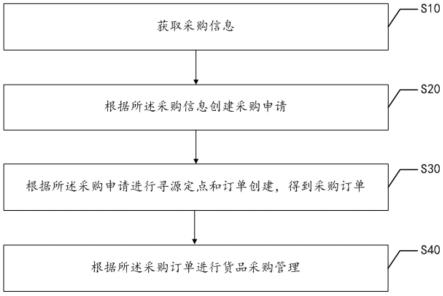
1.本发明属于工业过程中关键质量指标的软测量方法,具体涉及一种基于深度时空自编码器的软测量建模方法。
背景技术:
2.近年来,随着“碳高峰”和“碳中和”概念的提出,绿色智能制造越来越受到学术界和工业界的关注。为了实现这一目标,迫切需要在现代工业过程中实时准确地进行关键性能指标预测、控制和优化。然而,由于检测仪器的局限性和工业环境的恶劣性,许多与产品质量相关的关键变量很难测量。为此,研究人员提出了软测量技术,通过易于测量的辅助变量来预测难以测量的质量变量。目前,有两种典型的软测量方法:基于机理的模型和数据驱动的模型。基于机理的建模方法以物理化学理论为基础,需要依靠大量的先验知识,才能建立精确的数学模型。但由于工业过程的机理知识复杂,难以获取,导致机理建模十分困难。因此,数据驱动的软测量建模在工业过程中得到了广泛的应用。
3.在过去几十年中,随着人工智能和大数据的兴起,数据驱动的软测量模型已经广泛应用在流程工业中,如冶金、化工和炼油行业。传统的数据驱动建模方法主要包括各种多元统计分析方法和机器学习模型。如主成分分析(pca)、独立成分分析(ica)和偏最小二乘(pls)。但这些模型通常适用于从过程数据中获取线性相关性。为了提取复杂的非线性特征,一些著名的机器学习方法,如支持向量机(svm)和人工神经网络(ann)也被应用于工业过程。如今,随着人们对产品质量和环境保护要求的不断提高,现代工业过程变得非常复杂和大规模。浅层学习模型很难处理这些强非线性、高维、强耦合、动态的过程数据。为了克服这些方法固有的局限性,许多研究人员开始寻找一些深层的体系结构来对这些复杂的工业数据进行建模。hinton等人于2006年首次提出了无监督分层预训练和有监督微调方法,并成功解决了梯度消失和爆炸问题。至此,深度学习凭借其卓越自动捕获非线性特征的能力,获得了许多研究人员青睐。同时,也让深度网络模型成为了流程行业软测量的研究热点。
技术实现要素:
4.本发明针对工业过程中变量间具有较强的时空耦合关联性,导致关键质量质变难以预测的问题,创新性地提出了基于深度时空自编码器的软测量建模方法。
5.本发明采用以下技术方案实现:
6.本发明首先提供了一种基于深度时空自编码器的软测量建模方法,其包括如下步骤:
7.1)从实时工业过程数据库中读取相关的数据,并对数据进行预处理构造原始数据集;假设数据集中共有n个样本,其中m个辅助变量是易测量的,一个是需要预测的质量变量,那么原始数据集可以表示为 d(x,y)={(xj,yj)|j=1,2,3,...,n},其中j表示第j个样本,xj表示辅助变量,yj表示待测的质量变量;
8.2)利用滑窗思想对数据进行片段划分,以此构造训练集、验证集和测试集;滑窗的
时间片段长度为t,那么序列化之后的数据片段表示为
9.3)将自编码器按照时间顺序展开成链式结构,在相邻的两个自编码器中间嵌入记忆模块从而构造时序自编码器,所述的记忆模块用于存储有用的历史信息并传递给下一个自编码器,;
10.4)在时序自编码器获得隐层特征之后,将特征校准模块连接到时序自编码器的编码模块后面,并将隐层特征输入到特征校准模块中,量化提取的隐层特征与质量变量之间的重要度,搭建时空自编码器;然后将提取的时空特征输入到全连接层,对质量变量进行实时预测;
11.5)将单个时空自编码器进行堆叠搭建深度时空自编码器模型,对搭建的深度时空自编码器模型进行训练,并用测试数据集进行验证,最终得到经过验证的深度时空自编码器模型。
12.优选的,根据本发明的优选实施方式,所述的步骤1)中,从实际工业过程中搜集相关数据,利用数学分析和机理分析相结合的方法筛选出主要的辅助变量,然后对数据进行预处理,包括数据标注、数据清洗、数据转换、特征工程等步骤。
