1.本发明涉及工业过程的控制与故障诊断领域,具体是一种数据驱动的工业过程故障检测方法。
背景技术:
2.近年来,随着现代工业的不断发展,形成了许多规模巨大的工业生产制造系统和高度复杂的工业过程。在现代工业通过不断扩大和复杂化的工业过程为其带来便利的同时,也带来了一些问题和挑战。由于系统日趋复杂和大规模,生产制造过程中机器发生故障的概率大大增加,故障形成后容易在系统中扩散。若没有一个可靠的检测手段,可能会导致设备损坏,人员伤亡,产品不合格等严重后果。
3.针对大规模高复杂度的故障,目前检测方法一般有三类。第一类是基于知识的方法,优点为比较适用于当建立数学模型的过程比较容易的时候,这个方法被局限于那些过程变量较少的系统。第二类是基于模型的方法,特点是不需要精确的数学模型,只需要一些收集的基础数据,加入了一些固定的知识来进行检测但是通用性较差,局限性突出。第三类就是基于数据驱动的方法,特点是需要数据是运行的状态信息,通过基础数据,使用目前比较丰富的理论知识处理得到结果。
4.目前数据驱动的过程监测和故障检测是研究的热点,现在存在的方法主要存在训练网络复杂数据维度高,特征工程不够全面,导致检测单故障准确率高,多故障准确率低,计算量大等问题。因此需要改进现有技术从而能够准确快速地分析工业过程中的故障数据,保障工业生产稳定运行。
技术实现要素:
5.本发明要解决的技术问题是提供一种数据驱动的工业过程故障检测方法,用以解决目前工业过程中检测单一故障准确率高,多故障检测准确率低,数据维度高计算量大的问题。
6.为了解决上述技术问题,本发明提供一种数据驱动的工业过程故障检测方法,包括的过程如下:
7.s01、获取工业生产的过程数据,过程数据的维度为53,总条数为m;然后构建一个m行53列的过程数据的原始矩阵z
src
,将过程数据的原始矩阵z
src
的每一列都减去训练好的列平均值矩阵z
mean
,得到中心化的矩阵zo;
8.s02、将中心化的矩阵zo输入主成分分析法并利用训练好的特征向量矩阵a9计算特征数据y1_online=a9zo;将中心化的矩阵zo输入独立成分分析法并利用训练好的矢量矩阵计算特征数据将中心化的矩阵zo输入典型关联分析法并利用训练好的特征向量矩阵σ9和训练好的右奇异向量正交基v9计算特征数据y3_online:
9.10.其中,pk为中心化的矩阵zo的第k行;k∈(1,m)为过程数据的当前时刻的条数,将k从1到m依次带入式(23)后获得特征数据y3_online;
11.s03、工业过程故障检测网络包括pca通道、ica通道和cca通道的三通道卷积神经网络,将特征数据y1_online作为pca通道的输入,特征数据y2_online作为ica通道的输入,特征数据y3_online作为cca通道的输入,分别输入到工业过程故障检测网络中,推断得到过程数据的分类标签,分类标签为1-6属于推断结果异常,将数据打上异常标签存入数据库;如果分类标签为0属于推断结果正常,则将数据打上正常标签存入数据库。
12.作为本发明的一种数据驱动的工业过程故障检测方法的改进:
13.步骤s02中所述主成分分析进行特征提取的过程为:
14.s0201、主成分分析法提取特征:
15.s020101、根据输入的中心化的矩阵求出协方差矩阵c:
[0016][0017]
其中,z为输入的中心化的矩阵;
[0018]
s020102、求出协方差矩阵c的特征值λi和对应的特征向量;
[0019]
s020103、将协方差矩阵c的特征值λi从大到小排列作为主对角线的值,其它值全部为0,保存为特征值矩阵λ;设定η》85%,根据式(3)来确定选取的特征值的个数k:
[0020][0021]
s020104:将特征向量按照对应的特征值λi大小,按从大到小的顺序从上到下按行排列成矩阵,保存为特征向量矩阵a,取特征向量矩阵a的前k行记为ak;
[0022]
s020105:所述主成分分析后的特征数据y1:
[0023]
y1=akz
ꢀꢀꢀ
(4)
[0024]
经过主成分分析法的输出为特征数据y1和特征向量矩阵ak。
[0025]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0026]
