1.本发明设计视频处理领域,特别涉及一种融合特征的运动类视频关键帧提取的方法。
背景技术:
2.对于视频而言,视频都是一个图像序列,其内容比一张图像丰富很多,表现力强,信息量大,通常来讲,对于视频的分析都是将视频分解为视频帧后进行的,但视频帧通常存在大量冗余,提取出视频关键帧后进行分析,就能够有效减少运算时间。
3.随着网络的发展,多媒体信息检索对社会各领域产生越来越大的影响,传统的视频检索方法会运用图像检索方法逐帧进行检索,这种方法需要处理大量的图像信息,对信息传输和计算造成很大的负担。除此之外,在家用摄像设备普及的今天,我们经常需要将一段监控保存下来,但是视频类信息的保存需要占用大量存储空间,采用视频关键帧的方式存储,既能保持视频信息的真实性,又能很大程度地节省空间。
4.对于运动类视频,运动对象状态变化频繁,由于运动目标的多样性和动作的相似性,若只考虑运动特征很容易出现漏检的情况,特征提取的偏差可能较大,所以本发明通过融合特征的方式,对运动类视频进行关键帧提取技术的研究。
技术实现要素:
5.技术上述问题,本技术提供了一种融合特征的运动类视频关键帧提取的方法,利用人脸识别技术和马赛克技术实现对用户隐私的保护,并且在一定程度上提升了对于小尺寸人脸的识别准确性。
6.为达到上述目的,本发明技术方案如下:
7.一种基于人体姿态识别的融合特征运动类视频关键帧提取方法,包括以下步骤:
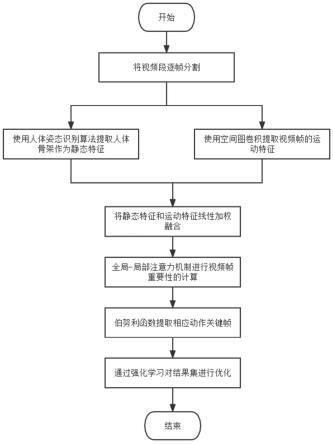
8.s1.对目标视频段进行逐帧分割,将视频分割为一系列视频帧;
9.s2.用残差网络进行静态特征提取,将数据进行降维处理,得到的视频帧静态特征ss=[s
s1
,s
s2
,
…
,s
st
];
[0010]
s3.对三维空间中人体的骨骼数据进行抽象,对视频帧进行运动特征的提取,得到运动特征sd=[s
d1
,s
d2
,
…
,s
dt
];
[0011]
s4.将提取出的静态特征ss和运动特征sd按照权重大小做线性加权处理,s=mss nsd,m和n分别为静态特征的权重因子和运动特征的权重因子;
[0012]
s5.对融合后的特征通过自注意力机制提取全局特征,而后计算视频帧的重要性,通过伯努利函数采取相应动作关键帧的提取,并使用强化学习进行结果集的优化。
[0013]
进一步优选的,步骤s3的具体方法如下:
[0014]
s31.针对视频中的每一帧进行人体骨架提取,并使用轻量级hrnet进行人体姿态分析;
[0015]
s32.将视频每一帧识别出的骨骼关键点坐标及置信度作为输入,根据骨骼之间的
物理联系构建拓扑图,而后对其进行批归一化处理;
[0016]
s33.将处理后的数据经过多个s-gcn单元进行特征提取,为不同的躯干赋予不同的权重系数,得到视频的特征表示sd={s
d1
,s
d2
,
…
,s
dt
}。
[0017]
进一步优选的,步骤s31的具体方法如下:
[0018]
s311.每个阶段每个分支的子网包括两个残差块和一个多分辨率融合模块;
[0019]
s312.以shufflenet的shuffle模块替换掉了原网络中所有的残差块,shuffle模块将通道分为两部分,一部分直接通过,不进行任何卷积操作,而另一部分,需进行深度可分离卷积;
[0020]
s313.将深度可分离卷积中的卷积用通道加权替换,通过平均池化下采样,并调整到与最小分辨率相同的尺寸,将处理好后i个分支不同分辨率的特征图进行通道相加的特征融合,利用se模块得到权重矩阵w
t
,将权重矩阵w
t
对每个分支进行上采样操作,恢复到原有尺寸,并对通道进行加权。
[0021]
进一步优选的,步骤s5的具体方法如下:
[0022]
s51.通过双向掩码建模视频帧之间的位置信息;
[0023]
