1.本发明涉及循环肿瘤细胞的形态学特征在构建在对象中预测或判断胃癌病况的系统中的应用。本发明建立了ctc形态与癌症特别是胃癌的关联性,实现了根据循环肿瘤细胞的形态学分类来预测或判断胃癌的病况。
背景技术:
2.循环肿瘤细胞(circulating tumor cells,ctc)是存在于外周血中的各类肿瘤细胞的统称。通常而言,己存在的肿瘤转移或释放循环肿瘤细胞是导致继发性肿瘤形成的原因。循环肿瘤细胞由于自发或诊疗操作从实体肿瘤病灶(原发灶、转移灶)脱落,其中大部分循环肿瘤细胞在进入外周血后发生凋亡或被吞噬,少数能够逃逸并锚着,继而发展成为转移灶,即所谓恶性肿瘤的转移。恶性肿瘤的侵袭转移是患者复发转移的关键环节,往往导致肿瘤治疗失败,增加恶性肿瘤患者死亡风险,危及患者生命。因此,如果能够在循环肿瘤细胞进入外周血后及早发现,则对医疗人员早期采取有效的治疗措施具有重要意义。
3.通常可以对癌症患者进行ctc检测来提供早期诊断,对原发性或继发性癌症生长和确定进行癌症治疗。分离富集ctc只需抽取患者少量外周血,对患者没有副作用,因此可以高频度的监测,达到实时监测疾病进展的目的。更为重要的是,ctc可作为分析患者肿瘤生物学特征的实时样本,可以发现患者的实时生物学变化,并根据结果及时调整治疗方案,实现实时的个体化治疗。另外,因为患者循环血液中存在的ctc的数量、类型和特征与整体预后和对治疗的响应具有相关性,因此可进一步提供针对癌症患者的预后的有效工具。
4.但是,目前并没有相关文献记载根据ctc形态进行癌症病况和肿瘤发展情况的预测或判断。现有的技术往往从ctc相关序列(包括但不限于ctc自身核酸序列、ctc所表达的蛋白质序列等)出发,从患者分离的生物样品中检测和/或定量上述序列,以诊断、检测或监测肿瘤疾病。
5.cn103597354a公开了一种用于预测和改善胃癌患者存活的方法,其中尝试预测具有早期胃癌的受试者在肿瘤手术后的术后存活。该方法依赖于检测获自受试者的癌细胞中信号转导蛋白分析物的特定组合的活化状态或水平,所述癌细胞选自原发性肿瘤细胞、循环肿瘤细胞(ctc)、腹水肿瘤细胞(atc)及其组合。但该方法并不是从细胞的形态出发进行检测。
技术实现要素:
6.本发明人通过对循环肿瘤细胞进行形态学分类,建立了ctc形态与癌症特别是胃癌的关联性,结果发现ctc形态与癌症病况具有相关性,从而实现了根据ctc的形态学分类预测或判断癌症的病况。
7.本发明是基于上述发现的发明,因此,本发明的一个方面涉及一种循环肿瘤细胞形态学特征在构建在对象中预测或判断癌症病况的系统中的应用。。
8.在一些实施方式中,所述预测或判断针对罹患胃癌或具有患胃癌风险或曾罹患胃
癌但已治愈的对象进行。
9.在一些实施方式中,所述循环肿瘤细胞的形态学特征通过免疫荧光染色获得。
10.在一些实施方式中,所述胃癌病况包括胃癌的分型、胃癌的ptnm分期、胃癌整体生存期、胃癌无进展生存期中的一种或多种。
11.在一些实施方式中,所述系统包括分类模块,将利用免疫荧光染色获得的循环肿瘤细胞的形态学特征输入分类模块,输出与循环肿瘤细胞所属对象的胃癌病况预测结果。
12.在一些实施方式中,所述分类模块中包含通过机器学习构建的分类器,所述分类器通过循环肿瘤细胞的形态学特征、对循环肿瘤细胞进行分类,确定循环肿瘤细胞的分类与对象的胃癌病况的相关关系。
13.在一些实施方式中,所述分类器采用k-均值聚类算法。
14.在一些实施方式中,所述形态学特征表征细胞核大小、细胞核形态、细胞膜和/或浆的大小、细胞膜和/或浆的形态、循环肿瘤细胞标志物表达量、循环肿瘤细胞标志物在细胞膜和/或浆的分布中的一种或多种。
15.在一些实施方式中,在将所述特征输入分类器前,进一步对获得表征循环肿瘤细胞形态的特征的参数进行筛选和/或主成分分析。
16.在一些实施方式中,使用如权利要求1所述的循环肿瘤细胞的形态学特征。
附图说明
17.图1示出了术前ctc检测中,独立观察各类型ctc情况下,患者的整体生存期曲线。。
18.图2示出了术前ctc检测中,综合t4类型和t6类型的ctc情况下,患者的整体生存期曲线。
19.图3示出了术后ctc检测中,独立观察各类型ctc情况下,患者的无进展生存期曲线。
20.图4示出了术后ctc检测中,综合t3类型和t6类型的ctc情况下,患者的无进展生存期曲线。
具体实施方式
21.本发明提供一种基于机器学习的、在形态学上进行了分类的ctc细胞在预测或判断癌症病况中的应用,以及利用基于机器学习的、在形态学上进行了分类的ctc细胞来预测或判断癌症病况的方法。
22.在对本发明的方法和对象进行描述前,要理解的是,本发明并不限于所描述的具体组合物、方法和实验条件,因为这些组合物、方法和条件可以变化。还要理解的是,本文所用的术语仅用于描述具体实施方式的目的,并不意图进行限制,因为本发明的范围基于权利要求书所要求的范围。
23.此外,说明书中和权利要求中的术语第一、第二等等用于在类似的要素之间进行区分,并且不一定用于在时间上、空间上、以排名或任何其他方式来描述序列。应该理解,如此使用的这些术语在合适情况下可以互换,并且本文描述的本发明的实施例能够以除了本文描述或说明的之外的其他序列来操作。
24.要注意,权利要求中使用的术语“包括”不应被解读为限定于其后列出的装置/手
段;它并不排除其他要素或步骤。由此其解读为指定所陈述的特征、整数、步骤或组件的存在,但不排除一个或多个其他特征、整数、步骤或组件,或其群组的存在或添加。
25.定义
26.如本文所用,术语“循环肿瘤细胞”或“ctc”意指表示受试者样本中存在的任何癌细胞或者癌细胞的群集。通常,ctc是指从实体肿瘤剥落的细胞。ctc常常是从具有晚期癌的患者的循环中以极低浓度存在的实体肿瘤脱落的上皮细胞。ctc也可以是来自肉瘤的间皮或者来自黑素瘤的黑素细胞。ctc也可以是源自初生、次生或第三肿瘤的细胞。ctc也可以是循环癌干细胞。ctc也可以是来自受试者样本中的任何能够指示癌症或其它病症的存在的细胞。
