用于音频处理的心理声学模型
1.相关申请的交叉引用
2.本技术要求于2019年12月5日提交的美国临时专利申请no.62/943,903以及于2019年12月5日提交的欧洲专利申请no.19213742.0的优先权,所述美国临时专利申请和欧洲专利申请两者均通过援引以其全文并入本文。
技术领域
3.本公开涉及音频处理领域,特别地,本公开涉及一种用于使用掩蔽模型(masking model)来处理音频信号的方法,所述掩蔽模型基于所述音频信号的频率区间的安静环境听觉阈值(hearing threshold in quiet)和所述音频信号的针对对应频率区间的测得能量值。本公开进一步涉及一种能够执行所述音频处理方法的设备。
背景技术:
4.人类大脑无法记录所有不同频率下的所有音频信号。因此,在对音频进行编码时,去除对于人类听觉系统而言不可感知的频率和水平下的信号是有益的。这通常是通过从音频信号中去除不相关的成分来完成的。在感知音频编码器的上下文内,提高编码器压缩效率的主要方法有两种。这些方法是去除信号冗余和不相关内容。冗余(可预测的)信号成分通常在编码器中被去除,并在解码器中得到恢复。不相关的信号成分通常通过量化在音频编码器中去除,并且不会被音频解码器恢复。
5.通常,编码器使用心理声学模型(有时也被称为感知模型)来估计音频频谱的掩蔽阈值。掩蔽阈值提供对音频频谱的多个频带中的每个频带中所允许的恰可察觉失真(just-noticeable distortion)jnd的估计。根据人类听觉系统的临界频带(critical band),频带在宽度上通常是不均匀的。在典型编码器中,掩蔽阈值被输入到速率控制环路,所述速率控制环路为多个比例因子带中的每一个选择比例因子(和量化噪声水平)。典型编码器的性能取决于掩蔽阈值估计与真实jnd噪声水平的接近程度,其中,掩蔽阈值估计超过jnd噪声水平会导致所分配的比特少于避免听觉失真所需的比特,而掩蔽阈值估计低于jnd噪声水平会导致所分配的比特多于所需比特(可能以相邻频带为代价)。
6.通常,编码器通过以下操作确定掩蔽阈值
7.1)在临界频带尺度上计算音频信号的信号能量。
8.2)通过将临界频带能量与一组扩展函数进行卷积来估计信号在经基底膜(basilar membrane)(也称为激励函数)处理后的频率响应。
9.3)在每个临界频带中,通过用以达到jnd噪声水平的所估计的量来在该频带中向下调整激励函数。
10.此外,用于确定掩蔽阈值的模型通常包括通过实验开发出的而非直接基于人类听觉的已知性质的启发式(hueristic)规则。
11.因此,在基于人类听觉的已知性质来计算掩蔽阈值的技术领域内存在有待改进音频信号的频带的比特分配的改进空间。
技术实现要素:
12.鉴于上文,因此本公开的目的是克服或减轻上文所讨论的问题中的至少一些问题。特别地,本公开的目的是提供一种基于频带中音频信号的能量值和该频带的安静环境听觉阈值的掩蔽模型。此外,本公开的另一个目的是提供一种根据上文所述的降低音频编码复杂度和提高经编码音频的质量的掩蔽模型。本公开的进一步和/或替代性目的对于本公开的读者来说将是清楚的。
13.根据第一方面,提供了一种处理音频信号的方法,音频信号包括多个频带中的音频数据,该方法包括
14.对于多个频带中的每个频带:
15.确定该频带的音频数据的能量值;
16.确定该频带的安静环境听觉阈值;
17.使用能量值和安静环境听觉阈值来计算该频带的灵敏度值(sensitivity value)sv;
18.使用灵敏度值和能量值来计算该频带的掩蔽阈值;
19.使用能量值和掩蔽阈值来确定该频带的比特分配值。
20.在本说明书的上下文中,术语“能量值”应当理解为可以使用不同方法来计算能量,例如,基于频带化修改型离散余弦变换(banded modified discrete cosine transform,mdct)、离散傅立叶变换(dft)或复mdct(cmdct)。应当注意,可以为一频带计算若干个能量值,然后以适当的方式进行组合,以形成频带的单个能量值。在本说明书中,“能量值”可以指以线性尺度或db尺度表示的能量。
21.在本说明书的上下文中,术语“频带”应当理解为频带是频域内的区间,其由下限频率和上限频率来定界,具有频率范围。应当注意,要编码的音频信号的多个频带不一定需要具有相同的宽度/范围。例如,相对较低的频带的宽度可以为100hz至200hz,而相对较高的频带的宽度可以为3000hz至3500hz。通常情况下,频带的宽度随着频率的增加而增加,使得介于相对较低的频带与相对较高的频带之间的频带的宽度通常可以处于100hz至3000hz范围内的任何位置。
22.在本说明书的上下文中,术语“灵敏度值”(sv)应当理解为对于具有正常听力的人类收听者而言在给定的临界频带中达到jnd失真所需的调整的近似。为了计及跨临界频带的掩蔽效应,每个频带的sv不仅可以取决于该频带内的信号特性,还可以取决于相邻频带中的信号。每个频带的sv通常作为对激励函数的偏移或调整来被应用,继之以应用安静环境阈值来得到最终掩蔽阈值。低于掩蔽阈值的任何噪声都不能被听见。
23.特定频带的sv可以例如使用该频带的能量值与该频带的安静环境听觉阈值之间的比率、或差异、或将能量值与安静环境听觉阈值进行比较的任何其他度量来计算。
24.在典型的现有技术编码器中,在临界频带中对激励函数做出的向下调整通常不会随信号水平而变化,除了在结束时安静环境阈值的应用以外。故此,通常情况下,所估计的掩蔽阈值可能不完全与人类听觉系统的掩蔽行为相关。
25.因此,jnd调整的表达式通常与水平无关(level-independent)。此类模型通常基于相对较响亮或相对较安静的信号的掩蔽数据。这种方法可能会限制编解码器性能,例如,因低估低水平信号成分的真实jnd阈值,从而导致向包含相对安静的信号通道的帧过度分
配比特。这一问题出现在运行在带有比特库(bit-reservoir)的恒定比特率模式下的编码器以及可变比特率编码器中。由极其动态的水平变化表征的音频内容(例如语音)将受到不利影响。
26.在本公开中,通过基于sv和能量值两者计算掩蔽阈值,掩蔽阈值可以更准确地捕捉观察到的人类听觉系统掩蔽行为,从而传递更高质量的音频信号。
27.此外,当使用更如实地捕捉观察到的人类听觉系统掩蔽行为的模型来对音频信号进行编码时,该方法可以更准确地估计满足提供恒定质量音频信号的预定义质量目标所需的比特数,并从而减少比特分配过度或分配不足。在期望恒定比特率的实施例中,由于改进的比特分配策略,该方法可以提供质量提高的音频信号。
28.该方法可以进一步提供与主观测量的掩蔽数据的更好匹配。使用所描述的音频编码模型,可以实现适用于所有录音水平或音频内容的单一模型。有利的是,模型可以促进以与要编码的音频信号的性质无关的恒定质量对音频信号进行编码。音频信号性质的一些示例是音高(pitch)、响度(loudness)或持续时间,但是应当注意,音频信号还有许多其他性质。
29.关于实施例的一般描述
30.根据一些实施例,计算掩蔽阈值包括对以下各项之一应用扩展函数:频带的能量值;或频带的经变换能量值;以确定频带的激励值,
31.以及将灵敏度值与激励值相组合。
32.可以将激励函数理解为沿着内耳基底膜的能量分布。因此,激励值是根据针对特定频带的该函数计算的值。
33.为了模拟耳朵基底膜中的声音处理,并且为了平滑跨频率的可预测性测量,将扩展函数应用于能量值或能量值的经变换版本。例如,可以将扩展函数应用于变换到响度域的能量值(即,将能量值提升到~0.25次幂至0.3次幂)。在其他实施例中,可以将扩展函数应用于提升到0.5次幂至0.6次幂的能量值。可以使用来自iso/iec 11172-3:1993(e)中的扩展函数。
34.在灵敏度值和激励值以分贝(db)定义的情况下,组合步骤可以包括通过从激励值中减去灵敏度值来计算掩蔽阈值。在强度尺度上,掩蔽阈值被计算为激励值和灵敏度值的商。
35.任选地,通过对安静环境阈值进行阈值化来得到掩蔽阈值,例如掩蔽阈值=max(掩蔽阈值,安静环境听觉阈值)。
36.根据一些实施例,计算掩蔽阈值包括将能量值与灵敏度值相组合以确定中间阈值,以及对中间阈值应用扩展函数以确定掩蔽阈值。
37.例如,掩蔽阈值可以被定义为max(中间阈值,安静环境听觉阈值)。
38.根据一些实施例,该方法进一步包括响应于比特分配值而量化频带的音频数据的音频样本。有利的是,编码器可以以恒定质量或者在伴随改进的音频质量的恒定比特率下对音频进行编码。编码器可以进一步将频带的经量化音频数据编码成比特流。
39.本文描述的方法也可以在解码器侧使用。根据一些实施例,音频信号是包括频带的经编码能量值的经编码比特流,其中,确定频带的音频数据的能量值包括对来自经编码比特流的经编码能量值进行解码。在解码器侧,所确定比特分配值可以用于从经编码比特
流中提取频带的音频数据的经量化音频样本。有利的是,每个音频帧的每个频带的比特分配值不需要被包括在比特流中,而是可改为在解码器侧被确定。因此,可以降低经编码比特流的比特率。
40.根据一些实施例,该方法进一步包括对频带的音频数据的经量化音频样本进行去量化,以及组合每个频带的音频数据的经去量化音频样本以生成经解码音频信号。
41.根据一些实施例,确定比特分配值包括调整掩蔽阈值以实现满足音频信号的目标比特率的比特分配。在该实施例中,如果标称掩蔽阈值所需的比特数可以大于(或小于)可用于满足比特率要求的比特数,则可以调整掩蔽阈值来分配更多或更少比特,以便在不超过目标比特率的情况下使用尽可能多的比特。例如,调整掩蔽阈值可以包括:通过在响度域中向掩蔽阈值添加恒定偏移直到音频信号的目标比特率得到满足来调整掩蔽阈值。
42.在确定和定义能量和听觉阈值时,可以使用不同的测量。根据一些实施例,能量值、安静环境听觉阈值和掩蔽阈值以分贝(db)定义,这提供了对模型的简化,因为分贝是音量/能量的常用测量。
43.根据一些实施例,该方法包括根据等效矩形带宽(equivalent rectangular bandwidth)erb尺度来确定音频信号的多个频带的步骤。erb尺度使用将听觉滤波器建模为矩形带通滤波器的便利简化来提供对人类听觉系统带宽的近似。有利的是,当根据人类听觉系统对音频信号进行编码时,使用erb可能是有益的。
