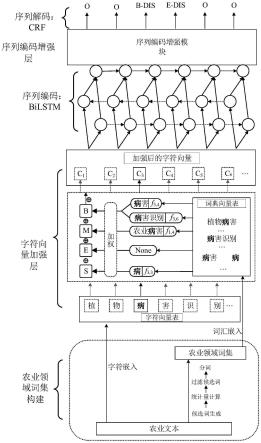
1.本发明属于农学技术领域,涉及信息抽取,具体涉及一种基于领域词典的中文农业命名实体识别方法。
背景技术:
2.命名实体识别是关系抽取等其它自然语言处理任务的基础和关键任务。它将具有特定意义的实体从非结构文本中提取出来,并将其归入预定类别。在中文农业领域,中文农业命名实体识别旨在从非结构化中文农业文本中识别农业相关实体的边界与类型,如病害、虫害、农药等实体。是从海量中文农业文本中自动挖掘知识的关键技术,同样也是构建农业知识图谱、构建农业智能问答系统等下游任务的基础。
3.中文农业命名实体识别任务的传统方法可以分为基于规则的、基于字典匹配、基于机器学习等方法。虽然这些方法可以取得不错的效果,但是他们严重依赖于耗费时间与精力的模式匹配与特征工程,而且泛化性不理想。随着深度学习在命名实体识别领域的深入应用,中文农业命名实体识别发展到了基于深度学习阶段。
4.对于基于深度学习的模型,在模型中引入分词信息对实体边界的识别有积极作用,有利于模型学到更多农业文本特征。由于中文农业文本中专业词汇多、领域特征强等特点,致使分词工具处理农业文本时易产生分词错误,因此目前基于深度学习的研究多为了避免在模型中引入分词错误而采用基于字符的模型。因此,如何改善分词工具对农业文本不敏感问题并构建领域词典,在模型中融入农业词汇信息进而准确识别农业相关命名实体,构造具备更强特征提取能力的模型,是本领域技术人员亟需解决的技术问题。
技术实现要素:
5.针对现有技术存在的不足,本发明的目的在于,提供一种基于领域词典的中文农业命名实体识别方法,解决现有技术中的识别方法的特征提取能力有待进一步提升的技术问题。
6.为了解决上述技术问题,本发明采用如下技术方案予以实现:
7.一种基于领域词典的中文农业命名实体识别方法,该方法按照以下步骤进行:
8.步骤一,原始中文农业文本标注:
9.选择bmeso标签对原始中文农业文本进行实体标注,同时在b、m、e和s后跟实体类别;
10.所述的bmeso标签中,b表示实体词的开始(begin),m表示实体词的中间(middle),e表示实体词的结束(end),s表示单个字为一个实体词(single),o表示其它的词(other);
11.所述的实体类别包含了农药、虫害、病害和作物;
12.步骤二,原始中文农业文本向量化:
13.用词嵌入技术word2vec将中文农业文本训练为字符向量,得到给定长度为n的输入序列x=(x1,x2,x3,
……
,xn)∈vc,vc是字符,每个字符都用经过训练的稠密向量来表示:
其中ec表示字符嵌入查找表;
14.步骤三,农业领域词集构建:
15.首先通过n-gram切词方法将原始中文农业文本切分为字符串,得到候选词;然后根据字符串的词频、互信息和邻接熵三个统计量依次过滤垃圾字符串得到新词集合;将新词集合补充到结巴分词工具内置词典中进行加强,用加强后的结巴分词工具对原始中文农业文本进行分词,得到农业领域词集;
16.步骤四,农业领域词典构建:
17.对步骤三得到的农业领域词集进行词嵌入操作后得到农业领域词典;
18.步骤五,字符向量加强:
19.对步骤四构造的农业领域词典加以应用,对模型输入序列s=(x1,x2,x3,
……
,xn)∈vc中每个字符进行词典匹配,并将匹配到的农业领域词典对应的步骤四得到的词汇向量融入到字符对应的步骤二得到的字符向量中,以实现字符向量加强;
20.步骤六,序列编码:
21.采用bilstm做序列编码层,将步骤五得到的加强后的字符向量输入序列编码层中进行序列编码,得到序列编码结果,即得到特征图h∈rc×w;
22.步骤七,序列编码增强:
23.构造通道注意力模块,基于通道注意力模块对特征图h∈rc×w进行序列编码增强,得到序列编码结果k∈rc×w;
24.步骤八,利用crf对序列编码结果k∈rc×w进行解码处理,crf可以根据步骤一中原始中文农业文本标注的结果,对序列编码结果k∈rc×w中每个字符对应的bmeso标签进行概率计算,并通过标准viterbi算法求解最大概率,得到每个字符的标签,实现中文农业命名实体识别。
25.本发明还具有如下技术特征:
26.步骤三中具体包括以下步骤:
27.步骤3.1,n-gram切词:
