1.本发明涉及用于在车厢中输出音频信号的装置,该装置包括至少一个音频输出设备,该音频输出设备被配置为在车厢中输出音频信号,特别是包括包含人类嗓音(特别是歌手嗓音)的至少一个音频信号分量的音频信号。
背景技术:
2.用于在车厢中输出音频信号的装置通常从现有技术中获知,该音频信号通常包含车厢中的人类嗓音(特别是歌手嗓音)的至少一个音频信号分量。
3.这些已知装置的缺点是它们通常设计复杂,例如需要特殊外部硬件,用于实施装置的特殊操作模式,诸如卡拉ok模式,在这种模式中,车厢中的一个或多个人可以随着音频信号(即,通常是音乐作品)唱歌,该音频信号经由装置在车厢中输出。这使得轻松且可靠地使用相应特殊操作模式(例如卡拉ok模式)麻烦且困难,因为用户必须提供所需的外部硬件并将其设置在车厢中。
技术实现要素:
4.本发明的目的是提供一种用于在车厢中输出音频信号的装置,其允许改进的(即,特别是容易且可靠的)特殊操作模式(例如卡拉ok模式)的实施,其特别不需要在车厢内需要设置的任何外部硬件。
5.该目的通过根据权利要求1的用于在车厢中输出音频信号的装置来实现。从属于权利要求1的权利要求涉及该装置的可能实施例。
6.本发明的第一方面涉及一种用于在车辆的车厢中输出音频信号的装置(以下称为“装置”),该音频信号特别是表示包括人声的音乐作品的音频信号,诸如流行歌曲、摇滚歌曲、嘻哈歌曲、经典歌曲等。该装置可以实施为车辆音频系统或形成车辆音频系统的一部分。术语“输出”通常被理解为作为声音输出或回放音频信号。
7.该装置被配置为在车厢中输出和/或再现音频信号,即特别是表示包括人声的音乐作品的音频信号,诸如流行歌曲、摇滚歌曲、嘻哈歌曲、经典歌曲等,该音频信号包括至少一个音频信号分量,该音频信号分量包含接收到的人类嗓音(特别是歌手的嗓音)。
8.相应音频信号可以从任何音频信号源提供,诸如数据载体设备(诸如u盘)、无线电设备(诸如fm收音机)、网络设备(诸如网络应用程序)、移动设备(诸如智能手机、智能手表、平板电脑、笔记本电脑)等。因此,该装置可以与相应音频信号源可连接或连接。
9.该装置包括至少一个音频输出设备,该音频输出设备被配置为在车厢中输出和/或再现至少一个音频信号(特别是包括至少一个音频信号分量的音频信号),该音频信号分量包含人类嗓音(特别是歌手的嗓音)。至少一个音频输出设备通常包括一个或多个音频输出元件,诸如扬声器。每个音频输出元件可以被分配到配备有该装置的车辆的该车厢或车厢中的特定位置或空间,即特别是特定座位。一个或多个音频输出元件通常可布置或布置成在该车厢中或车厢中输出相应音频信号。一个或多个音频输出元件可以可布置或布置在
配备有该装置的车辆的结构元件处和/或结构元件中,例如,仪表板、支柱、车门、天花板等。注意,一个或多个音频输出元件和至少一个音频输出设备可以分别是由该装置实施的车辆音频系统的标准部件。因此,至少从结构观点来看,该装置的至少一个音频输出设备可以是车辆音频系统的标准音频输出设备。
10.该装置还包括至少一个音频接收设备,该音频接收设备被配置为当至少一个音频输出设备在该车厢或车厢中输出该音频信号或音频信号时,接收位于配备有该装置的该车辆或车辆的该车厢或车厢中的至少一个人的人类嗓音信号,例如随着音频信号(特别是音乐作品)唱歌的至少一个人的嗓音。术语“人”通常是指该车厢或车厢中的任何人,诸如,例如驾驶员或副驾驶员。
11.至少一个音频接收设备通常包括一个或多个音频接收元件,诸如麦克风。每个音频接收元件可以被分配到配备有该装置的车辆的该车厢或车厢中的特定位置或空间,即特别是至少一个特定座位。一个或多个音频接收元件可以可布置或布置在配备有该装置的车辆的结构元件处和/或结构元件中,例如,仪表板、支柱、车门、天花板等,从而当至少一个音频输出设备在该车辆或车辆的该车厢或车厢中输出音频信号时,接收位于配备有该装置的该车辆或车辆的该车厢或车厢中的至少一个人的人类嗓音信号。注意,一个或多个音频接收元件和至少一个音频接收设备可以分别是由该装置实施的车辆音频系统的标准部件。因此,至少从结构观点来看,该装置的至少一个音频接收设备可以是车辆音频系统的标准音频接收设备。
12.至少一个音频接收设备因此允许在经由至少一个音频输出设备在该车厢中或车厢中输出音频信号期间在车厢中现场接收人类嗓音,即至少一个人的嗓音。经由至少一个音频接收设备在车厢中接收人类嗓音由此可以与经由至少一个音频输出设备在车厢中输出音频信号同时发生。