27.如本文所用,术语“受试者样本”意指采集自受试者的、用于检测其中的循环肿瘤细胞存在与否的样本。虽然使用术语“循环肿瘤细胞”,但受试者样本也可以不来自循环系统,即不来自血液。受试者样本可以是包含适于检测的ctc的任何样本,其来源包括全血、骨髓、胸膜液、腹膜液、中央脊髓液、乳液、尿液、泪液、汗液、唾液、器官分泌物以及支气管、鼻腔、咽喉等的冲洗液。在一个实例中,受试者样本是血液,包括例如全血或其任何部分或组分。适用于本发明的血液样本可提取自包括血细胞或其组分的任何己知来源,如静脉、动脉、外周、组织、脊髓及类似物。例如,可利用公知和常规的临床方法(例如,抽取和处理全血的程序)得到和处理获得的样本。示例性的样本可以是从癌症对象中抽取的外周血。如本文所用,“临床ctc样本”是指包含至少一个ctc的受试者样本,包括经ctc/wbc分类器判断包含至少一个ctc的受试者样本。
28.如本文所用,术语“癌症”包括本领域众所周知的多种癌症类型,包括但不限于发育不良、增生、固体肿瘤和造血癌。许多类型的癌症己知为转移和剥落循环肿瘤细胞或者是转移的,例如产生于己经转移的初生癌的次生癌。附加癌可包括但不限于下列器官或系统:脑、心脏、肺、胃肠、泌尿生殖道、肝脏、骨、神经系统、妇科的、血液的、皮肤、乳腺和肾上腺。附加类型的癌细胞包括神经胶质瘤(神经鞘瘤、神经胶母细胞瘤、星细胞瘤)、成神经细胞瘤、嗜铬细胞瘤、节瘤、脑膜瘤、肾上腺皮质癌、成神经管细胞瘤、横纹骨肉癌、肾癌、各种类型的血管癌、成骨细胞癌、前列腺癌、卵巢癌、子宫肌瘤、唾腺癌、脉络丛癌、乳腺癌、胰腺癌、结肠癌和成巨核细胞癌;以及皮肤癌包括恶性黑素瘤、基底细胞癌、鳞状细胞癌、karposi瘤、结构异常痣、脂肪瘤、血管瘤、皮肤纤维瘤、瘢痕瘤、肉瘤(例如纤维肉瘤或血管内皮瘤以及黑素瘤)。在本发明中,所述癌症优选胃癌。
29.在本发明中,“病况”是指受试者所罹患癌症后的各类信息,包括但不限于肿瘤类型、肿瘤部位、肿瘤分型、肿瘤分期、受试者的整体生存期、受试者的无进展生存期等等。
30.ptnm分期是胃癌的tnm分期系统中的病理学分期,其具体如f.l.格林尼d.l.佩基i.d.弗莱明a.g.弗瑞兹c.m.拜耳赤著《ajcc癌症分期手册》第七版所记载。不同部位的肿瘤均具有各自的分期标准,并根据肿瘤的不同各自分类。tnm分期中的t是指肿瘤原发灶的情况,随着肿瘤体积的增加和邻近组织受累范围的增加,依次用t1~t4来表示,并可以进一步细分。tnm分期中的n指区域淋巴结受累情况,淋巴结未受累时,用n0表示。随着淋巴结受累程度和范围的增加,依次用n1~n3表示。tnm分期中的m指远处转移,没有远处转移者用m0表示,有远处转移者用m1表示。以下是胃癌tnm分期中t、n、和m的分期标准:
31.tx:原发肿瘤无法评估
32.tis:原位癌:上皮内癌未浸润固有层
33.t1:肿瘤侵及黏膜固有层,黏膜肌层或黏膜下层
34.t1a:肿瘤侵及黏膜固有层或黏膜肌层
35.t1b:肿瘤侵及黏膜下层
36.t2:肿瘤侵及固有肌层
37.t3:肿瘤穿透浆膜下结缔组织,未侵及腹膜或邻近结构
38.t4:侵及浆膜或邻近结构
39.t4a:肿瘤侵透浆膜
40.t4b:肿瘤侵及邻近器官
41.nx:区域ln无法评估
42.n0:无区域ln转移
43.n1:1-2个淋巴结转移
44.n2:3-6个淋巴结转移
45.n3a:7-15个淋巴结转移
46.n3b:等于或多于16个淋巴结转移
47.mo:无远处转移
48.m1:远处转移
49.肿瘤穿透固有肌层,进入胃结肠或肝胃韧带,或进入大小网膜,但没有穿透覆盖这些结构的脏层腹膜,这种情况应分为t3。如果穿透覆盖这些结构的脏层腹膜就应分为t4。胃的上述邻近结构包括脾、横结肠、肝、膈、胰腺、腹壁、肾上腺、肾、小肠、腹膜后。肿瘤由壁内延伸至十二指肠或食管,由包括胃在内的浸润最深部位决定t分期。
50.用tnm三个指标的组合划出特定的分期。下表1示出了一个典型的分期表。
[0051][0052]
表1
[0053]
1965年lauren根据胃癌的组织结构和生物学行为,将胃癌分为肠型和弥漫型。肠型胃癌起源于肠化生黏膜,一般具有明显的腺管结构,瘤细胞呈柱状或立方形,可见刷状缘,瘤细胞分泌酸性黏液物质,类似于肠癌的结构;常伴有萎缩性胃炎和肠化生,多见于老年男性,病程较长,发病率较高,预后较好。弥漫型胃癌起源于胃固有黏膜,癌细胞分化较差,呈弥漫性生长,缺乏细胞连接,一般不形成腺管,许多低分化腺癌和印戒细胞癌属于此型;多见于年轻女性,易出现淋巴结转移和远处转移,预后较差。henson等在美国的调查显
示,肠型胃癌的发病率在美国男性、女性、非裔和白人中均呈现下降趋势,而弥漫型胃癌在同等人群中却呈上升趋势,发病率从1978年的0.3/100,000人增加至2000年的1.8/100,000人,其中以印戒细胞癌的增加最为明显。还有研究表明,部分弥漫型胃癌有家族聚集和遗传性,家系连锁研究发现cdh1基因胚系突变是其发病原因。lauren分型不仅反映肿瘤的生物学行为,而且体现其病因、发病机理和流行特征。该分型的另一优点是可以利用胃镜下活检组织进行胃癌分型,指导手术治疗。lauren分型简明有效,常被西方国家采用。但有10%~20%的病例兼有肠型和弥漫型的特征,难以归入其中任何一种,从而称为混合型。
[0054]
术语“整体生存期”包括描述在诊断为患病(如癌症)或治疗疾病后患者的临床生存时间。
[0055]
术语“无进展生存”包括特定疾病(例如,癌症)治疗期间和治疗后的时间的长度,其间患者在具有疾病但没有疾病的其他症状的情况下存活。
[0056]
如本文所用,“分类器”是指特定的算法与数据处理方法、参数的组合。只要特定的算法与数据处理方法、参数中的任一个存在种类、数值上的不同,就视为不同的分类器。所述数据处理是指为了消除数据本身对分类结果造成的影响而对数据进行的处理。数据处理方法包括但不限于数据中心化、数据归一化(标准化)、针对不平衡数据的前处理。
[0057]
在本发明中,使用了两个分类器:循环肿瘤细胞/白细胞分类器(以下也称为ctc/wbc分类器)和循环肿瘤细胞类型分类器(以下也称为ctc类型分类器)。ctc/wbc分类器被用于区分ctc和wbc,而ctc类型分类器被用于将不同种类的ctc区分开。因此,可以先使用ctc/wbc分类器,找到ctc,然后使用ctc类型分类器,将找到的ctc分为多个种类。
[0058]
方法
[0059]
本发明通过将ctc形态学分类与癌症、尤其是胃癌的病况相关联,为预测或判断癌症的分期、分型、患者的整体生存期、患者的无进展生存期提供了依据。