44.根据一些实施例,其中,sv以db为单位被定义为对激励函数的减法调整,确定比特分配值的步骤包括为具有较高sv的频带指派比具有较低sv的所述频带更多的比特。有利的是,可以实现经编码音频信号的恒定音频质量。sv控制激励函数的位移,位移在应用安静环境阈值后产生掩蔽阈值。正灵敏度值会向下推动掩蔽阈值。负灵敏度值会推升掩蔽阈值。因此,增加灵敏度值对应于降低掩蔽阈值,以及因此更多分配到的比特。因此,可以将频带的灵敏度值视为对应于人类听觉系统对音频信号频带中的噪声(编码伪像(coding artefact))的灵敏度。
45.根据一些实施例,计算频带的sv的步骤包括使用感觉水平(sensation level)计算第一sv,感觉水平是能量值与安静环境听觉阈值之间的差异(以db为尺度)。
46.在本说明书的上下文中,术语“差异”应该理解为从能量值(以db表示)中减去安静环境听觉阈值(以db表示)。
47.本文中所使用的术语感觉水平被定义为对于普通听众来说,声音相对于该声音的安静环境阈值的水平。这一术语是由c.j moore在“an introduction to the psychology of hearing(听觉心理学导论)”(第五版,第403页,学术出版社(academic press),2003年)中介绍。
48.应当注意,可以采用不同的方式确定准确的sv。
49.根据一些实施例,计算第一sv的步骤包括将感觉水平乘以第一标量。有利的是,可以按低复杂度方式实现关于人类听觉系统的更高准确度的sv。通过将第一标量乘以函数,差异和sv可被容易地映射至彼此,以更好地对应于人类听觉系统。
50.在所有频带上,第一标量可以是频率相关的或者是恒定的。
51.根据一些实施例,计算第一sv的步骤包括将第二标量与感觉水平乘以第一标量相加。在所有频带上,第二标量可以是频率相关的或者是恒定的。
52.有利的是,可以按低复杂度方式实现关于人类听觉系统的更高准确度的sv。通过将第二标量与函数相加,可以容易地改变差异和sv之间的映射,以更好地对应于人类听觉系统。
53.根据一些实施例,计算sv的步骤包括将第一sv用作频带的sv。
54.根据一些实施例,计算频带的sv的步骤包括使用感觉水平计算第二sv,以及基于音频信号的至少一个特性对第一sv和第二sv进行加权。
55.举例来说,音频信号的此类特性可以是带宽、音调(tone)对噪声、标称水平或以分贝(db)为单位的功率水平。然而,应当注意,音频信号具有可以在所述方法中使用的许多特性。通过对第一sv和第二sv进行加权,可以获得接近jnd的掩蔽阈值。有利的是,恒定音频质量可以独立于音频信号的音频内容来实现。
56.在该实施例中,当使用对两个sv进行计算和加权的上述模型时,嘈杂和响亮的音频信号可以产生经编码高质量音频信号。当使用相同模型时,不那么嘈杂且柔和的音频信号也可以产生相同质量水平的经编码音频信号。相反,在现有技术双模式编码器中,对于无法被可靠分类的音频信号(如混合有掌声(applause)的对话),编码器必须在例如掌声或默认模式之间进行选择,并且编码器所选的模式可能并非最优。替代性地,编码器可以选择用不同的模式对信号的不同片段进行编码,这可能导致可听见的切换假象(其降低经编码信号的质量)。在对第一sv和第二sv进行计算和加权的单一模式模型的情况下,无需确定要用不同模式对音频信号的哪些部分进行编码。此外,单一模式模型适用于各种音频信号而独立于所述音频信号的音频内容(语音、音乐等)。通过提供单一模型,无需对音频样本进行分类来确定哪种模式需要被应用于编码。此外,介于诸模式之间的为信号选择模式的问题得以缓解,并且避免了因编码器选择次优模式而导致的音频质量降低。
57.应当注意,在一些实施例中,在计算最终sv(通过加权》2个sv)时,可以定义和包括另外的sv。这些不同的sv可以基于音频信号的瞬态特性进行加权。
58.根据一些实施例,计算频带的第二sv的步骤包括将感觉水平乘以不同于第一标量的第三标量。在所有频带上,第三标量可以是频率相关的或者是恒定的。
59.通过将函数乘以第三标量,对于具有不同特性的音频信号(例如具有高度类噪声对类音调特性的音频信号),可以提高关于听觉系统的sv的准确度。第三标量可以允许sv被映射,以实现音频编码的一般性模型。如根据上文所理解并且将在下文进一步描述的,sv被定义为感觉水平的函数。通过根据音频信号的不同特性映射sv,可以保持听觉阈值与能量值之间的关系,同时sv相对于感觉水平的斜率可以根据音频信号的不同特性而改变。有利的是,可以分配比特以提供具有高质量的经编码音频信号。
60.根据一些实施例,计算第二sv的步骤包括将第四标量与感觉水平乘以第三标量相加,第四标量不同于第二标量。需要注意的是,第四标量可以被指派不同的值,其目的是为了提高关于人类听觉系统的sv的准确度。在所有频带上,第四标量可以是频率相关的或者是恒定的。
61.根据一些实施例,基于音频信号的至少一个特性对第一sv和第二sv进行加权的步骤包括计算表示权重的值,该值的范围介于0至1之间,其中,计算频带的sv的步骤包括将第一sv和第二sv中的一者与该值相乘,并将第一sv或第二sv中的另一者与一减去该值相乘,并将这两个结果加在一起以形成频带的sv。
62.换句话说,将第一sv和第二sv以线性组合的方式混合且权重总和为一,其中,权重取决于音频信号的所述至少一个特性。
63.通过对第一sv和第二sv进行加权来计算总体sv,感觉水平与sv之间的映射可以被调整为反映不同音频信号类型的掩蔽特性。有利的是,可以实现用于确定频带比特分配值的低复杂度且灵活的模型,所述低复杂度且灵活的模型提供高质量经编码音频信号。
64.根据一些实施例,至少一个特性定义音频信号的频带的经估计调性(tonality)。
65.应当注意,存在许多不同的方法来估计音频信号的调性。调性表示音频信号中的音调特性(例如音符(note)、和弦(chord)、调(key)、音高(pitch)等)之间的关系。有利的是,使用音频信号的频带的经估计调性作为特性对第一sv和第二sv进行加权可以提高关于人类听觉系统的sv的准确度。此外,通过使用调性,可以提高主观音频质量。
66.根据一些实施例,至少一个特性定义音频信号的频带中的经估计噪声水平。有利的是,可以掩蔽关于人类听觉系统的音频信号的噪声,以便实现高质量经编码音频信号。
67.根据一些实施例,经估计调性是使用从音频信号的频带计算的频率系数的自适应预测来计算的。在一些实施例中,同一组频率系数既被用于计算掩蔽阈值又被用于估计调性。在其他实施例中,使用单独的复值滤波器组(filterbank)来执行调性的估计。需要注意的是,取决于期望的经估计调性的准确度和可用的计算资源,任何组频率系数都是可能的。例如,从计算方面讲,仅使用实mdct系数比使用cmdct系数成本更低,但是准确度更低。通过获得准确的经估计调性,可以进一步提高主观音频质量。
68.根据一些实施例,线性预测编码lpc基于计算mdct系数所根据的音频信号的频带而被自适应地应用于mdct系数。与固定预测相反,可以使用lpc以便实现音频信号的更准确的调性估计。
69.需要注意的是,lpc分析窗口可以具有不同的长度。通过改变分析窗口长度,可以灵活地实现期望的可变时频框架。根据一些实施例,lpc分析窗口长度根据频带而变化。在一些实施例中,相对较长的lpc分析窗口用于相对较低的频带。
70.根据一些实施例,lpc的预测阶数根据频带而变化。举例来说,可以选择lpc的预测阶数,使得纯噪声输入和具有音调分量(羽管键琴(harpsichord)、语音等)的信号之间的区分被最大化。
71.需要注意的是,音频信号的频率范围可以被编码为不同的范围。
72.根据一些实施例,音频信号的频率范围介于200hz至7000hz之间。
73.根据一些实施例,确定频带的安静环境听觉阈值的步骤包括使用定义至少一些频率的听觉阈值的预定义表。预定义表可以被预存储在执行所述方法的编码器中,从而允许在不影响解码器兼容性的情况下对预定义表进行更新。有利的是,可能降低提供高质量经编码音频信号的复杂度。
74.根据一些实施例,在量化频带的音频数据的音频样本之前,使用压缩扩展(companding)算法减小音频信号的动态范围。通过在编码器中压缩扩展音频信号并在解码器中应用互补性扩张(complementary expansion),编码方法可以提供更高质量的经解码音频信号。压缩扩展音频信号可允许要编码的比特更少,同时保持高音频质量。
75.根据一些实施例,该方法包括以下步骤:定义用于频带的取决于感觉水平的扩展函数,使得扩展函数在具有相对较高感觉水平的频带中的效果相比于扩展函数在具有相对
较低感觉水平的频带中的效果而言较大。
76.根据第二方面,上述目标中的至少一个通过一种设备来实现,该设备包括:
77.被配置为接收音频信号的接收部件,音频信号包括多个频带中的音频数据;
78.被配置为确定音频信号的多个频带的分析部件;
79.分析部件进一步被配置为对于多个频带中的每个频带;
80.·
确定该频带的音频数据的能量值;
81.·
确定该频带的安静环境听觉阈值;
82.·
使用能量值和安静环境听觉阈值来计算该频带的灵敏度值sv;
83.·
使用灵敏度值和能量值来计算频带的掩蔽阈值;
84.·
使用能量值和掩蔽阈值来确定频带的比特分配值。
85.根据一些实施例,分析部件被配置为通过对以下各项之一应用扩展函数来计算掩蔽阈值:
86.频带的能量值;或
87.频带的经变换能量值;
88.以确定频带的激励值,
89.以及将灵敏度值与激励值相组合
90.根据一些实施例,分析部件被配置为通过将能量值和灵敏度值相组合以确定中间阈值并对中间阈值应用扩展函数以确定掩蔽阈值来计算掩蔽阈值。
91.根据一些实施例,其中,该设备为编码器,该设备进一步包括编码部件,该编码部件被配置为响应于比特分配值而量化频带的音频数据的音频样本。
92.根据一些实施例,编码部件进一步被配置为将频带的经量化音频数据编码成比特流。
