]
[0215]
[0216]
[0217]
[0218]
[0219]
[0220]
[0221]
[0222]
[0223]
[0224]
[0225]
[0226]
[0227]
[0228]
[0229]
[0230]
[0231]
[0232]
[0233]
[0234]
[0235]
[0236]
[0237]
[0238]
[0239]
[0240]
[0241]
[0242]
[0243]
[0244]
[0245]
[0246]
[0247]
[0248]
[0249]
[0250]
[0251]
[0252]
[0253]
[0254]
[0255]
[0256]
[0257]
[0258]
[0259]
[0260]
[0261]
[0262]
[0263]
[0264]
[0265]
[0266]
[0267]
[0268]
[0269]
[0270]
[0271]
[0272]
[0273]
[0274]
[0275]
[0276]
[0277]
[0278]
[0279]
[0280]
[0281]
[0282]
[0283]
[0284]
[0285]
[0286]
[0287]
[0288]
[0289]
[0290]
[0291]
[0292]
[0293]
[0294]
[0295]
[0296]
[0297]
[0298]
[0299]
[0300]
[0301]
[0302]
[0303]
[0304]
[0305]
[0306]
[0307]
[0308]
[0309]
[0310]
[0311]
[0312]
[0313]
[0314]
[0315]
[0316]
[0317]
[0318]
[0319]
[0320]
[0321]
[0322]
[0323]
[0324]
[0325]
[0326]
[0327]
[0328]
[0329]
[0330]
[0331]
[0332]
[0333]
[0334]
[0335]
[0336]
[0337]
[0338]
[0339]
[0340]
[0341]
[0342]
[0343]
[0344]
[0345]
[0346]
[0347]
[0348]
[0349]
[0350]
[0351]
[0352]
[0353]
[0354]
[0355]
[0356]
[0357]
[0358]
[0359]
[0360]
[0361]
[0362]
[0363]
[0364]
[0365]
[0366]
[0367]
[0368]
[0369]
[0370]
[0371]
[0372]
[0373]
[0374]
[0375]
[0376]
[0377]
[0378]
[0379]
[0380]
[0381]
[0382]
[0383]
[0384]
[0385]
[0386]
[0387]
[0388]
[0389]
[0390]
[0391]
[0392]
[0393]
[0394]
[0395]
[0396]
[0397]
[0398]
[0399]
[0400]
[0401]
[0402]
[0403]
[0404][0405]
1)美国国立保健院(nih)id,可以在相关网站上确认序列
[0406]
2)(主要等位基因,major allele)或(次要等位基因,minor allele)含义
[0407]
3)次要等位基因频率(minor allele frequency)=(2mm mm)/2(mm mm mm)
[0408]
4)三种基因型(m/m、m/m、m/m)的表型差异的统计显著性(m:主要等位基因,m:次要等位基因)
[0409]
5)随着次要等位基因逐一增加,表型(色素沉着)的增减变化程度(-:色素沉着减少, :色素沉着增加)、色素沉着程度=色素沉着发生的部位的面积与总面积的比例,但适用色素沉着部位的强度(intensity)权重值和阈(threshold)值,利用市售仪器(janus3,pie公司,韩国)
[0410]
6)使用beagle v5.1分析
[0411]
其结果,在总共7个基因组位点确定了主要显示与皮肤色素沉着的关联性的基因变异。
[0412]
在众多基因变异中,代表各基因组位点显示最高关联显著性的基因变异如下。
[0413]
[9p22处的bnc2(rs16935073;p-值=4.02х10-35
)、5q32处的ppargc1b(rs26127;p-值=6.40х10-59
)、10q26(rs11198143;p-值=9.24х10-41
)、
[0414]
16q24处的fanca(rs12921383;p-值=1.07х10-43
)、2q33(rs4675687;p-值=2.90х10-22
)以及19p13处的mfsd12(rs2240751;p-值=2.12х10-10
)、11q22(rs4794701;p-值=7.29х10-21
)]
[0415]
基于以上的说明,本发明所属技术领域的技术人员可以理解,在不改变本发明的技术思想或必要特征的情况下可以以其他具体形式实施本发明。与此相关,应当理解,上述实施例在所有方面均为示例性的而非限制性的。本发明的范围应被解释为包括所附的权利要求书的意思以及范围和从与其等同的概念导出的所有的变更或变形,不应被理解为仅包括上述详细的说明。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