[0060]
本发明的ctc可以获自已经确定罹患癌症的患者,也可以获自不确定是否罹患癌症的普通受试者。如果ctc获自不确定是否罹患癌症的普通受试者,则需要首先确认其受试者样本中是否存在ctc细胞。如上所述,我们将罹患癌症的患者的受试者样本称为“临床ctc样本”,即其中包含ctc。
[0061]
整个关联流程分为以下步骤:
[0062]
(1)确定受试者样本是否为临床ctc样本;
[0063]
(2)对临床ctc样本中的ctc进行分类;
[0064]
(3)建立ctc分类情况与癌症的各种病况之间的相关性。
[0065]
以下对各个步骤分别进行说明。
[0066]
确定受试者样本是否为临床ctc样本
[0067]
从受试者中采集受试者样本后,将样本制作为荧光图像,然后对原始荧光图像进行图像识别,以判断受试者样本是否包含ctc。
[0068]
〔荧光图像的制作〕
[0069]
从受试者中采集受试者样本后,对其进行前处理、富集和染色,制作原始荧光图像。
[0070]
将外周血液与红细胞特异性抗体和白细胞特异性抗体组合进行孵育,使全血样本中红细胞和白细胞耦联在一起,再通过密度梯度离心方法使血液中细胞根据自己的密度达
到分离分层的目的,经过梯密度离心的血液样本会分成4层,如图1所示:从上往下分别为血浆、单核细胞、密度梯度离心液以及红细胞和白细胞;ctc做为单核细胞会处于单核细胞层,将单核细胞层提取出来,达到血液中ctc的富集目的。
[0071]
单核细胞层中包含ctc和与ctc偶联的白细胞(wbc)。单核细胞层被提取出来后,进行清洗,然后进行后续的免疫荧光染色流程,包括固定、透化、荧光抗体染色等一系列流程,在染色流程中使用的荧光抗体的实例包括对细胞核进行染色的染料dapi(dapi通道)、特异性识别ctc上epcam/ck表位的染色剂tritc(tritc通道)、特异性识别wbc上cd45表位的染色剂cy5(cy5通道)。dapi是一种蓝色荧光dna染色剂,与dsdna的at区结合后,荧光增强约20倍。它被紫罗兰色(405nm)激光线激发,通常用作荧光显微镜,流式细胞仪和染色体染色中的核复染。tritc是罗丹明染料的高性能衍生物,经活化可轻松可靠地标记用作荧光探针的抗体,蛋白质和其他分子。cy5是一种明亮的,远红色荧光染料,具有激发光,非常适合633nm或647nm激光线;用于标记蛋白质和核酸偶联物。荧光抗体染色可使用的染料不限于以上,也可以使用fitc、rb200、pe、epcam、ck、cd45等常规使用的各种用于免疫荧光染色的染料。本领域技术人员可以根据本领域的常识选用合适的免疫荧光染料和染色方法。
[0072]
在免疫荧光染色流程后,最后剩余约200ul的样本,样本中会包含约0~100个ctc、白细胞、血小板以及杂质等。在一个实例中,白细胞的数量为0~200个,例如为50~150个,75~125个,85~115个,95~110个,100~105个,103~104个。经过上述荧光抗体染色后,ctc的判定标准是dapi 且tritc 且cy5-,wbc的判定标准是dapi 且cy5 ;其中“ ”指有荧光信号,
“‑”
指没有荧光信号。
[0073]
染好色的样本会转入96孔板中的其中一个孔内,然后进行扫描,扫描可以采用本领域常用的设备,例如商业化扫描仪thermofisher cx5。在使用thermofisher cx5的情况下,由于孔底的面积可能大于单次扫描仪拍照面积,所以可以将扫描仪置于自动移动载物台进行拍照,通过对不同位置进行拍照,然后再进行后期拼接,实现对单个孔内的样本完整扫描;由于是免疫荧光染色样本,因此可以在每个区域拍照时切换不同荧光通道进行拍照,再进行后期叠加。
[0074]
染好色的样本通过扫描后会生成多组图像覆盖整个样本区域,每组图像包含来自各个荧光通道的图像,即为本发明中输入图像前处理模块的临床样本的原始荧光图像。在一个实例中,每组图像包含来自dapi、tritc、cy5三个荧光通道的图像。在一个实例中,染好色的样本生成169组图像。
[0075]
〔图像识别〕
[0076]
将整个样本区域的图像用于图像识别,其包括以下步骤:
[0077]
步骤一、输入受试者样本的原始荧光图像;所述原始荧光图像是将受试者样本如上进行前处理、富集和荧光染色后扫描获得的原始荧光图像。
[0078]
步骤二、对所述受试者样本的原始荧光图像进行图像前处理;图像前处理包括步骤:(1)图像修正,修正不均一光照强度导致的不均一的图像信号和背景;(2)识别首要目标,识别在被设定为首要目标的通道中有信号的目标,并将图片切割成以该目标为中心的图像,即关于首要目标的单个细胞的图像;首要目标可以是一个或多个;在一个实例中,首要目标是dapi通道;(3)识别次级目标;在识别出首要目标有信号的基础上,识别次级目标,并分别将图片切割成以该目标为中心的图像,即关于次级目标的单个细胞的图像;次级目
标可以是一个或多个,以同时进行识别;在首要目标和次级目标以外,还可以存在一个或多个再次级目标,以及优先度低于再次级目标的其他目标。即,所有目标被按照识别优先度分为多个等级,每个等级中具有一个或多个目标,在同一个等级的目标同时识别的前提下,按照优先度的先后,依次识别所有目标;所有目标数量的总数为染色通道的数量;(4)计算各类特征参数,分别计算识别到的首要目标和次级目标的形态学参数,各通道荧光信号强度参数;(5)数据导出和保存,导出并保存各类形态学参数的数据,以及关于首要目标和次级目标的单个细胞图像;在一个实例中,首要目标是dapi通道,次要目标是tritc通道和cy5通道;在另一个实例中,首要目标是tritc通道,次要目标是dapi通道和cy5通道;在又一个实例中,首要目标是cy5通道,次要目标是tritc通道和dapi通道;前处理可以通过常规的细胞图像分析软件进行,包括但不限于cellprofiler、celleste、cmis。在一个实例中,前处理通过cellprofiler进行。
[0079]
步骤三、输出受试者样本中单个细胞的图像和特征参数;所述单个细胞包括ctc和wbc;分别输出关于首要目标、次级目标的单个细胞图像和特征参数;所述计算各类特征参数,包括但不限于计算首要目标和次级目标的形态学参数、各通道荧光信号强度;所述形态学参数包括但不限于细胞本身和细胞核等细胞器官的大小
