1.本发明涉及人工智能技术领域,尤其涉及一种基于半带滤波器的鼾声识别方法及装置。
背景技术:
2.目前通过麦克风拾取声音然后提取鼾声特征的方法目前有:1、提取鼾声的梅尔倒谱系数(mfcc)作为特征,送识别器进行识别。提取过程包括:预加重、加窗、快速傅立叶变换、功率谱估计、mel滤波、非线性变换和离散余弦变换;2、采用子带余弦调制滤波器组(cmfb)提取鼾声的子带特征。但是以上两种方法在进行鼾声提取时,需要耗费大量的运算资源,因此并不适用于不适合应用于运算能力不强、内存不多的嵌入式终端上。
技术实现要素:
3.本发明实施例提供一种基于半带滤波器的鼾声识别方法及装置,采用iir半带滤波器对声音数据流进行分频带滤波提取特征,在运算能力不强、内存不多的嵌入式终端上实现对鼾声信号的快速识别。
4.为实现上述目的,本技术实施例的第一方面提供了一种基于半带滤波器的鼾声识别方法,所述方法包括:
5.使待识别数字声音信号进入预设的高通滤波器进行高通滤波;
6.使进行高通滤波后的待识别数字声音信号进入预设的半带滤波器进行半带滤波,得到多个频带对应的半带滤波信号;每个频带的宽度大小相同,频带的数量由所述半带滤波器的结构决定;
7.对每个频带对应的半带滤波信号进行分帧处理并计算,得到每个频带对应的分帧信号和每个分帧信号的能量特征;
8.根据单高斯模型和每个分帧信号的能量特征,标记出每个分帧信号包含的语音帧,并将连续的语音帧标记为语音段;
9.根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别;每个单类别高斯混合模型由多个子高斯模型组成,且每个单类别高斯模型对应一种鼾声类别;
10.选出间隔时间小于预设间隔阈值的两个鼾声段作为鼾声段组合,全部的鼾声段组合构成鼾声识结果。
11.在第一方面的一种可能的实现方式中,所述根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别,具体包括:
12.根据每个鼾声种类建立一个对应的单类别高斯混合模型;
13.将每个语音段的语音特征遍历每个单类别高斯混合模型,计算每个单类别高斯混
合模型的概率密度;
14.若单类别高斯混合模型的概率密度大于预设概率阈值,标记语音段为鼾声段,所述鼾声段的类别与单类别高斯混合模型对应的鼾声类别相同。
15.在第一方面的一种可能的实现方式中,所述每个语音段的语音特征,具体包括每个语音段的时长、总能量、各频带能量、归一化能量、频带内峰值点的个数和周期。
16.在第一方面的一种可能的实现方式中,所述每个分帧信号的能量特征包括每个分帧信号的总能量、各频带能量、归一化能量。
17.在第一方面的一种可能的实现方式中,所述对每个频带对应的半带滤波信号进行分帧处理并计算的过程中,相邻帧之间不存在帧移。
18.在第一方面的一种可能的实现方式中,所述使待识别数字声音信号进入预设的高通滤波器进行高通滤波之前,还包括:
19.用ad转换器将待识别模拟声音信号转换为待识别数字声音信号。
20.本技术实施例的第二方面提供了一种基于半带滤波器的鼾声识别装置,包括:
21.高通滤波模块,用于使待识别数字声音信号进入预设的高通滤波器进行高通滤波;
22.半带滤波模块,用于使进行高通滤波后的待识别数字声音信号进入预设的半带滤波器进行半带滤波,得到多个频带对应的半带滤波信号;每个频带的宽度大小相同,频带的数量由所述半带滤波器的结构决定;
23.分帧计算模块,用于对每个频带对应的半带滤波信号进行分帧处理并计算,得到每个频带对应的分帧信号和每个分帧信号的能量特征;
24.语音识别模块,用于根据单高斯模型和每个分帧信号的能量特征,标记出每个分帧信号包含的语音帧,并将连续的语音帧标记为语音段;
25.鼾声识别模块,用于根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别;每个单类别高斯混合模型由多个子高斯模型组成,且每个单类别高斯模型对应一种鼾声类别;
26.鼾声筛选模块,用于选出间隔时间小于预设间隔阈值的两个鼾声段作为鼾声段组合,全部的鼾声段组合构成鼾声识结果。
