1.本发明属于声音识别技术领域,特别涉及多尺度环境声音事件识别方法。
背景技术:
2.家庭环境中,智能安全监控系统可以为老人和婴幼儿提供安全监控。传统监控技术主要以视频监控为主,但是,视频监控存在很多不容忽略的问题。比如,人们期望的是系统能够在房间内家人出现危险的时自动发出预警而不是人工时刻观察显示器判断家人有没有危险;视频监控也存在着一些隐私问题,并且视频文件需要较大的存储空间这就给小型家用的终端设备的存储性能提出了挑战。而基于家庭环境声音事件识别技术的声音监控则有效的避免了这些问题,所以将声音监控和视频监控有效的结合在一起,能够进一步提高智能安全监控系统的稳定性和准确性。
3.针对家庭环境声音事件识别领域,早期的研究人员通常采用与人耳听觉特性相关的声音特征如基于人耳听觉特征的梅尔频谱倒谱系数(mel frequency cepstral coefficients),和基于声道模型的线性预测倒谱系数(linear predictive cepstral)然后将获取到的声音特征输入到如高斯混合模型(gaussian mixed model),隐马尔科夫模型(hidden markov model),支持向量机(support vector machine)和多层感知机(multilayer perceptron)中进行数据的拟合,以实现对家庭环境声音事件的识别。近些年来随着深度学习领域的发展,越来越多的研究学者将深度学习引入了家庭环境声音事件领域。将基于原始家庭环境声音事件波形提取出来的二维声音特征输送到神经网络中,通过神经网络中神经元自动提取高维特征向量,然后将提取的高维特征向量送到池化层处理得到识别结果。
4.但是在真实环境中通常在同一时间内会发生多种声音事件,这不但给神经网络的识别带来了困难,而且给研究人员的数据标注带来了挑战。
5.为了充分利用大量的无标签数据,研究人员通过引入半监督学习算法来解决这一问题。但是大多数基于半监督学习算法设计的模型,需要student模型参数更新带动teacher模型参数更新,因此无法解决家庭环境声音事件帧级别预测和片段级别预测有关感受野之间的冲突。此外,针对神经网络输出概率矩阵的平滑处理,常用固定窗口值得中值滤波器,这种方法的缺点就是无法根据不同类型的家庭环境声音事件有针对性的设置合适的窗口大小,模糊了声音的边界定位。
技术实现要素:
6.针对现有技术存在的不足,本发明提供一种多尺度环境声音事件识别方法,在充分利用大量无标签多尺度环境声音事件数据的基础上,平衡帧级别预测和片段级预测之间有关感受野的冲突;同时通过多尺度的特征空间映射和自适应滤波窗口有效的拟合不同持续时间的多尺度环境声音事件数据;此外,本发明还通过双向的时间序列特征扫描和不同池化模块的相互作用进一步提升多尺度环境声音事件的识别精度。
7.为了解决上述技术问题,本发明采用的技术方案是:多尺度环境声音事件识别方法,包括以下步骤:s1、获取多尺度环境声音事件的原始波形数据;s2、将多尺度环境声音事件的原始波形数据转换为二维音频特征图;s3、基于改进mean-teacher算法进行双向定位多尺度环境声音事件识别,步骤如下:s301、构建两个不同感受野大小的神经网络模型,作为teacher模型和student模型,两个不同结构的模型相互约束训练,学习步骤s2获取的二维音频特征图帧级别的信息和片段级别的信息,提取帧级别特征和片段级特征,将训练好的模型作为高维特征提取模块;s302、构建两个具有相同网络结构的ps模型和pt模型,并采用mean-teacher算法联合训练利用无标签的数据:通过不同大小的卷积核对高维特征提取模块输出的特征图进行特征空间的重映射,得到不同细粒度的特征信息,然后通过双向扫描定位不同细粒度特征信息的聚合结果,得到时序特征图;将时序特征图经过基于注意机制的实例级池化方法处理得到多尺度环境声音事件识别的预测概率矩阵;s4、预测概率矩阵经过自适应窗口滤波器的平滑处理,得到平滑预测结果,逐元素的与设定的阈值比较,得到最终的多尺度环境声音事件识别结果。
