1.本发明涉及工业数据的异常检测领域,具体涉及一种基于自监督学习多头注意力网络的时序数据异常检测方法。
背景技术:
2.工业互联网在过去几年中得到了迅速的发展,比如在智慧工厂、无人物流分拣、协同生产等领域。工业互联网通过有线和无线传输将工业生产设备、工业传感器、监控设备和智能分析技术等集成到工业生产的不同环节。数据的处理和分析在工业生产过程中显得尤为重要。很多重要的数据都是由工业传感器进行捕获,并为后续的评估和决策提供有价值的信息。通过传感器数据及时发现系统的异常,对于保障工业生产的安全性和稳定性有重要意义。
3.工业传感器所在每一个时刻会采集到多个不同种类的传感器数据,比如:电流数据、电压数据、震动数据等,这些数据具有一定的异构性;同时针对单个传感器而言,所采集的数据是时序的,即,当前采集到的数据往往和该时刻之前的数据存在一定的关联,因此在时间上具有相关性。基于这样的特点,有效地提取传感器采集的时序数据的异常情况对于能够准确检测出工业系统的异常至关重要。
4.针对时序数据的异常检测可以分为基于传统的方法和基于深度学习的方法。传统的异常检测方法包括时间序列模型,例如自回归移动平均模型、马尔科夫模型、卡尔曼滤波等。这些方法在检测精度上一般不够高,同时对于异构的长时间序列,难以捕获序列间存在的时空关系。近些年来随着深度学习的发展,将机器学习算法应用于异常检测是当前研究的热点问题。总体上可以分为有监督学习和无监督学习。有监督学习在训练网络时需要所有的样本都含有标签,同时需要较多轮次的学习网络才能取得比较好的效果。无监督学习常用的方法包括长短期记忆网络(long short-term memory, lstm),自编码器(autoencoder, ae)和对抗生成网络(generative adversarial net, gan)。基于lstm网络往往需要先在正常数据集上做预测任务,随后在实际数据集中通过阈值来判断是否异常,异常检测的精度一定程度上依赖于阈值的选定。基于ae和gan的异常检测方法一般需要对原始数据进行重构,这往往比较消耗计算资源且是非必要的。
技术实现要素:
5.针对现有技术中的上述缺陷,本发明提出了一种基于自监督学习的多头注意力网络模型(multi-head attention self-supervised, mas),即,基于mas网络模型的时序数据异常检测,具体是针对工业传感器数据,基于多头注意力机制的神经网络,引入自监督学习的策略进行网络的预训练并应用于工业传感器时序数据的异常检测中。在预训练结束后,仅需少量的训练资源,就可以取得很高的异常检测精度。
6.本发明采用的技术方案如下:基于自监督学习多头注意力网络的时序数据异常检测方法,具体步骤如下:
s1:针对多个工业传感器采集到的所有时序数据,先做归一化处理,得到归一化后的时序数据x
norm
;s2:对所述归一化后的时序数据x
norm
进行数据增强,分别通过两种方式对x
norm
进行数据增强,得到两组增强后的时序数据x
aug1
和x
aug2
;第一种增强方式通过随机掩码方式去除掉一些数据,得到增强后的时序数据x
aug1
;第二种增强方式为加入噪声进行增强,得到增强后的时序数据x
aug2
;s3:通过增强后的时序数据x
aug1
和x
aug2
对特征提取网络进行预训练,包括:s3-1将增强后的时序数据x
aug1
和x
aug2
分别送入到特征提取网络f
ξ
与f
θ
中,得到对所述时序数据x
aug1
和x
aug2
的表征r1和r2;s3-2所述表征r1和r2被分别送入到网络g
ξ
和 (g
θ qθ
) 中,并得到最终的输出数据z和q;其中,特征提取网络f
ξ
和f
θ
结构一致,参数不共享;网络g
ξ
,g
θ
和q
θ
是辅助特征提取网络进行预训练的网络,网络g
ξ
,g
θ
和q
θ
的结构一致,参数不共享;网络g
ξ
和特征提取网络f
ξ
相连接,网络g
θ
和网络q
θ
和特征提取网络f
θ
相连接,(g
θ qθ
)代表数据先经过网络g
θ
,再经过网络q
θ
;下标ξ表示网络参数,下标θ表示网络权重;s4:对所述特征提取网络f
ξ
和f
θ
,以及网络g
θ
,q
θ
