1.本发明属于机器学习技术领域,具体涉及一种社交网络信息扩散预测方法。
背景技术:
2.在自然世界中,存在着形形色色各种各样的网络。人类关于网络结构的研究已经持续了数百年之久,网络科学的研究从最初的规则网络、随机网络发展到了复杂网络。复杂网络是对复杂系统的一种近似的抽象,在我们的现实世界之中,从交通系统到生态系统,都可以被抽象成复杂网络。社交网络是复杂网络的一种形式,是用户社交关系的抽象,随着因特网技术的发展,社交网络已经无处不在。当前,社交网络已经成为研究的一个热点,对社交网络中信息传播的演化研究是其中的一个关键研究点。
3.社交网络信息传播特指社交网络的信息传播过程。由于在线社交网络与生俱来的开放性和无限制性,使得社交网络成为了当今世界信息传播的重要媒介,信息传播在社交网络的活跃度达到了前所未有的程度。因此,社交网络上的信息传播研究得到了越来越多研究者的关注。当一个人接收了一条信息,那么他的邻居可能就会被影响,接收同样的信息,这样的场景在社交网络中无处不在,最常见的就是微博中的转发行为,当一个用户发了一条微博后,他的粉丝或者说关注者很可能转发这条微博,信息的传播往往是由用户行为引发的,因此信息的传播也可以被视为用户行为的传播。
4.信息传播预测是指在已知现有信息传播情况的基础上,遵循一定的方法和规律对未来的信息传播的趋势进行预测,从而预估信息传播的最终过程与结果,在此基础上,方便我们干预信息的传播,趋利避害。
5.基于不同的目的,当前的社交网络信息传播预测相关研究主要分为三类:传播范围预测、用户影响力预测以及用户行为预测。
6.针对本发明研究问题,主要介绍与用户行为预测相关的现有技术。用户行为预测主要关注用户个体的行为,在社交网络中,这通常表现为转发微博、加入群组等特定的行为。这方面的研究主要在于确定用户是否执行此类操作。zaman等人最早开始利用协同过滤模型基于用户过去的行为来预测用户的转发行为。chen等人通过对微博信息进行关键词提取来解决协同过滤模型中存在的数据稀疏问题,进一步提高预测效果。而hong等人基于用户的关注点不同,利用词袋模型计算文本相似性,他们认为相似度越大,用户转发的概率也就越大,并以此来预测用户的转发行为。得益与自然语言处理的迅速发展,基于隐狄利克雷分布的主题模型及其相关变种也在用户行为预测中被广泛应用。liu等人提出了一种生成图模型,该模型利用多层链接信息和与网络中每个节点相关联的文本信息内容来挖掘主题内容对转发行为的影响力大小。基于得到的影响力大小,他们进一步研究了发现的主题级别的影响如何帮助预测用户行为。yang等人对用户转发行为的特征进行了统计,提出了将因子图模型引入到监督学习方法中,通过用户的历史转发行为来预测用户未来的转发行为。xu等人把转发行为预测问题转化为二元分类问题,将影响用户转发行为的因素划分为基于社交关系的特征、基于用户的特征以及基于文本的特征,通过传统的机器学习方法(决
策树,svm(支持向量机),逻辑回归等) 进行训练,利用特征排除的方法对各个特征的有效性进行了对比,发现了基于社交关系的特征在信息传播中更为重要。此外,luo等人对潜在转发者进行了top-k排序,并基于pointwise的排序算法进行转发预测,同样得到了相对于其他特征,基于社交关系的特征更为重要的结论。
7.目前关于社交网络预测的研究如火如荼,但大多数模型忽略了一个事实,即信息传播本质上是一个时间动态的过程。在现有基于时间动态的信息传播研究中,satio等人通过研究独立级联模型和线性阈值模型的传播机制,将用户行为预测转化为最大似然估计问题,并利用最大化期望算法(em算法)求解,尽管该方法考虑了时间因素,但是因为其时间复杂度,不能用来处理海量数据。goyal等人提出了基于连续时间(ct)和基于离散时间(dt)的两种时变模型来计算社交影响力,并在统一阈值模型下用来进行动态信息传播预测,然而,在这种模型下信息传播的预测很大程度上依赖用户的激活阈值,这是很难在实践中设定的。此外,由于计算社交影响力的ct和dt模型的近似仿真机制本身对预测性能有副作用,因此该方法存在很大缺陷。基于博弈理论,li等人提出了gt模型并在统一阈值模型下进行用户行为预测,在gt模型中,他们把每一个节点都视为一个智能体,通过比较不同行为所带来的收益来判断节点未来的状态,考虑到时间动态,gt模型提出了基于用户历史信息的时变模型来计算社交影响力,因此在不同的时间点,同一用户不同行为的收益也具有了时间动态特性,不过,gt模型仍存在由于数据稀疏引起的冷启动问题。表1为现有考虑时间动态特性的用户行为预测模型在时间复杂度、准确率、信息获取以及应用能力的对比。
