1.本发明涉及汽油调和指标预测技术领域,更具体的说是涉及一种异质多模型辛烷值与抗爆系数分级预测集成建模方法。
背景技术:
2.油品调和作为炼油厂最后工序,是一项十分复杂同时又蕴藏巨大利润空间的工业过程。而作为成品汽油调和中的关键品质指标辛烷值与抗爆系数,至今却因测量技术的局限难以有效获取,对汽油调和过程中配方模型的准确建立带来困难,直接影响了产品质量与企业效益。软测量技术的兴起与发展无疑为此提供了有效解决途径。但由于数据或算法的制约,软测量模型的精度仍有较大提升空间,因此,如何基于现代工业过程的储存数据,建立更精准的辛烷值和抗爆系数预测模型,解决配方数据中辛烷值和抗爆系数的缺失问题,进而为成品汽油调和配方模型的建立奠定数据基础就显得尤为重要。
3.在实际应用中,高性能预测模型的建立,不仅取决于建模算法和集成策略的优选,更离不开对生产工艺和测量数据获取流程的深度解析。对于辛烷值和抗爆系数的预测,传统建模方法大多是将二者同时作为主导变量,或是采用相对单一建模算法,或是以加权平均集成方式融合几种算法,来建立它们与其它易测辅助变量的预测模型,但预测效果仍差强人意。其原因有三:一是忽视了工业测量数据获取中抗爆系数对辛烷值分析数据的依赖关系,粗略地将二者等同对待;二是单一建模算法的局限性,对存在批次加工原料生产的多工况,缺乏多样性与互补性;三是集成策略多为线性,对复杂工业过程的非线性因素,还难能适应。
4.因此,如何提供一种考虑异质模型的互补优势,以期提升模型的预测性能的异质多模型辛烷值与抗爆系数分级预测集成建模方法是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种异质多模型辛烷值与抗爆系数分级预测集成建模方法,考虑抗爆系数对辛烷值依赖的两类异质集成分级建模方法,具有更优的性能,可用于成品汽油调和过程中辛烷值和抗爆系数的准确预测,有望解决辛烷值和抗爆系数数据缺失问题,为后期配方模型的建立奠定数据基础。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种异质多模型辛烷值与抗爆系数分级预测集成建模方法,包括以下步骤:
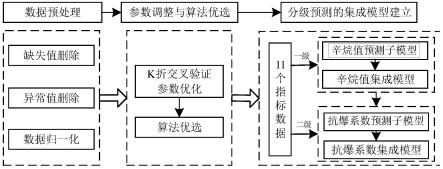
8.采用k折交叉验证法对多个异质学习器进行参数调优和优选,分别建立多个辛烷值预测子模型和多个抗爆系数预测子模型;
9.分别对多个所述辛烷值预测子模型和多个所述抗爆系数预测子模型进行线性集成或非线性集成,建立辛烷值集成模型和抗爆系数集成模型;
10.基于所述辛烷值集成模型得到辛烷值的预测结果;基于所述抗爆系数集成模型得到抗爆系数的预测结果。
11.进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,所述辛烷值预测子模型和所述抗爆系数预测子模型的建立过程包括:
12.确定与辛烷值和抗爆系数关联程度高、且易测的n种成品汽油指标,作为数据集一;
13.在所述数据集一上采用k折交叉验证法对多个异质学习器进行优选和参数调优,并基于最优参数利用数据集一对优选出的多个异质学习器进行训练,得到多个所述辛烷值预测子模型;
14.将所述辛烷值预测子模型预测输出的辛烷值和所述数据集一进行组合,得到数据集二;
15.基于所述数据集二对优选出的异质学习器进行训练,得到所述抗爆系数预测子模型。
16.进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,对优选出的异质学习器进行训练之前,还包括:对所述数据集一进行缺失值删除、异常值删除和归一化处理。
17.进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,对所述辛烷值预测子模型或所述抗爆系数预测子模型进行线性集成的过程包括:
18.确定目标函数,对目标函数最小化,确定各个所述辛烷值预测子模型或所述抗爆系数预测子模型的最优权重;
19.基于最优权重,采用加权平均集成算法对多个所述辛烷值预测子模型或所述抗爆系数预测子模型进行集成,得到所述辛烷值集成模型或所述抗爆系数集成模型。
20.进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,对目标函数引入l1正则项、l2正则项或混合l1&l2正则项,对通过最小化目标函数获得的最优权重进行调整。