8.进一步的,所述teacher模型包括多组卷积模块a、一层卷积核为1*1的卷积层、基于注意力机制的嵌入级池化模块和全连接层,其中每组卷积模块a均包括两层卷积层、一层最大池化层和一层遗忘层;所述student模型包括多组卷积模块b、基于注意力机制的嵌入级池化模块eatp和全连接层,其中每组卷积模块b包括一层卷积层和一层最大池化层,并且仅在特征维度进行压缩。
9.进一步的,s301高维特征提取模块具体训练流程如下:经过步骤s1、s2得到的特征图作为student模型的输入,对进行扰动得到,将作为teacher模型的输入,公式如下:其中random()为符合正态分布的随机噪声函数;通过student模型的输出、teacher模型的输出和损失函数bce()进行student模型参数和teacher模型参数的更新:
其中,为teacher模型和student模型弱标签预测结果和真实标签y的弱标签损失的加和;为teacher模型和student模型强标签预测结果和真实标签y的强标签损失的加和;为以teacher模型弱标签预测结果为真实标签与student模型弱标签预测结果的损失和倍以teacher模型强标签预测结果为真实标签与student模型强标签预测结果的损失;为倍以student模型弱标签预测结果为真实标签与teacher模型弱标签预测结果的损失和以student模型强标签预测结果为真实标签与teacher模型强标签预测结果的损失;为影响因子,y为真实标签,函数作用为获得预测结果,bce()为二元交叉熵函数;为真实标签y的弱标签,为student模型的弱标签预测结果,为teacher模型的弱标签预测结果,为真实标签y的强标签,为student模型的强标签预测结果,为teacher模型的强标签预测结果;通过最小化loss得到表征能力最好的student模型,改进的mean-teacher算法通过损失和利用无标签的数据并使不同网络架构的teacher模型和student模型共同训练,相互制约,其中,和中的取值如下:其中n为神经网络训练的总轮数,epoch为当前神经网络训练的轮次。
10.进一步的,所述ps模型和pt模型分别包括多组卷积模块c、双向定位模块和基于注意力机制的实例级池化模块,其中卷积模块c包括一层卷积层和一层最大池化层,并且仅在特征维度进行压缩;并且卷积模块c的网络参数由上一步骤s301训练好的student模型参数进行初始化,所述双向定位模块包括两组gru模块。
11.进一步的,步骤s302具体流程如下:将卷积模块c输出的特征图m,和经过加噪的分别输入到ps模型和pt模型的双向定位模块中;由于ps模型和pt模型的流程相同,下面仅描述ps模型流程:对于输入的特
征图m,采用卷积核大小为、、的卷积层进行不同尺度的特征空间映射,得到特征图、、; 特征图、、在通道域进行拼接得到特征图fk,最后通过卷积核大小为1的卷积层对特征图fk进行降维,得到特征图f;将特征图f分别以正序和反序输入到两组gru模块,然后按位置逐个取两组gru模块输出的最大值,得到时序特征图;最后将时序特征图输入到基于注意力机制的实例级池化模块,得到强标签预测概率矩阵和弱标签的预测概率矩阵,其中,为第一帧在类别1下的预测概率,为第t帧在类别1下的预测概率,为第一帧在类别n下的预测概率,第t帧在类别n下的预测概率;为类别1的总体预测概率,为类别2的总体预测概率,为类别n的总体预测概率。进一步的,通过ps模型的输出、pt模型的输出、损失函数bce()和mse()进行ps模型参数和pt模型参数的更新:的更新:的更新:其中为ps模型弱标签预测结果和真实弱标签的损失与ps模型强标签预测结果和真实强标签损失的加和,为ps模型强标签预测结果和pt模型强标签预测结果的损失和ps模型弱标签预测结果和pt模型弱标签预测结果损失的加和,mse()为均方差损失函数,bce()为二元交叉熵函数,为ps模型的弱标签预测结果,为ps模型的强标签预测结果,为pt模型的弱标签预测结果,为pt模型的强标签预测结果。