28.n-gram切词的具体过程为:将原始中文农业文本里面的内容按照字节进行大小为n的滑动窗口操作,形成了长度是n的字节片段序列,每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表;
29.步骤3.2,统计量计算:
30.对候选词进行词频、互信息和左右邻接熵计算,形成基于词频、互信息、左邻接熵和右邻接熵的候选词过滤体系;
31.步骤3.3,候选词筛选:
32.对每一个候选词进行词频、互信息和邻接熵计算后,依次设置相应阈值进行候选词过滤,将最后的过滤结果定为新词集合,并加入到基于词典的结巴分词工具的内置词典中,对结巴分词工具进行加强,以提高分词工具对农业文本的适应性;
33.步骤3.4,农业领域词集构建:
34.用加强后的结巴分词工具对原始中文农业文本进行分词,得到农业领域词集。
35.步骤四中,具体过程为:采用与步骤二相同的方法,用word2vec将农业领域词集中的每个词汇训练成词向量,得到给定长度为n的输入序列x=(x1,x2,x3,
……
,xn)∈vc,vc是
领域词集,x是词集合中的词,每个词都用经过训练的稠密向量来表示:其中ec表示词嵌入查找表;农业领域词集合中的词汇训练成向量后,构成农业领域词典。
36.步骤五中,具体过程为:
37.步骤501,模型输入序列中每个字符进行词汇匹配;
38.步骤501中具体包括:从步骤四构造的农业领域词典中匹配到包含该字符的词汇,为了保留所有字符信息以及其匹配到的词汇信息,依据模型输入序中每个字符xi在其匹配到的不同词汇中的开始位置、中间位置、结尾位置或者单字词位置,将词汇分为b(xi),m(xi),e(xi),s(xi)四个词汇集合,构造方式如下:
[0039][0040][0041][0042][0043]
其中:
[0044]
b(xi)表示b词汇集合,即开始位置词汇集合;
[0045]
m(xi)表示m词汇集合,即中间位置词汇集合;
[0046]
e(xi)表示e词汇集合,即结尾位置词汇集合;
[0047]
s(xi)表示s词汇集合,即单字词位置词汇集合;
[0048]
l表示词典;
[0049]
w表示匹配到的词汇,如果字符某个集合为空,用“none”来表示;
[0050]
步骤502,字符匹配到相应词汇之后,需要将词汇向量融入到相应字符向量表示中得到加强的字符表示,从而让编码层可以充分利用字符与词汇信息;
[0051]
步骤502中具体通过基于统计的静态加权方法来实现,即匹配到的词汇的权重用其词频来表示,静态词频统计所用的数据集是模型用于训练和开发的数据;
[0052]
如下公式为某个字符所匹配到的词汇集合s的加权表示vs(s)的计算方式:
[0053][0054][0055]
其中:
[0056]
s表示s词汇集合;
[0057]
z(w)为词汇集合中词汇在静态数据统计中出现的频率;
[0058]ew
是词嵌入查找表;
[0059]vs
(b)、vs(m)、vs(e)的计算方式与vs(s)的计算方式相同;
[0060]
最后将四个词汇集合的加权表示形式组合成一个一维特征,即es(b,m,e,s)=[vs(b);vs(m);vs(e);vs(s)],再拼接到该字符向量的表示上,即xc←
[xc;es(b,m,e,s)],从而得到最终的字符加强向量。
[0061]
步骤七中,具体过程为:
[0062]
步骤7.1,构造通道注意力模块:
[0063]
通道注意力模块中,对于图片特征矩阵a∈rc×h×w,首先将其转变为尺寸为rc×n的矩阵,之后通过如下公式将a与a的转置做矩阵乘法得到特征矩阵x∈rc×c:
[0064][0065]
其中:
[0066]
x
ji
表示通道i对通道j的影响;
[0067]
c表示图片的通道数;
[0068]
h表示图片的通宽度;
[0069]
w表示图片的长度;
[0070]
n表示h
×
w;
[0071]
通道注意力模块中,还对特征矩阵x与图片特征矩阵a做矩阵乘法,并与图片特征矩阵a做按元素相加操作,得到输出矩阵
[0072]
步骤7.2,基于通道注意力模块对特征图h∈rc×w进行序列编码增强:
[0073]