21.进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,所述目标函数的表达式为:
[0022][0023]
其中,j0为目标函数,为实际测量值,为各辛烷值预测子模型或抗爆系数预测子模型的预测输出,i=1
…
m,j=1
…
t,m为样本个数,t为异质学习器的个数,wj为各辛烷值预测子模型或抗爆系数预测子模型权重。
[0024]
进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,所述辛烷值集成模型或所述抗爆系数集成模型的表达式为:
[0025]
[0026]
其中,且wj≥0。
[0027]
进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,对所述辛烷值预测子模型或所述抗爆系数预测子模型进行非线性集成的过程包括:
[0028]
将优选出的用于建立所述辛烷值预测子模型或所述抗爆系数预测子模型的异质学习器作为初级学习器,将最终建立的辛烷值预测子模型和抗爆系数预测子模型作为初级子模型;
[0029]
采取非线性机器学习算法作为次级学习器;
[0030]
将所述初级子模型的预测输出和实际测量值组合作为新样本,并利用所述新样本对所述次级学习器进行参数优化和训练,得到最终的基于堆叠的非线性辛烷值集成模型或抗爆系数集成模型。
[0031]
进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,所述辛烷值集成模型或抗爆系数集成模型的表达式为:
[0032]
h(x)=h'(h1(x),h2(x),
…
,h
t
(x))
[0033]
其中,h'=γ(d
new
),表示辛烷值集成模型或抗爆系数集成模型;表示新样本,γ表示次级学习器,h
t
(x)表示第t个初级子模型。
[0034]
进一步的,在上述一种异质多模型辛烷值与抗爆系数分级预测集成建模方法中,所述初级学习器采用mlr算法、knn算法、cart算法、rf算法和svm算法;所述次级学习器采用knn算法、rf算法、bp算法和elm算法中的任意一种。
[0035]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种异质多模型辛烷值与抗爆系数分级预测集成建模方法,具有以下有益效果:
[0036]
1)本发明通过对辛烷值和抗爆系数分级预测建模,较传统2输出的一级模型,其将辛烷值预测输出增补为辅助变量,建立二级单输出抗爆系数预测模型,充分考虑了抗爆系数对辛烷值测量数据的依赖性,更好的挖掘了变量间的关系,可显著提升模型预测性能;
[0037]
2)本发明基于结构风险最小化理论,通过对传统目标函数引入l1、l2、l1&l2等正则约束,特别是混合l1&l2正则,既兼有对优质模型的权重突出,又不失对模型多样性的考虑,使加权平均集成算法可迭代获得更优的权值分配,从而以线性集成的方式获得性能更优的预测模型,尤其适用于辛烷值预测的一级建模。
[0038]
3)本发明基于机器学习堆叠思想提出的非线性集成策略,从更深层面挖掘了复杂工业过程的非线性特性,使其通过对子模型输出的堆叠集成得以呈现,不仅适用于辛烷值预测的一级建模,且在分级建模方案下堆叠集成的二级模型,其深度和复杂度更利于非线性的准确映射,更适合二级抗爆系数的预测建模。
[0039]
总体而言,本发明考虑采用异质多模型集成,来解决单一或同质模型对多工况、非线性缺乏优势互补、适应性不足等问题,具体包括子模型算法和集成方式两个层面。对于子模型算法,考虑不同算法的性能差异,优选异质学习器建立子模型,以期通过多样性模型的优势互补来提高集成模型的性能;对于集成方式,先从加权平均权重进一步优化获取入手,结合结构风险最小化理论,对实际值与预测值的误差为目标函数引入正则约束,以获得性能更优的线性集成模型;接着,考虑非线性算法应对复杂工业过程的优势,拟基于机器学习
的堆叠集成方式,对异质子模型进行非线性集成,以适应实际生产中的非线性特性。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0041]
图1为本发明提供的异质多模型辛烷值与抗爆系数分级预测集成建模方法的流程图;
[0042]
图2为本发明提供的对辛烷值预测子模型或抗爆系数预测子模型进行线性集成的流程图;
[0043]
图3为本发明提供的对辛烷值预测子模型或抗爆系数预测子模型进行非线性集成的流程图。
[0044]
