1.本技术属于人工智能领域,尤其涉及一种信息的推荐方法、装置、设备及存储介质。
背景技术:
2.卫生部颁布的《关于在公立医院施行预约诊疗服务工作的意见》提出:网络挂号,即在线挂号,是公立医院以病人为中心开展医疗服务的重要改革措施,对于方便群众就医、提高医疗服务水平具有重大意义。在公立医院率先施行预约诊疗服务工作,有利于患者进行就医咨询,提前安排就医计划,减少候诊时间,也有利于医院提升管理水平,提高工作效率和医疗质量,降低医疗安全风险。
3.随着互联网技术的发展越来越多的医院都推出了自己的在线挂号系统,由于在线挂号的方便性越来越多的人的也开始习惯在在线挂号,在在线挂号方便了大众生活的同时,也同样面临着用户不知道该挂哪个医生的号这样的问题。
4.现有技术中,已有在线挂号时在线推荐医生的方法,但是推荐的医生与用户提供的疾病描述信息匹配合理性较低。
技术实现要素:
5.本技术实施例提供一种在信息的推荐方法、装置、设备及存储介质,能够解决现有网上挂号时在线推荐医生的方法推荐的医生与用户提供的疾病描述信息匹配合理性较低的问题。
6.第一方面,本技术实施例提供一种信息的推荐方法,该方法包括:
7.获取用户输入的疾病描述信息;
8.根据疾病描述信息确定疾病类型和病情程度信息;
9.根据疾病类型确定医生信息;
10.根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息;其中,第一评分信息表征医生的受欢迎程度,目标评分信息表征医生与疾病类型的匹配程度。
11.进一步地,在一种实施例中,根据疾病描述信息确定疾病类型和病情程度信息,包括:
12.将疾病描述信息输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征;
13.根据疾病向量特征确定疾病类型以及病情程度信息。
14.进一步地,在一种实施例中,根据疾病向量特征确定疾病类型以及病情程度信息,包括:
15.计算疾病向量特征与多个预设疾病向量特征的相似度,预设疾病向量特征映射有相应的疾病类型及对应的疾病症状;
16.显示相似度超过预设阈值的预设疾病向量特征相应的疾病类型及对应的疾病症状,以供用户选择;
17.获取用户选择的疾病类型;
18.将疾病向量特征输入预设的病情程度分类模型,输出病情程度信息。
19.进一步地,在一种实施例中,在根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息前,方法还包括:
20.根据预设时间段内用户的历史挂号数量确定第一评分信息。
21.进一步地,在一种实施例中,第一评分信息s通过如下公式计算得出:
[0022][0023]
其中,n为预设时间段内当前医生放出的预约号总数,mi为当前医生在预设时间段内第i批次放出的预约号的数量,mi为第i批次预约号的截止时间前已被预约的预约号数量,ti第i批次预约号的可预约时间跨度,ki为医第i批预约号放出时间与获取用户输入的疾病描述信息的时间的差值,k为预设时间段的时间跨度。
[0024]
进一步地,在一种实施例中,根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息,包括:
[0025]
当病情程度信息表征出疾病描述信息对应重症时:
[0026]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0027][0028]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0029][0030]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0031]
进一步地,在一种实施例中,根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息,包括:
[0032]
当病情程度信息表征出疾病描述信息对应轻症时:
[0033]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0034][0035]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0036][0037]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0038]
第二方面,本技术实施例提供一种信息的推荐装置,该装置包括:
[0039]
获取模块,用于获取用户输入的疾病描述信息;
[0040]
确定模块,用于根据疾病描述信息确定疾病类型和病情程度信息;
[0041]
确定模块,还用于根据疾病类型确定医生信息;
[0042]