8.行为预测模型时间复杂度准确率信息获取应用能力似然估计模型最高高难小规模网络连续时间模型高较低容易小规模网络离散时间模型较低低容易中等规模网络博弈理论模型低高难大规模网络
9.表1
技术实现要素:
10.为解决上述问题,提供一种用于预测社交网络中基于时间动态特性的信息扩散,本发明采用了如下技术方案:
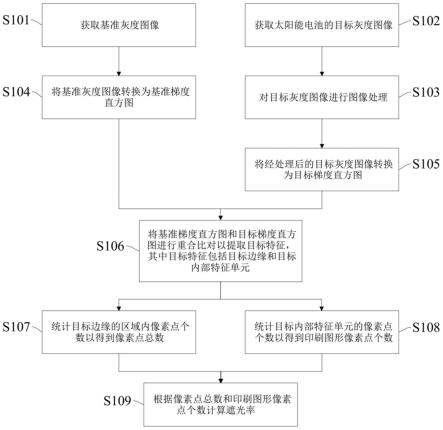
11.本发明提供了一种社交网络信息扩散预测方法,用于预测社交网络中基于时间动态特性的信息扩散,其特征在于,包括以下步骤:步骤s1,将曝光时间排序算法、引力排序算法以及级联相似性排序算法进行融合以构建信息扩散预测模型;步骤s2,将待预测话题、与该待预测话题相关的待预测用户集和历史传播信息作为信息扩散预测模型的输入;步骤s3,基于曝光时间排序算法获取待预测话题的曝光时间排序数组;步骤s4,基于社交网络拓扑结构导出待预测话题的参与用户,采用引力排序算法计算参与用户的影响力以及未参与用户的激活率得到引力排序数组;步骤s5,采用级联相似性排序算法对社交网络拓扑结构中的每个用户计算用户之间的相似度,并获取级联相似度排名;步骤s6,根据曝光时间排序数组、引力排序数组以及级联相似度排名对待预测用户集是否参与待预测话题进行预测。
12.在本发明提供的一种社交网络信息扩散预测方法中,还可以具有这样的技术特征,其中,曝光时间排序数组的获取过程为:统计所有参与待预测话题用户的总曝光时间分
布,并计算所有未参与待预测话题用户的总曝光时间,基于总曝光时间分布和总曝光时间计算所有未参与待预测话题用户的激活概率,对激活概率进行降序排序从而获得曝光时间排序数组。
13.在本发明提供的一种社交网络信息扩散预测方法中,还可以具有这样的技术特征,其中,引力排序数组的获取过程为:设u和v是两个在社交网络有向图中具有路径的用户,设path
uv
是从u到v的最短路径长度,u是参与话题用户集,则对于用户v的引力合力定义为:
[0014][0015]
式中,du是用户u的出度,dv是用户v的入度,对所有未参与话题用户根据引力合力进行排序,从而得到引力排序数组。
[0016]
在本发明提供的一种社交网络信息扩散预测方法中,还可以具有这样的技术特征,其中,级联相似度的获取过程为:提取每个级联中按时间戳排序的用户id,并将它们作为一个句子,使用one-hotencoding和skip-gram算法,将每个用户的id嵌入到128维向量中进行优化训练,窗口大小设置为10,u和v之间标签h的级联相似度由u和v之间的余弦相似度来衡量:
[0017][0018]
假设受v关注的转移用户的集合为su,则用户v的转移概率与成正比,将待预测用户按其相似度进行降序排序得到级联相似度排名。
[0019]
发明作用与效果
[0020]
根据本发明提供的社交网络信息扩散预测方法,通过将曝光时间排序算法、引力排序算法以及级联相似性排序算法进行融合从而提出了一个能够预测社交网络中信息扩散的新模型。其中,曝光时间排序算法在保证基于一个话题下信息传播的时间动态特性之外,还能考虑到不同话题下信息传播的时间动态特性差异较大的问题;引力排序算法从社交网络拓扑结构中导出,能够对所有参与到话题的用户计算他们对邻居影响力的综合并且对所有未参与到话题的用户按激活概率排序;级联相似性排序从每个用户的级联数据导出,使用一个向量来刻画用户,并用向量的余弦相似性衡量他们之间的相似程度。
[0021]
因此,本发明的社交网络信息扩散预测方法综合考虑社交网络中的社交影响力、信息扩散的时间动态特性以及非连通用户行为相似性三个关键因素,结合真实社交网络环境特性和复杂网络研究,给出了能够对社交网络中基于时间动态特性的用户行为进行准确预测的预测模型。利用该预测模型进行用户行为预测不仅提高了预测效果,而且在时间复杂性上有很大改进,在真实社交网络环境下有极其广泛的应用前景,为发布时间预测领域的研究提供了一定的参考意义。
附图说明
[0022]
