1.本发明涉及运动目标的视觉检测技术领域,更具体地,涉及一种基于视觉降噪的机器人运动方法。
背景技术:
2.机器人在野外自主运动过程中离不开视觉识别,例如用于导航和用于障碍物识别。无论哪种,都可以归为运动目标检测。运动目标检测是指当监控场景中有活动目标时,采用图像分割的方法从背景图像中提取出目标的运动区域。运动目标检测技术是智能视频分析的基础,因为目标跟踪、行为理解等视频分析算法都是针对目标区域的像素点进行的,目标检测的结果直接决定着智能视觉监控系统的整体性能。
3.现有技术中,运动目标检测的方法有很多种。根据背景是否复杂、摄像机是否运动等环境的不同,算法之间也有很大的差别。其中最常用的三类方法是:光流场法、帧间差分法、背景减法。下面对这三类方法进行介绍,通过实验结果,对它们各自的算法性能进行分析,为进一步的目标检测算法研究建立良好的基础。实践中,常采用卷积神经网络(convolutional neural networks,cnn)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforward neural networks),是深度学习(deep learning)的代表算法之一。近年来,人工智能技术与相关算法的融合越来越紧密,相关技术还包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理等。
4.然而,现有技术对于机器人视觉噪声的处理,多停留在非实时阶段的处理技术,例如topaz denoise ai是目前全球最好的ai智能图像降噪工具,其通过调整基础的参数就可以立即消除噪音,让图片细节得到优化,让您的图片看上去更加清晰,非常适合需要优化图片清晰度的情形。对于机器人在运动过程中的光线强弱、背景与目标物之间的彼此色彩和成像干扰,以及运动物体远近变化等因素叠加后的无规律性噪声,则尚无高效的噪声处理方式。
技术实现要素:
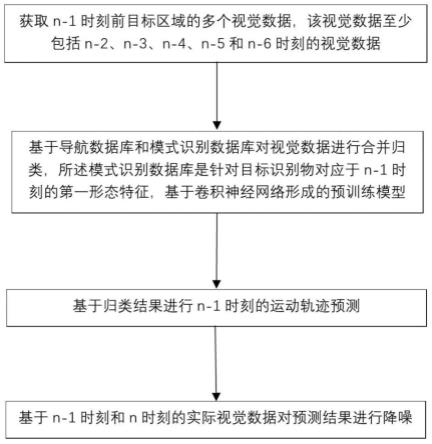
5.为了解决现有技术中的上述问题,本发明提供了一种基于视觉降噪的机器人运动方法,包括:
6.步骤110:获取n-1时刻前目标区域的多个视觉数据,该视觉数据至少包括n-2、n-3、n-4、n-5和n-6时刻的视觉数据;
7.步骤120:基于导航数据库和模式识别数据库对视觉数据进行合并归类,所述模式识别数据库是针对目标识别物对应于n-1时刻的第一形态特征,基于卷积神经网络形成的预训练模型库;
8.步骤130:基于归类结果进行n-1时刻的运动轨迹预测;
9.步骤140:基于n-1时刻和n时刻的实际视觉数据对预测结果进行降噪。
10.进一步地,所述步骤120包括:
11.步骤1201:根据步骤110确定的多个视觉数据覆盖的区域,获取导航数据库中的该区域内的路径数据;
12.步骤1202:将步骤110确定的视觉数据转换成像素阵;
13.步骤1203:将像素阵通过softmax函数取得概率排在前五位的归类目标;
14.步骤1204:将步骤1203得到的前五位的概率进行下列转换:
15.g(k
n-2
)=g(k
n-3
) g
′
(k
n-4
),
16.其中k
n-3
表示n-3时刻的视觉数据,其中k
n-2
表示n-2时刻的视觉数据,其中k
n-4
表示n-4时刻的视觉数据,g()运算表示经过步骤1203中的softmax函数后得到的前五位的概率的运算,g
′
(k
n-4
)表示以下运算:
[0017][0018]
其中,m和n分别为n-4时刻的视觉数据在通过softmax时得到的概率个数,以及n-3时刻的视觉数据在通过softmax时得到的概率个数;j和k表示从1开始的自然数;
[0019]
步骤1205:对经过步骤1204处理得到的g(k
n-2)数据,再次经过softmax函数,取得对应于n-2时刻的概率排在前两位的归类目标。
[0020]
进一步地,步骤130包括:
[0021]
