1.本技术涉及机器学习领域,特别涉及一种图像生成、装置、设备、存储介质及计算机程序产品。
背景技术:
2.图像合成用于对不同模态图像之间进行图像转换,不同模态图像指获得图像的方式不同,如:通过x射线(x-ray)获取的x光图像,和通过核磁共振获取的核磁共振成像磁共振成像(magnetic resonance imaging,mri)对应为两种不同模态图像,或者,不同模态图像是指图像的风格不同。
3.相关技术中,通常采用训练生成式对抗网络(generative adversarial networks,gan)的方式得到图像生成模型,用于生成不同模态的图像。在训练过程中,通过样本图像和参考图像对gan网络进行训练,其中,样本图像和参考图像是预先确定的具有匹配关系的样本图像组。
4.然而在上述方法中,通过获取具有匹配关系的样本图像组对gan网络进行训练的方式,由于用于训练的样本需要具有匹配关系,导致样本图像组的获取方式会存在难度较大的问题,同时在实际应用过程中,不同模态图像之间差异性较大,导致gan网络的输出结果准确度较低,模型性能表现较差。
技术实现要素:
5.本技术实施例提供了一种图像生成方法、装置、设备、存储介质及计算机程序产品,能够提高生成的目标三维图像的准确度。所述技术方案如下:
6.一方面,提供了一种图像生成方法,所述方法包括:
7.获取第一模态图像,所述第一模态图像对应第一模态;
8.通过第一候选网络对所述第一模态图像进行模态转换,得到第一生成图像,所述第一生成图像对应第二模态,且所述第一生成图像是三维图像,所述第一模态与所述第二模态是不同的模态;
9.通过第二候选网络对所述第一生成图像进行模态还原,得到第一还原图像,所述第一还原图像对应所述第一模态;
10.基于所述第一生成图像和所述第一还原图像,获取约束损失值,所述约束损失值用于指示所述第一候选网络将所述第一模态图像映射至三维图像空间时的映射损失;
11.基于所述约束损失值对所述第一候选网络进行训练,得到图像转换网络,所述图像转换网络用于对属于所述第一模态的图像进行模态转换,得到属于所述第二模态的三维图像。
12.另一方面,提供了一种图像生成装置,所述装置包括:
13.获取模块,用于获取第一模态图像,所述第一模态图像对应第一模态;
14.转换模态,用于通过第一候选网络对所述第一模态图像进行模态转换,得到第一
生成图像,所述第一生成图像对应第二模态,且所述第一生成图像是三维图像,所述第一模态与第二模态是不同的模态;
15.还原模块,用于通过第二候选网络对所述第一生成图像进行模态还原,得到第一还原图像,所述第一还原图像对应所述第一模态;
16.所述获取模块,还用于基于所述第一生成图像和所述第一还原图像,获取约束损失值,所述约束损失值用于指示所述第一候选网络将所述第一模态图像映射至三维图像空间时的映射损失;
17.训练模块,用于基于所述约束损失值对所述第一候选网络进行训练,得到图像转换网络,所述图像转换网络用于对属于所述第一模态的图像进行模态转换,得到属于所述第二模态的三维图像。
18.另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本技术实施例中任一所述图像生成方法。
19.另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本技术实施例中任一所述的图像生成方法。
20.另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中任一所述的图像生成方法。
21.本技术实施例提供的技术方案带来的有益效果至少包括:
22.通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失值,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
23.在医疗领域下,由于医学图像的模态更具多样化,不同模态图像反应的信息侧重点不同,因此将医学图像通过图像转换网络转换成三维医学图像的方式可以更好的对三维医学图像进行图像分割,用于辅助医疗诊断,在对第一候选网络进行训练的过程中,通过获取第一模态图像对应的第一生成图像和第一还原图像,从而确定第一候选网络对应的约束损失值,用于满足不同场景下,确定第一候选网络在三维图像空间中对应的不同特征的映射损失,从而有针对性的对第一候选网络进行训练,得到最终满足当前场景下的图像转换网络,适用于提高对医学图像进行模态转换的准确度,从而更好的进行后续医疗诊断。
附图说明
24.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使
用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
25.图1是本技术一个示例性实施例提供的图像生成方法相关技术示意图;
26.图2是本技术一个示例性实施例提供的实施环境示意图;
27.图3是本技术一个示例性实施例提供的图像生成方法流程图;
28.图4是本技术另一个示例性实施例提供的图像生成方法流程图;
29.图5是本技术另一个示例性实施例提供的图像生成方法流程图;
30.图6是本技术一个示例性实施例提供的图像生成方法示意图;
31.图7是本技术一个示例性实施例提供的脑部图像生成过程示意图;
32.图8是本技术一个示例性实施例提供的图像生成装置的结构框图;
33.图9是本技术另一个示例性实施例提供的图像生成装置的结构框图;
34.图10是本技术一个示例性实施例提供的服务器结构示意图。
具体实施方式
35.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
36.首先,针对本技术实施例中涉及的名词进行简单介绍。
37.模态(modality):每一种信息的来源或者形式,都可以成为一种模态,如:人有触觉、听觉;信息的媒介包括语音、视频、文字等;多种多样的传感器,包括:雷达、红外、加速度计等,以上的每一种都可以称之为一种模态。
38.本技术实施例中,将不同形式的图像作为不同模态图像,如:x光图像为一类模态图像,电子计算机断层扫描(computed tomography,ct)图像为一类模态图像,磁共振成像(magnetic resonance imaging,mri)为一类模态图像等,不同模态图像反应的图像信息侧重点是不同,x光射线图像观察骨骼更清晰,ct图像可以反应组织和出血状况,mri图像适合观察软组织。
39.生成式对抗网络(generative adversarial networks,gan):是一种用于无监督式的深度学习模型。gan网络包括至少两个模块:生成模型(generative model)和判别模型(discriminative model),在模型的训练过程中,两个模型通过互相博弈学习从而对gan网络进行训练,提高模型输出结果的准确度。