93.根据一些实施例,其中,该设备是解码器,音频信号是包括频带的经编码能量值的经编码比特流,并且该设备进一步包括解码部件,解码部件被配置为对来自经编码比特流的经编码能量值进行解码,并且分析部件在确定能量值时使用经解码能量值。
94.根据一些实施例,解码部件被配置为响应于比特分配值而从经编码比特流中提取频带的音频数据的经量化音频样本。
95.根据一些实施例,解码部件进一步被配置为对频带的音频数据的经量化音频样本进行去量化,并且组合每个频带的音频数据的经去量化音频样本,以生成经解码音频信号。
96.根据一些实施例,分析部件被配置为:在确定比特分配值时,调整掩蔽阈值以实现满足音频信号的目标比特率的比特分配。
97.根据一些实施例,分析部件被配置为:在调整掩蔽阈值时,通过在响度域中向掩蔽阈值添加恒定偏移直到音频信号的目标比特率得到满足来调整掩蔽阈值。
98.根据一些实施例,分析部件被配置为定义以分贝db为单位的能量值、安静环境听觉阈值以及掩蔽阈值。
99.根据一些实施例,分析部件被配置为根据等效矩形带宽erb尺度来确定音频信号的多个频带。
100.根据一些实施例,其中,sv以db为单位被定义为对激励函数的减法调整,分析部件被配置为通过为具有较高sv的频带指派比所述具有较低sv的频带更多的比特来确定比特
分配值。
101.根据一些实施例,分析部件被配置为通过使用感觉水平计算第一sv来计算频带的sv,所述感觉水平是能量值与安静环境听觉阈值之间的差异。
102.根据一些实施例,分析部件被配置为通过将感觉水平乘以第一标量来计算第一sv。
103.根据一些实施例,第一标量是频率相关的。
104.根据一些实施例,第一标量在所有频带上是恒定的。
105.根据一些实施例,分析部件被配置为通过将第二标量与感觉水平乘以第一标量相加来计算第一sv。
106.根据一些实施例,分析部件被配置为通过使用第一sv作为频带的sv来计算sv。
107.根据一些实施例,分析部件被配置为通过使用感觉水平进一步计算第二sv,以及基于音频信号的至少一个特性对第一sv和第二sv进行加权来计算频带的sv。
108.根据一些实施例,分析部件被配置为通过将感觉水平乘以不同于第一标量的第三标量来计算频带的第二sv。
109.根据一些实施例,分析部件被配置为通过将第四标量与感觉水平乘以第三标量相加来计算第二sv,第四标量不同于第二标量。
110.根据一些实施例,分析部件被配置为基于音频信号的至少一个特性通过以下操作对第一sv和第二sv进行加权:计算表示权重的值,该值的范围介于0至1之间;以及将第一sv和第二sv中的一者与该值相乘,并将第一sv或第二sv中的另一者与一减去该值相乘,并且将这两个结果加在一起以形成频带的sv来计算频带的sv。
111.根据一些实施例,至少一个特性定义音频信号的频带的经估计调性。
112.根据一些实施例,至少一个特性定义音频信号的频带中的经估计噪声水平。
113.根据一些实施例,分析部件被配置为使用从音频信号的频带计算的频率系数的自适应预测来计算经估计调性。
114.根据一些实施例,分析部件被配置为基于计算mdct系数所根据的音频信号的频带而自适应地将lpc应用于mdct系数。
115.根据一些实施例,lpc分析窗口长度根据频带而变化。
116.根据一些实施例,相对较长的lpc分析窗口用于相对较低的频带。
117.根据一些实施例,lpc的预测阶数根据频带而变化。
118.根据一些实施例,音频信号的频率范围介于200hz至7000hz之间。
119.根据一些实施例,该设备进一步包括存储器,存储器存储定义至少一些频率的安静环境听觉阈值的表,并且分析部件被配置为通过使用预定义表来确定频带的安静环境听觉阈值。
120.根据一些实施例,该设备进一步包括压缩扩展部件,所述压缩扩展部件被配置为在量化频带的音频数据的音频样本之前使用压缩扩展算法来减小音频信号的动态范围。
121.根据一些实施例,分析部件被配置为定义用于频带的取决于感觉水平的扩展函数,使得扩展函数在具有相对较高感觉水平的频带中的效果相比于扩展函数在具有相对较低感觉水平的频带中的效果而言较大。
122.根据一些实施例,在实时双向通信设备中实现该设备。
123.第二方面通常可以具有与第一方面相同的优点。
124.根据第三方面,提供了一种用于估计输入信号的调性的方法,所述方法包括以下步骤:
125.应用滤波器组以获得一组频率系数;
126.使用频率系数的自适应预测来计算经估计调性。
127.根据一些实施例,计算经估计调性的步骤包括基于计算频率系数所根据的音频信号的频带而将自适应线性预测lpc应用于频率系数。
128.根据一些实施例,lpc分析窗口长度根据频带而变化。
129.根据一些实施例,相对较长的lpc分析窗口用于相对较低的频带。
130.根据一些实施例,lpc的预测阶数根据频带而变化。
131.根据一些实施例,滤波器组包括以下各项之一:128频带复mdct或dft滤波器组,以及64频带复正交镜像滤波器cqmf滤波器组。
132.根据一些实施例,lpc分析窗口为非对称汉明窗口。
133.根据一些实施例,该方法包括以下步骤:
134.根据每个可预测性测量的相对感知重要性,对来自自适应预测的可预测性测量进行加权。
135.根据一些实施例,对被包含在每个时频瓦片(tile)内的可预测性测量进行加权的步骤包括以下各项之一:基于输入信号的能量或响度进行加权。
136.根据一些实施例,该方法进一步包括以下步骤:
137.组合来自频率系数的自适应预测的可预测性测量,以匹配滤波器组的时间和频率分辨率。
138.进一步应当注意的是,除非另有明确说明,否则本公开涉及所有可能的特征组合。
附图说明
139.本公开的上述以及另外的目的、特性和优点将通过以下参照附图对本公开的实施例进行的说明性且非限制性的详细说明而更好地得到理解,在附图中相同的附图标记将用于相似的元件,在附图中:
140.图1示出了音频信号的掩蔽数据。
141.图2示出了音频信号的掩蔽数据。
142.图3示出了与不同频率处的各种音调的感觉水平相关的信号掩蔽比(signal to mask ratio)smr的实验数据,以及所述数据的直线(straight line)模型。
143.图4示出了根据一些实施例的用于计算掩蔽阈值的方法的概览。
144.图5示出了根据一些实施例的与纯音调和纯噪声的感觉水平相关的sv。
145.图6示出了根据一些实施例的用于估计输入帧的频带的调性的框图。
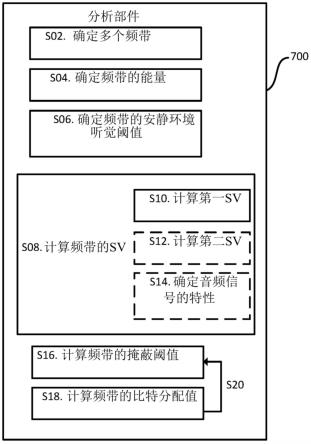
146.图7示出了根据一些实施例的用于确定输入音频信号的频带的比特分配值的分析部件,
147.图8示出了实施图7的分析部件的编码器,
148.图9示出了实施图7的分析部件的解码器,
149.图10示出了jnd的测得sv作为音调/噪声混合水平(snr)的函数的示例的结果,
150.图11示出了经估计调性相对于图6中关于现有技术所定义的不可预测性估计的曲线图。
具体实施方式
151.现在将在下文中参考附图对本公开进行更全面的描述,在附图中,示出了本公开的实施例。本文所公开的系统和设备将在操作期间进行描述。
152.在下文中,将使用已知的音频格式作为用于例示本公开的上下文。然而,应当注意,本公开的范围不限于这种已知格式,并且本文描述的不同实施例可以用于任何合适的音频格式。
153.对于示例性格式,目前有两种用于编码音频的常用模式。必须选择最适合音频信号的模式可能是复杂的决定,并且如果选择不太适合音频信号的模式,则经编码音频信号的质量可能会受到影响。这两种典型模式包括默认和掌声。当前模式是相异的,并且在这两种模式下,编码器根据信号的能量估计和不随信号水平变化的sv来估计掩蔽阈值,除了在结束时安静环境阈值的应用以外。默认模式附加地应用从mpeg层iii编码器继承的旧式(legacy)功能,但该功能的感知合理性并不充分。进一步地,掩蔽阈值被输入到速率控制环路,所述速率控制环路为多个比例因子带中的每一个选择比例因子(和量化水平)。因此,性能取决于掩蔽阈值估计与真实jnd噪声水平的接近程度。
154.在大多数现有技术模型中,在应用安静环境阈值之前,jnd所需smr的表达式与水平无关。此类模型通常基于相对响亮或相对安静的信号的掩蔽数据,但并非均为自适应地。这种方法可能会限制编解码器的性能,在一个示例中,因低估低水平信号成分的真实jnd阈值,从而导致向包含相对安静信号通道的帧过度分配比特。这一问题出现在运行在带有比特库的恒定比特率模式下的编码器以及可变比特率编码器中。由极其动态的水平变化表征的音频内容(例如语音)将受到不利影响。
155.现有技术模型的一个共同问题在于,这些模型产生的掩蔽阈值低于所需掩蔽阈值,从而还会导致频带内比特过度分配。相应地,这减少了其他频带的可用比特数,从而降低了经编码音频信号的质量。
156.本公开旨在通过提供单一模型来规避上述问题中的一些问题,所述单一模型通过估计更准确的smr来在大多数音频内容上表现得与现有技术的双模式模型或单模型相比一样好或更好。
157.使用单声道内容的主观听觉测试表明,新编码器在语音内容方面表现得优于当前编码器。此外,新编码器在可变比特率应用中明显更有效,在可变比特率应用中,编码器仅分配满足预定义质量目标所需的比特数,从而提供恒定的音频质量。
158.在一个实验中,使用三个编码器以及一组多样的音频测试项执行第一主观听觉测试以量化水平相关掩蔽的益处,其中一个编码器在默认模式下操作,一个编码器在掌声模式下操作,并且一个编码器使用水平相关掩蔽进行操作。相对于默认和掌声模式编码器,使用水平相关掩蔽的编码器的均值主观质量方面分别增加平均3个点和14个点。更重要的是,相对于默认编码器,水平相关掩蔽使两个语音项提高了平均8个点。
159.图7通过示例示出了分析部件700。如将在下文结合图8和图9进一步描述的,分析部件可以在编码器800或解码器900中实施。在其他实施例中,分析部件在单独的设备中实
施,并且例如连接到编码器或解码器。
160.分析部件700包括被配置为执行用于处理音频信号的方法以确定音频信号的频带的比特分配值的电路。该电路可以包括一个或多个处理器。
161.分析部件700被配置为执行将在下文例示的各种动作。