27.相比于现有技术,本发明实施例提供的基于半带滤波器的鼾声识别方法及装置,先对数字音频信号进行高通滤波,滤除低频干扰。然后通过半带滤波器滤波得到多个频带的信号,对各频带信号进行分帧处理后并提取信号特征,在采用单高斯模型识别出分帧信号中人的语音帧。进一步对连续语音帧构成的语音段提取特征,并通过比较前后鼾声段的类别和间隔得到识别结果。在整个识别过程中,通过分子带进行提取特征分帧识别处理,减少特征数量以降低计算量;通过分帧识别处理,避免不必存在帧移减少运算量;鼾声类型识别过程中运用多个单类别高斯混合模型进行概率匹配,从而准确地识别出鼾声类型,保证识别的稳定性。
28.综上,本发明实施例采用半带滤波器滤波,鼾声识别过程中计算量小、速度快、所需内存少,且识别率高。
附图说明
29.图1是本发明一实施例提供的一种基于半带滤波器的鼾声识别方法的流程示意图;
30.图2是本发明一实施例提供的一种半带滤波器结构示意图。
具体实施方式
31.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
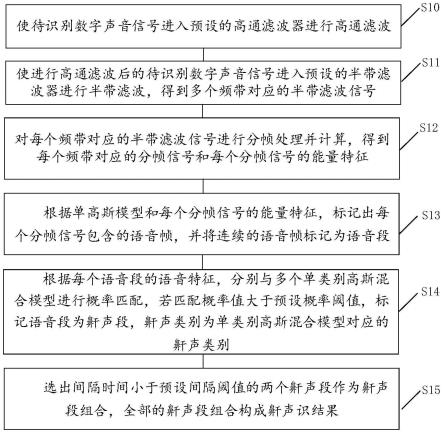
32.请参见图1,本发明一实施例提供了一种基于半带滤波器的鼾声识别方法,所述方法包括:
33.s10、使待识别数字声音信号进入预设的高通滤波器进行高通滤波。
34.s11、使进行高通滤波后的待识别数字声音信号进入预设的半带滤波器进行半带滤波,得到多个频带对应的半带滤波信号;每个频带的宽度大小相同,频带的数量由所述半带滤波器的结构决定。
35.s12、对每个频带对应的半带滤波信号进行分帧处理并计算,得到每个频带对应的分帧信号和每个分帧信号的能量特征。
36.s13、根据单高斯模型和每个分帧信号的能量特征,标记出每个分帧信号包含的语音帧,并将连续的语音帧标记为语音段。
37.s14、根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别;每个单类别高斯混合模型由多个子高斯模型组成,且每个单类别高斯模型对应一种鼾声类别。
38.s15、选出间隔时间小于预设间隔阈值的两个鼾声段作为鼾声段组合,全部的鼾声段组合构成鼾声识结果。
39.s11中将数字声音信号送入高通滤波器滤波,滤除低频干扰。高通滤波器的截止频率取值范围是60~80hz。根据实验结果,80hz以下包含的鼾声特征比较少。因此,在实际应用中,高通滤波器的截止频率一般选择为80hz。
40.a/d转换器采样得到的数字音频信号里往往含有直流信号和工频干扰信号,为了更准确地提取鼾声特征,需要将这些干扰信号滤除。本发明实施例采用一阶iir高通滤波器实现这一目的,其传递函数如下:
[0041][0042]
对高通滤波后的数字声音信号送入iir半带滤波器,进行滤波,得到滤波后多组不同频带的数字声音信号,然后进行分帧处理。在实际应用中,由于鼾声的最重要特征处于80
~4khz频带内,把80~4khz分为8个频带(每个频带的带宽为500hz),可以很好地提取到鼾声的特征。由于每个频带分别包含了不同的特征,分频带计算可以有效地减少特征数量以降低计算量。
[0043]
iir半带滤波器的传递函数为:
[0044]
低通部分:
[0045]
高通部分:
[0046]
其中a0(z)和a1(z)是两个不同的iir全通滤波器的传递函数:
[0047][0048][0049]
其中c1、c2是设计半带滤波器时根据设计要求,如归一化通带边缘频率、归一化阻带边缘频率、最大通带幅度纹波和最大阻带幅度纹波等,得到的两个常数。
[0050]
相比于现有技术,本发明实施例提供的基于半带滤波器的鼾声识别方法及装置,先对数字音频信号进行高通滤波,滤除低频干扰。然后通过半带滤波器滤波得到多个频带的信号,对各频带信号进行分帧处理后并提取信号特征,在采用单高斯模型识别出分帧信号中人的语音帧。进一步对连续语音帧构成的语音段提取特征,并通过比较前后鼾声段的类别和间隔得到识别结果。在整个识别过程中,通过分子带进行提取特征分帧识别处理,减少特征数量以降低计算量;通过分帧识别处理,避免不必存在帧移减少运算量;鼾声类型识别过程中运用多个单类别高斯混合模型进行概率匹配,从而准确地识别出鼾声类型,保证识别的稳定性。