图1是本发明实施例中社交网络信息扩散预测方法的流程图;
[0023]
图2是本发明实施例中的信息扩散预测模型的框架示意图;
[0024]
图3是本发明实施例中的曝光时间排序算法的流程图;
[0025]
图4是本发明实施例中的引力排序算法的流程图;
[0026]
图5是本发明实施例中在第一实验数据集上测试ct、dt、gt、tr 模型得到的平均准确率对比图;
[0027]
图6是本发明实施例中在第一实验数据集上测试ct、dt、gt、tr 模型得到的平均召回率对比图;
[0028]
图7是本发明实施例中在第一实验数据集上测试ct、dt、gt、tr 模型得到的平均f1-measure对比图;
[0029]
图8是本发明实施例中在第二实验数据集上测试ct、dt、gt、tr 模型得到的平均准确率对比图;
[0030]
图9是本发明实施例中在第二实验数据集上测试ct、dt、gt、tr 模型得到的平均召回率对比图;
[0031]
图10是本发明实施例中在第二实验数据集上测试ct、dt、gt、 tr模型得到的平均f1-measure对比图;
[0032]
图11是本发明实施例中在第三实验数据集上测试ct、dt、gt、 tr模型得到的平均准确率对比图;
[0033]
图12是本发明实施例中在第三实验数据集上测试ct、dt、gt、 tr模型得到的平均召回率对比图;
[0034]
图13是本发明实施例中在第三实验数据集上测试ct、dt、gt、 tr模型得到的平均f1-measure对比图。
具体实施方式
[0035]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的社交网络信息扩散预测方法作具体阐述。
[0036]
《实施例》
[0037]
图1是本发明实施例中社交网络信息扩散预测方法的流程图。
[0038]
如图1所示,社交网络信息扩散预测方法包括以下步骤:
[0039]
步骤s1,构建信息扩散预测模型。
[0040]
步骤s2,将待预测话题、与该待预测话题相关的待预测用户集和历史传播信息作为信息扩散预测模型的输入。
[0041]
图2是本发明实施例中信息扩散预测模型的框架示意图。
[0042]
如图2所示,本实施例中的信息扩散预测模型是通过将曝光时间排序算法、引力排序算法以及级联相似性排序算法进行融合得到的。
[0043]
步骤s3,基于曝光时间排序算法获取待预测话题的曝光时间排序数组从而获取时间动态因素影响状况。
[0044]
在社交网络中,假设有一个用户发布了话题a的消息,那么关注这个用户的所有粉丝就都能看到这条消息,从而有了接触话题a的信息渠道,对于进一步选择参与话题a的用户在接触到话题a之后到参与到话题a这之间会有一个时间差,这个时间差不会太短因为用户需要反应时间,也不会太长因为在线社交网络上的信息具有时效性,也就是说这个时间
差可能会有规律性,称这个时间差为曝光时间 (用户接触到话题的时间)。
[0045]
图3是本发明实施例中的曝光时间排序算法的流程图。
[0046]
如图3所示,本实施例中,设u是一个未参与话题的用户,v是参与某话题且被u关注的用户集。对于某特定话题a来说,u的总曝光时间定义为:
[0047][0048]
式中,t为当前时刻,tv为用户v的参与话题时间。
[0049]
为了更准确地刻画曝光时间函数,需要对所有参与话题用户统计总曝光时间分布p(t)。
[0050]
对所有未参与话题用户,计算他们的总曝光时间,然后用p(t= sumu)计算激活概率,接着对这些激活概率进行降序排序,得到的排序就称为曝光时间排序。
[0051]
本实施例还通过分析社交网络中不同节点周围邻居节点感染时间的分布状况来衡量时间动态因素对用户行为的影响,即时间动态因素影响状况。具体地:
[0052]
在历史传播信息中,每个传播用户参与传播时的感染时间总和 sumv=sumv t-tu。根据感染时间总和数据,统计得到感染时间总和分布p:
[0053]
在计算具体影响时,对待预测用户计算感染时间总和,然后获得感染时间总和激活概率p(ε=sumv)。
[0054]
本实施例的曝光时间排序算法的输入为:传播级联c、当前时间 t、信息a、用户集合ud;输出为:曝光时间排序x、候选者集合 ca。代码如下:
[0055]
[0056][0057]
