基于存储器的处理器
1.相关申请的交叉引用
2.本技术主张以下各者的优先权:2019年8月13日申请的美国临时申请第62/886,328号;2019年9月29日申请的美国临时申请第62/907,659号;2020年2月7日申请的美国临时申请第62/971,912号;及2020年2月28日申请的美国临时申请第62/983,174号。前述申请以全文引用的方式并入本文中。
技术领域
3.本公开大体上关于用于促进存储器密集型操作的装置。具体而言,本公开关于包括耦接至专用存储器组的处理元件的硬件芯片。本公开还关于用于改良存储器芯片的功率效率及速度的装置。具体而言,本公开关于用于在存储器芯片上实施部分刷新或甚至无刷新的系统及方法。本公开还关于大小可选择的存储器芯片及存储器芯片上的双端口能力。
背景技术:
4.随着处理器速度及存储器大小均继续增大,对有效处理速度的显着限制为冯诺依曼(von neumann)瓶颈。冯诺依曼瓶颈由常规计算机架构所导致的吞吐量限制造成。具体而言,相较于由处理器进行的实际计算,自存储器至处理器的数据传送常会遇到瓶颈。因此,用以对存储器进行读取及写入的时钟循环的数量随着存储器密集型处理程序而显着增大。这些时钟循环导致较低的有效处理速度,这是因为对存储器进行读取及写入会消耗时钟循环,该时钟循环无法用于对数据执行操作。此外,处理器的计算带宽通常大于处理器用以存取存储器的总线的带宽。
5.这些瓶颈对于以下各项特别明显:存储器密集型处理程序,诸如神经网络及其他机器学习算法;数据库建构、索引搜寻及查询;以及包括比数据处理操作多的读取及写入操作的其他任务。
6.另外,可用数字数据的容量及粒度的快速增长已产生开发机器学习算法的机会且已启用新技术。然而,这也为数据库及平行计算的领域带来棘手的挑战。例如,社交媒体及物联网(iot)的兴起以创记录的速率产生数字数据。此新数据可用以产生用于多种用途的算法,范围为新广告技术至工业处理程序的更精确控制方法。然而,新数据难以储存、处理、分析及处置。
7.新数据资源可为巨大的,有时为大约千兆(peta)字节至泽(zetta)字节。此外,这些数据资源的增长速率可能超过数据处理能力。因此,数据科学家已转向平行数据处理技术,以应对这些挑战。为了提高计算能力且处置大量数据,科学家已尝试产生能够进行平行密集型计算的系统及方法。但这些现有系统及方法跟不上数据处理要求,常常因为所使用的技术受该技术对用于数据管理、整合分隔数据及分析分段数据的额外资源的需求限制。
8.为了促进对大数据集的操控,工程师及科学家现在正设法改良用以分析数据的硬件。例如,新的半导体处理器或芯片(例如本文中所描述的半导体处理器或芯片)可通过在以更适合存储器操作而非算术计算的技术制造的单一基板中并入存储器及处理功能而特
定地针对数据密集型任务设计。利用特定地针对数据密集型任务而设计的集成电路,有可能满足新的数据处理要求。然而,应对大数据集的数据处理的此新方法需要解决芯片设计及制造中的新问题。例如,若针对数据密集型任务而设计的新芯片利用用于普通芯片的制造技术及架构制造,则该新芯片将具有不良的效能和/或不可接受的良率。此外,若该新芯片经设计以利用当前数据处置方法进行操作,则该新芯片将具有不良的效能,这是因为当前方法可限制芯片处置平行操作的能力。
9.本公开描述用于减轻或克服上文所阐述的问题中的一个或多个以及现有技术中的其他问题的解决方案。
技术实现要素:
10.在一些实施例中,一种集成电路可包括一基板及安置于该基板上的一存储器阵列,其中该存储器阵列包括多个离散存储器组。该集成电路还可包括安置于该基板上的一处理阵列,其中该处理阵列包括多个处理器子单元,该多个处理器子单元中的每一者与该多个离散存储器组当中的一个或多个离散存储器组相关联。该集成电路还可包括一控制器,该控制器被配置为相对于该集成电路的一操作实施至少一个安全措施且在该至少一个安全措施被触发的情况下采取一个或多个补救动作。
11.所公开实施例还可包括一种保护集成电路以防篡改的方法,其中该方法包括使用与集成电路相关联的控制器实施相对于集成电路的操作的至少一个安全措施及在至少一个安全措施被触发的情况下采取一个或多个补救动作,且其中该集成电路包括:基板;存储器阵列,其安置于基板上,该存储器阵列包括多个离散存储器组;及处理阵列,其安置于基板上,该处理阵列包括多个处理器子单元,该多个处理器子单元中的每一者与该多个离散存储器组当中的一个或多个离散存储器组相关联。
12.所公开实施例可包括一种集成电路,其包含:基板;存储器阵列,其安置于基板上,该存储器阵列包括多个离散存储器组;处理阵列,其安置于基板上,该处理阵列包括多个处理器子单元,该多个处理器子单元中的每一者与该多个离散存储器组当中的一个或多个离散存储器组相关联;及控制器,其被配置为:实施相对于集成电路的操作的至少一个安全措施;其中至少一个安全措施包括在至少两个不同存储器部分中复制程序代码。
13.在一些实施例中,提供一种分布式处理器存储器芯片,其包含:基板;存储器阵列,其安置于基板上;处理阵列,其安置于基板上;第一通信端口;及第二通信端口。该存储器阵列可包括多个离散存储器组。该处理阵列可包括多个处理器子单元,该多个处理器子单元中的每一者与多个离散存储器组当中的一个或多个离散存储器组相关联。该第一通信端口可被配置为在该分布式处理器存储器芯片与除另一分布式处理器存储器芯片以外的外部实体之间建立通信连接。该第二通信端口可被配置为在该分布式处理器存储器芯片与第一额外分布式处理器存储器芯片之间建立通信连接。
14.在一些实施例中,一种在第一分布式处理器存储器芯片与第二分布式处理器存储器芯片之间传送数据的方法可包括:使用与第一分布式处理器存储器芯片及第二分布式处理器存储器芯片中的至少一者相关联的控制器判定安置于第一分布式处理器存储器芯片上的多个处理器子单元当中的第一处理器子单元是否已准备好将数据传送至包括于第二分布式处理器存储器芯片中的第二处理器子单元;及在判定第一处理器子单元已准备好将
数据传送至第二处理器子单元之后,使用由控制器控制的时钟启用信号以起始数据自第一处理器子单元至第二处理器子单元的传送。
15.在一些实施例中,一种存储器单元可包括:存储器阵列,其包括多个存储器组;至少一个控制器,其被配置为控制相对于多个存储器组的读取操作的至少一个方面;至少一个零值侦测逻辑单元,其被配置为侦测储存于多个存储器组的特定地址中的多位零值;且其中该至少一个控制器及该至少一个零值侦测逻辑单元被配置为响应于由该至少一个零值侦测逻辑进行的零值侦测而将零值指示符传回至存储器单元外部的一个或多个电路。
16.一些实施例可包括一种用于侦测多个离散存储器组的特定地址中的零值的方法,其包含:自存储器单元外部的电路接收读取储存于多个离散存储器组的地址中的数据的请求;响应于所接收请求而藉由控制器启动零值侦测逻辑单元以侦测所接收地址中的零值;及响应于由该零值侦测逻辑单元进行的零值侦测而藉由该控制器将零值指示符传输至电路。
17.一些实施例可包括一种非暂时性计算机可读介质,其储存可由存储器单元的控制器执行以使存储器单元侦测多个离散存储器组的特定地址中的零值的指令集,该方法包含:自存储器单元外部的电路接收读取储存于多个离散存储器组的地址中的数据的请求;响应于所接收请求而藉由控制器启动零值侦测逻辑单元以侦测所接收地址中的零值;及响应于由该零值侦测逻辑单元进行的零值侦测而藉由该控制器将零值指示符传输至电路。
18.在一些实施例中,一种存储器单元可包括:一个或多个存储器组;组控制器;及地址产生器;其中地址产生器被配置为将相关联存储器组中待存取的当前行中的当前地址提供至组控制器,判定相关联存储器组中待存取的下一行的预测地址,且在相对于与当前地址相关联的当前行的读取操作完成之前将预测地址提供至组控制器。
19.在一些实施例中,一种存储器单元可包括:一个或多个存储器组,其中一个或多个存储器组中的每一者包括多个行;第一行控制器,其被配置为控制多个行的第一子集;第二行控制器,其被配置为控制多个行的第二子集;单个数据输入端,其用以接收待储存于多个行中的数据;及单个数据输出端,其用以提供自多个行撷取的数据。
20.在一些实施例中,一种分布式处理器存储器芯片可包括:基板;存储器阵列,其安置于基板上,该存储器阵列包括多个离散存储器组;处理阵列,其安置于基板上,该处理阵列包括多个处理器子单元,该些处理器子单元中的每一者与该多个离散存储器组中的对应的专用存储器组相关联;第一多个总线,其各将多个处理器子单元中的一者连接至其对应的专用存储器组;及第二多个总线,其各将多个处理器子单元中的一者连接至多个处理器子单元中的另一者。存储器组中的至少一者可包括安置于基板上的至少一个dram存储器垫。处理器单元中的至少一者可包括与至少一个存储器垫相关联的一个或多个逻辑组件。至少一个存储器垫及一个或多个逻辑组件可被配置为充当用于多个处理子单元中的一个或多个的高速缓存。
21.在一些实施例中,一种执行分布式处理器存储器芯片中的至少一个指令的方法可包括:自分布式处理器存储器芯片的存储器阵列撷取一个或多个数据值;将一个或多个数据值储存于形成于分布式处理器存储器芯片的存储器垫中的寄存器中;及根据由处理器组件执行的至少一个指令存取储存于寄存器中的一个或多个数据值;其中该存储器阵列包括安置于基板上的多个离散存储器组;其中该处理器组件为包括于安置在基板上的处理阵列
中的多个处理器子单元当中的处理器子单元,其中处理器子单元中的每一者与多个离散存储器组中的对应的专用存储器组相关联;且其中该寄存器由安置于基板上的存储器垫提供。
22.一些实施例可包括一种装置,其包含:基板;处理单元,其安置于基板上;及存储器单元,其安置于基板上,其中该存储器单元被配置为储存待由处理单元存取的数据,且其中该处理单元包含被配置为充当用于处理单元的高速缓存的存储器垫。
23.预期处理系统处理以极高速率处理增加的信息量。举例而言,预期第五代(5g)移动因特网接收大量信息串流且以增加的速率处理这些信息串流。
24.该处理系统可包括一个或多个缓冲器及一处理器。由处理器应用的处理操作可能具有某一潜时且此可能需要大量缓冲器。大量缓冲器可为代价高的和/或耗面积的。
25.将大量信息自缓冲器传送至处理器可能需要缓冲器与处理器之间的高带宽连接器和/或高带宽总线,此亦可增加处理系统的成本及面积。
26.越来越需要提供高效处理系统。
27.预期处理系统处理以极高速率处理增加的信息量。举例而言,预期第五代(5g)移动因特网接收大量信息串流且以增加的速率处理这些信息串流。
28.该处理系统可包括一个或多个缓冲器及处理器。由处理器应用的处理操作可能具有某一潜时且此可能需要大量缓冲器。大量缓冲器可为代价高的和/或耗面积的。
29.将大量信息自缓冲器传送至处理器可能需要缓冲器与处理器之间的高带宽连接器和/或高带宽总线,此亦可增加处理系统的成本及面积。
30.越来越需要提供高效处理系统。
31.一种分解式服务器包括多个子系统,而每一子系统具有独特作用。举例而言,一种分解式服务器可包括一个或多个交换子系统、一个或多个运算子系统及一个或多个储存子系统。
32.一个或多个运算子系统及一个或多个储存子系统经由一个或多个交换子系统彼此耦接。
33.运算子系统可包括多个运算单元。
34.交换子系统可包括多个交换单元。
35.储存子系统可包括多个储存单元。
36.此分解式服务器的瓶颈在于在子系统之间传送信息所需的带宽。
37.当执行需要在不同运算子系统的所有(或至少大部分)运算单元(诸如,图形处理单元)之间共享信息单元的分布式计算时,尤其为如此。
38.假定存在参与共享的n个运算单元,n为极大整数(例如,至少1024),且n个运算单元中的每一者必须将信息单元发送至所有其他运算单元(及自所有其他运算单元接收信息单元)。在这些假定下,需要执行信息单元的大约n
×
n个传送处理程序。大量传送处理程序系耗时且耗能量的,且将显著地限制分解式服务器的吞吐量。
39.越来越需要提供高效分解式服务器及执行分布式处理的高效方式。
40.数据库包括许多条目,该些条目包括多个字段。数据库处理通常包括执行一个或多个查询,该一个或多个查询包括一个或多个筛选参数(例如,识别一个或多个相关字段及一个或多个相关字段值)且亦包括一个或多个操作参数,该一个或多个操作参数可判定待
执行的操作的类型、待在应用操作时使用的变量或常数,及其类似者。
41.举例而言,数据库查询可请求对数据库的所有记录执行统计操作(操作参数),其中某一字段具有预定义范围内的值(筛选参数)。又对于另一实例,数据库查询可请求删除具有小于阈值(筛选参数)的某一字段的(操作参数)记录。
42.大型数据库通常储存于储存装置中。为了对查询作出响应,将数据库发送至存储器单元,通常为一个数据库区段接着另一数据库区段。
43.将数据库区段的条目自存储器单元发送至不属于与存储器单元相同的集成电路的处理器。该些条目接着由处理器处理。
44.对于储存于存储器单元中的数据库的每一数据库区段,处理包括以下步骤:(i)选择数据库区段的记录;(ii)将记录自存储器单元发送至处理器;(iii)藉由处理器筛选记录以判定记录是否相关;及(iv)对相关记录执行一个或多个额外操作(求和、应用任何其他数学运算和/或统计操作)。
45.筛选处理程序在所有记录被发送至处理器且处理器判定哪些记录相关之后结束。
46.在数据库区段的相关条目不储存于处理器中的状况下,则需要在筛选阶段之后将这些相关记录发送至处理器以供进一步处理(应用在处理之后的操作)。
47.当多个处理操作在单个筛选之后时,则可将每一操作的结果发送至存储器单元且接着再次发送至处理器。
48.此处理程序为耗带宽且耗时的。
49.越来越需要提供执行数据库处理的高效方式。
50.字嵌入为自然语言处理(nlp)中的语言模型化及特征学习技术的集合的统称,其中将来自词汇表的字或词组映射至元素的向量。在概念上,其涉及从每字具有许多维度的空间至具有低得多的维度的连续向量空间的数学嵌入(www.wikipedia.org)。
51.产生此映射的方法包括神经网络、字同现矩阵的降维、机率模型、可解释知识库方法及依据字出现的上下文的显式表示。
52.字及词组嵌入在用作基础输入表示时已展示为提高诸如语法剖析及情感分析的nlp任务的效能。
53.语句可分段成字或词组,且每一区段可由向量表示。语句可由矩阵表示,该矩阵包括表示语句的字或词组的所有向量。
54.将字映射至向量的词汇表可储存于存储器单元(诸如,动态随机存取存储器(dram))中,该存储器单元可使用字或词组(或表示字的索引)进行存取。
55.该些存取可为随机存取,此减少dram的吞吐量。此外,该些存取可使dram饱和,尤其在将大量存取馈入至dram时。
56.特定而言,包括于语句中的字通常相当随机。甚至在使用dram突发时,存取储存映射的dram存储器亦将通常导致随机存取的较低效能,这是因为通常在突发期间,dram存储器组条目(在同时被存取的不同存储器组的多个条目当中)的一小部分中的仅一者将储存与某一语句相关的条目。
57.因此,dram存储器的吞吐量低且为非连续的。
58.在主计算机的控制下自dram存储器撷取语句的每一字或词组,该主计算机在dram存储器的集成电路外部且必须基于对字的位置的了解来控制表示每一字或区段的每一向
量的每次撷取,此为耗时且耗资源的任务。
59.预期数据中心及其他计算机化系统以极高速率处理及交换增加量的信息。
60.增加量的数据的交换可为数据中心及其他计算机化系统的瓶颈,且可使此类数据中心及其他计算机化系统仅利用其能力的一部分。
61.图96a说明现有技术数据库12010及现有技术服务器主板12011的实例。数据库可包括多个服务器,每一服务器包括多个服务器主板(亦表示为“cpu 存储器 网络”)。每一服务器主板12011包括cpu 12012(诸如但不限于因特尔的xeon),该cpu接收业务,连接至存储器单元12013(表示为ram)及多个数据库加速器(db加速器)12014。
62.db加速器为可选的,且db加速操作可由cpu 12012执行。
63.所有业务流经cpu,且cpu可经由具有相对有限带宽的链路(诸如,pcie)耦接至db加速器。
64.大量资源专用于在多个服务器主板之间投送信息单元。
65.越来越需要提供高效数据中心及其他计算机化系统。
66.诸如神经网络的人工智能(ai)应用的大小显著增加。为了应对神经网络的增加的大小,各作为ai加速服务器(包括服务器主板)的多个服务器用以执行神经网络处理任务,诸如但不限于训练。包括配置于不同机架中的多个ai加速服务器的系统的实例展示于图1中。
67.在典型的训练会话中,同时处理大量图像以提供大量值,诸如损失。大量值在不同ai加速服务器之间输送且导致例外量的业务。举例而言,可跨越位于不同ai加速服务器中的多个gpu运算一些神经网络层,且可能需要消耗带宽的网络上聚集。
68.例外量的业务的传送需要超高带宽,其可能不可行或可能不具成本效益。
69.图97a说明包括子系统的系统12050,每一子系统包括:交换器12051,其用于连接具有服务器主板12055的ai加速服务器12052,该服务器主板包括ram存储器(ram 12056)、中央处理单元(cpu)12054、网络适配器(nic)12053,而cpu 12054连接(经由pcie总线)至多个ai加速器12057(诸如,图形处理单元、ai芯片(ai asic)、fpga及其类似者)。nic藉由网络(使用例如以太网络、udp链路及其类似者)耦接至彼此(例如,藉由一个或多个交换器),且这些nic可能够输送系统所需的超高带宽。
70.越来越需要提供高效ai运算系统。
71.根据本公开的其他实施例,非暂时性计算机可读储存媒体可储存程序指令,该程序指令由至少一个处理设备执行且执行本文中所描述的方法中的任一者。
72.前文的一般性描述和下文的详细描述仅是示例性和说明性的,并不限制权利要求。
附图说明
73.并入于本公开中且构成本公开的一部分的随附图式说明各种所公开实施例。在图式中:
74.图1为中央处理单元(cpu)的示意图。
75.图2为图形处理单元(gpu)的示意图。
76.图3a为符合所公开实施例的示例性硬件芯片的一实施例的示意图。
77.图3b为符合所公开实施例的示例性硬件芯片的另一实施例的示意图。
78.图4为由符合所公开实施例的示例性硬件芯片执行的通用命令的示意图。
79.图5为由符合所公开实施例的示例性硬件芯片执行的专门命令的示意图。
80.图6为供用于符合所公开实施例的示例性硬件芯片中的处理群组的示意图。
81.图7a为符合所公开实施例的处理群组的矩形阵列的示意图。
82.图7b为符合所公开实施例的处理群组的椭圆形阵列的示意图。
83.图7c为符合所公开实施例的硬件芯片的阵列的示意图。
84.图7d为符合所公开实施例的硬件芯片的另一阵列的示意图。
85.图8为描绘用于编译一系列指令以供在符合所公开实施例的示例性硬件芯片上执行的示例性方法的流程图。
86.图9为存储器组的示意图。
87.图10为存储器组的示意图。
88.图11为符合所公开实施例的具有子组控制件的示例性存储器组的一实施例的示意图。
89.图12为符合所公开实施例的具有子组控制件的示例性存储器组的另一实施例的示意图。
90.图13为符合所公开实施例的示例性存储器芯片的功能方块图。
91.图14为符合所公开实施例的示例性冗余逻辑区块集合的功能方块图。
92.图15为符合所公开实施例的示例性逻辑区块的功能方块图。
93.图16为符合所公开实施例的与总线连接的示例性逻辑区块的功能方块图。
94.图17为符合所公开实施例的串联连接的示例性逻辑区块的功能方块图。
95.图18为符合所公开实施例的成二维阵列连接的示例性逻辑区块的功能方块图。
96.图19为符合所公开实施例的处于复杂连接中的示例性逻辑区块的功能方块图。
97.图20为说明符合所公开实施例的冗余区块启用处理程序的示例性流程图。
98.图21为说明符合所公开实施例的地址指派处理程序的示例性流程图。
99.图22为符合所公开实施例的示例性处理设备的功能方块图。
100.图23为符合所公开实施例的示例性处理设备的功能方块图。
101.图24包括符合所公开实施例的示例性存储器配置图。
102.图25为说明符合所公开实施例的存储器配置处理程序的示例性流程图。
103.图26为说明符合所公开实施例的存储器读取处理程序的示例性流程图。
104.图27为说明符合所公开实施例的处理程序执行的示例性流程图。
105.图28为符合本公开的具有刷新控制器的存储器芯片的一实施例。
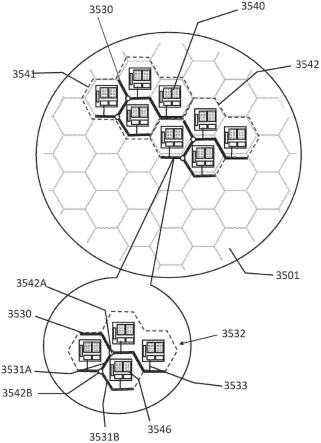
106.图29a为符合本公开的一实施例的刷新控制器。
107.图29b为符合本公开的另一实施例的刷新控制器。
108.图30为符合本公开的通过刷新控制器执行的处理程序的一实施例的流程图。
109.图31为符合本公开的由编译程序实施的处理程序的一实施例的流程图。
110.图32为符合本公开的由编译程序实施的处理程序的另一实施例的流程图。
111.图33展示符合本公开的通过所储存图案配置的示例刷新控制器。
112.图34为符合本公开的由刷新控制器内的软件实施的处理程序的示例流程图。
113.图35a展示符合本公开的包括晶粒的示例晶圆。
114.图35b展示符合本公开的连接至输入/输出总线的示例存储器芯片。
115.图35c展示符合本公开的包括成行布置且连接至输入输出总线的存储器芯片的示例晶圆。
116.图35d展示符合本公开的形成群组且连接至输入输出总线的两个存储器芯片。
117.图35e展示符合本公开的示例晶圆,其包括以六边形晶格置放且连接至输入输出总线的晶粒。
118.图36a至图36d展示符合本公开的连接至输入/输出总线的存储器芯片的各种可能配置。
119.图37展示符合本公开的共享胶合逻辑(glue logic)的晶粒的示例分组。
120.图38a至图38b展示符合本公开的穿过晶圆的示例切割。
121.图38c展示符合本公开的晶圆上的晶粒的示例布置及输入输出总线的布置。
122.图39展示符合本公开的具有互连处理器子单元的晶圆上的示例存储器芯片。
123.图40为符合本公开的从晶圆布局存储器芯片的群组的处理程序的一示例流程图。
124.图41a为符合本公开的从晶圆布局存储器芯片的群组的处理程序的另一示例流程图。
125.图41b至图41c为符合本公开的判定用于从晶圆切割存储器芯片的一个或多个群组的切割图案的处理程序的示例流程图。
126.图42为符合本公开的提供沿着列的双端口存取的存储器芯片内的电路系统的示例。
127.图43为符合本公开的提供沿着行的双端口存取的存储器芯片内的电路系统的示例。
128.图44为符合本公开的提供沿着行和列两者的双端口存取的存储器芯片内的电路系统的示例。
129.图45a为使用复制存储器阵列或垫的双读取。
130.图45b为使用复制存储器阵列或垫的双写入。
131.图46为符合本公开的具有用于沿着列的双端口存取的开关元件的存储器芯片内的电路系统的示例。
132.图47a为符合本公开的用于在单端口存储器阵列或垫上提供双端口存取的一处理程序的示例流程图。
133.图47b为符合本公开的用于在单端口存储器阵列或垫上提供双端口存取的另一处理程序的示例流程图。
134.图48为符合本公开的提供沿着行和列两者的双端口存取的存储器芯片内的电路系统的另一示例。
135.图49为符合本公开的用于存储器垫内的双端口存取的开关元件的示例。
136.图50为符合本公开的具有被配置为存取部分字的缩减单元的示例集成电路。
137.图51为用于使用如关于图50所描述的缩减单元的存储器组。
138.图52为符合本公开的使用集成至pim逻辑中的缩减单元的存储器组。
139.图53为符合本公开的使用pim逻辑以启动用于存取部分字的开关的存储器组。
140.图54a为符合本公开的具有用于撤销启动以存取部分字的分段列多任务器的存储器组。
141.图54b为符合本公开的用于存储器中的部分字存取的处理程序的示例流程图。
142.图55为包括多个存储器垫的现有存储器芯片。
143.图56为符合本公开的具有用于在线断开期间缩减功率消耗的启动电路的存储器芯片的一实施例。
144.图57为符合本公开的具有用于在线断开期间缩减功率消耗的启动电路的存储器芯片的另一实施例。
145.图58为符合本公开的具有用于在线断开期间缩减功率消耗的启动电路的存储器芯片的又一实施例。
146.图59为符合本公开的具有用于在线断开期间缩减功率消耗的启动电路的存储器芯片的再一实施例。
147.图60为符合本公开的具有用于在线断开期间缩减功率消耗的全局字线及区域字线的存储器芯片的一实施例。
148.图61为符合本公开的具有用于在线断开期间缩减功率消耗的全局字线及区域字线的存储器芯片的另一实施例。
149.图62为符合本公开的用于依序断开存储器中的线的处理程序的流程图。
150.图63为用于存储器芯片的现有测试器。
151.图64为用于存储器芯片的另一现有测试器。
152.图65为符合本公开的使用与存储器在相同基板上的逻辑单元测试存储器芯片的一实施例。
153.图66为符合本公开的使用与存储器在相同基板上的逻辑单元测试存储器芯片的另一实施例。
154.图67为符合本公开的使用与存储器在相同基板上的逻辑单元测试存储器芯片的又一实施例。
155.图68为符合本公开的使用与存储器在相同基板上的逻辑单元测试存储器芯片的再一实施例。
156.图69为符合本公开的使用与存储器在相同基板上的逻辑单元测试存储器芯片的另一实施例。
157.图70为符合本公开的用于测试存储器芯片的处理程序的流程图。
158.图71为符合本公开的用于测试存储器芯片的另一处理程序的流程图。
159.图72a为符合本发明的实施例的包括存储器阵列及处理阵列的集成电路的图解表示。
160.图72b为符合本发明的实施例的集成电路内部的存储器区的图解表示。
161.图73a为符合本发明的实施例的具有控制器的实例配置的集成电路的图解表示。
162.图73b为符合本发明的实施例的用于同时执行复制模型的配置的图解表示。
163.图74a为符合本发明的实施例的具有控制器的另一实例配置的集成电路的图解表示。
164.图74b为根据例示性所公开实施例的保护集成电路的方法的流程图表示。
165.图74c为根据例示性所公开实施例的位于芯片内的各个点处的侦测元件的图解表示。
166.图75a为符合本发明的实施例的包括多个分布式处理器存储器芯片的可扩展处理器存储器系统的图解表示。
167.图75b为符合本发明的实施例的包括多个分布式处理器存储器芯片的可扩展处理器存储器系统的图解表示。
168.图75c为符合本发明的实施例的包括多个分布式处理器存储器芯片的可扩展处理器存储器系统的图解表示。
169.图75d为符合本发明的实施例的双端口分布式处理器存储器芯片的图解表示。
170.图75e为符合本发明的实施例的实例时序图。
171.图76为符合本发明的实施例的具有整合式控制器及接口模块且构成可扩展处理器存储器系统的处理器存储器芯片的图解表示。
172.图77为符合本发明的实施例的用于在图75a中所展示的可扩展处理器存储器系统中的处理器存储器芯片之间传送数据的流程图。
173.图78a说明符合本发明的实施例的用于在芯片层级侦测储存于实施于存储器芯片中的多个存储器组的一个或多个特定地址中的零值的系统。
174.图78b说明符合本发明的实施例的用于在存储器组层级侦测储存于多个存储器组的特定地址中的一个或多个中的零值的存储器芯片。
175.图79说明符合本发明的实施例的用于在存储器垫层级侦测储存于多个存储器垫的特定地址中的一个或多个中的零值的存储器组。
176.图80为说明符合本发明的实施例的侦测多个离散存储器组的特定地址中的零值的例示性方法的流程图。
177.图81a说明符合本发明的实施例的用于基于下一行预测启动与存储器组相关联的下一行的系统。
178.图81b说明符合本发明的实施例的图81a的系统的另一实施例。
179.图81c说明符合本发明的实施例的每一存储器子组的第一及第二子组行控制器。
180.图81d说明符合本发明的实施例的下一行预测的实施例。
181.图81e说明符合本发明的实施例的存储器组的实施例。
182.图81f说明符合本发明的实施例的存储器组的另一实施例。
183.图82说明符合本发明的实施例的用于减少存储器行启动惩罚的双重控制存储器组。
184.图83a说明存取及启动存储器组的行的第一实例。
185.图83b说明存取及启动存储器组的行的第二实例。
186.图83c说明存取及启动存储器组的行的第三实例。
187.图84提供传统cpu/寄存器文件及外部存储器架构的图解表示。
188.图85a说明符合一个实施例的具有充当寄存器文件的存储器垫的例示性分布式处理器存储器芯片。
189.图85b说明符合另一实施例的具有被配置为充当寄存器文件的存储器垫的例示性分布式处理器存储器芯片。
190.图85c说明符合另一实施例的具有充当寄存器文件的存储器垫的例示性装置。
191.图86提供表示符合所公开实施例的用于在分布式处理器存储器芯片中执行至少一个指令的例示性方法的流程图。
192.图87a包括分解式服务器的实例;
193.图87b为分布式处理的实例;
194.图87c为存储器/处理单元的实例;
195.图87d为存储器/处理单元的实例;
196.图87e为存储器/处理单元的实例;
197.图87f为包括存储器/处理单元及一个或多个通信模块的集成电路的实例;
198.图87g为包括存储器/处理单元及一个或多个通信模块的集成电路的实例;
199.图87h为方法的实例;
200.图87i为方法的实例;
201.图88a为方法的实例;
202.图88b为方法的实例;
203.图88c为方法的实例;
204.图89a为存储器/处理单元及词汇表的实例;
205.图89b为存储器/处理单元的实例;
206.图89c为存储器/处理单元的实例;
207.图89d为存储器/处理单元的实例;
208.图89e为存储器/处理单元的实例;
209.图89f为存储器/处理单元的实例;
210.图89g为存储器/处理单元的实例;
211.图89h为存储器/处理单元的实例;
212.图90a为系统的实例;
213.图90b为系统的实例;
214.图90c为系统的实例;
215.图90d为系统的实例;
216.图90e为系统的实例;
217.图90f为方法的实例;
218.图91a为存储器及筛选系统、储存装置以及cpu的实例;
219.图91b为存储器及处理系统、储存装置以及cpu的实例;
220.图92a为存储器及处理系统、储存装置以及cpu的实例;
221.图92b为存储器/处理单元的实例;
222.图92c为存储器及筛选系统、储存装置以及cpu的实例;
223.图92d为存储器及处理系统、储存装置以及cpu的实例;
224.图92e为存储器及处理系统、储存装置以及cpu的实例;
225.图92f为方法的实例;
226.图92g为方法的实例;
227.图92h为方法的实例;
228.图92i为方法的实例;
229.图92j为方法的实例;
230.图92k为方法的实例;
231.图93a为混合集成电路的实例的横截面图;
232.图93b为混合集成电路的实例的横截面图;
233.图93c为混合集成电路的实例的横截面图;
234.图93d为混合集成电路的实例的横截面图;
235.图93e为混合集成电路的实例的俯视图;
236.图93f为混合集成电路的实例的俯视图;
237.图93g为混合集成电路的实例的俯视图;
238.图93h为混合集成电路的实例的横截面图;
239.图93i为混合集成电路的实例的横截面图;
240.图93j为方法的实例;
241.图94a为储存系统、一个或多个装置及运算系统的实例;
242.图94b为储存系统、一个或多个装置及运算系统的实例;
243.图94c为一个或多个装置及运算系统的实例;
244.图94d为一个或多个装置及运算系统的实例;
245.图94e为数据库加速集成电路的实例;
246.图94f为数据库加速集成电路的实例;
247.图94g为数据库加速集成电路的实例;
248.图94h为数据库加速单元的实例;
249.图94i为刀片以及数据库加速集成电路的群组的实例;
250.图94j为数据库加速集成电路的群组的实例;
251.图94k为数据库加速集成电路的群组的实例;
252.图94l为数据库加速集成电路的群组的实例;
253.图94m为数据库加速集成电路的群组的实例;
254.图94n为系统的实例;
255.图94o为系统的实例;
256.图94p为方法的实例;
257.图95a为方法的实例;
258.图95b为方法的实例;
259.图95c为方法的实例;
260.图96a为现有技术系统的实例;
261.图96b为系统的实例;
262.图96c为数据库加速器板的实例;
263.图96d为系统的一部分的实例;
264.图97a为现有技术系统的实例;
265.图97b为系统的实例;及
266.图97c为ai网络适配器的实例。
具体实施方式
267.以下详细描述参考随附图式。在任何方便之处,在图式及以下描述中使用相同参考编号来指代相同或类似部分。虽然本文中描述了若干说明性实施例,但修改、调适及其他实施为可能的。例如,可对图式中所说明的组件进行替代、添加或修改,且可通过替代、重排序、移除步骤或添加步骤至所公开方法来修改本文中所描述的说明性方法。因此,以下详细描述不限于所公开实施例及示例。反而,适当范畴由所附权利要求界定。
268.处理器架构
269.如贯穿本公开所使用,术语「硬件芯片」指半导体晶圆(诸如,硅或其类似物),其上形成有一个或多个电路元件(诸如,晶体管、电容器、电阻器和/或其类似物)。该电路元件可形成处理元件或存储器元件。「处理元件」指代共同执行至少一个逻辑功能(诸如,算术功能、逻辑门、其他布尔运算(boolean operations)或其类似物)的一个或多个电路元件。处理元件可为通用处理元件(诸如,可配置的多个晶体管)或专用处理元件(诸如,经设计以执行特定逻辑功能的特定逻辑门或多个电路元件)。「存储器元件」指可用以储存数据的一个或多个电路元件。「存储器元件」也可被称作「存储器胞元」。存储器元件可为动态(使得需要电刷新以维持数据储存)、静态(使得数据在失去电力之后持续存在至少一段时间)或非易失性的存储器。
270.处理元件可接合以形成处理器子单元。「处理器子单元」因此可包含可执行至少一个任务或指令(例如,属于一处理器指令集)的处理元件的最小分组。例如,一子单元可包含被配置为共同执行指令的一个或多个通用处理元件、与经配置成以互补方式执行指令的一个或多个专用处理元件配对的一个或多个通用处理元件,或其类似物。该处理器子单元可以以阵列布置在一基板(例如,一晶圆)上。尽管「阵列」可包含矩形形状,但阵列中的子单元的任何布置可形成于基板上。
271.存储器元件可接合以形成存储器组(memory bank)。例如,存储器组可包含沿着至少一条导线(或其他导电连接件)链接的存储器元件的一个或多个线。此外,存储器元件可在另一方向上沿着至少一条添加导线链接。例如,存储器元件可沿着字线及比特线布置,如下文所解释。尽管存储器组可包含线,但组中的元件的任何布置可用以在基板上形成组。此外,一个或多个组可电接合至至少一个存储器控制器以形成存储器阵列。尽管存储器阵列可包含组的矩形布置,但阵列中的组的任何布置可形成于基板上。
272.如贯穿本公开进一步所使用,「总线」指基板的组件之间的任何通信连接件。例如,导线或线(形成电连接件)、光纤(形成光学连接件)或进行元件之间的通信的任何其他连接件可被称作「总线」。
273.常规处理器使通用逻辑电路与共享存储器配对。共享存储器可储存用于由逻辑电路执行的指令集以及用于指令集的执行且由指令集的执行产生的数据两者。如下文所描述,一些常规处理器使用高速缓存系统来缩减执行自共享存储器提取时的延迟;然而,常规高速缓存系统保持共享。常规处理器包括中央处理单元(cpu)、图形处理单元(gpu)、各种特殊应用集成电路(asic)或其类似物。图1展示cpu的示例,且图2展示gpu的示例。
274.如图1所示,cpu 100可包含处理单元110,处理单元110可包括一个或多个处理器子单元,诸如处理器子单元120a及处理器子单元120b。尽管图1中未描绘,但每一处理器子单元可包含多个处理元件。此外,处理单元110可包括一个或多个层级的片上高速缓存。此
类高速缓存元件通常与处理单元110形成于相同半导体晶粒上,而非经由形成于基板中的一个或多个总线连接至处理器子单元120a及120b,该基板含有处理器子单元120a及120b以及高速缓存元件。对于常规处理器中的第一阶(l1)及第二阶(l2)高速缓存,直接在相同晶粒上而非经由总线连接的布置为常用的。替代地,在早期处理器中,l2高速缓存系使用子单元与l2高速缓存之间的背侧总线而在处理器子单元当中共享。背侧总线通常大于下文所描述的前侧总线。因此,因为高速缓存要供晶粒上的所有处理器子单元共享,所以高速缓存130可与处理器子单元120a及120b在相同晶粒上形成或经由一个或多个背侧总线以通信方式耦接至处理器子单元120a及120b。在不具有总线(例如,高速缓存直接形成于晶粒上)的实施例以及使用背侧总线的实施例两者中,高速缓存在cpu的处理器子单元之间共享。
275.此外,处理单元110与共享存储器140a及存储器140b通信。例如,存储器140a及140b可表示共享动态随机存取存储器(dram)的存储器组。尽管描绘为具有两个存储器组,但大部分常规存储器芯片包括介于八个与十六个之间的存储器组。因此,处理器子单元120a及120b可使用共享存储器140a及140b储存数据,该数据接着由处理器子单元120a及120b进行操作。然而,此布置导致存储器140a及140b与处理单元110之间的总线在处理单元110的时钟速度超过总线的数据传送速度时成为瓶颈。对于常规处理器,通常系如此情况,从而导致低于基于时钟速率及晶体管数量的规定处理速度的有效处理速度。
276.如图2中所展示,gpu中也存在类似缺陷。gpu 200可包含处理单元210,处理单元210可包括一个或多个处理器子单元(例如,子单元220a、220b、220c、220d、220e、220f、220g、220h、220i、220j、220k、220l、220m、220n、220o及220p)。此外,处理单元210可包括一个或多个层级的片上高速缓存和/或寄存器文件。此类高速缓存元件通常与处理单元210形成于相同半导体晶粒上。实际上,在图2的实施例中,高速缓存210与处理单元210形成于相同晶粒上且在所有处理器子单元当中共享,而高速缓存230a、230b、230c及230d分别形成于处理器子单元的子集上且专用于该处理器子单元。
277.此外,处理单元210与共享存储器250a、250b、250c及250d通信。例如,存储器250a、250b、250c及250d可表示共享dram的存储器组。因此,处理单元210的处理器子单元可使用共享存储器250a、250b、250c及250d储存数据,该数据接着由该处理器子单元进行操作。然而,此布置导致存储器250a、250b、250c及250d与处理单元210之间的总线成为瓶颈,其类似于上文关于cpu所描述的瓶颈。
278.所公开硬件芯片的概述
279.图3a为描绘示例性硬件芯片300的实施例的示意图。硬件芯片300可包含经设计以缓解上文关于cpu、gpu及其他常规处理器所描述的瓶颈的分布式处理器。分布式处理器可包括在空间上分布于单一基板上的多个处理器子单元。此外,如上文所解释,在本公开的分布式处理器中,对应存储器组还在空间上分布于基板上。在一些实施例中,分布式处理器可与一组指令相关联,且分布式处理器的处理器子单元中的每一个可负责执行包括于该组指令中的一个或多个任务。
280.如图3a中所描绘,硬件芯片300可包含多个处理器子单元,例如,逻辑及控制子单元320a、320b、320c、320d、320e、320f、320g及320h。如图3a中进一步所描绘,每一处理器子单元可具有一专用存储器实例。例如,逻辑及控制子单元320a可操作地连接至专用存储器实例330a,逻辑及控制子单元320b可操作地连接至专用存储器实例330b,逻辑及控制子单
元320c可操作地连接至专用存储器实例330c,逻辑及控制子单元320d可操作地连接至专用存储器实例330d,逻辑及控制子单元320e可操作地连接至专用存储器实例330e,逻辑及控制子单元320f可操作地连接至专用存储器实例330f,逻辑及控制子单元320g可操作地连接至专用存储器实例330g,且逻辑及控制子单元320h可操作地连接至专用存储器实例330h。
281.尽管图3a将每个存储器实例描绘为单一存储器组,但硬件芯片300可包括两个或多于两个存储器组作为用于硬件芯片300上的处理器子单元的专用存储器实例。此外,尽管图3a将每一处理器子单元描绘为包含逻辑组件及用于专用存储器组的控制件两者,但硬件芯片300可使用用于存储器组的控制件,该控制件至少部分地与该逻辑组件分开。此外,如图3a中所描绘,可将两个或多于两个处理器子单元及其对应存储器组分组成例如处理群组310a、310b、310c及310d。「处理群组」可表示上面形成有硬件芯片300的基板上的空间区别。因此,处理群组可包括用于群组中的存储器组的其他控制件,例如,控制件340a、340b、340c及340d。另外或替代地,「处理群组」可表示用于编译代码以供在硬件芯片300上执行的目的的逻辑分组。因此,用于硬件芯片300的编译程序(下文进一步描述)可在硬件芯片300上的处理群组之间划分整组指令。
282.此外,主机350可将指令、数据及其他输入提供至硬件芯片300且自该硬件芯片读取输出。因此,一组指令可全部在单一晶粒上,例如在代管硬件芯片300的晶粒上执行。实际上,晶粒外的仅有通信可包括指令至硬件芯片300的加载、发送至硬件芯片300的任何输入及从硬件芯片300读取的任何输出。因此,所有计算及存储器操作可在晶粒上(在硬件芯片300上)执行,这是因为硬件芯片300的处理器子单元与硬件芯片300的专用存储器组通信。
283.图3b为另一示例性硬件芯片300'的实施例的示意图。尽管描绘为硬件芯片300的替代,但图3b中所描绘的架构可至少部分地与图3a中所描绘的架构组合。
284.如图3b中所描绘,硬件芯片300'可包含多个处理器子单元,例如,处理器子单元350a、350b、350c及350d。如图3b中进一步所描绘,每一处理器子单元可具有多个专用存储器实例。例如,处理器子单元350a可操作地连接至专用存储器实例330a及330b,处理器子单元350b可操作地连接至专用存储器实例330c及330d,处理器子单元350c可操作地连接至专用存储器实例330e及330f,且处理器子单元350d可操作地连接至专用存储器实例330g及330h。此外,如图3b中所描绘,可将处理器子单元及其对应存储器组分组成例如处理群组310a、310b、310c及310d。如上文所解释,「处理群组」可表示上面形成有硬件芯片300'的基板上的空间区别和/或用于编译代码以供在硬件芯片300'上执行的目的的逻辑分组。
285.如图3b中进一步所描绘,处理器子单元可经由总线彼此通信。例如,如图3b所展示,处理器子单元350a可经由总线360a与处理器子单元350b通信,经由总线360c与处理器子单元350c通信,且经由总线360f与处理器子单元350d通信。类似地,处理器子单元350b可经由总线360a与处理器子单元350a通信(如上文所描述),经由总线360e与处理器子单元350c通信,且经由总线360d与处理器子单元350d通信。此外,处理器子单元350c可经由总线360c与处理器子单元350a通信(如上文所描述),经由总线360e与处理器子单元350b通信(如上文所描述),且经由总线360b与处理器子单元350d通信。因此,处理器子单元350d可经由总线360f与处理器子单元350a通信(如上文所描述),经由总线360d与处理器子单元350b通信(如上文所描述),且经由总线360b与处理器子单元350c通信(如上文所描述)。本领域技术人员将理解,可使用比图3b中所描绘的总线少的总线。例如,可消除总线360e,使得处
理器子单元350b与350c之间的通信经由处理器子单元350a和/或350d传递。类似地,可消除总线360f,使得处理器子单元350a与处理器子单元350d之间的通信经由处理器子单元350b或350c传递。
286.此外,本领域技术人员将理解,可使用除图3a及图3b中所描绘的架构以外的架构。例如,各具有单处理器子单元及存储器实例的处理群组的阵列可布置在基板上。处理器子单元可另外或替代地形成用于对应的专用存储器组的控制器的部分、用于对应的专用存储器的存储器垫的控制器的部分,或其类似物。
287.鉴于上文所描述的架构,相较于传统架构,硬件芯片300及300'可显着提高存储器密集型任务的效率。例如,数据库操作及人工智能算法(诸如,神经网络)为存储器密集型任务的示例,对于存储器密集型任务,传统架构在效率上低于硬件芯片300及300'。因此,硬件芯片300及300'可被称作数据库加速器处理器和/或人工智能加速器处理器。
288.配置所公开硬件芯片
289.上文所描述的硬件芯片架构可被配置为用于代码执行。例如,每一处理器子单元可与硬件芯片中的其他处理器子单元隔开而个别地执行代码(定义一组指令)。因此,替代依赖于操作系统来管理多线程处理或使用多任务处理(其为并发的而非平行的),本公开的硬件芯片可允许处理器子单元完全平行地操作。
290.除上文所描述的完全平行实施以外,指派给每一处理器子单元的指令中的至少一些可重叠。例如,分布式处理器上的多个处理器子单元可执行重叠指令作为例如操作系统或其他管理软件的实施,同时执行非重叠指令以便在操作系统或其他管理软件的内容背景内执行平行任务。
291.图4描绘通过处理群组410进行的用于执行通用命令的示例性处理程序400。例如,处理群组410可包含本公开的硬件芯片(例如,硬件芯片300、硬件芯片300'或其类似物)的一部分。
292.如图4中所描绘,命令可发送至与专用存储器实例420配对的处理器子单元430。外部主机(例如,主机350)可将该命令发送至处理群组410以供执行。替代地,主机350可能已发送包括该命令的指令集以用于储存于存储器实例420中,使得处理器子单元430可从存储器实例420取回命令且执行所取回的命令。因此,该命令可由处理元件440执行,该处理元件为可配置以执行所接收的命令的通用处理元件。此外,处理群组410可包括用于存储器实例420的控制件460。如图4中所描绘,控制件460可执行处理元件440在执行所接收的命令时所需的对存储器实例420的任何读取和/或写入。在执行命令之后,处理群组410可将命令的结果输出至例如外部主机或输出至相同硬件芯片上的不同处理群组。
293.在一些实施例中,如图4中所描绘,处理器子单元430还可以包括地址生成器450。「地址生成器」可包含多个处理元件,多个处理元件被配置为判定用于执行读取及写入的一个或多个存储器组中的地址,且也可对位于所判定地址处的数据执行操作(例如,加法、减法、乘法或其类似物)。例如,地址生成器450可判定用于对存储器进行的任何读取或写入的地址。在一个示例中,地址生成器450可通过在不再需要读取值时用基于命令所判定的新值覆写读取值来提高效率。另外或替代地,地址生成器450可选择可用地址以用于储存来自命令执行的结果。此可允许为后一时钟循环调度结果读出,这对于外部主机较为便利。在另一示例中,地址生成器450可在诸如向量或矩阵乘法累加(multiply-accumulate)计算的多循
环计算期间判定读取及写入的地址。因此,地址生成器450可维持或计算用于读取数据及写入多循环计算的中间结果的存储器地址,使得处理器子单元430可继续处理而不必储存这些存储器地址。
294.图5描绘通过处理群组510进行的用于执行专门命令的示例性处理程序500。例如,处理群组510可包含本公开的硬件芯片(例如,硬件芯片300、硬件芯片300'或其类似物)的一部分。
295.如图5中所描绘,专门命令(例如,乘法累加命令)可发送至与专用存储器实例520配对的处理元件530。外部主机(例如,主机350)可将该命令发送至处理元件530以供执行。因此,该命令可由处理元件530在来自主机的给定信号下执行,该处理元件为可配置以执行特定命令(包括所接收的命令)的专门处理元件。替代地,处理元件530可从存储器实例520取回命令以供执行。因此,在图5的示例中,处理元件530为乘法累加(mac)电路,该电路被配置为执行从外部主机接收或从存储器实例520取回的mac命令。在执行命令之后,处理群组410可将命令的结果输出至例如外部主机或输出至相同硬件芯片上的不同处理群组。尽管关于单一命令及单一结果来描绘,但可接收或取回并执行多个命令,且多个结果可在输出之前在处理群组510上组合。
296.尽管在图5中描绘为mac电路,但额外或替代的专门电路可包括于处理群组510中。例如,可实施max读取命令(其传回向量的最大值)、max0读取命令(也被称作整流器的常用功能,其传回整个向量,而且传回为0的最大值),或其类似物。
297.尽管分开地描绘,但图4的一般处理群组410及图5的专门处理群组510可组合。例如,通用处理器子单元可耦接至一个或多个专门处理器子单元以形成处理器子单元。因此,通用处理器子单元可用于不可由一个或多个专门处理器子单元执行的所有指令。
298.本领域技术人员将理解,可通过专门逻辑电路来处置神经网络实施及其他记忆密集型任务。例如,数据库查询、封包检测、字符串比较及其他功能在由本文中所描述的硬件芯片执行的情况下可提高效率。
299.用于分布式处理的基于存储器的架构
300.在符合本公开的硬件芯片上,专用总线可在该芯片上的处理器子单元之间和/或在该处理器子单元与其对应的专用存储器组之间传送数据。使用专用总线可降低仲裁成本,这是因为竞争请求系不可能的或容易使用软件而非使用硬件来避免。
301.图6示意性地描绘处理群组600的示意图。处理群组600可供用于硬件芯片(例如,硬件芯片300、硬件芯片300'或其类似物)中。处理器子单元610可经由总线630连接至存储器620。存储器620可包含随机可存取存储器(ram)元件,其储存用于由处理器子单元610执行的数据及代码。在一些实施例中,存储器620可为n路存储器(其中n为等于或大于1的数字,其暗示交错的存储器620中的区段的数量)。因为处理器子单元610经由总线630耦接至专用于处理器子单元610的存储器620,所以n可保持相对较小而不损害执行效能。此表示对常规多路寄存器文件或高速缓存的改良,其中较低n通常导致较低执行效能,且较高n通常导致大的面积及功率损失。
302.可根据例如一个或多个任务中所涉及的数据的大小而调整存储器620的大小、通路的数量及总线630的宽度以满足使用处理群组600的系统的任务及应用程序实施的要求。存储器元件620可包含此项技术中已知的一个或多个类型的存储器,例如,易失性存储器
(诸如,ram、dram、sram、相变ram(pram)、磁阻式ram(mram)、电阻式ram(reram)或其类似物)或非易失性存储器(诸如,快闪存储器或rom)。根据一些实施例,存储器元件620的一部分可包含第一存储器类型,而另一部分可包含另一存储器类型。例如,存储器元件620的代码区可包含rom元件,而存储器元件620的数据区可包含dram元件。此分割的另一示例为将神经网络的权重储存于快闪存储器中,而将用于计算的数据储存于dram中。
303.处理器子单元610包含处理元件640,该处理元件可包含处理器。该处理器可为管线式或非管线式的,可为定制精简指令集计算(risc)元件或其他处理方案,实施于此项技术中已知的任何商业集成电路(ic)(诸如,arm、arc、riscv等)上,如本领域技术人员所了解。处理元件640可包含控制器,该控制器在一些实施例中包括算术逻辑单元(alu)或其他控制器。
304.根据本公开的一些实施例,执行所接收或所储存的代码的处理元件640可包含通用处理元件,且因此为灵活的并能够执行广泛多种处理操作。当比较在特定操作的执行期间所消耗的功率时,非专用电路系统通常比特定操作专用电路系统消耗更多功率。因此,当执行特定的复杂算术计算时,处理元件640可比专用硬件消耗更多功率且执行效率更低。因此,根据一些实施例,处理元件640的控制器可经设计以执行特定操作(例如,加法或「移动」操作)。
305.在本公开的一实施例中,特定操作可由一个或多个加速器650执行。每一加速器可为专用的且经编程以执行特定计算(诸如,乘法、浮点向量运算或其类似物)。通过使用加速器,每个处理器子单元的每次计算所消耗的平均功率可降低,且计算吞吐量此后增大。可根据系统经设计以实施的应用程序(例如,执行神经网络、执行数据库查询或其类似物)而选择加速器650。加速器650可由处理元件640配置且可与处理元件串接地操作以用于降低功率消耗且加速计算及计算。加速器可另外或替代地用以在诸如智能型直接存储器存取(dma)周边设备的处理群组600的存储器与mux/demux/输入/输出端口(例如,mux 650及demux 660)之间传送数据。
306.加速器650可被配置为执行多种功能。例如,一个加速器可被配置为执行常用于神经网络中的16比特浮点计算或8比特整数计算。加速器功能的另一示例为常用于神经网络的训练阶段期间的32比特浮点计算。加速器功能的又一示例为查询处理,诸如用于数据库中的查询处理。在一些实施例中,加速器650可包含用以执行这些功能的专门处理元件和/或可根据储存于存储器元件620上的配置数据而配置使得其可加以修改。
307.加速器650可另外或替代地实施存储器移动的可配置的脚本处理列表以对数据至/从存储器620或至/从其他加速器和/或输入/输出的移动进行计时。因此,如下文进一步所解释,使用处理群组600的硬件芯片内部的所有数据移动可使用软件同步而非硬件同步。例如,一个处理群组(例如,群组600)中的加速器可每十个循环将数据从其输入端传送至其加速器,接着在下一个循环输出数据,藉此使信息从处理群组的存储器流送至另一存储器。
308.如图6中进一步所描绘,在一些实施例中,处理群组600还可包含连接至其输入端口的至少一个输入多任务器(mux)660及连接至其输出端口的至少一个输出demux 670。这些mux/demux可由来自处理元件640和/或来自加速器650中的一个的控制信号(未图标)控制,该控制信号系根据正由处理元件640进行的当前指令和/或由加速器650中的加速器执行的操作而判定。在一些情境中,可能需要处理群组600(根据来自其代码存储器的预定义
指令)将数据从其输入端口传送至其输出端口。因此,除demux/mux中的每个连接至处理元件640及加速器650以外,输入mux(例如,mux 660)中的一个或多个也可经由一个或多个总线直接连接至输出demux(例如,demux 670)。
309.图6的处理群组600可排成阵列以形成分布式处理器,例如,如图7a中所描绘。处理群组可安置于基板710上以形成阵列。在一些实施例中,基板710可包含诸如硅的半导体基板。另外或替代地,基板710可包含电路板,诸如可挠性电路板。
310.如图7a中所描绘,基板710可包括安置于其上的多个处理群组,诸如处理群组600。因此,基板710包括存储器阵列,该存储器阵列包括多个组,诸如组720a、720b、720c、720d、720e、720f、720g及720h。此外,基板710包括处理阵列,该处理阵列可包括多个处理器子单元,诸如子单元730a、730b、730c、730d、730e、730f、730g及730h。
311.此外,如上文所解释,每一处理群组可包括一处理器子单元及专用于该处理器子单元的一个或多个对应的存储器组。因此,如图7a中所描绘,每一子单元与一对应的专用存储器组相关联,例如:处理器子单元730a与存储器组720a相关联,处理器子单元730b与存储器组720b相关联,处理器子单元730c与存储器组720c相关联,处理器子单元730d与存储器组720d相关联,处理器子单元730e与存储器组720e相关联,处理器子单元730f与存储器组720f相关联,处理器子单元730g与存储器组720g相关联,处理器子单元730h与存储器组720h相关联。
312.为了允许每一处理器子单元与其对应的专用存储器组通信,基板710可包括将处理器子单元中的一个连接至其对应的专用存储器组的第一多个总线。因此,总线740a将处理器子单元730a连接至存储器组720a,总线740b将处理器子单元730b连接至存储器组720b,总线740c将处理器子单元730c连接至存储器组720c,总线740d将处理器子单元730d连接至存储器组720d,总线740e将处理器子单元730e连接至存储器组720e,总线740f将处理器子单元730f连接至存储器组720f,总线740g将处理器子单元730g连接至存储器组720g,且总线740h将处理器子单元730h连接至存储器组720h。此外,为了允许每一处理器子单元与其他处理器子单元通信,基板710可包括将处理器子单元中的一个连接至处理器子单元中的另一个的第二多个总线。在图7a的示例中,总线750a将处理器子单元730a连接至处理器子单元750e,总线750b将处理器子单元730a连接至处理器子单元750b,总线750c将处理器子单元730b连接至处理器子单元750f,总线750d将处理器子单元730b连接至处理器子单元750c,总线750e将处理器子单元730c连接至处理器子单元750g,总线750f将处理器子单元730c连接至处理器子单元750d,总线750g将处理器子单元730d连接至处理器子单元750h,总线750h将处理器子单元730h连接至处理器子单元750g,总线750i将处理器子单元730g连接至处理器子单元750g,且总线750j将处理器子单元730f连接至处理器子单元750e。
313.因此,在图7a中所展示的示例布置中,多个逻辑处理器子单元布置成至少一行及至少一列。该第二多个总线将每一处理器子单元连接至相同行中的至少一个邻近处理器子单元且连接至相同列中的至少一个邻近处理器子单元。图7a可被称作「部分块连接」。
314.图7a中所展示的配置可经修改以形成「完全块连接」。完全块连接包括连接对角线处理器子单元的额外总线。例如,该第二多个总线可包括处理器子单元730a与处理器子单元730f之间、处理器子单元730b与处理器子单元730e之间、处理器子单元730b与处理器子
单元730g之间、处理器子单元730c与处理器子单元730f之间、处理器子单元730c与处理器子单元730h之间以及处理器子单元730d与处理器子单元730g之间的额外总线。
315.完全块连接可用于卷积计算,在卷积计算中,使用储存于附近处理器子单元中的数据及结果。例如,在卷积图像处理期间,每一处理器子单元可接收图像的块(诸如,像素或像素群组)。为了计算卷积结果,每一处理器子单元可从所有八个邻近处理器子单元获取数据,该邻近处理器子单元中的每个已接收对应块。在部分块连接中,来自对角线邻近处理器子单元的数据可经由连接至该处理器子单元的其他邻近处理器子单元传递。因此,芯片上的分布式处理器可为人工智能加速器处理器。
316.在卷积计算的特定实施例中,可跨越多个处理器子单元来划分n
×
m图像。每一处理器子单元可在其对应块上通过a
×
b滤波器执行卷积。为了对块之间的边界上的一个或多个像素执行滤波,每一处理器子单元可能需要来自相邻处理器子单元的数据,该相邻处理器子单元具有包括相同边界上的像素的块。因此,针对每一处理器子单元产生的代码配置该子单元以计算卷积且每当需要来自邻近子单元的数据时从第二多个总线提取。将数据输出至第二多个总线的对应命令被提供至该子单元以确保所需数据传送的适当时序。
317.图7a的部分块连接可修改为n部分块连接。在此修改中,第二多个总线可进一步将每一处理器子单元连接至在图7a的总线延其所沿的四个方向(也即,上、下、左及右)上在该处理器子单元的阈值距离内(例如,在n个处理器子单元内)的处理器子单元。可对完全块连接进行类似修改(以产生n完全块连接),使得第二多个总线进一步将每一处理器子单元连接至在除两个对角线方向以外的图7a的总线延其所沿的四个方向上在该处理器子单元的阈值距离内(例如,在n个处理器子单元内)的处理器子单元。
318.其他布置也是可能的。例如,在图7b中所展示的布置中,总线750a将处理器子单元730a连接至处理器子单元730d,总线750b将处理器子单元730a连接至处理器子单元730b,总线750c将处理器子单元730b连接至处理器子单元730c,且总线750d将处理器子单元730c连接至处理器子单元730d。因此,在图7b中所展示的示例布置中,多个处理器子单元布置成星形图案。第二多个总线将每一处理器子单元连接至星形图案内的至少一个邻近处理器子单元。
319.其他布置(未示出)也是可能的。例如,可使用相邻者连接布置,使得多个处理器子单元布置在一个或多个线中(例如,类似于图7a中所描绘的情况)。在相邻者连接布置中,第二多个总线将每一处理器子单元连接至相同线中在左方的处理器子单元、相同线中在右方的处理器子单元、相同线中在左方及右方两者的处理器子单元,等等。
320.在另一实施例中,可使用n线性连接布置。在n线性连接布置中,第二多个总线将每一处理器子单元连接至在该处理器子单元的阈值距离内(例如,在n个处理器子单元内)的处理器子单元。n线性连接布置可与线阵列(上文所描述)、矩形阵列(图7a中所描绘)、椭圆形阵列(图7b中所描绘)或任何其他几何阵列共同使用。
321.在又一实施例中,可使用n对数连接布置。在n对数连接布置中,第二多个总线将每一处理器子单元连接至在该处理器子单元的二的幂的阈值距离内(例如,在2n个处理器子单元内)的处理器子单元。n对数连接布置可与线阵列(上文所描述)、矩形阵列(图7a中所描绘)、椭圆形阵列(图7b中所描绘)或任何其他几何阵列共同使用。
322.可组合上文所描述的连接方案中的任一者以用于相同硬件芯片中。例如,可在一
个区中使用完全块连接,而在另一区中使用部分块连接。在另一实施例中,可在一个区中使用n线性连接布置,而在另一区中使用n完全块连接。
323.替代存储器芯片的处理器子单元之间的专用总线或除该专用总线以外,也可使用一个或多个共享总线以互连分布式处理器的所有处理器子单元(或处理器子单元的子集)。仍可通过使用由处理器子单元执行的代码对共享总线上的数据传送进行计时来避免共享总线上的冲突,如下文进一步所解释。替代共享总线或除共享总线以外,也可使用可配置总线以动态地连接处理器子单元以形成连接至分开总线的处理器单元的群组。例如,可配置总线可包括晶体管或可由处理器子单元来控制以将数据传送引导至选定处理器子单元的其他机构。
324.在图7a及图7b两者中,处理阵列的多个处理器子单元在空间上分布于存储器阵列的多个离散存储器组当中。在其他替代实施例(未示出)中,多个处理器子单元可聚集在基板的一个或多个区中,且多个存储器组可聚集在基板的一个或多个其他区中。在一些实施例中,可使用空间分布与聚集的组合(未图标)。例如,基板的一个区可包括处理器子单元的丛集,基板的另一区可包括存储器组的丛集,且基板的又一区可包括分布于存储器组当中的处理阵列。
325.本领域技术人员将认识到,在基板上将处理器群组600排成阵列并非排他性实施例。例如,每一处理器子单元可与至少两个专用存储器组相关联。因此,可替代处理群组600或与处理群组600组合地使用图3b的处理群组310a、310b、310c及310d,以形成处理阵列及存储器阵列。可使用包括例如三个、四个或多于四个专用存储器组的其他处理群组(未示出)。
326.多个处理器子单元中的每个可被配置为相对于包括于多个处理器子单元中的其他处理器子单元独立地执行与特定应用程序相关联的软件代码。例如,如下文所解释,指令的多个子系列可分组为机器码且被提供至每一处理器子单元以供执行。
327.在一些实施例中,每一专用存储器组包含至少一个动态随机存取存储器(dram)。替代地,存储器组可包含诸如静态随机存取存储器(sram)、dram、快闪存储器或其类似物的存储器类型的混合。
328.在常规处理器中,处理器子单元之间的数据共享通常通过共享存储器来执行。共享存储器通常需要大部分芯片面积和/或执行由额外硬件(诸如,仲裁器)管理的总线。如上文所描述,该总线造成瓶颈。此外,可在芯片外部的共享存储器通常包括缓存一致性机制及更复杂的高速缓存(例如,l1高速缓存、l2高速缓存及共享dram),以便将准确且最新的数据提供至处理器子单元。如下文进一步所解释,图7a及图7b中所描绘的专用总线允许无硬件管理(诸如,仲裁器)的硬件芯片。此外,使用如图7a及图7b中所描绘的专用存储器允许消除复杂的高速缓存层及一致性机制。
329.反而,为了允许每一处理器子单元存取由其他处理器子单元计算和/或储存于专用于其他处理器子单元的存储器组中的数据,提供总线,该总线的时序系使用由每一处理器子单元个别地执行的代码动态地执行。此情形允许消除如常规地所使用的大部分(若非全部)总线管理硬件。此外,这些总线上的直接传送替换复杂的高速缓存机制,以缩减在存储器读取及写入期间的延时时间。
330.基于存储器的处理阵列
331.如图7a及图7b中所描绘,本公开的存储器芯片可独立地操作。替代地,本公开的存储器芯片可与诸如存储器设备(例如,一个或多个dram组)、系统单芯片、场可编程门阵列(fpga)或其他处理和/或存储器芯片的一个或多个额外集成电路可操作地连接。在这些实施例中,由该架构执行的一系列指令中的任务可在存储器芯片的处理器子单元与额外集成电路的任何处理器子单元之间进行划分(例如,通过编译程序,如下文所描述)。例如,其他集成电路可包含将指令和/或数据输入至存储器芯片且从其接收输出的主机(例如,图3a的主机350)。
332.为了将本公开的存储器芯片与一个或多个额外集成电路互连,存储器芯片可包括存储器接口,诸如遵从联合电子设备工程委员会(joint electron device engineering council;jedec)标准或其变体中的任一者的存储器接口。一个或多个额外集成电路接着可连接至该存储器接口。因此,若该一个或多个额外集成电路连接至本公开的多个存储器芯片,则数据可经由该一个或多个额外集成电路在存储器芯片之间共享。另外或替代地,该一个或多个额外集成电路可包括用以连接至本公开的存储器芯片上的总线的总线,使得该一个或多个额外集成电路可与本公开的存储器芯片串接地执行代码。在这些实施例中,该一个或多个额外集成电路进一步辅助分布式处理,即使该额外集成电路可与本公开的存储器芯片在不同基板上亦如此。
333.此外,本公开的存储器芯片可排成阵列以便形成分布式处理器的阵列。例如,一个或多个总线可将存储器芯片770a连接至额外存储器芯片770b,如图7c中所描绘。在图7c的实施例中,存储器芯片770a包括处理器子单元与专用于每一处理器子单元的一个或多个对应的存储器组,例如:处理器子单元730a与存储器组720a相关联,处理器子单元730b与存储器组720b相关联,处理器子单元730e与存储器组720c相关联,且处理器子单元730f与存储器组720d相关联。总线将每一处理器子单元连接至其对应的存储器组。因此,总线740a将处理器子单元730a连接至存储器组720a,总线740b将处理器子单元730b连接至存储器组720b,总线740c将处理器子单元730e连接至存储器组720c,且总线740d将处理器子单元730f连接至存储器组720d。此外,总线750a将处理器子单元730a连接至处理器子单元750e,总线750b将处理器子单元730a连接至处理器子单元750b,总线750c将处理器子单元730b连接至处理器子单元750f,且总线750d将处理器子单元730e连接至处理器子单元750f。例如,如上文所描述,可使用存储器芯片770a的其他布置。