13.这种同时在该车厢或车厢中输出音频信号并在该车厢或车厢中接收人类嗓音可以形成利用该装置实施特殊操作模式(诸如卡拉ok模式)的基础。从下面将更明显地,一个或多个音频接收元件也可以可布置或布置成接收在该车厢或车厢中可声学感知的噪声(特别是来自外部噪声源的噪声)和/或接收通过接收经由所述至少一个音频接收设备在该车厢或车厢中可输出或输出的音频信号而生成的该车厢或车厢中的不期望噪声(特别是声学反馈)。
14.该装置还包括至少一个硬件实现的和/或软件实现的处理设备(特别是信号处理设备),其被配置为例如通过音频混合来组合将要输出或输出在该车厢或车厢中的音频信号与接收到的人类嗓音信号,以生成包含音频信号和接收到的人类嗓音信号的组合音频信号。经由至少一个音频输出设备在该车辆或车辆的该车厢或车厢中可输出或输出组合音频信号。处理设备因此允许生成包括实际音频信号的音频内容和接收到的人类嗓音信号两者的组合音频信号。换句话说,组合音频信号允许同时输出音频信号(例如音乐作品)和接收到的人类嗓音信号(例如随着音频信号唱歌的人的嗓音)。结果,可以实施特殊操作模式,即特别是卡拉ok模式。
15.至少一个音频输出设备因此被配置为在该车厢或车厢中输出相应组合音频信号。在该车厢或车厢中输出组合音频信号通常意味着在该车厢或车厢中同时输出音频信号(其可以被修改,如将在下面更详细地解释)和接收到的人类嗓音信号(其可以被修改,如将在
下面被更详细地解释)。至少一个音频输出设备因此可以被配置为在车厢中输出相应组合音频信号,即包括包含人类嗓音(特别是歌手的嗓音)的至少一个音频信号分量的音频信号(例如音乐作品)以及接收到的随着该车厢或车厢中的音频信号唱歌的至少一个人的人类嗓音信号。
16.由于一个或多个音频输出元件和至少一个音频输出设备分别以及一个或多个音频接收元件和至少一个音频接收设备分别可以是车辆音频系统的标准部件,因此该装置允许利用车辆音频系统的标准部件实施相应特殊操作模式,即特别是卡拉ok模式。因此,相应特殊操作模式(即特别是卡拉ok模式)可以以简单且可靠的方式实施,而无需提供特殊外部硬件。
17.处理设备或者被分配或可分配给处理设备的硬件实现的和/或软件实现的抑制设备可以被配置为抑制在该车厢或车厢中可输出或输出的音频信号中的包含人类嗓音(特别是歌手的嗓音)的音频信号分量。处理设备或抑制设备因此可以(也)被视为或表示为嗓音抑制器。因此,如上所述,可以修改音频信号。修改音频信号可以特别通过抑制包含人类嗓音(特别是歌手的嗓音)的该至少一个音频信号分量或至少一个音频信号分量来实施。结果,组合音频信号可以包括修改后的音频信号,即特别是具有包含人类嗓音(特别是歌手的嗓音)的(原始)音频信号分量的抑制的音频信号。简而言之,处理设备被配置为通过抑制包含人类嗓音(特别是歌手的嗓音)的音频信号分量来生成与原始音频信号不同的修改后的音频信号。抑制设备可以体现为或包括一个或多个合适的过滤器设备。
18.处理设备或抑制设备可以被配置为以可预定义或预定义的动态或静态抑制水平来抑制包含人类嗓音(特别是歌手的嗓音)的相应音频信号分量。因此,0%的抑制水平意味着不抑制相应音频信号分量,使得在不抑制相应音频信号分量的情况下输出音频信号,并且100%的抑制水平意味着完全抑制音频信号分量,使得在完全抑制相应音频信号分量的情况下输出音频信号。换句话说,抑制或者导致降低相应音频信号分量的能量水平(即特别是音量水平)或者(完全)消除相应音频信号分量。在任一情况下,抑制相应音频信号分量通常导致接收到的人类嗓音信号的更清晰的输出结果并且因此导致接收到的人类嗓音信号的更清晰的声学可感知性。
19.抑制包含人类嗓音的音频信号分量可能需要在音频信号中确定和/或提取包含要被抑制的人类嗓音的相应音频信号分量。处理设备或抑制设备因此可以分别被配置为在音频信号中或从音频信号确定和/或提取要被抑制的相应音频信号分量。这种确定和/或提取可以通过分析与可以分配给包含人类嗓音(例如歌手的嗓音)的音频信号分量和/或可以与不包含人类嗓音(例如包含乐器)的音频信号成分区分开的(特征)声学属性(例如特定频率范围)相关的音频信号的声学属性(例如频谱)来实现。特别地,处理设备或抑制设备可以被配置为从在该车厢或车厢中可输出或输出的音频信号中提取包含人类嗓音(特别是歌手的嗓音)的音频信号分量,并且将包含人类嗓音(特别是歌手的嗓音)的提取的音频信号分量与相应音频信号的不包含人类嗓音(特别是歌手的嗓音)的其他音频信号分量分离。一旦以相应方式确定和/或提取,包含该人类嗓音或人类嗓音的音频信号分量就可以如上所述被抑制。
