1.本发明属于轴承故障诊断技术领域,具体涉及了一种轴承故障诊断模型训练方法及训练装置。
背景技术:
2.机械设备正在朝着大型化、精密化方向发展,智能化也日益提高,对设备运行中的可靠性也提出更高要求。轴承作为旋转机械中的核心回转支承部件,其表面的轻微缺陷就可能导致整个装置系统的运行故障,造成巨大人员伤亡和财产损耗。
3.传统的用于滚动轴承检测方法,需要工作人员定期从机械设备上将轴承卸下来进行安全检验,这个过程耗费大量人力物力,智能的检测方法就显得尤为重要近年来,出现了许多非线性动力学特征提取方法如样本熵、排列熵、散布熵、符号动力学熵等。这些熵算法可以有效提取信息特征,但却只包含了单一尺度的信息。因此,有学者提出了多尺度排列熵,通过提取多尺度序列的熵值信息,增强了排列熵算法的性能。但多尺度序列不能反应时间序列的所有构成模式,且排列熵忽略了时间序列的幅值信息,因此又有人提出了复合多尺度加权排列熵以改善多尺度排列熵的不足。然而复合多尺度加权排列熵仅反应了时间序列的低频信息,对于高频信息却无法反应,这就导致采集到的故障特征信息可能存在较大误差。
4.因此,找到一种能同时反应提取到时间序列的低频信息和高频信息的熵算法,对提高轴承故障诊断正确率有着至关重要的意义。
技术实现要素:
5.为了解决上述技术问题,本发明提出了一种轴承故障诊断模型训练方法及训练装置,利用差分方法提取时间序列的高频信息,利用平均方法提取序列的低频信息,使用斜率熵提取两种多尺度序列的复杂特征,对获取的高低频特征求平均,从而构成了增强复合多尺度斜率熵,将提取到的故障特征输入到蜜獾算法优化核极限学习机分类器中实现轴承的故障诊断。
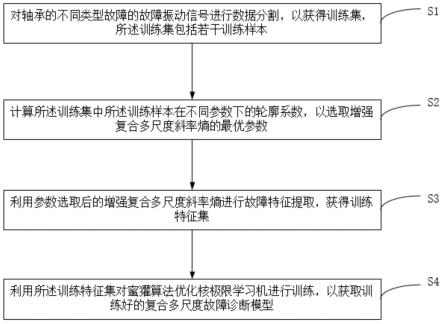
6.本发明提出一种轴承故障诊断模型训练方法,包括以下步骤:
7.对轴承的不同类型故障的故障振动信号进行数据分割,以获得训练集,所述训练集包括若干训练样本;
8.计算所述训练集中所述训练样本在不同参数下的轮廓系数,以选取增强复合多尺度斜率熵的最优参数;
9.利用参数选取后的增强复合多尺度斜率熵进行故障特征提取,获得训练特征集;
10.利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型。
11.在本发明的一个实施例中,所述不同类型故障包括正常状态、内圈单点故障、外圈单点故障、滚子单点故障、外圈滚子复合故障、内圈滚子复合故障、内圈多点故障、外圈多点
故障和滚子多点故障中的一种或多种组合。
12.在本发明的一个实施例中,所述不同参数包括尺度因子,延迟时间,嵌入维数,低阈值,高阈值。
13.在本发明的一个实施例中,所述增强复合多尺度斜率熵的最优参数的选取包括以下步骤:
14.设定尺度因子,延迟时间,嵌入维数为定值,观察不同低阈值和不同高阈值下所述训练集中所述训练样本的轮廓系数的变化趋势来确定最优的低阈值;
15.在确定最优的低阈值之后,观察不同的嵌入维数和不同高阈值下所述训练集中所述训练样本的轮廓系数来确定最优的嵌入维数和高阈值。
16.在本发明的一个实施例中,所述最优参数组合为:最大尺度因子为8,延迟时间为1,嵌入维数为3,低阈值为0.001
°
,高阈值为60
°
。
17.在本发明的一个实施例中,所述增强复合多尺度斜率熵是通过求每个尺度因子下的复合多尺度斜率熵和基于差分的复合多尺度斜率熵的平均值得到。
18.在本发明的一个实施例中,所述复合多尺度斜率熵通过以下方式获得:
19.计算尺度因子s下每个粗粒化序列的斜率熵值,并对s个斜率熵值求均值,以得到复合多尺度斜率熵在尺度因子s下的熵值。
20.在本发明的一个实施例中,所述基于差分的复合多尺度斜率熵通过以下方式获得:
21.计算尺度因子s下每个差分粗粒化序列的斜率熵值,并对s个斜率熵值求均值,以得到基于差分的复合多尺度斜率熵在尺度因子s下的熵值。
22.在本发明的一个实施例中,利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型,步骤包括:
23.输入训练特征集,初始化种群数量和位置,确定种群数量,最大迭代次数w
max