步骤s02中所述独立成分分析法进行特征提取的过程为:
[0027]
s0202、独立成分分析法提取特征
[0028]
s020201、获取白化矩阵w:
[0029][0030]
s020202:获取新的白化后的过程数据
[0031]znew
=wz
ꢀꢀꢀ
(6)
[0032]
其中,z为输入的中心化的矩阵;
[0033]
s020203:令需要估计的分量个数为r,迭代次数为n,初始化n=0且选择随机的初始向量ω(0);
[0034]
s020204:通过牛顿迭代法,按式(7)进行计算ω(n 1):
[0035]
ω(n 1)=e{z
new
g(ω(n)
tznew
)}-e{g’(ω
tznew
)}ω(n)
ꢀꢀꢀ
(7)
[0036]
其中,e表示均值,g代表非线性函数,a表示常数,g’(ω
tznew
)表示函数g的导数,n为计算次数,ω(n)表示通过迭代法计算了n次的结果;
[0037]
s020205、对得到的ω(n 1)按式(8)进行归一化,并按式(9)进行收敛判断:如果不
满足式(9)的条件,那么n=n 1后,重复步骤s020204计算ω(n 1);
[0038][0039]
||ω(n 1)ω(n)
t
|-1|《ε
ꢀꢀꢀ
(9)
[0040]
其中,ε为误差;
[0041]
如果满足式(9)的条件,当收敛的的矢量个数等于r,独立成分分析停止,得到矢量矩阵矩阵
[0042]
s020206、所述独立成分分析提取的特征数据y2为:
[0043][0044]
经过独立成分分析法的输出为特征数据y2和矢量矩阵
[0045]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0046]
步骤s02中所述典型关联分析法进行特征提取的过程为:
[0047]
s0203、典型关联分析法提取特征
[0048]
s020301、构建历史向量pk与历史数据集pk:
[0049]
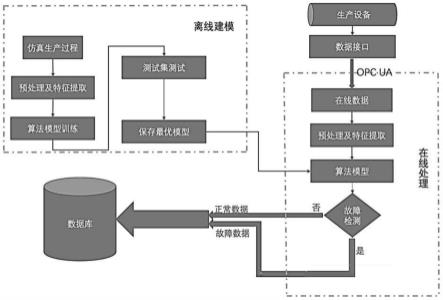
pk=[z
k-1
,z
k-2
,
…
,z
k-h
]
t
ꢀꢀꢀ
(12)
[0050]
pk=[p
k-1
,p
k-2
,
…
,p
k n-1
]∈r
mh
×nꢀꢀꢀ
(13)
[0051]
其中,h为历史向量长度,n为数据总条数,zk为输入的中心化的矩阵第k行数据,并记pk的协方差矩阵为σ
pp
;
[0052]
s020302:构建未来向量fk与未来数据集fk:
[0053]fk
=[zk,z
k 1
,
…
,z
k s
]
t
ꢀꢀꢀ
(14)
[0054]fk
=[fk,f
k 1
,
…
,f
k n-1
]∈r
sh
×nꢀꢀꢀ
(15)
[0055]
其中,s为未来向量长度;
[0056]
记未来数据集fk的协方差矩阵为σ
ff
,记未来向量fk与未来数据集fk的协方差为σ
pf
;
[0057]
s020303、使用典型关联分析法使历史数据集pk和未来数据集fk构成的数据集相关性最大,对相关系数进行奇异值分解:
[0058]
ρ
pf
=uσv
t
ꢀꢀꢀ
(16)
[0059]
根据奇异值分解公式可得:
[0060][0061]
其中,σ
ff
为未来数据集fk的协方差矩阵,σ
pf
是历史数据集pk和未来数据集fk的协方差,σ
pp
是历史数据集pk的协方差矩阵,v为右奇异向量正交基,u为左奇异向量正交基,σ为特征向量矩阵;可得:
[0062][0063]
σ=σ
pf
ꢀꢀꢀ
(19)
[0064][0065]
s020304、所述典型关联分析法得到的特征数据y3为:
[0066][0067]
其中,y(k)表示k时刻经过典型关联分析法得到的特征数据,k∈(1,m)表示输入的中心化的矩阵的当前时刻的条数,m为输入的中心化的矩阵的的总条数,将k从1到m带入式(21),得出经过所述典型关联分析得到的特征数据y3;
[0068]
经过典型关联分析法的输出为特征数据y3、特征向量矩阵σ和右奇异向量正交基v。
[0069]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0070]
