1.本发明涉及污水处理厂污泥膨胀故障诊断的技术领域,特别涉及一种基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法。
背景技术:
2.污水处理是实现水资源循环利用、应对水资源短缺的重要方法,其中,活性污泥法作为一种成本低廉且处理效果较好的污水处理的技术得到了广泛应用。然而,成因复杂的污泥膨胀会造成活性污泥结构松散、质量变轻,导致其沉降性能变差(基于格兰杰因果关系检验的炼化系统故障根原因诊断方法_胡瑾),严重时甚至会导致整个活性污泥系统的崩溃。因此,当污泥膨胀发生后,现场工作人员需要采取正确有效的维护措施,而这就要求发生污泥膨胀后能准确找到导致污泥膨胀的原因并分析出故障的传播路径。
3.将故障诊断技术发展至污水处理领域中为解决这一问题带来了解决办法。由传统的主成分分析(pca)导出的贡献图常常存在故障拖尾效应,即非故障变量会因受到故障变量的影响而贡献值增大,从而导致错误的诊断结果。此外,贡献图只能找出故障源,而无法展示故障在各个观测变量中的传播路径。而格兰杰因果分析可以得出各个变量之间的因果值,但却无法准确确定故障路径的起点和终点,但不够明显的观测变量被送入格兰杰因果分析后可能得出不准确的结果。
技术实现要素:
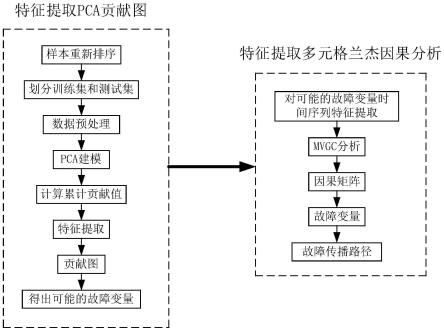
4.针对上述问题,本发明提出了基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法,利用特征提取方法将绝对均值、方根幅值、间隙系数、偏度、峰度或方差与传统的主成分分析(pca)残差相结合,从而导出更为精确的特征提取贡献值,得到了能克服故障拖尾效应的特征提取贡献图。此外,在得出可能的故障变量后,利用特征提取处理每个可能的故障变量原始观测数列,然后送入多元格兰杰因果分析(mvgc),得出确切的故障变量,并根据所得出的因果矩阵,以故障变量为起点,污泥体积指数(svi)为终点,画出故障传播路径。
5.本发明至少通过如下技术方案之一实现。
6.基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法,包括以下步骤:
7.(1)、确定观测变量并设定采样间隔,其中观测变量必须包括污泥体积指数svi;发生污泥膨胀后,对所有的历史观测样本重新排列,并对排列后的样本划分训练集和测试集;
8.(2)、对训练集进行预处理;
9.(3)、计算训练集的协方差矩阵,并对训练集的协方差矩阵进行特征值分解;
10.(4)、选取主元个数,并得出负载矩阵;
11.(5)、对测试集进行所述的预处理,计算出测试集中每个样本的残差向量,由此构成残差矩阵;
12.(6)、对残差矩阵的每一列特征提取并求和,得出每个变量的特征提取贡献值,以此画出特征提取贡献图,得出可能的故障变量;
13.(7)、对可能的故障变量原始观测时间序列特征提取;
14.(8)、估计各个变量的向量自回归模型的系数矩阵和阶数;
15.(9)、对特征提取完后的可能的故障变量时间序列进行多元格兰杰因果分析mvgc,得出可能发生故障的变量之间的因果矩阵;
16.(10)、由因果矩阵确定最确切的故障变量,并以最确切的故障变量为起点,svi为终点,寻找因果矩阵中因果值最大的方向,画出故障传播路径。
17.进一步地,所述对所有的历史观测样本重新排列是根据每个样本的svi值由小到大的顺序对每个样本重新排列,即svi值最小的样本排在第一个,svi值第二小的样本排在第二个,以此类推。
18.进一步地,所述预处理包括采用极差标准化法将从污水处理厂观测到的数据矩阵按照下式进行数据预处理:
[0019][0020]
其中,x∈rn×m是待处理的原始观测数据矩阵,rn×m表示n行m列的实矩阵,x的每一行代表一个观测样本,每一列代表一个观测变量,x'表示预处理后的训练集,x(i,j)、x'(i,j)分别表示x和x'的第i行第j列位置上的元素,x(j)
max
、x(j)
min
分别表示x的第j列中的最大值和最小值。
[0021]
进一步地,所述预处理包括采用0-1标准化法将从污水处理厂观测到的数据矩阵按照下式进行数据预处理:
[0022][0023]
其中,x∈rn×m是待处理的原始观测数据矩阵,rn×m表示n行m列的实矩阵,x的每一行代表一个观测样本,每一列代表一个观测变量,μ
x
和σ
x
表示x中各观测变量的样本均值和样本标准差,x'表示预处理后的训练集。
[0024]
进一步地,计算训练集的协方差矩阵,并对其进行特征值分解具体为:
[0025][0026]
其中∑
x'
为预处理后的训练集x'的协方差矩阵,n为x'中包含的样本个数,x'
t
代表x'的转置矩阵;是∑
x'
的特征矩阵,m是观测变量的个数,λ1,λ2,...,λm是∑
x'
的特征值且λ1≥λ2,...,≥λm;v是∑
x'
的特征矩阵,v的各列是λ1,λ2,...,λm所依次对应的特征向量,v
t
代表v的转置矩阵。
[0027]
进一步地,主元个数通过累计贡献率法选取,且负载矩阵p是由预处理后的训练集x'的协方差矩阵∑
x'
的前k个特征值对应的特征向量所组成的矩阵,其中k为主元个数且k≤m,m是观测变量的个数。
[0028]
进一步地,每个样本的残差向量计算为:
j)、x2(t-j)代表x1(t)、x2(t)的滞后项,j表示滞后项数,p'是滞后项数的最大值,又称剔除变量间的影响后的向量自回归模型的阶数,ε'1(t)和ε'2(t)分别是剔除变量间的影响后变量x1、x2的向量自回归模型中所包含的独立且不相关的白噪声,又称模型残差;
[0048]
③
求出ε1(t)、ε2(t)、ε'1(t)和ε'2(t)的方差,分别记为cov(ε1(t))、cov(ε'1(t))、cov(ε2(t))和cov(ε'2(t)),计算变量间的因果值:
[0049][0050][0051]
其中,f2→1代表因变量x2到因果变量x1的因果值即x2引起x1的可能性大小,f1→2代表因变量x1到果变量x2的因果值即x1引起x2的可能性大小;如果f2→1<0,则说明x2不可能引起x1,f2→1<0,则说明x1不可能引起x2;
[0052]
重复上述步骤
①
~
③
,对所有可能的故障变量和svi都两两计算出其间的因果值,并以此得到因果矩阵。
[0053]
进一步地,所述特征提取包括以下步骤:
[0054]
假设y(t)是需要特征提取的原始时间序列,y(i)表示y(t)在t=i时刻的值,对于时间序列第一个值y(1),保留其原值;依次计算时间序列y(t)在时间区间[1,2]、[1,3]、[1,4]、......、[1,t]内的绝对均值amav或方根幅值srav或间隙系数cli或偏度sk或峰度ku或方差va:
[0055][0056][0057][0058][0059][0060][0061]
其中,μ和σ分别代表时间序列y(t)在对应时间区间里的均值和标准差;
[0062]
按以下顺序依次组成新的y-amav或y-srav或y-cli或y-sk或y-ku或y-va时间序列:
[0063]
y-amav(1)=y(1);
[0064]
y-amav(2)=时间序列y(1)、y(2)的amav值;
[0065]
y-amav(3)=时间序列y(1)、y(2)、y(3)的amav值;
[0066]
y-amav(4)=时间序列y(1)、y(2)、y(3)、y(4)的amav值;
[0067]
……
[0068]
y-amav(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的amav值;
[0069]
y-srav(1)=y(1);
[0070]
y-srav(2)=时间序列y(1)、y(2)的srav值;
[0071]
y-srav(3)=时间序列y(1)、y(2)、y(3)的srav值;
[0072]
y-srav(4)=时间序列y(1)、y(2)、y(3)、y(4)的srav值;
[0073]
……
[0074]
y-srav(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的srav值;
[0075]
y-cli(1)=y(1);
[0076]
y-cli(2)=时间序列y(1)、y(2)的cli值;
[0077]
y-cli(3)=时间序列y(1)、y(2)、y(3)的cli值;
