1.本发明涉及文本分析技术领域,具体涉及文档层次结构联合全局与局部信息抽取关键短语方法及系统。
背景技术:
2.关键短语是文档中提供核心内容简明摘要的短语,可帮助读者在短时间内了解文章的内容。由于表达简洁准确,关键短语被广泛运用于信息检索、文档分类、推荐和搜索中。基于嵌入的方法被广泛用于无监督的关键短语提取任务。通常,这些方法只是简单地计算短语嵌入和文档嵌入之间的相似性,在方法实用性和有效性方面均存在提升空间。
3.已经有大量学者对文本的关键词抽取展开研究,相关方法总体上可以分为无监督抽取方式和有监督抽取方式。
4.有监督方法[sterckx et al.,2016;alzaidy et al.,2019;sun et al.,2020;mu et al.,2020]通常将关键短语抽取看作时一个二分类问题,他们不仅需要大规模带注释的训练数据,并且在转移到不同领域或类型的数据集时总是表现不佳。与有监督的方法相比,无监督的方法通过基于输入文档本身的信息提取短语,更具通用性和适应性。因此在本专利中,我们聚焦于无监督关键短语抽取模型。
[0005]
无监督关键短语抽取已经被大量学者研究,最近随着文本表示学习的进展,基于嵌入的方法,如embedrank[bennani-smires 2018]和sifrank[sun 2020]取得了很好的效果。通常这些方法都是通过静态的预训练模型word2vec或者动态的预训练模型bert对候选短语和文本进行嵌入,然后计算候选短语和整个文本之间的嵌入相似度,并根据得分进行排序。尽管基于嵌入的方法会比传统的基于统计(例如tf-idf[salton g,1975])、基于图(例如positionrank[corina florescu 2017])的方法表现更好,但是简单的计算候选短语和全文之间的相似度并不能捕获到不同类型的上下文。ccrank[liang et al.,2021]首次提出了联合建模全局信息和局部信息来进行关键词抽取,但是他的方法还存在两个问题。第一是由于bert模型的限制,他的方法在长文本上会自动截断前512个token,这样会导致大量的语义丢失;第二,由于全文向量和候选短语向量嵌入在语义空间上不对齐,因此他的全局相似度会给候选短语长的短语更高的分数,这样会导致模型更偏爱长的候选短语;第三,他只是简单的使用边界特性来建模局部信息并没有充分挖掘到文章的主题信息。本发明将关键短语和全文向量进行嵌入之后并可视化展示如下图4所示。五角星是文章的向量嵌入,有颜色加粗且靠近的节点属于同一个主题,以前的基于嵌入的方法只考虑了全局相似度,也就是只会选择黑色虚线框里面的候选短语,这显然是没有考虑到文章的局部主题的重要性,但是来自边界的短语通常只能代表文章的一小部分主题,并不能充分挖掘候选关键短语之间的主题信息。此外以前的短语没有考虑到bert只能编码512个token的限制,所以在面对长文本时通常选取截断的方式,只会获得标题 摘要的候选关键短语,没有得到结论部分的关键短语,导致没有获得充分的语义信息,使得效果不好。公开号为cn111160017a的现有发明专利文献《一种关键词抽取方法、装置、计算机设备和存储介质》
将待处理文本数据输入至利用携带集合编码的序列标注样本训练得到的关键词抽取网络模型,能够通过标准关键词充分发掘上下文的语义相关性,提高了关键词抽取的准确率。本技术还提供一种话术评分方法、装置、计算机设备和存储介质,通过将待评分话术输入已训练的关键词抽取网络模型,能够针对不同业务场景,抽取出只具备业务相关的话术中的关键词。该现有专利文献的说明书中还披露了服务器104中部署有基于ernie-bilstm-crf三层网络单元组成的初始关键词抽取网络模型,ernie网络单元是基于bert模型的改进版本,其针对中文词汇级别的任务进行了优化,对中文实体及实体关系抽取具有更好的效果。模型主体结构和bert模型相同,由12个编码器层组成的技术方案。