1.本发明属于数字音频篡改检测技术领域,特别指一种基于电网频率相位时序表征的数字音频篡改被动检测方法及装置。
背景技术:
2.数字音频是人们日常生活中最容易获得数字媒体之一。除了以购买、下载的方式获得音频文件外,还可以通过实时录制的方式生成音频/语音文件。然而,音频编辑和处理软件的不断发展和完善,使得对音频的编辑和修改变得更加简单和廉价。同时,人耳也很难察觉这种修改留下的痕迹。因此,如何有效验证数字音频的原始性、完整性和真实性,就成为了数字音频被动取证技术迫切需要解决的问题。
3.数字音频篡改被动检测是无需添加任何信息,仅靠音频自身特征来对数字音频的真实性和完整性进行分析判别的技术,对于复杂的取证环境具有现实意义。当录音设备采用电网供电时,录制的音频文件中残留有电网频率(electirc network frequency,enf)信号。当数字音频被篡改时这种enf信号也会随着篡改操作发生变化,于是利用enf信号的唯一性与稳定性进行音频篡改被动检测有了两种研究思路,第一是将音频中提取出的enf信号与供电部门的enf数据库进行对比,这种方法实现难度高,代价大;第二是提取enf信号中的某些特征,进行一致性与规律性分析。目前利用enf信号进行音频篡改取证的研究方法主要是利用传统机器学习方法对enf信号的相位变化、相位的不连续性、瞬时频率突变等特征进行分类,从而达到篡改检测的目的,。
4.目前存在的数字音频检测方法中,大多是对相应特征设置阈值门限进行检测或采用机器学习方法进行分类。这些方法往往存在经验成分过多或是对于某一种篡改方法针对性太强和识别率不够的问题。
5.近年来,随着机器学习算法性能的提升和计算机存储、计算能力的提高,深度神经网络(deep neural network,dnn)被应用到音频篡改检测领域中。在深度神经网络中可以dnn深层次的非线性变换更好的拟合音频篡改的特征,实现自动学习与检测,具有识别率高的优点。因此,本发明采用bi-lstm网络对电网频率相位时序表征进行训练,将enf相位分割成帧,使得每帧表示为一段时间内enf的变化信息。然后利用双向的lstm网络(bi-lstm)输出每个时间步的状态,可以通过enf突变点的前后时间步信息,共同决定该处异常区域是否为篡改区域。最后利用dnn分类器拟合后判决输出。充分利用enf时序信息,获得更高的检测精度。
技术实现要素:
6.本发明的上述技术问题主要是通过下述技术方案得以解决的:
7.一种基于电网频率相位时序表征的数字音频篡改被动检测方法,其特征在于,包括
8.对待检测音频数据进行处理得到电网频率(enf)成分,基于dft1变换对enf成分处理得到enf相位根据待检测最长时长音频计算出帧数与帧长,并对enf相位进行分帧处理获取相位时序表征;
9.利用神经网络从enf相位时序表征中获取enf时序信息,经过拟合后分类。
10.在上述的一种基于电网频率相位时序表征的数字音频篡改被动检测方法,对原始语音信号进行处理得到电网频率(enf)成分,具体包括:
11.下采样将信号重采样频率定为1000hz或者1200hz;
12.使用10000阶的线性零相位fir滤波器进行窄带滤波,中心频率在enf标准处,带宽为0.6hz,通带波纹0.5db,阻带衰减为100db。
13.在上述的一种基于电网频率相位时序表征的数字音频篡改被动检测方法,获取enf相位包括:
14.步骤2.1、计算enf信号x
enfc
[n]在点n处的近似一阶导数
[0015]
x
′
enfc
[n]=fd(x
enfc
[n]-x
enfc
[n-1])
ꢀꢀꢀ
(1)
[0016]
其中fd(*)表示近似求导操作,x
enfc
[n]表示enf成分第n个点的值;
[0017]
步骤2.2、对x
enfc
[n]和x
′
enfc
[n]进行分帧加窗,帧长为10个标准enf频率周期帧移为1个标准enf频率周期用汉宁窗w(n)对x
enfc
[n]和x
′
enfc
[n]进行加窗
[0018]
xn[n]=x
enf
[n]w(n)
ꢀꢀꢀ
(2)
[0019]
x
′n[n]=x
′
enfc
[n]w(n)
ꢀꢀꢀ
(3)
[0020]
其中汉宁窗
[0021][0022]
步骤2.3、每帧信号xn[n]和x
′n[n]分别执行n点离散傅里叶变换(dft)得到x(k)、x
′
(k);
[0023]
步骤2.4、令k
peak
为|x(k)|的峰值的索引;k
peak
用于求解
[0024]
步骤2.5、由enf信号的估计频率f
dft
,可以求出enf相位特征
[0025][0026]
