1.本发明涉及民用航空空中交通管制领域和语音增强领域,特别是一种面向语音识别的管制员语音增强方法及装置。
背景技术:
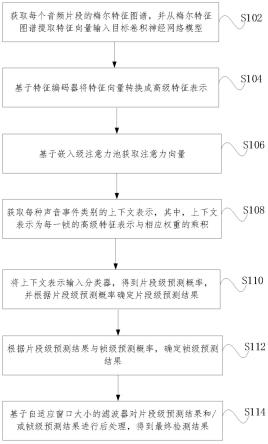
2.在空中交通管制(air traffic control, atc)领域里,管制员与飞行员之间的主要沟通方式是语音通话,语音信号通过甚高频(very high frequency, vhf)无线电进行传输。管制员向飞行员下达语音指令,飞行员复诵语音指令并回传给管制员。管制员和飞行员之间的语音发送确认机制确保了空管系统的有序运作。图1描述了空管语音的产生和传输过程,具体如下:(1)管制员使用麦克风输入语音,语音通过地空通话内话系统、通信服务器上行传输到无线电台并发送到飞行员端;(2)为了让管制员获悉语音指令是否安全传达给飞行员,空管无线电系统使用了特有的“回传机制”,当语音指令传递到无线电台时,无线电台处会将管制员发送的语音指令沿着同一无线电频率下行回传到管制员耳机,使得管制员能够听到自己发出的语音指令;(3)飞行员接收到管制员的语音指令后,复诵其语音指令并通过无线电台、通信服务器、地空通话内话系统下行传输给管制员,完成指令的交互;(4)为确保管制席位具有统一的语音接口,内话系统会将管制员上下行语音信号和飞行员下行语音信号采用叠加拼接的方式进行合并,合并后的语音会用于后续的语音处理任务,如语音识别、声纹识别等。
3.管制员发出的语音指令经过上下行传输,在内话系统叠加时会出现时延现象,由此得到的管制员语音信号就是一种空管内话系统特有的“管制回声”叠加信号。图2和图3描述了各传输线路上语音的波形以及对应波形图和语谱图,其中最上面的语音表示上行语音,中间的语音表示下行语音,最下面的语音表示混合语音,时延表示为图2中的。由图2和图3可知,当管制员语音信号发生叠加现象后,语音波形及对应语谱图都会附带上较多的“回声”噪声(如图3中方框所示)。此外,由于空管条件的复杂性,语音信号在传播过程中还会受到如采集设备、传输装置、天气环境和说话人特征等因素的影响,这些因素也会给语音信号带来更多的噪声数据污染。语音带上噪声会让其可懂度、清晰度降低,其信号的表示特征受到干扰,从而影响到后续的语音识别任务。
4.管制员语音信号可懂度、清晰度降低,会影响后续语音回听分析任务的听觉感知性,进而导致语音内容获取的准确度降低,不利于语音信息分析。此外,由目前的语音识别方法可知,存在回声的管制员语音的识别精度明显小于不含回声的飞行员语音,管制员作为地空通话信息交流的发起方,其语音信息在确保空管系统有序运作方面具有重要意义,管制员语音识别精度低会极大影响后续的语音处理任务。因此,需要一种能够消除回声影响,提高语音质量和提升语音识别正确率的管制员语音增强方法及装置。
技术实现要素:
5.本发明的目的在于克服现有技术中所存在的空管复杂无线电通信场景下带管制回声的管制员语音质量差、语音识别率低的问题,提供一种面向语音识别的管制员语音增强方法及装置。
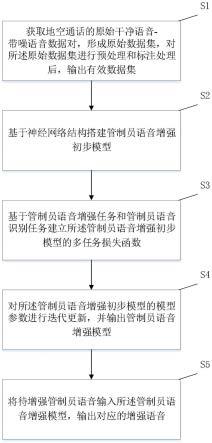
6.为了实现上述发明目的,本发明提供了以下技术方案:一种面向语音识别的管制员语音增强方法,包括:s1:获取地空通话的原始干净语音-带噪语音数据对,形成原始数据集,对所述原始数据集进行预处理和标注处理后,输出有效数据集;s2:基于神经网络结构搭建管制员语音增强初步模型;s3:基于管制员语音增强任务和管制员语音识别任务建立所述管制员语音增强初步模型的多任务损失函数;s4:基于所述多任务损失函数以及所述有效数据集,通过梯度下降神经网络训练算法对所述管制员语音增强初步模型的模型参数进行迭代更新,并输出管制员语音增强模型;s5:将待增强管制员语音输入所述管制员语音增强模型,输出对应的增强语音。本发明将真实场景下采集的经过预处理后的空管原始干净语音-带噪语音数据对作为数据集,搭建包括sasc模块和cssatt模块的管制员语音增强初步模型,并利用同时面向语音增强任务和面向语音识别任务的多任务损失函数训练的神经网络模型来对现有空管带噪管制员语音进行增强处理,消除了回声影响,提高了管制员语音的清晰度、可懂度,也有效的增加了管制员语音识别的识别准确率。
7.作为本发明的优选方案,所述步骤s1包括以下步骤:s1-1:获取地空通话的原始干净语音-带噪语音数据对,形成原始数据集;其中,所述原始干净语音-带噪语音数据对的获取方法为:在现有内话系统的基础上,在每一个空管席位添加一个辅助内话系统,并同时通过所述辅助内话系统以及所述现有内话系统对管制员的语音进行采集,获取所述原始干净语音-带噪语音数据对;s1-2:对所述原始数据集中的原始干净语音-带噪语音数据对进行预处理,并输出预处理后的所述原始干净语音-带噪语音数据对;所述预处理包含语音活动检测、说话人角色分类、冗余数据筛除以及时序对齐;s1-3:将预处理后的所述原始干净语音-带噪语音数据对随机分为有效训练集、有效验证集和有效测试集,并对所述有效测试集的数据对进行人工标注,输出有效训练集、有效验证集和标注后的有效测试集为有效数据集;所述人工标注内容为所述原始干净语音-带噪语音数据对对应的指令文本。本发明根据真实的空管场景下语音产生和收集机制,设计了一种处理原始语音的预处理方法,有效的提高了之后本发明所涉及到的模型方法的训练、测试乃至语音增强后进行语音识别流程的处理运算效率以及准确度。