图4(a)为本发明提供的单模型与集成模型对辛烷值和抗爆系数mse/ge的预测结果;
[0045]
图4(b)为本发明提供的单模型与集成模型对辛烷值和抗爆系数mae的预测结果;
[0046]
图4(c)为本发明提供的单模型与集成模型辛烷值和抗爆系数mape的预测结果;
[0047]
图4(d)为本发明提供的单模型与集成模型辛烷值和抗爆系数ped(0.15)的预测结果。
[0048]
图5(a)为本发明提供的采用加权5方法对辛烷值和抗爆系数预测的结果示意图;
[0049]
图5(b)为本发明提供的采用stacking3方法对辛烷值和抗爆系数预测的结果示意图;
[0050]
图5(c)为本发明提供的采用stacking4方法对辛烷值和抗爆系数预测的结果示意图。
具体实施方式
[0051]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0052]
如图1所示,本发明实施例公开了一种异质多模型辛烷值与抗爆系数分级预测集成建模方法,包括以下步骤:
[0053]
s1、采用k折交叉验证法对多个异质学习器进行参数调优和优选,分别建立多个辛烷值预测子模型和多个抗爆系数预测子模型;
[0054]
s2、分别对多个辛烷值预测子模型和多个抗爆系数预测子模型进行线性集成或非线性集成,建立辛烷值集成模型和抗爆系数集成模型;
[0055]
s3、基于辛烷值集成模型得到辛烷值的预测结果;基于抗爆系数集成模型得到抗爆系数的预测结果。
[0056]
其中,s1中,辛烷值预测子模型和抗爆系数预测子模型的建立过程包括:
[0057]
确定与辛烷值和抗爆系数关联程度高、且易测的n种成品汽油指标,作为数据集一;
[0058]
在数据集一上采用k折交叉验证法对多个异质学习器进行优选和参数调优,并基于最优参数利用数据集一对优选出的多个异质学习器进行训练,得到多个辛烷值预测子模型;
[0059]
将辛烷值预测子模型预测输出的辛烷值和数据集一进行组合,得到数据集二;
[0060]
基于数据集二对优选出的异质学习器进行训练,得到抗爆系数预测子模型。
[0061]
考虑实际成品汽油调和生产中,抗爆系数测量值取自马达法辛烷值与研究法辛烷值(后文统称辛烷值)的平均,即前者的量测值依赖于后者,因而鉴于此种关联,本发明拟采取分级方式对二者的预测分别建模。具体分级方式为:在成品汽油的二十余种质量指标中,视不易在线获取的辛烷值和抗爆系数作为主导变量,将易测量且与二者关联度高的10%蒸发温度、50%蒸发温度、90%蒸发温度、终馏点、蒸汽压、硫含量、苯含量、芳烃含量、烯烃含量、氧含量、密度等11个指标作为辅助变量,建立指标与辛烷值之间的一级辛烷值预测子模型;再考虑抗爆系数对辛烷值的强依赖性,将辛烷值也增补为抗爆系数预测的辅助变量,与11个指标同时作为输入,建立抗爆系数的二级抗爆系数预测子模型。以下将辛烷值预测子模型和抗爆系数预测子模型统称为子模型,将辛烷值集成模型和抗爆系数集成模型统称为集成模型。
[0062]
其中,对优选出的异质学习器进行训练之前,还包括:对数据集一进行缺失值删除、异常值删除和归一化处理。
[0063]
对于子模型算法,考虑不同算法的性能差异,优选异质学习器建立子模型,以期通过多样性模型的优势互补来提高集成模型的性能。
[0064]
对于集成方式,先从加权平均权重进一步优化获取入手,结合结构风险最小化理论,对实际值与预测值的误差为目标函数引入正则约束,以获得性能更优的线性集成模型;接着,考虑非线性算法应对复杂工业过程的优势,拟基于机器学习的堆叠集成方式,对异质子模型进行非线性集成,以适应实际生产中的非线性特性。
[0065]
在一个实施例中,如图2所示,对辛烷值预测子模型或抗爆系数预测子模型进行线性集成的过程包括:
[0066]
确定目标函数,对目标函数最小化,确定各个辛烷值预测子模型或抗爆系数预测子模型的最优权重;
[0067]
基于最优权重,采用加权平均集成算法对多个辛烷值预测子模型或抗爆系数预测子模型进行集成,得到辛烷值集成模型或抗爆系数集成模型。
[0068]
具体的,假设γ1,γ2,
…
,γ
t
为已优选出用于建立预测子模型的学习器,数据集为已优选出用于建立预测子模型的学习器,数据集为各个子模型的预测输出(i=1
…
m,j=1
…
t),m为样本个数,t为学习器的个数。其中,为模型输入的实际样本,n为输入变量个数(对于辛烷值:n=11,抗爆系数:n=12);为模型输出的实际样本,l为输出变量个数(对于辛烷值和抗爆系数均为1);为子模型预测输出数据。若采用加权平均集成算法,对于第i个样本t个子模型对应的集成模型输出为:
[0069][0070]
其中:且wj≥0,wj为各子模型权重。
[0071]
假设集成模型输出与实际测量值的误差为ε,则有:
[0072][0073]
由式(2)可知,当子模型确定之后,预测值与实际值的误差很大程度上取决于权重因子,因此,可通过最小化目标函数j0确定模型最优权重值。
[0074][0075]
基于式(3)最小化的权重确定,主要依据经验风险最小化原则,在一定程度上容易产生过拟合现象,因此为防止过拟合,提高模型的泛化能力,可考虑对目标函数引入正则化来增加约束项,通过调整目标函数所加惩罚项系数,使得偏差和方差之间达到某种最佳平衡,进而确定模型最优权重。这里分别对目标函数引入l1、l2以及混合l1&l2三种正则项,如式(4)(5)(6)所示。其中,引入l1正则,旨在发挥其良好的稀疏能力,加大优质模型权重,削弱或消除性能较差模型的影响,凸显优质子模型的作用;引入l2正则,意在用温和平滑的权值变化来考虑模型差异,以较好兼顾多个模型的作用;此外,为规避l1正则的稀疏性可能滤除过多模型,从而导致模型多样性不足,以及l2正则对优质模型权值体现过弱,难以发挥集成模型优势,为充分发挥l1、l2的优势,引入混合l1&l2正则,以期通过优势互补,获得更为合理的模型权值。
[0076][0077][0078][0079]
其中,α、β为l1、l2正则的惩罚系数,γ、ρ为混合l1&l2正则的惩罚系数。
[0080]
基于前述分析,对某大型炼油厂提供的真实测量数据预处理后,将其划分为训练集和测试集,在训练集上采用k折交叉验证对各算法进行参数优选,以此分别建立辛烷值和抗爆系数的异质子模型,并结合式(1),(4)~(6)建立基于改进加权平均的辛烷值集成模型和抗爆系数集成模型。其中,表1给出了基于改进加权平均的异质集成模型建模算法。
[0081]
表1改进加权平均的异质集成建模算法
[0082][0083]
表1中,子模型建立与权重优化中,辛烷值预测子模型为11输入1输出,抗暴系数预测子模型为12输入1输出。
[0084]
在另一个具体实施例中,如图3所示,对辛烷值预测子模型或抗爆系数预测子模型进行非线性集成的过程包括:
[0085]
将优选出的用于建立辛烷值预测子模型或抗爆系数预测子模型的异质学习器作为初级学习器,将最终建立的辛烷值预测子模型和抗爆系数预测子模型作为初级子模型;
[0086]
采取非线性机器学习算法作为次级学习器;
[0087]
将初级子模型的预测输出和实际测量值组合作为新样本,并利用新样本对次级学习器进行参数优化和训练,得到最终的基于堆叠的非线性辛烷值集成模型或抗爆系数集成模型。
[0088]
加权平均集成算法本质是一种线性集成方法,对存在非线性特性的工业过程,集成效果往往难免适应性不足。考虑神经网络等机器学习算法对非线性特性的良好拟合能力,本实施例基于堆叠思想,以此类非线性机器学习算法作为次级学习器,进一步挖掘数据中的非线性特征,建立堆叠的非线性集成辛烷值与抗爆系数分级预测模型。表2给出了基于stacking的异质集成模型建模算法。
[0089]
类似于上述描述,假设γ1,γ2,
…
,γ
t
为优选出用于建立预测子模型的初级学习器,γ为次级学习器,则根据各初级学习器算法,基于数据集d可训练得到初级子模型h
t
,(t
=1,
…
,t),以此可得到各子模型的预测输出进而得到新样本接着用此样本集对次级学习器γ进行参数优化与训练,即可得到次级集成模型h';结合初级子模型的预测输出,即可获得最终预测结果。
[0090]
表2基于stacking的异质集成模型建模算法
[0091][0092][0093]
表2中,对于初级子模型的建立,辛烷值预测模型为11输入1输出,抗爆系数预测模
型为12输入1输出;次级集成模型的建立,辛烷值预测和抗爆系数预测时,二者均为t输入1输出。
[0094]
下面,对本发明实施例得到的子模型和集成模型分别进行仿真验证。
[0095]
1、数据准备与模型评价指标
[0096]
实验样本数据取自某大型炼油厂2019-2021期间的部分实测数据,期间工况变化相对较小。为了减少由于测量噪声、数据缺失等带来的影响,确保数据质量,在建模之前,根据专业部门检测结果,对部分不合格数据进行删除,并采用三倍标准差准则剔除异常值,得到合格数据共计1105条,对其进行归一化等操作,同时采用自主抽样法对数据进行划分,得到约63.2%的数据用于模型的训练,其余数据用于测试。整个仿真过程基于16g内存的英特尔酷睿i764位笔记本电脑,使用python语言和是scikit-learn库等构建了不同的模型。