步骤s03中的所述工业过程故障检测网络包括三个等价通道的三通道卷积神经网络,分别为pca通道、ica通道和cca通道;每个通道均包括四层结构:第一层为16个2x2的卷积核,步长为1,padding为1,激活函数为relu,输出为16x4x4;第二层为32个2x2的卷积核,步长为1,padding为0,激活函数也为relu,输出为32x3x3;第三层为16个2x2的卷积核,步长为1,padding为0,激活函数同为relu,输出为16x2x2;第四层为全连接层;
[0071]
输入的特征数据经过pca通道、ica通道和cca通道后均获得32维数据,将三通道的32维数据进行连接,并在通过一层全连接层,输出32维数据,最终通过输出层输出0到6的分类结果。
[0072]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0073]
所述训练好的列平均值矩阵z
mean
、特征向量矩阵a9、矢量矩阵特征向量矩阵σ9和右奇异向量正交基v9的获取过程为:
[0074]
1)、田纳西伊斯曼的过程数据进行软件仿真获得样本数据并进行标签,正常数据的标签为0,异常数据的标签为1-6;将样本数据及其对应的标签按照8:2划分为训练集和测试集;
[0075]
2)、对训练集进行中心化的预处理后获得中心化的矩阵z
train
,同时保存训练集每一列的平均值为所述训练好的列平均值矩阵z
mean
=z
mean_1
,z
mean_2
,
…
,z
mean_53
;
[0076]
3)、中心化的矩阵z
train
通过所述主成分分析法的获得特征向量矩阵a,取特征向量矩阵a的前9行并保存为所述训练好的特征向量矩阵a9,输出特征数据y1=a9z
train
;
[0077]
4)、中心化的矩阵z
train
通过所述独立成分分析法获得矢量矩阵取矢量个数r=9并保存为所述训练好的矢量矩阵输出特征数据
[0078]
5)、中心化的矩阵z
train
通过所述经过典型关联分析法获得特征向量矩阵σ和右奇异向量正交基v,然后维度取n=9,保存特征向量矩阵σ的前9
×
9对角阵为所述训练好的特征向量矩阵σ9和右奇异向量正交基v的前9
×
9对角阵为所述训练好的右奇异向量正交基v9,将k从训练集的第一条到最后一条依次代入按式(23),输出特征数据y3:
[0079][0080]
其中,pk为中心化的矩阵z
train
的第k行。
[0081]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0082]
所述测试集构建一个m行53列的测试集的原始矩阵z
src
,将原始矩阵z
src
的每一列都减去训练好的列平均值矩阵z
mean
,得到中心化的矩阵z
test
,然后进行特征提取:
[0083]
将中心化的矩阵z
test
通过主成分分析法,并利用训练好的特征向量矩阵a9计算特
征数据y1_test=a9z
test
;将中心化的矩阵z
test
通过独立成分分析法,并利用训练好的矢量矩阵计算特征数据将中心化的矩阵z
test
通过典型关联分析法,并利用训练好的特征向量矩阵σ9和训练好的右奇异向量正交基v9,将k从训练集的第一条到最后一条依次代入式(23)后输出特征数据y3_test:
[0084][0085]
其中,pk为中心化的矩阵z
test
的第k行。
[0086]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0087]
所述中心化预处理为:将输入的数据构建一个m行53列的原始矩阵为z
src
=[z1,z2,z3,z4……
,z
53
],对53个维度进行归一化,操作为:
[0088][0089]
其中:z
i_new
是中心化之后的数据,zi是第i列的列向量,包括同一个维度的数据集合,mean(zi)表示zi所在列的平均值;
[0090]
中心化的预处理输出为矩阵
[0091]
作为本发明的一种数据驱动的工业过程故障检测方法的进一步改进:
[0092]