确定模块,还用于根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息;其中,第一评分信息表征医生的受欢迎程度,目标评分信息表征医生与疾病类型的匹配程度。
[0043]
进一步地,在一种实施例中,确定模块,包括:
[0044]
输入单元,将疾病描述信息输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征;
[0045]
确定单元,根据疾病向量特征确定疾病类型以及病情程度信息。
[0046]
进一步地,在一种实施例中,确定单元,具体用于:
[0047]
计算疾病向量特征与多个预设疾病向量特征的相似度,预设疾病向量特征映射有相应的疾病类型及对应的疾病症状;
[0048]
显示相似度超过预设阈值的预设疾病向量特征相应的疾病类型及对应的疾病症状,以供用户选择;
[0049]
获取用户选择的疾病类型;
[0050]
将疾病向量特征输入预设的病情程度分类模型,输出病情程度信息。
[0051]
第三方面,本技术实施例提供一种信息的推荐设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,计算机程序被处理器执行时实现上述信息的推荐方法。
[0052]
第四方面,本技术实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有信息传递的实现程序,程序被处理器执行时实现上述信息的推荐方法。
[0053]
本技术实施例的信息的推荐方法、装置、设备及存储介质,基于用户输入的疾病描述信息确定疾病类型及病情程度信息,进而确定该疾病类型对应的医生信息,能够推荐擅长处理该疾病类型的医生,并且得到了根据医生信息、表征了医生受欢迎程度的第一评分信息和病情程度信息确定的目标评分信息,使得目标评分信息能够表征出各医生与该疾病类型的匹配程度,能够使推荐的医生信息与用户提供的疾病描述信息匹配合理性较高。
附图说明
[0054]
为了更清楚地说明本技术实施例的技术方案,下面将对本技术实施例中所需要使用的附图作简单的介绍,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0055]
图1是本技术实施例提供的一种信息的推荐方法的流程示意图;
[0056]
图2是本技术实施例提供的一种信息的推荐装置的结构示意图;
[0057]
图3是本技术实施例提供的一种信息的推荐设备的结构示意图;
[0058]
图4是本技术实施例提供的资源库系统结构示意图;
[0059]
图5是本技术实施例提供的医生推荐系统;
[0060]
图6是本技术实施例提供的skip-gram模型的基本网络结构图。
具体实施方式
[0061]
下面将详细描述本技术的各个方面的特征和示例性实施例,为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及具体实施例,对本技术进行进一步详细描述。应理解,此处所描述的具体实施例仅被配置为解释本技术,并不被配置为限定本技术。对于本领域技术人员来说,本技术可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本技术的示例来提供对本技术更好的理解。
[0062]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0063]
随着互联网技术的发展,越来越多的医院都推出了自己的网上挂号系统,由于网上挂号的方便性越来越多的人的也开始习惯在网上挂号,网上挂号确实方便,但是现有的网上挂号方法推荐的医生与用户提供的疾病描述信息匹配合理性较低。
[0064]
为了解决现有技术问题,本技术实施例提供了一种信息的推荐方法、装置、设备及存储介质。本技术基于用户输入的疾病描述信息确定疾病类型及病情程度信息,进而确定该疾病类型对应的医生信息,能够推荐擅长处理该疾病类型的医生,并且得到了根据医生信息、表征了医生受欢迎程度的第一评分信息和病情程度信息确定的目标评分信息,使得目标评分信息能够表征出各医生与该疾病类型的匹配程度,能够使推荐的医生信息与用户提供的疾病描述信息匹配合理性较高。下面首先对本技术实施例所提供的信息的推荐方法进行介绍。
[0065]
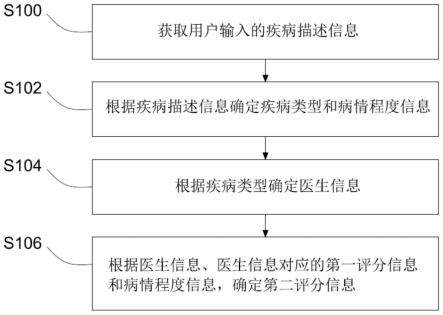
图1示出了本技术一个实施例提供的信息的推荐方法的流程示意图。如图1所示,该方法可以包括以下步骤:
[0066]
s100,获取用户输入的疾病描述信息。
[0067]
疾病描述信息通过用户输入而获得。
[0068]
s102,根据疾病描述信息确定疾病类型和病情程度信息。
[0069]
在一种实施例中,s102可以包括:
[0070]
s1020,将疾病描述信息输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征。
[0071]
在一种实施例中,s1020可以包括:
[0072]
将疾病描述信息输入预设分词模型,输出表征经分词后的疾病描述信息的第一特征。
[0073]
预设分词模型可以选用jieba模型。
[0074]
例如,疾病描述信息为“有点发烧头疼啊”,则将疾病描述信息输入预设分词模型后输出的第一特征为【有点,发烧,头疼,啊】。
[0075]
通过删除第一特征中符合预设停用词表记载的单词以得到第二特征。
[0076]
预设停用词表记载了对于理解描述属于哪一种疾病没有帮助的词语及各种符号的词语,如啊、哎、其次。例如,预设停用词表记载了“啊”为停用词,则第二特征为【有点,发烧,头疼】。
[0077]
筛选出第二特征中符合预设关键词表记载的单词以确定第三特征。
[0078]
关键词表记载了对于理解描述属于哪一种疾病至关重要的词语,如发烧、咳嗽、头晕;例如,预设关键词表记载了“发烧”、“头疼”为关键词,则确定“发烧”、“头疼”为第三特征。
[0079]
将第二特征中的第三特征个数增加预设倍数后,得到第四特征。
[0080]
例如,预设倍数为3,则第四特征为【有点,发烧,发烧,发烧,头疼,头疼,头疼】。
[0081]
将第四特征输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征。
[0082]
例如对于第四特征为【有点,发烧,发烧,发烧,头疼,头疼,头疼】的疾病描述,统计其词的个数为7,使用skip-gram模型对该词列表中各个词进行向量化后形成的向量分别为l1,l2,l2,l2,l3,l3,l3,则得到的疾病描述信息对应的疾病向量特征lp为
[0083]
预设词向量化模型可以选为skip-gram模型或者tf-idf模型,优选使用skip-gram模型,并可将该skip-gram模型的维度设为200,相比tf-idf模型,skip-gram模型具有以下优点:
[0084]
首先,tf-idf模型表示出的词向量维度与词表的大小成正比,是一种高维稀疏的表示方法,这种表示方法在计算上具有较低的效率,而词向量化方法skip-gram可以表示出低维稠密的词向量,具有较高的计算效率。
[0085]
其次,tf-idf模型这种表示方式追踪不到词与词之间的关联关系,而skip-gram则运用了具有相同上下文的词语包含相似的语义这一思想,使得语义相近的词在映射到欧式空间中具有较高的余弦相似度。
[0086]
s1022,根据疾病向量特征确定疾病类型以及病情程度信息。
[0087]
在一种实施例中,s1022可以包括:
[0088]
计算疾病向量特征与多个预设疾病向量特征的相似度,预设疾病向量特征映射有相应的疾病类型及对应的疾病症状;显示相似度超过预设阈值的预设疾病向量特征相应的疾病类型及对应的疾病症状,以供用户选择;获取用户选择的疾病类型。
[0089]
疾病症状映射有疾病类型,预设疾病向量特征可通过将疾病症状输入预设词向量化模型得到。
[0090]
例如,疾病症状为【发烧,头疼】,词的个数为2,使用预设的skip-gram模型对疾病症状的各个词进行向量化后形成的向量分别为l2,l3,则得到的疾病描述信息对应的疾病向量特征lz为
[0091]
可以通过计算lz与lp的余弦值作为相似度,以与预设阈值比较,余弦值为:余弦值越大说明lz与lp越相似。
[0092]
例如,可以预设阈值为α,从余弦值大于α的预设疾病向量特征中取相似度最大的三个预设疾病向量特征,向用户推荐该三个预设疾病向量特征对应的疾病类型及对应的疾病症状,不足三个的则有几个取几个。
[0093]
将疾病向量特征输入预设的疾病分类模型,输出病情程度信息。
[0094]
该预设的病情程度分类模型可以是xgboost模型。对于每一种疾病类型互联网上都会存在相应的疾病描述信息,对于每一种疾病描述信息进行标记,得到标签数据,具体可以标记为0或者1的标签,其中0代表该疾病描述信息对应的病情程度信息为轻症,1代表该疾病描述信息对应的病情程度信息为重症。即可根据上述疾病描述信息和标签数据训练得到各疾病类型的病情程度分类模型。
[0095]
例如,对于一种疾病类型如感冒,首先通过预设词向量化模型将其对应的疾病描述信息进行向量化,然后用各疾病描述信息对应的向量及标签数据训练一个xgboost分类模型。
[0096]
将疾病向量特征输入对应的疾病类型的预设的病情程度分类模型,即可输出病情程度信息。
[0097]
在一种实施例中,该方法还包括:
[0098]
s103,根据预设时间段内用户的历史挂号数量确定第一评分信息。
[0099]