334.类似地,存储器芯片770b包括处理器子单元与专用于每一处理器子单元的一个或多个对应的存储器组,例如:处理器子单元730c与存储器组720e相关联,处理器子单元730d与存储器组720f相关联,处理器子单元730g与存储器组720g相关联,且处理器子单元730h与存储器组720h相关联。总线将每一处理器子单元连接至其对应的存储器组。因此,总线740e将处理器子单元730c连接至存储器组720e,总线740f将处理器子单元730d连接至存储器组720f,总线740g将处理器子单元730g连接至存储器组720g,且总线740h将处理器子单元730h连接至存储器组720h。此外,总线750g将处理器子单元730c连接至处理器子单元750g,总线750h将处理器子单元730d连接至处理器子单元750h,总线750i将处理器子单元730c连接至处理器子单元750d,且总线750j将处理器子单元730g连接至处理器子单元750h。例如,如上文所描述,可使用存储器芯片770b的其他布置。
335.存储器芯片770a及770b的处理器子单元可使用一个或多个总线来连接。因此,在
图7c的实施例中,总线750e可将存储器芯片770a的处理器子单元730b与存储器芯片770b的处理器子单元730c连接,且总线750f可将存储器芯片770a的处理器子单元730f与存储器770b的处理器子单元730c连接。例如,总线750e可用作至存储器芯片770b的输入总线(且因此用作存储器芯片770a的输出总线),而总线750f可用作至存储器芯片770a的输入总线(且因此用作存储器芯片770b的输出总线),或反之亦然。替代地,总线750e及750f均可用作存储器芯片770a与770b之间的双向总线。
336.总线750e及750f可包括直接导线或可在高速连接上交错,以便缩减用于存储器芯片770a与集成电路770b之间的芯片间接口的接脚。此外,用于存储器芯片本身中的上文所描述的连接布置中的任一者可用以将存储器芯片连接至一个或多个额外集成电路。例如,存储器芯片770a及770b可使用完全块或部分块连接而非如图7c所展示仅使用两个总线来连接。
337.因此,尽管使用总线750e及750f来描绘,但架构760可包括更少总线或额外总线。例如,可使用处理器子单元730b与730c之间或处理器子单元730f与730c之间的单一总线。替代地,可使用例如处理器子单元730b与730d之间、处理器子单元730f与730d之间或其类似物的额外总线。
338.此外,尽管描绘为使用单一存储器芯片及一额外集成电路,但多个存储器芯片可使用如上文所解释的总线来连接。例如,如图7c的实施例中所描绘,存储器芯片770a、770b、770c及770d连接成一阵列。类似于上文所描述的存储器芯片,每个存储器芯片包括处理器子单元及专用存储器组。因此,此处不重复对这些组件的描述。
339.在图7c的实施例中,存储器芯片770a、770b、770c及770d连接成一回路。因此,总线750a连接存储器芯片770a与770d,总线750c连接存储器芯片770a与770b,总线750e连接存储器芯片770b与770c,且总线750g连接存储器芯片770c与770d。尽管存储器芯片770a、770b、770c及770d可利用完全块连接、部分块连接或其他连接布置来连接,但图7c的实施例允许存储器芯片770a、770b、770c及770d之间的更少接脚连接。
340.相对较大的存储器
341.本公开的实施例可使用大小与常规处理器的共享存储器相比相对较大的专用存储器。使用专用存储器而非共享存储器允许继续获得效率增益而不会随着存储器增大而逐渐缩减。此允许诸如神经网络处理及数据库查询的存储器密集型任务比在常规处理器中更高效地执行,在常规处理器中,增大共享存储器的效率增益由于冯诺伊曼瓶颈而逐渐缩减。
342.例如,在本公开的分布式处理器中,安置于分布式处理器的基板上的存储器阵列可包括多个离散存储器组。离散存储器组中的每个可具有大于一兆字节(megabyte)的容量;以及安置于该基板上的处理阵列,该处理阵列包括多个处理器子单元。如上文所解释,该处理器子单元中的每个可与多个离散存储器组中的对应的专用存储器组相关联。在一些实施例中,多个处理器子单元可在空间上分布于存储器阵列内的多个离散存储器组当中。通过将至少一兆字节的专用存储器而非几兆字节的共享高速缓存用于大型cpu或gpu,本公开的分布式处理器获得在常规系统中由于cpu及gpu中的冯诺依曼瓶颈而不可能达成的效率。
343.不同存储器可用作专用存储器。例如,每一专用存储器组可包含至少一个dram组。替代地,每一专用存储器组可包含至少一个静态随机存取存储器组。在其他实施例中,不同
类型的存储器可在单一硬件芯片上组合。
344.如上文所解释,每一专用存储器可为至少一兆字节。因此,每一专用存储器组可大小相同,或多个存储器组中的至少两个存储器组可具有不同大小。
345.此外,如上文所描述,该分布式处理器可包括:第一多个总线,其各将多个处理器子单元中的一个连接至一对应的专用存储器组;及第二多个总线,其各将多个处理器子单元中的一个连接至多个处理器子单元中的另一个。
346.使用软件的同步
347.如上文所解释,本公开的硬件芯片可使用软件而非硬件来管理数据传送。具体而言,因为总线上的传送、对存储器进行的读取及写入以及处理器子单元的计算的时序通过处理器子单元所执行的指令的子系列设定,所以本公开的硬件芯片可执行代码以防止总线上的冲突。因此,本公开的硬件芯片可避免常规地用以管理数据传送的硬件机构(诸如,芯片内的网络控制器、处理器子单元之间的封包剖析器及封包传送器、总线仲裁器、用以避免仲裁的多个总线,或其类似物)。
348.若本公开的硬件芯片常规地传送数据,则利用总线连接n个处理器子单元将需要由仲裁器控制的总线仲裁或宽mux。反而,如上文所描述,本公开的实施例可在处理器子单元之间使用仅为导线、光学缆线或其类似物的总线,其中该处理器子单元个别地执行代码以避免总线上的冲突。因此,本公开的实施例可节省基板上的空间以及材料成本及效率损失(例如,由于仲裁导致的功率及时间消耗)。相较于使用先进先出(fifo)控制器和/或信箱的其他架构,效率及空间增益甚至更大。
349.此外,如上文所解释,除一个或多个处理元件以外,每一处理器子单元也可包括一个或多个加速器。在一些实施例中,加速器可从总线而非从处理元件进行读取及写入。在这些实施例中,可通过允许加速器在处理元件执行一个或多个计算的相同循环期间传输数据来获得额外效率。然而,这些实施例需要用于加速器的额外材料。例如,可能需要额外晶体管以用于制造加速器。
350.代码也可考虑处理器子单元(例如,包括形成处理器子单元的部分的处理元件和/或加速器)的内部行为,包括时序及延时。例如,编译程序(如下文所描述)可执行当产生控制数据传送的指令子系列时考虑时序及延时的预处理。
351.在一个实施例中,多个处理器子单元可经指派计算神经网络层的任务,该神经网络层含有全部连接至较大多个神经元的前一层的多个神经元。假设前一层的数据均匀地散布在多个处理器子单元之间,执行该计算的一种方式可为配置每一处理器子单元,以依次将前一层的数据传输至主总线,且接着每一处理器子单元将此数据乘以子单元实施的对应神经元的权重。因为每一处理器子单元计算多于一个神经元,所以每一处理器子单元将数次传输前一层的数据,该次数等于神经元的数量。因此,每一处理器子单元的代码与用于其他处理器子单元的代码不相同,这是因为该子单元将在不同时间进行传输。
352.在一些实施例中,分布式处理器可包含基板(例如,诸如硅的半导体基板和/或诸如可挠性电路板的电路板),该基板具有:安置于该基板上的存储器阵列,该存储器阵列包括多个离散存储器组;及安置于该基板上的处理阵列,该处理阵列包括多个处理器子单元,如描绘于例如图7a及图7b中。如上文所解释,该处理器子单元中的每个可与多个离散存储器组中的对应的专用存储器组相关联。此外,如描绘于例如图7a及图7b中,分布式处理器还
可包含多个总线,多个总线中的每个将多个处理器子单元中的一个连接至多个处理器子单元中的至少另一者。
353.如上文所解释,多个总线可用软件来控制。因此,多个总线可能不含时序硬件逻辑组件,使得在处理器子单元之间及跨越多个总线中的对应者的数据传送不受时序硬件逻辑组件控制。在一个实施例中,多个总线可能不含总线仲裁器,使得在处理器子单元之间及跨越多个总线中的对应者的数据传送不受总线仲裁器控制。
354.在一些实施例中,如描绘于例如图7a及图7b中,分布式处理器还可包含第二多个总线,该第二多个总线将多个处理器子单元中的一个连接至一对应的专用存储器组。类似于上文所描述的多个总线,第二多个总线可能不含时序硬件逻辑组件,使得处理器子单元与对应的专用存储器组之间的数据传送不受时序硬件逻辑组件控制。在一个实施例中,第二多个总线可能不含总线仲裁器,使得处理器子单元与对应的专用存储器组之间的数据传送不受总线仲裁器控制。
355.如本文中所使用,词组「不含」未必暗示诸如时序硬件逻辑组件(例如,总线仲裁器、仲裁树、fifo控制器、信箱或其类似物)的组件的绝对不存在。这些组件仍可包括于描述为「不含」这些组件的硬件芯片中。反而,词组「不含」指硬件芯片的功能;也即,「不含」时序硬件逻辑组件的硬件芯片控制其数据传送的时序而不使用包括于其中的时序硬件逻辑组件(若存在)。例如,硬件芯片执行包括指令的子系列的代码,该指令控制该硬件芯片的处理器子单元之间的数据传送,即使该硬件芯片包括时序硬件逻辑组件作为防范由于所执行代码中的错误的冲突的辅助预防措施亦如此。
356.如上文所解释,多个总线可包含介于多个处理器子单元中的对应者之间的导线或光纤中的至少一个。因此,在一个实施例中,不含时序硬件逻辑组件的分布式处理器可仅包括导线或光纤,而无总线仲裁器、仲裁树、fifo控制器、信箱或其类似物。
357.在一些实施例中,多个处理器子单元被配置为根据由多个处理器子单元执行的代码跨越多个总线中的至少一个传送数据。因此,如下文所解释,编译程序可组织指令的子系列,每一子系列包含由单处理器子单元执行的代码。该子系列指令可指示处理器子单元何时将数据传送至总线中的一个上及何时从总线取回数据。当该子系列以串接方式跨越分布式处理器执行时,处理器子单元之间的传送的时序可通过包括于该子系列中的用以传送及取回的指令来控制。因此,代码规定跨越多个总线中的至少一个的数据传送的时序。编译程序可产生要由单处理器子单元执行的代码。另外,编译程序可产生要由处理器子单元的群组执行的代码。在一些状况下,编译程序可将所有处理器子单元共同视为该处理器子单元系一个超处理器(例如,分布式处理器),且编译程序可产生用于由其定义的超处理器/分布式处理器执行的代码。
358.如上文所解释且如图7a及图7b中所描绘,多个处理器子单元可在空间上分布于存储器阵列内的多个离散存储器组当中。替代地,多个处理器子单元可聚集在基板的一个或多个区中,且多个存储器组可聚集在基板的一个或多个其他区中。在一些实施例中,可使用空间分布与聚集的组合,如上文所解释。
359.在一些实施例中,分布式处理器可包含基板(例如,包括硅的半导体基板和/或诸如可挠性电路板的电路板),该基板具有安置于其上的存储器阵列,该存储器阵列包括多个离散存储器组。处理阵列也可安置于基板上,该处理阵列包括多个处理器子单元,如描绘于
例如图7a及图7b中。如上文所解释,该处理器子单元中的每个可与多个离散存储器组中的对应的专用存储器组相关联。此外,如描绘于例如图7a及图7b中,该分布式处理器还可包含多个总线,多个总线中的每个将多个处理器子单元中的一个连接至多个离散存储器组中的对应的专用存储器组。
360.如上文所解释,多个总线可用软件来控制。因此,多个总线可能不含时序硬件逻辑组件,使得处理器子单元与多个离散存储器组中的对应的专用离散存储器组之间及跨越多个总线中的对应者的数据传送不受时序硬件逻辑组件控制。在一个实施例中,多个总线可能不含总线仲裁器,使得在处理器子单元之间及跨越多个总线中的对应者的数据传送不受总线仲裁器控制。
361.在一些实施例中,如描绘于例如图7a及图7b中,分布式处理器还可包含第二多个总线,该第二多个总线将多个处理器子单元中的一个连接至多个处理器子单元中的至少另一者。类似于上文所描述的多个总线,第二多个总线可能不含时序硬件逻辑组件,使得处理器子单元与对应的专用存储器组之间的数据传送不受时序硬件逻辑组件控制。在一个实施例中,第二多个总线可能不含总线仲裁器,使得处理器子单元与对应的专用存储器组之间的数据传送不受总线仲裁器控制。
362.在一些实施例中,分布式处理器可使用软件时序组件与硬件时序组件的组合。例如,分布式处理器可包含基板(例如,包括硅的半导体基板和/或诸如可挠性电路板的电路板),该基板安置于其上的存储器阵列,该存储器阵列包括多个离散存储器组。处理阵列也可安置于基板上,该处理阵列包括多个处理器子单元,如描绘于例如图7a及图7b中。如上文所解释,该处理器子单元中的每个可与多个离散存储器组中的对应的专用存储器组相关联。此外,如描绘于例如图7a及图7b中,分布式处理器还可包含多个总线,多个总线中的每个将多个处理器子单元中的一个连接至多个处理器子单元中的至少另一者。此外,如上文所解释,多个处理器子单元可被配置为执行软件,该软件控制跨越多个总线的数据传送的时序,以避免与多个总线中的至少一个上的数据传送冲突。在此实施例中,软件可控制数据传送的时序,但传送本身可至少部分地由一个或多个硬件组件控制。
363.在这些实施例中,分布式处理器还可包含第二多个总线,该第二多个总线将多个处理器子单元中的一个连接至一对应的专用存储器组。类似于上文所描述的多个总线,多个处理器子单元可被配置为执行软件,该软件控制跨越该第二多个总线的数据传送的时序,以避免与该第二多个总线中的至少一个上的数据传送冲突。在此实施例中,如上文所解释,软件可控制数据传送的时序,但传送本身可至少部分地由一个或多个硬件组件控制。
364.代码的划分
365.如上文所解释,本公开的硬件芯片可跨越包括于形成硬件芯片的基板上的处理器子单元平行地执行代码。另外,本公开的硬件芯片可执行多任务处理。例如,本公开的硬件芯片可执行区域多任务处理,其中硬件芯片的处理器子单元的一个群组执行一个任务(例如,音频处理),而硬件芯片的处理器子单元的另一群组执行另一任务(例如,图像处理)。在另一实施例中,本公开的硬件芯片可执行时序多任务处理,其中硬件芯片的一个或多个处理器子单元在第一时间段期间执行一个任务且在第二时间段期间执行另一任务。也可使用区域多任务处理与时序多任务处理的组合,使得一个任务可在第一时间段期间指派给处理器子单元的第一群组,而另一任务可在第一时间段期间指派给处理器子单元的第二群组,
此后,第三任务可在第二时间段期间指派给包括于第一群组及第二群组中的处理器子单元。
366.为了组织供在本公开的存储器芯片上执行的机器码,机器码可在存储器芯片的处理器子单元之间进行划分。例如,存储器芯片上的处理器可包含基板及安置于该基板上的多个处理器子单元。该存储器芯片还可包含安置于该基板上的对应的多个存储器组,多个处理器子单元中的每个连接至不被多个处理器子单元中的任何其他处理器子单元共享的至少一个专用存储器组。该存储器芯片上的每一处理器子单元可被配置为独立于其他处理器子单元执行一系列指令。每一系列指令可通过以下操作执行:根据定义该系列指令的代码而配置处理器子单元的一个或多个一般处理元件和/或根据在定义该系列指令的该代码中所提供的序列而启动处理器子单元的一个或多个特殊处理元件(例如,一个或多个加速器)。
367.因此,每一系列指令可定义要由单处理器子单元执行的一系列任务。单一任务可包含在由处理器子单元中的一个或多个处理元件的架构定义的指令集内的指令。例如,该处理器子单元可包括特定寄存器,且单一任务可将数据推送至寄存器上,从寄存器提取数据,对寄存器内的数据执行算术函数,对寄存器内的数据执行逻辑运算,或其类似物。此外,处理器子单元可针对任何数量的操作数来配置,诸如0操作数处理器子单元(也被称作「堆叠机」)、1操作数处理器子单元(也被称作累加机)、2操作数处理器子单元(诸如,risc)、3操作数处理器子单元(诸如,复杂指令集计算机(cisc))或其类似物。在另一实施例中,处理器子单元可包括一个或多个加速器,且单一任务可启动一加速器以执行特定功能,诸如mac功能、max功能、max-0功能或其类似物。
368.该系列指令还可以包括用于对存储器芯片的专用存储器组进行读取及写入的任务。例如,一任务可包括将一段数据写入至专用于执行该任务的处理器子单元的存储器组、从专用于执行该任务的处理器子单元的存储器组读取一段数据,或其类似物。在一些实施例中,读取及写入可由处理器子单元与存储器组的控制器串接地执行。例如,处理器子单元可通过将控制信号发送至控制器以执行读取或写入来执行读取或写入任务。在一些实施例中,该控制信号可包括用于读取及写入的特定地址。替代地,处理器子单元可听从存储器控制器以选择可用于读取及写入的地址。
369.另外或替代地,读取及写入可由一个或多个加速器与存储器组的控制器串接地执行。例如,该加速器可产生用于存储器控制器的控制信号,此类似于处理器子单元如何产生控制信号,如上文所描述。
370.在上文所描述的实施例中的任一者中,地址生成器也可用以引导对存储器组的特定地址的读取及写入。例如,该地址生成器可包含被配置为产生用于读取及写入的存储器地址的处理元件。该地址生成器可被配置为产生地址以便提高效率,例如通过将稍后计算的结果写入至与先前计算的不再需要的结果相同的地址。因此,地址生成器可响应于来自处理器子单元(例如,来自包括于其中的处理元件或来自其中的一个或多个加速器)的命令抑或与处理器子单元串接地产生用于存储器控制器的控制信号。另外或替代地,地址生成器可基于一些配置或寄存器产生地址,例如产生巢套循环结构,从而以某一图案在存储器中的某些地址上进行反复。
371.在一些实施例中,每一系列指令可包含定义对应的一系列任务的一组机器码。因
此,上文所描述的该系列任务可囊封于包含该系列指令的机器码内。在一些实施例中,如下文关于图8所解释,该系列任务可由编译程序定义,该编译程序被配置为将较高阶系列的任务作为多个系列的任务分布于多个逻辑电路当中。例如,编译程序可基于较高阶系列的任务产生多个系列的任务,使得串接地执行对应的每一系列任务的处理器子单元执行与由较高阶系列的任务所概述的功能相同的功能。
372.如下文进一步所解释,较高阶系列的任务可包含用人类可读程序设计语言编写的一组指令。对应地,每一处理器子单元的该系列任务可包含较低阶系列任务,该任务中的每个包含以机器码编写的一组指令。
373.如上文关于图7a及图7b所解释,存储器芯片还可包含多个总线,每个总线将多个处理器子单元中的一个连接至多个处理器子单元中的至少另一者。此外,如上文所解释,多个总线上的数据传送可使用软件来控制。因此,跨越多个总线中的至少一个的数据传送可通过包括于连接至多个总线中的至少一个的处理器子单元中的该系列指令预定义。因此,包括于该系列指令中的任务中的一个可包括将数据输出至总线中的一个或从总线中的一个提取数据。这些任务可由处理器子单元的处理元件或由包括于处理器子单元中的一个或多个加速器执行。在后一实施例中,处理器子单元可执行计算或在相同循环中将控制信号发送至对应存储器组,在该循环期间,加速器从总线中的一个提取数据或将数据置放于总线中的一个上。
374.在一个实施例中,包括于连接至多个总线中的至少一个的处理器子单元中的该系列指令可包括发送任务,该发送任务包含针对连接至多个总线中的至少一个的处理器子单元的用以将数据写入至多个总线中的至少一个的命令。另外或替代地,包括于连接至多个总线中的至少一个的处理器子单元中的该系列指令可包括接收任务,该接收任务包含针对连接至多个总线中的至少一个的处理器子单元的用以从多个总线中的至少一个读取数据的命令。
375.除将代码分布在处理器子单元当中以外或替代将代码分布在处理器子单元当中,可在存储器芯片的存储器组之间划分数据。例如,如上文所解释,存储器芯片上的分布式处理器可包含安置于存储器芯片上的多个处理器子单元及安置于存储器芯片上的多个存储器组。多个存储器组中的每个可被配置为储存独立于储存在多个存储器组的其他者中的数据的数据,且多个处理器子单元中的一个可连接至多个存储器组当中的至少一个专用存储器组。例如,每一处理器子单元可存取专用于该处理器子单元的一个或多个对应存储器组的一个或多个存储器控制器,且其他处理器子单元不可存取这些对应的一个或多个存储器控制器。因此,储存于每个存储器组中的数据对于专用处理器子单元可为唯一的。此外,储存于每个存储器组中的数据可独立于储存在其他存储器组中的存储器,这是因为无存储器控制器可在存储器组之间共享。
376.在一些实施例中,如下文关于图8所描述,储存于多个存储器组中的每个中的数据可由编译程序定义,该编译程序被配置为将数据分布于多个存储器组当中。此外,该编译程序可被配置为使用分布于对应处理器子单元当中的多个较低阶任务将定义于较高阶系列的任务中的数据分布于多个存储器组当中。
377.如下文进一步所解释,较高阶系列的任务可包含用人类可读程序设计语言编写的一组指令。对应地,每一处理器子单元的该系列任务可包含较低阶系列任务,该任务中的每
个包含以机器码编写的一组指令。
378.如上文关于图7a及图7b所解释,存储器芯片还可包含多个总线,每个总线将多个处理器子单元中的一个连接至多个存储器组当中的一个或多个对应的专用存储器组。此外,如上文所解释,多个总线上的数据传送可使用软件来控制。因此,跨越多个总线中的特定总线的数据传送可由连接至多个总线中的该特定总线的对应处理器子单元来控制。因此,包括于该系列指令中的任务中的一个可包括将数据输出至总线中的一个或从总线中的一个提取数据。如上文所解释,这些任务可由(i)处理器子单元的处理元件或(ii)包括于处理器子单元中的一个或多个加速器执行。在后一实施例中,处理器子单元可执行计算或在相同循环中使用将该处理器子单元连接至其他处理器子单元的总线,在该循环期间,加速器从连接至一个或多个对应的专用存储器组的总线中的一个提取数据或将数据置放于该总线中的一个上。
379.因此,在一个实施例中,包括于连接至多个总线中的至少一个的处理器子单元中的该系列指令可包括发送任务。该发送任务可包含针对连接至多个总线中的至少一个的处理器子单元的用以将数据写入至多个总线中的至少一个以供储存于一个或多个对应的专用存储器组中的命令。另外或替代地,包括于连接至多个总线中的至少一个的处理器子单元中的该系列指令可包括接收任务。该接收任务可包含针对连接至多个总线中的至少一个的处理器子单元的用以从多个总线中的至少一个读取数据以供储存于一个或多个对应的专用存储器组中的命令。因此,这些实施例中的发送任务及接收任务可包含控制信号,该控制信号沿着多个总线中的至少一个发送至一个或多个对应的专用存储器组中的一个或多个存储器控制器。此外,发送任务及接收任务可与由处理子单元的另一部分(例如,由处理子单元的一个或多个不同加速器)执行的计算或其他任务并发地由处理子单元的一个部分(例如,由处理子单元的一个或多个加速器)执行。此并发执行的实施例可包括mac中继命令,其中接收、相乘及发送被串接地执行。
380.除将数据分布于存储器组当中以外,也可跨越不同存储器组复制数据的特定部分。例如,如上文所解释,存储器芯片上的分布式处理器可包含安置于存储器芯片上的多个处理器子单元及安置于存储器芯片上的多个存储器组。多个处理器子单元中的每个可连接至多个存储器组当中的至少一个专用存储器组,且多个存储器组中的每个存储器组可被配置为储存独立于储存在多个存储器组的其他者中的数据的数据。此外,储存于多个存储器组当中的一个特定存储器组中的数据中的至少一些可包含储存于多个存储器组中的至少另一存储器组中的数据的复制者。例如,该系列指令中所使用的数字、字符串或其他类型的数据可储存于专用于不同处理器子单元的多个存储器组中,而非从一个存储器组传送至存储器芯片中的其他处理器子单元。
381.在一个实施例中,平行字符串匹配可使用上文所描述的数据复制。例如,可将多个字符串与相同字符串进行比较。常规处理器可依序将多个字符串中的每一字符串与相同字符串进行比较。在本公开的硬件芯片上,可跨越存储器组复制相同字符串,使得处理器子单元可平行地将多个字符串中的分开字符串与所复制字符串进行比较。
382.在一些实施例中,如下文关于图8所描述,跨越多个存储器组当中的一个特定存储器组及多个存储器组中的至少另一存储器组复制的至少一些数据由编译程序定义,该编译程序被配置为跨越存储器组复制数据。此外,该编译程序可被配置为使用分布于对应处理
器子单元当中的多个较低阶任务来复制至少一些数据。
383.数据的复制可适用于跨越不同计算重复使用数据的相同部分的特定任务。通过复制数据的这些部分,不同计算可分布于存储器芯片的处理器子单元当中以用于平行执行,而每一处理器子单元可将数据的该部分储存于专用存储器组中且从专用存储器组存取所储存部分(而非跨越连接处理器子单元的总线推送及提取数据的该部分)。在一个实施例中,跨越多个存储器组当中的一个特定存储器组及多个存储器组中的至少另一存储器组复制的至少一些数据可包含神经网络的权重。在此实施例中,该神经网络中的每一节点可由多个处理器子单元当中的至少一个处理器子单元定义。例如,每一节点可包含由定义该节点的至少一个处理器子单元执行的机器码。在此实施例中,权重的复制可允许每一处理器子单元执行机器码以至少部分地实现对应节点,同时仅存取一个或多个专用存储器组(而非与其他处理器子单元执行数据传送)。因为对专用存储器组进行的读取及写入的时序独立于其他处理器子单元,而处理器子单元之间的数据传送的时序需要时序同步(例如,使用软件,如上文所解释),所以复制存储器以避免处理器子单元之间的数据传送可进一步提高总体执行的效率。
384.如上文关于图7a及图7b所解释,存储器芯片还可包含多个总线,每个总线将多个处理器子单元中的一个连接至多个存储器组当中的一个或多个对应的专用存储器组。此外,如上文所解释,多个总线上的数据传送可使用软件来控制。因此,跨越多个总线中的特定总线的数据传送可由连接至所述多个总线中的该特定总线的对应处理器子单元来控制。因此,包括于该系列指令中的任务中的一个可包括将数据输出至总线中的一个或从总线中的一个提取数据。如上文所解释,这些任务可由(i)处理器子单元的处理元件或(ii)包括于处理器子单元中的一个或多个加速器执行。如上文进一步所解释,这些任务可包括包含控制信号的发送任务和/或接收任务,该控制信号沿着多个总线中的至少一个发送至一个或多个对应的专用存储器组中的一个或多个存储器控制器。
385.图8描绘用于编译一系列指令以供在例如如图7a及图7b中所描绘的本公开的示例性存储器芯片上执行的方法800的流程图。方法800可通过任何常规处理器(无论系通用抑或专用的)实施。
386.方法800可作为形成编译程序的计算机程序的一部分执行。如本文中所使用,「编译程序」指将较高级语言(例如,程序性语言,诸如c、fortran、basic或其类似物;面向对象式语言,诸如java、c 、pascal、python或其类似物;等等)转换成较低级语言(例如,组合代码、目标代码、机器码或其类似物)的任何计算机程序。编译程序可允许人类以人类可读语言来程序设计一系列指令,接着将该人类可读语言转换成机器可执行语言。
387.在步骤810处,处理器可将与该系列指令相关联的任务指派给处理器子单元中的不同处理器子单元。例如,该系列指令可分成子群组,该子群组要跨越处理器子单元平行地执行。在一个实施例中,可将神经网络分成其节点,且可将一个或多个节点指派给分开的处理器子单元。在此实施例中,每一子群组可包含跨越不同层连接的多个节点。因此,处理器子单元可实施来自神经网络的第一层的节点、来自连接至由相同处理器子单元实施的来自第一层的节点的第二层的节点,及类似节点。通过基于节点的连接来指派节点,可缩减处理器子单元之间的数据传送,此可导致效率提高,如上文所解释。
388.如上文图7a及图7b中所描绘而解释,处理器子单元可在空间上分布于安置于存储
器芯片上的多个存储器组当中。因此,任务的指派可至少部分地为空间划分以及逻辑划分。
389.在步骤820处,处理器可产生用以在存储器芯片的成对的处理器子单元之间传送数据的任务,每一对处理器子单元由一总线连接。例如,如上文所解释,该数据传送可使用软件来控制。因此,处理器子单元可被配置为在同步时间将数据推送于总线上及提取总线上的数据。所产生的任务可因此包括用于执行数据的此同步推送及提取的任务。
390.如上文所解释,步骤820可包括预处理以考虑处理器子单元的内部行为,包括时序及延时。例如,处理器可使用处理器子单元的已知时间及延时(例如,将数据推送至总线的时间、从总线提取数据的时间、计算与推送或提取之间的延时,或其类似物)以确保所产生的任务同步。因此,包含由一个或多个处理器子单元进行的至少一次推送及由一个或多个处理器子单元进行的至少一次提取的数据传送可同时发生,而不会由于处理器子单元之间的时序差、处理器子单元的延时或其类似物而引起延迟。
391.在步骤830处,处理器可将所指派及产生的任务分组成子系列指令的多个群组。例如,该子系列指令可各包含供单处理器子单元执行的一系列任务。因此,子系列指令的多个群组中的每个可对应于多个处理器子单元中的不同处理器子单元。因此,步骤810、820及830可导致将该系列指令分成子系列指令的多个群组。如上文所解释,步骤820可确保不同群组之间的任何数据传送同步。
392.在步骤840处,处理器可产生对应于子系列指令的多个群组中的每个的机器码。例如,可将表示子系列指令的较高阶代码转换成可由对应处理器子单元执行的较低阶代码,诸如机器码。
393.在步骤850处,处理器可根据划分将对应于子系列指令的多个群组中的每个的所产生机器码指派给多个处理器子单元中的对应处理器子单元。例如,处理器可用对应处理器子单元的识别符来标记每一子系列指令。因此,当将子系列指令上传至存储器芯片以供执行(例如,由图3a的主机350)时,每一子系列可配置一正确的处理器子单元。
394.在一些实施例中,将与该系列指令相关联的任务指派给处理器子单元中的不同处理器子单元可至少部分地取决于存储器芯片上的处理器子单元中的两者或多于两者之间的空间接近性。例如,如上文所解释,可通过缩减处理器子单元之间的数据传送的数量来提高效率。因此,处理器可将跨越处理器子单元中的多于两者移动数据的数据传送减至最少。因此,处理器可结合一个或多个优化算法(诸如,贪婪算法)使用存储器芯片的已知布局,以便将子系列指派给处理器子单元,其指派方式使邻近传送达至最大(至少区域地)且使至非相邻处理器子单元的传送减至最少(至少区域地)。
395.方法800可包括针对本公开的存储器芯片的进一步优化。例如,处理器可基于划分将与该系列指令相关联的数据分组且根据该分组将数据指派给存储器组。因此,该存储器组可保存用于指派给每个存储器组所专用于的每一处理器子单元的子系列指令的数据。
396.在一些实施例中,将数据分组可包括判定在存储器组中的两者或多于两者中复制的数据的至少一部分。例如,如上文所解释,可跨越多于一个子系列指令使用一些数据。此数据可跨越专用于经指派不同子系列指令的多个处理器子单元的存储器组复制。此优化可进一步缩减跨越处理器子单元的数据传送。
397.可将方法800的输出输入至本公开的存储器芯片以供执行。例如,一存储器芯片可包含多个处理器子单元及对应的多个存储器组,每一处理器子单元连接至专用于该处理器
子单元的至少一个存储器组,且该存储器芯片的该处理器子单元可被配置为执行由方法800产生的机器码。如上文关于图3a所解释,主机350可将由方法800产生的机器码输入至处理器子单元以供执行。
398.子组及子控制器
399.在常规存储器组中,控制器设置在组层级处。每一组包括多个垫,所述多个垫通常以矩形方式布置,但可按任何几何形状布置。每一垫包括多个存储器胞元,所述多个存储器胞元还通常以矩形方式布置,但可按任何几何形状布置。每一胞元可储存单一数据比特(例如,取决于该胞元保持在高电压抑或低电压下)。
400.此常规架构的实施例描绘于图9及图10中。如图9中所展示,在组层级处,多个垫(例如,垫930-1、930-2、940-1及940-2)可形成组900。在常规矩形组织中,可跨越全局字线(例如,字线950)及全局比特线(例如,比特线960)控制组900。因此,行解码器910可基于传入控制信号(例如,对从地址读取的请求、对写入至地址的请求或其类似物)选择正确字线,且全局感测放大器920(和/或全局列解码器,图9中未展示)可基于该控制信号选择正确比特线。放大器920也可在读取操作期间放大来自选定组的任何电压电平。尽管描绘为将行解码器用于初始选择且沿着列执行放大,但组可另外或替代地将列解码器用于初始选择且沿着行执行放大。
401.图10描绘垫1000的实施例。例如,垫1000可形成诸如图9的组900的存储器组的一部分。如图10中所描绘,多个胞元(例如,胞元1030-1、1030-2及1030-3)可形成垫1000。每一胞元可包含储存至少一个数据比特的电容器、晶体管或其他电路系统。例如,一胞元可包含电容器或可包含触发器(flip-flop),该电容器经充电以表示「1」且放电以表示「0」,该触发器具有表示「1」的第一状态及表示「0」的第二状态。常规垫可包含例如512个比特
×
512个比特。在垫1000形成mram、reram或其类似物的一部分的实施例中,一胞元可包含晶体管、电阻器、电容器或用于隔离储存至少一个数据比特的材料的离子或一部分的其他机构。例如,一胞元可包含具有表示「1」的第一状态及表示「0」的第二状态的电解质离子、硫族化物玻璃的一部分,或其类似物。
402.如图10中进一步所描绘,在常规矩形组织中,可跨越区域字线(例如,字线1040)及区域比特线(例如,比特线1050)控制垫1000。因此,字线驱动器(例如,字线驱动器1020-1、1020-2、
……
、1020-x)可基于来自与存储器组(垫1000形成该存储器组的一部分)相关联的控制器的控制信号(例如,对从地址读取的请求、对写入至地址的请求、刷新信号)而控制选定字线以执行读取、写入或刷新。此外,区域感测放大器(例如,区域放大器1010-1、1010-2、
……
、1010-x)和/或区域列解码器(图10中未展示)可控制选定比特线以执行读取、写入或刷新。该区域感测放大器也可在读取操作期间放大来自选定胞元的任何电压电平。尽管描绘为将字线驱动器用于初始选择且沿着列执行放大,但垫可替代地将比特线驱动器用于初始选择且沿着行执行放大。
403.如上文所解释,复制大量垫以形成存储器组。可将存储器组群聚以形成存储器芯片。例如,存储器芯片可包含八个至三十二个存储器组。因此,使处理器子单元与常规存储器芯片上的存储器组配对可产生仅八个至三十二个处理器子单元。因此,本公开的实施例可包括具有额外子组阶层的存储器芯片。本公开的这些存储器芯片可接着包括具有用作与处理器子单元配对的专用存储器组的存储器子组的处理器子单元,以允许较大数量的子处
理器,此可接着达成存储器内计算的较高平行性及效能。
404.在本公开的一些实施例中,组900的全局行解码器及全局感测放大器可用子组控制器来替换。因此,存储器组的控制器可将控制信号引导至适当的子组控制器,而非将控制信号发送至存储器组的全局行解码器及全局感测放大器。引导可动态地加以控制或可为硬联机的(例如,经由一个或多个逻辑门)。在一些实施例中,熔断器可用以指示每一子组或垫的控制器是否阻断控制信号或传递控制信号至适当的子组或垫。在这些实施例中,可因此使用熔断器来撤销启动故障子组。
405.在这些实施例中的一个实施例中,一存储器芯片可包括多个存储器组,每个存储器组具有一组控制器及多个存储器子组,每个存储器子组具有一子组行解码器及一子组列解码器以允许对该存储器子组上的位置进行读取及写入。每一子组可包含多个存储器垫,每个存储器垫具有多个存储器胞元且可具有在内部的区域行解码器、列解码器和/或区域感测放大器。该子组行解码器及该子组列解码器可处理用于子组存储器上的存储器内计算的来自组控制器或来自子组处理器子单元的读取及写入请求,如下文所描述。另外,每个存储器子组可进一步具有一控制器,该控制器被配置为判定处理来自组控制器的读取请求及写入请求和/或将读取请求及写入请求转送至下一层级(例如,垫上的行解码器及列解码器的下一层级),抑或阻断该请求,例如以允许内部处理元件或处理器子单元存取存储器。在一些实施例中,该组控制器可同步至系统时钟。然而,该子组控制器可不同步至系统时钟。
406.如上文所解释,子组的使用可允许在存储器芯片中包括比在处理器子单元与常规芯片的存储器组配对的情况下更大数量的处理器子单元。因此,每一子组可进一步具有使用子组作为专用存储器的处理器子单元。如上文所解释,该处理器子单元可包含risc、cisc或其他通用处理子单元和/或可包含一个或多个加速器。另外,该处理器子单元可包括地址生成器,如上文所解释。在上文所描述的实施例中的任一者中,每一处理器子单元可被配置为使用专用于该处理器子单元的子组的行解码器及列解码器而不使用组控制器来存取该子组。与子组相关联的处理器子单元也可处置存储器垫(包括下文所描述的解码器及存储器冗余机构)和/或判定是否转送且因此处置来自上部层级(例如,组层级或存储器层级)的读取或写入请求。
407.在一些实施例中,子组控制器还可以包括储存子组的状态的寄存器。因此,在该寄存器指示该子组处于使用中时,若该子组控制器接收到来自存储器控制器的控制信号,则该子组控制器可传回错误。在每一子组还包括一处理器子单元的实施例中,若该子组中的该处理器子单元正存取与来自存储器控制器的外部请求冲突的存储器,则该寄存器可指示错误。
408.图11展示使用子组控制器的存储器组的另一实施例的实施例。在图11的实施例中,组1100具有行解码器1110、列解码器1120,及具有子组控制器(例如,控制器1130a、1130b及1130c)的多个存储器子组(例如,子组1170a、1170b及1170c)。该子组控制器可包括地址解算器(例如,解算器1140a、1140b及1140c),该地址解算器可判定是否将请求传递至由子组控制器控制的一个或多个子组。
409.该子组控制器还可以包括一个或多个逻辑电路(例如,逻辑1150a、1150b及1150c)。例如,包含一个或多个处理元件的逻辑电路可允许执行诸如刷新子组中的胞元、清除子组中的胞元或其类似物的一个或多个操作而无需来自组1100外部的处理请求。替代
地,逻辑电路可包含处理器子单元,如上文所解释,使得处理器子单元具有由子组控制器控制的任何子组作为对应的专用存储器。在图11的实施例中,逻辑1150a可具有子组1170a作为对应的专用存储器,逻辑1150b可具有子组1170b作为对应的专用存储器,且逻辑1150c可具有子组1170c作为对应的专用存储器。在上文所描述的实施例中的任一者中,逻辑电路可具有至子组的总线,例如,总线1131a、1131b或1131c。如图11中进一步所描绘,该子组控制器可各包括多个解码器,诸如子组行解码器及子组列解码器,以允许处理元件或处理器子单元或发布命令的较高阶存储器控制器对存储器子组上的地址进行读取及写入。例如,子组控制器1130a包括解码器1160a、1160b及1160c,子组控制器1130b包括解码器1160d、1160e及1160f,且子组控制器1130c包括解码器1160g、1160h及1160i。基于来自组行解码器1110的请求,子组控制器可使用包括于子组控制器中的解码器来选择字线。所描述系统可允许子组的处理元件或处理器子单元在不中断其他组及甚至其他子组的情况下存取存储器,藉此允许每一子组处理器子单元与其他子组处理器子单元平行地执行存储器计算。
410.此外,每一子组可包含多个存储器垫,每个存储器垫具有多个存储器胞元。例如,子组1170a包括垫1190a-1、1190a-2、
……
、1190a-x;子组1170b包括垫1190b-1、1190b-2、
……
、1190b-x;且子组1170c包括垫1190c-1、1190c-2、
……
、1190c-3。如图11中进一步所描绘,每一子组可包括至少一个解码器。例如,子组1170a包括解码器1180a,子组1170b包括解码器1180b,且子组1170c包括解码器1180c。因此,组列解码器1120可基于外部请求而选择全局比特线(例如,比特线1121a或1121b),而由组行解码器1110选择的子组可使用其列解码器基于来自子组所专用于的逻辑电路的区域请求而选择区域比特线(例如,比特线1181a或1181b)。因此,每一处理器子单元可被配置为使用子组的行解码器及列解码器来存取专用于该处理器子单元的子组而无需使用组行解码器及组列解码器。因此,每一处理器子单元可存取对应子组而不会中断其他子组。此外,当对子组的请求在处理器子单元外时,子组解码器可向组解码器反映所存取的数据。替代地,在每一子组仅具有一行存储器垫的实施例中,区域比特线可为垫的比特线,而非子组的比特线。
411.可使用以下实施例的组合:使用子组行解码器及子组列解码器的实施例;及图11中所描绘的实施例。例如,可消除组行解码器,但保留组列解码器且使用区域比特线。
412.图12展示具有多个垫的存储器子组1200的实施例的实施例。例如,子组1200可表示图11的子组1100的一部分或可表示存储器组的替代实施。在图12的实施例中,子组1200包括多个垫(例如,垫1240a及1240b)。此外,每一垫可包括多个胞元。例如,垫1240a包括胞元1260a-1、1260a-2、
……
、1260a-x,且垫1240b包括胞元1260b-1、1260b-2、
……
、1260b-x。
413.每一垫可经指派将指派给垫的存储器胞元的地址的范围。这些地址可在生产时配置,使得垫可到处移动且使得故障垫可被撤销启动且保持未使用(例如,使用一个或多个熔断器,如下文进一步所解释)。
414.子组1200接收来自存储器控制器1210的读取及写入请求。尽管图12中未描绘,但来自存储器控制器1210的请求可经由子组1200的控制器来筛选且引导至子组1200的适当垫以进行地址解算。替代地,来自存储器控制器1210的请求的地址的至少一部分(例如,较高比特)可传输至子组1200的所有垫(例如,垫1240a及1240b),使得仅当垫的经指派地址范围包括命令中所指定的地址时,每一垫方可处理完整地址及与该地址相关联的请求。类似于上文所描述的子组引导,垫判定可动态地加以控制或可为硬联机的。在一些实施例中,熔
断器可用以判定每一垫的地址范围,以还允许通过指派不合法地址范围来停用故障垫。垫可另外或替代地通过其他常用方法或熔断器的连接来停用。
415.在上文所描述的实施例中的任一者中,子组的每一垫可包括用于选择垫中的字线的行解码器(例如,行解码器1230a或1230b)。在一些实施例中,每一垫还可以包括熔断器及比较器(例如,1220a及1220b)。如上文所描述,比较器可允许每一垫判定是否处理传入请求,且熔断器可允许每一垫在发生故障的情况下撤销启动。替代地,可使用组和/或子组的行解码器,而非使用每一垫中的行解码器。
416.此外,在上文所描述的实施例中的任一者中,包括于适当垫中的列解码器(例如,列解码器1250a或1250b)可选择区域比特线(例如,比特线1251或1253)。区域比特线可连接至存储器组的全局比特线。在子组具有其自身的区域比特线的实施例中,胞元的区域比特线可进一步连接至子组的区域比特线。因此,可经由胞元的列解码器(和/或感测放大器)、接着经由子组的列解码器(和/或感测放大器)(在包括子组列解码器和/或感测放大器的实施例中)且接着经由组的列解码器(和/或感测放大器)来读取选定胞元中的数据。
417.垫1200可经复制及排成阵列以形成存储器组(或存储器子组)。例如,本公开的存储器芯片可包含多个存储器组,每个存储器组具有多个存储器子组,且每个存储器子组具有用于处理对存储器子组上的位置进行的读取及写入的子组控制器。此外,每个存储器子组可包含多个存储器垫,每个存储器垫具有多个存储器胞元且具有一垫行解码器及一垫列解码器(例如,如图12中所描绘)。该垫行解码器及该垫列解码器可处理来自子组控制器的读取及写入请求。例如,该垫解码器可接收所有请求且基于每一垫的已知地址范围判定(例如,使用比较器)是否处理请求,或该垫解码器可基于子组(或组)控制器对垫的选择而仅接收在已知地址范围内的请求。
418.控制器数据传送
419.除使用处理子单元来共享数据以外,本公开的存储器芯片中的任一者也可使用存储器控制器(或子组控制器或垫控制器)来共享数据。例如,本公开的存储器芯片可包含:多个存储器组(例如,sram组、dram组或其类似物),每个存储器组具有一组控制器、一行解码器及一列解码器,以允许对该存储器组上的位置进行读取及写入;以及多个总线,其将多个组控制器中的每一控制器连接至多个组控制器中的至少一个其他控制器。所述多个总线可类似于如上文所描述的连接处理子单元的总线,但所述多个总线直接地而非经由处理子单元来连接该组控制器。此外,尽管描述为连接组控制器,但总线可另外或替代地连接符组控制器和/或垫控制器。
420.在一些实施例中,可在不中断连接至一个或多个处理器子单元的存储器组的主总线上的数据传送的情况下存取所述多个总线。因此,存储器组(或子组)可在与将数据传输至不同存储器组(或子组)或从不同存储器组(或子组)传输数据相同的时钟循环中将数据传输至对应处理器子单元或从对应处理器子单元传输数据。在每一控制器连接至多个其他控制器的实施例中,该控制器可能可配置以用于选择其他控制器中的另一个用于发送或接收数据。在一些实施例中,每一控制器可连接至至少一个相邻控制器(例如,空间邻近控制器对可彼此连接)。
421.存储器电路中的冗余逻辑
422.本公开大体上系有关于具有用于芯片上数据处理的主要逻辑部分的存储器芯片。
该存储器芯片可包括冗余逻辑部分,该冗余逻辑部分可替换有缺陷的主要逻辑部分以提高芯片的制造良率。因此,该芯片可包括片上组件,该片上组件允许基于对该逻辑部分的个别测试来配置存储器芯片中的逻辑区块。该芯片的此特征可提高良率,这是因为具有专用于逻辑部分的较大面积的存储器芯片更容易发生制造故障。例如,具有大冗余逻辑部分的dram存储器芯片可容易发生制造问题,此降低良率。然而,实施冗余逻辑部分可导致提高良率及可靠性,这是因为该实施使dram存储器芯片的制造商或使用者能够在维持高平行性的同时接通或断开全部逻辑部分。应注意,在此处及贯穿本公开,可识别某些存储器类型(诸如,dram)的实施例,以便促进解释所公开实施例。然而,应理解,在这些情况下,识别的存储器类型并不意欲为限制性的。确切而言,诸如dram、快闪存储器、sram、reram、pram、mram、rom或任何其他存储器的存储器类型可与所公开实施例共同使用,即使在本公开的某一章节中特定地识别较少实施例亦如此。
423.图13为符合所公开实施例的示例性存储器芯片1300的功能方块图。存储器芯片1300可实施为dram存储器芯片。存储器芯片1300也可实施为任何类型之易失性或非易失性存储器,诸如快闪存储器、sram、reram、pram和/或mram等。存储器芯片1300可包括基板1301,该基板中布置有地址管理器1302、包括多个存储器组1304(a,a)至1304(z,z)的存储器阵列1304、存储器逻辑1306、商业逻辑1308及冗余商业逻辑1310。存储器逻辑1306及商业逻辑1308可构成主要逻辑区块,而冗余商业逻辑1310可构成冗余区块。此外,存储器芯片1300可包括配置开关,该配置开关可包括撤销启动开关1312及启动开关1314。撤销启动开关1312及启动开关1314也可安置于基板1301中。在本技术案中,存储器逻辑1306、商业逻辑1308及冗余商业逻辑1310也可统称为「逻辑区块」。
424.地址管理器1302可包括行和列解码器或其他类型的存储器辅助设备。替代地或另外,地址管理器1302可包括微控制器或处理单元。
425.在一些实施例中,如图13中所展示,存储器芯片1300可包括单一存储器阵列1304,该存储器阵列可将多个存储器区块以二维阵列布置在基板1301上。然而,在其他实施例中,存储器芯片1300可包括多个存储器阵列1304,且存储器阵列1304中的每个可按不同配置布置存储器区块。例如,存储器阵列中的至少一个中的存储器区块(也被称为存储器组)可按径向分布配置以促进地址管理器1302或存储器逻辑1306至存储器区块之间的路由。
426.商业逻辑1308可用以进行与用以管理存储器本身的逻辑无关的应用程序的存储器内计算。例如,商业逻辑1308可实施与ai相关的功能,诸如用作启动功能的浮点、整数或mac运算。此外,商业逻辑1308可实施数据库相关功能,如最小值、最大值、排序、计数以及其他。存储器逻辑1306可执行与存储器管理相关的任务,包括(但不限于)读取、写入及刷新操作。因此,可在组层级、垫层级或垫群组层级中的一个或多个中添加商业逻辑。商业逻辑1308可具有一个或多个地址输出及一个或多个数据输入/输出。例如,商业逻辑1308可通过至地址管理器1302的行\列线来寻址。然而,在某些实施例中,逻辑区块可另外或替代地经由数据输入\输出来寻址。
427.冗余商业逻辑1310可为商业逻辑1308的再制品。此外,冗余商业逻辑1310可连接至撤销启动开关1312和/或启动开关1314,其可包括小的熔断器\反熔断器,且用于逻辑停用或启用实例中的一个(例如,预设连接的实例)且启用其他逻辑区块中的一个(例如,预设断开的实例)。在一些实施例中,如关于图15进一步所描述,区块的冗余在诸如商业逻辑
1308的逻辑区块内可为区域的。
428.在一些实施例中,存储器芯片1300中的逻辑区块可通过专用总线连接至存储器阵列1304的子集。例如,存储器逻辑1306、商业逻辑1308及冗余商业逻辑1310的集合可连接至存储器阵列1304中的第一行存储器区块(也即,存储器区块1304(a,a)至1304(a,z))。专用总线可允许相关联逻辑区块快速地存取存储器区块的数据,而不要求经由例如地址管理器1302开放通信线。
429.多个主要逻辑区块中的每个可连接至多个存储器组1304中的至少一个。另外,诸如冗余商业区块1310的冗余区块可连接至存储器实例1304(a,a)至1304(z,z)中的至少一个。冗余区块可再制多个主要逻辑区块中的至少一个,诸如存储器逻辑1306或商业逻辑1308。撤销启动开关1312可连接至所述多个主要逻辑区块中的至少一个,且启动开关1314可连接至所述多个冗余区块中的至少一个。
430.在这些实施例中,在侦测到与多个主要逻辑区块中的一个(存储器逻辑1306和/或商业逻辑1308)相关联的故障后,撤销启动开关1312可被配置为停用多个主要逻辑区块中的该者。同时,启动开关1314可被配置为启用多个冗余区块中的再制多个主要逻辑区块中的一个的冗余区块,诸如冗余逻辑区块1310。
431.此外,可统称为「配置开关」的启动开关1314及撤销启动开关1312可包括用以配置开关的状态的外部输入。例如,启动开关1314可被配置为使得外部输入中的启动信号产生闭合开关条件,而撤销启动开关1312可被配置为使得外部输入中的撤销启动信号产生断开开关条件。在一些实施例中,1300中的所有配置开关可默认为撤销启动,且在测试指示相关联逻辑区块起作用且信号施加于外部输入中之后变得被启动或启用。替代地,在一些状况下,1300中的所有配置开关可默认为经启用,且可在测试指示相关联逻辑区块不起作用且撤销启动信号施加于外部输入中之后被撤销启动或停用。
432.无关于最初启用抑或停用配置开关,在侦测到与相关联逻辑区块相关联的故障后,配置开关可停用相关联逻辑区块。在最初启用配置开关的状况下,配置开关的状态可改变至停用,以便停用相关联逻辑区块。在最初停用配置开关的状况下,配置开关的状态可保持在其停用状态中,以便停用相关联逻辑区块。例如,可操作性测试的结果可指示,某一逻辑区块不操作或该逻辑区块不能在某些规格内操作。在这些状况下,可停用逻辑区块,可能不启用其对应配置开关。
433.在一些实施例中,配置开关可连接至两个或多于两个逻辑区块,且可被配置为在不同逻辑区块之间进行选择。例如,配置开关可连接至商业逻辑区块1308及冗余逻辑区块1310两者。配置开关可启用冗余逻辑区块1310,同时停用商业逻辑1308。
434.替代地或另外,多个主要逻辑区块中的至少一个(存储器逻辑1306和/或商业逻辑1308)可通过第一专用连接件连接至多个存储器组或存储器实例1304的子集。接着,多个冗余区块中的再制多个主要逻辑区块中的至少一个的至少一个冗余区块(诸如,冗余商业逻辑1310)可通过第二专用连接件连接至相同多个存储器组或实例1304的子集。
435.此外,存储器逻辑1306可具有不同于商业逻辑1308的功能及能力。例如,虽然存储器逻辑1306可经设计以实现存储器组1304中的读取及写入操作,但商业逻辑1308可经设计以执行存储器内计算。因此,若商业逻辑1308包括第一商业逻辑区块且商业逻辑1308包括第二商业逻辑区块(如冗余商业逻辑1310),则有可能将有缺陷的商业逻辑1308断开且重新
连接冗余商业逻辑1310使得不会失去任何能力。
436.在一些实施例中,配置开关(包括撤销启动开关1312及启动开关1314)可用熔断器、反熔断器或可编程设备(包括可一次性可编程设备)或其他形式的非易失性存储器来实施。
437.图14为符合所公开实施例的示例性冗余逻辑区块集合1400的功能方块图。在一些实施例中,冗余逻辑区块集合1400可安置于基板1301中。冗余逻辑区块集合1400可包括分别连接至开关1312及1314的商业逻辑1308及冗余商业逻辑1310中的至少一个。此外,商业逻辑1308及冗余商业逻辑1310可连接至地址总线1402及数据总线1404。
438.在一些实施例中,如图14中所展示,开关1312及1314可将逻辑区块连接至时钟节点。以此方式,配置开关可将逻辑区块与时钟信号接合或脱离,以有效地启动或撤销启动逻辑区块。然而,在其他实施例中,开关1312及1314可将逻辑区块连接至其他节点以用于启动或撤销启动。例如,配置开关可将逻辑区块连接至电压供应节点(例如,vcc)或连接至接地节点(例如,gnd)或时钟信号。以此方式,逻辑区块可由配置开关启用或停用,这是因为该配置开关可产生开路或截断逻辑区块供电。
439.在一些实施例中,如图14中所展示,地址总线1402及数据总线1404可在逻辑区块的相对侧中,该逻辑区块并联地连接至该总线中的每个。以此方式,可通过逻辑区块集合1400促进不同片上组件的路由。
440.在一些实施例中,多个撤销启动开关1312中的每个将多个主要逻辑区块中的至少一个与时钟节点耦接,且多个启动开关1314中的每个可将多个冗余区块中的至少一个与时钟节点耦接,以允许连接\断开时钟以作为简单的启动\撤销启动机制。
441.冗余逻辑区块集合1400的冗余商业逻辑1310允许设计者基于面积及路由而选择值得复制的区块。例如,芯片设计者可选择较大区块进行复制,这是因为较大区块可更容易出错。因此,芯片设计者可决定复制大的逻辑区块。另一方面,设计者可偏好复制较小逻辑区块,这是因为较小逻辑区块容易复制而无显着的空间损失。此外,使用图14中的配置,设计者可容易取决于每个区域的错误的统计数据来选择复制逻辑区块。
442.图15为符合所公开实施例的示例性逻辑区块1500的功能方块图。该逻辑区块可为商业逻辑1308和/或冗余商业逻辑1310。然而,在其他实施例中,示例性逻辑区块可描述存储器逻辑1306或存储器芯片1300的其他组件。
443.逻辑区块1500呈现在小型处理器管线内使用逻辑冗余的又一实施例。逻辑区块1500可包括寄存器1508、取得电路1504、解码器1506及写回电路1518。此外,逻辑区块1500可包括计算单元1510及复制计算单元1512。然而,在其他实施例中,逻辑区块1500可包括其他单元,该其他单元不包含控制器管线,但包括包含所需商业逻辑的分散的处理元件。
444.计算单元1510及复制计算单元1512可包括能够执行数字计算的数字电路。例如,计算单元1510及复制计算单元1512可包括算术逻辑单元(alu)以对二进制数执行算术及逐比特操作。替代地,计算单元1510及复制计算单元1512可包括对浮点数进行操作的浮点单元(fpu)。此外,在一些实施例中,计算单元1510及复制计算单元1512可实施数据库相关功能,如最小值、最大值、计数及比较操作以及其他。
445.在一些实施例中,如图15中所展示,计算单元1510及复制计算单元1512可连接至开关电路1514及1516。当经启动时,该开关电路可启用或停用该计算单元。
446.在逻辑区块1500中,复制计算单元1512可再制计算单元1510。此外,在一些实施例中,寄存器1508、取得电路1504、解码器1506及写回电路1518(统称为区域逻辑单元)的大小可小于计算单元1510。因为较大元件更容易在制造期间出现问题,所以设计者可决定复制较大单元(诸如,计算单元1510)而非复制较小单元(诸如,区域逻辑单元)。然而,取决于历史良率及错误率,除复制大单元(或整个区块)以外或替代复制大单元(或整个区块),设计者也可选择复制区域逻辑单元。例如,计算单元1510可比寄存器1508、取得电路1504、解码器1506及写回电路1518大,且因此更容易出错。设计者可选择复制计算单元1510而非复制逻辑区块1500中的其他元件或整个区块。
447.逻辑区块1500可包括多个区域配置开关,所述多个区域配置开关中的每个连接至计算单元1510或复制计算单元1512中的至少一个中的至少一者。当侦测到计算单元1510中的故障时,区域配置开关可被配置为停用计算单元1510且启用复制计算单元1512。
448.图16展示符合所公开实施例的与总线连接的示例性逻辑区块的功能方块图。在一些实施例中,逻辑区块1602(其可表示存储器逻辑1306、商业逻辑1308或冗余商业逻辑1310)可彼此独立,可经由总线连接,且可通过特定地寻址该逻辑区块而在外部启动。例如,存储器芯片1300可包括许多逻辑区块,每个逻辑区块具有一id号。然而,在其他实施例中,逻辑区块1602可表示由存储器逻辑1306、商业逻辑1308或冗余商业逻辑1310中的若干个(一个或多个)构成的较大单元。
449.在一些实施例中,逻辑区块1602中的每个可与其他逻辑区块1602冗余。所有区块可作为主要或冗余区块来操作的此完全冗余性可改良制造良率,这是因为设计者可断开故障单元同时维持整个芯片的功能性。例如,设计者可能够停用容易出错但维持类似计算能力的逻辑区域,这是因为所有复制区块可连接至相同的地址总线及数据总线。例如,逻辑区块1602的初始数量可大于目标容量。因而,停用一些逻辑区块1602将不会影响目标容量。
450.连接至逻辑区块的总线可包括地址总线1614、命令线1616及数据线1618。如图16中所展示,逻辑区块中的每个可独立于总线中的每一线而连接。然而,在某些实施例中,逻辑区块1602可按阶层式结构连接以促进路由。例如,总线中的每一线可连接至将该线路由至不同逻辑区块1602的多任务器。
451.在一些实施例中,为了在不知晓内部芯片结构(其可能由于启用及停用单元而改变)的情况下允许外部存取,逻辑区块中的每个可包括熔断id,诸如熔断标识1604。熔断标识1604可包括判定id的开关(如熔断器)的阵列,且可连接至管理电路。例如,熔断标识1604可连接至地址管理器1302。替代地,熔断标识1604可连接至较高存储器地址单元。在这些实施例中,熔断标识1604可能可配置以用于特定地址。例如,熔断标识1604可包括可编程的非易失性设备,其基于从管理电路接收到的指令而判定最终id。
452.存储器芯片上的分布式处理器可设计成具有图16中所描绘的配置。在芯片唤醒时或在工厂测试时执行为bist的测试程序可将运行id号指派给通过测试协议的多个主要逻辑区块(存储器逻辑1306及商业逻辑1308)中的区块。测试程序也可将不合法id号指派给未通过测试协议的多个主要逻辑区块中的区块。测试程序也可将运行id号指派给通过测试协议的多个冗余区块中的区块(冗余逻辑区块1310)。因为冗余区块替换发生故障的主要逻辑区块,所以经指派运行id号的多个冗余区块中的区块可等于或大于经指派不合法id号的多个主要逻辑区块中的区块,藉此停用区块。此外,多个主要逻辑区块中的每个及多个冗余区
块中的每个可包括至少一个熔断标识1604。另外,如图16中所展示,连接逻辑区块1602的总线可包括命令线、数据线及地址线。
453.然而,在其他实施例中,连接至总线的所有逻辑区块1602将开始被停用且不具有id号。逐个地测试,每一良好逻辑区块将得到运行id号,且不工作的这些逻辑区块将保留不合法id,此将停用这些区块。以此方式,冗余逻辑区块可通过替换在测试处理程序期间已知有缺陷的区块来改良制造良率。
454.地址总线1614可将管理电路耦接至多个存储器组中的每个、多个主要逻辑区块中的每个及多个冗余区块中的每个。这些连接允许管理电路在侦测到与主要逻辑区块(诸如,商业逻辑1308)相关联的故障后将无效地址指派给多个主要逻辑区块中的一个且将有效地址指派给多个冗余区块中的一个。
455.例如,如图16a中所展示,不合法id被配置至所有逻辑区块1602(a)至1602(c)(例如,地址0xfff)。在测试之后,逻辑区块1602(a)及1602(c)经验证为起作用,而逻辑区块1602(b)不起作用。在图16a中,无阴影逻辑区块可表示成功地通过功能性测试的逻辑区块,而阴影逻辑区块可表示未通过功能性测试的逻辑区块。因而,测试程序针对起作用的逻辑区块将不合法id改变为合法id,而为不作用的逻辑区块保留不合法id。作为一实施例,在图16a中,逻辑区块1602(a)及1602(c)的地址从0xfff分别改变为0x001及0x002。相比之下,逻辑区块1602(b)的地址仍为不合法地址0xfff。在一些实施例中,id通过编程对应熔断标识1604来改变。
456.来自逻辑区块1602的测试的不同结果可产生不同配置。例如,如图16b中所展示,地址管理器1302最初可将不合法id指派给所有逻辑区块1602(也即,0xfff)。然而,测试结果可指示两个逻辑区块1602(a)及1602(b)起作用。在这些状况下,对逻辑区块1602(c)的测试可能并非必要的,这是因为存储器芯片1300可能仅需要两个逻辑区块。因此,为了将测试资源减至最少,可仅根据1300的产品定义所需的起作用逻辑区块的最小数量来测试逻辑区块,以使其他逻辑区块未经测试。图16b还展示表示通过功能性测试的经测试逻辑区块的无阴影逻辑区块及表示未测试逻辑区块的阴影逻辑区块。
457.在这些实施例中,在起动时执行bist的生产测试器(外部或内部的,自动或人工的)或控制器可针对起作用的经测试逻辑区块将不合法id改变为运行id,而为未测试逻辑区块保留不合法id。作为一实施例,在图16b中,逻辑区块1602(a)及1602(b)的地址从0xfff分别改变为0x001及0x002。相比之下,未测试逻辑区块1602(c)的地址仍为不合法地址0xfff。
458.图17为符合所公开实施例的串联连接的示例性单元1702及1712的功能方块图。图17可表示整个系统或芯片。替代地,图17可表示含有其他起作用区块的芯片中的区块。
459.单元1702及1712可表示包括诸如存储器逻辑1306和/或商业逻辑1308的多个逻辑区块的完整单元。在这些实施例中,单元1702及1712也可包括执行操作所需的元件,诸如地址管理器1302。然而,在其他实施例中,单元1702及1712可表示诸如商业逻辑1308或冗余商业逻辑1310的逻辑单元。
460.图17呈现单元1702及1712可能需要在其本身之间通信的实施例。在此类状况下,单元1702及1712可串联连接。然而,非工作单元可破坏逻辑区块之间的连续性。因此,当单元由于缺陷而需要被停用时,单元之间的连接可包括旁路选项。该旁路选项也可为旁路单
元本身的部分。
461.在图17中,单元可串联连接(例如,1702(a)至1702(c)),且发生故障的单元(例如,1702(b))可在其有缺陷时被绕过。该单元可进一步与开关电路并联地连接。例如,在一些实施例中,单元1702及1712可与开关电路1722及1728连接,如图17中所描绘。在图17中所描绘的实施例中,单元1702(b)有缺陷。例如,单元1702(b)未通过电路功能性测试。因此,可使用例如启动开关1314(图17中未展示)来停用单元1702(b),和/或可启动开关电路1722(b)以绕过单元1702(b)且维持逻辑区块之间的连接性。
462.因此,当多个主要单元串联连接时,所述多个单元中的每个可与一并联开关并联地连接。在侦测到与多个单元中的一个相关联的故障后,可启动连接至所述多个单元中的该者的并联开关以连接所述多个单元中的两者。
463.在其他实施例中,如图17中所展示,开关电路1728可包括将致使一个或多个循环延迟的一或更多个取样点,以维持单元的不同线之间的同步。当停用一单元时,邻近逻辑区块之间的连接的短路可能会产生与其他计算的同步误差。例如,若一任务需要来自a线及b线两者的数据,且a及b中的每个系由独立的一系列单元承载,则停用一单元将导致将需要进一步数据管理的线之间的去同步。为了防止去同步,样本电路1730可仿真由经停用单元1712(b)引起的延迟。然而,在一些实施例中,并联开关可包括反熔断器而非取样电路1730。
464.图18为符合所公开实施例的成二维阵列连接的示例性单元的功能方块图。图18可表示整个系统或芯片。替代地,图18可表示含有其他起作用区块的芯片中的区块。
465.单元1806可表示包括诸如存储器逻辑1306和/或商业逻辑1308的多个逻辑区块的自主单元。然而,在其他实施例中,单元1806可表示诸如商业逻辑1308的逻辑单元。在方便时,图18的论述可参考图13(例如,存储器芯片1300)中所识别且上文所论述的元件。
466.如图18中所展示,单元可布置成二维阵列,其中单元1806(其可包括或表示存储器逻辑1306、商业逻辑1308或冗余商业逻辑1310中的一个或多个)经由开关箱1808及连接箱1810互连。此外,为了控制二维阵列的配置,二维阵列可在二维阵列的周边中包括i/o区块1804。
467.连接箱1810可为可编程且可重配置的设备,其可对从i/o区块1804输入的信号作出响应。例如,连接箱可包括来自单元1806的多个输入接脚且也可连接至开关箱1808。替代地,连接箱1810可包括将可编程逻辑胞元的接脚与路由轨线连接的开关的群组,而开关箱1808可包括连接不同轨线的开关的群组。
468.在某些实施例中,连接箱1810及开关箱1808可通过诸如开关1312及1314的配置开关实施。在这些实施例中,连接箱1810及开关箱1808可由生产测试器或在芯片起动时所执行的bist来配置。
469.在一些实施例中,连接箱1810及开关箱1808可在测试单元1806的电路功能性之后进行配置。在这些实施例中,i/o区块1804可用以将测试信号发送至单元1806。取决于测试结果,i/o区块1804可发送编程信号,该编程信号以停用未通过测试协议的单元1806且启用通过测试协议的单元1806的方式来配置连接箱1810及开关箱1808。
470.在这些实施例中,多个主要逻辑区块及多个冗余区块可成二维栅格安置于基板上。因此,多个主要单元1806中的每个及多个冗余区块中的每个(诸如,冗余商业逻辑1310)可用开关箱1808互连,且输入区块可安置于二维栅格的每一线及每一列的周边中。