所述工业过程故障检测网络的训练过程为:所述特征数据y1输入pca通道、特征数据y2输入ica通道、特征数据y3输入cca通道进行模型训练,学习率设置为0.001和损失函数为交叉熵损;共训练100个epoch病保存每个epoch训练好的模型,共保存100个训练好的工业过程故障检测网络模型,每个模型输出为训练集每一条样本数据对应的分类标签,其中标签0为正常数据,标签1-6代表故障数据;
[0093]
所述工业过程故障检测网络的测试过程为:将特征数据y1_test作为pca通道的输入,特征数据y2_test作为ica通道的输入,特征数据y3_test作为cca通道的输入,将测试集分别输入所述100个训练好的工业过程故障检测网络模型中测试,得出每个模型的测试的f1分数,取出分数最高的工业过程故障检测网络模型为在线使用的所述工业过程故障检测网络。
[0094]
本发明的有益效果主要体现在:
[0095]
1.本发明针对复杂流程进行分析,通过分析发现在一个复杂过程中产生的数据变化规律不仅包含高斯性也包含非高斯性,且在时序数据在时间维度上存在一定关联,因此,本发明通过使用三种特征提取方法,分别能够将信号的高斯特征,非高斯特征,自相关特征加入到数据特征中。并结合三通道神经网络进行三通道输入,结果发现能在多种分类过程中有效提升准确率,能够更好的对生产过程中的故障进行溯源。
[0096]
2.本发明通过数据驱动的方法来进行故障诊断,对比基于知识和模型的方法,通用性更强,建模过程通过手动特征提取后进行深度学习网络完成,能更好的适配规模较大和复杂的工业过程。
[0097]
3.本发明通过上面特征提取方式也完成了数据降维,同时使用一个层数较少的三层卷积神经网络作为模型,在基本不降低异常数据判断准确的前提下,能够使用更少的计算来完成。
附图说明
[0098]
图1为本发明的一种数据驱动的工业过程故障检测方法的整体流程图;
[0099]
图2为三通道卷积神经网络结构图;
[0100]
图3为实验中的单通道卷积神经网络结构图。
具体实施方式
[0101]
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
[0102]
实施例1、本发明针对工业过程故障检测模型复杂,计算量大,多故障检测准确率低等问题提出了一种数据驱动的工业过程故障检测方法。
[0103]
离线建模的数据为田纳西伊斯曼(tennessee eastman,te)过程中的数据,将te过程中的数据进行采集,完成建模过程。然后将建好的模型应用于实际生产亚硫酸氢铵过程中进行故障检测。如图1所示,包括以下步骤,步骤1-步骤4为离线建模阶段,步骤5为在线处理阶段,具体为:
[0104]
步骤1:对历史生产过程中的正常数据导入并打上为正常标签,故障数据同理,并将数据保存成方便处理的csv格式;
[0105]
数据集使用的是te过程的数据。te过程是依据实际化工反应过程,由美国eastman化学公司开发了具有开放性和挑战性的化工模型仿真平台,其产生的数据具有时变、强耦合和非线性特征,广泛用于测试复杂工业过程的控制和故障诊断模型。te过程主要包括如下5个操作单元:反应器(reactor)、冷凝器(condenser)、气/液分离器(separator)、压缩机(compressor)和汽提塔(stripper)。te过程的化学反应过程涉及a、b、c、d、e、f、g和h八种成分;其中,反应物包括气态物质a、c、d、e和惰性催化剂b,生成物包括液态产品g、h和副产品f,整体反应流程为,反应气体a、c、d、e进入反应器经过催化剂进行反应,产物通过冷凝器冷凝进行冷却,冷却后的形成气液混合流后进入分离器。分离器通过分离作用,将得到的气体重新循环进入反应仪器中,在进入循环压缩机前需要排出蒸汽,从分离器得到的冷凝成分会被放入气体塔进行分离,经过汽提塔的反应成分通过循环后在回到反应器中。反应过后在汽提塔底部获取生产得到生产产物g和h。过程中连续测量变量如表1:
[0106]
表1:连续测量变量
[0107][0108][0109]
成分分析变量如表2:
[0110]
表2:成分分析变量
[0111][0112][0113]
控制变量如表3:
[0114]
表3:控制变量
[0115]
