用于鉴定细胞类型命运特化的调控物的组合物和方法
1.与相关申请的交叉引用
2.本技术要求2019年8月19日提交的美国临时专利申请号62/888,922、2019年8月20日提交的美国临时专利申请号62/889,361和2020年1月14日提交的美国临时专利申请号62/961,084的优先权,每个所述临时申请整体通过参考并入本文。
3.关于联邦资助研究的陈述
4.本发明在美国国立卫生研究院(national institutes of health)授予的资助号为r21ns103007、dp2od008586、r01da036865、f31ns105419和t32gm008555以及由美国国家科学基金会(national science foundation)授予的资助号为efma-1830957的政府支持下做出。美国政府在本发明中具有一定权利。
技术领域
5.本公开涉及用于鉴定细胞类型命运特化的调控物的dna靶向组合物例如crispr/cas9组合物和方法。
背景技术:
6.对细胞命运进行重编程的方法的出现彻底改变了再生医学、疾病建模和细胞治疗。鉴于越来越多的证据将特定的神经元亚型定义为神经系统疾病的起源,在体外产生这些亚型的能力可能有助于这些复杂疾病的研究和治疗。一些当前的细胞重编程方法过表达转录因子(tf),以重新连接起始细胞的转录程序。尽管这种方法已成功地产生了临床相关的细胞类型,但以这种方式重新编程的细胞类型仍然相对较少。已做出努力对所有假定人类转录因子的集合进行分类并定义它们的组织特异性表达,然而,在细胞命运特化中的作用已被经验验证的tf相对较少。此外,为细胞重编程应用选择决定命运的tf通常依赖于评估一小部分tf或使用计算模型来预测最佳tf组合的方法。当前使用tf开发新的细胞重编程方案的策略缓慢、低效且费力。以前的研究主要在小鼠中进行,但从小鼠到人类细胞重编程的变化不可忽视。小鼠细胞与人类细胞的可塑性存在固有差异。小鼠细胞通常更易于重编程,通常获得更高的转化效率和更短的成熟时间。因此,人类细胞通常需要额外的辅助因子或完全不同的方案,以便实现与其小鼠对应物可比的转化结果。鉴于人脑中神经元细胞类型的多样性可能是由多种多样的tf编程的,因此仍然需要继续开发高通量方法来系统地分析tf在指导神经元细胞类型身份中的因果作用,特别是与人类密切相关的神经元细胞类型。
技术实现要素:
7.一方面,本公开涉及一种多核苷酸,其可以编码:(1)选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子;或(2)选自ngn3和ascl1或其组合的第一神经元特异性转录因子;以及选
自下述的第二神经元特异性转录因子:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l、e2f7;(iv)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(v)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(vi)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
8.另一方面,本公开涉及一种用于提高神经元特异性基因的表达的系统,所述系统可以包含:(a)选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子;或(b)靶向选自ngn3和ascl1或其组合的第一神经元特异性转录因子的第一grna;和靶向选自下述的第二神经元特异性转录因子的第二grna:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l、e2f7;(iv)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、
rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(v)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(vi)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx;以及cas蛋白或融合蛋白。在某些实施方式中,所述融合蛋白可以包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有选自转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、核酸酶活性、核酸结合活性、甲基化酶活性和脱甲基化酶活性的活性。在某些实施方式中,所述第二神经元特异性转录因子选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2、nkx2-2、hes3和zfp36l1。在某些实施方式中,所述第二神经元特异性转录因子可以选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2和nkx2-2。在某些实施方式中,所述第二神经元特异性转录因子可以选自hes3和zfp36l1。在某些实施方式中,所述第二神经元特异性转录因子可以选自:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7,并且其中所述第二多肽结构域具有转录激活活性。在某些实施方式中,所述融合蛋白可以包含
vp64
dcas9
vp64
或dcas9-p300。在某些实施方式中,所述第二神经元特异性转录因子可以选自:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、
irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx,并且其中所述第二多肽结构域具有转录阻遏活性。在某些实施方式中,所述融合蛋白可以包含dcas9-krab。在某些实施方式中,所述第一grna和第二grna各自单独地可以包含12-22个碱基对的靶dna序列的互补多核苷酸序列,随后是前间区序列邻近基序,并且任选地其中所述grna结合并靶向和/或包含含有选自seq id no:38-87的序列的多核苷酸,并且任选地其中所述第一grna和/或第二grna包含crrna、tracrrna或其组合。
9.本公开的另一方面提供了一种分离的多核苷酸,其可以编码本文中详述的系统。
10.本公开的另一方面提供了一种载体,其可以包含本文中详述的分离的多核苷酸。
11.另一方面,本公开涉及一种细胞,其可以包含本文中详述的分离的多核苷酸或本文中详述的载体。
12.另一方面,本公开涉及一种提高干细胞衍生的神经元的成熟的方法。所述方法可以包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
13.本公开的另一方面提供了一种提高干细胞衍生的神经元的成熟的方法。所述方法可以包括:提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、
tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
14.本公开的另一方面提供了一种提高干细胞向神经元的转化的方法。所述方法可以包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
15.本公开的另一方面提供了一种提高干细胞向神经元的转化的方法。所述方法可以包括:提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
16.本公开的另一方面涉及一种治疗有需要的对象的方法。所述方法可以包括:(a)提高所述对象中的干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、
sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述对象中的干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
17.本公开的另一方面提供了一种治疗有需要的对象的方法。所述方法可以包括:提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述对象中的干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
18.在某些实施方式中,提高所述第一神经元特异性转录因子的水平可以包括下述至少一者:(a)向所述干细胞给药编码所述第一神经元特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述第一神经元特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第一神经元特异性转录因子的锌指蛋白或靶向所述第一神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第一神经元特异性转录因子的grna。在某些实施方式中,提高所述第二神经元特异性转录因子的水平可以包括下述至少一者:(a)向所述干细胞给药编码所述第二神经元特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述第二神经元特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第二神经元特
异性转录因子的锌指蛋白或靶向所述第二神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第二神经元特异性转录因子的grna。在某些实施方式中,降低所述第二神经元特异性转录因子的水平可以包括向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第二神经元特异性转录因子的锌指蛋白或靶向所述第二神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录阻遏活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第二神经元特异性转录因子的grna。在某些实施方式中,所述干细胞可以不经历多能阶段直接转化成神经元。在某些实施方式中,所述干细胞可以是多能干细胞、诱导多能干细胞或胚胎干细胞。
19.本公开的另一方面提供了一种用于选择具有作为细胞类型特异性转录因子的活性的多核苷酸的系统。所述系统可以包含:编码报告蛋白和细胞类型标志物的多核苷酸;融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白,并且第二多肽结构域具有转录激活活性;以及指导rna(grna)的文库,每个grna靶向不同的假定细胞类型特异性转录因子。在某些实施方式中,所述细胞类型特异性转录因子可以是神经元特异性转录因子,其中所述细胞类型标志物是神经元标志物,并且其中所述神经元标志物包括tubb3。在某些实施方式中,所述细胞类型特异性转录因子可以是肌肉特异性转录因子,其中所述细胞类型标志物是成肌标志物,并且其中所述成肌标志物包括pax7。在某些实施方式中,所述细胞类型特异性转录因子可以是软骨细胞特异性转录因子,其中所述细胞类型标志物是胶原标志物,并且其中所述胶原标志物包括col2a1。在某些实施方式中,所述报告蛋白可以包括mcherry。
20.本公开的另一方面提供了一种分离的多核苷酸序列,其可以编码本文中详述的系统。
21.本公开的另一方面提供了一种载体,其可以包含本文中详述的分离的多核苷酸序列。
22.本公开的另一方面提供了一种细胞,其可以包含本文中详述的系统、本文中详述的分离的多核苷酸序列或本文中详述的载体或其组合。
23.本公开的另一方面提供了一种筛选细胞类型特异性转录因子的方法。所述方法可以包括:用本文中详述的系统以约0.2的感染复数(moi)转导细胞群体,使得大部分所述细胞各自独立地包括一种grna并靶向一种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中所述grna的水平。在某些实施方式中,所述报告蛋白的高表达可以被定义为在所述细胞群体内的前5%中;并且当所述假定转录因子对应于在所述具有报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述假定转录因子作为细胞类型特异性转录因子。
24.本公开的另一方面提供了一种筛选一对细胞类型特异性转录因子的方法。所述方法可以包括:用本文中详述的系统以约0.2的感染复数(moi)转导细胞群体,使得大部分所述细胞各自独立地包括两种grna并靶向两种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中所述两种grna的水平。在某些实施方式中,所述报告蛋白的高表达可以被定义为在所述细胞群体内的前5%中;并且当所
述假定转录因子对应于在所述具有报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述两种假定转录因子作为一对细胞类型特异性转录因子。在某些实施方式中,在每个细胞中所述报告蛋白的表达水平可以在从转导起约4天后确定。在某些实施方式中,在每个细胞中所述报告蛋白的表达水平可以通过流式细胞术来确定。在某些实施方式中,在每个具有所述报告蛋白的高表达的细胞中所述grna的水平可以通过深度测序来确定。在某些实施方式中,相对于非靶向grna,所述grna可以将所述细胞中所述报告蛋白的表达提高约2-50%。
25.本公开的另一方面提供了一种多核苷酸,其编码选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子。
26.本公开的另一方面提供了一种用于提高肌肉特异性基因的表达的系统。所述系统可以包含:(a)选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子;或(b)融合蛋白,其中所述融合蛋白包含两个异源多肽结构域。在某些实施方式中,第一多肽结构域可以包含cas蛋白、靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的锌指蛋白或靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的tale蛋白,其中第二多肽结构域具有选自转录激活活性、转录释放因子活性、组蛋白修饰活性、核酸结合活性、甲基化酶活性和脱甲基化酶活性的活性,并且其中当所述第一多肽结构域包含cas蛋白时,所述系统还包含靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的grna。在某些实施方式中,所述融合蛋白可以包含
vp64
dcas9
vp64
或dcas9-p300。
27.本公开的另一方面提供了一种分离的多核苷酸,其可以编码本文中详述的系统。
28.本公开的另一方面提供了一种载体,其可以包含本文中详述的分离的多核苷酸。
29.本公开的另一方面提供了一种细胞,其可以包含本文中详述的分离的多核苷酸或本文中详述的载体。
30.本公开的另一方面提供了一种提高干细胞向成肌细胞的分化的方法。所述方法可以包括:提高所述干细胞中选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的水平。
31.本公开的另一方面提供了一种治疗有需要的对象的方法。所述方法可以包括:提高来自于所述对象的干细胞中选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的水平。在某些实施方式中,提高所述肌肉特异性转录因子的水平可以包括下述至少一者:(a)向所述干细胞给药编码所述肌肉特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述肌肉特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述肌肉特异性转录因子的锌指蛋白或靶向所述肌肉特异性转录因子的tale蛋白,其中第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外给药靶向所述肌肉特异性转录因子的grna。
32.本公开还提供了其他方面和实施方式,它们根据下述具体实施方式和附图将变得显而易见。
附图说明
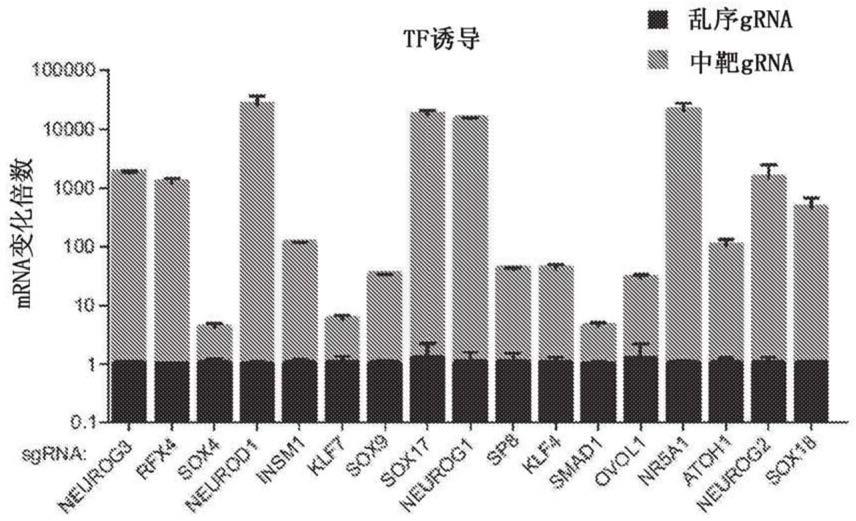
33.图1a-图1g.高通量crispra筛选鉴定候选神经源性转录因子。(图1a)人类多能干细胞中决定神经元命运的转录因子的crispra筛选的示意图。将
vp64
dcas9
vp64 tubb3-2a-mcherry报告细胞系用cas-tf合并慢病毒文库以0.2的moi转导,并通过facs分拣mcherry表达。每个细胞箱中的grna丰度通过深度测序来测量,并通过差异表达分析来鉴定被耗竭或富集的grna。(图1b)从以前的基因组广度的crispra文库(horlbeck,2016,紧凑且高度活跃的下一代文库(compact and highly active next-generation libraries),elife)提取cas-tf grna文库,其由靶向1496种假定转录因子的8,505个grna组成。(图1c)将tubb3-2a-mcherry细胞在mcherry信号的基础上分拣出表达最高和最低的5%的细胞。还对未分拣的主体细胞群体进行采样,以建立基线grna分布。(图1d)高mcherry和未分拣的细胞群体之间归一化的grna计数的差异表达分析。红色数据点表示通过差异deseq2分析fdr《0.01(n=3个生物学平行样)。蓝色数据点表示一组100个乱序非靶向grna。(图1e)在cas-tf筛选中鉴定到的17种tf的tf家族类型分析。(图1f)在cas-tf筛选中鉴定到的17种tf和三组随机的17种tf的跨多个发育时间点和解剖学脑区的平均基因表达的比较。(图1g)来自于三种已知原神经tf的所有5种grna与随机选择的5种乱序grna相比,来自于高mcherry和低mcherry细胞群体之间的差异表达分析的grna丰度的变化倍数。也参见图7a-图7d。
