一种基于改进的adaboost的乳腺癌生存预测方法
技术领域:
1.本发明涉及数据分类的技术,尤其是涉及一种基于改进的adaboost的乳腺癌生存预测方法,该方法在预测乳腺癌疾病方面有着很好的应用。
背景技术:
2.乳腺癌是人类第二常见的肿瘤,占女性癌症的四分之一,据统计,乳腺癌的5年,10年和15年相对生存率分别为89%,83%和78%。在其他类型的癌症中,它被认为是大多数国家妇女死亡的主要原因,一个有效的分类器,准确地帮助医生来预测这一慢性疾病是迫切需要的。许多学者采用集成学习分类技术来解决这一问题,然而,大多数集成学习分类算法都存在着弱分类器的冗余问题,这些技术可能在疾病预测发挥着至关重要的作用,本发明试图通过基于权值改进的选择性集成的adaboost算法来解决这一问题,从而来提高adaboost的性能。
技术实现要素:
3.本发明的目的就是为了解决上述现有相关技术存在的问题而提供的一种基于权值改进的选择性集成的adaboost算法的乳腺癌生存预测算法。
4.为了达到以上目的,本发明提供了如下技术方案:一种基于权值改进的选择性集成的adaboost算法的乳腺癌生存预测算法,包括以下步骤:
5.(1)数据输入模块,用于获取待预测的乳腺癌数据;
6.(2)数据预处理模块,用于对待预测的乳腺癌数据进行数据的预处理,对缺失数据进行填补,同时删除一些异常值;
7.(3)adaboost训练模块,将权值改进的选择性集成弱分类器的adaboost算法处理乳腺癌数据集,同时数据按照7:3的比值分为训练样本集和测试集两组;
8.(4)adaboost测试模块,测试数据用于加载训练好的adaboost模型,利用测试样本集对训练好的adaboost模型进行测试;
9.(5)乳腺癌生存预测模块,利用训练好的adaboost模型作为最终应用模型,用于乳腺癌的生存状况预测,关于乳腺癌的生存状况预测是一个二分类问题,包括活着和死亡两种状态;
10.(6)通过构造混淆矩阵,同时用precision、recall、f1-score、accuracy等作为评价指标进行对比。
11.有益效果:
12.1.本发明与黑盒分类器相比,在考虑模型精度的同时还考虑了模型的可解释性。
13.2.本发明的基本思想是弱分类器的加权参数不但与错误率有关,还与其对正样本的识别能力有关,改变弱分类器的权重值,同时采用一种弱分类器相似度度量方式,对弱分类器进行选择性集成,组合成强分类器,提高了分类的性能。
附图说明:
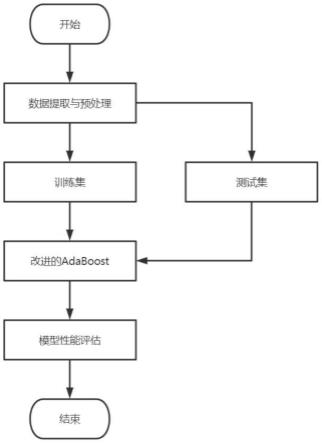
14.图1为本发明的结构示意图。
15.图2为本发明实施方式中的基于权值改进的选择性集成的adaboost算法的乳腺癌生存预测方法的步骤流程示意图。
16.图3为本发明实施方式中的传统的adaboost和改进的adaboost算法在不同数量的弱分类器的准确率图。
具体实施方式:
17.为了使本发明的实施例中的技术方案能够清楚和完整地描述,以下结合实施例中的附图,对本发明进行进一步的详细说明。
18.如图1所示,本发明实施例提供一种基于改进的adaboost的乳腺癌生存预测方法,包括以下步骤:
19.步骤1:数据输入模块,用于获取待预测的乳腺癌数据;
20.步骤2:数据预处理模块,用于对预测的乳腺癌数据进行数据的预处理。
21.具体为:
22.步骤2-1对缺失的特征值进行填补;
23.步骤2-2对异常值进行处理;
24.经数据预处理之后乳腺癌数据如表1所示:
25.表1乳腺癌数据集属性描述
26.fieldattribute属性取值(整数)1clump thickness肿块厚度[1,10]2uniformity of cell size细胞大小的均匀性[1,10]3uniformity o fcell shape细胞形状的均匀性[1,10]4marginal adhesion边缘粘[1,10]5single epithelial cell size单上皮细胞的大小[1,10]6bare nuclei裸核[1,10]7bland chromatin normal乏味染色体[1,10]8normal nucleoli正常核[1,10]9mitoses有丝分裂[1,10]10class类型-1,1