40.首先,相关技术中,请参考图1,其示出了本技术一个示例性实施例提供的图像生成相关技术示意图,如图1所示,针对一个图像生成的训练任务,设置一个候选生成网络100对其进行训练,首先获取样本图像101和参考图像102,其中,样本图像101和参考图像102是一组具有匹配关系的样本图像组,通过将样本图像101输入生成器103中,并加入随机噪音104,输出得到生成图像105,将参考图像102和生成图像105输入判别器106,输出得到生成图像105和参考图像102对应的判别结果107,其中,若生成图像105与参考图像102一致,则判别结果107为“1”,若生成图像105和参考图像102不一致,则判别结果107为“0”,根据判别结果107对候选生成网络100进行训练,最终得到目标生成网络108。
41.上述技术中,通过采用预先配置好的样本图像组对候选生成网络进行训练的方
式,由于图像与图像之间的差异性较大,获取具有匹配关系的样本图像组难度较高,同时,该训练过程得到目标生成网络在实际运用中泛化性能较差,导致输出的结果准确度较低,无法满足任务需求。
42.本技术提供的图像生成方法,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到属于第二模态的第一生成图像和属于第一模态的第一还原图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失值,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
43.其次,对本技术实施例中涉及的实施环境进行说明,示意性的,请参考图2,该实施环境中涉及终端210、服务器220,终端210和服务器220之间通过通信网络230连接。
44.在一些实施例中,终端210向服务器220发送图像生成请求,其中图像生成请求中包含用于进行模态转换的原始图像,服务器220接收到来自终端210发送的图像生成请求后,对原始图像进行模态转换,生成原始图像对应的目标三维图像,并将目标三维图像反馈至终端210。
45.其中,服务器220中包含图像转换网络221,图像转换网络221是通过第一模态图像222输入第一候选网络223后生成第一生成图像224,将第一生成图像224输入第二候选网络225,得到第一还原图像226,根据第一生成图像224和第一还原图像226确定约束损失值从而对第一候选网络223进行训练,最终得到图像转换网络221。
46.上述终端210可以是手机、平板电脑、台式电脑、便携式笔记本电脑、智能电视、智能车载等多种形式的终端设备,本技术实施例对此不加以限定。
47.值得注意的是,上述服务器220可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(content delivery network,cdn)、以及大数据和人工智能平台等基础云计算服务的云服务器。
48.其中,云技术(cloud technology)是指在广域网或局域网内将硬件、软件、网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术。云技术基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术、应用技术等的总称,可以组成资源池,按需所用,灵活便利。云计算技术将变成重要支撑。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站。伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,只能通过云计算来实现。
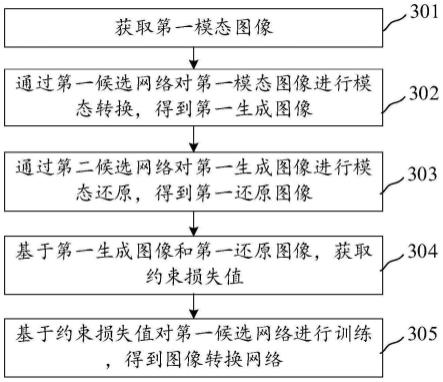
49.在一些实施例中,上述服务器220还可以实现为区块链系统中的节点。
50.需要说明的是,本技术所涉及的信息(包括但不限于用户设备信息、用户个人信息等)、数据(包括但不限于用于分析的数据、存储的数据、展示的数据等)以及信号,均为经用户授权或者经过各方充分授权的,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。例如,本技术中涉及到的用于训练的脑部图像是在充分授权的情况下获取的。
51.结合上述名词简介和实施环境,对本技术的应用场景进行举例。
52.1、应用于医疗场景下。以当前任务为生成三维脑部图像为例进行说明,获取公开数据集中包含的样本脑部图像,通过第一候选网络对样本脑部图像进行模态转换,得到脑部生成图像,脑部生成图像为样本脑部图像对应的三维图像,通过第二候选网络对脑部生成图像进行模态还原,得到脑部还原图像,根据脑部生成图像和脑部还原图像确定约束损失值,根据约束损失值对第一候选网络进行训练得到图像转换网络,用于将输入第一模态的脑部图像转换成第二模态的三维脑部图像,用于后续对脑部图像进行图像分割,进行辅助诊疗等,如:将t1加权图像转换为t2加权mri图像。
53.2、应用于广告场景下。为了获取更多的广告素材,将第一模态的样本广告素材输入第一候选网络进行模态转换,生成第二模态的样本生成图像,样本生成图像为第二模态下对应的一个三维图像,将样本生成图像输入第二候选网络进行模态还原,得到第一模态的样本还原图像,根据样本还原图像和样本生成图像确定约束损失值对第一候选网络进行训练,得到素材转换网络,在应用过程中,将目标素材输入素材转换网络中,输出得到目标素材对应的不同模态下的三维素材图像,用于提高素材的生成效率。
54.值得注意的是,上述应用场景仅为示意性的举例,本技术实施例中对图像生成方法的是应用场景不加以限定,此外,分类预测方法还可以用于实现医学图像对准、图像风格迁移等应用场景中。
55.示意性的,对本技术提供的图像生成方法进行说明,请参考图3,其示出了本技术一个示例性实施例提供的图像生成方法流程图,该方法可以由终端执行,也可以由服务器执行,或者,也可以由终端和服务器共同执行,本实施例中以该方法由服务器执行进行说明,如图3所示,该方法包括:
56.步骤301,获取第一模态图像。
57.其中,第一模态图像对应第一模态。
58.示意性的,第一模态图像为对应第一模态的图像。
59.可选地,第一模态根据图像的风格类型确定,如:当前第一模态下对应的为漫画图像,其他模态下的图像为人物写实图像;或者,第一模态根据图像的色彩值确定,如:当前第一模态下对应的图像为灰度图像;或者,第一模态根据图像的具体内容来确定,如:当前第一模态图像内容中包括猫,对此不做限定。
60.示意性的,第一模态图像为公开训练数据集中的样本训练图像,在此不做限定。
61.可选地,获取第一模态图像的方式包括从本地存储的图像数据集中获取;或者,从公开训练数据集中下载获取,在此不做限定。