8.作为本发明的优选方案,所述管制员语音增强初步模型包括第一scn模块、第二scn模块、若干编码器单元以及对应的解码器单元;所述第一scn模块设置于所述初步模型的输入端与所述编码器单元的输入端之间;所述第二scn模块设置于所述初步模型的输出端与所述解码器单元的输出端之间;所述编码器单元包括cnn模块以及cssatt模块;所述解
码器单元包括cnn模块以及cssatt模块;所述编码器单元以及对应的所述解码器单元之间通过bilstm模块以及sasc模块连接;所述第一scn模块用于对所述有效数据集中的语音数据进行特征上采样;所述第二scn模块用于对所述解码器单元输出的语音特征图进行下采样;所述cnn模块用于提取所述语音数据的初步语音特征图,并输出到所述cssatt模块;即所述cnn模块能够提取语音信号的局部特征,并在网络深层综合所述局部特征,以获得语音信号的全局特征;所述bilstm模块用于捕获所述语音数据时序变化的依赖关系,以及挖掘所述语音数据的信号帧之间的时序相关性;所述sasc模块架设在所述编码器与解码器对等层之间,通过跳步形式将所述语音数据的的同维度特征从浅层网络传递到深层网络;所述cssatt模块,用于引导所述初步模型分别从所述初步语音特征图的通道维度和空间维度上挖掘特征,并对通道空间的切分注意力参数进行优化。
9.本发明设计了一种全端到端的管制员语音增强模型,该模型的输入和输出都是语音原始波形,不涉及其他语音变换步骤,可以在不重新训练现有语音识别模型的基础上,直接将所述管制员语音增强模型应用在真实空管复杂环境下对输入现有语音识别模型的语音数据进行增强优化处理。
10.作为本发明的优选方案,所述sasc模块包括以下运行步骤:s2-1-1:获取所述语音数据经过第层所述编码器单元编码特征后得到编码特征图,,其中b表示批次大小,c表示通道数,l表示数据长度;s2-1-2:获取所述语音数据经过第层所述解码器单元解码特征后得到解码特征图,;s2-1-3:分别对所述编码特征图和所述解码特征图进行自注意力运算,得到所述编码特征图和所述解码特征图的初始自注意力权重,并对其进行拼接和激活处理,得到融合自注意力权重,运算式为:,,,,,其中,表示自注意力运算,表示初始自注意力权重,表示在通道维上的拼接操作,表示第一激活函数,所述relu激活函数用于提升神经网络拟合非线性函数的能力,表示编码器与解码器对等层融合的自注意力权重;s2-1-4:将所述融合自注意力权重经过自注意力运算以及激活处理,得到编码器和解码器对等层的跳步注意力权重系数,运算式为:, 其中,表示第二激活函数,表示跳步注意力权重系数;
s2-1-5:根据所述跳步注意力权重系数调整所述编码特征图在跳步时各特征点的权重,拼接所述解码特征图,输出经过所述sasc模块处理后的跳步连接语音特征图,运算式为:,其中表示按元素相乘操作,表示跳步连接语音特征图。
11.本发明根据模型的编码器-解码器结构,设计了用于语音处理的sasc模块,该模块使用自注意力机制挖掘剖析语音特征图在模型对等层之间的有用特征,抑制冗杂特征,引导模型关注数据特征编码解码规律,有助于模型能够更好地进行收敛。
12.作为本发明的优选方案,所述cssatt模块包括以下运行步骤:s2-2-1:输入一批次所述初步语音特征图,将一批次所述初步语音特征图划分为g组子特征图,并将每组子特征图切分为两个分支子特征图和,;其中,表示通道分支子特征图,表示空间分支子特征图,b表示批次大小,c表示通道数,l表示数据长度,g表示预设的组数;s2-2-2:基于所述,在通道维度上通过自适应平均池化操作生成初始化的通道注意力权重,运算式为:,其中表示自适应平均池化操作,表示通道维度,表示初始化的通道注意力权重;s2-2-3:基于所述,在空间维度上通过分组归一化操作生成初始化的空间注意力权重,运算式为:,其中表示分组归一化操作,表示空间维度,表示初始化的空间注意力权重;s2-2-4:通过可学习参数挖掘所述在通道维度上以及所述在空间维度上的特征依赖性,并通过激活函数激活后生成通道维度和空间维度上的注意力权重系数,运算式为:,,,其中和表示可学习参数,表示第二激活函数,表示按元素相乘操作,和分别表示通道注意力权重系数以及空间注意力权重系数;s2-2-5:根据所述通道注意力权重系数以及所述空间注意力权重系数分别调整所述和所述上每个特征点的权重,拼接所述和所述为子特征图,并使用通道混洗操作启用不同组所述子特征图之间的信息通信,输出经过所述cssatt模块处理后的语音特征图,运算式为:
,其中表示在通道维度上的特征图拼接操作,表示通道混洗操作,表示经过所述cssatt模块处理过后的语音特征图;所述通道混洗操作具体为:打乱同一批次特征图里不同子特征图之间的通道顺序,让不同通道的特征建立联系,进而使得不同子特征图之间实现信息互通,便于学习共性特征。
13.本发明设计了用于语音处理的cssatt模块,该模块对一批次语音特征图进行分组处理,分别对每组子特征图提取通道维度和空间维度特征,并在最后融合不同子特征图的维度特征,实现子特征图之间的特征通信,从而有利于不同样本之间的特征交流,增加模型对数据特征的鲁棒能力。
14.作为本发明的优选方案,所述步骤s3包括以下步骤:s3-1:基于lae构建面向语音增强任务的损失函数,在时域上直接衡量所述管制员语音增强初步模型的输出波形与真实波形之间的误差,记为lae损失函数;s3-2:基于多分辨率的stft幅度频谱构建面向语音增强任务的频域损失函数,衡量所述管制员语音增强初步模型输出语音与真实语音之间的stft幅度频谱的误差,记为stft损失函数;s3-3:基于多分辨率构建面向语音识别任务的特征损失函数,记为特征损失函数;s3-4:通过加权求和的方式构建所述管制员语音增强初步模型的多任务损失函数,计算式如下:其中为所述多任务损失函数,、和分别代表所述lae损失函数、所述stft损失函数以及所述特征损失函数的预设权重。
15.作为本发明的优选方案,所述步骤s3-2包括以下步骤:s3-2-1:构建用于stft操作的三元组参数;其中,所述三元组参数构成如下:[采样点,帧移,窗框];其中所述参数采样点表示在语音信号所有采样点中取n个采样点构成语音帧的采样点数目n,所述参数帧移表示相邻两帧起始位置的时间差,所述参数窗框表示语音信号处理的窗函数类型;s3-2-2:使用所述三元组参数对语音的stft幅度频谱进行构造,记第组三元组参数构造的stft幅度频谱的stft损失函数为;s3-2-3:构建所述stft损失函数,表示如下:其中表示三元组参数的组数。
[0016]
作为本发明的优选方案,所述步骤s3-3包括以下步骤:s3-3-1:对所述stft幅度频谱进行临界频带积分、响度预加重、立方根压缩、逆傅
里叶变换和线性预测处理,得到感知线性预测声学特征,建立基于所述感知线性预测特征的损失函数,衡量所述管制员语音增强初步模型的输出语音和真实语音感知线性预测声学特征之间的误差,记为plp损失函数;s3-3-2:对所述stft幅度频谱进行梅尔滤波以及对数变换处理,得到滤波器组声学特征,建立基于滤波器组特征的损失函数,衡量所述管制员语音增强初步模型的输出语音和真实语音的滤波器组特征之间的误差,记为fbank损失函数;s3-3-3:对所述滤波器组声学特征进行离散余弦变换,得到梅尔倒谱系数声学特征,建立基于梅尔倒谱系数特征的损失函数,衡量模型输出语音和真实语音梅尔倒谱系数特征之间的误差,记为mfcc损失函数;s3-3-4:构建面向语音识别任务的特征损失函数:。
[0017]
其中,所述stft损失函数以及所述特征损失函数具有相同的运算形式:其中表示所述stft幅度频谱、所述plp特征、所述fbank特征或者所述mfcc特征,表示干净语音信号,表示增强语音信号,表示求f范数;作为本发明的优选方案,所述步骤s4包括以下步骤:s4-1:从所述有效训练集中随机获取若干原始干净语音-带噪语音数据对作为训练集,并根据带燥语音波形和干净语音波形的差异,提取纯噪声数据波形,运算式为: ,其中,表示所述原始干净语音-带噪语音数据对中原始干净语音数据的干净语音波形,表示所述原始干净语音-带噪语音数据对中带噪语音数据的带噪语音波形,表示纯噪声波形,上述三者的形状均为,b表示批次大小,c表示通道数,l表示数据长度,表示按特征值相减操作;s4-2:在所述训练集内随机打乱所述纯噪声波形的分布,并与所述干净语音波形相加得到增强带噪语音波形,运算式为:,其中表示数据打乱操作,表示干净语音波形-纯噪声波形数据对,表示所述增强带噪语音波形,表示按特征值相加操作;s4-3:将所述干净语音波形和所述增强带噪语音波形组合为新的训练集,记为第二训练集;s4-4:基于所述第二训练集以及所述多任务损失函数,通过梯度下降算法迭代更新所述管制员语音增强初步模型的模型参数,训练过程中通过所述有效验证集验证所述管制员语音增强初步模型是否收敛,当模型训练收敛后输出当前所述管制员语音增强初步模
型为管制员语音增强模型;其中,判断所述模型训练收敛的依据为:每隔m个迭代轮次通过所述有效验证集计算所述初步模型的所述多任务损失函数,当经过连续n次计算后,所述多任务损失函数都不再下降时视作模型训练收敛;m、n为预设值;本发明设计了一种用于模型训练阶段的数据增强方法,该方法将样本噪声特征随机再分配,实现了扩充训练集数据量的目的,也有效地增加了模型的噪声鲁棒性,泛化不同的噪声分布。
[0018]
s4-5:用标注的所述有效测试集测试所述模型。
[0019]
s5:将待增强管制员语音输入所述管制员语音增强模型,输出对应的增强语音。
[0020]