[0078]
y-cli(4)=时间序列y(1)、y(2)、y(3)、y(4)的cli值;
[0079]
……
[0080]
y-cli(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的cli值;
[0081]
y-sk(1)=y(1);
[0082]
y-sk(2)=时间序列y(1)、y(2)的sk值;
[0083]
y-sk(3)=时间序列y(1)、y(2)、y(3)的sk值;
[0084]
y-sk(4)=时间序列y(1)、y(2)、y(3)、y(4)的sk值;
[0085]
……
[0086]
y-sk(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的sk值。
[0087]
y-ku(1)=y(1);
[0088]
y-ku(2)=时间序列y(1)、y(2)的ku值;
[0089]
y-ku(3)=时间序列y(1)、y(2)、y(3)的ku值;
[0090]
y-ku(4)=时间序列y(1)、y(2)、y(3)、y(4)的ku值;
[0091]
……
[0092]
y-ku(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的ku值。
[0093]
本发明与现有的技术相比,具有如下优点与有益效果:
[0094]
1、本发明充分考虑污泥膨胀发生时样本的特征,通过重新排列观测样本的方式,一方面保证了训练集中的样本都是最接近污水处理厂正常运行时的数据样本,另一方面能使测试集中的样本是最接近真实故障状态时的故障样本,在一定程度上解决了传统pca贡献图在诊断污泥膨胀时存在故障拖尾效应的问题。
[0095]
2、本发明能够通过特征提取方法有效提取出样本残差向量中的故障信息,得到更加准确的特征提取贡献值。
[0096]
3、本发明能够在进行格兰杰因果分析前通过特征提取方法有效放大原始观测变量中所蕴含的故障信息,从而得到更为准确的因果矩阵。
[0097]
4、本发明根据格兰杰因果分析得出的因果矩阵,得出可视化的故障转播路径,能为现场的工作人员做出维护决策提供一定的依据。
附图说明
[0098]
图1是本发明的故障诊断流程图;
[0099]
图2是本发明实施例一的srav特征提取贡献图;
[0100]
图3是本发明实施例二的sk特征提取贡献图;
[0101]
图4是本发明实施例三的ku统计量故障检测图;
[0102]
图5是本发明实施例四的cli统计量故障检测图;
[0103]
图6是本发明实施例二、三的va-mvgc故障传播路径图;
[0104]
图7是本发明实施例四的amav-mvgc故障传播路径图。
具体实施方式
[0105]
为了使本发明的技术方案更加清楚,下面结合附图和具体实施例进一步说明。
[0106]
实施例1
[0107]
如图1所示的基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法,该方法首先将历史观测数据按照每个样本的svi值重新排列,将svi值较小的样本作为训练集,svi值较大的样本作为测试集,构建特征提取pca贡献图,由此得到可能的几个故障变量。最后对这几个可能的几个故障变量原始观测数列特征提取,提取完后对其进行格兰杰因果分析,得出因果矩阵,可得出最确切的故障变量,然后寻找因果值最大的方向,并以此为依据画出主要的故障路径。具体包括以下步骤:
[0108]
1)、确定观测变量并设定采样间隔,其中观测变量必须包括污泥体积指数(svi)。发生污泥膨胀后,对所有的历史观测样本按照svi值由小到大的顺序重新排列,即svi值最小的样本排在第一个,svi值第二小的样本排在第二个,以此类推,并对重排的数据集划分训练集和测试集;
[0109]
2)、采用0-1标准化法,对训练集进行预处理:
[0110][0111]
其中,x∈rn×m是待处理的原始观测数据矩阵,rn×m表示n行m列的实矩阵,x的每一行代表一个观测样本,每一列代表一个观测变量,μ
x
和σ
x
表示x中各观测变量的样本均值和样本标准差,x'表示预处理后的训练集。