·
形状(area&shape)、信号强度(intensity)、表面结构(texture)、相关性(correlation)等可表征细胞形态的参数。另外,形态学参数还包括以上参数相互之间的关系,例如荧光信号在细胞中的分布等。
[0080]
〔进行ctc/wbc分类〕
[0081]
基于图像识别获得的细胞形态参数,采用ctc/wbc分类器进行自动化判读(分类),判断受试者样本中是否含有ctc,并将含有至少一个ctc的受试者样本判断为临床ctc样本。
[0082]
ctc/wbc分类器可以选择使用现有的分类器,也可以选择使用根据受试者样本和临床ctc样本的特征而进行了优化的分类器。在使用根据受试者样本和/或临床ctc样本的特征而进行了优化的分类器的情况下,可以使用基于已有的受试者样本和/或临床ctc样本而建立的分类器,也可以使用基于临时采集/获得的受试者样本和/或临床ctc样本的一部分进行训练而得的分类器。
[0083]
本发明的技术方案中,ctc/wbc分类器的建立可根据本领域通常建立有监督机器学习分类器的方法进行,其依次包括建立训练集、建立候选ctc/wbc分类器、优化候选ctc/wbc分类器、选择最佳ctc/wbc分类器。
[0084]
[建立训练集]
[0085]
训练集是用于训练ctc/wbc分类器的数据集。在本发明中,训练集包括ctc的数据和wbc的数据。每一条数据即为一个细胞,一条数据包括多个维度,即前述的各类特征参数。并且每一条数据还包括一个标签,该标签表示了该数据(细胞)是ctc还是wbc。
[0086]
标签的来源可以是已有的细胞形态数据库、免疫荧光数据库以及现有的论文文献等,也可以来源于对前述的步骤一~步骤三的单个细胞的图像和各类特征参数进行人工判断、标注而得的标签。在对前述的单个细胞的图像和各类特征参数进行人工判断、标注时,由于在这一阶段中的细胞只有ctc和wbc两种,因此判断、标注的结果只有“为ctc”和“非ctc”(即“为wbc”)。在标签来源于已有的细胞形态数据库、免疫荧光数据库以及现有的论文文献等时,直接选择被标注为ctc和wbc的细胞的数据,加以使用。本领域技术人员知晓如何从已有的数据库和资料文献中选择合适的数据。
[0087]
将标注了“为ctc”和“非ctc”的数据分为作为有监督机器学习中的正数据集和负数据集,用于之后的步骤。
[0088]
[选取特征参数]
[0089]
在单个细胞的图像和各类特征参数中,不同的特征参数指示不同的生物学意义。有一些特征参数可以更有效地表征细胞是否ctc,而有一些特征参数与细胞是否为ctc相关性较小。因此,筛选更能够表征细胞ctc的特征参数并赋予合适的权重将有助于提高ctc/wbc分类器的泛化性能,同时能够有效减小冗余的计算量。
[0090]
筛选最优特征参数集合的流程包括:
[0091]
(1)数据中心化和归一化;
[0092]
采用r语言包的scale()函数进行数据中心化和归一化。具体而言,针对每一个特征参数的数据集,进行如下处理:
[0093][0094]
其中,
[0095]
(2)基于每个特征参数的散点图,手动筛选能显著区分两种类别细胞的特征参数;
[0096]
(3)剔除高度相关的特征参数;
[0097]
一些形态学参数相关性高,重复使用则将导致其重要性(权重)被不合理地增加。例如,细胞核的大小本身一定程度地会影响到细胞的整体大小,但如果同时采用细胞核的大小和细胞的整体大小这两个参数,则将事实上加重细胞核的大小这一特征参数的权重。本发明采用pearson相关系数来剔除相关性高的形态学参数,该系数广泛用于度量两个变量之间的线性相关程度。
[0098]
pearson相关系数绝对值|r
xy
|:
[0099][0100]
其中,n是样本量,xi、yi是第i个样本的数值,分别是数据集x、y的平均值;
[0101]
采用|r
xy
|来衡量任意2个形态学参数对应的数据集合是否线性相关,如果|r
xy
|》0.75,则认为这两个形态学参数相关性较高,并剔除其中一个参数。0.75这个阈值是本领域的通用阈值,一般认为0.75以上属于较强相关性(strong correlation),0.45-0.75属于中等(moderate),低于0.45属于弱相关(weak correlation)。但也可以根据需要调高或调低阈值。上述计算内容均在r语言中实现,具体地,使用cor()和findcorrelation()函数实现。
[0102]
(4)计算特征参数重要性(rfe)(即权重),并最终确认用于模型建立的特征参数集合;
[0103]
特征参数重要性(rfe)的计算方式为每轮迭代中,选取不同特征子集,进行模型训
练并评估模型,通过计算其决策系数之和,最终得到不同特征的重要程度,然后保留最佳的特征组合。
[0104]
经过上述步骤将不重要的特征参数剔除掉,获得一个新的训练集。新的训练集所包括的数据的量(训练集中ctc和wbc的数量不变),但每一条数据中包括的特征参数的数量减少(即降维)。
[0105]
[建立、优化候选ctc/wbc分类器]
[0106]
对于新的训练集,分别使用多种有监督的机器学习算法以及融合模型算法、多种不平衡训练集的前处理方法、多种评估方法,交叉验证,对ctc/wbc分类器的参数进行优化,以了解每个候选ctc/wbc分类器所能实现的最佳性能。
[0107]
可以使用的有监督机器学习算法包括但不限于k邻近(k-nearestneighbors,knn)、随机梯度提升(stochastic gradient boosting,gbm)、adaboost分类树(adaboost classification trees,adaboost)、支持向量机(support vector machines,svm)、随机森林(random forest,rf)、朴素贝叶斯(bayes,nb)、极端梯度提升(extreme gradient boosting,xgb)、人工神经网络(artificial neural network,ann)、决策树(decision tree)、逻辑回归(logistics regression)、线性回归(linear regression)等本领域常用的算法。可以使用的融合模型算法包括但不限于堆叠(stacking),即将多种有监督机器学习算法融合在一起的算法。