在一种实施例中,第一评分信息s可以通过如下公式计算得出:
[0100][0101]
其中,n为预设时间段内当前医生放出的预约号总数,mi为当前医生在预设时间段内第i批次放出的预约号的数量,mi为第i批次预约号的截止时间前已被预约的预约号数量,ti第i批次预约号的可预约时间跨度,一个医生的预约号被放出来之后越快被预约完则ti的值越小,ki为医第i批预约号放出时间与获取用户输入的疾病描述信息的时间的差值,k为预设时间段的时间跨度,为时间衰减函数,能够使得越是最近的预约情况对医生的受欢迎程度评分的贡献越大。
[0102]
s104,根据疾病类型确定医生信息。
[0103]
医院数据库记录有医生可诊断疾病类型以及医生所在科室信息,基于医院数据库即可根据疾病类型确定医生信息。
[0104]
s106,根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息。
[0105]
其中,第一评分信息表征医生的受欢迎程度,目标评分信息表征医生与疾病类型的匹配程度。
[0106]
在一种实施例中,s106可以包括:
[0107]
当病情程度信息表征出疾病描述信息对应重症时:
[0108]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0109]
[0110]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0111][0112]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0113]
例如,专家级别可以分为一级专家、二级专家、三级专家;普通医生即为没有专家职称的医生。
[0114]
在一种实施例中,s106还可以包括:
[0115]
当病情程度信息表征出疾病描述信息对应轻症时:
[0116]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0117][0118]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0119][0120]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0121]
本技术基于用户输入的疾病描述信息确定疾病类型及病情程度信息,进而确定该疾病类型对应的医生信息,能够推荐擅长处理该疾病类型的医生,并且得到了根据医生信息、表征了医生受欢迎程度的第一评分信息和病情程度信息确定的目标评分信息,使得目标评分信息能够表征出各医生与该疾病类型的匹配程度,并且通过目标评分信息的计算手段实现了病患资源与医疗资源的合理推荐,即对于重症疾病类型患者专家医生的目标评分机制使得目标评分较高,对于重症疾病类型患者普通医生的目标评分机制使得目标评分较低,对于轻症疾病类型患者专家医生的目标评分机制使得目标评分较低,对于轻症疾病类型患者普通医生的目标评分机制使得目标评分较高。由于用户通常会优先选择目标评分较高的医生,进而实现了医疗资源与患病类型的合理分配。
[0122]
图1描述了信息的推荐方法,下面结合附图2和附图3描述本技术实施例提供的装置。
[0123]
图2示出了本技术一个实施例提供的信息的推荐装置的结构示意图,图2所示装置中各模块具有实现图1中各个步骤的功能,并能达到其相应技术效果。如图2所示,该装置可以包括:
[0124]
获取模块200,用于获取用户输入的疾病描述信息。
[0125]
疾病描述信息通过用户输入而获得。
[0126]
确定模块202,用于根据疾病描述信息确定疾病类型和病情程度信息。
[0127]
在一种实施例中,确定模块202可以包括:
[0128]
输入单元2020,用于将疾病描述信息输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征。
[0129]
在一种实施例中,输入单元2020可以具体用于:
[0130]
将疾病描述信息输入预设分词模型,输出表征经分词后的疾病描述信息的第一特
征。
[0131]
预设分词模型可以选用jieba模型。
[0132]
例如,疾病描述信息为“有点发烧头疼啊”,则将疾病描述信息输入预设分词模型后输出的第一特征为【有点,发烧,头疼,啊】。
[0133]
通过删除第一特征中符合预设停用词表记载的单词以得到第二特征。
[0134]
预设停用词表记载了对于理解描述属于哪一种疾病没有帮助的词语及各种符号的词语,如啊、哎、其次。例如,预设停用词表记载了“啊”为停用词,则第二特征为【有点,发烧,头疼】。
[0135]
筛选出第二特征中符合预设关键词表记载的单词以确定第三特征。
[0136]