一种面向语音识别的管制员语音增强设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任一项所述的方法。
[0021]
与现有技术相比,本发明的有益效果:1.本发明将真实场景下采集的经过预处理后的空管原始干净语音-带噪语音数据对作为数据集,搭建包括sasc模块和cssatt模块的管制员语音增强初步模型,并利用同时面向语音增强任务和面向语音识别任务的多任务损失函数训练的神经网络模型来对现有空管带噪管制员语音进行增强处理,消除了回声影响,提高了管制员语音的清晰度、可懂度,也有效的增加了管制员语音识别的识别准确率。
[0022]
2.本发明根据真实的空管场景下语音产生和收集机制,设计了一种处理原始语音的预处理方法,有效的提高了之后本发明所涉及到的模型方法的训练、测试乃至语音增强后进行语音识别流程的处理运算效率以及准确度。
[0023]
3.本发明设计了一种全端到端的管制员语音增强模型,该模型的输入和输出都是语音原始波形,不涉及其他语音变换步骤,可以在不重新训练现有语音识别模型的基础上,直接将所述管制员语音增强模型应用在真实空管复杂环境下对输入现有语音识别模型的语音数据进行增强优化处理。
[0024]
4.本发明根据模型的编码器-解码器结构,设计了用于语音处理的sasc模块,该模块使用自注意力机制挖掘剖析语音特征图在模型对等层之间的有用特征,抑制冗杂特征,引导模型关注数据特征编码解码规律,有助于模型能够更好地进行收敛。
[0025]
5.本发明设计了用于语音处理的cssatt模块,该模块对一批次语音特征图进行分组处理,分别对每组子特征图提取通道维度和空间维度特征,并在最后融合不同子特征图的维度特征,实现子特征图之间的特征通信,从而有利于不同样本之间的特征交流,增加模型对数据特征的鲁棒能力。
[0026]
6.本发明设计了一种用于模型训练阶段的数据增强方法,该方法将样本噪声特征随机再分配,实现了扩充训练集数据量的目的,也有效地增加了模型的噪声鲁棒性,泛化不同的噪声分布。
附图说明
[0027]
图1为本发明背景技术中空管语音的产生与传输示意图。
[0028]
图2为本发明背景技术中空管语音在不同传输线路上采集的语音信号及对应波形图。
[0029]
图3为本发明背景技术中空管语音在不同传输线路上采集的语音信号及对应语谱图。
[0030]
图4为本发明实施例1所述的一种面向语音识别的管制员语音增强方法的流程示意图。
[0031]
图5为本发明实施例2所述的一种面向语音识别的管制员语音增强方法中所述管制员语音增强初步模型的模型结构图。
[0032]
图6为本发明实施例2所述的一种面向语音识别的管制员语音增强方法中所述管制员语音增强初步模型的各个模块的结构示意图。
[0033]
图7为本发明实施例3所述的一种面向语音识别的管制员语音增强方法中对比实验的实验描述表。
[0034]
图8为本发明实施例3所述的一种面向语音识别的管制员语音增强方法中的管制员语音增强指标实验结果示意图。
[0035]
图9为本发明实施例3所述的一种面向语音识别的管制员语音增强方法中的管制员语音识别指标实验结果示意图。
[0036]
图10为本发明实施例4所述的一种利用了实施例1所述的一种面向语音识别的管制员语音增强方法的一种面向语音识别的管制员语音增强装置的结构示意图。
具体实施方式
[0037]
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
[0038]
实施例1如图4所示,一种面向语音识别的管制员语音增强方法,包括以下步骤:s1:获取地空通话的原始干净语音-带噪语音数据对,形成原始数据集,对所述原始数据集进行预处理和标注处理后,输出有效数据集;s2:基于神经网络结构搭建管制员语音增强初步模型;s3:基于管制员语音增强任务和管制员语音识别任务建立所述管制员语音增强初步模型的多任务损失函数;s4:基于所述多任务损失函数以及所述有效数据集,通过梯度下降神经网络训练算法对所述管制员语音增强初步模型的模型参数进行迭代更新,并输出管制员语音增强模型;s5:将待增强管制员语音输入所述管制员语音增强模型,输出对应的增强语音。
[0039]
实施例2本实施例为实施例1所述方法的一种具体实施方式,包括以下步骤:s1:获取地空通话的原始干净语音-带噪语音数据对,形成原始数据集,对所述原始数据集进行预处理和标注处理后,输出有效数据集。
[0040]
s1-1:获取地空通话的原始干净语音-带噪语音数据对,形成原始数据集;
其中,所述原始干净语音-带噪语音数据对的获取方法为:在现有内话系统的基础上,在每一个空管席位添加一个辅助内话系统,并同时通过所述辅助内话系统以及所述现有内话系统对管制员的语音进行采集,获取所述原始干净语音-带噪语音数据对。
[0041]
s1-2:对所述原始数据集中的原始干净语音-带噪语音数据对进行预处理,并输出预处理后的所述原始干净语音-带噪语音数据对;所述预处理包含语音活动检测、说话人角色分类、冗余数据筛除以及时序对齐。
