1.本发明涉及实时音频通信技术领域,尤其涉及一种音频传输抗丢包的错误隐藏技术方法。
背景技术:
2.音频通信是通过麦克风采集原始脉冲编码调制pcm音频帧、压缩编码成特定格式,比如g.722、g.718、amr-wb、opus,再通过ip网络发送给接收端解码,还原成脉冲编码调制pcm数据,并由声卡播放。压缩音频包经过网络传输后可能会丢失,如果通过带宽比较受限的链路,比如卫星信道,还可能造成大延迟及时延抖动,接收端一般通过jitter缓冲区对收到的压缩音频包进行排队并检测出rtp层包序号的不连续,对于因此而缺失的音频帧,可以使用错误隐藏plc算法将其重构出来,常规的plc包括但不限于:填零、重复前一帧、将前几帧外插值后得到等,jitter缓冲区要么将连续收到的包交由解码器解码,要么在发生丢包时通知解码器内置或外置的错误隐藏plc模块重构出一帧。
3.但现有的错误隐藏plc很难在通用兼容各种音频编码格式、开放待选的机器学习模块可随意增减、实时重构时仅运用缺失前的信号数据以及感官效果这四个方面都取得较优,缺乏在脉冲编码调制pcm的相空间重构psr分解映射以及相关参数的考量和计算,并在利用某个机器学习模型对正确传输并缓存下来的脉冲编码调制pcm数据进行学习建模时,不具备为丢失帧作出较复杂非线性预测的能力,造成错误隐藏帧与原始音频帧存在较大差异。
技术实现要素:
4.为此,本发明提供一种音频传输抗丢包的错误隐藏技术方法,用以克服现有技术中错误隐藏帧与原始音频帧存在较大差异的问题。
5.为实现上述目的,本发明提供一种音频传输抗丢包的错误隐藏技术方法,包括,
6.步骤s1,通过相空间重构将任意一音频帧数据的脉冲编码调制一维序列解构到若干个同相空间,获得该音频帧数据的高维序列,根据该音频帧数据的高维序列构造输入矩阵,再根据输入矩阵构造目标值矩阵;
7.步骤s2,将构造完成的输入矩阵与目标值矩阵分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型,将输入矩阵输入到回归模型中,得到预测值矩阵;
8.步骤s3,对即将接收的新的音频帧数据进行判定,根据新的音频帧数据的数据量判定是否通过预测值矩阵对新的音频帧数据的空缺进行错误隐藏,解构新的音频帧数据的高维序列,并将新的音频帧数据的高维序列与预测值矩阵中对应相预测值进行对比,根据对比结果计算预测值矩阵中对应相预测值的符合度,再根据预测值矩阵中对应相预测值的符合度判定是否对新的音频帧数据的高维序列进行学习,以对预测值矩阵进行修正。
9.进一步地,在所述步骤s1中,将任意一音频帧数据的脉冲编码调制一维序列x(t)进行相空间重构处理,得到该音频帧数据的高维序列x(t),
10.x(t)=[x(t),x(t τ),...,x(t (m-1)τ)]
[0011]
其中,τ为时延;m为嵌入维数度;t为基础帧值。
[0012]
进一步地,根据高维序列x(t)构造输入矩阵x,
[0013][0014]
其中,m为大于基础帧值的最小整数帧值。
[0015]
进一步地,根据输入矩阵x构造目标值矩阵y,
[0016][0017]
进一步地,在完成对输入矩阵x与目标值矩阵y的构建后,将输入矩阵x与目标值矩阵y分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,分别得到支持向量机、随机森林、前馈神经网络的回归模型,利用均方根误差rmse进行评价,
[0018][0019]
其中,yj为每组同相数据的目标值,即x(j),x(j τ),
…
x(j (m-1)τ)的期望值,j为任意一时刻帧值,pj为完成训练输出的预测值,τ
test
为从τ组同相数据最后划出的部分用于评价模型性能的数据集个数;
[0020]
根据评价结果选取出y~x回归模型,将输入矩阵x输入到y~x回归模型获得预测值矩阵p。
[0021]
进一步地,设置第一预设数据量n1与第二预设数据量n2,其中,n1<n2,在对新的音频帧数据进行接收时,先获取新的音频帧数据的数据量nx,并将新的音频帧数据的数据量nx与第一预设数据量n1、第二预设数据量n2进行对比,
[0022]
当nx<n1时,判定该音频帧数据量未达到第一预设数据量,将以预测值矩阵中对应相的预测值替换该音频帧数据,完成错误隐藏;
[0023]
当n1≤nx<n2时,判定该音频帧数据的数据量在第一预设数据量与第二预设数据量之间,将预测值矩阵中对应相的预测值与该音频帧数据的高维序列进行对比,以判定预
测值矩阵中对应相预测值的符合度;
