for”,“means”,“represents”或“i.e.”。
16.作为优选,全大写单词抽取规则为:抽取一个句子中的全大写单词,过滤掉只包含全大写单词的句子以及通用词。
17.作为优选,所述步骤(1)和(4)中的过滤规则是,只要满足如下任一情况则被过滤:候选术语已经存在于术语集中;候选术语是一个单词并且可以在wordnet中检索到;候选术语以一个停止词开始或结束;候选术语包括特殊字符表中的单词或字符。
18.作为优选,所述特殊字符表中的单词包括标记研究机构、会议、协会/组织名、期刊杂志和法律规章名称的单词。
19.作为优选,所述深度学习模型为bert或lstm-crf。
20.基于启发式规则和自举迭代训练的术语抽取系统,包括:
21.种子术语抽取模块,用于基于制定的启发式规则从英文科技文献中抽取候选术语,并过滤后得到种子术语;
22.以及,自举迭代训练模块,用于将抽取到的种子术语构成初始术语集;使用术语集对语料库进行标注,并训练深度学习模型;使用训练好的模型从语料库中抽取候选术语,并进行过滤;将过滤后的抽取结果添加到术语集中,形成新的术语集;再迭代使用新的术语集进行模型训练和抽取,直到无法再从语料库中识别出新的术语。
23.一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的基于启发式规则和自举迭代训练的术语抽取方法的步骤。
24.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的基于启发式规则和自举迭代训练的术语抽取方法的步骤。
25.有益效果:与现有技术相比,本发明提出的一种基于启发式规则和自举迭代训练的自动术语抽取方法,能适用于从英文科技文献中自动提取科技术语。该方法通过制定启发式规则、自举迭代的训练步骤、以及自动过滤的规则,显著提升了术语抽取的性能和效率,极大的节省了人力。
附图说明
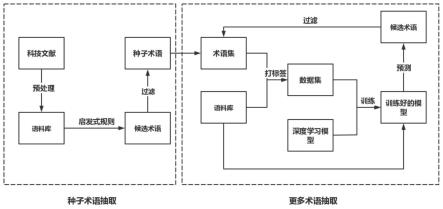
26.图1为本发明实施例的方法框架图。
具体实施方式
27.为了便于本领域技术人员的理解,下面结合附图和具体实施例对本发明作进一步的说明。
28.本发明实施例公开的一种基于启发式规则和自举迭代训练的术语抽取方法,首先通过启发式规则经过滤后产生高质量的种子术语。然后再用种子术语制作成数据集,运用自举迭代的训练策略来训练深度学习模型,再运用训练好的模型抽取更多术语。主要内容如下:
29.一、种子术语的抽取
30.深度学习方法需要高质量的数据集,本发明制定了缩写/全称对抽取、全大写单词
抽取以及连续首字母大写短语抽取三条启发式规则。
31.具体地,本发明制定了如下规则用来抽取术语:
32.(1)缩写、全称对抽取
33.一个缩写词,紧跟着括号内的一个短语,或者反之。它们通常都属于术语。例如:“the linked open data includes several resource description framework(rdf)knowledge bases.”、“...mapping institutional data to an event-based ontology called crm(conceptual reference model).”34.或者二者之间有这些标记:“:”,“stands for”,“means”,“represents”,“i.e.”35.例如:“ssp:semantic space projection for knowledge graph embedding...”36.(2)全大写单词抽取
37.如果一个大写单词出现在一个句子中,它可能是一个术语。我们首先过滤掉语料库中所有只包含大写单词的句子,这些句子往往是副标题或异常句型。然后我们使用通用字典过滤掉通用词。最后,我们将剩下的单词添加到术语集中。
38.(3)连续首字母大写短语抽取
39.如果一组连续的大写短语出现在一个句子中,它可能是一个术语。例如:“...the triples extracted for the semantic web knowledge graph and discuss the limitations...”短语“semantic web knowledge graph”是一个连续的首字母大写短语。
40.二、深度学习模型的训练和使用
41.首先通过评估后使用最适合于抽取科技文献术语的深度学习模型(本发明不涉及具体的深度学习模型,可以结合bert、lstm-crf等深度学习模型使用),然后将种子术语作为模型训练的初始数据集,将每一轮训练后得到的模型用来抽取术语,将抽取结果过滤后加入初始数据集中再次训练。迭代多次后经过评估选择最佳的参数设置。