62.步骤302,通过第一候选网络对第一模态图像进行模态转换,得到第一生成图像。
63.其中,第一生成图像对应第二模态,且第一生成图像是三维图像,第一模态与第二模态是不同的模态。
64.在一些实施例中,第一候选网络是用于对输入的第一模态图像进行模态转换的网络。
65.可选地,第一模态和第二模态的区别在于其各自图像对应的数据来源不同,如:第一模态的图像为网站上下载得到的图像,第二模态为通过拍摄获取的图像;或者,第一模态和第二模态的区别在于其各自图像对应的数据内容类型不同,如:第一模态的图像为卡通
图像,第二模态的图像为现实图像,对此不加以限定。
66.在一些实施例中,第一生成图像是第一候选网络将对应第一模态的第一模态图像进行模态转换后生成的图像,且第一生成图像对应为第二模态,表明第一生成图像与第一模态图像对应不同的模态。
67.可选地,第一生成图像与第一模态图像不具有内容对应关系,如:第一模态图像中包含狗,但第一生成图像中包含斑马;或者,第一生成图像与第一模态图像具有图像内容对应关系,也即,第一生成图像和第一模态图像对应的图像内容一致,如:第一模态图像和第一生成图像中包含的图像内容都为猫,对此不加以限定。
68.示意性的,模态转换的方式包括如下几种转换方式:
69.1.模态转换包括像素点序列重组,也即,获取第一模态图像中的各像素点分布序列,通过调整各像素点分布序列,实现模态转换;
70.2.模态转换包括进行维度转换,如:第一模态图像对应第一类型维度图像(如:二维图像),将其映射到第二类型维度空间后得到的第一生成图像为第二类型维度图像(如:三维图像);
71.3.模态转换包括特征融合,也即,获取第一模图像对应的各像素点对应的元素特征,通过将各个元素特征进行融合实现模态转换;
72.4.模态转换包括阈值转换,也即,通过获取第一模态图像对应的各区域阈值信息,通过调整各区域阈值信息,实现模态转换,如:第一模态图像中包含区域a和区域b,区域a颜色更突出,经过阈值转换后生成的第一生成图像区域b颜色更突出。
73.值得注意的是,上述关于模态转换方式仅为示意性的举例,本技术实施例对此不加以限定。
74.可选地,模态转换是随机转换的,或者,按照指定规律进行转换的,如:将现实图像转换为卡通图像,在此不做限定。
75.可选地,第一模态与第二模态具有关联关系,如:第一模态和第二模态都为脑部图像,但对应不同类型(mri图像和ct图像),或者,第一模态和第二模态不具有关联关系,在此不做限定。
76.步骤303,通过第二候选网络对第一生成图像进行模态还原,得到第一还原图像。
77.第一还原图像对应第一模态。
78.示意性的,第一还原图像为经过模态还原后对应第一模态的图像。
79.可选地,第一还原图像与第一模态图像相同或者不相同,对此不做限定。
80.示意性的,模态还原的方式包括如下几种方式中至少一种:
81.1.模态还原包括像素点分布还原,也即,获取第一生成图像中各像素点分布,通过将各像素点分布对应第一模态进行排列重组,实现模态还原;
82.2.模态还原包括进行维度还原,也即,将第一生成图像映射到第一类型维度空间后得到的第一还原图像为第一类型维度图像(如:二维图像);
83.3.模态还原包括特征分解,也即,获取第一生成像对应的图像特征,通过将图像特征进行结构分解以实现模态还原;
84.4.模态还原包括阈值还原,也即,通过获取第一模态图像对应的各区域阈值信息,通过还原各区域阈值信息,实现模态还原。
85.值得注意的是,上述关于模态还原方式仅为示意性的举例,本技术实施例对此不加以限定。
86.可选地,第一候选网络与第二候选网络为同架构类型的网络;或者,第一候选网络与第二候选网络为不同架构类型的网络,对此不加以限定。
87.步骤304,基于第一生成图像和第一还原图像,获取约束损失值。
88.其中,约束损失值用于指示第一候选网络将第一模态图像映射至三维图像空间中对应的映射损失。
89.示意性的,映射损失是指,第一候选网络将第一模态图像对应的图像特征表示映射到三维图像空间后,输出得到第一生成图像的过程中,产生的不同类型特征对应的损失值。
90.可选地,约束损失值包括以下几种类型中至少一种:
91.1.维度转换损失,即,在三维图像空间中将第一模态图像进行维度转换时对应的损失值;
92.2.域约束损失,即,第一候选网络在对第一模态图像进行模态转换的过程中,得到的第一生成图像对应第一模态图像存在对应的特征损失;
93.3.纹理约束损失,即,第一模态图像进行模态转换生成第一生成图像的过程中对应的区域分割损失;
94.4.轮廓约束损失,即,第一模态图像进行模态转换生成第一生成图像的过程中对应的图像轮廓边界损失。
95.值得注意的是,上述关于约束损失值仅为示意性的举例,本技术实施例对此不加以限定。
96.可选地,约束损失值的获取方式包括如下几种方式中至少一种:
97.1.通过获取第一生成图像和第一模态图像之间的差异性,确定约束损失值;
98.2.获取第一生成图像和第一模态图像各自对应的图像特征,将各自对应的图像特征进行融合,确定约束损失值;
99.3.获取第一生成图像和第一模态图像各自对应的图像特征,通过确定两者图像特征之间的距离,确定约束损失值;
100.4.获取第一生成图像和第一模态图像各自对应的图像特征,将各自对应的图像特征进行拼接,确定约束损失值;
101.5.构建约束损失模型,获取第一生成图像和第一模态图像各自对应的图像特征,将各自对应的图像特征输入约束损失模型,输出得到的结果作为约束损失值。
102.值得注意的是,上述关于约束损失值的获取方式仅为示意性的举例,本技术实施例对此不加以限定。
103.步骤305,基于约束损失值对第一候选网络进行训练,得到图像转换网络。
104.其中,图像转换网络用于对属于第一模态的图像进行模态转换,得到属于第二模态的三维图像。
105.可选地,通过约束损失值对第一候选网络进行梯度训练,或者,通过约束损失值对第一候选网络进行循环迭代训练,对此不加以限定。
106.示意性的,图像转换网络用于将属于第一模态的图像在三维图像空间中进行模态
转换,得到属于第二模态的三维图像。
107.可选地,第一模态的图像为二维图像,或者,第一模态的图像为三维图像,对此不加以限定。
108.可选地,图像转换网络进行模态转换的方式与上述第一候选网络进行模态转换的方式相同,或者不同,对此不加以限定。
109.综上所述,本技术实施例提供的图像生成方法,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失值,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
110.在一个可选的实施例中,约束损失值中包括维度转换损失,示意性的,请参考图4,其示出了本技术一个示例性实施例提供的图像生成方法流程图,该方法可以由终端执行,也可以由服务器执行,或者,也可以由终端和服务器共同执行,本实施例中以该方法由服务器执行进行说明,如图3所示,也即,步骤302中包括302a,步骤304还包括步骤3041a和步骤3041b,该方法包括如下步骤:
111.步骤302a,将第一模态图像输入生成器,输出得到第一生成图像。
112.示意性的,第一候选网络采用生成对抗网络架构中的生成器,将第一模态图像输入生成器后输出得到第一生成图像。
113.其中,生成器采用的是gan网络中对应的生成模型,将第一模态图像输入生成器,生成器将随机加入一个噪声对第一模态图像进行合成,输出得到属于第二模态的第一生成图像。
114.在一些实施例中,生成器通过将第一模态图像对应的图像特征表示映射到三维图像空间中,获取第一模态图像的图像特征表示对应在三维图像空间中的生成特征表示,根据生成特征表示确定第一生成图像。
115.本实施例中,第一候选网络中包含的生成器由三个卷积层、步幅为1,2,2作为前端,六个残差块、两个步幅为二分之一的分步卷积核一个步幅为1的后端卷积层组成,convolution-batch norm-relu被应用在除了输出层之外的各个地方,输出层在最后使用了tanh激活。每个残差块中包括两个卷积层,每个卷积层有128个滤波器。采用7
×
7的体积卷积核用于第一层和最后一层,使用3
×3×
3用在其他层上。
116.本实施例中,将第一候选网络中包含的生成器记作生成器g。
117.步骤303,通过第二候选网络对第一生成图像进行模态还原,得到第一还原图像。
118.其中,第一还原图像对应第一模态。
119.本实施例中,第二候选网络与第一候选网络对应为相同架构的网络,也即,第二候选网络中的生成器也采用gan网络中对应的生成模型,值得注意的是,第一候选网络中包含的生成器和第二候选网络中包含的生成器为两个候选网络中各自对应的生成器,本实施例中将第二候选网络中包含的生成器记为生成器f。
120.示意性的,第二候选网络中的生成器f的结构与生成器g结构相同,此处不再赘述。
121.步骤3041a,获取第二模态图像。
122.其中,第二模态图像为预先提供的第二模态的图像。
123.示意性的,第二模态图像为对应第二模态的图像。
124.示意性的,第二模态图像为公开训练数据集中的样本训练图像,在此不做限定。
125.可选地,获取第二模态图像的方式包括从本地存储的图像数据集中获取;或者,从现存的公开训练数据集中下载获取,在此不做限定。
126.可选地,第二模态图像与第一模态图像具有对应关系,也即,第一模态图像和第二模态图像为预先匹配好的一组图像样本;或者,第二模态图像与第一模态图像不具有对应关系,也即,第一模态图像和第二模态图像为各自随机获取的作为训练的样本图像,对此不加以限定。
127.本实施例中,第一模态图像首先输入生成器g生成第一生成图像,再将第一生成图像输入生成器f生成第一还原图像,实现由生成器g到生成器f的训练过程,也即,从第一候选网络到第二候选网络的过程,但为了提高模型的泛化性能,在另一种可行的实施例中,将第二模态图像首先输入生成器f生成第二生成图像,再将第二生成图像输入生成器g生成第二还原图像,基于第二生成图像和第二还原图像确定对应的约束损失值对第二候选网络进行训练,也即,实现从第二候选网络到第一候选网络的训练过程。
128.本技术提供的图像生成方法中,既包括从第一候选网络到第二候选网络的过程,也包括从第二候选网络到第一候选网络的训练过程,也即,生成器g和生成器f为在三维图像空间中构建的,用于第一模态图像和第二模态图像之间进行模态转换的双向映射函数。由于两侧训练过程一致,仅训练方向不同,本实施例中以从第一候选网络到第二候选网络的训练过程为例进行具体说明。
129.步骤3041b,基于第一生成图像和第二模态图像的图像特征分布差异,以及,基于第一模态图像和第一还原图像的图像特征分布差异,获取维度转换损失值。
130.其中,维度转换损失值用于指示第一候选网络在三维图像空间中维度转换过程的特征损失。
131.示意性的,维度转换损失值用于确定从第一模态图像进行模态转换生成第一生成图像的过程中,在三维图像空间中进行维度转换过程中对应的特征损失,其中,维度转换包括:二维图像转换为三维图像;或者,三维图像转换为三维图像,但是对应不同的图像特征分布,对此不加以限定。
132.在一些实施例中,基于第二模态图像和第一生成图像之间的图像特征分布差异,确定判别损失;基于第一模态图像和第一还原图像之间的图像特征分布差异,确定生成损失;将生成损失和判别损失作为维度转换损失值,维度转换损失值用于指示第一候选网络通过三维图像空间进行图像维度转换时产生的损失。
133.示意性的,维度转换损失值中包括两部分:判别损失和生成损失,其中,判别损失根据第二模态图像和第一生成图像确定;生成损失根据第一模态图像和第一还原图像确定。
134.在一些实施例中,第一候选网络中还包括生成式对抗网络架构中的判别器,用于确定第二模态图像和第一生成图像之间的图像特征分布差异,根据第二模态图像和第一生成图像之间的差异确定判别损失,也即,将第二模态图像输入判别器,输出得到参考预测结
果,参考预测结果用于指示第二模态图像作为参考图像的概率;将第一生成图像输入判别器,输出得到匹配预测结果,匹配预测结果用于指示第一生成图像和第二模态图像对应的匹配关系;基于参考预测结果和匹配预测结果,确定判别损失。
135.其中,判别器是gan网络中对应的判别模型,将第一生成图像和第二模态图像分别输入判别模型,判别模型的输出是概率值,概率值分布在0到1之间,1代表真实样本,也即第二模态图像,0为虚构样本,也即第一生成图像,用于确定第一生成图像与第二模态图像的相似度,当第一生成图像越接近第二模态图像时,输出的概率值越大,表明生成器生成图像的准确度越高。
136.本实施例中,判别器用于确定第二模态的第一生成图像与第二模态图像的差异,也即,第二模态图像作为参考图像,输入判别器中,输出得到第二模态图像对应的参考预测概率,此时,当前判别器以第二模态图像作为参考图像,将第一生成图像输入判别器后,输出得到的匹配预测概率作为当前第一生成图像与第二模态图像对应的匹配结果,如:在第二模态图像上显示第一生成图像对应的图像特征分布概率,该图像特征分布概率用于指示第一生成图像对应的图像特征对应在第二模态图像上的匹配结果。
137.值得注意的是,上述计算判别损失的方式为从第一候选网络到第二候选网络的训练过程对应的判别损失,而从第二候选网络到第一候选网络的训练过程中,第二候选网络中也包括判别器,因此,该训练过程中也存在判别损失。
138.根据参考预测概率和匹配预测结果,确定判别损失,示意性的,请参考公式一:
139.公式一:lb(dg,df,g,f)=l(g,dg) l(f,df)
140.其中,lb为总判别损失,l(g,dg)为第一候选网络中判别器对应的判别损失,l(f,df)为第二候选网络中判别器对应的判别损失。在实际应用过程中,采用总判别损失。当第一生成图像对应第二模态图像的图像特征分布概率越高,表明当前第一生成图像拟合到第二模态图像的真实性能越高,也即,判别损失值越小。