[0042]
s1-2-1:分析采集到的原始数据集数据,根据语音活动检测将连续的语音信号分割成指令语音段,分割后的语音指令段时长在0.1~10s之间。
[0043]
s1-2-2:由于内话系统将管制员上下行语音和飞行员下行语音叠加合并,所以存在语音数据是同时包含管制员语音和飞行员语音的混合语音。采用说话人角色分类模型对分割语音段进行角色分类,分类结果包含三类:管制员语音、飞行员语音、管制员飞行员混合语音。丢弃飞行员语音和管制员飞行员混合语音,本发明仅使用管制员语音作为后续处理的实验样本。
[0044]
s1-2-3:根据得到的管制员语音,筛除掉静音、噪声和时长低于1s的数据,并对齐时序保证同一语音指令文本的干净语音和带噪语音时长一致;原始干净语音-带噪语音数据对经过上述步骤处理后得到有效原始干净语音-带噪语音数据对,其包含如下特征:(1)所述语音数据对包括识别场景中使用的语种。
[0045]
(2)所述语音数据对包括多种发音状态下的语音;所述发音状态包括语速慢、语速一般、语速快、舒适情绪、紧张情绪、口音化中的一种或者多种。
[0046]
(3)所述语音数据对包括空管领域专业性的管制用语。
[0047]
s1-3:将预处理后的所述原始干净语音-带噪语音数据对随机分为有效训练集、有效验证集和有效测试集,并对所述有效测试集的数据对进行人工标注,输出有效训练集、有效验证集和标注后的有效测试集为有效数据集;所述人工标注内容为所述原始干净语音-带噪语音数据对对应的指令文本。
[0048]
s1-3-1:将获取的有效的原始干净语音-带噪语音数据对按照8:1:1比例随机分为训练集、验证集和测试集。
[0049]
s1-3-2:以测试集的干净语音数据为基准,对测试集数据进行人工标注并筛除语义不明的数据,得到测试集每对语音的指令文本。
[0050]
s1-3-3:分别将训练集数据和验证集数据成对存储,每对数据包含两条语音,分别是干净语音和带噪语音。将测试集数据和其对应指令文本组织存储,形成带标注的有效测试集。
[0051]
s2:如图5所示,基于神经网络结构搭建管制员语音增强初步模型,所述管制员语音增强初步模型包括第一scn模块、第二scn模块、若干编码器单元以及对应的解码器单元;所述第一scn模块设置于所述初步模型的输入端与所述编码器单元的输入端之间;所述第二scn模块设置于所述初步模型的输出端与所述解码器单元的输出端之间;所述编码器单元包括cnn模块以及cssatt模块;所述解码器单元包括cnn模块以及cssatt模块;所述编码器单元以及对应的所述解码器单元之间通过bilstm模块以及sasc模块连接。
[0052]
所述scn模块利用信号处理中的sinc滤波器特性,采用sinc插值卷积网络对语音信号进行特征提取,能够重构语音信号因为采样而缺失的数据点,保证语音信号数据完整性。
[0053]
所述第一scn模块用于对所述有效数据集中的语音数据进行特征上采样。
[0054]
所述第二scn模块用于对所述解码器单元输出的语音特征图进行下采样。
[0055]
所述cnn模块用于提取所述语音数据的初步语音特征图,并输出到所述cssatt模块。cnn模块能够提取语音信号的局部特征,并在网络深层综合所述局部特征,以获得语音信号的全局特征。cnn模块具体包含:卷积(反卷积)网络,其中表示卷积核大小,表示步长,relu激活函数,卷积网络,glu激活函数。
[0056]
所述bilstm模块用于捕获所述语音数据时序变化的依赖关系,以及挖掘所述语音数据的信号帧之间的时序相关性。
[0057]
所述sasc模块架设在所述编码器与解码器对等层之间,该模块能引导语音特征关注自身有用特征,抑制冗余特征,以跳步形式将所述语音数据的的同维度特征从浅层网络传递到深层网络,有利于深层网络学习浅层特征,恢复浅层网络细节;模型结构如图6所示,具体包括以下处理步骤:s2-1-1:获取所述语音数据经过第层所述编码器单元编码特征后得到编码特征图,,其中b表示批次大小,c表示通道数,l表示数据长度;s2-1-2:获取所述语音数据经过第层所述解码器单元解码特征后得到解码特征图,;s2-1-3:分别对所述编码特征图和所述解码特征图进行自注意力运算,得到所述编码特征图和所述解码特征图的初始自注意力权重,并对其进行拼接和激活处理,得到融合自注意力权重,运算式为:,,,,,其中,表示自注意力运算,表示初始自注意力权重,表示在通道维上的拼接操作,表示第一激活函数,所述激活函数用于提升神经网络拟合非线性函数的能力,表示编码器与解码器对等层融合的自注意力权重;s2-1-4:将所述融合自注意力权重经过自注意力运算以及激活处理,得到编码器和解码器对等层的跳步注意力权重系数,运算式为:, 其中,表示第二激活函数,表示跳步注意力权重系数,本方案中、和采用相同的神经网络结构,均为1x1 卷积网络;所述第一激活函数以及所述第二激活函数为任意两种不同的激活函数(如sigmoid 激活函数、tanh激活函数、relu激活函数、leaky relu函数、elu激活函数、mish激活函数、swish 激活函数以及silu激活函数等激活
