1.本发明属于联邦学习参与设备选择技术领域,具体涉及一种面向数据异构性的联邦学习参与设备选择方法。
背景技术:
2.随着训练数据的增大和多样化的增多,机器学习可以实现大规模的高性能网络模型,然而,传统机器学习却需要面临两大问题。首先就是数据隐私问题,法律规定不得共享个人数据,而单个参与者,要么数据持有量有限,要么数据多样性不足,甚至两者兼有;另外,海量训练数据传输到云端进行集中处理会带来巨大的网络负载压力以及通信成本,并且容易造成传输拥堵和延迟。
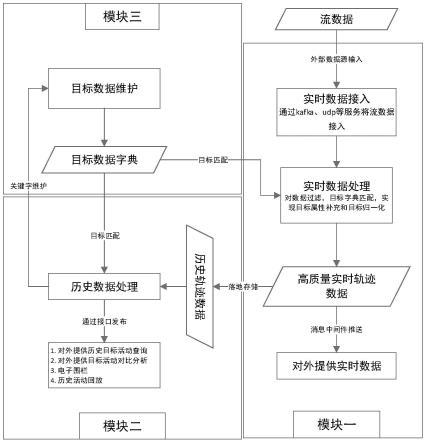
3.联邦学习允许多个参与设备在中央服务器的协调下,跨设备的进行模型训练和参数聚合。无需上传数据,而是上传模型,保持训练数据的本地化,从而减少隐私泄露,降低通信计算开销。联邦学习流程如图1所示,迭代选择参与设备执行下述四个步骤:
4.1)参与设备下载模型;
5.2)参与设备在本地数据进行模型训练;
6.3)向服务器上传训练好的本地模型参数;
7.4)服务器进行模型聚合,得到更新后的全局模型。
8.然而联邦学习框架面临着参与节点可能具有高度异构的本地数据集以及计算资源的问题,非独立同分布的异构数据会给模型训练带来偏差,导致模型训练需要更多轮次才能达到期望的收敛效果,甚至训练模型性能的下降。
9.在现实场景中,受限于用户状态、网络条件等多种因素,每轮训练只有很小一部分用户参与到模型训练中,而随机选择很可能会进一步加剧数据异构性的不利影响。因此,结合上述背景分析,开发和理解有偏差的参与方选择策略尤为重要。
技术实现要素:
10.针对目前的联邦学习框架面对高度异构数据训练时存在偏差、训练性能下降的缺陷和问题,本发明提供一种面向数据异构性的联邦学习参与设备选择方法,该方法能够有偏差的选择参与设备,更大程度地实现数据样本均衡,提高模型聚合效率。
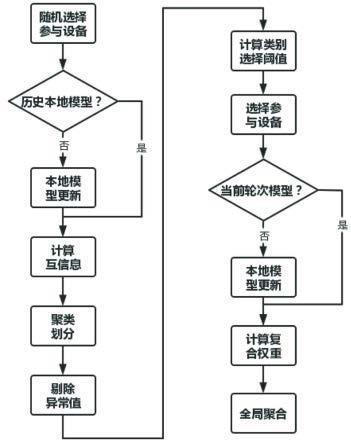
11.本发明解决其技术问题所采用的方案是:一种面向数据异构性的联邦学习参与设备选择方法,包括以下步骤:
12.步骤一、从包含所有参与方的集合中无偏差随机选择出c个参与方并放入一个子集中得到参与方子集s
t
;
13.步骤二、根据参与设备是否拥有历史的本地训练模型将参与方子集s
t
中的参与设备分为有历史本地训练模型的s
t-1
以及没有历史本地训练模型的s
t-s
t-1
,随后集合s
t-s
t-1
中的参与设备进行本地更新得到本地模型并与s
t-1
中参与设备的历史本地模型共同构成当前轮次的本地模型localmodel
t
;
14.步骤三、根据得到的本地模型localmodel
t
参数和上一轮聚合得到的全局模型globalmodel
t-1
参数构建各自的一维频率直方图,分别生成本地模型和全局模型的概率分布以及两者的联合分布,并计算两者的互信息;随机选择的参与方子集s
t
中的所有参与设备将自己持有的数据分布信息以及计算得到的互信息上传到服务器;
15.步骤四、服务器接收到各参与设备上传的数据分布信息和计算的互信息后,使用k-means算法,根据参与设备的数据分布情况对参与方进行聚类划分,得到划分的类别数量cluster_numsr和每个类别下对应的参与设备其中:k∈cluster_numsr;然后统计得到每个类别簇中参与设备互信息值的箱线图,服务器通过将箱线图异常点认定为异常参与设备而将其剔除;
16.步骤五、剔除类别簇中的异常值后,服务器根据接收到的互信息集合计算每个类别下互信息的选择阈值δ,
[0017][0018]
式中:是剔除异常值后每个类别下参与设备的互信息集合;std(
·
)表示计算标准差,mean(
·
)表示求统计平均值运算;
[0019]