变量描述编号d进料量(流2)xmv(1)e进料量(流3)xmv(2)a进料量(流l)xmv(3)总进料量(流4)xmv(4)压缩机再循环阀xmv(5)
排放阀(流9)xmv(6)分离器罐液流量(流10)xmv(7)汽提塔液体产品流量(流ii)xmv(8)汽提塔水流阀xmv(9)反应器冷却水流量xmv(10)冷凝器冷却水流量xmv(11)搅拌速度xmv(12)
[0116]
故障类型如表4:
[0117]
表4:故障类型
[0118]
[0119][0120]
te过程的数据维度一共53维,包含21种故障的异常情况。数据均通过matlab仿真获得。
[0121]
主要做了以下几种仿真:
[0122]
1.针对正常情况进行73h仿真,获得了1460条正常数据。
[0123]
2.针对21种异常情况进行仿真,每种异常情况均运行24h,获取到21种异常情况、每种异常情况为480条数据。
[0124]
3.针对先正常情况后异常情况,对21种异常情况进行仿真,正常情况运行8h,异常情况运行40h,可以获得160条正常数据和800条对应的异常数据。如此,共进行了21次正常后异常的仿真,共获得正常数据是160*21条,21种异常数据每种各有800*21条。
[0125]
将上述数据按表4的“分类”栏的值进行标签:正常数据的标签为0,异常数据按照
表4“分类”栏进行分组合并,例如出现编号为8的异常数据打上的标签为2。样本总共1460 21*(480 960)=31700条数据,其中正常数据4820条,21种异常数据每种各1280条。
[0126]
步骤2:对数据进行预处理,即进行中心化处理;
[0127]
将输入的数据构建一个m行53列的原始矩阵为z
src
=[z1,z2,z3,z4……
,z
53
],原始矩阵z
src
的数据行数为m对应于输入的数据的条数,代表时间,原始矩阵z
src
的列和输入数据的维度相对应,代表着温度、含量、压力等信息;对53个维度进行归一化,操作为:
[0128][0129]
其中:z
i_new
是中心化之后的数据,zi是第i列的列向量,包括同一个维度的数据集合,mean(zi)表示zi所在列的平均值,i∈(1,53);
[0130]
中心化的矩阵记为z,
[0131]
步骤3:采用主成分分析、独立成分分析和典型关联分析三种方法分别对中心化处理后的数据进行分析,获得三种不同特征矩阵作为下一步所建立的工业过程故障检测网络的输入;
[0132]
步骤3-1:主成分分析法提取特征:
[0133]
步骤3-1-1:根据步骤2中的中心化的矩阵z,求出z的协方差矩阵c:
[0134][0135]
步骤3-1-2:求出协方差矩阵c的特征值λi和对应的特征向量;
[0136]
步骤3-1-3:将协方差矩阵c的特征值λi从大到小排列,并记为λ=[λ1,λ2,λ3,λ4,λ5……
λm];将从大到小排列的特征值λi作为主对角线的值,其它值全部为0,保存为特征值矩阵记作λ,选取贡献率η超过一个百分比,一般选取η》85%,根据式(3)来确定选取的特征值的个数k:
[0137][0138]
步骤3-1-4:将特征向量按照对应的特征值λi大小,按从大到小的顺序从上到下按行排列成矩阵,保存为特征向量矩阵a,取特征向量矩阵a的前k行记为ak;
[0139]
步骤3-1-5:计算主成分分析后的数据:
[0140]
y1=akz
ꢀꢀꢀ
(5)
[0141]
其中,y1为主成分分析后获得的特征数据,z为中心化的矩阵;
[0142]
中心化的矩阵z经过主成分分析法的输出为特征数据y1和特征向量矩阵ak;
[0143]
步骤3-2:使用独立成分分析法提取特征,并保存特征矩阵;
[0144]
步骤3-2-1:获取白化矩阵w,获取方法为:
[0145][0146]
其中λ为步骤3-1-3中的特征值矩阵,a为步骤3-1-5中的特征向量矩阵;
[0147]
步骤3-2-2:获取新的白化后的过程数据z
new
,
[0148]znew
=wz
ꢀꢀꢀ
(7)
[0149]
z为中心化的矩阵;
[0150]
步骤3-2-3:令需要估计的分量个数为r,迭代次数为n,初始化n=0且选择随机的
初始向量ω(0);
[0151]
步骤3-2-4:通过牛顿迭代法,按式(7)进行计算:
[0152]
