1.本发明涉及电力系统负荷短期预测技术领域,尤其是一种基于长短期记忆网络(lstm)的短期负荷预测方法。
背景技术:
2.负荷预测是能源规划、经济运行和能源管理的重要基础,通常包括长期负荷预测,中期负荷预测和短期负荷预测,其中,短期负荷预测一般指的是对预测对象未来一天或者一周的负荷进行预测,短期负荷的特点在于会受到天气、设备状况、重大社会活动等因素的影响较大,因此准确的对短期负荷进行预测存在较大的困难。工业、民用、公用事业用电负荷特性迥异,电力负荷往往因天气等的变化而具有很大的波动性和季节性,对电力负荷做出准确的预测,是电力系统制订扩容、运行、检修等计划的基础。
3.为了电力系统运行的有效性和运行效率,准确地预测短期负荷尤为重要。如果短期负荷预测过高,系统发电容量偏大导致运行成本过高;相反,如果系统负荷预测偏低,将会影响到电力系统的可靠性和安全性。
4.现有用于短期负荷预测的神经网络方法有循环神经网络(rnn)方法和基于循环神经网络改进的长短期记忆网络方法。循环神经网络在处理数据时,易出现梯度消失、梯度爆炸问题。长短期记忆网络(lstm)是循环神经网络(rnn)的一种,相较于基础版的循环神经网络(rnn),增加了三个门:输入门、输出门和遗忘门;通过门控装置,有效缓解循环神经网络出现的梯度消失和爆炸问题。现有基于长短期记忆网络的短期负荷预测模型存在神经网络隐藏层神经元节点、学习率参数最优值依靠经验选择的问题,仅仅依靠经验设置的参数,短期负荷预测效果较差;神经网络处理线性数据效果较好,处理非线性、非平稳数据效果较差。
技术实现要素:
5.为了解决现有技术中存在的不足,本技术提出了一种基于长短期记忆网络(lstm)的短期负荷预测方法,通过引入鲸鱼算法进行长短期记忆网络参数寻优和变分模态信号分解技术进行负荷数据分解,能够有效解决现有技术中利用神经网络进行短期负荷预测效果差等问题;同时,引入vmd分解,能够将非线性、非平稳数据分解成若干个线性、平稳数据。
6.本发明所采用的技术方案如下:
7.一种基于长短期记忆网络的短期负荷预测方法,包括如下步骤:
8.s1、采集短期负荷数据,将所采集的短期负荷数据作为训练样本进行vmd分解,得到n个随机分量imf;
9.s2、对于s1中分解出的n个分量,每个分量构建对应的woa-lstm模型,利用woa对模型中lstm参数寻优,找出最合适的参数;采用最优参数的lstm分别对分量数据imf进行训练,得到各个分量的预测结果;
10.s3、基于s2中分别寻优后构建的lstm模型,分别利用lstm模型对短期负荷数据进
行预测,每个lstm模型输出相应的预测结果;通过将所有预测结果进行相加得到最终的负荷预测结果。
11.进一步,构建woa-lstm模型方法如下:
12.s2.1,将vmd分解出的分量分别作为每个woa-lstm的输入;
13.s2.2,限定和初始化lstm参数;
14.s2.3,初始化鲸鱼算法的参数;
15.s2.4,利用鲸鱼算法寻优lstm参数,过程如下:
16.每迭代一次,鲸鱼算法寻优输出当前lstm参数;
17.将当前输出的lstm参数输入lstm模型,构建出当前的lstm模型;
18.将vmd分量输入当前构建的lstm模型进行训练,获得当前lstm模型的输出;
19.计算模型当前输出与实际数据的均方根误差;
20.s2.5,根据每次迭代中计算的预测结果与实际数据的均方根误差;若当前迭代计算的均方根误差小于前一次迭代的计算的均方根误差,则判断是否为最优参数,若是,转s2.6;若否,转s2.7;
21.s2.6,本次的隐藏层神经元个数和学习率作为最新lstm参数,更新lstm参数;
22.s2.7,保持上一次迭代输出的lstm参数;
23.s2.8,判断是否达到迭代次数,若是,输出最优lstm参数,利用最优lstm参数进行lstm训练;若否,返回s2.4;
24.进一步,lstm参数包括学习率下限、学习率上限、长短期记忆网络隐藏层神经元个数下限、长短期记忆网络隐藏层神经元个数上限、迭代次数、输入维度、输出维度;