20.处理设备可以被配置为经由将音频信号拆分为多个音频信号分量来从音频信号中提取相应音频信号分量。由此,经由将音频信号拆分为多个音频信号分量而获得的一个
音频信号分量表示包含该人类嗓音或人类嗓音(特别是歌手嗓音)的音频信号分量。音频信号的拆分可以包括关于要从不包含该人类嗓音或人类嗓音(特别是歌手的嗓音)的其他音频信号分量中拆分出的相应音频信号分量来分析音频信号。音频信号的分析可以基于可预定义或预定义的声学属性来执行,例如包含该人类嗓音或人类嗓音(特别是歌手的嗓音)的音频信号分量的幅度和/或频率。
21.附加地或替代地,处理设备或者被分配或可分配给处理设备的硬件实现和/或软件实现的拆分设备可以被配置为将音频信号拆分为多个音频信号分量,以获得至少一个中心信号分量、左信号分量和右信号分量。中心信号分量是表示从包括左音频输出通道和右音频输出通道的至少一个音频输出设备的中心方向和/或中心位置输出的由人声学感知的该音频信号分量或音频信号分量的音频信号的该分量或分量。左信号分量是表示从包括左音频输出通道和右音频输出通道的至少一个音频输出设备的相对于中心方向和/或中心位置(更)左方向和/或左位置输出的由人声学感知的音频信号分量的音频信号的该分量或分量。右信号分量是表示从包括左音频输出通道和右音频输出通道的至少一个音频输出设备的相对于中心方向和/或中心位置(更)右方向和/或右位置输出的由人声学感知的音频信号分量的音频信号的该分量或分量。
22.将音频信号相应拆分为相应中心信号分量、左信号分量和右信号分量是基于中心分量通常包含人类嗓音(特别是歌手的嗓音)的见解。因此,当获得中心分量时,通常还获得包含人类嗓音(特别是歌手的嗓音)的音频信号分量。
23.在这种情况下,音频信号通常是包括左音频信号分量和右音频信号分量的立体声信号。
24.所述至少一个音频接收设备可以被配置为接收位于该车厢或车厢中的至少一个第一人的人类嗓音信号以及位于该车厢或车厢中的至少一个另外的人的人类嗓音信号。从而,至少一个处理设备可以进一步被配置为利用至少一个第一声学修改参数修改接收到的位于该车厢或车厢中的至少一个第一人的人类嗓音信号,并且利用至少一个另外的声学修改参数修改接收到的位于该车厢或车厢中的至少一个另外的人的人类嗓音信号。可能需要将接收到的至少一个第一人(也包括一组第一人)的人类嗓音信号与接收到的至少一个另外的人(也包括一组另外的人)的人类嗓音信号分离,以用于不同地处理相应接收到的人类嗓音信号。相应接收到的人类嗓音信号的不同处理的示例是不同地改变音调和/或添加混响。
25.至少一个音频接收设备可以被配置为接收位于该车厢或车厢中的至少一个第一人(例如,驾驶员或副驾驶员)的人类嗓音信号以及位于该车厢或车厢中的至少一个另外的人的人类嗓音信号。因此,处理设备或者被分配或可分配给处理设备的抑制设备可以进一步被配置为抑制接收到的位于车厢中的至少一个另外的人的人类嗓音信号并且生成包含(仅)至少一个第一人的人类嗓音信号和至少一个另外的人的受抑制的人类嗓音信号的最终接收到的人类嗓音信号。因此,接收到的至少一个第一人(也包括一组第一人)的人类嗓音可以通过抑制接收到的至少一个另外的人的人类嗓音信号而与接收到的至少一个另外的人(也包括一组另外的人)的嗓音分离。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对接收到的至少一个另外的人的人类嗓音信号的抑制。抑制接收到的至少一个另外的人的人类嗓音信号可能需要将至少一个另外的人的人类嗓音信号
与至少一个第一人的人类嗓音信号分离,反之亦然。在这点上,以上关于从音频信号中确定和/或提取特定音频信号分量的注解以类似的方式适用。抑制设备可以体现为或包括一个或多个合适的过滤器设备。
26.使不同的接收到的人类嗓音信号能够被不同地处理和/或抑制,并从不同的音频输出元件(例如扬声器)输出可以在装置的卡拉ok模式中增加“兴奋度”。当存在多个音频接收元件(例如麦克风)时,自动选择接收例如最清晰的人类嗓音信号的音频接收元件并使其他音频接收元件静音可能是有用的,——这可以视为一种噪声抑制形式。此外,可以将多个接收到的人类嗓音信号进行处理并合并为一个信号,从而增强嗓音并抑制噪声——可以视为麦克风波束成形。
