1.本发明涉及人工智能技术领域,尤其涉及一种结合采样和集成学习的不平衡图数据处理方法。
背景技术:
2.机器学习算法会严重的受到数据集类别不平衡的负面影响,不平衡的数据集分布会使得模型拟合能力不足,模型难以在分布不均匀的数据集中学习到有用的信息。然而,现有的分类器的一般都是基于样本类别分布大致平衡的假设设计,若直接使用不均衡的样本集训练分类器,分类器会倾向于将所有类别的样本都分类为多数类别的样本,容易出现分类结果不准确问题。
3.在图神经网络领域,对不平衡数据集的研究较少。2019年,fiore等人提出graphsmote,将节点生成和边缘生成结合。通过为少数类别的节点合成新的样本,然后使用边生成器来合成节点之间的链路的方式改善样本类别不平衡的影响。graphsmote模型的效果依赖于新生成的节点之间的连接关系,而连接关系难以准确地构造。2020年,shi等人在以类为条件的对抗性训练和无标签节点的潜在分布作为约束,提出了双正则图卷积网络,该模型使用条件对抗正则化层和潜在分布对齐正则化层两种正则化层来解决数量不平衡的问题。相对于之前的deepwalk、gcn和gat等方法,该双正则图卷积网络在不均衡数据集上具有更好的效果。但是,双正则图卷积网络使用对抗训练强化不同类别样本的差异,而对抗训练的引入导致模型的复杂度急剧增大,导致模型难以训练。
技术实现要素:
4.为了提高对不平衡图数据进行分类的分类准确率,本发明提供一种结合采样和集成学习的不平衡图数据处理方法。
5.本发明提供的一种结合采样和集成学习的不平衡图数据处理方法,包括:
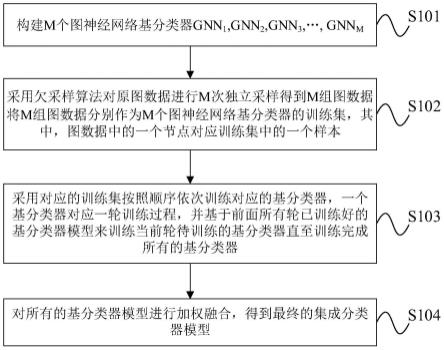
6.步骤1:构建m个图神经网络基分类器gnn1,gnn2,gnn3,
…
,gnnm;
7.步骤2:采用欠采样算法对原图数据进行m次独立采样得到m组图数据将m组图数据分别作为m个图神经网络基分类器的训练集,其中,图数据中的一个节点对应训练集中的一个样本;
8.步骤3:采用对应的训练集按照顺序依次训练对应的基分类器,一个基分类器对应一轮训练过程,并基于前面所有轮已训练好的基分类器模型来训练当前轮待训练的基分类器直至训练完成所有的基分类器;
9.步骤4:对所有的基分类器模型进行加权融合,得到最终的集成分类器模型。
10.进一步地,步骤1中,所有的基分类器均采用相同类别的图神经网络。
11.进一步地,步骤1中,至少存在两个基分类器采用不同类别的图神经网络。
12.进一步地,步骤3中,还包括:为每个样本分配权重以对样本进行加权,采用加权后
样本组成训练集;并将所有样本的权重组成向量,记作样本权重向量
13.在进行第一轮训练时,初始化所有样本的权重相同,即样本权重向量其中
14.在后续轮的训练过程中,按照公式(1)更新样本权重,并将上一轮训练之后得到的样本权重作为下一轮对应样本的样本权重,进而得到下一轮训练用的样本权重向量;
[0015][0016]
其中,表示在进行第m轮训练之前第i个样本的权重,表示在进行第m轮训练之后第i个样本的权重,a表示自定义系数,a∈(0,1),pm(xi)表示将xi输入至基分类器后gnnm后的输出向量,(xi,yi)表示训练集t中的一个样本,xi是第i个样本的特征向量,yi是第i个样本的类别标签,yi∈{1,...,c},c为类别的总数,n表示样本的总数。
[0017]
进一步地,步骤3中,在基分类器的训练过程中,每个基分类器均采用指数损失函数作为损失函数。
[0018]
进一步地,步骤4中,采用公式(3)表示经过m轮训练得到的集成分类器:
[0019][0020]
其中,m表示第m轮训练,gm(x;θm)表示在第m轮训练过程中对gnnm进行训练后得到的基分类器模型,θm是基分类器gnnm学习到的最优参数,αm是基分类器gnnm的权重。
[0021]
进一步地,步骤4中,按照公式(4)计算得到基分类器gnnm的权重αm:
[0022][0023]
其中,εm表示基分类器模型gm(x;θm)的分类错误率。
[0024]
进一步地,按照公式(5)计算得到基分类器模型gm(x;θm)的分类错误率εm:
[0025][0026]
其中,π(
·