ω(n 1)=e{z
new
g(ω(n)
tznew
)}-e{g’(ω
tznew
)}ω(n)
ꢀꢀꢀ
(8)
[0153]
其中,e表示均值,g代表非线性函数,可以取g1(x)=tanhax,g2(x)=x3等,a表示常数,g’(ω
tznew
)表示函数g的导数,n为计算次数,ω(n)表示通过迭代法计算了n次的结果;
[0154]
步骤3-2-5:对得到的ω(n 1)按式(8)进行归一化(第一次迭代是代入ω(0),n取0,得到的是ω(1)),并按式(9)进行收敛判断:
[0155]
如果不满足式(9)的条件,那么n=n 1后,重复步骤3-2-4计算ω(n 1);
[0156][0157]
||ω(n 1)ω(n)
t
|-1|《ε
ꢀꢀꢀ
(10)
[0158]
其中,ε为误差;
[0159]
如果满足式(9)的条件,当收敛的的矢量个数等于r,独立成分分析停止,得到矢量矩阵
[0160][0161]
步骤3-2-6:计算独立成分分析后的特征数据:
[0162][0163]
其中,y2为独立成分分析后获得的特征数据,z为步骤2中心化过后的矩阵
[0164]
中心化的矩阵z经过独立成分分析法的输出为特征数据y2和矢量矩阵
[0165]
步骤3-3:使用典型关联分析法提取特征,并保存特征矩阵;
[0166]
步骤3-3-1:选取历史向量长度为h,zk为步骤2中的中心化之后的数据z
i_new
的第k行,构建历史向量pk与历史矩阵pk:
[0167]
pk=[z
k-1
,z
k-2
,
…
,z
k-h
]
t
ꢀꢀꢀ
(13)
[0168]
pk=[p
k-1
,p
k-2
,
…
,p
k n-1
]∈r
mh
×nꢀꢀꢀ
(14)
[0169]
其中,n为数据总条数,并记pk的协方差矩阵为σ
pp
;
[0170]
步骤3-3-2:选取未来向量长度为s,构建未来向量fk与未来矩阵fk:
[0171]fk
=[zk,z
k 1
,
…
,z
k s
]
t
ꢀꢀꢀ
(15)
[0172]fk
=[fk,f
k 1
,
…
,f
k n-1
]∈r
sh
×nꢀꢀꢀ
(16)
[0173]
记未来矩阵fk的协方差矩阵为σ
ff
,记历史矩阵pk与未来矩阵fk的协方差为σ
pf
;
[0174]
步骤3-3-3:使用典型关联分析法使历史矩阵pk和未来矩阵fk构成的数据集相关性最大,对相关系数进行奇异值分解:
[0175]
ρ
pf
=uσv
t
ꢀꢀꢀ
(17)
[0176]
根据奇异值分解公式可得:
[0177][0178]
其中,σ
ff
为未来矩阵fk的协方差矩阵,σ
pf
是历史矩阵pk和未来矩阵fk的协方差,σ
pp
是历史数据集pk的协方差矩阵,v为右奇异向量正交基,u为左奇异向量正交基,σ为特征向量矩阵。
[0179]
可得:
[0180]
σ=σ
pf
ꢀꢀꢀ
(20)
[0181][0182]
步骤3-3-4:典型关联分析法得到的数据
[0183][0184]
k∈(1,m)为输入数据的当前时刻的条数,m为输入数据的总条数,将k从1到m带入式(21),得出经过所述典型关联分析得到的特征数据y3;
[0185]
中心化的矩阵z经过典型关联分析法的输出为特征数据y3、特征向量矩阵σ和右奇异向量正交基v。
[0186]
步骤4:建立并训练工业过程故障检测网络
[0187]
步骤4-1:构建工业过程故障检测网络
[0188]
构建三通道卷积神经网络作为本发明的工业过程故障检测网络的模型,三通道卷积神经网络模型结构如图2所示,包括pca通道、ica通道和cca通道。pca通道、ica通道和cca通道的卷积核是相同的,所以三个通道是等价的。每个通道均包括四层结构:第一层为16个2x2的卷积核,步长为1,padding为1,激活函数为relu,输出为16x4x4;第二层为32个2x2的卷积核,步长为1,padding为0,激活函数也为relu,输出为32x3x3;第三层为16个2x2的卷积核,步长为1,padding为0,激活函数同为relu,输出为16x2x2;第四层为全连接层,将16x2x2的数据压平到32维。输入的特征数据分别经过pca通道、ica通道和cca通道后均获得32维数据,将三通道的32维数据进行连接,并在通过一层全连接层,输出32维数据,最终通过输出层输出7种数据即0到6的分类结果,其中分类结果0为正常,其他故障如表4标签。