25.进一步,初始化lstm参数包括限定学习率下限0.05和上限0.08;限定长短期记忆网络隐藏层神经元个数下限50,上限200;初始化迭代次数:50次;初始化输入维度、输出维度都为1;
26.进一步,所述鲸鱼算法的参数包括最大迭代次数maxnum,常数b和l为鲸鱼寻优系数;
27.进一步,鲸鱼寻优系数表示为:l=(-2 k*((-1)/maxnum))*rand 1,k为迭代次数,rand为(0,1)之间的随机数;
28.进一步,初始化鲸鱼算法的参数,最大迭代次数maxnum=30;常数b=1;
29.进一步,利用vmd分解将短期负荷数据分解为三个分量,分别是imf1、imf2、imf3。
30.本发明的有益效果:
31.本方法通过vmd对短期负荷数据进行分解,能够将非线性、非平稳数据分解成若干个线性、平稳数据。
32.此外本技术还通过鲸鱼算法对lstm参数进行寻优,进而获得最优的参数,利用最优的参数构建lstm模型,并且使用该模型对短期负荷数据进行。本方法通过对lstm参数进行寻优,从而解决了现有技术中神经网络隐藏层神经元节点、学习率参数最优值依靠经验选择的问题,仅仅依靠经验设置的参数,短期负荷预测效果较差;神经网络处理线性数据效果较好,处理非线性、非平稳数据效果较差。提高短期负荷预测精度以及提高曲线拟合速度。
附图说明
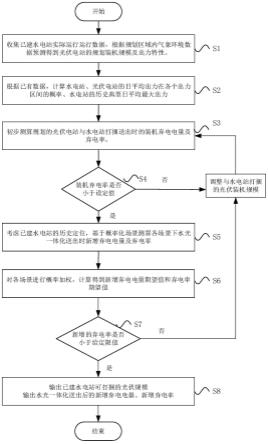
33.图1是本方法预测方法流程图示意图;
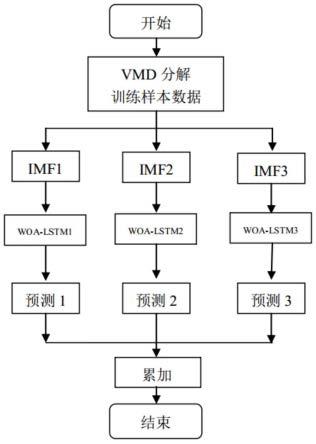
34.图2是本方法woa-lstm流程框图;
35.图3是线路电流曲线示意图;
36.图4是lstm模型预测结果图;
37.图5是lstm模型预测误差图;
38.图6是woa-lstm模型预测结果图;
39.图7是woa-lstm模型预测误差图;
40.图8是原始数据vmd分解后分量图;
41.图9是vmd-woa-ls tm模型预测结果图;
42.图10是vmd-woa-lstm模型预测误差。
具体实施方式
43.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
44.本技术提出了如图1所示的一种基于长短期记忆网络的短期负荷预测方法,包括如下步骤:
45.s1、采集短期负荷数据,在本技术是每15分钟采集一次获得某地区某个月份内的短期负荷数据,如图3所示。
46.将所采集的短期负荷数据作为训练样本,并对对短期负荷数据(训练样本)进行vmd分解(变分态模分解),得到随机分量imf。分解得到假定所有分量都是集中在各自中心频率附近的窄带信号,根据分量窄带条件建立约束优化问题,从而估计信号分量的中心频率以及重构相应的分量imf。
47.短期负荷数据通过vmd分解后得到n个分量,在本技术中,将短期负荷数据通过vmd分解成三个分量时最后预测得到的结果误差最小,故vmd分解得到的三个分量分别是imf1、imf2、imf3,如图8所示。
48.s2、构建如图2所示的woa-lstm模型。对于s1中分解出的分量,分别构建woa-lstm模型,利用woa-lstm模型对lstm参数寻优,找出最合适的参数。采用最优参数的lstm分别对分量数据imf进行训练,得到各个分量的预测结果;
49.在本实施例中,由于在s1中分解出了imf1、imf2、imf3这三个分量,故分别构建三个分量对应的woa-lstm1、woa-lstm2、woa-lstm3模型,即对每个分量imf,分别用woa算法对lstm参数寻优,找出最合适的参数。
50.其中,构建woa-lstm模型方法如下:
51.s2.1,将vmd分解出的分量分别作为每个woa-lstm的输入;
52.s2.2,限定和初始化lstm参数。lstm参数包括限定学习率下限0.05和上限0.08;限定长短期记忆网络隐藏层神经元个数下限50,上限200;初始化迭代次数:50次;初始化输入维度、输出维度,都为1。