[0112]
3)、计算训练集的协方差矩阵,并对其进行特征值分解:
[0113][0114]
其中∑
x'
为预处理后的训练集x'的协方差矩阵,n为x'中包含的样本个数,x'
t
代表
x'的转置矩阵;是∑
x'
的特征矩阵,m是观测变量的个数,λ1,λ2,...,λm是∑
x'
的特征值且λ1≥λ2,...,≥λm;v是∑
x'
的特征矩阵,v的各列是λ1,λ2,...,λm所依次对应的特征向量,v
t
代表v的转置矩阵。
[0115]
4)、通过累计贡献率法选取主元个数,且负载矩阵p构建为v的前k列即∑
x'
的前k个特征值对应的特征向量所组成的矩阵,其中k为主元个数且k≤m,m是观测变量的个数,∑
x'
为预处理后的训练集x'的协方差矩阵,v是∑
x'
的特征矩阵。
[0116]
5)、计算每个样本的残差向量:
[0117]
e(t)=x(t)(i-pp
t
)
[0118]
其中,x(t)代表t时刻的观测样本,e(t)代表x(t)对应的残差向量,i代表k阶单位矩阵,k为主元个数且k≤m,m是观测变量的个数,p为负载矩阵,p
t
为的p的转置矩阵。
[0119]
6)、构建残差矩阵:
[0120][0121]
其中,e代表残差矩阵,e(1)、e(2)、
…
、e(n')分别代表第1、2、
…
、n'个样本的残差向量,n'是训练集中包含的样本个数。
[0122]
7)、计算第i个观测变量的特征提取贡献值:
[0123][0124]
其中,conti代表第i个观测变量的特征提取贡献值,m是观测变量的个数,n'是训练集中包含的样本个数,e'代表特征提取每一列后的残差矩阵,e'i代表e'的第i列,e'i(t)代表e'i的第t个值。
[0125]
其中,特征提取包括以下步骤:
[0126]
假设y(t)是需要特征提取的原始时间序列,y(i)表示y(t)在t=i时刻的值,对于时间序列第一个值y(1),保留其原值;依次计算时间序列y(t)在时间区间[1,2]、[1,3]、[1,4]、
……
、[1,t]内的绝对均值amav或方根幅值srav或间隙系数cli或偏度sk或峰度ku或方差va:
[0127][0128]
[0129][0130][0131][0132][0133]
其中,μ和σ分别代表y(i)在对应时间区间里的均值和标准差;
[0134]
按以下顺序依次组成新的y-amav或y-srav或y-cli或y-sk或y-ku或y-va时间序列:
[0135]
y-amav(1)=y(1);
[0136]
y-amav(2)=时间序列y(1)、y(2)的amav值;
[0137]
y-amav(3)=时间序列y(1)、y(2)、y(3)的amav值;
[0138]
y-amav(4)=时间序列y(1)、y(2)、y(3)、y(4)的amav值;
[0139]
……
[0140]
y-amav(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的amav值;
[0141]
y-srav(1)=y(1);
[0142]
y-srav(2)=时间序列y(1)、y(2)的srav值;
[0143]
y-srav(3)=时间序列y(1)、y(2)、y(3)的srav值;
[0144]
y-srav(4)=时间序列y(1)、y(2)、y(3)、y(4)的srav值;
[0145]
……
[0146]
y-srav(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的srav值;
[0147]
y-cli(1)=y(1);
[0148]
y-cli(2)=时间序列y(1)、y(2)的cli值;
[0149]
y-cli(3)=时间序列y(1)、y(2)、y(3)的cli值;
[0150]
y-cli(4)=时间序列y(1)、y(2)、y(3)、y(4)的cli值;
[0151]
……
[0152]
y-cli(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的cli值;
[0153]
y-sk(1)=y(1);
[0154]