34.图2a-图2f.许多候选因子从多能干细胞产生神经元细胞。(图2a)在grna转导后4天17种因子的tubb3-2a-mcherry表达的验证(*p《0.05,通过全局单向anova和dunnett事后检验,将所有组与乱序物1比较,门控被设定到对于乱序grna来说1%阳性,n=3个生物学平行样。误差条表示sem)。(图2b)对来自于atoh1和nr5a1的所有5种grna来说,通过个体验证评估的tubb3-2a-mcherry表达与来自于文库选集的差异表达分析的grna丰度变化倍数之间的关系。(图2c)在grna转导后4天17种因子对泛神经元标志物ncam(上图)和map2(下图)的诱导的验证(*p《0.05,通过全局单向anova和dunnett事后检验,将所有组与乱序物1比较,n=3个生物学平行样,误差条表示sem)。(图2d)在用带有编码指定因子的cdna的四环素诱导型慢病毒载体或用仅仅m2rtta阴性对照转导后4天,ipsc的免疫荧光染色,用于评估tubb3表达。标尺条,50μm。(图2e)在与星形胶质细胞长期共培养后,使用指定因子的ipsc的免疫荧光染色,用于评估map2表达。标尺条,50μm。(图2f)在用指定因子转导后4天,h9 hesc的免疫荧光染色,用于评估tubb3表达。也参见图8a-图8c、图9a-图9d和图10a-图10e。
35.图3a-图3g.组合grna筛选鉴定神经元分化的辅助因子。(图3a)人类多能干细胞中决定神经元命运的转录因子的组合crispra筛选的示意图。使用双grna表达载体将神经源性因子与cas-tf grna文库共表达。使用sgascl1和sgngn3进行两次独立的筛选。(图3b)对于sgngn3成对筛选来说,显著性(p值)相对于基于高mcherry与未分拣的细胞群体之间的差异deseq2分析的grna丰度变化倍数的火山图。红色数据点指示fdr《0.001(n=3个生物学平行样)。蓝色数据点指示一组100种乱序非靶向grna。(图3c)sgascl1相比于sgngn3成对筛选,对于两种筛选中所有正富集的grna来说grna丰度的变化倍数。(图3d)对于来自于两种成对筛选的阳性命中物来说,tf家族类型和在多能干细胞中的基础表达水平的分析。(图3e)预计单独没有活性但在sgascl1和sgngn3成对筛选中具有协同活性的一组tf的grna丰度的变化倍数。tf辅助因子的验证对于sgngn3来说使用tubb3-2a-mcherry(图3f),并且对于sgascl1来说使用ncam染色(图3g)。(*p《0.05,通过全局单向anova和dunnett事后检验,
将所有组与乱序物1比较,n=3个生物学平行样,误差条表示sem)。也参见图11a-图11b和图12a-图12d。
36.图4a-图4f.由单种转录因子产生的神经元的转录多样性。(图4a)在atoh1和neurog3衍生的神经元中检测到的差异上调的基因(fdr《0.01并且log2(变化倍数)》1)。(图4b)在atoh1和neurog3之间共有且上调的2846个基因的集合的富集基因本体(go)条目。(图4c)在分析的所有平行样品中一组泛神经元基因的表达水平(log2(tpm 1))。(图4d)atoh1和neurog3衍生的神经元之间所有检测到的基因的比较。红色和蓝色圆圈分别代表使用neurog3或atoh1时差异表达的基因。(图4e)在仅使用neurog3或atoh1时上调的标志物的go条目分析。(图4f)一组多巴胺能和谷氨酸能标志物的表达水平(log2(tpm 1))和相应的z-分值。
37.图5a-图5n.使用成对转录因子产生的神经元的转录和功能成熟。(图5a)在源自于成对tf的神经元中检测到的差异上调的基因(fdr《0.01并且log2(变化倍数)》1)。(图5b)使用成对tf与单独的neurog3相比,在差异上调的基因集合中富集的go条目。分别添加runx3或e2f7时(图5c)ntrk3和(图5d)cdkn1a的上调。(图5e)在添加lhx8时差异上调的基因集合的syngo条目。(图5f)一组突触标志物的表达水平(下图:log2(变化倍数);上图:log2(tpm 1))。使用单独的或与lhx8组合的neurog3产生的神经元第7天的包括(图5g)静息膜电位(v
rest
)、(图5h)输入电阻(rm)和(图5i)膜电容(cm)在内的膜性质的平均值。使用单独的或与lhx8组合的neurog3产生的神经元第7天的包括(图5j)动作电位阈值(ap
threshold
)、(图5k)动作电位高度(ap
height
)和(图5l)动作电位半宽度(ap
half-width
)在内的动作电位性质的平均值。(图5m)产生的动作电位平均数量相对于注入电流振幅的变化(*p《0.05,双向anova)。(图5n)具有失败(左)、单个(中)或多个(右)动作电位的细胞的示例性迹线。相应的饼图表示所分析的细胞对单个去极化电流注入做出响应不能产生ap(深色度)、产生单个ap(中色度)或产生多个ap(浅色度)的总分数。对于图5g至图5l来说:ns,不显著;*p《0.05,非配对t-检验(如果数据通过正态性验证;α=0.05)或mann-whitney检验(如果数据未通过正态性验证;α=0.05);对于单独的neurog3来说n=19个细胞;对于neurog3 lhx8来说n=22个细胞。
38.图6a-图6i.组合grna筛选鉴定神经元分化的负调控物。(图6a)sgascl1与sgngn3成对筛选相比,两种筛选中所有负富集的grna的grna丰度变化倍数。(图6b)tf的一个子集的验证,评估了tubb3-2a-mcherry阳性细胞的百分数和(图6c)泛神经元标志物ncam的表达(*p《0.05,通过全局单向anova和dunnett事后检验,将所有组与sgngn3 乱序grna条件进行比较,n=3个生物学平行样,误差条表示sem)。(图6d)同样的负调控物在h9 hesc中的验证。(图6e)ipsc与esc相比,grna对神经元分化的影响的比较。(图6f)正交基因激活和阻遏的示意图。(图6g)在测试的所有三个组之间,通过z-分值定量的变化最大的100个基因的相对表达。(图6h)在zfp36l1敲减的sgngn3衍生的神经元中,在差异表达的基因集合中富集的go条目。(图6i)与神经元分化和形态发育相关的差异表达的基因的示例性集合。也参见图13a-图13c和图14a-图14d。
39.图7a-图7d.tubb3-2a-mcherry报告细胞系的产生和表征。(图7a)使用cas9核酸酶和供体模板,在人类多能干细胞系中tubb3的外显子4中敲入p2a-mcherry表达盒的示意图。(图7b)使用
vp64
dcas9
vp64
和一组4个靶向neurog2启动子的grna,在多能干细胞中靶向激活内源neurog2。靶向激活neurog2时ncam(中)和map2(右)的表达(n=2个生物学平行样)。(图
7c)使用
vp64
dcas9
vp64
和一组4个靶向启动子的grna靶向激活neurog2时,通过流式细胞术测定的tubb3-2a-mcherry表达。(图7d)在用
vp64
dcas9
vp64
和grna激活neurog2后,在分拣的具有最高和最低mcherry表达的tubb3-2a-mcherry细胞中tubb3和map2的表达(n=1个生物学平行样)。
40.图8a-图8c.具有单种富集的grna的tf的验证。(图8a)在单因子cas-tf筛选中,mcherry高表达细胞相比于mcherry低表达细胞之间grna丰度的变化倍数的排序表。ascl1、atoh7和atoh8均具有显著富集的单种grna。(图8b)sgascl1、sgatoh7和sgatoh8的个体验证,以评估grna转导后4天(图8b)tubb3-2a-mcherry表达的百分率和(图8c)map2(左)和ncam(右)表达(*p《0.05,通过全局单向anova和dunnett事后检验,将所有组与乱序grna进行比较,n=3个生物学平行样,误差条表示sem)。
41.图9a-图9d.使用
vp64
dcas9
vp64
内源诱导tf。(图9a)使用
vp64
dcas9
vp64
和富集排名靠前的grna对在单因子cas-tf筛选中富集的17种tf的子集的诱导倍数(相对于乱序grna的变化倍数,n=2个生物学平行样)。(图9b)每种tf的诱导倍数与该tf的基础表达相对于gapdh表达之间的相关性。(图9c)对于两种neurog2 grna来说,来自于单因子cas-tf筛选的grna富集的比较。(图9d)这两种neurog2 grna的tf诱导和下游神经元标志物的表达的验证(*p《0.05,通过全局单向anova和tukey事后检验,比较了所述两种neurog2 grna,n=3个生物学平行样,误差条表示sem)。
42.图10a-图10e.cas-tf子文库grna筛选。(图10a)在人类多能干细胞中决定神经元命运的转录因子的crispra子文库筛选的示意图。将
vp64
dcas9
vp64 tubb3-2a-mcherry报告细胞系用cas-tf合并慢病毒文库以0.2的moi转导,并通过facs分拣mcherry的表达。每个细胞箱中的grna丰度通过深度测序来测量,并通过差异表达分析来鉴定被耗竭或富集的grna。(图10b)从几个以前的基因组广度的crispra文库提取cas-tf grna子文库,其由靶向109种假定转录因子的3,874个grna组成(每个基因~33个grna)。(图10c)高mcherry和低mcherry细胞群体之间归一化的grna计数的差异表达分析。红色数据点表示通过差异deseq2分析fdr《0.01(n=3个生物学平行样)。(图10d)每个基因富集的grna的百分率的排序表。(图10e)在grna转导后4天,10种因子的tubb3-2a-mcherry表达的验证(n=2个生物学平行样)。
43.图11a-图11b.使用sgascl1的成对grna筛选。对于sgascl1成对筛选来说,显著性(p值)相比于(图11a)高mcherry相比于未分拣的细胞群体和(图11b)高mcherry相比于低mcherry细胞群体的基于差异deseq2分析的grna丰度变化倍数的火山图。红色数据点表示fdr《0.001(n=3个生物学平行样)。
44.图12a-图12d.单因子和成对cas-tf筛选的比较。高mcherry表达与低mcherry表达的细胞之间grna丰度的变化倍数;(图12a和图12b)sgngn3相比于单因子cas-tf筛选,在两种筛选中所有正(图12a)和负(图12b)富集的grna;以及(图12c和图12d)sgascl1相比于单因子cas-tf筛选,在两种筛选中所有正(图12c)和负(图12d)富集的grna。
45.图13a-图13c.使用正交crispr系统的基因激活和阻遏。(图13a)使用靶向启动子的dsacas9
krab
和单种grna 7天,在多能干细胞中靶向阻遏zfp36l1和hes3(*p《0.05,通过双尾t-检验,n=3个生物学平行样,误差条表示sem)。在zfp36l1和hes3敲减细胞系中使用sgngn3(图13b)或sgaslc1(图13c)对分化的影响(*p《0.05,通过全局单向anova和dunnett事后检验,将使用sgngn3或sgascl1的所有组与接受乱序非靶向金黄色葡萄球菌
(s.aureus)grna的对照细胞系进行比较,n=3个生物学平行样,误差条表示sem)。
46.图14a-图14d.使用基于正交crispr的基因调控的基因组广度的表达分析。具有(图14a)hes3敲减和(图14b)zfp36l1敲减的sgngn3衍生的神经元的差异表达分析。红色数据点表示使用deseq2的差异表达分析fdr《0.01(n=3个生物学平行样)。(图14c)在示出的三种条件下,酿脓链球菌(s.pyogenes)grna靶基因neurog3的表达。(图14d)在示出的三种条件下,使用酿脓链球菌grna慢病毒载体上gfp的表达作为转导水平和grna表达的替代物。
47.图15a-图15e.人类esc中pax7-2a-gfp报告细胞系的产生和验证。(图15a)pax7基因靶向策略。grna被设计成靶向pax7的终止密码子,并设计了含有可切除选择标记的2a-gfp供体表达盒用于通过同源重组进行插入。(图15b)使用同源臂之外的引物对克隆进行的pcr验证显示出报告基因表达盒的杂合插入。(图15c)2.6kb产物的测序确认了2a-gfp报告基因表达盒的插入。(图15d)通过crispra靶向单个克隆的pax7启动子用于激活证实了gfp的变化。(图15e)排名前15%和后15%的表达gfp的细胞分别对应于高和低pax7 mrna表达。
48.图16a-图16e.pax7的上游调控物的cra-tf筛选。(图16a)cra-tf筛选的示意图。将稳定表达
vp64
dcas9
vp64
的h9 pax7-2a-gfp细胞用cra-tf慢病毒文库以0.2的moi转导。使用小分子chiron99021(chir)和bfgf将细胞选择并分化14天。分拣出前10%和后10%的表达gfp的细胞,并对dna进行深度测序以回收grna。(图16b)分化第14天的柱状图证实了与无文库对照相比,在cra-tf筛选的三份平行样中出现了gfp 群体。(图16c)ma图证实了与未分拣的细胞相比,在前10%的细胞中显著的grna命中(p《0.05)。(图16d)各个grna命中物的验证,证实了pax7的诱导。(图16e)命中物的cdna递送也证实了pax7的诱导(平均值
±
sem,n=3)。
49.图17a-图17c.用于鉴定pax7辅助因子的组合cra-tf筛选。(图17a)在初始筛选的第二个版本中,对慢病毒构建物进行了重新设计,以包括靶向pax7的grna。将慢病毒以0.2的moi转导,使得每个细胞接受一个拷贝的pax7 grna和来自于cra-tf文库的grna。(图17b)分化第7天的柱状图证实了与无文库对照相比,在第二种cra-tf筛选的三份平行样中gfp变化。(图17c)维恩图,示出了来自于所述筛选的两个版本的独特和重叠的显著(p《0.05)命中物。
50.图18a-图18d.通过cra-tf命中物诱导成肌谱系的验证。(图18a)通过命中物的诱导型表达进行验证的示意图。将表达teto-vp64
dcas
vp64
的h9 pax7-2a-gfp用各个grna命中物和rtta3转导。将细胞在dox存在下分化28天。在分析前14天通过撤除dox来诱导终末分化。(图18b)终末分化后的rna分析证实了与非靶向grna对照相比pax7表达提高。(图18c)终末分化后的rna分析证实了与非靶向grna对照相比myog表达提高(平均值
±
sem,n=3)。
51.(图18d)细胞的图像。
52.图19a-图19b.多克隆反式激活物细胞系的产生和验证。(图19a)
vp64
dcas9
vp64-2a-杀稻瘟菌素表达盒的示意图。(图19b)在ngn2转导后内源ngn2的激活。
53.图20a-图20c.tf靶向grna筛选以鉴定软骨形成的调控物。(图20a)实验示意图,演示了在报告细胞系中激活物细胞系的产生的grna文库的慢病毒包装。在文库转导和成软骨分化后,分拣出gfp
高
和gfp
低
细胞并从两个群体回收grna。使用下一代测序比较grna的差异表达。(图20b)文库转导和成软骨分化后gfp荧光的柱状图。门示出了gfp
高
和gfp
低
的分拣群体。(图20c)火山图,示出了在gfp
高
和gfp
低
群体中显著富集的grna(红色)以及未满足显著性标准但具有高(》3)的log2(变化倍数)的grna。更大的火山图参见附录b。
54.图21a-图21c.在定向分化的背景下sox9的验证。(图21a)实验设计的示意图。具有sox9过表达的报告hipsc分化成生骨节,然后在第6天进行流式细胞术。(图21b)未修饰的细胞系与含有(红色)和不含(黑色)sox9慢病毒的报告细胞系在第6天的流式细胞术的比较。(图21c)分化第6天的数据与第21天的gfp荧光(蓝色)的比较。
具体实施方式
55.本文中详细描述了细胞类型特异性转录因子和使用它们提高细胞类型特异性基因的表达、提高干细胞衍生的神经元的成熟、提高干细胞向神经元的转化效率和治疗有需要的对象的方法。本文中还详细描述了一种高通量合并crispr激活(crispra)筛选方法,用于绘制人类细胞命运调控物图并剖析假定的人类转录因子对多能干细胞的神经元细胞命运特化的贡献。crispra筛选用于在高通量方法中剖析人类基因组中的数千种假定转录因子。与传统方法相比,基于crispr的grna文库更容易设计和规模缩放,并且更易于测试组合基因相互作用和质询非编码基因组。使用神经元定型的报告物,对人类多能干细胞中所有转录因子的神经源性活性进行了剖析。进行了单因子筛选以鉴定人类神经元命运的主要调控物,并且鉴定到许多已知和以前未表征的tf。进行了组合筛选,并鉴定到分别增强或减少神经元分化的协同和拮抗性tf相互作用。tf被发现可以提高转化效率,影响亚型特化,并促进体外衍生的人类神经元的成熟。
56.总的来说,本工作突出了dna靶向系统例如基于crispr的技术在调节内源性基因表达方面的效用,并为鉴定细胞命运调控物在定义任何感兴趣的细胞类型中的因果作用提供了一个框架。从本文详述的研究挑选出的一组候选原神经转录因子可以充当建立方案的资源,以产生人脑中的每种细胞类型。
57.1.定义
58.除非另有定义,否则本文中使用的所有技术和科学术语均具有与本领域普通技术人员通常理解的相同的含义。在有冲突的情况下,以包括定义在内的本文件为准。下文描述优选的方法和材料,尽管与本文中描述的相似或等效的方法和材料也可用于本发明的实践和试验。本文中提到的所有出版物、专利申请、专利和其他参考文献整体通过参考并入本文。本文公开的材料、方法和实例仅仅是说明性的而不打算是限制性的。
59.当在本文中使用时,术语“包含”、“包括”、“具有”、“可以”、“含有”及其变化形式打算作为开放性过渡短语、术语或词语,其不排除其他行动或结构的可能性。没有具体数目的指称包括复数指称物,除非上下文明确叙述不是如此。本公开还设想了“包含”本文中呈现的实施方式或要素、“由它们组成”和“基本上由它们组成”的其他实施方式,不论是否明确阐述。
60.对于本文中的数字范围的叙述来说,明确设想了在其间具有相同精度的每个居间数字。例如,对于6-9的范围来说,除了6和9之外还设想了数字7和8,并且对于6.0-7.0的范围来说,明确设想了数字6.0、6.1、6.2、6.3、6.4、6.5、6.6、6.7、6.8、6.9和7.0。
61.当在本文中使用时,术语“约”在应用于一个或多个感兴趣的值时,是指与所陈述的参比值相近的值。在某些情况下,术语“约”是指落于所陈述的参比值在任一方向上(大于或小于)的20%、19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或更小范围之内的值的范围,除非另有陈述或从上下文明确看
出不是如此(除了这样的数字将超过可能值的100%的情况之外)。
62.在本文中可互换使用的“腺相关病毒”或“aav”是指属于细小病毒科的依赖病毒属的一种感染人类和一些其他灵长类动物的小病毒。目前尚不知道aav会引起疾病,因此所述病毒引起非常温和的免疫应答。