和g
ξ
进行更新;s5:在特征提取网络f
θ
之后再加入一个全连接层,对加入的所述全连接层进行训练。
7.进一步的,所述s1中的归一化处理公式为:x
norm
=(x-mean)/std其中,x
norm
表示归一化后的时序数据,x表示多个工业传感器采集到的所有时序数据,是由一段时间内每一个工业传感器所采集到的时序数据序列组合形成的多维时序数据,mean表示一段时间内所述所有时序数据的均值,具体通过在一段时间内对每个工业传感器采集到的时序数据取均值得到,std表示采集到的所有时序数据的标准差。
8.进一步的,所述s2中第二种增强方式具体为:x
aug2 = x
norm r
noise · normal(0,std)其中,r
noise
表示噪声率,是一个超参数;normal(0,std)表示生成均值为0,标准差是std的高斯白噪声。
9.进一步的,所述s4具体包括:s4-1在最终的输出数据z和q的基础上,计算二者的损失l
loss
,计算公式如下:其中,,;s4-2基于计算得到的所述损失l
loss
,对特征提取网络f
θ
,网络g
θ
和q
θ
采用随机梯度下降的方式进行网络参数的更新,得到更新后的网络权重θ;s4-3对特征提取网络f
ξ
和网络g
ξ
采用动量的方式进行更新,更新的公式如下所示:
其中,τ为一个超参数,体现网络权重θ更新的速度。
10.进一步的,所述s5具体包括:仅保留特征提取网络f
θ
和特征提取网络f
θ
的网络权重,并在特征提取网络f
θ
后面加入全连接层,采用有标签的数据对加入的所述全连接层进行训练,并采用随机梯度下降的方式更新所述全连接层的权重;训练完成后将所述特征提取网络f
θ
和加入的所述全连接层作为一个整体网络应用于时序数据的异常检测。
11.进一步的,所述s3-1具体包括:s3-1-1将增强后的时序数据 x
aug1
和x
aug2
作为输入数据,输入数据经过含有残差架构的空洞因果卷积进行特征的提取,将提取后的特征作为输出数据;s3-1-2对s3-1-1的输入数据和s3-1-1的输出数据进行求和,求和后得到的数据经过batchnorm模块进行归一化处理,将归一化处理后的数据作为输出数据;s3-1-3将s3-1-2的输出数据输入到含有残差结构的多头注意力机制中进行处理,输出处理后的数据;s3-1-4对s3-1-2的输出数据和s3-1-3输出的处理后的数据进行求和,求和后的数据经过batchnorm模块进行归一化处理,输出归一化处理后的数据;s3-1-5将s3-1-4输出的归一化处理后的数据经过一个全连接层,最终得到时序数据x
aug1
和x
aug2
的表征r1和r2。
12.进一步的,s3-2具体包括:s3-2-1:将所述表征r1和r2作为输入数据,经过一个线性层;s3-2-2:s3-2-2输出的数据经过batchnorm模块进行归一化处理s3-2-3:s-2-2输出的数据再经过一个relu层;s3-2-4:s-2-3输出的数据再经过一个线性层,得到最终输出的数据z和q。
13.进一步的,所述网络g
θ
为投影网络,所述网络q
θ
为预测网络。
14.相比于现有技术,本发明的有益效果在于:1. 效率高。不需要人工设计进行时序特征的提取。在工业生产环境中,存在着各种传感器,这些传感器的采样值均分布在不同的范围。在采用本发明的msa模型时,只需要原始传感器数据进行检测即可。
15.2. 在训练样本中不需要剔除所有的异常样本。由于本发明在进行对比学习时,需要对数据做不同形式的增强,异常样本也可以看作是对数据增强的一种方式;同时在实际情况中,异常样本的数量本身较少。因此,在前期的预训练阶段不需要对异常数据进行剔除。
16.在下游任务中训练速度快。由于在预训练阶段已经完成了特征提取的工作,因此在应用于异常检测任务时,只需要进行较少轮训练即可以实现较高的检测精度。
附图说明
17.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的
附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1为本发明的检测方法整体流程简图;图2为本发明的检测方法中的空洞因果卷积示意图;图3为本发明的检测方法验证的仿真试验平台结构。