12.进一步的,所述基于注意力机制的嵌入级池化模块和基于注意力机制的实例级池化模块在处理数据时,分别如下:所述基于注意力机制的嵌入级池化模块,对输入的高维特征进行特征空间的映射得到不同帧在不同类别下的注意力权重值,其中t为帧长,c为类别;然后基于高维特征和权重值得到上下文特
征:上下文特征h经过全连接层的降维得到最终的网络输出结果,其中d为上层输出高维特征,为特征向量,为不同帧在类别c下的注意力权重矩阵,为不同帧在类别c下的注意力权重向量;所述基于注意力机制的实例级池化模块,对输入的高维特征,其中为不同帧的高维特征向量,先通过全连接层的映射得出强标签的预测概率矩阵 ,其中为第一帧在类别1下的预测概率,为第t帧在类别1下的预测概率,为第一帧在类别n下的预测概率,第t帧在类别n下的预测概率;然后强标签的预测概率矩阵进行特征空间的映射得到不同位置的注意力权重值,其中为第一帧在类别1下的注意力权重,为第t帧在类别1下的注意力权重,为第一帧在类别n下的注意力权重,第t帧在类别n下的注意力权重;最后强标签的预测概率矩阵与对应位置的注意力权重值点乘得到最终的网络输出结果。
13.进一步的,步骤s4中,根据不同类别的多尺度环境声音事件的平均持续时间,自适应的设置中值滤波器窗口的大小window:其中,为参数;将平滑处理后的概率矩阵逐元素的与设定的阈值进行比较,得出最终的识别结果。
14.与现有技术相比,本发明优点在于:(1)本发明提出一种基于改进mean-teacher算法的双向定位多尺度环境声音事件识别方法,尤其适用于家庭环境声音事件识别方法,为了进一步的提高家庭环境声音事件的识别能力,引入了神经网络模型,通过神经元学习拟合家庭环境声音数据。通过数据增强和改进的mean-teacher解决了大量无标签数据无法有效利用的问题。
15.(2)针对家庭环境声音事件帧级别预测和片段级别预测感受野之间的冲突,通过设计合理的损失函数,使得两个不同细粒度的神经网络模型能够相互学习,相互约束,提高最终的环境声音识别精度。
16.(3)由于不同声音事件在一段事件内的持续事件不同,叠加状态不同难以得到剥离和识别。通过设计双向定位模块,先采用不同的细粒度提取特征信息,然后将不同细粒度信息聚合起来,极大的丰富了特征图。双向的扫描定位和自适应滤波窗口的引入,更加精准的标记出了声音事件的边界,提高识别精度。
附图说明
17.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图:图1为实施例中的一段时间内家庭环境声音的示意图;图2为实施例中的家庭环境声音事件的数据分布;图3为实施例中的高维特征提取模块示意图;图4 为实施例中的ps模型示意图;图5 为本发明的基于注意力机制的实例级池化模块;图6 为本发明的基于注意力机制的嵌入级池化模块;图7 为本发明的总体流程图。
具体实施方式
18.下面结合附图及具体实施例对本发明作进一步的说明。
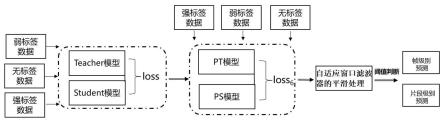
19.本发明提供一种多尺度环境声音事件识别方法,适用于多种场景下的多尺度声音事件,尤其适用于家庭环境声音事件识别。本实施例以家庭环境声音事件识别为例说明,结合图7,本发明包括以下步骤:s1、获取多尺度(家庭)环境声音事件的原始波形数据。
20.s2、将多尺度(家庭)环境声音事件的原始波形数据转换为二维音频特征图。