[0024]
当nx=n2时,判定该音频帧数据量达到第二预设数据量,不对该音频帧数据进行补充或替换。
[0025]
进一步地,设置第一预设符合度g1与第二预设符合度g2,其中,g1<g2,在判定新的音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,将获取新的音频帧数据的高维序列,再将新的音频帧数据的高维序列与预测值矩阵中对应相的预测值进行逐位对比,根据相同位占总位数的比值计算预测值矩阵中对应相的预测值的符合度gu,并将预测值的符合度gu与第一预设符合度g1、第二预设符合度g2进行对比,
[0026]
当gu<g1时,判定该预测值矩阵中对应相的预测值的符合度低于第一预设符合度,将以高维序列x(t)对该音频帧数据高维序列缺失位进行补充,完成错误隐藏;
[0027]
当g1≤gu<g2时,判定该预测值矩阵中对应相的预测值的符合度在第一预设符合度与第二预设符合度之间,将通过预测值矩阵中对应相的预测值对新的音频帧数据的高维序列中缺失位进行补充,并根据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’到y~x回归模型获得预测值矩阵p’;
[0028]
当gu≥g2时,判定该预测值矩阵中对应相的预测值的符合度达到第二预设符合度,将通过预测值矩阵中对应相的预测值对该音频帧数据的高维序列中缺失位进行补充,并根据该音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,将输入矩阵x’与目标值矩阵y’输入到y~x回归模型获得预测值矩阵p’。
[0029]
进一步地,在判定该预测值矩阵中对应相的预测值的符合度低于第一预设符合度时,将根据新的音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,将输入矩阵x’与目标值矩阵y’分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型y’~x’,将输入矩阵输入到回归模型y’~x’中,得到预测值矩阵pn。
[0030]
进一步地,设置标准符合度gb与标准符合度差δgb,当判定该音频帧数据量达到第二预设数据量时,将获取新的音频帧数据的高维序列,计算预测值矩阵中对应相的预测值的符合度ge,根据标准符合度gb与预测值的符合度ge计算预测值的符合度差δge,δge=|gb-ge|,将预测值的符合度差δge与标准符合度差δgb进行对比,
[0031]
当δge≤δgb时,判定预测值矩阵中对应相的预测值的符合度在标准范围内,将根据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’到y~x回归模型获得预测值矩阵p’;
[0032]
当δge>δgb时,判定预测值的符合度差高于标准符合度差,将预测值的符合度与标准符合度进行对比,以确定是否对预测值矩阵进行修正。
[0033]
进一步地,在判定预测值的符合度差高于标准符合度差时,将预测值矩阵中对应相的预测值的符合度ge与标准符合度gb进行对比,
[0034]
当ge<gb时,判定预测值矩阵中对应相的预测值的符合度低于标准符合度,将根据新的音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,并确定回归模型y’~x’,将输入矩阵输入到回归模型y’~x’中,得到预测值矩阵pf;
[0035]
当ge>gb时,判定预测值矩阵中对应相的预测值的符合度高于标准符合度,将根
据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’、输入矩阵x与目标值矩阵y分为训练数据和测试数据,并选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型y”~x”,将输入矩阵x’输入到回归模型y”~x”中,得到预测值矩阵pa。
[0036]
与现有技术相比,本发明的有益效果在于,通过对音频数据接收过程中的一音频帧数据进行相空间重构,获得该音频帧数据的高维序列,高维向量空间比音频帧数据的一维脉冲编码调制采样值能更好的刻划音频数据随时间不断演进的动态特性,并通过结合不同的机器学习模型能对下一帧音频数据作出更好的预测,使用预测值屏蔽缺失的影响,完成错误隐藏,并在新的音频帧数据进行接收时对其判定,根据新的音频帧数据的数据量以及对应相预测值的符合度,判定错误隐藏选取方式,并且通过调整新的音频帧数据学习方式对预测值矩阵进行不同的修正,不断使预测值矩阵的预测值接近原始音频帧数据,降低错误隐藏帧与原始音频帧的差异,提高了音频数据的传输质量。