该现有专利文献并未完全公开本技术的技术方案,也无法达到本技术的技术效果。公开号为cn113255340a的现有发明专利文献《一种面向科技需求的主题提取方法、装置和存储介质》中披露的方法包括:获取科技需求文本数据,所述科技需求文本数据中携带行业领域一级主题类别标签;基于属于同一一级主题类别的科技需求文本数据分别获得单词向量和文档向量;利用基于深度学习的主题模型基于所述单词向量和文档向量获取主题词向量表示和主题词集;以主题词向量为基础基于预定的聚类数目对科技需求文本数据进行聚类;利用文本排序算法对主题词集内的主题词作为关键词进行提取并对提取的主题词进行排序,根据主题词得分筛选出作为二级聚类主题类别标签词的主题词,并将得分最高的主题词作为本类别二级主题代表。该现有专利文献并未完全披露本技术的技术方案,也无法达到本技术的技术效果。
[0006]
综上,现有技术存在语义丢失、偏爱长短语、主体信息挖掘不充分导致关键短语抽取准确率低的技术问题。
技术实现要素:
[0007]
本发明所要解决的技术问题在于如何解决现有技术中语义丢失、偏爱长短语、主体信息挖掘不充分导致关键短语抽取准确率低的技术问题。
[0008]
本发明是采用以下技术方案解决上述技术问题的:文档层次结构联合全局局部信息抽取关键短语方法包括:
[0009]
s1、利用standfordcorenlp工具对输入文档进行分词和词性标注,根据预置抽取规则进行np分块,以生成候选关键短语集合;
[0010]
s2、判断所述输入文档的长度是否小于或等于预置文档长度阈值,若是,则利用bert模型嵌入处理所述输入文档,以得到向量表达,若否,则根据预置范围获取所述输入文档的指定范围内容,将所述指定范围内容输入所述simcse模型,以进行嵌入获取所述候选关键短语的向量表达、标题向量及结尾向量;
[0011]
s3、处理所述标题向量及所述结尾向量,以对候选关键短语进行全局相似性度量,据以得到全局相似度;
[0012]
s4、利用主题中心度,以预置逻辑对所述输入文档全文的所述候选关键短语进行主题划分和聚类,据以局部相似度评估得到局部相似度,其中,所述步骤s4还包括:
[0013]
s41、以所述候选关键短语作为节点、以所述节点间的相似度作为边,据以构建完全无向图;
[0014]
s42、根据每一所述输入文档的最大值及最小值设置自适应滤噪阈值;
[0015]
s43、根据所述自适应滤噪阈值更新将所述边的权重,以得到局部显著性数据,根
据所述局部显著性数据得到更新边;
[0016]
s44、获取所述输入文档全文的所述候选关键短语的位置信息;
[0017]
s45、根据所述位置信息计算得到所述局部相似度;
[0018]
s5、结合处理所述位置信息、所述全局相似度、所述局部相似度,以对所述候选关键短语进行综合评估并打分,据以排序处理所述候选关键短语,以得到关键短语排名数据;
[0019]
s6、根据所述关键短语排名数据得到候选关键短语排序数据集,对所述候选关键短语进行后处理操作,删除所述候选关键短语集合的子集,以获取语义多样性关键短语,获取词汇频率数据,据以去除所述候选关键短语排序数据集上的高频通用短语,以滤除高频无效短语干扰。
[0020]
本发明提出的方法对关键短语抽取有很大提升。通过对比实验结果可以看出本发明提出的全局相似度和局部相似度都起到了作用。在局部相似度的计算中,本发明提出的噪声过滤阈值θ。此外本发明提出的模型在长文本上面取得了巨大的进步,这得益于本发明充分利用了文档的层次结构。本发明通过多样性操作使得候选短语具有更高的语义多样性,使得结果更加被人接受。
[0021]
在更具体的技术方案中,步骤s2包括:
[0022]
s21、以bert模型在所述输入文档的开始位置插入cls标记,结束位置插入sep标记;
[0023]
s22、嵌入学习所述输入文档,据以得到每一个token的向量:
[0024]
{h1,h2,
…