[0051]
综上,本发明实施例采用半带滤波器滤波,鼾声识别过程中计算量小、速度快、所需内存少,且识别率高。
[0052]
本发明实施例采用的半带滤波器滤波结构(划分为8个子频带过滤分析)如图2所示,当有n个音频数据通过级联的半带滤波器滤波时,只需要6n 14次乘法和9n 14次加法就可以得到滤波后8个子频带的音频数据。
[0053]
示例性地,所述每个分帧信号的能量特征包括每个分帧信号的总能量、各频带能量、归一化能量。
[0054]
示例性地,所述对每个频带对应的半带滤波信号进行分帧处理并计算的过程中,相邻帧之间不存在帧移。
[0055]
将滤波后的数据进行分帧处理,一般而言,每帧时长可选择划分为20~40ms,优选地,选择30ms时长。分帧处理的目的在于识别该帧音频是否是人发出的声音,为鼾声识别作准备,因此相邻帧之间不必存在帧移,这样可以减少运算量。(在分帧的过程中,经常在相邻两帧数据间有一部分重叠数据,称为“帧移”)。
[0056]
然后对各组滤波后的分帧数字信号进行计算,提取出总能量、各频带能量、归一化能量等语音能量特征。得到语音能量特征后,利用概率统计理论对人的语音概率分布进行高斯建模,其概率密度统计函数为:
[0057][0058]
其中x为多维的特征样本数据,μ为数据均值(期望),∑为协方差,d为音频特征维度,也就是总能量、各频带能量、归一化能量等特征的数量。
[0059]
建立单高斯模型后,再根据多维的音频特征,计算出该语音帧属于人发出的声音的概率,如果概率大于阈值(0.95),则标记该帧为语音帧。
[0060]
直到识别到某帧不是语音帧为止,则将之前连续的语音帧标记为语音段。
[0061]
对语音段进行计算,提取出该语音段的时长、总能量、各频带能量、归一化能量、频带内峰值点的个数和周期等特征。利用高斯混合模型来判别这些特征是否符合某一类鼾声特征,如符合则标记该语音段为鼾声段并记录下鼾声类别;如果连续两个鼾声段之间的间隔时间处于某个区间内,且类别相同,则可以确定这两个鼾声段是真正的鼾声。
[0062]
示例性地,所述根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别,具体包括:
[0063]
根据每个鼾声种类建立一个对应的单类别高斯混合模型。
[0064]
将每个语音段的语音特征遍历每个单类别高斯混合模型,计算每个单类别高斯混合模型的概率密度。
[0065]
若单类别高斯混合模型的概率密度大于预设概率阈值,标记语音段为鼾声段,所述鼾声段的类别与单类别高斯混合模型对应的鼾声类别相同。
[0066]
这里建立了单类别高斯混合模型,其概率密度统计函数为:
[0067][0068]
其中,k为混合模型中子高斯模型的数量;αk是特征样本数据属于第k个子高斯模型的概率,αk≥0,
[0069]
φ(x|θk)是第k个子模型的高斯分布密度函数,具体如下式:
[0070][0071]
其中x为多维的特征样本数据,μ为数据均值(期望),∑为协方差,d为音频特征维度,也就是语音段的时长、总能量、各频带能量、归一化能量、频带内峰值点的个数和周期等
特征的数量。
[0072]
以一种应用场景的为例:建立概率的统计模型后,根据鼾声信号的的时长、总能量、各频带能量、归一化能量、频带内峰值点的个数和周期等特征对鼾声进行分类,如男人轻中度打鼾者、女人轻中度打鼾者、男人重度打鼾者、女人重度打鼾者等,分为5~10种鼾声类型。举一个例子,大部分男人轻中度打鼾者其鼾声能量主要集中在80~500hz频带内,而大部分女人轻中度打鼾者其鼾声能量主要集中在1000~1500hz频带内。每一种分类用5~8个子高斯模型组成混合高斯模型。当语音段特征通过计算遍历每一种分类的混合高斯模型概率密度,找出其中概率最大的鼾声分类,检测是否达到预设的阈值,例如可以设置概率阈值为0.90,当概率最大的鼾声分类对应的概率大于该阈值0.90时,即标记该语音段为鼾声段。如果连续两个鼾声段之间的间隔时间处于某个区间内,且类别相同,则可以确定这两个鼾声段是真正的鼾声。
