1.本发明属于机器视觉的语义分割技术领域,特别涉及于一种注意力双支路特征融合的食管早癌病灶分割方法。
背景技术:
2.食管图像背景复杂且患者的患病区域千差万别,因此食管病变及早癌的筛查工作是一项极具挑战性的任务。食管病灶前景背景对比度低、形状各异且不规则,此外受到内镜成像的噪声影响,食管病变图像容易出现高亮光斑,使得传统分割算法难以将病灶在内镜图像中分割出来。与传统方法相比,基于深度学习的分割方法能够有效捕获图像的低层细节特征和高层语义特征,对背景复杂的食管图像分割具有一定的优势。特别是ronneberger等人提出的u-net以及相继出现的u-net变体已被广泛用于医学图像分割,这些方法采用了对称结构和跳跃连接,有效地融合了低级别和高级别的图像特征,解决了用于医学图像分割的普通卷积神经网络定位不准确的问题。
3.近年来,基于深度学习的人工智能方法在各个医学领域取得了显著的进展,尤其是作为一种医学图像筛选系统。这些领域包括放射肿瘤学诊断、皮肤癌分类、糖尿病视网膜病变分割、胃活检标本的组织学分类、以及使用内窥镜对大肠病变进行表征。在食管早癌筛查领域,深度学习也成为了强大的支持工具。xue等人通过微血管形态学类型分类进行食管早癌检测,他们在caffe中开发了一个模型,使用卷积神经网络(convolutional neural networks, cnn)进行特征提取,使用支持向量机(support vector machines, svm)进行分类,开创了使用深度学习方法进行食管早癌筛查的先河。hong等人使用cnn来区分胃生化、肠生化和胃肿瘤。该体系结构由四个卷积层、两个最大池化层和两个完全连接层(fully connected layers, fc)组成,分类准确率为80.77%。2019年徐瑞华教授团队通过使用样本率可信区间估计法(clopper-pearson)鉴别癌性病变方面的诊断准确性,在五个外部验证集中,诊断准确率范围为0.915至0.977。2021年胡兵教授团队提出了一种基于深度学习模型的食管癌诊断算法,利用6473张经过专业医师标记的癌前病变和食管鳞状细胞癌(narrow band imaging,nbi)图像,通过cnn模型segnet提取图像特征,构建了灵敏度(sensitivity, se)和特异性(specificity, sp)均超过90%的早筛模型。综上所述,在食管早癌分割领域,通过深度学习的方法获得高精度尤其是高灵敏度和高特异性的方法仍然是主要方向。
技术实现要素:
4.在食管早癌筛查中,早期食管癌的内镜表现非常轻微,内镜医生不容易准确发现病灶区域。本发明利用空洞卷积和深度可分离卷积提出金字塔引导特征融合模块,引导融合不同层次特征增强有效信息的表达,利用双三次插值法和像素重构的方法提出双支路上采样模块,在空间和通道同时进行上采样,减少了上采样过程中的有用信息的损失,对deeplabv3 网络参数进行调整,使其符合二分类语义分割任务,同时结合卷积注意力模块、
金字塔特征融合模块和双支路上采样模块搭建结合注意力机制的双支路特征融合网络,提高对食管早癌病灶区域的分割精度。
5.本发明的技术方案如下:一种基于注意力双支路特征融合的食管早癌病灶分割方法,主要包含以下步骤:步骤1,搭建amff-dunet网络,将本发明提出的金字塔引导特征融合模块(pyramid-guided feature fusion module, pgfm)和双支路上采样模块(dual-branch upsampling module, dbum)加入骨干网络;步骤2,读取内镜图像,进行剪裁、颜色空间变换图像预处理;步骤3,使用amff-dunet对食管内镜图像进行精准语义分割;步骤4,将实验结果与目前先进的食管早癌病灶分割方法比较分析。
附图说明
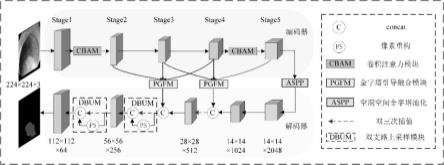
6.图1为本发明的amff-dunet网络结构图。
7.图2为本发明的金字塔引导融合模块图。
8.图3为本发明的双支路上采样模块图。
9.图4为本发明的双三次插值法示意图。
10.图5为本发明的amff-dunet热力图对比图。
11.图6为本发明的amff-dunet分割图对比图。
具体实施方式