63.当在本文中使用时,“氨基酸”是指天然存在的氨基酸和非天然的合成氨基酸,以及以与天然存在的氨基酸相似的方式起作用的氨基酸类似物和氨基酸模拟物。天然存在的氨基酸是由遗传密码编码的氨基酸。氨基酸在本文中可以通过它们通常已知的三字母符号或由iupac-iub生物化学命名委员会推荐的单字母符号指称。氨基酸包括侧链和多肽骨架部分。
64.当在本文中使用时,“结合区”是指核酸酶靶区域内被所述核酸酶识别并结合的区域。
65.当在本文中使用时,“编码序列”或“编码核酸”意味着包含编码蛋白质的核苷酸序列的核酸(rna或dna分子)。编码序列还可以包括可操作连接到调控元件的起始和终止信号,包括启动子和多聚腺苷化信号,其能够在所述核酸给药到的个体或哺乳动物的细胞中指导表达。编码序列可以是密码子优化的。
66.当在本文中使用时,“互补体”或“互补的”意味着核酸可以在所述核酸分子的核苷酸或核苷酸类似物之间包含watson-crick(例如a-t/u和c-g)或hoogsteen碱基配对。“互补性”是指两个核酸序列之间享有的性质,使得当它们彼此反平行对齐时,每个位置处的核苷酸碱基将是互补的。
67.术语“对照”、“参比水平”和“参比”在本文中可互换使用。所述参比水平可以是预定的值或范围,其被用作评估测量结果的基准。当在本文中使用时,“对照组”是指对照对象的组。所述预定水平可以是来自于对照组的截止值。所述预定水平可以是来自于对照组的平均值。截止值(或预定截止值)可以通过自适应指数模型(aim)方法来确定。截止值(或预定截止值)可以通过来自于患者组的生物样品的对象工作曲线(roc)分析来确定。正如生物学技术领域中公知的,roc分析是某种测试区分一种情况与另一种情况、例如确定每种标志物在鉴定crc患者中的表现的能力的确定。roc分析的描述提供在p.j.heagerty等(biometrics 2000,56,337-44)中,其公开内容整体通过参考并入本文。或者,截止值可以通过患者组的生物学样品的四分位数分析来确定。例如,截止值可以通过选择对应于第25至75百分位数范围之内的任何值的值,优选为对应于第25百分位数、第50百分位数或第75百分位数、更优选为第75百分位数的值来确定。此类统计分析可以使用本领域中已知的任何方法来进行,并且可以通过任何数目的可商购的软件包(例如来自于analyse-it software ltd.,leeds,uk;statacorp lp,college station,tx;sas institute inc.,cary,nc.)来进行。靶或蛋白质活性的健康或正常水平或范围可以根据标准实践来定义。对照可以是不具有本文详述的激动剂的对象或细胞。对照可以是疾病状态已知的对象或来自于其的样品。所述对象或来自于其的样品可能是健康的、患病的、在治疗前患病的、在治疗期间患病的或在治疗后患病的或其组合。
68.当在本文中使用时,“融合蛋白”是指通过两个或更多个联结的最初编码独立蛋白质的基因的翻译产生的嵌合蛋白。所述融合基因的翻译产生单一多肽,其具有源自于每个最初的独立蛋白质的功能特性。
69.当在本文中使用时,“遗传构建物”是指包含编码蛋白的多核苷酸的dna或rna分子。所述编码序列包括可操作连接到调控元件的起始和终止信号,包括启动子和多聚腺苷化信号,其能够在所述核酸分子给药到的个体的细胞中指导表达。当在本文中使用时,术语“可表达形式”是指含有可操作连接到编码蛋白的编码序列必需调控元件的基因构建物,使得当存在于个体的细胞中时,所述编码序列被表达。
70.当在本文中使用时,“基因组编辑”是指改变基因。基因组编辑可以包括校正或恢复突变基因。基因组编辑可以包括敲除基因例如突变基因或正常基因。基因组编辑可用于通过改变感兴趣的基因来治疗疾病或增强肌肉修复。
71.当在本文中使用时,“同一的”或“同一性”在两个或更多个核酸或多肽序列的情形中意味着所述序列在规定的区域内具有规定百分数的相同残基。所述百分数可以如下计算:将所述两个序列最佳比对,在所述规定区域内比较所述两个序列,确定在两个序列中存在相同残基的位置的数目以得到匹配位置数,将所述匹配位置数除以所述规定区域中的总位置数并将结果乘以100,以得到序列同一性百分数。在所述两个序列具有不同长度或所述比对产生一个或多个交错末端和所述比较的规定区域只包括单个序列的情况下,单个序列的残基包括在所述计算的分母中但不包括在分子中。当比较dna和rna时,胸腺嘧啶(t)和尿嘧啶(u)可以被认为是等同的。同一性分析可以人工或通过使用计算机序列算法例如blast或blast 2.0来进行。
72.在本文中可互换使用的“突变基因”和“突变的基因”是指已经历可检测突变的基因。突变基因已经历影响基因的正常传递和表达的变化,例如遗传物质的丧失、获得或交换。当在本文中使用时,“破坏的基因”是指具有导致过早终止密码子的突变的突变基因。所述破坏的基因的产物相对于全长未破坏基因的产物被截短。
73.当在本文中使用时,“正常基因”是指尚未经历变化例如遗传物质的丧失、获得或交换的基因。所述正常基因经历正常的基因传递和基因表达。例如,正常基因可以是野生型基因。
74.当在本文中使用时,“核酸”或“寡核苷酸”或“多核苷酸”意味着共价连接在一起的至少两个核苷酸。单链的描绘也定义了互补链的序列。因此,多核苷酸也涵盖所描绘的单链的互补链。多核苷酸的许多变体可用于与给定多核苷酸相同的目的。因此,多核苷酸也涵盖基本上同一的多核苷酸及其互补体。单链提供了可以在严紧杂交条件下与靶序列杂交的探针。因此,多核苷酸还涵盖在严紧杂交条件下杂交的探针。多核苷酸可以是单链或双链的,或者可能含有双链和单链序列两者的部分。多核苷酸可以是天然或合成的核酸、dna、基因组dna、cdna、rna或杂合体,其中所述多核苷酸可以含有脱氧核糖核苷酸和核糖核苷酸的组合以及包括例如尿嘧啶、腺嘌呤、胸腺嘧啶、胞嘧啶、鸟嘌呤、肌苷、黄嘌呤、次黄嘌呤、异胞嘧啶和异鸟嘌呤在内的碱基的组合。多核苷酸可以通过化学合成方法或通过重组方法来获得。
75.当在本文中使用时,“可操作连接的”意味着基因的表达在空间上与其相连的启动子的控制之下。启动子可能位于在其控制之下的基因的5'(上游)或3'(下游)。启动子与基因之间的距离可以与在所述启动子所源自的基因中所述启动子与其控制的基因之间的距离大致相同。正如本领域中已知的,可以容许这个距离的变动而不丧失启动子功能。
76.当在本文中使用时,“部分有功能的”描述了由突变基因编码并具有比有功能蛋白
质更低但比无功能蛋白质更高的生物学活性的蛋白质。
[0077]“肽”或“多肽”是通过肽键相连的两个或更多个氨基酸的连接的序列。多肽可以是天然多肽、合成多肽或天然和合成多肽的修饰或组合。肽和多肽包括蛋白质例如结合蛋白、受体和抗体。术语“多肽”、“蛋白质”和“肽”在本文中可互换使用。“一级结构”是指特定肽的氨基酸序列。“二级结构”是指多肽内局部有序的三维结构。这些结构通常被称为结构域,例如酶结构域、细胞外结构域、跨膜结构域、孔结构域和胞质尾部结构域。“结构域”是多肽的形成所述多肽的紧凑单元的部分,通常为15至350个氨基酸长。示例性结构域包括具有酶活性或配体结合活性的结构域。典型的结构域由组织化较低的区段例如β-折叠和α-螺旋的区段组成。“三级结构”是指多肽单体的完整三维结构。“四级结构”是指由独立的三级单元的非共价缔合形成的三维结构。“基序”是多肽序列的一部分,并包括至少两个氨基酸。基序的长度可以是2至20、2至15或2至10个氨基酸。在某些实施方式中,基序包括3、4、5、6或7个连续氨基酸。结构域可以由一系列相同类型的基序组成。
[0078]
在本文中可互换使用的“过早终止密码子”或“框外终止密码子”是指dna序列中的无义突变,其在野生型基因中通常不存在的位置中产生终止密码子。过早终止密码子可以产生与全长版本的蛋白质相比被截短或更短的蛋白质。
[0079]
当在本文中使用时,“启动子”意味着能够在细胞中赋予、激活或增强核酸表达的合成或天然来源的分子。启动子可以包含一个或多个特定的转录调控序列,以进一步增强表达和/或改变其空间表达和/或时间表达。启动子还可以包含远端增强子或阻遏蛋白元件,它们可以位于距转录起始位点多达数千碱基对处。启动子可以源自于包括病毒、细菌、真菌、植物、昆虫和动物在内的来源。启动子可以组成性地或相对于在其中进行表达的细胞、组织或器官或相对于发生表达的发育阶段或对外部刺激例如生理胁迫、病原体、金属离子或诱导剂做出响应而差异性地调节基因组分的表达。启动子的代表性实例包括噬菌体t7启动子、噬菌体t3启动子、sp6启动子、lac操纵基因-启动子、tac启动子、sv40晚期启动子、sv40早期启动子、rsv-ltr启动子、cmv ie启动子、sv40早期启动子或sv40晚期启动子、人类u6(hu6)启动子和cmv ie启动子。
[0080]
当在本文中使用时,“样品”或“试验样品”可以指要在其中检测或确定靶的存在和/或水平的任何样品,或包含本文中详述的dna靶向系统或其组分的任何样品。样品可以包括液体、溶液、乳液或悬液。样品可以包括医学样品。样品可以包括任何生物学流体或组织,例如血液、全血、血液级分例如血浆和血清、肌肉、组织间隙液、汗液、唾液、尿液、泪液、滑膜液、骨髓、脑脊液、鼻分泌物、痰液、羊水、支气管肺泡灌洗液、胃灌洗液、呕吐物、粪便、肺组织、外周血单核细胞、总白细胞、淋巴结细胞、脾细胞、扁桃体细胞、癌细胞、肿瘤细胞、胆汁、消化液、皮肤或其组合。在某些实施方式中,样品包含等分试样。在其他实施方式中,样品包含生物学流体。样品可以通过本领域中已知的任何手段来获得。样品可以在从患者获得时直接使用,或者可以进行预处理,例如通过过滤、蒸馏、提取、浓缩、离心、干扰组分的失活、添加试剂等,以便以本文中讨论的或本领域中已知的某种方式改变所述样品的特性。
[0081]
在本文中可互换使用的“间隔物”和“间隔区”是指tale或锌指靶区域中位于两个tale或锌指蛋白的结合区之间但不是所述结合区的一部分的区域。
[0082]
当在本文中使用时,“对象”或“患者”可以意味着想要或需要本文中描述的组合物或方法的动物。对象可以是人类或非人类。对象可以是任何脊椎动物。对象可以是哺乳动
物。哺乳动物可以是灵长动物或非灵长动物。哺乳动物可以是非灵长动物例如狗、猫、马、奶牛、猪、小鼠、大鼠、小鼠、骆驼、美洲驼、山羊、兔、绵羊、仓鼠和豚鼠。哺乳动物可以是灵长动物例如人类。哺乳动物可以是非人类灵长动物例如猴、食蟹猴、恒河猴、黑猩猩、大猩猩、猩猩和长臂猿。对象可以处于任何年龄或发育阶段,例如成人、青少年或婴儿。对象可以是雄性。对象可以是雌性。在某些实施方式中,对象具有特定遗传标志物。对象可能正经历其他形式的治疗。
[0083]“基本上同一的”可以指第一和第二氨基酸或多核苷酸序列分别在1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、200、300、400、500、600、700、800、900、1000、1100个氨基酸或核苷酸的区域内至少具有60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%的同一性。
[0084]“转录激活因子样效应物”或“tale”是指识别并结合特定dna序列的蛋白质结构。“tale dna结合结构域”是指包括串联的被称为rvd模块的33-35个氨基酸的重复序列的阵列的dna结合结构域,每个所述模块特异性识别dna的单个碱基对。rvd模块可以以任何顺序排列,以组装识别限定序列的阵列。tale dna结合结构域的结合特异性由所述rvd阵列和随后的单个20个氨基酸的截短的重复序列决定。“重复序列可变双残基”或“rvd”是指tale dna结合结构域的包括33-35个氨基酸的dna识别基序(也被称为“rvd模块”)内的一对相邻氨基酸残基。所述rvd决定rvd模块的核苷酸特异性。可以将rvd模块组合以产生rvd阵列。当在本文中使用时,“rvd阵列长度”是指rvd模块的数目,其对应于被talen识别的talen靶区域、即结合区内的核苷酸序列的长度。tale dna结合结构域可以具有12至27个rvd模块,每个模块含有一个rvd并识别dna的单个碱基对。已鉴定到识别四种可能的dna核苷酸(a、t、c和g)的特异性rvd。由于tale dna结合结构域是模块式的,因此可以将识别所述四种不同dna核苷酸的重复序列连接在一起以识别任何特定dna序列。然后可以将这些靶向的dna结合结构域与催化结构域组合以产生有功能的酶,包括人造转录因子、甲基转移酶、整合酶、核酸酶和重组酶。
[0085]
当在本文中使用时,“靶基因”是指编码已知或假定基因产物的任何核苷酸序列。靶基因可以是参与遗传疾病的突变的基因。在某些实施方式中,所述靶基因是编码转录因子的基因。
[0086]
当在本文中使用时,“靶区域”是指基于crispr/cas9的基因编辑系统被设计与其结合的靶基因的区域。
[0087]
当在本文中使用时,“转入基因”是指含有已从一个生物体分离并被引入到不同生物体中的基因序列的基因或遗传物质。这个非本源dna区段可以在转基因生物体中保留产生rna或蛋白质的能力,或者它可以改变所述转基因生物体的遗传密码的正常功能。转入基因的引入具有改变生物体的表型的潜力。
[0088]“治疗”在指称保护对象对抗疾病时,意味着抑制、阻遏、改善或完全消除所述疾病。预防疾病涉及在所述疾病发作之前向对象给药本发明的组合物。抑制疾病涉及在诱导所述疾病之后但在其临床表现出现之前向对象给药本发明的组合物。阻遏或改善疾病涉及在所述疾病临床表现出现之后向对象给药本发明的组合物。
[0089]
对于多核苷酸来说,本文使用的“变体”意味着(i)参比核苷酸序列的一部分或片
段;(ii)参比核苷酸序列或其部分的互补体;(iii)与参比核酸或其互补体基本上同一的核酸;或(iv)在严紧条件下与参比核酸、其互补体或与其基本上同一的序列杂交的核酸。
[0090]
对于肽或多肽来说,“变体”通过氨基酸的插入、缺失或保守替换而在氨基酸序列上有差异,但保留至少一种生物学活性。变体也可以指具有与参比蛋白质所具有的氨基酸序列基本上同一的氨基酸序列,并保留至少一种生物学活性的蛋白质。“生物学活性”的代表性实例包括被特异性抗体或多肽结合的能力或促进免疫应答的能力。变体可以指其功能性片段。变体也可以指多肽的多个拷贝。所述多个拷贝可以是串联的或者被连接物分开。氨基酸的保守替换,即将氨基酸用性质(例如亲水性、带电荷区域的程度和分布)相近的不同氨基酸代替,在本领域中被认为通常涉及微小改变。这些微小改变可以部分地通过考虑氨基酸的亲水指数来鉴定,正如本领域中所理解的。kyte等,j.mol.biol.157:105-132(1982)。氨基酸的亲水指数基于对其疏水性和电荷的考虑。在本领域中,已知亲水指数相近的氨基酸可以被替换并仍保留蛋白质功能。在一种情况下,具有
±
2的亲水指数的氨基酸被替换。氨基酸的亲水性也可用于揭示导致蛋白质保留生物学功能的替换。在肽的背景中考虑氨基酸的亲水性允许计算该肽的最大局部平均亲水性。替换可以使用彼此之间亲水性值在
±
2以内的氨基酸来进行。氨基酸的疏水指数和亲水性值两者均受到该氨基酸的具体侧链的影响。与该观察相一致,与生物学功能相容的氨基酸替换被理解为取决于氨基酸的相对相似性,特别是那些氨基酸的侧链,正如由疏水性、亲水性、电荷、尺寸和其他性质所揭示的。
[0091]
当在本文中使用时,“载体”意味着含有复制原点的核酸序列。载体可以是病毒载体、噬菌体、细菌人工染色体或酵母人工染色体。载体可以是dna或rna载体。载体可以是自身复制的染色体外载体,并且优选为dna质粒。例如,载体可以编码cas9蛋白和至少一种grna分子。
[0092]
当在本文中使用时,“锌指”是指一种识别并结合dna序列的蛋白质。锌指结构域是人类蛋白质组中最常见的dna结合基序。单个锌指含有大约30个氨基酸,并且所述结构域通常通过每个碱基对与单个氨基酸侧链的相互作用,通过结合dna的3个连续碱基对来发挥作用。
[0093]
除非在本文中另有定义,否则与本公开相结合使用的科学和技术术语均应具有本领域普通技术人员通常理解的含义。例如,本文描述的与细胞和组织培养、分子生物学、免疫学、微生物学、遗传学和蛋白质和核酸化学以及杂交相结合使用的任何术语及其技术,在本领域中是公知且常用的。所述术语的含义和范围应该是清晰的;然而,在存在任何潜在歧义的情况下,本文提供的定义优先于任何字典或外来定义。此外,除非上下文另有需要,否则单数术语应包括复数,并且复数术语应包括单数。
[0094]
2.转录因子
[0095]
本文中提供了细胞类型特异性转录因子。转录因子(tf)是一种通过与特定dna序列结合来控制遗传信息从dna向信使rna转录的速率的蛋白质。tf对基因进行调控,以确保在细胞和生物体的整个生命中它们在正确的细胞中在正确的时间和以正确的量表达。tf将内在和外在信号的复杂模式传输到定义细胞类型身份的动态基因表达程序中。成组的tf可能以协调的方式发挥作用,以指导例如整个一生中的细胞分裂、细胞生长和细胞死亡,胚胎发育过程中的细胞迁移和组织化(身体计划),并间歇性地响应来自于细胞外的信号例如激
素。tf可以单独地或与复合物中的其他蛋白质一起工作,例如通过促进或阻断rna聚合酶的召集。所述tf可能对特定细胞类型特异。所述tf可以是神经元特异性的。所述tf可以是肌肉特异性的。所述tf可以是软骨细胞特异性的。所述tf可以对任何细胞类型特异,例如来自于选自骨髓、皮肤、骨骼肌、脂肪组织和外周血的组织的细胞。所述细胞可以是肌肉细胞(例如平滑肌细胞、骨骼肌细胞和心肌细胞)、上皮细胞、内皮细胞、尿路上皮细胞、成纤维细胞、肝细胞、成肌细胞、神经元、成骨细胞、破骨细胞、t细胞、角质形成细胞、毛囊细胞、人脐静脉内皮细胞(huvec)、脐带血细胞、神经祖细胞、软骨细胞、成软骨细胞、胆管细胞、胰岛细胞、甲状腺细胞、甲状旁腺细胞、肾上腺细胞、下丘脑细胞、垂体细胞、卵巢细胞、睾丸细胞、唾液腺细胞、脂肪细胞、前体细胞、造血干细胞(hsc)、脂肪间充质干细胞(msc)、骨髓间充质干细胞(msc)、少突胶质细胞、少突胶质细胞前体、中性粒细胞、嗜碱性粒细胞、嗜酸性粒细胞、淋巴细胞、单核细胞或心肌细胞。所述tf可以是例如c2h2 zf、bhlh或hmg/sox dna结合结构域家族的成员。所述tf可以是激活型tf(其激活或提高基因表达),或者所述tf可以是阻遏型tf(其阻遏或降低基因表达)。
[0096]
tf可能使用各种不同的机制来调控基因表达。例如,tf可以稳定或阻断rna聚合酶与dna的结合。tf可以将共激活蛋白或共阻遏蛋白召集到转录因子dna复合物。tf可以直接或间接催化组蛋白的乙酰化或去乙酰化。组蛋白乙酰转移酶(hat)活性使组蛋白乙酰化,从而削弱dna与组蛋白的结合,这可以使dna更容易被转录,从而上调转录。组蛋白去乙酰化酶(hdac)活性使组蛋白去乙酰化,从而加强dna与组蛋白的结合,这可能使dna不易被转录,从而下调转录。tf可能影响dna的三维成环,进而可以影响基因表达。
[0097]