13.作为本发明的优选方案,所述的步骤2)中,为了更好地保留历史信息并有效获取时序特征,这里将自编码串联起来,形成链式结构,并设计一种记忆模块(memory module)嵌入其中,用于存储上一时刻的有效信息,并传入下一时刻。照此结构,依次连接,即可构成tae网络。
14.优选的,根据本发明的优选实施方式,所述的步骤3)中,对于给定的输入序列x={x1,x2,x3,...,x
t
},其中x
t
表示当前t时刻的辅助变量序列,时序自编码器的隐藏层表示为:
[0015][0016]
其中,分别代表当前时刻t时刻自编码器的权重和偏置, d是隐藏层h
t
的维数,m
t
代表当前时刻的记忆状态,f
t
代表时序自编码器的编码函数,h
t
代表时序自编码器获得的隐层特征,[]代表对向量进行拼接。
[0017]
优选的,根据本发明的优选实施方式,作为本发明的优选方案,步骤3)中,为了准确的描述tae提取的特征与质量变量的相关性,这里先使用一维全局平均池化对tae抽取的特征进行处理,然后将获得的矩阵输入到一个两层的全连接网络,用于学习每个特征的贡献度。这里为了更好学习到与质量变量相关的特征,将标签信息引入到网络中,并作为损失函数进行训练,这样可以获得目标相关的时空特征,提高软测量建模的精度。
[0018]
具体的,所述的步骤3)中所述记忆模块的处理流程如下:
[0019]
在记忆模块中,包含一种门控单元g
t-1
用于动态控制有多少历史信息需要保留或者遗忘,以便将有用的历史信息传递给下一个状态的自编码器,
[0020][0021]
特征构造函数用于构造一个大的特征向量,并作为评分函数g的输入,其的表达式为:
[0022][0023]
其中,x
t-1
代表上一时刻的输入,h
t-1
代表上一时刻的隐层特征,x
t
为当前的输入变
量,[]代表对这几个向量进行拼接;可以表示为:w
α
,w
β
,和w
λ
是需要学习的权重参数;
[0024]
门控单元采用两层简单全连接网络进行计算,和分别表示需要学习的权重,和分别代表两层网络的偏置,σ和tanh分别代表sigmoid激活函数和双曲正弦激活函数;
[0025][0026]
记忆模块的状态m
t
表达为:
[0027]mt
=g
t-1
gru(x
t-1
) (1-g
t-1
)m
t-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0028]
其中,gru代表记忆函数,由门控循环单元实现,用于捕获上一时刻的需要记忆的历史信息。
[0029]
优选的,根据本发明的优选实施方式,步骤4)中,设计特征校准模块去计算隐层特征与质量变量的重要程度,以便更加高效地抽取和质量变量相关的隐层特征;
[0030]
假设一个批量的输入变量为b代表批量大小,那么时序自编码器的输出表示为特征校准模块包括两个操作,第一个操作是采用一维全局平均池化对h在批量维度进行压缩,求平均值得到第二个操作是将q输入到一个两层的神经网络,用来自适应地学习每个隐层特征的权重,即代表了特征重要度;接着,将标签信息引入到时空自编码器网络中,用于有监督学习,捕获隐层特征和质量变量的空间关系。
[0031]
本发明所述深度时空自编码器是通过层次化堆叠多个时空自编码器构成的,可以逐层学习到与质量变量相关的分层特征。首先将原始数据输入到第一个时空自编码器,进行非线性变换后,通过最小化输入与输出的误差,获得第一个隐层特征,然后将得到的第一个隐层特征作为第二个时空自编码器的输入,获得第二个隐层特征,以此类推,便可构建深度时空自编码器。最后,通过预训练将获得的时空特征输给一个全连接层进行质量指标的在线预测。
[0032]
优选的,根据本发明的优选实施方式,步骤5)中,在构造了时空自编码器后,将多个时空自编码器进行堆叠构成深度时空自编码器,具体为:
[0033]
首先,对第一个时空自编码器进行预训练,获得隐层特征h1;然后将第一个时空自编码器的参数冻结,并将第一个隐层h1作为下一个自编码器的输入;同理,通过最小化输入与输出的误差,获得第二个时空自编码器的隐藏层特征h2,并作为第三个时空自编码器的输入;依次类推,一系列的时空自编码器不断分层堆叠,最终构成深度时空自编码器;最后,将提取的时空特征输入到全连接层,实现质量指标的在线预测。
[0034]
优选的,所述的步骤5)中,根据工业过程中的实时数据,关键质量指标在线监测模型的参数实时调整,不断优化迭代,使得模型具有较强的鲁棒性。
[0035]
本发明的有益效果在于:
[0036]
1、对于流程工业而言,整个生产过程是一个连续的物化反应过程,数据往往具有较强的时序性。自编码器是一种静态的网络结构,针对这种时序性数据,难以有效地提取数据的高层语义特征,给软测量建模带来了一些困难。为此本发明提出了一种时序自编码器(temporal autoencoder,tae),用于捕获数据内在的时间关联性,提高模型的特征表达能力。
[0037]
2、在实际工业生产中,过程变量众多,每个变量对质量指标的重要程度是不一样的。而原始的自编码器在进行特征学习时,是没有考虑标签信息的,这使得在预训练过程中提取的特征没有学习到和标签的相关性。针对这个问题,本发明将一种新的特征校准模块(feature recalibration module)嵌入到tae中构成时序自编码器(temporal autoencoder,stae),以此来显式地量化(explicitlyquantify)空间维度上特征贡献的差异性。特征重构模块并嵌入到时空自编码器中,用于提取与质量指标相关的潜在特征,提高模型的鲁棒性。
附图说明
[0038]
图1为基于深度时空自编码器的软测量建模示意图;
[0039]
图2时序自编码器示意图;
[0040]
图3时空自编码器示意图;
[0041]
图4深度时空自编码器示意图;
[0042]
图5基于深度时空自编码器的软测量模型在测试样本中预测结果对比图。
具体实施方式
[0043]
下面结合附图和实施例对本发明作进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
[0044]
图1提供了基于深度时空自编码器的软测量模型的具体构建与应用步骤,本发明的过程可以概述如下:首先,通过机理分析和专家知识,选取与质量指标相关的变量,并从实际工厂中读取相关数据和预处理,采用滑窗思想构建数据集;然后,分别搭建时序自编码器和时空自编码器,用于获取数据间的时间相关性和空间相关性;随后,将多个时空自编码器进行堆叠构成深度时空自编码器,用于提取数据的高层语义特征,并将得到的时空特征输入到一个全连接层中,实现对关键质量指标的实时预测;最后,对模型结果进行调试,并在实际工业现场检验。
[0045]
本实施例提供该基于深度时空自编码器的软测量建模方法的具体步骤,包括如下步骤:
[0046]
1)从实时工业过程数据库中读取相关的数据,并对数据进行预处理构造原始数据集;假设数据集中共有n个样本,其中m个辅助变量是易测量的,一个是需要预测的质量变量,那么原始数据集可以表示为 d(x,y)={(xj,yj)|j=1,2,3,...,n},其中j表示第j个样本,xj表示辅助变量,yj表示待测的质量变量;
[0047]
2)利用滑窗思想对数据进行片段划分,以此构造训练集、验证集和测试集;滑窗的时间片段长度为t,那么序列化之后的数据片段表示为
[0048]
3)将自编码器按照时间顺序展开成链式结构,在相邻的两个自编码器中间嵌入记忆模块从而构造时序自编码器,所述的记忆模块用于存储有用的历史信息并传递给下一个自编码器,如图2所示。对于给定的输入序列x={x1,x2,x3,...,x
t