162.分析部件700被配置为确定s02输入音频信号的多个频带。多个频带各自包括一频率范围。应当注意,要编码的音频信号的多个频带中的每一个不一定需要具有相同的宽度/范围。在一个示例中,第一相对较低的频带的范围可以介于100hz至200hz之间,而另一个相对较高的频带的范围可以介于3000hz至3500hz之间。在一个实施例中,音频信号的频率范围可以为200hz至7000hz。进一步地,应当注意,音频信号有许多不同的频率范围,这些频率范围可以延伸到高于7000hz和/或低于200hz。如所理解的,存在确定音频信号的频带的不同方式。在一个实施例中,分析部件700被配置为根据等效矩形带宽erb尺度来确定s02频带。erb尺度给出了人类听觉系统的滤波器带宽的近似。此外,使用erb尺度提供了将滤波器建模为矩形带通滤波器的简化。
163.分析部件进一步被配置为使用每个频带的音频数据的以下分析来确定s18每个频带的比特分配值。
164.分析部件700确定s04频带的音频数据的能量值。能量值例如可以是频带化mdct能量。
165.进一步地,分析部件700确定s06频带的安静环境听觉阈值。在一个实施例中,分析部件700包括存储器部件或者连接到这种部件。存储器部件存储定义至少一些频率的安静环境听觉阈值的表。需要注意的是,这种存储器部件可以存储不同的信息。换言之,确定s06频带的安静环境听觉阈值可以包括使用定义至少一些频率的听觉阈值的预定义表。在一些实施例中,定义听觉阈值的预定义表可以是可替换的,从而允许在不影响解码器兼容性的情况下对编码器做出改进。
166.可以使用能量值和安静环境听觉阈值计算s08灵敏度值(sv)。应当理解,可以使用能量值和安静环境听觉阈值以不同方式计算s08 sv。sv可以例如使用能量值与安静环境听觉阈值之间的比率、或差异、或将能量值与安静环境听觉阈值进行比较的任何其他度量来被计算s08。应将灵敏度值理解为例如以db为单位定义的参量。
167.在一个实施例中,使用能量值与安静环境听觉阈值之间的差异(在本公开中也被称为“感觉水平”)来计算s10第一sv。可选地,可以通过将感觉水平乘以第一标量来计算s10第一sv。在一些实施例中,可以通过将第二标量与该差异乘以第一标量相加来计算s10第一sv。在该实施例中,频带的第一sv因此被计算为α*(频带能量-hthresh) β,其中α是第一标量,β是第二标量,频带能量是频带中的音频信号的能量值,并且hthresh是频带的安静环境阈值。在一些实施例中,为了降低复杂度,第二标量未被包括在sv的计算中。
168.第一sv随不同频带的能量值与安静环境阈值之间的差异而变化的程度通过检查各种测得掩蔽数据来确定。应该注意的是,作为示例,下文结合图1至图3描述的测量结果和图表是使用每个频带处的能量值与安静环境听觉阈值之间的差异(即感觉水平)来提供的。然而,本领域技术人员应理解,如果采用其他方式计算sv,例如使用每个频带的能量与安静环境听觉阈值之间的比率,则其他数据将从实验中产生。
169.图1通过示例示出了在不同声压级spl处200hz音调的测得掩蔽数据。掩蔽阈值
104、106、108、110、112相对于安静环境听觉阈值102(粗线)呈现。掩蔽阈值1 104涉及60db spl处的200hz音调。掩蔽阈值2 106涉及80db spl处的200hz音调。掩蔽阈值3 108涉及90db spl处的200hz音调。掩蔽阈值4 110涉及100db spl处的200hz音调。掩蔽阈值5 112涉及105db spl处的200hz音调。如从图1中可以看出的,音调掩蔽器(tone masker)的水平(即,在60db、80db、90db、100db和105db处,图1中没有具体示出,但是通过遵循竖直轴线上的标记从相应的声级到水平轴线上标记的200hz可以容易地看出)与200hz处的掩蔽阈值之间的差异随着音调掩蔽器的声音强度增加而增加。对于60db音调掩蔽器,该差异大约为18db(音调掩蔽器为60db,而掩蔽阈值104为42db),并且对于105db音调掩蔽器,该差异约为32db(音调掩蔽器为105db,而掩蔽阈值112为73)。
170.图2示出了500hz音调掩蔽器的类似图案。在图2中,相对于安静环境听觉阈值102(粗线)呈现了不同声压级spl(与图2中的水平相同,除了图2中未示出105db音调掩蔽器)处掩蔽数据的掩蔽阈值204、206、208、210。
171.在一个示例中,当考虑音调或正弦波信号时,测得掩蔽数据(即,如图1和2中例示的)可以用于得到灵敏度值sv与感觉水平的关系。如所理解的,除了图1至图2中例示的参数之外,还存在可以用于得到所需sv的其他可能参数。在该示例中,考虑了用于对正弦波掩蔽器频率处听觉临界频带内的伪像进行编码的掩蔽。
172.图3通过示例示出了smr模型,所述smr模型作为对不同音调感觉水平和频率的音调掩蔽窄带噪声的合并。利用直线模型302将smr呈现为感觉水平的函数。直线模型302是对测得smr曲线1至6的合并,所述曲线1至6在图3中被称为304、306、310、312、314、316。曲线1 304示出了频率为200hz的信号的测得smr值。曲线2 306示出了频率为500hz的信号的测得smr值。曲线3 310示出了频率为500hz的另一个信号的测得smr值。曲线4 312示出了频率为1000hz的信号的测得smr值。曲线5 314示出了频率为2000hz的信号的测得smr值。曲线6 316示出了频率为5000hz的信号的测得smr值。
173.图3示出了针对该示例,对于200hz至4,000hz的频率范围,smr对感觉水平的斜率0.35db*(在该频率下相对于安静环境阈值的掩蔽器水平) 3db可能是合理的近似。然而,需要注意的是,对于其他频率范围,图3中的直线模型302可能是合理的近似。在该示例中,所需smr的分贝偏移在中水平处变化多达10db,但在高水平和低水平处变化显得收敛。
174.在一些实施例中,可以通过将低于4khz的所有频带的阈值设置为全局最小阈值来修改安静环境阈值。当编码时,应将安静环境阈值设置为每个频带内的最小值。例如,在具有自适应块切换的变换编解码器中,最短变换块的最低频带可以为750hz宽。如从图1至图2中可以看出的,安静环境听觉阈值水平(以db为单位)从20hz至750hz迅速地下降。然后,可以将该整个频带的阈值设置为750hz处的实际安静环境阈值。将同样的步骤应用于最短块中的所有其他频带。随后对这些值进行插值,以获得所有其他变换块长度的安静环境阈值。这种方法确保所有块长度的安静环境阈值处于一致水平,并且在编解码器切换变换长度时避免不期望的量化噪声调制伪像。另一种更简单的方法是将低于4khz的所有频带的阈值设置为全局最小阈值。如本领域技术人员所理解的,使用这种经调整的安静环境阈值将产生第一和/或第二标量的其他值。
175.应该注意的是,图1至图2中的安静环境阈值被保守地设置为比105db spl峰值回放水平的传统假设下的阈值低20db。在一个实施例中,基于115db峰值回放水平来设置阈
值。当以不同于假设水平的水平播放经解码音频时,这提供了一定程度的鲁棒性,尤其是对于可变比特率应用。
176.图3中的模型是通过对各种频率的音调掩蔽窄带噪声实验结果求平均而得到的。感觉水平越高的信号成分接收越高的sv。在一个示例中,频带能量值每高于安静环境听觉阈值3db,sv就增加1db。图3中频带j的水平相关sv模型sv(j)被表示为:
177.sv(j)=max(0,0.35*(eb(j)
–
q(j)) 3)
178.其中,eb(j)和q(j)(在本示例中以db标识)分别为频带化mdct能量和安静环境阈值。
179.如所理解的,通过改变分析部件的配置来改变上述等式中呈现的标量将是明显的。可以修改标量来调整sv的计算,以更好地适合一些音频信号。第一标量的范围例如可以介于0.2与0.5之间。第二标量的范围例如可以介于2.5与3.5之间。
180.在图3的模型中,在所有频带上,第一标量和第二标量是恒定的。然而,在其他实施例中,第一标量和/或第二标量是频率相关的。
181.如图3所示,在一个实施例中,计算s10第一sv,并将其用作频带的sv。
182.在一个实施例中,图3中的直线模型302被延伸以更准确地估计具有高水平噪声的输入信号的sv。具有高水平噪声的输入信号的一些示例可以是掌声、或雨声或语音齿擦音(speech sibilant)。然而,如所理解的,许多信号都带有高水平噪声。举例来说,在使用与音调掩蔽噪声情况相同的方法时,可以更准确地计算某些信号的sv。
183.在第二实施例中,建议在高水平噪声下在sv与感觉水平之间存在相同的直线关系,但是具有不同的斜率。最佳拟合线的斜率大致是音调掩蔽噪声情况的一半。这种对应关系已经使用如图1至图3所示的类似实验进行了验证,只是用噪声掩蔽器代替了音调掩蔽器。因此,可以通过取决于输入信号特性适配sv规则来实现一般性模型。
184.因此,在一个实施例中,计算s12可选的第二sv,并可选地使用固定或自适应加权组合将第二sv与第一sv相组合,以定义最终sv。在这些实施例中,分析部件700被进一步配置成在计算s08频带的sv时,使用确定s04的能量与确定s06的安静环境听觉阈值之间的差异(感觉水平)来计算s12第二sv,并且基于输入音频信号的至少一个确定s14的特性对第一sv和第二sv进行加权。正如所理解的,音频信号的任何合适的特性都可以用于计算s08 sv。在一个实施例中,至少有一个特性是信号的经估计调性。替代性地,在一个实施例中,至少有一个特性是信号的经估计噪声水平。
185.在一个实施例中,经估计调性是使用从音频信号的频带计算的频率系数的自适应预测来计算的。下文将描述用于估计音频信号的调性的实施例。