,常数c和ρ,以核极限学习机的正则优化参数a和核函数参数α作为蜜獾的位置信息;
24.建立以训练集的分类错误率作为适应度函数,计算每个蜜獾的适应度,将最佳适应度的位置记为x
prey
;
25.若迭代次数w≤w
max
,则利用预定义公式更新蜜獾群体的位置,并更新每次迭代的最优位置;
26.输出最终蜂蜜位置,即最优参数a和α,利用其构建核极限学习机模型。
27.为了实现上述目的及其它相关目的,本发明还提出一种轴承故障诊断模型的训练装置,所述训练装置包括:
28.训练集获取模块,用于对轴承的不同类型故障的故障振动信号进行数据分割,以获得训练集,所述训练集包括若干训练样本;
29.参数选取模块,用于计算所述训练集中所述训练样本在不同参数下的轮廓系数,以选取增强复合多尺度斜率熵的最优参数;
30.特征集获取模块,用于利用参数选取后的增强复合多尺度斜率熵进行故障特征提取,获得训练特征集;
31.模型训练模块,用于利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型。
32.本发明提出一种轴承故障诊断模型训练方法及训练装置,利用差分方法提取时间序列的高频信息,利用平均方法提取序列的低频信息,使用斜率熵提取两种多尺度序列的复杂特征,对获取的高低频特征求平均,从而构成了增强复合多尺度斜率熵,将提取到的故障特征输入到蜜獾算法优化核极限学习机分类器中实现轴承的故障诊断。
33.本发明提出的增强复合多尺度斜率熵兼具时间序列的高低频信息,相对于一般的熵算法,提取的时间序列及尺度信息更加全面、丰富;同时利用蜜獾算法优化核极限学习机的正则化系数和核函数参数,实现参数的自适应。
34.本发明方法能有效提取不同健康状态的轴承故障特征,对轴承的单一和复合故障均有良好的识别能力,能有区分不同类型和损伤程度的轴承故障,平均识别率达99.9%。
附图说明
35.图1为本发明提出的轴承故障诊断方法的流程框图。
36.图2为本发明提出的轴承故障诊断方法的流程图。
37.图3为时间序列差分与符号的关系图。
38.图4为一种轴承故障诊断模型的训练装置结构框图。
39.图5为轴承试验装置的结构框图。
40.图6三种高阈值下不同低阈值δ的轮廓系数条形图。
41.图7为不同嵌入维数和高阈值组合的轮廓系数条形图。
42.图8-1为利用增强复合多尺度斜率熵算法提取9种故障信号样本的特征,t-sne可视化降维结果图。
43.图8-2为利用复合多尺度斜率熵算法提取9种故障信号样本的特征,t-sne可视化降维结果图。
44.图8-3为利用基于差分的复合多尺度斜率熵算法提取9种故障信号样本的特征,t-sne可视化降维结果图。
45.图8-4为利用精细复合多尺度散步熵算法提取9种故障信号样本的特征,t-sne可视化降维结果图。
46.图8-5为利用复合多尺度加权排列熵算法提取9种故障信号样本的特征,t-sne可视化降维结果图。
47.图9-1为利用增强复合多尺度斜率熵算法一次实验的诊断结果图。
48.图9-2为利用复合多尺度斜率熵算法一次实验的诊断结果图。
49.图9-3为利用基于差分的复合多尺度斜率熵算法一次实验的诊断结果图。
50.图9-4为利用精细复合多尺度散步算法一次实验的诊断结果图。
51.图9-5为利用复合多尺度加权排列熵熵算法一次实验的诊断结果图。
52.图10为利用五种算法进行30次故障实验的识别正确率折线图。
53.图11为利用五种算法故障实验的平均识别正确率条形图。
具体实施方式
54.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实
施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
55.需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
56.本发明提出一种轴承故障诊断模型训练方法,利用差分方法提取时间序列的高频信息,利用平均方法提取序列的低频信息,使用斜率熵提取两种多尺度序列的复杂特征,对获取的高低频特征求平均,从而构成了增强复合多尺度斜率熵,用来解决现有算法在提取有效信息特征时,包含信息不全的问题。