},其中x
t
表示当前t时刻的辅助变量序列,时序自编码器的隐藏层表示为:
[0049]
[0050]
其中,分别代表当前时刻t时刻自编码器的权重和偏置,d 是隐藏层h
t
的维数,m
t
代表当前时刻的记忆状态,f
t
代表时序自编码器的编码函数,h
t
代表时序自编码器获得的隐层特征,[]代表对向量进行拼接。
[0051]
记忆模块的计算流程如下:
[0052]
在记忆模块中,包含一种门控单元g
t-1
用于动态控制有多少历史信息需要保留或者遗忘,以便将有用的历史信息传递给下一个状态的自编码器,
[0053][0054]
特征构造函数用于构造一个大的特征向量,并作为评分函数g的输入,其的表达式为:
[0055][0056]
其中,x
t-1
代表上一时刻的输入,h
t-1
代表上一时刻的隐层特征,x
t
为当前的输入变量,[]代表对这几个向量进行拼接;可以表示为:w
α
,w
β
,和w
λ
是需要学习的权重参数;
[0057]
门控单元采用两层简单全连接网络进行计算,和分别表示需要学习的权重,和分别代表两层网络的偏置,σ和tanh分别代表sigmoid激活函数和双曲正弦激活函数;
[0058][0059]
记忆模块的状态m
t
表达为:
[0060]mt
=g
t-1
gru(x
t-1
) (1-g
t-1
)m
t-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0061]
其中,gru函数代表记忆函数,用于捕获上一时刻的需要记忆的历史信息。在本实施例中,gru由门控循环单元(gate recurrent unit)实现,是一种循环神经网络。
[0062]
那么,tae的decoder部分可以表示为:
[0063][0064]
其中,和分别代表t时刻tae需要学习的权重和偏置。
[0065]
tae的损失函数为:
[0066][0067]
其中,n代表样本数量。
[0068]
4)在时序自编码器的基础上,开发一个特征校准模块,用于量化提取的特征与目标变量之间的重要度,搭建时空自编码器,如图3所示。然后将提取的时空特征输入到全连接层,对质量变量进行实时预测。设计特征校准模块去计算特征与质量变量的重要程度,以便更加高效地抽取和质量变量相关的潜特征。假设一个批量的输入变量为b代表批量大小,那么编码部分的输出可以表示为特征校准模块包括两个操作,第一个操作是采用一维全局平均池化(gap)对h在批量维度进行压缩,求平均值得到第二个操作是将q输入到一个两层的神经网络,用来自适应地学习每个特征的权重,即代表了特征重要度。接着,将标签信息引入到网络中,用于有监督学习,这样可以捕获特征和标签的空间关系。其中,q的表达式可以形式化为:
[0069][0070]
其中,q(t,m)表示经过gap操作后,第m个变量在t时刻的值,b为每个批次样本的数量。
[0071]
然后,采用带有两层全连接网络的门控机制来抽取特征的关联性,s代表每个特征的权重系数张量。
[0072][0073]
其中,和分别是两层全连接层的权重参数,σ代表sigmoid激活函数。
[0074]
接着,该权重系数张量s经过一个指数函数exp进行缩放处理,
[0075][0076]
此时,缩放后的张量表示提取的特征的重要度系数,通过哈达玛乘积后可以得到新的隐层特征表示,
[0077][0078]
然后,将新生成的隐层特征输入到一个全连接层,用来预测质量变量进行监督学习:
[0079][0080]
wh和bh分别代表全连接层的权重和偏置。
[0081]
在此监督学习过程中的损失函数可以表示为:
[0082][0083]
其中,y(i)代表第i个质量变量的真实值。
[0084]
最后,整个stae的代价函数表示为:
[0085]
loss
stae
=loss1 loss2.