[0097]
模型评价是检验所建立模型性能的重要环节,本实验主要采用均方误差(mean square error,mse)、平均绝对误差(mean absolute error,mae)、平均绝对百分比误差(mean absolute percentage error,mape)、泛化误差(generalization error,ge),以及自定义的预测误差分布(prediction error distribution,ped)等指标来对本文建立模型的性能进行评价。具体mse、mae、mape、ped(0.15)评价模型准确性,ge评价模型泛化能力。
[0098]
1)均方误差(mse)
[0099][0100]
2)平均绝对误差(mae)
[0101][0102]
3)平均绝对百分比误差(mape)
[0103][0104]
4)预测误差分布
[0105][0106]
式中,num(δ≤δ)表示误差在δ范围之内的个数,num(n)表示预测总个数,δ表示误差集合。ped在误差范围之内的比重越大,即说明预测效果越好。
[0107]
5)泛化误差(ge)
[0108]
给定训练样本集d与学习算法,训练得到估计器y(x;d),对每个测试样本x有预测输出则学习器的期望泛化误差可分解偏差、方差和噪声之和:
[0109]
ge=bias2 varience ε2ꢀꢀꢀꢀꢀꢀ
(11)
[0110]
其中,ε2=ed[(y
d-y)]2,为样本x的期望。由于数据的噪声主要来自传感器、人为等多方面,通常很难获取,此处取0,则有:
[0111]
ge=bias2 varience
ꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0112]
前式中,n为样本的个数,yi为真实值,yd为测量值,为预测值。
[0113]
2、异质子模型分级建模与分析
[0114]
为实现辛烷值和抗爆系数的更准确预测,建模方案以及算法的合理选择至关重要。因此,基于前文分析,本实验首先对可能用于建模的多种机器学习算法调参与优选,并基于此对传统两输出建模方案及本文的分级建模方案进行对比分析。
[0115]
2.1算法优选与参数设置
[0116]
首先采用k折交叉验证和网格搜索对多元线性回归(multiple linear regression,mlr)、岭回归(ridge regression,rr)、套索回归(leastabsolute shrinkage and selection operator,lasso)、弹性网络(elastic network,en)、支持向量机(support vector regression,svm)、分类回归树(classification and regression tree,cart)、随机森林(random forest,rf)、k邻近分类算法(k-nearest neighbors,knn)等多个机器学习算法的参数进行调整,分别建立辛烷值和抗爆系数的预测模型,并对模型性能进行评估,优选出性能较好的mlr、knn、cart、rf、svm等5个算法用于后续子模型的建立。其中,模型算法的参数选择主要基于k折交叉验证和网格搜索,优选参数如表3所示。
[0117]
表3单模型算法最优参数设置
[0118][0119]
表3中,n_neighbor为最近邻点个数k,即取k个最近的样本来预测目标点,该值决定着模型的准确性,调整k值可以防止模型过拟合;
[0120]
max_leaf_nodes、min_samples_leaf分别为最大叶子节点数和叶子节点包含的最少样本数;其中通过权衡二者的取值,可有效防止过拟合;
[0121]
n_estimators、min_samples_split、max_depth分别为决策树的个数(太小容易欠拟合,太大不能显著提升模型性能)、节点可分的最小样本数、最大树深(构建最优模型的时候子树的深度);
[0122]
kernel、c、max_iter分别为核函数、惩罚系数以及最大迭代次数,其中c值越小,泛化能力越强。
[0123]
2.2异质子模型仿真结果分析
[0124]
为验证分级建模方案的优势,将其与传统辛烷值和抗爆系数建模方案进行对比,