本文提供了编码至少一种转录因子的多核苷酸或所述转录因子多肽本身。在某些实施方式中,所述转录因子是内源转录因子。在这里,“内源”是指在染色体dna中,在对象的基因组中的天然位置中编码tf的基因拷贝。所述转录因子可以指导基因在神经元中的表达。所述转录因子可以指导细胞分化成神经元。在某些实施方式中,第一转录因子可以与第二转录因子一同工作。所述转录因子可以是假定的。所述转录因子可以被选择或鉴定为神经元特异性转录因子。神经元特异性转录因子可以被称为神经源性因子。
[0098]
所述细胞类型特异性转录因子可以是激活型或阻遏型的。例如,激活型或正神经元特异性转录因子提高细胞分化成神经元或提高基因在神经元中的表达。正神经元特异性转录因子的表达提高可以促进或提高细胞分化成神经元或提高基因在神经元中的表达。阻遏型或负神经元特异性转录因子抑制细胞分化成神经元或抑制基因在神经元中的表达。敲减或抑制负神经元特异性转录因子的表达可以促进或提高细胞分化成神经元或提高基因在神经元中的表达。所述神经元特异性转录因子的表达或蛋白质水平的调节可以不经历多能阶段将干细胞直接转化成神经元。
[0099]
本文提供了第一神经元特异性转录因子,其选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2。还提供了编码所述第一神经元特异性转录因子的多核苷酸。在某些实施方式中,所述第一神经元特异性转录因子选自ngn3和ascl1或其组合。
[0100]
在某些实施方式中,本文还提供了第二神经元特异性转录因子或编码所述第二神经元特异性转录因子的多核苷酸。第一神经元特异性转录因子可以与第二神经元特异性转
录因子组合。在此类实施方式中,所述第一神经元特异性转录因子可以选自ngn3和ascl1或其组合。所述第二神经元特异性转录因子可以选自:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1、plagl2(选自表1中的“正单一因子cra-tf”);(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3(选自表1中的“正sgngn3 cra-tf”);(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l、e2f7(选自表1中的“正sgascl1 cra-tf”);(iv)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3(选自表2中的“负单一因子cra-tf”);(v)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791(选自表2中的“负sgngn3 cra-tf”);和(vi)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3、bsx(选自表2中的“负sgascl1 cra-tf”)。
[0101]
在某些实施方式中,所述第二神经元特异性转录因子选自neurog3、sox4和sox9。在某些实施方式中,所述第二神经元特异性转录因子选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2、nkx2-2、hes3和zfp36l1。在某些实施方式中,所述第二神经元特异性转录因子是选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2、nkx2-2的激活型转录因子。在某些实施方式中,所述第二神经元特异性转录因子是选自hes3和zfp36l1的阻遏型转录因子。
[0102]
本文还提供了一种肌肉特异性转录因子。所述肌肉特异性转录因子可以选自twist1、pax3、myod、myog、sox9、sox10和dmrt1。还提供了编码所述肌肉特异性转录因子的多核苷酸。
[0103]
3.基于crispr/cas的基因编辑系统
[0104]
所述系统可以是基于crispr/cas的基因编辑系统。所述基于crispr/cas的基因编辑系统可以包括针对tf基因中的靶区域或tf基因的启动子或调控元件或其部分的核酸酶失活的cas蛋白(dcas)或dcas融合蛋白,导致tf的内源表达的激活或阻遏。所述系统可以是基于crispr/cas9的基因编辑系统。在本文中可互换使用的“簇集规则间隔短回文重复序
列”和“crispr”是指含有在大约40%的被测序细菌和90%的被测序古菌的基因组中存在的多个短直接重复序列的基因座。crispr系统是一种微生物的核酸酶系统,参与针对入侵噬菌体和质粒的防御,提供了一种形式的获得性免疫。微生物宿主中的crispr基因座含有crispr相关(cas)基因与能够编程crispr介导的核酸切割的特异性的非编码rna元件的组合。被称为间隔物的短的外来dna区段被并入到基因组中crispr重复序列之间,并充当过去暴露的“记忆”。cas蛋白例如cas9蛋白与sgrna(在本文中也可互换地称为“grna”)的3’末端形成复合体,并且所述蛋白质-rna对通过所述sgrna序列的5’末端与被称为前间区序列的预定的20bp dna序列之间的互补碱基配对来识别它的基因组靶。这种复合体通过crrna内编码的区域即前间区序列和病原体基因组内的前间区序列邻近基序(pam),被导向病原体dna的同源基因座。所述非编码crispr阵列被转录,并在直接重复序列内被切割成含有单个间隔物序列的短crrna,其将cas核酸酶导向靶位点(前间区序列)。通过简单地交换所述表达的sgdna的20bp识别序列,可以将cas9核酸酶导向新的基因组靶。crispr间隔物以与真核生物体中的rnai类似的方式被用于识别并沉默外源遗传元件。
[0105]
已知三种类型的crispr系统(i、ii和iii型效应物系统)。ii型效应物系统在4个顺序步骤中进行靶向dna双链断裂,并使用单个效应酶例如cas9来切割dsdna。与需要多个不同效应物作为复合体起作用的i型和iii型效应物系统相比,ii型效应物系统可以在可选背景例如真核细胞中起作用。所述ii型效应物系统由从含有间隔物的crispr基因座转录的长的pre-crrna、cas9蛋白和参与pre-crrna加工的tracrrna组成。所述tracrrna杂交到分隔pre-crrna的间隔物的重复序列区,从而通过内源rna酶iii启动dsrna切割。这个切割之后是每个间隔物内由cas9进行的第二个切割事件,产生保持与tracrrna和cas9结合的成熟的crrna,形成cas9:crrna-tracrrna复合体。
[0106]
所述cas9:crrna-tracrrna复合体解开dna双链体并搜索与crrna匹配的序列进行切割。当检测到靶dna中的“前间区”序列与crrna中的剩余间隔物序列之间的互补性时,发生靶识别。如果在前间区序列的3’末端处也存在正确的前间区序列邻近基序(pam),则cas9介导靶dna的切割。对于前间区序列靶向来说,在所述序列后必须紧跟前间区序列邻近基序(pam),这是被dna切割所需的cas9核酸酶识别的短序列。不同的ii型系统具有不同的pam要求。酿脓链球菌(streptococcus pyogenes)crispr系统可以具有5
’‑
nrg-3’作为这种cas9(spcas9)的pam序列,其中r是a或g,并以这种系统在人类细胞中的特异性为特征。基于crispr/cas9的基因编辑系统的独特能力是能够通过单个cas9蛋白与两个或更多个sgrna的共表达直接地同时靶向多个不同基因组基因座。例如,酿脓链球菌ii型系统天然偏好使用“ngg”序列,其中“n”可以是任何核苷酸,但是在工程化改造的系统中也接受其他pam序列例如“nag”(hsu等,nature biotechnology 2013doi:10.1038/nbt.2647)。同样地,源自于脑膜炎奈瑟氏菌(neisseria meningitidis)的cas9(nmcas9)正常情况下具有nnnngatt的天然pam(seq id no:12),但具有跨多种pam的活性,包括高度简并的nnnngnnn pam(seq id no:13)(esvelt等,nature methods 2013doi:10.1038/nmeth.2681)。
[0107]
金黄色葡萄球菌的cas9分子识别序列基序nngrr(r=a或g)(seq id no:8),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrrn(r=a或g)(seq id no:9),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序
列基序nngrrt(r=a或g)(seq id no:10),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrrv(r=a或g)(seq id no:11),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在上述实施方式中,n可以是任何核苷酸残基,例如a、g、c或t中的任一者。cas9分子可以被工程化改造,以改变所述cas9分子的pam特异性。
[0108]
一种工程化改造形式的酿脓链球菌ii型效应物系统显示出在人类细胞中具有基因组化改造的功能。在这个系统中,通过一种合成重构的“指导rna”(“grna”,在本文中也可与嵌合单一指导rna(“sgrna”)互换使用)将cas9蛋白导向基因组靶位点,所述指导rna是crrna-tracrrna融合体,免除了一般而言对rna酶iii和crrna加工的需求。本文中提供了用于基因组编辑和治疗遗传疾病的基于crispr/cas9的工程化改造的系统。所述基于crispr/cas9的工程化改造的系统可以被设计成靶向任何基因,包括参与遗传疾病、衰老、组织再生或伤口愈合的基因。所述基于crispr/cas9的基因编辑系统可以包括cas9蛋白或cas9融合蛋白和至少一种grna。在某些实施方式中,所述系统包含两种grna分子。所述cas9融合蛋白可以例如包括与cas9内源的结构域具有不同活性的结构域,例如反式激活结构域。
[0109]
所述靶基因可以参与细胞的分化或其中可能需要激活基因的任何其他过程,或者可以具有突变例如移码突变或无义突变。在某些实施方式中,所述靶或靶基因包括假定转录因子的基因或其部分。所述基于crispr/cas9的基因编辑系统可以介导也可以不介导基因组的蛋白质编码区的脱靶变化。所述基于crispr/cas9的基因编辑系统可以结合并识别靶区域。
[0110]
a.cas蛋白
[0111]
所述基于crispr/cas9的基因编辑系统可以包括cas蛋白或cas融合蛋白。在某些实施方式中,所述cas蛋白是cas12蛋白(也被称为cpf1),例如cas12a蛋白。所述cas12蛋白可以来自于任何细菌或古菌物种,包括但不限于新凶手弗朗西丝氏菌(francisella novicida)、氨基酸球菌属菌种(acidaminococcus sp.)、毛螺菌科菌种(lachnospiraceae sp.)和普氏菌属菌种(prevotella sp)。在某些实施方式中,所述cas蛋白是cas9蛋白。cas9蛋白是一种内切核苷酸,其切割核酸,由crispr基因座编码,并参与ii型crispr系统。所述cas9蛋白可以来自于任何细菌或古菌物种,包括但不限于酿脓链球菌、金黄色葡萄球菌(staphylococcus aureus(s.aureus))、燕麦食酸菌(acidovorax avenae)、胸膜肺炎放线杆菌(actinobacillus pleuropneumoniae)、产琥珀酸放线杆菌(actinobacillus succinogenes)、猪放线杆菌(actinobacillus suis)、放线菌属菌种(actinomyces sp.)、cycliphilus denitrificans、aminomonas paucivorans、蜡样芽孢杆菌(bacillus cereus)、斯密氏芽孢杆菌(bacillus smithii)、苏云金芽孢杆菌(bacillus thuringiensis)、拟杆菌属菌种(bacteroides sp.)、blastopirellula marina、慢生根瘤菌属菌种(bradyrhizobium sp.)、侧孢短芽孢杆菌(brevibacillus laterosporus)、大肠弯曲杆菌(campylobacter coli)、空肠弯曲杆菌(campylobacter jejuni)、红嘴鸥弯曲杆菌(campylobacter lari)、candidatus puniceispirillum、解纤维素梭菌(clostridium cellulolyticum)、产气荚膜梭菌(clostridium perfringens)、拥挤棒状杆菌(corynebacterium accolens)、白喉棒状杆菌(corynebacterium diphtheria)、马氏棒状杆菌(corynebacteriummatruchotii)、dinoroseobacter shibae、细长真杆菌
(eubacterium dolichum)、γ变形杆菌(gamma proteobacterium)、重氮营养葡糖醋杆菌(gluconacetobacter diazotrophicus)、副流感嗜血杆菌(haemophilus parainfluenzae)、haemophilus sputorum、加拿大螺旋杆菌(helicobacter canadensis)、helicobacter cinaedi、helicobacter mustelae、ilyobacter polytropus、kingella kingae、卷曲乳杆菌(lactobacillus crispatus)、listeria ivanovii、单核细胞增多性李斯特菌(listeria monocytogenes)、李斯特氏菌科(listeriaceae)细菌、甲基孢囊菌属菌种(methylocystis sp.)、methylosinus trichosporium、羞怯动弯杆菌(mobiluncus mulieris)、neisseria bacilliformis、灰色奈瑟氏菌(neisseria cinerea)、金黄奈瑟氏菌(neisseria flavescens)、乳糖奈瑟氏菌(neisseria lactamica)、奈瑟氏菌属菌种(neisseria sp.)、neisseria wadsworthii、亚硝化单胞菌属菌种(nitrosomonas sp.)、parvibaculum lavamentivorans、多杀巴氏杆菌(pasteurella multocida)、phascolarctobacterium succinatutens、ralstonia syzygii、沼泽红假单胞菌(rhodopseudomonas palustris)、小红卵菌属菌种(rhodovulum sp.)、simonsiella muelleri、鞘氨醇单胞菌属菌种(sphingomonas sp.)、sporolactobacillus vineae、路邓葡萄球菌(staphylococcus lugdunensis)、链球菌属菌种(streptococcus sp.)、subdoligranulum sp.、tistrella mobilis、密螺旋体属菌种(treponema sp.)或verminephrobacter eiseniae。在某些实施方式中,所述cas9分子是酿脓链球菌cas9分子(在本文中也被称为“spcas9”)。在某些实施方式中,所述cas9分子是金黄色葡萄球菌(staphylococcus aureus)cas9分子(在本文中也被称为“sacas9”)。
[0112]
cas分子或cas融合蛋白可以与一种或多种grna分子相互作用,并且与所述grna分子合作,可以定位到包含靶结构域并且在某些实施方式中pam序列的位点。cas分子或cas融合蛋白识别pam序列的能力可以例如使用本领域中已知的转化测定法来确定。
[0113]
在某些实施方式中,cas分子或cas融合蛋白与靶核酸相互作用并切割靶核酸的能力是前间区序列邻近基序(pam)序列依赖性的。pam序列是靶核酸中的序列。在某些实施方式中,所述靶核酸的切割发生在pam序列上游。来自于不同细菌菌种的cas分子可以识别不同的序列基序(例如pam序列)。在某些实施方式中,新凶手弗朗西丝氏菌的cas12分子识别序列基序tttn(seq id no:35)。在某些实施方式中,酿脓链球菌的cas9分子识别序列基序ngg(seq id no:1),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,嗜热链球菌(s.thermophilus)的cas9分子识别序列基序nggng(seq id no:5)和/或nnagaaw(w=a或t)(seq id no:6),并指导靶核酸序列1至10在例如这些序列上游3至5bp处的切割。在某些实施方式中,变形链球菌(s.mutans)的cas9分子识别序列基序ngg(seq id no:1)和/或naar(r=a或g)(seq id no:7),并指导靶核酸序列1至10在例如这个序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrr(r=a或g)(seq id no:8),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrrn(r=a或g)(seq id no:9),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrrt(r=a或g)(seq id no:10),并指导靶核酸序列1至10在例如该序列上游3至5bp处的切割。在某些实施方式中,金黄色葡萄球菌的cas9分子识别序列基序nngrrv(r=a或g;v=a或c或g)(seq id no:11),并指导靶核酸序列
1至10在例如该序列上游3至5bp处的切割。在上述实施方式中,n可以是任何核苷酸残基,例如a、g、c或t中的任一者。cas9分子可以被工程化改造,以改变所述cas9分子的pam特异性。
[0114]
在某些实施方式中,所述载体编码至少一个识别nngrrt(seq id no:10)或nngrrv(seq id no:11)的前间区序列邻近基序(pam)的cas9分子。在某些实施方式中,所述至少一个cas9分子是金黄色葡萄球菌cas9分子。在某些实施方式中,所述至少一个cas9分子是突变的金黄色葡萄球菌cas9分子。
[0115]
