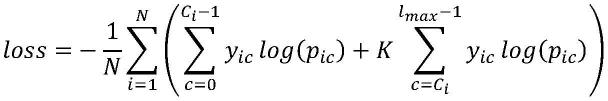技术特征:
1.一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,包括如下步骤:步骤1,从中文语音数据集获取音频数据并进行预处理,得到语音数据训练集、验证集和测试集;构建基于拼音的双阶段解耦合中文语音识别模型,包括声学模型和语言模型;步骤2,对所得语音数据训练集的mel谱特征做动态数据增强,包括时间掩蔽和频率掩蔽;步骤3,将动态数据增强后的mel谱特征送入声学模型,进行声学模型训练,得到联结时序分类损失,优化声学模型参数;重复步骤2和步骤3所述的动态数据增强和声学模型训练过程,直到声学模型收敛;步骤4,进行声学模型性能评估;步骤5,从中文文本数据集获取文本数据并进行预处理;步骤6,根据步骤5中预处理后的文本数据建立拼音词典、汉字词典和同音字词典,得到包括中文文本的文本数据训练集;步骤7,将所得文本数据训练集中中文文本对应的拼音序列以及同音字序列送入语言模型,进行语言模型训练,得到交叉熵损失,优化语言模型参数;重复步骤7所述的的语言模型训练过程,直到语言模型收敛;步骤8,进行语言模型性能评估和基于拼音的双阶段解耦合中文语音识别模型的联合评估。2.根据权利要求1所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤1中所述数据预处理包括:将所有音频数据以统一的采样率进行重采样;对音频数据进行预加重、分帧和加窗得到有重叠的分帧信号;对分帧信号进行短时傅里叶变换得到短时幅度谱;通过mel滤波器组得到mel谱特征数据;将所得mel谱特征数据划分为不相交的训练集、验证集和测试集。3.根据权利要求2中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤2中对所得语音数据训练集的mel谱特征做动态数据增强过程中,对时间掩蔽和频率掩蔽的掩蔽比例为随机数。4.根据权利要求3中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤3中,所述声学模型由混合下采样模块、多路径交叉卷积模块和多层前馈神经网络组成;其中,混合下采样模块使用多路径融合使用最大池化和均匀池化,减少下采样过程中有用信息的丢失;多路径交叉卷积模块包含两个相同的分组,其中每个分组由多路不同分辨率的二维卷积级联而得,提取不同感受野下的低层特征,多路径交叉卷积模块内部还使用了密集连接的残差结构;多层前馈神经网络将输入的高级特征映射到拼音的维度空间,并使用softmax函数获得概率分布。5.根据权利要求4中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤4中所述声学模型性能评估,包括:测试集字符识别错误率和推理延迟;其中,字符识别错误率cer通过动态字符串对齐计算得到,方法如下:其中,s表示对齐过程中产生的替换次数,d表示删除次数,i表示插入次数,n表示目标
句子中的字符数。6.根据权利要求5中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤5中所述中文文本数据集为现存的数据集或收集整理得到的中文文本;所述预处理包括:复句分割为多个单句、数字转汉字、繁体转简体、去除句末标点符号以及去除包含非汉字字符的句子,得到仅包含简体汉字的句子;将所得句子划分为不相交的训练集、验证集,同时去除与最终测试所用数据集中重叠的句子。7.根据权利要求6中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤6中所述词典以python字典格式存储;其中,拼音词典以拼音为键,以递增索引为值;汉字词典以汉字为键,以递增索引为值;同音字词典以拼音为键,以子词典为值,该子字典的键为同拼音的汉字,值为递增索引。8.根据权利要求7中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤7中所述语言模型为基于同音字建模的transformer模型,将拼音到汉字的转录过程作为一对一的翻译过程,并将翻译结果限制在输入拼音对应的同音字空间中。9.根据权利要求8中所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤8中,语言模型性能评估包括测试集识别准确率和推理延迟;基于拼音的双阶段解耦合中文语音识别模型的联合评估包括整体模型参数量大小、测试集识别准确率和推理延迟。10.根据权利要求9所述的一种基于拼音的双阶段解耦合中文语音识别模型,其特征在于,步骤1中所述验证集和测试集中的说话人均不在训练集中出现。
技术总结
本发明公开了一种基于拼音的双阶段解耦合中文语音识别模型,将语音识别过程分解为从语音到拼音,从拼音到汉字两个步骤,独立构建和训练从语音到拼音的声学模型和从拼音到汉字的语言模型:构建基于混合下采样和多路径交叉卷积模块的全卷积声学模型,进行从音频Mel谱特征到拼音的识别;构建基于同音字建模方案的Transformer语言模型,进行从拼音到汉字的转录。声学模型中,提出并采用混合下采样和多路径交叉卷积结构,大幅减少参数量,降低复杂度,节省训练时间和计算资源开销,提高了模型的泛化性能。语言模型中,采用同音字建模,将输出特征维度从4000以上减至55,减少参数量,降低模型学习难度,提高转录准确率。提高转录准确率。提高转录准确率。
技术研发人员:陈力军 刘佳 林华健 陈星宇 鄢伟
受保护的技术使用者:江苏图客机器人有限公司
技术研发日:2022.04.19
技术公布日:2022/7/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。