27.至少一个音频接收设备可以被配置为接收位于该车厢或车厢中的至少一个人的人类嗓音信号,以及在该车厢或车厢中可声学感知的噪声,特别是来自外部噪声源(即特别是该车厢或车厢外部或车辆外部的噪声源)的噪声。从而,处理设备或者被分配或可分配给处理设备的抑制设备可以被配置为抑制在该车厢或车厢中可声学感知的噪声并生成包含至少一个人的人类嗓音信号和受抑制的噪声的最终接收到的人类嗓音信号。因此,人的接收到的人类嗓音可以与例如在该车厢或车厢中可声学感知的外部噪声源的接收到的信号分离。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对在该车厢或车厢中可声学感知的接收到的噪声的信号的抑制。抑制在该车厢或车厢中可声学感知的接收到的噪声的信号可能需要将人类嗓音信号与在该车厢或车厢中可声学感知的接收到的噪声的信号分离,反之亦然。在这点上,以上关于从音频信号中确定和/或提取特定音频信号分量的注解以类似的方式适用。抑制设备可以体现为或包括一个或多个合适的过滤器设备。
28.处理设备或者被分配或可分配给处理设备的硬件实现和/或软件实现的抑制设备可以附加地或替代地被配置为抑制通过接收经由至少一个音频输出设备在该车厢或车厢中可输出或输出的音频信号而生成的该车厢或车厢中的不期望噪声,特别是声学反馈。因此,通过接收经由至少一个音频输出设备在该车厢或车厢中可输出或输出的音频信号而生成的该车厢或车厢中的不期望噪声(特别是声学反馈)可以被抑制。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对通过接收经由至少一个音频输出设备在该车厢或车厢中可输出或输出的音频信号而生成的不期望噪声的抑制。抑制通过接收在该车厢或车厢中可输出或输出的音频信号而生成的不期望噪声的信号可能需要将人类嗓音信号与通过接收在该车厢或车厢中可输出或输出的音频信号而生成的不期望噪声信号分离,反之亦然。在这点上,以上关于从音频信号中确定和/或提取特定音频信号分量的注解以类似的方式适用。抑制设备可以体现为或包括一个或多个合适的过滤器设备。
29.处理设备或者被分配或可分配给处理设备的硬件实现和/或软件实现的修改设备可以进一步被配置为修改在该车厢或车厢中可输出或输出的音频信号的至少一个音频信号分量(特别是包含人类嗓音(特别是歌手的嗓音)的音频信号分量)的至少一个声学可感知参数(特别是音调和/或混响),和/或被配置为修改接收到的在该车厢或车厢中的至少一个人的人类嗓音信号或接收到的人类嗓音信号的至少一个声学可感知参数(特别是音调和/或混响)。处理设备或修改设备因此可以(也)被视为或表示为声音增强器。修改相应音频信号分量和/或相应接收到的人类嗓音信号的声学可感知参数(诸如音调和/或混响)允
许协同调节相应组合音频信号的声学可感知参数,并且因此调节该车厢或车厢中的声学回放情况,例如,这对于实施特殊操作模式(诸如卡拉ok模式)可能是有用的。作为示例,通过改变音调和/或添加混响,唱歌人的接收到的人类嗓音信号可以声学适应该人随其唱歌的音乐作品,反之亦然。
30.修改在该车厢或车厢中可输出或输出的音频信号的至少一个音频信号分量的至少一个声学可感知参数(特别是音调和/或混响)也可能需要确定和/或提取要修改的相应音频信号分量。在这点上,以上关于从音频信号中确定和/或提取特定音频信号分量的注解以类似的方式适用。这同样适用于修改接收到的人类嗓音信号的至少一个声学可感知参数,特别是音调和/或混响。
31.至少一个音频接收设备可以被构建为或者可以包括至少一个移动音频接收元件,特别是手持音频接收元件。相应移动音频接收元件可以体现为移动麦克风,特别是手持麦克风。移动麦克风可以体现为有线麦克风或无线麦克风。
32.至少一个移动音频接收元件可以被分配或可分配给该车厢或车厢中的至少一个人座位。因此,该装置可以基于相应音频接收元件到该车厢或车厢中的相应人座位的分配来区分接收到的人类人嗓音。
33.还可想到的情况是,至少一个音频接收设备包括多个移动音频接收元件(特别是手持音频接收元件),由此相应移动音频接收元件的接收电平是可单独调节的。因此,可以实施表示至少一个主嗓音的信号和表示至少一个次嗓音的信号。
34.还可想到的情况是,麦克风提供有可以用作移动音频接收元件的至少一个人的移动终端,例如智能手机、智能手表、平板电脑、笔记本电脑等。在这种情况下,需要将相应移动终端与该装置连接,这可以通过有线或无线连接来实现。作为示例,在该车厢中或车厢中可以建立蓝牙或wifi连接。
35.本发明的第二方面涉及用于根据本发明第一方面的装置的硬件实现和/或软件实现的处理设备。处理设备被配置为组合(例如混合)音频信号和接收到的人类嗓音信号,以生成包含音频信号和接收到的人类嗓音信号的组合音频信号,经由至少一个音频输出设备在该车厢或车厢中可输出该组合音频信号。