y-sk(2)=时间序列y(1)、y(2)的sk值;
[0155]
y-sk(3)=时间序列y(1)、y(2)、y(3)的sk值;
[0156]
y-sk(4)=时间序列y(1)、y(2)、y(3)、y(4)的sk值;
[0157]
……
[0158]
y-sk(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的sk值。
[0159]
y-ku(1)=y(1);
[0160]
y-ku(2)=时间序列y(1)、y(2)的ku值;
[0161]
y-ku(3)=时间序列y(1)、y(2)、y(3)的ku值;
[0162]
y-ku(4)=时间序列y(1)、y(2)、y(3)、y(4)的ku值;
[0163]
……
[0164]
y-ku(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的ku值。
[0165]
y-va(1)=y(1);
[0166]
y-va(2)=时间序列y(1)、y(2)的va值;
[0167]
y-va(3)=时间序列y(1)、y(2)、y(3)的va值;
[0168]
y-va(4)=时间序列y(1)、y(2)、y(3)、y(4)的va值;
[0169]
……
[0170]
y-va(t)=时间序列y(1)、y(2)、y(3)、y(4)、
…
、y(t)的va值。
[0171]
8)、根据每个观测变量的特征提取贡献值画成柱状图,且在柱状图中较高的贡献值对应的观测变量是可能的故障变量;
[0172]
9)、对每个可能的故障变量原始观测时间序列特征提取,特征提取方法与步骤7)中所述特征提取做法相同;
[0173]
10)、利用最小二乘法估计向量自回归模型的系数矩阵,利用赤池信息准则(aic)或者贝叶斯信息准则(bic)估计向量自回归模型的阶数;
[0174]
11)、对可能的故障变量进行格兰杰因果分析(mvgc),具体步骤如下:
[0175]
①
假设x1(t)、x2(t)是需要格兰杰因果分析的变量x1、x2时间序列,对应的向量自回归模型为:
[0176][0177][0178]
其中,a
11,j
、a
12,j
、a
21,j
、a
22,j
表示向量自回归模型的系数矩阵,x1(t-j)、x2(t-j)表示x1(t)、x2(t)的滞后项,j表示滞后项数,p是滞后项数的最大值,又称向量自回归模型的阶数,ε1(t)和ε2(t)分别是变量x1、x2的向量自回归模型中所包含的独立且不相关的白噪声,又称模型残差;
[0179]
②
剔除变量间的影响,即
[0180][0181][0182]
其中,b
11,j
、b
22j,
代表剔除变量间的影响后的向量自回归模型的系数矩阵,x1(t-j)、x2(t-j)代表x1(t)、x2(t)的滞后项,j表示滞后项数,p'是滞后项数的最大值,又称剔除变量间的影响后的向量自回归模型的阶数,ε'1(t)和ε'2(t)分别是剔除变量间的影响后变
量x1、x2的向量自回归模型中所包含的独立且不相关的白噪声,又称模型残差;
[0183]
③
求出ε1(t)、ε2(t)、ε'1(t)和ε'2(t)的方差,分别记为cov(ε1(t))、cov(ε'1(t))、cov(ε2(t))和cov(ε'2(t)),计算变量间的因果值:
[0184][0185][0186]
其中,f2→1代表因变量x2到因果变量x1的因果值即x2引起x1的可能性大小,f1→2代表因变量x1到果变量x2的因果值即x1引起x2的可能性大小;如果f2→1<0,则说明x2不可能引起x1,f2→1<0,则说明x1不可能引起x2;
[0187]
重复上述步骤
①
~
③
,对所有可能的故障变量和svi都两两计算出其间的因果值,并以此得到因果矩阵。
[0188]
12)、根据因果矩阵,确定最可能的故障变量,并以该变量为起点,svi为终点,画出主要的故障传播路径。
[0189]
在本实施例中以北京某污水厂提供的污泥膨胀数据对其进行验证。该观测数据包括213个样本,均以1天为间隔进行采样,观测变量一共23个,包括srt、t、mlss等,各观测变量的含义如表1所示。大约从观测的第71天起,由于水温较低,活性污泥的微生物生态系统的平衡被打破,使得污泥膨胀现象略有发生,持续时间约半年以上。