53.s2.3,初始化鲸鱼算法相关参数。最大迭代次数maxnum=30;常数b=1;l为鲸鱼寻
优系数;l=(-2 k*((-1)/maxnum))*rand 1,k为迭代次数,rand为(0,1)之间的随机数。
54.s2.4,利用鲸鱼算法寻优lstm参数,过程如下:
55.每迭代一次,鲸鱼算法寻优输出当前lstm参数;
56.将当前输出的lstm参数输入lstm模型,构建出当前的lstm模型;
57.将输入(即某一组vmd分量)输入当前构建的lstm模型进行训练,获得当前lstm模型的输出;
58.计算模型当前输出与实际数据(即短期负荷数据)的均方根误差。
59.鲸鱼算法寻优lstm参数的具体过程如下:
60.s2.4.1,鲸鱼whalea的位置作为学习率的数值,鲸鱼whaleb的位置作为长短期记忆网络隐藏层神经元个数个数。
61.s2.4.2,鲸鱼算法中参数a、a、c的公式定义如下:
62.at=2atr1t-at、ct=2r2t
63.其中,t表示当前的迭代次数,t表示总迭代次数,r1和r2是属于[0,1]之间的随机值;a∈[-a,a]。
[0064]
s2.4.2,抛硬币,正面(概率p大于等于0.5),用公式:计算鲸鱼a和b的位置;
[0065]
反面(概率小于0.5),接着计算a的绝对值,a的绝对值大于等于1,用公式计算鲸鱼a和b的位置;a的绝对值小于1,用公式计算鲸鱼a和b的位置。
[0066]
其中,x
t 1
是第t 1次迭代时鲸鱼a和b的位置,是最优位置,b是常数,l是鲸鱼寻优系数,表示前一次迭代时的位置。
[0067]
s2.4.3,得到lstm最优的参数。
[0068]
s2.5,根据每次迭代中计算的预测结果与实际数据的均方根误差;若当前迭代计算的均方根误差小于前一次迭代的计算的均方根误差,则判断是否为最优参数,若是,转s2.6;若否,转s2.7。
[0069]
s2.6,本次的隐藏层神经元个数和学习率作为最新lstm参数,更新lstm参数。
[0070]
s2.7,保持上一次迭代输出的lstm参数
[0071]
s2.8,判断是否达到迭代次数,若是,输出最优lstm参数,利用最优lstm参数进行lstm训练;若否,返回s2.4;
[0072]
s3、基于s2中分别寻优后构建的lstm模型,分别利用lstm模型对短期负荷数据进行测,每个lstm模型输出相应的预测结果;通过将所有预测结果进行相加得到最终的负荷预测结果。
[0073]
为了进一步验证本方法的效果,以下结合附图4-10做详细说明。
[0074]
现有技术中通常采用人为设定lstm模型的参数,为了验证本方法的效果,故选用一个未寻优、人为设定参数的lstm模型与本方法进行对比,下图4和5即为将待预测短期负荷输入固定参数的lstm模型的结果,该均lstm模型预测结果与实际数据的方根误差rmse=
5.4734,平均绝对误差mae=4.055,平均绝对百分比误差mape=8.4063%。
[0075]
图9和10是本方法采用vmd-woa-lstm模型预测结果和预测误差,将待预测短期负荷输入本方法得到的lstm模型,本方法lstm模型预测结果与实际数据的均方根误差rmse=4.9776,平均绝对误差mae=3.792,平均绝对百分比误差mape=8.3955%。
[0076]
从以上三个误差可以看出,本方法的预测结果明显优于现有固定参数的lstm模型。
[0077]
图6和7是本方法未进行vmd分解的woa-lstm模型预测结果和预测误差,将待预测短期负荷输入该未进行vmd分解的lstm模型中,得到的均方根误差rmse=5.4067,平均绝对误差mae=3.9047,平均绝对百分比误差mape=8.3543%。跟本方法的预测结果相比,明显进行vmd分解的预测结果要更优。
[0078]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。