其中分级预测模型为:11输入1输出(辛烷值)、12输入1输出(抗爆系数),传统预测模型为:11输入2输出(辛烷值、抗暴系数)。同时,为减少随机性因素带来的影响,客观评价模型性能,采用自助抽样法对数据重复实验100次,得到与训练样本集数目相等的100个样本子集,即对于给定训练样本集从中有放回抽样m次,得到样本量为m的样本子集重复该过程100次,得到样本集合d
new
={d1,
…
,d
100
},其中且满足d=d1∪...∪d
100
,以此为训练集,采用前述优选出的5个算法,分别建立辛烷值和抗爆系数的单一预测模型,并用同一测试集对同一算法的100个模型进行测试,对mse、mae、mape、ped(0.15)以及ge等评价结果取平均,其仿真结果如表4~表7所示。
[0125]
表4传统辛烷值模型预测结果(11-2)
[0126][0127]
表5传统抗爆系数模型预测结果(11-2)
[0128][0129][0130]
观察表4~5中11输入-2输出传统模型,对于辛烷值和抗爆系数的预测,无论是模型的准确性还是泛化能力,rf均有着良好的表现,knn、svm次之,mlr、cart相对较差,说明在传统建模方案下单模型rf更适合辛烷值和抗爆系数的共同预测。
[0131]
表6分级辛烷值模型预测结果(11-1)
[0132][0133]
表7分级抗爆系数模型预测结果(12-1)
[0134][0135]
结合表6~7中11输入-1输出、12输入-1输出分级模型,对于辛烷值,从模型的准确性和泛化能力来看,rf均表现最优,knn、svm次之,mlr、cart较差;对于抗爆系数,rf亦表现最优,mlr,cart次之,svm,knn较差。
[0136]
进一步比较表4与表6、表5与表7的预测结果可以看出,在分级建模方案下建立的5种异质单模型较传统2输出模型,性能均有明显提升。对于辛烷值,分级下的1输出较传统的2输出,尽管输入相同,但性能仍有一定提升,其原因是1输出相对于2输出更容易找到最优解。对于抗爆系数,分级模型性能整体提升更为显著,特别是从mse、ge、mape等指标来看,大部分算法性能约5~8倍提升,其余指标也约1~5倍提升不等,其原因是:分级模型考虑了抗爆系数与辛烷值之间的强关联性,即二级输出的抗爆系数依赖于一级辛烷值输出预测值,在辛烷值预测较为准确的情况下,抗爆系数的预测也更为精准。这充分说明,分级建模方案较未考虑关联度的传统双输出的一级建模方案,更适宜建立高质量的辛烷值和抗爆系数预测模型。后续将在分级建模方案下建立二者的异质集成预测模型。
[0137]
3、异质集成模型仿真结果与分析
[0138]
为了验证本发明提出的异质集成模型性能,本实验分别对提出的基于改进加权平
均的集成模型以及基于stacking的集成模型进行仿真验证,为陈述简洁,分别将上述集成建模方法记为methodⅰ和methodⅱ。其中对methodⅰ进行了5种不同的加权集成,分别记为加权1~加权5,其中加权1为mlr、knn、cart、rf和svm等5种算法的结果平均集成;加权2为使公式(3)目标函数最小化的加权集成;加权3、加权4以及加权5则为对目标函数公式(3)引入l1正则、l2正则以及混合l1&l2正则约束的加权集成。methodⅱ中以mlr等5种算法为初级学习器,分别以knn、rf、bp、elm等4种非线性算法作为次级学习器,建立stacking集成模型,分别记为stacking1、stacking2、stacking3、stacking4。仿真结果如表8~11所示,其中表8、表9为辛烷值和抗爆系数在methodⅰ下的权重系数表,仿真过程如2.2节类似,仍采用自助抽样法重复100次实验,对最终结果取均值。
[0139]
表8辛烷值模型权重系数
[0140] mlrknncartrfsvm加权10.2000.2000.2000.2000.200加权20.1340.3140.1040.4090.039加权300.0330.0010.9660加权40.0020.3650.0810.4770.075加权500.3490.0230.5800.048
[0141]
表9抗爆系数模型权重系数
[0142] mlrknncartrfsvm加权10.2000.2000.2000.2000.200加权20.1390.2390.2060.2980.118加权30.0170.0580.0120.9130加权40.0270.2020.1320.6370.002加权50.1400.2280.2020.3310.099
