1.本发明属于语音识别技术领域,涉及一种语音分离方法,具体涉及一种基于声纹特征的语音分离方法。
背景技术:
2.语音分离技术就是利用硬件或软件方法,将目标说话人音频中从背景干扰中分离出来。语音分离方法包括传统方法和深度学习方法。相较于传统的语音分离方法,深度学习方法具有精度高、准确率高、端到端训练测试等特点,是目前主流的语音分离方法。深度学习方法主要包括基于置换不变训练的方法、基于深度吸引子网络的方法和基于深度聚类的方法。这些方法通常是根据固定说话人数量来对分离模型进行训练,而且只能将多人音频中的所有说话人音频同时分离出来,而不能单独分离出一个目标说话人的音频,而且对于多个声音特征相似的说话人无法分离出高质量的多个音频。
3.随着声纹特征提取模型的不断改进,在语音分离模型中融合声纹特征在目标说话人的语音分离方法中得到了应用。例如申请公布号为cn 113990344a,名称为“一种基于声纹特征的多人语音分离方法、设备及介质”的专利申请,公开了一种基于声纹特征的多人语音分离方法,该方法先对目标说话人音频提取声纹特征,并对混合音频进行短时傅里叶变换得到混合音频的频谱特征,将提取到的声纹特征和频谱特征拼接后使用深度聚类模型dpcl进行掩码生成,将生成的掩码与混合音频的频谱特征相乘得到目标说话人的纯净音频的频谱,最后通过短时傅里叶逆变换得到目标说话人的纯净音频。该方法通过在语音分离网络的输入中拼接混合音频的频谱特征和目标说话人的声纹特征提高了语音分离的精度,但是其将混合音频采用短时傅里叶变换从时域信号转换为幅度谱,这会导致在分离后的幅度谱在恢复成时域信号的过程中所用到的是含有噪声的相位谱,从而使得分离后音频的信号失真比降低,且该方法中使用的分离模型dpcl网络结构复杂,训练时间较长。
技术实现要素:
4.本发明的目的在于克服上述现有技术存在的缺陷,提出了一种基于声纹特征的语音分离方法,旨在提高在多人音频中分离出目标说话人音频的信号失真比和效率。
5.为实现上述目的,本发明采取的技术方案包括如下步骤:
6.(1)获取训练样本集和测试样本集:
7.(1a)获取n个非目标说话人的纯净音频数据f={f1,f2,
…
,fn,...,fn},以及目标说话人的m条纯净音频数据k={k1,k2,...,km,...,km},并将目标说话人的每条纯净音频数据km与f中任意两个说话人的纯净音频数据f
p
、fq以及自然噪音进行混合,得到混合音频数据集g={g1,g2,...,gm,...,gm},其中n≥200,fn表示第n个说话人的一条纯净音频数据,m≥8000,km表示目标说话人的第m条纯净音频数据,p∈[1,n],q∈[1,n],p≠q,gm表示km对应的混合音频数据;
[0008]
(1b)对每条纯净音频数据km进行短时傅里叶变换,并将km、gm和对km进行短时傅里
叶变换得到的辅助语音频谱hm组成样本数据,得到包括m条样本数据的集合,然后将该集合中随机选取的半数以上条样本数据组成训练样本集t,将剩余的样本数据组成测试样本集r;
[0009]
(2)构建基于声纹特征的语音分离模型o:
[0010]
构建包括声纹特征提取模块和conv-tasnet模型的语音分离模型o;conv-tasnet模型包括音频编码模块、语音分离网络和音频解码模块;音频编码模块与音频解码模块连接,音频编码模块和声纹特征提取模块与语音分离网络连接,语音分离网络与音频解码模块连接;其中,声纹特征提取模块包括顺次连接的双向lstm层、全连接层和平均池化层;音频编码模块包括一维卷积层;语音分离网络包括多个归一化层、多个一维卷积层、依次级联的多组时间卷积模块tcn、prelu层;音频解码模块包括一维反卷积层;
[0011]
(3)对语音分离模型o进行迭代训练:
[0012]
(3a)初始化迭代次数j,最大迭代次数为j,j≥100,当前语音分离模型为oj,并令j=0;
[0013]
(3b)将训练样本集t作为语音分离模型o的输入进行前向传播:
[0014]
(3b1)音频编码模块对每个训练样本中的混合音频数据进行编码,输出混合音频编码,同时声纹特征提取模块对每个训练样本中的辅助语音频谱进行声纹特征提取,输出混合音频编码对应的声纹特征向量;
[0015]
(3b2)语音分离网络使用film-dctasnet融合算法对每对混合音频编码和声纹特征向量进行掩码计算,得到混合音频中目标说话人音频对应的非负掩码矩阵;音频解码模块将混合音频编码与混合音频中目标说话人音频对应的非负掩码矩阵点乘后使用一维反卷积层进行解码,得到每个训练样本分离后的目标说话人音频数据;
[0016]
