1.本发明涉及药物代谢动力学数据建模及深度学习领域,特别是涉及一种基于梯度一致性判断的药-时数据扩增方法。
背景技术:
2.药物代谢动力学(pharmacokinetics,pk),简称药动学,指定量研究药物在生物体内吸收、分布、代谢、排泄的动态过程
1.。药动学的重要研究对象之一是血药浓度-时间曲线,简称药-时曲线,通过早期药-时数据预测患者的反应过程,为临床研发、给药方案制定奠定基础。近年来神经网络的发展为药代动力学建模提供了新思路,在药-时数据预测任务中表现出优于传统药代动力学建模方法的结果
[2-3]
。然而,由于临床pk数据获取的有创性(需要采血),pk数据面临数据量少的问题,影响神经网络的预测可信度。
[0003]
目前由于神经网络在药动学建模方面的应用尚处于早期发展阶段,专门针对pk数据的扩增方法少之又少。一方面,现有的用神经网络预测pk数据的文献中主要采用的扩增方法为截断法
[2-3]
,优点是保留了药-时曲线中全部的给药事件,但通过截断法生成的新训练样本可能会忽略超出时间窗部分体内实时药物浓度对药物吸收、分布的影响。另一方面,基于药-时曲线的时序性,可以借鉴同样具备时序特征的心电图(electrocardiogram,ecg)数据扩增方法,例如窗口切片
[4]
和置换
[5]
。虽然这类方法在ecg数据上有成熟且广泛的应用,但这类方法会造成pk数据中重要生理药理规律的损失,例如窗口切片不能涵盖完整的给药事件,切片所形成的部分药-时数据可能会忽略体内实时药物浓度对药-时曲线变化的影响,置换同样会破坏pk数据的时间变化规律。
[0004]
上述背景技术引用文献如下:
[0005]
[1]王广基,刘晓东,柳晓泉.药物代谢动力学[m].化学工业出版社,2005。
[0006]
[2]lu j,bender b,jin jy,et al.deep learning prediction ofpatient response time course from early data vianeural-pharmacokinetic/pharmacodynamic modeling[j].2020.arxiv:2010.11769[cs.lg]。
[0007]
[3]lu j,deng k,zhang x,et al.neural-ode for pharmacokinetics modeling and its advantage to alternative machine learning models in predicting new dosing regimens[j].iscience.2021;24:102804。
[0008]
[4]cui z,chen w,chen y.multi-scale convolutional neural networks for time series classification[j].arxiv preprint arxiv:1603.06995,2016。
[0009]
[5]um t t,pfister f m j,pichler d,et al.data augmentation ofwearable sensor data for parkinson’s disease monitoring using convolutional neural networks[c]//proceedings ofthe 19th acm international conference on multimodal interaction.2017:216-220。
[0010]
需要说明的是,在上述背景技术部分公开的信息仅用于对本技术的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
[0011]
本发明的目的在于克服现有技术会造成pk数据中重要生理药理规律的损失,提供一种基于梯度一致性判断的药-时数据扩增方法。
[0012]
为实现上述目的,本发明采用以下技术方案:
[0013]
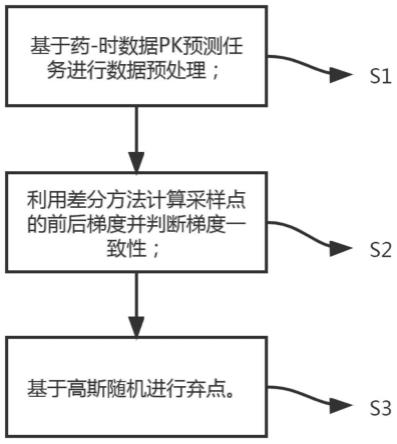