141.本实施例中,第一候选网络中的判别器记作dg。在构建判别器dg的过程中,将块大小以重叠的方式固定为70
×
70
×
70的体积元素(volume pixel,体素),并使用convolution-batchnorm-leaky relu层的堆栈来训练判别器dg,判别器dg在整个体素中进行卷积运算,通过平均所有的结果确定相应的预测结果。
142.在一些实施例中,确定第一模态图像对应的第一特征表示;确定第一还原图像对应的第二特征表示;基于第一特征表示与第二特征表示之间的特征表示距离,确定生成损失。
143.本实施例中,第一模态图像对应第一模态的情况下,其对应的图像特征表示作为第一特征表示,第一还原图像对应第一模态的情况下,其对应的图像生成表示作为第二特征表示。
144.本实施例中,根据第一特征表示和第一特征表示对应的特征表示距离,来确定生成损失,示意性的,请参考公式二:
145.公式二:
[0146][0147]
其中,x为第一模态图像,l(g(x))为第一还原图像,y为第二模态图像,g(f(y))为从第二候选网络到第一候选网络的训练过程中得到的第二还原图像(此处第二还原图像的
获取过程与第一还原图像的获取过程相同,故此处不做具体说明),为总生成损失,表示第一模态图像和第一还原图像对应的特征表示距离,得到生成器g对应的生成损失,也即,该生成损失为从第一候选网络到第二候选网络的训练过程中对应的生成损失,为生成器f对应的生成损失,也即,该生成损失为从第二候选网络到第一候选网络的训练过程中产生的生成损失,在实际应用过程中,采用总生成损失进行训练。从第一候选网络到第二候选网络的训练过程当中,当x-f(g(x))越小时,表明当前第一模态图像与第一还原图像的特征分布的距离越小,也即生成损失越小,从第二候选网络到第一候选网络的训练过程与其一致,在此不做赘述。
[0148]
本实施例中,将总生成损失和总判别损失,作为维度转换损失值对应的两部分损失,用于确定第一候选网络和第二候选网络对应的双向映射函数在三维图像空间中进行维度转换对应的损失。
[0149]
综上所述,本技术实施例提供的图像生成方法,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失值,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
[0150]
本技术实施例中,通过确定生成器对应的生成损失,以及判别器对应判别损失,作为维度转换损失,能够提高第一候选网络在三维图像空间中对第一模态图像进行特征映射从而实现维度转换过程中的转换准确度,能够较好的降低维度转换对应的损失,提高模型精度。
[0151]
在一个可选的实施例中,约束损失值中还包括域约束损失值、纹理约束损失值和轮廓约束损失值,示意性的,请参考图5,其示出了本技术一个示例性实施例提供的图像生成方法流程图,该方法可以由终端执行,也可以由服务器执行,或者,也可以由终端和服务器共同执行,本实施例中以该方法由服务器执行进行说明,如图5所示,也即,当约束损失值中包括约束损失值时,步骤304还包括步骤3042a、步骤3042b和步骤3042c,当约束损失值中包括纹理约束损失值时,步骤304还包括步骤3043a、步骤3043b和步骤3043c,当约束损失值中包括轮廓约束损失值时,步骤304还包括步骤3044a、步骤3044b和步骤3044c,该方法包括如下步骤:
[0152]
1.当约束损失值中包括域约束损失值。
[0153]
步骤3042a,获取第一模态图像在三维图像空间的第一特征分布。
[0154]
本实施例中,在将第一模态图像输入生成器得到第二模态的第一生成图像的过程中,通常会假设两种图像模态的特征分布在其对应的图像域中是不变的,但实际情况为当对图像进行跨模态的转换时,其特征分布在图像域中存在变化,尤其是在多序列医学图像的采集过程中,医学图像序列用于指示描述疾病或者病症状况的不同模式,为了提高模型的泛化性能,减少在跨模态转换的过程中,由于模态与模态之间对应的各自的图像域的差
异带来的影响,因此引入域约束损失。
[0155]
本实施例中,将第一模态图像输入第一候选网络的过程中,将第一模态图像映射到三维图像空间中,用于抽取第一模态图像对应的图像特征分布,作为第一特征分布,用于表示第一模态对应的特征分布结果。
[0156]
步骤3042b,获取第一生成图像在三维图像空间的第二特征分布。
[0157]
示意性的,将第一生成图像映射到三维图像空间中,用于确定第一生成图像对应的图像特征分布。
[0158]
步骤3042c,基于第一特征分布和第二特征分布之间的距离,得到域约束损失值。
[0159]
其中,域约束损失值用于指示在三维图像空间中从第一特征分布到第二特征分布的转换损失。
[0160]
示意性的,域约束损失值用于确定第一特征分布和第二特征分布在三维图像空间中对应的特征相似度,也即,当前第一模态和第二模态中对应的相似特征。
[0161]
本实施例中,域约束损失值通过最大平均差异(maximum mean discrepancy,mmd)确定,示意性的,具体确定方式具体请参考公式三:
[0162]
公式三:
[0163]
其中,e
x
[φ(x)]对应第一模态的第一特征分布,ey[φ(y)]表示对应第二模态的第二分布分特征,当第一分布特征与第二分布特征的差值越小,表明第一分布特征与第二分布特征的特征距离越短,当前第一分布特征与第二分布特征的相似度越高。
[0164]
2.当约束损失值中包括纹理约束损失值。
[0165]
步骤3043a,获取第一生成图像对应的第一分割结果。
[0166]
其中,第一分割结果用于指示第一生成图像对应第一模态图像的参考概率分布。
[0167]
在一些实施例中,将第一生成图像输入分割器,输出得到第一分割结果,分割器用于对输入图像进行区域分割。
[0168]
示意性的,第一候选网络中还包括分割器,分割器用于对输入图像进行区域分割,用于确定输入图像对应区域与区域之间对应的纹理表示。
[0169]
本实施例中,通过将第一生成图像输入分割器,输出得到第一分割结果,用于确定第一生成图像对应的纹理特征。
[0170]
示意性的,采用全卷积神经网络(fully convolutional networks,fcn)作为本实施中的分割器。
[0171]
步骤3043b,获取第二模态图像对应的第二分割结果。
[0172]
示意性的,将第二模态图像输入分割器,输出得到第二分割结果,第二分割结果用于表示第二模态图像对应的纹理特征。
[0173]
步骤3043c,基于第一分割结果和第二分割结果之间的分割差异,确定纹理约束损失值。
[0174]
其中,纹理约束损失值用于指示第一候选网络在将第一模态图像映射至三维图像空间时的纹理特征损失。