36.关于本发明第一方面的装置的所有注解都经必要的变更适用于本发明的第二方面的处理设备。
37.本发明的第三方面涉及一种包括车厢和根据本发明的第一方面的装置的车辆,特别是客车,诸如轿车、卡车、货车等。该装置被配置为在该车厢或车厢中输出音频信号。
38.关于本发明第一方面的装置的所有注解都经必要的变更适用于本发明的第三方面的车辆。
39.本发明的第四方面涉及一种用于在车厢中输出和/或再现音频信号的方法。该方法包括以下步骤:
[0040]-特别是经由至少一个音频输出设备在车厢中输出音频信号、特别是包括至少一个音频信号分量的音频信号,该音频信号分量包含人类嗓音、特别是歌手的嗓音;
[0041]-当在车厢中输出音频信号时,特别是经由至少一个音频接收设备接收位于车厢中的至少一个人的人类嗓音信号;
[0042]-经由至少一个处理设备组合音频信号和接收到的人类嗓音信号以生成包含音频
信号和接收到的人类嗓音信号的组合音频信号;以及
[0043]-经由至少一个音频输出设备在车厢中输出和/或再现组合音频信号。
[0044]
关于本发明第一方面的装置的所有注解都经必要的变更适用于本发明的第四方面的方法。
附图说明
[0045]
参照附图描述了本发明的示例性实施例,其中唯一的附图示出了包括根据示例性实施例的装置的车辆的原理图。
具体实施例
[0046]
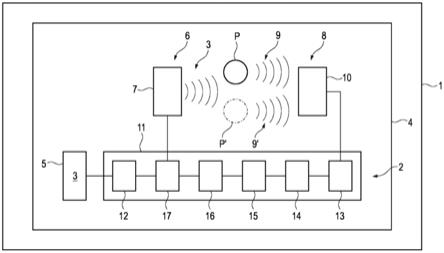
唯一的附图示出了包括根据示例性实施例的装置2的车辆1的原理图。
[0047]
装置2被配置为在车辆1的车厢4中输出和/或再现音频信号3,即特别是表示包括人声的音乐作品的音频信号3,诸如流行歌曲、摇滚歌曲、嘻哈歌曲、经典歌曲等,该音频信号3包括至少一个音频信号分量,该音频信号分量包含接收到的人类嗓音,特别是歌手的嗓音。
[0048]
音频信号3可以从任何音频信号源5提供,诸如数据载体设备(诸如u盘)、无线电设备(诸如fm收音机)、网络设备(诸如网络应用程序)、移动设备(诸如智能手机、智能手表、平板电脑、笔记本电脑)等。因此,装置2可以与相应音频信号源5可连接或连接。
[0049]
装置2包括音频输出设备6,该音频输出设备6被配置为在车厢4中输出和/或再现音频信号3、特别是包括至少一个音频信号分量的音频信号3,该音频信号分量包含人类嗓音、特别是歌手的嗓音。音频输出设备6包括一个或多个音频输出元件7,诸如扬声器。每个音频输出元件7可以被分配到车厢4中的特定位置或空间,即特别是特定座位(未示出)。音频输出元件7可布置或布置成在车厢4中输出相应音频信号3。音频输出元件7可以可布置或布置在车辆的结构元件处和/或结构元件中,例如仪表板、支柱、车门、天花板等。注意,音频输出元件7和音频输出设备6可以分别是由装置2实施的车辆音频系统的标准部件。因此,至少从结构观点来看,装置2的音频输出设备6可以是车辆音频系统的标准音频输出设备6。
[0050]
装置2还包括音频接收设备8,该音频接收设备8被配置为当音频输出设备6在车厢4中输出音频信号3时,接收位于车厢4中的至少一个人p的人类嗓音信号9,例如随着音频信号3(特别是音乐作品)唱歌的至少一个人p的嗓音。音频接收设备8包括一个或多个音频接收元件10,诸如麦克风。每个音频接收元件10可以被分配到车厢4中的特定位置或空间,即特别是至少一个特定座位。音频接收元件10可布置或布置在车辆2的结构元件处和/或结构元件中,例如,仪表板、支柱、车门、天花板等,从而当音频输出设备6在车厢4中输出音频信号3时,接收位于车厢4中的至少一个人p的人类嗓音信号。注意,音频接收元件10和音频接收设备8可以分别是由装置2实施的车辆音频系统的标准部件。因此,至少从结构观点来看,装置2的音频接收设备8可以是车辆音频系统的标准音频接收设备。
[0051]
音频接收设备8因此允许在经由音频输出设备6在车厢4中输出音频信号3期间在车厢4中现场接收人类嗓音,即至少一个人p的嗓音。经由音频接收设备8在车厢4中接收至少一个人p的人类嗓音因此可以与经由音频输出设备6在车厢4中输出音频信号3同时发生。
[0052]
这种同时在车厢4中输出音频信号3和在车厢4中接收人类嗓音可以形成利用装置
2实施特殊操作模式(诸如卡拉ok模式)的基础。从下面将更明显地,音频接收元件10也可以可布置或布置成接收在车厢4中可声学感知的噪声(特别是来自外部噪声源(未示出)的噪声)和/或接收通过接收经由音频接收设备8在车厢4中可输出或输出的音频信号3而生成的车厢4中的不期望噪声(特别是声学反馈)。