将长度为w的步骤六得到的特征图h∈rc×w视作长度为w、宽度为1以及通道数为c的图片,通过unsqueeze操作将特征图h∈rc×w进行维度扩充,变为图片特征矩阵a∈rc×h×w;
[0074]
对于图片特征矩阵a∈rc×h×w:
[0075]
首先,将其转变为尺寸为rc×n的矩阵,之后通过如下公式将a与a的转置做矩阵乘法得到特征矩阵x∈rc×c;
[0076][0077]
其次,通过串联的卷积核依次为1、3和5的卷积神经网络conv1、conv3和conv5,对图片特征矩阵a做特征加强处理,以增强对序列局部特征提取能力的到特征矩阵d=conv5(conv3(conv1(a))),其中d∈rc×w×h;
[0078]
再次,对特征矩阵x与图片特征矩阵a做矩阵乘法,并与图片特征矩阵a做按元素相加操作,得到输出矩阵其中e∈rc×w×h;
[0079]
最后,将输出矩阵e进行squeeze操作,得到特征图h∈rc×w经过序列编码增强后的序列编码结果k∈rc×w。
[0080]
本发明与现有技术相比,具有如下技术效果:
[0081]
(ⅰ)本发明对分词工具进行加强后构造农业领域词典,并通过字符向量加强层,将词汇信息融入字符向量中,可以让模型充分利用字符信息与词汇信息。
[0082]
(ⅱ)本发明提出序列编码增强模块,提高模型的特征提取能力。
[0083]
(ⅲ)本发明在基于字符的bilstm-crf模型基础上,引入农业领域词集构建流程,改善分词工具对农业文本分词不敏感问题,以构建农业领域词典。
[0084]
(ⅳ)本发明引入字符向量增强模块,对农业领域词典加以运用,将词汇信息融入字符信息中。
[0085]
(
ⅴ
)本发明能够进一步提高中文农业文本命名实体识别方法的表现。
附图说明
[0086]
图1是本发明实施例的模型流程示意图。
[0087]
图2是通道注意力模块示意图。
[0088]
图3是序列编码增强模块示意图。
[0089]
图4是对比例1的模型流程示意图。
[0090]
图5是对比例2的模型流程示意图。
[0091]
图6是对比例3的模型流程示意图。
[0092]
以下结合实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
[0093]
需要说明的是,本发明中的所有的软件、模块和层,如无特殊说明,全部均采用现有技术中已知的软件、模块和层。
[0094]
遵从上述技术方案,以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本技术技术方案基础上做的等同变换均落入本发明的保护范围。
[0095]
实施例:
[0096]
本实施例给出一种基于领域词典的中文农业命名实体识别方法,如图1所示,该方法按照以下步骤进行:
[0097]
步骤一,原始中文农业文本标注:
[0098]
选择bmeso标签对原始中文农业文本进行实体标注,同时在b、m、e和s后跟实体类别。
[0099]
所述的bmeso标签中,b表示实体词的开始(begin),m表示实体词的中间(middle),e表示实体词的结束(end),s表示单个字为一个实体词(single),o表示其它的词(other)。
[0100]
所述的实体类别包含了农药、虫害、病害和作物。
[0101]
本实施例以包含8590个句子的中文农业文本为基础进行标注。
[0102]
本实施例中,如b-disease表示病害实体的开始。
[0103]
步骤二,原始中文农业文本向量化:
[0104]
用词嵌入技术word2vec将中文农业文本训练为字符向量,得到给定长度为n的输入序列x=(x1,x2,x3,
……
,xn)∈vc,vc是字符,每个字符都用经过训练的稠密向量来表示:其中ec表示字符嵌入查找表。
[0105]
本实施例中,词嵌入技术word2vec采用已知的词嵌入技术word2vec。
[0106]
步骤三,农业领域词集构建:
[0107]
首先通过n-gram切词方法将原始中文农业文本切分为字符串,得到候选词;然后根据字符串的词频、互信息和邻接熵三个统计量依次过滤垃圾字符串得到新词集合;将新词集合补充到结巴分词工具内置词典中进行加强,用加强后的结巴分词工具对原始中文农业文本进行分词,得到农业领域词集。
[0108]
步骤三中具体包括以下步骤:
[0109]
步骤3.1,n-gram切词:
[0110]
n-gram切词的具体过程为:将原始中文农业文本里面的内容按照字节进行大小为
n的滑动窗口操作,形成了长度是n的字节片段序列,每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表。
[0111]
本实施例中,中文农业文本“农业病害识别”的2-gram切词结果为“农业、业病、病害、害识、识别”。
[0112]
本发明首先将中文农业文本用n-gram方法进行切分,得到候选字符串,即候选词。
[0113]
步骤3.2,统计量计算:
[0114]
对候选词进行词频、互信息和左右邻接熵计算,形成基于词频、互信息、左邻接熵和右邻接熵的候选词过滤体系。
[0115]
其中:
[0116]
词频即为该词出现的频率;一个词出现的频率高,则说明这个词经常用到,是常用词。反之,则说明该词并非常用词汇。对于出现频率较低的词,可以进行剔除。
[0117]
词语的各个字之间存在一定的相关性,所以字与字或词与字之间的相关性越大,说明字与字或词与字成词的概率也就越大,互信息可以计算两个物体相互依赖的程度,而且互信息值越大,表示两个物体的依赖程度也就越大,所以可以用互信息计算新词的内部成词概率。
[0118]
邻接熵是当前确定新词左右边界的一种方法,邻接熵可以衡量候选新词的左右邻接字符的不确定性,其不确定性越大,说明其邻接字符包含的信息越多,其成词的概率就越高。
[0119]
步骤3.3,候选词筛选:
[0120]
对每一个候选词进行词频、互信息和邻接熵计算后,依次设置相应阈值进行候选词过滤,将最后的过滤结果定为新词集合,并加入到基于词典的结巴分词工具的内置词典中,对结巴分词工具进行加强,以提高分词工具对农业文本的适应性。
[0121]
步骤3.4,农业领域词集构建:
[0122]
用加强后的结巴分词工具对原始中文农业文本进行分词,得到农业领域词集。
[0123]
步骤四,农业领域词典构建:
[0124]
对步骤三得到的农业领域词集进行词嵌入操作后得到农业领域词典。
[0125]
步骤四的具体过程为:采用与步骤二相同的方法,用word2vec将农业领域词集中的每个词汇训练成词向量,得到给定长度为n的输入序列x=(x1,x2,x3,
……
,xn)∈vc,vc是领域词集,x是词集合中的词,每个词都用经过训练的稠密向量来表示:其中ec表示词嵌入查找表;农业领域词集合中的词汇训练成向量后,构成农业领域词典。
[0126]
步骤五,字符向量加强:
[0127]
对步骤四构造的农业领域词典加以应用,对模型输入序列s=(x1,x2,x3,
……
,xn)∈vc中每个字符进行词典匹配,并将匹配到的农业领域词典对应的步骤四得到的词汇向量融入到字符对应的步骤二得到的字符向量中,以实现字符向量加强。
[0128]
步骤五的具体过程为:
[0129]
步骤501,模型输入序列中每个字符进行词汇匹配。
[0130]
步骤501中具体包括:从步骤四构造的农业领域词典中匹配到包含该字符的词汇,为了保留所有字符信息以及其匹配到的词汇信息,依据模型输入序中每个字符xi在其匹配到的不同词汇中的开始位置、中间位置、结尾位置或者单字词位置,将词汇分为b(xi),m
(xi),e(xi),s(xi)四个词汇集合,构造方式如下:
[0131][0132][0133][0134][0135]
其中:
[0136]
b(xi)表示b词汇集合,即开始位置词汇集合;
[0137]
m(xi)表示m词汇集合,即中间位置词汇集合;
[0138]
e(xi)表示e词汇集合,即结尾位置词汇集合;
[0139]
s(xi)表示s词汇集合,即单字词位置词汇集合;
[0140]
l表示词典;
[0141]
w表示匹配到的词汇,如果字符某个集合为空,用“none”来表示。
[0142]
本实施例中,以输入序列“植物病害”为例,字符“物”与预先构造的词集进行词汇匹配,匹配到了“植物病害”、“植物”两个词汇,那么字符“物”所对应的四个词典为:b={“none”},m={“植物病害”},e={“植物”},s={“none”}。字符“病”与预先构造的词典进行词汇匹配,匹配到了“病害”、“病”两个词汇,那么字符“病”所对应的四个词汇集合为:b={“病害”},m={“none”},e={“none”},s={“病”}。