42.自举迭代的训练策略可以有效地应用于资源较少的领域,这些领域中可用的标记数据集较少。对于术语提取任务,其具体步骤如下:
43.步骤1:准备一个小的高质量术语集(由启发式规则的抽取结果生成),称为种子或初始术语集。
44.步骤2:使用术语集对语料库进行自动标注,生成数据集,然后训练深度学习模型。这里自动标注采用bio标注策略,对于给定一个待标注的文本,以及术语集,通过程序自动匹配文本和术语集。根据文本的每个部分是否存在于术语集中,将文本中的每一个单词标记为“b”或“i”或“o”。其中“b”(begin)表示为一个术语的开头,“i”(inside)表示一个术语的中间或结尾,“o”(outside)表示非术语。
45.例如:给定一个待标注的句子:
[0046]“the linked open data includes several resource description framework(rdf)knowledge bases.”[0047]
以及术语集:
[0048]
{“resource description framework”,“rdf”,“knowledge base(s)”,...}
[0049]
标注好的结果如下表所示。
[0050]
表1自动标注结果示例
[0051]
oooooobi
thelinkedopendataincludesseveralresourcedescriptioniobobio-framework(rdf)knowledgebases.-[0052]
步骤3:使用步骤2训练的模型从语料库中抽取术语。
[0053]
步骤4:过滤提取结果,保证质量。
[0054]
步骤5:将过滤后的抽取结果添加到术语集中,形成新的术语集。
[0055]
步骤6:重复步骤2到步骤5,直到无法再识别出新的术语则终止迭代。
[0056]
其中,步骤4以及启发式规则中的过滤规则如下,只要满足任一情况将被过滤:
[0057]
(1)该候选术语已经存在于术语集中。
[0058]
(2)该候选术语是一个单词并且可以在wordnet中检索到。wordnet是一个通用领域的英语词汇数据库的api接口,若一个候选术语只包含一个单词且能在该字典中检索到,说明其为通用词汇而非专业术语。
[0059]
(3)该候选术语以一个停止词开始或结束。
[0060]
(4)该候选术语包含其他特殊字符。其中特殊字符表如下,只要包含以下任意单词或字符的候选术语将不被认为是术语而被过滤。
[0061]
表2特征字符表
[0062][0063]
基于相同的发明构思,本发明实施例公开的一种基于启发式规则和自举迭代训练的术语抽取系统,包括:种子术语抽取模块,用于基于制定的启发式规则从英文科技文献中抽取候选术语,并过滤后得到种子术语;以及,自举迭代训练模块,用于将抽取到的种子术语构成初始术语集;使用术语集对语料库进行标注,并训练深度学习模型;使用训练好的模型从语料库中抽取候选术语,并进行过滤;将过滤后的抽取结果添加到术语集中,形成新的术语集;再迭代使用新的术语集进行模型训练和抽取,直到无法再从语料库中识别出新的术语。
[0064]
本领域技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的各模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。所述模块的划分仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块可以结合或者可以集成到另一个系统。
[0065]
基于相同的发明构思,本发明实施例公开的一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的基于启发式规则和自举迭代训练的术语抽取方法的步骤。
[0066]
基于相同的发明构思,本发明实施例公开的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的基于启发式规则和自举迭代训练的术语抽取方法的步骤。
[0067]
本领域技术人员可以理解的是,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机系统(可以是个人计算机,服务器,或者网络设备等)执行本发明实施例所述方法的全部或部分步骤。存储介质包括:u盘、移动硬盘、只读存储器rom、随机存取存储器ram、磁碟或者光盘等各种可以存储计算机程序的介质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。