471.图19为符合所公开实施例的处于复杂连接中的示例性单元的功能方块图。图19可表示整个系统。替代地,图19可表示含有其他起作用区块的芯片中的区块。
472.图19的复杂连接包括单元1902(a)至1902(f)及配置开关1904(a)至1904(f)。单元1902可表示包括诸如存储器逻辑1306和/或商业逻辑1308的多个逻辑区块的自主单元。然而,在其他实施例中,单元1902可表示诸如存储器逻辑1306、商业逻辑1308或冗余商业逻辑1310的逻辑单元。配置开关1904可包括撤销启动开关1312及启动开关1314中的任一者。
473.如图19中所展示,该复杂连接可包括两个平面中的单元1902。例如,复杂连接可包括在z轴上分开的两个独立基板。替代地或另外,单元1902可布置在基板的两个表面中。例如,出于缩减存储器芯片1300的面积的目的,基板1301可布置在两个重叠表面中且与在三维上布置的配置开关1904连接。配置开关可包括撤销启动开关1312和/或启动开关1314。
474.基板的第一平面可包括「主」单元1902。这些区块可预设为经启用。在这些实施例中,第二平面可包括「冗余」单元1902。这些单元可默认为经停用。
475.在一些实施例中,配置开关1904可包括反熔断器。因此,在测试单元1902之后,区块可通过将某些反熔断器切换至「始终接通」及停用选定单元1902来连接于起作用单元的块中,即使该单元在不同平面中亦如此。在图19中所呈现的实施例中,「主」单元中的一个(单元1902(e))不工作。图19可将不起作用区块或未测试区块表示为阴影区块,而经测试或起作用区块可为无阴影的。因此,配置开关1904被配置为使得不同平面中的逻辑区块中的一个(例如,单元1902(f))变为作用中。以此方式,即使主逻辑区块中的一个有缺陷,存储器芯片仍通过替换备用逻辑单元而工作。
476.图19另外展示不测试或启用第二平面中的单元1902中的一个(也即,1902(c)),这是因为主逻辑区块起作用。例如,在图19中,两个主单元1902(a)及1902(d)通过功能性测试。因此,单元1902(c)未被测试或启用。因此,图19展示特定地选择取决于测试结果而变为在作用中的逻辑区块的能力。
477.在一些实施例中,如图19中所展示,并非第一平面中的所有单元1902均可具有对应的备用或冗余区块。然而,在其他实施例中,所有单元可彼此冗余以实现完全冗余,其中所有单元均为主要或冗余的。此外,虽然一些实施可遵循图19中所描绘的星形网络拓朴,但其他实施可使用并联连接、串联连接和/或将不同元件与配置开关并联地或串联地耦接。
478.图20为说明符合所公开实施例的冗余区块启用处理程序2000的示例性流程图。可针对存储器芯片1300且特别地针对dram存储器芯片实施启用处理程序2000。在一些实施例中,处理程序2000可包括以下步骤:测试存储器芯片的基板上的多个逻辑区块中的每个的至少一个电路功能性;基于测试结果识别多个主要逻辑区块中的故障逻辑区块;测试存储器芯片的基板上的至少一个冗余或额外逻辑区块的至少一个电路功能性;通过将外部信号施加至撤销启动开关来停用至少一个故障逻辑区块;及通过将该外部信号施加至启动开关来启用该至少一个冗余区块,该启动开关与该至少一个冗余区块连接且安置于该存储器芯片的该基板上。以下图20的描述进一步详述处理程序2000的每一步骤。
479.处理程序2000可包括测试诸如商业区块1308的多个逻辑区块(步骤2002)及多个冗余区块(例如,冗余商业区块1310)。测试可在封装之前使用例如用于晶圆上测试的探测站进行。然而,步骤2000也可在封装之后执行。
480.步骤2002中的测试可包括将有限序列的测试信号施加至存储器芯片1300中的每
个逻辑区块或存储器芯片1300中的逻辑区块的子集。该测试信号可包括请求预期得到0或1的计算。在其他实施例中,测试信号可请求读取存储器组中的特定地址或写入特定存储器组中。
481.可在步骤2002中实施测试技术以测试逻辑区块在反复处理程序下的响应。例如,该测试可涉及通过传输将数据写入存储器组中的指令及接着验证写入数据的完整性来测试逻辑区块。在一些实施例中,该测试可包括利用反转数据重复算法。
482.在替代实施例中,步骤2002的测试可包括运行逻辑区块的模型以基于一组测试指令产生目标存储器图像。接着,可对存储器芯片中的逻辑区块执行相同序列的指令,且可记录结果。模拟的残余存储器图像也可与自测试获得的图像进行比较,且任何失配可标示为故障。
483.替代地,在步骤2002中,该测试可包括阴影模型化,在阴影模型化中会产生诊断,但未必预测结果。反而,使用阴影模型化的测试可对存储器芯片及模拟两者平行地执行。例如,当存储器芯片中的逻辑区块完成指令或任务时,仿真可经发信以执行相同指令。一旦存储器芯片中的逻辑区块完成该指令,便可将两个模型的架构状态进行比较。若存在失配,则标示故障。
484.在一些实施例中,可在步骤2002中测试所有逻辑区块(包括例如存储器逻辑1306、商业逻辑1308或冗余商业逻辑1310中的每个)。然而,在其他实施例中,可在不同测试回合中仅测试逻辑区块的子集。例如,在第一测试回合中,可仅测试存储器逻辑1306及相关联区块。在第二回合中,可仅测试商业逻辑1308及相关联区块。在第三回合中,取决于前两个回合的结果,可测试与冗余商业逻辑1310相关联的逻辑区块。
485.处理程序2000可继续至步骤2004。在步骤2004中,可识别故障逻辑区块,且也可识别故障冗余区块。例如,未通过步骤2002的测试的逻辑区块可在步骤2004中识别为故障区块。然而,在其他实施例中,最初仅可识别某些故障逻辑区块。例如,在一些实施例中,仅可识别与商业逻辑1308相关联的逻辑区块,且仅在需要故障冗余区块以替代故障逻辑区块的情况下识别故障冗余区块。此外,识别故障区块可包括在存储器组或非易失性存储器上写入经识别故障区块的标识信息。
486.在步骤2006中,可停用故障逻辑区块。例如,使用配置电路,可通过将故障逻辑区块与时钟、接地和/或电源节点断开来停用故障逻辑区块。替代地,可通过以避开逻辑区块的布置来配置连接箱来停用故障逻辑区块。另外,在其他实施例中,可通过从地址管理器1302接收不合法地址来停用故障逻辑区块。
487.在步骤2008中,可识别复制故障逻辑区块的冗余区块。即使一些逻辑区块已发生故障,为了支持存储器芯片的相同能力,在步骤2008中,可识别可用且可复制故障逻辑区块的冗余区块。例如,若执行向量的乘法的逻辑区块经判定为发生故障,则在步骤2008中,地址管理器1302或片上控制器可识别还执行向量的乘法的可用冗余逻辑区块。
488.在步骤2010中,可启用在步骤2008中所识别的冗余区块。与步骤2006的停用操作相比,在步骤2010中,可通过将经识别冗余区块连接至时钟、接地和/或电源节点来启用该经识别冗余区块。替代地,可通过以连接经识别冗余区块的布置来配置连接箱来启用经识别冗余区块。另外,在其他实施例中,可通过在测试程序运行时间接收运行地址来启用经识别冗余区块。
489.图21为说明符合所公开实施例的地址指派处理程序2100的示例性流程图。可针对存储器芯片1300且特别地针对dram存储器芯片实施地址指派处理程序2100。如关于图16所描述,在一些实施例中,存储器芯片1300中的逻辑区块可连接至数据总线且具有地址标识。处理程序2100描述地址指派方法,该地址指派方法停用故障逻辑区块且启用通过测试的逻辑区块。处理程序2100中所描述的步骤将描述为由生产测试器或在芯片起动时所执行的bist执行;然而,存储器芯片1300的其他组件和/或外部设备也可执行处理程序2100的一个或多个步骤。
490.在步骤2102中,测试器可通过在芯片层级将不合法标识指派给每个逻辑区块来停用所有逻辑区块及冗余区块。
491.在步骤2104中,测试器可执行逻辑区块的测试协议。例如,测试器可针对存储器芯片1300中的逻辑区块中的一个或多个执行步骤2002中所描述的测试方法。
492.在步骤2106中,取决于步骤2104中的测试的结果,测试器可判定逻辑区块是否有缺陷。若逻辑区块无缺陷(步骤2106:否),则地址管理器可在步骤2108中将运行id指派给经测试逻辑区块。若逻辑区块有缺陷(步骤2106:是),则地址管理器1302可在步骤2110中为有缺陷逻辑区块保留不合法id。
493.在步骤2112中,地址管理器1302可选择复制有缺陷逻辑区块的冗余逻辑区块。在一些实施例中,复制有缺陷逻辑区块的冗余逻辑区块可具有与有缺陷逻辑区块相同的组件及连接。然而,在其他实施例中,冗余逻辑区块可具有不同于有缺陷逻辑区块的组件和/或连接,但能够执行等效操作。例如,若有缺陷逻辑区块经设计以执行向量的乘法,则选定冗余逻辑区块将能够执行向量的乘法,即使选定冗余逻辑区块不具有与有缺陷单元相同的架构亦如此。
494.在步骤2114中,地址管理器1302可测试冗余区块。例如,测试器可将步骤2104中应用的测试技术应用于经识别冗余区块。
495.在步骤2116中,基于步骤2114中的测试的结果,测试器可判定冗余区块是否有缺陷。在步骤2118中,若冗余区块无缺陷(步骤2116:否),则测试器可将运行id指派给经识别冗余区块。在一些实施例中,处理程序2100可在步骤2118之后返回至步骤2104,以产生测试存储器芯片中的所有逻辑区块的反复循环。
496.若测试器判定冗余区块有缺陷(步骤2116:是),则在步骤2120中,测试器可判定额外冗余区块是否可用。例如,测试器可向存储器组查询关于可用冗余逻辑区块的信息。若冗余逻辑区块可用(步骤2120:是),则测试器可返回至步骤2112且识别再制有缺陷逻辑区块的新的冗余逻辑区块。若冗余逻辑区块不可用(步骤2120:否),则在步骤2122中,测试器可产生错误信号。该错误信号可包括有缺陷逻辑区块及有缺陷冗余区块的信息。
497.耦接的存储器组
498.本公开所公开的实施例还包括分布式高效能处理器。该处理器可包括介接存储器组及处理单元的存储器控制器。该处理器可能可配置以加快将数据递送至处理单元以用于计算。例如,若处理单元需要两个数据例项以执行任务,则存储器控制器可被配置为使得通信线独立地提供对来自两个数据例项的信息的存取。所公开的存储器架构试图将与复杂高速缓存及复杂寄存器文件方案相关联的硬件要求降至最低。通常,处理器芯片包括允许核心直接与寄存器一起工作的高速缓存阶层。然而,高速缓存操作需要相当大的晶粒面积且
消耗额外功率。所公开的存储器架构通过在存储器中添加逻辑组件来避免使用高速缓存阶层。
499.所公开架构还实现数据在存储器组中的策略性(或甚至优化)置放。即使存储器组具有单一端口及高延时,所公开的存储器架构也可通过将数据策略性地定位于存储器组的不同区块中来实现高效能及避免存储器存取瓶颈。以将数据的连续串流提供至处理单元为目标,编译优化步骤可针对特定或一般任务判定数据应如何储存于存储器组中。接着,介接处理单元及存储器组的存储器控制器可被配置为在特定处理单元需要数据以执行操作时向该特定处理单元授权存取。
500.存储器芯片的配置可由处理单元(例如,配置管理者)或外部接口执行。该配置也可由编译程序或其他sw工具写入。此外,存储器控制器的配置可基于存储器组中的可用端口及存储器组中的数据的组织。因此,所公开架构可向处理单元提供来自不同存储器区块的恒定数据流或同时信息。以此方式,存储器内的计算任务可通过避免延时瓶颈或高速缓存要求来快速地处理。
501.此外,储存于存储器芯片中的数据可基于编译优化步骤进行布置。编译可允许建置处理程序,其中处理器将任务高效地指派给处理单元而无存储器延时相关联的延迟。该编译可由编译程序执行且被传输至连接至基板中的外部接口的主机。通常,某些存取图案的高延时和/或少量端口将导致需要数据的处理单元的数据瓶颈。然而,所公开编译可按使得处理单元能够甚至在不利存储器类型的情况下仍连续地接收数据的方式将数据定位于存储器组中。
502.此外,在一些实施例中,配置管理器可基于任务所需的计算向所需处理单元发信。芯片中的不同处理单元或逻辑区块可具有针对不同任务的专门硬件或架构。因此,取决于将执行的任务,可选择处理单元或处理单元群组来执行任务。基板上的存储器控制器可能可配置以根据处理子单元的选择来投送数据或授权存取,以改良数据传输速度。例如,基于编译优化及存储器架构,当需要处理单元以执行任务时,可授权该处理单元对存储器组的存取。
503.此外,芯片架构可包括片上组件,该片上组件通过缩减存取存储器组中的数据所需的时间来促进数据的传送。因此,本公开描述用于能够使用简单的存储器实例执行特定或一般任务的高效能处理器的芯片架构连同编译优化步骤。存储器实例可具有高的随机存取延时和/或少量端口,诸如dram设备或其他存储器定向技术中所使用的这些存储器实例,但所公开架构可通过实现从存储器组至处理单元的连续(或几乎连续)数据流来克服这些缺点。
504.在本技术案中,同时通信可指一时钟循环内的通信。替代地,同时通信可指在预定时间量内发送信息。例如,同时通信可指在几奈秒内的通信。
505.图22提供符合所公开实施例的示例性处理设备的功能方块图。图22a展示处理设备2200的第一实施例,其中存储器控制器2210使用多任务器连接第一存储器区块2202及第二存储器区块2204。存储器控制器2210也可连接至少一配置管理器2212、一逻辑区块2214及多个加速器2216(a)至2216(n)。图22b展示处理设备2200的第二实施例,其中存储器控制器2210使用总线连接存储器区块2202及2204,该总线连接存储器控制器2210与至少一配置管理器2212、一逻辑区块2214及多个加速器2216(a)至2216(n)。此外,主机2230可在处理设
备2200外部且经由例如外部接口连接至处理设备。
506.存储器区块2202及2204可包括dram垫或垫群组、dram组、mram\pram\reram\sram单元、快闪存储器垫或其他存储器技术。存储器区块2202及2204可替代地包括非易失性存储器、快闪存储器设备、电阻式随机存取存储器(reram)设备或磁阻式随机存取存储器(mram)设备。
507.存储器区块2202及2204可另外包括多个存储器胞元,所述多个存储器胞元在多条字线(未示出)与多条比特线(未示出)之间布置成行和列。每一行存储器胞元的栅极可连接至多条字线中的各别者。每一列存储器胞元可连接至多条比特线中的各别者。
508.在其他实施例中,存储器区域(包括存储器区块2202及2204)由简单的存储器实例建置。在本技术案中,术语「存储器实例」可与术语「存储器区块」互换使用。存储器实例(或区块)可具有不良特性。例如,存储器可为仅单端口存储器且可具有高随机存取延时。替代地或另外,存储器在列及线改变期间可能无法存取且面临与例如电容充电和/或电路系统设置相关的数据存取问题。然而,通过允许存储器实例与处理单元之间的专用连接及以考虑区块的特性的某一方式来布置数据,图22中所呈现的架构仍促进存储器设备中的平行处理。
509.在一些设备架构中,存储器实例可包括若干端口,以促进平行操作。然而,在这些实施例中,当数据基于芯片架构来编译及组织时,芯片仍可达成改良效能。例如,编译程序可通过提供指令及组织数据置放来改良存储器区域中的存取的效率,因此即使使用单端口存储器,仍能够容易存取存储器区域。
510.此外,存储器区块2202及2204可为单一芯片中的存储器的多个类型。例如,存储器区块2202及2204可为eflash及edram。另外,存储器区块可包括具有rom实例的dram。
511.存储器控制器2210可包括用以处置存储器存取及将结果传回至模块的其余部分的逻辑电路。例如,存储器控制器2210可包括地址管理器及诸如多任务器的选择设备,以在存储器区块与处理单元之间投送数据或授权对存储器区块的存取。替代地,存储器控制器2210可包括用以驱动ddr sdram的双数据速率(ddr)存储器控制器,其中数据在系统的存储器时钟的上升边缘及下降边缘上传送。
512.此外,存储器控制器2210可构成双通道存储器控制器。双通道存储器的并入可促进存储器控制器2210对平行存取线的控制。该平行存取线可被配置为具有相同长度,以在结合使用多个线时促进数据同步。替代地或另外,该平行存取线可允许存取存储器组的多个存储器端口。
513.在一些实施例中,处理设备2200可包括可连接至处理单元的一个或多个多任务器。该处理单元可包括可直接至多任务器的配置管理器2212、逻辑区块2214及加速器2216。另外,存储器控制器2210可包括来自多个存储器组或区块2202及2204的至少一个数据输入端,及连接至多个处理单元中的每个的至少一个数据输出端。通过此配置,存储器控制器2210可经由两个数据输入端同时从存储器组或存储器区块2202及2204接收数据,且经由两个数据输出端同时将经由接收的数据传输至至少一个选定处理单元。然而,在一些实施例中,至少一个数据输入端及至少一个数据输出端可实施于单一端口中,以允许仅读取或写入操作。在这些实施例中,单一端口可实施为包括数据线、地址线及命令线的数据总线。
514.存储器控制器2210可连接至多个存储器区块2202及2204中的每个,且也可经由例
如选择开关连接至处理单元。基板上的处理单元(包括配置管理器2212、逻辑区块2214及加速器2216)也可独立地连接至存储器控制器2210。在一些实施例中,配置管理器2212可接收要执行的任务的指示,且作为响应,根据储存于存储器中或从外部供应的配置而配置存储器控制器2210、加速器2216和/或逻辑区块2214。替代地,存储器控制器2210可由外部接口配置。该任务可能需要可用以从多个处理单元选择至少一个选定处理单元的至少一次计算。替代地或另外,该选择可至少部分地基于选定处理单元执行至少一次计算的能力。作为响应,存储器控制器2210可授权对存储器组的存取,或使用专用总线和/或以管线式存储器存取在至少一个选定处理单元与至少两个存储器组之间投送数据。
515.在一些实施例中,至少两个存储器区块中的第一存储器区块2202可布置在多个处理单元的第一侧上;且至少两个存储器组中的第二存储器组2204可布置在所述多个处理单元的与该第一侧相对的第二侧上。另外,用以执行任务的选定处理单元(例如,加速器2216(n))可被配置为在至第一存储器组或第一存储器区块2202的通信线开放的时钟循环期间存取第二存储器组2204。替代地,该选定处理单元可被配置为在至第一存储器区块2202的通信线开放的时钟循环期间将数据传送至第二存储器区块2204。
516.在一些实施例中,存储器控制器2210可实施为独立元件,如图22中所展示。然而,在其他实施例中,存储器控制器2210可嵌入于存储器区域中或可沿着加速器2216(a)至2216(n)安置。
517.处理设备2200中的处理区域可包括配置管理器2212、逻辑区块2214及加速器2216(a)至2216(n)。加速器2216可包括具有预定义功能的多个处理电路且可由特定应用程序定义。例如,加速器可为处置模块之间的存储器移动的向量乘法累加(mac)单元或直接存储器存取(dma)单元。加速器2216也可能够计算其自身地址且向存储器控制器2210请求数据或将数据写入至存储器控制器。例如,配置管理器2212可向加速器2216中的至少一个发信该加速器可存取存储器组。接着,加速器2216可配置存储器控制器2210以投送数据或向加速器本身授权存取。此外,加速器2216可包括至少一个算术逻辑单元、至少一个向量处置逻辑单元、至少一个字符串比较逻辑单元、至少一个寄存器及至少一个直接存储器存取件。
518.配置管理器2212可包括用以配置加速器2216及指示任务的执行的数字处理电路。例如,配置管理器2212可连接至存储器控制器2210及多个加速器2216中的每个。配置管理器2212可具有其自身的专用存储器以保存加速器2216的配置。配置管理器2212可使用存储器组以经由存储器控制器2210取得命令及配置。替代地,配置管理器2212可经由外部接口来编程。在某些实施例中,配置管理器2212可用具有自身的高速缓存阶层的片上精简指令集计算机(risc)或片上复杂cpu来实施。在一些实施例中,也可省略配置管理器2212,且加速器可经由外部接口来配置。
519.处理设备2200也可包括外部接口(未示出)。该外部接口允许从上部层级(此存储器组控制器,其接收来自外部主机2230或片上主处理器的命令)对存储器进行存取,或从外部主机2230或片上主处理器对存储器进行存取。该外部接口可通过经由存储器控制器2210将配置或代码写入至存储器以供配置管理器2212或单元2214及2216本身稍后使用来允许对配置管理器2212及加速器2216进行编程。然而,该外部接口也可直接编程处理单元而不经由存储器控制器2210进行路由。在配置管理器2212为微控制器的状况下,配置管理器2212可允许经由外部接口将代码从主存储器加载至控制器区域存储器。存储器控制器2210
可被配置为响应于接收到来自外部接口的请求而中断任务。
520.该外部接口可包括与逻辑电路相关联的多个连接器,该连接器提供至处理设备上的多种元件的无胶合接口。该外部接口可包括:用于数据读取的数据i/o输入端及用于数据写入的输出端;外部地址输出端;外部ce0芯片选择接脚;低有效芯片选择器;字节启用接脚;用于存储器循环的等待状态的接脚;写入启用接脚;输出启用有效接脚;及读取写入启用接脚。因此,该外部接口具有所需输入端及输出端以控制处理程序且从处理设备获得信息。例如,该外部接口可符合jedec ddr标准。替代地或另外,外部接口可符合其他标准,诸如spi\ospi或uart。
521.在一些实施例中,该外部接口可安置于芯片基板上且可连接外部主机2230。外部主机可经由外部接口存取存储器区块2202及2204、存储器控制器2210以及处理单元。替代地或另外,外部主机2230可对存储器进行读取及写入,或可经由读取及写入命令向配置管理器2212发信以执行操作,诸如开始处理程序和/或停止处理程序。此外,外部主机2230可直接配置加速器2216。在一些实施例中,外部主机2230能够直接对存储器区块2202及2204执行读取/写入操作。
522.在一些实施例中,配置管理器2212及加速器2216可被配置为取决于目标任务而使用直接总线来连接设备区域与存储器区域。例如,当加速器2216的子集能够执行任务执行所需的计算时,加速器的该子集可与存储器实例2204连接。通过进行此分开,有可能确保专用加速器获得存储器区块2202及2204所需的带宽(bw)。此外,具有专用总线的此配置可允许将大存储器分裂成较小实例或区块,这是因为将存储器实例连接至存储器控制器2210允许甚至在具有高行延时时间的情况下也可快速存取不同存储器中的数据。为达成连接的平行化,存储器控制器2210可用数据总线、地址总线和/或控制总线连接至存储器实例中的每个。
523.存储器控制器2210的上述包括可消除对处理设备中的高速缓存阶层或复杂寄存器文件的要求。尽管可添加高速缓存阶层以得到添加的能力,但处理设备处理设备2200中的架构可允许设计者基于处理操作而添加足够存储器区块或实例且在无高速缓存阶层的情况下相应地管理该实例。例如,处理设备处理设备2200中的架构可通过实施管线式存储器存取来消除对高速缓存阶层的需求。在管线式存储器存取中,处理单元可在某些数据线可开放(或启动)而其他数据线接收或传输数据的每个循环中接收持续数据流。使用独立通信线的持续数据流可能由于线改变而实现改良的执行速度及最小延时。
524.此外,图22中的所公开架构实现管线式存储器存取,有可能将数据组织在少量存储器区块中且节省由线切换造成的功率损耗。例如,在一些实施例中,编译程序可向主机2230传达数据在存储器组中的组织或用以将数据组织在存储器组中的方法,以促进在给定任务期间存取数据。接着,配置管理器2212可定义哪些存储器组且在一些状况下存储器组的哪些端口可由加速器存取。存储器组中的数据的位置与数据访问方法之间的此同步通过以最小延时将数据馈入至加速器来改良计算任务。例如,在配置管理器2212包括risc\cpu的实施例中,该方法可用脱机软件(sw)来实施,且接着配置管理器2212可经编程以执行该方法。该方法可用可由risc/cpu计算机执行的任何语言来开发且可在任何平台上执行。该方法的输入可包括存储器控制器后方的存储器的配置及数据本身,连同存储器存取的图案。此外,该方法可用特定于实施例的语言或机器语言来实施,且也可仅为以二进制或文字
表示的一系列配置值。
525.如上文所论述,在一些实施例中,编译程序可将指令提供至主机2230以用于在准备管线式存储器存取时将数据组织在存储器区块2202及2204中。该管线式存储器存取通常可包括以下步骤:接收多个存储器组或存储器区块2202及2204的多个地址;根据所接收的地址使用独立数据线存取所述多个存储器组;经由第一通信线将来自第一地址的数据供应至多个处理单元中的至少一个且开放至第二地址的第二通信线,该第一地址在所述多个存储器组中的第一存储器组中,该第二地址在所述多个存储器组中的第二存储器组2204中;及在第二时钟循环内,经由该第二通信线将来自该第二地址的数据供应至所述多个处理单元中的该至少一者且开放至第一线中的第一存储器组中的第三地址的第三通信线。在一些实施例中,该管线式存储器存取可在两个存储器区块连接至单一端口的情况下执行。在这些实施例中,存储器控制器2210可将两个存储器区块隐藏在单一端口后,但利用管线式存储器访问方法将数据传输至处理单元。
526.在一些实施例中,编译程序可在主机2230上执行,之后执行任务。在这些实施例中,编译程序可能够基于存储器设备的架构而判定数据流的配置,这是因为该配置将为编译程序已知的。
527.在其他实施例中,若存储器区块2204及2202的配置在脱机时间系未知的,则管线式方法可在主机2230上执行,该主机可在开始计算之前将数据布置在存储器区块中。例如,主机2230可将数据直接写入存储器区块2204及2202中。在这些实施例中,诸如配置管理器2212及存储器控制器2210的处理单元在运行时间之前可能不会具有关于所需硬件的信息。接着,可能有必要延迟对加速器2216的选择,直至任务开始运行。在这些情形中,处理单元或存储器控制器2210可随机地选择加速器2216且产生测试数据存取图案,该存取图案可在执行任务时加以修改。
528.然而,当任务预先已知时,编译程序可将数据及指令组织在存储器组中以供主机2230提供至诸如配置管理器2212的处理单元,以设定将存取延时减至最少的信号连接。例如,在一些状况下,加速器2216可能同时需要n个字。然而,每个存储器实例支持每次仅取回m个字,其中「m」及「n」为整数且m《n。因此,编译程序可跨越不同存储器实例或区块置放所需数据,以促进数据存取。另外,为了避免线错漏延时,在处理设备2200包括多个存储器存储器的情况下,主机可在不同存储器实例的不同线中分裂数据。数据的划分可允许存取下一实例中的下一数据线,同时仍使用来自当前实例的数据。
529.例如,加速器2216(a)可被配置为将两个向量相乘。向量中的每个可储存于诸如存储器区块2202及2204的独立存储器区块中,且每个向量可包括多个字。因此,为了完成需要加速器2216(a)进行乘法的任务,可能有必要存取两个存储器区块且取回多个字。然而,在一些实施例中,存储器区块仅允许每个时钟循环存取一个字。例如,存储器区块可具有单一端口。在这些状况下,为了在操作期间加快数据传输,编译程序可将构成向量的字组织于不同存储器区块中,以允许对字的平行和/或同时读取。在这些情形中,编译程序可将字储存于具有专用线的存储器区块中。例如,若每个向量包括两个字且存储器控制器能够直接存取四个存储器区块,则编译程序可将数据布置在四个存储器区块中,每个存储器区块传输一字且加快数据递送。此外,在实施例中,当存储器控制器2210可具有至每个存储器区块的多于单一连接时,编译程序可指示配置管理器2212(或其他处理单元)存取端口特定端口。
以此方式,处理设备2200可执行管线式存储器存取,以通过同时在一些线中加载字及在其他线中传输数据来将数据连续地提供至处理单元。因此,此管线式存储器存取避免可避免延时问题。
530.图23为符合所公开实施例的示例性处理设备2300的功能方块图。该功能方块图展示简化的处理设备2300,其显示呈mac单元2302形式的单一加速器、配置管理器2304(等效或类似于配置管理器2212)、存储器控制器2306(等效或类似于存储器控制器2210)及多个存储器区块2308(a)至2308(d)。
531.在一些实施例中,mac单元2302可为用于处理特定任务的特定加速器。作为实施例,处理设备2300可以2d卷积为任务。接着,配置管理器2304可向具有适当硬件的加速器发信以执行与任务相关联的计算。例如,mac单元2302可具有四个内部递增计数器(用以管理卷积计算所需的四个回路的逻辑加法器及寄存器)及一乘法累加单元。配置管理器2304可向mac单元2302发信以处理传入数据且执行任务。配置管理器2304可将指示传输至mac单元2302以执行任务。在这些情形中,mac单元2302可在所计算地址上进行反复,将数字相乘,且将其累加至内部寄存器。
532.在一些实施例中,配置管理器2304可配置加速器,而存储器控制器2306授权使用专用总线存取区块2308及mac单元2302。然而,在其他实施例中,存储器控制器2306可基于从配置管理器2304或外部接口接收的指令而直接配置加速器。替代地或另外,配置管理器2304可预先加载几个配置且允许加速器反复地在具有不同大小的不同地址上运行。在这些实施例中,配置管理器2304可包括高速缓存,该高速缓存储存命令,之后该命令被传输至诸如加速器2216的多个处理单元中的至少一者。然而,在其他实施例中,配置管理器2304可能不包括高速缓存。
533.在一些实施例中,配置管理器2304或存储器控制器2306可接收为了任务需要存取的地址。配置管理器2304或存储器控制器2306可检查寄存器以判定地址是否已经在至存储器区块2308中的一个的加载的线中。若在加载的线中,则存储器控制器2306可从存储器区块2308读取字且将该字传递至mac单元2302。若地址不在加载的线中,则配置管理器2304可请求存储器控制器2306可加载该线且向mac单元2302发信以延迟,直至取回该加载的线。
534.在一些实施例中,如图23中所展示,存储器控制器2306可包括形成两个独立地址的两个输入。但若应同时存取多于两个地址,且这些地址在单一存储器区块中(例如,地址仅在存储器区块2308(a)中),则存储器控制器2306或配置管理器2304可能会引发例外状况。替代地,当两个地址仅可经由单一线来存取时,配置管理器2304可传回无效数据信号。在其他实施例中,该单元可延迟处理程序执行,直至有可能取回所有需要的数据。此可降低总体效能。然而,编译程序可能够找到将防止延迟的配置及数据置放。
535.在一些实施例中,编译程序可产生用于处理设备2300的配置或指令集,该配置或指令集可配置配置管理器2304及存储器控制器2306以及加速器2302以处置需要从单一存储器区块存取多个地址但该存储器区块具有一个端口的情形。例如,编译程序可将数据重新布置在存储器区块2308中,使得处理单元可存取存储器区块2308中的多个线。
536.此外,存储器控制器2306也可在相同时间同时对多于一个输入进行工作。例如,存储器控制器2306可允许经由一个端口存取存储器区块2308中的一个及在于另一输入端中接收对不同存储器区块的请求时供应数据。因此,此操作可导致以示例性2d卷积为任务的
加速器2216从相关存储器区块的专用通信线接收数据。
537.另外或替代地,存储器控制器2306或逻辑区块可保持针对每个存储器区块2308的刷新计数器且处置所有线的刷新。具有此计数器允许存储器控制器2306插入设备的停滞访问时间之间的刷新循环中。
538.此外,存储器控制器2306可能可配置以执行管线式存储器存取,以接收地址且开放存储器区块中的线,之后供应数据。该管线式存储器存取可在不中断或不延迟时钟循环的情况下将数据提供至处理单元。例如,虽然存储器控制器2306或逻辑区块中的一个在图23中利用右方线存取数据,但存储器控制器或逻辑区块可正在左方线中传输数据。将关于图26更详细地解释这些方法。
539.响应于所需数据,处理设备2300可使用多任务器和/或其他开关设备来选择服务哪些设备以执行给定任务。例如,配置管理器2304可配置多任务器,使得至少两个数据线到达mac单元2302。以此方式,需要来自多个地址的数据的任务(诸如,2d卷积)可较快地执行,这是因为在卷积期间需要乘法的向量或字可在单一时钟中同时到达处理单元。此数据传送方法可允许诸如加速器2216的处理单元快速地输出结果。
540.在一些实施例中,配置管理器2304可能可配置以基于任务的优先权执行处理程序。例如,配置管理器2304可被配置为使运行中处理程序无任何中断地完成。在此状况下,配置管理器2304可将任务的指令或配置提供至加速器2216,使该加速器不间断地运行,且仅在任务完成时切换多任务器。然而,在其他实施例中,配置管理器2304可在其接收到优先任务(诸如,来自外部接口的请求)时中断任务且重新配置数据路由。然而,在存储器区块2308足够的情况下,存储器控制器2306可能可配置以利用专用线将数据投送至处理单元或向处理单元授权存取,该专用线在任务完成之前不必改变。此外,在一些实施例中,所有设备可通过总线连接至配置管理器2304的实体,且设备可管理设备本身与总线之间的存取(例如,使用与多任务器相同的逻辑)。因此,存储器控制器2306可直接连接至数个存储器实例或存储器区块。
541.替代地,存储器控制器2306可直接连接至存储器子实例。在一些实施例中,每个存储器实例或区块可由子实例建置(例如,dram可由布置在多个子区块中的具有独立数据线的垫建置)。另外,实例可包括dram垫、dram、组、快闪存储器垫或sram垫或任何其他类型的存储器中的至少一个。接着,存储器控制器2306可包括专用线以直接寻址子实例,以将管线式存储器存取期间在延时减至最少。
542.在一些实施例中,存储器控制器2306也可保持特定存储器实例所需的逻辑(诸如,行\列解码器、刷新逻辑等),且存储器区块2308可处置其自身的逻辑。因此,存储器区块2308可获得地址且产生用于传回\写入数据的命令。
543.图24描绘符合所公开实施例的示例性存储器配置图。在一些实施例中,产生用于处理设备2200的代码或配置的编译程序可执行用以通过将数据预先布置在每个区块中来配置自存储器区块2202及2204的加载的方法。例如,编译程序可预先布置数据,使得任务所需的每一字与一存储器实例或存储器区块的线相关。但对于需要比处理设备2200中可用的存储器区块多的存储器区块的任务,编译程序可实施使数据适配每个存储器区块的多于一个存储器位置的方法。编译程序也可依序储存数据且评估每个存储器区块的延时以避免线错漏延时。在一些实施例中,主机可为处理单元的部分,诸如配置管理器2212,但在其他实
施例中,编译程序主机可经由外部接口连接至处理设备2200。在这些实施例中,主机可运行编译功能,诸如针对编译程序所描述的编译功能。
544.在一些实施例中,配置管理器2212可为cpu或微控制器(uc)。在这些实施例中,配置管理器2212可能必须存取存储器以取得置放于存储器中的命令或指令。特定编译程序可产生代码且以一方式将该代码置放于存储器中,该方式允许在相同存储器线中及跨越数个存储器组储存连续命令,以允许还对所取得命令进行管线式存储器存取。在这些实施例中,配置管理器2212及存储器控制器2210可能够通过促进管线式存储器存取来避免线性执行中的行延时。
545.程序的线性执行的先前状况描述供编译程序辨识及置放指令以允许管线式存储器执行的方法。然而,其他软件结构可能更复杂且将需要编译程序辨识其他软件结构且相应地采取动作。例如,在任务需要循环及分支的状况下,编译程序可将所有循环代码置放于单一线内,使得单一线可在不具有线开放延时的情况下进行循环。接着,存储器控制器2210可能不需要在执行期间改变线。
546.在一些实施例中,配置管理器2212可包括内部高速缓存或小存储器。内部高速缓存可储存由配置管理器2212执行以处置分支及循环的命令。例如,内部高速缓存中的命令可包括用以配置用于存取存储器区块的加速器的指令。
547.图25为说明符合所公开实施例的可能存储器配置处理程序2500的示例性流程图。在便于描述存储器配置处理程序2500的情况下,可参考图22中所描绘及上文所描述的元件的识别符。在一些实施例中,处理程序2500可由编译程序执行,该编译程序将指令提供至经由外部接口连接的主机。在其他实施例中,处理程序2500可由处理设备2200的组件(诸如,配置管理器2212)执行。
548.一般而言,处理程序2500可包括:判定执行任务同时所需的字的数量;判定可同时自多个存储器组中的每个存取的字的数量;及当同时所需的字的数量大于可同时存取的字的数量时,在多个存储器组之间划分同时所需的该数量的字。此外,划分同时所需的该数量的字可包括执行字的循环组织及依序地每个存储器组指派一个字。
549.更具体而言,处理程序2500可以步骤2502开始,在该步骤中,编译程序可接收任务规格。该规格包括所需计算和/或优先权等级。
550.在步骤2504中,编译程序可识别可执行任务的加速器或加速器群组。替代地,编译程序可产生指令,因此处理单元(诸如,配置管理器2212)可识别加速器以执行该任务。例如,使用所需计算配置管理器2212可识别加速器2216的群组中的可处理该任务的加速器。
551.在步骤2506中,编译程序可判定为了执行该任务需要同时存取的字的数量。例如,两个向量的乘法需要存取至少两个向量,且编译程序因此可判定必须同时存取向量字以执行操作。
552.在步骤2508中,编译程序可判定执行该任务必需的循环的数量。例如,若该任务需要对四个附带产生结果的卷积运算,则编译程序可判定至少4个循环将为执行该任务所必需的。
553.在步骤2510中,编译程序可将需要同时存取的字置放于不同存储器组中。以此方式,存储器控制器2210可被配置为开放至不同存储器实例的线且在一时钟循环内存取所需存储器区块,而不需要任何高速缓存数据。
554.在步骤2512中,编译程序将依序存取的字置放于相同存储器组中。例如,在需要操作的四个循环的状况下,编译程序可产生指令以在依序循环中将所需字写入单一存储器区块中,以避免在执行期间在不同存储器区块之间改变线。
555.在步骤2514中,编译程序产生用于编程诸如配置管理器2212的处理单元的指令。该指令可指定操作开关设备(诸如,多任务器)或配置数据总线的条件。通过这些指令,配置管理器2212可根据任务配置存储器控制器2210以使用专用通信线将数据自存储器区块投送至处理单元或授权对该存储器区块的存取。
556.图26为说明符合所公开实施例的存储器读取处理程序2600的示例性流程图。在便于描述存储器读取处理程序2600的情况下,可参考图22中所描绘及上文所描述的元件的识别符。在一些实施例中,如下文所描述,处理程序2600可由存储器控制器2210实施。然而,在其他实施例中,处理程序2600可由处理设备2200中的其他元件(诸如,配置管理器2212)实施。
557.在步骤2602中,存储器控制器2210、配置管理器2212或其他处理单元可接收投送来自存储器组的数据或授权对存储器组的存取的指示。请求可指定地址及存储器区块。
558.在一些实施例中,该请求可经由线2218中指定读取命令及线2220中指定地址的数据总线接收。在其他实施例中,该请求可经由连接至存储器控制器2210的解多任务器接收。
559.在步骤2604中,配置管理器2212、主机或其他处理单元可查询内部寄存器。该内部寄存器可包括关于至存储器组的开放线、开放地址、开放存储器区块和/或即将进行的任务的信息。基于内部寄存器中的信息,可判定是否存在至存储器组的开放线和/或存储器区块是否在步骤2602中接收到请求。替代地或另外,存储器控制器2210可直接查询该内部寄存器。
560.若该内部寄存器指示存储器组未加载开放线中(步骤2606:否),则处理程序2600可继续至步骤2616,且可将线加载至与所接收地址相关联的存储器组。此外,存储器控制器2210或诸如配置管理器2212的处理单元可在步骤2616中将延迟发信至请求来自存储器地址的信息的元件。例如,若加速器2216正请求位于已被占用的存储器区块的存储器信息,则在步骤2618中,存储器控制器2210可将延迟信号发送至加速器。在步骤2620中,配置管理器2212或存储器控制器2210可更新内部寄存器以指示已开放至新存储器组或新存储器区块的线。
561.若该内部寄存器指示存储器组加载开放线中(步骤2606:是),则处理程序2600可继续至步骤2608。在步骤2608中,可判定加载有存储器组的线是否正用于不同地址。若该线正用于不同地址(步骤2608:是),则此将指示单一区块中存在两个实例,且因此,不能同时存取该两个实例。因此,可在步骤2616中将错误或免除信号发送至请求来自存储器地址的信息的元件。但若该线并未正用于不同地址(步骤2608:否),则可开放针对该地址的线并从目标存储器组取回数据,且继续至步骤2614以将数据传输至请求来自存储器地址的信息的元件。
562.利用处理程序2600,处理设备2200能够建立处理单元与含有执行任务所需的信息的存储器区块或存储器实例之间的直接连接。数据的此组织将使得能够自不同存储器实例中的经组织向量读取信息,以及允许在设备请求多个这些地址时同时自不同存储器区块取回信息。
563.图27为说明符合所公开实施例的执行处理程序2700的示例性流程图。在便于描述执行处理程序2700的情况下,可参考图22中所描绘及上文所描述的元件的识别符。
564.在步骤2702中,编译程序或诸如配置管理器2212的区域单元可接收需要执行的任务的指示。该任务可包括单一运算(例如,乘法)或更复杂运算(例如,矩阵之间的卷积)。该任务也可指示所需计算。
565.在步骤2704中,编译程序或配置管理器2212可判定执行该任务同时所需的字的数量。例如,配置编译程序可判定同时需要两个字来执行向量之间的乘法。在另一实施例(2d卷积任务)中,配置管理器2212可判定矩阵之间的卷积需要「n」乘「m」个字,其中「n」及「m」为矩阵维度。此外,在步骤2704中,配置管理器2212也可判定执行该任务必需的循环的数量。
566.在步骤2706中,取决于步骤2704中的判定,编译程序可将需要同时存取的字写入安置于基板上的多个存储器组中。例如,当可从多个存储器组中的一者同时存取的字的数量的数量小于同时所需的字的数量时,编译程序可将数据组织在多个存储器组中以促进在一时钟内存取不同所需字。此外,当配置管理器2212或编译程序判定执行任务必需的循环的数量时,编译程序可在依序循环中将所需的字写入多个存储器组中的单一存储器组中,以防止存储器组之间的线的切换。
567.在步骤2708中,存储器控制器2210可被配置为使用第一存储器线从多个存储器组或区块中的第一存储器组读取至少一个第一字或授权对该至少一个第一字的存取。
568.在步骤2170中,处理单元(例如,加速器2216中的一个)可使用至少一个第一字来处理任务。
569.在步骤2712中,存储器控制器2210可被配置为开放第二存储器组中的第二存储器线。例如,基于任务且使用管线式存储器访问方法,存储器控制器2210可被配置为开放在步骤2706中写入有任务所需的信息的第二存储器区块中的第二存储器线。在一些实施例中,该第二存储器线可在步骤2170中的任务将要完成时开放。例如,若一任务需要100个时钟,则该第二存储器线可在第90个时钟中开放。
570.在一些实施例中,步骤2708至2712可在一个线存取循环内执行。
571.在步骤2714中,存储器控制器2210可被配置为授权使用在步骤2710中开放的第二存储器线存取来自第二存储器组的至少一个第二字的数据。
572.在步骤2176中,处理单元(例如,加速器2216中的一个)可使用至少第二字来处理任务。
573.在步骤2718中,存储器控制器2210可被配置为开放第一存储器组中的第二存储器线。例如,基于任务且使用管线式存储器访问方法,存储器控制器2210可被配置为开放至第一存储器区块的第二存储器线。在一些实施例中,至第一区块的第二存储器线可在步骤2176中的任务将要完成时开放。
574.在一些实施例中,步骤2714至2718可在一个线存取循环内执行。
575.在步骤2720中,存储器控制器2210可使用第一记忆组中的第二存储器线或第三记忆组中的第一线及在不同存储器组中继续而从多个存储器组或区块中的第一存储器组读取至少一个第三字或授权对该至少一个第三字的存取。
576.诸如动态随机存取存储器(dram)芯片的一些存储器芯片使用刷新以避免所储存数据(例如,使用电容)由于芯片的电容器或其他电组件中的电压衰减而失去。例如,在dram
中,必须时常刷新每一胞元(基于特定处理程序及设计)以恢复电容器中的电荷,使得数据不会丢失或损坏。随着dram芯片的存储器容量增加,刷新存储器所需的时间量变得显着。在正刷新存储器的某一线的时间段期间,不能存取含有正刷新的该线的组。此可导致效能降低。另外,与刷新处理程序相关联的功率也可为显着的。先前已努力尝试缩减执行刷新的速率以缩减与刷新存储器相关联的不利影响,但大部分这些努力集中于dram的物理层。
577.刷新类似于读取及写回存储器的行。使用此原理且集中于存取存储器的图案,本公开的实施例包括软件及硬件技术以及对存储器芯片的修改,以使用较少功率用于刷新且缩减刷新存储器期间的时间量。例如,作为概述,一些实施例可使用硬件和/或软件以追踪线存取时序且在刷新循环内跳过最近存取行(例如,基于时序阈值)。在另一实施例中,一些实施例可依赖于由存储器芯片的刷新控制器执行的软件来指派读取及写入,使得对存储器的存取为非随机的。因此,软件可更精确地控制刷新以避免浪费刷新循环和/或线。这些技术可单独使用或与编码用于刷新控制器的命令及用于处理器的机器码的编译程序组合使用,使得对存储器的存取同样为非随机的。使用下文详细描述的这些技术及配置的任何组合,所公开实施例可通过缩减刷新存储器单元期间的时间量来降低存储器刷新功率要求和/或提高系统效能。
578.图28描绘符合本公开的具有刷新控制器2803的实施例存储器芯片2800。例如,存储器芯片2800可包括基板上的多个存储器组(例如,存储器组2801a及其类似物)。在图28的实施例中,基板包括四个存储器组,其各具有四个线。一线可指存储器芯片2800的一个或多个存储器组或存储器芯片2800内的存储器胞元的任何其他集合(诸如,存储器组的一部分或沿着存储器组的一整行或存储器组的群组)内的字线。
579.在其他实施例中,基板可包括任何数量的存储器组,且每个存储器组可包括任何数量的线。一些存储器组可包括相同数量的线(如图28中所展示),而其他存储器组可包括不同数量的线。如图28中进一步描绘,存储器芯片2800可包括控制器2805,该控制器用以接收至存储器芯片2800的输入且自存储器芯片2800传输输出(例如,如上文在「码的划分」中所描述)。
580.在一些实施例中,多个存储器组可包含动态随机存取存储器(dram)。然而,多个存储器组可包含储存需要周期性刷新的数据的任何易失性存储器。
581.如下文将更详细地论述,本公开所公开的实施例可使用计数器或电阻器-电容器电路以对刷新循环进行计时。例如,计数器或定时器可用以对自最后完整刷新循环的时间进行计数,且接着当计数器达到其目标值时,可使用另一计数器对所有行进行反复。本公开的实施例可另外追踪对存储器芯片2800的区段的存取且缩减所需的刷新功率。例如,尽管未在图28中描绘,但存储器芯片2800还可以包括数据储存器,该数据储存器被配置为储存指示多个存储器组中的一个或多个区段的存取操作的存取信息。例如,该一个或多个区段可包含存储器芯片2800内的存储器胞元的线、列或任何其他分组的任何部分。在一个特定实施例中,该一个或多个区段可包括多个存储器组内的至少一行的存储器结构。刷新控制器2803可被配置为至少部分地基于所储存的存取信息而执行该一个或多个区段的刷新操作。
582.例如,该数据储存器可包含与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联的一个或多个寄存器、静态随机存取存储器
(sram)胞元,或其类似物。另外,该数据储存器可被配置为储存指示相关联的区段是否在一个或多个先前循环中经存取的比特。「比特」可包含储存至少一个比特的任何数据结构,诸如寄存器、sram胞元、非易失性存储器或其类似物。此外,比特可通过将数据结构的对应开关(或开关元件,诸如晶体管)设定为接通(其可等效于「1」或「真」)来设定。另外或替代地,比特可通过修改数据结构内的任何其他性质(诸如,对快闪存储器的浮动门充电,修改sram中的一个或多个触发器的状态或其类似物)以便将「1」写入至该数据结构(或指示比特的设定的任何其他值)来设定。若一比特被判定为作为存储器控制器的刷新操作的部分而经设定,则刷新控制器2803可跳过相关联区段的刷新循环且清空与其部分相关联的寄存器。
583.在另一实施例中,数据储存器可包含与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联的一个或多个非易失性存储器(例如,快闪存储器或其类似物)。非易失性存储器可被配置为储存指示相关联的区段是否在一个或多个先前循环中经存取的比特。
584.一些实施例可另外或替代地在每一行或行群组(或存储器芯片2800的其他区段)上添加时间戳寄存器,该时间戳寄存器保存当前刷新循环内线被存取的最后时刻。此意谓在每一行存取的情况下,刷新控制器可更新行时间戳寄存器。因此,当下一次刷新发生时(例如,在刷新循环结束时),刷新控制器可比较所储存时间戳,且若相关联区段先前在某一时间段内(例如,在如应用于所储存时间戳的某一阈值内)经存取,则刷新控制器可跳至下一区段。此避免系统在最近已存取的区段上消耗刷新功率。此外,刷新控制器可继续追踪存取以确保在下一循环存取或刷新每个区段。
585.因此,在又一实施例中,数据储存器可包含与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联的一个或多个寄存器或非易失性存储器。该寄存器或非易失性存储器可被配置为储存指示相关联区段的最近存取的时间戳或其他信息,而非使用比特来指示是否已存取相关联区段。在此实施例中,刷新控制器2803可基于储存于相关联寄存器或存储器中的时间戳与当前时间(例如,来自定时器,如下文在图29a及图29b中所解释)之间的时间量是否超过预定阈值(例如,8ms、16ms、32ms、64ms或其类似物)来判定是否刷新或存取相关联区段。
586.因此,预定阈值可包含确保相关联区段在每个刷新循环内被刷新(若并非存取)至少一次的刷新循环的时间量。替代地,预定阈值可包含短于刷新循环所需的时间量的时间量(例如,以确保任何所需刷新或存取信号可在刷新循环完成之前到达相关联区段)。例如,预定时间可包含用于具有8ms刷新时段的存储器芯片的7ms,使得若区段在7ms内尚未被存取,则刷新控制器将发送在8ms刷新时段结束时到达该区段的刷新或存取信号。在一些实施例中,预定阈值可取决于相关联区段的大小。例如,对于存储器芯片2800的较小区段,预定阈值可较小。
587.尽管上文关于存储器芯片进行描述,但本公开的刷新控制器也可用于分布式处理器架构中,如在上文及贯穿本公开的章节中描述的这些架构。此类架构的一个实施例描绘于图7a中。在这些实施例中,与存储器芯片2800相同的基板可包括安置于其上的多个处理群组,例如,如图7a中所描绘。如上文关于图3a所解释,「处理群组」可指基板上的两个或多于两个处理器子单元及其对应存储器组。该群组可表示用于编译代码以供在存储器芯片2800上执行的目的的基板上的空间分布和/或逻辑分组。因此,该基板可包括存储器阵列,
该存储器阵列包括多个组,诸如图28中所展示的组2801a及其他组。此外,该基板可包括处理阵列,该处理阵列可包括多个处理器子单元(诸如,图7a中所展示的子单元730a、730b、730c、730d、730e、730f、730g及730h)。
588.如上文关于图7a进一步所解释,每一处理群组可包括一处理器子单元及专用于该处理器子单元的一个或多个对应存储器组。此外,为了允许每一处理器子单元与其对应的专用存储器组通信,该基板可包括将处理器子单元中的一个连接至其对应的专用存储器组的第一多个总线。
589.在这些实施例中,如图7a中所展示,该基板可包括用以将每一处理器子单元连接至至少一个其他处理器子单元(例如,相同行中的邻近子单元、相同列中的邻近处理器子单元,或基板上的任何其他处理器子单元)的第二多个总线。第一多个总线和/或第二多个总线可能不含时序硬件逻辑组件,使得在处理器子单元之间及跨越所述多个总线中的对应者的数据传送不受时序硬件逻辑组件控制,如上文在「使用软件的同步」章节中所解释。
590.在与存储器芯片2800相同的基板可包括安置于其上的多个处理群组(例如,如图7a中所描绘)的实施例中,处理器子单元还可以包括地址生成器(例如,如图4中所描绘的地址生成器450)。此外,每一处理群组可包括一处理器子单元及专用于该处理器子单元的一个或多个对应存储器组。因此,地址生成器中的每个可与所述多个存储器组中的对应的专用存储器组相关联。此外,该基板可包括多个总线,每个总线将所述多个地址生成器中的一个连接至其对应的专用存储器组。
591.图29a描绘符合本公开的实施例刷新控制器2900。刷新控制器2900可并入本公开的存储器芯片(诸如,图28的存储器芯片2800)中。如图29a中所描绘,刷新控制器2900可包括定时器2901,该定时器可包含用于刷新控制器2900的片上振荡器或任何其他时序电路。在图29a中所描绘的配置中,定时器2901可周期性地(例如,每8ms、16ms、32ms、64ms或其类似时间)触发刷新循环。刷新循环可使用行计数器2903以循环通过对应存储器芯片的所有行,且使用加法器2901结合有效比特2905来针对每一行产生一刷新信号。如图29a中所展示,比特2905可固定为1(「真」)以确保每一行在一循环期间刷新。
592.在本公开的实施例中,刷新控制器2900可包括数据储存器。如上文所描述,该数据储存器可包含与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联的一个或多个寄存器或非易失性存储器。该寄存器或非易失性存储器可被配置为储存指示相关联区段的最近存取的时间戳或其他信息。
593.刷新控制器2900可使用所储存的信息来跳过存储器芯片2900的区段的刷新。例如,若该信息指示一区段在一个或多个先前刷新循环期间已刷新,则刷新控制器2900可在当前刷新循环中跳过该区段。在另一实施例中,若针对一区段所储存的时间戳与当前时间之间的差低于阈值,则刷新控制器2900可在当前刷新循环中跳过该区段。刷新控制器2900可进一步经由多个刷新循环继续追踪存储器芯片2800的区段的存取及刷新。例如,刷新控制器2900可使用定时器2901更新所储存时间戳。在这些实施例中,刷新控制器2900可被配置为在阈值时间间隔之后,使用定时器的输出来清除储存于数据储存器中的存取信息。例如,在数据储存器储存相关联区段的最近存取或刷新的时间戳的实施例中,每当将存取命令或刷新信号发送至该区段时,刷新控制器2900便可将新时间戳储存于数据储存器中。若数据储存器储存比特而非时间戳,则定时器2901可被配置为清除经设定持续长于阈值时间
段的比特。例如,在数据储存器储存指示相关联区段在一个或多个先前循环中经存取的实施例中,每当定时器2901触发新的刷新循环,刷新控制器2900便可清除数据储存器中的比特(例如,将其设定为0),该新的刷新循环在设定相关联比特(例如,设定为1)后经过临界数量的循环(例如,一个、两个或其类似物)的循环。
594.刷新控制器2900可协同存储器芯片2800的其他硬件追踪存储器芯片2800的区段的存取。例如,存储器芯片使用感测放大器以执行读取操作(例如,如上文在图9及图10中所展示)。该感测放大器可包含多个晶体管,所述多个晶体管被配置为感测来自将数据储存于一个或多个存储器胞元中的存储器芯片2800的区段的低功率信号,且将小的电压摆动放大至较高电压电平,使得数据可由诸如如上文所解释的外部cpu或gpu或集成式处理器子单元的逻辑解译。尽管在图29a中未描绘,但刷新控制器2900可进一步与感测放大器通信,该感测放大器被配置为存取一个或多个区段且改变至少一个比特寄存器的状态。例如,当感测放大器存取一个或多个区段时,其可设定与该区段相关联的比特(例如,设定为1),该比特指示相关联区段在前一循环中经存取。在数据储存器储存相关联区段的最近存取或刷新的时间戳的实施例中,当感测放大器存取一个或多个区段时,其可触发将来自定时器2901的时间戳写入至寄存器、存储器或包含数据储存器的其他元件。
595.在上文所描述的实施例中的任一者中,刷新控制器2900可与用于多个存储器组的存储器控制器集成。例如,类似于图3a中所描绘的实施例,刷新控制器2900可并入至与存储器芯片2800的存储器组或其他区段相关联的逻辑及控制子单元中。
596.图29b描绘符合本公开的另一实施例刷新控制器2900'。刷新控制器2900'可并入本公开的存储器芯片(诸如,图28的存储器芯片2800)中。类似于刷新控制器2900,刷新控制器2900'包括定时器2901、行计数器2903、有效比特2905及加法器2907。另外,刷新控制器2900'可包括数据储存器2909。如图29b中所展示,数据储存器2909可包含与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联的一个或多个寄存器或非易失性存储器,且数据储存器内的状态可被配置为响应于一个或多个区段经存取而改变(例如,通过感测放大器和/或刷新控制器2900'的其他元件,如上文所描述)。因此,刷新控制器2900'可被配置为基于数据储存器内的状态跳过一个或多个区段的刷新。例如,若与区段相关联的状态经启动(例如,通过接通、使性质变更以便储存「1」或其类似物而设定为1),则刷新控制器2900'可跳过相关联区段的刷新循环且清除与其部分相关联的状态。该状态可至少通过一比特寄存器或被配置为储存至少一个数据比特的任何其他存储器结构来储存。
597.为了确保存储器芯片的区段在每一刷新循环期间经刷新或存取,刷新控制器2900'可重设或以其他方式清除状态以便在下一刷新循环期间触发刷新信号。在一些实施例中,在一区段被跳过之后,刷新控制器2900'可清除相关联状态,以便确保在下一刷新循环刷新该区段。在其他实施例中,刷新控制器2900'可被配置为在阈值时间间隔之后重设数据储存器内的状态。例如,每当从相关联状态经设定(例如,通过接通、使性质变更以便储存「1」或其类似物而设定为1)起,定时器2901超过阈值时间,刷新控制器2900'便可清除数据储存器中的状态(例如,将其设定为0)。在一些实施例中,刷新控制器2900'可使用临界数量的刷新循环(例如,一个、两个或其类似物)或使用临界数量的时钟循环(例如,两个、四个或其类似物)而非阈值时间。
598.在其他实施例中,该状态可包含相关联区段的最近刷新或存取的时间戳,使得若该时间戳与当前时间(例如,来自图29a及图29b的定时器2901)之间的时间量超过预定阈值(例如,8ms、16ms、32ms、64ms或其类似时间),则刷新控制器2900'可将存取命令或刷新信号发送至相关联区段且更新与其部分相关联的时间戳(例如,使用定时器2901)。另外或替代地,若刷新时间指示符指示最后刷新时间在预定时间阈值内,则刷新控制器2900'可被配置为跳过相对于多个存储器组中的一个或多个区段的刷新操作。在这些实施例中,在跳过相对于一个或多个区段的刷新操作之后,刷新控制器2900'可被配置为更改与一个或多个区段相关联的所储存的刷新时间指示符,使得在下一操作循环期间,将刷新该一个或多个区段。例如,如上文所描述,刷新控制器2900'可使用定时器2901来更新所储存的刷新时间指示符。
599.因此,数据储存器可包括被配置为储存刷新时间指示符的时间戳寄存器,该刷新时间指示符指示最后刷新多个存储器组中的一个或多个区段的时间。此外,刷新控制器2900'可在阈值时间间隔之后,使用定时器的输出来清除储存于数据储存器中的存取信息。
600.在上文所描述的实施例中的任一者中,对一个或多个区段的存取可包括与一个或多个区段相关联的写入操作。另外或替代地,对一个或多个区段的存取可包括与一个或多个区段相关联的读取操作。
601.此外,如图29b中所描绘,刷新控制器2900'可包含被配置为至少部分地基于数据储存器内的状态而辅助更新数据储存器2909的行计数器2903及加法器2907。数据储存器2909可包含与多个存储器组相关联的比特表。例如,该比特表可包含被配置为保存用于相关联区段的比特的开关(或开关元件,诸如晶体管)或寄存器(例如,sram或其类似物)的阵列。另外或替代地,数据储存器2909可储存与多个存储器组相关联的时间戳。
602.此外,刷新控制器2900'可包括刷新门2911,该刷新门被配置为基于储存于比特表中的对应值而控制是否进行对一个或多个区段的刷新。例如,刷新门2911可包含逻辑门(诸如,「与(and)门」,该逻辑门在数据储存器2909的对应状态指示相关联区段在一个或多个先前时钟循环期间经刷新或存取的情况下使来自行计数器2903的刷新信号无效。在其他实施例中,刷新门2911可包含微处理器或其他电路,该微处理器或其他电路被配置为在来自数据储存器2909的对应时间戳指示相关联区段在预定阈值时间值内经刷新或存取的情况下使来自行计数器2903的刷新信号无效。
603.图30为用于存储器芯片(例如,图28的存储器芯片2800)中的部分刷新的处理程序3000的实施例流程图,处理程序3000可由符合本公开的刷新控制器执行,诸如图29a的刷新控制器2900或图29b的刷新控制器2900'。
604.在步骤3010处,刷新控制器可存取指示多个存储器组中的一个或多个区段的存取操作的信息。例如,如上文关于图29a及图29b所解释,刷新控制器可包括数据储存器,该数据储存器与存储器芯片2800的区段(例如,存储器芯片2800内的存储器胞元的线、列或任何其他分组)相关联且被配置为储存指示相关联区段的最近存取的时间戳或其他信息。
605.在步骤3020处,刷新控制器可至少部分地基于所存取信息而产生刷新和/或存取命令。例如,如上文关于图29a及图29b所解释,若所存取信息指示最后刷新或访问时间在预定时间阈值内和/或若所存取信息指示最后刷新或存取发生在一个或多个先前时钟循环期间,则刷新控制器可跳过相对于多个存储器组中的一个或多个区段的刷新操作。另外或替
代地,刷新控制器可基于所存取信息是否指示最后刷新或访问时间超过预定阈值和/或所存取信息是否指示最后刷新或存取并未在一个或多个先前时钟循环期间发生,而产生刷新或存取相关联区段的意见。
606.在步骤3030处,刷新控制器可更改与一个或多个区段相关联的所储存的刷新时间指示符,使得在下一操作循环期间,将刷新该一个或多个区段。例如,在跳过相对于一个或多个区段的刷新操作之后,刷新控制器可更改指示该一个或多个区段的存取操作的信息,使得在下一时钟循环期间,将刷新该一个或多个区段。因此,在跳过刷新循环之后,刷新控制器可清除区段的状态(例如,设定为0)。另外或替代地,刷新控制器可设定在当前循环期间刷新和/或存取的区段的状态(例如,设定为1)。在指示一个或多个区段的存取操作的信息包括时间戳的实施例中,刷新控制器可更新与在当前循环期间刷新和/或存取的区段相关联的任何所储存的时间戳。
607.方法3000还可以包括额外步骤。例如,除步骤3030以外或作为该步骤的替代,感测放大器可存取一个或多个区段且可改变与该一个或多个区段相关联的信息。另外或替代地,感测放大器可在存取已发生时向刷新控制器发信,使得刷新控制器可更新与一个或多个区段相关联的信息。如上文所解释,感测放大器可包含多个晶体管,所述多个晶体管被配置为感测来自将数据储存于一个或多个存储器胞元中的存储器芯片的区段的低功率信号,且将小的电压摆动放大至较高电压电平,使得数据可由诸如如上文所解释的外部cpu或gpu或集成式处理器子单元的逻辑解译。在此实施例中,每当感测放大器存取一个或多个区段时,其可设定(例如,设定为1)与区段相关联的比特,该比特指示相关联区段在前一循环中经存取。在指示一个或多个区段的存取操作的信息包括时间戳的实施例中,每当感测放大器存取一个或多个区段时,其便可触发将来自刷新控制器的定时器的时间戳写入至数据储存器以更新与该区段相关联的任何所储存的时间戳。
608.图31为用于判定存储器芯片(例如,图28的存储器芯片2800)的刷新的处理程序3100的一实施例流程图。处理程序3100可实施于符合本公开的编译程序内。如上文所解释,「编译程序」指将较高级语言(例如,程序性语言,诸如c、fortran、basic或其类似物;面向对象式语言,诸如java、c 、pascal、python或其类似物;等等)转换成较低级语言(例如,组合代码、目标代码、机器码或其类似物)的任何计算机程序。编译程序可允许人类以人类可读语言来程序设计一系列指令,接着将该人类可读语言转换成机器可执行语言。编译程序可包含由一个或多个处理器执行的软件指令。
609.在步骤3110处,一个或多个处理器可接收较高阶计算机代码。例如,该较高阶计算机代码可编码于存储器(例如,诸如硬盘机或其类似物的非易失性存储器、诸如dram的易失性存储器,或其类似物)上的一个或多个文件中或经由网络(例如,因特网或其类似物)接收。另外或替代地,可从使用者接收该较高阶计算机代码(例如,使用诸如键盘的输入设备)。
610.在步骤3120处,一个或多个处理器可识别要由较高阶计算机代码存取的在与存储器芯片相关联的多个存储器组上分布的多个存储器区段。例如,一个或多个处理器可存取定义存储器芯片的多个存储器组及一对应结构的数据结构。一个或多个处理器可从存储器(例如,诸如硬盘机或其类似物的非易失性存储器、诸如dram的易失性存储器,或其类似物)存取数据结构,或经由网络(例如,因特网或其类似物)接收数据结构。在这些实施例中,数
据结构包括于可由编译程序存取的一个或多个库中,以准许编译程序产生用于要存取的特定存储器芯片的指令。
611.在步骤3130处,一个或处理器可评估较高阶计算机代码以识别在多个存储器存取循环内出现的多个存储器读取命令。例如,一个或多个处理器可识别需要自存储器读取的一个或多个读取命令和/或写入至存储器的一个或多个写入命令的较高阶计算机代码内的每一操作。这些指令可包含变量初始化、变量重新指派、对变量进行逻辑运算、输入输出操作或其类似物。
612.在步骤3140处,一个或多个处理器可致使与多个存储器存取命令相关联的数据跨越多个存储器区段中的每个的分布,使得在多个存储器存取循环中的每个期间存取多个存储器区段中的每个。例如,一个或多个处理器可自定义存储器芯片的结构的数据结构识别存储器区段,且接着将来自较高阶代码的变量指派给存储器区段中的各者,使得在每一刷新循环(其可包含特定数量的时钟循环)期间存取(例如,经由写入或读取)每个存储器区段至少一次。在此实施例中,一个或多个处理器可存取指示较高阶代码的每一线需要多少个时钟循环的信息,以便指派来自较高阶代码的线的变量,使得在特定数量的时钟循环期间存取(例如,经由写入或读取)每个存储器区段至少一次。