[0108]
另外,由于ctc是稀有细胞,而wbc是常见细胞,因此如果训练集来源于使用基于临时采集/获得的受试者样本和/或临床ctc样本,则训练集中正负数据的数量相差巨大,训练集成为不平衡训练集(也称有偏训练集)。这将导致一些常用的用于评价ctc/wbc分类器的指标失效。因此需要对不平衡训练集进行前处理。
[0109]
可以用以对不平衡训练集进行前处理的方法包括但不限于原始(original)、上采样(up-sampling)、下采样(down-sampling)、合成少数类过采样技术(synthetic minority over-sampling technique,smote)、随机过采样(random over sampling examples,rose)等。
[0110]
[选择最佳ctc/wbc分类器]
[0111]
在对新的训练集进行前处理后,对训练集使用有监督机器学习算法以及融合模型算法,在优化各个ctc/wbc分类器的参数后,获得每个候选ctc/wbc分类器所能实现的最佳性能,然后对每个ctc/wbc分类器的性能进行评估。评估指标包括但不限于混淆矩阵、roc、pr、map、auc等。
[0112]
在各个性能评估指标中,针对不平衡数据集而言,在各项指标均表现良好情况下,f1打分、召回率、tpr指标更关注于识别ctc的灵敏度,所以,f1打分、召回率、tpr数值越高,系统识别ctc的灵敏度越高。据此选出性能优良的ctc/wbc分类器。
[0113]
f1打分是精确率和召回率的调和值,更接近两个数较小的那个,所以精确率和召回率接近时,f1值最大。
[0114]
f1=2*(prescision*召回率)/(精确率 召回率)
[0115]
其中
[0116]
precision:精确率,正确预测正样本例数/预测正样本总数,精确率=tp/(tp fp)。
[0117]
recall:召回率,正确预测正样本例数/实际正样本总数,召回率=tp/(tp fn)。
[0118]
tp:true positive,真阳,预测为正样本,实际也为正样本。
[0119]
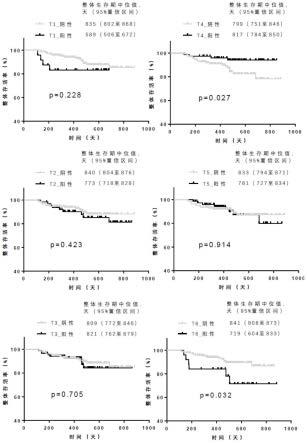
fp:false positive,假阳,预测为正样本,实际为负样本。
[0120]
fn:false negative,假阴,预测为负样本,实际为正样本。
[0121]
tn:true negative,真阴,预测为负样本,实际为负样本。
[0122]
tpr(true positive rate)为真阳性率,正确预测正样本例数/实际正样本总数,tpr=tp/(tp fn)。
[0123]
fpr:false positive rate,假阳性率,错误预测为正样本例数/实际负样本总数,fpr=fp/(fp tn)。
[0124]
pr是由精确率precision(y轴)和召回率recall(x轴)构成的曲线。
[0125]
roc(receiver operating characteristic)是衡量分类器好坏的一个标准,其主要分析工具是一个画在二维平面上的曲线——roc曲线。平面的横坐标是fpr,纵坐标是tpr。对某个分类器而言,可以根据其在测试样本上的表现得到一个tpr和fpr点对。这样,此分类器就可以映射成roc平面上的一个点。调整这个分类器分类时候使用的阈值,可以得到一个经过(0,0),(1,1)的曲线,这就是此分类器的roc曲线。一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,roc曲线下方的那部分面积越大,分类器效果越好。
[0126]
auc(area under curve)是一种用来衡量分类器好坏的一个数值化的标准,auc越大,分类器分类效果越好。auc为roc曲线下方部分面积的值。
[0127]
ctc一致性(ctc concordance)是指图像识别系统识别到的ctc与人工判读ctc结果的一致性,ctc一致性=100%*(图像系统识别与人工判读的同一ctc的数量/人工判读得到的ctc数量),ctc一致性值越高,图像识别系统识别ctc灵敏度越高。
[0128]
正样本一致性(positive sample concordance)是指图像识别系统识别到的阳性样本(≥1个ctc)与人工判读结果的一致性,positive sample concordance=100%*(人工判读为阳性,图像识别系统判读也为阳性的样本数量/人工判读的阳性样本数量),positive sample concordance值越高,图像识别系统识别阳性样本灵敏度越高。
[0129]
筛选效率(screening efficiency)为100%*(图像识别系统排除掉的非ctc数量/该样本中的细胞总数),screening efficiency值越高,图像识别系统识别ctc特异性越高。
[0130]
也可以直接使用临床上已知是否为ctc的细胞来检测、评估ctc/wbc分类器的泛化性能。在直接使用临床上已知是否为ctc的细胞来进行评估时,评估指标包括但不限于ctc一致性(ctc concordance)、正样本一致性(positive sample concordance)、筛选效率(screening efficiency)等。在临床检测ctc时,首先期望正样本一致性尽可能高,理想的是达到100%;在满足正样本一致性要求的情况下,尽可能选择ctc一致性和筛选效率高的ctc/wbc分类器。
[0131]
在同时使用交叉验证和临床样本来评估ctc/wbc分类器性能的情况下,根据以下原则选出最佳ctc/wbc分类器:f1打分、召回率、tpr数值尽量高,正样本一致性达到100%,在此基础上,优选ctc一致性高于90%或筛选效率高于95%。如有多个符合条件的ctc/wbc分类器,根据实际需要选择其中一个,例如,可以选择几个ctc/wbc分类器中ctc一致性最高的一个。
[0132]
对临床ctc样本中的ctc进行分类
[0133]