一种基于梯度一致性判断的药-时数据扩增方法,用于解决深度学习预测药-时数据过程中样本量不足的问题,该方法在增加训练样本数量的同时,能够保留药-时数据的药理和生理特征,从而提升扩增样本的质量,所述扩增方法包括以下步骤:s1、基于药-时数据预测任务进行数据预处理;s2、利用差分方法计算采样点的前后梯度并判断梯度一致性;s3、基于高斯随机进行弃点。
[0014]
在一些实施例中,有可能包含如下技术方案:
[0015]
步骤s1具体包括:
[0016]
s1.1、采用以下映射表示药-时数据预测任务:
[0017][0018]
式中,t∈{t1,
…
,t
l
}表示受试者i的第1至l次给药时刻,t1为首轮给药时刻,t2为第二次给药时刻,t
l
为第l次给药时刻;t∈{t1,
…
,tk}表示每个受试者的第1至k个血药浓度观测时刻点;pki(t)表示受试者i的血药浓度,为受试者i在时刻0≤t《t2的血药浓度测量值,0≤t《t2表示第一个给药周期内;dosingi(t)表示给药方案,{dosingi(t)}
0≤t《∞
为受试者i在时刻0≤t《∞的给药剂量;{covi}为受试者i的协变量集合,{pki(t)}
0≤t《∞
为受试者i在时刻0≤t《∞的血药浓度预测值,0≤t《∞表示整个观察周期内;
[0019]
s1.2、删除tk≤t2的受试者i的药-时数据,保留有多轮给药的受试者的药-时数据。
[0020]
步骤s2具体包括:
[0021]
s2.1、利用差分方法计算采样点处单侧的前向差分和后向差分;
[0022]
s2.2、判断所有血药浓度采样点的前后梯度一致性;对受试者i,如果tk时刻血药浓度测量值前向差分和后向差分的符号一致,表示tk时刻血药浓度趋势不发生变化,则将pki(tk)划入可被丢弃的点集合x;如果tk时刻血药浓度测量值前向差分和后向差分的符号不一致,表示tk时刻血药浓度趋势发生了改变,则将pki(tk)划入不可被丢弃的点集合y。
[0023]
步骤s2还包括:
[0024]
s2.3、计算可被丢弃的点集合x中的元素数量x;若x≥1,则对集合x中的元素进行从0到x-1的编号,并进入步骤s3;若x=0,则终止算法,输出原始药-时数据。
[0025]
步骤s2.1中,对于离散序列f(t),在f(tk)处的前向差分为:
[0026][0027]
后向差分为:
[0028][0029]
步骤s2.2中,前向差分和后向差分的符号一致时表示为:
[0030]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))≥0,(2≤k≤k-1)
[0031]
前向差分和后向差分的符号不一致时表示为:
[0032]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))《0,(2≤k≤k-1)。
[0033]
步骤s3具体包括:
[0034]
s3.1:定义高斯随机变量α;
[0035]
s3.2:计算所有可能的弃点方案数量p:
[0036]
s3.3:弃点,生成新的药-时序列;
[0037]
s3.4:可弃点集合x中每一个点都有唯一的编号,在确定随机数α后,所有弃点方案表示为弃点编号的组合,将编号组合存储为列表,通过循环每一个弃点组合直至循环数p=p,得到对应弃点方案的新药-时数据;
[0038]
s3.5:输出原始药-时数据和扩增后的药-时数据。
[0039]
所述高斯随机变量α定义为α∈(0,1),且
[0040]
所述弃点方案数量p采用组合方式计算的公式如下:
[0041]
p=c(x,[α
·
x])
[0042]
式中,表示向上取整。
[0043]
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述所述方法的步骤。
[0044]
与现有技术相比,本发明的技术方案具有如下有益效果:
[0045]
本发明提出一种基于梯度一致性判断的药-时数据扩增方法,通过差分方法计算采样点测量值前后梯度,并利用高斯随机进行弃点。解决了现有技术会忽略超出时间窗部分体内实时药物浓度对药物吸收、分布的影响以及造成pk数据中重要生理药理规律的损失的问题。本发明在增加训练样本数量的同时,最小程度减轻了对pk数据时序规律及背后所反映的生理药理特征的影响,提升了扩增样本的质量。
附图说明
[0046]
图1是本发明实施例中的基于梯度一致性的药-时数据扩增方法中的扩增方法流程图;
[0047]
图2是本发明实施例中的差分算法示意图;
[0048]
图3是本发明实施例中的受试者药-时数据示意图;
