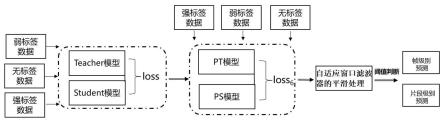
1.本发明涉及音频处理技术领域,具体涉及一种用于通话语音的噪声实时消除的方法。
背景技术:
2.在如今的现实生活中,通话语音信号通常会收到或多或少的噪音干扰,使得通话质量下降。语音去噪,是指取出语音片段中的不需要的干扰噪声,生成相对纯净的音频。
3.目前已有的降噪技术存在着以下局限:
4.传统去噪方法谱减法使用带噪的音频信号减去噪声信号的频谱。频谱法中假设语音中的噪声皆为加性噪声,所以将带噪语音频谱减去噪声频谱就可以得出纯净的语音信号。用这种方式去噪的前提是噪声信号是相对平稳的,而且当某些地方噪音强度大于平均值的时候,难以将噪声有效去除。维纳滤波去噪方法将带噪信号经过线性滤波器变换逼近原信号。维纳滤波去噪方法同样在非平稳噪声场景下效果欠佳。基于循环神经网络的去噪模型能利用丰富的数据集学习出参数,达到较好的去噪效果。但是循环神经网络的模型普遍参数里很大导致难以满足实时性。
5.可见当某些地方噪音强度大于平均值以及非平稳噪声场景下时,传统的降噪方式并不能达到较佳的效果,因此需要在传统的降噪技术的基础上进行改进。
技术实现要素:
6.针对现有技术的不足,本发明提供了一种用于通话语音的噪声实时消除的方法,通过设置前置数据段以及对音频数据进行去噪处理,一定程度上保证了音频的处理实时性和音频的去噪性能,同时还能够较快的对待处理音频信号做出响应,提高了整体效率。
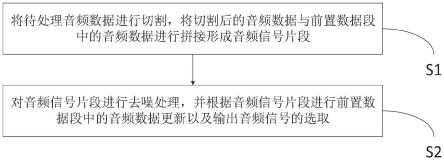
7.为了实现本发明的目的,本发明提供一种用于通话语音的噪声实时消除的方法,包括如下步骤:
8.s1:将待处理音频数据进行切割,将切割后的音频数据与前置数据段中的音频数据进行拼接形成音频信号片段;
9.s2:对音频信号片段进行去噪处理,并根据音频信号片段进行前置数据段中的音频数据更新以及输出音频信号的选取。
10.优选的,所所述步骤s2中去噪处理具体包括:
11.采用编码器对音频信号片段进行处理得到中间表示,在通过中间层对中间表示进行增强,最终通过解码器对增强后的中间表示进行处理得到增强后的音频数据。
12.优选的,所述编码器对音频信号片段进行处理得到中间表示的具体步骤为:
13.通过编码器中的卷积层和门控线性单元层进行运算处理得到中间表示,得到中间表示的计算公式为:
14.z=e(x)=f(f(f(f(f(x)))))
15.其中,z为中间表示,e(x)为编码器的处理操作,f(x)代表一个卷积块的处理操作;
16.所述编码器包括多组卷积块,其中,卷积块的计算公式为:
17.f(x)=glu(conv1d(relu(conv1d(x))))
18.其中,f(x)代表一个卷积块的处理操作,conv1d代表卷积操作,relu代表relu激活函数,glu代表门控线性单元操作,x代表输入的音频信号片段的数据。
19.优选的,通过解码器对增强后的中间表示进行处理得到增强后的音频数据的具体步骤为:
20.通过解码器中的卷积层和门控线性单元层对增强后的中间表示进行运算处理得到增强后的音频数据,其具体步骤为:
[0021][0022]
其中,为增强后的音频数据,为解码器中卷积层和门控线性单元层的运算处理,为一个卷积块的处理操作,为增强后的中间表示;
[0023]
其中,解码器包括多组依次连接的卷积块,卷积块的计算公式为:
[0024][0025]
其中,为一个卷积块的处理操作,conv1d代表卷积操作,relu代表relu激活函数,convtr1d代表转置卷积操作,glu代表门控线性单元操作。
[0026]
优选的,所述通过中间层对中间表示进行增强具体包括:
[0027]
通过中间层moglstm对中间表示进行增强得到增强后的中间表示,得到的中间表示的计算公式为:
[0028][0029]
其中,为增强后的中间表示,r(z)为中间层的处理操作,z为经过编码器处理得到的中间表示,moglstm表示的是moglstm模块的处理操作。
[0030]
优选的,所述moglstm模块处理的计算公式为:
[0031][0032]
其中,
[0033][0034]
其中,x、c
prev
和h
prev
均为moglstm模块中的运算符号,lstm是moglstm的基础,表示原始的lstm操作,σ是sigmold激活函数的激活操作,x
↑
,分别表示xi,中上标最大的那个取值,ri和qi为moglstm模块中的训练参数,i为[1
……
r]中的奇数,r为超参数。
[0035]
优选的,所述步骤s2之后还包括步骤s21,所述步骤s21为:
[0036]
重复执行步骤s1,待所述待处理音频信号处理完毕。
[0037]
优选的,所述步骤s2中进行前置数据段的更新以及输出音频信号的选取的具体步骤为:
[0038]
根据去噪前的音频信号片段中的音频数据进行前置数据段的音频数据更新,根据去噪后的音频信号片段进行输出音频信号的选取。
[0039]
优选的,所述步骤s1之前还包括步骤s01,所述步骤s01为:
[0040]
对前置数据段的数据容量进行配置。
[0041]
本发明的有益效果为:本发明提供的用于对通话语音的噪声实时消除的方法,通过设置前置数据段以及对音频数据进行去噪处理,一定程度上保证了音频的处理实时性和音频的去噪性能,同时还能够较快的对待处理音频信号做出响应,提高了整体效率。
附图说明
[0042]
通过附图中所示的本发明优选实施例更具体说明,本发明上述及其它目的、特征和优势将变得更加清晰。在全部附图中相同的附图标记指示相同的部分,且并未刻意按实际尺寸等比例缩放绘制附图,重点在于示出本的主旨。
[0043]
图1为本发明实施例提供的用于通话语音的噪声实时消除的方法的部分流程示意图;
[0044]
图2为本发明实施例提供的用于通话语音的噪声实时消除的方法的整体流程示意图;
[0045]
图3为本发明实施例提供的整体流程的简单示意图;
[0046]
图4为本发明实施例提供的用于对通话语音进行实时去噪方法的去噪模型的处理流程图;
具体实施方式
[0047]
下面结合附图和具体实施例对本发明技术方案作进一步的详细描述,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0048]
请参考图1-4,本发明实施例提供一种用于通话语音的噪声实时消除的方法,包括如下步骤:
[0049]
s1:将待处理音频数据进行切割,将切割后的音频数据与前置数据段中的音频数据进行拼接形成音频信号片段;
[0050]
s2:对音频信号片段进行去噪处理,并根据去噪处理后的音频信号片段进行输出音频信号的选取以及前置数据段中的数据更新。
[0051]
去噪处理主要是将待处理的音频数据送入去噪模型中进行去噪处理,当输入一个32毫秒的音频帧时(将待处理音频数据切割成32毫秒的音频数据时),将前置数据段中的64毫秒音频数据和输入音频帧收尾拼接,得到一个96毫秒的待处理音频信号片段,送入网络处理。
[0052]
请参考图1-4,本发明提供的用于通话语音的噪声实时消除的方法,主要解决的技术问题为:去除带噪音频噪声的语音增强问题,特别是在实时性要求极高的场景下的语音去噪,此场景下,需要对输入的带噪音频快速响应,以满足实时性要求。本方面旨在同时解决现有方法的去噪性能和去噪实时性。
[0053]
本发明的有益效果为:本技术主要采用流失处理(通过将待处理音频数据进行切割呈多个数据段,例如:待处理音频数据为128毫秒,则切割成32毫秒为一个音频数据进行处理,通过将较长的音频数据切割成多个较短的音频数据,从而对较短的音频数据进行单个处理)来保证音频的处理实时性,通过前置数据段的设置,使当前音频数据在进行处理的
时候,有历史的数据可以用于参考,同时对音频信号进行模型去噪处理,增强了模型的性能同时还保障了模型的实时性。
[0054]
所谓流式处理是指实时地处理一个或多个事件流,流式处理是一种编程范式,是一种思想。流的定义不依赖任何一个特定的框架、api或特性,只要持续地从一个无边界的数据集读取数据,然后对它们进行处理并生成结果,那就是在进行流式处理,重点是,整个处理过程必须是持续的。
[0055]
本技术所提供的用于通话语音的噪声实时消除的方法,能够有效的提高模型的去噪性能,使得经过模型去噪后的音频能够有效地消除环境中的诸多噪声,解决了由此导致的沟困难的问题,同时,模型在强实时的场景下表现良好,能较快地对输入音频作出响应,输出降噪后的音频,显著减少了系统响应时间。
[0056]
请参考图3-4,在优选实施例中,步骤s2中去噪处理具体包括:
[0057]
采用编码器对音频信号片段进行处理得到中间表示,在通过中间层对中间表示进行增强,最终通过解码器对增强后的中间表示进行处理得到增强后的音频数据。
[0058]
请参考图4,在优选实施例中,所述编码器对音频信号片段进行处理得到中间表示的具体步骤为:
[0059]
通过编码器中的卷积层和门控线性单元层进行运算处理得到中间表示,得到中间表示的计算公式为:
[0060]
z=e(x)=f(f(f(f(f(x)))))
[0061]
其中,z为中间表示,e(x)为编码器的处理操作,f(x)代表一个卷积块的处理操作;
[0062]
编码器包括多组卷积块(每个卷积块包括多个卷积层,其中门控线性单元层堆叠卷积层从而并行处理数据),其中,卷积块的计算公式为:
[0063]
f(x)=glu(conv1d(relu(conv1d(x))))
[0064]