步骤s4,基于社交网络拓扑结构导出待预测话题的参与用户,采用引力排序算法计算参与用户的影响力以及未参与用户的激活率得到引力排序数组。
[0058]
在社交网络中,用户之间应该是存在着影响的,特别地,在只存在单向关注关系的社交网络中,这个影响就具体体现在被关注者对其粉丝的影响。在万有引力公式中两个物体的质量被用来计算,迁移到社交网络中,两个物体对应着被关注者和粉丝,两个物体的质量也应该相应换成被关注者的出度和粉丝的入度。被关注者的出度和粉丝的入度类比物体的质量在引力中的作用,被关注者的出度越大说明这个节点对其他节点的影响力越大,粉丝的入度越大说明这个节点更倾向于接受新的信息,被关注者对粉丝的影响大小应该与这两个因素成正比。而当两个节点不存在直接的关注关系而存在间接关注关系时,也认为影响能依间接关注关系对应的路径进行传递,但是比起直接关注的强度要小得多,这也是为什么引力模型计算公式中让引力与路径长度的平方成反比。
[0059]
图4是本发明实施例中的引力排序算法的流程图。
[0060]
本实施例中,如图4所示,设u和v是两个在社交网络有向图中具有路径的用户。设path
uv
是从u到v的最短路径长度,u是参与话题用户集,则对于用户v的引力合力定义为:
[0061][0062]
式中,du是用户u的出度,dv是用户v的入度。
[0063]
对所有未参与话题用户根据引力合力进行排序,就得到了引力排序数组。
[0064]
排序数组中排序值较低的用户一般来说有着更高的被感染概率。无论是曝光时间排序还是引力排序,它们都无法单独对用户的发布信息概率做出综合性评估,而将曝光时间排序和引力排序结合起来进行预测是一个很有潜力的解决方案。
[0065]
本实施例的引力排序算法的代码如下所示:
[0066][0067][0068]
步骤s5,采用级联相似性排序算法对社交网络拓扑结构中的每个用户计算用户之间的相似度,并获取级联相似度排名。
[0069]
本实施例中,级联相似性排序从每个用户的级联数据导出,使用一个向量来刻画用户,并用向量的余弦相似性衡量他们之间的相似程度。具体地:
[0070]
首先,提取每个级联中按时间戳排序的用户id,并将它们作为一个句子。
[0071]
然后,使用one-hot encoding和skip-gram算法将每个用户的id 嵌入到128维向量中,类似于自然语言处理参考中广泛采用的词嵌入。在对skip-gram算法进行优化训练中,窗口大小设置为10,遵循现有研究中的常见做法。
[0072]
其次,u和v之间标签h的级联相似度由u和v之间的余弦相似度来衡量,即:假设受v关注的转移用户的集合为su,则用户v的转移概率与成正比。
[0073]
最后,将候选者集合即待预测用户按其相似度进行降序排序得到级联相似度排名
(csr)。
[0074]
本实施例的级联相似性排序算法的输入为:传播行为记录ω、候选者集合ca、当前时间t、信息a;输出为:级联排序z。代码如下:
[0075][0076]
步骤s6,根据时间动态因素影响状况、引力排序数组以及级联相似度排名对待预测用户集是否参与待预测话题进行预测。
[0077]
本实施例中将三种算法融合得到融合排序算法,该算法的输入为:传播行为记录ω、候选者集合ca、信息集合λ;输出为:预测结果 tp,fn,fp,tn。代码如下:
[0078]
[0079]
l.v.lakshmanan,
ꢀ“
learning influence probabilities in social networks,”in proceedings ofthe third acm international conference on web search and data mining, 2010,pp.241
–
250)、gt(摘自d.li,s.zhang,x.sun,h.zhou,s.li, and x.li,“modeling information diffusion over social networks fortemporal dynamic prediction,”ieee transactions on knowledge anddata engineering,vol.29,no.9,pp.1985
–
1997,sep.2017)模型。