步骤1301:根据下式,对n-2时刻的概率排在前两位的归类目标中概率较大的归类目标,进行n-1时刻的运动轨迹预测:
[0022][0023]
其中,r
rout
表示n-1时刻的运动轨迹预测结果,ln为取对数函数,f(tj)表示tj时刻排在前两位的归类目标中概率较大的归类目标的概率,g(tk)表示tk时刻排在前两位的归类目标中概率较小的归类目标的概率,f(tj)在t1时表示n-3、n-4和n-5时刻对应的视觉数据经过步骤120后得到的对应于n-2时刻的、排在前两位的归类目标中概率较大的归类目标的概率,g(tk)在t1时表示n-3、n-4和n-5时刻对应的视觉数据经过步骤120后得到的对应于n-2时刻的、排在前两位的归类目标中概率较小的归类目标的概率,f(tj)在t2时表示n-4、n-5和n-6时刻对应的视觉数据经过步骤120后得到的对应于n-3时刻的、排在前两位的归类目标中概率较大的归类目标的概率,g(tk)在t2时表示n-4、n一5和n-6时刻对应的视觉数据经过步骤120后得到的对应于n-3时刻的、排在前两位的归类目标中概率较小的归类目标的概率;
[0024]
步骤1302:当r
rout
小于预定阈值时,对n-2时刻的概率排在前两位的归类目标中概率较大的归类目标,作为归类得到的最终目标;否则,对n-2时刻的概率排在前两位的归类目标中概率较小的归类目标,作为归类得到的最终目标;
[0025]
步骤1303:将归类得到的最终目标,根据在n-1时刻和n-2时刻于步骤110得到的视觉数据得到的速度,应用于导航数据库进行位置对应。
[0026]
进一步地,所述步骤140包括:
[0027]
步骤1401:获得n时刻,最终目标在视觉数据上的第二形态特征;
[0028]
步骤1402:将第一形态特征和第二形态特征分别进行像素矩阵模值的计算并得到两个模值的比值,作为第一比值;
[0029]
步骤1403:根据步骤1303获得的最终目标在n-1及n-2时刻的速度进行比值,作为第二比值;
[0030]
步骤1404:判断第一比值和第二比值的增大或减小趋势是否相同,如果相同,则设定修正因数为1;否则,将n时刻的视觉图像上的第二形态特征与n-1时刻的第一形态特征之间的比值作为修正因数;
[0031]
步骤1405:在对n 1时刻获得的视觉数据进行像素阵转换时,将得到的矩阵乘以所述修正因数。
[0032]
进一步地,步骤140还包括:
[0033]
步骤1406:根据修正因数是否为1,对导航数据库中的道路信息,根据视觉数据对应的位置信息进行修正。
[0034]
进一步地,所述像素阵在进行softmax函数处理前,还要经过卷积。
[0035]
进一步地,所述卷积为基于双层卷积神经网络的卷积。
[0036]
本发明的有益效果是:可以实现机器人在无人值守场景下的探路、无人区拍摄等过程中,获得图像效果的自适应调整能力,从而在保证图像清晰度的前提下大大降低了机器人对摄像设备的依赖。此外,本发明还能够在识别出危险目标物时自动从导航地图上进行规避,而无需人为参数调整或干涉。
附图说明
[0037]
图1示出了本发明基于视觉降噪的机器人运动方法的流程图。
具体实施方式
[0038]
如图1所示,本发明提供了一种基于视觉降噪的机器人运动方法,包括:
[0039]
步骤110:获取n-1时刻前目标区域的多个视觉数据,该视觉数据至少包括n-2、n-3、n-4、n-5和n-6时刻的视觉数据;
[0040]
步骤120:基于导航数据库和模式识别数据库对视觉数据进行合并归类,所述模式识别数据库是针对目标识别物对应于n-1时刻的第一形态特征,基于卷积神经网络形成的预训练模型库;
[0041]
步骤130:基于归类结果进行n-1时刻的运动轨迹预测;
[0042]
步骤140:基于n-1时刻和n时刻的实际视觉数据对预测结果进行降噪。
[0043]
优选地,所述步骤120包括:
[0044]
步骤1201:根据步骤110确定的多个视觉数据覆盖的区域,获取导航数据库中的该区域内的路径数据;
[0045]