613.在另一实施例中,一个或多个处理器可首先自较高阶代码产生机器码或其他较低阶代码。一个或多个处理器可接着将来自较低阶代码的变量指派给存储器区段中的各者,使得在每一刷新循环(其可包含特定数量的时钟循环)期间存取(例如,经由写入或读取)每个存储器区段至少一次。在此实施例中,较低阶代码的每一线可能需要单一时钟循环。
614.在上文所给出的实施例中的任一者中,一个或多个处理器可将使用临时输出的逻辑运算或其他命令进一步指派给存储器区段中的各者。这些临时输出也可产生读取和/或写入命令,使得即使尚未将指明的变量指派给经指派的存储器区段,在此刷新循环期间仍存取该存储器区段。
615.方法3100还可以包括额外步骤。例如,在变量在编译之前经指派的实施例中,一个或多个处理器可从较高阶代码产生机器码或其他较低阶代码。此外,一个或多个处理器可传输经编译代码以供存储器芯片及对应的逻辑电路执行。该逻辑电路可包含诸如gpu或cpu的常规电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。因此,如上文所描述,该基板可包括存储器阵列,该存储器阵列包括多个组,诸如图28中所展示的组2801a及其他组。此外,该基板可包括处理阵列,该处理阵列可包括多个处理器子单元(诸如,图7a中所展示的子单元730a、730b、730c、730d、730e、730f、730g及730h)。
616.图32为用于判定存储器芯片(例如,图28的存储器芯片2800)的刷新的处理程序3200的另一实施例流程图。处理程序3200可实施于符合本公开的编译程序内。处理程序3200可由执行包含编译程序的软件指令的一个或多个处理器执行。处理程序3200可与图31的处理程序3100分开地或组合地实施。
617.在步骤3210处,类似于步骤3110,一个或多个处理器可接收较高阶计算机代码。在步骤3220处,类似于步骤3210,一个或多个处理器可识别要由较高阶计算机代码存取的在与存储器芯片相关联的多个存储器组上分布的多个存储器区段。
618.在步骤3230处,一个或多个处理器可评估较高阶计算机代码以识别各涉及多个存储器区段中的一个或多个的多个存储器读取命令。例如,一个或多个处理器可识别需要自
存储器读取的一个或多个读取命令和/或写入至存储器的一个或多个写入命令的较高阶计算机代码内的每一操作。这些指令可包含变量初始化、变量重新指派、对变量进行逻辑运算、输入输出操作或其类似物。
619.在一些实施例中,一个或多个处理器可使用逻辑电路及多个存储器区段模拟较高阶代码的执行。例如,该模拟可包含较高阶代码的逐线逐步通过,其类似于除错器或其他指令集仿真器(iss)的情况。该模拟可进一步维持表示多个存储器区段的地址的内部变量,其类似于除错器可如何维持表示处理器的寄存器的内部变量。
620.在步骤3240处,一个或多个处理器可基于对存储器存取命令的分析且针对多个存储器区段当中的每个存储器区段而追踪自对存储器区段的最后一次存取起所累积的时间量。例如,使用上文所描述的模拟,一个或多个处理器可判定对多个存储器区段中的每个内的一个或多个地址的每一存取(例如,读取或写入)之间的时间长度。可按绝对时间、时钟循环或刷新循环(例如,由存储器芯片的已知刷新速率判定)来量测时间长度。
621.在步骤3250处,响应于自任何特定存储器区段的最后一次存取起经过的时间量将超过预定阈值的判定,一个或多个处理器可将被配置为致使对特定存储器区段的存取的存储器刷新命令或存储器存取命令中的至少一个引入至较高阶计算机代码中。例如,一个或多个处理器可包括供刷新控制器(例如,图29a的刷新控制器2900或图29b的刷新控制器2900')执行的刷新命令。在逻辑电路不嵌入与存储器芯片相同的基板上的实施例中,一个或多个处理器可产生与用于发送至逻辑电路的较低阶代码分开的用于发送至存储器芯片的刷新命令。
622.另外或替代地,一个或多个处理器可包括供存储器控制器(其可与刷新控制器分开或并入至刷新控制器中)执行的存取命令。该存取命令可包含虚设命令,该虚设命令被配置为触发对存储器区段的读取操作,但不使逻辑电路对来自存储器区段的经读取或写入变量执行任何其他操作。
623.在一些实施例中,编译程序可包括来自处理程序3100的步骤及来自处理程序3200的步骤的组合。例如,编译程序可根据步骤3140指派变量且接着根据步骤3250运行上文所描述的模拟以加入任何额外的存储器刷新命令或存储器存取命令中。此组合可允许编译程序跨越尽可能多的存储器区段来分布变量,且为无法在预定阈值时间量存取的任何存储器区段产生刷新或存取命令。在另一组合实施例中,编译程序可根据步骤3230模拟代码,且基于该模拟指示在预定阈值时间量内将不存取的任何存储器区段而根据步骤3140指派变量。在一些实施例中,此组合还可以包括步骤3250以允许编译程序为在预定阈值时间量内无法存取的任何存储器区段产生刷新或存取命令,即使在根据步骤3140的指派完成之后亦如此。
624.本公开的刷新控制器可允许由逻辑电路(无论系诸如cpu及gpu的常规逻辑电路抑或与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘)执行的软件停用由刷新控制器执行的自动刷新,且替代地经由所执行软件控制刷新。因此,本公开的一些实施例可将具有已知存取图案的软件提供至存储器芯片(例如,若编译程序能够存取定义存储器芯片的多个存储器组及一对应结构的数据结构)。在这些实施例中,编译后优化器可停用自动刷新,且仅针对存储器芯片的在阈值时间量内未被存取的区段手动地设定刷新控制。因此,类似于上文所描述的步骤3250但在编译之后,编译后优化器可产生刷新命令以确保使用预
定阈值时间量存取或刷新每个存储器区段。
625.缩减刷新循环的另一实施例可包括使用对存储器芯片的存取的预定义图案。例如,若由逻辑电路执行的软件可控制其用于存储器芯片的存取图案,则一些实施例可产生用于超出常规线性线刷新的刷新的存取图案。例如,若控制器判定由逻辑电路执行的软件规则地每隔一行存储器进行存取,则本公开的刷新控制器可使用并非每隔一线进行刷新的存取图案以便加速存储器芯片且缩减功率使用量。
626.此刷新控制器的实施例展示于图33中。图33描绘符合本公开的通过所储存图案配置的实施例刷新控制器3300。刷新控制器3300可并入本公开的存储器芯片中,该存储器芯片例如具有多个存储器组及包括于多个存储器组中的每个中的多个存储器区段,诸如图28的存储器芯片2800。
627.刷新控制器3300包括定时器3301(类似于图29a及图29b的定时器2901)、行计数器3303(类似于图29a及图29b的行计数器2903)及加法器3305(类似于图29a及图29b的加法器2907)。此外,刷新控制器3300包括数据储存器3307。不同于图29b的数据储存区2909,数据储存器3307可储存至少一个存储器刷新图案,该至少一个存储器刷新图案要被实施以刷新包括于多个存储器组中的每个中的多个存储器区段。例如,如图33中所描绘,数据储存器3307可包括成行和/或列定义存储器组中的区段的li(例如,在图33的实施例中,l1、l2、l3及l4)及hi(例如,在图33的实施例中,h1、h2、h3及h4)。此外,每个区段可与inci变量(例如,在图33的实施例中,inc1、inc2、inc3及inc4)相关联,该变量定义与区段相关联的行如何递增(例如,是否存取或刷新每一行,是否每隔其他行进行存取或刷新,或其类似物)。因此,如图33中所展示,刷新图案可包含一表,该表包括由软件指派的多个存储器区段识别符,所述多个存储器区段识别符用以识别特定存储器组中的在刷新循环期间需刷新的多个存储器区段的范围,及该特定存储器组中的在该刷新循环期间不需刷新的多个存储器区段的范围。
628.因此,数据储存器3308可定义由逻辑电路(无论系诸如cpu及gpu的常规逻辑电路抑或与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘)执行的软件可选择以供使用的刷新图案。存储器刷新图案可使用软件可配置,以识别在刷新循环期间,特定存储器组中的多个存储器区段中的哪些需刷新,而特定存储器组中的多个存储器区段中的哪些在该刷新循环期间不需刷新。因此,刷新控制器3300可根据inci刷新在当前循环期间未被存取的所定义区段内的一些或所有行。刷新控制器3300可跳过经设定为在当前循环期间被存取的所定义区段的其他行。
629.在刷新控制器3300的数据储存器3308包括多个存储器刷新图案的实施例中,每个存储器刷新图案可表示不同的刷新图案,用于刷新包括于多个存储器组中的每个中的多个存储器区段。存储器刷新图案可为可选择的以用于多个存储器区段上。因此,刷新控制器3300可被配置为允许选择在特定刷新循环期间实施多个存储器刷新图案中的哪一个。例如,由逻辑电路(无论系诸如cpu及gpu的常规逻辑电路抑或与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘)执行的软件可选择不同存储器刷新图案以供在一个或多个不同刷新循环期间使用。替代地,由逻辑电路执行的软件可选择一个存储器刷新图案以供贯穿不同刷新循环中的一些或全部而使用。
630.可使用储存于数据储存器3308中的一个或多个变量来编码存储器刷新图案。例
如,在多个存储器区段布置成行的实施例中,每个存储器区段识别符可被配置为识别在存储器的行内,存储器刷新应开始或结束的特定位置。例如,除li及hi以外,一个或多个额外变量也可定义由li及hi定义哪些行的哪些部分在区段内。
631.图34为用于判定存储器芯片(例如,图28的存储器芯片2800)的刷新的处理程序3400的实施例流程图。处理程序3100可由符合本公开的刷新控制器(例如,图33的刷新控制器3300)内的软件实施。
632.在步骤3410处,刷新控制器可储存至少一个存储器刷新图案,该至少一个存储器刷新图案要被实施以刷新包括于多个存储器组中的每个中的多个存储器区段。例如,如上文关于图33所解释,刷新图案可包含一表,该表包括由软件指派的多个存储器区段识别符,所述多个存储器区段识别符用以识别特定存储器组中的在刷新循环期间需刷新的多个存储器区段的范围,及该特定存储器组中的在刷新循环期间不需刷新的多个存储器区段的范围。
633.在一些实施例中,至少一个刷新图案可在制造期间编码至刷新控制器上(例如,编码至与刷新控制器相关联或至少可由刷新控制器存取的只读存储器上)。因此,刷新控制器可存取至少一个存储器刷新图案,但不储存该至少一个存储器刷新图案。
634.在步骤3420及3430处,刷新控制器可使用软件以识别特定存储器组中的多个存储器区段中的哪些在刷新循环期间需刷新,而特定存储器组中的多个存储器区段中的哪些在该刷新循环期间不需刷新。例如,如上文关于图33所解释,由逻辑电路(无论系诸如cpu及gpu的常规逻辑电路抑或与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘)执行的软件可选择至少一个存储器刷新图案。此外,刷新控制器可存取选定的至少一个存储器刷新图案以在每一刷新循环期间产生对应刷新信号。刷新控制器可根据该至少一个存储器刷新图案刷新在当前循环期间未被存取的所定义区段内的一些或所有部分,且可跳过经设定为在当前循环期间被存取的所定义区段的其他部分。
635.在步骤3440处,刷新控制器可产生对应刷新命令。例如,如图33中所描绘,加法器3305可包含逻辑电路,该逻辑电路被配置为根据数据储存器3307中的至少一个存储器刷新图案来使用于未被刷新的特定区段的刷新信号无效。另外或替代地,微处理器(图33中未展示)可基于根据数据储存器3307中的至少一个存储器刷新图案将刷新哪些区段而产生特定刷新信号。
636.方法3400还可以包括额外步骤。例如,在至少一个存储器刷新图案被配置为每一个、两个或其他数量的刷新循环而改变(例如,自l1、h1及inc1移动至l2、h2及inc2,如图33中所展示)的实施例中,刷新控制器可根据步骤3430及3440存取数据储存器的不同部分以用于刷新信号的下一判定。类似地,若由逻辑电路(无论系诸如cpu及gpu的常规逻辑电路抑或与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘)执行的软件自数据储存器选择新的存储器刷新图案以用于一个或多个未来刷新循环中,则刷新控制器可根据步骤3430及3440存取数据储存器的不同部分以用于刷新信号的下一判定。
637.当设计存储器芯片且目标为存储器的某一容量时,存储器容量改变至较大大小或较小大小可能需要重新设计产品及重新设计整个光罩集。通常,产品设计与市场研究平行地进行,且在一些状况下,产品设计在市场研究可用之前完成。因此,产品设计与市场的实际需求之间可能存在脱节。本公开提出灵活地提供具有满足市场需求的存储器容量的存储
器芯片的方式。设计方法可包括在晶圆上设计晶粒连同适当的互连电路系统,使得可从晶圆选择性地切割可含有一个或多个晶粒的存储器芯片,以便提供自单一晶圆生产具有大小可变的存储器容量的存储器芯片的机会。
638.本公开系关于用于通过从晶圆切割存储器芯片来制造存储器芯片的系统及方法。该方法可用于从晶圆生产大小可选择的存储器芯片。含有晶粒3503的晶圆3501的实施例实施例展示于图35a中。晶圆3501可由半导体材料(例如,硅(si)、硅锗(sige)、绝缘体上硅(soi)、氮化镓(gan)、氮化铝(aln)、氮化铝镓(algan)、氮化硼(bn)、砷化镓(gaas)、砷化镓铝(algaas)、氮化铟(inn)、以上各者的组合及其类似物)形成。晶粒3503可包括任何合适的电路元件(例如,晶体管、电容器、电阻器和/或其类似物),该电路元件可包括任何合适的半导体、介电或金属组件。晶粒3503可由可能与晶圆3501的材料相同或不同的半导体材料形成。除晶粒3503以外,晶圆3501也可包括其他结构和/或电路系统。在一些实施例中,可提供一个或多个耦接电路且该一个或多个耦接电路将晶粒中的一个或多个耦接在一起。在一实施例实施例中,此耦接电路可包括由两个或多于两个晶粒3503共享的总线。另外,该耦接电路可包括经设计以控制与晶粒3503相关联的电路系统和/或将信息导引至晶粒3503/导引来自晶粒3503的信息的一个或多个逻辑电路。在一些状况下,该耦接电路可包括存储器存取管理逻辑。此逻辑可将逻辑存储器地址转译成与晶粒3503相关联的实体地址。应注意,如本文中所使用,术语制造可共同地指用于建置所公开晶圆、晶粒和/或芯片的步骤中的任一者。例如,制造可指包括于晶圆上的各种晶粒(及任何其他电路系统)的同时布置及形成。制造也可指从晶圆切割大小可选择的存储器芯片以在一些状况下包括一个晶粒,或在其他状况下包括多个晶粒。当然,术语制造并不欲限于这些实施例,而是可包括与所公开存储器芯片及中间结构中的任一者或全部的产生相关联的其他方面。
639.晶粒3503或一群组的晶粒可用于制造存储器芯片。存储器芯片可包括分布式处理器,如本公开的其他章节中所描述。如图35b中所展示,晶粒3503可包括基板3507及安置于该基板上的存储器阵列。该存储器阵列可包括一个或多个存储器单元,诸如经设计以储存数据的存储器组3511a至3511d。在各种实施例中,存储器组可包括基于半导体的电路元件,诸如晶体管、电容器及其类似物。在一实施例实施例中,一存储器组可包括多行及多列储存单元。在一些状况下,此存储器组可具有大于一兆字节的容量。该存储器组可包括动态或静态存取存储器。
640.晶粒3503还可以包括安置于基板上的处理阵列,该处理阵列包括多个处理器子单元3515a至3515d,如图35b中所展示。如上文所描述,每个存储器组可包括由一专用总线连接的专用处理器子单元。例如,处理器子单元3515a经由总线或连接件3512与存储器组3511a相关联。应理解,存储器组3511a至3511d与处理器子单元3515a至3515d之间的各种连接系可能的,且仅一些说明性连接展示于图35b中。在一实施例实施例中,处理器子单元可对相关联的存储器组执行读取/写入操作,且可进一步相对于储存于各种存储器组中的存储器执行刷新操作或任何其他合适的操作。
641.如所提到,晶粒3503可包括被配置为将处理器子单元与其对应存储器组连接的总线的第一群组。实施例总线可包括连接电组件的一组导线或导体,且允许将数据及地址传送至每个存储器组及其相关联的处理器子单元以及从每个存储器组及其相关联的处理器子单元传送数据。在一实施例中,连接件3512可用作用于将处理器子单元3515a连接至存储
器组3511a的专用总线。晶粒3503可包括此类总线的群组,每个总线将一处理器子单元连接至一对应的专用存储器组。另外,晶粒3503可包括总线的另一群组,每个总线将处理器子单元(例如,子单元3515a至3515d)彼此连接。例如,此类总线可包括连接件3516a至3516d。在各种实施例中,用于存储器组3511a至3511d的数据可经由输入输出总线3530递送。在一实施例中,输入输出总线3530可携载数据相关信息,及用于控制晶粒3503的存储器单元的操作的命令相关信息。数据信息可包括用于储存于存储器组中的数据、自存储器组读取的数据、基于相对于储存于对应存储器组中的数据执行的操作的来自处理器子单元中的一个或多个的处理结果、命令相关信息、各种代码等。
642.在各种状况下,由输入输出总线3530传输的数据及命令可由输入输出(io)控制器3521控制。在一实施例中,io控制器3521可控制自总线3530至处理器子单元3515a至3515d及来自处理器子单元3515a至3515d的数据流。io控制器3521可判定自处理器子单元3515a至3515d中的哪一个取回信息。在各种实施例中,io控制器3521可包括被配置为撤销启动io控制器3521的熔断器3554。若多个晶粒组合在一起以形成较大存储器芯片(也被称作多晶粒存储器芯片,作为仅含有一个晶粒的单晶粒存储器芯片的替代),则可使用熔断器3554。该多晶粒存储器芯片可接着使用形成该多晶粒存储器芯片的晶粒单元中的一个的io控制器中的一个,同时通过使用对应于与其他晶粒单元相关的其他io控制器的熔断器来停用其他io控制器。
643.如所提到,每个存储器芯片或前置晶粒或一群组的晶粒可包括与对应存储器组相关联的分布式处理器。在一些实施例中,这些分布式处理器可布置在与多个存储器组安置在相同基板上的处理阵列中。另外,该处理阵列可包括各包括一地址生成器(也被称作地址生成器单元(agu))的一个或多个逻辑部分。在一些状况下,该地址生成器可为至少一个处理器子单元的部分。该地址生成器可产生自与存储器芯片相关联的一个或多个存储器组取得数据所需的存储器地址。地址产生计算可涉及整数算术运算,诸如加法、减法、模数运算或比特移位。该地址生成器可被配置为一次对多个操作数进行运算。此外,多个地址生成器可同时执行多于一个地址计算运算。在各种实施例中,地址生成器可能与对应存储器组相关联。地址生成器可藉助于对应总线线与其对应存储器组连接。
644.在各种实施例中,大小可选择的存储器芯片可通过选择性地切割晶圆3501的不同区而由该晶圆形成。如所提到,该晶圆可包括晶粒3503的群组,该群组包括晶圆上所包括的两个或多于两个晶粒(例如,2个、3个、4个、5个、10个或多于10个晶粒)的任何群组。如将在下文进一步所论述,在一些状况下,单一存储器芯片可通过切割晶圆的仅包括一群组的晶粒中的一个晶粒的一部分来形成。在这些状况下,所得存储器芯片将包括与一个晶粒相关联的存储器单元。然而,在其他状况下,大小可选择的存储器芯片可形成为包括多于一个晶粒。这些存储器芯片可通过切割晶圆的包括晶圆上所包括的一群组的晶粒中的两个或多于两个晶粒的区来形成。在这些状况下,晶粒连同将晶粒耦接在一起的耦接电路提供多晶粒存储器芯片。一些额外电路元件也可板载地线连接于芯片之间,诸如时钟元件、数据总线或任何合适的逻辑电路。
645.在一些状况下,与一群组的晶粒相关联的至少一个控制器可被配置为控制一群组的晶粒作为单一存储器芯片(例如,多存储器单元存储器芯片)进行操作。该控制器可包括管理进入存储器芯片及来自存储器芯片的数据流的一个或多个电路。存储器控制器可为存
储器芯片的一部分,或其可为不与存储器芯片直接相关的分开芯片的一部分。在一实施例中,控制器可被配置为促进与存储器芯片的分布式处理器相关联的读取及写入请求或其他命令,且可被配置为控制存储器芯片的任何其他合适的方面(例如,刷新存储器芯片,与分布式处理器相互作用等)。在一些状况下,控制器可为晶粒3503的部分,且在其他状况下,控制器可邻近于晶粒3503布置。在各种实施例中,控制器也可包括存储器芯片上所包括的存储器单元中的至少一个的至少一个存储器控制器。在一些状况下,用于存取存储器芯片上的信息的协议可能与可存在于存储器芯片上的复制逻辑及存储器单元(例如,存储器组)无关。该协议可被配置为具有用于充分存取存储器芯片上的数据的不同id或地址范围。具有此协议的芯片的实施例可包括具有联合电子设备工程委员会(jedec)双数据速率(ddr)控制器的芯片,其中不同存储器组可具有不同地址范围、串行周边接口(spi)连接,其中不同存储器单元(例如,存储器组)具有不同标识(id),及其类似物。
646.在各种实施例中,可从晶圆切割多个区,其中各个区包括一个或多个晶粒。在一些状况下,每一分开区可用以建置一多晶粒存储器芯片。在其他状况下,要从晶圆切割的每个区可包括单一晶粒以提供单晶粒存储器芯片。在一些状况下,该区中的两者或多于两者可具有相同形状且具有以相同方式耦接至耦接电路的相同数量的晶粒。替代地,在一些实施例中,区的第一群组可用以形成第一类型的存储器芯片,且区的第二群组可用以形成第二类型的存储器芯片。例如,如图35c中所展示,晶圆3501可包括区3505,该区可包括单一晶粒,且第二区3504可包括两个晶粒的群组。当从晶圆3501切割区3505时,将提供单晶粒存储器芯片。当从晶圆3501切割区3504时,将提供多晶粒存储器芯片。图35c中所展示的群组仅为说明性,且可从晶圆3501切下晶粒的各种其他区及群组。
647.在各种实施例中,晶粒可形成于晶圆3501上,使得其沿着晶圆的一或多行布置,如展示于例如图35c中。晶粒可共享对应于一或多行的输入输出总线3530。在一实施例中,可使用各种切割形状从晶圆3501切下一群组的晶粒,其中当切下可用以形成存储器芯片的一群组的晶粒时,可能不包括共享的输入输出总线3530的至少一部分(例如,仅可包括输入输出总线3530的一部分作为形成为包括一群组的晶粒的存储器芯片的一部分)。
648.如先前所论述,当多个晶粒(例如,晶粒3506a及3506b,如图35c中所展示)用以形成存储器芯片3517时,对应于所述多个晶粒中的一个的一个io控制器可经启用且被配置为控制至晶粒3506a及3506b的所有处理器子单元的数据流。例如,图35d展示经组合以形成存储器芯片3517的存储器晶粒3506a及3506b,该存储器芯片包括存储器组3511a至3511h、处理器子单元3515a至3515h、io控制器3521a及3521b,以及熔断器3554a及3554b。应注意,在从晶圆移除存储器芯片3517之前,该存储器芯片对应于晶圆3501的区3517。换言之,如此处且在本公开中别处所使用,一旦从晶圆3501切割,晶圆3501的区3504、3505、3517等便将产生存储器芯片3504、3505、3517等。另外,本文中的熔断器也被称作停用元件。在一实施例中,熔断器3554b可用以撤销启动io控制器3521b,且io控制器3521a可用以通过将数据传达至处理器子单元3515a至3515h来控制至所有存储器组3511a至3511h的数据流。在一实施例中,io控制器3521a可使用任何合适的连接来连接至各种处理器子单元。在一些实施例中,如下文进一步所描述,处理器子单元3515a至3515h可互连,且io控制器3521a可被配置为控制至形成存储器芯片3517的处理逻辑的处理器子单元3515a至3515h的数据流。
649.在一实施例中,诸如控制器3521a及3521b的io控制器以及对应熔断器3554a及
3554b可连同形成存储器组3511a至3511h及处理器子单元3515a至3515h一起在晶圆3501上形成。在各种实施例中,当形成存储器芯片3517时,可启动熔断器中的一个(例如,熔断器3554b)使得晶粒3506a及3506b被配置为形成存储器芯片3517,该存储器芯片用作单一芯片且受单一输入输出控制器(例如,控制器3521a)控制。在一实施例中,启动熔断器可包括施加电流以触发熔断器。在各种实施例中,当多于一个晶粒用于形成存储器芯片时,可经由对应熔断器撤销启动除一个io控制器之外的所有其他io控制器。
650.在各种实施例中,如图35c中所展示,多个晶粒连相同组输入输出总线和/或控制总线一起形成于晶圆3501上。输入输出总线3530的实施例绘示于图35c中。在一实施例中,输入输出总线中的一个(例如,输入输出总线3530)可连接至多个晶粒。图35c展示接近晶粒3506a及3506b通过的输入输出总线3530的实施例。如图35c中所展示的晶粒3506a及3506b以及输入输出总线3530的配置仅为说明性的,且可使用各种其他配置。例如,图35e说明形成于晶圆3501上且布置成六边形形式的晶粒3540。可从晶圆3501切下包括四个晶粒3540的存储器芯片3532。在一实施例中,存储器芯片3532可包括通过合适的总线线(例如,线3533,如图35e中所展示)连接至四个晶粒的输入输出总线3530的一部分。为了将信息投送至存储器芯片3532的适当存储器单元,存储器芯片3532可包括置放于输出总线3530的分支点处的输入/输出控制器3542a及3542b。控制器3542a及3542b可经由输入输出总线3530接收命令数据,且选择总线3530的分支用于将信息传输至适当存储器单元。例如,若命令数据包括自/至与晶粒3546相关联的存储器单元的读取/写入信息,则控制器3542a可接收命令请求且将数据传输至总线3530的分支3531a,如图35d中所展示,而控制器3542b可接收命令请求且将数据传输至分支3531b。图35e指示可进行的不同区的各种切割,其中切割线由虚线表示。
651.在一实施例中,一群组的晶粒及互连电路系统可经设计以包括于如图36a中所展示的存储器芯片3506中。此实施例可包括可被配置为彼此通信的处理器子单元(用于存储器内处理)。例如,要包括于存储器芯片3506中的每一晶粒可包括诸如存储器组3511a至3511d的各种存储器单元、处理器子单元3515a至3515d,以及io控制器3521及3522。io控制器3521及3522可并联连接至输入输出总线3530。io控制器3521可具有熔断器3554,且io控制器3522可具有熔断器3555。在一实施例中,处理器子单元3515a至3515d可藉助于例如总线3613连接。在一些状况下,io控制器中的一个可使用对应熔断器来停用。例如,可使用熔断器3555停用io控制器3522,且io控制器3521可经由处理器子单元3515a至3515d控制至存储器组3511a至3511d中的数据流,该处理器子单元经由总线3613彼此连接。
652.如图36a中所展示的存储器单元的配置仅为说明性的,且各种其他配置可通过切割晶圆3501的不同区来形成。例如,图36b展示具有三个域3601至3603的配置,该三个域含有存储器单元且连接至输入输出总线3530。在一实施例中,域3601至3603系使用可由对应熔断器3554至3556停用的io控制模块3521至3523连接至输入输出总线3530。布置含有存储器单元的域的实施例的另一实施例绘示于图36c中,其中使用总线线3611、3612及3613将三个域3601、3602及3603连接至输入输出总线3530。图36d展示经由io控制器3521至3524连接至输入输出总线3530a及3530b的存储器芯片3506a至3506d的另一实施例。在一实施例中,可使用对应熔断器元件3554至3557撤销启动io控制器,如图36d中所展示。
653.图37展示晶粒3503的各种群组,诸如可包括一个或多个晶粒3503的群组3713及群
组3715。在一实施例中,除在晶圆3501上形成晶粒3503以外,晶圆3501也可含有被称作胶合逻辑3711的逻辑电路3711。相较于在不存在胶合逻辑3711的情况下可能已制造的晶粒的数量,胶合逻辑3711可占用晶圆3501上的一些空间,以导致每晶圆3501制造较少数量的晶粒。然而,存在胶合逻辑3711可允许多个晶粒被配置为共同用作单一存储器芯片。例如,胶合逻辑可连接多个晶粒,而不必改变配置且不必为仅用于将晶粒连接在一起的电路系统指明晶粒本身中的任一者内的区域。在各种实施例中,胶合逻辑3711提供与其他存储器控制器的接口,使得多晶粒存储器芯片用作单一存储器芯片。胶合逻辑3711可连同一群组的晶粒(例如,如由群组3713展示)一起切割。替代地,若存储器芯片仅需要一个晶粒,例如,如对于群组3715,则可能不切割胶合逻辑。例如,在不需要实现不同晶粒之间的协作之处,可选择性地消除胶合逻辑。在图37中,可进行不同区的各种切割,例如,如由虚线区所展示。在各种实施例中,如图37中所展示,对于每两个晶粒3506,可在晶圆上布置一个胶合逻辑元件3711。在一些状况下,一个胶合逻辑元件3711可用于形成一群组的晶粒的任何合适数量的晶粒3506。胶合逻辑3711可被配置为连接至来自一群组的晶粒的所有晶粒。在各种实施例中,连接至胶合逻辑3711的晶粒可被配置为形成多晶粒存储器芯片,且可被配置为在晶粒不连接至胶合逻辑3711时形成分开的单晶粒存储器芯片。在各种实施例中,连接至胶合逻辑3711且经设计以共同起作用的晶粒可作为群组从晶圆3501切下,且可包括胶合逻辑3711,例如,如由群组3713所指示。未连接至胶合逻辑3711的晶粒可从晶圆3501切下而不包括胶合逻辑3711,例如,如由群组3715所指示,以形成单晶粒存储器芯片。
654.在一些实施例中,在从晶圆3501制造多晶粒存储器芯片期间,可判定一个或多个切割形状(例如,形成群组3713、3715的形状)用于产生多晶粒存储器芯片中的所要集合。在一些状况下,如由群组3715所展示,切割形状可能不包括胶合逻辑3711。
655.在各种实施例中,胶合逻辑3711可为用于控制多晶粒存储器芯片的多个存储器单元的控制器。在一些状况下,胶合逻辑3711可包括可由各种其他控制器修改的参数。例如,用于多晶粒存储器芯片的耦接电路可包括用于配置胶合逻辑3711的参数或存储器控制器的参数的电路(例如,处理器子单元3515a至3515d,如展示于例如图35b中)。胶合逻辑3711可被配置为进行多种任务。例如,逻辑3711可被配置为判定哪些晶粒可能需要寻址。在一些状况下,逻辑3711可用以使多个存储器单元同步。在各种实施例中,逻辑3711可被配置为控制各种存储器单元,使得存储器单元作为单一芯片操作。在一些状况下,可在输入输出总线(例如,总线3530,如图35c中所展示)与处理器子单元3515a至3515d之间添加放大器以放大来自总线3530的数据信号。
656.在各种实施例中,从晶圆3501切割复杂形状在技术可能为困难/昂贵的,且可采用较简单的切割方法,其限制条件为晶粒在晶圆3501上对准。例如,图38a展示经对准以形成矩形栅格的晶粒3506。在一实施例中,可进行跨越整个晶圆3501的竖直切割3803及水平切割3801以分开切下的一群组的晶粒。在一实施例中,竖直切割3803及水平切割3801可产生含有选定数量的晶粒的群组。例如,切割3803及3801可产生含有单一晶粒的区(例如,区3811a)、含有两个晶粒的区(例如,区3811b)及含有四个晶粒的区(例如,区3811c)。由切割3801及3803形成的区仅为说明性的,且可形成任何其他合适的区。在各种实施例中,取决于晶粒对准,可进行各种切割。例如,若晶粒布置成三角形栅格,如图38b中所展示,则诸如线3802、3804及3806的切割线可用以制成多晶粒存储器芯片。例如,一些区可包括六个晶粒、
五个晶粒、四个晶粒、三个晶粒、两个晶粒、一个晶粒任何其他合适数量的晶粒。
657.图38c展示布置成三角形栅格的总线线3530,其中晶粒3503在通过总线线3530相交形成的三角形的中心对准。晶粒3503可经由总线线3820连接至所有相邻的总线线。通过切割含有两个或多于两个邻近晶粒的区(例如,区3822,如图38c中所展示),至少一个总线线(例如,线3824)保留在区3822内,且总线线3824可用以将数据及命令供应至使用区3822形成的多晶粒存储器芯片。
658.图39展示可形成于处理器子单元3515a至3515p之间以允许存储器单元的群组用作单一存储器芯片的各种连接件。例如,各种存储器单元的群组3901可包括处理器子单元3515b与子单元3515e之间的连接件3905。连接件3905可用作用于将数据及命令自子单元3515b传输至可用以控制各别存储器组3511e的子单元3515e的总线线。在各种实施例中,处理器子单元之间的连接件可在晶圆3501上形成晶粒期间实施。在一些状况下,额外连接件可在由若干晶粒形成的存储器芯片的封装阶段期间制造。
659.如图39中所展示,处理器子单元3515a至3515p可使用各种总线(例如,连接件3905)彼此连接。连接件3905可能不含时序硬件逻辑组件,使得在处理器子单元之间及跨越连接件3905的数据传送可能不受时序硬件逻辑组件控制。在各种实施例中,连接处理器子单元3515a至3515p的总线可在晶圆3501上制造各种电路之前布置于晶圆3501上。
660.在各种实施例中,处理器子单元(例如,子单元3515a至3515p)可互连。例如,子单元3515a至3515p可通过合适总线(例如,连接件3905)连接。连接件3905可将子单元3515a至3515p中的任一者与子单元3515a至3515p中的任何其他子单元连接。在一实施例中,连接的子单元可在相同晶粒上(例如,子单元3515a及3515b),且在其他状况下,连接的子单元可在不同晶粒上(例如,子单元3515b及3515e)。连接件3905可包括用于连接符单元的专用总线且可被配置为在子单元3515a至3515p之间高效地传输数据。
661.本公开的各种方面系关于用于从晶圆生产大小可选择的存储器芯片的方法。在一实施例中,大小可选择的存储器芯片可由一个或多个晶粒形成。如前文所提到,晶粒可沿着一或多行布置,如展示于例如图35c中。在一些状况下,对应于一或多行的至少一个共享的输入输出总线可布置于晶圆3501上。例如,总线3530可如图35c中所展示而布置。在各种实施例中,总线3530可电连接至晶粒中的至少两个的存储器单元,且连接的晶粒可用以形成多晶粒存储器芯片。在一实施例中,一个或多个控制器(例如,输入输出控制器3521及3522,如图35b中所展示)可被配置为控制用以形成多晶粒存储器芯片的至少两个晶粒的存储器单元。在各种实施例中,可从晶圆切下具有连接至总线3530的存储器单元的晶粒,其具有共享的输入输出总线(例如,总线3530,如图35b中所展示)的一个对应部分,该共享的输入输出总线将信息传输至至少一个控制器(例如,控制器3521、3522)以配置控制器以控制所连接晶粒的存储器单元,以用作单一芯片。
662.在一些状况下,可在通过切割晶圆3501的区来制造存储器芯片之前测试位于晶圆3501上的存储器单元。可使用至少一个共享的输入输出总线(例如,总线3530,如图35c中所展示)进行该测试。当存储器单元通过测试时,存储器芯片可由含有所述存储器单元的晶粒的群组形成。可舍弃未通过测试的存储器单元,且不将所述存储器单元用于制造存储器芯片。
663.图40展示从一群组的晶粒建置存储器芯片的处理程序4000的一实施例。在处理程
序4000的步骤4011处,可在半导体晶圆3501上布置晶粒。在步骤4015处,可使用任何合适的方法在晶圆3501上制造晶粒。例如,可通过蚀刻晶圆3501,沉积各种电介质、金属或半导体层及进一步蚀刻所沉积层等来制造晶粒。例如,可沉积及蚀刻多个层。在各种实施例中,可使用任何合适的掺杂元素对层进行n型掺杂或p型掺杂。例如,可用磷对半导体层进行n型掺杂有且用硼对半导体层进行p型掺杂。如图35a中所展示,晶粒3503可通过可用以从晶圆3501切下晶粒3503的空间彼此分开。例如,晶粒3503可通过间隔区彼此隔开,其中可选择间隔区的宽度以允许在间隔区中进行晶圆切割。
664.在步骤4017处,可使用任何合适的方法从晶圆3501切下晶粒3503。在一实施例中,可使用雷射切下晶粒3503。在一实施例中,可首先刻划(scribe)晶圆3501,其后接着进行机械划割。替代地,可使用机械划割锯。在一些状况下,可使用隐式划割处理程序。在划割期间,一旦切下晶粒,晶圆3501便可安装于用于固持晶粒的划割带上。在各种实施例中,可进行大的切割,例如,如在图38a中由切割3801及3803所展示或在图38b中由切割3802、3804或3806所展示。一旦个别地或以群组切下晶粒3503,如在图35c中例如由群组3504所展示,便可封装晶粒3503。晶粒的封装可包括形成至晶粒3503的接点,在接点上方沉积保护层,附接热管理设备(例如,散热片)及囊封晶粒3503。在各种实施例中,取决于选择多少晶粒来形成一存储器芯片,可使用接点及总线的适当配置。在一实施例中,可在存储器芯片封装期间制作形成存储器芯片的不同晶粒之间的接点中的一些。
665.图41a展示用于制造含有多个晶粒的存储器芯片的处理程序4100的一实施例。处理程序4100的步骤4011可与处理程序4000的步骤4011相同。在步骤4111处,如图37中所展示,可将胶合逻辑3711布置于晶圆3501上。胶合逻辑3711可为用于控制晶粒3506的操作的任何合适的逻辑,如图37中所展示。如前文所描述,胶合逻辑3711的存在可允许多个晶粒用作单一存储器芯片。胶合逻辑3711可提供与其他存储器控制器的接口,使得由多个晶粒形成的存储器芯片用作单一存储器芯片。
666.在处理程序4100的步骤4113处,可将总线(例如,输入输出总线及控制总线)布置于晶圆3501上。总线可布置为使得其与各种晶粒及诸如胶合逻辑3711的逻辑电路连接。在一些状况下,总线可连接存储器单元。例如,总线可被配置为连接不同晶粒的处理器子单元。在步骤4115处,可使用任何合适的方法制造晶粒、胶合逻辑及总线。例如,可通过蚀刻晶圆3501,沉积各种电介质、金属或半导体层及进一步蚀刻所沉积层等来制造逻辑元件。可使用例如金属蒸镀来制造总线。
667.在步骤4140处,可使用切割形状以切割连接至单一胶合逻辑3711的晶粒的群组,如展示于例如图37中。可使用含有多个晶粒3503的存储器芯片的存储器要求来判定切割形状。例如,图41b展示处理程序4101,该处理程序可为处理程序4100的变体,其中步骤4117及4119可置于处理程序4100的步骤4140之前。在步骤4117处,用于切割晶圆3501的系统可接收描述存储器芯片的要求的指令。例如,要求可包括形成包括四个晶粒3503的存储器芯片。在一些状况下,在步骤4119处,程序软件可判定用于一群组的晶粒及胶合逻辑3711的周期性图案。例如,周期性图案可包括两个胶合逻辑3711元件及四个晶粒3503,其中每两个晶粒连接至一个胶合逻辑3711。替代地,在步骤4119处,可由存储器芯片的设计者提供该图案。
668.在一些状况下,可选择该图案以使从晶圆3501形成的存储器芯片的产率达至最大。在一实施例中,可测试晶粒3503的存储器单元以识别具有故障存储器单元的晶粒(此类
晶粒被称作发生故障晶粒),且基于故障晶粒的位置,可识别含有通过测试的存储器单元的晶粒3503的群组且可判定适当的切割图案。例如,若在晶圆3501的边缘处,大量晶粒3503发生故障,则可判定切割图案以避开晶圆3501的边缘处的晶粒。处理程序4101的诸如步骤4011、4111、4113、4115及4140的其他步骤可与处理程序4100的相同编号步骤相同。
669.图41c展示可为处理程序4101的变化形式的处理程序4102的实施例。处理程序4102的步骤4011、4111、4113、4115及4140可与处理程序4101的相同编号步骤相同,处理程序4102的步骤4131可替代处理程序4101的步骤4117,且处理程序4102的步骤4133可替代处理程序4101的步骤4119。在步骤4131处,用于切割晶圆3501的系统可接收描述第一存储器芯片集合及第二存储器芯片集合的要求的指令。例如,要求可包括:形成具有由四个晶粒3503组成的存储器芯片的第一存储器芯片集合;及形成具有由两个晶粒3503组成的存储器芯片的第二存储器芯片集合。在一些状况下,可能需要从晶圆3501形成多于两个存储器芯片集合。例如,第三存储器芯片集合可包括仅由一个晶粒3503组成的存储器芯片。在一些状况下,在步骤4133处,程序软件可判定用于一群组的晶粒及胶合逻辑3711的周期性图案,以用于形成每个存储器芯片集合的存储器芯片。例如,第一存储器芯片集合可包括含有两个胶合逻辑3711及四个晶粒3503的存储器芯片,其中每两个晶粒连接至一个胶合逻辑3711。在各种实施例中,用于相同存储器芯片的胶合逻辑单元3711可链接在一起以用作单一胶合逻辑。例如,在制造胶合逻辑3711期间,可形成将胶合逻辑单元3711彼此链接的适当总线线。
670.第二存储器芯片集合可包括含有一个胶合逻辑3711及两个晶粒3503的存储器芯片,其中晶粒3503连接至胶合逻辑3711。在一些状况下,当选择第三存储器芯片集合时且当第三存储器芯片集合包括由单一晶粒3503组成的存储器芯片时,这些存储器芯片可能不需要胶合逻辑3711。
671.当设计存储器芯片或芯片内的存储器实例时,一个重要的特性为在单一时钟循环期间可同时存取的字的数量。对于读取和/或写入,可同时存取的地址愈多(例如,沿着也被称作字或字线的行及也被称作比特或比特线的列的地址),存储器芯片愈快。虽然在开发包括多路端口的存储器时已存在一些活动,该端口允许同时存取多个地址,例如用于建置寄存器文件、现金或共享存储器,但大部分实例使用大小较大且支持多个地址存取的存储器垫。然而,dram芯片通常包括连接至每个存储器胞元的每一电容器的单一比特线及单一行线。因此,本公开的实施例试图提供对现有dram芯片的多端口存取,而不修改dram阵列的此常规单端口存储器结构。
672.本公开的实施例可使用存储器以两倍于逻辑电路的速度来对存储器实例或芯片进行时钟控制。使用存储器的任何逻辑电路可因此「对应于」存储器及其任何组件。因此,本公开的实施例可在两个存储器阵列时钟循环中对两个地址进行撷取或写入,该两个存储器阵列时钟循环等效于用于逻辑电路的单一处理时钟循环。该逻辑电路可包含诸如控制器、加速器、gpu或cpu的电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。如上文关于图3a所解释,「处理群组」可指基板上的两个或多于两个处理器子单元及其对应存储器组。该群组可表示用于编译代码以供在存储器芯片2800上执行的目的的基板上的空间分布和/或逻辑分组。因此,如上文关于图7a所描述,具有存储器芯片的基板可包括存储器阵列,该存储器阵列具有多个组,诸如图28中所展示的组2801a及其他组。此
外,该基板也可包括处理阵列,该处理阵列可包括多个处理器子单元(诸如,图7a中所展示的子单元730a、730b、730c、730d、730e、730f、730g及730h)。
673.因此,本公开的实施例可在两个连续存储器循环中的每个内从阵列取回数据,以便针对每个逻辑循环处置两个地址,且向逻辑提供两个结果,就如同单端口存储器阵列为双端口存储器芯片一般。额外时钟控制可允许本公开的存储器芯片如同单端口存储器阵列为双端口存储器实例、三端口存储器实例、四端口存储器实例端口或任何其他多端口存储器实例一般起作用。
674.图42描绘符合本公开的提供沿着存储器芯片的列的双端口存取的电路系统4200的实施例,在该存储器芯片中使用电路系统4200。图42中所描绘的实施例可使用具有两个列多任务器(「mux」)4205a及4205b以在用于逻辑电路的相同时钟循环期间存取相同行上的两个字的一个存储器阵列4201。例如,在一存储器时钟循环期间,rowaddra用于行解码器4203中且coladdra用于多任务器4205a中以缓冲来自具有地址(rowaddra,coladdra)的存储器胞元的数据。在相同存储器时钟循环期间,coladdrb用于多任务器4205b中以缓冲来自具有地址(rowaddra,coladdrb)的存储器胞元的数据。因此,电路系统4200可允许沿着相同行或字线对储存于两个不同地址处的存储器胞元上的数据(例如,dataa及datab)进行双端口存取。因此,两个地址可共享行使得行解码器4203针对两次取回启动相同字线。此外,如图42中所描绘的实施例可使用列多任务器,使得可在相同存储器时钟循环期间存取两个地址。
675.类似地,图43描绘符合本公开的提供沿着存储器芯片的行的双端口存取的电路系统4300的一实施例,在该存储器芯片中使用电路系统4300。图43中所描绘的实施例可使用具有与多任务器(「mux」)耦接的行解码器4303以在用于逻辑电路的相同时钟循环期间存取相同列上的两个字的一个存储器阵列4301。例如,在两个存储器时钟循环中的第一存储器时钟循环上,rowaddra用于行解码器4303中且coladdra用于列多任务器4305中以缓冲来自具有地址(rowaddra,coladdra)的存储器胞元的数据(例如,至图43的「缓冲字」缓冲器)。在两个存储器时钟循环中的第二存储器时钟循环上,rowaddrb用于行解码器4303中且coladdra用于列多任务器4305中以缓冲来自具有地址(rowaddrb,coladdra)的存储器胞元的数据。因此,电路系统4300可允许沿着相同列或比特线对储存于两个不同地址处的存储器胞元上的数据(例如,dataa及datab)进行双端口存取。因此,两个地址可共享行使得列解码器(其可与一个或多个列多任务器分开或组合,如图43中所描绘)针对两次取回启动相同比特线。如图43中所描绘的实施例可使用两个存储器时钟循环,这是因为行解码器4303启动每一字线都可能需要一个存储器时钟循环。因此,若以至少两倍于对应的逻辑电路的速度进行时钟控制,则使用电路系统4300的存储器芯片可用作双端口存储器。
676.因此,如上文所解释,图43可在比用于对应的逻辑电路的时钟循环快的两个存储器时钟循环期间取回dataa及datab。例如,行解码器(例如,图43的行解码器4303)及列解码器(其可与一个或多个列多任务器分开或组合,如图43中所描绘)可被配置为以至少两倍于对应的逻辑电路产生两个地址的速率的速率进行时钟控制。例如,用于电路系统4300的时钟电路(图43中未展示)可根据至少两倍于对应的逻辑电路产生两个地址的速率的速率对电路系统4300进行时钟控制。
677.可分开地或组合地使用图42的实施例及图43的实施例。因此,在单端口存储器阵
列或垫上提供双端口功能性的电路系统(例如,电路系统4200或4300)可包含沿着至少一行及至少一列布置的多个存储器组。所述多个存储器组在图42中描绘为存储器阵列4201及在图43中描绘为存储器阵列4301。该实施例可进一步使用被配置为在单一时钟循环期间接收用于读取或写入的两个地址的至少一个行多任务器(如图43中所描绘)或至少一个列多任务器(如图42中所描绘)。此外,该实施例可使用行解码器(例如,图42的行解码器4203及图43的行解码器4303)及列解码器(其可与一个或多个列多任务器分开或组合,如图42及图43中所描绘)以从两个地址读取或写入至两个地址。例如,行解码器及列解码器可在第一循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第一地址,且解码对应于第一地址的字线及比特线。此外,行解码器及列解码器可在第二循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第二地址,且解码对应于第二地址的字线及比特线。该取回可各包含使用行解码器启动对应于地址的字线及使用列解码器启动经启动的字线上的对应于地址的比特线。
678.尽管上文针对取回进行了描述,但图42及图43的实施例(无论系分开地抑或组合地实施)均可包括写入命令。例如,在第一循环期间,行解码器及列解码器可将从至少一个行多任务器或至少一个列多任务器取回的第一数据写入至两个地址中的第一地址。例如,在第二循环期间,行解码器及列解码器可将从至少一个行多任务器或至少一个列多任务器取回的第二数据写入至两个地址中的第二地址。
679.图42绘示在第一地址及第二地址共享字线地址时的此处理程序的实施例,而图43绘示在第一地址及第二地址共享行地址时的此处理程序的实施例。如下文关于图47进一步所描述,在第一地址及第二地址不共享字线地址抑或行地址时,可实施相同处理程序。
680.因此,尽管上文的实施例提供沿着行或列中的至少一个的双端口存取,但额外实施例可提供沿着行和列两者的双端口存取。图44描绘符合本公开的提供沿着存储器芯片的行和列两者的双端口存取的电路系统4400的实施例,在该存储器芯片中使用电路系统4400。因此,电路系统4700可表示图42的电路系统4200与图43的电路系统4300的组合。
681.图44中所描绘的实施例可使用具有与多任务器(「mux」)耦接的行解码器4403以在用于逻辑电路的相同时钟循环期间存取两行的一个存储器阵列4401。此外,图44中所描绘的实施例可使用具有与多任务器(「mux」)耦接的列解码器(或多任务器)4405以在相同时钟循环期间存取两列的存储器阵列4401。例如,在两个存储器时钟循环中的第一存储器时钟循环上,rowaddra用于行解码器4403中且coladdra用于列多任务器4405中以缓冲来自具有地址(rowaddra,coladdra)的存储器胞元的数据(例如,至图44的「缓冲字」缓冲器)。在两个存储器时钟循环中的第二存储器时钟循环上,rowaddrb用于行解码器4403中且coladdrb用于列多任务器4405中以缓冲来自具有地址(rowaddrb,coladdrb)的存储器胞元的数据。因此,电路系统4400可允许对储存于两个不同地址处的存储器胞元上的数据(例如,dataa及datab)进行双端口存取。如图44中所描绘的实施例可使用额外缓冲器,这是因为行解码器4403启动每一字线可能都需要一个存储器时钟循环。因此,若以至少两倍于对应的逻辑电路的速度进行时钟控制,则使用电路系统4400的存储器芯片可用作双端口存储器。
682.尽管在图44中未描绘,但电路系统4400还可以包括沿着行或字线的图46(下文进一步描述)的额外电路系统和/或沿着列或比特线的类似额外电路系统。因此,电路系统4400可启动对应电路系统(例如,通过断开一个或多个开关元件,诸如图46的开关元件
4613a、4613b及其类似物中的一个或多个)以启动包括地址的断开部分(例如,通过连接电压或允许电流流动至断开部分)。因此,当电路系统的元件(诸如,线或其类似物)包括识别地址的位置时和/或当电路系统的元件(诸如,开关元件)控制至由地址识别的存储器胞元的供应或电压和/或电流时,该电路系统可「对应」。电路系统4400可接着使用行解码器4403及列多任务器4405以解码对应字线及比特线,以从位于经启动的断开部分中的地址取回数据或将数据写入至该地址。
683.如图44中进一步所描绘,电路系统4400可进一步使用被配置为在单一时钟循环期间接收用于读取或写入的两个地址的至少一个行多任务器(描绘为与行解码器4403分开,但可并入其中)和/或至少一个列多任务器(例如,描绘为与列多任务器4405分开,但可并入其中)。因此,实施例可使用行解码器(例如,行解码器4403)及列解码器(其可与列多任务器4405分开或组合)以从两个地址读取或写入至两个地址。例如,行解码器及列解码器可在存储器时钟循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第一地址,且解码对应于第一地址的字线及比特线。此外,行解码器及列解码器可在相同存储器循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第二地址,且解码对应于第二地址的字线及比特线。
684.图45a及图45b描绘用于在单端口存储器阵列或垫上提供双端口功能性的现有复制技术。如图45a中所展示,双端口读取可通过跨越存储器阵列或垫使数据的复本保持同步来提供。因此,可从存储器实例的两个复本执行读取,如图45a中所描绘。此外,如图45b中所展示,双端口写入可通过跨越存储器阵列或垫复制所有写入来提供。例如,存储器芯片可能需要使用存储器芯片的逻辑电路重复地发送写入命令,每一数据复本发送一个写入命令。替代地,在一些实施例中,如图45a中所展示,额外电路系统可允许使用存储器实例的逻辑电路发送单写入命令,单写入命令由额外电路系统自动地复制以跨越存储器阵列或垫产生写入数据的复本,以便使复本保持同步。图42、图43及图44的实施例可通过使用多任务器在单一存储器时钟循环中存取两条比特线(例如,如图42中所描绘)和/或通过比对应的逻辑电路更快地时钟控制存储器(例如,如图43及图44中所描绘)及提供额外多任务器以处置额外地址而非复制存储器中的所有数据来缩减来自这些现有复制技术的冗余。
685.除上文所描述的更快时钟控制和/或额外多任务器以外,本公开的实施例也可使用在存储器阵列内的一些点处断开比特线和/或字线的电路系统。这些实施例可允许对阵列的多个同时存取,只要行解码器及列解码器存取不耦接至断开电路系统的相同部分的不同位置即可。例如,可同时存取具有不同字线及比特线的位置,这是因为断开电路系统可允许行和列解码存取不同地址而无电干扰。在设计存储器芯片期间,可权衡存储器阵列内的断开区的粒度与断开电路系统所需的额外区域。
686.用于实施此同时存取的架构描绘于图46中。具体而言,图46描绘在单端口存储器阵列或垫上提供双端口功能性的电路系统4600的实施例。如图46中所描绘,电路系统4600可包括沿着至少一行及至少一列布置的多个存储器垫(例如,存储器垫4609a、垫4609b及其类似物)。电路系统4600的布局还包括多条字线,诸如对应于行的字线4611a及4611b,以及对应于列的比特线4615a及4615b。
687.图46所绘示的实施例包括十二个存储器垫,每个存储器垫具有两条线及八个列。在其他实施例中,基板可包括任何数量的存储器垫,且每个存储器垫可包括任何数量条线
及任何数量的列。一些存储器垫可包括相同数量的线及列(如图46中所展示),而其他存储器垫可包括不同数量的线和/或列。
688.尽管在图46中未描绘,但电路系统4600可进一步使用被配置为在单一时钟循环期间接收用于读取或写入的两个(或三个或任何多个)地址的至少一个行多任务器(与行解码器4601a和/或4601b分开或与该行解码器合并)或至少一个列多任务器(例如,列多任务器4603a和/或4603b)。此外,实施例可使用行解码器(例如,行解码器4601a和/或4601b)及列解码器(其可与列多任务器4603a和/或4603b分开或组合)以从两个(或多于两个)地址读取或写入至两个(或多于两个)地址。例如,行解码器及列解码器可在存储器时钟循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第一地址,且解码对应于第一地址的字线及比特线。此外,行解码器及列解码器可在相同存储器循环期间从至少一个行多任务器或至少一个列多任务器取回两个地址中的第二地址,且解码对应于第二地址的字线及比特线。如上文所解释,只要两个地址处于不耦接至断开电路系统(例如,开关元件,诸如4613a、4613b及其类似物)的相同部分的不同位置中,便可在相同存储器时钟循环期间进行存取。另外,电路系统4600可在第一存储器时钟循环期间同时存取前两个地址,且接着在第二存储器时钟循环期间同时存取接下来两个地址。在这些实施例中,若以至少两倍于对应的逻辑电路的速度进行时钟控制,则使用电路系统4600的存储器芯片可用作四端口存储器。
689.图46还包括被配置为用作开关的至少一个行电路及至少一个列电路。例如,诸如4613a、4613b及其类似物的对应开关元件可包含晶体管或任何其他电元件,其被配置为允许或停止电流流动和/或连接或断开电压与连接至诸如4613a、4613b及其类似物的开关元件的字线或比特线。因此,对应开关元件可将电路系统4600分成断开部分。尽管描绘为包含单一行且每一行包含十六列,但电路系统4600内的断开区可取决于电路系统4600的设计而包括不同粒度等级。
690.电路系统4600可使用控制器(例如,行控制件4607)以启动至少一个行电路及至少一个列电路中的对应者,以便在上文所描述的地址操作期间启动对应断开区。例如,电路系统4600可传输一个或多个控制信号以闭合开关元件(例如,开关元件4613a、4613b及其类似物)中的对应者。在开关元件4613a、4613b及其类似物包含晶体管的实施例中,控制信号可包含断开晶体管的电压。
691.取决于包括地址的断开区,可由电路系统4600启动开关元件中的多于一者。例如,为到达图46的存储器垫4609b内的地址,必须断开允许存取存储器垫4609a的开关元件以及允许存取存储器垫4609b的开关元件。行控制件4607可判定要启动的开关元件,以便根据特定地址取回电路系统4600内的特定地址。
692.图46表示用以划分存储器阵列(例如,包含存储器垫4609a、垫4609b及其类似物)的字线的电路系统4600的实施例。然而,其他实施例可使用类似电路系统(例如,将存储器芯片4600分成断开区的开关元件)以划分存储器阵列的比特线。因此,电路系统4600的架构可用于双列存取(如图42或图44中所描绘的情况)以及双行存取(如图43或图44中所描绘的情况)中。
693.用于对存储器阵列或垫进行多循环存取的处理程序描绘于图47a中。具体而言,图47a为用于在单端口存储器阵列或垫上提供双端口存取(例如,使用图43的电路系统4300或
图44的电路系统4400)的处理程序4700的实施例的流程图,可使用符合本公开的行解码器及列解码器执行处理程序4700,诸如分别图43或图44的行解码器4303或4403,及列解码器(其可与一个或多个列多任务器分开或组合,诸如分别描绘于图43或图44中的列多任务器4305或4405)。
694.在步骤4710处,在第一存储器时钟循环期间,该电路系统可使用至少一个行多任务器及至少一个列多任务器以解码对应于两个地址中的第一地址的字线及比特线。例如,至少一个行解码器可启动字线,且至少一个列多任务器可放大来自沿着经启动的字线并对应于第一地址的存储器胞元的电压。可将经放大电压提供至使用包括该电路系统的存储器芯片的逻辑电路,或根据下文所描述的步骤4720缓冲经放大电压。该逻辑电路可包含诸如gpu或cpu的电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
695.尽管上文描述为读取操作,但方法4700可类似地处理写入操作。例如,至少一个行解码器可启动字线,且至少一个列多任务器可将电压施加至沿着经启动的字线并对应于第一地址的存储器胞元,以将新数据写入至该存储器胞元。在一些实施例中,该电路系统可将对写入的确认提供至使用包括该电路系统的存储器芯片的逻辑电路,或根据下文步骤4720缓冲该确认。
696.在步骤4720处,该电路系统可缓冲第一地址的所取回数据。例如,如图43及图44中所描绘,缓冲器可允许电路系统取回两个地址中的第二地址(如下文描述于步骤4730中)且将两次取回的结果一起传回。缓冲器可包含寄存器、sram、非易失性存储器或任何其他数据储存设备。
697.在步骤4730处,在第二存储器时钟循环期间,该电路系统可使用至少一个行多任务器及至少一个列多任务器以解码对应于两个地址中的第二地址的字线及比特线。例如,至少一个行解码器可启动字线,且至少一个列多任务器可放大来自沿着经启动的字线并对应于第二地址的存储器胞元的电压。可将经放大电压提供至使用包括该电路系统的存储器芯片的逻辑电路,无论系个别地抑或连同例如来自步骤4720的经缓冲电压一起。该逻辑电路可包含诸如gpu或cpu的电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
698.尽管上文描述为读取操作,但方法4700可类似地处理写入操作。例如,至少一个行解码器可启动字线,且至少一个列多任务器可将电压施加至沿着经启动的字线并对应于第二地址的存储器胞元,以将新数据写入至该存储器胞元。在一些实施例中,该电路系统可将对写入的确认提供至使用包括该电路系统的存储器芯片的逻辑电路,无论系个别地抑或连同例如来自步骤4720的经缓冲电压一起。
699.在步骤4740处,该电路系统可输出第二地址与经缓冲第一地址的所取回数据。例如,如图43及图44中所描绘,该电路系统可将两次取回的结果(例如,来自步骤4710及4730)一起传回。该电路系统可将结果传回至使用包括该电路系统的存储器芯片的逻辑电路,该逻辑电路可包含诸如gpu或cpu的电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
700.尽管参考多个循环进行描述,但若两个地址共享一字线,如图42中所描绘,则方法4700可允许对两个地址的单循环存取。例如,步骤4710及4730可在相同存储器时钟循环期
间进行,这是因为多个列多任务器可在相同存储器时钟循环期间解码相同字线上的不同比特线。在这些实施例中,可跳过缓冲步骤4720。
701.用于同时存取(例如,使用上文所描述的电路系统4600)的处理程序描绘于图47b中。因此,尽管依序地展示,图47b的步骤可全部在相同存储器时钟循环期间进行,且可同时执行至少一些步骤(例如,步骤4760与4780或步骤4770与4790)。具体而言,图47b为用于在单端口存储器阵列或垫上提供双端口存取(例如,使用图42的电路系统4200或图46的电路系统4600)的处理程序4750的实施例的流程图,可使用符合本公开的行解码器及列解码器执行处理程序4750,诸如分别图42或图46的行解码器4203或行解码器4601a及4601b,及列解码器(其可与一个或多个列多任务器分开或组合,诸如分别描绘于图42或图46中的列多任务器4205a及4205b或列多任务器4603a及4306b)。
702.在步骤4760处,在一存储器时钟循环期间,该电路系统可基于两个地址中的第一地址启动至少一个行电路及至少一个列电路中的对应者。例如,该电路系统可传输一个或多个控制信号以闭合包含至少一个行电路及至少一个列电路的开关元件中的对应者。因此,该电路系统可存取包括两个地址中的第一地址的对应断开区。
703.在步骤4770处,在该存储器时钟循环期间,该电路系统可使用至少一个行多任务器及至少一个列多任务器以解码对应于第一地址的字线及比特线。例如,至少一个行解码器可启动字线,且至少一个列多任务器可放大来自沿着经启动的字线并对应于第一地址的存储器胞元的电压。可将经放大电压提供至使用包括该电路系统的存储器芯片的逻辑电路。例如,如上文所描述,该逻辑电路可包含诸如gpu或cpu的电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
704.尽管上文描述为读取操作,但方法4500可类似地处理写入操作。例如,至少一个行解码器可启动字线,且至少一个列多任务器可将电压施加至沿着经启动的字线并对应于第一地址的存储器胞元,以将新数据写入至该存储器胞元。在一些实施例中,该电路系统可将对写入的确认提供至使用包括该电路系统的存储器芯片的逻辑电路。
705.在步骤4780处,在相同循环期间,该电路系统可基于两个地址中的第二地址启动至少一个行电路及至少一个列电路中的对应者。例如,该电路系统可传输一个或多个控制信号以闭合包含至少一个行电路及至少一个列电路的开关元件中的对应者。因此,该电路系统可存取包括两个地址中的第二地址的对应断开区。
706.在步骤4790处,在相同循环期间,该电路系统可使用至少一个行多任务器及至少一个列多任务器以解码对应于第二地址的字线及比特线。例如,至少一个行解码器可启动字线,且至少一个列多任务器可放大来自沿着经启动的字线并对应于第二地址的存储器胞元的电压。可将经放大电压提供至使用包括该电路系统的存储器芯片的逻辑电路。例如,如上文所描述,该逻辑电路可包含诸如gpu或cpu的常规电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
707.尽管上文描述为读取操作,但方法4500可类似地处理写入操作。例如,至少一个行解码器可启动字线,且至少一个列多任务器可将电压施加至沿着经启动的字线并对应于第二地址的存储器胞元,以将新数据写入至该存储器胞元。在一些实施例中,该电路系统可将对写入的确认提供至使用包括该电路系统的存储器芯片的逻辑电路。
708.尽管参考单一循环进行描述,但若两个地址处于共享字线或比特线(或以其他方
式共享至少一个行电路及至少一个列电路中的开关元件)的断开区中,则方法4500可允许对两个地址的多循环存取。例如,步骤4760及4770可在第一存储器时钟循环期间进行,在该第一存储器时钟循环中,第一行解码器及第一列多任务器可解码对应于第一地址的字线及比特线,而步骤4780及4790可在第二存储器时钟循环期间进行,在该第二存储器时钟循环中,第二行解码器及第二列多任务器可解码对应于第二地址的字线及比特线。
709.用于沿着行和列两者的双端口存取的架构的另一实施例描绘于图48中。具体而言,图48描绘使用多个行解码器结合多个列多任务器提供沿着行和列两者的双端口存取的电路系统4800的一实施例。在图48中,行解码器4801a可存取第一字线,且列多任务器4803a可解码来自沿着第一字线的一个或多个存储器胞元的数据,而行解码器4801b可存取第二字线,且列多任务器4803b可解码来自沿着第二字线的一个或多个存储器胞元的数据。
710.如关于图47b所描述,此存取可在一个存储器时钟循环期间同时进行。因此,类似于图46的架构,图48的架构(包括下文描述于图49中的存储器垫)可允许在相同时钟循环中存取多个地址。例如,图48的架构可包括任何数量的行解码器及任何数量的列多任务器,使得与行解码器及列多任务器的数量对应的数量的地址可全部在单一存储器时钟循环内存取。
711.在其他实施例中,此存取沿着两个存储器时钟循环可依序进行。通过比对应的逻辑电路更快地时钟控制存储器芯片4800,两个存储器时钟循环可等效于使用存储器的逻辑电路的一个时钟循环。例如,如上文所描述,该逻辑电路可包含诸如gpu或cpu的常规电路,或可包含与存储器芯片在相同基板上的处理群组,例如,如图7a中所描绘。
712.其他实施例可允许同时存取。例如,如关于图42所描述,多个列解码器(其可包含列多任务器,诸如4803a及4803b,如图48中所展示)可在单一存储器时钟循环期间读取沿着相同字线的多条比特线。另外或替代地,如关于图46所描述,电路系统4800可并有额外电路系统使得此存取可为同时的。例如,行解码器4801a可存取第一字线,且列多任务器4803a可在相同存储器时钟循环期间解码来自沿着第一字线的存储器胞元的数据,在该存储器时钟循环中,行解码器4801b存取第二字线,且列多任务器4803b解码来自沿着第二字线的存储器胞元的数据。