步骤六、根据互信息选择阈值以及每个参与设备的互信息的值筛选出最为有效增加全局模型性能的参与设备集合s
′
t
,判断被筛选出的参与设备是否具有当前轮次的本地更新模型,对于参与设备k∈s
′
t
,如果k∈s
t-s
t-1
,不再重复进行本地训练;如果k∈s
t-1
,在此步骤更新出当前轮次的本地训练模型;
[0020]
步骤七、所有被选择的参与设备将其本地的当前轮次模型上传到服务器参与全局模型聚合。
[0021]
上述的面向数据异构性的联邦学习参与设备选择方法,步骤二中对于有历史本地训练模型的s
t-1
中的参与设备使用历史本地训练模型;对于没有历史本地训练模型的参与设备s
t-s
t-1
进行本地模型训练,将本地数据集按照给定的数据切片大小划分多个数据切片,然后每轮本地训练下在切分好的数据切片上进行本地梯度计算,最终得到全局模型在本地数据集上的平均梯度随后使用学习率η去更新参与设备k在当前轮次t的本地模型
[0022][0023]
上述的面向数据异构性的联邦学习参与设备选择方法,步骤三中将一维数据的所有n个样本进行升序排列记作{x1,x2,...,xn},将整个取值范围[x1,xn]划分为一系列连续的间隔,计算间隔内的样本频数m,计算样本频率将样本频率作为概率估计值,生成本地模型和全局模型的概率分布p(x),p(y)以及二者的联合分布p(x,y),并计算两者的互信息,
[0024]
[0025]
式中:h(x)=-∑
x∈χ
p(x)logp(x)表示熵。
[0026]
上述的面向数据异构性的联邦学习参与设备选择方法,步骤七中采取基于互信息和数据量的复合权重方式参与全局模型聚合,
[0027][0028][0029][0030]
式中:w
t
是聚合得到的全局共享模型;是集合s
′
t
中参与设备k的本地模型;权重θk体现了参与设备k的互信息在s
′
t
中所有互信息之和的比例;mi
sec
表示集合s
′
t
中所有参与设备的互信息之和;mik表示参与设备k的互信息;是参与设备k的数据量占s
′
t
中参与设备数据总量的比例;n
sec
表示集合s
′
t
中所有参与设备的数据总量;nk表示参与设备k的数据量。
[0031]
本发明的有益效果:本方法基于深度学习中无监督特征提取的互信息方法和聚类划分的k-means算法,提出一种根据局部模型和全局模型之间互信息衡量参与方本地模型对全局模型的影响程度,进而有偏差的选择参与设备的机制。同时在聚类后的类别簇中构建互信息分布的箱线图,通过将箱线图可能存在的异常点对应的参与设备认定为异常参与设备而移除,可以更大程度地实现数据样本均衡,提高模型聚合效率。
[0032]
本发明充分考虑参与设备数据异构性和选择公平性,能够有效应对数据异构性带来的模型性能下降和训练不稳定问题,同时实现更快收敛、更低开销的联邦学习。
附图说明
[0033]
图1为联邦学习流程图。
[0034]
图2为本发明选择方法流程图。
[0035]
图3为本发明技术路线示意图。
[0036]
图4为本发明实例示意图。
具体实施方式
[0037]
为了实现理想的联邦学习参与设备选择,在数据异构性、数据隐私安全保障等多重因素约束条件下,实现模型性能(模型准确率和收敛速度)与训练开销之间的权衡,有效应对数据异构性带来的模型性能下降和训练不稳定问题,同时实现更快收敛、更低开销的联邦学习,本发明提供一种能够有效缓解本地数据异构性影响,并且实现模型训练快速收敛的基于互信息的参与设备选择策略,同时引入聚类分簇以及箱线图异常点的概念,从而保证每一轮相对均衡的数据样本选择的同时,实现稳定、快速的训练收敛的面向数据异构性的联邦学习参与设备选择方法。下面结合附图和实施例对本发明进一步说明。
[0038]
实施例1:本实施例提供一种面向数据异构性的联邦学习参与设备选择方法,该方法包括以下步骤:
[0039]
步骤一、随机选择参与方:从包含所有参与方的集合中无偏差随机选择出c个参与方并放入一个集合中得到参与方子集s
t
;其中每个参与方都维护着自身持有的本地数据集的分布信息;所述分布信息包括数据类别分布和数据量大小;
[0040]
步骤二、本地训练模型更新,包括以下步骤:
[0041]
(1)确认历史模型
[0042]
根据参与设备是否拥有历史的本地训练模型将参与方子集s
t
中的参与设备分为有历史本地训练模型的s
t-1
以及没有历史本地训练模型的s
t-s
t-1
;
[0043]
(2)本地模型更新
[0044]
将没有历史本地训练模型的参与设备s
t-s
t-1
进行本地模型训练,将本地数据集按照给定的数据切片大小划分多个数据切片,然后每轮本地训练下在切分好的数据切片上进行本地梯度计算,最终得到全局模型在本地数据集上的平均梯度随后使用学习率η去更新参与设备k在当前轮次t的本地模型
[0045][0046]
有历史本地训练模型的s
t-1
中的参与设备使用历史本地训练模型,两者共同构成当前的本地模型localmodel
t
。
[0047]
步骤三、根据得到的本地模型localmodel
t
参数和上一轮聚合得到的全局模型globalmodel
t-1
参数构建各自的一维频率直方图。
[0048]
将一维数据的所有n个样本进行升序排列记作{x1,x2,...,xn};
[0049]
将整个取值范围[x1,xn]划分为一系列连续的间隔,计算间隔内的样本频数m,计算样本频率将样本频率作为概率估计值,生成本地模型和全局模型的概率分布p(x),p(y)以及二者的联合分布p(x,y),并计算两者的互信息,
[0050][0051]
其中h(x)=-∑
x∈χ
p(x)logp(x)表示熵;
[0052]
随机选择的参与方子集s
t
中的所有参与设备将自己持有的数据分布信息以及计算得到的互信息上传到服务器。
[0053]
步骤四、聚类划分并进行异常值剔除
[0054]
(1)聚类划分:服务器接收到各参与设备上传的数据分布信息和计算的互信息后,使用k-means算法,根据参与设备的数据分布情况对参与方进行聚类划分,得到划分的类别数量cluster_numsr和每个类别下对应的参与设备其中:k∈cluster_numsr,表示聚类划分得到的类别。
[0055]
(2)异常值筛查:统计得到每个类别簇中参与设备互信息值的箱线图,服务器通过
将箱线图异常点认定为异常参与设备而将其剔除,其中互信息过大以及过小均认为其为异常。
[0056]
步骤五、计算各类别选择阈值
[0057]
剔除类别簇中可能存在的异常值后,服务器根据接收到的互信息集合计算每个类别下互信息的选择阈值δ:
[0058][0059]
其中是剔除异常值后每个类别下参与设备的互信息集合;std(
·
)表示计算标准差,mean(
·
)表示求统计平均值运算。
[0060]
步骤六、选择参与设备上传更新模型
[0061]
结合计算得到的互信息选择阈值以及每个参与设备的互信息的值来筛选出最为有效增加全局模型性能的参与设备集合s
′
t
。
[0062]
判断被选择的参与设备是否具有当前轮次的本地更新模型,具体的,对于参与设备k∈s
′
t
,如果k∈s
t-s
t-1
,不再重复进行本地训练;如果k∈s
t-1
,在此步骤更新出当前轮次的本地训练模型。
[0063]
步骤七、聚合全局共享模型
[0064]
所有被选择的参与设备上传其本地的当前轮次模型到服务器,采取基于互信息和数据量的复合权重方式聚合参与全局模型聚合,
[0065][0066][0067][0068]
式中:w
t
是聚合得到的全局共享模型;是集合s
′
t
中参与设备k的本地模型;权重θk体现了参与设备k的互信息在s