所述cas蛋白可以被突变,使得核酸酶活性失活。所述没有内切核酸酶活性的失活的cas9蛋白(“icas9”,也被称为“dcas9”)已通过grna靶向细菌、酵母和人类细胞中的基因,以通过空间位阻沉默基因表达。参考酿脓链球菌cas9序列,示例性突变包括d10a、e762a、h840a、n854a、n863a和/或d986a。参考金黄色葡萄球菌cas9序列,示例性突变包括d10a和n580a.。在某些实施方式中,所述cas9分子是突变的金黄色葡萄球菌cas9分子。在某些实施方式中,所述dcas9是参考酿脓链球菌cas9序列包括选自d10a、e762a、h840a、n854a、n863a和/或d986a的至少两个突变的cas9分子。在某些实施方式中,所述cas蛋白是dcas9蛋白。在某些实施方式中,所述cas蛋白是dcas12蛋白。
[0116]
在某些实施方式中,所述突变的金黄色葡萄球菌cas9分子包含d10a突变。编码这种突变的金黄色葡萄球菌cas9分子的核苷酸序列阐述在seq id no:22中。
[0117]
在某些实施方式中,所述突变的金黄色葡萄球菌cas9分子包含n580a突变。编码这种突变的金黄色葡萄球菌cas9分子的核苷酸序列阐述在seq id no:23中。
[0118]
编码cas9分子的多核苷酸可以是合成多核苷酸。例如,所述合成多核苷酸可以被化学修饰。所述合成多核苷酸可以被密码子优化,例如至少一个不常用密码子或使用频率较低的密码子已被常用密码子代替。例如,所述合成多核苷酸可以指导优化的信使mrna的合成,例如被优化以在例如本文中所描述的哺乳动物表达系统中表达。
[0119]
此外或可选地,编码cas9分子或cas9多肽的核酸可以包含核定位序列(nls)。核定位序列在本领域中是已知的。编码酿脓链球菌的cas9分子的示例性密码子优化的核酸序列阐述在seq id no:14中。相应的酿脓链球菌cas9分子得氨基酸序列阐述在seq id no:15中。
[0120]
编码金黄色葡萄球菌的cas9分子并任选地含有核定位序列(nls)的示例性密码子优化的核酸序列阐述在seq id no:16-20和24-25中。编码金黄色葡萄球菌的cas9分子的另一个示例性密码子优化的核酸序列包含seq id no:27的第1293-4451位核苷酸。金黄色葡萄球菌cas9分子的一个氨基酸序列阐述在seq id no:21中。金黄色葡萄球菌cas9分子的一个氨基酸序列阐述在seq id no:26中。
[0121]
b.融合蛋白
[0122]
可选地或此外,所述基于crispr/cas的基因编辑系统可以包括融合蛋白。所述融合蛋白可以包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有诸如转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、核酸酶活性、核酸结合活性、甲基化酶活性或脱甲基化酶活性的活性。所述融合蛋白可以包括第一多肽结构域例如cas9蛋白或突变的cas9蛋白,其融合到具有诸如转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、核酸酶活性、核酸结合活性、甲基化酶活性或脱甲基化酶活性的活性的第二多肽结构域。在某
螺旋区、亮氨酸拉链区、有翼螺旋区、有翼螺旋-转角-螺旋区、螺旋-环-螺旋区、免疫球蛋白折叠、b3结构域、锌指、hmg盒、wor3结构域、tal效应物dna结合结构域。
[0135]
vii)甲基化酶活性
[0136]
所述第二多肽结构域可以具有甲基化酶活性,其参与甲基向dna、rna、蛋白质、小分子、胞嘧啶或腺嘌呤的转移。在某些实施方式中,所述第二多肽结构域包括dna甲基转移酶。
[0137]
viii)脱甲基化酶活性
[0138]
所述第二多肽结构域可以具有脱甲基化酶活性。所述第二多肽结构域可以包括从核酸、蛋白质(特别是组蛋白)和其他分子移除甲基(ch3-)的酶。或者,所述第二多肽可以通过使dna脱甲基化的机制将甲基转变成羟甲基胞嘧啶。所述第二多肽可以催化这个反应。例如,催化这个反应的第二多肽可以是tet1。
[0139]
c.grna
[0140]
所述基于crispr/cas的基因编辑系统包括至少一种grna分子。例如,所述基于crispr/cas的基因编辑系统可以包括两种grna分子。所述grna提供基于crispr/cas的基因编辑系统的靶向。所述grna是两个非编码rna即crrna和tracrrna的融合体。在某些实施方式中,所述多核苷酸包括crrna和/或tracrrna。所述sgrna可以通过交换编码20bp前间区序列的序列来靶向任何所需dna序列,所述前间区序列通过与所需dna靶的互补碱基配对而提供靶向特异性。grna模拟参与ii型效应物系统的天然存在的crrna:tracrrna双链体。这个可以包括例如42个核苷酸的crrna和75个核苷酸的tracrrna的双链体充当cas9切割靶核酸的指导物。“靶区域”、“靶序列”或“前间区序列”是指所述基于crispr/cas9的基因编辑系统靶向并结合的靶基因的区域。所述grna的靶向基因组中的靶序列的部分可以被称为“靶向序列”或“靶向部分”或“靶向结构域”。“前间区序列”或“grna间隔物”可以是指所述基于crispr/cas9的基因编辑系统靶向并结合的靶基因的区域;“前间区序列”或“grna间隔物”也可以是指所述grna的与基因组中的被靶向序列互补的部分。所述grna可以包括grna支架。grna支架促进cas9与所述grna结合并且可以促进内切核酸酶活性。所述grna支架是在所述grna的对应于grna所靶向的序列的部分之后的多核苷酸序列。所述grna靶向部分和grna支架合在一起形成一个多核苷酸。所述支架可以包含seq id no:158的多核苷酸序列。所述基于crispr/cas9的基因编辑系统可以包括至少一种grna,其中所述grna靶向不同的dna序列。所述靶dna序列可以是交叠的。所述靶序列或前间区序列后面跟有基因组中所述前间区序列的3’末端处的pam序列。不同的ii型系统具有不同的pam要求。例如,酿脓链球菌ii型系统使用“ngg”序列(seq id no:1),其中“n”可以是任何核苷酸。在某些实施方式中,所述pam序列可以是“ngg”,其中“n”可以是任何核苷酸。在某些实施方式中,所述pam序列可以是nngrrt(seq id no:10)或nngrrv(seq id no:11)。所述至少一种grna分子可以结合并识别靶区域。
[0141]
由遗传构建物(例如aav载体)编码的grna分子的数目可以是至少1种grna、至少2种不同的grna、至少3种不同的grna、至少4种不同的grna、至少5种不同的grna、至少6种不同的grna、至少7种不同的grna、至少8种不同的grna、至少9种不同的grna、至少10种不同的grna、至少11种不同的grna、至少12种不同的grna、至少13种不同的grna、至少14种不同的grna、至少15种不同的grna、至少16种不同的grna、至少17种不同的grna、至少18种不同的
grna、至少18种不同的grna、至少20种不同的grna、至少25种不同的grna、至少30种不同的grna、至少35种不同的grna、至少40种不同的grna、至少45种不同的grna或至少50种不同的grna。由本文公开的载体编码的grna的数目可以在至少1种grna到至少50种不同的grna、至少1种grna到至少45种不同的grna、至少1种grna到至少40种不同的grna、至少1种grna到至少35种不同的grna、至少1种grna到至少30种不同的grna、至少1种grna到至少25种不同的grna、至少1种grna到至少20种不同的grna、至少1种grna到至少16种不同的grna、至少1种grna到至少12种不同的grna、至少1种grna到至少8种不同的grna、至少1种grna到至少4种不同的grna、至少4种grna到至少50种不同的grna、至少4种不同的grna到至少45种不同的grna、至少4种不同的grna到至少40种不同的grna、至少4种不同的grna到至少35种不同的grna、至少4种不同的grna到至少30种不同的grna、至少4种不同的grna到至少25种不同的grna、至少4种不同的grna到至少20种不同的grna、至少4种不同的grna到至少16种不同的grna、至少4种不同的grna到至少12种不同的grna、至少4种不同的grna到至少8种不同的grna、至少8种不同的grna到至少50种不同的grna、至少8种不同的grna到至少45种不同的grna、至少8种不同的grna到至少40种不同的grna、至少8种不同的grna到至少35种不同的grna、8种不同的grna到至少30种不同的grna、至少8种不同的grna到至少25种不同的grna、8种不同的grna到至少20种不同的grna、至少8种不同的grna到至少16种不同的grna或8种不同的grna到至少12种不同的grna之间。在某些实施方式中,所述遗传构建物(例如aav载体)编码一种grna分子即第一grna分子和任选的cas9分子。在某些实施方式中,第一遗传构建物(例如第一aav载体)编码一种grna分子即第一grna分子和任选的cas9分子,并且第二遗传构建物(例如第二aav载体)编码一种grna分子即第二grna分子和任选的cas9分子。
[0142]
所述grna分子包含靶向结构域,其是与靶dna序列互补的多核苷酸序列,后面跟有pam序列。所述grna可以在所述靶向结构域或互补多核苷酸序列的5’末端处包含“g”。grna分子的靶向结构域可以包含至少10个碱基对、至少11个碱基对、至少12个碱基对、至少13个碱基对、至少14个碱基对、至少15个碱基对、至少16个碱基对、至少17个碱基对、至少18个碱基对、至少19个碱基对、至少20个碱基对、至少21个碱基对、至少22个碱基对、至少23个碱基对、至少24个碱基对、至少25个碱基对、至少30个碱基对或至少35个碱基对的靶dna序列的互补多核苷酸序列,后面跟有pam序列。在某些实施方式中,grna分子的靶向结构域具有19-25个核苷酸的长度。在某些实施方式中,grna分子的靶向结构域具有20个核苷酸的长度。在某些实施方式中,grna分子的靶向结构域具有21个核苷酸的长度。在某些实施方式中,grna分子的靶向结构域具有22个核苷酸的长度。在某些实施方式中,grna分子的靶向结构域具有23个核苷酸的长度。
[0143]
所述grna可以靶向编码转录因子的基因内或其附近的区域。在某些实施方式中,所述grna可以靶向所述基因的外显子、内含子、启动子区、增强子区或转录区中的至少一者。
[0144]
在某些实施方式中,所述grna靶向神经元特异性转录因子。所述grna可以包括靶向结构域,其包含对应于表3中所示的seq id no:38-97中的至少一者的多核苷酸序列或其互补体或其变体。所述grna可以靶向包含选自seq id no:38-97的序列的多核苷酸或其互补体、部分或变体。所述grna可以由包含选自seq id no:38-97的序列的多核苷酸或其互补体、部分或变体编码。所述grna可以包含对应于(例如其rna版本)seq id no:38-97中的至
少一者的多核苷酸序列或其互补体、部分或变体。
[0145]
表3.靶向假定神经元特异性转录因子的示例性grna
[0146]
[0147]
[0148][0149]
在某些实施方式中,所述grna靶向肌肉特异性转录因子。所述肌肉特异性转录因子可以选自twist1、pax3、myod、myog、sox9、sox10和dmrt1。所述grna可以包括靶向结构域,其包含对应于表5中所示的seq id no:98-104中的至少一者的多核苷酸序列或其互补体或其变体。所述grna可以靶向包含选自seq id no:98-104的序列的多核苷酸或其互补体、部分或变体。所述grna可以由包含选自seq id no:98-104的序列的多核苷酸或其互补体、部分或变体编码。所述grna可以包含对应于(例如其rna版本)seq id no:98-104中的至少一者的多核苷酸序列或其互补体、部分或变体。
[0150]
表5.靶向肌肉特异性转录因子的示例性grna
[0151]
基因grna靶序列seq id notwist1cggctaggaggcgggtgga98
pax3cgggccaaccttctctcct99myodcgcgcacgccagtgtggag100myoggggccatgcgggagaaaga101sox9ggaggggatcgcagccaaa102sox10ggaggagccctgagtgttg103dmrt1gcaagcagctggagagcgg104
[0152]
用本文中详述的系统转化或转录的细胞可以表达至少一种grna。所述细胞可以各自独立地包括一种grna并靶向一种假定转录因子。细胞中所述至少一种grna的水平可以通过本领域中已知的任何适合的手段例如深度测序来确定。至少一种grna可以在细胞中富集。例如,至少一种grna可以在细胞中富集,所述细胞具有报告蛋白的高表达。“富集”可以是指在具有报告基因高表达的细胞中grna丰度的统计显著(p《0.05)的提高。这可以使用r中的差异表达分析软件包deseq2来计算。所述grna或细胞中的至少一种grna可以将所述细胞中所述报告蛋白的表达相对于对照提高约2%、约3%、约4%、约5%、约6%、约7%、约8%、约9%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%、约50%、约55%、约60%、约65%、约70%、约75%、约80%、约85%或约90%。对照可以是具有非靶向grna的细胞。在某些实施方式中,相对于非靶向grna,所述grna可以将所述细胞中所述报告蛋白的表达提高约2-50%。
[0153]
d.遗传构建物
[0154]
所述用于鉴定细胞类型特异性转录因子或用于提高细胞类型特异性基因的表达的系统或其一种或多种组分,可以由遗传构建物编码或者包含在遗传构建物内。遗传构建物可以包括多核苷酸例如载体和质粒。所述构建物可以是重组的。在某些实施方式中,所述遗传构建物包含可操作连接到所述编码至少一种grna分子和/或cas分子或融合蛋白的多核苷酸的启动子。在某些实施方式中,所述遗传构建物包含可操作连接到所述编码至少一种grna分子和/或dcas分子或融合蛋白的多核苷酸的启动子。在某些实施方式中,所述遗传构建物包含可操作连接到所述编码至少一种grna分子和/或cas9分子或融合蛋白的多核苷酸的启动子。在某些实施方式中,所述启动子被可操作连接到编码grna分子、报告蛋白、神经元标志物和/或cas9分子的多核苷酸。在某些实施方式中,所述启动子被可操作连接到所述编码第一grna分子、第二grna分子、报告蛋白、神经元标志物和/或cas9分子的多核苷酸。所述遗传构建物可以作为有功能的染色体外分子存在于细胞中。所述遗传构建物可以是包括着丝粒、端粒的线性微型染色体,或质粒或粘粒。所述遗传构建物可以被转化或转导到细胞中。所述遗传构建物可以被配制成任何适合类型的递送介质,包括例如病毒载体、慢病毒表达、mrna电穿孔和脂质介导的转染。本文还提供了一种用本文中详细描述的系统或其组分转化或转导的细胞。在某些实施方式中,所述细胞是干细胞。所述干细胞可以是人类干细胞。在某些实施方式中,所述细胞是胚胎干细胞。所述干细胞可以是人类多能干细胞(ipsc)。还提供了干细胞衍生的神经元,例如从用本文中详述的dna靶向系统或其组分转化或转导的ipsc衍生的神经元。
[0155]
本文中还提供了一种病毒递送系统。病毒递送系统可以包括如慢病毒、反转录病毒、mrna电穿孔或纳米粒子。在某些实施方式中,所述载体是腺相关病毒(aav)载体。所述aav载体是属于细小病毒科依赖病毒属的小病毒,感染人类和一些其他的灵长动物物种。
aav载体可用于利用各种不同的构建物配置来递送基于crispr/cas9的基因编辑系统。例如,aav载体可以在分开的载体上或在同一载体上递送cas9和grna表达盒。或者,如果使用源自于诸如金黄色葡萄球菌或脑膜炎奈瑟氏菌的物种的小cas9蛋白,则可以将在4.7kb包装限度内的cas9和至多两个grna表达盒合并在单个aav载体中。
[0156]
在某些实施方式中,所述aav载体是修饰的aav载体。所述修饰的aav载体可以具有增强的心肌和/或骨骼肌组织嗜性。所述修饰的aav载体可能能够在哺乳动物细胞中递送和表达所述基于crispr/cas9的基因编辑系统。例如,所述修饰的aav载体可以是aav-sastg载体(piacentino等,human gene therapy 2012,23,635
–
646)。所述修饰的aav载体可以基于几种衣壳类型中的一者或多者,包括aav1、aav2、aav5、aav6、aav8和aav9。所述修饰的aav载体可以基于具有可选的肌肉嗜性aav衣壳的aav2假型,例如aav2/1、aav2/6、aav2/7、aav2/8、aav2/9、aav2.5和aav/sastg载体,其通过系统性或局部递送高效转导骨骼肌或心肌(seto等,current gene therapy 2012,12,139-151)。所述修饰的aav载体可以是aav2i8g9(shen等,j.biol.chem.2013,288,28814-28823)。
[0157]
4.用于提高基因的神经元特异性转录的系统
[0158]
本文提供了一种用于提高基因的神经元特异性转录或用于提高神经元特异性基因的表达的系统。所述系统可以包括靶向第一神经元特异性转录因子、其调控区、启动子区或部分的第一grna,以及如上所详述的cas蛋白或融合蛋白。所述系统可以包括靶向第一神经元特异性转录因子、其调控区、启动子区其部分的第一grna,靶向第二神经元特异性转录因子、其调控区、启动子区或部分的第二grna,以及如上所详述的cas蛋白或融合蛋白。在某些实施方式中,所述第二神经元特异性转录因子是正或激活型转录因子,并且所述融合蛋白的第二多肽结构域具有转录激活活性。在某些实施方式中,所述第二神经元特异性转录因子是负或阻遏型转录因子,并且所述融合蛋白的第二多肽结构域具有转录阻遏活性。
[0159]
5.用于鉴定细胞类型特异性转录因子的系统
[0160]
本文提供了用于选择或鉴定细胞类型特异性转录因子例如神经元特异性转录因子或肌肉特异性转录因子或软骨细胞特异性转录因子的组合物和方法。所述系统包括编码报告蛋白和细胞类型标志物的多核苷酸,如上所详述的cas蛋白或融合蛋白,以及靶向假定转录因子的grna的文库。本文还提供了一种细胞类型特异性转录因子或编码所述细胞类型特异性转录因子的多核苷酸序列或编码靶向所述细胞类型特异性转录因子的grna的多核苷酸序列,其通过本文中详述的组合物和方法选择或鉴定。
[0161]
a.报告蛋白
[0162]
所述多核苷酸可以编码报告蛋白。报告蛋白由报告基因编码,并在重组系统中在另一个基因表达的同时产生一些可测定或可检测的特征,以指示该另一个基因的表达。所述报告蛋白能够产生可检测信号。可以使用各种不同的报告蛋白,它们在信号转导的物理本质(例如荧光、电化学、核磁共振(nmr)和电子顺磁共振(epr))和报告蛋白的化学本质方面有差异。在某些实施方式中,所述来自于报告蛋白的信号是荧光信号。