在使用ctc/wbc分类器,筛选出ctc细胞后,可以使用ctc类型分类器对ctc的类型进行分类。也可以直接提供已知确定为ctc的多个细胞,对其进行分类。
[0134]
一类ctc是指在细胞形态、免疫荧光响应等方面具有相近特性的ctc。在本发明中,将ctc细胞的形态学参数和ctc免疫荧光标志物作为特征,将ctc分为多个类型。
[0135]
〔荧光图像制作〕
[0136]
在对使用ctc/wbc分类器筛选出的ctc细胞进行分类时,ctc细胞已经经过了荧光图像制作,可直接采用ctc/wbc分类器中采用的图像。
[0137]
在对直接提供已知确定为ctc的多个细胞进行分类时,需要从头开始对细胞进行荧光图像制作。可使用与ctc/wbc分类器中相同的方法获得荧光图像。
[0138]
〔图像识别〕
[0139]
在对使用ctc/wbc分类器筛选出的ctc细胞进行分类时,ctc细胞已经经过图像识别,可直接采用ctc/wbc分类器中采用的细胞形态学参数。
[0140]
在对直接提供已知确定为ctc的多个细胞进行分类时,需要从头开始对细胞进行图像识别。可使用与ctc/wbc分类器中相同的方法进行图像识别并获得细胞形态学参数。
[0141]
〔进行ctc类型分类〕
[0142]
在本发明中,采用无监督机器学习进行ctc类型分类。在无监督机器学习中,不需要带有标签的训练集,而是直接将所有数据的特征参数输入分类器中。
[0143]
[选取特征参数]
[0144]
如前所述,对特征参数进行选择和处理将有助于提高分类泛化性能,优化分类结果。在进行ctc类型分类时,根据需要对特征参数进行数据的中心化和归一化,数据的中心化和归一化采用与前述的数据的中心化和归一化中相同的方法来进行
[0145]
然后对特征参数进行如下选择和处理,以获得最优特征参数的集合:
[0146]
(a)剔除高度相关的特征参数
[0147]
(b)主成分分析(pca)。
[0148]
可以根据需要进行(a)剔除高度相关的特征参数或(b)主成分分析,也可以依次对特征参数进行(a)剔除高度相关的特征参数和(b)主成分分析。
[0149]
《剔除高度相关的特征参数》
[0150]
如前所述,一些形态学参数相关性高,重复使用则将导致其重要性(权重)被不合理地增加,因此此处采用和前述相同的方法,用pearson相关系数来剔除相关性高的形态学参数。其具体实现也如前所述。
[0151]
《主成分分析》
[0152]
主成分分析(principal component analysis,pca)是一种统计方法。主成分分析旨在利用降维的思想,把多指标转化为少数几个综合指标,是一种简化数据集的技术,简化后的这组指标称为主成分。具体而言,主成分分析通过矩阵的压缩算法,在减少矩阵维数的同时尽可能的保留矩阵中所存在的主要特性,从而可以大大节省空间和数据量,以较小的存储代价和计算复杂度获得较高的准确性。
[0153]
在本发明中,通过主成分分析的正交化线性变换,将数据变换到一个新的坐标系统中。例如,假设在经过如上的数据处理后,整个数据集包括n个特征参数和n个数据(即n个ctc细胞),则将数据变换到一个新的坐标系统中,该坐标系统包括n个坐标轴。此时该坐标
系统是一个高维坐标系统。在这个新的坐标系统中,将坐标轴中心移到数据的中心,然后旋转坐标轴,使得数据在某个轴上的方差最大,即全部n个数据个体在该方向上的投影最为分散。轴上的方差越大、全部的数据个体在该方向上的投影越分散则代表该轴中保留了越多的信息。按照数据集在各个轴上对方差的贡献依次从大到小进行排列,将轴上的方差最大的轴称为pc1轴,其为第一主成分。以此类推,获得找到第二主成分(pc2)、第三主成分(pc3)等等,直至第n主成分(pcn)。
[0154]
在一个实例中,其具体实现如下:
[0155]
i.使用prcomp()函数,进行主成分分析,分析结果按照主成分pc1到pcn上数据集对方差的贡献(proportion of variance)从大到小依次进行排列。
[0156]
ii.以保留95%以上的累计方差信息(cumulative proportion)的最少的主成分数量为最终主成分的组成。例如,如上图所示,保留pc1到pc8的8个主成分后,可以保留约96%的累计方差信息。以上95%的数值是统计学中置信度的常用值,也可以根据需要,采用大于95%或小于95%的值。该值越大,则最终主成分所包括的信息越全面,但特征参数降维效果就越差;该值越小,则最终主成分所包括的信息越少,但特征参数降维效果越好。本领域技术人员可根据实际需要进行调整,以获得这两者的平衡,这是本领域技术人员公知的。另外,也可以根据随后的验证效果(即最终细胞聚类的效果),对该值进行调整。
[0157]
〔建立ctc类型分类器〕
[0158]
在ctc类型分类器中,可使用常用的无监督的机器学习算法来建立分类器,包括但不限于层次聚类(hierarchical clustering)、期望最大化聚类(em)、受限波尔兹曼机、人工神经网络、k-均值聚类(k-means)、异常检测法(anomaly detection)、自编码器(auto-encoder)、深度信念网络(deepbeliefnetwork,dbn)、赫比学习法(hebbian learning)、生成式对抗网络(generative adversarial networks,gan)、自组织映射网络(som)、mean-shift聚类、dbscan聚类、凝聚和分裂的层次聚类(hierarchical clustering)等。
[0159]
可以通过本领域常用的语言包、软件、脚本来实现以上算法,其选择方法是本领域技术人员公知的。在一个实例中,采用r语言包来实现以上算法。
[0160]
在一个实例中,采用k-均值聚类来建立ctc类型分类器。k-均值算法是一种聚类分析算法,其是来计算数据聚集的算法,其算法步骤如下:
[0161]
i.从数据中选择k个对象作为初始聚类中心;
[0162]
ii.计算每个聚类对象到聚类中心的距离来划分;
[0163]
iii.再次计算每个聚类中心;
[0164]
iv.计算标准测度函数,直到达到最大迭代次数,则停止,否则,继续操作;
[0165]
v.确定最优的聚类中心。
[0166]
建立ctc分类情况与癌症的各种病况之间的相关性