步骤2.6、再估算dft1变换的enf相位重新令k
peak
为|x
′
(k)|的峰值的索引;并将|x
′
(k)|乘一个尺度系数f(k)
[0027][0028]
得到dft0[k]=x(k),dft1[k]=f(k)|x
′
(k)|;因此估计频率值为
[0029]
[0030]
步骤2.7、k
peak
应是最接近的整数(fd为重采样频率),这样才是一个合理的频率值;可将表示为
[0031][0032]
其中对于θ的值,由x
′
(k)进行线性插值求得,令floor[a]表示小于a的最大整数,ceil[b]表示大于b的最小整数;
[0033]
由于因此在(k
low
,θ
low
)=arg[x
′
(k
low
)]和(k
high
,θ
high
)=arg[x
′
(k
high
)]进行线性插值可以逼近点求出的值与上式中的θ的值保持一致;
[0034][0035]
步骤2.8、用以上方法求出的具有两个可能的值,因此使用作为参考,选择中最接近的值作为最终的
[0036]
在上述的一种基于电网频率相位时序表征的数字音频篡改被动检测方法,步骤3中,计算enf相位时序表征的具体方法包括:
[0037]
步骤3.1、获取待检测音频数据中的最长时长音频数据;
[0038]
步骤3.2、对最长时长音频,dft变换获取相位
[0039]
步骤3.3、设置帧长m并根据计算出帧数
[0040]
步骤3.4、对所有音频数据;计算出帧移overlap=m-floor(length(φ)/n);
[0041]
步骤3.5、由于存在无法整除的情况,将分帧分为两个部分步骤3.5、由于存在无法整除的情况,将分帧分为两个部分帧的帧移比帧小1;k=length(φ)-(m-overlap)
×n[0042]
步骤3.6、enf相位时序表征为
[0043]
在上述的一种基于电网频率相位时序表征的数字音频篡改被动检测方法,步骤4中,网络模型部分包括:
[0044]
步骤4.1、采用两个双向的长短期记忆神经网络bi-lstm模块对enf相位时序表征进行训练,并输出每个时间步的状态;每个bi-lstm模块包含一层双向lstm层、一层layernormalization层与激活函数leakyrelu;
[0045]
步骤4.2、将bi-lstm网络输出的每个时间步状态特征进行拟合并分类;采用两个全连接层对特征充分拟合(神经元数量分别为1024、256,激活函数为relu);在两个全连接层之间添加dropout层(dropout rate=0.2),以防止过拟合;最后,通过全连接层(神经元数量为2,激活函数为softmax)作为输出层;
[0046]
步骤4.3、最后输出层得到的概率可得出待测语音是否被篡改,计算所有测试语音正确识别是否被篡改的概率,即系统的识别率。
[0047]
一种基于电网频率相位时序表征的数字音频篡改被动检测装置,其特征在于,包括
[0048]
第一模块:对待检测音频数据进行处理得到电网频率(enf)成分,基于dft1变换对enf成分处理得到enf相位对enf相位进行分帧处理获取相位时序表征;
[0049]
第二模块:利用神经网络从enf相位时序表征中获取enf时序信息,经过拟合后分类。
[0050]
因此,本发明具有如下优点:与传统数字音频篡改检测相比,本法发明提出对enfs相位时序表征采用深度学习方法来进行分类。针对传统方法特征表达不够,未充分利用enf时序信息的问题。设计了enf相位时序表征,将enf相位分割成帧,使得每帧表示为一段时间内enf的变化信息。利用双向的lstm网络(bi-lstm)输出每个时间步的状态,可以通过enf突变点的前后时间步信息,共同决定该处异常区域是否为篡改区域。最后利用dnn分类器拟合后判决输出。本发明的数字音频篡改检测方法与传统数字音频篡改检测方法相比能够有效提升系统的识别性能提高了模型泛化能力,优化了系统结构,提高了相应设备源识别产品的竞争力。
附图说明
[0051]
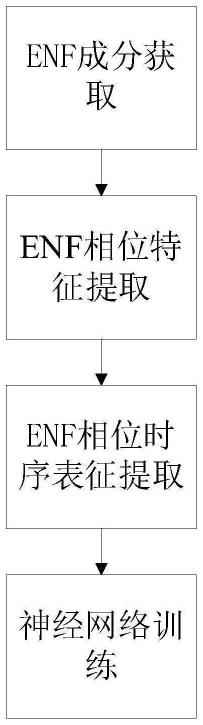
图1是本发明的方法流程示意图。
[0052]
图2是神经网络结构图。
具体实施方式
[0053]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0054]
实施例:
[0055]
本发明一种基于电网频率相位时序表征的数字音频篡改被动检测方法,本发明的算法流程图如图1所示,可以分为四部分:1)enf成分获取;2)enf相位特征提取;3)enf时序表征获取;4)神经网络训练。