12.以下将对本发明的基于注意力双支路特征融合的食管早癌病灶分割方法结合实例和附图作进一步的详细描述。
13.步骤1,搭建amff-dunet网络。如图1所示,在图右侧列出了相关操作的图例名称,网络输入大小为224
×
224
×
3,网络结构使用了deeplabv3 作为基本框架,整个网络被划分为stage1~stage5五个阶段。在编码器开始阶段和最后阶段使用卷积注意力模块(convolutional block attention module, cbam)引入通道和空间双注意力,增强非显著病灶区域的特征表达。在编-解码器之间使用本发明提出的金字塔引导特征融合模块(pgfm)和网络本身的空洞空间金字塔池化(atrous spatial pyramid pooling, aspp)在多个尺度上捕获上下文信息和强化特征表达。在解码器阶段使用本发明提出的双支路上采样模块(dbum),该模块通过融合图像的空间和通道信息来减少细节信息在上采样过程中的丢失,增强网络分割能力。本发明提出的模块具体解释如下:(1)使用金字塔引导特征融合模块(pgfm)进行多尺度特征提取。如图2所示,pgfm通过规则的3
×
3卷积将阶段3和阶段4的特征映射到与阶段2相同的通道空间。生成的特征映射f3和f4向上采样到与f2相同的大小并拼接。之后为了从不同级别的特征映射中提取全局上下文信息,同时防止上采样过程丢失空间信息,使用空洞率为r=1、r=2和r=4的空洞卷积叠加,扩大感受野并且弥补相关性的损失,考虑到上述操作会增大模型参数,对网络的计算速度造成影响,所以在进行空洞卷积之前对拼接之后的特征映射进行深度可分离卷积。最后,使用普通卷积得到最终的特征映射。pgfm模块输出如式(1):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中pk表示插入第k阶段的pgfm的输出,fk表示第k阶段的特征映射编码器,表示速率为2
i-k
的上采样操作,conv3×3表示3
×
3的卷积,conv
ds
表示深度可分离卷积,conv
dc
r2
i-k
表示扩张率为2
i-k
的空洞卷积,cat表示concat操作,m表示参与特征引导的阶段数。
14.(2)使用双支路上采样模块(dbum)减少细节信息在上采样过程中的丢失。如图3所示,使用双三次插值(bicubic interpolation, bic)和像素重构(pixelshuffle, ps)并行上采样。图3中ps表示像素重构上采样的方法,该方法先通过卷积的方式得到r2个通道的特征图,r为图像扩大倍率。再通过周期筛选的方式将低分辨率图像中的每一个像素的r2个通道展开成r
×
r的大像素重组在一起,所以通道数r2c缩减成c,图像尺寸h
×
w扩展成rh
×
rw。总的来说,dbum是对输入在空间上进行双三次插值上采样得到特征图fs,在通道上进行像素重构上采样得到fc,将fs和fc进行相加融合得到输出。双支路上采样模块的输出如式(2):output=bicubic(input) conv(ps(input))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)其中conv表示卷积运算,bicubic表示双三次插值,ps表示像素重构(pixelshuffle),input表示输入图像,output表示输出图像。
15.对比双线性插值,双三次插值不仅会考虑4个直接相邻点的像素值,还会利用待采样点周围16个相邻点的像素值作三次插值。如图4中p点为经过放大后目标图像b(x, y)点对应的源图像坐标点,通过计算p点周围16个点的系数,加权得到p的像素值,以左上角的点a为例,其距离p点的距离为(1 u,1 v),代入式(3)中最常用的双三次插值基函数:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)则a点对应系数为k
00
=f(1 u)*f(1 v)。同理可得其余15个相邻点的系数,16个相邻点的像素值分别乘以相应的系数再相加即为p点的像素值。由于双三次插值考虑到了各相邻点像素值变化对图像的影响,因此该方法会得到细节信息更丰富的高分辨率图像。