步骤1202:将步骤110确定的视觉数据转换成像素阵;
[0046]
步骤1203:将像素阵通过softmax函数取得概率排在前五位的归类目标;
[0047]
步骤1204:将步骤1203得到的前五位的概率进行下列转换:
[0048]
g(k
n-2)=g(k
n-3) g
′
(k
n-4
),
[0049]
其中k
n-3
表示n-3时刻的视觉数据,其中k
n-2
表示n-2时刻的视觉数据,其中k
n-4
表示n-4时刻的视觉数据,g()运算表示经过步骤1203中的softmax函数后得到的前五位的概率的运算,g
′
(k
n-4
)表示以下运算:
[0050][0051]
其中,m和n分别为n-4时刻的视觉数据在通过softmax时得到的概率个数,以及n-3时刻的视觉数据在通过softmax时得到的概率个数;j和k表示从1开始的自然数;
[0052]
步骤1205:对经过步骤1204处理得到的g(k
n-2
)数据,再次经过softmax函数,取得对应于n-2时刻的概率排在前两位的归类目标。
[0053]
优选地,步骤130包括:
[0054]
步骤1301:根据下式,对n-2时刻的概率排在前两位的归类目标中概率较大的归类目标,进行n-1时刻的运动轨迹预测:
[0055][0056]
其中,r
rout
表示n-1时刻的运动轨迹预测结果,ln为取对数函数,f(tj)表示tj时刻排在前两位的归类目标中概率较大的归类目标的概率,g(tk)表示tk时刻排在前两位的归类目标中概率较小的归类目标的概率,f(tj)在t1时表示n-3、n-4和n-5时刻对应的视觉数据经过步骤120后得到的对应于n-2时刻的、排在前两位的归类目标中概率较大的归类目标的概率,g(tk)在t1时表示n-3、n-4和n-5时刻对应的视觉数据经过步骤120后得到的对应于n-2时刻的、排在前两位的归类目标中概率较小的归类目标的概率,f(tj)在t2时表示n-4、n-5和n-6时刻对应的视觉数据经过步骤120后得到的对应于n-3时刻的、排在前两位的归类目标中概率较大的归类目标的概率,g(tk)在t2时表示n-4、n-5和n-6时刻对应的视觉数据经过步骤120后得到的对应于n-3时刻的、排在前两位的归类目标中概率较小的归类目标的概率;
[0057]
步骤1302:当r
rout
小于预定阈值时,对n-2时刻的概率排在前两位的归类目标中概率较大的归类目标,作为归类得到的最终目标;否则,对n-2时刻的概率排在前两位的归类目标中概率较小的归类目标,作为归类得到的最终目标;
[0058]
步骤1303:将归类得到的最终目标,根据在n-1时刻和n-2时刻于步骤110得到的视觉数据得到的速度,应用于导航数据库进行位置对应。
[0059]
优选地,所述步骤140包括:
[0060]
步骤1401:获得n时刻,最终目标在视觉数据上的第二形态特征;
[0061]
步骤1402:将第一形态特征和第二形态特征分别进行像素矩阵模值的计算并得到两个模值的比值,作为第一比值;
[0062]
步骤1403:根据步骤1303获得的最终目标在n-1及n-2时刻的速度进行比值,作为第二比值;
[0063]
步骤1404:判断第一比值和第二比值的增大或减小趋势是否相同,如果相同,则设定修正因数为1;否则,将n时刻的视觉图像上的第二形态特征与n-1时刻的第一形态特征之间的比值作为修正因数;
[0064]
步骤1405:在对n 1时刻获得的视觉数据进行像素阵转换时,将得到的矩阵乘以所述修正因数。
[0065]
优选地,步骤140还包括:
[0066]
步骤1406:根据修正因数是否为1,对导航数据库中的道路信息,根据视觉数据对
应的位置信息进行修正。
[0067]
优选地,所述像素阵在进行softmax函数处理前,还要经过卷积。
[0068]
优选地,所述卷积为基于双层卷积神经网络的卷积。
[0069]
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