(3c)计算每个训练样本分离出的目标说话人音频数据及其对应的纯净音频数据的尺度不变信号失真比si-snr,并采用adam优化器,通过最大化si-snr值对语音分离模型o的权值进行更新,得到第j次迭代后的基于声纹特征的语音分离模型oj;
[0017]
(3d)判断j≥j是否成立,若是,得到训练好的基于声纹特征的语音分离模型o',否则,令j=j 1,并执行步骤(3b);
[0018]
(4)获取语音分离结果:
[0019]
将测试样本集r作为训练好的基于声纹特征的语音分离模型o'的输入进行前向传播,得到测试样本集r对应的分离后的目标说话人音频数据。
[0020]
本发明与现有技术相比,具有如下优点:
[0021]
1.本发明在对语音分离模型进行训练以及获取语音分离结果的过程中,采用film-dctasnet融合算法对每对混合音频编码和声纹特征向量进行掩码计算,使得分离网络可以多次融入目标说话人的声纹特征,解决了现有技术中直接以点乘融合声纹特征导致的分离出音频中含有其他与目标说话人声音特征相似的说话人音频的问题,有效提高了分离后音频信号的信号失真比。
[0022]
2.本发明在语音分离模型中使用conv-tasnet模型中的分离网络进行掩码计算,该分离网络为深度卷积神经网络,相较于现有技术中使用循环神经网络构建模型具有更简单的模型结构、更快的训练速度和更好的信息抽象能力,使得语音分离模型的训练时间更短,模型分离出的目标说话人音频信号失真比更高。
[0023]
3.本发明在编解码器的选择上采用时域编码,即使用一维卷积层直接对音频时域信号进行编码,该方式相较于时频编码具有帧长更短、可训练参数、没有相位重建的特点,避免了现有技术中在信号编码的过程中时域与时频域转换造成的信号损失,使其分离出的音频信号失真比更高。
附图说明
[0024]
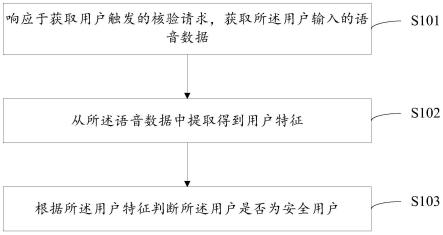
图1是本发明的实现流程图;
[0025]
图2是本发明所构建的基于声纹特征的语音分离模型结构示意图。
具体实施方式
[0026]
以下结合附图和具体实施例,对本发明作进一步的详细描述。
[0027]
参照图1,本发明包括如下步骤:
[0028]
步骤1)获取训练样本集和测试样本集:
[0029]
(1a)获取n个非目标说话人的纯净音频数据f={f1,f2,...,fn,...,fn},以及目标说话人的m条纯净音频数据k={k1,k2,...,km,...,km},并将目标说话人的每条纯净音频数据km与f中任意两个说话人的纯净音频数据f
p
、fq以及自然噪音进行混合,得到混合音频数据集g={g1,g2,...,gm,...,gm},其中n≥200,fn表示第n个说话人的一条纯净音频数据,m≥8000,km表示目标说话人的第m条纯净音频数据,p∈[1,n],q∈[1,n],p≠q,gm表示km对应的混合音频数据;
[0030]
使用目标说话人纯净音频与其他说话人音频及噪音混合的做法可以使得该纯净音频为语音分离模型分离的目标音频,从而使得训练得到的语音分离模型分离得到音频更接近真实音频,本实施例中,n=300,m=10000;
[0031]
(1b)对每条纯净音频数据km进行短时傅里叶变换,并将km、gm和对km进行短时傅里叶变换得到的辅助语音特征hm组成样本数据,得到包括m条样本数据的集合,然后将该集合中随机选取的半数以上条样本数据组成训练样本集t,将剩余的样本数据组成测试样本集r;
[0032]
不同于已有的语音分离算法中将混合音频先经过短时傅里叶变换提取频谱后输入语音分离模型,本发明将混合音频的时域信号直接输入语音分离模型,可以避由于时域、时频域的转化带来的噪声加入,从而使得语音分离模型得到音频具有更少的噪声,本实施例中,选取的训练样本数量为8000条,测试样本数量为2000条;
[0033]
步骤2)构建基于声纹特征的语音分离模型o,其结构如图2所示;
[0034]
构建包括声纹特征提取模块和conv-tasnet模型的语音分离模型o;conv-tasnet模型包括音频编码模块、语音分离网络和音频解码模块;音频编码模块与音频解码模块连接,音频编码模块和声纹特征提取模块与语音分离网络连接,语音分离网络与音频解码模块连接;其中,声纹特征提取模块包括顺次连接的双向lstm层、全连接层和平均池化层;音频编码模块包括一维卷积层;语音分离网络包括多个归一化层、多个一维卷积层、依次级联的多组时间卷积模块tcn、prelu层;音频解码模块包括一维反卷积层;
[0035]
语音分离网络包括第一归一化层、第一一维卷积层、第一tcn组、第二tcn组、第三tcn组、prelu层、第二一维卷积层和第二归一化层,其中每组tcn包括八个依次级联的tcn,