)为指示函数,输入为真时,指示函数值为1,反之为0。
[0027]
本发明的有益效果:
[0028]
集成学习和采样算法都是减小数据集不平衡负面影响的有效方法,本发明提供的一种结合采样和集成学习的不平衡图数据处理方法,通过采样构造基分类器不同的输入,然后使用不同的输入序列化的训练基分类器,最后对训练得到的一系列基分类器进行聚合,得到的聚合模型,能够有效地减小不平衡类别分布对图神经网络的负面影响,在数据集类别不平衡的条件下,达到较高的性能。
附图说明
[0029]
图1为本发明实施例提供的一种结合采样和集成学习的不平衡图数据处理方法的流程示意图;
[0030]
图2为本发明实施例提供的对原图数据进行采样得到m组图数据的示意图;
[0031]
图3为本发明实施例提供的m个基分类器模型进行聚合的示意图。
具体实施方式
[0032]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
实施例1
[0034]
如图1所示,本发明实施例提供一种结合采样和集成学习的不平衡图数据处理方法,包括以下步骤:
[0035]
s101:构建m个图神经网络基分类器gnn1,gnn2,gnn3,
…
,gnnm;
[0036]
具体地,所有的基分类器均采用相同类别的图神经网络,例如均采用gat,或者均采用gcn,或者均采用agcn。或者,至少存在两个基分类器采用不同类别的图神经网络,例如有的基分类器采用gat,有的基分类器采用gcn,有的基分类器采用agcn。
[0037]
s102:采用欠采样算法对原图数据进行m次独立采样得到m组图数据将m组图数据分别作为m个图神经网络基分类器的训练集(如图2所示),其中,图数据中的一个节点对应训练集中的一个样本;
[0038]
具体地,使用欠采样算法对多数类别的样本进行随机选取以得到样本类别分布相对平衡的训练集数据。
[0039]
s103:采用对应的训练集按照顺序依次训练对应的基分类器,一个基分类器对应一轮训练过程,并基于前面所有轮已训练好的基分类器模型来训练当前轮待训练的基分类器直至训练完成所有的基分类器;
[0040]
s104:对所有的基分类器模型进行加权融合,得到最终的集成分类器模型。
[0041]
集成学习和采样算法都是减小数据集不平衡负面影响的有效方法,本发明实施例提供的一种结合采样和集成学习的不平衡图数据处理方法,通过采样构造基分类器不同的输入,然后使用不同的输入序列化的训练基分类器,最后对训练得到的一系列基分类器进行聚合,得到的聚合模型,能够有效地减小不平衡类别分布对图神经网络的负面影响,在数据集类别不平衡的条件下,达到较高的性能。
[0042]
实施例2
[0043]
在上述实施例的基础上,本发明实施例提供一种结合采样和集成学习的不平衡图数据处理方法,包括以下步骤:
[0044]
s201:构建m个图神经网络基分类器gnn1,gnn2,gnn3,
…
,gnnm;
[0045]
s202:采用欠采样算法对原图数据进行m次独立采样得到m组图数据将图数据中的一个节点对应训练集中的一个样本,为每个样本分配权重以对样本进行加权,采用加权后样本组成新的训练集,m组图数据对应有m组新的训练集,将m组新的训练集分别作为m个图神经网络基分类器的训练集;
[0046]
s203:采用对应的训练集按照顺序依次训练对应的基分类器,一个基分类器对应
一轮训练过程,并基于前面所有轮已训练好的基分类器模型来训练当前轮待训练的基分类器直至训练完成所有的基分类器;
[0047]
具体地,将所有样本的权重组成向量,记作样本权重向量
[0048]
在进行第一轮训练时,初始化所有样本的权重相同,即样本权重向量其中
[0049]
在后续轮的训练过程中,按照公式(1)更新样本权重,并将上一轮训练之后得到的样本权重作为下一轮对应样本的样本权重,进而得到下一轮训练用的样本权重向量,如图3所示的d1、d2、d3、
…
、dm的传递过程。此外,图3中,w1至wm分别表示m个基分类器的可学习参数,a1至am分别表示m组图数据对应的邻接矩阵。
[0050][0051]