[0088]
其中,ct和dt模型将用户的行为看作被其所有父节点对其影响的总和,并引入了时延因素以预测具体时间。gt模型将社交网络中的节点视作智能理性个体,对这些个体能做出的不同决策计算对应的收益。通过引入基于传播数据的时间相关收益,gt模型可以被用来预测具有时间动态特性的信息传播过程。
[0089]
具体的实验设定如下,本方法中使用了一个非负k维向量来表示曝光时间概率分布,超参数k值越大,则预测准确度越高,但是也耗费更多的运行时间。反之超参数k值越小,由于向量长度变小丢失了曝光时间概率分布的信息,预测精确度也下降,但耗费的运行时间也随之下降。在本实验中,结合收集到的社交网络数据特征,如果将 k设为常数是不合适的,因为不同话题下曝光时间概率分布差距较大,因此k随不同话题下曝光时间最大值变化而变化。
[0090]
除此以外,为预测用户参与时间还需要用到时间步的概念。由于模型是对每个时间步进行预测,因此若将增加时间步个数,会使预测的发生时间更精确,因为时间步个数增多时间间隔变小,做出的预测在时间上也就更精细,但是也需要更多时间。时间步个数设置得太多,会使运行时间无意义地上升,例如时间步个数多到时间间隔为一秒。时间步个数设置的太少,则预测结果就不具有实际意义,例如时间步个数太少,时间间隔为1个月,当预测一个用户会参与到信息传播时,这个行为可以在做出预测后立即发生,也可以是1个月后发生,考虑到热点话题更迭迅速,这是无意义的。
[0091]
因此,为综合考虑运行时间和数据特征,本实施例的实验中,设置时间步个数为8,时间间隔长度也就随着时间步个数确定。
[0092]
实验评测指标使用准确率(precision)、召回率(recall)和f1
‑ꢀ
measure,具体计算公式如下:
[0093][0094][0095][0096]
式中,tp、fp、tn、fn分别代表真阳性(true positive)、假阳性(false positive)、真阴性(true negative)、假阴性(false negative)。
[0097]
实验结果分别在图5至图13中展示。从实验结果可以看出,本发明所提出的方法在准确率和f1-measure上优于其他模型。
[0098]
而gt模型在召回率上更好,是因为gt模型有较低的激活阈值,所以大量的潜在用
户都被预测为阳性,这个设定很大程度上改善了 gt模型的召回率表现,但也剧烈地降低了它的准确率。
[0099]
上述实验从时间复杂性和预测效果两个角度论证了本发明的信息扩散预测模型(tr)的优越性,真实社交网络环境下,用户关系网络规模往往高达几十万乃至上百万、上千万,时间复杂性上的提升让 tr模型在真实社交网络中的应用前景更为广泛,意义重大。
[0100]
实施例作用与效果
[0101]
根据本实施例提供的社交网络信息扩散预测方法,该方法综合考虑社交网络中的社交影响力、信息扩散的时间动态特性以及非连通用户行为相似性三个关键因素,结合真实社交网络环境特性和复杂网络研究,通过将曝光时间排序算法、引力排序算法以及级联相似性排序算法进行融合,从而涵盖社交网络信息的传播范围预测、用户影响力预测以及用户行为预测,提出一个能够对社交网络中基于时间动态特性的信息扩散进行准确预测的模型。同时,在数据集上的实验结果充分展示了本实施例所提出的信息扩散预测模型在性能表现、计算复杂度和鲁棒性方面都超过了领域内现有的先进算法,为发布时间预测领域的研究提供了一定的参考意义。
[0102]
实施例中,曝光时间排序算法在保证基于一个话题下信息传播的时间动态特性之外,还能考虑到不同话题下信息传播的时间动态特性差异较大的问题。同时,通过分析社交网络中不同节点周围邻居节点感染时间的分布状况来衡量时间动态因素对用户行为的影响。
[0103]
实施例中,引力排序算法从社交网络拓扑结构中导出,能够对所有参与到话题的用户计算他们对邻居影响力的综合并且对所有未参与到话题的用户按激活概率排序。
[0104]
实施例中,级联相似性排序从每个用户的级联数据导出,使用一个向量来刻画用户,并用向量的余弦相似性衡量他们之间的相似程度,从而获取社交网络中的非连通用户行为相似性。
[0105]
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。