[0189]
其中,激活函数:relu(x)=max(0,x)
ꢀꢀꢀ
(23)。
[0190]
步骤4-2:模型训练
[0191]
将步骤1中所获得的31700条样本数据及其对应的标签按照8:2划分为训练集和测试集,并使得正常数据和异常数据均按8:2的比例分布于训练集和测试集,所得训练集有25360条样本数据,测试集一共6340条样本数据。
[0192]
首先对训练集按步骤2进行中心化的预处理获得中心化的矩阵z
train
,同时保存训练集每一列的平均值为训练好的列平均值矩阵z
mean
=[z
mean_1
,z
mean_1
,
…
,z
mean_53
],然后提取特征:
[0193]
1)、中心化的矩阵z
train
通过步骤3-1主成分分析法的获得特征向量矩阵a,取特征向量矩阵a的前9行并保存为训练好的特征向量矩阵a9,输出特征数据y1=a9z
train
;
[0194]
2)、中心化的矩阵z
train
通过步骤3-2独立成分分析法获得矢量矩阵取矢量个数r=9并保存为训练好的矢量矩阵输出特征数据
[0195]
3)、中心化的矩阵z
train
通过步骤3-3经过典型关联分析法获得特征向量矩阵σ和右奇异向量正交基v,然后维度取n=9,保存特征向量矩阵σ的前9
×
9对角阵σ9(即训练好的特征向量矩阵σ9)和右奇异向量正交基v的前9
×
9对角阵v9(即训练好的右奇异向量正交基v9),式(21)更新为:
[0196][0197]
其中,pk为中心化的矩阵z
train
的第k行,将k从1到25360代入式(23)后输出特征数据y3。
[0198]
将上述中得到的训练集的特征数据y1输入pca通道、特征数据y2输入ica通道、特征数据y3输入cca通道进行模型训练,学习率设置为0.001和损失函数为交叉熵损;训练集所有数据都训练过一次为一个epoch,训练100个epoch,并保存每个epoch训练好的模型,共保存100个模型,模型输出为训练集每一条样本数据对应的分类标签,其中标签0为正常数据,标签1-6代表故障数据。
[0199]
步骤4-3:模型测试
[0200]
首先对测试集按步骤2进行中心化处理:将输入的测试集构建一个m行的原始矩阵z
src
,将原始矩阵z
src
的每一列都减去步骤4-2中保存的训练好的列平均值矩阵z
mean
,即测试集的原始矩阵z
src
第一列减去z
mean_1
,以此类推,得到中心化的矩阵z
test
,然后进行特征提取:
[0201]
1):将中心化的矩阵z
test
通过主成分分析法,并利用训练好的特征向量矩阵a9计算特征数据y1_test=a9z
test
;
[0202]
2):将中心化的矩阵z
test
通过独立成分分析法,并利用训练好的矢量矩阵计算特征数据
[0203]
3):将中心化的矩阵z
test
通过典型关联分析法,并利用训练好的特征向量矩阵σ9和训练好的右奇异向量正交基v9计算特征数据y3_test:
[0204][0205]
其中,pk为中心化的矩阵z
test
的第k行,将k从1到6340依次代入式(23)后输出特征数据y3_test。
[0206]
将上述提取的特征数据y1_test作为pca通道的输入,特征数据y2_test作为ica通道的输入,特征数据y3_test作为cca通道的输入,将测试集分别输入步骤4-2保存的100个模型中测试,得出每个模型的测试的f1分数,取出分数最高的模型保存为可以在线使用的工业过程故障检测网络。
[0207]
其中f1分数的计算方法为:
[0208][0209]
其中,α为参数,取α=1,得到f1指标,p为准确率,r为召回率:
[0210][0211][0212]
其中,tp代表将正类预测为正类数,tn代表将负类预测为负类数,fn代表将负类预测为正类数,fp代表将正类预测为负类数。
[0213]
步骤5:在线处理工业过程故障检测及预警
[0214]
在线处理与离线处理不同,离线处理是保存好的数据进行离线模型训练,是一个