186.正如所理解的,可以使用任何一组频率系数。举例来说,一种现有技术方法基于跨时间对dft幅值和相位的2阶固定预测(iso/iec 11172-3:1993(e),“information technology-coding of moving pictures and associated audio for digital storage media at up to about 1.5mbit/s-part 3:audio(信息技术-以高达约1.5兆比特/秒编码数字存储介质的运动图片和相关联音频-第3部分:音频)”)。根据该方法,为了实现不同频率的不同时间/频率分辨率折衷,并行计算长度512和128(即,复dft系数的数量)的交叠dft。分析部件700可以将现有技术方法一般化为使用复mdct(cmdct)系数的自适应线性预测。在一些实施例中,线性预测编码(lpc)可以基于计算mdct系数所根据的音频信号的频带
而自被适应地应用于mdct系数。相比固定预测,自适应线性预测允许有声语音(voiced speech)和音乐中的迅速演变的中间范围谐波生成更高的调性估计。此外,可以通过根据频率改变lpc分析窗口长度和/或预测阶数来灵活地实现期望的可变时间/频率框架,而不需要并联的cmdct滤波器组。换句话说,可以根据频带改变lpc分析窗口长度。进一步地,也也可以根据频带改变lpc的预测阶数。可以通过最大化质询信号(challenging signal)和独立且等同分布(iid)的高斯噪声的平均预测增益方面的差异来离线选择每个频带的最优lpc分析参数。质询信号的示例可以是语音或羽管键琴。然而,应当理解,有许多不同的信号可以被分类为质询信号。最长的lpc分析窗口通常在低频下使用,而渐进变短的lpc分析窗口在较高频率下使用。换句话说,相对较长的lpc分析窗口可以用于相对较低的频带,以便捕获这种信号的较长周期性。lpc分析参数提供了用于控制编码器的量化噪声整形特性的灵活手段。
187.下文将结合图6进一步描述如何估计音频信号的调性的实施例。
188.在一些实施例中,第一sv和第二sv的加权基于调性估计t。t是范围从针对纯噪声信号的0到针对纯正弦波和稀疏谐波信号成分的1的连续变量。因此,可以将第一sv和第二sv以总和为一的权重混合为线性组合,其中权重取决于t。换句话说,基于音频信号的至少一个特性对第一sv和第二sv进行加权可以包括计算表示权重的值,该值的范围介于0至1之间,其中计算s08频带的sv的步骤包括将第一sv和第二sv中的一个与该值相乘,并将第一sv或第二sv中的另一个与一减该值相乘,并将这两个所得总数加在一起以形成s08频带的sv。
189.应当理解,可以通过修改标量以不同方式修改计算s08 sv的函数。
190.在一个实施例中,分析部件704被配置为在计算s12第二sv时使用第三标量。
191.举例来说,可以通过将差异乘以不同于第一标量的第三标量来计算s12第二sv。应当理解,可以为第三标量指派不同的值。第三标量可以例如是范围介于0.05与0.2之间的值。第三标量的范围可以介于0.1与0.15之间。
192.在一个实施例中,分析部件704被配置为在计算s12第二sv时使用第四标量。
193.举例来说,可以通过将第四标量和差异与第三标量的乘积相加来计算s12第二sv,第四标量不同于第二标量。应当理解,可以为第四标量指派不同的值。第四标量的范围可以例如介于3.5与4.5之间。第四标量通常根据安静环境阈值来设置。
194.应该注意的是,第二标量和第四标量可取决于安静环境阈值的设置而有很大差异。这些术语的一个重要方面在于,它们允许对换分配给音调信号和类噪声信号的比特数。它们还可以用于校准模型,使得精确分配给掩蔽阈值的水平和形状的噪声对于普通听众来说是刚好可察觉的。
195.在一个实施例中,分析部件被配置为通过将差异乘以0.15并将4与结果相加来计算s12第二sv。
196.然后,举例来说,可以将总体sv计算s08为纯正弦波和纯噪声信号的sv规则的加权组合,例如:
197.sv(j)=max(0,t*(0.32*(eb(j)
–
q(j)) 3) (1-t)*(0.13*(eb(j)
–
q(j)) 4)).
198.图5示出了三种不同信号类型的sv对感觉水平模型。音调sv模型502描绘了t=1的信号的模型行为。噪声sv模型504描绘了t=0的信号的模型行为。混合音调和噪声sv模型506描绘了t=0.65时的模型行为。
199.相应地,分析部件700可以被配置为在音调掩蔽模型与噪声掩蔽模型之间融合。换句话说,对于非常类似于音调的信号,编码器将主要使用适合类音调信号的配置。对于非常类似于噪声的信号,编码器将主要使用适合类噪声信号的配置。对于介于之间的信号,编码器将使用所述配置的融合,其中类音调配置和类噪声配置的比例取决于带内(in-band)调性。
200.回到图7;使用灵敏度值和能量值,然后可以计算s16掩蔽阈值,所述掩蔽阈值随后可以与能量值相组合用于确定s18频带比特分配值。
201.有利的是,分析部件700通过从信号能量或基于信号能量计算的值减去可变偏移(灵敏度值)来计算s16掩蔽阈值。如上所述,可变偏移基于例如能量值与安静环境听觉阈值之间的差异(感觉水平)。具体来说,可变偏移随着感觉水平的增大而增大,并且反之亦然。这种掩蔽阈值计算方式提供了与主观测量的掩蔽数据的更好匹配,并且因此导致比特分配的改善。对于较高水平信号,经解码音频信号的主观质量的改善可能是最明显的。对于较安静的信号,使用水平独立偏移的现有技术模型产生的掩蔽阈值低于必要值,从而导致比特的过度分配,并且因此减少其他频带和包含较响信号成分的其他帧的可用比特数。
202.相比之下,现有技术模型通常简单地通过从带内信号能量减去固定偏移来确定掩蔽阈值。例如,在一些情况下,无论频带能量与听觉阈值有多接近,都使用相同偏移。相反,分析部件700通过从信号能量减去可变偏移来确定掩蔽阈值。
203.可以按不同的方式计算s16掩蔽阈值。在一个实施例中,计算掩蔽阈值包括对以下各项中的一个应用扩展函数:频带的线性能量值;或频带的经变换能量值。换句话说,在一个实施例中,对频带的能量值应用扩展函数。在另一个实施例中,在应用扩展函数之前,首先对能量值进行变换。该变换可以包括通过将能量值提升到~0.25次幂至0.3次幂来将线性能量值变换到响度域。该变换还可以包括将能量值提升到0.5次幂至0.6次幂,已经发现这会为一些音频格式提供甚至更好的音质。
204.由此,为频带确定激励值。随后,将激励值与灵敏度值进行组合,以计算掩蔽阈值。在db尺度中,灵敏度值和激励值的组合包括从激励值减去灵敏度值。在强度域中,用除法来代替。
205.在另一个实施例中,在组合能量值和灵敏度值以确定中间阈值之后应用扩展函数。在该实施例中,计算掩蔽阈值包括将能量值与灵敏度值相组合以确定中间阈值,以及对中间阈值应用扩展函数以确定掩蔽阈值。
206.可选地,对于所有上述实施例,通过用安静环境阈值进行阈值化来得出掩蔽阈值,例如掩蔽阈值=max(掩蔽阈值,安静环境听觉阈值)。
207.在一个实施例中,频带的扩展函数取决于感觉水平,使得扩展函数在具有相对较高感觉水平的频带中的效果相比于扩展函数在于具有相对较低感觉水平的频带中的效果而言较大。通常,扩展函数是在绝对spl尺度上定义的。使用用于定义扩展函数的替代方法可以提供更一般化的心理声学模型,而仅引起最小的附加计算复杂度。迄今为止,许多编码器似乎都应用了最适合安静信号的扩展函数。这是一种保守的设计方法,但对于较响亮的信号,频域掩蔽的程度将被低估,这可能导致某些频带中所分配的比特多于所需比特,从而相应地为其他频带留下较少可用比特并且可能导致质量降低。相应地,分析部件700可以被配置为定义用于频带的取决于确定s04的能量值与确定s06的安静环境听觉阈值之间的差
异的扩展函数,从而导致比特分配的改善。
208.在一些实施例中,确定s18频带的比特分配值包括计算频带的smr,smr是频带的能量值减去频带的计算s16的掩蔽阈值。在一些实施例中,减去另外的固定偏移。然后,确定s18比特分配值是基于smr的参量。在一些实施例中,在所定义的最大比特分配值(例如12比特)处阈值化比特分配值。
209.在一些实施例中,确定s18比特分配值包括调整s20掩蔽阈值以实现满足音频信号的目标比特率的比特分配。调整s20掩蔽阈值可以包括通过在响度域中向掩蔽阈值添加恒定偏移直到音频信号的目标比特率得到满足来调整掩蔽阈值。如上所述,从线性能量域变换到响度域包括将每个能量提升到~0.25次幂至0.3次幂。
210.通常,与具有较高sv的频带会具有较低sv的情况相比,分析部件700为具有较高sv的频带指派s18更多比特(当sv以db为单位被定义为对激励函数的减法调整时)。
211.在一些实施例中,分析部件700可以在编码器800中实施。图8中示出了这种实施例。在这一实施例中,编码器800包括被配置为接收音频信号806的接收部件802。编码器进一步包括编码部件804,所述编码部件被配置为使用由分析部件700确定s18用于编码目的的比特分配值。举例来说,编码部件804被配置为响应于比特分配值而量化频带的音频数据的音频样本,并将频带的经量化音频数据编码成比特流808。在一些实施例中,编码器800进一步包括压缩扩展部件(未示出),所述压缩扩展部件被配置为在量化频带的音频数据的音频样本之前使用压缩扩展算法来减小音频信号的动态范围。在变换编码之前,压缩扩展特征减小输入信号的动态范围。压缩扩展特征可以有益于包含如雨声和掌声等密集瞬变混合的信号的经编码质量。在一个示例中,输入信号压缩扩展和仅计算s10第一sv并使用s08所述第一sv作为sv的实施例可以协同工作,以产生比单独任一特征的情况下更高的性能。在这一实施例中,在使用相关联sv对音频信号进行编码的步骤之前,使用压缩扩展算法减小音频信号的动态范围。压缩扩展特征可以进一步减小要编码的比特数,同时仍然保持高音频质量。
212.在一些实施例中,分析部件700在解码器900中实施。图9中示出了此实施例。在这一实施例中,解码器900包括接收部件902,所述接收部件被配置为接收经编码比特流形式的音频信号906,所述经编码比特流包括音频信号的频带的经编码能量值。解码器进一步包括解码部件904,所述解码部件被配置为使用由分析部件700确定s18用于解码目的的比特分配值。解码部件904被配置为解码来自经编码比特流906的经编码能量值,其中分析部件700在确定能量值时使用经解码能量值。解码部件904被进一步配置成响应于比特分配值而从经编码比特流906中提取频带的音频数据的经量化音频样本。解码部件904被进一步配置成去量化频带的音频数据的经量化音频样本,并且组合每个频带的音频数据的经去量化音频样本以生成经解码音频信号908。
