一种基于svm和混合采样算法的乳腺癌生存预测系统
技术领域:
1.本发明属于数据分类领域,涉及一种非平衡数据集处理方法,特 别是一种基于svm和混合采样算法的乳腺癌生存预测系统。
背景技术:
2.乳腺癌是全世界女性群体中最常见的癌症之一,随着医疗技术水 平的发展,越来越多的乳腺癌患者接受了更加规范和全面的治疗。研 究乳腺癌5年的生存状况,能够降低医生因疲劳或经验不足带来的影 响,同时对乳腺癌临床治疗有重要意义。但目前对乳腺癌生存数据存 在类别失衡,预测方法存在精度低等不足。
技术实现要素:
3.本发明的目的是为了解决在医学数据集中存在的类不平衡问题, 提供一种基于svm和混合采样算法的乳腺癌生存预测系统。
4.为了达到上述目的,本发明提出的技术方案为:一种基于svm和 混合采样算法的乳腺癌生存预测系统,包括以下步骤:
5.(1)首先从seer数据库中提取乳腺癌临床数据,并做乳腺癌数据 的预处理;
6.(2)将处理好的数据按照7:3的比例划分为训练数据和测试数据;
7.(3)针对训练数据的样本不平衡问题,用rsmote对少数类进行 过采样,使用关键规则欠采样对多数类进行欠采样,通过提出的混合 采样算法对数据进行平衡处理;
8.(4)平衡训练集运用支持向量机进行分类训练测试,并与smote、 enn等经典过采样和欠采样方法对比,评估模型预测乳腺癌生存状 况的性能;
9.(5)具体地,选择5组数据集上实验,采用十折交叉检验法,并使 用f-value和g-mean等作为评价指标进行对比;
10.(6)更进一步地,通过构造混淆矩阵,同时用f-value和g-mean等 作为评价指标进行对比;
11.(7)其中f-value结合准确率和召回率的比值,g-mean能很准确判 断分类器的性能。
附图说明:
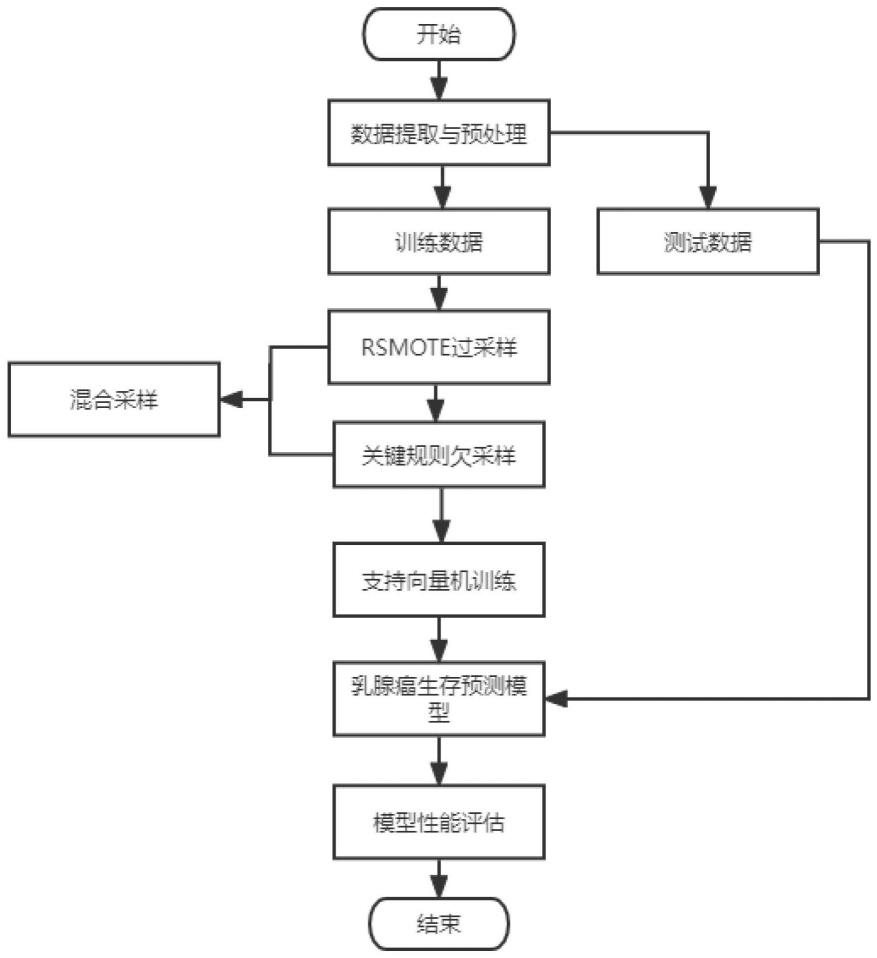
12.图1为本发明一种基于svm和混合采样算法的乳腺癌生存预测 系统的步骤流程示意图。
13.图2为本发明分类所构造混合采样算法步骤流程示意图。
14.图3为本发明分类所构造混合采样算法中rsmote算法步骤流 程示意图。
15.图4为本发明分类所构造混合采样算法中关键规则欠采样算法步 骤流程示意图。
具体实施方式:
16.为了使本发明的实施例中的技术方案能够清楚和完整地描述,结 合实施例及附图对本发明作进一步详细的描述。
17.本实例提出了一种基于svm和混合采样算法的乳腺癌生存预测 系统,本实例的方法如图1所示,主要包括以下步骤:
18.(1)提取筛选后的seer数据库2010-2015年乳腺癌患者的数据。 包括:性别,年龄,肿瘤大小,肿瘤尺寸,肿瘤扩展,区域淋巴结转 移,远处转移分期,患者肤色。去除不需要、无意义的字段,将连续 数值离散化,特征变量数值化。使用filter过滤法过滤掉不相关的特 征变量;因为乳腺癌的死亡率远远低于存活率,所以数据存在失衡的 现象,为了更好的研究乳腺癌的生存特征和生存状况的关系,在(2)中 提出混合采样模块;
19.(2)将rsmote过采样和关键规则欠采样结合在一起,解决数据 的不平衡问题,具体的混合采样算法的流程图如图2,步骤如下:
20.(2.1)设置目标平衡尺度为1,同时将不平衡数据集分成两类,多数 类sd和少数类ss;
21.(2.2)对少数类样本使用rsmote算法,增加样本数量;
22.(2.3)对多数类样本使用关键规则欠采样算法,删除噪声样本;
23.(2.4)合并两个样本,得到平衡数据集;
24.(2.5)根据sd/ss的值是否等于1判断多数类样本和少数类样本是否 相等;
25.(2.6)不相等就重复2-3;
26.(2.7)如果相等,合并样本,生成新的少数类样本和多数类样本相 等的数据集;
27.具体的rsmote算法的流程图如图3,步骤如下:
28.(2.2.1)过滤噪声样本,生成新的样本集合p
′
,计算p
′
中样本的相对 密度;
29.(2.2.2)根据p
′