函数),本实施例中所述第一激活函数采用relu激活函数,第二激活函数采用sigmoid激活函数。
[0058]
s2-1-5:根据所述跳步注意力权重系数调整所述编码特征图在跳步时各特征点的权重,拼接所述解码特征图,输出经过所述sasc模块处理后的跳步连接语音特征图,运算式为: ,其中表示按元素相乘操作,表示跳步连接语音特征图。
[0059]
所述管制员语音增强初步模型的所述cssatt模块,用于引导模型分别从语音特征图的通道维度和空间维度上关注有用信息,挖掘特征,并对通道空间的切分注意力参数进行优化。模型结构如图6所示,具体包含以下处理步骤:s2-2-1:输入一批次所述初步语音特征图,将一批次所述初步语音特征图划分为g组子特征图,并将每组子特征图切分为两个分支子特征图和,;其中,表示通道分支子特征图,表示空间分支子特征图,b表示批次大小,c表示通道数,l表示数据长度,g表示预设的组数;s2-2-2:基于所述,在通道维度上通过自适应平均池化操作生成初始化的通道注意力权重,运算式为:,其中表示自适应平均池化操作,表示通道维度,表示初始化的通道注意力权重;s2-2-3:基于所述,在空间维度上通过分组归一化操作生成初始化的空间注意力权重,运算式为:,其中表示分组归一化操作,表示空间维度,表示初始化的空间注意力权重;s2-2-4:通过可学习参数挖掘所述在通道维度上以及所述在空间维度上的特征依赖性,并通过激活函数激活后生成通道维度和空间维度上的注意力权重系数,运算式为:,,,其中和表示可学习参数,表示按元素相乘操作,和分别表示通道注意力权重系数以及空间注意力权重系数;s2-2-5:根据所述通道注意力权重系数以及所述空间注意力权重系数分别调整所述和所述上每个特征点的权重,拼接所述和所述为子特征图,并使用通道混洗操作启用不同组所述子特征图之间的信息通信,输出经过所述cssatt模块处理后的语音特征图,运算式为:
,其中表示在通道维度上的特征图拼接操作,表示通道混洗操作,表示经过所述cssatt模块处理过后的语音特征图;所述通道混洗操作具体为:打乱同一批次特征图里不同子特征图之间的通道顺序,让不同通道的特征建立联系,进而使得不同子特征图之间实现信息互通,便于学习共性特征。
[0060]
s3:基于管制员语音增强任务和管制员语音识别任务建立所述管制员语音增强初步模型的多任务损失函数;所述步骤s3包括以下步骤:s3-1:基于lae(least absolute error,最小绝对误差)构建面向语音增强任务的损失函数,在时域上直接衡量所述管制员语音增强初步模型的输出波形与真实波形之间的误差,记为lae损失函数;s3-2:基于多分辨率的stft(short time fourier transform,短时傅里叶变换)幅度频谱构建面向语音增强任务的频域损失函数,衡量所述管制员语音增强初步模型输出语音与真实语音之间的stft幅度频谱的误差,记为stft损失函数;s3-2-1:构建用于stft操作的三元组参数;其中,所述三元组参数构成如下:[采样点,帧移,窗框]其中所述参数采样点表示在语音信号所有采样点中取n个采样点构成语音帧的采样点数目n,所述参数帧移表示相邻两帧起始位置的时间差,所述参数窗框表示语音信号处理的窗函数类型;本发明中,所述三元组取值为[512,100,汉明窗]、[1024,200,汉明窗]、[256,50,汉明窗]。
[0061]
以第一组三元组为例,所述参数采样点取512,即512个采样点为一帧。所述参数帧移设置100,即100个采样点为帧移,若采样点不够512个则将其补零凑齐。所述参数窗框选择汉明窗函数。
[0062]
s3-2-2:使用所述三元组参数对语音的stft幅度频谱进行构造,记第组三元组参数构造的stft幅度频谱的stft损失函数为;s3-2-3:构建所述stft损失函数,表示如下:其中表示三元组参数的组数,本发明中取m为3。
[0063]
s3-3:基于多分辨率构建面向语音识别任务的特征损失函数,记为特征损失函数;s3-3-1:对所述stft幅度频谱进行临界频带积分、响度预加重、立方根压缩、逆傅里叶变换和线性预测处理,得到感知线性预测(perceptual linear predictive,plp)声学特征,建立基于所述感知线性预测特征的损失函数,衡量所述管制员语音增强初步模型的输出语音和真实语音感知线性预测声学特征之间的误差,记为plp损失函数;s3-3-2:对所述stft幅度频谱进行梅尔滤波以及对数变换处理,得到滤波器组
(filter bank,fbank)声学特征,建立基于滤波器组特征的损失函数,衡量所述管制员语音增强初步模型的输出语音和真实语音的滤波器组特征之间的误差,记为fbank损失函数;s3-3-3:对所述滤波器组声学特征进行离散余弦变换,得到梅尔倒谱系数声学特征,建立基于梅尔倒谱系数(mel-frequency cepstral coefficients,mfcc)特征的损失函数,衡量模型输出语音和真实语音梅尔倒谱系数特征之间的误差,记为mfcc损失函数;s3-3-4:构建面向语音识别任务的特征损失函数:。