关键词表记载了对于理解描述属于哪一种疾病至关重要的词语,如发烧、咳嗽、头晕;例如,预设关键词表记载了“发烧”、“头疼”为关键词,则确定“发烧”、“头疼”为第三特征。
[0137]
将第二特征中的第三特征个数增加预设倍数后,得到第四特征。
[0138]
例如,预设倍数为3,则第四特征为【有点,发烧,发烧,发烧,头疼,头疼,头疼】。
[0139]
将第四特征输入预设词向量化模型,得到疾病描述信息对应的疾病向量特征。
[0140]
例如对于第四特征为【有点,发烧,发烧,发烧,头疼,头疼,头疼】的疾病描述,统计其词的个数为7,使用skip-gram模型对该词列表中各个词进行向量化后形成的向量分别为l1,l2,l2,l2,l3,l3,l3,则得到的疾病描述信息对应的疾病向量特征lp为
[0141]
预设词向量化模型可以选为skip-gram模型或者tf-idf模型,优选使用skip-gram模型,并可将该skip-gram模型的维度设为200,相比tf-idf模型,skip-gram模型具有以下优点:
[0142]
首先,tf-idf模型表示出的词向量维度与词表的大小成正比,是一种高维稀疏的表示方法,这种表示方法在计算上具有较低的效率,而词向量化方法skip-gram可以表示出低维稠密的词向量,具有较高的计算效率。
[0143]
其次,tf-idf模型这种表示方式追踪不到词与词之间的关联关系,而skip-gram则运用了具有相同上下文的词语包含相似的语义这一思想,使得语义相近的词在映射到欧式空间中具有较高的余弦相似度。
[0144]
确定单元2022,用于根据疾病向量特征确定疾病类型以及病情程度信息。
[0145]
在一种实施例中,确定单元2022可以具体用于:
[0146]
计算疾病向量特征与多个预设疾病向量特征的相似度,预设疾病向量特征映射有相应的疾病类型及对应的疾病症状;显示相似度超过预设阈值的预设疾病向量特征相应的疾病类型及对应的疾病症状,以供用户选择;获取用户选择的疾病类型。
[0147]
疾病症状映射有疾病类型,预设疾病向量特征可通过将疾病症状输入预设词向量化模型得到。
[0148]
例如,疾病症状为【发烧,头疼】,词的个数为2,使用预设的skip-gram模型对疾病症状的各个词进行向量化后形成的向量分别为l2,l3,则得到的疾病描述信息对应的疾病向
量特征lz为
[0149]
可以通过计算lz与lp的余弦值作为相似度,以与预设阈值比较,余弦值为:余弦值越大说明lz与lp越相似。
[0150]
例如,可以预设阈值为α,从余弦值大于α的预设疾病向量特征中取相似度最大的三个预设疾病向量特征,向用户推荐该三个预设疾病向量特征对应的疾病类型及对应的疾病症状,不足三个的则有几个取几个。
[0151]
将疾病向量特征输入预设的疾病分类模型,输出病情程度信息。
[0152]
该预设的病情程度分类模型可以是xgboost模型。对于每一种疾病类型互联网上都会存在相应的疾病描述信息,对于每一种疾病描述信息进行标记,得到标签数据,具体可以标记为0或者1的标签,其中0代表该疾病描述信息对应的病情程度信息为轻症,1代表该疾病描述信息对应的病情程度信息为重症。即可根据上述疾病描述信息和标签数据训练得到各疾病类型的病情程度分类模型。
[0153]
例如,对于一种疾病类型如感冒,首先通过预设词向量化模型将其对应的疾病描述信息进行向量化,然后用各疾病描述信息对应的向量及标签数据训练一个xgboost分类模型。
[0154]
将疾病向量特征输入对应的疾病类型的预设的病情程度分类模型,即可输出病情程度信息。
[0155]
在一种实施例中,确定模块202还可以用于:
[0156]
根据预设时间段内用户的历史挂号数量确定第一评分信息。
[0157]
在一种实施例中,第一评分信息s可以通过如下公式计算得出:
[0158][0159]
其中,n为预设时间段内当前医生放出的预约号总数,mi为当前医生在预设时间段内第i批次放出的预约号的数量,mi为第i批次预约号的截止时间前已被预约的预约号数量,ti第i批次预约号的可预约时间跨度,一个医生的预约号被放出来之后越快被预约完则ti的值越小,ki为医第i批预约号放出时间与获取用户输入的疾病描述信息的时间的差值,k为预设时间段的时间跨度,为时间衰减函数,能够使得越是最近的预约情况对医生的受欢迎程度评分的贡献越大。
[0160]
确定模块202,还用于根据疾病类型确定医生信息。
[0161]
医院数据库记录有医生可诊断疾病类型以及医生所在科室信息,基于医院数据库即可根据疾病类型确定医生信息。
[0162]
确定模块202,还用于根据医生信息、医生信息对应的第一评分信息和病情程度信息,确定目标评分信息。
[0163]
其中,第一评分信息表征医生的受欢迎程度,目标评分信息表征医生与疾病类型的匹配程度。
[0164]