s52.在得到视频序列的全局上下文信息后,基于全局相关性特征计算出特征匹配度,然后采用全连接层预测视频帧的重要性分数score;
[0024]
s53.得到每一个视频帧的帧得分之后,,通过伯努利分布针对相应动作进行关键帧的选择a
t
~b(y),a
t
表示为把当前帧作为关键帧的概率;
[0025]
s54.使用强化学习评判提取的关键帧结果集质量的高低,本文使用状态-动作值为结果集重要性与多样性的和进行表征,用关键帧集合对完整视频信息的覆盖能力来评估结果集的重要性,用所选帧之间特征空间的差异大小来评估结果集的多样性。
[0026]
进一步优选的,步骤s51的具体方法如下:
[0027]
s511.正向掩码表示注意力权重至于当前位置之前的计算结果有关,反向掩码表示当前位置的权重至于之后的计算结果有关;
[0028]
s512.输入t帧视频x={xi|i=1,
…
,t},每一帧包含了n个关键点,通过自注意力机制,可以计算出相关系数
[0029][0030]
其中t,i∈[0,t),u和v分别为两帧的权重矩阵,m为位置编码矩阵,正向掩码则保留上三角信息,反向掩码则保留下三角信息,λ是融合特征矩阵特征值,s
t
是当前帧的融合特征,si是该帧前后帧的融合特征;
[0031]
s513.将相关系数与帧的相对位置(表征与前后帧的位置关系)信息结合,得到并将正反两个方向融合,映射回原视频帧序列,得到包含上下文信息的序列c={c
t
|t=1,
…
,t}。
[0032]
有益效果
[0033]
(1)本发明通过人体姿态识别、空间图卷积和特征融合提供了一种融合特征的运动类视频关键帧提取技术,满足了对于关键帧提取准确性和完整性的要求。
[0034]
(2)本发明通过提出一种提取视频帧特征的方式,将人体姿态识别提取出的静态
特征和空间图卷积提取出的运动特征进行融合后作为最终视频帧特征,对此进行重要性分析,能有效避免漏检误检的问题。
[0035]
(3)本发明通过替换残差模块并加入注意力机制,轻量化改进了hrnet,在不损失准确度的基础上,大幅降低运算量。
附图说明
[0036]
图1为本发明实施例所公开的一种融合特征的运动类视频关键帧提取的方法的阶段示意图;
[0037]
图2为本发明实施例所公开的一种融合特征的运动类视频关键帧提取的方法的人体姿态识别模块具体示意图;
[0038]
图3为本发明实施例所公开的一种融合特征的运动类视频关键帧提取的方法的关键帧提取结果示意图;
具体实施方式
[0039]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0040]
本发明提供了一种融合特征的运动类视频关键帧提取的方法,如图1所示,该方法将轻量化人体姿态识别算法提取静态特征和空间图卷积提取的运动特征进行融合,提升了关键帧检测的准确性和完整性,具体实施例如下:
[0041]
(1)对目标视频段进行逐帧分割,将视频分割为一系列视频帧。
[0042]
(2)为了更好地保留输入图像中的原始信息,减少损失,用残差网络resnet50进行静态特征提取,将数据维度降到256维,得到的视频帧静态特征表示为ss=[s
s1
,s
s2
,
…
,s
st
]。
[0043]
(3)对三维空间中人体的骨骼数据进行抽象,使用轻量化hrnet算法进行人体姿态分析,然后以st-gcn网络对视频帧进行运动特征的提取,得到运动特征sd=[s
d1
,s
d2
,
…
,s
dt
]。
[0044]
步骤(3)的具体方法如下:
[0045]
(3.1)针对视频中的每一帧进行人体骨架提取,为了提升准确度的同时不过多加重运算负担,本技术使用了轻量级hrnet进行人体姿态分析。
[0046]
如图2所示,步骤(3.1)的具体方法如下:
[0047]