,hn}=bert({t1,t2,
…
,tn})
[0025]
s23、再根据所述预置抽取规则得到所述候选关键短语的向量表示,以得到所述候选短语向量集合:
[0026][0027]
s24、将所述输入文档的标题和结尾送入所述bert模型,以得到标题向量h
title
及结尾向量h
end
。
[0028]
s25将所述输入文档的结论部分及摘要部分分别输入到所述bert模型进行嵌入操作,以得到所述向量表达;
[0029]
s26利用simcse模型对所述输入文档进行长文本上的表达。
[0030]
本发明针对bert编码长度受限制导致传统的基于嵌入的方法面对长文本只能截断,导致大量语义丢失的问题,本发明依据文档层次结构和人类的书写习惯,提出在面对长本文时将标题和摘要为一组,结论为一组分成两次送进预训练模型进行嵌入,这样即节省时间和空间,又能最大化保存全文的语义信息。
[0031]
本发明针对传统方法对于长文本处理的不足,创造性的提出使用simcse分段编码文档的摘要和结论,使得本发明提出的模型可以充分学习到文档的信息,能够得到更高质量的关键短语。
[0032]
在更具体的技术方案中,步骤s3中,以下述逻辑处理标题向量h
title
和结尾向量h
end
,据以获取每一所述候选关键短语i的所述全局相似度:
[0033]
[0034]
其中,‖.‖表示曼哈顿距离,表示候选短语i与整个文档的全局相似度。
[0035]
本发明针对语义空间对齐导致的偏爱长短语问题,根据人类的书写习惯,使用标题和结尾最后一句话替代传统的全文向量,从而解决长短语得分偏高的问题。
[0036]
在更具体的技术方案中,步骤s42包括:
[0037]
s421、利用图中心性计算方法,以下述逻辑处理所述候选关键短语i:
[0038][0039]
其中,
[0040]
s422、利用下述逻辑设置所述自适滤噪应阈值θ;
[0041]
θ=min(e
ij
) β
×
(max(e
ij
)-min(e
ij
))
[0042]
本发明对候选短语进行了一步后处理操作。设置了一个阈值,过滤掉每一个特定领域top20%高频出现的候选短语,避免高频无效词的干扰,然后通过删除子集的方式来提高候选关键短语的语义多样性。
[0043]
在更具体的技术方案中,步骤s43包括:
[0044]
s431、利用下述逻辑处理得到所述局部显著性数据:
[0045][0046]
其中,代表候选短语i的局部显著性;
[0047]
s432、根据所述局部显著性数据获取所述更新边,在所述更新边的权重小于0时,设置该所述更新边的权重为0。
[0048]
在更具体的技术方案中,步骤s44包括:
[0049]
s441、以下述逻辑计算所述候选关键短语在所述输入文档中首次出现位置,以作为候选关键短语位置得分:
[0050][0051]
其中,p1是候选术语i首次出现的位置;
[0052]
s442、利用softmax函数平滑处理所述候选关键短语位置得分,以利用下述逻辑处理得到所述位置信息:
[0053][0054]
在更具体的技术方案中,步骤s45中,利用下述逻辑处理所述位置信息,据以得所述候选关键短语i的所述局部相似度
[0055][0056]
本发明在局部文本信息建模上,采用主题中心度,这样可以识别全文上的主题信息,相较于边界中心度可以更好的捕获到局部主题信息。
[0057]
在更具体的技术方案中,步骤s5包括:
[0058]
s51、利用下述逻辑对所述候选关键短语的所述全局相似度及所述局部相似度进行乘法综合处理,据以得到候选关键短语评分:
[0059][0060]
s52、根据所述候选关键短语评分排序处理所述候选关键短语,以得到所述关键短语排名数据。
[0061]
在更具体的技术方案中,步骤s6中,根据细粒度关键短语删除粗粒度的关键短语,据以获取所述语义多样性关键短语。
[0062]
在更具体的技术方案中,文档层次结构联合全局局部信息抽取关键短语系统包括:
[0063]
候选短语生成模块,利用standfordcorenlp工具对输入文档进行分词和词性标注,根据预置抽取规则进行np分块,以生成候选关键短语集合;
[0064]
bert模型嵌入模块,用以判断所述输入文档的长度是否小于或等于预置文档长度阈值,若是,则利用bert模型嵌入处理所述输入文档,以得到向量表达,若否,则根据预置范围获取所述输入文档的指定范围内容,将所述指定范围内容输入所述simcse模型,以进行嵌入获取所述候选关键短语的向量表达、标题向量及结尾向量,所述simcse模型嵌入模块与所述候选短语生成模块连接;
[0065]
全局相似性度量模块,用以处理所述标题向量及所述结尾向量,以对候选关键短语进行全局相似性度量,据以得到全局相似度,所述全局相似性度量模块与所述bert模型嵌入模块连接;
[0066]
局部相似度评估模块,用以利用主题中心度,以预置逻辑对所述输入文档全文的所述候选关键短语进行主题划分和聚类,据以局部相似度评估得到局部相似度,所述局部相似度评估模块与所述候选短语生成模块连接,其中,所述局部相似度评估模块还包括:
[0067]
无向图构建模块,用于以所述候选关键短语作为节点、以所述节点间的相似度作为边,据以构建完全无向图;
[0068]
滤噪阈值设置模块,用以根据每一所述输入文档的最大值及最小值设置自适应滤噪阈值;
[0069]
滤噪模块,用以根据所述自适应滤噪阈值更新将所述边的权重,以得到局部显著性数据,根据所述局部显著性数据得到更新边,所述滤噪模块与所述无向图构建模块及所述滤噪阈值设置模块连接;
[0070]
位置获取模块,用以根据所述新完全无向图获取所述输入文档全文的所述候选关键短语的位置信息;
[0071]
局部相似度计算模块,用以根据所述位置信息计算得到所述局部相似度,所述局部相似度计算模块与所述位置获取模块连接;
[0072]
关键短语排名模块,用以结合处理所述位置信息、所述全局相似度、所述局部相似度,以对所述候选关键短语进行综合评估并打分,据以排序处理所述候选关键短语,以得到关键短语排名数据,所述关键短语排名模块与所述全局相似性度量模块及所述局部相似度评估模块连接;
[0073]
后处理模块,用以根据所述关键短语排名数据得到候选关键短语排序数据集,对所述候选关键短语进行后处理操作,删除所述候选关键短语集合的子集,以获取语义多样
性关键短语,获取词汇频率数据,据以去除所述候选关键短语排序数据集上的高频通用短语,以滤除高频无效短语干扰,所述后处理模块与所述关键短语排名模块连接。
[0074]
本发明相比现有技术具有以下优点:本发明提出的方法对关键短语抽取有很大提升。通过对比实验结果可以看出本发明提出的全局相似度和局部相似度都起到了作用。在局部相似度的计算中,本发明提出的噪声过滤阈值θ。此外本发明提出的模型在长文本上面取得了巨大的进步,这得益于本发明充分利用了文档的层次结构。本发明通过多样性操作使得候选短语具有更高的语义多样性,使得结果更加被人接受。
[0075]
本发明针对bert编码长度受限制导致传统的基于嵌入的方法面对长文本只能截断,导致大量语义丢失的问题,本发明依据文档层次结构和人类的书写习惯,提出在面对长本文时将标题和摘要为一组,结论为一组分成两次送进预训练模型进行嵌入,这样即节省时间和空间,又能最大化保存全文的语义信息。
[0076]
本发明针对传统方法对于长文本处理的不足,创造性的提出使用simcse分段编码文档的开头和结论,使得本发明提出的模型可以充分学习到文档的信息,能够得到更高质量的关键短语。
[0077]
本发明针对语义空间对齐导致的偏爱长短语问题,根据人类的书写习惯,使用标题和结尾最后一句话替代传统的全文向量,从而解决长短语得分偏高的问题。
[0078]
本发明对候选短语进行了一步后处理操作。设置了一个阈值,过滤掉每一个特定领域top20%高频出现的候选短语,避免高频无效短语的干扰,然后通过删除子集的方式来提高候选关键短语的语义多样性。