[0056]
步骤一:enf成分获取,步骤如下:
[0057]
a、将音频进行下采样,重采样频率定为1000hz或者1200hz;
[0058]
b、使用10000阶的线性零相位fir滤波器进行窄带滤波,中心频率在enf标准(50hz或60hz)处,带宽为0.6hz,通带波纹0.5db,阻带衰减为100db;
[0059]
步骤二:enf相位特征提取,步骤如下:
[0060]
a、求信号一阶导数、分帧加窗、离散傅里叶变换、线性插值估算相位、计算相位波动特征:
[0061]
(a-1)计算enf信号x
enfc
[n]在点n处的近似一阶导数
[0062]
x
′
enfc
[n]=fd(x
enfc
[n]-x
enfc
[n-1])
ꢀꢀꢀ
(1)
[0063]
其中fd(*)表示近似求导操作,x
enfc
[n]表示enf成分第n个点的值。
[0064]
(a-2)对x
enfc
[n]和x
′
enfc
[n]进行分帧加窗,帧长为10个标准enf频率周期
帧移为1个标准enf频率周期用汉宁窗w(n)对x
enfc
[n]和x
′
enfc
[n]进行加窗
[0065]
xn[n]=x
enf
[n]w(n)
ꢀꢀꢀ
(2)
[0066]
x
′n[n]=x
′
enfc
[n]w(n)
ꢀꢀꢀ
(3)
[0067]
其中汉宁窗l为窗长。
[0068]
(a-3)每帧信号xn[n]和x
′n[n]分别执行n点离散傅里叶变换(dft)得到x(k)、x
′
(k)。
[0069]
(a-4)令k
peak
为|x(k)|的峰值的索引。k
peak
用于求解
[0070]
(a-5)由enf信号的估计频率f
dft
,可以求出enf相位特征
[0071][0072]
(a-6)再估算dft1变换的enf相位重新令k
peak
为|x
′
(k)|的峰值的索引。并将|x
′
(k)|乘一个尺度系数f(k)
[0073][0074]
得到dft0[k]=x(k),dft1[k]=f(k)|x
′
(k)|。因此估计频率值为
[0075][0076]
(a-7)k
peak
应是最接近的整数(fd为重采样频率),这样才是一个合理的频率值。可将表示为
[0077][0078]
其中对于θ的值,由x
′
(k)进行线性插值求得,令floor[a]表示小于a的最大整数,ceil[b]表示大于b的最小整数。
[0079]
由于因此在(k
low
,θ
low
)=arg[x
′
(k
low
)]和(k
high
,θ
high
)=arg[x
′
(k
high
)]进行线性插值可以逼近点求出的值与上式中的θ的值保持一致。
[0080]
[0081]
(a-8)用以上方法求出的具有两个可能的值,因此使用作为参考,选择中最接近的值作为最终的
[0082]
步骤三:enf相位时序表征获取,步骤如下:
[0083]
a、计算enf相位时序表征
[0084]
(a-1)获取待检测音频数据中的最长时长音频数据。
[0085]
(a-2)对最长时长音频,dft变换获取相位
[0086]
(a-3)设置帧长m并根据计算出帧数
[0087]
(a-4)对所有音频数据。计算出帧移overlap=m-floor(length(φ)/n)。
[0088]
(a-5)由于存在无法整除的情况,将分帧分为两个部分5)由于存在无法整除的情况,将分帧分为两个部分帧的帧移比帧小1。k=length(φ)-(m-overlap)
×n[0089]
(a-6)enf相位时序表征为
[0090]
步骤四:网络模型,步骤如下:
[0091]
a、获取bi-lstm网络每个时间步状态。采用两个双向的长短期记忆神经网络bi-lstm模块对enf相位时序表征进行训练,并输出每个时间步的状态。每个bi-lstm模块包含一层双向lstm层、一层layernormalization层与激活函数leakyrelu。
[0092]
b、将bi-lstm网络输出的每个时间步状态特征进行拟合并分类。采用两个全连接层对特征充分拟合(神经元数量分别为1024、256,激活函数为relu)。在两个全连接层之间添加dropout层(dropout rate=0.2),以防止过拟合。最后,通过全连接层(神经元数量为2,激活函数为softmax)作为输出层。
[0093]
c、最后输出层得到的概率可得出待测语音是否被篡改,计算所有测试语音正确识别是否被篡改的概率,即系统的识别率。
[0094]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