713.图48的架构可与形成存储器组的经修改存储器垫一起使用,如图49中所展示。在图49中,通过两条字线及两条比特线存取每个存储器胞元(描绘为类似于dram的电容器,但也可包含以类似于sram或任何其他存储器胞元的方式布置的数个晶体管)。因此,图49的存储器垫4900允许通过两个不同逻辑电路同时存取两个不同比特,或甚至存取相同比特。然而,图49的实施例使用对存储器垫的修改而非在标准dram存储器垫上实施双端口解决方案,该存储器垫经线连接以用于单端口存取,如上文实施例一般。
714.尽管描述为具有两个端口,但上文所描述的实施例中的任一者可扩展至多于两个端口。例如,图42、图46、图48及图49的实施例可分别包括额外的列多任务器或行多任务器,以在单一时钟循环期间提供对额外列或行的存取。作为另一实施例,图43及图44的实施例可包括额外的行解码器和/或列多任务器,以在单一时钟循环期间分别提供对额外行或列的存取。
715.存储器中的可变字长存取
716.如上文及下文进一步所使用,术语「耦接」可包括直接连接、间接连接、电通信及其
类似物。
717.此外,如「第一」、「第二」及其类似物的术语用以区分具有相同或类似名称或标题的元件或方法步骤,且未必指示空间或时间次序。
718.通常,存储器芯片可包括存储器组。存储器组可耦接至行解码器及列解码器,该解码器被配置为选择要读取或写入的特定字(或其他固定大小的数据单元)。每个存储器组可包括用以储存数据单元的存储器胞元、用以放大来自通过行解码器及列解码器选择的存储器胞元的电压,及任何其他适当电路。
719.每个存储器组通常具有特定i/o宽度。例如,i/o宽度可包含字。
720.虽然由使用存储器芯片的逻辑电路执行的一些处理程序可受益于使用极长字,但一些其他处理程序可仅需要该字的一部分。
721.实际上,存储器内计算单元(诸如,与存储器芯片安置于相同基板上的处理器子单元,例如,如图7a中所描绘及描述)频繁地执行仅需要该字的一部分的存储器存取操作。
722.为了缩减在仅使用一部分时与存取整个字相关联的延时,本公开的实施例可提供用于仅取得一字的一个或多个部分的方法及系统,藉此缩减与传送该字的不需要部分相关联的数据损失且允许存储器设备中的功率节省。
723.此外,本公开的实施例也可缩减存储器芯片与其他实体(诸如,逻辑电路,无论系分开的,如cpu及gpu,抑或与存储器芯片包括于相同基板上,诸如图7a中所描绘及描述的处理器子单元)之间的相互作用的功率消耗,该其他实体存取存储器芯片,其可仅接收或写入该字的一部分。
724.存储器存取命令(例如,来自使用存储器的逻辑电路)可包括存储器中的地址。例如,该地址可包括列地址及行地址,或可例如通过存储器的存储器控制器转移成列地址及行地址。
725.在诸如dram的许多易失性存储器中,将列地址发送(例如,直接由逻辑电路或使用存储器控制器)至行解码器,该行解码器启动整个行(也被称作字线)且加载包括于该行中的所有比特线。
726.该行地址识别经启动行上的比特线,其在包括比特线的存储器组外部转送且传送至下一层级电路系统。例如,下一层级电路系统可包含存储器芯片的i/o总线。在使用存储器内处理的实施例中,下一层级电路系统可包含存储器芯片的处理器子单元(例如,如图7a中所描绘)。
727.因此,下文所描述的存储器芯片可包括于如图3a、图3b、图4至图6、图7a至图7d、图11至图13、图16至图19、图22或图23中的任一者中所说明的存储器芯片中,或以其他方式包含该存储器芯片。
728.该存储器芯片可通过针对存储器胞元而非逻辑胞元优化的第一制造处理程序来制造。例如,由第一制造处理程序制造的存储器胞元可展现比由第一制造处理程序制造的逻辑电路的临界尺寸小的临界尺寸(例如,小超过2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍及其类似物)。例如,第一制造处理程序可包含模拟制造处理程序、dram制造处理程序及其类似物。
729.此存储器芯片可包含集成电路,该集成电路可包括存储器单元。该存储器单元可包括存储器胞元、输出端口及读取电路系统。在一些实施例中,该存储器单元还可以包括处
理单元,诸如,如上文所描述的处理器子单元。
730.例如,该读取电路系统可包括缩减单元及存储器内读取路径的第一群组,该存储器内读取路径用于经由输出端口输出多达第一数量的比特。该输出端口可连接至芯片外逻辑电路(诸如,加速器、cpu、gpu或其类似物)或片上处理器子单元,如上文所描述。
731.在一些实施例中,该处理单元可包括缩减单元,可为缩减单元的部分,可不同于缩减单元,或可以其他方式包含缩减单元。
732.存储器内读取路径可包含于集成电路中(例如,可在存储器单元中),且可包括被配置用于从存储器胞元读取和/或写入至存储器胞元的任何电路和/或链路。例如,存储器内读取路径可包括感测放大器、耦接至存储器胞元的导体、多任务器及其类似物。
733.该处理单元可被配置为将一读取请求发送至该存储器单元以从该存储器单元读取第二数量的比特。另外或替代地,该读取请求可源自芯片外逻辑电路(诸如,加速器、cpu、gpu或其类似物)。
734.该缩减单元可被配置为例如通过使用本文中所描述的部分字存取中的任一者来辅助缩减与存取请求相关的功率消耗。
735.该缩减单元可被配置为在由该读取请求触发的读取操作期间基于该第一数量的比特及该第二数量的比特而控制该存储器内读取路径。例如,来自缩减单元的控制信号可影响读取路径的存储器消耗,以缩减与所请求的第二数量的比特不相关的存储器读取路径的能量消耗。例如,该缩减单元可被配置为在第二数量小于第一数量时控制不相关的存储器读取路径。
736.如上文所解释,该集成电路可包括于如图3a、图3b、图4至图6、图7a至图7d、图11至图13、图16至图19、图22或图23中的任一者中所说明的存储器芯片中,可包括该存储器芯片或以其他方式包含该存储器芯片。
737.不相关的存储器内读取路径可与第一数量的比特中的不相关的比特相关,诸如第一数量的比特中的不包括于第二数量的比特中的比特。
738.图50说明本公开的一实施例中的集成电路5000,其包括:存储器胞元阵列5050中的存储器胞元5001至5008;输出端口5020,其包括比特5021至5028;读取电路系统5040,其包括存储器读取路径5011至5018;及缩减单元5030。
739.当使用对应的存储器读取路径读取第二数量的比特时,第一数量的比特中的不相关比特可对应于不应读取的比特(例如,不包括于第二数量的比特中的比特)。
740.在读取操作期间,缩减单元5030可被配置为启动对应于第二数量的比特的存储器读取路径,使得经启动的存储器读取路径可被配置为输送第二数量的比特。在这些实施例中,可仅启动对应于第二数量的比特的存储器读取路径。
741.在读取操作期间,缩减单元5030可被配置为切断每一不相关的存储器读取路径的至少一部分。例如,不相关的存储器读取路径可对应于第一数量的比特中的不相关比特。
742.应注意,替代切断不相关的存储器路径的至少一部分,缩减单元5030可替代地保证不启动不相关的存储器路径。
743.另外或替代地,在读取操作期间,缩减单元5030可被配置为将不相关的存储器读取路径维持在低功率模式中。例如,低功率模式可包含分别向不相关的存储器路径供应低于正常工作电压或电流的电压或电流。
744.缩减单元5030可被进一步配置为控制不相关的存储器读取路径的比特线。
745.因此,缩减单元5030可被配置为加载相关的存储器读取路径的比特线,且将不相关的存储器读取路径的比特线维持在低功率模式中。例如,仅可加载相关的存储器读取路径的比特线。
746.另外或替代地,缩减单元5030可被配置为加载相关的存储器读取路径的比特线,同时将不相关的存储器读取路径的比特线维持为撤销启动。
747.在一些实施例中,缩减单元5030可被配置为在读取操作期间利用相关的存储器读取路径的部分,且将每一不相关的存储器读取路径的一部分维持在低功率模式中,其中该部分不同于比特线。
748.如上文所解释,存储器芯片可使用感测放大器以放大来自包括于存储器芯片中的存储器胞元的电压。因此,缩减单元5030可被配置为在读取操作期间利用相关的存储器读取路径的部分,且将与不相关的存储器读取路径中的至少一些读取路径相关联的感测放大器维持在低功率模式中。
749.在这些实施例中,缩减单元5030可被配置为在读取操作期间利用相关的存储器读取路径的部分,且将与所有不相关的存储器读取路径相关联的一个或多个感测放大器维持在低功率模式中。
750.另外或替代地,缩减单元5030可被配置为在读取操作期间利用相关的存储器读取路径的部分,且将在与不相关的存储器读取路径相关联的一个或多个感测放大器之后(例如,在空间上和/或在时间上)的不相关的存储器读取路径的部分维持在低功率模式中。
751.在上文所描述的实施例中的任一者中,该存储器单元可包括列多任务器(未示出)。
752.在这些实施例中,缩减单元5030可耦接于列多任务器与输出端口之间。
753.另外或替代地,缩减单元5030可嵌入于列多任务器中。
754.另外或替代地,缩减单元5030可耦接于存储器胞元与列多任务器之间。
755.缩减单元5030可包含可为可独立控制的缩减子单元。例如,不同的缩减子单元可与不同的存储器单元列相关联。
756.尽管上文关于读取操作及读取电路系统进行描述,但上文实施例可类似地应用于写入操作及写入电路系统。
757.例如,根据本公开的集成电路可包括存储器单元,该存储器单元包含存储器胞元、输出端口及写入电路系统。在一些实施例中,该存储器单元还可以包括处理单元,诸如,如上文所描述的处理器子单元。该写入电路系统可包括缩减单元及用于经由输出端口输出多达第一数量的比特的存储器内写入路径的第一群组。该处理单元可被配置为将一写入请求发送至该存储器单元以写入来自该存储器单元的第二数量的比特。另外或替代地,该写入请求可源自芯片外逻辑电路(诸如,加速器、cpu、gpu或其类似物)。缩减单元5030可被配置为在由该写入请求触发的写入操作期间基于该第一数量的比特及该第二数量的比特而控制该存储器写入路径。
758.图51说明存储器组5100,该存储器组包括使用列地址及行地址(例如,来自片上处理器子单元或芯片外逻辑电路,诸如加速器、cpu、gpu或其类似物)来寻址的存储器胞元的阵列5111。如图51中所展示,存储器胞元馈接至比特线(竖直)及字线(水平,为简单起见省
略许多字线)。此外,行解码器5112可馈入有列地址(例如,来自片上处理器子单元、芯片外逻辑电路,或图51中未展示的存储器控制器),列多任务器5113可馈入有行地址(例如,来自片上处理器子单元、芯片外逻辑电路,或图51中未展示的存储器控制器),且列多任务器5113可经由输出总线5115接收来自多达整个线的输出及多达一字的输出。在图51中,列多任务器5113的输出总线5115耦接至主i/o总线5114。在其他实施例中,输出总线5115可耦接至存储器芯片(例如,如图7a中所描绘)的发送列地址及行地址的处理器子单元。为简单起见,未展示将存储器组分成存储器垫。
759.图52说明存储器组5101。在图52中,存储器组还说明为包括存储器内处理(pim)逻辑5116,该逻辑具有耦接至输出总线5115的输入端。pim逻辑5116可产生地址(例如,包含列地址及行地址)且经由pim地址总线5118输出地址以存取存储器组。pim逻辑5116为还包含处理单元的缩减单元(例如,单元5030)的实施例。pim逻辑5016可控制图52未展示的辅助缩减功率的其他电路。pim逻辑5116可进一步控制包括存储器组5101的存储器单元的存储器路径。
760.如上文所解释,在一些状况下,字长(例如,选择一次传送的比特线的数量)可为大的。
761.在这些状况下,用于读取和/或写入的每一字可与可在读取和/或写入操作的各种阶段消耗功率的存储器路径相关联,例如:
762.a.加载比特线——为了将比特线加载至所需值(在读取循环中从比特线上的电容器,抑或在写入循环中要写入至电容器的新值),需要停用位于存储器阵列的末端处的感测放大器且确保保存数据的电容器不放电或充电(否则,储存于其上的数据将被破坏);及
763.b.经由选择比特线的列多任务器将来自感测放大器的数据移动至芯片的其余部分(移动至将数据传入及传出芯片的i/o总线或移动至将使用数据的嵌入式逻辑,诸如与存储器在相同基板上的处理器子单元)。
764.为了达成功率节省,本公开的集成电路可在行启动时间判定一字的一些部分为不相关的且接着针对该字的该不相关的部分将停用信号发送至一个或多个感测放大器。
765.图53说明存储器单元5102,该存储器单元包括存储器胞元阵列5111、行解码器5112、耦接至输出总线5115的列多任务器5113,及pim逻辑5116。
766.存储器单元5102还包括启用或停用比特至列多任务器5113的通道的开关5201。开关5201可包含模拟开关、被配置为用作开关的晶体管,被配置为控制至存储器单元5102的部分的供应或电压和/或电流流动。感测放大器(未示出)可位于存储器胞元阵列的末端处,例如,在开关5201之前(在空间上和/或在时间上)。
767.开关5201可由从pim逻辑5116经由总线5117发送的启用信号控制。当断开时,该开关被配置为断开存储器单元5102的感测放大器(未示出),且因此不对与感测放大器断开的比特线放电或充电。
768.开关5201及pim逻辑5116可形成缩减单元(例如,缩减单元5030)。
769.在又一实施例中,pim逻辑5116可将启用信号发送至感测放大器(例如,当感测放大器具有启用输入时)而非发送至开关5201。
770.比特线可另外或替代地在其他点处断开,例如,不在比特线的末端处及在感测放大器之后断开。例如,比特线可在进入阵列5111之前断开。
771.在这些实施例中,在从感测放大器及转送硬件(诸如,输出总线5115)的数据传送上,也可节省功率。
772.其他实施例(其可节省较少功率,但可较容易实施)聚焦于节省列多任务器5113的功率且将损失从列多任务器5113转移至下一层级电路系统。例如,如上文所解释,下一层级电路系统可包含存储器芯片的i/o总线(诸如,总线5115)。在使用存储器内处理的实施例中,下一层级电路系统可另外或替代地包含存储器芯片的处理器子单元(诸如,pim逻辑5116)。
773.图54a说明分段为区段5202的列多任务器5113。列多任务器5113的每个区段5202可通过从pim逻辑5116经由总线5119发送的启用和/或停用信号来个别地启用或停用。列多任务器5113也可由地址列总线5118馈入。
774.图54a的实施例可提供对来自列多任务器5113的输出的不同部分的较佳控制。
775.应注意,对不同存储器路径的控制可具有不同分辨率,例如范围为从一比特分辨率至多比特分辨率。前者在功率节省的意义上可能更有效。后者的实施可能较简单且需要较少控制信号。
776.图54b说明方法5130的实施例。例如,可使用上文关于图50、图51、图52、图53或图54a所描述的存储器单元中的任一者来实施方法5130。
777.方法5130可包括步骤5132及5134。
778.步骤5132可包括:通过集成电路的处理单元(例如,pim逻辑5116)将存取请求发送至集成电路的存储器单元以从该存储器单元读取第二数量的比特。该存储器单元可包括存储器胞元(例如,阵列5111的存储器胞元)、输出端口(例如,输出总线5115),及读取/写入电路系统,该读取/写入电路系统可包括缩减单元(例如,缩减单元5030)及存储器读取/写入路径的第一群组,该存储器读取/写入路径用于经由输出端口输出和/或输入多达第一数量的比特。
779.存取请求可包含读取请求和/或写入请求。
780.存储器输入/输出路径可包含存储器读取路径、存储器写入路径和/或用于读取及写入两者的路径。
781.步骤5134可包括对存取请求作出响应。
782.例如,步骤5134可包括在由存取请求触发的存取操作期间通过缩减单元(例如,单元5030)基于第一数量的比特及第二数量的比特而控制存储器读取/写入路径。
783.步骤5134还可以包括以下操作中的任一者和/或以下操作中的任一者的任何组合。下文列出的操作中的任一者可在对存取请求作出响应期间执行,但也可在对存取请求作出响应之前和/或之后执行。
784.因此,步骤5134可包含以下操作中的至少一个:
785.a.在第二数量小于第一数量时控制不相关的存储器读取路径,其中不相关的存储器读取路径与第一数量的比特中的不包括于第二数量的比特中的比特相关联;
786.b.在读取操作期间启动相关的存储器读取路径,其中相关的存储器读取路径被配置为输送第二数量的比特;
787.c.在读取操作期间切断不相关的存储器读取路径中的每个的至少一部分;
788.d.在读取操作期间将不相关的存储器读取路径维持在低功率模式中;
789.e.控制不相关的存储器读取路径的比特线;
790.f.加载相关的存储器读取路径的比特线且将不相关的存储器读取路径的比特线维持在低功率模式中;
791.g.加载相关的存储器读取路径的比特线,同时将不相关的存储器读取路径的比特线维持为撤销启动;
792.h.在读取操作期间利用相关的存储器读取路径的部分且将每一不相关的存储器读取路径的一部分维持在低功率模式中,其中该部分不同于比特线;
793.i.在读取操作期间利用相关的存储器读取路径的部分且将用于不相关的存储器读取路径中的至少一些读取路径的感测放大器维持在低功率模式中;
794.j.在读取操作期间利用相关的存储器读取路径的部分且将不相关的存储器读取路径中的至少一些读取路径的感测放大器维持在低功率模式中;及
795.k.在读取操作期间利用相关的存储器读取路径的部分且将在不相关的存储器读取路径的感测放大器之后的不相关的存储器读取路径维持在低功率模式中。
796.低功率模式或闲置模式可包含存储器存取路径的功率消耗低于在存储器存取路径用于存取操作时存储器存取路径的功率消耗的模式。在一些实施例中,低功率模式可甚至涉及切断存储器存取路径。低功率模式可另外或替代地包括不启动存储器存取路径。
797.应注意,在比特线阶段期间发生的功率缩减可能需要在开放字线之前应知晓存储器存取路径的相关性或不相关性。在别处发生(例如,在列多任务器中)的功率缩减可替代地允许在每次存取时决定存储器存取路径的相关性或不相关性。
798.快速及低功率启动以及快速存取存储器
799.dram及其他存储器类型(诸如,sram、快闪存储器或其类似物)常常从存储器组建置,该存储器组通常建置为允许行和列存取方案。
800.图55说明存储器芯片5140的实施例,该存储器芯片包括多个存储器垫及相关联逻辑(诸如,行和列解码器,在图55中分别描绘为rd及col)。在图55的实施例中,垫被分组成组且具有通过其的字线及比特线。存储器垫及相关联逻辑在图55中标明为5141、5142、5143、5144、5145及5146,且共享至少一个总线5147。
801.存储器芯片5140可包括于如图3a、图3b、图4至图6、图7a至图7d、图11至图13、图16至图19、图22或图23中的任一者中所说明的存储器芯片中,可包括该存储器芯片或以其他方式包含该存储器芯片。
802.例如,在dram中,与启动新行(例如,准备用于存取的新线)相关联的开销很大。一旦一线经启动(也被称作开放),该行内的数据便可用于更快存取。在dram中,此存取可能以随机方式进行。
803.与启动新线相关联的两个问题为功率及时间:
804.c.由于共同存取该线上的所有电容器及必须加载该线所导致的电流骤增,功率会上升(例如,当开放仅具有几个存储器组的线时,功率可达到若干安培);及
805.d.时间延迟问题主要与加载行(字)线及接着加载比特(列)线所花费的时间相关联。
806.本公开的一些实施例可包括用以在启动线期间缩减峰值功率消耗且缩减线启动时间的系统及方法。一些实施例可至少在一定程度上牺牲一线内的完全随机存取,以缩减
这些功率及时间成本。
807.例如,在一个实施例中,存储器单元可包括第一存储器垫、第二存储器垫及启动单元,该启动单元被配置为启动包括于第一存储器垫中的存储器胞元的第一群组,而不启动包括于第二存储器垫中的存储器胞元的第二群组。存储器胞元的该第一群组及存储器胞元的该第二群组可均属于该存储器单元的单一行。
808.替代地,该启动单元可被配置为启动包括于第二存储器垫中的存储器胞元的第二群组,而不启动存储器胞元的第一群组。
809.在一些实施例中,该启动单元可被配置为在启动存储器胞元的第一群组之后启动存储器胞元的第二群组。
810.例如,该启动单元可被配置为在存储器胞元的第一群组的启动已完成之后起始的延迟时段期满之后启动存储器胞元的第二群组。
811.另外或替代地,该启动单元可被配置为基于信号的值而启动存储器胞元的第二群组,该信号在耦接至存储器胞元的第一群组的第一字线区段上产生的。
812.在上文所描述的实施例中的任一者中,该启动单元可包括安置于第一字线区段与第二字线区段之间的中间电路。在这些实施例中,第一字线区段可耦接至第一存储器胞元且第二字线区段可耦接至第二存储器胞元。中间电路的非限制性实施例包括开关、触发器、缓冲器、反相器及其类似物,其中的一些贯穿图56至图61加以说明。
813.在一些实施例中,第二存储器胞元可耦接至第二字线区段。在这些实施例中,第二字线区段可耦接至通过至少第一存储器垫的旁路字线路径。此类旁路路径的实施例说明于图61中。
814.该启动单元可包含控制单元,该控制单元被配置为基于来自与单一行相关联的字线的启动信号而控制电压(和/或电流)至存储器胞元的第一群组及存储器胞元的第二群组的供应。
815.在另一实施例中,存储器单元可包括第一存储器垫、第二存储器垫及启动单元,该启动单元被配置为将启动信号供应至第一存储器垫的存储器胞元的第一群组且延迟该启动信号至第二存储器垫的存储器胞元的第二群组的供应,至少直至存储器胞元的第一群组的启动已完成。存储器胞元的该第一群组及存储器胞元的该第二群组可属于该存储器单元的单一行。
816.例如,该启动单元可包括可被配置为延迟供应启动信号的延迟单元。
817.另外或替代地,该启动单元可包括比较器,该比较器可被配置为在其输入端处接收启动信号且基于启动信号的至少一个特性而控制延迟单元。
818.在另一实施例中,存储器单元可包括第一存储器垫、第二存储器垫及隔离单元,该隔离单元可被配置为:在第一存储器垫的第一存储器胞元被启动的初始启动时段期间将该第一存储器胞元与第二存储器垫的第二存储器胞元相隔离;及在该初始启动时段之后将该第一存储器胞元耦接至该二存储器胞元。第一存储器胞元及第二存储器胞元可属于存储器单元的单一行。
819.在以下实施例中,可能不需要对存储器垫本身进行修改。在某些示例中,实施例可依赖于对存储器组的少量修改。
820.以下图式描绘缩短添加至存储器组的字信号,藉此将字线分裂成数个较短部分的
机构。
821.在以下诸图中,为了清楚起见省略各种存储器组组件。
822.图56至图61说明存储器组的部分(分别标明为5140(1)、5140(2)、5140(3)、5140(4)、5140(5)及5149(6)),该部分包括分组于不同群组内的行解码器5112及多个存储器垫(诸如,5150(1)、5150(2)、5150(3)、5150(4)、5150(5)、5150(6)、5151(1)、5151(2)、5151(3)、5151(4)、5151(5)、5151(6)、5152(1)、5152(2)、5152(3)、5152(4)、5152(5)及5152(6))。
823.布置成行的存储器垫可包括不同群组。
824.图56至图59及图61说明存储器垫的九个群组,其中每一群组包括一对存储器垫。可使用任何数量的群组,每一群组具有任何数量的存储器垫。
825.存储器垫5150(1)、5150(2)、5150(3)、5150(4)、5150(5)及5150(6)布置成行,共享多条存储器线,且分成三个群组:第一上部群组,其包括存储器垫5150(1)及5150(2);第二上部群组,其包括存储器垫5150(3)及5150(4);及第三上部群组,其包括存储器垫5150(5)及5150(6)。
826.类似地,存储器垫5151(1)、5151(2)、5151(3)、5151(4)、5151(5)及5151(6)布置成行,共享多条存储器线且分成三个群组:第一中间群组,其包括存储器垫5151(1)及5151(2);第二中间群组,其包括存储器垫5151(3)及5151(4);及第三中间群组,其包括存储器垫5151(5)及5151(6)。
827.此外,存储器垫5152(1)、5152(2)、5152(3)、5152(4)、5152(5)及5152(6)布置成行,共享多条存储器线且分组成三个群组:第一下部群组,其包括存储器垫5152(1)及5152(2);第二下部群组,其包括存储器垫5152(3)及5152(4);及第三下部群组,其包括存储器垫5152(5)及5152(6)。任何数量的存储器垫可布置成行并共享存储器线,且可分成任何数量的群组。
828.例如,每个群组的存储器垫的数量可为一个、两个或可超过两个。
829.如上文所解释,启动电路可被配置为启动存储器垫的一个群组,而不启动共享相同存储器线或至少耦接至具有相同线地址的不同存储器线区段的存储器垫的另一群组。
830.图56至图61说明启动电路的不同示例。在一些实施例中,启动电路的至少一部分(诸如,中间电路)可位于存储器垫群组之间,以允许启动一个群组的存储器垫,而不启动相同行的存储器垫的另一群组。
831.图56说明如定位于存储器的第一上部群组的不同线与存储器垫的第二上部群组的不同线之间的中间电路,诸如延迟或隔离电路5153(1)至5153(3)。
832.图56还说明如定位于存储器的第二上部群组的不同线与存储器垫的第三上部群组的不同线之间的中间电路,诸如延迟或隔离电路5154(1)至5154(3)。另外,一些延迟或隔离电路定位于由中间群组的存储器垫形成的群组之间。此外,一些延迟或隔离电路定位于由下部群组的存储器垫形成的群组之间。
833.该延迟或隔离电路可延迟或停止字线信号从行解码器5112沿着一行传播至另一群组。
834.图57说明包含触发器(诸如,5155(1)至5155(3)及5156(1)至5156(3))的中间电路,诸如延迟或隔离电路。
835.当将启动信号注入至字线时,启动第一垫群组中的一者(取决于该字线),而沿着该字线的其他群组保持撤销启动。可在下一时钟循环启动其他群组。例如,可在下一时钟循环启动其他群组中的第二群组,且可在又一时钟循环之后启动其他群组中的第三群组。
836.触发器可包括d型触发器或任何其他类型的触发器。为简单起见,从图式省略馈入至d型触发器的时钟。
837.因此,对第一群组的存取可使用电力以仅对与第一群组相关联的字线的部分充电,此比对整条字线充电更快且需要更少电流。
838.可在存储器垫群组之间使用多于一个触发器,藉此增加开放部分之间的延迟。另外或替代地,实施例可使用较慢时钟以增加延迟。
839.此外,经启动的群组可仍含有来自所使用的先前线值的群组。例如,该方法可允许启动新的线区段,同时仍存取先前线的数据,藉此缩减与启动新线相关联的损失。
840.因此,一些实施例可具有经启动的第一群组且允许先前启动线的其他群组保持在作用中,其中比特线的信号彼此不干扰。
841.另外,一些实施例可包括开关及控制信号。该控制信号可由组控制器控制或通过在控制信号之间添加触发器(例如,产生上文所描述的机构具有的相同时序效应)来控制。
842.图58说明诸如延迟或隔离电路的中间电路,其为开关(诸如,5157(1)至5157(3)及5158(1)至5158(3))且定位于另一群组的一群组之间。定位于群组之间的一组开关可由专用控制信号控制。在图58中,控制信号可由行控制单元5160(1)发送且由不同组开关之间的一个或多个延迟单元的序列(例如,单元5160(2)及5160(3))延迟。
843.图59说明诸如延迟或隔离电路的中间电路,其为反相器门或缓冲器(诸如,5159(1)至5159(3)及5159'1(0-5159'(3))的序列且定位于存储器垫群组之间。
844.替代开关,可在存储器垫群组之间使用缓冲器。缓冲器可能不允许开关之间沿着字线降低电压,此为在使用单一晶体管结构时有时会发生的效应。
845.其他实施例可允许更多的随机存取,且通过使用添加至存储器组的区域仍提供极低的启动功率及时间。
846.图60绘示一实施例,用以说明使用接近存储器垫定位的全局字线(诸如,5152(1)至5152(8))。这些字线可能通过或可能不通过存储器垫且经由诸如开关(诸如,5157(1)至5157(8))的中间电路耦接至存储器垫内的字线。该开关可控制将启动哪一存储器垫且允许存储器控制器在每一时间点处仅启动相关线部分。不同于上文所描述的使用线部分的依序启动的实施例,图60的实施例可提供更好的控制。
847.诸如行部分启用信号5170(1)及7150(2)的启用信号可源自未展示的逻辑,诸如存储器控制器。
848.图61说明全局字线5180通过存储器垫且形成用于可能不需要在垫外部投送的字线信号的旁路路径。因此,图61中所展示的实施例可以一些存储器密度为代价来缩减存储器组的面积。
849.在图61中,全局世界线可不间断地通过存储器垫且可能不连接至存储器胞元。区域字线区段可由开关中的一个控制且连接至垫中的存储器胞元。
850.当存储器垫群组提供字线的实质分割区时,存储器组可实际上支持完全随机存取。
851.用于减缓启动信号沿着字线的散布的另一实施例也可节省一些布线及逻辑,在存储器垫之间使用开关和/或其他缓冲或隔离电路,而不使用专用启用信号及专用线来输送启用信号。
852.例如,比较器可用以控制开关或其他缓冲或隔离电路。当由比较器监测的字线区段上的信号的电平达到某一电平时,比较器可启动开关或其他缓冲或隔离电路。例如,某一电平可指示完全加载先前字线区段。
853.图62说明用于操作存储器单元的方法5190。例如,可使用上文关于图56至图61所描述的存储器组中的任一者来实施方法5130。
854.方法5190可包括步骤5192及5194。
855.步骤5192可包括通过启动单元启动包括于存储器单元的第一存储器垫中的存储器胞元的第一群组,而不启动包括于存储器单元的第二存储器垫中的存储器胞元的第二群组。存储器胞元的该第一群组及存储器胞元的该第二群组可均属于该存储器单元的单一行。
856.步骤5194可包括通过启动单元启动存储器胞元的第二群组,例如,在步骤5192之后。
857.可在启动存储器胞元的第一群组时,在完全启动存储器胞元的第一群组之后,在存储器胞元的第一群组的启动已完成之后起始的延迟时段期满之后,在存储器胞元的第一群组撤销启动之后及在类似情况下执行步骤5194。
858.延迟时段可为固定或可调整的。例如,延迟时段的持续时间可基于存储器单元的预期存取图案,或可与预期存取图案无关地设定。延迟时段的范围可介于少于一毫秒与多于一秒之间。
859.在一些实施例中,步骤5194可基于信号的值起始,该信号在耦接至存储器胞元的第一群组的第一字线区段上产生的。例如,当信号的值超过第一阈值时,其可指示存储器胞元的第一群组完全启动。
860.步骤5192及5194中的任一者可涉及使用安置于第一字线区段与第二字线区段之间的中间电路(例如,启动单元的中间电路)。第一字线区段可耦接至第一存储器胞元且第二字线区段可耦接至第二存储器胞元。
861.中间电路的实施例贯穿图56至图61予以说明。
862.步骤5192及5194还可以包括通过控制单元来控制启动信号至存储器胞元的第一群组及存储器胞元的第二群组的供应,该启动信号来自与单一行相关联的字线。
863.使用存储器平行性来加速测试时间及使用向量测试存储器中的逻辑
864.本公开的一些实施例可使用芯片内测试单元来加速测试。
865.一般而言,存储器芯片测试需要大量测试时间。缩减测试时间可缩减生产成本且还允许进行更多测试,以产生更可靠的产品。
866.图63及图64说明测试器5200及芯片(或芯片的晶圆)5210。测试器5200可包括管理测试的软件。测试器5200可将不同数据序列运行至所有存储器5210,且接着读回该序列以识别存储器5210的发生故障比特位于何处。一旦辨识到,测试器5200便可发出修复比特的命令,且若能够修复问题,则测试器5200可声明存储器5210通过。在其他状况下,可声明一些芯片未通过。
867.测试器5200可写入测试序列且接着读回数据以将其与预期结果进行比较。
868.图64展示测试系统,其具有测试器5200及被平行地测试的芯片(诸如,5210)的完整晶圆5202。例如,测试器5200可通过导线总线连接至芯片中的每个。
869.如图64中所展示,测试器5200必须数次读取及写入所有存储器芯片,且该数据必须经由外部芯片接口传递。
870.此外,例如使用可编程配置信息测试集成电路的逻辑及存储器组两者可为有益的,可使用规则i/o操作提供该配置信息。
871.该测试也可受益于集成电路内存在测试单元。
872.该测试单元可属于集成电路且可分析测试结果,并找到例如逻辑(例如,如图7a中所描绘及所描述的处理器子单元)和/或存储器(例如,跨越多个存储器组)中的故障。
873.存储器测试器通常极简单且根据简单格式与集成电路交换测试向量。例如,可存在写入向量,该写入向量包括成对的要写入的存储器条目的地址与要写入至存储器条目的值。也可存在读取向量,该读取向量包括要读取的存储器条目的地址。写入向量的地址中的至少一些可与读取向量中的至少一些地址相同。写入向量的至少一些其他地址可不同于读取向量的至少一些其他地址。当经编程时,存储器测试器也可接收预期结果向量,该预期结果向量可包括要读取的存储器条目的地址及要读取的预期值。存储器测试器可将预期值与其读取值进行比较。
874.根据一实施例,集成电路(具有或不具有集成电路的存储器)的逻辑(例如,处理器子单元)可通过存储器测试器使用相同协议/格式来测试。例如,写入向量中的一些值可为要由集成电路的逻辑执行的命令(且可例如涉及计算和/或存储器存取)。可运用读取向量及预期结果向量来编程存储器测试器,该预期结果向量可包括存储器条目地址,其中的一些储存计算的预期值。因此,存储器测试器可用于测试逻辑以及存储器。存储器测试器通常比逻辑测试器更简单且更便宜,且所提议方法允许使用简单的存储器测试器执行复杂的逻辑测试。
875.在一些实施例中,存储器内的逻辑可通过仅使用向量(或其他数据结构)而不使用逻辑测试中常见的更复杂机制(诸如,例如经由接口与控制器通信,告知逻辑测试哪一电路)来启用对存储器内的逻辑的测试。
876.替代使用测试单元,存储器控制器可被配置为接收存取包括于配置信息中的存储器条目的指令,且执行存取指令并输出结果。
877.图65至图69中所说明的集成电路中的任一者可执行测试,甚至在缺乏测试单元的情况下或在存在不能够执行测试的情况下。
878.本公开的实施例可包括使用存储器平行性及内部芯片带宽来加速及改良测试时间的方法及系统。
879.该方法及系统可基于存储器芯片测试本身(相对于测试器运行测试、读取测试结果及分析结果),保存结果且最终允许测试器读取该结果(且在需要时,将存储器芯片编程回,例如启动冗余机构)。该测试可包括测试存储器或测试存储器组及逻辑(在具有要测试的起作用逻辑部分的计算存储器的状况下,诸如上文在图7中所描述的状况)。
880.在一个实施例中,该方法可包括读取及写入芯片内的数据使得外部带宽不限制测试。
881.在存储器芯片包括处理器子单元的实施例中,每一处理器子单元可通过测试代码或配置来编程。
882.在存储器芯片具有无法执行测试代码的处理器子单元或不具有处理器子单元但具有存储器控制器的实施例中,存储器控制器接着可被配置为读取及写入图案(例如,在外部编程至控制器)且标记故障的位置(例如,将值写入至存储器条目,读取该条目,及接收不同于写入值的值)以供进一步分析。
883.应注意,测试存储器可能需要测试大量比特,例如,测试存储器的每一比特及验证受测比特是否起作用。此外,有时可在不同电压及温度条件下重复存储器测试。
884.对于一些缺陷,可启动一个或多个冗余机构(例如,通过编程快闪存储器或otp或烧断熔断器)。此外,可能还必须测试存储器芯片的逻辑及模拟电路(例如,控制器、调节器、i/o)。
885.在一个实施例中,集成电路可包括:基板、安置于基板上的存储器阵列、安置于基板上的处理阵列,及安置于基板上的接口。
886.本文中所描述的集成电路可包括于如图3a、图3b、图4至图6、图7a至图7d、图11至图13、图16至图19、图22或图23中的任一者中所说明的存储器芯片中,可包括该存储器芯片,或以其他方式包含该存储器芯片。
887.图65至图69说明各种集成电路5210及测试器5200。
888.该集成电路说明为包括存储器组5212、芯片接口5211(诸如,由该存储器组共享的i/o控制器5214及总线5213)及逻辑单元(在下文中为「逻辑」)5215。图66说明熔断器接口5216及耦接至熔断器接口及不同存储器组的总线5217。
889.图65至图70还说明测试处理程序中的各种步骤,诸如:
890.a.写入测试序列5221(图65、图67、图68及图69);
891.b.读回测试结果5222(图67、图68及图69);
892.c.写入预期结果序列5223(图65);
893.d.读取故障地址以修复5224(图66);及
894.e.程序熔断器5225(图66)。
895.每个存储器组可耦接至其自身的逻辑单元5215和/或由该逻辑单元来控制。然而,如上文所描述,可提供对逻辑单元5215的任何存储器组分配。因此,逻辑单元5215的数量可不同于存储器组的数量,逻辑单元可控制多于单一存储器组或一存储器组的一部分,及其类似物。
896.逻辑单元5215可包括一个或多个测试单元。图65说明逻辑5215内的测试单元(tu)5218。tu可包括于所有或一些逻辑单元5212中。应注意,测试单元可与逻辑单元分开或与逻辑单元集成。
897.图65还说明tu 5218内的测试图案生成器(标明为gen)5219。
898.测试图案生成器可包括于所有或一些测试单元中。为简单起见,测试图案生成器及测试单元未说明于图66至图70中,但可包括于这些实施例中。
899.该存储器阵列可包括多个存储器组。此外,该处理阵列可包括多个测试单元。所述多个测试单元可被配置为测试多个存储器组以提供测试结果。该接口可被配置为将指示测试结果的信息输出至在集成电路外部的设备。
900.所述多个测试单元可包括至少一个测试图案生成器,该至少一个测试图案生成器被配置为产生至少一个测试图案以用于测试多个存储器组中的一个或多个。在一些实施例中,如上文所解释,所述多个测试单元中的每个可包括一测试图案生成器,该测试图案生成器被配置为产生一测试图案以供所述多个测试单元中的特定测试单元使用以测试多个存储器组中的至少一个。如上文所指示,图65说明测试单元内的测试图案生成器(gen)5219。一个或多个或甚至所有逻辑单元可包括测试图案生成器。
901.至少一个测试图案生成器可被配置为从接口接收用于产生至少一个测试图案的指令。测试图案可包括在测试期间应存取(例如,读取和/或写入)的存储器条目和/或要写入至该条目的值,及其类似物。
902.该接口可被配置为从可在集成电路外部的外部单元接收配置信息,该配置信息包括用于产生至少一个测试图案的指令。
903.至少一个测试图案生成器可被配置为从存储器阵列读取配置信息,该配置信息包括用于产生至少一个测试图案的指令。
904.在一些实施例中,该配置信息可包括向量。
905.该接口可被配置为从可在集成电路外部的设备接收配置信息,该配置信息可包括可为至少一个测试图案的指令。
906.例如,至少一个测试图案可包括要在存储器阵列的测试期间存取的存储器阵列条目。
907.至少一个测试图案进一步可包括要写入至在存储器阵列的测试期间存取的存储器阵列条目的输入数据。
908.另外或替代地,至少一个测试图案进一步可包括要写入至在存储器阵列的测试期间存取的存储器阵列条目的输入数据,及要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的预期值。
909.在一些实施例中,所述多个测试单元可被配置为从存储器阵列取回一旦由所述多个测试单元执行便使所述多个测试单元测试该存储器阵列的测试指令。
910.例如,该测试指令可包括于配置信息中。
911.配置信息可包括存储器阵列的测试的预期结果。
912.另外或替代地,该配置信息可包括要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的值。
913.另外或替代地,该配置信息可包括向量。
914.在一些实施例中,所述多个测试单元可被配置为从存储器阵列取回一旦由所述多个测试单元执行便使所述多个测试单元测试该存储器阵列且测试该处理阵列的测试指令。
915.例如,该测试指令可包括于配置信息中。
916.该配置信息可包括向量。
917.另外或替代地,该配置信息可包括存储器阵列及处理阵列的测试的预期结果。
918.在一些实施例中,如上文所描述,所述多个测试单元可能缺乏测试图案生成器,该测试图案生成器用于产生在多个存储器组的测试期间使用的测试图案。
919.在这些实施例中,所述多个测试单元中的至少两个可被配置为平行地测试多个存储器组中的至少两个。
920.替代地,所述多个测试单元中的至少两个可被配置为串行地测试多个存储器组中的至少两个。
921.在一些实施例中,指示测试结果的信息可包括故障存储器阵列条目的识别符。
922.在一些实施例中,该接口可被配置为在存储器阵列的测试期间多次取回由多个测试电路获得的部分测试结果。
923.在一些实施例中,该集成电路可包括错误校正单元,该错误校正单元被配置为校正在存储器阵列的测试期间侦测到的至少一个错误。例如,该错误校正单元可被配置为使用任何适当技术来修复存储器误差,例如,通过停用一些存储器字及用冗余字替换这些字。
924.在上文所描述的实施例中的任一者中,该集成电路可为存储器芯片。
925.例如,该集成电路可包括分布式处理器,其中处理阵列可包括分布式处理器的多个子单元,如图7a中所描绘。
926.在这些实施例中,该处理器子单元中的每个可与多个存储器组中的对应的专用存储器组相关联。
927.在上文所描述的实施例中的任一者中,指示测试结果的信息可指示至少一个存储器组的状态。可用一个或多个粒度来提供存储器组的状态:每个存储器字,每一条目群组,或每一完整存储器组。
928.图65至图66说明测试器测试阶段中的四个步骤。
929.在第一步骤中,测试器写入(5221)测试序列,且组的逻辑单元将数据写入至其存储器。该逻辑也可足够复杂以从测试器接收命令且其自身产生序列(如下文所解释)。
930.在第二步骤中,测试器将预期结果写入(5223)至受测存储器,且逻辑单元将预期结果与从其存储器组读取的数据进行比较,保存错误清单。若逻辑足够复杂以自身产生预期结果的序列(如下文所解释),则可简化预期结果的写入。
931.在第三步骤中,测试器从逻辑单元读取(5224)故障地址。
932.在第四步骤中,测试器对结果采取动作(5225)且可恢复错误。例如,测试器可连接至特定接口以编程存储器中的熔断器,但也可使用允许编程存储器内的错误校正机构的任何其他机构。
933.在这些实施例中,存储器测试器可使用向量以测试存储器。
934.例如,每个向量可从输入系列及输出系列建置。
935.输入系列可包括成对的地址与写入至存储器的数据(在许多实施例中,此系列可模型化为允许程序在需要时产生的公式,该程序诸如由逻辑单元执行的程序)。
936.在一些实施例中,测试图案生成器可产生此类向量。
937.应注意,向量为数据结构的一实施例,但一些实施例可使用其他数据结构。该数据结构可与由位于集成电路外部的测试器产生的其他测试数据结构兼容。
938.该输出系列可包括地址与数据对,其包含要从存储器读回的预期数据(在一些实施例中,该系列可另外或替代地由程序在运行时间产生,例如通过逻辑单元)。
939.存储器测试通常包括执行向量清单,每个向量根据输入系列将数据写入至存储器,且接着根据输出系列读回数据并将该数据与其预期数据进行比较。
940.在失配的状况下,存储器可分类为发生故障的,或若存储器包括用于冗余的机构,则可启动冗余机构使得再次在经启动冗余机构上测试向量。
941.在存储器包括处理器子单元(如上文关于图7a所描述)或含有许多存储器控制器的实施例中,整个测试可由组的逻辑单元操控。因此,存储器控制器或处理器子单元可执行测试。
942.该存储器控制器可从测试器编程,且测试结果可保存于控制器本身中以稍后由测试器读取。
943.为了配置及测试逻辑单元的操作,测试器可配置逻辑单元以用于存储器存取且确认结果可通过存储器存取来读取。
944.例如,输入向量可含有用于逻辑单元的编程序列,且输出向量可含有此测试的预期结果。例如,若诸如处理器子单元的逻辑单元包含被配置为对存储器中的两个地址执行计算的乘法器或加法器,则输入向量可包括将数据写入至存储器的一组命令以及至加法器/乘法器逻辑的一组命令。只要可将加法器/乘法器结果读回至输出向量,便可将结果发送至测试器。
945.该测试还可以包括从存储器加载逻辑配置及使逻辑输出发送至存储器。
946.在逻辑单元从存储器加载其配置(例如,若该逻辑为存储器控制器)的实施例中,该逻辑单元可运行来自存储器本身的代码。
947.因此,该输入向量可包括用于逻辑单元的程序,且该程序本身可测试逻辑单元中的各种电路。
948.因此,测试可能不限于接收呈由外部测试器使用的格式的向量。
949.若加载至逻辑单元的命令指示逻辑单元将结果写回至存储器组中,则测试器可读取这些结果且将这些结果与预期输出系列进行比较。
950.例如,写入至存储器的向量可为或可包括用于逻辑单元的测试程序(例如,测试可假定存储器有效,但即使存储器无效,写入的测试程序将不工作且测试将未通过,此为可接受的结果,这是因为芯片无论如何为无效的)和/或逻辑单元如何运行代码及将结果写回至存储器。由于逻辑单元的所有测试可经由存储器进行(例如,将逻辑测试输入写入至存储器及将测试结果写回至该存储器),因此测试器可运用输入序列及预期输出序列来运行简单的向量测试。
951.逻辑配置及结果可存取为读取和/或写入命令。
952.图68说明发送写入测试序列5221的测试器5200,该写入测试序列为向量。
953.向量的部分包括在耦接至处理阵列的逻辑5215的存储器组5212之间分裂的测试代码5232。
954.每个逻辑5215可执行储存于其相关联存储器组中的代码5232,且该执行可包括存取一个或多个存储器组,执行计算及将结果(例如,测试结果5231)储存于存储器组5212中。
955.测试结果可由测试器5200发送回(例如,读回结果5222)。
956.此可允许逻辑5215受由i/o控制器5214接收的命令控制。
957.在图68中,i/o控制器5214连接至存储器组及逻辑。在其他实施例中,逻辑可连接于i/o控制器5214与存储器组之间。
958.图70说明用于测试存储器组的方法5300。例如,可使用上文关于图65至图69所描述的存储器组中的任一者来实施方法5300。
959.方法5300可包括步骤5302、5310及5320。步骤5302可包括接收测试集成电路的存
储器组的请求。该集成电路可包括:基板、安置于基板上且包含存储器组的存储器阵列、安置于基板上的处理阵列,及安置于基板上的接口。该处理阵列可包括多个测试单元,如上文所描述。
960.在一些实施例中,该请求可包括配置信息、一个或多个向量、命令,及其类似物。
961.在这些实施例中,该配置信息可包括存储器阵列的测试的预期结果、指令、数据、要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的值、测试图案,及其类似物。
962.该测试图案可包括以下各者中的至少一个:(i)要在存储器阵列的测试期间存取的存储器阵列条目,(ii)要写入至在存储器阵列的测试期间存取的存储器阵列条目的输入数据,或(iii)要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的预期值。
963.步骤5302可包括以下各者中的至少一个和/或其后可接着以下各者中的至少一个:
964.a.通过至少一个测试图案生成器从接口接收用于产生至少一个测试图案的指令;
965.b.通过该接口及从在集成电路外部的外部单元接收配置信息,该配置信息包括用于产生至少一个测试图案的指令;
966.c.通过至少一个测试图案生成器从存储器阵列读取配置信息,该配置信息包括用于产生至少一个测试图案的指令;
967.d.通过该接口及从在集成电路外部的外部单元接收配置信息,该配置信息包含为至少一个测试图案的指令;
968.e.通过多个测试单元及从存储器阵列取回一旦由所述多个测试单元执行便使所述多个测试单元测试存储器阵列的测试指令;及
969.f.通过多个测试单元及从该存储器阵列接收一旦由所述多个测试单元执行便使所述多个测试单元测试存储器阵列且测试处理阵列的测试指令。
970.步骤5302之后可接着步骤5310。步骤5310可包括通过多个测试单元且响应于请求而测试多个存储器组以提供测试结果。
971.方法5300还可以包括通过该接口在存储器阵列的测试期间接收由多个测试电路获得的部分测试结果。
972.步骤5310可包括以下各者中的至少一个和/或其后可接着以下各者中的至少一个:
973.a.通过一个或多个测试图案生成器(例如,包括于多个测试单元中的一个、一些或全部中)产生测试图案以供一个或多个测试单元用于测试多个存储器组中的至少一个;
974.b.通过所述多个测试单元中的至少两个平行地测试多个存储器组中的至少两个;
975.c.通过所述多个测试单元中的至少两个串行地测试多个存储器组中的至少两个;
976.d.将值写入至存储器条目,读取存储器条目及比较结果;及
977.e.通过错误校正单元校正在存储器阵列的测试期间侦测到的至少一个错误。
978.步骤5310之后可接着步骤5320。步骤5320可包括通过接口及在集成电路外部输出指示测试结果的信息。
979.指示测试结果的该信息可包括故障存储器阵列条目的识别符。通过不发送关于每
个存储器条目的读取数据,可节省时间。
980.另外或替代地,指示测试结果的该信息可指示至少一个存储器组的状态。
981.因此,在一些实施例中,指示测试结果的该信息可比在测试期间写入至存储器组或从存储器组读取的数据单元的总大小小得多,且可比在无测试单元辅助的情况下可从测试存储器的测试器发送的输入数据小得多。
982.受测集成电路可包含如先前诸图中的任一者中所说明的存储器芯片和/或分布式处理器。例如,本文中所描述的集成电路可包括于如图3a、图3b、图4至图6、图7a至图7d、图11至图13、图16至图19、图22或图23中的任一者中所说明的存储器芯片中,可包括该存储器芯片,或以其他方式包含该存储器芯片。
983.图71说明用于测试集成电路的存储器组的方法5350的实施例。例如,可使用上文关于图65至图69所描述的存储器组中的任一者来实施方法5350。
984.方法5350可包括步骤5352、5355及5358。步骤5352可包括通过集成电路的接口接收包含指令的配置信息。包括接口的集成电路也可包括基板、包含存储器组且安置于基板上的存储器阵列、安置于基板上的处理阵列,及安置于基板上的接口。
985.该配置信息可包括存储器阵列的测试的预期结果、指令、数据、要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的值、测试图案,及其类似物。
986.另外或替代地,该配置信息可包括指令、用以写入指令的存储器条目的地址、输入数据,且也可包括用以接收在指令执行期间计算得的输出值的存储器条目的地址。
987.该测试图案可包括以下各者中的至少一个:(i)要在存储器阵列的测试期间存取的存储器阵列条目,(ii)要写入至在存储器阵列的测试期间存取的存储器阵列条目的输入数据,或(iii)要从在存储器阵列的测试期间存取的存储器阵列条目读取的输出数据的预期值。
988.步骤5352之后可接着步骤5355。步骤5355可包括通过处理阵列执行指令,该执行通过存取存储器阵列,执行计算操作及提供结果来进行。
989.步骤5355之后可接着步骤5358。步骤5358可包括通过接口及在集成电路外部输出指示结果的信息。
990.网络(cyber)安全性及篡改侦测技术
991.存储器芯片和/或处理器可为恶意行动者的目标,且可能会受到各种类型的网络攻击。在一些状况下,此类攻击可能尝试改变储存于一个或多个存储器资源中的数据和/或代码。相对于经训练神经网络或取决于储存于存储器中的大量数据的其他类型的人工智能(ai)模型,网络攻击可能尤其成问题。若所储存数据被操纵或甚至遮蔽,则此操纵可为有害的。举例而言,若数据密集型ai模型所依赖的数据被破坏或遮蔽,则依赖于该些模型以识别其他车辆或行人等的自主车辆系统可能会不正确地评估主车辆的环境。结果,可能会发生事故。随着ai模型在广泛技术中变得越来越普遍,针对与此类模型相关联的数据的网络攻击可能造成重大破坏。
992.在其他状况下,网络攻击可包括一个或多个行动者篡改或尝试篡改与处理器或其他类型的基于集成电路的逻辑元件相关联的操作参数。举例而言,处理器通常经设计以在某些操作规格内操作。涉及篡改的网络攻击可试图改变处理器、存储器单元或其他电路的操作参数中的一个或多个,使得处理器、存储器单元或其他电路超出其设计操作规格(例
如,时钟速度、带宽规格、温度限制、操作速率等)。此篡改可导致目标硬件发生故障。
993.用于防御网络攻击的传统技术可包括在处理器层级操作的计算机程序(例如,防病毒软件或防恶意软件的软件)。其他技术可包括使用与路由器或其他硬件相关联的基于软件的防火墙。虽然这些技术可使用在存储器单元外部执行的软件程序来对抗网络攻击,但仍需要用于高效地保护储存于存储器单元中的数据的额外或替代技术,尤其在该数据的准确性及可用性对诸如神经网络等的存储器密集型应用的操作至关重要的情况下。本发明的实施例可提供包含存储器的抵抗对存储器的网络攻击的各种集成电路设计。
994.以安全方式将敏感信息及命令撷取至集成电路(例如,在至芯片/集成电路外部的接口尚未起作用时的开机处理(boot)程序期间)及接着维护集成电路内的敏感信息及命令而不将其曝露于集成电路外部,此可增加敏感信息及命令的安全性。cpu及其他类型的处理单元易受网络攻击,尤其在那些cpu/处理单元与外部存储器一起操作时。包括安置于存储器阵列当中的存储器芯片上的分布式处理器子单元的所公开实施例可以不易受到网络攻击及篡改(例如,这是因为处理在存储器芯片内发生),该存储器阵列包括多个存储器组。包括在下文更详细地论述的所公开安全措施的任何组合可进一步降低所公开实施例对网络攻击和/或篡改的易感性。
995.图72a为符合本发明的实施例的包括存储器阵列及处理阵列的集成电路7200的图解表示。举例而言,集成电路7200可包括在以上章节中且贯穿本发明描述的存储器芯片上分布式处理器架构(及特征)中的任一者。存储器阵列及处理阵列可形成于共同基板上,且在某些所公开实施例中,集成电路7200可构成存储器芯片。举例而言,如上文所论述,集成电路7200可包括存储器芯片,该存储器芯片包括多个存储器组及在空间上分布于存储器芯片上的多个处理器子单元,其中多个存储器组中的每一者与多个处理器子单元中的专用的一个或多个相关联。在一些状况下,每一处理器子单元可专用于一个或多个存储器组。
996.在一些实施例中,存储器阵列可包括多个离散存储器组7210_1、7210_2
……
7210_j1、7210_jn,如图72a中所展示。根据本发明的实施例,存储器阵列7210可包含一或多种类型的存储器,包括例如易失性存储器(诸如,ram、dram、sram、相变ram(pram)、磁阻式ram(mram)、电阻式ram(reram)或其类似者)或非易失性存储器(诸如,闪存或rom)。根据本发明的一些实施例,存储器组7210_1至7210_jn可包括多个mos存储器结构。
997.如上文所提及,处理阵列可包括多个处理器子单元7220_1至7220_k。在一些实施例中,处理器子单元7220_1至7220_k中的每一者可与多个离散存储器组7210_1至7210_jn当中的一个或多个离散存储器组相关联。虽然图72a的实例实施例说明每一处理器子单元与两个离散存储器组7210相关联,但应了解,每一处理器子单元可与任何数目个离散的专用存储器组相关联。且反之亦然,每一存储器组可与任何数目个处理器子单元相关联。根据本发明的实施例,包括于集成电路7200的存储器阵列中的离散存储器组的数目可等于、小于或大于包括于集成电路7200的处理阵列中的处理器子单元的数目。
998.集成电路7200可进一步包括符合本发明的实施例(且如描述于以上章节中)的多个第一总线7260。每一总线7260可将处理器子单元7220_k连接至对应的专用存储器组7210_j。根据本发明的一些实施例,集成电路7200可进一步包括多个第二总线7261。每一总线7261可将处理器子单元7220_k连接至另一处理器子单元7220_k 1。如图72a中所展示,多个处理器子单元7220_1至7220_k可经由总线7261连接至彼此。虽然图72a将形成回路的多
个处理器子单元7220_1至7220_k说明为其经由总线7261串联连接,但应了解,处理器单元7220可用任何其他方式连接。举例而言,在一些状况下,特定处理器子单元可能不经由总线7261连接至其他处理器子单元。在其他状况下,特定处理器子单元可仅连接至一个其他处理器子单元,且在另外其他状况下,特定处理器子单元可经由一个或多个总线7261连接至两个或多于两个其他处理器子单元(例如,形成串联连接、并联连接、分支连接等)。应注意,本文中所描述的集成电路7200的实施例仅为例示性的。在一些状况下,集成电路7200可具有不同的内部组件及连接,且在其他状况下,可省略内部组件及所描述连接中的一个或多个(例如,取决于特定应用的需要)。
999.返回参看图72a,集成电路7200可包括用于相对于集成电路7200实施至少一个安全措施的一个或多个结构。在一些状况下,这种结构可被配置为侦测操纵或遮蔽(或尝试操纵或遮蔽)储存于存储器组中的一个或多个中的数据的网络攻击。在其他状况下,这种结构可被配置为侦测篡改与集成电路7200相关联的操作参数或篡改直接或间接影响与集成电路7200相关联的一个或多个操作的一个或多个硬件元件(无论包括于集成电路7200内抑或集成电路7200外部)。
1000.在一些状况下,控制器7240可包括于集成电路7200中。控制器7240可经由一个或多个总线7250连接至例如处理器子单元7220_1
……
7220_k中的一个或多个。控制器7240亦可连接至存储器组7210_1
……
7210_jn中的一个或多个。虽然图72a的实例实施例展示一个控制器7240,但应理解,控制器7240可包括多个处理器元件和/或逻辑电路。在所公开实施例中,控制器7240可被配置为相对于集成电路7200的至少一个操作实施至少一个安全措施。另外,在所公开实施例中,若至少一个安全措施被触发,则控制器7240可被配置为采取(或引起)一个或多个补救动作。
1001.根据本发明的一些实施例,至少一个安全措施可包括用于锁定对集成电路7200的某些方面的存取的控制器实施处理程序。存取锁定涉及使控制器防止自芯片外部对存储器的某些区的存取(读取和/或写入)。可按地址分辨率、存储器组分辨率的部分、存储器组分辨率及其类似者来应用存取控制。在一些状况下,可锁定与集成电路7200相关联的存储器中的一个或多个实体位置(例如,集成电路7200的一个或多个存储器组或存储器组中的一个或多个的任何部分)。在一些实施例中,控制器7240可锁定对与人工智能模型(或其他类型的基于软件的系统)的执行相关联的集成电路7200的某些部分的存取。举例而言,在一些实施例中,控制器7240可锁定对储存于与集成电路7200相关联的存储器中的神经网络模型的权重的存取。应注意,软件程序(亦即,模型)可包括三个组件,包括:程序的输入数据、程序的代码数据及执行程序的输出数据。这种组件亦可适用于神经网络模型。在此模型的操作期间,可产生输入数据并将其馈入至模型,且执行模型可产生输出数据以供读取。然而,与使用所接收输入数据执行模型相关联的程序代码及数据值(例如,预定模型权重等)可保持固定。
1002.如本文中所描述,锁定可指控制器例如不允许自芯片/集成电路外部起始的相对于存储器的某些区的读取或写入操作的操作。芯片/集成电路的i/o可通过的控制器不仅可锁定全部存储器组,而且可锁定存储器组内的存储器地址的任何范围,自单个存储器地址至包括可用存储器组的所有地址的地址范围(或两者之间的任何地址范围)。
1003.因为与接收输入数据及储存输出数据相关联的存储器位置与改变值及与集成电
路7200外部的组件(例如,供应输入数据或接收输出数据的组件)的交互相关联,所以锁定对那些存储器位置的存取在一些状况下可能不切实际。另一方面,限制对与模型程序代码及固定数据值相关联的存储器位置的存取可有效抵抗某些类型的网络攻击。因此,在一些实施例中,作为安全措施,可锁定与程序代码及数据值相关联的存储器(例如,不用于写入/接收输入数据及用于读取/提供输出数据的存储器)。限制存取可包括锁定某些存储器位置使得无法对某些程序代码和/或数据值(例如,与基于所接收输入数据执行模型相关联的那些程序代码和/或数据值)进行改变。另外,亦可锁定与中间数据(例如,在执行模型期间产生的数据)相关联的存储器区域以抵抗外部存取。因此,虽然各种运算逻辑(无论为在集成电路7200板上抑或位于集成电路7200外部)可将数据提供至与接收输入数据或撷取所产生输出数据相关联的存储器位置或自该些存储器位置接收数据,但此运算逻辑将不能够基于所接收输入数据来存取或修改储存与程序执行相关联的程序代码及数据值的存储器位置。
1004.除锁定集成电路7200上的存储器位置以提供安全措施以外,亦可藉由限制对被配置为执行与特定程序或模型相关联的程序代码的某些运算逻辑元件(及其存取的存储器区)的存取来实施其他安全措施。在一些状况下,可相对于位于集成电路7200上的运算逻辑(及其相关联的存储器区)(例如,运算存储器(例如,包括运算能力的存储器,诸如本文中所公开的存储器芯片上的分布式处理器)等)实现此存取约束。亦可锁定/限制对与储存于集成电路7200的锁定存储器部分中的代码的任何执行相关联或与对储存于集成电路7200的锁定存储器部分中的数据值的任何存取相关联的运算逻辑(及相关联的存储器位置)的存取,而无关于该运算逻辑是否位于集成电路7200板上。限制对负责执行程序/模型的运算逻辑的存取可进一步确保与对所接收输入数据的操作相关联的代码及数据值仍受到保护以免被操纵、遮蔽等。
1005.可用任何合适的方式实现控制器实施的安全措施,包括锁定或限制对与集成电路7200的存储器阵列的某些部分相关联的基于硬件的区的存取。在一些实施例中,可藉由将命令添加或供应至被配置为使控制器7240锁定某些存储器部分的控制器7240来实施此锁定。在一些实施例中,待锁定的基于硬件的存储器部分可由特定存储器地址(例如,与存储器组7210_1
……
7210_j2等的任何存储器元件相关联的地址)指明。在一些实施例中,存储器的锁定区可在程序或模型执行期间保持固定。在其他状况下,锁定区可为可配置的。亦即,在一些状况下,可向控制器7240供应命令使得在程序或模型的执行期间,锁定区可改变。举例而言,在特定时间,可将某些存储器位置添加至存储器的锁定区。或在特定时间,可自存储器的锁定区排除某些存储器位置(例如,先前锁定的存储器位置)。
1006.可用任何合适的方式实现某些存储器位置的锁定。在一些状况下,锁定存储器位置的记录(例如,储存及识别锁定存储器地址的文件、数据库、数据结构等)可为可由控制器7240存取的,使得控制器7240可判定某一存储器请求是否与锁定存储器位置相关。在一些状况下,控制器7240维护锁定地址的数据库以使用控制对某些存储器位置的存取。在其他状况下,控制器可具有可配置直至锁定的表或一个或多个寄存器的集合,且可包括识别待锁定的存储器位置(例如,应限制自芯片外部对该些存储器位置的存储器存取)的固定预定值。举例而言,当请求存储器存取时,控制器7240可比较与存储器存取请求相关联的存储器地址与锁定存储器地址。若判定与存储器存取请求相关联的存储器地址在锁定存储器地址的列表内,则可拒绝存储器存取请求(例如,读取抑或写入操作)。
1007.如上文所论述,至少一个安全措施可包括锁定对不用于接收输入数据或用于提供对所产生输出数据的存取的存储器阵列7210的某些存储器部分的存取。在一些状况下,可调整锁定区内的存储器部分。举例而言,可将锁定存储器部分解除锁定,且可锁定非锁定存储器部分。任何合适的方法可用于将锁定存储器部分解除锁定。举例而言,所实施的安全措施可包括需要用于将锁定存储器区的一个或多个部分解除锁定的复杂密码。
1008.在侦测到对抗所实施的安全措施的任何动作后,可触发所实施的安全措施。举例而言,尝试对锁定存储器部分进行存取(无论为读取抑或写入请求)可触发安全措施。另外,若所键入的复杂密码(例如,试图将锁定存储器部分解除锁定)不匹配预定复杂密码,则可触发安全措施。在一些状况下,若在可允许的阈值数目次复杂密码条目尝试(例如,1次、2次、3次等)中未提供正确的复杂密码,则可触发安全措施。
1009.可在任何合适的时间锁定存储器部分。举例而言,在一些状况下,可在程序执行期间的各个时间锁定存储器部分。在其他状况下,可在起动后或在程序/模型执行之前锁定存储器部分。举例而言,可连同程序/模型程序代码的编程或在产生及储存待由程序/模型存取的数据后判定及识别待锁定的存储器地址。藉此,可在程序/模型执行开始时或之后、在已产生及储存待由程序/模型使用的数据之后等的时间期间减少或消除对存储器阵列7210的攻击的漏洞。
1010.可藉由任何合适的方法或在任何合适的时间实现锁定存储器的解除锁定。如上文所描述,可在接收到正确的复杂密码或密码等之后将锁定存储器部分解除锁定。在其他状况下,可藉由重新启动(藉由命令或藉由断电及通电)或删除整个存储器阵列7210将锁定存储器解除锁定。另外或替代地,可实施释放命令序列以将一个或多个存储器部分解除锁定。
1011.根据本发明的实施例且如上文所描述,控制器7240可被配置为控制去往和来自集成电路7200的业务(traffic),尤其来自集成电路7200外部的源的业务。举例而言,如图72a中所展示,可藉由控制器7240控制在集成电路7200外部的组件与在集成电路7200内部的组件(例如,存储器阵列7210或处理器子单元7220)之间的业务。此业务可通过控制器7240或由控制器7240控制或监视的一个或多个总线(例如,7250、7260或7261)。
1012.根据本发明的一些实施例,集成电路7200可在开机处理程序期间接收不可改变数据(例如,固定数据;例如模型权重、系数等)及某些命令(例如,代码;例如识别待锁定的存储器部分)。此处,不可改变数据可指在程序或模型的执行期间保持固定且可保持不变直至后续开机处理程序的数据。在程序执行期间,集成电路7200可与可改变数据交互,该可改变数据可包括待处理的输入数据和/或由与集成电路7200相关联的处理产生的输出数据。如上文所论述,可在程序或模型执行期间限制对存储器阵列7210或处理阵列7220的存取。举例而言,存取可限于存储器阵列7210的某些部分或限于某些处理器子单元,该些处理器子单元与以下各者相关联:关于待写入的传入输入数据的处理或与待写入的传入输入数据的交互,或关于待读取的所产生输出数据的处理或与待读取的所产生输出数据的交互。在程序或模型执行期间,可锁定含有不可改变数据的存储器部分且藉此使其不可存取。在一些实施例中,与待锁定的存储器部分相关联的不可改变数据和/或命令可包括于任何适当的数据结构中。举例而言,可经由可在开机序列期间或之后存取的一个或多个配置文件使此类数据和/或命令可用于控制器7240。