21.s3、基于改进mean-teacher算法进行双向定位多尺度环境声音事件识别,步骤如下:s301、构建两个不同感受野大小的神经网络模型,作为teacher模型和student模型,两个不同结构的模型相互约束训练,学习步骤s2获取的二维音频特征图帧级别的信息和片段级别的信息,提取帧级别特征和片段级特征,将训练好的模型作为高维特征提取模块,其中teacher模型和student模型的输入为弱标签数据、无标签数据、强标签数据;s302、构建两个具有相同网络结构的ps模型和pt模型,并采用mean-teacher算法联合训练利用无标签的数据,其中ps模型和pt模型的输入为弱标签数据、无标签数据、强标签数据:通过不同大小的卷积核对高维特征提取模块输出的特征图进行特征空间的重映射,得到不同细粒度的特征信息,然后将不同细粒度特征信息聚合,通过双向扫描定位不同细粒度特征信息的聚合结果,得到时序特征图;将时序特征图经过基于注意机制的实例级池化方法处理得到多尺度环境声音事件识别的预测概率矩阵;
s4、预测概率矩阵经过自适应窗口滤波器的平滑处理,得到平滑预测结果,逐元素的与设定的阈值比较,得到最终的多尺度环境声音事件识别结果(可获得帧级别预测和片段级别预测)。
22.首先需要说明的是,家庭声音事件数据难以标注和需要有效利用的必要性。从图1可以看出,在一段声音的持续时间内,可能同时发生多种家庭声音事件,如讲话、盘子破碎、吸尘器等声音事件可能同时发生。不同的家庭声音事件相互重叠,给研究人员的数据标签标注和声音事件的头尾划分带来了挑战。从图2可以看出,其中,弱标签和无标签的数据占据了大约90%的总数据量。如果不能有效的利用弱标签数据和无标签数据进行训练,无疑会丢失大量的样本信息,从而影响神经网络模型的识别精度。即使通过数据增强等方法扩充强标签数据的数据量,也会带来过拟合和引入噪声的问题。其中弱标签数据是指仅有声音事件类型标注的数据,强标签数据是指既有声音事件类型的标注而且有起止时间标注的数据,无标签数据是指没有进行标注的数据。
23.为解决这一问题,本发明设计了步骤s3改进的mean-teacher算法。由于半监督领域常用的mean-teacher算法,是通过构建两个相同结构相同的网络模型,然后将student模型的参数加权平均传递给teacher模型,通过损失函数优化,进行联合训练。而家庭环境声音的识别需要神经网络同时输出帧级别的预测和片段级别预测。帧级别预测需要较小的感受野,而片段级别预测需要较大的感受野,这种感受野的冲突,导致不能通过构建单一的网络模型架构解决家庭环境声音的识别问题。本发明设计了一种新的适用于家庭环境等多尺度环境声音事件识别的模型架构,基于对输入数据进行轻微扰动不影响神经网络输出这一前提,将提取出来的二维音频特征图和加入白噪声的二维音频特征图分别输入到student模型和teacher模型来利用无标签的数据。本发明使得两个不同感受野尺度的神经网络模型既能够联合训练又能利用大量的无标签数据,进而有效提取帧级别特征和片段级特征,解决帧级别预测和片段级别预测有关神经网络感受野设计之间的冲突。下面结合附图介绍本发明的模型架构。
24.结合图3、图7所示,teacher模型包括多组卷积模块a(卷积模块a设置为5组时效果较好)、一层卷积核为1*1的卷积层、基于注意力机制的嵌入级池化模块(eatp)和全连接层,其中每组卷积模块a均包括两层卷积层、一层最大池化层和一层遗忘层。这种较深的网络结构设计使得teacher模型拥有较大的感受野,使得teacher模型拥有对片段级别预测更好的性能。
25.student模型包括多组卷积模块b(卷积模块b设置为4组时效果较好)、基于注意力机制的嵌入级池化模块(eatp)和全连接层,其中每组卷积模块b包括一层卷积层和一层最大池化层,并且仅在特征维度进行压缩,保留了丰富的时序信息。student模型相较于teacher模型拥有较浅的网络结构,这种网络结构设计使得student模型拥有更好的细节感知能力,使得student模型拥有对帧级别更好的预测效果。本发明通过改进mean-teacher算法的损失函数使网络不但能够利用无标签的数据,而且使student模型同样具有良好的片段级预测能力。
26.作为一个优选的实施方式,步骤s301高维特征提取模块具体训练流程如下:经过步骤s1、s2得到的特征图作为student模型的输