[0053]
装置2还包括硬件实现和/或软件实现的处理设备11(特别是信号处理设备),其被配置为例如通过经由混合设备17进行音频混合来组合将要输出或输出在车厢4中的音频信号3与接收到的人类嗓音信号9,以生成包含音频信号3和接收到的人类嗓音信号9的组合音频信号。经由音频输出设备6在车厢4中可输出或输出组合音频信号。处理设备11因此允许生成包括实际音频信号3的音频内容和接收到的人类嗓音信号9两者的组合音频信号。换句话说,组合音频信号允许同时输出音频信号3(例如音乐作品)和接收到的人类嗓音信号9(例如随着音频信号3唱歌的人p的嗓音)。结果,可以实施特殊操作模式,即特别是卡拉ok模式。
[0054]
音频输出设备6因此被配置为在车厢4中输出相应组合音频信号。在车厢4中输出组合音频信号意味着在车厢4中同时输出音频信号3(其可以被修改,如将在下面更详细地解释)和接收到的人类嗓音信号9(其可以被修改,如将在下面被更详细地解释)。音频输出设备6因此可以被配置为在车厢4中输出相应组合音频信号,即包括包含人类嗓音(特别是歌手的嗓音)的至少一个音频信号分量的音频信号3(例如音乐作品)以及随着车厢4中的音频信号3唱歌的至少一个人p的接收到的人类嗓音信号9。
[0055]
由于音频输出元件7和音频输出设备6以及音频接收元件10和音频接收设备8分别可以是车辆音频系统的标准部件,因此装置2允许利用车辆音频系统的标准部件实施相应特殊操作模式,即特别是卡拉ok模式。因此,相应特殊操作模式(即特别是卡拉ok模式)可以以简单且可靠的方式实施,而无需提供特殊外部硬件。
[0056]
处理设备11或者被分配或可分配给处理设备11的硬件实现和/或软件实现的抑制设备12可以被配置为抑制在车厢4中可输出或输出的音频信号3中的包含人类嗓音(特别是歌手的嗓音)的音频信号分量。处理设备11或抑制设备12因此可以(也)被视为或表示为嗓音抑制器。因此,如上所述,可以修改音频信号3。修改音频信号3可以特别通过抑制包含人类嗓音(特别是歌手的嗓音)的该至少一个音频信号分量或至少一个音频信号分量来实施。结果,组合音频信号可以包括修改后的音频信号,即特别是具有包含人类嗓音(特别是歌手的嗓音)的(原始)音频信号分量的抑制的音频信号。简而言之,处理设备11被配置为通过抑制包含人类嗓音(特别是歌手的嗓音)的音频信号分量来生成与原始音频信号3不同的修改后的音频信号。
[0057]
处理设备11或抑制设备12可以被配置为以可预定义或预定义的动态或静态抑制水平来抑制包含人类嗓音(特别是歌手的嗓音)的相应音频信号分量。因此,0%的抑制水平意味着不抑制相应音频信号分量,使得在不抑制相应音频信号分量的情况下输出音频信号3,并且100%的抑制水平意味着完全抑制音频信号分量,使得在完全抑制相应音频信号分量的情况下输出音频信号3。换句话说,抑制或者导致降低相应音频信号分量的能量水平(即特别是音量水平)或者(完全)消除相应音频信号分量。在任一情况下,抑制相应音频信号分量通常导致接收到的人类嗓音信号9的更清晰的输出结果并且因此导致接收到的人类嗓音信号9的更清晰的声学可感知性。
[0058]
抑制包含人类嗓音的音频信号分量可能需要在音频信号3中确定和/或提取包含要被抑制的人类嗓音的相应音频信号分量。处理设备或抑制设备因此可以分别被配置为在音频信号3中或从音频信号3确定和/或提取要被抑制的相应音频信号分量。这种确定和/或提取可以通过分析与可以分配给包含人类嗓音(例如歌手的嗓音)的音频信号分量和/或可以与不包含人类嗓音(例如包含乐器)的音频信号成分区分开的(特征)声学属性(例如特定频率范围)相关的音频信号3的声学属性(例如频谱)来实现。特别地,处理设备11或抑制设备12可以被配置为从在车厢4中可输出或输出的音频信号3中提取包含人类嗓音(特别是歌手的嗓音)的音频信号分量,并且将包含人类嗓音(特别是歌手的嗓音)的提取的音频信号分量与相应音频信号3的不包含人类嗓音(特别是歌手的嗓音)的其他音频信号分量分离。一旦以相应方式确定和/或提取,包含该人类嗓音或人类嗓音的音频信号分量就可以如上所述被抑制。
[0059]
处理设备11可以被配置为经由将音频信号3拆分为多个音频信号分量来从音频信号3中提取相应音频信号分量。由此,经由将音频信号3拆分为多个音频信号分量而获得的一个音频信号分量表示包含该人类嗓音或人类嗓音(特别是歌手嗓音)的音频信号分量。音频信号3的拆分可以包括关于要从不包含该人类嗓音或人类嗓音(特别是歌手的嗓音)的其他音频信号分量中拆分出的相应音频信号分量来分析音频信号3。音频信号3的分析可以基于可预定义或预定义的声学属性来执行,例如包含该人类嗓音或人类嗓音(特别是歌手的嗓音)的音频信号分量的幅度和/或频率。