1013.返回参看图72a,集成电路7200可进一步包括通信端口7230。如图72a中所展示,控
制器7240可耦接于通信端口7230与总线7250之间,该总线在处理子单元7220_1至7220_k之间共享。在一些实施例中,通信端口7230可间接地或直接地耦接至主计算机7270,该主计算机与可包括例如非易失性存储器的主机存储器7280相关联。在一些实施例中,主计算机7270可从其相关联的主机存储器7280撷取可改变数据7281(例如,待在程序或模型的执行期间使用的输入数据)、不可改变数据7282和/或命令7283。可改变数据7181、不可改变数据7282及命令7283可在开机处理程序期间经由7230自主计算机7270上传至控制器7240。
1014.图72b为符合本发明的实施例的集成电路内部的存储器区的图解表示。如所展示,图72b描绘包括于主机存储器7280中的数据结构的实例。
1015.现参看图73a,其为符合本发明的实施例的集成电路的另一实例。如图73a中所展示,控制器7240可包括网络攻击侦测器7241及响应模块7242。在本发明的一些实施例中,控制器7240可被配置为储存或存取存取控制规则7243。根据本发明的一些实施例,存取控制规则7243可包括于控制器7240可存取的配置文件中。在一些实施例中,存取控制规则7243可在开机处理程序期间上传至控制器7240。存取控制规则7243可包含提示与以下各者中的任一者相关联的存取规则的信息:可改变数据7281、不可改变数据7282及命令7283以及其对应存储器位置。如上文所解释,存取控制规则7243或配置文件可包括识别存储器阵列7210当中的某些存储器地址的信息。在一些实施例中,控制器7240可被配置为提供锁定机制和/或功能,该锁定机制和/或功能锁定存储器阵列7210的各种地址,例如用于储存命令或不可改变数据的地址。
1016.控制器7240可被配置为强制执行存取控制规则7243,例如以防止未经授权实体改变不可改变数据或命令。在一些实施例中,可根据存取控制规则7243禁止对不可改变数据或命令的读取。根据本发明的一些实施例,控制器7240可被配置为判定是否对某些命令或不可改变数据的至少一部分进行了存取尝试。控制器7240(例如,包括网络攻击侦测器7241)可比较与存取请求相关联的存储器地址与用于不可改变数据及命令的存储器地址,以侦测是否已对一个或多个锁定存储器位置进行了未经授权存取尝试。以此方式,例如,控制器7240的网络攻击侦测器7241可被配置为判定是否发生疑似网络攻击,例如更改一个或多个命令或改变或遮蔽与一个或多个锁定存储器部分相关联的不可改变数据的请求。响应模块7242可被配置为判定如何对侦测到的网络攻击作出响应和/或实施对侦测到的网络攻击的响应。举例而言,在一些状况下,响应于侦测到对一个或多个锁定存储器位置中的数据或命令的攻击,控制器7240的响应模块7242可实施或使得实施响应,该响应可包括例如停止一个或多个操作,诸如与侦测到的攻击相关联的存储器存取操作。对侦测到的攻击的响应还可包括停止与程序或模型的执行相关联的一个或多个操作,传回所尝试攻击的警告或其他指示符,向主机确证(assert)提示线,或删除整个存储器等。
1017.除锁定存储器部分以外,亦可实施用于抵御网络攻击的其他技术以提供与集成电路7200相关联的所描述安全措施。举例而言,在一些实施例中,控制器7240可被配置为在与集成电路7200相关联的不同存储器位置及处理器子单元内复制程序或模型。以此方式,可独立地执行程序/模型及程序/模型的复制者,且可比较独立程序/模型执行的结果。举例而言,可在两个存储器组7210中复制且在集成电路7200中的不同处理器子单元7220执行程序/模型。在其他实施例中,可在两个不同集成电路7200中复制程序/模型。在任一状况下,可比较程序/模型执行的结果以判定复制程序/模型执行之间是否存在任何差异。执行结果
(例如,中间执行结果、最终执行结果等)的侦测到的差异可提示存在已变更程序/模型或其相关联数据的一个或多个方面的网络攻击。在一些实施例中,可指派不同存储器组7210及处理器子单元7220以基于相同输入数据执行两个复制模型。在一些实施例中,可在基于相同输入数据执行两个复制模型期间比较中间结果,且若在同一阶段,两个中间结果之间存在失配,则作为潜在的补救动作,可暂时中止执行。在同一集成电路的处理器子单元执行两个复制模型的状况下,该集成电路亦可比较结果。此可在不通知集成电路外部的任何实体关于两个复制模型的执行的情况下进行。换言之,芯片外部的实体不知晓复制模型正在集成电路上并行地运行。
1018.图73b为符合本发明的实施例的用于同时执行复制模型的配置的图解表示。
1019.虽然将单个程序/模型复制描述为用于侦测可能网络攻击的一个实例,但可使用任何数目个复制(例如,1个、2个、3个或多于3个)以侦测可能网络攻击。随着复制及独立程序/模型执行的数目增加,网络攻击的侦测的置信度亦可增加。复制的较大数目亦可降低网络攻击的潜在成功率,因为攻击者可能更难影响多个程序/模型复制者。可在运行时间判定程序或模型复制者的数目,以进一步增加网络攻击者成功地影响程序或模型执行的困难。
1020.在一些实施例中,复制模型可在彼此不同的一个或多个方面中不相同。在此实例中,可使与两个程序/模型相关联的代码彼此不同,但该些程序/模型可经设计使得两者传回相同输出结果。至少以此方式,两个程序/模型可被视为彼此的复制者。举例而言,两个神经网络模型在一层中相对于彼此可能具有不同的神经元排序。然而,尽管模型程序代码具有此改变,但两个神经网络模型均可传回相同输出结果。以此方式复制程序/模型可使得网络攻击者更难以识别待破解的程序或模型的这些有效复制者,且结果,复制模型/程序不仅可提供用以提供冗余以最小化网络攻击影响的方式,而且可增强网络攻击侦测(例如,藉由突出显示篡改或未经授权存取,其中网络攻击者更改一个程序/模型或其数据,但未能对程序/模型复制者作出对应改变)。
1021.在许多状况下,复制程序/模型(尤其包括展现代码差异的复制程序/模型)可经设计使得其输出不完全匹配,而是构成软值(例如,近似相同的输出值),而非准确的固定值。在这种实施例中,可比较(例如,使用专用模块或藉由主机处理器)来自两个或多于两个有效程序/模型复制者的输出结果,以判定其输出结果(无论为中间结果抑或最终结果)之间的差是否处于预定范围内。所输出软值的差不超过预定阈值或范围可被视为无篡改、未经授权存取等的证据。另一方面,若所输出软值的差超过预定阈值或范围,则此差可被视为已发生呈篡改、对存储器的未经授权存取等的形式的网络攻击的证据。在这些状况下,将触发复制程序/模型安全措施且可采取一个或多个补救动作(例如,停止执行程序或模型,关闭集成电路7200的一个或多个操作,在具有有限功能性的安全模式中操作,连同许多其他动作)。
1022.与集成电路7200相关联的安全措施亦可涉及对与执行中或已执行程序或模型相关联的数据的定量分析。举例而言,在一些实施例中,控制器7240可被配置为计算关于储存于存储器阵列7210的至少一部分中的数据的一个或多个校验和(checksum)/散列/循环冗余检查(crc)/校验(parity)值。可将所计算的值与一个或多个预定值进行比较。若所比较值之间存在偏差,则此偏差可解译为篡改储存于存储器阵列7210的至少部分中的数据的证据。在一些实施例中,可针对与存储器阵列7210相关联的所有存储器位置而计算校验和/散
列/crc/校验位值以识别数据的改变。在此实例中,可藉由例如主计算机7270或与集成电路7200相关联的处理器读取所讨论的整个存储器(或存储器组),以用于计算校验和/散列/crc/校验位值。在其他状况下,可针对与存储器阵列7210相关联的存储器位置的预定子集而计算校验和/散列/crc/校验位值,以识别与存储器位置的子集相关联的数据的改变。在一些实施例中,控制器7240可被配置为计算与预定数据路径相关联(例如,与存储器存取图案(pattern)相关联)的校验和/散列/crc/校验位值,且所计算值可彼此进行比较或与预定值进行比较以判定是否已发生篡改或另一形式的网络攻击。
1023.藉由保护集成电路7200内或集成电路7200可存取的位置中的一个或多个预定值(例如,预期校验和/散列/crc/校验位值、中间或最终输出结果的预期差值、与某些值相关联的预期差范围等),可使集成电路7200甚至更安全地抵抗网络攻击。举例而言,在一些实施例中,一个或多个预定值可储存于存储器阵列7210的寄存器中,且可在模型的每次运行期间或之后用以(例如,藉由集成电路7200的控制器7240)评估中间或最终输出结果、校验和等。在一些状况下,可使用“保存最后结果数据”命令来更新寄存器值以在运作中计算预定值,且可将所计算值保存于寄存器或另一存储器位置中。以此方式,有效输出值可用以在每一程序或模型执行或部分执行之后更新用于比较的预定值。此技术可增加网络攻击者在尝试修改或以其他方式篡改经设计以曝露网络攻击者活动的一个或多个预定参考值时可能体验的困难。
1024.在操作中,crc计算器可用以追踪存储器存取。举例而言,此计算电路可安置于存储器组层级处、处理器子单元中或控制器处,其中每一计算电路可被配置为在进行每一存储器存取时累加至crc计算器。
1025.现参看图74a,其提供集成电路7200的另一实施例的图解表示。在由图74a表示的实例实施例中,控制器7240可包括篡改侦测器7245及响应模块7246。类似于其他所公开实施例,篡改侦测器7245可被配置为侦测潜在篡改尝试的证据。根据本发明的一些实施例,与集成电路7200相关联且由控制器7240实施的安全措施例如可包括将实际程序/模型操作图案与预定/所允许操作图案进行比较。若在一个或多个方面中,实际程序/模型操作图案与预定/所允许操作图案不同,则可触发安全措施。且若触发安全措施,则控制器7240的响应模块7246可被配置为作为响应而实施一个或多个补救措施。
1026.图74c为根据例示性所公开实施例的可位于芯片内的各个点处的侦测元件的图解表示。如上文所描述,可使用位于芯片内的各个点处的侦测元件执行网络攻击及篡改的侦测,如展示于例如图74c中。举例而言,某一代码可与某一时间段内的预期数目个处理事件相关联。图74c中所展示的侦测器可对系统在某一时间段(由时间计数器监视)期间经历的事件(由事件计数器监视)的数目进行计数。若事件的数目超过某一预定阈值(例如,在预定义时间段期间的预期事件的数目),则可提示篡改。此类侦测器可包括于系统的多个点中以监视各种类型的事件,如图74c中所展示。
1027.更具体而言,在一些实施例中,控制器7240可被配置为储存或存取预期程序/模型操作图案7244。举例而言,在一些状况下,操作图案可表示为提示每时间图案的所允许负载及每时间图案的禁止或不合法负载的曲线7247。篡改尝试可使存储器阵列7210或处理阵列7220在某些操作规格的外操作。此可使存储器阵列7210或处理阵列7220产生热或发生故障,且可使得能够改变与存储器阵列7210或处理阵列7220相关的数据或代码。这种改变可
导致操作图案超出如由曲线7247提示的所允许操作图案。
1028.根据本发明的一些实施例,控制器7240可被配置为监视与存储器阵列7210或处理阵列7220相关联的操作图案。操作图案可与存取请求的数目、存取请求的类型、存取请求的时序等相关联。控制器7240可经进一步配置以在操作图案不同于可允许操作图案的情况下侦测篡改攻击。
1029.应注意,所公开实施例不仅可用以抵御网络攻击,而且用以抵御操作中的非恶意错误。举例而言,所公开实施例亦可有效保护诸如集成电路7200的系统免受由诸如温度或电压改变或电平的环境因素引起的错误的影响,尤其在这种电平超出用于集成电路7200的操作规格的情况下。
1030.响应于侦测到疑似网络攻击(例如,作为对所触发安全措施的响应),可实施任何合适的补救动作。举例而言,补救动作可包括停止与程序/模型执行相关联的一个或多个操作,在安全模式中操作与集成电路7200相关联的一个或多个组件,将集成电路7200的一个或多个组件锁定至额外输入或存取等。
1031.图74b提供根据例示性所公开实施例的保护集成电路以防篡改的方法7450的流程图表示。举例而言,步骤7452可包括使用与集成电路相关联的控制器相对于集成电路的操作实施至少一个安全措施。在步骤7454处,若触发至少一个安全措施,则可采取一个或多个补救动作。集成电路包括:基板;存储器阵列,其安置于基板上,该存储器阵列包括多个离散存储器组;及处理阵列,其安置于基板上,该处理阵列包括多个处理器子单元,该多个处理器子单元中的每一者与多个离散存储器组当中的一个或多个离散存储器组相关联。
1032.在一些实施例中,所公开安全措施可实施于多个存储器芯片中,且所公开安全机制中的至少一个或多个可针对每一存储器芯片/集成电路而实施。在一些状况下,每一存储器芯片/集成电路可实施相同的安全措施,但在一些状况下,不同的存储器芯片/集成电路可实施不同的安全措施(例如,当不同的安全措施可能更适合于与特定集成电路相关联的某一类型的操作时)。在一些实施例中,可由集成电路的特定控制器实施多于一个安全措施。举例而言,特定集成电路可实施任何数目或类型的所公开安全措施。另外,特定集成电路控制器可被配置为响应于所触发安全措施而实施多个不同的补救措施。
1033.亦应注意,可组合上述安全机制中的两者或多于两者以改善针对网络攻击或篡改攻击的安全性。另外,可跨越不同集成电路而实施安全措施,且这些集成电路可协调安全措施实施。举例而言,可在一个存储器芯片内执行或可跨越不同存储器芯片执行模型复制。在此实例中,可比较来自一个存储器芯片的结果或来自两个或多于两个存储器芯片的结果以侦测潜在网络攻击或篡改攻击。在一些实施例中,跨越多个集成电路而应用的复制安全措施可包括以下各者中的一个或多个:所公开的存取锁定机制、散列保护机制、模型复制、程序/模型执行图案分析,或这些或其他所公开实施例的任何组合。
1034.dram中的多端口处理器子单元
1035.如上文所描述,本发明所公开的实施例可包括分布式处理器存储器芯片,该存储器芯片包括处理器子单元阵列及存储器组阵列,其中处理器子单元中的每一者可专用于存储器组阵列中的至少一者。如在以下章节中所论述,分布式处理器存储器芯片可充当可扩展系统的基础。亦即,在一些状况下,分布式处理器存储器芯片可包括被配置为将数据从一个分布式处理器存储器芯片传送至另一分布式处理器存储器芯片的一个或多个通信端口。
以此方式,任何所要数目个分布式处理器存储器芯片可链接在一起(例如,串联、并联、以回路或其任何组合)以形成分布式处理器存储器芯片的可扩展阵列。此阵列可提供用于高效地执行存储器密集型操作及用于扩展与存储器密集型操作的效能相关联的计算资源的灵活解决方案。因为分布式处理器存储器芯片可包括具有不同时序图案的时钟,所以本发明所公开的实施例包括用以甚至在存在时钟时序差异的情况下亦准确地控制分布式处理器存储器芯片之间的数据传送的特征。此些实施例可使得能够在不同的分布式处理器存储器芯片间进行高效数据共享。
1036.图75a为符合本发明的实施例的包括多个分布式处理器存储器芯片的可扩展处理器存储器系统的图解表示。根据本发明的实施例,可扩展处理器存储器系统可包括多个分布式处理器存储器芯片,诸如第一分布式处理器存储器芯片7500、第二分布式处理器存储器芯片7500'及第三分布式处理器存储器芯片7500”。第一分布式处理器存储器芯片7500、第二分布式处理器存储器芯片7500'及第三分布式处理器存储器芯片7500”中的每一者可包括与描述于本发明分布式处理器中的实施例中的任一者相关联的配置和/或特征中的任一者。
1037.在一些实施例中,第一分布式处理器存储器芯片7500、第二分布式处理器存储器芯片7500'及第三分布式处理器存储器芯片7500”中的每一者可类似于图7200中所展示的集成芯片7200而实施。如图75a中所展示,第一分布式处理器存储器芯片7500可包含存储器阵列7510、处理阵列7520及控制器7540。存储器阵列7510、处理阵列7520及控制器7540可类似于图72a中的存储器阵列7210、处理阵列7220及控制器7240而配置。
1038.根据本发明的实施例,第一分布式处理器存储器芯片7500可包括第一通信端口7530。在一些实施例中,第一通信端口7530可被配置为与一个或多个外部实体通信。举例而言,通信端口7530可被配置为建立分布式处理器存储器芯片7500与除另一分布式处理器存储器芯片(诸如,分布式处理器存储器芯片7500'及7500”)以外的外部实体之间的通信连接。举例而言,通信端口7530可间接地或直接地耦接至主计算机(例如,如图72a中所说明)或任何其他运算装置、通信模块等。
1039.根据本发明的实施例,第一分布式处理器存储器芯片7500可进一步包含被配置为与例如7500'或7500”的其他分布式处理器存储器芯片通信的一个或多个额外通信端口。在一些实施例中,一个或多个额外通信端口可包括第二通信端口7531及第三通信端口7532,如图75a中所展示。第二通信端口7531可被配置为与第二分布式处理器存储器芯片7500'通信,且建立第一分布式处理器存储器芯片7500与第二分布式处理器存储器芯片7500'之间的通信连接。类似地,第三通信端口7532可被配置为与第三分布式处理器存储器芯片7500'通信,且建立第一分布式处理器存储器芯片7500与第三分布式处理器存储器芯片7500”之间的通信连接。在一些实施例中,第一分布式处理器存储器芯片7500(及本文中所公开的存储器芯片中的任一者)可包括多个通信端口,包括任何适当数目个通信端口(例如,2个、3个、4个、5个、6个、7个、8个、9个、10个、20个、50个、100个、1000个等)。
1040.在一些实施例中,第一通信端口、第二通信端口及第三通信端口与对应总线相关联。对应总线可为第一通信端口、第二通信端口及第三通信端口中的每一者所共同的总线。在一些实施例中,与第一通信端口、第二通信端口及第三通信端口中的每一者相关联的对应总线皆连接至多个离散存储器组。在一些实施例中,第一通信端口连接至存储器芯片内
部的主总线或包括于存储器芯片中的至少一个处理器子单元中的至少一者。在一些实施例中,第二通信端口连接至存储器芯片内部的总线或包括于存储器芯片中的至少一个处理器子单元中的至少一者。
1041.虽然相对于第一分布式处理器存储器芯片7500解释了所公开的分布式处理器存储器芯片的配置,但应注意,第二处理器存储器芯片7500'及第三处理器存储器芯片7500”可类似于第一分布式处理器存储器芯片7500而配置。举例而言,第二分布式处理器存储器芯片7500'亦可包含存储器阵列7510'、处理阵列7520'、控制器7540'和/或多个通信端口,诸如端口7530'、7531'及7532'。类似地,第三分布式处理器存储器芯片7500”可包含存储器阵列7510”、处理阵列7520”、控制器7540”和/或多个通信端口,诸如端口7530”、7531”及7532”。在一些实施例中,第二分布式处理器存储器芯片7500'的第二通信端口7531'及第三通信端口7532'可被配置为分别与第三分布式处理器存储器芯片7500”及第一分布式处理器存储器芯片7500通信。类似地,第三分布式处理器存储器芯片7500”的第二通信端口7531”及第三通信端口7532”可被配置为分别与第一分布式处理器存储器芯片7500及第二分布式处理器存储器芯片7500'通信。分布式处理器存储器芯片间的此配置类似性可便利基于所公开的分布式处理器存储器芯片而扩展运算系统。另外,与每一分布式处理器存储器芯片相关联的通信端口的所公开布置及配置可使得能够灵活地布置分布式处理器存储器芯片的阵列(例如,包括串联连接、并联连接、环形连接、星形连接或网络连接等)。
1042.根据本发明的实施例,例如第一至第三分布式处理器存储器芯片7500、7500'及7500”的分布式处理器存储器芯片可经由总线7533彼此通信。在一些实施例中,总线7533可连接两个不同的分布式处理器存储器芯片的两个通信端口。举例而言,第一处理器存储器芯片7500的第二通信端口7531可经由总线7533连接至第二处理器存储器芯片7500'的第三通信端口7532'。根据本发明的实施例,例如第一至第三分布式处理器存储器芯片7500、7500'及7500”的分布式处理器存储器芯片亦可经由诸如总线7534的总线与外部实体(例如,主计算机)通信。举例而言,第一分布式处理器存储器芯片7500的第一通信端口7530可经由总线7534连接至一个或多个外部实体。分布式处理器存储器芯片可用各种方式彼此连接。在一些状况下,分布式处理器存储器芯片可展现串联连接性,其中每一分布式处理器存储器芯片连接至一对邻近分布式处理器存储器芯片。在其他状况下,分布式处理器存储器芯片可展现较高程度的连接性,其中至少一个分布式处理器存储器芯片连接至两个或多于两个其他分布式处理器存储器芯片。在一些状况下,多个存储器芯片内的所有分布式处理器存储器芯片可连接至多个存储器芯片中的所有其他分布式处理器存储器芯片。
1043.如图75a中所展示,总线7533(或与图75a的实施例相关联的任何其他总线)可为单向的。虽然图75a将总线7533说明为单向的且具有某一数据传送流(如由图75a中所展示的箭头提示),但总线7533(或图75a中的任何其他总线)可实施为双向总线。根据本发明的一些实施例,连接于两个分布式处理器存储器芯片之间的总线可被配置为具有比连接于分布式处理器存储器芯片与外部实体之间的总线的通信速度高的通信速度。在一些实施例中,分布式处理器存储器芯片与外部实体之间的通信可在有限时间期间发生,例如在执行准备(从主计算机加载程序代码、输入数据、权重数据等)期间,在将由神经网络模型的执行产生的结果等输出至主计算机的时段期间发生。在与芯片7500、7500'及7500”的分布式处理器相关联的一个或多个程序的执行期间(例如,在与人工智能应用程序相关联的存储器密集
型操作期间等),分布式处理器存储器芯片之间的通信可经由总线7533、7533'等进行。在一些实施例中,相比两个处理器存储器芯片之间的通信,分布式处理器存储器芯片与外部实体之间的通信发生的频率可能较低。根据通信要求及实施例,分布式处理器存储器芯片与外部实体之间的总线可被配置为具有等于、大于或小于分布式处理器存储器芯片之间的总线的通信速度的通信速度。
1044.在一些实施例中,如由图75a表示,诸如第一至第三分布式处理器存储器芯片7500、7500'及7500”的多个分布式处理器存储器芯片可被配置为彼此通信。如所提到,此能力可便利可扩展分布式处理器存储器芯片系统的组装。举例而言,来自第一至第三处理器存储器芯片7500、7500'及7500”的存储器阵列7510、7510'及7510”及处理阵列7520、7520'及7520”在藉由通信通道(诸如,图75a中所展示的总线)链接时可被视为实际上属于单个分布式处理器存储器芯片。
1045.根据本发明的实施例,可用任何合适的方式管理多个分布式处理器存储器芯片之间的通信和/或分布式处理器存储器芯片与一个或多个外部实体之间的通信。在一些实施例中,可藉由诸如分布式处理器存储器芯片7500中的处理阵列7520的处理资源来管理这些通信。在一些其他实施例中,例如为了减轻由分布式处理器的阵列提供的处理资源所受的由通信管理强加的运算负荷,分布式处理器存储器芯片的诸如控制器7540、7540'、7540”等的控制器可被配置为管理分布式处理器存储器芯片之间的通信和/或分布式处理器存储器芯片与一个或多个外部实体之间的通信。举例而言,相对于其他分布式处理器存储器芯片,第一至第三处理器存储器芯片7500、7500'及7500”的每一控制器7540、7540'及7540”可被配置为管理与其对应分布式处理器存储器芯片相关的通信。在一些实施例中,控制器7540、7540'及7540”可被配置为经由诸如端口7531、7531'、7531”、7532、7532'及7532”等的对应通信端口控制这些通信。
1046.控制器7540、7540'及7540”亦可被配置为在考虑可存在于分布式处理器存储器芯片间的时序差的同时管理分布式处理器存储器芯片之间的通信。举例而言,分布式处理器存储器芯片(例如,7500)可由内部时钟馈入,该内部时钟相对于其他分布式处理器存储器芯片(例如,7500'及7500”)的时钟可能不同。因此,在一些实施例中,控制器7540可被配置为实施用于考虑分布式处理器存储器芯片间的不同时钟时序图案的一个或多个策略,且藉由考虑分布式处理器存储器芯片之间的可能时间偏差来管理分布式处理器存储器芯片之间的通信。
1047.举例而言,在一些实施例中,第一分布式处理器存储器芯片7500的控制器7540可被配置为使得能够在某些条件下将数据从第一分布式处理器存储器芯片7500传送至第二处理器存储器芯片7500'。在一些状况下,若第一分布式处理器存储器芯片7500的一个或多个处理器子单元未准备好传送数据,则控制器7540可抑制数据传送。替代地或另外,若第二分布式处理器存储器芯片7500'的接收处理器子单元未准备好接收数据,则控制器7540可抑制数据传送。在一些状况下,控制器7540可在确定发送处理器子单元准备好发送数据且接收处理器子单元准备好接收数据之后,起始将数据从发送处理器子单元(例如,在芯片7500中)传送至接收处理器子单元(例如,在芯片7500'中)。在其他实施例中,控制器7540可仅基于发送处理器子单元是否准备好发送数据来起始数据传送,尤其在数据可在控制器7540或7540'中缓冲例如直至接收处理器子单元准备好接收所传送数据的情况下。
1048.根据本发明的实施例,控制器7540可被配置为判定是否满足一个或多个其他时序约束以便使得能够进行数据传送。这种时间约束可与以下各者相关:从发送处理器子单元的传送时间到接收处理器子单元中的接收时间之间的时间差、来自外部实体(例如,主计算机)的对所处理数据的存取请求、对与发送或接收处理器子单元相关联的存储器资源(例如,存储器阵列)执行的刷新操作,以及其他。
1049.图75e为符合本发明的实施例的实例时序图。图75e说明以下实例。
1050.在一些实施例中,控制器7540及与分布式处理器存储器芯片相关联的其他控制器可被配置为使用时钟启用信号来管理芯片之间的数据传送。举例而言,处理阵列7520可由时钟馈入。在一些实施例中,可例如藉由控制器7540使用时钟启用信号(例如,在图75a展示为“至ce”)来控制一个或多个处理器子单元是否对所供应时钟信号作出响应。每一处理器子单元,例如7520_1至7520_k,可执行程序代码,且程序代码可包括通信命令。根据本发明的一些实施例,控制器7540可藉由控制至处理器子单元7520_1至7520_k的时钟启用信号来控制通信命令的时序。举例而言,根据一些实施例,当发送处理器子单元(例如,在第一处理器存储器芯片7500中)经编程以在某一循环(例如,第1000个时钟循环)传送数据且接收处理器子单元(例如,在第二处理器存储器芯片7500'中)经编程以在某一循环(例如,第1000个时钟循环)接收数据时,第一处理器存储器芯片7500的控制器7540及第二处理器存储器芯片7500'的控制器7540'可能不允许数据传送,直至发送处理器子单元及接收处理器子单元两者均准备好执行数据传送。举例而言,控制器7540可藉由向芯片7500中的发送处理器子单元供应某一时钟启用信号(例如,逻辑低)来“抑制”从发送处理器子单元的数据传送,该时钟启用信号可防止发送处理器子单元响应于所接收时钟信号而发送数据。某一时钟启用信号可“冻结”整个分布式处理器存储器芯片或分布式处理器存储器芯片的任何部分。另一方面,控制器7540可藉由向发送处理器子单元供应相反的时钟启用信号(例如,逻辑高)来使发送处理器子单元起始数据传送,该时钟启用信号使发送处理器子单元对所接收时钟信号作出响应。可使用由控制器7540'发出的时钟启用信号来控制类似操作,例如藉由芯片7500'中的接收处理器子单元接收或不接收。
1051.在一些实施例中,可将时钟启用信号发送至处理器存储器芯片(例如,7500)中的所有处理器子单元(例如,7520_1至7520_k)。一般而言,时钟启用信号可具有使处理器子单元对其各别时钟信号作出响应或忽略那些时钟信号的效应。举例而言,在一些状况下,当时钟启用信号为高(取决于特定应用的惯例)时,处理器子单元可对其时钟信号作出响应且可根据其时钟信号时序执行一个或多个指令。另一方面,当时钟启用信号为低时,防止处理器子单元对其时钟信号作出响应,使得其不响应于时钟时序而执行指令。换言之,当时钟启用信号为低时,处理器子单元可忽略所接收时钟信号。
1052.返回图75a的实例,控制器7540、7540'或7540”中的任一者可被配置为使用时钟启用信号,从而藉由使各别阵列中的一个或多个处理器子单元对所接收时钟信号作出响应或不作出响应来控制各别分布式处理器存储器芯片的操作。在一些实施例中,控制器7540、7540'或7540”可被配置为选择性地推进程序代码执行,例如在此代码与数据传送操作及其时序相关或包括数据传送操作及其时序时。在一些实施例中,控制器7540、7540'或7540”可被配置为使用时钟启用信号来控制两个不同的分布式处理器存储器芯片之间经由通信端口7531、7531'、7531”、7532、7532'及7532”等中的任一者的数据传输的时序。在一些实施例
中,控制器7540、7540'或7540”可被配置为使用时钟启用信号来控制两个不同的分布式处理器存储器芯片之间经由通信端口7531、7531'、7531”、7532、7532'及7532”等中的任一者的数据接收的时间。
1053.在一些实施例中,两个不同的分布式处理器存储器芯片之间的数据传送时序可基于编译优化步骤而配置。编译可允许建置处理程序,其中可将任务高效地指派给处理子单元而不受连接于两个不同处理器存储器芯片之间的总线上的传输延迟影响。编译可由主计算机中的编译程序执行,或传输至主计算机。通常,两个不同处理器存储器芯片之间的总线上的传送延迟将导致需要数据的处理子单元的数据瓶颈。所公开编译可用使得处理单元能够甚至在总线上具有不利传输延迟的情况下仍连续地接收数据的方式调度数据传输。
1054.虽然图75a的实施例针对每个分布式处理器存储器芯片(7500'、7500”、7500”')包括三个端口,但根据所公开实施例,任何数目个端口可包括于分布式处理器存储器芯片中。举例而言,在一些状况下,分布式处理器存储器芯片可包括更多或更少端口。在图75b的实施例中,每一分布式处理器存储器芯片(例如,7500a至7500i)可配置有多个端口。这些端口可大体上彼此相同或可能不同。在所展示的实例中,每一分布式处理器存储器芯片包括五个端口,包括一主机通信端口7570及四个芯片端口7572。主机通信端口7570可被配置为在阵列(如图75b中所展示)中的分布式处理器中的任一者与例如相对于分布式处理器存储器芯片的阵列位于远程的主计算机之间进行通信(经由总线7534)。芯片端口7572可被配置为使得能够经由总线7535在分布式处理器存储器芯片之间进行通信。
1055.任何数目个分布式处理器存储器芯片可彼此连接。在图75b中所展示的每分布式处理器包括四个芯片端口的实例中可实现阵列,在该阵列中,每一分布式处理器存储器芯片连接至两个或多于两个其他分布式处理器存储器芯片,且在一些状况下,某些芯片可连接至四个其他分布式处理器存储器芯片。在分布式处理器存储器芯片中包括更多芯片端口可实现分布式处理器存储器芯片之间的更多互连性。
1056.另外,虽然分布式处理器存储器芯片7500a至7500i在图75b中展示为具有两种不同类型的通信端口7570及7572,但在一些状况下,单种类型的通信端口可包括于每一分布式处理器存储器芯片中。在其他状况下,多于两种不同类型的通信端口可包括于分布式处理器存储器芯片中的一个或多个中。在图75c的实例中,分布式处理器存储器芯片7500a'至7500c'中的每一者包括两个(或多于两个)相同类型的通信端口7570。在此实施例中,通信端口7570可被配置为使得能够经由总线7534与诸如主计算机的外部实体进行通信,且亦可被配置为使得能够经由总线7535在分布式处理器存储器芯片之间(例如,在分布式处理器存储器芯片7500b'与7500c'之间)进行通信。
1057.在一些实施例中,设置于一个或多个分布式处理器存储器芯片上的端口可用以提供对多于一个主机的存取。举例而言,在图75d中所展示的实施例中,分布式处理器存储器芯片包括两个或多于两个端口7570。端口7570可构成主机端口、芯片端口,或主机端口与芯片端口的组合。在所展示的实例中,两个端口7570及7570'可使两个不同主机(例如,主计算机或计算元件或其他类型的逻辑单元)能够经由总线7534及7534'存取分布式处理器存储器芯片7500a。此实施例可使两个(或多于两个)不同主计算机能够存取分布式处理器存储器芯片7500a。然而,在其他实施例中,总线7534及7534'两者可连接至同一主机实体,例如其中该主机实体需要额外带宽或对分布式处理器存储器芯片7500a的处理器子单元/存储
器组中的一个或多个的并行存取。
1058.在一些状况下,如图75d中所展示,多于一个控制器7540及7540'可用以控制对分布式处理器存储器芯片7500a的分布式处理器子单元/存储器组的存取。在其他状况下,单个控制器可用以处置来自一个或多个外部主机实体的通信。
1059.另外,分布式处理器存储器芯片7500a内部的一个或多个总线可使得能够对分布式处理器存储器芯片7500a的分布式处理器子单元/存储器组进行并行存取。举例而言,分布式处理器存储器芯片7500a可包括第一总线7580及第二总线7580',该些总线使得能够对例如分布式处理器子单元7520_1至7520_6及其对应的专用存储器组7510_1至7510_6进行并行存取。此配置可允许同时存取分布式处理器存储器芯片7500a中的两个不同位置。另外,在不同时使用所有端口的状况下,该些端口可共享分布式处理器存储器芯片7500a内的硬件资源(例如,共同总线和/或共同控制器),且可构成多任务(mux)至该硬件的io。
1060.在一些实施例中,运算单元中的一些(例如,处理器子单元7520_1至7520_6)可连接至额外端口(7570')或控制器,而其他者不连接至额外端口或控制器。然而,来自不连接至额外端口7570'的运算单元的数据可通过到连接至端口7570'的运算单元的连接的内部网格(grid)。以此方式,可同时在两个端口7570及7570'处执行通信而无需添加额外总线。
1061.虽然通信端口(例如,7530至7532)及控制器(例如,7540)已说明为分开组件,但应了解,通信端口及控制器(或任何其他组件)可实施为根据本发明的实施例的集成单元。图76提供符合本发明的实施例的具有整合的控制器及接口模块的分布式处理器存储器芯片7600的图解表示。如图76中所展示,处理器存储器芯片7600可实施为具有整合的控制器及接口模块7547,该模块被配置为执行图75中的控制器7540以及通信端口7530、7531及7532的功能。如图76中所展示,控制器及接口模块7547被配置为经由类似于通信端口(例如,7530、7531及7532)的接口7548_1至7548_n与诸如外部实体、一个或多个分布式处理器存储器芯片等的多个不同实体通信。控制器及接口模块7547可经进一步配置以控制分布式处理器存储器芯片之间或分布式处理器存储器芯片7600与诸如主计算机的外部实体之间的通信。在一些实施例中,控制器及接口模块7547可包括被配置为与一个或多个其他分布式处理器存储器芯片及与诸如主计算机、通信模块等的外部实体并行地通信的通信接口7548_1至7548_n。
1062.图77提供表示符合本发明的实施例的用于在图75中所展示的可扩展处理器存储器系统中的分布式处理器存储器芯片之间传送数据的处理程序的流程图。出于说明的目的,将参看图75描述用于传送数据的流程,且假定数据是从第一处理器存储器芯片7500传送至第二处理器存储器芯片7500'。
1063.在步骤s7710处,可接收数据传送请求。然而,应注意且如上文所描述,在一些实施例中,数据传送请求可能并非必需的。举例而言,在一些状况下,数据传送的时序可为预定的(例如,藉由特定软件代码)。在此状况下,数据传送可在无分开的数据传送请求的情况下继续进行。步骤s7710可由例如控制器7540以及其他者执行。在一些实施例中,数据传送请求可包括将数据从第一分布式处理器存储器芯片7500的一个处理器子单元传送至第二分布式处理器存储器芯片7500'的另一处理器子单元的请求。
1064.在步骤s7720处,可判定数据传送时序。如所提到,数据传送时序可为预定的且可取决于特定软件程序的执行次序。步骤s7720可由例如控制器7540以及其他者执行。在一些
实施例中,可藉由考虑(1)发送处理器子单元是否准备好传送数据和/或(2)接收处理器子单元是否准备好接收数据,来判定数据传送时序。根据本发明的实施例,亦可考虑是否满足一个或多个其他时序约束以使得能够进行此数据传送。一个或多个时间约束可与以下各者相关:从发送处理器子单元的传送时间到接收处理器子单元处的接收时间之间的时间差、来自外部实体(例如,主计算机)的对所处理数据的存取请求、对与发送或接收处理器子单元相关联的存储器资源(例如,存储器阵列)执行的刷新操作等。根据本发明的实施例,处理子单元可由时钟馈入。在一些实施例中,可例如使用时钟启用信号来控制供应至处理子单元的时钟。根据本发明的一些实施例,控制器7540可藉由控制给处理器子单元7520_1至7520_k的时钟启用信号来控制通信命令的时序。
1065.在步骤s7730处,可基于在步骤s7720处判定的数据传送时序而执行数据传输。步骤s7730可由例如控制器7540以及其他者执行。举例而言,第一处理器存储器芯片7500的发送处理器子单元可根据在步骤s7720处判定的数据传送时序将数据传送至第二处理器存储器芯片7500'的接收处理器子单元。
1066.所公开架构可适用于多种应用。举例而言,在一些状况下,以上架构可便利在不同分布式处理器存储器芯片间共享数据,诸如与神经网络(尤其为大型神经网络)相关联的权重或神经元值或部分神经元值。另外,在诸如sum、avg等的某些运算中可能需要来自多个不同的分布式处理器存储器芯片的数据。在此状况下,所公开架构可便利共享来自多个分布式处理器存储器芯片的此数据。又另外,例如,所公开架构可便利在分布式处理器存储器芯片之间共享记录以支持查询的接合操作。
1067.亦应注意,虽然已相对于分布式处理器存储器芯片描述了以上实施例,但相同原理及技术可应用于例如不包括分布式处理器子单元的常规存储器芯片。举例而言,在一些状况下,多个存储器芯片可一起组合成多端口存储器芯片,以形成甚至不具有处理器子单元的阵列的存储器芯片的阵列。在另一实施例中,多个存储器芯片可组合在一起以形成所连接存储器的阵列,从而实际上向主机提供包含多个存储器芯片的一个较大存储器。
1068.端口的内部连接可至主总线或至包括于处理阵列中的内部处理器子单元中的一者。
1069.存储器内(in-memory)零侦测
1070.本发明的一些实施例有关于用于侦测储存于多个存储器组的一个或多个特定地址中的零值的存储器单元。所公开存储器单元的此零值侦测特征可适用于减少运算系统的功率消耗,且另外或替代地,亦可减少用于自存储器撷取零值所需的处理时间。此特征可在以下系统中尤其相关:在该系统中,读取的大量数据实际上为0值且亦用于计算运算,诸如乘法\加法\减法\及更多运算,对于该些运算,自存储器撷取零值可能不必要(例如,零值与任何其他值的乘积为零),且运算电路可使用操作数中的一者为零的事实且在时间及能量上更高效地计算结果。在此些状况下,可使用对零值的存在的侦测来代替存储器存取及自存储器撷取零值。
1071.贯穿此章节,相对于读取功能来描述所公开实施例。然而,应注意,所公开架构及技术同样适用于零值写入操作,或在其他值可能更经常出现的状况下,亦用于其他特定预定非零值操作。
1072.在所公开实施例中,替代自存储器撷取零值,当在特定地址处侦测到此值时,存储
器单元可将零值指示符传回至存储器单元外部的一个或多个电路(例如,位于存储器单元外部的一个或多个处理器、cpu等)。零值为多位零值零(例如,零值字节,零值字,小于一字节、大于一字节的多位零值,及其类似者)。零值指示符为提示储存于存储器中的零值的1位信号,因此相比传送储存于存储器中的n个数据位,传送提示信号的1位零值为有益的。所传输的零提示可将用于传送的能量消耗减少至1/n,且可加速运算,例如其中在藉由神经元的权重计算输入、卷积、将核心应用于输入数据以及与经训练神经网络、人工智能及广泛其他类型的运算相关联的许多其他计算中涉及乘法运算。为提供此功能性,所公开存储器单元可包括一个或多个零值侦测逻辑单元,该一个或多个零值侦测逻辑单元可侦测存储器中的特定位置中存在零值,防止撷取零值(例如,经由读取命令)且使得替代地将零值指示符传输至存储器单元外部的电路系统(例如,使用存储器的一或多条控制线、与存储器单元相关联的一个或多个总线等)。可在存储器垫层级、在组层级、在子组层级、在芯片层级等执行零值侦测。
1073.应注意,虽然相对于将零指示符递送至在存储器芯片外部的位置而描述了所公开实施例,但所公开实施例及特征亦可在处理可在存储器芯片内部进行的系统中提供显著益处。举例而言,在诸如本文中所公开的分布式处理器存储器芯片的实施例中,可藉由对应处理器子单元对各种存储器组中的数据执行处理。在许多状况下,诸如相关联数据可包括许多零的神经网络执行或数据分析,所公开技术可加速处理和/或减少与由分布式处理器存储器芯片中的处理器子单元执行的处理相关联的功率消耗。
1074.图78a说明符合本发明的实施例的用于在芯片层级侦测储存于多个存储器组的一个或多个特定地址中的零值的系统7800,该多个存储器组实施于存储器芯片7810中。系统7800可包括存储器芯片7810及主机7820。存储器芯片7810可包括多个控制单元且每一控制单元可具有专用存储器组。举例而言,控制单元可用可操作方式连接至专用存储器组。
1075.在一些状况下,例如相对于此处所公开的分布式处理器存储器芯片,存储器芯片内的处理可涉及存储器存取(无论为读取抑或写入),该些分布式处理器存储器芯片包括在空间上分布于存储器组的阵列当中的处理器子单元。甚至在存储器芯片内部的处理的状况下,侦测与读取或写入命令相关联的零值的所公开技术可允许内部处理器单元或子单元放弃传送实际零值。实情为,响应于零值侦测及零值指示符传输(例如,至一个或多个内部处理子单元),分布式处理器存储器芯片可节省否则将已用于传输存储器芯片内的零数据值的能量。
1076.在另一实例中,存储器芯片7810及主机7820中的每一者可包括输入/输出(io),以使得能够在存储器芯片7810与主机7820之间进行通信。每一io可与零值指示符线7830a及总线7840a耦接。零值指示符线7830a可将零值指示符从存储器芯片7810传送至主机7820,其中零值指示符可包括在侦测到储存于由主机7820请求的存储器组的特定地址中的零值后由存储器芯片7810产生的1位信号。在经由零值指示符线7830a接收到零值指示符后,主机7820可执行与零值指示符相关联的一个或多个预定义动作。举例而言,若主机7820向存储器芯片7810请求撷取用于乘法的操作数,则主机7820可更高效地计算乘法,这是因为主机7820将从所接收零值指示符确认(不接收实际存储器值)操作数中的一者为零。主机7820亦可经由总线7840将指令、数据及其他输入提供至存储器芯片7810,且从存储器芯片7810读取输出。在从主机7820接收到通信后,存储器芯片7810可撷取与所接收通信相关联的数
据,且经由总线7840将所撷取数据传送至主机7820。
1077.在一些实施例中,主机可将零值指示符而非零数据值发送至存储器芯片。以此方式,存储器芯片(例如,安置于存储器芯片上的控制器)可储存或刷新存储器中的零值而不必接收零数据值。此更新可基于零值指示符(例如,作为写入命令的部分)的接收而发生。
1078.图78b说明符合本发明的实施例的用于在存储器组层级侦测储存于多个存储器组7811a至7811b的一个或多个特定地址中的零值的存储器芯片7810。存储器芯片7810可包括多个存储器组7811a至7811b及io总线7812。尽管图78b描绘实施于存储器芯片7810的两个存储器组7811a至7811b,但存储器芯片7810可包括任何数目个存储器组。
1079.io总线7812可被配置为经由总线7840b将数据传送至外部芯片(例如,图78a中的主机7820)/从该外部芯片传送数据。总线7840b可类似于图78a中的总线7840a起作用。io 7812亦可经由零值指示符线7830b传输零值指示符,其中零值指示符线7830b可类似于图78a中的零值指示符线7830a起作用。io总线7812亦可被配置为经由内部零值指示符线7831及总线7841与存储器组7811a至7811b通信。io总线7812可将来自外部芯片的所接收数据传输至存储器组7811a至7811b中的一者。举例而言,io总线7812可经由总线7841传送数据,该数据包含用以读取储存于存储器组7811a的特定地址中的数据的指令。多任务器可包括于io总线7812与存储器组7811a至7811b之间,且可藉由内部零值指示符线7831及总线7841a连接。多任务器可被配置为将来自io总线7812的所接收数据传输至特定存储器组,且可经进一步配置以将来自特定存储器组的所接收数据或所接收零值指示符传输至io总线7812。
1080.在一些状况下,主机实体可仅被配置为接收常规数据传输,且可不经装备以解译所公开的零值指示符或对该零值指示符作出响应。在此状况下,所公开实施例(例如,控制器/芯片io等)可在至主机io的数据线上重新产生零值来代替零值指示符信号,且因此可节省芯片内部的数据传输功率。
1081.存储器组7811a至7811b中的每一者可包括控制单元。控制单元可侦测储存于存储器组的所请求地址中的零值。在侦测到所储存零值后,控制单元可产生零值指示符且经由内部零值指示符线7831将所产生的零值指示符传输至io总线7812,其中零值指示符经由零值指示符线7830b进一步传送至外部芯片。
1082.图79说明符合本发明的实施例的用于在存储器垫层级侦测储存于多个存储器垫的特定地址中的一个或多个中的零值的存储器组7911。在一些实施例中,存储器组7911可组织成存储器垫7912a至7912b,该些存储器垫中的每一者可被独立地控制及独立地存取。存储器组7911可包括存储器垫控制器7913a至7913b,该些控制器可包括零值侦测逻辑单元7914a至7914b。存储器垫控制器7913a至7913b中的每一者可允许对存储器垫7912a至7912b上的位置进行读取及写入。存储器组7911可进一步包括读取停用组件、区域感测放大器7915a至7915b和/或全局感测放大器7916。
1083.存储器垫7912a至7912b中的每一者可包括多个存储器胞元。多个存储器胞元中的每一者可储存一个二进制信息位。举例而言,存储器胞元中的任一者可个别地储存零值。若特定存储器垫中的所有存储器胞元皆储存零值,则零值可与整个存储器垫相关联。
1084.存储器垫控制器7913a至7913b中的每一者可被配置为存取专用存储器垫,且读取储存于专用存储器垫中的数据或将数据写入专用垫中。
1085.在一些实施例中,零值侦测逻辑单元7914a或7914b可实施于存储器组7911中。一
个或多个零值侦测逻辑单元7914a至7914b可与存储器组、存储器子组、存储器垫及一个或多个存储器胞元的集合相关联。零值侦测逻辑单元7914a或7914b可侦测所请求的特定地址(例如,存储器垫7912a或7912b)储存零值。该侦测可用许多方法执行。
1086.第一方法可包括使用相对于零的数字比较器。数字比较器可被配置为获取两个数字作为二进制形式的输入,且判定第一数字(所撷取数据)是否等于第二数字(零)。若数字比较器判定两个数字相等,则零值侦测逻辑单元可产生零值指示符。零值指示符可为1位信号,且可使可将数据位发送至下一层级(例如,图78b中的io总线7812)的放大器(例如,区域感测放大器7915a至7915b)、传输器及缓冲器停用。零值指示符可经由零值指示符线7931a或7931b进一步传输至全局感测放大器7916,但在一些状况下,可绕过全局感测放大器。
1087.用于零侦测的第二方法可包括使用模拟比较器。除了将两个模拟输入的电压用于比较以外,模拟比较器亦可类似于数字比较器起作用。举例而言,可感测所有位,且比较器可充当信号之间的逻辑或(or)函数。
1088.用于零值侦测的第三方法可包括使用从区域感测放大器7915a至7915b至全局感测放大器7916中的传送信号,其中全局感测放大器7916被配置为感测输入中的任一者是否为高(非零)且使用该逻辑信号以控制放大器的下一层级。区域感测放大器7915a至7915b及全局感测放大器7916可包括多个晶体管,该多个晶体管被配置为感测来自多个存储器组的低功率信号,且该些放大器将小的电压摆动放大至较高电压电平使得储存于多个存储器组中的数据可由诸如存储器垫控制器7913a或7913b的至少一个控制器解译。举例而言,存储器胞元可按行及列布置于存储器组7911上。每一线可附接至行中的每一存储器胞元。沿着行延行的线被称作字线,该些字线藉由将电压选择性地施加至字线来启动。沿着列延行的线被称作位线,且两个这种互补位线可在存储器阵列的边缘处附接至感测放大器。感测放大器的数目可对应于存储器组7911上的位线(列)的数目。为了从特定存储器胞元读取位,接通沿着胞元行的字线,从而启动该行中的所有存储器胞元。来自每一胞元的所储存值(0或1)接着在与特定胞元相关联的位线上可用。在两个互补位线的末端处,感测放大器可将小的电压放大至正常逻辑电平。可接着将来自所要胞元的位自胞元的感测放大器锁存至缓冲器中且置于输出总线上。
1089.用于零值侦测的第四方法可包括:若值为0,则针对保存至存储器且在写入时间储存的每一字使用一额外位,且在读出数据时使用该额外位以知晓数据是否为零。该方法可避免将所有零写入至存储器,因此节省更多能量。
1090.如上文且贯穿本发明所描述,一些实施例可包括存储器单元(诸如,存储器单元7800),该存储器单元包括多个处理器子单元。这些处理器子单元可在空间上分布于单个基板(例如,诸如存储器单元7800的存储器芯片的基板)上。此外,多个处理器子单元中的每一者可专用于存储器单元7800的多个存储器组当中的对应存储器组。且专用于对应处理器子单元的这些存储器组亦可在空间上分布于基板上。在一些实施例中,存储器单元7800可与特定任务(例如,执行与运行神经网络相关联的一个或多个操作等)相关联,且存储器单元7800的处理器子单元中的每一者可负责执行此任务的一部分。举例而言,每一处理器子单元可装备有可包括数据处置及存储器操作、算术及逻辑运算等的指令。在一些状况下,零值侦测逻辑可被配置为将零值指示符提供至在空间上分布于存储器单元7800上的所描述处理器子单元中的一个或多个。
1091.现参看图80,其为说明符合本发明的实施例的侦测储存于多个存储器组的特定地址中的零值的例示性方法8000的流程图。方法8000可由存储器芯片(例如,图78b的存储器芯片7810)执行。特定而言,存储器单元的控制器(例如,图79的控制器7913a)及零值侦测逻辑单元(例如,零值侦测逻辑单元7914a)可执行方法8000。
1092.在步骤8010中,可藉由任何合适的技术起始读取或写入操作。在一些状况下,控制器可接收对读取储存于多个离散存储器组(例如,图78中所描绘的存储器组)的特定地址中的数据的请求。控制器可被配置为控制相对于多个离散存储器组的读取/写入操作的至少一个方面。
1093.在步骤8020中,一个或多个零值侦测电路可用以侦测与读取或写入命令相关联的零值的存在。举例而言,零值侦测逻辑单元(例如,图78的零值侦测逻辑单元7830)可侦测与特定地址相关联的零值,该特定地址与读取或写入相关联。
1094.在步骤8030中,控制器可响应于由零值侦测逻辑单元在步骤8020中进行的零值侦测而将零值指示符传输至存储器单元外部的一个或多个电路。举例而言,零值侦测逻辑可侦测到所请求地址储存零值,且可将值为零的提示传输至存储器芯片外部(或存储器芯片内,例如在所公开的分布式处理器存储器芯片包括分布于存储器组的阵列当中的处理器子单元的状况下)的实体(例如,一个或多个电路)。若未侦测到与读取或写入命令相关联的零值,则控制器可传输数据值而非零值指示符。在一些实施例中,被传回零值指示符的一个或多个电路可在存储器单元内部。
1095.虽然所公开实施例已关于零值侦测进行了描述,但相同原理及技术将适用于侦测其他存储器值(例如,1等)。在一些状况下,除零值指示符以外,侦测逻辑亦可传回与读取或写入命令相关联的其他值(例如,1等)的一个或多个指示符,且这些指示符可在侦测到对应于值指示符的任何值的情况下被传回/传输。在一些状况下,可藉由使用者(例如,经由更新一个或多个寄存器)调整该些值。在可能知晓关于数据集的特性且了解到(例如,就使用者而言)某些值在数据中可能比其他值更普遍的情况下,这种更新可能尤其有用。在此状况下,一个、两个、三个或多于三个值指示符可与最普遍数据相关联,该些最普遍数据与数据集相关联。
1096.补偿dram启动惩罚
1097.在某些类型的存储器(例如,dram)中,存储器胞元可按阵列配置于存储器组内,且一次可针对阵列中的一排存储器胞元存取及撷取(读取)包括于存储器胞元中的值。此读取处理程序可涉及首先开放(启动)存储器胞元的一排(line)(或行)以使由存储器胞元储存的数据值可用。接下来,可同时感测开放排中的存储器胞元的值,且列地址可用以循环通过个别存储器胞元值或存储器胞元值的群组(亦即,字),且将每一存储器胞元值连接至外部数据总线以便读取存储器胞元值。这些处理程序耗费时间。在一些状况下,开放用于读取的存储器排可能需要运算时间的32个循环,且从开放排读取值可能需要另外32个循环。若仅在当前开放排的读取操作完成之后开放待读取的下一排,则可产生显著潜时。在此实例中,在开放下一排所需的32个循环期间,无数据被读取,且读取每一排有效地需要总计64个循环而非仅需要32个循环来遍历排数据。传统存储器系统不允许在正读取或写入第一排时开放同一组中的第二排。为节省潜时,待开放的下一排可因此在用于双排存取的特殊组中的不同组o中,如下文进一步详细地论述。在开放下一排之前,当前排可皆取样至触发器
(flipflop)或锁存器,且在可开放下一排时,所有处理皆在触发器\锁存器上完成。若下一预测排在同一组中(且以上情形中无一者存在),则可能无法避免潜时且系统可能需要等待。这些机制与标准存储器且尤其与存储器处理装置两者均相关。
1098.本发明所公开的实施例可藉由例如在当前开放存储器排的读取操作已完成之前预测待开放的下一存储器排来减少此潜时。亦即,若可预测待开放的下一排,则用于开放下一排的处理程序可在当前排的读取操作已完成之前开始。取决于在处理程序中何时进行下一排预测,与开放下一排相关联的潜时可从32个循环(在上文所描述的特定实例中)减少至少于32个循环。在一个特定实例中,若提前20个循环预测下一排开放,则额外潜时仅为12个循环。在另一实例中,若提前32个循环预测下一排开放,则根本不存在潜时。结果,替代需要总计64个循环来串行地开放及读取每一行,藉由在读取当前行的同时开放下一行,可减少读取每一行的有效时间。
1099.以下机制可能需要当前排及预测排在相同组中,但若存在可支持在一排上同时启动及工作的此组,则亦可使用该些机制。
1100.在所公开实施例中,可使用各种技术(在下文更详细地论述)执行下一行预测。举例而言,下一行预测可基于图案辨识,基于预定行存取调度,基于人工智能模型(例如,用以分析行存取且进行待开放的下一行的预测的经训练神经网络)的输出或基于任何其他合适的预测技术。在一些实施例中,可藉由使用如下文所描述的延迟地址产生器或公式或其他方法来达成100%成功预测。预测可包含建置具有在需要存取待开放的下一排之前充分预测该排的能力的系统。在一些状况下,下一行预测可由下一行预测器执行,该下一行预测器可用各种方式实施。举例而言,用以产生用于对存储器行进行读取和/或写入的当前地址的预测地址产生器。产生用于存取存储器(读取或写入)的地址的实体可基于执行软件指令的任何逻辑电路或控制器\cpu。预测地址产生器可包括图案(pattern)学习模型,该图案学习模型观测所存取行,识别与存取(例如,依序排存取,对每第二排的存取,对每第三排的存取等)相关联的一个或多个图案且基于观测到的图案而估计待存取的下一行。在其他实例中,预测地址产生器可包括应用公式/算法以预测待存取的下一行的单元。在另外其他实施例中,预测地址产生器可包括经训练神经网络,该经训练神经网络基于诸如正存取的当前地址行、经存取的最后2个、3个、4个或多于4个地址/行等的输入来输出待存取的所预测下一行(包括与所预测行相关联的一个或多个地址)。使用所描述的预测地址产生器中的任一者预测待存取的下一存储器排可显著减少与存储器存取相关联的潜时。所描述的预测地址/行产生器可适用于涉及存取存储器以撷取数据的任何系统中。在一些状况下,所描述的预测地址/行产生器及用于预测下一存储器排存取的相关联技术可尤其适合于执行人工智能模型的系统中,因为ai模型可与可便利下一行预测的重复存储器存取图案相关联。
1101.图81a说明符合本发明的实施例的用于基于下一行预测启动与存储器组8180相关联的下一行的系统8100。系统8100可包括当前及预测地址产生器8192、组控制器8191及存储器组8180a至8180b。地址产生器可为产生用于存取存储器组8180a至8180b的地址的实体,且可基于执行软件程序的任何逻辑电路、控制器或微处理器。组控制器8191可被配置为存取存储器组8180a的当前行(例如,使用由地址产生器8192产生的当前行识别符)。组控制器8191亦可被配置为基于由地址产生器8192产生的预测行识别符启动存储器组8180b内待存取的所预测下一行。以下实例描述两个组。在其他实例中,可使用更多组。在一些实施例
中,可存在允许一次存取多于一行(如下文所论述)的存储器组,且因此可在单个组上进行相同处理程序。如上文所描述,待存取的所预测下一行的启动可在相对于正存取的当前行执行的读取操作完成之前开始。因此,在一些状况下,地址产生器8192可预测待存取的下一行,且可在对当前行的存取已完成之前的任何时间将所预测下一行的识别符(例如,一个或多个地址)发送至组控制器8191。此时序可允许组控制器在正存取当前行期间且在对当前行的存取完成之前的任何时间点起始所预测下一行的启动。在一些状况下,组控制器8291可在待存取的当前行的启动完成和/或相对于当前行的读取操作已开始的同时(或在几个时钟循环内)起始存储器组8180的所预测下一行的启动。
1102.在一些实施例中,相对于与当前地址相关联的当前行的操作可为读取或写入操作。在一些实施例中,当前行及下一行可在同一存储器组中。在一些实施例中,同一存储器组可允许在正存取当前行的同时存取下一行。当前行及下一行可在不同存储器组中。在一些实施例中,存储器单元可包括被配置为产生当前地址及预测地址的处理器。在一些实施例中,存储器单元可包括分布式处理器。分布式处理器可包括在空间上分布于存储器阵列的多个离散存储器组当中的处理阵列的多个处理器子单元。在一些实施例中,预测地址可藉由对延迟产生的地址进行取样的一系列触发器产生。该延迟可为可经由在储存经取样地址的触发器之间进行选择的多任务器来配置的。
1103.应注意,在确认所预测下一行实际上为执行软件请求以存取的下一行后(例如,在完成相对于当前行的读取操作之后),所预测下一行可成为待存取的当前行。在所公开实施例中,因为可在完成当前行读取操作之前起始用于启动所预测下一行的处理程序,所以在确认所预测下一行为待存取的正确的下一行后,可能已完全或部分启动待存取的下一行。此可显著减少与排启动相关联的潜时。若启动下一行使得启动在当前行的读取结束之前或同时结束,则可获得功率减少。
1104.当前及预测地址产生器8192可包括被配置为识别存储器组8180中待存取的行(例如,基于程序执行)且预测待存取的下一行(例如,基于行存取中的所观测图案,基于预定图案(n 1、n 2)等)的任何合适的逻辑组件、运算单元、存储器单元、算法、经训练模型等。举例而言,在一些实施例中,当前及预测地址产生器8192可包括计数器8192a、当前地址产生器8192b及预测地址产生器8192c。当前地址产生器8192b可被配置为基于计数器8192a的输出,例如基于来自运算单元的请求而产生存储器组8180中待存取的当前行的当前地址。可将与待存取的当前行相关联的地址提供至组控制器8191。预测地址产生器8192c可被配置为基于计数器8192a的输出、基于预定存取图案(例如,结合计数器8192a)或基于经训练神经网络的输出或其他类型的图案预测算法来判定存储器组8180中待存取的下一行的预测地址,该图案预测算法观测排存取且基于例如与所观测到的排存取相关联的图案来预测待存取的下一排。地址产生器8192可将来自预测地址产生器8192c的所预测下一行地址提供至组控制器8191。
1105.在一些实施例中,当前地址产生器8192b及预测地址产生器8192c可实施于系统8100内部或外部。外部主机亦可实施于系统8100外部且进一步连接至系统8100。举例而言,当前地址产生器8192b可为执行程序的外部主机处的软件,且为避免任何潜时,预测地址产生器8192c可实施于系统8100内部或系统8100外部。
1106.如所提到,可使用经训练神经网络判定所预测下一行地址,该经训练神经网络基
于可包括一个或多个先前存取的行地址的输入来预测待存取的下一行。经训练神经网络或其他类型的模型可在与预测地址产生器8192c相关联的逻辑内运行。在一些状况下,经训练神经网络等可藉由预测地址产生器8192c外部但与该预测地址产生器通信的一个或多个运算单元执行。
1107.在一些实施例中,预测地址产生器8192c可包括当前地址产生器8192b的复制者或实质复制者。另外,当前地址产生器8192b及预测地址产生器8192c的操作的时序可相对于彼此固定或可调整。举例而言,在一些状况下,预测地址产生器8192c可被配置为相对于当前地址产生器8192b发出与待存取的下一行相关联的地址识别符时在固定时间(例如,固定数目个时钟循环)输出与所预测下一行相关联的地址识别符。在一些状况下,在待存取的当前行的启动开始之前或之后,在与待存取的当前行相关联的读取操作开始之前或之后,或在与正存取的当前行相关联的读取操作完成之前的任何时间,可产生所预测下一行识别符。在一些状况下,可在待存取的当前行的启动开始的同时或在与待存取的当前行相关联的读取操作开始的同时产生所预测下一行识别符。
1108.在其他状况下,所预测下一行识别符的产生与待存取的当前行的启动或与当前行相关联的读取操作的起始之间的时间可为可调整的。举例而言,在一些状况下,此时间可在存储器单元8100的操作期间基于与一个或多个操作参数相关联的值而延长或缩短。在一些状况下,与存储器单元或运算系统的另一组件相关联的当前温度(或任何其他参数值)可使当前地址产生器8192b及预测地址产生器8192c改变其相对操作时序。在实施例中,其中在存储器处理中,预测机制可为该逻辑的部分。
1109.当前及预测地址产生器8192可产生与所预测下一行相关联的置信度以存取判定。此置信度(其可作为预测处理程序的部分由预测地址产生器8192c判定)可用于判定例如是否在当前行的读取操作期间(亦即,在当前行读取操作已完成之前且在待存取的下一行的识别已确认之前)起始所预测下一行的启动。举例而言,在一些状况下,可将与待存取的所预测下一行相关联的置信度与阈值等级进行比较。若置信度降至低于阈值等级,则例如存储器单元8100可放弃启动所预测下一行。另一方面,若置信度超过阈值等级,则存储器单元8100可起始存储器组8180中的所预测下一行的启动。
1110.可用任何合适的方式实现测试相对于阈值等级的所预测下一行的置信度及所预测下一行的启动之后续起始或非起始的机制。在一些状况下,例如,若与所预测下一行相关联的置信度降至低于阈值,则预测地址产生器8192c可放弃将其所预测下一行结果输出至下游逻辑组件。替代地,在此状况下,当前及预测地址产生器8192可抑制来自组控制器8191的所预测下一行识别符,或组控制器(或另一逻辑单元)可经装备以使用所预测下一行的置信度以判定是否在与正读取的当前行相关联的读取操作完成之前开始启动所预测下一行。
1111.可用任何合适的方式产生与所预测下一行相关联的置信度。在一些状况下,诸如在基于预定的已知存取图案识别所预测下一行的情况下,预测地址产生器8192c可产生高置信度或鉴于行存取的预定图案,可完全放弃产生置信度。另一方面,在预测地址产生器8192c执行一个或多个算法以监视行存取,且基于相对于所监视的行存取而计算的图案输出所预测行,或在一个或多个经训练神经网络或其他模型被配置为基于包括最近行存取的输入而输出所预测下一行的情况下,可基于任何相关参数判定所预测下一行的置信度。举例而言,在一些状况下,置信度可取决于一个或多个先前的下一行预测是否证明为准确的
(例如,过去效能指示符)。置信度亦可基于算法/模型的输入的一个或多个特性。举例而言,包括遵循图案的实际行存取的输入可导致比展现较少图案化的实际行存取高的置信度。且在相对于包括最近行存取的输入的串流侦测随机性的一些状况下,例如,所产生的置信度可为低的。另外,在侦测到随机性的状况下,可完全中止下一行预测处理程序,存储器单元8100的组件中的一个或多个可忽略下一行预测,或可采取任何其他动作以放弃启动所预测下一行。
1112.在一些状况下,可相对于存储器8100的操作包括反馈机制。举例而言,周期性地或甚至在每下一行预测之后,可判定预测地址产生器8192c预测待存取的实际下一行的准确性。在一些状况下,若在预测待存取的下一行时存在错误(或在预定数目个错误之后),则可暂时中止预测地址产生器8192c的下一行预测操作。在其他状况下,预测地址产生器8192c可包括学习元件,使得其预测操作的一个或多个方面可基于关于其预测待存取的下一行的准确性的所接收反馈而调整。此能力可改进预测地址产生器8192c的操作,使得地址产生器8192c可适应于改变的存取图案等。
1113.在一些实施例中,所预测下一行的产生和/或所预测下一行的启动的时序可取决于存储器单元8100的整体操作。举例而言,在通电之后或在重设存储器单元8100之后,可暂时中止预测待存取的下一行(或将所预测下一行转送至组控制器8191)(例如,持续预定时间量或时钟循环,直至预定数目个行存取/读取已完成,直至所预测下一行的置信度超过预定阈值,或基于任何其他合适的准则)。