57.现结合图1及图2来对本实施例的用于轴承故障诊断模型的训练方法进行描述,所述用于轴承故障诊断模型的训练方法包括以下步骤:
58.s1、对轴承的不同类型故障的故障振动信号进行数据分割,以获得训练集,所述训练集包括若干训练样本;
59.s2、计算所述训练集中所述训练样本在不同参数下的轮廓系数,以选取增强复合多尺度斜率熵的最优参数;
60.s3、利用参数选取后的增强复合多尺度斜率熵进行故障特征提取,获得训练特征集;
61.s4、利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型。
62.在步骤s1中,通过对采集到的轴承的不同类型的故障振动信号进行数据分割,每个故障信号选取n个样本,随机选取m个样本作为训练集,剩下的n-m个样本作为测试集。
63.在步骤s1中,所述不同类型故障包括正常状态、内圈单点故障、外圈单点故障、滚子单点故障、外圈滚子复合故障、内圈滚子复合故障、内圈多点故障、外圈多点故障及滚子多点故障中的一种或多种的组合。
64.在步骤s2中,所述不同参数包括尺度因子s、延迟时间τ、嵌入维数m,低阈值δ,高阈值γ。
65.所述轮廓系数sc通过定义凝聚度和离散度来衡量数据之间的距离,取值范围分布在[0 1]之间,数值越接近1,说明类内离散度越小,类间离散度越大,此时特征的提取效果越好,并且所述增强复合多尺度斜率熵的尺度因子s、延迟时间τ、嵌入维数m,低阈值δ,高阈值γ的数值选取会影响所述轮廓系数sc的结果,具体影响下文所述轮廓系数sc的计算公式中a(i)和b(i)的值。所述轮廓系数sc的计算公式为:
[0066][0067]
式中:n为总样本数,a(i)为样本i到簇内其他样本的平均距离,b(i)为样本i到其他簇的最小平均距离。
[0068]
在本实施例中,步骤s2进一步包括,首先设定尺度因子s,延迟时间τ,嵌入维数m为定值,观察不同低阈值和不同高阈值下所述训练集中所述训练样本的轮廓系数的变化趋势来确定最优的低阈值;在确定最优的低阈值之后,观察不同的嵌入维数和不同高阈值下所
述训练集中所述训练样本的轮廓系数来确定最优的嵌入维数和高阈值。
[0069]
在步骤3中所述增强复合多尺度斜率熵ecmse是通过求每个尺度因子下的复合多尺度斜率熵cmse和基于差分的复合多尺度斜率熵dbcmse这两者的平均值得到,即:
[0070][0071]
ecmse的主要参数包括嵌入维数m,延迟时间τ,尺度因子s,低阈值δ和高阈值γ。延迟时间τ对熵值几乎没有影响,通常设定τ=1即可。尺度因子的选择没有特定的要求,选取适中即可,在一具体示例中,选取最大尺度因子s
max
=8。嵌入维数m和阈值(低阈值δ和高阈值γ)对ecmse的特征提取效果有一定影响。通常m在[2 7]之间,阈值的设定没有具体的标准,但高阈值δ需要在一个合理的区间,γ过小和过大都不能反应斜率的真实变化状况。为了方便描述阈值区间,本实施例用角度作为阈值的计量单位。将δ的选取范围设定为:{10-1
°
,10-2
°
,10-3
°
,10-4
°
,10-5
°
,10-6
°
},γ的范围为{30
°
,45
°
,60
°
}。
[0072]
在本实施例中,所述复合多尺度斜率熵cmse通过以下方式获得:
[0073]
计算尺度因子s下每个粗粒化序列的斜率熵值se,并对s个斜率熵值se求均值,以得到复合多尺度斜率熵在尺度因子s下的熵值,即:
[0074][0075]
其中粗粒化序列可以按照xi定义,需要说明的是其中1≤k≤s,s=1,2
…
,s
max
,当s=1时,粗粒化序列即为原始序列。[
·
]表示对数字取整,表示第s个尺度因子下的第k个平均粗粒化序列,j表示第k个粗粒化序列的第j个点。
[0076]
现对其中提到的斜率熵值se做进一步说明:
[0077]
首先假定一个时间序列x={xi,i=1,2,
…
,},对其进行相空间重构后可以获得子空间序列:其中m为嵌入维数,τ为延迟时间,t=1,2,
…