[0079]
本发明在局部文本信息建模上,采用主题中心度,这样可以识别全文上的主题信息,相较于边界中心度可以更好的捕获到局部主题信息。本发明解决了现有技术中存在的语义丢失、偏爱长短语、主体信息挖掘不充分导致关键短语抽取准确率低的技术问题。
附图说明
[0080]
图1为本发明实施例1的文档层次结构联合全局局部信息抽取关键词方法步骤示意图;
[0081]
图2为本发明实施例1的文档层次结构联合全局与局部信息抽取关键词方法整体流程示意图;
[0082]
图3为本发明实施例1的结构相似度向量及相似度示意图;
[0083]
图4为本发明实施例1的关键短语和全文向量嵌入可视化原理图;
[0084]
图5为本发明实施例3的测试样例示意图。
具体实施方式
[0085]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0086]
实施例1
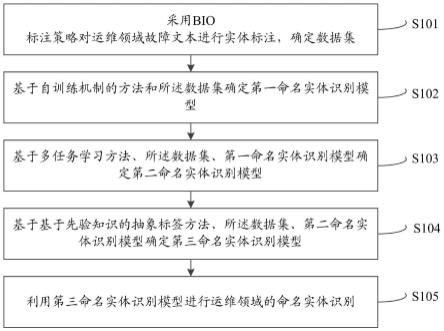
[0087]
如图1及图2所示,本发明提供的文档层次结构联合全局与局部信息抽取关键短语
方法包括以下步骤:
[0088]
s1、输入文档分词和词性标注,并根据规则进行候选关键短语生成;
[0089]
在本实施例中,利用standfordcorenlp工具对输入文档进行分词和词性标注,根据规则生成候选关键短语;在本实施例中,使用标准的自然语言处理工具stanford corenlp来对文档d进行分词和词性标注。分词之后,文档可以用d={t1,t2,
…
,tn}表示。
[0090]
在本实施例中,使用标准的stanford corenlp工具来对文档d进行分词和词性标注。首先设置通用的停用词表来过滤没有任何意义的词和符号。具体做法是如果一个词出现在停用词表中,那么就将它的词性标记为’in’。然后使用规则《nn.*|jj》*《nn.*》,其中nn.*代表的是名词,jj代表的是形容词。这个规则抽取以名词或者形容词开始,以名词结束的任意长度的短语。使用这个规则可以得到候选的关键短语集合kp={kp0,kp1,
…
,kpn}。
[0091]
s2、短文档全部送进bert进行嵌入,长文档选择前512和最好512个单词进行嵌入并获得标题、结尾一句话和候选关键短语的向量表示;
[0092]
在本实施例中,判断输入文档长度,若文档长度不超过阈值,则直接使用bert模型进行嵌入得到向量表达,如果文档长度超过阈值,则将文档指定范围的内容输入simcse模型进行嵌入并得到向量表达;
[0093]
在本实施例中,经过预处理之后,文档d就被预处理成tokens集合t={t1,t2,
…
,tn}和候选关键短语序列kp={kp0,kp1,
…
,kpm}。和以前采取静态向量进行编码不同的是,本发明中采用bert进行向量嵌入,这是一个很强的预训练模型,可以获得上下文的动态向量表示。这样就可以得到候选关键短语和文档的向量表示,考虑到文档的层次结构信息,这里文档的向量表示采用标题h
title
和结尾最后一句话h
end
。
[0094]
在本实施例中,如下图3所示,其中参数符号定义如下表1:
[0095]
表1:参数符号定义
[0096][0097]
如图3所示,将第一步得到的d={t1,t2,
…
,tn},输入到bert模型中并在其开始插入cls标记,结束位置插入sep标记,然后进行嵌入学习得到每一个token的向量,即:{h1,
h2,
…
,hn}=bert({t1,t2,
…
,tn})。再根据第二步的抽取规则得到候选关键短语的向量表示,其中对于”key phrase extraction”这种由多个单词组成的候选关键短语,选择maxpooling方式得到其向量。即候选关键短语向量集合为在这一步可以将标题和结尾送进bert模型得到相应的向量h
title
、h
end
。
[0098]