1114.图81b说明根据例示性所公开实施例的存储器单元8100的另一配置。在图81b的系统8100b中,高速缓存8193可与组控制器8191相关联。举例而言,高速缓存8193可被配置为在一个或多个数据行被存取之后储存该一个或多个数据行,且防止需要再次启动该些数据行。因此,高速缓存8193可使得组控制器8191能够存取来自高速缓存8193的行数据而非存取存储器组8180。举例而言,高速缓存8193可储存最后x行数据(或任何其他高速缓存节省策略),且组控制器8191可根据所预测行来填充高速缓存8193。此外,若所预测行已在高速缓存8193中,则不需要再次开放所预测行,且组控制器(或实施于高速缓存8193中的高速缓存控制器)可保护所预测行不被调换。高速缓存8193可提供若干益处。首先,由于高速缓存8193将行加载至高速缓存8193且组控制器可存取高速缓存8193以撷取行数据,因此不需要特殊组或多于一个组用于下一行预测。其次,对高速缓存8193进行读取及写入可节省能量,因为从组控制器8191至高速缓存8193的实体距离小于从组控制器8191至存储器组8180的实体距离。第三,相较于存储器组8180,由高速缓存8193引起的潜时通常较低,因为高速缓存8193更小且更接近控制器8191。在一些状况下,当藉由组控制器8191在存储器组8180中启动所预测下一行时,由预测地址产生器产生的所预测下一行的识别符例如可储存于高速缓存8193中。基于程序执行等,当前地址产生器8192b可识别存储器组8191中待存取的实际下一行。可将与待存取的实际下一行相关联的识别符与储存于高速缓存8193中的所预测下一行的识别符进行比较。若待存取的实际下一行与待存取的所预测下一行相同,则组控制器8191可在待存取的实际下一行的启动已完成之后开始相对于该行的读取操作(其可能由于下一行预测处理程序而完全或部分启动)。另一方面,若待存取的实际下一行(由当前地址产生器8192b判定)不匹配储存于高速缓存8193中的所预测下一行识别符,则将不会相对于完全或部分启动的所预测下一行开始读取操作,而是系统将开始启动待存取的实际下一
行。
1115.双重启动组
1116.如所论述,描述若干机制为有价值的,该些机制允许建置能够在一行仍正被处理的同时启动另一行的组。可针对在另一行正被存取的同时启动额外行的组提供若干实施例。虽然实施例仅描述两行启动,但应了解,其可适用于更多行。在首先建议的实施例中,存储器组可分成存储器子组,且所描述实施例可用以执行相对于一个子组中的一排的读取操作,同时启动另一子组中的所预测或所需下一行。举例而言,如图81c中所展示,存储器组8180可被配置为包括多个存储器子组8181。另外,与存储器组8180相关联的组控制器8191可包括与对应子组相关联的多个子组控制器。多个子组控制器中的第一子组控制器可被配置为使得能够存取包括于多个子组中的第一子组的当前行中的数据,而多个子组控制器中的第二子组控制器可启动多个子组中的第二子组中的下一行。当一次仅存取一个子组中的字时可使用仅一个列解码器。两个组可系结至同一输出总线以呈现为单个组。新的单个组输入亦可为单个地址及用于开放下一行的额外行地址。
1117.图81c说明每一存储器子组8181的第一及第二子组行控制器(8183a、8183b)。存储器组8180可包括多个子组8181,如图81c中所展示。另外,组控制器8191可包括各与对应子组8181相关联的多个子组控制器8183a至8183b。多个子组控制器中的第一子组控制器8183a可被配置为使得能够存取包括于子组8181中的第一部分的当前行中的数据,而第二子组控制器8183b可启动子组8181的第二部分中的下一行。
1118.因为启动直接邻近于正被存取的行的行可能会使所存取行失真和/或损坏正自所存取行读取的数据,所以所公开实施例例如可被配置为使得待启动的所预测下一行可与第一子组中正被存取数据的当前行隔开至少两行。在一些实施例中,待启动的行可隔开至少一垫,使得启动可在不同垫中执行。第二子组控制器可被配置为使得存取包括于第二子组的当前行中的数据,而第一子组控制器启动第一子组中的下一行。第一子组的经启动的下一行可与第二子组中正被存取数据的当前行隔开至少两行。
1119.正被读取/存取的行与正被启动的行之间的此预定义距离可由例如将存储器组的不同部分耦接至不同行解码器的硬件判定,且软件可维持该预定义距离以免破坏数据。当前行之间的间隔可超过两列(例如可为3行、4行、5行及甚至多于5行)。该距离可随时间改变,例如基于关于所储存数据中引入的失真的评估。可用各种方式评估失真,例如藉由计算信噪比、错误率、修复失真所需的错误码及其类似者。若两行足够远且两个组控制器实施于同一组上,则实际上可启动两行。新架构(在同一组上实施两个控制器)可防止开放同一垫中的多个排。
1120.图81d说明符合本发明的实施例的下一行预测的实施例。实施例可包括触发器(地址寄存器a至c)的额外管线。管线可藉由任何数目个触发器(级)实施为在地址产生器之后启动及延迟整体执行以使用所延迟地址所需的延迟,接着预测可为所产生的新地址(在管线的开头,在地址寄存器c下方)且当前地址为管线的末尾。在此实施例中,不需要复制地址产生器。可添加选择器(图81d中所展示的多任务器)以配置延迟,而地址寄存器提供延迟。
1121.图81e说明符合本发明的实施例的存储器组的实施例。存储器组可实施为若新启动的排距当前排足够远,则启动新排将不会破坏当前排。如图81e中所展示,存储器组可包括垫的每两排之间的额外存储器垫(黑色)因此,控制单元(诸如,行解码器)可启动隔开一
垫的多个排。
1122.在一些实施例中,存储器单元可被配置为在预定时间接收第一地址以用于处理及接收第二地址以启动及存取。
1123.图81f说明符合本发明的实施例的存储器组的另一实施例。存储器组可实施为若新启动的排距当前排足够远,则启动新排将不会破坏当前排。图81f中所描绘的实施例可藉由确保在存储器组的上半部分处实施所有偶数排且在存储器组的下半部分处实施所有奇数排来允许行解码器开放排n及n 1。实施方案可允许存取始终足够远的连续排。
1124.根据所公开实施例,双重控制存储器组可允许存取及启动单个存储器组的不同部分,即使在双重控制存储器组被配置为一次输出一个数据单元时亦如此。举例而言,如所描述,双重控制可使得存储器组能够在启动第二行(例如,所预测下一行或待存取的预定下一行)时存取第一行。
1125.图82说明符合本发明的实施例的用于减少存储器行启动惩罚(例如,潜时)的双重控制存储器组8280。双重控制存储器组8280可包括输入,该些输入包括数据输入(din)8290、行地址(row)8291、列地址(column)8292、第一命令输入(command_1)8293及第二命令输入(command_2)8294。存储器组8280可包括数据输出(dout)8295。
1126.假定地址可包括行地址及列地址,且存在两个行解码器。可提供地址的其他配置,行解码器的数目可超过两个,且可存在多于单个列解码器。
1127.行地址(row)8291可识别与诸如启动命令的命令相关联的行。因为行启动后可接着从该行读取或写入至该行,所以接着在该行开放(在其启动之后),可能不需要发送用于写入至开放行或从开放行读取的行地址。
1128.第一命令输入(command_1)8293可用以将命令(诸如但不限于启动命令)发送至由第一行解码器存取的行。第二命令(command_2)输入8294可用以将命令(诸如但不限于启动命令)发送至由第二行解码器存取的行。
1129.数据输入(din)8290可用以在执行写入操作时馈入数据。
1130.因为无法一次读取整行,所以可依序读取单个行区段,且列地址(column)8292可提示待读取该行的哪一区段(哪些列)。为解释简单起见,可假定存在2q个区段且列输入具有q个位;q为超过一的正整数。
1131.双重控制存储器组8280可在具有或不具有上文关于图81a至图81b所描述的地址预测的情况下操作。当然,为减少操作潜时,根据所公开实施例,双重控制存储器组可在具有地址预测的情况下操作。
1132.图83a、图83b及图83c说明存取及启动存储器组8180的列的实例。如上文所提及,假定在一个实例中,读取行及启动行两者均需要32个循环(区段)。另外,为了减少启动惩罚(具有表示为差量(delta)的长度),预先(在需要存取下一行之前至少差量)知晓应开放下一行可为有益的。在一些状况下,差量可等于四个循环。图83a、图83b及图83c中所描绘的每一存储器组可包括两个或多于两个子组,在该两个或多于两个子组内,在一些实施例中,在任何给定时间可仅开放一个行。在一些状况下,偶数行可与第一子组相关联,且奇数行可与第二子组相关联。在此实例中,使用所公开的预测性寻址实施例可使得能够在到达相对于另一存储器子组的行的读取操作的末尾之前(在到达末尾之前的延迟时段)起始某一存储器子组的一个行的启动。以此方式,可用高效方式进行依序存储器存取(例如,预定义存储
器存取序列,其中行1、2、3、4、5、6、7、8
……
待读取,且行1、3、5
……
等与第一存储器子组相关联且行2、4、6
……
等与第二不同存储器子组)相关联。
1133.图83a可说明用于存取包括于两个不同存储器子组中的存储器行的状态。在图83a中所展示的状态中:
1134.a.行a可为可由第一行解码器存取的。可在第一行解码器启动行a之后存取第一区段(以灰色标记的最左区段)。
1135.b.行b可为可由第二行解码器存取的。在图83a中所展示的这些状态中,行b被关闭且尚未启动。
1136.图83a中所说明的状态之前可为将启动命令及行a的地址发送至第一行解码器。
1137.图83b说明用于在存取行a之后存取行b的状态。根据此实例:行a可为可由第一行解码器存取的。在图83b中所展示的状态中,第一行解码器启动行a且已存取除四个最右区段(未以灰色标记的四个区段)以外的所有区段。因为差量(行a中的四个白色区段)等于四个循环,所以组控制器可使得第二行解码器能够在存取行a中的最右区段之前启动行b。在一些状况下,启动行b可响应于预定存取图案(例如,依序行存取,其中奇数行指明于第一子组中且偶数行指明于第二子组中)。在其他状况下,启动行b可响应于上文所描述的任何行预测技术。组控制器可使得第二行解码器能够预先启动行b,使得当存取行b时,已启动(开放)行b而非等待启动行b以开放行b。
1138.图83b中所说明的状态之前可为以下操作:
1139.a.将启动命令及行a的地址发送至第一行解码器。
1140.b.写入或读取行a的前二十八个区段。
1141.c.在对行的二十八个区段进行读取或写入操作之后,将相对于行b的地址的启动命令发送至第二行解码器。
1142.在一些实施例中,偶数编号列位于一个或多个存储器组的一半中。在一些实施例中,奇数编号列位于一个或多个存储器组的一半中。
1143.在一些实施例中,一排额外冗余垫置放于两个垫排中的每一者之间以建立用于允许启动的距离。在一些实施例中,可能不同时启动彼此接近的多个排。
1144.图83c可说明用于在存取行a之后存取行c(例如,包括于第一子组中的下一奇数行)的状态。如图83c中所展示,行b可为可由第二行解码器存取的。如所展示,第二行解码器已启动行b且已存取除四个最右区段(未以灰色标记的四个剩余区段)以外的所有区段。因为在此实例中,差量等于四个循环,组控制器可使得第一行解码器能够在存取行b中的最右区段之前启动行c。组控制器可使得第一行解码器能够预先启动行c,使得当存取行c时,已启动行c而非等待启动行c。以此方式操作可减少或完全消除与存储器读取操作相关联的潜时。
1145.作为寄存器文件的存储器垫
1146.在计算机架构中,处理器寄存器构成计算机处理器(例如,中央处理单元(cpu))可快速存取的储存位置。寄存器通常包括最接近处理器核心(l0)的存储器单元。寄存器可提供存取某些类型的数据的最快方式。计算机可具有若干类型的寄存器,其各根据其储存的信息的类型或基于对某一类型的寄存器中的信息操作的指令的类型而分类。举例而言,计算机可包括:数据寄存器,其保存数值信息、操作数、中间结果及配置;地址寄存器,其储存
由指令使用以存取主要存储器的地址信息;通用寄存器,其储存数据及地址信息两者;及状态寄存器;以及其他寄存器。寄存器文件包括可供计算机处理单元使用的寄存器的逻辑群组。
1147.在许多状况下,计算机的寄存器文件位于处理单元(例如,cpu)内且由逻辑晶体管实施。然而,在所公开实施例中,运算处理单元可能不驻存于传统的cpu中。实情为,这种处理元件(例如,处理器子单元)可作为处理阵列在空间上分布于(如以上章节中所描述)存储器芯片内。每一处理器子单元可与一个或多个对应及专用的存储器单元(例如,存储器组)相关联。经由此架构,每一处理器子单元可在空间上位于储存特定处理器子单元要对其操作的数据的一个或多个存储器元件附近。如本文中所描述,此架构可藉由例如消除由典型cpu及外部存储器架构所经历的存储器存取瓶颈来显著加速某些存储器密集型操作中的操作。
1148.然而,本文中所描述的分布式处理器存储器芯片架构可仍利用寄存器文件,其包括用于对来自专用于对应处理器子单元的存储器元件的数据进行操作的各种类型的寄存器。然而,由于处理器子单元可分布于存储器芯片的存储器元件当中,因此有可能将一个或多个存储器元件(相较于特定制造制程中的逻辑组件,该一个或多个存储器元件可受益于该同一制程)添加于对应处理器子单元中,以充当用于对应处理器子单元的寄存器文件或高速缓存,而非充当主要存储器储存器。
1149.此架构可提供若干优点。举例而言,由于寄存器文件为对应处理器子单元的部分,因此处理器子单元可在空间上位于相关寄存器文件附近。此配置可显著增加操作效率。传统寄存器文件由逻辑晶体管实施。举例而言,传统寄存器文件的每一位由约12个逻辑晶体管制成,且因此16个位的寄存器文件由192个逻辑晶体管制成。此寄存器文件可能需要大量逻辑组件来存取逻辑晶体管,且因此可占用大的空间。相较于由逻辑晶体管实施的寄存器文件,本发明所公开的实施例的寄存器文件可能需要显著更少的空间。此大小减小可藉由使用包括存储器胞元的存储器垫实施所公开实施例的寄存器文件来实现,该些存储器胞元藉由经优化以用于制造存储器结构而非用于制造逻辑结构的制程来制造。大小减小亦可允许较大寄存器文件或高速缓存。
1150.在一些实施例中,可提供分布式处理器存储器芯片。分布式处理器存储器芯片可包括:基板;存储器阵列,其安置于基板上且包括多个离散存储器组;及处理阵列,其安置于基板上且包括多个处理器子单元。该些处理器子单元中的每一者可与多个离散存储器组中的对应的专用存储器组相关联。分布式处理器存储器芯片还可包括第一多个总线及第二多个总线。第一多个总线中的每一者可将多个处理器子单元中的一者连接至其对应的专用存储器组。第二多个总线中的每一者可将多个处理器子单元中的一者连接至多个处理器子单元中的另一者。在一些状况下,第二多个总线可将多个处理器子单元中的一个或多个连接至多个处理器子单元当中的两个或多于两个其他处理器子单元。处理器子单元中的一个或多个还可包括安置于基板上的至少一个存储器垫。至少一个存储器垫可被配置为充当用于多个处理子单元中的一个或多个的寄存器文件的至少一个寄存器。
1151.在一些状况下,寄存器文件可与一个或多个逻辑组件相关联以使得存储器垫能够充当寄存器文件的一个或多个寄存器。举例而言,这种逻辑组件可包括开关、放大器、反相器、感测放大器以及其他者。在寄存器文件由动态随机存取存储器(dram)垫实施的实例中,
可包括逻辑组件以执行刷新操作从而防止所储存数据丢失。这种逻辑组件可包括行及列多任务器(“mux”)。此外,由dram垫实施的寄存器文件可包括冗余机构以对抗良率下降。
1152.图84说明包括cpu 8402及外部存储器8406的传统计算机架构8400。在操作期间,可将来自存储器8406的值加载至与包括于cpu 8402中的寄存器文件8504相关联的寄存器中。
1153.图85a说明符合所公开实施例的例示性分布式处理器存储器芯片8500a。相比于图84的架构,分布式处理器存储器芯片8500a包括安置于同一基板上的存储器组件及处理器组件。亦即,芯片8500a可包括存储器阵列及处理阵列,该处理阵列包括各与包括于存储器阵列中的一个或多个专用存储器组相关联的多个处理器子单元。在图85的架构中,由处理器子单元使用的寄存器藉由安置于同一基板上的一个或多个存储器垫提供,存储器阵列及处理阵列形成于该基板上。
1154.如图85a中所描绘,分布式处理器存储器芯片8500a可藉由安置于基板8502上的多个处理群组8510a、8510b及8510c形成。更具体而言,分布式处理器存储器芯片8500a可包括安置于基板8502上的存储器阵列8520及处理阵列8530。存储器阵列8520可包括多个存储器组,诸如存储器组8520a、8520b及8520c。处理阵列8530可包括多个处理器子单元,诸如处理器子单元8530a、8530b及8530c。
1155.此外,处理群组8510a、8510b及8510c中的每一者可包括处理器子单元及专用于该处理器子单元的一个或多个对应存储器组。在图85a中所描绘的实施例中,处理器子单元8530a、8530b及8530c中的每一者可与对应的专用存储器组8520a、8520b或8520c相关联。亦即,处理器子单元8530a可与存储器组8520a相关联;处理器子单元8530b可与存储器组8520b相关联;且处理器子单元8530c可与存储器组8520c相关联。
1156.为了允许每一处理器子单元与其对应的专用存储器组通信,分布式处理器存储器芯片8500a可包括将处理器子单元中的一者连接至其对应的专用存储器组的第一多个总线8540a、8540b及8540c。在图85a中所描绘的实施例中,总线8540a可将处理器子单元8530a连接至存储器组8520a;总线8540b可将处理器子单元8530b连接至存储器组8520b;且总线8540c可将处理器子单元8530c连接至存储器组8520c。
1157.此外,为了允许每一处理器子单元与其他处理器子单元通信,分布式处理器存储器芯片8500a可包括将处理器子单元中的一者连接至至少另一处理器子单元的第二多个总线8550a及8550b。在图85中所描绘的实施例中,总线8550a可将处理器子单元8530a连接至处理器子单元8530b,且总线8550b可将处理器子单元8530a连接至处理器子单元8550b,等等。
1158.离散存储器组8520a、8520b及8520c中的每一者可包括多个存储器垫。在图84中所描绘的实施例中,存储器组8520a可包括存储器垫8522a、8524a及8526a;存储器组8520b可包括存储器垫8522b、8524b及8526b;且存储器组8520c可包括存储器垫8522c、8524c及8526c。如先前关于图10所公开,存储器垫可包括多个存储器胞元,且每一胞元可包含电容器、晶体管或储存至少一个数据位的其他电路系统。传统存储器垫可包含例如512个位
×
512个位,但本文中所公开的实施例不限于此。
1159.处理器子单元8530a、8530b及8530c中的至少一者可包括被配置为充当用于对应处理器子单元8530a、8530b及8530c的寄存器文件的至少一个存储器垫,诸如存储器垫
8532a、8532b及8532c。亦即,至少一个存储器垫8532a、8532b及8532c提供由处理器子单元8530a、8530b及8530c中的一个或多个使用的寄存器文件的至少一个寄存器。寄存器文件可包括一个或多个寄存器。在图85a中所描绘的实施例中,处理器子单元8530a中的存储器垫8532a可充当用于处理器子单元8530a(和/或包括于分布式处理器存储器芯片8500a中的任何其他处理器子单元)的寄存器文件(亦被称作“寄存器文件8532a”);处理器子单元8530b中的存储器垫8532b可充当用于处理器子单元8530b的寄存器文件;且处理器子单元8530c中的存储器垫8532c可充当用于处理器子单元8530c的寄存器文件。
1160.处理器子单元8530a、8530b及8530c中的至少一者还可包括至少一个逻辑组件,诸如逻辑组件8534a、8534b及8534c。每一逻辑组件8534a、8534b或8534c可被配置为使得对应存储器垫8532a、8532b或8532c能够充当用于对应处理器子单元8530a、8530b或8530c的寄存器文件。
1161.在一些实施例中,至少一个存储器垫可安置于基板上,且至少一个存储器垫可含有被配置为提供用于多个处理器子单元中的一个或多个的至少一个冗余寄存器的至少一个冗余存储器位。在一些实施例中,处理器子单元中的至少一者可包括用以停止当前任务且在某些时间触发存储器刷新操作以刷新存储器垫的机制。
1162.图85b说明符合所公开实施例的例示性分布式处理器存储器芯片8500b。图85b中所说明的存储器芯片8500b与图85a中所说明的存储器芯片8500大体上相同,除了图85b中的存储器垫8532a、8532b及8532c不包括于对应处理器子单元8530a、8530b及8530c中以外。实情为,图85b中的存储器垫8532a、8532b及8532c安置于对应处理器子单元8530a、8530b及8530c外部但在空间上靠近该些处理器子单元。以此方式,存储器垫8532a、8532b及8532c仍可充当用于对应处理器子单元8530a、8530b及8530c的寄存器文件。
1163.图85c说明符合所公开实施例的装置8500c。装置8500c包括基板8560、第一存储器组8570、第二存储器组8572及处理单元8580。第一存储器组8570、第二存储器组8572及处理单元8580安置于基板8560上。处理单元8580包括处理器8584及由存储器垫实施的寄存器文件8582。在处理单元8580的操作期间,处理器8584可存取寄存器文件8582以读取或写入数据。
1164.分布式处理器存储器芯片8500a、8500b或装置8500c可基于处理器子单元对由存储器垫提供的寄存器的存取而提供多种功能。举例而言,在一些实施例中,分布式处理器存储器芯片8500a或8500b可包括处理器子单元,该处理器子单元充当耦接至存储器的加速器,从而允许其使用更多存储器带宽。在图85a中所描绘的实施例中,处理器子单元8530a可充当加速器(亦被称作“加速器8530a”)。加速器8530a可使用安置于加速器8530a中的存储器垫8532a以提供寄存器文件的一个或多个寄存器。替代地,在图85b中所描绘的实施例中,加速器8530a可使用安置于加速器8530a外部的存储器垫8532a作为寄存器文件。又另外,加速器8530a可使用存储器组8520b中的存储器垫8522b、8524b及8526b中的任一者或存储器组8520c中的存储器垫8522c、8524c及8526c中的任一者,以提供一个或多个寄存器。
1165.所公开实施例可尤其适用于某些类型的图像处理、神经网络、数据库分析、压缩及解压缩以及更多应用。举例而言,在图85a或图85b的实施例中,存储器垫可提供用于与存储器垫包括在同一芯片上的一个或多个处理器子单元的寄存器文件的一个或多个寄存器。一个或多个寄存器可用以储存由处理器子单元频繁存取的数据。举例而言,在卷积图像处理
期间,卷积加速器可在保存于存储器中的整个图像上反复使用相同系数。用于此卷积加速器的所建议实施方案可将所有这些系数保存于在一个或多个寄存器内的“关闭”寄存器文件中,该一个或多个寄存器包括于专用于一个或多个处理器子单元的存储器垫内,该一个或多个处理器子单元与寄存器文件存储器垫位于同一芯片上。此架构可将寄存器(及所储存的系数值)置放成紧密接近对系数值操作的处理器子单元。因为由存储器垫实施的寄存器文件可充当在空间上紧密的高效高速缓存,所以可达成数据传送的显著较低损失及存取的较低潜时。
1166.在另一实例中,所公开实施例可包括可将字输入至由存储器垫提供的寄存器中的加速器。加速器可将寄存器处置为循环缓冲器以在单个循环中将向量相乘。举例而言,在图85c中所说明的装置8500c中,处理单元8580中的处理器8584充当加速器,其使用由存储器垫实施的寄存器文件8582作为循环缓冲器以储存数据a1、a2、a3
……
。第一存储器组8570储存待与数据a1、a2、a3
……
相乘的数据b1、b2、b3
……
。第二存储器组8572储存乘法结果c1、c2、c3
……
。亦即,ci=ai
×
bi。若处理单元8580中不存在寄存器文件,则处理器8584将需要更多存储器带宽及更多循环以从诸如存储器组8570或8572的外部存储器组读取数据a1、a2、a3
……
及数据b1、b2、b3
……
两者,此可产生显著延迟。另一方面,在本实施例中,数据a1、a2、a3
……
储存于形成于处理单元8580内的寄存器文件8582中。因此,处理器8584将仅需要自外部存储器组8570读取数据b1、b2、b3
……
。因此,可显著减少存储器带宽。
1167.在存储器处理程序中,存储器垫通常允许单向存取(亦即,单次存取)。在单向存取中,存在至存储器的一个端口。结果,可在某一时间仅执行对特定地址的一个存取操作,例如读取或写入。然而,若存储器垫本身允许双向存取,则双向存取可为有效选项。在双向存取中,可在某一时间存取两个不同地址。存取存储器垫的方法可基于面积及要求而判定。在一些状况下,若由存储器垫实施的寄存器文件连接至需要读取两个源且具有一个目的地寄存器的处理器,则该些寄存器文件可允许四向存取。在一些状况下,当寄存器文件由dram垫实施以储存配置或高速缓存数据时,寄存器文件可仅允许单向存取。标准cpu可包括多向存取垫,而单向存取垫对于dram应用可为更佳的。
1168.当控制器或加速器以其仅需要单次存取寄存器(在可能的少数情况下)的方式设计时,可使用存储器垫实施的寄存器而非传统的寄存器文件。在单次存取中,一次仅可存取一个字。举例而言,处理单元可在某一时间从两个寄存器文件存取两个字。两个寄存器文件中的每一者可藉由仅允许单次存取的存储器垫(例如,dram垫)实施。
1169.在大多数技术中,存储器垫ip(其为自制造商获得的封闭区块(ip))将附带有处于适当位置以用于行及列存取的布线,诸如字线及行线。但存储器垫ip不包括环绕逻辑组件。因此,由揭示于本发明实施例中的存储器垫实施的寄存器文件可包括逻辑组件。可基于寄存器文件的所需大小选择存储器垫的大小。
1170.当使用存储器垫以提供寄存器文件的寄存器时,可能会出现某些挑战,且这些挑战可取决于用以形成存储器垫的特定存储器技术。举例而言,在存储器生产中,并非所有制造的存储器胞元皆可在生产之后适当地操作。此为已知问题,尤其在芯片上存在高密度的sram或dram的情况下。为了解决存储器技术中的此问题,可使用一个或多个冗余机构以便将良率维持于合理水平。在所公开实施例中,因为用以提供寄存器文件的寄存器的存储器例项(例如,存储器组)的数目可相当小,所以冗余机构可能不如正常存储器应用中那样重
要。另一方面,影响存储器功能性的相同生产问题亦可影响特定存储器垫在提供一个或多个寄存器时是否可适当地起作用。结果,冗余元件可包括于所公开实施例中。举例而言,至少一个冗余存储器垫可安置于分布式处理器存储器芯片的基板上。至少一个冗余存储器垫可被配置为针对多个处理器子单元中的一个或多个提供至少一个冗余寄存器。在另一实例中,垫可大于所需大小(例如,620
×
620而非512
×
512),且冗余机构可建置至512
×
512区或其等效物外部的存储器垫的区中。
1171.另一挑战可与时序相关。加载字及位线的时序通常由存储器的大小判定。由于寄存器文件可由相当小的单个存储器垫(例如,512
×
512个位)实施,因此从存储器垫加载字所需的时间将为少的,相较于逻辑,时序可足以相当快速地运行。
1172.刷新(refresh)—如dram的一些存储器类型需要周期性地刷新。刷新可在暂停处理器或加速器时执行。对于小的存储器垫,刷新时间可为时间的一小部分。因此,即使系统在短时间段内停止,自总效能来看,藉由使用存储器垫作为寄存器所获得的增益亦值得停工时间。在一个实施例中,处理单元可包括从预定义数目向后计数的计数器。当计数器到达“0”时,处理单元可停止由处理器(例如,加速器)执行的当前任务,且触发逐排刷新存储器垫的刷新操作。当刷新操作完成时,处理器可重新继续其任务,且计数器可经重设以从预定义数目向后计数。
1173.图86提供表示符合所公开实施例的用于在分布式处理器存储器芯片中执行至少一个指令的例示性方法的流程图8600。举例而言,在步骤8602处,可从分布式处理器存储器芯片的基板上的存储器阵列撷取至少一个数据值。在步骤8604处,可将所撷取的数据值储存于由分布式处理器存储器芯片的基板上的存储器阵列的存储器垫提供的寄存器中。在步骤8606处,诸如分布式处理器存储器芯片板上的分布式处理器子单元中的一个或多个的处理器元件可对来自存储器垫寄存器的所储存数据值操作。
1174.此处且贯穿全文,应理解,对寄存器文件的所有参考皆应等同地指高速缓存,因为寄存器文件可为最低层级高速缓存。
1175.处理瓶颈
1176.术语“第一”、“第二”、“第三”及其类似者仅用以区分不同术语。这些术语可能不提示组件的次序和/或时序和/或重要性。举例而言,第一处理程序之前可为第二处理程序,及其类似者。
1177.术语“耦接”可意谓直接连接和/或间接连接。
1178.术语“存储器/处理”、“存储器及处理”及“存储器处理”以可互换方式使用。
1179.可提供可为存储器/处理单元的多个方法、计算机可读介质、存储器/处理单元和/或系统。
1180.存储器/处理单元为具有存储器及处理能力的硬件单元。
1181.存储器/处理单元可为存储器处理集成电路,可包括于存储器处理集成电路中或可包括一个或多个存储器处理集成电路。
1182.存储器/处理单元可为如pct专利申请公开案wo2019025892中所说明的分布式处理器。
1183.存储器/处理单元可包括如pct专利申请公开案wo2019025892中所说明的分布式处理器。
1184.存储器/处理单元可属于如pct专利申请公开案wo2019025892中所说明的分布式处理器。
1185.存储器/处理单元可为如pct专利申请公开案wo2019025892中所说明的存储器芯片。
1186.存储器/处理单元可包括如pct专利申请公开案wo2019025892中所说明的存储器芯片。
1187.存储器/处理单元可为如pct专利申请案第pct/ib2019/001005号中所说明的分布式处理器。
1188.存储器/处理单元可属于如pct专利申请案第pct/ib2019/001005号中所说明的分布式处理器。
1189.存储器/处理单元可为如pct专利申请案第pct/ib2019/001005号中所说明的存储器芯片。
1190.存储器/处理单元可包括如pct专利申请案第pct/ib2019/001005号中所说明的存储器芯片。
1191.存储器/处理单元可属于如pct专利申请案第pct/ib2019/001005号中所说明的存储器芯片。
1192.存储器/处理单元可为使用晶圆间接合及多个导体彼此连接的集成电路。
1193.对分布式处理器存储器芯片、分布式存储器处理集成电路、存储器芯片、分布式处理器的任何参考可实施为藉由晶圆间接合及多个导体彼此连接的一对集成电路。
1194.存储器/处理单元可藉由相比逻辑胞元更佳地适合存储器胞元的第一制造制程来制造。因此,第一制造制程可被视为存储器类别的制造制程。存储器胞元可包括多个晶体管中的一者。逻辑胞元可包括一个或多个晶体管。可应用第一制造制程以制造存储器组。逻辑胞元可包括一起实施逻辑功能的一个或多个晶体管,且可用作较大逻辑电路的基本建置区块。存储器胞元可包括一起实施存储器功能的一个或多个晶体管,且可用作较大逻辑电路的基本建置区块。对应逻辑胞元可实施相同逻辑功能。
1195.存储器/处理单元可不同于处理器、处理集成电路和/或处理单元中的任一者,该处理器、处理集成电路和/或处理单元藉由相比存储器胞元更佳地适合于逻辑胞元的第二制造制程来制造。因此,第一制造制程可被视为逻辑类别的制造制程。第二制造制程可用以制造中央处理单元、图形处理单元及其类似者。
1196.相比处理器、处理集成电路和/或处理单元,存储器/处理单元可更适合于执行较少算术密集型运算。
1197.举例而言,由第一制造制程制造的存储器胞元可展现超过且甚至大大超过(例如,超过2倍、3倍、4倍、5倍、9倍、7倍、8倍、9倍、10倍及其类似者)由第一制造制程制造的逻辑电路的临界尺寸的临界尺寸。
1198.第一制造制程可为模拟制造制程,第一制造制程可为dram制造制程,及其类似者。
1199.由第一制造制程制造的逻辑胞元的大小可超过由第二制造制程制造的对应逻辑胞元的大小至少两倍。对应逻辑呼叫可具有与由第一制造制程制造的逻辑胞元相同的功能性。
1200.第二制造制程可为数字制造制程。
1201.第二制造制程可为互补金属氧化物半导体(cmos)、双极、双极cmos(bicoms)、双扩散金属氧化物半导体(dmos)、氧化物上硅制造制程及其类似者中的任一者。
1202.存储器/处理单元可包括多个处理器子单元。
1203.一个或多个存储器/处理单元的处理器子单元可彼此独立地操作和/或可彼此相配合和/或执行分布式处理。可以各种方式,例如以平面方式或以阶层式方式执行分布式处理。
1204.平面方式可涉及使处理器子单元执行相同操作(且可能在或可能不在处理器子单元之间输出处理结果)。
1205.阶层式方式可涉及执行不同层级的处理操作序列,而某一层的处理操作在又一层级的处理操作之后进行。处理器子单元可经分配(动态地或静态地)给不同层且参与阶层式处理。
1206.分布式处理亦可涉及其他单元,例如存储器/处理单元的控制器和/或不属于存储器/处理单元的单元。
1207.以可互换方式使用术语逻辑及处理器子单元。
1208.可以任何方式(分布式和/或非分布式及其类似者)执行本技术案中所提及的任何处理。
1209.在以下申请案中,对pct专利申请公开案wo2019025892及pct专利申请案第pct/ib2019/001005号(2019年9月9日)进行各种参考和/或以参考方式并入。pct专利申请公开案wo2019025892和/或pct专利申请案第pct/ib2019/001005号提供各种方法、系统、处理器、存储器芯片及其类似者的非限制性实例。可提供其他方法、系统、处理器。
1210.可提供处理系统(系统),其中处理器之前为一个或多个存储器/处理单元,每一存储器及处理单元(存储器/处理单元)具有处理资源及储存资源。
1211.处理器可请求或发指令给一个或多个存储器/处理单元以执行各种处理任务。各种处理任务的执行可减轻处理器的负担,减少潜时,且在一些状况下减少一个或多个存储器/处理单元与处理器之间的总信息带宽,及其类似者。
1212.处理器可用不同粒度提供指令和/或请求,例如处理器可发送针对某些处理资源的指令或可发送针对存储器/处理单元的较高阶指令,而不指定任何处理资源。
1213.存储器/处理单元可用任何方式(动态、静态、分布式、集中式、脱机、在线及其类似者)管理其处理和/或存储器资源。资源的管理可在以下情况下执行:自主地、在处理器的控制下、在处理器进行配置之后,及其类似者。
1214.举例而言,可将任务分割成可能需要一个或多个存储器/处理单元的一个或多个处理资源和/或存储器资源执行或一个或多个指令的子任务。每一处理资源可被配置为执行(例如,独立地或非独立地)至少一个指令。参见例如藉由诸如pct专利申请公开案wo2019025892的处理器子单元的处理资源对指令子系列的执行。
1215.亦可至少将存储器资源的分配提供至除一个或多个存储器/处理单元以外的实体,例如可耦接至一个或多个存储器/处理单元的直接存取存储器(dma)单元。
1216.编译程序可针对由存储器/处理单元执行的任务的每个类型准备配置文件。配置文件包括与任务类型相关联的存储器分配及处理资源分配。配置文件可包括可由不同处理资源执行和/或可定义存储器分配的指令。
1217.举例而言,与矩阵乘法(将矩阵a乘以矩阵b,a*b=c)的任务相关的配置文件可提示在何处储存矩阵a的元素,在何处储存矩阵b的元素,在何处储存矩阵c的元素,在何处储存在矩阵乘法期间产生的中间结果,且可包括针对用于执行与矩阵乘法相关的任何数学运算的处理资源的指令。配置文件为数据结构的实例,可提供其他数据结构。
1218.可藉由一个或多个存储器/处理单元以任何方式执行矩阵乘法。
1219.一个或多个存储器/处理单元可将矩阵a乘以向量v。此可用任何方式进行。举例而言,此可涉及每处理资源维护矩阵的一行或列(每不同处理资源维护行的不同行),及循环(在不同处理资源之间)矩阵的行或列与向量的乘法的最终结果(在第一迭代期间),及循环先前乘法的最终结果(在第二至最后迭代期间)。
1220.假定矩阵a为4
×
4矩阵,向量v为1
×
4向量,且存在四个处理资源。在此假设下,矩阵a的第一行储存于第一处理器子单元处,矩阵a的第二行储存于第二处理器子单元处,矩阵a的第三行储存于第三处理资源处,且矩阵a在第四行储存于第四处理器子单元处。藉由以下操作开始乘法:将向量v的第一至第四元素发送至第一至第四处理资源;及将向量v的第一至第四元素乘以a的不同向量以提供第一中间结果。藉由以下操作循环第一中间结果来继续乘法:藉由每一处理资源将由第一处理资源计算的第一中间结果发送至其相邻处理资源。每一处理资源将第一乘法结果乘以向量以提供第二乘法结果。此过程重复多次,直至矩阵a与向量v的乘法结束。
1221.图90a为包括一个或多个存储器/处理单元(共同地表示为10910)及处理器10920的系统10900的实例。处理器10920可将请求或指令发送(经由链路10931)至一个或多个存储器/处理单元10920,该一个或多个存储器/处理单元又完成(或选择性地完成)请求和/或指令且将结果发送(经由链路10932)至处理器10920,如上文所说明。处理器10920可进一步处理结果以提供(经由链路10933)一个或多个输出。
1222.一个或多个存储器/处理单元可包括j(j为正整数)个存储器资源10912(1,1)至10912(1,j)及k(k为正整数)个处理资源10911(1,1)至10911(1,k)。
1223.j可等于k或可不同于k。
1224.处理资源10911(1,1)至10911(1,k)可为例如处理群组或处理器子单元,如pct专利申请公开案wo2019025892中所说明。
1225.存储器资源10912(1,1)至10912(1,j)可为存储器例项、存储器垫、存储器组,如pct专利申请公开案wo2019025892中所说明。
1226.一个或多个存储器/处理单元的资源(存储器或处理)中的任一者之间可存在任何连接性和/或任何功能关系。
1227.图90b为存储器/处理单元10910(1)的实例。
1228.在图90b中,k(k为正整数)个处理资源10911(1,1)至10911(1,k)形成回路,因为该些处理资源彼此串联连接(参见链路10915)。每一处理资源亦耦接至其自身的一对专用存储器资源(例如,处理资源10911(1)耦接至存储器资源10912(1)及10912(2),且处理资源10911(k)耦接至存储器资源10912(j-1)及10912(j))。处理资源可用任何其他方式彼此连接。每一处理资源所分配的存储器资源的数目可不同于两个。不同资源之间的连接性的实例说明于pct专利申请公开案wo2019025892中。
1229.图90c为n(n为正整数)个存储器/处理单元10910(1)至10910(n)及处理器10920的
系统10901的实例。处理器10920可将请求或指令发送(经由链路10931(1)至10931(n))至存储器/处理单元10920(1)至10910(n),该些存储器/处理单元又完成请求和/或指令且将结果发送(经由链路10932(1)至3232(n))至处理器10920,如上文所说明。处理器10920可进一步处理结果以提供(经由链路10933)一个或多个输出。
1230.图90d为包括n(n为正整数)个存储器/处理单元10910(1)至10910(n)及处理器10920的系统10902的实例。图90d说明在存储器/处理单元10910(1)至10910(n)之前的预处理器10909。预处理器可执行各种预处理操作,诸如帧提取、标头侦测及其类似者。
1231.图90e为包括一个或多个存储器/处理单元10910及处理器10920的系统10903的实例。图90e说明在一个或多个存储器/处理单元10910及dma控制器10908之前的预处理器10909。
1232.图90f说明用于至少一个信息串流的分布式处理的方法10800。
1233.方法10800可开始于藉由一个或多个存储器处理集成电路经由第一通信通道接收至少一个信息串流的步骤10810;其中每一存储器处理集成单元包含控制器、多个处理器子单元及多个存储器单元。
1234.步骤10810之后可接着步骤10820及10830。
1235.步骤10820可包括藉由一个或多个存储器处理集成电路缓冲信息串流。
1236.步骤10830可包括藉由一个或多个存储器处理集成电路对至少一个信息串流执行第一处理操作以提供第一处理结果。
1237.步骤10830可涉及压缩或解压缩。
1238.因此,信息串流的总大小可超过第一处理结果的总大小。信息串流的总大小可反映在给定持续时间的时段期间接收的信息量。第一处理结果的总大小可反映在同一给定持续时间的任何时段期间输出的第一处理结果的量。
1239.替代地,信息串流(在本说明书中所提及的任何其他信息实体)的总大小小于第一处理结果的总大小。在此状况下,获得压缩。
1240.步骤10830之后可接着为将第一处理结果发送至一个或多个处理集成电路的步骤10840。
1241.一个或多个存储器处理集成电路可由存储器类别的制造制程制造。
1242.一个或多个存储器处理集成电路可由逻辑类别的制造制程制造。
1243.在存储器处理集成单元中,存储器单元中的每一者可耦接至处理器子单元。
1244.步骤10840之后可接着为藉由一个或多个处理集成电路对第一处理结果执行第二处理操作以提供第二处理结果的步骤10850。
1245.步骤10820和/或步骤10830可藉由一个或多个处理集成电路发指令,可藉由一个或多个处理集成电路请求,可藉由一个或多个处理集成电路在一个或多个存储器处理集成电路进行配置之后执行,或可独立地执行而无需一个或多个处理集成电路的介入。
1246.第一处理操作可具有比第二处理操作低的算术强度。
1247.步骤10830和/或步骤10850可为以下各者中的至少一者:(a)蜂窝网络处理操作;(b)其他网络相关处理操作(不同于蜂窝网络的网络的处理);(c)数据库处理操作;(d)数据库分析处理操作;(e)人工智能处理操作;或任何其他处理操作。
1248.分解式系统存储器/处理单元及用于分布式处理的方法
1249.可提供分解式系统、用于分布式处理的方法、处理/存储器单元、用于操作分解式系统的方法、用于操作处理/存储器单元的方法及计算机可读介质,该计算机可读介质为非暂时性的且储存用于执行该些方法中的任一者的指令。分解式系统分配不同子系统以执行不同功能。举例而言,储存器可主要实施于一个或多个储存子系统中,而运算可主要在一个或多个储存子系统中进行。
1250.分解式系统可为一分解式服务器、一个或多个分解式服务器和/或可不同于一个或多个服务器。
1251.分解式系统可包括一个或多个交换子系统、一个或多个运算子系统、一个或多个储存子系统及一个或多个处理/存储器子系统。
1252.一个或多个处理/存储器子系统、一个或多个运算子系统及一个或多个储存子系统经由一个或多个交换子系统彼此耦接。
1253.一个或多个处理/存储器子系统可包括于分解式系统的一个或多个子系统中。
1254.图87a说明分解式系统的各种实例。
1255.可提供任何数目个任何类型的子系统。分解式系统可包括图87a中不包括的类型的一个或多个额外子系统,可包括较少类型的子系统,及其类似者。
1256.分解式系统7101包括两个储存子系统7130、运算子系统7120、交换子系统7140及处理/存储器子系统7110。
1257.分解式系统7102包括两个储存子系统7130、运算子系统7120、交换子系统7140、处理/存储器子系统7110及加速器子系统7150。
1258.分解式系统7103包括两个储存子系统7130、运算子系统7120及包括处理/存储器子系统7110的交换子系统7140。
1259.分解式系统7104包括两个储存子系统7130、运算子系统7120、包括处理/存储器子系统7110的交换子系统7140,及加速器子系统7150。
1260.将处理/存储器子系统7110包括于交换子系统7140中可减少分解式系统7101及7102内的业务,可减少切换的潜时,及其类似者。
1261.分解式系统的不同子系统可使用各种通信协议彼此通信。已发现,使用以太网络及甚至以太网络rdma通信协议可增加吞吐量,且可能甚至降低与分解式系统的组件之间的信息单元的交换相关的各种控制及/储存操作的复杂度。
1262.分解式系统可藉由允许处理/存储器子系统参与计算(尤其藉由执行存储器密集型计算)来执行分布式处理。
1263.举例而言,假定n个运算单元应在其间共享信息单元(全部共享),则(a)可将n个信息单元发送至一个或多个处理/存储器子系统的一个或多个处理/存储器单元,(b)一个或多个处理/存储器单元可执行需要全部共享的计算,且(c)将n个经更新信息单元发送至n个运算单元。此将需要大约n个传送操作。
1264.举例而言,图87b说明更新神经网络的模型(该模型包括指派给神经网络的节点的权重)的分布式处理。
1265.n个运算单元pu(1)7120(1)至pu(n)7120(n)中的每一者可属于分解式系统7101、7102、7103及7104中的任一者的运算子系统7120。
1266.n个运算单元计算n个部分模型更新(经更新的n个不同部分)7121(1)至7121(n),
且将其发送(经由交换子系统7140)至处理/存储器子系统7110。
1267.处理/存储器子系统7110计算经更新模型7122且将经更新模型发送(经由交换子系统7140)至n个运算单元pu(1)7120(1)至pu(n)7120(n)。
1268.图87c、图87d及图87e分别说明存储器/处理单元7011、7012及7013的实例,且图87f及图87g说明集成电路7014及7015,集成电路包括存储器/处理单元9010诸如以太网络模块及以太网络rdma模块22的一个或多个通信模块。
1269.存储器/处理单元包括控制器9020、内部总线9021以及多对逻辑9030及存储器组9040。控制器被配置为作为通信模块操作或可耦接至通信模块。
1270.可用其他方式实施控制器9020与多对逻辑9030及存储器组9040之间的连接性。可用其他方式(不成对)配置存储器组及逻辑。
1271.处理/存储器子系统7110的一个或多个存储器/处理单元9010可并行地处理(使用不同逻辑且从不同存储器组并行地撷取模型的不同部分)模型更新,且受益于海量存储器资源、存储器组与逻辑之间的连接的极高带宽,可用高效方式执行这些计算。
1272.图87c至图87e的存储器/处理单元7011、7012及7013以及图87c至图87e的集成电路7014及7015包括一个或多个通信模块,诸如以太网络模块7023(在图87c至图87g中)及以太网络rdma模块7022(在图87e及图87g中)。
1273.具有这种rdma和/或以太网络模块(在存储器/处理单元内或在与存储器/处理单元相同的集成电路内)大大加速分解式系统的不同元件之间的通信,且在rdma的状况下,大大简化分解式系统的不同元件之间的通信。
1274.应注意,包括rdma和/或以太网络模块的存储器/处理单元在其他环境中可为有益的,即使当存储器/处理单元不包括于分解式系统中时亦如此。
1275.亦应注意,例如出于减少成本原因,可针对存储器/处理单元的每个群组分配rdma和/或以太网络模块。
1276.应注意,存储器/处理单元、存储器/处理单元的群组及甚至处理/存储器子系统可包括其他通信端口,例如pcie通信端口。
1277.使用rdma和/或以太网络模块可具有成本效益,因为可消除将存储器/处理单元连接至网桥的需要,该网桥连接至可具有以太网络端口的网络集成电路(nic)。
1278.使用rdma和/或以太网络模块可使以太网络(或以太网络rdma)为存储器/处理单元中原生的。
1279.应注意,以太网络仅为局域网络(lan)协议的实例。pcie仅为可在比以太网络更长的距离上使用的另一通信协议的实例。
1280.图87h说明用于分布式处理的方法7000。
1281.方法7000可包括一个或多个处理迭代。
1282.处理迭代可由分解式系统的一个或多个存储器处理集成电路执行。
1283.处理迭代可由分解式系统的一个或多个处理集成电路执行。
1284.由更多存储器处理集成电路执行的处理迭代之后可接着为由一个或多个处理集成电路执行的处理迭代。
1285.由更多存储器处理集成电路执行的处理迭代可在由一个或多个处理集成电路执行的处理迭代之前。
1286.又一处理迭代可由分解式系统的其他电路执行。举例而言,一个或多个预处理电路可执行任何类型的预处理,包括准备用于一个或多个存储器处理集成电路执行的处理迭代的信息单元。
1287.方法7000可包括藉由分解式系统的一个或多个存储器处理集成电路接收信息单元的步骤7020。
1288.每一存储器处理集成单元可包括控制器、多个处理器子单元及多个存储器单元。
1289.一个或多个存储器处理集成电路可由存储器类别的制造制程制造。
1290.信息单元可输送神经网络的模型的部分。
1291.信息单元可输送至少一个数据库查询的部分结果。
1292.信息单元可输送至少一个聚集数据库查询的部分结果。
1293.步骤7020可包括从分解式系统的一个或多个储存子系统接收信息单元。
1294.步骤7020可包括从分解式系统的一个或多个运算子系统接收信息单元,一个或多个运算子系统可包括由逻辑类别的制造制程制造的多个处理集成电路。
1295.步骤7020之后可接着为藉由一个或多个存储器处理集成电路对信息单元执行处理操作以提供处理结果的步骤7030。
1296.信息单元的总大小可超过,可等于或可小于处理结果的总大小。
1297.步骤7030之后可接着为藉由一个或多个存储器处理集成电路输出处理结果的步骤7040。
1298.步骤7040可包括将处理结果输出至分解式系统的一个或多个运算子系统,一个或多个运算子系统可包括由逻辑类别的制造制程制造的多个处理集成电路。
1299.步骤7040可包括将处理结果输出至分解式系统的一个或多个储存子系统。
1300.信息单元可从多个处理集成电路的处理单元的不同群组发送,且可为藉由多个处理集成电路以分布式方式执行的处理程序的中间结果的不同部分。处理单元的群组可包括至少一个处理集成电路。
1301.步骤7030可包括处理信息单元以提供整个处理程序的结果。
1302.步骤7040可包括将整个处理程序的结果发送至多个处理集成电路中的每一者。
1303.中间结果的不同部分可为经更新神经网络模型的不同部分,且其中整个处理程序的结果为经更新神经网络模型。
1304.步骤7040可包括将经更新神经网络模型发送至多个处理集成电路中的每一者。
1305.步骤7040之后可接着为藉由多个处理集成电路至少部分地基于至多个处理集成电路的处理结果来执行另一处理的步骤7050。
1306.步骤7040可包括使用分解式系统的交换子单元输出处理结果。
1307.步骤7020可包括接收信息单元,该些信息单元为经预处理的信息单元。
1308.图87i说明用于分布式处理的方法7001。
1309.方法7001与方法7000的不同之处在于包括藉由多个处理集成电路预处理信息以提供经预处理的信息单元的步骤7010。
1310.步骤7010之后可接着为步骤7010、7020、7030及7040。
1311.数据库分析加速
1312.提供一种装置、方法及计算机可读介质,该装置、该方法及该计算机可读介质储存
用于藉由属于与存储器单元相同的集成电路的筛选单元至少执行筛选的指令,而筛选器可提示哪些条目与某一数据库查询相关。仲裁器或任何其他流程控制管理器可将相关条目发送至处理器且不将不相关条目发送至处理器,因此节省了去往处理器及来自处理器的几乎大部分业务。
1313.参见例如图91a,其展示处理器(cpu 9240)、包括存储器及筛选系统9220的集成电路。存储器及筛选系统9220可包括耦接至存储器单元条目9222及一个或多个仲裁器(诸如,用于将相关条目发送至处理器的仲裁器9229)的筛选单元9224。可应用任何仲裁处理程序。条目的数目、筛选单元的数目及仲裁器的数目之间可存在任何关系。
1314.仲裁器可由能够控制信息流的任何单元替换,例如通信接口、流控制器及其类似者。
1315.参考筛选,其基于一个或多个相关性/筛选准则。
1316.可针对每个数据库查询设定相关性,且可用任何方式提示相关性,例如存储器单元可储存提示哪一条目相关的相关性旗标9224'。亦存在储存k个数据库区段9220(k)的储存装置9210,而k的范围为1与k之间。应注意,整个数据库可储存于存储器单元中而不储存于储存装置中(该解决方案亦被称作易失性存储器储存的数据库)。
1317.存储器单元条目可能太小而无法储存整个数据库,且因此一次可接收一个区段。
1318.筛选单元可执行筛选操作,诸如比较字段的值与阈值,比较字段的值与预定义值,判定字段的值是否在预定义范围内,及其类似者。
1319.因此,筛选单元可执行已知数据库筛选操作,且可为紧密且廉价的电路。
1320.将筛选操作的最终结果(例如,相关数据库条目之内容)9101发送至cpu9420以供处理。
1321.存储器及筛选系统9220可由如图91b中所说明的存储器及处理系统替换。
1322.存储器及处理系统9229包括耦接至存储器单元条目9222的处理单元9225。处理单元9225可执行筛选操作,且可至少部分地参与对相关记录执行一个或多个额外操作。
1323.处理单元可经定制以执行特定操作和/或可为被配置为执行多个操作的可编程单元。举例而言,处理单元可为管线化处理单元,可包括alu,可包括多个alu,及其类似者。
1324.处理单元9225可执行全部的一个或多个额外操作。
1325.替代地,一个或多个额外操作的一部分由处理单元执行,且处理器(cpu9240)可执行一个或多个额外操作的另一部分。
1326.将处理操作的最终结果(例如,对数据库查询的部分响应9102,或完整响应9103)发送至cpu 9420。
1327.部分响应需要进一步处理。
1328.图92a说明包括被配置为执行筛选及额外处理的存储器/处理单元9227的存储器/处理系统9228。
1329.存储器/处理系统9228藉由存储器/处理单元9227实施图91的处理单元及存储器单元。
1330.处理器的作用可包括控制处理单元、执行一个或多个额外操作的至少一部分,及其类似者。
1331.存储器条目与处理单元的组合可至少部分地由一个或多个存储器/处理单元实
施。
1332.图92b说明实例存储器/处理单元9010。
1333.存储器/处理单元9010包括控制器9020、内部总线9021以及多对逻辑9030及存储器组9040。控制器被配置为作为通信模块操作或可耦接至通信模块。
1334.可用其他方式实施控制器9020与多对逻辑9030及存储器组9040之间的连接性。可用其他方式(不成对)配置存储器组及逻辑。多个存储器组可耦接至单个逻辑和/或由单个逻辑管理。
1335.存储器/处理系统经由接口9211接收数据库查询9100。接口9211可为总线、端口、输入/输出接口及其类似者。
1336.应注意,对数据库查询的响应可由以下各者中的至少一者(或以下各者中的一个或多个的组合)产生:一个或多个存储器/处理系统、一个或多个存储器及处理系统、一个或多个存储器及筛选系统、位于这些系统外部的一个或多个处理器,及其类似者。
1337.应注意,对数据库查询的响应可由以下各者中的至少一者(或以下各者中的一个或多个的组合)产生:一个或多个筛选单元、一个或多个存储器/处理单元、一个或多个处理单元、一个或多个其他处理器(诸如,一个或多个其他cpu),及其类似者。
1338.任何处理程序可包括寻找相关数据库条目,及其处理相关数据库条目。处理可由一个或多个处理实体执行。
1339.处理实体可为以下各者中的至少一者:存储器及处理系统的处理单元(例如,存储器及处理系统9229的处理单元9225)、存储器/处理单元的处理器子单元(或逻辑)、另一处理器(例如,图91a、图91b及图74的cpu 9240),及其类似者。
1340.在产生对数据库查询的响应中所涉及的处理可由以下各者中的任一者或以下各者的组合产生:
1341.a.存储器及处理系统9229的处理单元9225。
1342.b.不同存储器及处理系统9229的处理单元9225。
1343.c.存储器/处理系统9228的一个或多个存储器/处理单元9227的处理器子单元(或逻辑9030)。
1344.d.不同存储器/处理系统9228的存储器/处理单元9227的处理器子单元(或逻辑9030)。
1345.e.存储器/处理系统9228的一个或多个存储器/处理单元9227的控制器。
1346.f.不同存储器/处理系统9228的一个或多个存储器/处理单元9227的控制器。
1347.因此,在对数据库查询的响应中所涉及的处理可由以下各者的组合或子组合产生:(a)一个或多个存储器/处理单元的一个或多个控制器、(b)存储器处理系统的一个或多个处理单元、(c)一个或多个存储器/处理单元的一个或多个处理器子单元,及(d)一个或多个其他处理器,及其类似者。
1348.由多于一个处理实体执行的处理可被称作分布式处理。
1349.应注意,筛选可由一个或多个筛选单元和/或一个或多个处理单元和/或一个或多个处理器子单元中的筛选实体执行。在此意义上,执行筛选操作的处理单元和/或处理器子单元可被称作筛选单元。
1350.处理实体可为筛选实体或可不同于筛选实体。
1351.处理实体可执行由另一筛选实体视为相关的数据库条目的处理操作。
1352.处理实体亦可执行筛选操作。
1353.对数据库查询的响应可利用一个或多个筛选实体及一个或多个处理实体。
1354.一个或多个筛选实体及一个或多个处理实体可属于同一系统(例如,存储器/处理系统9228、存储器及处理系统9229、存储器及筛选系统9220)或属于不同系统。
1355.存储器/处理单元可包括多个处理器子单元。处理器子单元可彼此独立地操作,可彼此部分地合作,可参与分布式处理,及其类似者。
1356.图92c说明多个存储器及筛选系统9220、多个其他处理器(诸如,cpu9240)及储存装置9210。
1357.多个存储器及筛选系统9220可基于多个数据库查询中的一者内的一个或多个筛选准则来参与(同时或不同时)一个或多个数据库条目的筛选。
1358.图92d说明多个存储器及处理系统9229、多个其他处理器(诸如,cpu9240)及储存装置9210。
1359.多个存储器及处理系统9229可参与(同时或不同时)在对多个数据库查询中的一者作出响应中所涉及的筛选及至少部分处理。
1360.图92f说明多个存储器/处理系统9228、多个其他处理器(诸如,cpu9240)及储存装置9210。
1361.多个存储器/处理系统9228可参与(同时或不同时)在对多个数据库查询中的一者作出响应中所涉及的筛选及至少部分处理。
1362.图92g说明用于数据库分析加速的方法9300方法。
1363.方法9300可开始于藉由存储器处理集成电路接收数据库查询的步骤9310,该数据库查询包含提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则。
1364.数据库中与数据库查询相关的数据库条目可能并非数据库的数据库条目,可为数据库的数据库条目中的一者、一些或全部。
1365.存储器处理集成电路可包括控制器、多个处理器子单元及多个存储器单元。
1366.步骤9310之后可接着为藉由存储器处理集成电路且基于至少一个相关性准则而判定储存于存储器处理集成电路中的相关数据库条目的群组的步骤9320。
1367.步骤9320之后可接着为将相关数据库条目的群组发送至一个或多个处理实体以供进一步处理而实质上不将储存于存储器处理集成电路中的不相关数据条目发送至该一个或多个处理实体的步骤9330。
1368.词组“而实质上不发送”意谓根本不发送(在对数据库查询作出响应期间)或发送数目不多的不相关条目。不多可意谓至多1、2、3、4、5、9、7、8、9、10个百分比,或发送对带宽无显著影响的任何量。
1369.步骤9330之后可接着为处理相关数据库条目的群组以提供对数据库查询的响应的步骤9340。
1370.图92h说明用于数据库分析加速的方法9301。
1371.假定对数据库查询作出响应所需的筛选及整个处理由存储器处理集成电路执行。
1372.方法9301可开始于藉由存储器处理集成电路接收数据库查询的步骤9310,该数据库查询包含提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则。
1373.步骤9310之后可接着为藉由存储器处理集成电路且基于至少一个相关性准则而判定储存于存储器处理集成电路中的相关数据库条目的群组的步骤9320。
1374.步骤9320之后可接着为将相关数据库条目的群组发送至存储器处理集成电路的一个或多个处理实体以供完全处理而实质上不将储存于存储器处理集成电路中的不相关数据条目发送至该一个或多个处理实体的步骤9331。
1375.步骤9331之后可接着为完全处理相关数据库条目的群组以提供对数据库查询的响应的步骤9341。
1376.步骤9341之后可接着为从存储器处理集成电路输出对数据库查询的响应的步骤9351。
1377.图92i说明用于数据库分析加速的方法9302。
1378.假定对数据库查询作出响应所需的筛选以及处理的仅一部分由存储器处理集成电路执行。存储器处理集成电路将输出部分结果,该些部分结果将由位于存储器处理集成电路外部的一个或多个其他处理实体处理。
1379.方法9301可开始于藉由存储器处理集成电路接收数据库查询的步骤9310,该数据库查询包含提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则。
1380.步骤9310之后可接着为藉由存储器处理集成电路且基于至少一个相关性准则而判定储存于存储器处理集成电路中的相关数据库条目的群组的步骤9320。
1381.步骤9320之后可接着为将相关数据库条目的群组发送至存储器处理集成电路的一个或多个处理实体以供部分处理而实质上不将储存于存储器处理集成电路中的不相关数据条目发送至该一个或多个处理实体的步骤9332。
1382.步骤9332之后可接着为部分地处理相关数据库条目的群组以提供对数据库查询的中间响应的步骤9342。
1383.步骤9342之后可接着为从存储器处理集成电路输出对数据库查询的中间响应的步骤9352。
1384.步骤9352之后可接着为进一步处理中间响应以提供对数据库的响应的步骤9390。
1385.图92j说明用于数据库分析加速的方法9303。
1386.假定存储器处理集成电路执行相关数据库条目的筛选,但不执行相关数据库条目的处理。存储器处理集成电路将输出将由位于存储器处理集成电路外部的一个或多个其他处理实体完全处理的相关数据库条目的群组。
1387.方法9301可开始于藉由存储器处理集成电路接收数据库查询的步骤9310,该数据库查询包含提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则。
1388.步骤9310之后可接着为藉由存储器处理集成电路且基于至少一个相关性准则而判定储存于存储器处理集成电路中的相关数据库条目的群组的步骤9320。
1389.步骤9320之后可接着为将相关数据库条目的群组发送至位于存储器处理集成电路外部的一个或多个处理实体而实质上不将储存于存储器处理集成电路中的不相关数据条目发送至该一个或多个处理实体的步骤9333。
1390.步骤9333之后可接着为完全处理中间响应以提供对数据库的响应的步骤9391。
1391.图92k说明数据库分析加速的方法9304。
1392.方法9303可开始于藉由集成电路接收数据库查询的步骤9315,该数据库查询包含
提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则;其中该集成电路包含控制器、筛选单元及多个存储器单元。
1393.步骤9315之后可接着为藉由筛选单元且基于至少一个相关性准则来判定储存于集成电路中的相关数据库条目的群组的步骤9325。
1394.步骤9325之后可接着为将相关数据库条目的群组发送至位于集成电路外部的一个或多个处理实体以供进一步处理而实质上不将储存于集成电路中的不相关数据条目发送至一个或多个处理实体的步骤9335。
1395.步骤9335之后可接着为步骤9391。
1396.图92l说明数据库分析加速的方法9305。
1397.方法9305可开始于藉由集成电路接收数据库查询的步骤9314,该数据库查询包含提示数据库中与数据库查询相关的数据库条目的至少一个相关性准则;其中集成电路包含控制器、筛选单元及多个存储器单元。
1398.步骤9314之后可接着为藉由处理单元且基于至少一个相关性准则来判定储存于集成电路中的相关数据库条目的群组的步骤9324。
1399.步骤9324之后可接着为藉由处理单元处理相关数据库条目的群组而不藉由处理单元处理储存于集成电路中的不相关数据条目以提供处理结果的步骤9334。
1400.步骤9334之后可接着为从集成电路输出处理结果的步骤9344。
1401.在方法9300、9301、9302、9304及9305中的任一者中,存储器处理集成电路输出一输出。该输出可为相关数据库条目、一个或多个中间结果或一个或多个(完整)结果的群组。
1402.该输出之前可为从存储器处理集成电路的筛选实体和/或处理实体撷取一个或多个相关数据库条目和/或一个或多个结果(完整或中间)。
1403.该撷取可用一或多种方式控制且可由存储器处理集成电路的仲裁器和/或一个或多个控制器控制。
1404.输出和/或撷取可包括控制撷取和/或输出的一个或多个参数。该些参数可包括撷取时序、撷取速率、撷取源、带宽、次序或撷取、输出时序、输出速率、输出源、带宽、次序或输出、撷取方法的类型、仲裁方法的类型及其类似者。
1405.输出和/或撷取可执行流控制处理程序。
1406.输出和/或撷取(例如,应用流控制处理程序)可对从一个或多个处理实体输出的关于群组的数据库条目的处理的完成的指示符作出响应。指示符可提示中间结果是否已准备好被自处理实体撷取。
1407.输出可包括尝试将在输出期间使用的带宽匹配到链路上的最大可允许带宽,该链路将存储器处理集成电路耦接至请求者单元。该链路可为至存储器处理集成电路的输出的接收者的链路。最大可允许带宽可藉由链路的容量和/或可用性、所输出内容的接收者的容量和/或可用性及其类似者规定。
1408.输出可包括尝试以最佳或次最佳方式输出所输出内容。
1409.所输出内容的输出可包括尝试维持输出业务速率的波动低于阈值。
1410.方法9300、9301、9302及9305的任何方法可包括藉由一个或多个处理实体产生处理状态指示符,处理状态指示符可提示相关数据库条目的群组的进一步处理的进展。
1411.当包括于上文所提及的方法中的任一者中的处理由多于单个处理实体执行时,则
处理可被视为分布式处理,因为处理以分布式方式执行。
1412.如上文所提示,可以阶层式方式或以平面方式执行处理。
1413.方法9300至9305中的任一者可由可同时或依序地对一个或多个数据库查询作出响应的多个系统执行。
1414.字嵌入
1415.如上文所提及,字嵌入(word embedding)为自然语言处理(nlp)中的语言模型化及特征学习技术的集合的总称,其中来自词汇表的字或词组映射至元素的向量。概念上,字嵌入涉及自每个字具有许多维度的空间至具有低得多的维度的连续向量空间的数学嵌入。
