1.本发明涉及轨道交通领域,尤其涉及轨道交通维修管理中的设备故障监测方法。
背景技术:
2.城市城市轨道交通设备系统众多,覆盖全线路、全车站等多个区域,设备之间存在着各种依赖关系,构成了相互关联的复杂系统,共同维系着轨道交通的运营。城市轨道交通作为城市公共交通系统中的重要组成部分,具有大运量、准时、快速、节能等优势,随着乘客对轨道交通的认可,越来越多的乘客选择轨道交通出行,大客流已成为轨道交通的常见现象,轨道交通的高强度运行,增加了设备的使用频率,因而设备单元发生失效或故障的频率也日益增高。
3.设备维修对于保证城市轨道交通系统的正常工作和安全运行具有重要意义。目前轨道系统中最常用的设备检查策略主要是故障维修和定期检修。若设备突发故障,且故障响应延迟,造成维修不及时,最严重的可能是影响整条线路的正常运营。如何根据监测设备运行状态和故障数据,分析潜在的故障隐患和预警,及时排查和预防,降低维修成本,实现设备无停机运行,是安全运营保障系统面临的主要问题。
技术实现要素:
4.针对上述问题,本发明公开了一种基于深度学习的轨道交通设备故障预测方法,该方法首先对设备监测数据进行探索性数据分析(eda),完善数据缺失值和异常值,修正数据;并基于随机森林对设备数据进行特征选择和简化;再将设备数据转化成由样本,时间步,特征组成的三维数据,构建lstm预测模型,进行设备故障分析与预测。该方法可行性强,利用故障案例库中的历史数据和实时监测数据,进行设备故障预测分析,预测设备发生故障的时期,及早对相关设备进行预防性维修,为科学的维修管理提供依据,大大提高了设备的可靠性,同时也降低了设备的管理成本.避免设备故障造成运营损失。
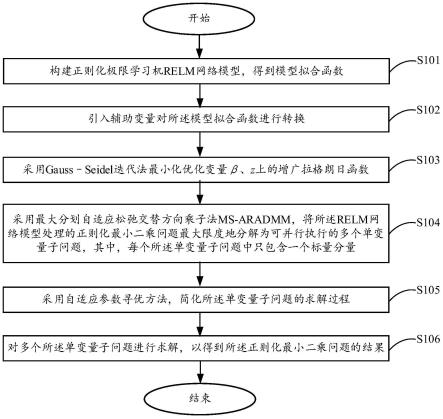
5.为达到上述目的,本发明通过以下技术方案实现:一种基于深度学习的轨道交通设备故障预测方法,具体包含以下步骤:
6.s1:对设备故障案例库、设备历史库数据进行预处理,构建设备数据库
7.s2:基于eda数据分析库的pandas profiling工具对设备数据库中的设备数据进行数据预览分析,了解数据的总体概况;
8.s3:根据s2的数据分析情况,对数据中的异常值或缺失值做删除或填充处理;
9.s4:采用series_to_supervised()函数以平移的方式将设备状态平移一个时间单位,给数据添加标签;
10.s5:结合s2的数据分析结果中变量的相关性,采用随机森林进行特征选择,计算各个特征的重要性,从所有特征中选择出重要性靠前的特征;选择与设备故障相关性较高的特征,简化数据特征;
11.s6:将数据分成训练数据和验证数据,构建训练样本、时间步和特征的三维数据;
12.s7:创建lstm模型,将三维数据作为输入,进行时间序列预测;
13.s8:利用验证数据进行模型验证,并预测设备故障。
14.进一步的,所述s1中的数据包括设备寿命、设备使用时间、设备温度、设备状态和探测时间;所述构建的设备数据库具体表达为:
[0015][0016]
进一步的,所述s5具体为:
[0017]
s5.1:从数据中提取n(n≥10)个样本作为一个训练集,形成一个决策树;
[0018]
s5.2:将s5.1中提取的样本放回后,再提取n个样本作为一个训练集,形成一个决策树,
[0019]
s5.3:不断重复s5.2,建立t个决策树并以此组成随机森林;其中,10≤t≤200;
[0020]
s5.4:用训练得到的随机森林进行特征选择;
[0021]
s5.5:利用基尼指数作为评价指标对数据特征的重要性进行排序,获得最优特征集。
[0022]
进一步的,所述s6具体为:
[0023]
假设设备有m个特征x1,x2,
…
xm,公式如(a)所示:
[0024][0025]
其中,gi表示基尼系数,gia表示节点a的基尼知识,k表示样本类别个数,p
ak
表示节点a在类别k所占的比例;
