1.本发明涉及电子物证分析技术领域,具体为一种软件获取手机聊天人员与机主之间关系的方法。
背景技术:
2.随着科学技术的不断发展,电子物证在刑事案件中作为证据的作用越来越明显,然而,当破案人员获取到电子物证后,要对电子物证里的人员进行排查,对其聊天人员进行人物身份关系刻画,可是这需要耗费大量的人力时间。
3.现造成耗费大量人力的主要原因是:人工排查,难免漏掉关键信息;一部手机无法做到多人同时排查;犯罪嫌疑人的聊天记录太多太长,逐个排查需要大量时间;因此,需要一种软件,来实现对于如何区分手机聊天人员与手机机主的关系属性。
技术实现要素:
4.本发明要解决的技术问题是克服现有技术的缺陷,提供一种软件获取手机聊天人员与机主之间关系的方法。
5.为了解决上述技术问题,本发明提供了如下的技术方案:
6.本发明一种软件获取手机聊天人员与机主之间关系的方法,包括:
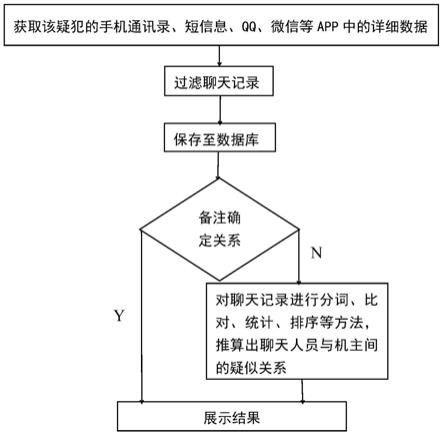
7.获取当前手机通讯录、短信息、qq、微信的等app中的详细数据;
8.将获取结果进行过滤,保存有效数据。
9.对所述运行数据进行数据聚合,以及将聚合后的所述运行数据保存至数据库;
10.对数据库中保存的所述运行数据进行数据分类;
11.对分类后的数据进行数据分析,分析排查出确定关系的、疑似关系的以及无关系的数据。
12.作为本发明的一种优选技术方案,所述获取当前手机通讯录、短信息、qq、微信的app中的详细数据。
13.作为本发明的一种优选技术方案,所述对于语气词、广告推送、表情等消息进行过滤。
14.与现有技术相比,本发明的有益效果如下:
15.本发明方法使用软件分析,对于过长的聊天记录,通过软件获取手机聊天人员与机主之间关系的方法可以大幅度节约工作人员的时间,从而提高效率:
16.本发明随着使用时间的增长,关系属性大数据字典会越来越丰富,通过软件获取手机聊天人员与机主之间关系的方法从而精度越来越高;
17.本发明软件既可以做到机器分析,也可以人工分析,通过软件获取手机聊天人员与机主之间关系的方法,从而在节约时间的基础上,达到更好的效果;
附图说明
18.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
19.图1是本发明使用框架结构示意图;
20.图2是本发明的聊天记录过滤示意图;
具体实施方式
21.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
22.实施例1
23.如图1-2所示,本发明提供一种软件获取手机聊天人员与机主之间关系的方法,包括:
24.获取当前手机通讯录、短信息、qq、微信的等app中的详细数据;
25.将获取结果进行过滤,保存有效数据。
26.对所述运行数据进行数据聚合,以及将聚合后的所述运行数据保存至数据库;
27.对数据库中保存的所述运行数据进行数据分类;
28.对分类后的数据进行数据分析,分析排查出确定关系的、疑似关系的以及无关系的数据,进一步的,所述获取当前手机通讯录、短信息、qq、微信的app中的详细数据,对于语气词、广告推送、表情等消息进行过滤。
29.具体的,使用时(工作时),1.将涉案手机连接电脑,从手机内获取该疑犯的手机通讯录、短信息、qq、微信等app中的详细数据,但由于现在市面上手机系统、手机类型、手机型号众多,提取方式各有不一,提取结果数据展示也有不同,故本文借助了美亚柏科dc-4501手机取证系统对任意机型的手机信息进行提取,并按照电子物证的行业规范将数据导为bcp格式。
30.2.将bcp数据进行过滤,由于在实际操作过程中发现,尤其是qq,微信等社交软件聊天记录内,大量语气词、表情、广告、公众号推送这些冗余数据,不仅会对人员关系进行干扰,而且会占用大量无效信息。故在将bcp数据导入数据库之前,必须对其进行一遍过滤,在对大量数据进行调研分析之后,对于以上提出的冗余数据,基本分为以下几种过滤方法。
31.1)过滤大量语气词时发现,往往语气词都是以一个字形成一句话,故直接对单字构成一句话的格式进行过滤;
32.2)过滤表情是发现,表情在数据保存时,被保存为[x]或[xx]的格式,故表情只需对[x]和[xx]的结构进行过滤;
[0033]
3)过滤广告推送时发现,无论是广告还是推送,在qq或微信中都是以xml的格式进行保存,虽然xml中内容各有不同,但xml结构依旧保持完整,故直接对xml的格式进行过滤即可。
[0034]
3.将过滤后的bcp详细信息保存在mysql数据库中,按照collect_target_id、contact_account_type、account_id、account、regis_nickname、friend_id、friend_account、friend_nickname、content、mail_send_time、local_action的格式进行分类,保存到mysql数据库中。
[0035]
4.当bcp数据存入数据库后,我们对大量样本数据进行分析后得知,对于嫌疑人关系,若机主已备注关系,则可直接确定人物关系。其余无法直接确定人物关系的,则通过与机主的聊天记录内容来做进一步分析。
[0036]
5.对聊天记录内容进行分词,按照中文词性,将聊天记录中的名词使用jieba.net软件单独提取出来,按照聊天人员,分词的格式进行分类,存储到数据库的另一张表中。这里使用的是分词软件是jieba.net,下面简单对其特点进行分析。
[0037]
1)支持三种分词模式:
[0038]
1.1)精确模式,试图将句子最精确地切开,适合文本分析;
[0039]
1.2)全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。具体来说,分词过程不会借助于词频查找最大概率路径,亦不会使用hmm;
[0040]
1.3)搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
[0041]
2)支持繁体分词;
[0042]
3)支持添加自定义词典和自定义词;
[0043]
4)mit授权协议。
[0044]
6.将已经分好的名词与一直的关系属性大数据字典进行匹配比对。软件实现逻辑是,名词中一些工作词汇将其标注为同事关系,若反复出现改词汇,便可将其定义为疑似同事关系(亲属关系同理)。
[0045]
7.对其疑似词汇出现次数和疑似关系进行整理是发现,若在二人聊天记录中出现第三方人物关系,则会对二人关系产生误差。例如:我姐姐喊你来吃饭。往往这种句子会被程序判断为是聊天一方为机主的姐姐。故在应对这种情况时,需要对各个关系的概率进行统计,并设置关系词出现的阈值。这样则可极大程度的避免这种情况的发生。
[0046]
8.将匹配结果进行排序,算出聊天人员与机主之间的疑似关系最大值,即聊天人员与机主之间的疑似关系。
[0047]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。