′
t
中所有互信息之和的比例;mi
sec
表示集合s
′
t
中所有参与设备的互信息之和;mik表示参与设备k的互信息;是参与设备k的数据量占s
′
t
中参与设备数据总量的比例;n
sec
表示集合s
′
t
中所有参与设备的数据总量;nk表示参与设备k的数据量。
[0069]
实施例2:本实施例以具体示例为例对本发明的面向数据异构性的联邦学习参与设备选择方法进行进一步阐述。本实施例认为使用的数据集包含十个类别class0~class9,每个参与设备自身的数据构成都符合80%的主类别数据 20%的其他类别数据,比如某个参与设备拥有600条数据,其中480条数据属于class0,而剩余的120条数据属于其他9个类别。另外假设参与设备池共有100个参与设备,每次服务器会随机选择20个参与设备作为初始参与方子集s
t
,然后再根据互信息从中筛选出对总的训练目标增益最为有效的一部分参与设备进行全局模型聚合。该方法技术路线如图3所示。
[0070]
步骤一、随机选择参与方子集
[0071]
服务器通过随机采样的方式从总的参与设备池中选择出一小部分的c个参与方放入到一个子集,记为s
t
。每个参与设备都维护着自身持有的本地数据集的分布信息(包括数据类别分布和数据量大小等内容)。如图4所示,当前轮次服务器初始选择了20个参与设备,即s
t
[1,2,3,...,19,20],然后将全局共享模型下发到集合中的每一个参与设备作为其自己的本地模型进行更新。
[0072]
步骤二、本地训练模型更新,分别包括以下两方面内容。
[0073]
(1)确认历史模型
[0074]
参与方子集s
t
中的参与设备检查自身是否拥有历史的本地训练模型。
[0075]
在本实施例中,假设此次随机选择的20个参与设备中共有5个拥有历史模型,如图4中被标记的5个参与设备,即s
t-1
[5,9,12,15,18],所以此步骤中不进行本地模型更新。而另外15个参与设备(k∈s
t-s
t-1
)上一轮次未参与联合训练,此步骤需要使用下载的全局模型在本地数据集上训练以更新本地模型。
[0076]
(2)本地模型更新
[0077]
将本地数据集按照给定的数据切片大小划分多个数据切片,然后每轮本地训练下在切分好的数据切片上进行本地梯度计算,最终得到全局模型在本地数据集上的平均梯度随后使用学习率去更新本地模型得到更新后的本地模型m∈s
t-s
t-1
;而5个有历史本地模型的参与设备则使用历史的本地模型n∈s
t-1
[5,9,12,15,18]。这5个参与设备只有在随后根据互信息被服务器选择后才会进行本轮次的本地模型更新,而如果没有被选择则本轮就不会进行模型更新,因此可以一定程度减少计算开销。两者共同构成当前的本地模型k∈s
t
[1,2,3,...,19,20]用以进行互信息计算。
[0078]
步骤三、计算互信息:
[0079]
分别根据步骤二中得到的本地模型参数和上一轮次聚合得到的全局模型globalmodel
t-1
参数构建一维频率直方图。将一维数据的所有n个样本升序排列,记作{x1,x2,...,xn};将整个取值范围[x1,xn]划分为一系列连续的间隔;计算间隔内的样本频数,将样本频率(频数/n)作为概率的估计值,从而生成本地模型和全局模型的概率分布p(x),p(y)以及二者的联合分布p(x,y)。则可根据下式计算它们之间的互信息。
[0080][0081]
其中:h(x)=-∑
x∈χ
p(x)logp(x)表示熵。最终得到20个参与设备与全局模型之间的互信息值,见表1。
[0082]
表1参与设备的互信息值
[0083]
编号12345678910
互信息mi1mi2mi3mi4mi5mi6mi7mi8mi9mi
10