[0064]
其中,所述stft损失函数以及所述特征损失函数具有相同的运算形式:其中表示所述stft幅度频谱、所述plp特征、所述fbank特征或者所述mfcc特征,表示干净语音信号,表示增强语音信号,表示求f范数;s3-4:通过加权求和的方式构建所述管制员语音增强初步模型的多任务损失函数,计算式如下:其中为所述多任务损失函数,、和分别代表所述lae损失函数、所述stft损失函数以及所述特征损失函数的预设权重,本发明中均预设为1。
[0065]
s4:基于所述多任务损失函数以及所述有效数据集,通过梯度下降神经网络训练算法对所述管制员语音增强初步模型的模型参数进行迭代更新,并输出管制员语音增强模型;s4-1:从所述有效训练集中随机获取若干原始干净语音-带噪语音数据对作为训练集,并根据带燥语音波形和干净语音波形的差异,提取纯噪声数据波形,运算式为:,其中,表示所述原始干净语音-带噪语音数据对中原始干净语音数据的干净语音波形,表示所述原始干净语音-带噪语音数据对中带噪语音数据的带噪语音波形,表示纯噪声波形,上述三者的形状均为,b表示批次大小,c表示通道数,l表示数据长度,表示按特征值相减操作;s4-2:在所述训练集内随机打乱所述纯噪声波形的分布,并与所述干净语音波形相加得到增强带噪语音波形,运算式为:,其中表示数据打乱操作,表示干净语音波形-纯噪声波形数据对,表示所述增强带噪语音波形,表示按特征值相加操作;s4-3:将所述干净语音波形和所述增强带噪语音波形组合为新的训练集,记为第
二训练集;s4-4:基于所述第二训练集以及所述多任务损失函数,通过梯度下降算法迭代更新所述管制员语音增强初步模型的模型参数,训练过程中通过所述有效验证集验证所述管制员语音增强初步模型是否收敛,当模型训练收敛后输出当前所述管制员语音增强初步模型为管制员语音增强模型其中,判断所述模型训练收敛的依据为:每隔m个迭代轮次通过所述有效验证集计算所述初步模型的所述多任务损失函数,当经过连续n次计算后,所述多任务损失函数都不再下降时视作模型训练收敛;本发明中m设置为10,n设置为5;s4-5:用标注的所述有效测试集测试所述模型。
[0066]
s5:将待增强管制员语音输入所述管制员语音增强模型,输出对应的增强语音。
[0067]
实施例3本实施例为本发明所述方法在以下数据条件下的实际运行分析,用于验证本发明所述技术方案的可行性和性能,具体如下:1、数据准备:在真实管制场景下采集语音数据,并按照本发明提出的预处理方案进行预处理形成本方案语音增强方法所需的有效数据集,按照本方法所述数据集划分步骤形成训练集、验证集和测试集,数据集具体描述如下:训练集:总计47253条数据(42.83小时),包含中文数据42189条(37.28小时)、英文数据5064条(5.55小时);验证集:总计4764条数据(4.31小时),包含中文数据4188条(3.69小时)、英文数据558条(0.62小时);测试集:总计6514条数据(5.62小时),包含中文数据6012条(5.08小时)、英文数据502条(0.54小时);其中训练集和验证集均取自相同日期的语音数据,测试集取自与训练集和验证集不同日期的语音数据,所有数据的采样率均为8khz。本实施例的测试结果均为在测试集上进行语音增强和语音识别的结果。
[0068]
2、语音增强基线模型:本实施例采用步骤s2所述scn模块、cnn模块和bilstm模块构成模型为基线模型,损失函数采用步骤s3-1和步骤s3-2所述仅面向语音增强的非多分辨率损失函数,模型训练阶段使用本发明所述数据增强机制。模型输入输出均为原始波形。
[0069]
使用pytorch框架实现基线模型和本发明模型。模型训练的超参数配置描述如下:(1)优化器:采用adam优化器,初始化学习率为0.0003,学习率衰减速率为0.999;(2)模型超参数:特征通道数为48,卷积核大小为8,步长为4;(3)批训练尺寸:32。
[0070]
实验采用的硬件环境为:ubuntu linux 16.04操作系统,cpu为2
×
intel core i7-6800k,显卡为2
×
nvidia geforce rtx 2080ti,显存为2
×
11gb,内存为64gb。
[0071]
在上述训练数据和配置情况下,一共进行5组实验分别证明本发明所提出模型与损失函数的优点,具体如下:a1:将基线模型在上述有效训练数据上进行训练;a2:在a1基础上,将非多分辨率损失函数改为多分辨率损失函数,并在上述有效训练数据上进行训练;
a3:在a2基础上,添加sasc模块和cssatt模块,并在上述训练数据上进行训练;a4:在a2基础上,采用同时面向语音增强任务和语音识别任务的多任务损失函数,并在上述训练数据上进行训练;a5:在a2基础上,添加a3所述模块和采用a4所述多任务损失函数,并在上述训练数据上进行训练;实验描述如图7所示。