[0049]
图4是本发明实施例中的扩增方法的步骤流程图。
具体实施方式
[0050]
下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
[0051]
需要说明的是,本实施例中的左、右、上、下、顶、底等方位用语,仅是互为相对概念,或是以产品的正常使用状态为参考的,而不应该认为是具有限制性的。
[0052]
在介绍本发明实施例之前,对本发明的思路进行如下详细说明:
[0053]
为了使扩增方法保留药-时数据的重要药理和生理特征,本发明需要着重解决两个核心问题:1、保留受试者给药过程中pk测量值趋势发生变化的采样点,以确保所有给药事件被完整纳入;2、不改变受试者给药过程中pk采样点的先后顺序,以确保与药物吸收速率、清除速率等重要药代动力学参数相关的规律不被误判。
[0054]
本发明提供一种基于梯度一致性判断的药-时数据扩增方法,用于解决深度学习预测药-时数据过程中样本量不足的问题,该方法在增加训练样本数量的同时,能够保留药-时数据的药理和生理特征,从而提升扩增样本的质量,该方法主要包括:(1)基于药-时数据预测任务的数据预处理;(2)利用差分方法计算采样点的前后梯度一致性;(3)基于高斯随机数的弃点方法。本发明在增加训练样本数量的同时,最小程度减轻了对pk数据时序规律及背后所反映的生理药理特征的影响,提升了扩增样本的质量。
[0055]
如图4所示,本发明实施例的基于梯度一致性判断的药-时数据扩增方法中,所述扩增方法包括以下步骤:
[0056]
s1、基于药-时数据预测任务进行数据预处理;
[0057]
s2、利用差分方法计算采样点的前后梯度并判断梯度一致性;
[0058]
s3、基于高斯随机进行弃点。
[0059]
其中,步骤s1中:
[0060]
第一步,采用以下映射表示药-时数据预测任务:
[0061][0062]
式中,t∈{t1,
…
,t
l
}表示受试者i的第1至l次给药时刻,t1为首轮给药时刻,t2为第二次给药时刻,t
l
为第l次给药时刻;t∈{t1,
…
,tk}表示每个受试者的第1至k个血药浓度观测时刻点;pki(t)表示受试者i的血药浓度,为受试者i在时刻0≤t《t2的血药浓度测量值,0≤t《t2表示第一个给药周期内;dosingi(t)表示给药方案,{dosingi(t)}
0≤t《∞
为受试者i在时刻0≤t《∞的给药剂量;{covi}为受试者i的协变量集合,{pki(t)}
0≤t《∞
为受试者i在时刻0≤t《∞的血药浓度预测值,0≤t《∞表示整个观察周期内;
[0063]
第二步,删除tk≤t2的受试者i的药-时数据,保留有多轮给药的受试者的药-时数据。
[0064]
其中,步骤s2具体包括:
[0065]
s2.1、利用差分方法计算采样点处单侧的前向差分和后向差分;
[0066]
对于离散序列f(t),在f(tk)处的前向差分为:
[0067][0068]
后向差分为:
[0069][0070]
s2.2、判断所有血药浓度采样点的前后梯度一致性;对受试者i,如果tk时刻血药浓度测量值前向差分和后向差分的符号一致,表示tk时刻血药浓度趋势不发生变化,则将pki(tk)划入可被丢弃的点集合x;如果tk时刻血药浓度测量值前向差分和后向差分的符号不一致,表示tk时刻血药浓度趋势发生了改变,则将pki(tk)划入不可被丢弃的点集合y。
[0071]
前向差分和后向差分的符号一致时表示为:
[0072]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))≥0,(2≤k≤k-1)
[0073]
前向差分和后向差分的符号不一致时表示为:
[0074]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))《0,(2≤k≤k-1)。
[0075]
s2.3、计算可被丢弃的点集合x中的元素数量x;若x≥1,则对集合x中的元素进行从0到x-1的编号,并进入步骤s3;若x=0,则终止算法,输出原始药-时数据。
[0076]
其中,步骤s3具体包括:
[0077]
s3.1:定义高斯随机变量α;
[0078]
所述高斯随机变量α定义为α∈(0,1),且
[0079]
s3.2:计算所有可能的弃点方案数量p:
[0080]
所述弃点方案数量p采用组合方式计算的公式如下:
[0081][0082]
式中,表示向上取整。
[0083]
s3.3:弃点,生成新的药-时序列;
[0084]
s3.4:可弃点集合x中每一个点都有唯一的编号,在确定随机数α后,所有弃点方案表示为弃点编号的组合,将编号组合存储为列表,通过循环每一个弃点组合直至循环数p=p,得到对应弃点方案的新药-时数据;
[0085]
s3.5:输出原始药-时数据和扩增后的药-时数据。
[0086]
本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述方法的步骤。
[0087]
下面通过实施例对基于梯度一致性判断的药-时数据扩增方法进行具体说明。
[0088]
实施例1
[0089]
基于梯度一致性的药-时数据扩增方法如图1所示,具体包括以下步骤:
[0090]
s1、数据预处理
[0091]
pk预测任务的主要目的是通过输入首次给药后的血药浓度测量值,预测后续给药过程中的血药浓度随时间变化情况。考虑n个受试者i∈{1,
…
,n}接受同种药物治疗,给药方案为dosingi(t),其中t∈{t1,
…
,t
l
}表示受试者i的第1至l次给药时刻(t1为首轮给药时刻,t2为第二次给药时刻,依次类推),给药方案包括给药时间t∈{t1,
…
,t
l
}和给药剂量dosingi(t),给药时间是不独立于观察时间t∈{t1,
…
,tk}的,即某一个pk观察点也可能是给药时间点。观察受试者i的血药浓度pki(t),其中t∈{t1,
…
,tk}表示每个受试者i的第1至k个血药浓度观测时刻点,{covi}为受试者i的协变量集合,包含年龄、性别、种族等与受试者生理特征相关的变量。pk预测任务可以用以下映射表示:
[0092][0093]
其中,为受试者i在时刻0≤t《t2(即第一个给药周期内)的血药浓度测量值,{dosingi(t)}
0≤t《∞
为受试者i在时刻0≤t《∞(即整个观察周期内)的给药剂量,{covi}为受试者i的协变量集合,{pki(t)}
0≤t《∞
为受试者i在时刻0≤t《∞(即整个观察周期内)的血药浓度预测值。为了使(1)式的输入输出有意义,我们需要对药-时数据进行预处理,删除tk≤t2的受试者i的药-时数据,保留有多轮给药的受试者的药-时数据。
[0094]
s2、判断梯度一致性
[0095]
为了尽可能保留药-时数据所反映的药理生理特征,生成更符合研究需要的扩增数据,本发明设计了一种利用血药浓度采样点前后梯度方向一致性判断方法。
[0096]
梯度是有方向的导数,在离散数学中,常用有限差分方法来估计离散数据的梯度。
某点处单侧的差分计算主要分为前向差分和后向差分,差分的符号可以表示在某点处观测值的变化趋势。图2是差分算法示意图。其中线条1表示f(tk)处的前向差分,线条2表示f(tk)处的后向差分。
[0097]
可以看到,对于离散序列f(t),在f(tk)处的前向差分为:
[0098][0099]
后向差分为:
[0100][0101]
其中,图2中tk处的前向差分小于0表示t
k 1
处的观测值相对tk处的观测值有所下降;而tk处的后向差分大于0表示tk处的观测值相对t
k-2
处的观测值有所上升。
[0102]
回到药-时数据中,对受试者i,若存在tk,使得
[0103]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))≥0,(2≤k≤k-1),
ꢀꢀꢀ
#(5)
[0104]
式#(5)是差分的定义“回到药时数据中”的写法。而且式#(5)相比式#(3)、式#(4),是为了判断tk处前后向差分是否符号一致,所以作乘法。
[0105]
即对受试者i,tk时刻血药浓度测量值前向差分和后向差分的符号一致,表示tk时刻血药浓度趋势不发生变化,则将pki(tk)划入可被丢弃的点集合x。反之,对受试者i,若存在tk,使得
[0106]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
))《0,(2≤k≤k-1),
ꢀꢀꢀ
#(6)
[0107]
即对受试者i,tk时刻血药浓度测量值前后梯度不一致,表示tk时刻血药浓度趋势发生了改变,则将pki(tk)划入不可被丢弃的点集合y。
[0108]
离散数学中用差分估计梯度,式#(5)、式#(6)是判断前后向差分符号一致性的,即梯度一致性。