213.需要注意的是,分析部件700和对应方法可以用于任何音频格式。
214.使用本发明的方法进行的掩蔽提供了与主观测量掩蔽数据的更好匹配,并且因此导致比特分配的改善。使用计算s10的第一sv作为频带的sv的实施例提供了优于用于语音信号的默认编码器的最多改进。这是重要的,因为语音信号是常见广播和电影内容的非常关键的元素。
215.在一些实施例中,实施此实施例(或者替代性地,也计算s12第二sv的实施例)的编
码器800和/或解码器900在实时双向通信设备中被实现。有利的是,给定这种编码方法的较低复杂度,在这种设备中可以采用更简单的实施例。然而,需要注意的是,存在编码器800和/或解码器900的许多应用和可能的用途。
216.因此,编码器800准确地捕捉人类听觉系统的观察到的掩蔽行为。对于恒定比特率应用和可变比特率应用两者,这导致比默认编码器更高的编解码器性能。
217.在一些实施例中,主观改善对于相对高水平的信号而言可能是最明显的,因为基于水平独立偏移(而非使用sv)来得到掩蔽阈值的默认编码器往往向低水平信号成分过度分配比特。
218.图4示出了上述计算掩蔽阈值的示例性方法的概述,其中,使用调性估计对第一sv和第二sv进行加权。如图4所示,输入音频帧被输入到mdct滤波器组。输入到mdct滤波器组的(多个)变换长度还由调性估计单元接收(下文将结合图6进一步描述)。调性估计单元每个mdct变换一组地输出范围为0至1的调性估计tj(m),如下文进一步描述的。在这种命名法(nomenclature)中,j是频带索引,m是mdct块索引。
219.mdct变换系数用于确定每个频带的能量值。对频带的能量值应用扩展函数,以得到激励函数。在图4的示例性方法的最后步骤中,如本文所述,能量值和安静环境阈值用于计算第一sv和第二sv,然后通过调性估计tj(m)对第一sv和第二sv进行加权并将其应用于激励值,以最终产生每个频带的掩蔽阈值。
220.现在将结合图6描述基于自适应预测的调性估计方法的实施例。
221.输入帧602提供输入样本。滤波器组604被配置为从输入帧602接收输入样本。需要注意的是,可以使用不同的滤波器组604。在一个示例中,使用cmdct,其中n=128。在另一个示例中,可以使用cqmf,其中n=64。滤波器组604被配置为向lpc分析部件608和不可预测性估计部件605发送复频率系数606(xk(n),在时间n处的频带k)。对每个cmdct/cqmf频带重复图6的结构。lpc分析部件608结合不可预测性估计部件605被配置为提供与频率系数606相对应的一组不可预测性值609(μk(n))。
222.考虑到一个cmdct块中的时间样本会影响三个毗邻cmdct块的事实,在两级(two-stage)平滑级620中使用3抽头(3-tap)fir滤波器来平滑不可预测性估计。这提高了调性估计(以及因此同样经解码音频)的平滑度。为其他滤波器组采用类似的方法,例如cqmf,其中n=64。
223.映射部件610被配置为接收经平滑的不可预测性值、变换长度612和频带的能量(由图6中的框611计算)。在对不可预测性估计进行平滑之后,它们被跨时间地组合在一起,以反映它们稍后将被应用到的mdct窗的非零部分。尤其对于动态变化的信号(如语音),这可能是重要的,从而最大化经解码输出信号的清晰度。映射部件610被进一步配置成将经映射的输入数据613(zk(n))作为输出数据发送给扩展和归一化部件614。扩展和归一化部件614被配置为将扩展函数应用于输入数据613,并将一组经修改的数据615(uk(n))发送给调性映射部件616。调性映射部件616被配置为将输入数据615(不可预测性)映射到一组或多组音调估计618。
224.进一步了解图6的更多细节,根据一些实施例,将正弦窗口应用于从一个长度为4096的帧602中取得的输入样本的50%交叠块,继之以128点(128-pt)cmdct。滤波器组604的选择并非至关重要的;例如,还可以使用已知编码器中已有的复qmf滤波器组604。对于来
自块604的一组复频率系数606,xk(n),k=1,...,n,生成对应的一组不可预测性值609。频带k在时间n处的不可预测性μk(n)被定义为
[0225][0226]
其中,
[0227][0228]aki
是第k个频带的一组pk复预测系数,并且pk是相同频带的lpc预测阶数。对于纯音调和纯噪声,不可预测性值μk(n)609的范围分别为从0到1。
[0229]
在每个cmdct频率仓(bin)k中,一组lk个连续系数xk(n-m),m=1,...,lk被加窗并进行分析,以产生pk阶(pk《lk)复预测系数。预测系数a
ki
,i=1,...pk,随后用于计算与xk(n)相对应的不可预测性值609。在所评估的各种lpc分析窗口中,发现了近似对称汉明窗口,以最大化预测增益。不对称程度根据cmdct仓而变化。然后,所有频带的不可预测性值被一组两级平滑滤波器620过滤,以避免跨时间的突然变化。示例两级滤波器包括与传统指数平滑滤波器级联的3抽头fir。fir滤波器接收不可预测性值609μk(n)并产生部分平滑的输出信号μk′
(n)。然后,指数平滑滤波器对fir输出信号进行进一步处理以产生μk″
(n)。
[0230]
在一个实施例中,快起音(fast-attack)、慢衰减(slow-decay)iir滤波器可以用于指数平滑滤波器。这些滤波器提供了用于独立控制起音和衰减时间的手段。输入在调性域(1-μk′
(n))中,并且差分方程由下式给出:
[0231]
yk(n)=max((1-μk′
(n)),βkyk(n-1))
[0232]
tk″
(n)=α
tkt
″
(n-1) (1-αk)yk(n)
[0233]
μk″
(n)=1-tk″
(n)
[0234]
其中,αk和βk分别是频带k的起音系数和衰减系数,tk″
(n)是经平滑调性估计,并且yk(n)是中间状态变量。起音和衰减时间常数通常根据频带数而变化。在上述第三个等式中,快起音、慢衰减滤波器的输出被转换回不可预测性,用于随后在610中处理。
[0235]
在未平滑的情况下,调性估计趋向于跨连续变换块波动,从而导致掩蔽阈值估计的波动。这进而可能导致解码器输出中的可听见量化噪声调制,尤其是在低频到中频。有效解决这个问题的方法是根据人类听觉滤波器的已知时间特性来设计起音/衰减滤波器系数。这种方法导致起音/衰减时间常数通常为低频处最长且高频处最短。
[0236]
在图6的下一阶段,来自所有cmdct块的cmdct仓能量和经平滑的不可预测性值被重新采样并组合成(经映射)组610,以匹配当前帧中每个mdct变换的时间和频率分辨率。重新采样后的不可预测性值613根据其自身相对感知重要性进行加权,并根据需要跨时间进行组合。示例感知权重包括l2范数平方(能量)和响度。接下来,为了匹配应用于频带化mdct能量的扩展,通过应用例如来自iso/iec 11172-3:1993(e)的扩展函数614,跨频率扩展不可预测性值。在最后一步中,将重新采样、扩展和归一化的不可预测性值615被映射616到范围从0到1(包括0和1)的一组或多组调性估计618,每个mdct变换对应一组音调估计。
[0237]
图10示出了作为各种音调 窄带噪声混合比(snr)的函数的jnd的实验测量sv的示例结果。500hz 804、1khz 802和4khz 806的中心频率用于范围从﹣10db到40db的掩蔽器
snr。以80db的spl水平将掩蔽器呈现给受试者。平均曲线808(粗线)代表跨所有三个中心频率的ta sv平均值。
[0238]
在实施例中,至少部分基于混合音调 窄带噪声信号的感知掩蔽实验结果来校准另一个调性映射函数(不同于iso/iec 11172-3:1993中的调性映射规则)。该实施例的目的是确定由音调 窄带噪声混合构成的掩蔽器和由相同频率下的不相关窄带噪声构成的被掩蔽器(maskee)的jnd水平。在各种掩蔽器音调/噪声混合水平和各种频率下重复所述实验。如下文所述,实验结果可以用于校准调性映射。
[0239]
在一个实施例中,首先,每个音调 窄带噪声刺激被注入调性估计器中,以捕获相关联的不可预测性值。根据这些结果,生成将每个不可预测性值与所需smr相关联的表。通过将该表和与smr范围匹配的音调 窄带噪声掩蔽的调性-smr规则相结合,在定义校准模型所需的不可预测性到调性的映射的曲线上得到点。在最后一步中,得到近似所得到的校准曲线的参数函数。可以在各种频率和输入信号水平下重复掩蔽实验和校准步骤。
[0240]
图11通过示例示出了一个实施例的实验结果。其呈现了近似具有正弦窗口和50%交叠的128点cmdct的所得到的校准曲线的目标校准曲线904和参数模型/函数902(虚点线)。图中包含了现有技术示例用于比较(虚线906)在该示例中,lpc分析是第3阶,窗口长度为6。在该实施例中,参数函数t(μ)根据下式将不可预测性映射到调性:
[0241]
t(μ)=min(max(a*μ3 b*μ2 c*μ d,0),1)
[0242]
得到四个参数(a,b,c,d)的值以近似目标校准曲线。在图11所示的示例中,a、b、c和d的模型参数值为﹣13.0233、15.9513、﹣8.1012、2.1319。
[0243]
尽管在感知模型中采用调性估计在现有技术(iso/iec 11172-3:1993(e),图11中的虚线906)中是众所周知的,但是现有技术的模型以水平独立方式操作。在iso/iec 11172-3:1993(e)中,对于纯噪声和音调信号,smr模型分别基于6db与大约30db之间的估计调性来调整。本文描述的具有校准调性映射函数的水平相关模型已经在仿真中实现,并且如通过客观质量测量和听觉测试确定的,该模型优于现有技术模型。
[0244]
在研究了以上描述之后,本公开的进一步实施例对于本领域技术人员将变得显而易见。尽管本说明书和附图公开了实施例和示例,但是本公开不限于这些具体示例。在不脱离由所附权利要求限定的本公开的范围的情况下,可以做出许多修改和变化。在权利要求中出现的任何附图标记不应被理解为限制其范围。