[0190]
表1实验数据观测变量
[0191]
序号符号描述单位1srt生物固体停留时间天2t水温摄氏度3mlss氧化沟混合液悬浮固体浓度毫克每升4sno二沉池出水硝态氮浓度毫克每升5sno2二沉池出水亚硝态氮浓度毫克每升6icod总进水化学需氧量毫克每升7ocod二沉池出水化学需氧量毫克每升8itp总进水总磷量毫克每升9otp二沉池出水总磷量毫克每升10ibod5总进水5日生物化学需氧量毫克每升11obod5二沉池出水5日生物化学需氧量毫克每升12iss总进水固体悬浮固体浓度毫克每升13oss二沉池出水固体悬浮固体浓度毫克每升14itkn总进水凯氏氮量毫克每升15otkn二沉池出水凯氏氮量毫克每升16iph总进水氢离子浓度指数无17oph二沉池出水氢离子浓度指数无
18snh二沉池出水铵态氮浓度毫克每升19ich总进水色度度20och二沉池出水色度度21son二沉池出水有机氮浓度毫克每升22mlvss氧化沟混合液挥发性悬浮固体浓度毫克每升23svi曝气池出口混合液的污泥容积指数毫克每升
[0192]
由于污泥膨胀发生在第71天,因此取前71天的观测数据作为历史观测数据用于分析故障诊断,如图1所示,上述基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法,首先按照每个样本的svi值重新排列,将svi值较小的样本作为训练集,svi值较大的样本作为测试集,构建特征提取pca贡献图,由此得到可能的几个故障变量。最后对这几个可能的几个故障变量原始观测数列特征提取,提取完后对其进行格兰杰因果分析,得出因果矩阵,可得出最确切的故障变量,然后寻找因果值最大的方向,并以此为依据画出主要的故障路径。具体步骤如下:
[0193]
1)、确定观测变量并设定采样间隔,其中观测变量必须包括污泥体积指数(svi)。发生污泥膨胀后,对所有的历史观测样本按照svi值由小到大的顺序重新排列,即根据每个样本的svi值由小到大的顺序对每个样本重新排列,即svi值最小的样本排在第一个,svi值第二小的样本排在第二个,以此类推,并对重排的数据集划分训练集和测试集,前50个样本作为训练集,后21个样本作为测试集;
[0194]
2)、采用0-1标准化法,对训练集进行预处理:
[0195][0196]
其中,x∈r
50
×
23
是待处理的原始观测数据矩阵,r
50
×
23
表示50行23列的实矩阵,x的每一行代表一个观测样本,每一列代表一个观测变量,μ
x
和σ
x
表示x中各观测变量的样本均值和样本标准差,x'表示预处理后的训练集。
[0197]
3)、计算训练集的协方差矩阵,并对其进行特征值分解:
[0198][0199]
其中∑
x'
为预处理后的训练集x'的协方差矩阵,x'
t
代表x'的转置矩阵;
[0200]
是∑
x'
的特征矩阵,λ1,λ2,...,λ
23
是∑
x'
的特征值且λ1≥λ2,...,≥λ
23
;v是∑
x'
的特征矩阵,v的各列是λ1,λ2,...,λ
23
所依次对应的特征向量,v
t
代表v的转置矩阵。
[0201]
4)、通过累计贡献率法选取主元个数k=15,且负载矩阵p构建为v的前k列即∑
x'
的前k个特征值对应的特征向量所组成的矩阵,∑
x'
为预处理后的训练集x'的协方差矩阵,v是∑
x'
的特征矩阵。
[0202]
5)、计算每个样本的残差向量:
[0203]
e(t)=x(t)(i-pp
t
)
[0204]
其中,x(t)代表t时刻的观测样本,e(t)代表x(t)对应的残差向量,i代表k=15阶单位矩阵,p为负载矩阵,p
t
为的p的转置矩阵。
[0205]
6)、构建残差矩阵:
[0206][0207]
其中,e代表残差矩阵,e(1)、e(2)、
…
、e(21)分别代表第1、2、
…
、21个样本的残差向量。
[0208]
7)、计算第i个观测变量的特征提取贡献值:
[0209][0210]
其中,conti代表第i个观测变量的特征提取贡献值,e'代表特征提取每一列后的残差矩阵,e'i代表e'的第i列,e'i(t)代表e'i的第t个值。