入,对进行扰动得到,将作为teacher模型的输入,公式如下:其中random()为符合正态分布的随机噪声函数;通过student模型的输出、teacher模型的输出和损失函数bce()进行student模型参数和teacher模型参数的更新:的更新:的更新:的更新:的更新:其中,为teacher模型和student模型弱标签预测结果和真实标签y的弱标签损失的加和;为teacher模型和student模型强标签预测结果和真实标签y的强标签损失的加和;为以teacher模型弱标签预测结果为真实标签与student模型弱标签预测结果的损失和倍以teacher模型强标签预测结果为真实标签与student模型强标签预测结果的损失;为倍以student模型弱标签预测结果为真实标签与teacher模型弱标签预测结果的损失和以student模型强标签预测结果为真实标签与teacher模型强标签预测结果的损失;为影响因子,y为真实标签,函数作用为获得预测结果,bce()为二元交叉熵函数;为真实标签y的弱标签,为student模型的弱标签预测结果,为teacher模型的弱标签预测结果,为真实标签y的强标签,为student模型的强标签预测结果,为teacher模型的强标签预测结果;通过最小化loss得到表征能力最好的student模型,改进的mean-teacher算法通过损失和利用无标签的数据并使不同网络架构的teacher模型和student
模型共同训练,相互制约,其中,和中的取值如下:其中n为神经网络训练的总轮数,epoch为当前神经网络训练的轮次,由于student模型对片段级预测的能力不如teacher模型,而teacher模型的帧级别预测能力不如student模型。所以在经过10个epoch以后,才通过student模型对teacher模型的弱标签预测进行约束和通过teacher模型对student模型的强标签预测进行约束,平滑了训练过程,最终得到拥有片段级预测能力和帧级预测能力的student模型,并将其用于下一阶段(步骤s302)的训练。
27.作为一个优选的实施方式,步骤s302设计了ps模型、pt模型,并采用mean-teacher算法联合训练利用无标签的数据。不同于上一阶段的训练,ps模型和pt模型具有相同的网络结构。ps模型和pt模型分别包括多组卷积模块c(卷积模块c设置为4组时效果较好)、双向定位模块和基于注意力机制的实例级池化模块(iatp),其中卷积模块c包括一层卷积层和一层最大池化层,并且仅在特征维度进行压缩;并且卷积模块c的网络参数由上一步骤s301训练好的student模型参数进行初始化。双向定位模块包括两组gru模块,不同细粒度特征信息聚合后的结果分别以正序和反序输入到ps模型和pt模型的gru模块获取时序特征图。
28.步骤s302具体流程如下:由于,不同家庭环境声音事件的时间跨度不同,将卷积模块c输出的特征图m,和经过加噪的分别输入到ps模型和pt模型的双向定位模块中;由于ps模型和pt模型的流程相同,结合图4、图7所示,下面仅描述ps模型流程:对于输入的特征图m,采用卷积核大小为、、的卷积层进行不同尺度的特征空间映射,得到特征图、、; 特征图、、在通道域进行拼接得到特征图fk,最后通过卷积核大小为1的卷积层对特征图fk进行降维,得到特征图f。
29.将特征图f分别以正序和反序输入到两组gru模块,然后按位置逐个取两组gru模型输出的最大值,得到时序特征图。
30.最后将时序特征图输入到基于注意力机制的实例级池化模块(iatp),得到强标签预测概率矩阵和弱标签的预测概率矩阵,其中,为第一帧在类别1下的预测概率,为