1416.可对该些向量进行数学处理。举例而言,可对属于矩阵的向量进行加总以提供加总向量。
1417.又对于另一实例,可计算(语句的)矩阵的协方差。此可包括将矩阵乘以其转置矩阵。
1418.存储器/处理单元可储存词汇表。特定而言,词汇表的部分可储存于存储器/处理单元的多个存储器组中。
1419.因此,可使用将表示语句的词组的字的集合的存取信息(诸如,撷取密钥)来存取存储器/处理单元,使得将从存储器/处理单元的存储器组中的至少一些撷取表示语句的词组的字的向量。
1420.存储器/处理单元的不同存储器组可储存词汇表的不同部分,且可被并行地存取(取决于语句的索引的分布)。即使在需要依序存取存储器组的多于单排时,预测亦可减少惩罚。
1421.可优化在存储器/处理单元的不同存储器组之间分配词汇表的字,或该分配在可增加每语句对存储器/处理单元的不同存储器组的并行存取的机会的意义上为高度有益的。该分配可按每个使用者学习,可按每个一般群体学习或可按每个人群来学习。
1422.此外,存储器/处理单元亦可用以执行处理操作中的至少一些(藉由其逻辑),且藉此可减少从存储器/处理单元外部的总线所需的带宽,可用高效方式(甚至并行)计算多个运算(并行地使用存储器/处理单元的多个处理器)。
1423.存储器组可与逻辑相关联。
1424.处理操作的至少一部分可由一个或多个额外处理器(诸如,向量处理器,包括但不限于向量加法器)执行。
1425.存储器/处理单元可包括可分配给存储器组(逻辑对)中的一些或全部的一个或多个额外处理器。
1426.因此,可将单个额外处理器分配给存储器组(逻辑对)中的全部或一些。又对于另一实例,该些额外处理器可用阶层式方式配置,使得某一层级的额外处理器处理来自较低层级的额外处理器的输出。
1427.应注意,处理操作可在不使用任何额外处理器的情况下执行,但可由存储器/处理单元的逻辑执行。
1428.图89a、图89b、图89c、图89d、图89e、图89f及图89g分别说明存储器/处理单元9010、9011、9012、9013、9014、9015及9019的实例。存储器/处理单元9010包括控制器9020、内部总线9021以及多对逻辑9030及存储器组9040。
1429.应注意,逻辑9030及存储器组9040可用其他方式耦接至控制器和/或彼此耦接,例如,多个总线可设置于控制器与逻辑之间,逻辑可配置于多个层中,单个逻辑可由多个存储器组共享(参见例如图89e),及其类似者。
1430.可用任何方式定义存储器/处理单元9010内的每一存储器组的页面的长度,例如,其可足够小,且存储器组的数目可足够大以使得能够并行地输出大量向量而不会在不相关信息上浪费许多位。
1431.逻辑9020可包括完整alu、部分alu、存储器控制器、部分存储器控制器及其类似者。部分alu(存储器控制器)单元能够仅执行可由完整alu(存储器控制器)执行的功能的一部分。在本技术案中说明的任何逻辑或子处理器可包括完整alu、部分alu、存储器控制器、部分存储器控制器及其类似者。
1432.可用其他方式实施控制器9020与多对逻辑9030及存储器组9040之间的连接性。可用其他方式(不成对)配置存储器组及逻辑。
1433.存储器/处理单元9010可能不具有额外向量,且向量(来自存储器组)的处理由逻辑9030进行。
1434.图89b说明额外处理器,诸如耦接至内部总线9021的向量处理器9050。
1435.图89c说明额外处理器,诸如耦接至内部总线9021的向量处理器9050。一个或多个额外处理器执行(单独或与逻辑相配合)处理操作。
1436.图89d亦说明经由总线9022耦接至存储器/处理单元9010的主机9018。
1437.图89d亦说明将字/词组9072映射至向量9073的词汇表9070。使用撷取密钥9071存取存储器/处理单元,每一撷取密钥表示先前辨识的字或词组。主机9018将表示语句的多个撷取密钥9071发送至存储器/处理单元,且存储器/处理单元可输出向量9070或由与语句相关的向量所应用的处理操作的最终结果。字/词组通常不储存于存储器/处理单元9010中。
1438.用于控制存储器组的存储器控制器功能性可包括(单独或部分地)于逻辑中,可包括(单独或部分地)于控制器9020中和/或可包括(单独或部分地)于存储器/处理单元9010内的一个或多个存储器控制器(未图标)中。
1439.存储器/处理单元可被配置为最大化发送至主机9018的向量/结果的吞吐量,或可应用用于控制内部存储器/处理单元业务和/或控制存储器/处理单元与主计算机(或存储器/处理单元外部的任何其他实体)之间的业务的任何处理程序。
1440.不同逻辑9030耦接至存储器/处理单元的存储器组9040,且可对向量执行(较佳并行地)数学运算以产生经处理向量。一个逻辑9030可将向量发送至另一逻辑(参见例如图89g的线38),且另一逻辑可对所接收向量及其计算的向量应用数学运算。逻辑可按层级配置,且某一层级的逻辑可处理来自前一层级逻辑的向量或中间结果(由应用数学运算产生)。该些逻辑可形成树(二元、三元及其类似者)。
1441.当经处理向量的总大小超过结果的总大小时,则获得输出带宽(在存储器/处理单元外部)的减少。举例而言,当k个向量由存储器/处理单元加总以提供单个输出向量时,则获得带宽的k:1减少。
1442.控制器9020可被配置为藉由广播待存取的不同向量的地址来并行地开放多个存储器组。
1443.控制器可被配置为至少部分地基于语句中的字或词组的次序来控制从多个存储
器组(或从储存不同向量的任何中间缓冲或储存电路,参见图89d的缓冲器9033)撷取不同向量的次序。
1444.控制器9020可被配置为基于与在存储器/处理单元9010外部输出向量相关的一个或多个参数来管理不同向量的撷取,例如,从存储器组撷取不同向量的速率可设定为实质上等于从存储器/处理单元9010输出不同向量的可允许速率。
1445.控制器可藉由应用任何业务塑形处理程序来在存储器/处理单元9010外部输出不同向量。举例而言,控制器9020可旨在以尽可能接近主计算机或将存储器/处理单元9010耦接至主计算机的链路可允许的最大速率的速率输出不同向量。又对于另一实例,控制器可输出不同向量,同时最少化或至少实质上减少业务速率随时间的波动。
1446.控制器9020属于与存储器组9040及逻辑9030相同的集成电路,且因此可易于自不同逻辑/存储器组接收关于不同向量的撷取状态(例如,向量是否准备好,向量是否准备好但自同一存储器组正撷取或将要撷取另一向量)的反馈,及其类似者。可用任何方式提供反馈:经由专用控制线,经由共享控制线。使用一个或多个状态位及其类似者(参见图89f的状态线9039)。
1447.控制器9020可独立地控制不同向量的撷取及输出,且因此可减少主计算机的参与。替代地,主计算机可能不知晓控制器的管理能力,且可能继续发送详细指令,且在此状况下,存储器/处理单元9010可忽略详细指令,可隐藏控制器的管理能力,及其类似者。可基于可由主计算机管理的协议使用所提及的以上解决方案。
1448.已发现,在存储器/处理单元中执行处理操作为极有益的(就能量而言),即使当这些操作相比在主机中的处理操作消耗更多功率时且即使当这些操作相比在主机与存储器/处理单元之间的传送操作消耗更多功率时亦如此。举例而言,假定向量足够大,传送数据单元的能量消耗为4pj,数据单元的处理操作(藉由主机)的能量消耗为0.1pj,则当藉由存储器/处理单元处理数据单元的能量消耗低于5pj时,藉由存储器/处理单元处理数据单元更有效。
1449.(表示语句的矩阵的)每一向量可由字(或其他多位区段)的序列表示。为解释简单起见,假定多个位区段为字。
1450.当向量包括零值字时,可获得额外功率节省。替代输出整个零值字,可输出短于字(例如,位)的零值旗标(甚至经由专用控制线输送)而非整个字。可将旗标分配给其他值(例如,值1的字)。
1451.图88a说明用于嵌入的方法9400,或确切而言,可为用于撷取特征向量相关信息的方法。特征向量相关信息可包括特征向量和/或处理特征向量的结果。
1452.方法9400可开始于藉由存储器处理集成电路接收撷取信息以用于撷取多个所请求特征向量的步骤9410,该些特征向量可映射至多个语句区段。
1453.存储器处理单元可包括控制器、多个处理器子单元及多个存储器单元。存储器单元中的每一者可耦接至处理器子单元。
1454.步骤9410之后可接着为从多个存储器单元中的至少一些撷取多个所请求特征向量的步骤9420。
1455.该撷取可包括向两个或多于两个存储器单元同时请求储存于该两个或多于两个存储器单元中的所请求特征向量。
1456.该请求基于语句区段与映射至语句区段的特征向量的位置之间的已知映射而执行。
1457.该映射可在存储器处理集成电路的开机处理程序期间上传。
1458.一次撷取尽可能多的所请求特征向量可为有益的,但此取决于所请求特征向量储存之处及不同存储器单元的数目。
1459.若多于一个所请求特征向量储存于同一存储器组中,则可应用预测性撷取以用于减少与自存储器组撷取信息相关联的惩罚。在本技术案的各种章节中说明用于减少惩罚的各种方法。
1460.撷取可包括应用储存于单个存储器单元中的所请求特征向量的集合中的至少一些所请求特征向量的预测性撷取。
1461.所请求特征向量可用最佳方式分布于存储器单元之间。
1462.所请求特征向量可基于预期撷取图案而分布于存储器单元之间。
1463.多个所请求特征向量的撷取可根据某一次序执行。举例而言,根据语句区段在一个或多个语句中的次序。
1464.多个所请求特征向量的撷取可至少部分无序地执行;且其中撷取进一步可包括将多个所请求特征向量重新排序。
1465.多个所请求特征的撷取可包括在多个所请求特征向量可由控制器读取之前缓冲该多个所请求特征向量。
1466.多个所请求特征的撷取可包括产生缓冲状态指示符,该些缓冲状态指示符提示与多个存储器单元相关联的一个或多个缓冲器何时储存一个或多个所请求特征向量。
1467.该方法可包括经由专用控制线输送缓冲状态指示符。
1468.可每存储器单元分配一个专用控制线。
1469.缓冲状态指示符可为储存于一个或多个缓冲器中的状态位。
1470.该方法可包括经由一个或多个共享控制线输送缓冲状态指示符。
1471.步骤9420之后可接着为处理多个所请求特征向量以提供处理结果的步骤9430。
1472.另外或替代地,步骤9420之后可接着为从存储器处理集成电路输出可包括以下各者中的至少一者的输出的步骤9440:(a)所请求特征向量;及(b)处理所请求特征向量的结果。(a)所请求特征向量及(b)处理所请求特征向量的结果中的至少一者亦被称作特征向量相关信息。
1473.当执行步骤9430时,则步骤9440可包括输出(至少)处理所请求特征向量的结果。
1474.当跳过步骤9430时,则步骤9440包括输出所请求特征向量且可能不包括输出处理所请求特征向量的结果。
1475.图88b说明用于嵌入的方法9401。
1476.假定输出包括所请求特征向量,但不包括处理所请求特征向量的结果。
1477.方法9401可开始于藉由存储器处理集成电路接收撷取信息以用于撷取多个所请求特征向量的步骤9410,该些特征向量可映射至多个语句区段。
1478.步骤9410之后可接着为从多个存储器单元中的至少一些撷取多个所请求特征向量的步骤9420。
1479.步骤9420之后可接着为从存储器处理集成电路输出包括所请求特征向量但不包
括处理所请求特征向量的结果的输出的步骤9431。
1480.图88c说明用于嵌入的方法9402。
1481.假定输出包括处理所请求特征向量的结果。
1482.方法9402可开始于藉由存储器处理集成电路接收撷取信息以用于撷取多个所请求特征向量的步骤9410,该些特征向量可映射至多个语句区段。
1483.步骤9410之后可接着为从多个存储器单元中的至少一些撷取多个所请求特征向量的步骤9420。
1484.步骤9420之后可接着为处理多个所请求特征向量以提供处理结果的步骤9430。
1485.步骤9430之后可接着为从存储器处理集成电路输出可包括处理所请求特征向量的结果的输出的步骤9442。
1486.该输出的输出可包括对输出应用业务塑形。
1487.该输出的输出可包括尝试匹配在输出期间使用的带宽与链路上的最大可允许带宽,该链路将存储器处理集成电路耦接至请求者单元。
1488.该输出的输出可包括尝试维持输出业务速率的波动低于阈值。
1489.撷取及输出中的任何步骤可在主机的控制下和/或独立地或部分地由控制器执行。
1490.主机可发送具有不同粒度的撷取命令,从一般发送撷取信息而无关于所请求特征向量在多个存储器单元内的位置,直至基于所请求特征向量在多个存储器单元内的位置而发送详细撷取信息。
1491.主机可控制(或尝试控制)存储器处理集成电路内的不同撷取操作的时序,但可能与时序无关。
1492.控制器可藉由主机在各种层级中控制,且可甚至忽略主机的详细命令,且独立地至少控制撷取和/或输出。
1493.所请求特征向量的处理可由以下各者中的至少一者(以下各者中的一个或多个的组合)执行:一个或多个存储器/处理单元,及位于一个或多个存储器/处理单元外部的一个或多个处理器,及其类似者。
1494.应注意,所请求特征向量的处理可由以下各者中的至少一者(以下各者中的一个或多个的组合)执行:一个或多个处理器子单元、控制器、一个或多个向量处理器,及位于一个或多个存储器/处理单元外部的一个或多个存储器/处理单元。
1495.所请求特征向量的处理可由以下各者中的任一者或以下各者的组合执行,可由以下各者中的任一者或以下各者的组合产生:
1496.a.存储器/处理单元的处理器子单元(或逻辑9030)。
1497.b.多个存储器/处理单元的处理器子单元(或逻辑9030)。
1498.c.存储器/处理单元的控制器。
1499.d.多个存储器/处理单元的控制器。
1500.e.存储器/处理单元的一个或多个向量处理器。
1501.f.一个或多个向量处理器、多个存储器/处理单元。
1502.因此,所请求特征向量的处理可由以下各者的任何组合或子组合执行:(a)一个或多个存储器/处理单元的一个或多个控制器;(b)一个或多个存储器/处理单元的一个或多
个处理器子单元;(c)一个或多个存储器/处理单元的一个或多个向量处理器;及(d)位于一个或多个存储器/处理单元外部的一个或多个其他处理器。
1503.由多于一个处理实体执行的处理可被称作分布式处理。
1504.存储器/处理单元可包括多个处理器子单元。处理器子单元可彼此独立地操作,可彼此部分地合作,可参与分布式处理,及其类似者。
1505.可用平面方式执行处理,其中所有处理器子单元执行相同操作(且在其之间可能输出或可能不输出处理结果)。
1506.可用阶层式方式执行处理,其中处理涉及不同层级的处理操作序列,而某一层的处理操作在又一层级的处理操作之后。处理器子单元可经分配(动态地或静态地)给不同层且参与阶层式处理。
1507.所请求特征向量的任何处理可由多于一个处理实体(处理器子单元、控制器、向量处理器、其他处理器)执行,可用任何方式(用平面、阶层式或其他方式)进行分布式处理。举例而言,处理器子单元可将其处理结果输出至控制器,该控制器可进一步处理该些结果。位于一个或多个存储器/处理单元外部的一个或多个其他处理器可进一步处理存储器处理集成电路的输出。
1508.应注意,撷取信息还可包括用于撷取不映射至语句区段的所请求特征向量的信息。这些特征向量可映射至一个或多个人员、装置或可与语句区段相关的任何其他实体。举例而言,感测语句区段的装置的用户、感测区段的装置、识别为语句区段的来源的使用者、在产生语句时存取的网站、俘获语句的位置,及其类似者。
1509.在细节上作必要修改后,方法9400、9401及9402可适用于不映射至语句区段的处理和/或所请求撷取向量。
1510.特征向量的处理的非限制性实例可包括加总、加权和、平均、减法或应用任何其他数学函数。
1511.混合装置
1512.随着处理器速度及存储器大小两者均继续增加,对有效处理速度的显著限制系冯诺依曼(von neumann)瓶颈。冯诺依曼瓶颈由传统计算机架构所导致的吞吐量限制造成。特定而言,相较于由处理器进行的实际运算,从存储器至处理器的数据传送(在诸如外部dram存储器的逻辑晶粒外部)常常遇到瓶颈。因此,用以对存储器进行读取及写入的时钟循环的数目随着存储器密集型处理程序而显著增加。这些时钟循环导致较低的有效处理速度,这是因为对存储器进行读取及写入会消耗时钟循环,该些时钟循环无法用于对数据执行操作。此外,处理器的运算带宽通常大于处理器用以存取存储器的总线的带宽。
1513.这些瓶颈对于以下各者特别明显:存储器密集型处理程序,诸如神经网络及其他机器学习算法;数据库建构、索引搜寻及查询;以及包括比数据处理操作多的读取及写入操作的其他任务。
1514.本发明描述用于减轻或克服上文所阐述的问题中的一个或多个以及现有技术中的其他问题的解决方案。
1515.可提供一种用于存储器密集型处理的混合装置,该混合装置可包括基础晶粒、多个处理器、至少另一晶粒的第一存储器资源,及至少一个其他晶粒的第二存储器资源。
1516.该基础晶粒及该至少另一晶粒藉由晶圆上晶圆接合彼此连接。
1517.多个处理器被配置为执行处理操作,且撷取储存于第一存储器资源中的所撷取信息。
1518.第二存储器资源被配置为将来自第二存储器资源的额外信息发送至第一存储器资源。
1519.基础晶粒与至少另一晶粒之间的第一路径的总带宽超过至少另一晶粒与至少一个其他晶粒之间的第二路径的总带宽,且第一存储器资源的储存容量为第二存储器资源的储存容量的一部分。
1520.第二存储器资源为高带宽存储器(hbm)资源。
1521.至少一个其他晶粒为高带宽存储器(hbm)芯片的堆叠。
1522.第二存储器资源中的至少一些可属于另一晶粒,该另一晶粒藉由不同于晶圆间接合的连接性而连接至基础晶粒。
1523.第二存储器资源中的至少一些属于另一晶粒,该另一晶粒藉由不同于晶圆间接合的连接性而连接至另一晶粒。
1524.第一存储器资源及第二存储器资源为不同层级的高速缓存。
1525.第一存储器资源定位于基础晶粒与第二存储器资源之间。
1526.第一存储器资源定位于第二存储器资源的一侧。
1527.另一晶粒被配置为执行额外处理,其中另一晶粒包含多个处理器子单元及第一存储器资源。
1528.每一处理器子单元耦接至分配给处理器子单元的第一存储器资源的唯一部分。
1529.第一存储器资源的唯一部分为至少一个存储器组。
1530.多个处理器为包括于为存储器处理芯片第一存储器资源中的多个处理器子单元。
1531.基础晶粒包含多个处理器,其中多个处理器为经由使用晶圆间接合形成的导体耦接至第一存储器资源的多个处理器子单元。
1532.每一处理器子单元耦接至分配给处理器子单元的第一存储器资源的唯一部分。
1533.可提供混合集成电路,其可利用晶圆上晶圆(wow)连接性以将基础晶粒的至少一部分耦接至第二存储器资源,该些第二存储器资源包括于一个或多个其他晶粒中且使用不同于wow连接性的连接性而连接。第二存储器资源的实例可为高带宽存储器(hbm)存储器资源。在各种附图中,第二存储器资源包括于hbm存储器单元的堆叠中,可使用硅穿孔(tsv)连接性而耦接至控制器。控制器可包括于基础晶粒中或耦接(例如,经由微凸块)至基础晶粒的至少部分。
1534.基础晶粒可为逻辑晶粒,但可为存储器/处理单元。
1535.wow连接性用以将基础晶粒的一个或多个部分耦接至另一晶粒(wow连接的晶粒)的一个或多个部分,该另一晶粒可为存储器晶粒或存储器/处理单元。wow连接性为极高吞吐量连接性。
1536.高带宽存储器(hbm)芯片的堆叠可耦接至基础晶粒(直接或经由wow连接的晶粒),且可提供高吞吐量连接及极广泛存储器资源。
1537.wow连接的晶粒可耦接于hbm芯片的堆叠与基础晶粒之间以形成hbm存储器芯片堆叠,该堆叠具有tsv连接性且在其底部具有wow连接的晶粒。
1538.具有tsv连接性且在底部具有wow连接的晶粒的hbm芯片堆叠可提供多层存储器阶
层,其中wow连接的晶粒可用作基础晶粒可存取的较低层级存储器(例如,3阶高速缓存),其中自较高层级hbm存储器堆叠的提取和/或预提取操作填充wow连接的晶粒。
1539.hbm存储器芯片可为hbm dram芯片,但可使用任何其他存储器技术。
1540.使用wow连接性与hmb芯片的组合使得能够提供多层存储器结构,该多层存储器结构可包括可提供带宽与存储器密度之间的不同取舍的多个存储器层。
1541.所建议解决方案可充当传统的dram存储器/hbm至逻辑晶粒的内部高速缓存之间的额外的全新存储器阶层,从而在dram侧实现更多带宽以及更佳管理及重复使用。
1542.此可在dram侧提供以快速方式较佳地管理存储器读取的新的存储器阶层。
1543.图93a至图93i分别说明混合集成电路11011'至11019'。
1544.图93a说明具有tsv连接性且在最低层级具有微凸块的hbm dram堆叠(共同表示为11030),该堆叠包括彼此耦接且使用tsv(11039)耦接至基础晶粒的第一存储器控制器11031的hdm dram存储器芯片11032的堆叠。
1545.图93a亦说明至少具有存储器资源且使用wow技术耦接的晶圆(共同表示为11040),该晶圆包括经由一个或多个wow中间层(11023)耦接至dram晶圆(11021)的基础晶粒11019的第二存储器控制器11022。一个或多个wow中间层可由不同材料制成,但可不同于垫连接性和/或可不同于tsv连接性。
1546.穿过一个或多个wow中间层的导体11022'将dram晶粒电耦接至基础晶粒的组件。
1547.基础晶粒11019耦接至中介层11018,该中介层又使用微凸块耦接至封装基板11017。封装基板在其下表面处具有微凸块的阵列。
1548.微凸块可由其他连接性替换。中介层11018及封装基板11017可由其他层替换。
1549.第一和/或第二存储器控制器(分别为11031及11032)可定位于(至少部分)基础晶粒11019外部,例如定位于dram晶圆中,dram晶圆与基础晶粒之间,hbm存储器单元的堆叠与基础晶粒之间,及其类似者。
1550.第一和/或第二存储器控制器(分别为11031及11032)可属于同一控制器或可属于不同控制器。
1551.hbm存储器单元中的一个或多个可包括逻辑以及存储器,且可为或可包括存储器/处理单元。
1552.第一及第二存储器控制器藉由多个总线11016彼此耦接,以用于在第一存储器资源与第二存储器资源之间输送信息。图93a亦说明自第二存储器控制器至基础晶粒的组件(例如,多个处理器)的总线11014。图93a进一步说明自第一存储器控制器至基础晶粒的组件(例如,多个处理器,如图93c中所展示)的总线11015。
1553.图93b说明混合集成电路11012,其与图93a的混合集成电路11011的不同之处在于具有存储器/处理单元11021'而非dram晶粒11021。
1554.图93c说明混合集成电路11013,其与图93a的混合集成电路11011的不同之处在于具有hbm存储器芯片堆叠,该堆叠具有tsv连接性且在其底部具有wow连接的晶粒(共同表示为11040),该晶粒包括hbm存储器单元的堆叠与基础晶粒11018之间的dram晶粒11021。
1555.dram晶粒11021使用wow技术(参见wow中间层11023)耦接至基础晶粒11019的第一存储器控制器11031。hbm存储器晶粒11032中的一个或多个可包括逻辑以及存储器,且可为或可包括存储器/处理单元。
1556.最下部dram晶粒(在图93c中表示为deam晶粒11021)可为hbm存储器晶粒或可不同于hbm晶粒。最下部dram晶粒(dram晶粒11021)可由存储器/处理单元11021'替换,如由图93d的混合集成电路11014所说明。
1557.图93e至图93g分别说明混合集成电路11015、11016及11016',其中基础晶粒11019耦接至具有tsv连接性且在最低层级处具有微凸块的hbm dram堆叠(11020)及至少具有存储器资源且使用wow技术耦接的晶圆(11030)的多个例项,和/或耦接至具有tsv连接性且在底部具有wow连接的晶粒的hbm存储器芯片堆叠(11040)的多个例项。
1558.图93h说明混合集成电路11014',该混合集成电路与图93d的混合集成电路11014的不同之处在于说明存储器单元53、二阶高速缓存(l2高速缓存52)、多个处理器11051。多个处理器11051耦接至l2高速缓存11052,且可馈入有储存于存储器单元11053及l2高速缓存11052中的系数和/或数据。
1559.上文所提及的混合集成电路中的任一者可用于人工智能(ai)处理,该处理为带宽密集的。
1560.当使用wow技术耦接至存储器控制器时,图93d及93h的存储器/处理单元11021'可执行ai计算,且可用极高速率自hbm dram堆叠和/或自wow连接的晶粒接收数据及系数两者。
1561.任何存储器/处理单元可包括分布式存储器阵列及处理器阵列。分布式存储器及处理器阵列可包括多个存储器组及多个处理器。多个处理器可形成处理阵列。
1562.参看图93c、图93d及图93h且假定需要混合集成电路(11013、11014或11014')来执行一般的矩阵向量乘法(gemv),该些乘法包括计算矩阵与向量的乘积。因为不存在对所撷取矩阵的重复使用,所以此类型的计算为带宽密集的。因此,仅需要撷取及使用整个矩阵一次。
1563.gemv可为数学运算序列的一部分,其涉及(i)将第一矩阵(a)乘以第一向量(v1)以提供第一中间向量,对第一中间向量应用第一非线性运算(nlo1)以提供第一中间结果;(ii)将第二矩阵(b)乘以第一中间结果以第二中间向量,对第二中间向量应用第二非线性运算(nlo2)以提供第二中间结果,等等(直至接收第n中间结果,n可超过2)。
1564.假定每一矩阵为大的(例如,1gb),计算将需要1tbs运算功率及1tbs的带宽/吞吐量。可并行地执行运算及计算。
1565.假定gemv计算展现n=4且具有以下形式:结果=nlo4(d*(nlo3(c*(nlo2(b*(nlo1(a*v1)))))))。
1566.亦假定dram晶粒11021(或存储器/处理单元11021')不具有足够的存储器资源以同时储存a、b、c及d,则这些矩阵中的至少一些将储存于hdm dram晶粒11032中。
1567.假定基础晶粒为包括诸如但不限于处理器、算术逻辑单元及其类似者的计算单元的逻辑晶粒。
1568.在第一晶粒计算a*v1时,第一存储器控制器11031自一个或多个hbm dram晶粒11032撷取其他矩阵的缺失部分以用于接下来的计算。
1569.参看图93h且假定(a)dram晶粒11021具有2tbs带宽及512mb容量,(b)hbm dram晶粒11032具有0.2tbs带宽及8gb容量,且(c)l2高速缓存11052为具有6ts带宽及10mb容量的sram。
1570.矩阵乘法涉及重复使用数据,将大的矩阵分段成多个区段(例如,5mb个区段以适合可在双缓冲器配置下使用的l2高速缓存)及将所提取的第一矩阵区段乘以第二矩阵的区段(一个第二矩阵区段接着另一第二矩阵区段)。
1571.在将第一矩阵区段乘以第二矩阵区段时,将另一第二矩阵区段自(存储器处理单元11021'的)dram晶粒11021提取至l2高速缓存。
1572.假定矩阵各为1gb,在执行取得及计算时,dram晶粒11021或存储器/处理单元11021'馈入有来自hbm dram晶粒11032的矩阵区段。
1573.dram晶粒11021或存储器/处理单元11021'聚集矩阵区段,且矩阵区段接着经由wow中间层(11023)馈入至基础晶粒11019。
1574.存储器/处理单元11021'可藉由执行计算及发送结果而非发送经计算以提供结果的中间值来减少经由wow中间层(11023)发送至基础晶粒11019的信息的量。当处理多个(q个)中间值以提供结果时,则压缩比可为q比1。
1575.图93i说明使用wow技术实施的存储器处理单元11019'的实例。逻辑单元9030(可为处理器子单元)、控制器9020及总线9021位于一个芯片111061中,分配给不同逻辑单元的存储器组9040位于第二芯片11062中,而第一及第二芯片使用穿过wow接合部11061的导体11012'彼此连接,该wow接合部可包括一个或多个wow中间层。
1576.图93j为用于存储器密集型处理的方法11100的实例。存储器密集意谓处理需要高带宽存储器消耗或与高带宽存储器消耗相关联。
1577.方法11100可开始于步骤11110、11120及11130。
1578.步骤11110包括藉由多个处理器混合装置执行处理操作,该混合装置包含基础晶粒、至少另一晶粒的第一存储器资源及至少一个其他晶粒的第二存储器资源;其中基础晶粒及至少另一晶粒藉由晶圆上晶圆接合彼此连接。
1579.步骤11120包括藉由多个处理器撷取储存于第一存储器资源中的所撷取信息。
1580.步骤11130可包括将来自第二存储器资源的额外信息发送至第一存储器资源,其中基础晶粒与至少另一晶粒之间的第一路径的总带宽超过至少另一晶粒与至少一个其他晶粒之间的第二路径的总带宽,且其中第一存储器资源的储存容量为第二存储器资源的储存容量的一部分。
1581.方法11100还可包括藉由包括多个处理器子单元及第一存储器资源的另一晶粒执行额外处理的步骤11140。
1582.每一处理器子单元可耦接至分配给处理器子单元的第一存储器资源的唯一部分。
1583.第一存储器资源的唯一部分为至少一个存储器组。
1584.步骤11110、11120、11130及11140可同时、以部分重叠方式及其类似方式执行。
1585.第二存储器资源可为高带宽存储器(hbm)存储器资源或可不同于hbm存储器资源。
1586.至少一个其他晶粒为高带宽存储器(hbm)存储器芯片的堆叠。
1587.通信芯片
1588.数据库包括许多条目,该些条目包括多个字段。数据库处理通常包括执行一个或多个查询,该一个或多个查询包括一个或多个筛选参数(例如,识别一个或多个相关字段及一个或多个相关字段值)且亦包括一个或多个操作参数,该一个或多个操作参数可判定待执行的操作的类型、待在应用操作时使用的变量或常数,及其类似者。数据处理可包括数据
库分析或其他数据库处理程序。
1589.举例而言,数据库查询可请求对数据库的所有记录执行统计操作(操作参数),其中某一字段具有预定义范围内的值(筛选参数)。又对于另一实例,数据库查询可请求删除具有小于阈值(筛选参数)的某一字段的(操作参数)记录。
1590.大型数据库通常储存于储存装置中。为了对查询作出响应,将数据库发送至存储器单元,通常为一个数据库区段接着另一数据库区段。
1591.将数据库区段的条目自存储器单元发送至不属于与存储器单元相同的集成电路的处理器。该些条目接着由处理器处理。
1592.对于储存于存储器单元中的数据库的每一数据库区段,处理包括以下步骤:(i)选择数据库区段的记录;(ii)将记录自存储器单元发送至处理器;(iii)藉由处理器筛选记录以判定记录是否相关;及(iv)对相关记录执行一个或多个额外操作(求和、应用任何其他数学运算和/或统计操作)。
1593.筛选处理程序在所有记录被发送至处理器且处理器判定哪些记录相关之后结束。
1594.在数据库区段的相关条目不储存于处理器中的状况下,则需要在筛选阶段之后将这些相关记录发送至处理器以供进一步处理(应用在处理之后的操作)。
1595.当多个处理操作在单个筛选之后时,则可将每一操作的结果发送至存储器单元且接着再次发送至处理器。
1596.此处理程序为耗带宽且耗时的。
1597.越来越需要提供执行数据库处理的高效方式。
1598.可提供一种可包括数据库加速集成电路的装置。
1599.可提供一种可包括数据库加速集成电路的一个或多个群组的装置,该些数据库加速集成电路可被配置为在数据库加速集成电路的一个或多个群组中的数据库加速集成电路之间交换信息和/或加速结果(藉由数据库加速集成电路进行的处理的最终结果)。
1600.群组的数据库加速度集成电路可连接至同一印刷电路板。
1601.群组的数据库加速度集成电路可属于计算机化系统的模块化单元。
1602.不同群组的数据库加速集成电路可连接至不同印刷电路板。
1603.不同群组的数据库加速集成电路可属于计算机化系统的不同模块化单元。
1604.该装置可被配置为藉由一个或多个群组的数据库加速集成电路执行分布式处理程序。
1605.该装置可被配置为使用至少一个交换器以用于在一个或多个群组中的不同群组的数据库加速集成电路之间交换(a)信息及(b)数据库加速结果中的至少一者。
1606.该装置可被配置为藉由一个或多个群组中的一些的数据库加速集成电路中的一些执行分布式处理程序。
1607.该装置可被配置为执行第一及第二数据结构的分布式处理程序,其中第一及第二数据结构的总大小超过多个存储器处理集成电路的储存能力。
1608.该装置可被配置为藉由执行以下步骤的多个迭代来执行分布式处理程序:(a)执行将第一数据结构部分及第二数据结构部分的不同对新分配给不同数据库加速集成电路;及(b)处理不同对。
1609.图94a及图9b说明储存系统11560、计算机系统11150及用于数据库加速的一个或
多个装置11520的实例。用于数据库加速的一个或多个装置11520可用各种方式(藉由监听或藉由定位于计算机系统11150与储存系统11560之间)监视储存系统11560与计算机系统11150之间的通信。
1610.储存系统11560可包括许多(例如,多于20个、50个、100个、100个及其类似者)储存单元(诸如,磁盘或磁盘的raid),且可例如储存多于100万亿字节信息。计算系统11510可为大型计算机系统且可包括数十、数百及甚至数千个处理单元。
1611.运算系统11510可包括由管理器11511控制的多个运算节点11512。
1612.运算节点可控制或以其他方式与用于数据库加速的一个或多个装置11520交互。
1613.用于数据库加速的一个或多个装置11520可包括一个或多个数据库加速集成电路(参见例如图94a及图94b的数据库加速集成电路11530)及存储器资源11550。存储器资源可属于专用于存储器但可属于存储器/处理单元的一个或多个芯片。
1614.图94c及图94d说明计算机系统11150及用于数据库加速的一个或多个装置11520的实例。
1615.用于数据库加速的一个或多个装置11520的一个或多个数据库加速集成电路可由管理单元11513控制,该管理单元可位于计算机系统内(参见图94c)或位于用于数据库加速的一个或多个装置11520内(图94d)。
1616.图94e说明用于数据库加速的装置11520,该装置包括数据库加速集成电路11530及多个存储器处理集成电路1151。每一存储器处理集成电路可包括控制器、多个处理器子单元及多个存储器单元。
1617.数据库加速集成电路11530经说明为包括网络通信接口11531、第一处理单元11532、存储器控制器11533、数据库加速单元11535、互连件11536及管理单元11513。
1618.网络通信接口(11531)可被配置为自大量储存单元接收(例如,经由网络通信接口的第一端口11531(1))大量信息。每一储存单元可用超过数十及甚至数百兆字节/秒的速率输出信息,而数据传输速度预期随时间增加(例如,每2至3年加倍)。储存数据单元的数目(大数目)可超过10个、50个、100个、200个及甚至更多个。大量信息可超过数十、数百千兆位组/秒,且甚至可在万亿字节/秒及千兆字节/秒的范围内。
1619.第一处理单元11532可被配置为对大量信息进行第一处理(预处理)以提供第一经处理信息。
1620.存储器控制器11533可被配置为经由大吞吐量接口11534将第一经处理信息发送至多个存储器处理集成电路。
1621.多个存储器处理集成电路11551可被配置为藉由多个存储器处理集成电路对第一经处理信息的至少部分进行第二处理(处理)以提供第二经处理信息。
1622.存储器控制器11533可被配置为自多个存储器处理集成电路撷取所撷取信息。所撷取信息可包括以下各者中的至少一者:(a)第一经处理信息的至少一部分;及(b)第二经处理信息的至少一部分。
1623.数据库加速单元11535可被配置为对所撷取信息执行数据库处理操作,以提供数据库加速结果。
1624.数据库加速集成电路可被配置为输出数据库加速结果,例如经由网络通信接口的一个或多个第二端口11531(2)。
1625.图94e亦说明管理单元11513,该管理单元被配置为管理以下各者中的至少一者:所撷取信息的撷取、第一处理(预处理)、第二处理(处理)及第三处理(数据库处理)。管理单元11513可位于数据库加速集成电路外部。
1626.管理单元可被配置为基于执行计划而执行该管理。执行计划可由管理单元产生,或可由位于数据库加速集成电路外部的实体产生。执行计划可包括以下各者中的至少一者:(a)待由数据库加速集成电路的各种组件执行的指令、(b)实施执行计划所需的数据和/或系数、(c)指令和/或数据的存储器分配。
1627.管理单元可被配置为藉由分配以下各者中的至少一些来执行管理:(a)网络通信网路接口资源、(b)解压缩单元资源、(c)存储器控制器资源、(d)多个存储器处理集成电路资源,及(e)数据库加速单元资源。
1628.如图94e及图94g中所说明,网络通信网路接口可包括不同类型的网络通信端口。
1629.不同类型的网络通信端口可包括储存接口协议端口(例如,sata端口、ata端口、iscsi端口、网络文件系统、光纤通道端口)及通用网络储存接口协议端口(例如,以太网络ata、以太网络光纤通道、nvme、roce及其他)。
1630.不同类型的网络通信端口可包括储存接口协议端口及pcie端口。
1631.图94f包括虚线,该些虚线说明大量信息、第一经处理信息、所撷取信息及数据库加速结果的流。图94f将数据库加速集成电路11530说明为耦接至多个存储器资源11550。多个存储器资源11550可能不属于存储器处理集成电路。
1632.用于数据库加速的装置11520可被配置为藉由数据库加速集成电路11530同时执行多个任务,这是因为网络通信接口11531可接收多个信息串流(同时),第一处理单元11532可同时对多个信息单元执行第一处理,存储器控制器11533可同时将多个第一经处理信息单元发送至多个存储器处理集成电路11551,数据库加速单元11535可同时处理多个所撷取信息单元。
1633.用于数据库加速的装置11520可被配置为藉由大型运算系统的运算节点基于发送至数据库加速集成电路的执行计划而执行撷取、第一处理、发送及第三处理中的至少一者。
1634.用于数据库加速的装置11520可被配置为用实质上优化数据库加速集成电路的利用的方式管理撷取、第一处理、发送及第三处理中的至少一者。该优化考虑潜时、吞吐量及任何其他时序或储存或处理考虑因素,且尝试使沿着流径的所有组件保持忙碌且无瓶颈。
1635.数据库加速集成电路可被配置为输出数据库加速结果,例如经由网络通信接口的一个或多个第二端口11531(2)。
1636.用于数据库加速的装置11520可被配置为实质上优化藉由网络通信网路接口交换的业务的带宽。
1637.用于数据库加速的装置11520可被配置为用实质上优化数据库加速集成电路的利用的方式实质上防止在撷取、第一处理、发送及第三处理中的至少一者中形成瓶颈。
1638.用于数据库加速的装置11520可被配置为根据时间i/o带宽来分配数据库加速集成电路的资源。
1639.图94g说明用于数据库加速的装置11520,该装置包括数据库加速集成电路11530及多个存储器处理集成电路1151。图94g亦说明耦接至数据库加速集成电路11530的各种单元:远程ram 11546、以太网络存储器dimm11547、储存系统11560、本地储存单元11561及非
易失性存储器(nvm)11563(该非易失性存储器可为快速nvm单元(nvme))。
1640.数据库加速集成电路11530经说明为包括以太网络端口11531(1)、rdma单元11545、串行扩展端口11531(15)、sata控制器11540、pcie端口11531(9)、第一处理单元11532、存储器控制器11533、数据库加速单元11535、互连件11536、管理单元11513、用于执行密码操作的密码编译引擎11537,及二阶静态随机存取存储器(l2 sram)11538。
1641.数据库加速单元经说明为包括dma引擎11549、三阶(l3)存储器11548及数据库加速子单元11547。数据库加速子单元11547可为可配置单元。
1642.以太网络端口11531(1)、rdma单元11545、串行扩展端口11531(15)、sata控制器11540、pcie端口11531(9)可被视为网络通信接口11531的部分。
1643.远程ram 11546、以太网络存储器dimm 11547、储存系统11560耦接至以太网络端口11531(1),该以太网络端口又耦接至rdma单元11545。
1644.本地储存单元11561耦接至sata控制器11540。
1645.pcie端口11531(9)耦接至nvm 11563。pcie端口亦可用于交换命令,例如用于管理目的。
1646.图94h为数据库加速单元11535的实例。
1647.数据库加速单元11535可被配置为藉由数据库处理子单元11573同时执行数据库处理指令,其中数据库加速单元可包括共享一共享存储器单元11575的数据库加速器子单元的群组。
1648.数据库加速子单元11535的不同组合可动态地彼此链接(经由可配置链路或互连件11576)以提供执行可包括多个指令的数据库处理操作所需的执行管线。
1649.每一数据库处理子单元可被配置为执行特定类型的数据库处理指令(例如,筛选、合并、累加及其类似者)。
1650.图94h亦说明耦接至高速缓存11571的独立数据库处理单元11572。替代db加速器的可重配置阵列11574或除db加速器的可重配置阵列11574以外,亦可提供数据库处理单元11572及高速缓存11571。
1651.该装置可便利向内扩展和/或向外扩展,因此使得多个数据库加速集成电路11530(及其相关联的存储器资源11550或其相关联的多个存储器处理集成电路11551)能够例如藉由参与数据库操作的分布式处理而彼此相配合。
1652.图94i说明包括两个数据库加速集成电路11530(及其相关联的存储器资源11550)的模块化单元,诸如刀片(blade)11580。该刀片可包括一个、两个或多于两个存储器处理集成电路11551及其相关联的存储器资源11550。
1653.该刀片还可包括一个或多个非易失性存储器单元、以太网络交换器、pcie交换器及以太网络交换器。
1654.多个刀片可使用任何通信方法、通信协议及连接性彼此通信。
1655.图94i说明彼此完全连接的四个数据库加速集成电路11530(及其相关联的存储器资源11550),每一数据库加速集成电路11530连接至所有三个其他数据库加速集成电路11530。连接性可使用任何通信协议,例如藉由使用以太网络rdma协议达成。
1656.图94i亦说明数据库加速集成电路11530,该数据库加速集成电路连接至其相关联的存储器资源11550以及包括ram存储器及以太网络端口的单元11531。
1657.图94j、图94k、图94l及图94m说明数据库加速集成电路的四个群组11580,每一群组包括四个数据库加速集成电路11530(彼此完全连接)及其相关联的存储器资源11550。不同群组经由交换器11590彼此连接。
1658.群组的数目可为两个、三个或多于四个。每群组的数据库加速集成电路的数目可为两个、三个或多于四个。群组的数目可相同于(或可不同于)每群组的数据库加速集成电路的数目。
1659.图94k说明两个表a及b,该两个表过大(例如,1万亿字节)而无法一次高效地接合(join)。
1660.将表实际上分段成分片且将接合操作应用于包括表a的分片及表b的分片的对。
1661.数据库加速集成电路的群组可用各种方式处理分片。
1662.举例而言,装置可被配置为藉由以下操作来执行分布式处理程序:
1663.g.将不同的第一数据结构部分(表a的分片,例如第一至第十六分片a0至a15)分配给一个或多个群组的不同数据库加速集成电路。
1664.h.执行以下各者的多个迭代:(i)将不同的第二数据结构部分(表b的分片,例如第一直至第十六分片b0至b15)新分配给一个或多个群组的不同数据库加速集成电路;及(ii)藉由数据库加速集成电路处理第一及第二数据结构部分。
1665.装置可被配置为用与当前迭代的处理至少部分时间重叠的方式执行下一迭代的新分配。
1666.装置可被配置为藉由在不同数据库加速集成电路之间交换第二数据结构部分来执行新分配。
1667.交换可用与处理程序至少部分时间重叠的方式执行。
1668.装置可被配置为藉由以下操作来执行新分配:在群组的不同数据库加速集成电路之间交换第二数据结构部分;及一旦该交换已完成,则在数据库加速集成电路的不同群组之间交换第二数据结构部分。
1669.在图94k中,展示接合操作中的一些的四个循环,例如参考左上方群组的左上方数据库加速集成电路11530,四个循环包括计算join(a0,b0)、join(a0,b3)、join(a0,b2)及join(a0,b1)。在这四个循环期间,a0保持在同一数据库加速集成电路11530处,而矩阵b的分片(b0、b1、b2及b3)在数据库加速集成电路11530的同一群组的成员之间旋转。
1670.在图94l中,第二矩阵的分片在不同群组之间旋转,(a)将分片b0、b1、b2及b3(先前由左上方群组处理)自左上方群组发送至左下方群组,(b)将分片b4、b5、b6及b7(先前由左下方群组处理)自左下方群组发送至右上方群组,(c)将分片b8、b9、b10及b11(先前由右上方群组处理)自右上方群组发送至右下方群组,且(d)将分片b12、b13、b14及b15(先前由右下方群组处理)自右下方群组发送至左上方群组。
1671.图94n为系统的实例,该系统包括多个刀片11580、sata控制器11540、本地储存单元11561、nvme 11563、pcie交换器11601、以太网络存储器dimm 11547及以太网络端口11531(4)。
1672.刀片11580可耦接至pcie交换器11601、以太网络端口11531及sata控制器11540中的每一者。
1673.图94o说明两个系统11621及11622。
1674.系统11621可包括用于数据库加速的一个或多个装置11520、交换系统11611、储存系统11612及运算系统11613。交换系统11611提供用于数据库加速的一个或多个装置11520、储存系统11612及运算系统11613之间的连接性。
1675.系统11622可包括储存系统以及用于数据库加速的一个或多个装置11615、交换系统11611及运算系统11613。交换系统11611提供储存系统以及用于数据库加速的一个或多个装置11615及运算系统11613之间的连接性。
1676.图95a说明用于数据库加速的方法11200。
1677.方法11200可开始于藉由数据库加速集成电路的网络通信网路接口自大量储存单元撷取大量信息的步骤11210。
1678.连接至大量储存单元(例如,使用多个不同总线)使得网络通信网路接口能够接收大量信息,即使当单个储存单元具有有限吞吐量时亦如此。
1679.步骤11210之后可接着为对大量信息进行第一处理以提供第一经处理信息。第一处理可包括缓冲、自有效负载提取信息、移除标头、解压缩、压缩、解密、筛选数据库查询或执行任何其他处理操作。第一处理亦可能限于缓冲。
1680.步骤11210之后可接着为藉由数据库加速集成电路的存储器控制器且经由大吞吐量接口将第一经处理信息发送至多个存储器处理集成电路的步骤11220,其中每一存储器处理集成电路可包括控制器、多个处理器子单元及多个存储器单元。存储器处理集成电路可为存储器/处理单元或分布式处理器或存储器芯片,如本专利申请案的任何其他部分中所说明。
1681.步骤11220之后可接着为藉由多个存储器处理集成电路对第一经处理信息的至少部分进行第二处理以提供第二经处理信息的步骤11230。
1682.步骤11230可包括藉由数据库加速集成电路同时执行多个任务。
1683.步骤11230可包括藉由数据库处理子单元同时执行数据库处理指令,其中数据库加速单元可包括共享一共享存储器单元的数据库加速器子单元的群组。
1684.步骤11230之后可接着为藉由数据库加速集成电路的存储器控制器自多个存储器处理集成电路撷取所撷取信息的步骤11240,其中所撷取信息可包括以下各者中的至少一者:(a)第一经处理信息的至少一部分;及(b)第二经处理信息的至少一部分。
1685.步骤11240之后可接着为藉由数据库加速集成电路的数据库加速单元对所撷取信息执行数据库处理操作以提供数据库加速结果的步骤11250。
1686.步骤11250可包括根据时间i/o带宽分配数据库加速集成电路的资源。
1687.步骤11250之后可接着为输出数据库加速结果的步骤11260。
1688.步骤11260可包括动态地链接数据库处理子单元以提供执行可包括多个指令的数据库处理操作所需的执行管线。
1689.步骤11260可包括将数据库加速结果输出至本地储存器及自本地储存器撷取数据库加速结果。
1690.应注意,方法11100的步骤11210、11220、11230、11240、11250及11260或任何其他步骤可用管线化方式执行。可同时或以不同于上文所提及的次序的次序执行这些步骤。
1691.举例而言,步骤1120之后可接着为步骤11250,使得第一经处理信息由数据库加速单元进一步处理。
1692.又对于另一实例,第一经处理信息可发送至多个存储器处理集成电路,且接着发送(不由多个存储器处理集成电路处理)至数据库加速单元。
1693.又对于另一实例,第一经处理信息和/或第二经处理信息可自数据库加速集成电路输出,而不由数据库加速度单元进行数据库处理。
1694.该方法可包括藉由大型运算系统的运算节点基于发送至数据库加速集成电路的执行计划而执行以下操作中的至少一者:撷取、第一处理、发送及第三处理。
1695.该方法可包括以实质上优化数据库加速集成电路的利用的方式管理撷取、第一处理、发送及第三处理中的至少一者。
1696.该方法可包括实质上优化藉由网络通信网路接口交换的业务的带宽。
1697.该方法可包括以实质上优化数据库加速集成电路的利用的方式实质上防止在撷取、第一处理、发送及第三处理中的至少一者中形成瓶颈。
1698.方法11200还可包括以下步骤中的至少一者:
1699.步骤11270可包括藉由数据库加速集成电路的管理单元来管理撷取、第一处理、发送及第三处理中的至少一者。
1700.该管理可基于由数据库加速集成电路的管理单元产生的执行计划而执行。
1701.该管理可基于由数据库加速集成电路的管理单元接收而并非由管理单元产生的执行计划而执行。
1702.该管理可包括分配以下各者中的至少一些:(a)网络通信网路接口资源、(b)解压缩单元资源、(c)存储器控制器资源、(d)多个存储器处理集成电路资源,及(e)数据库加速单元资源。
1703.步骤11271可包括藉由大型运算系统的运算节点控制撷取、第一处理、发送及第三处理中的至少一者中的至少一者。
1704.步骤11272可包括藉由位于数据库加速集成电路外部的管理单元来管理撷取、第一处理、发送及第三处理中的至少一者。
1705.图95b说明用于操作数据库加速集成电路的群组的方法11300。
1706.方法11300可开始于藉由数据库加速集成电路执行数据库加速操作的步骤11310。步骤11310可包括执行方法11200的一个或多个步骤。
1707.方法11300还可包括在数据库加速集成电路的一个或多个群组的数据库加速集成电路之间交换(a)信息及(b)数据库加速结果中的至少一者的步骤11320。
1708.步骤11310及11320的组合可相当于藉由一个或多个群组的数据库加速集成电路执行分布式处理。
1709.可使用一个或多个群组的数据库加速集成电路的网络通信网路接口执行交换。
1710.可经由多个群组执行交换,该些群组可藉由星形连接而彼此连接。
1711.步骤11320可包括使用至少一个交换器以用于在一个或多个群组中的不同群组的数据库加速集成电路之间交换以下各者中的至少一者:(a)信息;及(b)数据库加速结果。
1712.步骤11310可包括藉由一个或多个群组中的一些的数据库加速集成电路中的一些执行分布式处理的步骤11311。
1713.步骤11311可包括执行第一及第二数据结构的分布式处理,其中第一及第二数据结构的总大小超过多个存储器处理集成电路的储存能力。
1714.分布式处理的执行可包括执行以下各者的多个迭代:(a)执行将第一数据结构部分及第二数据结构部分的不同对新分配给不同数据库加速集成电路;及(b)处理不同对。
1715.分布式处理的执行可包括执行数据库接合操作。
1716.步骤11310可包括(a)将不同的第一数据结构部分分配给一个或多个群组的不同数据库加速集成电路的步骤11312;及(b)执行以下各者的多个迭代:将不同的第二数据结构部分新分配给一个或多个群组的不同数据库加速集成电路的步骤11314;及藉由数据库加速集成电路处理第一及第二数据结构部分的步骤11316。
1717.可用与当前迭代的处理至少部分时间重叠的方式执行步骤11314。
1718.步骤11314可包括在不同数据库加速集成电路之间交换第二数据结构部分。
1719.可用与步骤11310至少部分时间重叠的方式执行步骤11320。
1720.步骤11314可包括在群组的不同数据库加速集成电路之间交换第二数据结构部分;及一旦交换已完成,便在数据库加速集成电路的不同群组之间交换第二数据结构部分。
1721.图95c说明用于数据库加速的方法11350。
1722.方法11350可包括藉由数据库加速集成电路的网络通信网路接口自大量储存单元撷取大量信息的步骤11352。
1723.步骤11352之后可接着为对大量信息进行第一处理以提供第一经处理信息的步骤11354。
1724.步骤11352之后可接着藉由数据库加速集成电路的存储器控制器且经由大吞吐量接口将第一经处理信息发送至多个存储器资源的步骤11354。
1725.步骤11354之后可接着为自多个存储器资源撷取所撷取信息的步骤11356。
1726.步骤11356之后可接着为藉由数据库加速集成电路的数据库加速单元对所撷取信息执行数据库处理操作以提供数据库加速结果的步骤11358。
1727.步骤11358之后可接着为输出数据库加速结果的步骤11359。
1728.该方法还可包括对第一经处理信息进行第二处理以提供第二经处理信息的步骤11355。第二处理由多个处理器执行,该多个处理器位于进一步包含多个存储器资源的一个或多个存储器处理集成电路中。步骤11355在步骤11354之后且在步骤11356之前。
1729.第二经处理信息的总大小可小于第一经处理信息的总大小。
1730.第一经处理信息的总大小可小于大量信息的总大小。
1731.第一处理可包括筛选数据库条目。因此,在执行任何其他处理之前和/或甚至在将不相关的数据库条目储存于多个存储器资源之前,筛选出与查询不相关的数据库条目,藉此节省带宽、储存资源及其他处理资源。
1732.第二处理可包括筛选数据库条目。筛选可在筛选条件可为复杂的(包括多个条件)时应用,且可能需要在筛选进行之前接收多个数据库条目字段。举例而言,当搜寻(a)超过某一年龄且喜欢香蕉的人及(b)超过另一年龄且喜欢苹果的人时。
1733.数据库
1734.以下实例可参考数据库。数据库可为数据中心,可为数据中心的部分,或可能不属于数据中心。
1735.数据库可经由一个或多个网络耦接至多个用户。数据库可为云端数据库。
1736.可提供包括一个或多个管理单元及多个数据库加速器板的数据库,该些加速器板
包括一个或多个存储器/处理单元。
1737.图96b说明数据库12020,该数据库包括管理单元12021及多个db加速器板12022,该些加速器板各包括通信/管理处理器(处理器12024)及多个存储器/处理单元12026。
1738.处理器12024可支持各种通信协议,诸如但不限于pcie、类似roce的协议,及其类似者。
1739.数据库命令可由存储器/处理单元12026执行,且处理器可在存储器/处理单元12026之间、在不同db加速器板12022之间且与管理单元12021投送业务。
1740.尤其在包括大型内部存储器组时,使用多个存储器/处理单元12026可显著加速数据库命令的执行且避免通信瓶颈。
1741.图96c说明包括处理器12024及多个存储器/处理单元12026的db加速器板12022。处理器12024包括多个通信专用组件,诸如用于与存储器/处理单元12026、rdma引擎12031、db查询数据库引擎12034及其类似者通信的ddr控制器12033。ddr控制器为通信控制器的实例,且rdma引擎为任何通信引擎的实例。
1742.可提供一种用于操作图96b、图96c及图96d中的任一者的系统(或操作系统的任何部分)的方法。
1743.应注意,数据库加速集成电路11530可与多个存储器资源相关联,该些存储器资源不包括于多个存储器处理集成电路中或以其他方式不与处理单元相关联。在此状况下,处理主要且甚至仅由数据库加速集成电路执行。
1744.图94p说明用于数据库加速的方法11700。
1745.方法11700可包括藉由数据库加速集成电路的网络通信接口从储存单元撷取信息的步骤11710。
1746.步骤11710之后可接着为对信息量进行第一处理以提供第一经处理信息的步骤11720。
1747.步骤11720之后可接着为藉由数据库加速集成电路的存储器控制器且经由吞吐量接口将第一经处理信息发送至多个存储器资源的步骤11730。
1748.步骤11730之后可接着为自多个存储器资源撷取信息的步骤11740。
1749.步骤11740之后可接着为藉由数据库加速集成电路的数据库加速单元对所撷取信息执行数据库处理操作以提供数据库加速结果的步骤11750。
1750.步骤11750之后可接着为输出数据库加速结果的步骤11760。
1751.第一处理和/或第二处理可包括筛选数据库条目,判定应进一步处理哪些数据库条目。
1752.第二处理包含筛选数据库条目。
1753.混合系统
1754.存储器/处理单元在执行可为存储器密集的和/或瓶颈与撷取操作相关的计算时可为高效的。当瓶颈与运算操作相关时,面向处理(且较少面向存储器)的处理器单元(诸如但不限于图形处理单元、中央处理单元)可更有效。
1755.混合系统可包括彼此可完全或部分连接的一个或多个处理器单元及一个或多个存储器/处理单元两者。
1756.存储器/处理单元(mpu)可藉由相比逻辑胞元更佳地适合存储器胞元的第一制造
制程来制造。举例而言,由第一制造制程制造的记忆胞元可展现相比由第一制造制程制造的逻辑电路的临界尺寸较小且甚至小得多(例如,小超过2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍及其类似者)的临界尺寸。举例而言,第一制造制程可为模拟制造制程,第一制造制程可为dram制造制程,及其类似者。
1757.处理器可由较佳地适合逻辑的第二制造制程制造。举例而言,由第二制造制程制造的逻辑电路的临界尺寸可比由第一制造制程制造的逻辑电路的临界尺寸小且甚至小得多。又对于另一实例,由第二制造制程制造的逻辑电路的临界尺寸可比由第一制造制程制造的存储器胞元的临界尺寸小且甚至小得多。举例而言,第二制造制程可为模拟制造制程,第二制造制程可为cmos制造制程,及其类似者。
1758.可藉由考虑每一单元的益处及与在单元之间传送数据相关的任何惩罚而以静态或动态方式在不同单元之间分配任务。
1759.举例而言,可将存储器密集型处理程序分配给存储器/处理单元,而可将处理密集型存储器轻处理分配给处理单元。
1760.处理器可请求或发指令给一个或多个存储器/处理单元以执行各种处理任务。各种处理任务的执行可减轻处理器的负担,减少潜时,且在一些状况下减少一个或多个存储器/处理单元与处理器之间的总信息带宽,及其类似者。
1761.处理器可用不同粒度提供指令和/或请求,例如处理器可发送针对某些处理资源的指令或可发送针对存储器/处理单元的较高阶指令,而不指定任何处理资源。
1762.图96d为包括一个或多个存储器/处理单元(mpu)12043及处理器12042的混合系统12040的实例。处理器12042可将请求或指令发送至一个或多个mpu 12043,该一个或多个mpu又完成(或选择性地完成)请求和/或指令且将结果发送至处理器12042,如上文所说明。
1763.处理器12042可进一步处理结果以提供一个或多个输出。
1764.每一mpu包括存储器资源、处理资源(诸如,紧凑微控制器12044)及高速缓存12049。微控制器可具有有限运算能力(例如,可主要包括乘法累加单元)。
1765.微控制器12044可出于存储器内加速目的而应用处理程序,亦可为cpu或整个整db处理引擎或其子集。
1766.mpu 12043可包括可用网状/环形/或其他拓朴连接以用于快速组间通信的微处理器及封包处理单元。
1767.可存在多于一个ddr控制器以用于快速dimm间通信。
1768.存储器内封包处理器的目标为减少bw、数据移动、功率消耗,且增加效能。相比标准解决方案,使用存储器内封包处理器将使效能/tco显著增加。
1769.应注意,管理单元为可选的。
1770.每一mpu可作为人工智能(ai)存储器/处理单元操作,这是因为其可执行ai计算且仅将结果传回至处理器,藉此减少业务量,尤其在mpu接收及储存待用于多个计算中的神经网络系数时,且每次使用神经网络的一部分以处理新数据时不需要自外部芯片接收系数。
1771.mpu可判定系数何时为零,且通知处理器不需要执行包括零值系数的乘法。
1772.应注意,第一处理及第二处理可包括筛选数据库条目。
1773.mpu可为本说明书中、pct专利申请案wo2019025862及pct专利申请案第pct/ib2019/001005号中的任一者中所说明的任何存储器处理单元。
1774.可提供ai运算系统(及可由系统执行的系统),其中网络适配器具有ai处理能力且被配置为执行一些ai处理任务,以便减少待经由耦接多个ai加速服务器的网络发送的业务的量。
1775.举例而言,在一些推断系统中,输入为网络(例如,连接至ai服务器的ip相机的多个串流)。在此状况下,在处理及网络连接单元上利用rdma ai可减小cpu及pcie总线的负载且对处理及网络连接单元提供处理,而非由不包括于处理及网络连接单元中的gpu提供处理。
1776.举例而言,替代计算初始结果及将初始结果发送至目标ai加速服务器(应用一个或多个ai处理操作),处理及网络连接单元可执行减少发送至目标ai加速服务器的值的量的预处理。目标ai运算服务器为经分配以对由其他ai加速服务器提供的值执行计算的ai运算服务器。此减少在ai加速服务器之间交换的业务的带宽且亦减小目标ai加速服务器的负载。
1777.可藉由使用负载平衡或其他分配算法以动态或静态方式分配目标ai加速服务器。可存在多于单个目标ai加速服务器。
1778.举例而言,若目标ai加速服务器添加了多个损失,则处理及网络连接单元可添加由其ai加速服务器产生的损失且将损失总和发送至目标ai加速服务器,藉此减少带宽。当执行诸如导数计算及聚集以及其类似者的其他预处理操作时,可获得相同益处。
1779.图97b说明包括子系统的系统12060,每一子系统包括用于将具有服务器主板12064的ai处理及网络连接单元12063连接至彼此的交换器12061。服务器主板包括具有网络能力且具有ai处理能力的一个或多个ai处理及网络连接单元12063。ai处理及网络连接单元12063可包括一个或多个nic及alu或用于执行预处理的其他计算电路。
1780.ai处理及网络连接单元12063可为芯片,或可包括多于单个芯片。具有为单个芯片的ai处理及网络连接单元12063可为有益的。
1781.ai处理及网络连接单元12063可包括(仅或主要)处理资源。ai处理及网络连接单元12063可包括存储器内运算电路,或可不包括存储器内运算电路,或可能不包括海量存储器内运算电路。
1782.ai处理及网络连接单元12063可为集成电路,可包括多于单个集成电路,可为集成电路的一部分,及其类似者。
1783.ai处理及网络连接单元12063可在包括ai处理及网络连接单元12063的ai加速服务器与其他ai加速服务器之间输送(参见例如图97c)业务(例如,藉由使用诸如ddr通道、网络通道和/或pcie通道的通信端口)。ai处理及网络连接单元12063亦可耦接至诸如ddr存储器的外部存储器。处理及网络连接单元可包括存储器和/或可包括存储器/处理单元。
1784.在图97c中,ai处理及网络连接单元12063经说明为包括本地ddr连接、ddr通道、ai加速器、ram存储器、加密/解密引擎、pcie交换器、pcie接口、多个核心处理阵列、快速网络连接及其类似者。
1785.可提供一种用于操作图97b及图97c中的任一者的系统(或操作系统的任何部分)的方法。
1786.可提供在本技术案中所提及的任何方法的任何步骤的任何组合。
1787.可提供在本技术案中所提及的任何单元、集成电路、存储器资源、逻辑、处理子单
元、控制器、组件的任何组合。
1788.对“包括”和/或“包含”的任何参考可在细节上作必要修改后应用于“组成”、“实质上组成”。
1789.已出于说明的目的呈现先前描述。先前描述并不详尽且不限于所公开的精确形式或实施例。从本说明书的考虑及所公开实施例的实践,修改及调适对本领域技术人员将为显而易见的。另外,尽管所公开实施例的方面描述为储存于存储器中,但本领域技术人员将了解,这些方面也可储存于其他类型的计算机可读介质上,诸如次要储存设备,例如硬盘或cd rom,或其他形式的ram或rom、usb媒体、dvd、蓝光、4k超hd蓝光,或其他光驱介质。
1790.基于书面描述及所公开方法的计算机程序在有经验开发者的技能范围内。可使用本领域技术人员已知的技术中的任一者产生或可结合现有软件设计各种程序或程序模块。例如,程序区段或程序模块可用或藉助于.net framework、.net compact framework(及相关语言,诸如visual basic、c等)、java、c 、objective-c、html、html/ajax组合、xml或包括java小程序的html来设计。
1791.此外,尽管本文已经描述了说明性实施例,但是本领域技术人员基于本公开将了解具有等效组件、修改、省略、组合(例如,跨各种实施例的方面的组合)、调适和/或更改的任何及所有实施例的范畴。权利要求中的限制应基于权利要求中所使用的语言来广泛地解释,且不限于本说明书中所描述或在本技术的审查期间的实施例。实施例应解释为非排他性的。此外,所公开方法的步骤可用任何方式进行修改,包括通过对步骤重排序和/或插入或删除步骤。因此,本说明书及实施例仅被认为是说明性的,其中真实的范围和精神由所附权利要求及其等同物的全部范围指示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。