[0026]
特征xj在节点a中的重要性即取节点a分支后的基尼指数变化量,特征重要性计算公式如(b)所示:
[0027]
vim
ja
=gi
a-gi
b-gic(b)
[0028]
其中,vim
aj
表示xj在节点a中的重要性,gib和gic表示节点a在分支后产生的两个新节点b和c的基尼指数;
[0029]
假设在第i棵树中,特征xj出现在a个节点上,则特征xj在第i棵树的重要性为:
[0030][0031]
假设随机森林有n棵树,则特征xj在所有树上的重要性为:
[0032][0033]
特征xj的特征重要性如(e)所示,其中表示m个特征在n棵树上所有重要性之和:
[0034][0035]
通过对所有特征的特征重要性从大到小进行排序,选择出特征重要性较高即排序前p个的特征作为最优特征集。
[0036]
进一步的,所述s7具体为:
[0037]
s7.1:样本作为第一维度,时间步为第二维度,特征为第三维度作为模型的输入;
[0038]
s7.2:将三维数据转换为二维数据,总数据量保持不变;
[0039]
s7.3:将二维数据分成多块,每块对应一个lstm单元输入;
[0040]
s7.4:对第一个单元的输入,使用平均绝对误差(mae)损失函数和adam随机梯度下降方法进行lstm训练;
[0041][0042]
s7.5:将前一个单元的训练结果与当前单元的输入结合,再次进行lstm训练;
[0043]
s7.6:重复(5),直到完成所有单元的训练。
[0044]
进一步的,所述s8具体为:
[0045]
使用验证数据对模型验证,采用均方根误差损失法(rmse)对模型的准确性进行衡量,其公式如下:
[0046][0047]
其中,y表示真实值,f(x)为训练模型的预测值;最后,在预测模型中输入设备的特征值和设备信息,进行设备故障预测。
[0048]
与现有技术相比,本发明的其有益效果在于,
[0049]
1、本发明采用随机森林算法进行特征选择,对轨道交通中这类特征维度高、数据量大的设备数据,训练速度快、适应性强,且不容易产生过拟合,大大提高了特征选择的处理效率和准确度;
[0050]
2、本发明采用lstm进行设备故障预测,可以根据前一轮训练获取的数据对模型进行更新训练,将工作重点聚焦到具有价值的数据信息上,而不是始终使用全部的数据信息,增加了预测效率,且普适性强。
[0051]
3、本发明能够提前对设备进行故障预测,诊断并预测设备故障的发展趋势,便于工作人员尽早发现设备故障隐患,提前制定预测性维修计划并实施检查维修行为,避免故障恶化,保障设备在安全的情况下工作,增加了设备检修的及时性、高效性和设备工作的可持续性。同时,避免了定期维修的资源浪费,有效减少了设备维修时间。该方法应用性广,可行性高,为轨道交通运营管理避免设备故障引起重大损失提供支持,是提高轨道交通设备管理水平的必经之路,也是必然趋势。
附图说明
[0052]
图1是本发明的一种基于深度学习的轨道交通设备故障预测方法流程图。
[0053]
图2是本发明的基于随机森林的特征选择流程图。
[0054]
图3是本发明的lstm模型流程图。
[0055]
图4是本发明的三维数据立方体结构示意图。
[0056]
图5是本发明的三维数据转二维数据结构示意图。
具体实施方式
[0057]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0058]
如图1所示,本发明的设备故障预测方法包括:
[0059]
s101:对设备故障案例库和设备历史数据进行预处理,每条数据包括属性信息如设备寿命、设备使用时间、设备温度、设备状态、探测时间等,构建的设备数据库如下所示:
[0060][0061]
s102:采用eda的pandasprofiling工具对设备数据库中的数据进行数据分析,了解数据概况,包括缺失值、异常值和参数相关性等。
