1.本发明涉及在线教育领域,具体涉及一种音乐教学方法及系统。
背景技术:
2.在线教育是通过网络平台和手机平台进行学习的一种方式,在线学习可以扩大学生的学习范围,还可以增加更多的课外知识,在网络环境下实现了真正的因材施教;学生学习不受年龄的限制,并且可以避免传统教学模式下的时间和空间的限制。网络环境下的学习对学生来说拥有宽松的学习氛围,可以使学生发挥他们的聪明才智,他们在学习活动中相互启发、协作交流,学会交流与合作。网络背景下的学习是一种多向的信息交流活动,学生在获取不同的学习资源时可进行比较,集思广益,取长补短,深入理解和消化所学的知识,益于对新知识的意义建构。学生学习动机呈多样性,学习压力因素各异;而在网络背景下的学习者可根据自身的特点采取不同的学习方法。第八,有益于实现教育的民主化。
3.但是现有技术的不足之处在于学生端与教师端需要同时在线,教学交互性要求高,只能适用于学生与教师之间一对一的教学条件下。
技术实现要素:
4.为了解决现有技术的不足之处,降低教师与学生教学过程中的交互性要求,提高学生的自主学习能力,本发明提供了以下技术方案:
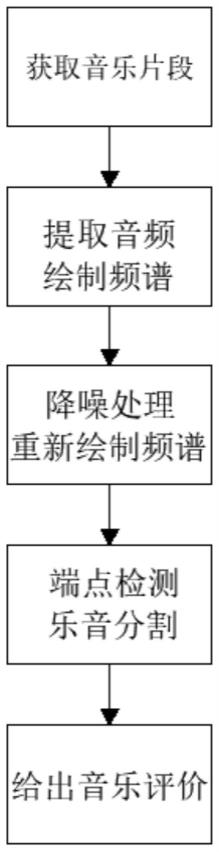
5.一种音乐教学方法,包括以下步骤:
6.获取音乐片段;
7.提取音频,绘制频谱;
8.降噪处理,重新绘制频谱;
9.端点检测,乐音分割;
10.给出音乐评价。
11.上述的音乐教学方法,将获取的音乐片段转换成wav格式。
12.上述的音乐教学方法,获取的信息包括声音频率,包括声道数,量化位数,声音频率,压缩类型以及压缩类型的描述。以取样的间t(单位s)为横坐标,声音频率(单位hz)为纵坐标绘制音乐片段的频谱图。
13.上述的音乐教学方法,通过傅里叶变换将步骤一中提供的音乐片段文件进行噪声数据处理;基于逆向傅里叶变换,生成新的音频信号,绘制音频时域的时间/位移图像;重新生成去除噪声之后的音频文件。
14.上述的音乐教学方法,通过fred端点检测方法将降噪后的音频文件分割成一段一段的乐音文件以及频谱。
15.上述的音乐教学方法,分割出的每段乐音的频谱,对学生提供的乐音的音质做出评价,包括音质丰满、力度、圆润以及柔和。
16.一种音乐教学系统,包括存储模块、语音模块、处理模块以及分析模块;所述语音
模块用于录制学生歌唱的一段乐音以及播放音乐评价;所述存储模块用于储存学生上传的含有乐音的文件以及保存处理模块处理过后的文件和频谱。
17.上述的音乐教学系统,所述处理模块用于提取音频、绘制频谱,降噪处理、重新绘制频谱以及点检测、乐音分割。
18.上述的音乐教学系统,所述分析模块用于分析处理模块处理过后的文件以及频谱,并给出评价。
19.上述的音乐教学系统,所述语音模块还可以实现教师与学生之间的教学互动。
附图说明
20.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
21.图1为本发明实施例提供的音乐教学方法示意图;
22.图2为本发明实施例提供的音乐教学系统示意图;
23.图3为本发明另一个实施例提供的音乐教学系统示意图;
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.本发明提供了一种音乐教学方法,应用于音乐在线学习过程中。
26.所述基于乐音识别的音乐教学方法,包括以下步骤:
27.步骤一:获取音乐片段。
28.在此步骤中,所述音乐片段可以是学生歌唱或者演奏的一段连续的乐音,也可以是学生录制的含有乐音的文件;进一步的,一段连续的乐音是由诸多的单音构成的,单音主要由基频、振幅及倍频三个要素构成;乐音通过人耳的听觉系统反映到听觉神经中枢,引起听者的主观感觉,这种感觉形成乐音三要素,即音调、响度、音色,这三个特性分别和三个客观上易于确定的物理量密切相关。乐音的这种特性使其能够用物理的方法进行分析和测量。
29.步骤二、提取音频,绘制频谱。
30.在此步骤中,提取步骤一中获取的音乐片段的音频,并根据音频绘制音乐信号的频谱,为后续步骤做准备。
31.具体的,打开步骤一中获取的音乐片段;进一步的,所述音乐片段为上传的音乐文件类型一般为mp3、midi、wma、vqf、amr等,提取这些类型的文件时,需要先将mp3、midi、wma、vqf、amr等音乐文件类型的文件转换为wav类型的文件,再读取wav文件的格式和数据;优选的,学生录制的音乐片段为wav类型的文件,直接可读取学生录制的音乐片段的格式和数据。
32.读取格式信息之后一次性返回所有的wav文件的格式信息,它返回的是一个组元:
包括声道数,量化位数,声音频率,压缩类型以及压缩类型的描述。读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),将波形数据转换成数组,通过取样点数和取样频率计算出每个取样的时间。以取样的间t(单位s)为横坐标,声音频率(单位hz)为纵坐标绘制音乐片段的频谱图。
33.步骤三、降噪处理,重新绘制频谱。
34.在此步骤中,通过傅里叶变换将步骤一中提供的音乐片段文件进行噪声数据处理;具体的,读取音频文件,获取音频文件基本信息:采样个数,采样周期,与每个采样的声音信号值。绘制音频时域的:时间/位移图像。基于傅里叶变换,获取音频频域信息,绘制音频频域的:频率/能量图像。将低能噪声去除后绘制频率/能量的音频频域图像;基于逆向傅里叶变换,生成新的音频信号,绘制音频时域的时间/位移图像;最后重新生成去除噪声之后的音频文件。
35.步骤四、端点检测,乐音分割。
36.乐音信号是典型的时变信号,在一个音乐片段中包含多个不同频率的单音;从频域角度来看,单一的音符是典型的平稳时不变信号;乐音的频域组成具有其明显的平稳特性,从一个音符的发音来看,从开始发音直到乐音消失,幅值逐渐减小,但是频率成分不变。
37.在此步骤中,对于步骤三中保存的降噪处理后的文件对其进行端点检测,以分割出单音,分割单音的目的在于使连续乐音的识别转化为单音识别,并且分割单音后可以准确计算音符的时值。
38.在语音的端点检测方法中,优选的端点检测方法是fred(feature-basedreal-timeendpointdetection,基于语音特征的实时端点检测算法)算法,该算法基于两级端点检测方案,可以更好地适应环境的干扰和变化,提高端点检测的精度。进一步的,由于乐音中的频率构成单一,并且单音的能量在持续期内呈一致振荡衰减,所以选用使用第一级fred。
39.在使用之前要将乐音进行分帧,设置帧长为m,分成k帧。逐帧求出其短时能量和过零率s
ij
、q
ij
(下标表示第i帧的第j个采样),元素为布尔值:
[0040][0041]
构成短时能量和过零率矩阵:
[0042][0043]
将短时能量和过零率矩阵求积:edge=a*z
[0044]
edge称为乐音的端点判断矩阵,其元素为乐音帧的短时突变状态。基于端点判断矩阵进行实际端点判定的过程简单表述如下:
[0045]
(1)设置每次参与判定的帧数端点判定标志:0表示无乐音,1表示从无乐音到有乐音;2表示从有乐音到无乐音;
[0046]
(2)0状态向1状态转换:此时必须再检测本帧后连续t帧的情况,如连续t帧均有乐
音,则可确定本帧为端点开始点,否则是短时高频尖峰噪声;
[0047]
(3)2状态向0状态转换:此时必须再检测本帧后连续t帧的情况,如连续t帧均无乐音,则可确定本帧为端点结束点。
[0048]
将确定的端点位置数据映射到乐音中就是乐音中的单音端点位置。用这种方法计算量不大,检测的效果很明显。
[0049]
步骤五、给出音乐评价。
[0050]
声音是由以下几个要素构成:音量、音高、音色和音品。
[0051]
音量:音量即声音的响度,评价尺度是声音的振幅大小。
[0052]
音高:音高即音调,其的客观评价尺度是声音的频率。
[0053]
音色:音色即声音的频频谱,
[0054]
音品:音品即音质,即声音的波形包络。声音的谐波组成和波形的包络,包括声音的开始和结束的瞬态,通过音质的评价确定声音的特征。
[0055]
在此步骤中,根据步骤四中的分割出的每段乐音的频谱,对学生提供的乐音的音质做出评价,包括音质丰满、力度、圆润、柔和等。
[0056]
丰满:是指声音的中音充足、高音适度、响度合适、听感温暖、舒适、有弹性,反之则单薄、干瘪;
[0057]
力度:是指声音坚实有力,能有呼之欲出感,同时能反映出音源的动态范围,反之则力度不足;
[0058]
圆润:是指声音优美动听,有光泽而不尖噪,反之则粗噪;
[0059]
柔和:是指声音松弛不紧、高音不刺耳、听感悦耳、舒服,反之则尖、硬;
[0060]
本发明实施例还提供了一种音乐教学系统,包括存储模块、语音模块、处理模块以及分析模块;所述语音模块用于录制学生歌唱的一段乐音以及播放音乐评价;所述存储模块用于储存学生上传的含有乐音的文件以及保存处理模块处理过后的文件和频谱;所述处理模块用于提取音频、绘制频谱,降噪处理、重新绘制频谱以及点检测、乐音分割;所述分析模块用于分析处理模块处理过后的文件以及频谱,并给出评价。
[0061]
在本发明提供的一个优选的实施例中,如图2所示,学生上传一段自己演唱的一段音乐至所述音乐教学系统的存储模块中,处理模块对这段音乐进行处理;