[0163]
在某些实施方式中,所述报告蛋白是荧光蛋白。荧光蛋白包括例如萤光素酶、增强型蓝色荧光蛋白(ebfp)、增强型蓝色荧光蛋白-2(ebfp2)、mkate、irfp(红外荧光蛋白)、增强型黄色荧光蛋白(eyfp)、黄色荧光蛋白(yfp)、katushka、ds-red express、红色荧光蛋白、红色荧光蛋白turbo、turborfp、tagrfp、绿色荧光蛋白(gfp)、蓝色荧光蛋白(bfp)、蓝绿
色荧光蛋白(cfp)、增强型绿色荧光蛋白(egfp)、acgfp、turbogfp、emerald、azami green、zsgreen、sapphire、t-sapphire、增强蓝绿色荧光蛋白(ecfp)、mcfp、cerulean、cypet、amcyanl、midori-ishi cyan、mtfpl(teal)、topaz、venus、mcitrine、ypet、phiyfp、zsyellowl、mbanana、kusabira orange、morange、dtomato、dtomato-tandem、dsred、dsred2、dsred-express(tl)、dsred-单体、mtangerine、mstrawberry、asred2、mrfpl、jred、mcherry、hcredl、mraspberry、hcredl、hcred-tandem、mplum和aq143或其组合。在某些实施方式中,所述报告蛋白包含mcherry。mcherry可以包含具有seq id no:28的氨基酸序列的多肽,并且可以由包含seq id no:29的多核苷酸编码。在某些实施方式中,所述报告蛋白是可以通过免疫组织化学或抗体染色鉴定的任何多肽。
[0164]
用所述多核苷酸转染或转化的细胞可以表达所述报告蛋白。可以例如确定细胞中所述报告蛋白的表达水平。所述报告蛋白的表达水平可以在用本文中详述的系统转染所述细胞后的各个不同时间点测定。例如,细胞中所述报告蛋白的表达水平可以在从转导起约1、2、3、4、5、6、7、8、9或10天后确定。在某些实施方式中,细胞中所述报告蛋白的表达水平在从转导起约4天后确定。荧光蛋白可以通过本领域中已知的任何适合的手段来测定,例如通过facs或流式细胞术或荧光显微镜。在某些实施方式中,用所述多核苷酸转染或转化的细胞相对于对照具有所述报告蛋白的高表达。所述对照可以是用包括不同grna的多核苷酸转染或转化的另外一个或多个细胞。所述报告蛋白的“高表达”可以被定义为在所述细胞群体内的前5%的表达水平中。
[0165]
b.细胞类型标志物
[0166]
所述多核苷酸可以编码在某些细胞类型或状态或阶段下指示表达的标志物。例如,所述多核苷酸可以编码神经元标志物。神经元标志物是仅在或主要在神经元细胞中表达的基因。所述神经元标志物可以是仅在神经元的某些亚型中表达的亚型特异性标志物。所述神经元标志物可以是泛神经元标志物。泛神经元标志物是仅在或主要在神经元细胞中并在大多数神经元细胞中表达的基因。所述泛神经元标志物也可以被成为神经元谱系标志物。所述神经元标志物可以在神经发生中的任何时间点并在已分化成神经元的细胞中表达。神经元标志物可以选自例如tubb3、neurod1、neurog1、neurog2、ascl1、syn1、ncam和map2。在某些实施方式中,所述泛神经元标志物是tubb3。tubb3是编码β-3-微管蛋白(也被称为β-微管蛋白iii)多肽的基因,所述多肽是几乎专门存在于神经元中的微管蛋白家族的微管元件。在某些实施方式中,所述细胞类型特异性转录因子是神经元特异性转录因子,所述细胞类型标志物是神经元标志物,并且所述神经元标志物包括tubb3。
[0167]
在其他实施方式中,所述细胞类型标志物是肌肉或成肌标志物。肌肉或成肌标志物是仅在或主要在肌细胞中表达的基因。所述肌肉或成肌标志物可以是仅在肌细胞的某些亚型中表达的亚型特异性标志物。所述肌肉或成肌标志物可以是泛肌肉或泛成肌标志物。泛肌肉或泛成肌标志物是仅在或主要在肌细胞中并且在大多数肌细胞中表达的基因。所述成肌标志物可以包括pax7。在某些实施方式中,所述细胞类型特异性转录因子是肌肉特异性转录因子,所述细胞类型标志物是成肌标志物,并且所述成肌标志物包括pax7。
[0168]
在其他实施方式中,所述细胞类型标志物是胶原标志物。胶原标志物是仅在或主要在软骨细胞中表达的基因。所述胶原标志物可以是仅在软骨细胞的某些亚型中表达的亚型特异性标志物。所述胶原标志物可以是泛胶原标志物。泛胶原标志物是仅在或主要在软
骨细胞中并且在大多数软骨细胞中表达的基因。所述胶原标志物可以包括col2a1。在某些实施方式中,所述细胞类型特异性转录因子是软骨细胞特异性转录因子,所述细胞类型标志物是胶原标志物,并且所述胶原标志物包括col2a1。
[0169]
所述编码报告蛋白的多核苷酸可以被可操作连接到编码如上详述的细胞类型标志物的多核苷酸。所述编码报告蛋白的多核苷酸可以与所述编码细胞类型标志物的多核苷酸在同一阅读框中。因此,所述报告蛋白可以充当所述细胞类型标志物的表达或翻译报告物。
[0170]
用所述多核苷酸转染或转化的细胞可以表达所述细胞类型标志物。可以例如测定细胞中所述细胞类型标志物的表达水平。所述细胞类型标志物的表达水平可以在用本文详述的系统转染所述细胞后的各个不同时间点测定。例如,细胞中所述细胞类型标志物的表达水平可以在从转导起约1、2、3、4、5、6、7、8、9或10天后确定。细胞类型标志物可以通过本领域中已知的任何适合的手段来测定,例如通过免疫组织化学、qrt-pcr和rna测序。
[0171]
c.grna文库
[0172]
所述用于选择或鉴定转录因子的系统还可以包含grna文库。所述grna文库可以靶向假定转录因子。例如,grna可以靶向编码转录因子的基因的启动子。每个grna可以是不同的。所述grna文库可以包括多种grna,每种grna靶向假定转录因子。在某些实施方式中,每种grna靶向不同的假定转录因子。某些grna可能靶向同一种假定转录因子,其中每种grna靶向编码所述转录因子的基因的不同部分。在某些实施方式中,所述不同部分可能交叠。在某些实施方式中,所述grna文库可以包含针对转录因子的每个转录起始位点的1、2、3、4、5、6、7、8、9或10种grna。所述grna文库可以包括至少约1000种、至少约2000种、至少约3000种、至少约4000种、至少约5000种、至少约6000种、至少约7000种、至少约8000种或至少约9000种grna。
[0173]
6.药物组合物
[0174]
本文中提供了包含上述遗传构建物或系统的药物组合物。本文中所描述的系统或其至少一种组分可以按照制药领域中的专业技术人员公知的标准技术配制成药物组合物。所述药物组合物可以按照待使用的给药方式来配制。在药物组合物是注射用药物组合物的情况下,它们是无菌、无热原且无颗粒物的。优选地使用等渗剂型。通常,用于等渗的添加剂可以包括氯化钠、右旋糖、甘露糖醇、山梨糖醇和乳糖。在某些情况下,等渗溶液例如磷酸盐缓冲盐水是优选的。稳定剂包括明胶和白蛋白。在某些实施方式中,向所述剂型添加血管收缩剂。
[0175]
所述组合物还可以包含可药用赋形剂。所述可药用赋形剂可以是功能性分子例如介质、佐剂、载体或稀释剂。术语“可药用载体”可以是无毒惰性的固体、半固体或液体填充剂、稀释剂、包封材料或任何类型的配制辅料。可药用载体包括例如稀释剂、润滑剂、粘合剂、崩解剂、着色剂、调味剂、甜味剂、抗氧化剂、防腐剂、助流剂、溶剂、悬浮剂、润湿剂、表面活性剂、润肤剂、推进剂、保湿剂、粉末、ph调节剂及其组合。所述可药用赋形剂可以是转染促进剂,其可以包括表面活性剂例如免疫刺激复合物(iscoms)、弗氏不完全佐剂、lps类似物包括单磷酰脂a、胞壁酰肽、醌类似物、囊泡例如角鲨烯和角鲨烯、透明质酸、脂质、脂质体、钙离子、病毒蛋白、聚阴离子、聚阳离子或纳米粒子,或其他已知的转染促进剂。
[0176]
所述转染促进剂可以是聚阴离子、聚阳离子包括聚l-谷氨酸(lgs)或脂质。所述转
染促进剂是聚l-谷氨酸,并且更优选地,所述聚l-谷氨酸以低于6mg/ml的浓度存在于所述用于在骨骼肌和心肌中进行基因组编辑的组合物中。所述转染促进剂还可以包括表面活性剂例如免疫刺激复合物(iscoms)、弗氏不完全佐剂、lps类似物包括单磷酰脂a、胞壁酰肽、醌类似物和囊泡例如角鲨烯和角鲨烯,并且也可以使用透明质酸与所述遗传构建物联合给药。在某些实施方式中,编码所述组合物的dna载体也可以包括转染促进剂例如脂质、脂质体包括卵磷脂脂质体或本领域中已知的其他脂质体作为dna-脂质体混合物(参见例如国际专利申请号w09324640)、钙离子、病毒蛋白、聚阴离子、聚阳离子或纳米粒子或其他已知的转染促进剂。在某些实施方式中,所述转染促进剂是聚阴离子、聚阳离子包括聚l-谷氨酸(lgs)或脂质。
[0177]
7.给药
[0178]
本文中详述的系统或其至少一种组分或包含它们的药物组合物可以被给药到对象。此类组合物可以以医学领域的专业技术人员公知的剂量和技术,将诸如特定对象的年龄、性别、体重和状况和给药途径等因素考虑在内来给药。本文公开的系统或其至少一种组分、遗传构建物或包含它们的组合物可以通过不同途径给药到对象,所述途径包括口服、肠胃外、舌下、透皮、直肠、透黏膜、局部、鼻内、阴道内、通过吸入、通过颊给药、胸膜内、静脉内、动脉内、腹膜内、皮下、真皮内、表皮、肌肉内、鼻内、鞘内、颅内和关节内或其组合。在某些实施方式中,所述系统、遗传构建物或包含它们的组合物肌肉内、静脉内或其组合给药到对象。对于兽医用途来说,所述dna靶向系统、遗传构建物或包含它们的组合物可以按照常用兽医实践适合可接受的剂型给药。兽医可以容易地确定最适合于特定动物的给药方案和给药途径。所述系统、遗传构建物或包含它们的组合物可以通过传统注射器、无针注射装置、“微弹道轰击基因枪”或其他物理方法例如电穿孔(“ep”)、“流体动力学方法”或超声来给药。
[0179]
所述系统、遗传构建物或包含它们的组合物可以通过几种技术递送到对象,包括使用和不使用体内电穿孔、脂质体介导、纳米粒子辅助、重组载体例如重组慢病毒、重组腺病毒和重组腺相关病毒的dna注射(也被称为dna疫苗接种)。所述组合物可以被注射到脑或中枢神经系统的其他组分中。
[0180]
8.方法
[0181]
a.提高干细胞的神经元成熟的方法
[0182]
本文提供了提高干细胞的神经元成熟的方法或提高干细胞衍生的神经元的成熟的方法。所述方法可以包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平;或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并提高所述干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是激活型或正神经元特异性转录因子。在其他实施方式中,所述方法可以包括提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并降低所述干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是阻遏型或负神经元特异性转录因子。
[0183]
在某些实施方式中,提高所述第一神经元特异性转录因子的水平包括下述中的至
少一者:a)向干细胞给药编码所述第一神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第一神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第一神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0184]
在某些实施方式中,提高所述第二神经元特异性转录因子的水平包括下述中的至少一者:(a)向干细胞给药编码所述第二神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第二神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0185]
在某些实施方式中,降低所述第二神经元特异性转录因子的水平包括向干细胞给药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录阻遏活性。
[0186]
b.提高干细胞向神经元的转化的方法
[0187]
本文提供了提高干细胞向神经元的转化的方法。所述方法可以包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平;或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并提高所述干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是激活型或正神经元特异性转录因子。在其他实施方式中,所述方法可以包括提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并降低所述干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是阻遏型或负神经元特异性转录因子。
[0188]
在某些实施方式中,提高所述第一神经元特异性转录因子的水平包括下述中的至少一者:(a)向干细胞给药编码所述第一神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第一神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第一神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0189]
在某些实施方式中,提高所述第二神经元特异性转录因子的水平包括下述中的至少一者:(a)向干细胞给药编码所述第二神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第二神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0190]
在某些实施方式中,降低所述第二神经元特异性转录因子的水平包括向干细胞给
药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录阻遏活性。
[0191]
c.治疗对象的方法
[0192]
本文提供了治疗有需要的对象的方法。所述方法可以包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平;或(b)提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并提高所述对象中的干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是激活型或正神经元特异性转录因子。在其他实施方式中,所述方法可以包括提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平,并降低所述对象中的干细胞中第二神经元特异性转录因子的水平,其中所述第二神经元特异性转录因子是阻遏型或负神经元特异性转录因子。
[0193]
在某些实施方式中,提高所述第一神经元特异性转录因子的水平包括下述中的至少一者:(a)向干细胞给药编码所述第一神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第一神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第一神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0194]
在某些实施方式中,提高所述第二神经元特异性转录因子的水平包括下述中的至少一者:(a)向干细胞给药编码所述第二神经元特异性转录因子的多核苷酸;(b)向干细胞给药包含所述第二神经元特异性转录因子的多肽;和(c)向干细胞给药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录激活活性。
[0195]
在某些实施方式中,降低所述第二神经元特异性转录因子的水平包括向干细胞给药靶向所述第二神经元特异性转录因子、其调控区、启动子区或部分的grna和融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含dna结合蛋白例如cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有转录阻遏活性。
[0196]
d.筛选神经元特异性转录因子的方法
[0197]
本文提供了筛选神经元特异性转录因子的方法。所述方法可以包括用权利要求1-3中的任一项所述的系统以约0.2的感染复数(moi)转导细胞群体,使得大多数所述细胞各自独立地包含一种grna并靶向一种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中的grna水平,其中所述报告蛋白的高表达被定义为在所述细胞群体内的前5%中;以及当所述假定转录因子对应于在具有所述报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述假定转录因子作为神经元特异性转录因子。“富集”可以是在具有报告基因高表达的细胞中grna丰度的统计显著(p《0.05)的提高。
[0198]
在某些实施方式中,每个细胞中所述报告蛋白的表达水平在从转导起约4天后确定。在某些实施方式中,所述每个细胞中报告蛋白的表达水平通过流式细胞术来确定。在某些实施方式中,每个具有所述报告蛋白的高表达的细胞中所述grna的水平通过深度测序来确定。在某些实施方式中,相对于非靶向grna,所述grna将所述细胞中所述报告蛋白的表达提高约2-50%。
[0199]
e.筛选一对神经元特异性转录因子的方法
[0200]
本文提供了筛选一对神经元特异性转录因子的方法。所述方法可以包括用权利要求1-3中的任一项所述的系统以约0.2的感染复数(moi)转导细胞群体,使得大多数所述细胞各自独立地包含两种grna并靶向两种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中所述两种grna的水平,其中所述报告蛋白的高表达被定义为在所述细胞群体内的前5%中;以及当所述假定转录因子对应于在具有所述报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述两种假定转录因子作为一对神经元特异性转录因子。
[0201]