第t帧在类别1下的预测概率,为第一帧在类别n下的预测概率,第t帧在类别n下的预测概率;为类别1的总体预测概率,为类别2的总体预测概率,为类别n的总体预测概率。通过ps模型的输出、pt模型的输出、损失函数bce()和mse()进行ps模型参数和pt模型参数的更新:的更新:的更新:其中为ps模型弱标签预测结果和真实弱标签的损失与ps模型强标签预测结果和真实强标签损失的加和,为ps模型强标签预测结果和pt模型强标签预测结果的损失和ps模型弱标签预测结果和pt模型弱标签预测结果损失的加和,mse()为均方差损失函数,bce()为二元交叉熵函数,为ps模型的弱标签预测结果,为ps模型的强标签预测结果,为pt模型的弱标签预测结果,为pt模型的强标签预测结果。通过最小化得到性能最好的ps模型。
31.作为一个优选的实施方式,步骤s301和步骤s302这两个阶段最终决策层分别采用基于注意力机制的嵌入级池化模块和基于注意力机制的实例级池化模块。结合图6所示,基于注意力机制的嵌入级级池化模块,对输入的高维特征进行特征空间的映射得到不同帧在不同类别下的注意力权重值,其中t为帧长,c为类别;然后基于高维特征和权重值得到上下文特征:上下文特征h经过全连接层的降维得到最终的网络输出结果,其中d为上层输出高维特征,为特征向量,为不同帧在类别c下的注意力权重矩阵,为不同帧在类别c下的注意力权重向量。
32.结合图5所示,基于注意力机制的实例级池化模块,对输入的高维特征,其中为不同帧的高维特征向量,先通过全连接层的映射得出强标签的预测概
率矩阵 ,(其中为第一帧在类别1下的预测概率,为第t帧在类别1下的预测概率,为第一帧在类别n下的预测概率,第t帧在类别n下的预测概率);然后强标签的预测概率矩阵进行特征空间的映射得到不同位置的注意力权重值,(其中为第一帧在类别1下的注意力权重,为第t帧在类别1下的注意力权重,为第一帧在类别n下的注意力权重,第t帧在类别n下的注意力权重);最后强标签的预测概率矩阵与对应位置的注意力权重值点乘得到最终的网络输出结果。
33.基于注意力机制的嵌入级池化模块更加依赖输入的高维特征,所以本发明将基于注意力机制的嵌入级池化模块应用于第一阶段(步骤s301)的训练,以求得到更好的特征提取前端。而基于注意力机制的实例级池化模块更加依赖强标签的预测精度,经过双向定位模块的处理,得到了较好的强标签预测,所以将基于注意力机制的实例级池化模块应用于第二阶段(步骤s302)。本发明在不同阶段根据其特性应用不同的池化模块进一步提高了家庭环境声音事件识别的精度。
34.最后ps模型输出的预测概率矩阵经过自适应窗口滤波器的平滑处理。
35.作为一个优选的实施方式,步骤s4中,根据不同类别的多尺度环境声音事件的平均持续时间,自适应的设置中值滤波器窗口的大小window:其中,为参数;将平滑处理后的概率矩阵逐元素的与设定的阈值进行比较,得出最终的识别结果。
36.综上所述,本发明实现了多尺度环境声音事件的高精度识别,尤其适用于家庭环境声音事件的识别,基于改进mean-teacher算法进行双向定位家庭环境声音事件,本发明具有以下优点:1) 针对家庭环境声音识别精度低,难以与视频监控有效的结合在一起。本发明提出一种基于改进mean-teacher算法的双向定位家庭环境声音事件识别方法,有效的提高了神经网络对家庭环境声音的识别能力。
37.2) 通过改进的mean-teacher算法,有效的利用了大量因标注困难而没有标签的数据,大大扩充了特征信息,提高了家庭环境声音的识别精度。
38.3) 通过改进的mean-teacher算法构建teacher模型和student模型联合训练,不但有效利用了无标签的数据而且解决了帧级预测和片段级预测之间有关感受野的冲突。
39.4)通过引入自适应的滤波窗口、多尺度特征空间映射和双向时间序列特征扫描解
决了因不同类型的家庭环境声音事件持续时间不同而导致的家庭环境声音事件边界定位模糊的问题。
40.当然,上述说明并非是对本发明的限制,本发明也并不限于上述举例,本技术领域的普通技术人员,在本发明的实质范围内,做出的变化、改型、添加或替换,都应属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。