[0062]
学生上传的音乐文件类型一般为mp3、midi、wma、vqf、amr等,所述处理模块先将文件类型转换成wav类型,记为音乐文件1,并保存转化格式后的音乐片段文件;若学生上传的音乐文件类型为wav格式,直接将文件保存至所述存储模块,并将学生上传的文件记为音乐文件1;随后读取学生录制的音乐片段的格式和数据,读取格式信息之后一次性返回所有的wav文件的格式信息,包括声道数,量化位数,声音频率,压缩类型以及压缩类型的描述,并将这些信息上传至所述存储模块进行保存;最后以取样的间t(单位s)为横坐标,声音频率(单位hz)为纵坐标绘制音乐片段的频谱图,再次将绘制的频谱图进行保存,并将频谱图记为频谱文件1;
[0063]
所述处理模块对学生上传音乐片段文件通过傅里叶变换进行降噪处理;读取存储模块中的wap格式的音频文件,获取音频文件基本信息:采样个数,采样周期,与每个采样的声音信号值;绘制音频时域的:时间/位移图像;基于傅里叶变换,获取音频频域信息,绘制音频频域的:频率/能量图像。将低能噪声去除后绘制频率/能量的音频频域图像;基于逆向
傅里叶变换,生成新的音频信号,绘制音频时域的时间/位移图像,并将上述图像记为频谱文件2;最后重新生成去除噪声之后的音频文件,记为音乐文件2,将音乐文件2保存到所处存储模块。
[0064]
对音乐文件2的频谱文件进行端点检测,将音乐文件分割成一段一段的乐音,并保存至所述存储模块,记为音乐文件2.1、2.2。分析模块根据音乐文件2.1、2.2
……
以及存储模块中的声道数、量化位数、声音频率等音乐文件信息给出评价,最后语音模块播放这段音乐的评价,并将评价保存至所述存储模块。
[0065]
在本发明提供的另一个实施例中,学生和教师在音乐教学过程中进行交互学习,如图3所示;
[0066]
学生通过所述语音模块演唱一段音乐,所述存储模块保存这段音乐,并保存为wav格式,记为音乐文件1;此时教师通过语音模块也获得学生演唱的这段音乐;
[0067]
随后所处理模块读取学生录制的音乐片段的格式和数据,读取格式信息之后一次性返回所有的wav文件的格式信息,包括声道数,量化位数,声音频率,压缩类型以及压缩类型的描述,并将这些信息上传至所述存储模块进行保存;最后以取样的间t(单位s)为横坐标,声音频率(单位hz)为纵坐标绘制音乐片段的频谱图,再次将绘制的频谱图进行保存,并将频谱图记为频谱文件1;
[0068]
所述处理模块对学生上传音乐片段文件通过傅里叶变换进行降噪处理;读取存储模块中的wap格式的音频文件,获取音频文件基本信息:采样个数,采样周期,与每个采样的声音信号值;绘制音频时域的:时间/位移图像;基于傅里叶变换,获取音频频域信息,绘制音频频域的:频率/能量图像。将低能噪声去除后绘制频率/能量的音频频域图像;基于逆向傅里叶变换,生成新的音频信号,绘制音频时域的时间/位移图像,并将上述图像记为频谱文件2;最后重新生成去除噪声之后的音频文件,记为音乐文件2,将音乐文件2保存到所处存储模块。
[0069]
对音乐文件2的频谱文件进行端点检测,将音乐文件分割成一段一段的乐音,并保存至所述存储模块,记为音乐文件2.1、2.2。
[0070]
分析模块根据音乐文件2.1、2.2
……
以及存储模块中的声道数、量化位数、声音频率等音乐文件信息给出评价,最后语音模块播放这段音乐的评价,并将评价保存至所述存储模块;评价包括:清晰:是指声音中对言语的可懂度高,音乐层次分明,反之则模糊、浑浊;
[0071]
平衡:是指音乐各声部的比例协调、左、右声道的一致性好。反之则不平衡;
[0072]
丰满:是指声音的中音充足、高音适度、响度合适、听感温暖、舒适、有弹性,反之则单薄、干瘪;
[0073]
力度:是指声音坚实有力,能有呼之欲出感,同时能反映出音源的动态范围,反之则力度不足;
[0074]
圆润:是指声音优美动听,有光泽而不尖噪,反之则粗噪;
[0075]
柔和:是指声音松弛不紧、高音不刺耳、听感悦耳、舒服,反之则尖、硬;
[0076]
融合:是指声音能整个交融在一起、整体感、群感好,反之则散;
[0077]
真实感:是指声音能保持原始声音的特点;
[0078]
临场感:重放声音时使人有身临其境的感觉;
[0079]
立体感:指声音有空间感,声像定位基本准确,并有宽度感和纵深感;
[0080]
总印象:是指对声音的总体感觉。
[0081]
以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。