[0027]
本发明实施方式中的基于权值改进的选择性集成的adaboost算法的乳腺癌生存预测方法,如图2所示,具体过程如下:
[0028]
步骤3:adaboost训练模块,将权值改进的选择性集成弱分类器adaboost算法处理乳腺癌数据集,同时数据按照7:3的比值分为训练样本集和测试集两组,具体为:
[0029]
步骤3-1从数据中调用训练集train={(x1,y1),(x2,y2),
…
,(xn,yn)},其中)},其中是第i个实例的第j个特征,n为训练集实例个数,n为特征总数;
[0030]
步骤3-2初始化训练样本权值:每一个样本初始权重均为初始化权值向量为
[0031]
步骤3-3在训练集上训练得到弱分类器h
t
,并计算分类器的错误率ε
t
,其计算公式为:
[0032][0033]
其中,h
t
(xn)为弱分类器h
t
对样本xn的预测结果;
[0034]
步骤3-4计算当前的弱分类器h
t
的权重值,其计算公式为:
[0035][0036]
其中,p
t
是识别正确的正样本的权值和,
[0037]
步骤3-5如果ε
t
《0.5,则回到回到步骤3-3,重新训练h
t
;
[0038]
步骤3-6更新样本权重值。统计第n个样本在前t个弱分类器的组合下能正确分类的概率为:
[0039][0040]
根据e
t
(n)计算第n个样本第t 1次的权值w
t 1
(n),前t次的分类准确率越低,权值提升1越大,其计算公式为:
[0041][0042]
其中,z
t
是归一化因子,其计算公式为:
[0043][0044]
步骤3-7返回训练阶段得到的t个弱分类器集合h={h1,h2,
…
,h
t
};
[0045]
步骤3-8定义两个弱分类器hi和hj之间分类结果的相似度为rim(i,j),即被两个弱分类器划分到相同类别的样本数量占总样本数n的比重,其计算公式为:
[0046][0047]
根据两个弱分类器之间的分类结果去除相似性过高的弱分类器,剔除了冗余的弱分类器,得到最终的弱分类器集合h={h1,h2,
…
,h
t
},并且能够保持相同甚至更高的分类准确率。
[0048]
步骤4:adaboost测试模块,测试数据用于加载训练好的adaboost模型,利用测试样本集对训练好的adaboost模型进行测试,具体为:
[0049]
步骤4-1从数据中调用测试集train={(x1,y1),(x2,y2),
…
,(xn,yn)},其中)},其中是第i个实例的第j个特征,n为测试集实例个数,n为特征总数;
[0050]
步骤4-2根据最终得到的弱分类器集合h={h1,h2,
…
,h
t
},预测训练集,每个样本
的训练结果为
[0051][0052]
步骤5:乳腺癌生存预测模块,利用训练好的adaboost模型作为最终应用模型,用于乳腺癌的生存状况预测,关于乳腺癌的生存状况预测是一个二分类问题,包括活着和死亡两种状态。
[0053]
本实施例采用的数据集来源于某肿瘤医院提供的乳腺癌超声数据实例,本发明与传统adaboost分类进行相比,性能有所提高,选择如下算法评价分类指标:precision、recall、f1-score、accuracy作为算法的分类性能指标,本发明与adaboost分类算法的比较如表2所示。
[0054]
表2结果比较
[0055][0056]
以上所述是结合附图对本发明的实施例进行的详细介绍,需要指出的是,本文的具体实施方式只是用于帮助理解本发明的方法,对于本技术领域的普通技术人员在依据本发明的前提下,可以做出若干变化和修改,上述变化和修改的技术方案,皆应在由权利要求。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。