[0167]
在对ctc进行了分类的基础上,我们建立了ctc分类与胃癌ptnm分期、胃癌lauren分型、胃癌整体生存期、以及胃癌无进展生存期的相关性。实施例表明了ctc分类与胃癌ptnm分期、胃癌lauren分型、胃癌整体生存期、以及胃癌无进展生存期存在正相关性。
[0168]
实施例
[0169]
实施例中所使用的ctc可以获自已经确定罹患癌症的患者,也可以获自不确定是否罹患癌症的普通受试者。如果ctc获自不确定是否罹患癌症的普通受试者,则需要首先采
用前述的分类方法或其他诊断手段来确认其受试者样本中存在ctc细胞。在确认该受试者样本为临床ctc样本后,再根据上述的方法将临床ctc样本中包含的ctc分类,将其分类与病况相关联。
[0170]
实施例1ctc分类与胃癌ptnm分期
[0171]
研究目的:
[0172]
实施例1研究了术前ctc检测中各类型ctc数量与胃癌ptnm分期的相关性,观察哪个类型ctc的数量与胃癌ptnm分期最具相关性。
[0173]
人群入组条件:
[0174]
在可进行手术的胃癌人群中,针对术前ctc检测为阳性(ctc≥1/5ml)的患者人群(共计211例),按照胃癌ptnm分期进行分组:早中期(ptnm 1期和ptnm 2期,n=115),晚期(ptnm 3期和ptnm 4期,n=96);
[0175]
分析方法:
[0176]
在比较不同分组之间的ctc数量是否存在显著差异时,采用了kruskal-wallis检验,分别计算全部类型ctc数量、t1类型ctc数量、t2类型ctc数量、t3类型ctc数量、t4类型ctc数量、t5类型ctc数量、t6类型ctc数量在不同分组(早中期,晚期)中是否具有显著性差异(p值),如果p值《0.05,即该类型ctc数量在两组人群之间存在显著差异。上述分析均在spss软件中实现。
[0177]
分析结果:
[0178]
在两组人群(早中期,晚期)中发现,整体ctc数量(全部类型ctc的数量)没有显著差异(p=0.812),t1类型ctc数量(p=0.044《0.05)以及t6类型ctc数量(p=0.039《0.05)存在显著差异(如表1),且在晚期人群中t1类型ctc数量以及t6类型ctc数量显著高于早中期人群中这两个类型的ctc数量(如表1)。从上述结果来看,通过ctc的形态学分类,我们找到了与胃癌ptnm分期显著相关的2个类型(t1、t6)的ctc,并且这两个类型的ctc在晚期人群(ptnm 3期和ptnm 4期)中的数量显著高于早中期人群(ptnm 1期和ptnm 2期),具体示于下表2。
[0179][0180]
表2比较不同类型ctc数量在早中期和晚期人群中的差异实施例2ctc分类与胃癌lauren分型
[0181]
研究目的:
[0182]
研究术前ctc检测中各类型ctc数量与胃癌lauren分型的相关性,观察哪个类型ctc的数量与胃癌lauren分型最具相关性。
[0183]
人群入组条件:
[0184]
在可进行手术的胃癌人群中,针对术前ctc检测为阳性(ctc≥1/5ml)的患者人群(共计167例),按照胃癌lauren分型进行分组:弥漫型(n=35),肠型(n=66),混合型(n=66)。
[0185]
分析方法:
[0186]
在比较不同分组之间的ctc数量是否存在显著差异时,采用了kruskal-wallis检验,分别计算全部类型ctc数量、t1类型ctc数量、t2类型ctc数量、t3类型ctc数量、t4类型ctc数量、t5类型ctc数量、t6类型ctc数量在不同分组(弥漫型,肠型,混合型)中是否具有显著性差异(p值),如果p值《0.05,即该类型ctc数量在不同人群之间存在显著差异。
[0187]
分析结果:
[0188]
在不同人群(弥漫型,肠型,混合型)中发现,整体ctc数量(全部类型ctc的数量)没有显著差异(p=0.464》0.05),t1类型ctc数量(p=0.024《0.05)以及t6类型ctc数量(p=0.001《0.05)存在显著差异(下表3),且在弥漫型人群中t1类型ctc数量以及t6类型ctc数量显著高于肠型或混合型人群中这两个类型的ctc数量(如表2)。若仅比较肠型和混合型人群中各类型ctc数量的差异,发现均无显著差异。从上述结果来看,通过ctc的形态学分类,我们找到了与胃癌lauren分型显著相关的2个类型(t1、t6)的ctc,并且这两个类型的ctc在弥漫型人群中的数量显著高于肠型或混合型人群。
[0189][0190]
表3比较不同类型ctc数量在弥漫型,肠型,混合型人群中的差异
[0191]
实施例3ctc分类与胃癌整体生存期
[0192]
研究目的:
[0193]
探索术前ctc检测中各类型ctc数量与胃癌整体生存期的相关性,观察哪个类型ctc的数量与胃癌整体生存期最具相关性。
[0194]
人群入组条件:
[0195]
在可进行手术的胃癌人群中,针对术前ctc检测为阳性(ctc≥1/5ml)的患者人群(共计211例)进行分组,人群分组情况如下表4所示:
[0196][0197]
表4
[0198]
分析方法:
[0199]
按照上述表格内容,在每一个分析批次内部,将人群分成2组:tn_阴性和tn_阳性(n=1,2,3,4,5,6),然后采用kaplan-meier法绘制整体生存期曲线,整体生存期的计算是从手术开始,随访至患者死亡的时间,以天为单位,曲线的比对使用log-rank检验;在比较人群之间的性别差异时,采用了χ2检验,在比较人群之间的年龄、胃癌分期时,采用了wilcoxon轶和检验。p《0.05为两组人群之间有显著差异。上述分析方法在spss软件中实现。
[0200]
分析结果:
[0201]
在不同分析批次中发现,按照t4类型ctc分类的两个人群(t4_阴性,t4_阳性)的整体生存期曲线存在显著差异(p=0.027),t4_阴性人群的整体生存期(中位值799,95%置信区间:751至846)短于t4_阳性人群的整体生存期(中位值817,95%置信区间:784至850)。图1示出了术前ctc检测中,独立观察各类型ctc情况下,患者的整体生存期曲线。
[0202]
同时,我们也发现按照t6类型ctc分类的两个人群(t6_阴性,t6_阳性)的整体生存