其中,表示在进行第m轮训练之前第i个样本的权重,表示在进行第m轮训练之后第i个样本的权重,a表示自定义系数,a∈(0,1),pm(xi)表示将xi输入至基分类器后gnnm后的输出向量,(xi,yi)表示训练集t中的一个样本,xi是第i个样本的特征向量,yi是第i个样本的类别标签,yi∈{1,...,c},c为类别的总数,n表示样本的总数。
[0052]
从上述的公式(1)可以看出,若被错误分类的样本的输出向量pm(xi)和输出标签yi不相关,则他们的内积得到一个小的值,指数项得到一个大的值(因为负号),这就意味着,被错误分类的样本在下一个基分类器中得到了更大的样本权重。相同的,被正确分类的样本则在下一个基分类器中得到了更小的样本权重。使得正确分类的样本权重降低而错分样本的权重升高,从而能够在后续的基分类器的训练过程重点关注学习之前被错误分类的样本,从而使得学习到的分类器模型能够提高被错误分类的样本的分类准确率。
[0053]
需要说明的是,由于不同组训练集之间所包含的训练样本是不完全相同的,因此上一轮训练之后更新得到的样本权重和下一轮需要用到的样本之间并不是完全一一对应的关系,因此只需更新下一轮中对应样本的权重,没有对应到的样本的权重仍采用之前的样本权重。例如,第3组训练集包括:节点1、节点2、节点5、节点7、节点8共5个样本;第4组训练集包括:节点2、节点3、节点4、节点5、节点7、节点9、节点10共7个样本;两组训练集之间均包括节点2、节点5、节点7这三个样本,因此在第3轮训练之后,仅需将节点2、节点5和节点7这三个样本的权重传递到第4轮中,第4轮涉及到的其他样本的权重仍采用之前的权重,具体情况如下:如果在第1轮、第2轮中均未更新这些样本的权重,则这些样本的权重仍为初始化的权重;否则,则采用最近一轮更新后的样本权重;例如,节点3这一样本在第1轮训练之后和第2轮训练之后均被更新,则在第4轮中,节点3的样本权重采用第2轮更新后的样本权重。
[0054]
作为一种可实施方式,在基分类器的训练过程中,每个基分类器均采用指数损失函数作为损失函数。
[0055]
具体地,指数损失函数的表达式为l(y,f(x))=e-y*f(x)
。其中,f(x)表示基分类器的表达式。
[0056]
由于在本发明实施例中,当前轮待训练的基分类器是在前面所有轮已训练好的基分类器模型的基础上来完成训练的,设定f
m-1
(x)为在进行第m轮训练之前已训练完成的前m-1个基分类器进行聚合后的分类器模型,以采用加权聚合的聚合方式为例,可以将每个基分类器的指数损失函数表示为公式(2):
[0057][0058]
其中,(xi,yi)表示训练集t中的一个样本,xi是第i个样本的特征向量,yi是第i个样本的类别标签,yi∈{1,...,c},c为类别的总数,n表示样本的总数;gm(x;θm)表示在第m轮训练过程中对gnnm进行训练后得到的基分类器模型,θm是基分类器gnnm学习到的最优参数(即可学习参数wm的最优取值),αm是基分类器gnnm的权重。
[0059]
s204:对所有的基分类器模型进行加权融合,得到最终的集成分类器模型,如图3中所示的聚合过程。
[0060]
具体地,采用公式(3)表示经过m轮训练得到的集成分类器:
[0061][0062]
其中,m表示第m轮训练,gm(x;θm)表示在m轮训练过程中对gnnm进行训练后得到的基分类器模型,θm是基分类器gnnm学习到的最优参数,αm是基分类器gnnm的权重。
[0063]
在本发明实施例中,为了使得分类错误率较高的分类器模型具有较低的权重,作为一种可实施方式,按照公式(4)计算得到基分类器gnnm的权重αm:
[0064][0065]
其中,εm表示基分类器模型gm(x;θm)的分类错误率。
[0066]
在本发明实施例中,除了引入了分类器的权重,还引入了样本的权重,而样本的权重则必然会对分类器模型的分类错误率带来一定影响,作为一种可实施方式,按照公式(5)计算得到基分类器模型gm(x;θm)的分类错误率εm:
[0067][0068]
其中,π(
·
)为指示函数,输入为真时,指示函数值为1,反之为0。
[0069]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