其中,f(x)代表一个卷积块的处理操作,conv1d代表卷积操作,relu代表relu激活函数,glu代表门控线性单元操作,x代表输入的音频信号片段的数据。
[0065]
请参考图4,编码器中包含五组依次连接的卷积块,在第i个卷积块中,第一个卷积操作的卷积核大小为k,步长为s,输出通道为2
i-1
h,h为模型的超参数,在模型训练时一般设置为48,激活函数使用relu激活函数。第二个卷积操作的卷积核大小为k,步长为s,输出通道数与第一个卷积操作相同,激活函数使用glu激活函数;
[0066]
请参考图4,在优选实施例中,通过解码器对增强后的中间表示进行处理得到增强后的音频数据的具体步骤为:
[0067]
通过解码器中的卷积层和门控线性单元层对增强后的中间表示进行运算处理得到增强后的音频数据,其具体步骤为:
[0068][0069]
其中,为增强后的音频数据,为解码器中卷积层和门控线性单元层的运算处理,为一个卷积块的处理操作,为增强后的中间表示;
[0070]
其中,解码器包括多组依次连接的卷积块,卷积块的计算公式为:
[0071]
[0072]
其中,为一个卷积块的处理操作,conv1d代表卷积操作,relu代表relu激活函数,convtr1d代表转置卷积操作,glu代表门控线性单元操作。
[0073]
在第i个卷积块中,第一个卷积操作的卷积核大小为k,步长为s,输出通道为2
i-1
h,h为模型的超参数,在模型训练时一般设置为48,激活函数使用relu激活函数。第二个反卷积操作的卷积核大小为k,步长为s,输出通道数与第一个卷积操作相同,激活函数使用glu激活函数。
[0074]
在所述编码器和所述解码器中,卷积层和门控线性单元层需要进行多次运算来得到去噪模型的输出,其中门控线性单元是一种激活函数,具体公式为其中x代表输入,w、v、b、c都是要学习的参数,σ是sigmoid函数,是对应元素相乘。
[0075]
请参考图1-4,在进一步的优选实施例中,所述通过中间层对中间表示进行增强具体包括:
[0076]
通过中间层moglstm对中间表示进行增强得到增强后的中间表示,得到的中间表示的计算公式为:
[0077][0078]
其中,为增强后的中间表示,r(z)为中间层的处理操作,z为经过编码器处理得到的中间表示,moglstm表示的是moglstm模块的处理操作。
[0079]
请参考图1,在进一步的优选实施例中,所述moglstm模块处理的计算公式为:
[0080][0081]
其中,
[0082][0083]
其中,x、c
prev
和h
prev
均为moglstm模块中的运算符号,lstm是moglstm的基础,表示原始的lstm操作,σ是sigmold激活函数的激活操作,x
↑
,分别表示xi,中上标最大的那个取值,ri和qi为moglstm模块中的训练参数,i为[1
……
r]中的奇数,r为超参数。
[0084]
所述moglstm是在原始lsmt的基础上增加一个前置操作,来计算x
↑
和其中x
↑
和由上述公式进行迭代计算生成。
[0085]
请参考图1-2,在进一步的优选实施例中,所述步骤s2之后还包括步骤s21,所述步骤s21为:
[0086]
重复执行步骤s1,待所述待处理音频信号处理完毕。
[0087]
请参考图1-4,在优选实施例中,所述步骤s2中进行前置数据段的更新以及输出音频信号的选取的具体步骤为:
[0088]
根据去噪前的音频信号片段中的音频数据进行前置数据段的音频数据更新,根据去噪后的音频信号片段进行输出音频信号的选取。
[0089]
在优选实施例中,设切割后的音频数据为32毫秒音频数据,前置数据段为64毫秒的音频数据,从而拼接成96毫秒的音频数据,在进行前置数据段的音频数据更新时,主要将拼接后的96毫秒的音频数据中的后64毫秒的音频数据进行填充至前置数据段中,从而对前
置数据段进行更新,在进行输出音频信号选取时,选取去噪后的96毫秒的音频数据中的后32毫秒的音频数据作为输出音频信号或增强后的音频信息。
[0090]
请参考图1-4,在优选实施例中,所述步骤s1之前还包括步骤s01,所述步骤s01为:
[0091]
对前置数据段的数据容量进行配置。
[0092]
前置数据段的容量通常设置为64毫秒的音频信息,在去噪模型处理第一个待处理的音频信号之前,前置数据段使用64毫秒的空白音频信号填充,以保持方法执行的全程一致性。
[0093]
本发明的有益效果为:本发明提供了一种用于通话语音的噪声实时消除的方法,通过设置前置数据段以及对音频数据进行去噪处理,一定程度上保证了音频的处理实时性和音频的去噪性能,同时还能够较快的对待处理音频信号做出响应,提高了整体效率。
[0094]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。