[0175]
示意性的,为了确定第一生成图像对应的上下文信息,需要确定第二模态图像中包含的纹理表示可以在第一生成图像中进行正确体现,如:第二模态图像为脑部图像时,脑部图像对应的脑部纹理信息是生成对应的三维脑部图像的重要因素,因为脑部纹理信息与
疾病进展、功能变化等信息作为脑部病理分析的关键性因素,因此,引入纹理约束损失值用于,确定第一模态图像输入第一候选网络生成第一生成图像的过程中对应在三维图像空间中纹理特征的损失值。
[0176]
本实施例中,通过预设一个两阶段的纹理损失函数,用于保留第一模态图像通过第一候选网络生成第一生成图像对应的过程中对应的纹理特征,示意性的,请参考公式四:
[0177]
公式四:
[0178][0179]
其中,表示总纹理约束损失值,表示从第一候选网络到第二候选网络的训练过程中对应的纹理约束损失值,也即,第一分割结果和第二分割结果之间的分割差异,表示从第二候选网络到第一候选网络的训练过程中对应的纹理约束损失值,以第一候选网络到第二候选网络的训练过程为例,表示第一生成图像对应的第一分割结果,表示第二模态图像对应的第二分割结果,当第一分割结果和第二分割结果的差异越小时,表明第一生成图像和第二模态图像对应的纹理特征相似度越高,则纹理约束损失值越小。
[0180]
3.当约束损失值中包括轮廓约束损失值。
[0181]
步骤3044a,将第一生成图像输入判别器,输出得到匹配预测结果。
[0182]
其中,匹配预测结果用于指示第一生成图像和第二模态图像对应的匹配关系。
[0183]
步骤3044a中关于匹配预测结果的内容已在上述步骤3041b中进行详细说明,此处不再赘述。
[0184]
步骤3044b,将第一生成图像输入分割器,输出得到第一分割结果。
[0185]
其中,分割器用于对输入图像进行区域分割。
[0186]
步骤3044b中关于第一分割结果的内容已在上述步骤3043a中进行详细说明,此处不再赘述。
[0187]
步骤3044c,基于匹配预测结果和第一分割结果,确定轮廓约束损失值。
[0188]
其中,轮廓约束损失值用于指示第一生成图像对应在三维图像空间中的边界特征损失。
[0189]
本实施例中,图像的轮廓信息可用于图像分析和对图像进行语义分割,轮廓信息用于提供语义信息和图像对应的上下文关系,如:当第一模态图像是脑部图像时,脑部图像对应的轮廓信息便于更好的理解脑部对应的解剖结构,推动疾病进展。将第一模态的脑部图像生成对应的第二模态的脑部mri图像的过程中,保证第一模态的脑部图像的轮廓在跨模态的过程中保持清晰的界限,是实现脑部mri图像具有较好轮廓边界显示的关键,因此引入轮廓约束损失值,用于确定第一生成图像在三维图像空间中对应第一模态图像的边界特征损失。
[0190]
本实施例中,从第一候选网络到第二候选网络的训练过程中,将第一生成图像分别输入第一候选网络对应的判别器和分割器中,而从第二候选网络到第一候选网络的训练过程中,将第二生成图像分别输入第二候选网络对应的判别器和分割器中,用于确定轮廓约束损失值,其中,第一候选网络中的分割器和第二候选网络中的分割器实现为反卷积操
作,遵循fcn网络。
[0191]
步骤305,基于约束损失值对第一候选网络进行训练,得到图像转换网络。
[0192]
示意性的,本技术实施例提供的四种约束损失值可以根据不同的任务场景进行不同的搭配,对第一候选网络的模型参数进行调整。
[0193]
综上,本技术实施例提供的图像生成方法,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失值,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
[0194]
本实施例中,通过设置域约束损失值、纹理约束损失值和轮廓约束损失值的方式,可以使图像转换网络满足不同任务场景下的图像生成任务,用于提高图像转换网络的模型准确度以及泛化性能。
[0195]
在一个可选的实施例中,示意性的,请参考图6,其示出了本技术一个示例性实施例提供的图像生成方法训练过程示意图,如图6所示,该方法包括:
[0196]
获取第一模态图像610,其中,第一模态图像610为从公开的数据集中获取的第一模态的脑部图像,将第一模态图像输入第一候选网络中的生成器(g)620中,生成第一生成图像630,其中,第一生成图像630为第二模态的三维脑部图像,将第一生成图像630输入第二候选网络中的生成器(f)640中,输出得到第一还原图像650,第一还原图像650对应为第一模态的脑部图像,其中,第一模态和第二模态对应为不同的模态。
[0197]
在模型训练的过程中,还包含第二模态图像660,第二模态图像660为从公开的数据集中获取的第二模态的脑部图像。根据第一生成图像630和第二模态图像660的图像特征分布差异,以及根据第一模态图像610和第一还原图像650的图像特征分布差异,确定四种不同的约束损失值,其中,包括维度转换损失值、域约束损失值、纹理约束损失值和轮廓约束损失值。
[0198]
此外,第一候选网络中还包括分割器670和判别器680,第一生成图像630输入分割器670,输出得到第一分割结果671,第二模态图像660输入分割器670,输出得到第二分割结果672,并将第一生成图像630和第二模态图像660输入判别器680,输出得到匹配预测结果690,在匹配预测结果690中,输出值为“1”表示当前第一生成图像630和第二模态图像660匹配,输出值为“0”表示当前第一生成图像630和第二模态图像660不匹配。
[0199]
在训练过程中,根据第一模态图像610和第一还原图像650之间的确定生成损失,根据第一生成图像630和第二模态图像660确定对抗损失,将生成损失和对抗损失作为维度转换损失。
[0200]
根据第一模态图像610对应的第一特征分布和第一生成图像630对应的第二特征分布确定域约束损失值。
[0201]
根据第一分割结果和第二分割结果确定纹理约束损失值。
[0202]
根据匹配预测结果和第一分割结果确定轮廓约束损失值。
[0203]
根据四种不同的约束损失值,根据当前任务场景选择至少一个对第一候选网络进
行训练,最终得到图像转换网络,用于生成目标三维脑部图像。
[0204]
本实施例中图像生成方法在三个数据集上进行评估:第一公开数据集、第二公开数据集和第三公开数据集。这三个数据集中包含四种序列的脑部图像,分别为t1加权图像、t2加权图像、质子密度(proton density,pd)加权图像和磁共振成像液体衰减反转恢复序列(fluid attenuated inversion recovery,flair)图像,四种序列对应不同的模态,四种序列图像显示的脑部特征不同,在三个场景中评估图像生成方法,这些场景是根据匹配第一模态对应的图像域和第二模态对应的图像域的复杂性选择的:(1)第一公开数据集对应的任务为:将pd加权图像转换为t2加权图像;(2)第二公开数据集对应的任务为:将t1加权图像转换为t2加权图像;(3)第三公开数据集应的任务为:将flair图像转换为t1加权图像。在场景(1)下,示意性的,请参考图7,其示出了本技术一个示例性实施例提供的脑部图像生成过程示意图,如图7所示,将pd加权图像701作为第一模态图像输入第一候选网络,输出得到t2加权合成图像702作为目标三维图像,图7中还包括作为第二模态图像的t2加权图像703(该图像从公开数据集中获取)。