19.附图标记说明:1-第一电磁阀,2-第二电磁阀,3-水箱,4-水泵,5-急停按钮,6-电机,7-逆变器,8-嵌入式测控系统compactrio,9-用于轴不对中的机械杠杆,10-通水管路。
具体实施方式
20.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
21.下面针对mas模型对时序数据异常检测的技术方案进行详细的说明:1. 本发明的基于自监督学习多头注意力网络的时序数据异常检测方法的整体流程如图1所示,包括以下步骤:s1:针对工业传感器采集到的数据,先做归一化处理,归一化的步骤为:x
norm
=(x-mean)/std其中,x
norm
代表了归一化后的时序数据,x代表了多个工业传感器采集的多维时序数据,mean代表一段时间内多维时序数据的均值,std代表多维时序数据的标准差。
22.s2:分别用两种方式对x
norm
做数据增强。第一种方式为随机掩码掉一些数据,得到增强后的时序数据x
aug1
;第二种增强方式为加入噪声,具体为:x
aug2 = x
norm r
noise · normal(0,std)其中,x
aug2
代表增强后的时序数据,r
noise
代表噪声率,是一个超参数,normal(0,std)表示生成均值为0,标准差是std的高斯白噪声。
23.s3:通过增强后的时序数据x
aug1
和x
aug2
对特征提取网络进行预训练,具体预训练步骤如下:首先,将增强后的时序数据x
aug1
和x
aug2
分别送入到特征提取网络f
ξ
和f
θ
中,得到对所述时序数据x
aug1
和x
aug2
的表征r1和r2,其中,特征提取网络f
ξ
和f
θ
结构一致,但是参数不共享;其中,特征提取网络f
ξ
和f
θ
的具体特征提取步骤如下:步骤1:输入数据经过含有残差结构的空洞因果卷积进行特征的提取,输出提取后的特征;步骤2:对步骤1的输入数据和步骤1的输出数据进行求和,求和后得到的数据经过batchnorm模块进行归一化处理,输出归一化处理后的数据;步骤3:将步骤2的输出数据输入到含有残差结构的多头注意力机制模型中进行处理,输出处理后的数据;步骤4:对步骤2的输出数据和步骤3的输出数据进行求和,求和后的数据再次经过
batchnorm模块进行归一化处理,输出归一化处理后的数据;步骤5:将步骤4的输出数据经过一个全连接层,最终得到时序数据x
aug1
和x
aug2
的表征r1和r2。
24.然后,所述表征r1和r2被分别送入到网络g
ξ
和 (g
θ qθ
) 中,并得到最终的输出结果特征z和q;其中,网络g
ξ
,g
θ
和q
θ
的网络结构一致,但是参数不共享,网络g
ξ
,g
θ
可以称为投影器,即投影网络,网络q
θ
可以称作预测器,即预测网络;网络g
ξ
和特征提取网络f
ξ
相连接,网络g
θ
和q
θ
和特征提取网络f
θ
相连接,(g
θ qθ
)代表数据先经过网络g
θ
,再经过网络q
θ
;下标ξ代表的f
ξ
和g
ξ
的网络参数,下标θ表示网络权重;其中,网络g
ξ
,g
θ
和q
θ
网络的具体结构如下:首先,输入数据经过一个线性层;随后,输出的数据经过一个batchnorm模块进行归一化处理和relu层,最后,输出数据在经过一个线性层输出,得到最终的输出的数据z和q;其中,特征提取网络f
ξ
和f
θ
、网络g
ξ
,g
θ
和q
θ
都属于深度学习的网络形式;网络g
ξ
,g
θ
和q
θ
的作用是辅助特征提取网络训练的,加入后可以使得f
θ
训练的更好;在预训练结束后,g
ξ
,g
θ
和q
θ
就不需要的。
25.其中,空洞卷积和多头注意力机制模型均采用现有计算方法,具体如下:空洞因果卷积的结构可以如图2所示,空洞因果卷积包含了因果卷积和空洞卷积,因果卷积每一层的输出都是由前一层对应未知的输入及其前一个位置的输入共同得到;空洞卷积在卷积核元素之间加入一些空格(零)来扩大卷积核的过程,通过跳过部分输入来使得卷积核可以应用于大于卷积核本身长度的区域,从而可以获得更大的感受野。