[0037]
进一步地,通过对音频帧数据的脉冲编码调制一维序列进行相空间重构处理,结合音频帧数据的基础帧值、时延与嵌入维数度,将音频帧数据一维序列映射至多维相形成该音频帧数据的的高维序列,高维向量空间比音频帧数据的一维脉冲编码调制采样值能更好的刻划音频数据随时间不断演进的动态特性,根据精准的高维序列数据进行矩阵构建与模型预测,能够使预测结果更加符合实际音频帧数据,降低错误隐藏帧与原始音频帧的差异,提高了音频数据的传输质量。
[0038]
进一步地,根据音频帧数据的高维序列构造输入矩阵,通过构建大于基础帧值的输入矩阵相数,能够对矩阵的构建范围进行控制,从而达到对预测结果范围的确定,提高对新的音频帧数据预测的准确性。
[0039]
进一步地,根据已将构建完成的输入矩阵再次构建目标值矩阵,能够充分体现被构建的原始音频帧数据的动态特征,进一步对预测基础支撑数据的精准化设置,提高对新的音频帧数据预测的准确性。
[0040]
尤其,通过将输入矩阵与目标值矩阵分为训练数据和测试数据,并选用支持向量机、随机森林、前馈神经网络多种算法进行训练与测试,得到多个回归模型,在通过均方根误差对多个回归模型的预测进行评价,选取最终的回归模型,进一步提高了模型选择的优越性,同时将输入矩阵输入回归模型获得预测值矩阵,利用预测值矩阵对未接收音频帧数据进行预测,提升了模型对丢失帧作出较复杂非线性预测的性能。
[0041]
尤其,在对新的音频帧数据进行接收时,对音频帧数据的数据量进行判定,通过设置第一预设数据量与第二预设数据量,确定该音频帧数据的状态,在音频帧数据量未达到第一预设数据量时,表明接收到的数据量较低或未接收,不能够通过修复的方法进行空缺补充,判定为丢包状态,利用预测值替换该音频帧数据,完成错误隐藏,在音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,表明接收到的数据量不完全,但是能够对其进行补充修复,通过结合预测值矩阵中对应相预测值的符合度,确定缺失数据的补充方式,当音频帧数据量达到第二预设数据量时,表明接收到的音频帧数据为完全的音频帧数据,不对音频帧数据进行补充或替换,保障了音频传输的真实性。
[0042]
进一步地,在音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,将获取新的音频帧数据的高维序列,再将新的音频帧数据的高维序列与预测值矩阵中对应
相的预测值进行逐位对比,计算预测值的符合度,在预测值的符合度低于第一预设符合度时,表示预测值准确性较低,通过利用上一音频帧数据的高维序列对该音频帧数据高维序列缺失位进行补充,保障了音频数据传输的质量,在预测值的符合度在第一预设符合度与第二预设符合度之间或达到第二预设符合度时,通过预测值矩阵中对应相的预测值对新的音频帧数据的高维序列中缺失位进行补充,进一步提高了音频数据传输的质量,同时使用不同的方式对该音频帧数据进行学习,修正预测值矩阵,也提高了预测模型的预测精度。
[0043]
进一步地,在预测值矩阵中对应相的预测值的符合度低于第一预设符合度时,将放弃上一音频帧数据的预测模型,对新的音频帧数据进行重新的构建矩阵与模型训练,形成新的回归模型,并得到新的音频帧数据的预测值矩阵,减小错误预测对预测模型的影响,保障预测模型的预测精准度,也提高了音频数据传输的质量。
[0044]
尤其,通过对数据量达到第二预设数据量的音频帧数据进行标准符合度的判定,确定回归模型的学习方式,在预测值矩阵中对应相的预测值的符合度在标准范围内时,表示数据完整,且符合度较高,通过将该音频帧数据叠加至回归模型中,获得新的预测值矩阵,进一步提高了预测模型的性能。
[0045]
进一步地,在预测值的符合度差高于标准符合度差时,将预测值的符合度与标准符合度进行对比,当预测值矩阵中对应相的预测值的符合度低于标准符合度时,对新的音频帧数据进行重新的建模与预测,以减小错误预测对预测模型的影响,保障预测模型的预测精准度,也提高了音频数据传输的质量,在预测值矩阵中对应相的预测值的符合度高于标准符合度时,体现预测值的符合度很高,将对新的音频帧数据进行与原回归模型的基础数据进行重新建模,将回归模型的预测精度再次提升,保障音频数据传输的质量。
附图说明
[0046]