[0072]
3、语音增强效果评价指标:本实验采用客观语音质量评价指标来衡量模型语音增强效果,具体如下:(1)pesq(perceptual evaluation of speech quality):感知语音质量评估,其值位于0~5之间,数值越高代表增强效果越好;(2)csig(mean opinion score (mos) prediction of the signal distortion attending only to the speech signal):语音失真的平均意见得分,其值位于1~5之间,数值越高代表增强效果越好;(3)cbak(mos prediction of the intrusiveness of background noise):背景噪声侵入性的平均意见得分,其值位于1~5之间,数值越高代表增强效果越好;(4)covl(mos prediction of the overall effect):整体效果的平均意见得分,其值位于1~5之间,数值越高代表增强效果越好;(5)stoi(short-time objective intelligibility):短时客观可懂度,是一个百分比值,其值位于0~100之间,数值越高代表增强效果越好。
[0073]
以干净语音为基准,分别将带噪语音和增强语音与干净语音成对计算获得上述评价指标分数,计算得分越高说明前者语音波形特征与干净语音波形特征更相近,即反映语音质量越好。
[0074]
4、语音识别模型:本实验采用现有的deepspeech2声学模型(ds2)作为语音识别效果验证模型,不用重新训练ds2模型。将本实施例所述5组实验所得实验结果分别经过ds2模型得到指令文本,并将干净/带噪测试数据经过ds2模型得到干净/带噪指令文本,以干净指令文本为基准,分析比较所有指令文本结果;5、语音识别效果评价指标:采用基于中文汉字和英文字母的字符错误率(character error rate,cer)衡量语音识别效果,数值越低代表语音识别效果越好,cer计算方式如下:,其中为真实指令文本的长度,、和分别代表将预测指令文本转换到真实指令文本所需要的插入、删除和替换操作数。
[0075]
6、实验结果:本发明所述实验结果如图8和图9所示,由实验结果可知,本发明所提出的模块以及损失函数机制均能够在本实施例的数据集上提升语音增强和语音识别的效果。具体来说:(1)由实验a1和a2可知,在引入损失函数的多分辨率机制后,语音增强效果和语音识别效果相较于基线模型均有提升,这说明设置多组傅里叶变换三元组参数能够从多个方面、多个尺度去构造语音的幅度频谱,有利于模型深度挖掘语音的有效信息,从而支撑语音
增强任务和语音识别任务研究。
[0076]
(2)由实验a3可知,在实验a2的基础上引入本发明提出的sasc模块和cssatt模块对带噪数据进行增强,对应实验的客观评价分数指标优于基准模型a2和采用多任务损失的模型a4,这一实验结果表明了本发明提出的模块有利于模型网络较深时语音特征的长距离传输和重构,也有利于模型在解析语音特征图时从多个维度捕获语音信息,从而提高模型的鲁棒性,使得增强效果更佳。
[0077]
(3)由实验a4可知,在实验a2的基础上引入本发明提出的多任务损失,其语音识别效果相较于其他不采用多任务损失的模型更优,且所有实验均使用现有的语音识别模型进行测试。这说明在不需要重新训练语音识别模型的基础上,直接在前沿增强任务上考虑语音识别任务的特征,利用模型学习带噪语音和干净语音在识别上的公共特征表示,能够使得优化后的语音数据具有更好的识别效果。
[0078]
(4)由实验a5可知,同时引入本发明所述多分辨率机制、模型模块和采用多任务损失函数,能够使基线模型在本实施例的测试集上获得最优的语音增强和语音识别性能,证明了本发明所提出方法的有效性。
[0079]
实施例4如图10所示,一种面向语音识别的管制员语音增强装置,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述实施例所述的一种面向语音识别的管制员语音增强方法。所述输入输出接口可以包括显示器、键盘、鼠标、以及usb接口,用于输入输出数据;电源用于为电子设备提供电能。
[0080]
本领域技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(read only memory,rom)、磁碟或者光盘等各种可以存储程序代码的介质。
[0081]
当本发明上述集成的单元以软件功能单元的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、rom、磁碟或者光盘等各种可以存储程序代码的介质。
[0082]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。