[0143]
步骤502,字符匹配到相应词汇之后,需要将词汇向量融入到相应字符向量表示中得到加强的字符表示,从而让编码层可以充分利用字符与词汇信息。
[0144]
步骤502中具体通过基于统计的静态加权方法来实现,即匹配到的词汇的权重用其词频来表示,静态词频统计所用的数据集是模型用于训练和开发的数据。
[0145]
如下公式为某个字符所匹配到的词汇集合s的加权表示vs(s)的计算方式:
[0146][0147][0148]
其中:
[0149]
s表示s词汇集合;
[0150]
z(w)为词汇集合中词汇在静态数据统计中出现的频率;
[0151]ew
是词嵌入查找表;
[0152]vs
(b)、vs(m)、vs(e)的计算方式与vs(s)的计算方式相同。
[0153]
最后将四个词汇集合的加权表示形式组合成一个一维特征,即es(b,m,e,s)=[vs(b);vs(m);vs(e);vs(s)],再拼接到该字符向量的表示上,即xc←
[xc;es(b,m,e,s)],从而得到最终的字符加强向量。
[0154]
步骤六,序列编码:
[0155]
采用bilstm做序列编码层,将步骤五得到的加强后的字符向量输入序列编码层中进行序列编码,得到序列编码结果,即得到特征图h∈rc×w。
[0156]
rnn(基本的循环神经网络)由于训练过程中存在梯度爆炸原因不能很好的学习到
长距离依赖关系。
[0157]
lstm(长短期记忆网络)在rnn的基础上引入记忆单元来记录状态信息,通过输入门、遗忘门、和输出门这三个门结构来更新隐藏状态和记忆单元。lstm是单向的循环神经网络,只能获取目标词单向的上下文信息。
[0158]
bilstm(双向长短期记忆网络)在nlp(自然语言处理)任务中有广泛应用,在处理序列编码问题时有很好表现,bilstm可以从正向和反向充分获取目标字符的上下文信息,从而获取更深层次的特征表示。因此本实施例选用bilstm做序列编码层。
[0159]
首先介绍lstm的实现细节,lstm由遗忘门、输入门、输出门组成,三个门用来控制信息流。假设时间步t的字符x
t
经过本发明公开的词典构造方法处理后得到了加强得字符表示那么单向lstm计算如下所示:
[0160][0161][0162][0163][0164][0165]ht
=o
t
⊙
tanh(c
t
)
[0166]
其中:
[0167]
σ表示sigmoid激活函数;
[0168]
tanh为双曲正切激活函数;
[0169]
i、f、o、c分别表示时刻t的输入门、忘记门、输出门、记忆细胞;
[0170]
w与b分别表示相应门中的权重矩阵与偏置向量;
[0171]
x
t
表示t时刻的输入向量;
[0172]
表示t时刻的候选记忆细胞;
[0173]ht
是lstm单元的隐藏状态,即每个单元的输出;
[0174]
⊙
为按元素点成计算。
[0175]
那么bilstm可以形式化的表示为如下公式。前向与后向lstm的输出通过级联操作得到时间步t字符x
t
的编码表示,并作为下一层crf层的输入。
[0176][0177][0178][0179]
步骤七,序列编码增强:
[0180]
构造通道注意力模块,基于通道注意力模块对特征图h∈rc×w进行序列编码增强,得到序列编码结果k∈rc×w。
[0181]
步骤7.1,构造通道注意力模块:
[0182]
如图2所示,通道注意力模块常用于语义分割领域,用于增强模型对图片不同像素点之间依赖提取能力。
[0183]
通道注意力模块中,对于图片特征矩阵a∈rc×h×w,首先将其转变为尺寸为rc×n的矩阵,之后通过如下公式将a与a的转置做矩阵乘法得到特征矩阵x∈rc×c:
[0184][0185]
其中:
[0186]
x
ji
表示通道i对通道j的影响;
[0187]
c表示图片的通道数;
[0188]
h表示图片的通宽度;
[0189]
w表示图片的长度;
[0190]
n表示h
×
w。
[0191]
通道注意力模块中,还对特征矩阵x与图片特征矩阵a做矩阵乘法,并与图片特征矩阵a做按元素相加操作,得到输出矩阵
[0192]
步骤7.2,基于通道注意力模块对特征图h∈rc×w进行序列编码增强:
[0193]