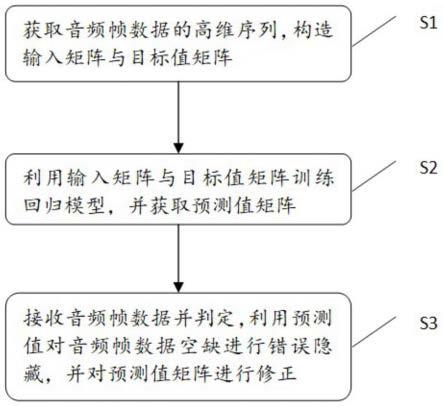
图1为本发明所述音频传输抗丢包的错误隐藏技术方法的流程图。
具体实施方式
[0047]
为了使本发明的目的和优点更加清楚明白,下面结合实施例对本发明作进一步描述;应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
[0048]
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非在限制本发明的保护范围。
[0049]
需要说明的是,在本发明的描述中,术语“上”、“下”、“左”、“右”、“内”、“外”等指示的方向或位置关系的术语是基于附图所示的方向或位置关系,这仅仅是为了便于描述,而不是指示或暗示所述装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
[0050]
此外,还需要说明的是,在本发明的描述中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域技术人员而言,可根据具体情况理解上述术语在本发明中的具体含义。
[0051]
请参阅图1所示,其为本发明所述音频传输抗丢包的错误隐藏技术方法的流程图。
本发明公布一种音频传输抗丢包的错误隐藏技术方法,包括,
[0052]
步骤s1,通过相空间重构将任意一音频帧数据的脉冲编码调制一维序列解构到若干个同相空间,获得该音频帧数据的高维序列,根据该音频帧数据的高维序列构造输入矩阵,再根据输入矩阵构造目标值矩阵;
[0053]
步骤s2,将构造完成的输入矩阵与目标值矩阵分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型,将输入矩阵输入到回归模型中,得到预测值矩阵;
[0054]
步骤s3,对即将接收的新的音频帧数据进行判定,根据新的音频帧数据的数据量判定是否通过预测值矩阵对新的音频帧数据的空缺进行错误隐藏,解构新的音频帧数据的高维序列,并将新的音频帧数据的高维序列与预测值矩阵中对应相预测值进行对比,根据对比结果计算预测值矩阵中对应相预测值的符合度,再根据预测值矩阵中对应相预测值的符合度判定是否对新的音频帧数据的高维序列进行学习,以对预测值矩阵进行修正。
[0055]
通过对音频数据接收过程中的一音频帧数据进行相空间重构,获得该音频帧数据的高维序列,高维向量空间比音频帧数据的一维脉冲编码调制采样值能更好的刻划音频数据随时间不断演进的动态特性,并通过结合不同的机器学习模型能对下一帧音频数据作出更好的预测,使用预测值屏蔽缺失的影响,完成错误隐藏,并在新的音频帧数据进行接收时对其判定,根据新的音频帧数据的数据量以及对应相预测值的符合度,判定错误隐藏选取方式,并且通过调整新的音频帧数据学习方式对预测值矩阵进行不同的修正,不断使预测值矩阵的预测值接近原始音频帧数据,降低错误隐藏帧与原始音频帧的差异,提高了音频数据的传输质量。
[0056]
进一步地,在所述步骤s1中,将任意一音频帧数据的脉冲编码调制一维序列x(t)进行相空间重构处理,得到该音频帧数据的高维序列x(t),
[0057]
x(t)=[x(t),x(t τ),...,x(t (m-1)τ)]
[0058]
其中,τ为时延;m为嵌入维数度;t为基础帧值。
[0059]
通过对音频帧数据的脉冲编码调制一维序列进行相空间重构处理,结合音频帧数据的基础帧值、时延与嵌入维数度,将音频帧数据一维序列映射至多维相形成该音频帧数据的的高维序列,高维向量空间比音频帧数据的一维脉冲编码调制采样值能更好的刻划音频数据随时间不断演进的动态特性,根据精准的高维序列数据进行矩阵构建与模型预测,能够使预测结果更加符合实际音频帧数据,降低错误隐藏帧与原始音频帧的差异,提高了音频数据的传输质量。
[0060]
进一步地,根据高维序列x(t)构造输入矩阵x,
[0061][0062]
其中,m为大于基础帧值的最小整数帧值。
[0063]
根据音频帧数据的高维序列构造输入矩阵,通过构建大于基础帧值的输入矩阵相
数,能够对矩阵的构建范围进行控制,从而达到对预测结果范围的确定,提高对新的音频帧数据预测的准确性。
[0064]
进一步地,根据输入矩阵x构造目标值矩阵y,
[0065][0066]
根据已将构建完成的输入矩阵再次构建目标值矩阵,能够充分体现被构建的原始音频帧数据的动态特征,进一步对预测基础支撑数据的精准化设置,提高对新的音频帧数据预测的准确性。