(3.1.1)对于hrnet而言,准确度大幅高于其他自下而上的算法,但明显的缺陷在于,参数量很大,运算速度慢,所以本文针对这一明显缺点进行了轻量化改进,建立了加快分析速度。
[0048]
(3.1.2)为了使模型尽可能轻量,首先减少了原hrnet网络的深度和宽度,将每个阶段每个分支的子网,削减为两个残差块和一个多分辨率融合模块。
[0049]
(3.1.3)以shufflenet的shuffle模块替换掉了原网络中的所有的残差块,该模块将通道分为两部分,一部分直接通过,不进行任何卷积操作,而另一部分,则需进行深度可分离卷积。
[0050]
(3.1.4)将深度可分离卷积中的1
×
1卷积用通道加权替换,同样达到了信息交换
的效果,但时间复杂度远低于1
×
1卷积。通过平均池化下采样,将feature map调整到与最小分辨率相同的尺寸,将处理好后i个分支不同分辨率的特征图进行add操作(通道相加的特征融合),然后以se模块(包含squeeze和excitation两部分)得到权重矩阵w
t
,将权重矩阵w
t
对每个分支进行上采样操作,恢复到原有尺寸,并对通道进行加权。
[0051]
(3.2)将视频每一帧识别出的骨骼关键点坐标及置信度作为输入,根据骨骼之间的物理联系构建拓扑图,而后对其进行批归一化处理,将分散的数据进行统一。
[0052]
(3.3)将处理后的数据经过9个s-gcn单元进行特征提取,为不同的躯干赋予不同的权重系数,得到视频的特征表示sd={s
d1
,s
d2
,
…
,s
dt
}。
[0053]
(4)将提取出的静态特征和运动特征按照权重大小做线性加权处理,s=mss nsd,m和n分别为静态特征的权重因子和运动特征的权重因子;
[0054]
(5)对融合后的特征通过自注意力机制提取全局特征,而后计算视频帧的重要性,通过伯努利函数采取相应动作关键帧的提取,并使用强化学习进行结果集的优化。
[0055]
步骤(5)的具体方法如下:
[0056]
(5.1)通过双向掩码建模视频帧之间的位置信息,可以保证当前视频帧的重要性不仅受之前视频帧的影响,同时也受之后视频帧的影响。
[0057]
步骤(5.1)的具体方法如下:
[0058]
(5.1.1)正向掩码表示注意力权重至于当前位置之前的计算结果有关,反向掩码表示当前位置的权重至于之后的计算结果有关。
[0059]
(5.1.2)输入t帧视频x={xi|i=1,
…
,t},每一帧包含了n个关键点,通过自注意力机制,可以计算出相关系数
[0060][0061]
其中t,i∈[0,t),u和v分别为两帧的权重矩阵,m为位置编码矩阵,正向掩码则保留上三角信息,反向掩码则保留下三角信息。
[0062]
(5.1.3)将相关系数与帧的相对位置(表征与前后帧的位置关系)信息结合,得到并将正反两个方向融合,映射回原视频帧序列,得到包含上下文信息的序列c={c
t
|t=1,
…
,t}。
[0063]
(5.2)在得到视频序列的全局上下文信息后,基于全局相关性特征计算出特征匹配度,然后采用全连接层预测视频帧的重要性分数score。
[0064]
(5.3)得到每一个视频帧的帧得分之后,通过伯努利分布针对相应动作进行关键帧的选择a
t
~b(y),a
t
表示为把当前帧作为关键帧的概率。
[0065]
(5.4)使用强化学习评判提取的关键帧结果集质量的高低,本文使用状态-动作值为结果集重要性与多样性的和进行表征,用关键帧集合对完整视频信息的覆盖能力来评估结果集的重要性,用所选帧之间特征空间的差异大小来评估结果集的多样性。
[0066]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理相一致的最宽的
范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。