在某些实施方式中,每个细胞中所述报告蛋白的表达水平在从转导起约4天后确定。在某些实施方式中,所述每个细胞中报告蛋白的表达水平通过流式细胞术来确定。在某些实施方式中,每个具有所述报告蛋白的高表达的细胞中所述grna的水平通过深度测序来确定。在某些实施方式中,相对于非靶向grna,所述grna将所述细胞中所述报告蛋白的表达提高约2-50%。
[0202]
9.实施例
[0203]
实施例1
[0204]
材料和方法
[0205]
tubb3-2a-mcherry多能干细胞系的构建。使用人类ips细胞系(rvr-ipsc)构建tubb3-2a-mcherry报告细胞系。按照以前所做将rvr-ipsc从bj成纤维细胞通过反转录病毒重编程并表征(lee等,cell 2012,51,547-558)。为了产生tubb3-2a-mcherry报告细胞系,将3x106个细胞用accutase(stemcell tech,7920)解离,并使用p3原代细胞4d-nucleofector试剂盒(lonza,v4xp-3032)用6μg grna-cas9表达载体和3μg tubb3靶向载体电穿孔。将转染的细胞铺于用基质胶(corning,354230)包被的10cm培养皿中增补有10μm rock抑制剂(y-27632,stemcell tech,72304)的完全mtesr(stemcell tech,85850)中。转染后24小时,开始使用1μg/ml嘌呤霉素进行7天的正选择。在选择后,将细胞用cmv-cre重组酶表达载体转染,以除去两侧带有lox p的嘌呤霉素选择盒。将转染的细胞扩增并以低密度铺板,用于集落分离(180个细胞/cm2)。将得到的克隆机械挑取并扩增,并使用quickextract dna提取液(lucigen,qe09050)提取gdna,用于靶向载体整合的pcr筛选。在
vp64
dcas9
vp64
的慢病毒转导后,使用相同的方案进行第二轮集落分离。
[0206]
质粒构建。通过修饰addgene质粒#59791以将gfp用bsd杀稻瘟菌素抗性基因代替,产生了慢病毒
vp64
dcas9
vp64
质粒。通过修饰addgene质粒#106249以插入带有zfp36l1、hes3或乱序非靶向grna的金黄色葡萄球菌grna盒,产生了慢病毒dsacas9
krab
质粒。通过修饰addgene质粒#83925以包含优化的grna支架(chen等,cell 2013,155,1479-149)并用嘌呤霉素抗性基因代替bsr,产生了用于单一cas-tf筛选的grna表达质粒。通过进一步修饰所述单一grna表达质粒以包含带有以前描述的修饰的grna支架(adamson等,cell 2016,167,
biotechnology)进行。在分拣后,使用dneasy血液和组织试剂盒(qiagen,69506)收获基因组dna。
[0218]
grna文库测序。在100μl pcr反应中,从每个基因组dna样品扩增grna文库,使用q5热启动聚合酶(neb,m0493)和每个反应1μg基因组dna。pcr扩增按照制造商的说明书进行,使用60℃的退火温度下的25个循环,并使用下述引物:
[0219]
fwd:5
′‑
aatgatacggcgaccaccgagatctacacaatttcttgggtagtttgcagtt
[0220]
rev:5
′‑
caagcagaagacggcatacgagat-(6-bp索引序列)-gactcggtgccactttttcaa
[0221]
将所述扩增的文库用agencourt ampure xp珠子(beckman coulter,a63881),使用0.65
×
原始体积、然后是1
×
原始体积的双尺寸选择进行纯化,以纯化282bp的扩增子。在纯化后,将每个样品用qubit dsdna高灵敏度测定试剂盒(thermo fisher,q32854)定量。将样品合并,使用20-bp配对末端测序法在miseq(illumina)上使用下述自定义读出和索引引物进行测序:
[0222]
读出1:5
′‑
gatttcttggctttatatatcttgtggaaaggacgaaacaccg(seq id no:32)。
[0223]
索引:5
′‑
gctagtccgttatcaacttgaaaaagtggcaccgagtc(seq id no:33)。
[0224]
读出2:5
′‑
gttgataacggactagccttatttaaacttgctatgctgtttccagcatagctcttaaac(seq id no:34)。
[0225]
数据处理和富集分析。使用bowtie 2(langmead和salzberg nat.methods 2012,9,357-359)将fastq文件与8,505个前间区序列的自定义索引(从bowtie2-build函数生成)对齐。提取每种grna的计数并用于进一步分析。所有富集分析均使用r进行。各个grna富集使用deseq2(love等,genome biol.2014,15,550)软件包来进行,以比较每个筛选的高和低、未分拣的和低或未分拣的和高条件之间的grna丰度。如果相对于未分拣和低mcherry细胞箱两者来说在高mcherry细胞箱中两种或更多种grna被显著富集(fdr《0.01),则将所述tf选为命中物。
[0226]
体内表达比较。下载了作为脑发育转录组图谱(brainspan developmental transcriptome atlas)的一部分生成的rna测序数据(miller等,nature 2014,508,199-206)。在受孕后8至13周之间,为列出的每个发育时间点和解剖区域计算在单因子cas-tf筛选中鉴定到的17种tf的平均表达。对一组随机的17种tf进行了相同的分析,代表性比较示出在图1f中。
[0227]
grna和cdna验证。如前所述将来自于所述筛选的排名靠前的富集grna克隆到适合的grna表达载体中。grna验证的执行与筛选类似,区别在于转导在24孔板中进行,并且病毒以高的moi递送。在grna转导后4天收获细胞用于流式细胞术或qrt-pcr。
[0228]
对于免疫荧光染色实验来说,如前所述将编码排名靠前的富集tf的cdna pcr扩增,并克隆到强力霉素诱导型表达载体中。将细胞在增补有10μm rock抑制剂的mtesr中,用指定的tf和编码m2rtta的独立的慢病毒(addgene#20342)悬浮共转导。将未修饰的ipsc用于这些实验,以便能够在不受mcherry报告物干扰的情况下用红色荧光团染色。在转导后18-20小时,将培养基更换成增补有0.1μg/ml强力霉素(sigma,d9891)的神经源性培养基。在转导后4天如前所述进行染色。对于一部分tf来说,在转导后3天,使用tubb3-2a-mcherry细胞系分拣出mcherry表达最高的细胞。将所述细胞在预先建立的人类星形胶质细胞(lonza,cc-2565)的单层上重新铺板,并在染色前在神经源性培养基中继续培养8天。h9人
类胚胎干细胞中的grna和cdna验证的执行与为ipsc所描述的相似。通过慢病毒转导建立多克隆
vp64
dcas9
vp64
h9 esc细胞系。并使用独立的慢病毒递送grna。
[0229]
定量rt-pcr。将细胞用accutase(stemcell tech,7920)解离,并以300g离心5min。使用rneasy plus(qiagen,74136)和qiashredder试剂盒(qiagen,79656)分离总rna。在10μl反应中,使用superscript vilo反转录试剂盒(invitrogen,11754)对每种样品0.1μg总rna进行反转录。每个pcr反应使用1.0μl cdna,使用perfecta sybr green fastmix(quanta biosciences,95072)并使用cfx96实时pcr检测系统(bio-rad)。使用纯化的扩增子的稀释液来优化在所有引物的适合动态范围内的扩增效率。所有扩增子产物均通过凝胶电泳和解链曲线分析进行验证。所有qrt-pcr结果均表示为归一化的gapdh表达的rna的变化倍数。在本研究中使用的引物参见表4。
[0230]
表4.在本研究中使用的所有qrt-pcr引物
[0231]
[0232]
[0233][0234]
免疫荧光染色.将细胞用pbs简短清洗,然后用4%多聚甲醛(santa cruz,sc-281692)在室温固定20分钟。将细胞用pbs清洗两次,然后与阻断缓冲液(含有10%山羊血清(sigma,g6767)、2%bsa(sigma,a7906)的pbs)在室温温育30min。将细胞用0.2%triton-x 100(sigma,t8787)在室温通透化10min。使用下述第一抗体在室温温育2小时:小鼠抗tubb3抗体(1:1000稀释,biolegend,801201);兔抗map2抗体(1:500稀释,sigma,ab5622)。将细胞用pbs清洗三次,然后与第二抗体和dapi(invitrogen,d3571)在阻断溶液中在室温温育1小时。使用下述第二抗体:alexa fluor 488山羊抗小鼠抗体(1:500稀释,invitrogen,a-11001);alexa fluor 594山羊抗兔抗体(1:500稀释,invitrogen,a-11012)。将细胞用pbs清洗三次,并用zeiss 780直立式共聚焦显微镜成像。
[0235]
对于用于grna验证的活细胞ncam染色,将细胞用accutase(stemcell tech,7920)解离,以300g离心5min,并以10x106个细胞/ml的密度重悬浮在染色缓冲液(含有0.5%bsa(sigma,a7906)和2mm edta(sigma,e7889)的pbs)中。以每1x106个细胞0.6μg的量添加小鼠抗cd56抗体(ncam,invitrogen,12-0567),并在4℃温育30min。将细胞用1ml染色缓冲液清洗,以300g离心5min并重悬浮在染色缓冲液中,用于在sh800 facs细胞分拣仪(sony biotechnology)上分析。
[0236]
rna-测序和teto cdna表达。将tubb3-2a-mcherry ipsc用编码m2rtta的慢病毒和指定teto-cdna共转导。细胞在含有10μm rock抑制剂的mtesr中转导。第二天,将培养基更换成增补有0.1μg/ml强力霉素的神经源性培养基(dmem/f-12营养混合物(gibco,11320),1x b-27无血清增补物(gibco,17504),1x n-2增补物(gibco,17502)和25μg/ml庆大霉素(sigma,g1397))。在转入基因表达2或3天后,使用sh800 facs细胞分拣仪以半纯度模式对
细胞进行分拣。将分拣的细胞在基质胶包被的24孔板上重新铺板,并在增补有各10ng/ml的bdnf、gdnf和nt-3(peprotech)的神经源性培养基中培养,直至6或7天后收获。
[0237]
使用rneasy小提试剂盒(qiagen)提取总rna,并将100ng rna用于开发rna-seq文库。rna-测序文库使用truseq标准mrna试剂盒(illumina),按照制造商的方案来制备。将所述文库在nextseq 500上以高输出模式,使用75bp配对末端读出来测序。将读出序列首先用trimmomatic v0.32裁剪以除去接头,然后使用star aligner(langmead等,nat.methods 2012,9,357-359)与grch38比对。使用gencode v22中的综合基因注释,使用来自于亚读出软件包(1.4.6-p4版)的特征计数获得基因计数。差异表达分析使用deseq2来确定,其中将基因计数拟合到负二项式广义线性模型(glm),并用wald统计确定显著命中物。如果在所有测试的条件下至少三个样品具有tpm》1,则将基因纳入分析。基因本体分析使用基因本体联合数据库(ashburner等,2000,the gene ontology consortium,2017)和突触基因本体联合数据库(koopmans等,neuron 2019,103,217-234e214)来进行。
[0238]
电生理学。将tubb3-2a-mcherry ipsc用编码m2rtta的慢病毒和单独的或与teto-lhx8组合的teto-neurog3共转导。细胞在含有10μm rock抑制剂的mtesr中转导。第二天,将培养基更换成增补有0.1μg/ml强力霉素的神经源性培养基。在转入基因表达3天后,使用sh800 facs细胞分拣仪以半纯度模式对细胞进行分拣。将分拣的细胞在基质胶包被的盖玻片上重新铺板,并在实验的剩余部分中在增补有各10ng/ml的bdnf、gdnf和nt-3(peprotech)的神经源性培养基中培养。
[0239]
在诱导转入基因表达后7天,在zeiss axio examiner.d1显微镜下对培养的细胞进行全细胞膜片钳记录。为避免渗透压休克,将培养基在大约5分钟内以逐步方式逐渐更换为人工csf(acsf),然后将盖玻片移至记录室。acsf含有124mm nacl,26mm nahco3,10mm d-葡萄糖,2mm cacl2,3mm kcl,1.3mm mgso4和1.25mm nah2po4(310mosm/l),并在室温下用95%o2和5%co2连续鼓泡。使用红外照明和微分干涉对比光学元件(ir-dic),在20x水浸物镜下检查细胞。实验人员对条件不知情,并选择形态学上最复杂的神经元进行记录。使用p-97拉拔器(sutter instrument)从硼硅酸盐玻璃毛细管拉出电极(4-7mω),并填充含有135mm甲磺酸钾、8mm nacl、10mm hepes、0.3mm egta、4mm mgatp和0.3mm na2gtp的细胞内溶液(用koh调节到ph 7.3,用蔗糖调节到295mosm/l)。在千兆欧姆密封破裂后,在电压钳模式下用短暂的超极化脉冲测量膜电阻,并从放大器的电容补偿电路估算膜电容。然后,在电流钳模式下记录静息膜电位。最后,施加小的保持电流以将膜电位调整到-60mv左右,并通过注入越来越多的电流来生成输入-输出曲线。数据使用multiclamp 700b放大器(molecular devices)来记录,并使用digidata 1550(molecular devices)在50khz下进行数字化。基于使用自定义matlab脚本生成的第一个动作电位来计算动作电位性质。无论峰值幅度如何,如果动作电位具有特征性的双分量上升阶段,则通过目测来计数它们。所有实验都在对条件不知情的情况下进行分析,并且仅使用在整个数据收集期间保持稳定的记录。
[0240]
基于正交crispr的基因调控。将tubb3-2a-mcherry vp64
dcas9
vp64 ipsc用含有zfp36l1、hes3或乱序金黄色葡萄球菌grna的一体化dsacas9
krab
慢病毒(thankore等,nat.commun.2018,9,1674)转导。2天后,使用0.5μg/ml嘌呤霉素开始抗生素选择,并将细胞在mtesr中继续培养7天。在用dsacas9
krab
和金黄色葡萄球菌grna转导后9天后,将细胞用编
码sgngn3或sgascl1的慢病毒转导,并切换成神经源性培养基。对于mrna测序来说在grna转导后3天收获细胞,对于流式细胞术来说在grna转导后4天收获细胞。
[0241]
使用rneasy plus(qiagen,74136)和qiashredder试剂盒(qiagen,79656)分离总rna。制备文库,并由genewiz在illumina hiseq上使用2x150bp配对末端读出进行测序。测序运行的平均质量得分为39.03,并且94.48%的读出≥30。每个样品的平均读出数目为~50,000,000个读出。mrna测序分析如前为teto cdna实验所述来进行。gfp转入基因的表达使用bowtie2来定量,以将修剪后的读出与使用bowtie2-build函数生成的自定义gfp索引对齐。将原始计数针对测序深度进行标准化,并显示为在所分析的三种条件下的相对计数。
[0242]
统计方法。统计分析使用graphpad prism 7来进行。关于为每个实验运行的特定统计检验的详细信息参见图例。统计显著性用星号(*)表示,并指示计算的p值《0.05。
[0243]
实施例2
[0244]
用于神经元细胞命运的crispra筛选的人类多能干细胞系的产生
[0245]
为了能够在crispra筛选框架内富集神经元细胞,我们将2a-mcherry序列插入到人类多能干细胞系中泛神经元标志物tubb3的外显子4中(图7a)。tubb3几乎专门表达在神经元中,并在细胞体外分化并重编程成神经元后很早被诱导。2a介导的核糖体跳跃确保mcherry充当tubb3的翻译报告物,同时还减轻了可能由直接蛋白质融合引起的对内源tubb3功能的任何干扰。
[0246]
为了能够在我们的tubb3-p2a-mcherry细胞系中实现高效稳健的靶向基因激活,我们使用慢病毒载体建立了一种克隆细胞系,其在人类遍在蛋白c启动子的控制下表达在n-和c-端两端均融合到vp64反式激活结构域的dcas9(
vp64
dcas9
vp64
)(kabadi等,nucleic acids res.2014,42,e147)。
vp64
dcas9
vp64
以前已被用于实现足以用于细胞命运重编程的稳健的内源基因激活。
[0247]
为了在我们的
vp64
dcas9
vp64 tubb3-2a-mcherry细胞系中评估用于神经元分化的crispra方法,我们递送了靶向neurog2的近端启动子的4种慢病毒grna的合并物,所述neurog2是神经发生的一种主要调控物,当被异位过表达时或用crispra内源激活时足以从多能干细胞产生神经元(chavez等,nat.methods 2015,12,326-328;zhang等,neuron 2013,78,785-798)。在grna表达5天后,我们检测到靶基因neurog2以及早期泛神经元标志物ncam和map2的上调(图7b)。靶向基因激活仅在
vp64
dcas9
vp64
和neurog2 grna两者被共表达的情况下实现(图7b)。
[0248]
在递送neurog2 grna后,我们在转导后6天相对于未处理的对照细胞检测到15%mcherry阳性细胞(图7c)。为了评估我们的tubb3-2a-mcherry报告细胞系作为神经元表型的替代性指标的适用性,我们使用荧光激活细胞分拣(facs)分离了mcherry表达最高和最低的10%细胞。高mcherry细胞也具有mcherry标记的基因tubb3以及map2的较高的mrna表达水平(图7d)。所述tubb3-2a-mcherry细胞和crispra方法被用于本研究中描述的所有筛选中。
[0249]
实施例3
[0250]