[0060]
附加地或替代地,处理设备11或者被分配或可分配给处理设备11的硬件实现和/或软件实现的拆分设备(未示出)可以被配置为将音频信号3拆分为多个音频信号分量,以获得至少一个中心信号分量、左信号分量和右信号分量。中心信号分量是表示从该音频输出设备6或音频输出设备6的中心方向和/或中心位置输出的由人p声学感知的该音频信号分量或音频信号分量的音频信号3的该分量或分量。左信号分量是表示从音频输出设备6的相对于中心方向和/或中心位置(更)左方向和/或左位置输出的由人p声学感知的音频信号分量的音频信号3的该分量或分量。右信号分量是表示从音频输出设备6的相对于中心方向和/或中心位置(更)右方向和/或右位置输出的由人p声学感知的音频信号分量的音频信号3的该分量或分量。这特别适用于包括左音频输出通道和右音频输出通道的音频输出设备6的配置。
[0061]
将音频信号3相应拆分为相应中心信号分量、左信号分量和右信号分量是基于中心分量通常包含人类嗓音(特别是歌手的嗓音)的见解。因此,当获得中心分量时,通常还获得包含人类嗓音(特别是歌手的嗓音)的音频信号分量。
[0062]
在这种情况下,音频信号3通常是包括左音频信号分量和右音频信号分量的立体声信号。
[0063]
音频接收设备8可以被配置为接收位于车厢4中的至少一个第一人p的人类嗓音信号9和位于车厢4中的至少一个另外的人p’的人类嗓音信号9’。从而,处理设备11可以进一步被配置为利用至少一个第一声学修改参数修改接收到的位于车厢4中的至少一个第一人p的人类嗓音信号9并且利用至少一个另外的声学修改参数修改接收到的位于车厢4中的至少一个另外的人p’的人类嗓音信号9’。可能需要将接收到的至少一个第一人p(也包括一组第一人)的人类嗓音信号9与接收到的至少一个另外的人p’(也包括一组另外的人)的人类
嗓音信号分离,以用于不同地处理相应接收到的人类嗓音信号9、9’。相应接收到的人类嗓音信号9、9’的不同处理的示例是不同地改变音调和/或添加混响。
[0064]
音频接收设备8可以被配置为接收位于车厢4中的至少一个第一人p(例如,驾驶员或副驾驶员)的人类嗓音信号9和位于车厢4中的至少一个另外的人p’的人类嗓音信号9’。因此,处理设备11或者被分配或可分配给处理设备11的抑制设备13可以进一步被配置为抑制接收到的位于车厢4中的至少一个另外的人p’的人类嗓音信号9’并且生成包含(仅)至少一个第一人p的人类嗓音信号9’和至少一个另外的人p’的受抑制的人类嗓音信号9’的最终接收到的人类嗓音信号。因此,接收到的至少一个第一人9(也包括一组第一人9)的人类嗓音可以通过抑制接收到的至少一个另外的人p’的人类嗓音信号9’而与接收到的至少一个另外的人9’(也包括一组另外的人9’)的嗓音分离。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对接收到的至少一个另外的人p’的人类嗓音信号9’的抑制。抑制接收到的至少一个另外的人p’的人类嗓音信号9’可能需要将至少一个另外的人p’的人类嗓音信号9’与至少一个第一人p的人类嗓音信号9分离,反之亦然。在这点上,以上关于从音频信号3中确定和/或提取特定音频信号分量的注解以类似的方式适用。
[0065]
音频接收设备8可以被配置为接收位于车厢4中的至少一个人p的人类嗓音信号9,以及在车厢4中可声学感知的噪声,特别是来自外部噪声源(未示出)(即特别是车厢4外部或车辆1外部的噪声源)的噪声。从而,处理设备11或者被分配或可分配给处理设备11的抑制设备14可以被配置为抑制在车厢4中可声学感知的噪声并生成包含人p的人类嗓音信号9和受抑制的噪声的最终接收到的人类嗓音信号。因此,接收到的人p的人类嗓音可以与接收到的在车厢4中可声学感知的噪声的信号分离。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对接收到的在车厢4中可声学感知的噪声的信号的抑制。抑制接收到的在车厢4中可声学感知的噪声的信号可能需要将人类嗓音信号与接收到的在车厢4中可声学感知的噪声的信号分离,反之亦然。在这点上,以上关于从音频信号3中确定和/或提取特定音频信号分量的注解以类似的方式适用。
[0066]