在一种实施例中,确定模块202可以具体用于:
[0165]
当病情程度信息表征出疾病描述信息对应重症时:
[0166]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0167][0168]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0169][0170]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0171]
例如,专家级别可以分为一级专家、二级专家、三级专家;普通医生即为没有专家职称的医生。
[0172]
在一种实施例中,确定模块202可以具体用于:
[0173]
当病情程度信息表征出疾病描述信息对应轻症时:
[0174]
医生信息表征出的专家医生的目标评分信息u通过如下公式确定:
[0175][0176]
医生信息表征出的普通医生的目标评分信息u通过如下公式确定:
[0177][0178]
其中,j为专家级别,s为第一评分信息,z为看诊时间距离获取用户输入的疾病描述信息的时间的差值。
[0179]
本技术基于用户输入的疾病描述信息确定疾病类型及病情程度信息,进而确定该疾病类型对应的医生信息,能够推荐擅长处理该疾病类型的医生,并且得到了根据医生信息、表征了医生受欢迎程度的第一评分信息和病情程度信息确定的目标评分信息,使得目标评分信息能够表征出各医生与该疾病类型的匹配程度,并且通过目标评分信息的计算手段实现了病患资源与医疗资源的合理推荐,即对于重症疾病类型患者专家医生的目标评分机制使得目标评分较高,对于重症疾病类型患者普通医生的目标评分机制使得目标评分较低,对于轻症疾病类型患者专家医生的目标评分机制使得目标评分较低,对于轻症疾病类型患者普通医生的目标评分机制使得目标评分较高。由于用户通常会优先选择目标评分较高的医生,进而实现了医疗资源与患病类型的合理分配。
[0180]
图3示出了本技术一个实施例提供的信息的推荐设备的结构示意图。如图3所示,该设备可以包括处理器301以及存储有计算机程序指令的存储器302。
[0181]
具体地,上述处理器301可以包括中央处理器(central processing unit,cpu),或者特定集成电路(application specific integrated circuit,asic),或者可以被配置成实施本技术实施例的一个或多个集成电路。
[0182]
存储器302可以包括用于数据或指令的大容量存储器。举例来说而非限制,存储器302可包括硬盘驱动器(hard disk drive,hdd)、软盘驱动器、闪存、光盘、磁光盘、磁带或通用串行总线(universal serial bus,usb)驱动器或者两个或更多个以上这些的组合。在一
个实例中,存储器302可以包括可移除或不可移除(或固定)的介质,或者存储器302是非易失性固态存储器。存储器302可在综合网关容灾设备的内部或外部。
[0183]
在一个实例中,存储器302可以是只读存储器(read only memory,rom)。在一个实例中,该rom可以是掩模编程的rom、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、电可改写rom(earom)或闪存或者两个或更多个以上这些的组合。
[0184]
处理器301通过读取并执行存储器302中存储的计算机程序指令,以实现图1所示实施例中的方法,并达到图1所示实例执行其方法达到的相应技术效果,为简洁描述在此不再赘述。
[0185]
在一个示例中,该信息的推荐设备还可包括通信接口303和总线310。其中,如图3所示,处理器301、存储器302、通信接口303通过总线310连接并完成相互间的通信。
[0186]
通信接口303,主要用于实现本技术实施例中各模块、装置、单元和/或设备之间的通信。
[0187]
总线310包括硬件、软件或两者,将在线数据流量计费设备的部件彼此耦接在一起。举例来说而非限制,总线可包括加速图形端口(accelerated graphics port,agp)或其他图形总线、增强工业标准架构(extended industry standard architecture,eisa)总线、前端总线(front side bus,fsb)、超传输(hyper transport,ht)互连、工业标准架构(industry standard architecture,isa)总线、无限带宽互连、低引脚数(lpc)总线、存储器总线、微信道架构(mca)总线、外围组件互连(pci)总线、pci-express(pci-x)总线、串行高级技术附件(sata)总线、视频电子标准协会局部(vlb)总线或其他合适的总线或者两个或更多个以上这些的组合。在合适的情况下,总线310可包括一个或多个总线。尽管本技术实施例描述和示出了特定的总线,但本技术考虑任何合适的总线或互连。