[0143]
表10辛烷值集成模型预测结果
[0144][0145]
表11抗爆系数集成模型预测结果
[0146][0147][0148]
为了更直观的展示出两种异质集成模型集成方法对辛烷值和抗爆系数的预测性能,将其与5种异质单模型预测结果对比(此处忽略噪声的影响,ge等于mse)如图4(a)-4(d)所示。
[0149]
结合表8~表11、图4(a)-4(d),可以看出本发明提出的两类异质集成模型建模方法,无论是对辛烷值还是抗爆系数的预测,method
ꢀⅰ
及method
ꢀⅱ
总体上较单模型性能均有明显的提升,表现出良好的预测性能。
[0150]
在method
ꢀⅰ
中,从预测准确性和泛化性能来看,加权5性能最好,加权3、加权4次之,加权1、加权2相对较差。究其原因:由于加权1仅对权重系数简单取平均,未考虑各子模型之间的差异,使得集成模型的预测性能不尽人意;加权2仅以最小化输出实际值与预测值的误差为目标,通过经验最小化原则对模型权重进行迭代寻优,但受训练数据的影响,模型适用性较差,即对优质子模型的考虑仍存在不足,因此仍难以充分发挥各异质子模型的优势。如对于辛烷值的预测,性能较好的rf权重占比仅有0.409,而对性能相对较差的mlr、knn,cart等权重均有一定占比(0.134、0.314、0.104);而加权3~加权5方法从集成算法自身出发,对目标函数引入正则约束,一方面降低了模型的复杂性,防止了权值优化过程中过拟合现象的发生,另一方面又能充分考虑各异质子模型对结果的影响,使得模型性能提升较为明显。如加权3方法,l1正则的引入,使模型权重更易接近于0或1(辛烷值:wrf=0.966,wmlr=wsvm=0,抗爆系数:wrf=0.913,wsvm=0),能弱化劣质子模型,突出优质子模型的优势,因此模型性能提升较为突出;加权4方法因l2正则的引入,模型权重的求解更为平滑,所有子模型对集成模型均有一定贡献,模型性能也提升明显;加权5方法则综合了l1、l2正则的优点,一方面充分利用各子模型的信息,一方面又削弱了劣质子模型的权重,通过二者之间的平衡,较好的改善了模型的性能。
[0151]
对于method
ꢀⅱ
,因采用了基于堆叠集成的非线性算法对各子模型进行集成,在一定程度上能学习到线性算法无法表达的非线性特征,性能较单一模型也有明显的提升,且
整体优于线性集成模型。其中stacking4性能最好,stacking3、stacking2次之,stacking1较差。原因是stacking1集成算法中,knn本身对数据分布较为敏感,因此模型性能相对较差;stacking2充分发挥了树模型结构的优势,集成了多树的优点,提升了集成模型的性能;stacking3采用bp网络作为次级学习器,隐含层节点个数和激活函数的选取,能很好的学习数据的非线性特征,较单模型和method
ꢀⅰ
性能均明显提升;stacking4采用elm作为次级学习器,既提高了模型的训练速度,又提升了集成模型的精度,在所有模型中性能最优。
[0152]
综上可知,本发明提出的两类异质多模型辛烷值与抗爆系数分级预测集成方法,均可在一定程度上提升集成模型的性能。且在一级建模过程中,模型复杂度相对较低,因而线性和非线性集成建模方法均可建立精准的辛烷值预测模型,而在二级建模过程中,模型复杂度较高,故非线性集成方法更有优势。其中加权5方法和stacking3、stacking4堆叠集成模型更适合成品汽油调和中辛烷值和抗爆系数的预测建模。
[0153]
4、最优模型预测结果
[0154]
将上述性能较优的集成线性加权5,非线性stacking3、stacking4用于辛烷值和抗爆系预测问题中,结果如图5(a)-5(c)所示。
[0155]
从图5(a)-5(c)可以更直观的看出,本发明提出的线性和非线性两类集成方法中性能最优的几种预测模型(加权5,stacking3,stacking4),其预测值与真实值的重叠度很高,少量偏离点也有较高的接近度,这也进一步验证了本发明提出的分级预测集成模型,对于辛烷值和抗爆系数的预测,均可获得相对满意的预测效果,可用于成品汽油调和过程中辛烷值和抗爆系数的准确预测中,有望解决后期配方建模过程中配方数据完备问题。
[0156]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0157]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。