由于bert只能编码512个token,所以现有方法无法很好处理长文本,对于大多数长文档或新闻文章,作者倾向于将关键信息写在文档的开头和结尾,因此为了便于实际操作,本发明将文章的结论和文章的摘要分别输入到bert模型中进行嵌入,以此获得数量更多、多样性更高的候选关键短语,从而充分挖掘文档信息。但是,[lingxiaowang,2020]的研究指出bert编码出来的向量表达具有各异向性,表现出来的形式就是分布不均匀,低频词分布稀疏而高频词分布紧密,因此无法衡量两个句子的相似度。受到[tianyu gao,2021]研究的启发,本发明使用simcse来替代bert在长文本上的表达。simcse是普林斯顿大学陈丹琦组提出的模型,旨在解决bert编码的向量的各异向性问题。
[0099]
s3、使用标题、最后一句话和候选关键短语向量进行全局相似度计算;
[0100]
在本实施例中,全局相似性度量,本发明创新性地使用文档标题和结尾来对候选关键短语进行全局相似度评估,解决因为向量空间对齐造成的对较长候选关键短语的偏爱;
[0101]
在本实施例中,对于每个候选关键短语,使用相似度方法分别计算它与标题h
title
和最后一句话h
end
。在本实施例中,经过前面的步骤,已经得到了每一个候选关键短语的向量表示标题的向量表示h
title
和结尾的向量表示h
end
。短语与文章越相似则越有可能是关键短语,但是,bert模型中文档和短语的输入序列长度不相等,导致语义空间难以对齐,长短语比单个单词更具有优势。受到文档结构的启发,考虑到人们通常会将自己的核心观点放在文章的开始和结束,本发明采用标题和结尾来替代全文向量,因为可以做到尽量与候选关键短语长度差距减小,采用标题和结尾替代全文向量会减少部分噪音。
[0102]
对于每一个候选关键短语i的全局相似度由下面公式计算:
[0103][0104]
其中‖.‖表示的是曼哈顿距离,表示的是候选关键短语i与整个文档的全局相似度。h
title
表示的是标题的向量,h
end
表示的是结尾的向量。
[0105]
s4、构建完全无向图,其中节点是候选关键短语,边是节点之间的相似度,然后根据每一个文档的最大最小值设置一个自适应阈值,边的权重更新为权重-阈值,令新的边的权重小于0的直接设置为0,通过这种方式实现主题划分,计算局部相似度;
[0106]
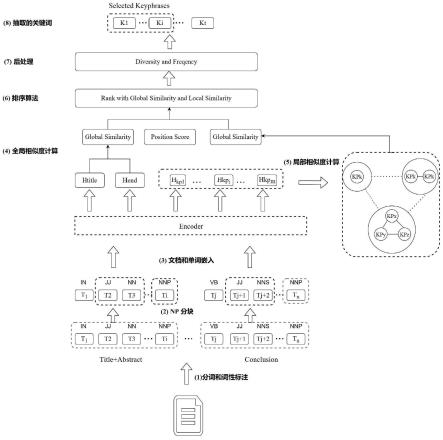
如图4所示,在本实施例中,局部相似度评估,采用全新的主题中心度,对全文的候选关键短语进行主题划分和聚类,充分捕获到局部显著信息。本发明将关键短语和全文向量进行嵌入之后并可视化展示,五角星是文章的向量嵌入,有同样填充的节点属于同一个主题。
[0107]
在本实施例中,构建一个完全无向图,其中顶点是候选关键短语。边的初始权重是两个术语向量之间的点积结果,考虑到文章是由多个小主题组成的,采用动态阈值的方法过滤不相关主题对候选关键短语的噪音。
[0108]
在本实施例中,首先构建一个完全无向图g=(v,e),其中点是在本实施例中,首先构建一个完全无向图g=(v,e),其中点是即点是候选关键短语。边是e={e
ij
},表示的是候选关键短语之间的权重,传统的图中心性计算方法是:
[0109][0110]
其中,根据我们前面所述,一个文档会有多个局部主题,候选关键短语会形成多个局部主题,因此如何精确找出这些小主题是一个难题,从图4中可以看出来,每一个小主题包括的候选关键短语都是聚集在一起的。而且在主题差异度不是特别大时,一个候选关键短语可能包括在多个主题中。对于一个候选关键短语来说,如果他包含在越多的小主题中,说明他越重要。但是在完全相反的主题中的短语会对候选关键短语造成噪声干扰。基于这种假设,本发明设计一个阈值θ来过滤噪声。
[0111]
θ=min(e
ij
) β
×
(max(e
ij
)-min(e
ij
))