[0067]
进一步地,在完成对输入矩阵x与目标值矩阵y的构建后,将输入矩阵x与目标值矩阵y分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,分别得到支持向量机、随机森林、前馈神经网络的回归模型,利用均方根误差rmse进行评价,
[0068][0069]
其中,yj为每组同相数据的目标值,即x(j),x(j τ),
…
x(j (m-1)τ)的期望值,j为任意一时刻帧值,pj为完成训练输出的预测值,τ
test
为从τ组同相数据最后划出的部分用于评价模型性能的数据集个数;
[0070]
根据评价结果选取出y~x回归模型,将输入矩阵x输入到y~x回归模型获得预测值矩阵p。
[0071]
通过将输入矩阵与目标值矩阵分为训练数据和测试数据,并选用支持向量机、随机森林、前馈神经网络多种算法进行训练与测试,得到多个回归模型,在通过均方根误差对多个回归模型的预测进行评价,选取最终的回归模型,进一步提高了模型选择的优越性,同时将输入矩阵输入回归模型获得预测值矩阵,利用预测值矩阵对未接收音频帧数据进行预测,提升了模型对丢失帧作出较复杂非线性预测的性能。
[0072]
进一步地,设置第一预设数据量n1与第二预设数据量n2,其中,n1<n2,在对新的音频帧数据进行接收时,先获取新的音频帧数据的数据量nx,并将新的音频帧数据的数据量nx与第一预设数据量n1、第二预设数据量n2进行对比,
[0073]
当nx<n1时,判定该音频帧数据量未达到第一预设数据量,将以预测值矩阵中对应相的预测值替换该音频帧数据,完成错误隐藏;
[0074]
当n1≤nx<n2时,判定该音频帧数据的数据量在第一预设数据量与第二预设数据量之间,将预测值矩阵中对应相的预测值与该音频帧数据的高维序列进行对比,以判定预测值矩阵中对应相预测值的符合度;
[0075]
当nx=n2时,判定该音频帧数据量达到第二预设数据量,不对该音频帧数据进行补充或替换。
[0076]
在对新的音频帧数据进行接收时,对音频帧数据的数据量进行判定,通过设置第一预设数据量与第二预设数据量,确定该音频帧数据的状态,在音频帧数据量未达到第一预设数据量时,表明接收到的数据量较低或未接收,不能够通过修复的方法进行空缺补充,判定为丢包状态,利用预测值替换该音频帧数据,完成错误隐藏,在音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,表明接收到的数据量不完全,但是能够对其进行补充修复,通过结合预测值矩阵中对应相预测值的符合度,确定缺失数据的补充方式,当音频帧数据量达到第二预设数据量时,表明接收到的音频帧数据为完全的音频帧数据,不对音频帧数据进行补充或替换,保障了音频传输的真实性。
[0077]
进一步地,设置第一预设符合度g1与第二预设符合度g2,其中,g1<g2,在判定新的音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,将获取新的音频帧数据的高维序列,再将新的音频帧数据的高维序列与预测值矩阵中对应相的预测值进行逐位对比,根据相同位占总位数的比值计算预测值矩阵中对应相的预测值的符合度gu,并将预测值的符合度gu与第一预设符合度g1、第二预设符合度g2进行对比,
[0078]
当gu<g1时,判定该预测值矩阵中对应相的预测值的符合度低于第一预设符合度,将以高维序列x(t)对该音频帧数据高维序列缺失位进行补充,完成错误隐藏;
[0079]
当g1≤gu<g2时,判定该预测值矩阵中对应相的预测值的符合度在第一预设符合度与第二预设符合度之间,将通过预测值矩阵中对应相的预测值对新的音频帧数据的高维序列中缺失位进行补充,并根据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’到y~x回归模型获得预测值矩阵p’;
[0080]
当gu≥g2时,判定该预测值矩阵中对应相的预测值的符合度达到第二预设符合度,将通过预测值矩阵中对应相的预测值对该音频帧数据的高维序列中缺失位进行补充,并根据该音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,将输入矩阵x’与目标值矩阵y’输入到y~x回归模型获得预测值矩阵p’。
[0081]