,l-τ(m-1)。定义垂直增量阈值γ,水平增量阈值δ;γ为一个较大的量,用来衡量向量序列之间的显著差异,以区分不同的涨落幅值;δ为一个非常小的数值,以此来归类近似等幅值的情况。其次对时间序列的相邻元素进行差分,通过阈值将子序列定义为不同的符号,图3展示了时间序列差分与符号的关系。
[0078]
通过上述定义可以获得符号子空间,统计所有符号子空间出现的排列模式总数z,每种排列出现的次数为hi,其中i=1,2,l,z,可以得到相对应的概率为pi=hi/z,斜率熵可以定义为:
[0079][0080]
在本实施例中,所述基于差分的复合多尺度斜率熵dbcmse通过以下方式获得:
[0081]
计算尺度因子s下每个差分粗粒化序列的斜率熵值,并对s个斜率熵值求均值,以得到基于差分的复合多尺度斜率熵在尺度因子s下的熵值,即:
[0082][0083]
其中,基于差分的粗粒化序列可以按照来定义,需要说明的是其中a=i-[(j-1)s k],1)s k],1≤k≤s,s=1,2
…
,s
max
,表示在s-1个数中任选a个数的组合,[
·
]表示对数字取整,表示第s个尺度因子下的第k个差分粗粒化序列,j表示第k个粗粒化序列的第j个点。
[0084]
在步骤s4中,利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型,具体步骤包括:
[0085]
输入训练集特征,初始化种群数量和位置,确定种群数量,最大迭代次数w
max
,确定常数c和ρ,以a和α作为蜜獾的位置信息。
[0086]
建立以训练集的分类错误率作为适应度函数,计算每个蜜獾的适应度,将最佳适应度的位置记为x
prey
。
[0087]
若迭代次数w≤w
max
,则利用下式更新蜜獾群体的位置,并更新每次迭代的最优位置。
[0088][0089][0090]
其中,ρ是一个≥1的常数,默认为6,代表蜜獾寻找食物的能力。r3、r4、r5均为[0 1]之间的随机数。
[0091]
当0.5≤r≤1时,此时蜜獾跟随蜜鸟到达蜂巢,最终位置由x
new2
决定。
[0092]
其中r7为[0 1]之间的随机数。
[0093]
输出最终蜂蜜位置,即最优参数a和α,利用其构建核极限学习机kelm模型。
[0094]
现对前文提到的核极限学习机和蜜獾寻优算法做进一步解释:
[0095]
核极限学习机
[0096]
核函数通过将特征空间映射到更高维的特征空间,从而获得更好的特征区分效果。核极限学习机是将核函数和极限学习机结合后得到的,相较于极限学习机,核极限学习机通常具有更好的稳定性,特征拟合能力更强。根据mercer定理,核函数ω可以定义为:
[0097]
ω=hh
t
,ω(i,j)=h(xi)h(xj)=k(xi,xj),
[0098]
其中,h为隐藏层的输出矩阵,h(xi)、h(xj)为输入向量为xi、xj时对应的输出行向量。
[0099]
单隐层前馈网络模型可以表示为:g(x)=h(x)β=hβ,其中,β是隐藏层与输出层之间的权重矩阵,通过求解多输出elm的对偶优化问题,可以得到:其中,i为单位矩阵,a为正则化系数,t为期望输出矩阵。结合核函数ω、单隐层前馈网络模型及是隐
藏层与输出层之间的权重矩阵的表达式可以得到实际输出为:
[0100][0101]
本发明选择核函数为径向基函数,即:
[0102][0103]
其中α为待定核参数,通过调整α可以改善核函数的性能。
[0104]
蜜獾寻优算法
[0105]
蜜獾算法是由fatma a.hashima等人在2021年提出的一种生物启发式算法,该算法模拟了蜜獾寻找蜂蜜的过程。蜜獾在搜索阶段,通过蜂蜜气味定位蜂巢;如果气味很强,蜜罐的运动会加剧,反之则会减缓移动速度。蜜獾的移动轨迹为心型曲线,运动方向具有一定的随机性。当有蜜鸟带领时,蜜獾将跟随蜜鸟直接前往蜂巢,这种觅食行为,能避免算法陷入局部最优。蜜獾算法的数学理论如下:
[0106]
(1)初始化蜜獾群体
[0107]
x
t
=lb
t
r1×
(ub
t-lb
t
)
[0108]
其中x
t
表示第t个蜜獾的位置,r1是[0,1]之间的随机数,ub
t
和lb
t
为搜索上界和搜索下界。
[0109]
(2)定义气味强度
[0110]