[0073]
示例性地,所述使待识别数字声音信号进入预设的高通滤波器进行高通滤波之前,还包括:
[0074]
用ad转换器将待识别模拟声音信号转换为待识别数字声音信号。
[0075]
声音信号是一种连续的模拟信号,在实际应用中需要用a/d转换器按照一定的采样频率将之转换为数字信号。由于鼾声的最重要特征处于80~4khz频带内,根据奈奎斯特采样定理,a/d转换器的采样频率优选地采用8khz,鼾声中4khz及以下的信息被完整地保留下来,同时减少了数据量从而减少了计算量。a/d转换器的量化位数在8bit~16bit范围内,量化位数越高声音质量越好,计算量也越大,同时器件的成本也越高。优选地:兼顾声音质量和计算量,量化位数选择为12bit。
[0076]
本发明实施例实现了用a/d转换器将模拟音频信号转换为数字音频信号,并对其进行高通滤波,然后通过半带滤波器滤波得到8个频带的信号,对各频带信号进行分帧处理后提取特征用单高斯模型识别是否是人发出的声音,进一步对连续语音帧构成的语音段提取特征,并通过比较前后鼾声段的类别和间隔得到识别结果。本发明采用半带滤波器滤波,计算量小、速度快、所需内存少、识别率高。
[0077]
本技术实施例的第二方面提供了一种基于半带滤波器的鼾声识别装置,包括:高通滤波模块、半带滤波模块、分帧计算模块、语音识别模块、鼾声识别模块和鼾声筛选模块。
[0078]
高通滤波模块,用于使待识别数字声音信号进入预设的高通滤波器进行高通滤波。
[0079]
半带滤波模块,用于使进行高通滤波后的待识别数字声音信号进入预设的半带滤波器进行半带滤波,得到多个频带对应的半带滤波信号;每个频带的宽度大小相同,频带的数量由所述半带滤波器的结构决定。
[0080]
分帧计算模块,用于对每个频带对应的半带滤波信号进行分帧处理并计算,得到每个频带对应的分帧信号和每个分帧信号的能量特征。
[0081]
语音识别模块,用于根据单高斯模型和每个分帧信号的能量特征,标记出每个分帧信号包含的语音帧,并将连续的语音帧标记为语音段。
[0082]
鼾声识别模块,用于根据每个语音段的语音特征,分别与多个单类别高斯混合模型进行概率匹配,若匹配概率值大于预设概率阈值,标记语音段为鼾声段,鼾声类别为单类别高斯混合模型对应的鼾声类别;每个单类别高斯混合模型由多个子高斯模型组成,且每
个单类别高斯模型对应一种鼾声类别。
[0083]
鼾声筛选模块,用于选出间隔时间小于预设间隔阈值的两个鼾声段作为鼾声段组合,全部的鼾声段组合构成鼾声识结果。
[0084]
相比于现有技术,本发明实施例提供的基于半带滤波器的鼾声识别装置,先对数字音频信号进行高通滤波,滤除低频干扰。然后通过半带滤波器滤波得到多个频带的信号,对各频带信号进行分帧处理后并提取信号特征,在采用单高斯模型识别出分帧信号中人的语音帧。进一步对连续语音帧构成的语音段提取特征,并通过比较前后鼾声段的类别和间隔得到识别结果。在整个识别过程中,通过分子带进行提取特征分帧识别处理,减少特征数量以降低计算量;通过分帧识别处理,避免不必存在帧移减少运算量;鼾声类型识别过程中运用多个单类别高斯混合模型进行概率匹配,从而准确地识别出鼾声类型,保证识别的稳定性。
[0085]
综上,本发明实施例采用半带滤波器滤波,鼾声识别过程中计算量小、速度快、所需内存少,且识别率高。
[0086]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赞述。
[0087]
需要说明的是,上述终端设备可包括,但不仅限于,处理器、存储器,本领域技术人员可以理解,上述终端设备仅仅是示例,并不构成对终端设备的限定,可以包括更多或更少的部件,或者组合某些部件,或者不同的部件。
[0088]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。