在音频帧数据的数据量在第一预设数据量与第二预设数据量之间时,将获取新的音频帧数据的高维序列,再将新的音频帧数据的高维序列与预测值矩阵中对应相的预测值进行逐位对比,计算预测值的符合度,在预测值的符合度低于第一预设符合度时,表示预测值准确性较低,通过利用上一音频帧数据的高维序列对该音频帧数据高维序列缺失位进行补充,保障了音频数据传输的质量,在预测值的符合度在第一预设符合度与第二预设符合度之间或达到第二预设符合度时,通过预测值矩阵中对应相的预测值对新的音频帧数据的高维序列中缺失位进行补充,进一步提高了音频数据传输的质量,同时使用不同的方式对该音频帧数据进行学习,修正预测值矩阵,也提高了预测模型的预测精度。
[0082]
进一步地,在判定该预测值矩阵中对应相的预测值的符合度低于第一预设符合度时,将根据新的音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,将输入矩阵x’与目标值矩阵y’分为训练数据和测试数据,分别选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型y’~x’,将输入矩阵输入到回归模型y’~x’中,得到预测值矩阵pn。
[0083]
在预测值矩阵中对应相的预测值的符合度低于第一预设符合度时,将放弃上一音频帧数据的预测模型,对新的音频帧数据进行重新的构建矩阵与模型训练,形成新的回归模型,并得到新的音频帧数据的预测值矩阵,减小错误预测对预测模型的影响,保障预测模型的预测精准度,也提高了音频数据传输的质量。
[0084]
进一步地,设置标准符合度gb与标准符合度差δgb,当判定该音频帧数据量达到第二预设数据量时,将获取新的音频帧数据的高维序列,计算预测值矩阵中对应相的预测值的符合度ge,根据标准符合度gb与预测值的符合度ge计算预测值的符合度差δge,δge=|gb-ge|,将预测值的符合度差δge与标准符合度差δgb进行对比,
[0085]
当δge≤δgb时,判定预测值矩阵中对应相的预测值的符合度在标准范围内,将根据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’到y~x回归模型获得预测值矩阵p’;
[0086]
当δge>δgb时,判定预测值的符合度差高于标准符合度差,将预测值的符合度与标准符合度进行对比,以确定是否对预测值矩阵进行修正。
[0087]
通过对数据量达到第二预设数据量的音频帧数据进行标准符合度的判定,确定回归模型的学习方式,在预测值矩阵中对应相的预测值的符合度在标准范围内时,表示数据完整,且符合度较高,通过将该音频帧数据叠加至回归模型中,获得新的预测值矩阵,进一步提高了预测模型的性能。
[0088]
进一步地,在判定预测值的符合度差高于标准符合度差时,将预测值矩阵中对应相的预测值的符合度ge与标准符合度gb进行对比,
[0089]
当ge<gb时,判定预测值矩阵中对应相的预测值的符合度低于标准符合度,将根据新的音频帧数据的高维序列构建输入矩阵x’,再根据输入矩阵x’构造目标值矩阵y’,并确定回归模型y’~x’,将输入矩阵输入到回归模型y’~x’中,得到预测值矩阵pf;
[0090]
当ge>gb时,判定预测值矩阵中对应相的预测值的符合度高于标准符合度,将根据该音频帧数据的高维序列构建输入矩阵x’,将输入矩阵x’、输入矩阵x与目标值矩阵y分为训练数据和测试数据,并选用支持向量机、随机森林、前馈神经网络算法进行训练与测试,根据支持向量机、随机森林、前馈神经网络三种算法的测试预测值确定回归模型y”~x”,将输入矩阵x’输入到回归模型y”~x”中,得到预测值矩阵pa。
[0091]
在预测值的符合度差高于标准符合度差时,将预测值的符合度与标准符合度进行对比,当预测值矩阵中对应相的预测值的符合度低于标准符合度时,对新的音频帧数据进行重新的建模与预测,以减小错误预测对预测模型的影响,保障预测模型的预测精准度,也提高了音频数据传输的质量,在预测值矩阵中对应相的预测值的符合度高于标准符合度时,体现预测值的符合度很高,将对新的音频帧数据进行与原回归模型的基础数据进行重新建模,将回归模型的预测精度再次提升,保障音频数据传输的质量。
[0092]
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
[0093]
以上所述仅为本发明的优选实施例,并不用于限制本发明;对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、
等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。