[0112]
低于这个阈值θ,我们就令边的权重e
ij
=0,就样就可以过滤完全不相关的短语的干扰。这样我们就将传统的度中心性计算公式改写成
[0113][0114]
在这里代表的是候选关键短语i的局部显著性。
[0115]
对于大多数文档,作者倾向于将关键信息写在文档的开头。[florescu,2017]指出,位置偏置权重可以极大地提高关键短语提取的性能,他们采用位置与文档中单词的倒数之和作为权重。举个例子,如果一个候选关键短语出现在第二个、第五个和第十个位置,那么他的位置得分防止重复计算,本发明只计算候选关键短语第一次出现的位置作为他的位置得分,也就是其中p1是候选关键短语i第一次出现的位置。为了防止位置信息主宰最后的得分,所以采用softmax函数来平滑位置得分,因此本发明将位置信息公式修改为:
[0116][0117]
因此综合考虑位置信息后,本发明将候选关键短语i的局部相似度公式改写为。
[0118][0119]
本发明最终使用来衡量候选关键短语i的局部相似度。
[0120]
s5、排序算法:结合位置信息,全局相似度和局部相似度对后续关键短语进行评分并排序;
[0121]
在本实施例中,结合位置信息、全局相似度、局部相似度对候选关键短语进行综合评估并打分,然后根据得分进行排名;
[0122]
在本实施例中,大量已有文献证明,对于大多数论文新闻文章,作者倾向于将关键
信息写在文档的开头和结尾。因此候选关键短语的位置信息很重要,此外一个短语在文章中出现的次数越多,那么它越有可能是关键短语,考虑到已经在局部相似度计算过程中使用过词频信息,为了防止重复计算,所以,本发明仅是记录短语出现的第一个位置,将候选关键短语的位置的倒数作为位置得分。综合计算一个短语的全局相似性得分;局部相似性得分和位置得分。最后输出得分列表。在本实施例中,本发明将候选关键短语的全局相似度和局部相似度以最简洁的乘法综合起来,因此得到一个候选关键短语最终的得分是:
[0123][0124]
s6、后处理:对经过排序算法后的候选关键术语,通过删除候选关键短语中的子集提升多样性然后删除高频通用词,整体提升用户体验;
[0125]
在本实施例中,进行后处理操作,去除数据集上的高频通用词汇,避免高频无效词的干扰,然后通过删除子集的方式来提高候选关键短语的语义多样性。
[0126]
在本实施例中,对关键短语进行一个语义多样性操作,然后对高频通用短语进行过滤,最后挑选topn做为关键短语。
[0127]
在本实施例中,考虑到关键短语的多样性,在一篇文章中都会使用更详细的关键短语替代粒度粗的关键短语,因此本发明选择使用细粒度关键短语来删除粗粒度的关键短语。例如候选关键短语列表中出现了”government policies”和”government”,“policies”,那么我们就将”government”和“policies”这两个更粗粒度的候选关键短语删除,这样就得到更具有多样性和更符合人类需求的关键短语。
[0128]
一个候选关键短语可以形式化表示为kpi={w1,w2,
…
,wn},本方法删除候选关键短语中的只有单个单词的w1,w2,
…
,wn,这样就可以得到更具语义多样性的关键短语。
[0129]
实施例2
[0130]
本发明提供的文档层次结构联合全局与局部信息抽取关键词方法已经在三个公共数据集inspec、duc2001和semeval2010中进行了验证,结果显示,本发明提出的文档层次结构联合全局与局部信息的关键短语抽取方法与装置能够有效实现文档关键短语抽取。
[0131]
实验结果:
[0132]
数据集
[0133]
本发明在三个公共数据集上进行实验,数据集分别为inspec[hulth,2003],duc2001[wan,2008]和semeval2010[kim,2010]。inspec数据集包含来自科学期刊摘要的2000个摘要文档。在我们的实验中使用500个测试文档和读者标注的关键短语版本作为groundtruth。duc2001是308篇长篇新闻文章的集合。semeval2010包含acm全长论文。在本实验中,使用100个测试文档以及作者和读者注释的组合关键短语。