编号11121314151617181920互信息mi
11
mi
12
mi
13
mi
14
mi
15
mi
16
mi
17
mi
18
mi
19
mi
20
[0084]
之后,随机选择的20个参与设备将自己持有的数据分布信息以及计算得到的互信息上传到服务器。
[0085]
步骤四、聚类划分并剔除异常值,分为以下两个步骤;
[0086]
(1)聚类划分
[0087]
服务器在接收到由参与设备上传的数据分布信息和计算的互信息后,使用k-means算法,根据参与设备的数据分布情况对参与方进行聚类划分,如图4实例图所示,最终划分得到4个类别簇,以及每个类别下对应的参与设备,见表2。
[0088]
表2每个类别下对应的参与设备
[0089]
类别簇cluster1cluster2cluster3cluster4包含设备2,5,7,8,16,201,4,6,12,179,13,193,10,11,14,15,18
[0090]
(2)筛选异常值
[0091]
将类别簇中参与设备的互信息值构建箱线图,根据各个类别簇下互信息的箱线图存在的异常点,cluster1内8号和cluster4内14号被认为是异常参与设备而移除,得到新的各类别簇下对应的参与设备,见表3。
[0092]
表3新的各类别簇下对应的参与设备
[0093]
类别簇cluster1cluster2cluster3cluster4包含设备2,5,7,16,201,4,6,12,179,13,193,10,11,15,18
[0094]
步骤五、计算各类别选择阈值
[0095]
剔除异常值后,服务器根据参与设备的互信息值计算每个类别下剩余参与设备互信息的选择阈值其中是每个类别下剔除异常值后剩余参与设备的互信息集合,见表4。
[0096]
表4每个类别下剔除异常值后的互信息选择阈值
[0097]
类别簇cluster1cluster2cluster3cluster4互信息阈值δ1δ2δ3δ4[0098]
步骤六、选择参与设备上传更新模型
[0099]
根据每个类别簇中的参与设备互信息值以及对应类别簇的选择阈值,可以选择出符合条件的参与设备集合s
′
t
,即互信息小于其所属类别簇对应的互信息阈值,见图4中被五角星标记的参与设备。根据前面分析可知,这些参与设备的本地模型对于提高全局模型性能最为有效,见表5。
[0100]
表5每个类别簇下被选择的参与设备
[0101]
类别簇cluster1cluster2cluster3cluster4被选择参与设备s
′
t
2,204,6,17911,15
[0102]
结合步骤2可知,s
′
t
中编号为9和15的参与设备使用的是历史本地模型计算互信息,还没有当前轮次模型,本步骤需要进行本地更新得到当前轮次的训练模型然后上传服务器参与聚合,而s
′
t
中其他参与设备在步骤2中已经更新当前轮次模型,不需要再重复更
新。参见见图2和图3。
[0103]
步骤七、聚合全局共享模型
[0104]
所有被选择的参与设备上传其本地的当前轮次模型到服务器参与全局模型聚合,聚合采取基于互信息和数据量的复合权重方式,如下所示:
[0105][0106][0107][0108]
式中:w
t
是聚合得到的全局共享模型;是集合s
′
t
中参与设备k的本地模型;权重θk体现了参与设备k的互信息在s
′
t
中所有互信息之和的比例;mi
sec
表示集合s
′
t
中所有参与设备的互信息之和;mik表示参与设备k的互信息;是参与设备k的数据量占s
′
t
中参与设备数据总量的比例;n
sec
表示集合s
′
t
中所有参与设备的数据总量;nk表示参与设备k的数据量。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。