[0188]
该信息的推荐设备可以执行本技术实施例中的信息的推荐方法,从而实现图1描述的信息的推荐方法的相应技术效果。
[0189]
图4示出了本技术一个实施例提供的资源库系统结构示意图,该资源库系统400用于为本技术的上述方法实施例步骤提供数据来源,如图4所示,该资源库系统包括:
[0190]
疾病描述词库,用于存储疾病名称及其对应的疾病向量特征以及疾病描述信息;医生信息库,用于存储医生信息、医生可诊断疾病类型以及医生所在科室信息;识别信息库,用于存储预设停用词表和预设关键词表。
[0191]
图5示出了本技术一个实施例提供的医生推荐系统,如图5所示,该医生推荐系统包括本技术上述实施例的获取模块200、确定模块202、以及资源库系统400。
[0192]
图6示出了本技术上述实施例提供的skip-gram模型的基本网络结构图,如图6所示,skip-gram模型的基本网络包括:
[0193]
输入向量input vector层,输入向量层设有10000个位置positions,“1”为目标词汇所在位置。
[0194]
隐含层hidden layer,可以是线性神经元linear neurons,包含300个神经元neurons。
[0195]
输出层output layer,可以是softmax分类器classifier,包含10000个神经元。
[0196]
另外,结合上述实施例中的信息的推荐方法,本技术实施例可提供一种计算机存储介质来实现。该计算机存储介质上存储有计算机程序指令;该计算机程序指令被处理器
执行时实现上述实施例中的任意一种信息的推荐方法。
[0197]
需要明确的是,本技术并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本技术的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本技术的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
[0198]
以上所述的结构框图中所示的功能块可以实现为硬件、软件、固件或者它们的组合。当以硬件方式实现时,其可以例如是电子电路、专用集成电路(application specific integrated circuit,asic)、适当的固件、插件、功能卡等等。当以软件方式实现时,本技术的元素是被用于执行所需任务的程序或者代码段。程序或者代码段可以存储在机器可读介质中,或者通过载波中携带的数据信号在传输介质或者通信链路上传送。“机器可读介质”可以包括能够存储或传输信息的任何介质。机器可读介质的例子包括电子电路、半导体存储器设备、rom、闪存、可擦除rom(erom)、软盘、cd-rom、光盘、硬盘、光纤介质、射频(radio frequency,rf)链路,等等。代码段可以经由诸如因特网、内联网等的计算机网络被下载。
[0199]
还需要说明的是,本技术中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本技术不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。
[0200]
上面参考根据本技术的实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本技术的各方面。应当理解,流程图和/或框图中的每个方框以及流程图和/或框图中各方框的组合可以由计算机程序指令实现。这些计算机程序指令可被提供给通用计算机、专用计算机、或其它可编程数据处理装置的处理器,以产生一种机器,使得经由计算机或其它可编程数据处理装置的处理器执行的这些指令使能对流程图和/或框图的一个或多个方框中指定的功能/动作的实现。这种处理器可以是但不限于是通用处理器、专用处理器、特殊应用处理器或者现场可编程逻辑电路。还可理解,框图和/或流程图中的每个方框以及框图和/或流程图中的方框的组合,也可以由执行指定的功能或动作的专用硬件来实现,或可由专用硬件和计算机指令的组合来实现。
[0201]
以上所述,仅为本技术的具体实施方式,所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的系统、模块和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。应理解,本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。