[0062]
s103:根据s102的数据分析结果,对数据进行修正,结合实际情况,修改异常值,补充缺失值,或删除异常、缺失数据。
[0063]
s104:采用series_to_supervised()方法通过shift()函数以平移的方式将设备状态平移一个时间单位,给数据添加标签;
[0064]
s105:基于随机森林进行特征选择,选择重要性靠前的特征,简化数据特征,基于随机森林的特征选择流程如图2所示。
[0065]
(1)从数据中提取n(n≥10)个样本作为一个训练集,形成一个决策树;
[0066]
(2)将(1)中提取的样本放回后,再提取n个样本作为一个训练集,形成一个决策树;
[0067]
(3)不断重复(2),建立t个决策树(10≤t≤200)并以此组成随机森林;
[0068]
(4)用训练得到的随机森林进行特征选择;
[0069]
(5)利用基尼指数作为评价指标对数据特征的重要性进行排序,获得最优特征集;
[0070]
·
假设设备有m个特征x1,x2,
…
xm,公式如(a)所示:
[0071][0072]
其中,gi表示基尼系数,gia表示节点a的基尼知识,k表示样本类别个数,p
ak
表示节点a在类别k所占的比例;
[0073]
·
特征xj在节点a中的重要性即取节点a分支后的基尼指数变化量,特征重要性计算公式如(b)所示:
[0074]
vim
ja
=gi
a-gi
b-gic(b)
[0075]
其中,vim
aj
表示xj在节点a中的重要性,gib和gic表示节点a在分支后产生的两个新节点b和c的基尼指数;
[0076]
·
假设在第i棵树中,特征xj出现在a个节点上,则特征xj在第i棵树的重要性为:
[0077][0078]
·
假设随机森林有n棵树,则特征xj在所有树上的重要性为:
[0079][0080]
·
特征xj的特征重要性如(e)所示,其中表示m个特征在n棵树上所有重要性之和:
[0081][0082]
·
通过对所有特征的特征重要性从大到小进行排序,选择出特征重要性较高即排序前n个的特征作为特征子集。
[0083]
s106:根据最优特征集,对数据进一步精简,并转化为时间步,特征,样本的三维数据。
[0084]
s107:如图3所示,构建lstm模型,将三维数据分为训练集和测试集,训练集和测试集分别作为输入和输出变量,训练获得时间序列模型;所述三维数据立方体结构如图4所示,三维数据转二维数据的结构如图5所示。
[0085]
(1)样本作为第一维度,时间步为第二维度,特征为第三维度作为模型的输入;
[0086]
(2)将三维数据转换为二维数据,总数据量保持不变;
[0087]
(3)将二维数据分成多块,每块对应一个lstm单元输入;
[0088]
(4)对第一个单元的输入,使用平均绝对误差(mae)损失函数和adam随机梯度下降方法进行lstm训练;
[0089][0090]
(5)将前一个单元的训练结果与当前单元的输入结合,再次进行lstm训练;
[0091]
(6)重复(5),直到完成所有单元的训练
[0092]
s108:使用验证数据对模型验证,采用均方根误差损失法(rmse)对模型的准确性进行衡量,其公式如下:
[0093][0094]
其中,y表示真实值,f(x)为训练模型的预测值。
[0095]
最后,在预测模型中输入设备的特征值和日期等相关信息,进行设备故障预测。
[0096]
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是
按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明的权利要求书的保护范围之内。本发明未涉及的技术均可通过现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。