样本的相对密度采用2均值聚类算法将密度向量 rd(p
′
)划分为两个聚类ca和cb,其中ca和cb分别代表ca和cb的 聚类中心,ca≥cb。p
′a、p
′b分别对应于ca、cb中的少数样本;
30.(2.2.3)根据其k个最近邻居中多数样本的数量m,对xi生成的数 量重新加权,并分别在每个聚类中生成新的样本。对于每个聚类p
′j, j∈{a,b}中的每个少数样本xi,计算广义权重,初始化ωi,公式如下:
[0031][0032]
其中|p'j|表示|p'j|的基数;
[0033]
(2.2.4)因此,我们给安全样本分配更多的权重,给混沌样本分配更 少的权重。然后我们计算每个少数样本xi需要生成的合成样本数ni:
[0034]
ni=ωi*nj[0035]
其中j∈{a,b};
[0036]
(2.2.5)最后,直接使用populate(ni,i,narray)在每个聚类中生成新 的样本,生成的样本的并集作为所有合成数据集返回;
[0037]
具体的关键规则欠采样算法的流程图如图4,步骤如下:
[0038]
(2.3.1)使用关联规则算法前要将数值型的值变成离散型的值,也 就是离散化;
[0039]
(2.3.2)利用关联规则算法,生成规则集,fp-tree算法速度较快,这 里选择fp-tree算法生成规则集;
[0040]
(2.3.3)按先置信度,对规则集进行降序排序处理,得到有序规则集 ra;
[0041]
(2.3.4)对多数类样本执行k-means聚类,得到k个簇;
[0042]
(2.3.5)根据如下公式确定第i个簇应该保留的样本数量,初始i=1:
[0043][0044]
式中,ni表示第i个簇应该保留的多数类样本数,m表示采样前 多数类样本总数目,mi表示采样前第i个簇中样本总数目,n表示采 样后需要保留的多数类样本数;
[0045]
(2.3.6)选取样本集s
i(j-1)
中满足规则集ra中第j条规则的样本,构 成s
ij
,其中s
ij
表示第i个簇中满足前j条规则的样本集,初始j=1。 若s
ij
中样本数|s
ij
|不大于ni则执行第(7)步,不然执行第(8)步;
[0046]
(2.3.7)从s
i(j-1)
-s
ij
中随机选择ni-|s
ij
|个样本添加到s
ij
中构成第 i个簇应该保留的样本集si,转到第(10)步;
[0047]
(2.3.8)如果遍历了规则集ra所有的规则,即j大于规则集ra中的 规则数|ra|,则转到第(9)步,否则j=j 1,并返回第(6)步;
[0048]
(2.3.9)从s
ij
中选择ni个样本构成第i个簇应该保留的样本集si, 转到第(10)步;
[0049]
(2.3.10)如果遍历了所有的簇即i≥k,则合并所有的si(i=1,2,
…
, k),得到欠采样后的多数类数据集s,结束;否则令i=i 1,并转到第 (5)步。
[0050]
(3)将关键规则欠采样与rsmote混合算法处理平衡后的数据按 照7:3的比值分为训练样本集和测试集两组;
[0051]
(4)所述测试数据用于加载训练好的支持向量机模型,利用测试样 本集对训练好的支持向量机模型进行测试;
[0052]
(5)利用训练好的支持向量机模型作为最终应用模型,用于乳腺癌 的生存状况预测,关于乳腺癌的生存状况预测是一个二分类问题,包 括活着和死亡两种状态;
[0053]
(6)运用支持向量机进行分类训练测试,并与smote、enn等经 典过采样和欠采样方法对比,使用混淆矩阵、f-value、g-mean评估 系统性能。
[0054]
综上所述,本发明在乳腺癌生存临床数据的研究中,使得少数类 医学样本和多数类医学样本达到平衡,使得过采样和欠采样的混合方 法能够得到合理分布的样本,有效解决乳腺癌医学数据的类别失衡问 题,同时为乳腺癌生存预测提供一套智能预测系统。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。