[0245]
另外地,通过对附图、本公开和所附权利要求的研究,本领域技术人员在实施本公开时可以理解和实现所公开的实施例的变型。在权利要求中,词语“包括”并不排除其他要素或步骤,并且不定冠词“一个(a)”或“一种(an)”并不排除复数。在相互不同的从属权利要求中陈述某些措施的简单事实并不表明这些措施的组合不能被有利地利用。
[0246]
上文所公开的系统和方法可以被实施为软件、固件、硬件或其组合。在硬件实施方式中,以上描述中所提及的功能单元之间的任务划分不一定对应于物理单元的划分;相反,一个物理部件可以具有多个功能,并且一个任务可以由若干个物理部件协作地执行。某些部件或所有部件可以被实施为由数字信号处理器或微处理器执行的软件,或者被实施为硬件或专用集成电路。这种软件可以分布在计算机可读介质上,所述计算机可读介质可以包括计算机存储介质(或非暂态介质)和通信介质(或暂态介质)。如本领域技术人员所熟知的,术语计算机存储介质可以包括以用于存储如计算机可读指令、数据结构、程序模块或其
他数据等信息的任何方法或技术实施的易失性和非易失性、可移除和不可移除的介质。计算机存储介质包括但不限于:ram、rom、eeprom、闪速存储器或其他存储器技术、cd-rom、数字通用盘(dvd)或其他光盘存储设备、磁带盒、磁带、磁盘存储或其他磁性存储设备、或可以用于存储期望信息并且可以被计算机访问的任何其他介质。进一步地,本领域技术人员所熟知的是,通信介质通常以如载波等经调制数据信号或其他传输机制的形式来实施计算机可读指令、数据结构、程序模块或其他数据,并且包括任何信息传递介质。
[0247]
可以从以下枚举的示例实施例(eee)中理解本公开的各个方面:
[0248]
eee1.一种用于处理音频信号的方法,所述音频信号包括多个频带中的音频数据,所述方法包括
[0249]
对于所述多个频带中的每个频带:
[0250]
确定所述频带的音频数据的能量值;
[0251]
确定所述频带的安静环境听觉阈值;
[0252]
使用所述能量值和所述安静环境听觉阈值来计算所述频带的灵敏度值sv;
[0253]
使用所述灵敏度值和所述能量值来计算所述频带的掩蔽阈值;
[0254]
使用所述能量值和所述掩蔽阈值来确定所述频带的比特分配值。
[0255]
eee2.如eee1所述的方法,其中,计算所述掩蔽阈值包括对以下各项之一应用扩展函数:
[0256]
所述频带的能量值;或
[0257]
所述频带的变换能量值;
[0258]
以确定所述频带的激励值,
[0259]
以及将所述灵敏度值与所述激励值相组合。
[0260]
eee3.如eee1所述的方法,其中,计算所述掩蔽阈值包括将所述能量值与所述灵敏度值相组合以确定中间阈值,以及对所述中间阈值应用扩展函数以确定所述掩蔽阈值。
[0261]
eee4.如任一前述eee所述的方法,进一步包括响应于所述比特分配值而量化所述频带的音频数据的音频样本。
[0262]
eee5.如eee4所述的方法,进一步包括将所述频带的经量化音频数据编码成比特流。
[0263]
eee6.如eee1至eee3中任一项所述的方法,其中,所述音频信号是包括所述频带的经编码能量值的经编码比特流,并且其中,确定所述频带的音频数据的能量值包括根据所述经编码比特流对所述经编码能量值进行解码。
[0264]
eee7.如eee6所述的方法,进一步包括响应于所述比特分配值而从所述经编码比特流中提取所述频带的音频数据的经量化音频样本。
[0265]
eee8.如eee7所述的方法,进一步包括对所述频带的音频数据的经量化音频样本进行去量化,以及组合每个频带的音频数据的去量化音频样本以生成经解码音频信号。
[0266]
eee9:如任一前述eee所述的方法,其中,确定所述比特分配值包括调整所述掩蔽阈值以实现满足所述音频信号的目标比特率的比特分配。
[0267]
eee10.如eee9所述的方法,其中,调整所述掩蔽阈值包括:
[0268]
通过在响度域中向所述掩蔽阈值添加恒定偏移量直到满足所述音频信号的目标比特率来调整所述掩蔽阈值。
[0269]
eee11.如任一前述eee所述的方法,其中,所述能量值、安静环境听觉阈值和掩蔽阈值以分贝db为单位定义。
[0270]
eee12.如任一前述eee所述的方法,进一步包括根据等效矩形带宽erb尺度来确定所述音频信号的多个频带的步骤。
[0271]
eee13.如eee2或从属于eee2的任一前述eee所述的方法,其中,所述sv以db为单位被定义为对所述激励值的减法调整,其中,确定比特分配值的步骤包括为具有较高sv的频带分配比所述具有较低sv的频带更多的比特。
[0272]
eee14.如任一前述eee所述的方法,其中,计算所述频带的sv的步骤包括使用感觉水平计算第一sv,所述感觉水平是所述能量值与所述安静环境听觉阈值之间的差异,以db为尺度。
[0273]
eee15.如eee14所述的方法,其中,计算第一sv的步骤包括将所述感觉水平乘以第一标量。
[0274]
eee16.如eee15所述的方法,其中,所述第一标量是频率相关的。
[0275]
eee17.如eee15所述的方法,其中,所述第一标量在所有频带上是恒定的。
[0276]
eee18.如eee15至eee17中任一项所述的方法,其中,计算第一sv的步骤包括将第二标量与所述感觉水平乘以所述第一标量相加。
[0277]
eee19.如eee14至eee18中任一项所述的方法,其中,计算sv的步骤包括使用所述第一sv作为所述频带的sv。
[0278]
eee20.如eee14至eee18中任一项所述的方法,其中,计算所述频带的sv的步骤包括使用所述感觉水平计算第二sv,以及基于所述音频信号的至少一个特性对所述第一sv和所述第二sv进行加权。
[0279]
eee21.如eee20所述的方法,其中,计算所述频带的第二sv的步骤包括将所述感觉水平乘以不同于所述第一标量的第三标量。
[0280]
eee22.如eee21所述的方法,其中,计算第二sv的步骤包括将第四标量与所述感觉水平乘以所述第三标量相加,所述第四标量不同于所述第二标量。
[0281]
eee23.如eee20至eee22中任一项所述的方法,其中,基于所述音频信号的至少一个特性对所述第一sv和所述第二sv进行加权的步骤包括计算表示权重的值,所述值的范围介于0至1之间,其中,计算所述频带的sv的步骤包括将所述第一sv和所述第二sv中的一者乘以所述值,并将所述第一sv或所述第二sv中的另一者乘以一减去所述值的差异,并将两个结果相加,得出所述频带的sv。
[0282]
eee24.如eee20至eee23中任一项所述的方法,其中,所述至少一个特性定义所述音频信号的频带的估计调性。
[0283]
eee25.如eee20至eee23中任一项所述的方法,其中,所述至少一个特性定义所述音频信号的频带中的估计噪声水平。
[0284]
eee26.如eee24所述的方法,其中,所述估计调性是使用根据所述音频信号的频带计算的频率系数的自适应预测来计算的。
[0285]
eee27.如eee26所述的方法,其中,线性预测编码lpc基于计算mdct系数所根据的所述音频信号的频带而自适应地应用于所述mdct系数。
[0286]
eee28.如eee27所述的方法,其中,lpc分析窗口长度根据所述频带而变化。
[0287]
eee29.如eee28所述的方法,其中,相对较长的lpc分析窗口用于相对较低的频带。
[0288]
eee30.如eee27至eee29中任一项所述的方法,其中,所述lpc的预测阶数根据所述频带而变化。
[0289]
eee31.如前述eee中任一项所述的方法,其中,所述音频信号的频率范围介于200hz至7000hz之间。
[0290]
eee32.如前述eee中任一项所述的方法,其中,确定所述频带的安静环境听觉阈值的步骤包括使用定义至少一些频率的听觉阈值的预定义表。
[0291]
eee33.如eee4或从属于eee4的任何其他eee所述的方法,其中,在量化所述频带的音频数据的音频样本之前,使用压缩扩展算法减小所述音频信号的动态范围。
[0292]
eee34.如eee14或当从属于eee14时eee15至eee33中任一项所述的方法,进一步包括以下步骤:根据所述感觉水平定义所述频带的扩展函数,使得扩展函数在具有相对较高感觉水平的频带中的效果大于所述扩展函数在具有相对较低感觉水平的频带中的效果。
[0293]
eee35.一种设备,包括:
[0294]
被配置为接收音频信号的接收部件,所述音频信号包括多个频带中的音频数据;被配置为确定所述音频信号的多个频带的分析部件;
[0295]
所述分析部件进一步被配置为对于所述多个频带中的每个频带;
[0296]
确定所述频带的音频数据的能量值;
[0297]
确定所述频带的安静环境听觉阈值;
[0298]
使用所述能量值和所述安静环境听觉阈值来计算所述频带的灵敏度值sv;
[0299]
使用所述灵敏度值和所述能量值来计算所述频带的掩蔽阈值;
[0300]
使用所述能量值和所述掩蔽阈值来确定所述频带的比特分配值。
[0301]
eee36.如eee35所述的设备,其中,所述分析部件被配置为通过对以下各项之一应用扩展函数来计算所述掩蔽阈值:
[0302]
所述频带的能量值;或
[0303]
所述频带的变换能量值;
[0304]
以确定所述频带的激励值,
[0305]
以及将所述灵敏度值与所述激励值相组合
[0306]
eee37.如eee35所述的设备,其中,所述分析部件被配置为通过将所述能量值和所述灵敏度值相组合以确定中间阈值,并对所述中间阈值应用扩展函数以确定所述掩蔽阈值来计算所述掩蔽阈值。
[0307]
eee38.如eee35至eee37中任一项所述的设备,所述设备为编码器,所述设备进一步包括编码部件,所述编码部件被配置为响应于所述比特分配值而量化所述频带的音频数据的音频样本。
[0308]
eee39.如eee38所述的设备,其中,所述编码部件进一步被配置为将所述频带的经量化音频数据编码成比特流。
[0309]