[0211]
其中,特征提取包括以下步骤:
[0212]
假设y(t)是需要特征提取的原始时间序列,y(i)表示y(t)在t=i时刻的值,对于时间序列第一个值y(1),保留其原值;依次计算时间序列y(t)在时间区间[1,2]、[1,3]、[1,4]、
……
、[1,t]内的方根幅值srav:
[0213][0214]
按以下顺序依次组成新的:
[0215]
y-srav(1)=y(1);
[0216]
y-srav(2)=时间序列y(1)、y(2)的srav值;
[0217]
y-srav(3)=时间序列y(1)、y(2)、y(3)的srav值;
[0218]
y-srav(4)=时间序列y(1)、y(2)、y(3)、y(4)的srav值;
[0219]
……
[0220]
y-srav(t)=时间序列y(1)、y(2)、y(3)、y(4)、...、y(t)的srav值;
[0221]
8)、根据每个观测变量的特征提取贡献值画成柱状图作为srav特征提取贡献图,且在柱状图中较高的贡献值对应的观测变量是可能的故障变量,最终得出可能的故障变量是t和svi;
[0222]
9)、对t和svi的原始观测变量特征提取,特征提取方法与步骤7)中所述特征提取做法相同;
[0223]
10)、利用最小二乘法估计向量自回归模型的系数矩阵,利用赤池信息准则(aic)估计向量自回归模型的阶数为5;
[0224]
11)、对可能的故障变量进行多元格兰杰因果分析,具体步骤如下:
[0225]
①
假设x1(t)、x2(t)是需要格兰杰因果分析的变量x1、x2时间序列,对应的向量自回归模型为:
[0226][0227][0228]
其中,a
11,j
、a
12,j
、a
21,j
、a
22,j
表示向量自回归模型的系数矩阵,x1(t-j)、x2(t-j)表示x1(t)、x2(t)的滞后项,j表示滞后项数,p是滞后项数的最大值,又称向量自回归模型的阶数,ε1(t)和ε2(t)分别是变量x1、x2的向量自回归模型中所包含的独立且不相关的白噪声,又称模型残差;
[0229]
②
剔除变量间的影响,即
[0230][0231][0232]
其中,b
11,j
、b
22j,
代表剔除变量间的影响后的向量自回归模型的系数矩阵,x1(t-j)、x2(t-j)代表x1(t)、x2(t)的滞后项,j表示滞后项数,p'是滞后项数的最大值,又称剔除变量间的影响后的向量自回归模型的阶数,ε'1(t)和ε'2(t)分别是剔除变量间的影响后变量x1、x2的向量自回归模型中所包含的独立且不相关的白噪声,又称模型残差;
[0233]
③
求出ε1(t)、ε2(t)、ε'1(t)和ε'2(t)的方差,分别记为cov(ε1(t))、cov(ε'1(t))、cov(ε2(t))和cov(ε'2(t)),计算变量间的因果值:
[0234][0235][0236]
其中,f2→1代表因变量x2到因果变量x1的因果值即x2引起x1的可能性大小,f1→2代表因变量x1到果变量x2的因果值即x1引起x2的可能性大小;如果f2→1<0,则说明x2不可能引起x1,f2→1<0,则说明x1不可能引起x2。
[0237]
由于可能的故障变量只有t和svi,所以只需对它们进行格兰杰分析即可,得到因果矩阵:
[0238]
表2 t和svi的srav-mvgc因果矩阵
[0239][0240]
其中,行表示因变量,列表示果变量。
[0241]
12)、根据因果矩阵,确定最可能的故障变量为t,并以该变量为起点,svi为终点,
画出主要的故障传播路径。
[0242]
在采取上述方案后,可以在污泥膨胀后确定出最确切的故障变量,并得出主要的故障路径。从图2可知,变量t和变量svi的贡献值均较大,可以得出它们是可能的故障变量。然后通过srav处理变量t和变量svi的前71个样本并mvgc分析后得出表2,由表2可知,0.1663>0.0304,说明t引起svi的可能性比svi引起t的可能性更大,所以t才是最可能的故障变量。而由此得出的故障传播路径只有一条,就是t
→
svi。
[0243]
实施例2
[0244]