26.多头注意力机制模型,其计算过程如下所示:其中,代表的是查询(queries);代表的是键(keys),代表的是值(values),n是时间序列的长度,softmax代表将计算结果进行softmax函数的计算softmax函数的计算其中代表的是不同的投影头,,,是权重矩阵,分别代表的是计算queries的权重,计算keys的权重,计算values的权重。concat代表的是将不同的投影头合并其起来。wo代表的是z到最终输出的权重矩阵。
27.s4:首先,在得到网络的输出z和q的基础上,计算二者的损失l
loss
。计算公式如下:
其中,,。
28.然后,根据计算得到的损失l
loss
,对f
θ
,g
θ
和q
θ
采用随机梯度下降的方式进行网络参数的更新。这是深度学习里面经典的sgd梯度更新方法。
29.最后,对f
ξ
和g
ξ
采用动量的方式进行更新,更新的公式如下所示:其中,τ为一个超参数,体现了网络权重更新的速度;s5:在前面预训练结束之后,只保留特征提取器f
θ
的结构和权重。固定f
θ
的权重并在f
θ
后面加入一个新的全连接层,采用有标签的数据对加入的全连接层进行训练。其中,有标签的数据指的是对于一段数据,标签会指明每一个数值点是异常的或者是正常的。无标签数据指的是只有一段数据,对于其中正常或者异常的片段未知。采用随机梯度下降的方式更新全连接层的权重。训练完成后就可以将f
θ
与加入的全连接层作为一个整体的网络作为时序数据异常数据的检测。
30.对本发明的基于自监督学习多头注意力网络的时序数据异常检测方法的检测进行仿真验证,并与其他检测方法仿真验证结构进行比对,具体如下:采用仿真平台如图3所示:仿真平台包括第一电磁阀1,第二电磁阀2,水箱3,水泵4,急停按钮5,电机6,逆变器7,嵌入式测控系统compactrio8,用于轴不对中的机械杠杆9,通水管路10。
31.在上述仿真平台上设置多种传感器,采集到的传感器数据包括:两组加速度计数据,电流数据,压力数据,温度数据,热电偶数据,电压数据,体积流率数据。
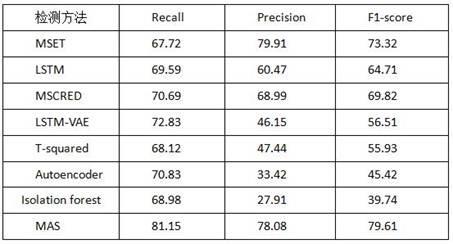
32.对采集到的传感器时序数据通过多种方法进行异常检测,得到的仿真结果如下:其中,多种检测方法包括:mset:multivariate state estimation technique,多元状态估计技术;lstm: long short-term memory,长短期记忆网络;mscred: multi-scale convolutional recurrent encoder-decoder,多尺度卷积循环编码器-解码器;lstm-vae:lstm-variational autoencoder 长短期记忆网络变分自编码器;t-squared statistic:t平方统计;autoencoder:自动编码器;isolation forest:随机森林;mas:本发明的基于mas模型的对时序数据检测方法;其中,对仿真结果进行评价,评价指标的标准如下:tp:将正类预测为正类数;fn:将正类预测为负类数;fp:将负类预测为正类数;tn:将负类预测为负类数;
精确率定义为:召回率定义为:精确率和召回率的调和均值为f1值:其中,f1由于是精确率和召回率的调和均值,因此该指标更能反映性能。
33.对各种检测方法的评价结构如下表1所示:表1本发明的检测方法与其他几种检测方法进行比较,其中,f1得分是表现异常检测性能的重要指标,因为该指标是精确度和召回率的调和均值。只有在精确度和召回率都高时,f1的值才会很高。在这些方法中,自动编码器和lstm网络的分数并不是特别高,因为这些方法只是一般性的针对数据进行预测或者是重建。本发明基于mas网络模型的检测方法在所有的方法中获得了最高的f1得分,其中precision为78.08%,recall为81.15%,f1为79.61%。总体结果表明,本发明的方法可以有效的提取传感器数据的时序特征,并且可以较好的将异常值和正常值进行区分。
34.显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。