将长度为w的步骤六得到的特征图h∈rc×w视作长度为w、宽度为1以及通道数为c的图片,通过unsqueeze操作将特征图h∈rc×w进行维度扩充,变为图片特征矩阵a∈rc×h×w。
[0194]
如图3所示,对于图片特征矩阵a∈rc×h×w:
[0195]
首先,将其转变为尺寸为rc×n的矩阵,之后通过如下公式将a与a的转置做矩阵乘法得到特征矩阵x∈rc×c。
[0196][0197]
其次,通过串联的卷积核依次为1、3和5的卷积神经网络conv1、conv3和conv5,对图片特征矩阵a做特征加强处理,以增强对序列局部特征提取能力的到特征矩阵d=conv5(conv3(conv1(a))),其中d∈rc×w×h。
[0198]
再次,对特征矩阵x与图片特征矩阵a做矩阵乘法,并与图片特征矩阵a做按元素相加操作,得到输出矩阵其中e∈rc×w×h。
[0199]
最后,将输出矩阵e进行squeeze操作,得到特征图h∈rc×w经过序列编码增强后的序列编码结果k∈rc×w。
[0200]
步骤八,利用crf对序列编码结果k∈rc×w进行解码处理,crf可以根据步骤一中原始中文农业文本标注的结果,对序列编码结果k∈rc×w中每个字符对应的bmeso标签进行概率计算,并通过标准viterbi算法求解最大概率,得到每个字符的标签。
[0201]
本实施例中crf,即为条件随机场,利用crf对序列编码结果k∈rc×w进行解码处理的具体方法采用已知的条件随机场常规处理方法。
[0202]
本实施例中,可将本发明方法编为程序代码,通过计算机刻度存储介质存储该代码,将程序代码传输给处理器,通过处理器执行本发明方法。
[0203]
对比例1:
[0204]
本对比例给出一种中文农业命名实体识别方法,其中给出基于字符的bilstm-crf
模型,即是在本发明实施例的模型的基础上去掉字符增强层和序列编码增强层,是本发明实施例的基线模型,结构如图4所示(本发明的模型示意图如图1所示)。
[0205]
对比例2:
[0206]
本对比例给出一种中文农业命名实体识别方法,其中给出基于词典的bilstm-crf模型,即是在本发明实施例的模型的基础上去掉序列编码增强层,结构如图5所示。
[0207]
对比例3:
[0208]
本对比例给出一种中文农业命名实体识别方法,其中给出基于词典的bilstm-crf模型,即是将本发明实施例的模型中的序列编码增强层替换为未经改进通道注意力机制,结构如图6所示。
[0209]
对比例4:
[0210]
本对比例给出一种中文农业命名实体识别方法,本对比例的步骤3对结巴分词进行了增强,本对比例在实施过程中采用未增强的结巴分词,其余与本发明实施例的方式一样。
[0211]
性能测试:
[0212]
对于命名实体识别模型进行评测的常用标准主要为精度(precision),召回率(recall),f1分数,计算公式为:
[0213][0214][0215][0216]
表1为不同模型之间的比较,从表中可以看到,本发明所提出的方法在精度、召回率、f1分数(即综合评价份数)三个评价标准基准上,都取得了最好的结果,充分展示了本发明的优越性。对比例2比对比例1在f1分数上取得了3.47的提升,说明在处理农业命名实体识别任务时,构建农业领域词典并通过字符增强层将词汇信息融入字符表示的有效性。对比例3比对比例2在f1分数上取得了0.85的提升,说明采用通道注意力机制可以有效增强模型的特征提取能力。实验4即本发明方法,相比实验三在f1分数上取得了0.72的效果提升,说明本发明基于通道注意力机制,融入三级卷积神经网络所提出的序列编码增强模块的有效性。本发明实施例相比对比例4取得了0.94的f1分数提高,说明本发明针对农业文本,采用步骤3中一系列操作,对结巴分词工具进行增强的有效性。
[0217]
表1 本发明与两个对比方法的效果表
[0218]
实验方法精度召回率f1分数1对比例183.3585.1784.262对比例286.3488.3587.733对比例387.1590.0488.584本发明实施例87.1491.6089.305对比例487.2689.4888.36
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。