仍然采用实施例一中的实验数据,在求特征提取贡献图时将所用的统计指标由srav改为sk,其他参数不变,最后得出sk特征提取贡献图如图3所示。从图3的实验结果可以看出,贡献值最高的变量为t,其次为iss,所以它们为可能的故障变量。而svi常作为衡量活性污泥性能的一个指标,污泥膨胀可以看做是其他观测变量直接或间接地导致的svi变大,因此svi值应作为故障传播路径的终点。而此处得出的可能的故障变量并没有svi,在进行格兰杰因果分析时应将其加入其中。
[0245]
在特征提取t、iss和svi的观测时间序列时,所采用的统计指标由实施例一的srav改为va,向量自回归模型的阶数由aic法则确定为3,最终得出的因果矩阵如表3所示。
[0246]
表3 t、svi和iss的va-mvgc因果矩阵
[0247][0248]
其中,行表示因变量,列表示果变量。
[0249]
由表3可见,0.1632>0.1270,即t引起iss的可能性比iss引起t的可能性更大,同样地,t引起svi的可能性比svi引起t的可能性更大。另一方面,0.1632>0.1007,说明t对svi的影响比iss对svi的影响更大,同样可以确定出t是故障变量,而iss是t和svi的一个故障传播的中间变量。由此可得这三个变量间有两条故障传播路径,一条是t
→
svi,另一条是t
→
iss
→
svi,具体的故障传播路径如图6所示,其中箭头上的数字表示对应因变量和果变量之间的因果值。
[0250]
实施例3
[0251]
仍然采用实施例二中的实验数据,在求特征提取贡献图时将所用的统计指标由sk改为ku,其他参数不变,最后得出sk特征提取贡献图如图4所示。从图4的实验结果可以看出,t的贡献值最高,其次是iss和svi,它们的贡献值均超过600,因此可能的故障变量为t、iss和svi。
[0252]
由于需要进行多元格兰杰因果分析的变量仍为t、iss和svi,因此特征提取所用的统计指标仍然采用va,且向量自回归模型的阶数由aic法则确定为3,最终得出的因果矩阵和故障传播路径仍然为表3和图6,在此不再赘述。
[0253]
实施例4
[0254]
仍然采用实施例三中的实验数据,在求特征提取贡献图时将所用的统计指标由ku改为cli,其他参数不变,最后得出cli特征提取贡献图如图4所示。从图4的实验结果可以看出,t的贡献值最高,其次是srt、ocod、iss和svi,它们的贡献值均超过800,因此可能的故障变量为t、srt、ocod、iss和svi。
[0255]
在特征提取srt、t、ocod、iss和svi的观测时间序列时,所采用的统计指标由实施例一的va改为amav,向量自回归模型的阶数由aic法则确定为2。此时如果利用前71个样本,则得出的部分故障路径无法收敛至svi,这是因为此时分析的变量较多,前71天的样本中所蕴含的故障信息不够充分。为此,采用前85天的样本进行分析以提高结果的准确性,最终得出的因果矩阵如表4所示。
[0256]
表4 srt、t、ocod、iss和svi的amav-mvgc因果矩阵
[0257][0258][0259]
其中,行表示因变量,列表示果变量。
[0260]
由表4的最后一列可见,t引起svi的可能性最高,且其余三个变量引起svi的可能性也较高,所以t是故障变量,而其他四个变量是故障传播的中间变量。同样寻找因果值较大的方向,画出各条故障传播路径,此时由于故障变量较多,因此一些因果值较小的路径可以忽略不计,最终得出4条故障传播路径,如图7所示。图7中为了区分出各个路径的重要程度,将因果值较大的路径用实线表示,作为主要故障路径,因果值较小的故障路径用虚线表示,作为次要传播路径。
[0261]
通过以上实施例可以看出本发明开发的基于改进贡献图和格兰杰因果分析的污泥膨胀诊断方法能在发生污泥膨胀后及时、准确地确定出故障变量,找到最可能导致svi变大的原因,并得出故障传播路径。各个特征提取的指标性能不尽相同,因此效果也有所区别,现场的工作人员可根据实际选用,并依据得出的故障路径采取相应的维护措施来阻止故障传播至svi。
[0262]
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。