气味强度由蜂蜜的集中程度s和蜜獾与蜂蜜之间的距离决定,如果气味强度很高,则蜜獾会加速移动,反之运动会减缓。
[0111]
s=(x
t-x
t 1
)2[0112]di
=x
prey-x
t
[0113][0114]
其中d
t
表示蜂蜜和第t个蜜獾之间的距离,x
prey
表示迄今为止发现的最佳猎物位置,i
t
表示蜂蜜与第i个蜜獾之间的气味强度,r2是是[0 1]之间的随机数。
[0115]
(3)更新密度因子
[0116]
密度因子随着时间的变化逐渐减小以确保搜索过程的平稳性。
[0117][0118]
其中c是一个≥1的常数,默认为2,w
max
为最大迭代次数。
[0119]
(4)搜索和蜜鸟带领阶段
[0120]
蜜獾的行动模式由r决定,r是一个[0 1]之间的随机数。当0≤r《0.5时,此时蜜獾根据气味进行搜索时,其运动轨迹呈心形,通过设置搜索方向f以更好地发现蜂蜜位置。x
new1
表示蜜獾通过自主搜索更新的最佳位置。
[0121][0122][0123]
其中ρ是一个≥1的常数,默认为6,代表蜜獾寻找食物的能力。r3、r4、r5均为[0 1]之间的随机数。
[0124]
当0.5≤r≤1时,此时蜜獾跟随蜜鸟到达蜂巢,最终位置由x
new2
决定。
[0125]
其中r7为[0 1]之间的随机数。
[0126]
如图4所示,本发明还提出一种轴承故障诊断模型的训练装置100,该装置应用了如上述实施例描述的轴承故障诊断方法,具体的所述轴承故障诊断装置100包括训练集获取模块1、参数选取模块2、特征集获取模块3、模型训练模块4。其中所述训练集获取模块1用于对轴承的不同类型故障的故障振动信号进行数据分割,以获得训练集,所述训练集包括若干训练样本;所述参数选取模块2,用于计算所述训练集中所述训练样本在不同参数下的轮廓系数,以选取增强复合多尺度斜率熵的最优参数;所述特征集获取模块3,用于利用参数选取后的增强复合多尺度斜率熵进行故障特征提取,获得训练特征集;所述模型训练模块4,用于利用所述训练特征集对蜜獾算法优化核极限学习机进行训练,以获取训练好的复合多尺度故障诊断模型。
[0127]
下面将结合一具体示例来说明本发明的轴承故障诊断模型的训练过程。
[0128]
为了体现本发明方法的有效性和可行性,采用试验台现场采集的数据进行验证。数据采集来自本单位的航空发动机轴承试验台(也即轴承实验装置)。如图5所示,所述轴承实验装置2包括轴承试验机21、加载站22、润滑系23、冷却系统24。
[0129]
轴承损伤类型包含健康、内圈、外圈、滚子单点和多点故障,以及外圈/滚子、内圈/滚子复合故障,一共9种状态,分别以数字1~9作为不同故障的类别标签,表1为它们的对应关系。
[0130]
表1轴承故障类型、数量及位置对应表
[0131][0132]
实验数据使用lms test.lab软件采集,采样频率为20480hz,轴承工况为轴向载荷
2kn,转速2000rpm,将所有故障信号按每段1024个样本点进行数据分割,每种故障取100个样本。随机采用其中20个样本作为样本集,其余80个样本作为测试集,样本集样本共180个,测试集样本共720个,测试集用于测试训练好的诊断模型。
[0133]
在本实施例,为了简化参数的选择,首先观察低阈值δ的变化规律。设定嵌入维数m=3,延迟时间τ=1,最大尺度因子s
max
=8,不同低阈值δ在高阈值γ下的轮廓系数如图6所示。可见在3种高阈值γ下,随着δ的降低,对应的轮廓系数逐渐增加,且均在10-3
°
时到达最大。当δ继续减小时,轮廓系数不再发生变化,故选择δ=10-3
作为最优低阈值。其次,观察嵌入维数m=2~7与3种高阈值的轮廓系数,其对应关系如图7所示,可见m=3,γ=60
°
为最优组合。确定最终参数为τ=1,s
max
=8,m=3,δ=0.001
°
,γ=60
°
,其中,s
max
为最大尺度因子。
[0134]
同时,在本示例中,为了验证增强复合多尺度斜率熵算法的特征提取性能,将其和复合多尺度斜率熵(cmse)、基于差分的复合多尺度斜率熵(dbcmse)、精细复合多尺度散布熵(rcmde)、复合多尺度加权排列熵(cmwpe)这四种算法进行对比。为了保证实验的公平性,将所有的嵌入维数均设为m=3,延迟时间均为τ=1,最大尺度因子设为s