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0086]
然后,整个网络通过反向传播,不断优化损失函数,学习模型的最优参数。这样可以让网络学习更好地进行特征学习,可以将每个特征重要度进行显示表达。
[0087]
5)根据图4方式,将单个时空自编码器进行堆叠,对搭建深度时空自编码器模型进行训练,并用测试数据集进行验证。首先,对第一个时空自编码器进行预训练,获得隐层特征h1;然后将第一个时空自编码器的参数冻结,并将第一个隐层h1作为下一个自编码器的输入。同理,通过最小化输入与输出的误差,获得第二个时空自编码器的隐藏层特征h2,并作为第三个时空自编码器的输入。依次类推,一系列的时空自便器进行不断分层堆叠,最终构成深度时空自编码器。最后,将提取的时空特征输入到全连接层,实现质量指标的在线预测。
[0088]
以下结合具体案例对本发明做进一步的说明。
[0089]
(1)脱硫过程描述与变量确定
[0090]
这个技术主要是为垃圾焚烧行业开发的hcl脱除干法系统,由此产生的副产物成分为氯化钠,被用来循环利用,回收作为原料再生产纯碱。sds干法脱酸喷射技术是将高效脱硫剂(20-25μm)均匀喷射在管道内,脱硫剂在管道内被热激活,比表面积迅速增大,与酸性烟气充分接触,发生物理、化学反应,烟气中的so2等酸性物质被吸收净化,具体化学反应
过程如式(16)和(17)所示。脱硫过程是一个机理复杂、影响因素众多、不确定性、强非线性、大滞后性、高耦合性的动态时变过程,难以建立精准的数学模型,数据驱动的软测量方法将是一个有效地解决方法。通过机理分析和专家知识,选择与烧结终点btp相关的辅助变量有14个,见表1所示。
[0091][0092]
2nahco3 so3→
na2so4 2co2 h2o
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17) 表1输入变量和输出变量
[0093][0094][0095]
(2)数据集的建立
[0096]
针对该过程,从脱硫工厂中等间隔采集了5000个样本,前3000个样本作为训练集,1000个样本作为验证集,剩下的1000个样本作为测试集。然后通过滑动窗口进行采样,窗口大小取10,这样可以获得不同的数据片段,用于构造数据集。模型结果采用决定系数r2、均方根误差rmse和平均绝对误差mae这三个评价指标来衡量,来表示其中,代表预测值,y代表真实值。
[0097][0098][0099][0100]
(3)模型建立
[0101]
步骤1:离线建模;
[0102]
步骤1.1:通过对脱硫机理分析,可以确定15个关键变量作为模型的输入特征,比
如入口温度、入口压力、入口标杆流量等关键变量。然后从数据库中实时读取数据,并进行数据滤波处理、数据平滑处理、数据归一化处理等预处理。
[0103]
步骤1.2:将处理好的数据输入到第一个时空自编码器模型,得到的隐层特征作为第二个时空自编码器的输入,以此类推,通过逐层学习获得原始数据的高层语义特征,最后通过一个全连接层进行在线预测,即可以实现脱硫后硫化物浓度的预测。并通过以上三个评价指标对模型进行参数调优和结构调整,直至获得一个精准的预测模型。
[0104]
步骤2:在线检测;
[0105]
步骤2.1:通过传感器和数据库实时读取在线数据,搜集辅助变量,并进行预处理,构造数据集。然后,将建立的预报模型部署在烧结专家系统里面,根据这些实时数据进行在线预报。
[0106]
步骤3:模型更新
[0107]
根据烧结过程中的实时数据,编码解码模型的参数也在实时调整,不断优化迭代,重复步骤1,使得模型具有较强的鲁棒性。
[0108]
(4)模型性能对比
[0109]
为了比较本发明所建立的模型深度时空自编码器模型(stackedspatial-temporal autoencoder,s2tae)优劣,这里使用的对比模型为两种传统的机器学习模型多层感知机mlp、堆叠自编码sae,变量加权自编码器vw-sae。
[0110]
表2展示了基于深度时空自编码器模型的预测效果。可以看出,传统的机器学习模型mlp在多步预测。sae模型由于可以进行堆叠获取高层语义特征,权值也是经过预训练得到的,结果表现比mlp更好。但是原始sae没法保证获得的特征与预测目标的相关性,为此,vw-sae通过计算特征与预测目标的相关性进行针对性学习,获取的特征更为有效,故表现比sae要好。本发明提出的s2tae 模型既考虑了时间相关性又考虑了空间相关性,表现最好,具体真实值和预测的对比如图5所示。结果表明该模型可以为脱硫工艺操作工调整工艺参数提供了充足的时间,可以提高产品的产量和质量,给企业带来较大的经济效应。
[0111]
表2模型预测结果对比
[0112][0113]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。