[0134]
实验结果:
[0135]
如下表所示,本发明和以往工作一样,选择了f1@5,f1@10,f1@15这三个指标来评估本发明所提出的方法(dhsrank )的准确度。
[0136][0137]
由实验结果可以看出,本发明提出的方法对关键短语抽取有很大提升。通过对比实验结果可以看出本发明提出的全局相似度和局部相似度都起到了作用。在局部相似度的计算中,本发明提出的噪声过滤阈值θ尤其至关重要。此外本发明提出的模型在长文本上面取得了巨大的进步,这得益于本发明充分利用了文档的层次结构,尤其是针对传统方法对于长文本处理的不足,创新性的提出使用simcse分段编码文档的开头和结论,使得本发明提出的模型可以充分学习到文档的信息,能够得到更高质量的关键短语。最后,本发明通过多样性操作使得候选关键短语具有更高的语义多样性,使得结果更加被人接受。
[0138]
实施例3
[0139]
样例展示:
[0140]
如图5所示,duc2001中的一个例子
[0141]
duc2001是来自新闻文章的数据集。正确的关键短语有实线下划线。黑色加粗文本表示标准关键短语,以虚线下划线标识的文本表示我们的模型提取的短语。
[0142]
我们可以看到黄金标准对应的是文章的各个主题。我们的模型提取了许多与标准关键短语相同的正确短语,并提取了与标准关键短语中的“lower net income”语义相同的短语“net income”。
[0143]
值得一提的是,我们的模型侧重于文档的边界,大多数提取的短语位于文档的开头与结尾,这证明了我们提出的标题 结尾做为全局向量的有效性。从图中我们还可以发现,错误的短语与文档的各个小主题高度相关,这证明了我们的主题感知中心性的有效性。这个例子表明,全局和局部上下文的联合建模可以提高关键短语提取的性能,我们的模型真正捕获了局部和全局信息。
[0144]
综上,本发明提出的方法对关键短语抽取有很大提升。通过对比实验结果可以看
出本发明提出的全局相似度和局部相似度都起到了作用。在局部相似度的计算中,本发明提出的噪声过滤阈值θ。此外本发明提出的模型在长文本上面取得了巨大的进步,这得益于本发明充分利用了文档的层次结构。本发明通过多样性操作使得候选关键短语具有更高的语义多样性,使得结果更加被人接受。
[0145]
本发明针对bert编码长度受限制导致传统的基于嵌入的方法面对长文本只能截断,导致大量语义丢失的问题,本发明依据文档层次结构和人类的书写习惯,提出在面对长本文时将标题和摘要为一组,结论为一组分成两次送进预训练模型进行嵌入,这样即节省时间和空间,又能最大化保存全文的语义信息。
[0146]
本发明针对传统方法对于长文本处理的不足,创造性的提出使用simcse分段编码文档的开头和结论,使得本发明提出的模型可以充分学习到文档的信息,能够得到更高质量的关键短语。
[0147]
本发明针对语义空间对齐导致的偏爱长短语问题,根据人类的书写习惯,使用标题和结尾最后一句话替代传统的全文向量,从而解决长短语得分偏高的问题。
[0148]
本发明对候选关键短语进行了一步后处理操作。设置了一个阈值,过滤掉每一个特定领域top20%高频出现的候选关键短语,避免高频无效短语的干扰,然后通过删除子集的方式来提高候选关键短语的语义多样性。
[0149]
本发明在局部文本信息建模上,采用主题中心度,这样可以识别全文上的主题信息,相较于边界中心度可以更好的捕获到局部主题信息。本发明解决了现有技术中存在的语义丢失、偏爱长短语、主体信息挖掘不充分导致关键词抽取准确率低的技术问题。
[0150]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。