期曲线存在显著差异(p=0.032),t6_阴性人群的整体生存期(中位值841,95%置信区间:808至873)长于t6_阳性人群的整体生存期(中位值719,95%置信区间:604至833)。为了排除上述人群之间显著差异是受其他临床特征影响,我们进一步得分析了人群之间在性别、年龄、胃癌分期是否存在显著差异。统计分析结果显示(下表5、表6),按t4类型ctc分类的人群在性别、年龄、胃癌分期上均无显著差异,按t6类型ctc分类的人群在上述临床基本特征上也无显著差异。
[0203][0204]
表5术前ctc检测中,按t4类型ctc分类的两个人群的基本临床特征的相关性分析
[0205][0206]
表6术前ctc检测中,按t6类型ctc分类的两个人群的基本临床特征的相关性分析
[0207]
综上所述,通过对ctc形态进行分类后,如果只从t4类型ctc的统计结果来看,发现没有t4类型ctc的患者相比于有t4类型ctc的患者有更短的整体生存期;如果只从t6类型ctc的统计结果来看,发现有t6类型ctc的患者相比于没有t6类型ctc的患者有更短的整体生存期。
[0208]
考虑到患者检测出的ctc中,可能同时存在t4类型和t6类型的ctc,我们重新对人群进行了划分,来进一步挖掘同时考量两种类型ctc对患者整体生存期的影响。同样,采用kaplan-meier法绘制了上述4个人群的整体生存期曲线(图2),其中t4_阳性&t6_阳性的人群数量太少(n=4),没有纳入进一步的统计分析当中。图2示出了术前ctc检测中,综合t4类型和t6类型的ctc情况下,患者的整体生存期曲线。
[0209]
统计分析发现,三组人群(t4_阴性&t6_阴性,t4_阴性&t6_阳性,t4_阳性&t6_阴性)的整体生存期曲线存在显著差异(p=0.033),t4_阳性&t6_阴性人群(n=71)的整体生存期最长(中位值825,95%置信区间:796至854),t4_阴性&t6_阳性人群(n=21)的整体生存期最短(中位值726,95%置信区间:606至847)。
[0210]
综上所述,将ctc按形态学分类后发现,在术前ctc检测中,t4类型ctc和t6类型ctc均与患者的整体生存期存在显著相关性,综合两种类型ctc的结果发现,t4_阳性&t6_阴性的患者的整体生存期显著高于t4_阴性&t6_阳性的患者。
[0211]
实施例4ctc分类与胃癌无进展生存期
[0212]
研究目的:
[0213]
探索术后ctc检测中各类型ctc数量与胃癌无进展生存期的相关性,观察哪个类型
ctc的数量与胃癌无进展生存期最具相关性。
[0214]
人群入组条件:
[0215]
在术后胃癌人群中,针对术后ctc检测的患者人群(共计229例)进行分组,人群分组情况如下表7所示。
[0216][0217]
表7
[0218]
分析方法:
[0219]
按照表7的内容,在每一个分析批次内部,将人群分成2组:tn_阴性和tn_阳性(n=1,2,3,4,5,6),然后采用kaplan-meier法绘制无进展生存期曲线,无进展生存期的计算是从术后ctc检测时间点开始,随访至患者出现复发或转移的时间点,以天为单位,曲线的比对使用log-rank检验;在比较人群之间的性别差异时,采用了χ2检验,在比较人群之间的年龄、胃癌分期时,采用了wilcoxon轶和检验。p《0.05为两组人群之间有显著差异。上述分析方法在spss软件中实现。
[0220]
分析结果:
[0221]
在不同分析批次中发现,按照t3类型ctc分类的两个人群(t3_阴性,t3_阳性)的无进展生存期曲线存在显著差异(p=0.011),t3_阴性人群的无进展生存期(中位值743,95%置信区间:700至786)短于t3_阳性人群的无进展生存期(中位值776,95%置信区间:741至811)。图3示出了术后ctc检测中,独立观察各类型ctc情况下,患者的无进展生存期曲线。
[0222]
同时,我们也发现按照t6类型ctc分类的两个人群(t6_阴性,t6_阳性)的无进展生存期曲线存在显著差异(p=0.039),t6_阴性人群的无进展生存期(中位值779,95%置信区间:744至814)长于t6_阳性人群的无进展生存期(中位值572,95%置信区间:439至705)(上图)。为了排除上述人群之间显著差异是受其他临床特征影响,我们进一步得分析了人群之间在性别、年龄、胃癌分期是否存在显著差异。统计分析结果显示(下表8、表9),按t3类型ctc分类的人群在性别、年龄、胃癌分期上均无显著差异,按t6类型ctc分类的人群在上述临床基本特征上也无显著差异。
[0223][0224]
表8术后ctc检测中,按t3类型ctc分类的两个人群的基本临床特征的相关性分析
[0225][0226]
表9术后ctc检测中,按t6类型ctc分类的两个人群的基本临床特征的相关性分析
[0227]
综上所述,通过对ctc形态进行分类后,如果只从t3类型ctc的统计结果来看,发现没有t3类型ctc的患者相比于有t3类型ctc的患者有更短的无进展生存期;如果只从t6类型ctc的统计结果来看,发现有t6类型ctc的患者相比于没有t6类型ctc的患者有更短的无进展生存期。
[0228]
考虑到患者检测出的ctc中,可能同时存在t3类型和t6类型的ctc,我们重新对人群进行了划分,来进一步挖掘同时考量两种类型ctc对患者无进展生存期的影响。同样,采用kaplan-meier法绘制了上述4个人群的无进展生存期曲线(图4),其中t3_阳性&t6_阳性的人群数量太少(n=6),没有纳入进一步的统计分析当中。图4示出了术后ctc检测中,综合t3类型和t6类型的ctc情况下,患者的无进展生存期曲线。
[0229]
统计分析发现,三组人群(t3_阴性&t6_阴性,t3_阴性&t6_阳性,t3_阳性&t6_阴性)的无进展生存期曲线存在显著差异(p=0.002),t3_阳性&t6_阴性人群(n=47)的无进展生存期最长(中位值775,95%置信区间:737至812),t3_阴性&t6_阳性人群(n=13)的无进展生存期最短(中位值505,95%置信区间:335至675)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。