处理设备11或者被分配或可分配给处理设备11的硬件实现和/或软件实现的抑制设备15可以附加地或替代地被配置为抑制通过接收经由音频输出设备6在车厢4中可输出或输出的音频信号3而生成的车厢4中的不期望噪声,特别是声学反馈。因此,通过接收经由音频输出设备6在车厢4中可输出或输出的音频信号3而生成的车厢4中的不期望噪声(特别是声学反馈)可以被抑制。可以以范围从100%(完全抑制)到0%(无抑制)的动态或静态抑制水平来执行对通过接收经由音频输出设备6在车厢4中可输出或输出的音频信号3而生成的不期望噪声的抑制。抑制通过接收在车厢4中可输出或输出的音频信号3而生成的不期望噪声的信号可能需要将人类嗓音信号与通过接收在车厢4中可输出或输出的音频信号3而生成的不期望噪声信号分离,反之亦然。在这点上,以上关于从音频信号3中确定和/或提取特定音频信号分量的注解以类似的方式适用。
[0067]
处理设备11或者被分配或可分配给处理设备11的硬件实现和/或软件实现的修改设备16可以进一步被配置为修改在车厢4中可输出或输出的音频信号3的至少一个音频信号分量(特别是包含人类嗓音(特别是歌手的嗓音)的音频信号分量)的至少一个声学可感知参数(特别是音调和/或混响),和/或被配置为修改接收到的在车厢4中的人p的人类嗓音信号9或接收到的人类嗓音信号9的至少一个声学可感知参数(特别是音调和/或混响)。处
理设备11或修改设备16因此可以(也)被视为或表示为声音增强器。修改相应音频信号分量和/或相应接收到的人类嗓音信号9的声学可感知参数(诸如音调和/或混响)允许协同调节相应组合音频信号的声学可感知参数,并且因此调节车厢4中的声学回放情况,例如,这对于实施特殊操作模式(诸如卡拉ok模式)可能是有用的。作为示例,通过改变音调和/或添加混响,接收到的唱歌人p的人类嗓音信号9可以声学适应人p随其唱歌的音乐作品,反之亦然。
[0068]
修改在车厢4中可输出或输出的音频信号3的至少一个音频信号分量的至少一个声学可感知参数(特别是音调和/或混响)也可能需要确定和/或提取要修改的相应音频信号分量。在这点上,以上关于从音频信号3中确定和/或提取特定音频信号分量的注解以类似的方式适用。这同样适用于修改接收到的人类嗓音信号9的至少一个声学可感知参数,特别是音调和/或混响。
[0069]
至少一个音频接收设备8可以被构建为或者可以包括至少一个移动音频接收元件10,特别是手持音频接收元件10。相应移动音频接收元件可以体现为移动麦克风,特别是手持麦克风。移动麦克风可以体现为有线麦克风或无线麦克风。
[0070]
至少一个移动音频接收元件10可以被分配或可分配给车厢4中的至少一个人座位。因此,装置2可以基于相应音频接收元件10到车厢4中的相应人座位的分配来区分接收到的人类人嗓音。
[0071]
还可想到的情况是,音频接收设备8包括多个移动音频接收元件10,特别是手持音频接收元件10,由此相应移动音频接收元件10的接收电平是可单独调节的。因此,可以实施表示至少一个主嗓音的信号和表示至少一个次嗓音的信号。
[0072]
还可想到的情况是,麦克风提供有可以用作移动音频接收元件10的人p的移动终端(未示出),例如智能手机、智能手表、平板电脑、笔记本电脑等。在这种情况下,需要将相应移动终端与装置2连接,这可以通过有线或无线连接来实现。作为示例,在车厢4中可以建立蓝牙或wifi连接。
[0073]
单个、多个或所有设备(例如被分配或可分配给处理设备11的抑制设备12-15和/或修改设备16)可以组合在一个或多个上级设备中。设备(例如被分配或可分配给处理设备11的抑制设备12-15和/或修改设备16)也可以体现为处理设备11的功能块。
[0074]
抑制设备12-15可以体现为或包括一个或多个合适的过滤器设备。
[0075]
装置2允许实施用于在车厢4中输出和/或再现音频信号的方法。该方法包括以下步骤:
[0076]-特别是经由至少一个音频输出设备6在车厢4中输出音频信号3,该音频信号3包括至少一个音频信号分量,该音频信号分量包含的人类嗓音,特别是歌手的嗓音;
[0077]-当在车厢4中输出音频信号3时,特别是经由至少一个音频接收设备8接收位于车厢4中的至少一个人p的人类嗓音信号9;
[0078]-经由至少一个处理设备11组合音频信号3和接收到的人类嗓音信号9以生成包含音频信号3和接收到的人类嗓音信号9的组合音频信号;以及
[0079]-经由至少一个音频输出设备6在车厢4中输出和/或再现组合音频信号。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。