max
=8,。其中精细复合多尺度散步熵的类别个数选取为c=5。利用五种算法提取9种故障信号样本的特征,t-sne可视化降维结果如图8-1至图8-5所示。
[0135]
由图8-1至图8-5可知,增强复合多尺度斜率熵ecmse除外圈/滚子复合故障和内圈/滚子复合故障类间距离较近,其余的故障类型都由明显的区分度。整体来看,增强复合多尺度斜率熵ecmse的轴承故障特征类内距离紧凑,故障特征之间没有互相交叉的情况。复合多尺度斜率熵cmse存在滚子单点故障、外圈/滚子复合故障和内圈/滚子复合故障特征交叉的现象,且有部分内圈单点故障被划分为正常类别。基于差分的复合多尺度斜率熵dbcmse的可视化效果要优于复合多尺度斜率熵cmse,但存在多种故障类间距离较近,轻微故障交叉的不足。由此可见,同时具备高低频特征的增强复合多尺度斜率熵ecmse拥有比复合多尺度斜率熵cmse和基于差分的复合多尺度斜率熵dbcmse更好的性能。精细复合多尺度斜率熵rcmde和复合多尺度斜率熵cmwpe均存在类内距离不够紧凑的问题,同时故障之间存在很严重的重叠现象,整体区分度都比较差。综上,本发明提出的复合多尺度斜率熵ecmse拥有最好的区分特性,其特征提取能力最佳。
[0136]
另外,在本实施例汇总,为了验证本文滚动轴承故障诊断方法的效果,将所述的五种算法输入到蜜獾算法优化核极限学习机分类器中,验证分类性能。在本实施例中,初始化hba算法的种群数为30,最大迭代次数为50,图9-1至图9-5,为五种算法一次实验的诊断结果。
[0137]
由图9-1至图9-5可知,ecmse的诊断正确率达100%,720个故障全部分类正确。dbcmse有6个故障发生误诊,相比cmse,dbcmse的诊断性能更高,体现了差分方法的优越性。而rcmde和cmwpe存在较多的故障分类错误,故障识别性能不佳。实验表明,ecmse hba-kelm诊断正确率最高,拥有最佳的诊断能力。
[0138]
同时,为了进一步探究ecmse的稳定性,将五种算法做30次实验,每次实验的训练集和测试集为随机选取,训练集和测试集的数量仍为180个和720个,实验结果如图10所示。由图10可知,30次实验中,ecmse的正确率始终为最高,且波动程度很低。dbmse在部分实验中表现出和cmse相近的正确率,但整体效果要优于cmse。rcmde和cmwpe的识别结果波动幅度较大,且诊断能力较差。五种方法的平均正确率如图11所示,本发明提出的ecmse平均正
确率达99.9%,是一种较为理想的轴承故障诊断方法。
[0139]
综上,本发明提出一种轴承故障诊断模型训练方法及训练装置,利用差分方法提取时间序列的高频信息,利用平均方法提取序列的低频信息,使用斜率熵提取两种多尺度序列的复杂特征,对获取的高低频特征求平均,从而构成了增强复合多尺度斜率熵,将提取到的故障特征输入到蜜獾算法优化核极限学习机分类器中实现轴承的故障诊断。
[0140]
本发明提出的增强复合多尺度斜率熵相对于一般的熵算法,提取的时间序列及尺度信息更加全面、丰富;同时利用蜜獾算法全局寻优能力实现对核极限学习机的参数自动确定。
[0141]
本发明方法能有效提取不同健康状态的轴承故障特征,对轴承的单一和复合故障均有良好的识别能力,能有效区分不同类型和损伤程度的轴承故障,平均识别率达99.9%。
[0142]
以上描述仅为本技术的较佳实施例以及对所运用技术原理的说明,本领域技术人员应当理解,本技术中所涉及的范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案,例如上述特征与本技术中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
[0143]
除说明书所述的技术特征外,其余技术特征为本领域技术人员的已知技术,为突出本发明的创新特点,其余技术特征在此不再赘述。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。