16.步骤2,读取内镜图像,进行剪裁、颜色空间变换图像预处理。本文使用的数据集为白光内镜图像、经卢戈氏液染色的内镜图像和nbi内镜图像组成的自建数据集,共3503张,白光图像783张,nbi图像791张,碘染色图像1929张,由四川绵阳四0四医院提供,所有病例均经组织学证实。数据均为医生在病患做胃镜检查时采集,具有随机性、一般性和真实性,数据先经过医院的消化科专家按照内镜报告确定病灶区域进行标记,再通过lableme软件对数据进行精细标注工作,将图像裁剪为224
×
224后进行图像预处理。为了减少反光和低对比度对模型的影响,加快模型训练效率,增强模型的泛化能力,针对内镜图像本身的特点进行如下预处理:(1)使用随机水平翻转和随机剪裁,使食管早癌出现在不同位置,减轻模型对病灶
出现位置的依赖性;(2)将rgb图像转化为hsv图像;(3)为了减少反光和强光对内镜图像的影响,对步骤(2)处理后的图像在0.8-1.2之间进行亮度和对比度的随机调整,降低模型对高亮和低对比度的敏感度;(4)使用标准正态分布的方法进行数据标准化,加快模型收敛。
17.步骤3,使用amff-dunet对食管内镜图像进行精准语义分割。实验依托pytorch平台搭建神经网络,版本为1.8.0,python版本为3.6.5。训练策略如下:将数据集按照7:2:1划分训练集、验证集和测试集,训练过程中使用sgd作为优化器,初始学习率设置为0.5
×
103,并在前10个训练轮次中使用预热学习来加快模型收敛。每迭代 1 轮保存 1 次网络模型,共迭代300 轮。保存测试结果最好的模型。因食管早癌数据正负样本分布不平衡,选用focal loss作为损失函数,增加了难分正样本在损失函数中的权重,提高了总体正样本的分割准确度。focal loss如公式(4)所示,pt表示反映了与真实值接近程度,pt越大说明越接近真实值,即分类越准确,γ为可调节因子,取值在0到1之间,l
fl
表示focal loss。
18.l
fl
=-(1-p
t
)
γ
log(p
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)表1和2分别是pgfm和dbum在自建数据集上的消融实验结果,以deeplabv3 作为基准网络。从表1的消融实验可知,添加两个pgfm的模型,即表中pgfm2在自建数据集上的平均交并比(mean intersection over union, miou)、se和sp指标分别从79.10%、85.40%和89.53%提升至79.86%、87.89%和90.26%。以表1指标最佳模型为基础模型,表2展示了基础模型在组合使用转置卷积(transposed convolution, tc)、双三次插值(bic)和像素重构(ps)后的模型精度变化,由表2可知转置卷积在上采样过程中,会因其补0操作产生“棋盘效应”,对其参数的设定需要经过大量尝试才能达到最优效果,因此使用实验7中双三次插值和像素重构组合的效果最好,将miou、se和sp指标分别提升至80.25%、88.95%和92.02%。通过消融实验可知,提出的模块都能够提高食管早癌分割精度,组合使用效果更佳。
19.表1 cbam与pgfm模块的消融实验结果表2 dbum模块中不同类型上采样方式的消融实验结果
步骤4,将实验结果与目前先进的食管早癌病灶分割方法比较分析。在自建数据集上使用近几年发表的主流医学图像分割方法进行实验。表3是不同分割方法的实验结果,本发明方法在miou、se、f1-score三个指标上均表现最好。
20.表3 在自建数据集中不同分割方法实验结果除了量化的实验数据,还使用了grad-cam可视化结果进行定性分析,在图5中清楚地显示了本发明的amff-dunet方法关注的病灶区与其他方法相比更好地覆盖了目标病灶,表明所提出的模型能够更好地完成病灶区域分割任务。图6展示了与华西医院“深度学习辅助早期食管癌诊断模型共享平台”的分割模型对比结果,在随机选用的五张图片中可以看出本发明方法的分割结果更接近真实值(ground truth)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。