[0205]
在每个数据集中,存在由不同成像方式获得的具有显着外观变化的对齐良好的配对图像。所有配对数据都用作验证合成结果质量的标准图像。定量地,从第一公开数据集中手动选择239个未配对的pd加权图像和t2加权图像,从第二公开数据集中选择8个未配对的t1加权图像和t2加权图像,以及90个未配对的t1加权图像和flair图像进行训练。其余数据:第一公开数据集中的100个图像,第二公开数据集中的4个图像,第三公开数据集中的40个图像用于测试。对于fcn,同时提供真实扫描和合成结果,以产生三个主要的脑组织类别:脑脊液(cerebral spinal fluid,csf)、灰质(gray matter,gm)和白质(white matter,wm),给出脑容量的平均量化。组织先验概率模板为预先设置的好的脑部图像分割模板,用于验证其模型对应的分割结果。对于评估标准,使用峰值信噪比(peak signal-to-noise ratio,psnr)、结构相似性指数度量(structural similarity index,ssim)和骰子分数(dice score)(分割重叠的度量,分数越高表示结果准确度越高)来比较结果。
[0206]
示意性的,请参考表1,其示出了本技术实施例提供的约束损失值对应不同搭配下的模型训练效果,如表1所示:
[0207]
表1
[0208]
[0209][0210]
为了评估图像生成方法的性能,首先进行消融研究以检查各个约束损失值,以评估图像转换网络中每个组件的重要性。具体来说,对于第一公开数据集上将pd加权图像转换为t2加权图像,分别采用了维度转换损失值、域约束损失值、纹理约束损失值和轮廓约束损失值,并自由地将它们与gan网络结合以研究图像方面的效果质量及其分割性能,详细结果显示在表1的第一部分。
[0211]
从表1可以看出,在维度转换损失值、域约束损失值、纹理约束损失值和轮廓约束损失值的帮助下,视觉和分割结果都得到了很大的提升。外观分数对维度转换损失值、域约束损失值和纹理约束损失值敏感,而分割结果对域约束损失值、轮廓约束损失值更敏感。
[0212]
分析表明,域约束损失值和轮廓约束损失值对视觉效果和分割结果很重要。表1中的第二部分结果表明,维度转换损失值和域约束损失值是四个约束中最重要的成对组合。表1中的第三部分显示了三个约束的不同组合的性能。其结果表明基于gan网络,维度转换损失值、域约束损失值和纹理约束损失值的组合在psnr、ssim和dice分数方面分别实现了3.23db,0.0414,13.39%的提升,而进一步结合轮廓约束损失值实现了最佳分割性能,在dice得分方面提高了14.07%。
[0213]
综上所述,本技术实施例提供的图像生成方法,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
[0214]
在本方案中,提出的图像生成方法,能够生成具有丰富语义特征、纹理细节和解剖结构保留的可转移模态表示。通过引入了四个约束损失值,有效地定制了gan框架以实现不同序列的脑部图像合成。本方法是以医疗图像合成为技术背景,但实际中,该技术可以被应用于其他无监督类的合成任务中,如自然图像风格迁移等,对此不作限定。
[0215]
图8是本技术一个示例性实施例提供的图像生成装置的结构框图,如图8所示,该装置包括如下部分:
[0216]
获取模块810,用于获取第一模态图像,所述第一模态图像对应第一模态;
[0217]
转换模块820,用于通过第一候选网络对所述第一模态图像进行模态转换,得到第一生成图像,所述第一生成图像对应第二模态,且所述第一生产图像是三维图像,所述第一模态和所述第二模态是不同的模态;
[0218]
还原模块830,用于通过第二候选网络对所述第一生成图像进行模态还原,得到第一还原图像,所述第一还原图像对应所述第一模态;
[0219]
所述获取模块810,还用于基于所述第一生成图像和所述第一还原图像,获取约束损失值,所述约束损失值用于指示所述第一候选网络将所述第一模态图像映射至三维图像空间中的映射损失;
[0220]
训练模块840,用于基于所述约束损失值对所述第一候选网络进行训练,得到图像转换网络,所述图像转换网络用于对属于所述第一模态的图像进行模态转换,得到属于所述第二模态的三维图像。
[0221]
在一个可选的实施例中,所述约束损失值中包括维度转换损失值;
[0222]
所述获取模块810,包括:
[0223]
获取单元811,用于获取第二模态图像,所述第二模态图像为预先提供的第二模态的图像;
[0224]
所述获取单元811,还用于基于所述第一生成图像和所述第二模态图像的图像特征分布差异,以及,基于所述第一模态图像和所述第一还原图像的图像特征分布差异,获取所述维度转换损失值,所述维度转换损失值用于指示所述第一候选网络通过所述三维图像空间进行图像维度转换时产生的特征损失。
[0225]
在一个可选的实施例中,所述获取单元811,还用于基于所述第二模态图像和所述第一生成图像之间的所述图像特征分布差异,确定判别损失;基于所述第一模态图像和所述第一还原图像之间的所述图像特征分布差异,确定生成损失;将所述生成损失和所述判别损失作为所述维度转换损失值。
[0226]
在一个可选的实施例中,所述第一候选网络中包括判别生成网络架构中的判别器;
[0227]
所述获取单元811,还用于将所述第二模态图像输入所述判别器,输出得到参考预测结果,所述参考预测结果用于指示所述第二模态图像作为参考图像的概率;将所述第一生成图像输入所述判别器,输出得到匹配预测结果,所述匹配预测结果用于指示所述第一生成图像和所述第二模态图像对应的匹配关系;基于所述参考预测结果和所述匹配预测结果,确定所述判别损失。
[0228]
在一个可选的实施例中,所述获取单元811,还用于确定所述第一模态图像对应的第一特征表示;确定所述第一还原图像对应的第二特征表示;基于所述第一特征表示与所述第二特征表示之间的特征表示距离,确定所述生成损失。
[0229]
在一个可选的实施例中,所述第一候选网络中包括生成式对抗网络架构中的生成器;
[0230]
所述获取单元811,还用于将所述第一模态图像输入所述生成器,输出得到所述第一生成图像。
[0231]
在一个可选的实施例中,所述约束损失值中包括域约束损失值;
[0232]