建模的过程,在线处理是实际运用的过程。通过在某化工厂生产亚硫酸氢铵中的过程来验证本模型的有效性。通过获取生产亚硫酸氢铵过程的数据,然后根据步骤4中训练得到的相关矩阵及模型,输出生产亚硫酸氢铵过程数据的分类标签,通过表4中的“分类”栏查询获得对应的故障“描述”栏。
[0215]
步骤5-1:通过opc ua协议获取生产亚硫酸氢铵中的实时过程数据,由于工厂已有采集传感设备,只需用opc ua协议从中获取过程数据。采集的实时过程数据与步骤1中的te过程的数据维度相同,也为53维,共采集5000条数据。
[0216]
步骤5-2:在线处理方式与测试集一样,所有参与运算矩阵都来源于训练集计算。
[0217]
首先对采集的实时过程数据按步骤2进行中心化处理:将输入的实时过程数据构建一个m行的原始矩阵z
src
,将原始矩阵z
src
的每一列都减去步骤4-2中保存的训练好的列平均值矩阵z
mean
,即实时过程数据的原始矩阵z
src
第一列减去列平均值矩阵z
mean_1
,以此类推,得到中心化的矩阵zo,然后进行特征提取:
[0218]
1)、将中心化的矩阵zo通过主成分分析法,并利用训练好的特征向量矩阵a9计算特征数据y1_online=a9zo;
[0219]
2)、将中心化的矩阵zo通过独立成分分析法,并利用训练好的矢量矩阵计算特征数据
[0220]
3)、将中心化的矩阵zo通过典型关联分析法,并利用训练好的特征向量矩阵σ9和训练好的右奇异向量正交基v9计算特征数据y3_online:
[0221][0222]
其中,pk为中心化的矩阵zo的第k行,将k从1到5000依次代入式(23)后输出特征数据y3_online。
[0223]
步骤5-3:将上述提取的特征数据y1_online作为pca通道的输入,特征数据y2_online作为ica通道的输入,特征数据y3_online作为cca通道的输入,分别输入到步骤4中获得的可在线使用的工业过程故障检测网络中,推断得到生产亚硫酸氢铵过程数据的分类标签;
[0224]
步骤5-4:如果分类标签属于推断结果异常即判断标签不为0,则将当前数据,即原始收集到的生产亚硫酸氢铵过程数据53维数据打上异常标签存入数据库。如果分类标签属于推断结果正常即判断标签为0,则将数据打上正常标签存入数据库。
[0225]
实验1:
[0226]
为了验证本发明的有效性,为减少不同数据对最终分析结果的影响,统一采用实施例1中的实验数据来进行训练和测试,训练集有25360条数据,测试集有6340条数据,即与离线建模阶段所用的数据集和测试集一致。测试用机为macbook pro 2020m1,内存为16g。选取三种方案进行对比:
[0227]
1)、基于主成分分析pca的检测:
[0228]
通过使用主成分分析法,将输入的训练集数据降维,根据t2统计量得出设置阈值,超出阈值的数据则判断为异常:
[0229]
[0230]
其中,是带有a个和n-a个自由度、置信水平为的f分布临界值,a代表pca处理后的维度,n代表原始维度,令得出阈值的方法来进行检验;
[0231]
2)、使用常规卷积神经网络cnn
[0232]
将训练集数据的中心化的矩阵z
train
直接输入卷积神经网络cnn来进行网络训练,从而获得训练好的故障预警模型;
[0233]
3)、单通道卷积神经网络
[0234]
处理过程与本方法步骤完全一致,仅保留一个pca通道,且删去另外两路通道同时去掉图2中的连接,最终模型图如图3所示。
[0235]
4)、实施例1所述方法;
[0236]
对四种方法使用测试集的测试结果分别统计f1指标、处理时间秒/万条,最终结果如表5:
[0237]
表5:对比测试结果
[0238][0239][0240]
根据结果不难看出,本发明在准确率方面是最高的。方法1通过pca的方法来进行预测,虽然时间很短,但是准确率偏低。本方法的优越性为在构建三通道网络的过程中,对比传统网络降低了数据维度,减少了计算量,减少了运算时间,对比计算量小的方法1和方法3,本发明有效提高了多种故障检测的准确率。
[0241]
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