eee40.如eee35至eee37中任一项所述的设备,所述设备为编码器,其中,所述音频信号是包括所述频带的经编码能量值的经编码比特流,所述设备进一步包括解码部件,所述解码部件被配置为根据所述经编码比特流对所述经编码能量值进行解码,其中,所述分析部件在确定所述能量值时使用所述经解码能量值。
[0310]
eee41.如eee40所述的设备,其中,所述解码部件被配置为响应于所述比特分配值而从所述经编码比特流中提取所述频带的音频数据的经量化音频样本。
[0311]
eee42.如eee41所述的设备,其中,所述解码部件进一步被配置为对所述频带的音频数据的经量化音频样本进行去量化,并且组合每个频带的音频数据的去量化音频样本,以生成经解码音频信号。
[0312]
eee43.如eee35至eee42中任一项所述的设备,其中,所述分析部件被配置为:在确定所述比特分配值时,调整所述掩蔽阈值以实现满足所述音频信号的目标比特率的比特分配。
[0313]
eee44.如eee43所述的设备,其中,所述分析部件被配置为:在调整所述掩蔽阈值时,通过在响度域中向所述掩蔽阈值添加恒定偏移量直到满足所述音频信号的目标比特率来调整所述掩蔽阈值。
[0314]
eee45.如eee35至eee44中任一项所述的设备,其中,所述分析部件被配置为定义以分贝db为单位的能量值、安静环境听觉阈值以及掩蔽阈值。
[0315]
eee46.如eee35至eee45中任一项所述的设备,其中,所述分析部件被配置为根据等效矩形带宽erb尺度确定所述音频信号的多个频带。
[0316]
eee47.如eee36或当从属于eee36时eee37至eee46中任一项所述的设备,其中,所述sv以db为单位被定义为对所述激励值的减法调整,其中,所述分析部件被配置为通过为具有较高sv的频带分配比所述具有较低sv的频带更多的比特来确定比特分配值。
[0317]
eee48.如eee35至eee47中任一项所述的设备,其中,所述分析部件被配置为通过使用感觉水平计算第一sv来计算所述频带的sv,所述感觉水平是所述能量值与所述安静环境听觉阈值之间的差异,以db为尺度。
[0318]
eee49.如eee48所述的设备,其中,所述分析部件被配置为通过将所述感觉水平乘以第一标量来计算所述第一sv。
[0319]
eee50.如eee49所述的设备,其中,所述第一标量是频率相关的。
[0320]
eee51.如eee49所述的设备,其中,所述第一标量在所有频带上是恒定的。
[0321]
eee52.如eee49至ee51所述的设备,其中,所述分析部件被配置为通过将第二标量与所述感觉水平乘以所述第一标量相加来计算所述第一sv。
[0322]
eee53.如eee48至eee52中任一项所述的设备,其中,所述分析部件被配置为通过使用所述第一sv作为所述频带的sv来计算所述sv。
[0323]
eee54.如eee48至eee52中任一项所述设备,其中,所述分析部件被配置为通过使用所述感觉水平进一步计算第二sv,以及基于所述音频信号的至少一个特性对所述第一sv和所述第二sv进行加权来计算所述频带的sv。
[0324]
eee55.如eee54所述的设备,其中,所述分析部件被配置为通过将所述感觉水平乘以不同于所述第一标量的第三标量来计算所述频带的第二sv。
[0325]
eee56.如eee55所述的设备,其中,所述分析部件被配置为通过将第四标量与所述感觉水平乘以所述第三标量相加来计算所述第二sv,所述第四标量不同于所述第二标量。
[0326]
eee57.如eee54至eee55中任一项所述设备,其中,所述分析部件被配置为基于所述音频信号的至少一个特性通过以下操作对所述第一sv和所述第二sv进行加权:计算表示权重的值,所述值的范围介于0至1之间,以及通过将所述第一sv和所述第二sv中的一者乘
以所述值,并且将所述第一sv或所述第二sv中的另一者乘以一减去所述值的差异,并且将两个结果相加得出所述频带的sv来计算所述频带的sv。
[0327]
eee58.如eee54至eee57中任一项所述设备,其中,所述至少一个特性定义所述音频信号的频带的估计调性。
[0328]
eee59.如eee54至eee57中任一项所述设备,其中,所述至少一个特性定义所述音频信号的频带中估计噪声水平。
[0329]
eee60.如eee58所述的设备,其中,所述分析部件被配置为使用根据所述音频信号的频带计算的频率系数的自适应预测来计算估计调性。
[0330]
eee61.如eee60所述的设备,其中,所述分析部件被配置为基于计算mdct系数所根据的所述音频信号的频带而自适应地将lpc应用于所述mdct系数。
[0331]
eee62.如eee61所述的设备,其中,lpc分析窗口长度根据所述频带而变化。
[0332]
eee63.如eee62所述的设备,其中,相对较长的lpc分析窗口用于相对较低的频带。
[0333]
eee64.如eee62至eee63中任一项所述的设备,其中,所述lpc的预测阶数根据所述频带而变化。
[0334]
eee65.如eee35至eee64中任一项所述的设备,其中,所述音频信号的频率范围介于200hz至7000hz之间。
[0335]
eee66.如eee35至eee65中任一项所述的设备,进一步包括存储器,所述存储器存储定义至少一些频率的安静环境听觉阈值的表,其中,所述分析部件被配置为通过使用预定义表来确定所述频带的安静环境听觉阈值。
[0336]
eee67.如eee38或当从属于eee38时前述eee任一项所述的设备,进一步包括压缩扩展部件,所述压缩扩展部件被配置为在量化所述频带的音频数据的音频样本之前使用压缩扩展算法来减小所述音频信号的动态范围。
[0337]
eee68.如eee48或当从属于eee48时eee49至eee67中任一项所述的设备,其中,所述分析部件被配置为根据所述感觉水平定义所述频带的扩展函数,使得扩展函数在具有相对较高感觉水平的频带中的效果大于扩展函数在于具有相对较低感觉水平的频带中的效果。
[0338]
eee69.如eee35至eee67中任一项所述的设备,所述设备在实时双向通信设备中实施。
[0339]
eee70.一种用于估计输入信号的调性的方法,所述方法包括:
[0340]
应用滤波器组以获得一组频率系数;
[0341]
使用频率系数的自适应预测来计算估计调性。
[0342]
eee71.如eee70所述的方法,其中,计算估计调性的步骤包括基于计算所述频率系数所根据的音频信号的频带而将自适应线性预测应用于所述频率系数。
[0343]
eee72.如eee70所述的方法,其中,lpc分析窗口长度根据所述频带而变化。
[0344]
eee73.如eee72所述的方法,其中,相对较长的lpc分析窗口用于相对较低的频带。
[0345]
eee74.如eee72至eee73中任一项所述的方法,其中,所述lpc的预测阶数根据所述频带而变化。
[0346]
eee75.如eee70至eee74中任一项所述的方法,其中,所述滤波器组包括以下各项之一:128频带复mdct或dft滤波器组以及64频带复qmf滤波器组。
[0347]
eee76.如eee71至eee73中任一项所述的方法,其中,所述lpc分析窗口为非对称汉明窗口。
[0348]
eee77.如eee70至eee76中任一项所述的方法,包括以下步骤:
[0349]
根据每个可预测性度量的相对感知重要性,对来自自适应预测的可预测性度量进行加权。
[0350]
eee78.如eee77所述的方法,其中,对包含在每个时频片内的所述可预测性度量进行加权的步骤包括以下各项之一:基于所述输入信号的能量或响度进行加权。
[0351]
eee79.如eee70至eee78中任一项所述的方法,进一步包括以下步骤:
[0352]
组合来自频率系数的自适应预测的可预测性度量,以匹配滤波器组的时间和频率分辨率。
[0353]
eee80.如eee2或当从属于eee2时eee4至eee34中任一项所述的方法,其中,所述灵敏度值和所述激励值以分贝db定义,并且组合步骤包括从所述激励值中减去所述灵敏度值,或者其中,所述灵敏度值和所述激励值以强度尺度定义,并且组合步骤包括计算所述激励值和所述灵敏度值的商。
[0354]
eee81.如eee3或当从属于eee3时eee4至eee34中任一项所述的方法,其中,所述能量值和所述灵敏度值以分贝db定义,并且组合步骤包括从所述能量值中减去所述灵敏度值,或者其中,所述能量值和所述灵敏度值以强度尺度定义,并且组合步骤包括计算所述能量值和所述灵敏度值的商。
[0355]
eee82.如eee1至eee34或eee80至eee81中任一项所述的方法,其中,计算所述灵敏度值包括计算所述频带的能量值与所述频带的安静环境听觉阈值之间的比率或差异。
[0356]
eee83.一种计算机程序产品,所述计算机程序产品包括具有指令的计算机可读存储介质,所述指令被适配成当由具有处理能力的设备执行时执行如eee1至eee34或eee80至eee82中任一项所述的方法。
[0357]
eee84.一种计算机程序产品,所述计算机程序产品包括具有指令的计算机可读存储介质,所述指令被适配成当由具有处理能力的设备执行时执行如eee70至eee79中任一项所述的方法。
[0358]
eee85.如eee36或当从属于eee36时eee38至eee69中任一项所述的设备,其中,所述灵敏度值和所述激励值以分贝db定义,并且组合步骤包括从所述激励值中减去所述灵敏度值,或者其中,所述灵敏度值和所述激励值以强度尺度定义,并且组合步骤包括计算所述激励值和所述灵敏度值的商。
[0359]
eee86.如eee37或当从属于eee37时eee38至eee69中任一项所述的设备,其中,所述能量值和所述灵敏度值以分贝db定义,并且组合步骤包括从所述能量值中减去所述灵敏度值,或者其中,所述能量值和所述灵敏度值以强度尺度定义,并且组合步骤包括计算所述能量值和所述灵敏度值的商。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。