所述获取模块810,还用于获取所述第一模态图像在所述三维图像空间的第一特征分布;获取所述第一生成图像在所述三维图像空间的第二特征分布;基于所述第一特征分布和所述第二特征分布之间的距离,得到所述域约束损失值,所述域约束损失值用于指示从所述第一特征分布到所述第二特征分布的转换损失。
[0233]
在一个可选的实施例中,所述约束损失值中包括纹理约束损失值;
[0234]
所述获取模块810,还用于获取所述第一生成图像对应的第一分割结果,所述第一分割结果用于指示所述第一生成图像对应所述第一模态图像的参考概率分布;获取所述第一模态图像对应的第二分割结果;基于所述第一分割结果和所述第二分割结果之间的分割差异,确定纹理约束损失值,所述纹理约束损失值用于指示所述第一候选网络在将所述第一模态图像映射至所述三维图像空间时的纹理特征损失。
[0235]
在一个可选的实施例中,所述获取模块810,还用于将所述第一生成图像输入分割器,输出得到所述第一分割结果,所述分割器用于对输入图像进行区域分割。
[0236]
在一个可选的实施例中,所述约束损失值中包括轮廓约束损失值;
[0237]
所述获取模块810,还用于将所述第一生成图像输入判别器,输出得到匹配预测结果,所述匹配预测结果用于指示所述第一生成图像和所述第二模态图像对应的匹配关系;将所述第一生成图像输入分割器,输出得到所述第一分割结果,所述分割器用于对输入图像进行区域分割;基于所述匹配预测结果和所述第一分割结果,确定所述轮廓约束损失值,所述轮廓约束损失值用于指示所述第一生成图像对应在所述三维图像空间中的边界特征损失。
[0238]
综上所述,本技术实施例提供的图像生成装置,通过第一候选网络与第二候选网络对第一模态图像分别进行模态转换以及模态还原,分别得到第一生成图像和第一还原图像,其中,第一候选网络用于将第一模态图像转换为第二模态的三维图像,根据第一生成图像和第一还原图像确定第一候选网络在三维图像空间中对应的约束损失,从而对第一候选网络进行训练的方式,能够使得最终训练得到的图像转换网络生成的目标三维图像的效果更好,也即,通过在第一候选网络中引入三维图像空间的方式能够提高图像转换网络的训练效果,从而使输出的目标三维图像准确度更高。
[0239]
需要说明的是:上述实施例提供的图像生成装置,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的图像生成装置与图像生成方法实施例属于同一构思,其具体实现过程详见方法实施例,此处不再赘述。
[0240]
图10示出了本技术一个示例性实施例提供的服务器的结构示意图。具体来讲:
[0241]
服务器1000包括中央处理单元(central processing unit,cpu)1001、包括随机存取存储器(random access memory,ram)1002和只读存储器(read only memory,rom)1003的系统存储器1004,以及连接系统存储器1004和中央处理单元1001的系统总线1005。服务器1000还包括用于存储操作系统1013、应用程序1014和其他程序模块1015的大容量存储设备1006。
[0242]
大容量存储设备1006通过连接到系统总线1005的大容量存储控制器(未示出)连接到中央处理单元1001。大容量存储设备1006及其相关联的计算机可读介质为服务器1000
提供非易失性存储。也就是说,大容量存储设备1006可以包括诸如硬盘或者紧凑型光盘只读存储器(compact disc read only memory,cd-rom)驱动器之类的计算机可读介质(未示出)。
[0243]
不失一般性,计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括ram、rom、可擦除可编程只读存储器(erasable programmable read only memory,eprom)、带电可擦可编程只读存储器(electrically erasable programmable read only memory,eeprom)、闪存或其他固态存储技术,cd-rom、数字通用光盘(digital versatile disc,dvd)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知计算机存储介质不局限于上述几种。上述的系统存储器1004和大容量存储设备1006可以统称为存储器。
[0244]
根据本技术的各种实施例,服务器1000还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即服务器1000可以通过连接在系统总线1005上的网络接口单元1011连接到网络1012,或者说,也可以使用网络接口单元1011来连接到其他类型的网络或远程计算机系统(未示出)。
[0245]
上述存储器还包括一个或者一个以上的程序,一个或者一个以上程序存储于存储器中,被配置由cpu执行。
[0246]
本技术的实施例还提供了一种计算机设备,该计算机设备包括处理器和存储器,该存储器中存储有至少一条指令、至少一段程序、代码集或指令集,至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行以实现上述各方法实施例提供的图像生成方法。
[0247]
本技术的实施例还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有至少一条指令、至少一段程序、代码集或指令集,至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行,以实现上述各方法实施例提供的图像生成方法。
[0248]
本技术的实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中任一所述的图像生成方法。
[0249]
可选地,该计算机可读存储介质可以包括:只读存储器(rom,read only memory)、随机存取记忆体(ram,random access memory)、固态硬盘(ssd,solid state drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(reram,resistance random access memory)和动态随机存取存储器(dram,dynamic random access memory)。上述本技术实施例序号仅仅为了描述,不代表实施例的优劣。
[0250]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0251]
以上所述仅为本技术的可选实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。