每个tcn的具体结构为:一维卷积层、relu层、归一化层、深度可分离卷积层、relu层、归一化层和一维卷积层,且输入与输出间进行残差连接;每个tcn具有各自的膨胀卷积结构,其中卷积过程的扩张因子即卷积核的步长从1开始以指数2逐渐增大,即1、2、4、
…
,且每组tcn的第一个tcn的扩张因子重置为1;
[0036]
本发明中采用的tcn模块是shaojie bai等人在2018年提出的一种新型的可以用来解决时间序列预测的算法;由于rnn网络一次只读取、解析输入文本中的一个单词或字符,深度神经网络必须等前一个单词处理完,才能进行下一个单词的处理,这意味着rnn不能像卷积神经网络那样进行大规模并行处理,耗时较长,因此相比于rnn网络,tcn模块在使用时序数据的预测任务中的表现更为出色,在分离模型中使用基于tcn模块的conv-tasnet模型可以提高分离效率和分离出音频的信号失真比;
[0037]
步骤3)对语音分离模型o进行迭代训练:
[0038]
(3a)初始化迭代次数j,最大迭代次数为j,j≥100,当前语音分离模型为oj,并令j=0,本实施例中j=100;
[0039]
(3b)将训练样本集t作为语音分离模型o的输入进行前向传播:
[0040]
(3b1)音频编码模块对每个训练样本中的混合音频数据进行编码,输出混合音频编码,同时声纹特征提取模块对每个训练样本中的辅助语音特征进行声纹特征提取,输出声纹特征向量;
[0041]
(3b2)语音分离网络对每个训练样本的混合音频编码和声纹特征向量进行掩码计算,得到混合音频中目标说话人音频对应的非负掩码矩阵;音频解码模块将混合音频编码与混合音频中目标说话人音频对应的非负掩码矩阵点乘后使用一维反卷积层进行解码,得到每个训练样本分离后的目标说话人音频数据;
[0042]
语音分离网络对每个训练样本的混合音频编码和声纹特征向量进行掩码计算的实现步骤为:混合音频编码依次输入第一归一化层、第一一维卷积层进行向前传播得到分离网络的中间表征l0,l0与声纹特征向量经过film层的仿射变换后的结果输入第一tcn组进行向前传播得到分离网络的中间表征l1,l1与声纹特征向量经过film层的仿射变换后的结果输入第二tcn组进行向前传播得到分离网络的中间表征l2,l2与声纹特征向量经过film层的仿射变换后的结果输入第三tcn组进行向前传播得到第三tcn组的最后一个tcn模块的输出,将该输出与其他所有tcn的输出求和后输入prelu层、第二一维卷积层和第二归一化层进行向前传播,得到混合音频中目标说话人音频对应的非负掩码矩阵;其中l
i,c
与声纹特征向量经过film层的仿射变换按照如下公式计算:
[0043]
γ
i,c
=fc(e)
[0044]
β
i,c
=hc(e)
[0045]
film(l
i,c
|γ
i,c
,β
i,c
)=γ
i,c
l
i,c
β
i,c
[0046]
其中e为从目标说话人的纯净语音中提取出的声纹特征向量,fc、hc为对e进行的第c次仿射变换函数,l
i,c
为第i个tcn组融合声纹特征向量前的中间表征的第c个特征;
[0047]
相较于大多语音分离算法中直接以点乘融合声纹特征,本发明中使用film-dctasnet融合算法在分离网络中融合声纹特征,为每一次融合过程单独构建一组可训练参数,可以更好地将目标说话人的声纹特征表现在目标说话人音频对应的非负掩码矩阵中,从而提高语音分离模型的得到的目标说话人音频的信号失真比;
[0048]
(3c)计算每个训练样本分离出的目标说话人音频数据及其对应的纯净音频数据的尺度不变信号失真比si-snr,采用adam优化器,通过最大化si-snr值对语音分离模型o的权值进行更新,得到第j次迭代后的基于声纹特征的语音分离模型oj;
[0049]
si-snr的计算方法按照如下公式定义:
[0050][0051][0052][0053]
其中s为纯净音频数据,为分离后的目标说话人音频数据;
[0054]
本发明采用的性能评价指标si-snr将生成向量投影到真实向量的垂直方向,相较于传统方法中采用的信号失真率snr能够更直接反映分离后的目标说话人音频数据与纯净音频数据之间的相似性,从而得到效果更好的语音分离模型;
[0055]
(3d)判断j≥j是否成立,若是,得到训练好的基于声纹特征的语音分离模型o',否则,令j=j 1,并执行步骤(3b)
[0056]
步骤4)获取语音分离结果:
[0057]
将测试样本集r作为训练好的基于声纹特征的语音分离模型o'的输入进行前向传播,得到测试样本集r对应的分离后的目标说话人音频数据。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。