[0109]
对受试者i,在判断完毕所有血药浓度采样点得前后梯度一致性后,计算可被丢弃的点集合x中的元素数量x。若x≥1,则对集合x中的元素进行从0到x-1的编号,并进行下一步基于高斯随机的弃点;若x=0,则终止算法,输出原始药-时数据。
[0110]
s3、基于高斯的随机弃点
[0111]
本发明前一步骤通过判断采样点前后梯度一致性,能实现对关键采样数据点的保留,同时不改变血药浓度值的先后测量顺序,在很大限度上不损失药-时数据背后所反映的生理药理特征。接下来,本发明将基于高斯随机,对集合x中的点进行弃点。
[0112]
对受试者i,若弃点集合x中的元素数量x≥1,则进行基于高斯随机的弃点。定义高斯随机变量α∈(0,1),且则所有可能的弃点方案数量p可以用组合方式算出:
[0113][0114]
其中,表示向上取整。
[0115]
p是用组合方式算出的,c()表示组合算法。
[0116]
可弃点集合x中每一个点都有唯一的编号,在确定随机数α后,所有弃点方案可以表示为弃点编号的组合,将该编号组合存储为列表,在这之后通过循环每一个弃点组合直至循环数p=p,可以得到对应弃点方案的新药-时数据。最后输出原始药-时数据和扩增后
的药-时数据共计p 1个样本。
[0117]
实施例2
[0118]
下面举一个具体例子对本发明的步骤进行详细介绍,
[0119]
假设受试者的药-时测量数据如图3所示,该受试者在观测时间内采取每三周给药一次的方案,分别在第0、21、42天接受共3轮给药,在观测时间内共有18个血药浓度数据采样点。图3中方格3表示前后梯度一致的血药浓度采样点,并根据采样时间进行编号,方格4表示第一轮给药周期中前后梯度不一致的血药浓度采样点,方格5表示除第一轮给药周期外前后梯度不一致的血药浓度采样点。
[0120]
s1.数据预处理。如图3所示,该受试者共有3轮给药的血药浓度测量数据,不属于仅有一轮给药的情况,故保留该受试者的药-时数据,进入扩增的下一个步骤。
[0121]
s2.判断梯度一致性。对除了首个和末个采样点以外的16个血药浓度数据分别判定前后梯度一致性,即判断下式的符号:
[0122]
(pki(t
k 1
)-pki(tk))
·
(pki(tk)-pki(t
k-1
)),(2≤k≤17),
ꢀꢀꢀ
#(8)
[0123]
可以得到其中10个采样点的前后梯度一致,即为图3中方格3的血药浓度采样点。依据采样时间顺序对这10个点进行从0到9的编号。
[0124]
s3.基于高斯的随机弃点。定义高斯随机变量α=0.2,即每次从10个可丢弃的采样点中选择2个进行丢弃,根据公式(7)计算所有弃点方案数量为:
[0125]
种。
[0126]
这些弃点方案可以用编号表示,弃点组合分别为:(0,1);(0,2);(0,3);(0,4);(0,5);(0,6);(0,7);(0,8);(0,9);(1,2);(1,3);(1,4);(1,5);(1,6);(1,7);(1,8);(1,9);(2,3);(2,4);(2,5);(2,6);(2,7);(2,8);(2,9);(3,4);(3,5);(3,6);(3,7);(3,8);(3,9);(4,5);(4,6);(4,7);(4,8);(4,9);(5,6);(5,7);(5,8);(5,9);(6,7);(6,8);(6,9);(7,8);(7,9);(8,9)。这代表着在训练集中该受试者的一条药-时数据,可以被扩增成45条不同的药-时数据。扩增后的样本各不相同,且都保留了重要的生理药理特性。
[0127]
下表为不同扩增方法效果对比表。
[0128]
[0129]
如此表所示,将本发明的扩增方法与现有的时序数据扩增方法进行了效果对比,对于同一条药-时数据样本,可以看到基于梯度一致性判断的药-时数据扩增方法的优点包括:
[0130]
(1)扩增后的样本数量大,从而提升预测模型的鲁棒性;
[0131]
(2)保留所有给药信息,从而保留了重要的生理药理特性;
[0132]
(3)不改变采样点先后顺序,从而确保与药物吸收速率、清除速率等重要药代动力学参数相关的规律不被误判。
[0133]
综上,可以见得本发明的药-时数据扩增方法是高效且有针对性的。
[0134]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。