神经元细胞命运的主要调控物的crispra筛选
[0251]
为了以无偏倚的方式鉴定一组神经元细胞命运调控物,我们在tubb3-2a-mcherry细胞系中进行了crispra合并grna筛选(图1a)。所述grna文库由靶向一组假定的人类tf的
grna组成(vaquerizas等,nat.rev.genet.2009,10,252-263)。tf对于细胞命运特化来说是必需的,并已广泛用于细胞重编程和定向分化应用。我们选择了一组1,496个tf,并构建了每个转录起始位点5种grna的靶向grna文库,其从优化的crispra grna的基因组广度的文库提取(horlbeck,2016,紧凑且高度活跃的下一代文库(compact and highly active next-generation libraries),elife)(图1b)。
[0252]
将所述crispra-tf grna慢病毒文库(被命名为crispr-激活筛选tf或cas-tf)以0.2的感染复数(moi)和550倍的文库覆盖率转导,以确保大多数细胞激活单种tf,并考虑了体外细胞分化的随机且通常低效的本质(图1a)。在grna表达5天后,我们使用facs分离了mcherry表达最高和最低的5%的细胞(图1c),然后在对每个分拣的箱中的前间区序列进行深度测序后使用差异表达分析定量grna丰度。我们收集了mcherry分布的5%的尾部,以便能够识别tubb3表达的细微变化。细胞在转导后第5天进行分拣,以便有足够的时间进行tf表达和报告基因的诱导,同时限制了由长时间培养或通过传代造成的有丝分裂后神经元的丧失。
[0253]
与未分拣的本体细胞群体相比,在高表达mcherry的细胞箱中存在显著富集的grna(fdr《0.01;图1d)。当将mcherry高表达细胞与mcherry低表达细胞进行比较时,我们观察到类似的结果(图8a)。在不同细胞箱之间,一组100个乱序非靶向grna保持不变(图1d)。
[0254]
对于给定靶基因来说,在一组grna中使用基于dcas9的激活物实现的转录激活程度可以变化。因此,我们预期对于大多数靶基因来说将观察到有活性和无活性grna的混合物。此外,脱靶grna活性可能通过独立于预测的tf靶调节报告基因的表达而促进假阳性。为了确保我们不会过度解释单种grna的结果,如果tf具有至少两个相对于未分拣的细胞和低mcherry细胞箱在mcherry高表达细胞箱中显著富集的grna(fdr《0.01),则它们被选为高置信度命中物。这种方法产生了作为候选神经源性因子的17个tf的名单(图1e)。这些tf中的大部分属c2h2 zf、bhlh或hmg/sox dna结合结构域家族这三个所有人类转录因子中最丰富的家族(图1e)。
[0255]
我们使用作为brainspan(miller等,nature 2014,508,199-206)(http://brainspan.org)的一部分展示的可公开获得的发育人脑中的基因表达数据分析了所述17个候选神经源性因子的表达。我们观察到横跨人脑的几个解剖学区域和发育时间点计算的所述17种因子的平均表达(参见实施例1)比随机产生的一组17种tf的平均表达更高(图1f)。
[0256]
作为cas-tf筛选的保真度的进一步证明,我们观察到三种充分表征的原神经因子neurod1、neurog1和neurog2各自具有几个在高表达mcherry的细胞中富集的grna,而5个乱序非靶向grna的随机集合不变(图1g)。基于我们的严格选择标准,具有预期的原神经活性的第四个基因ascl1未被选为高置信度命中物。然而,在高表达mcherry的细胞中富集了单种ascl1 grna(图8a),并且这个grna足以产生表达ncam和map2的mcherry阳性细胞(图8b和图8c)。
[0257]
实施例4
[0258]
候选神经源性转录因子的验证
[0259]
为了验证候选神经源性tf的活性,我们对在cas-tf筛选中鉴定到的17种tf的最富集的grna进行了单独测试。我们将这些grna以高moi转导到tubb3-2a-mcherry细胞系中,并
在4天后评估了报告物表达(图2a)。相对于乱序非靶向grna的递送,所有测试的grna均不同程度地提高mcherry阳性细胞的数目(~2%至~50%),尽管只有一部分即10种因子以统计显著性做到这一点(图2a;α=0.05)。为了验证crispra活性,我们确认了所有tf均对适合的grna的表达做出响应而上调(图9a)。tf诱导的程度与靶基因的基础表达水平直接相关,这与以前的报道相一致(konerman nature 2015,517,583-588)(图9b)。
[0260]
对atoh1和nr5a1的在cas-tf文库中代表的所有5种grna的进一步验证表明,当所述grna被单独测试时,在从合并筛选计算的富集与使用报告基因表达评估的分化程度之间存在直接相关性(图2b)。在某些情况下,在筛选中未被显著富集的grna仍然能够进行适度基因激活和神经元诱导(图9c和图9d)。例如,neurog2 grna足以上调neurog2,这与ncam和map2诱导并行,但在cas-tf筛选中未被富集(图9c和图9d)。
[0261]
鉴于我们依靠单种报告基因作为神经元表型的替代性指标,我们预计在cas-tf筛选中富集的tf将包括足以启动分化的神经元命运的主要调控物,以及辅助因子或仅调控一个或一部分神经元基因的下游效应物。为了在我们的一组候选因子中使这些差异更清楚,我们首先在grna递送后4天评估了另外两种神经元标志物ncam和map2的表达。几种tf上调这些标志物中的一种或两种,而其他tf不产生变化或甚至下调(图2c)。例如,诱导平均为34%的mcherry表达百分数的最大提高之一的sox4,对ncam和map2表达没有可检测的影响(图2a和图2c)。
[0262]
利用在我们的cas-tf筛选中鉴定到的一部分tf的表达,我们使用免疫荧光染色评估了神经元形态的存在(图2d)。为了确保稳健的tf表达并控制差异grna活性,我们过表达了编码每种tf的cdna。包括neurog3和neurod1在内的几种因子在表达4天之内产生tubb3染色呈阳性的具有复杂的树突分枝的细胞(图2d)。相比之下,许多tf正如预期上调tubb3,但未能产生具有神经元形态的细胞。我们推断在这些细胞中缺乏形态发育可能归因于较慢的分化动力学。其他神经元重编程范式通常需要长期培养才能实现形态成熟。考虑到这一点,我们进一步将所述细胞与原代星形胶质细胞一起培养11天,并发现随着培养时间延长,atoh1、atoh7和ascl1足以产生map2染色呈阳性的具有复杂神经元形态的细胞(图2e)。对于klf7、nr5a1和ovol1来说,随着培养延长,我们没有观察到类似的形态成熟。
[0263]
为了解释不同多能干细胞对这些tf的表达的响应的差异,并且为了观察对于几种因子来说缺少完整的神经元分化是否是细胞系特异性现象,我们还在h9胚胎干细胞中测试了klf7、nr5a1和ovol1。我们同样观察到tubb3的明显上调而没有神经元形态的发生(图2f)。正如预期,neurog3能够诱导快速分化并伴有清晰的神经元形态的发生。
[0264]
尽管所述17种高置信度tf命中物具有高验证率,但我们怀疑许多原神经tf与ascl1类似,不满足我们的严格截止标准。事实上,有另外109种tf至少含有单种在mcherry高表达细胞中显著富集的grna,但不被称为命中物。为了进一步调查这些tf,我们首先关注与17种高置信度命中物之一共享一个亚家族的tf。例如,atoh1是具有几种富集的grna的高置信度命中物,但atoh7和atoh8都只有单种富集的grna(图8a)。当这些grna被单独测试时,atoh7和atoh8均足以产生表达ncam和/或map2的mcherry阳性细胞(图8b和图8c),表明在这个截止值下仅具有单种富集的grna的许多命中物代表了真阳性。
[0265]
为了更全面地验证这109种tf的活性,我们进行了只靶向这些tf的二次子文库筛选(图10a-图10e)。这个筛选以与初次cas-tf筛选相同的方式进行(图10a),但所述新的子
文库由每种tf平均33种grna组成(图10b)。该筛选揭示出在高mcherry细胞中富集的其他grna(图10c)。然而,所述子文库中的大部分基因具有相对少的富集grna,类似于乱序非靶向grna合并物(图10d)。几种基因在mcherry高表达细胞箱中富集超过40%的grna。然而,这些grna的个体验证揭示出对mcherry报告基因的影响大多是轻微的(图10e)。该分析既为稳健crispra筛选的设计提供信息,也证实了我们的筛选设计在鉴定最稳健的神经源性因子方面是成功的。
[0266]
实施例5
[0267]
组合grna筛选鉴定神经元辅助因子
[0268]
tf通常协同作用以协调基因表达程序。同样,tf介导的细胞重编程通常受益于tf组合的共表达,以提高转化效率、成熟度和亚型特化。由于隐含在使用共表达的tf时观察到的改善背后的机制通常是未知的,并且由于有效的辅助因子在单独表达时可能具有极小活性,因此预测有效的tf混合物可能具有挑战性。为了应对这一挑战,我们使用成对grna进行了合并筛选,以鉴定调节人类多能干细胞的神经元分化的调控物的新组合。
[0269]
我们假设神经元分化的某些共调控物在自身单独表达时会缺少可检测的活性,因此不能在我们的初始单因子cas-tf筛选中鉴定出来。相反,这些辅助因子可能需要与另一种神经源性因子配对才能揭示出它们的活性。为了能够鉴定此类tf,我们选择将从单因子筛选鉴定到的验证过的神经源性tf与剩余的cas-tf文库配对来进行筛选(图3a)。使用针对neurog3(sgngn3)或ascl1(sgascl1)的单种grna进行了两次这样的独立筛选(图3a)。以从以前的研究改变的形式(adamson等,cell 2016,167,1867-1882e1821),将一对grna在单个慢病毒载体上从两个独立的rna聚合酶iii启动子共表达。选择neurog3和ascl1是因为它们具有强的神经源性活性,但分化动力学不同(图2d和图2e)。所述成对筛选如对单因子筛选所述的方式进行,其中每个细胞现在接受一对grna。
[0270]
由于在每个细胞中组成性存在验证过的神经源性因子,因此出现了明确的mcherry阳性细胞群体。由于这种基础神经源性刺激,除了检测到新的分化正辅助因子之外,我们还可以容易地在mcherry低表达细胞中检测到负调控物(图3b和图11a和图11b)。
[0271]
提高转化效率的有效辅助因子通常在不同的神经元重编程范式中共有,但可以以背景依赖性方式促进亚型特化。同样,我们假设在neurog3与ascl1之间共有许多辅助因子。与这个假设相一致,我们发现在所述两个筛选之间共有大多数正调控物(图3c)。然而,当与neurog3或ascl1组合时,有几种因子被独特地富集(图3c)。例如,fev仅仅随着neurog3正富集,而nkx2.2仅随着ascl1正富集。重要的是,sgngn3和sgascl1筛选都鉴定到在单因子cas-tf筛选中未观察到的新的tf(图12a-图12d)。许多这些tf,包括lhx6、lhx8和hmx2,都与神经元发育和亚型特化有关,但在神经元的体外产生中尚未被深入表征。在所有三种筛选中鉴定到的所有候选神经源性因子的名单可以在表1中找到。
[0272]
表1.三种神经元分化筛选中的所有阳性命中物
[0273]
[0274]
[0275]
[0276][0277]
来自于两个成对cas-tf筛选的阳性命中物涵盖了不同的一组tf家族(图3d)。这些tf中的大部分在多能干细胞中不表达或低表达,但有几种因子表达较高(consortium.nature 2012,489,57-74)(图3d)。选择了一组8种tf进行进一步验证。预计这些tf本身具有极小活性,而在与neurog3和/或ascl1共表达时增强神经源性活性(图3e)。尽管选择了这组8种tf用于进一步表征,但仍有大量通过crispra成对筛选揭示的其他候选因子可供进一步研究(表1)。
[0278]
相比于与乱序grna共表达的sgngn3,所有测试的tf在与sgngn3配对时将mcherry阳性细胞的转化效率提高多达3倍(图3f)。由于sgascl1仅将mcherry报告基因提高到适度水平,因此我们选择使用ncam染色来进行grna验证,以获得与这种grna的配对。只有e2f7和hmx2自身对ncam表达具有轻度影响(图3g)。然而,几种tf显著提高ascl1的神经源性活性,其中e2f7提高多达8倍(图3g)。与来自于所述筛选的预测结果相一致,nkx2.2仅在使用ascl1时而不在使用neurog3时具有显著影响(图3e、图3f和图3g)。
[0279]
实施例6
[0280]
神经源性转录因子调节亚型特异性和成熟
[0281]
神经元亚型身份和突触成熟度是决定体外衍生的神经元在疾病建模和细胞疗法应用中的效用的重要特点。因此,开发改进成熟动力学和亚型特化纯度的方案已成为本领域中的首要关注点。考虑到通过我们的crispra筛选鉴定到的神经源性tf的多样性以及通过验证实验观察到的转化效率的范围,我们推断许多这些tf可能以不同方式影响亚型身份和成熟。为了开始解决这个问题,我们进行了批量mrna测序,以便更全面地评估神经元转化的程度并比较使用不同tf产生的神经元群体中的转录多样性。
[0282]
我们首先分析了源自于单种tf的神经元。尽管tf的组合通常增强亚型产生的特异性并提高转化效率和成熟动力学,但单种tf可能足以产生具有亚型倾向性的有功能的神经元。我们选择首先对源自于atoh1或neurog3过表达的神经元进行mrna测序(图4a-图4f)。这些tf具有一些通过验证实验确定的最高转化效率(图2a-图2f),这有助于分离足够的材料用于测序。此外,尽管atoh1和neurog3两者的神经源性活性以前已被证实,但我们对atoh1和neurog3在体外神经元分化中的作用的理解仍不完整。
[0283]
我们过表达了编码atoh1或neurog3的cdna,使用facs纯化了tubb3-mcherry阳性细胞,并在转入基因表达7天后进行了mrna测序。相对于起始的未分化多能干细胞群体,两种神经元群体都具有超过3000个上调的基因(图4a)。这组共有基因富集在与神经元分化和发育相关的基因本体(go)条目中(图4b)。重要的是,相对于多能干细胞,在atoh1(3个平行实验)和neurog3(2个平行实验)的所有平行实验中高度富集了一组泛神经元基因(图4c)。
[0284]
令人吃惊的是,我们在atoh1和neurog3衍生的神经元之间,在所有可检测的基因
中观察到强相关性,表明在核心神经元程序的诱导和多能性网络的抑制中具有惊人的一致性(图4d)。然而,在使用atoh1或neurog3时一部分基因表达更高(图4d)。这些基因富集在对于neurog3来说与谷氨酸能活性相关并且对于atoh1来说与多巴胺能活性相关的go条目中(图4e)。事实上,当我们检查所述两种神经元亚型的一组预期标志物时,我们发现对于atoh1来说明显富集多巴胺能标志物,并且对于neurog3来说明显富集谷氨酸能标志物(图4f)。在atoh1衍生的神经元中,尽管多巴胺能神经元的某些典型标志物例如酪氨酸羟化酶(th)保持低表达,但与多巴胺能特化相关的许多tf例如lmx1a表达更高(图4f)。
[0285]
在许多情况下,tf的组合可能有助于神经元亚型特化的精确性或提高转化效率和成熟度。我们推断在我们的成对grna筛选中鉴定到的辅助因子,当与在单因子筛选中鉴定到的神经源性因子组合时,将充当调节亚型身份和成熟的主要候选物。因此,我们选择对源自于单独的或与e2f7、runx3或lhx8组合的neurog3的神经元进行mrna测序。优先选择这三种辅助因子是因为它们对通过grna验证评估的分化效率具有实质性影响(图3a-图3g)。我们选择neurog3是由于它明确地偏好产生谷氨酸能神经元,通常被认为是默认亚型。我们过表达了编码单独的或与e2f7、runx3或lhx8组合的neurog3的cdna,并在转入基因表达6天后进行了mrna测序。
[0286]
与atoh1和neurog3的比较相似,所有tf对共有一组核心的上调基因(图5a)。然而,相对于单独的neurog3,在使用每个tf对时被独特上调的基因富集在与神经元分化和发育相关的go条目中,这与以前测量到的在表达这些神经元辅助因子时tubb3表达的提高和转化效率的改进相一致(图5b)。
[0287]
重要的是,每个tf对独特地上调与特定神经元亚型的特化和成熟相关的基因。例如,添加runx3导致编码与本体感受背根神经节神经元的发育相关的trkc neutrophin-3受体的ntrk3的表达提高(图5c)。添加e2f7导致编码参与神经元命运定型和形态发生的p21细胞周期调控物的cdkn1a的提高(图5d)。添加lhx8时表达更高的一部分基因富集在与突触发育这种神经元成熟的标志相关的突触基因本体(syngo)条目中(图5e)。与go条目分析相一致,在添加lhx8时,一组与突触发育、调节和功能相关的基因被明显上调(图5f)。
[0288]
为了评估添加lhx8是否影响neurog3衍生的神经元的电生理成熟,我们在转入基因诱导后7天对tubb3-2a-mcherry阳性细胞进行了膜片钳记录。相对于单独的neurog3,在添加lhx8时尽管我们没有观察到静息膜电位的差异(图5g),但我们确实观察到了膜电阻的降低(图5h)和膜电容的提高(图5i)。lhx8改善了动作电位成熟的几个指标,包括放电阈值的降低(图5j)、动作电位高度的提高(图5k)和动作电位半宽度的降低(图5l)。此外,对于给定的使用电流注入的去极化步骤来说,含有lhx8的神经元以更高的频率触发动作电位(图5m),并且记录到的触发多个动作电位的细胞的比例更高(图5n)。使用单独的neurog3产生的细胞更通常不能触发动作电位或仅触发单个低幅度动作电位(图5n)。
[0289]
实施例7
[0290]
组合grna筛选鉴定神经元命运的负调控物
[0291]
通过细胞重编程和分化方案实现的转化效率通常随着起始和终止细胞类型而变。通常,亲缘关系更远的细胞类型或更衰老的细胞系不太易于转化。例如,星形胶质细胞向神经元的重编程通常比成纤维细胞向神经元的重编程更高效,并且相对于胚胎成纤维细胞,在成人成纤维细胞中效率进一步降低。这些重编程结果的差异可以部分用不同类型或发育
年龄的细胞的基因表达谱和表观遗传景观的变化来解释。因此,这种细胞环境可以产生阻碍正常tf活性的障碍,从而降低转化效率和保真度。
[0292]
高通量功能丧失性rnai筛选有助于鉴定阻止细胞类型重编程和影响转化效率的分子障碍。重要的是,消除这些障碍通常引起重编程结果的显著改善。通过我们的成对crispra筛选,我们鉴定到其激活阻碍神经元分化的tf(图3b和图11a和图11b)。这些候选负调控物除了许多其他未表征的tf之外,还包括notch信号传导下游的经典神经元阻遏物的hes基因家族的几个成员。在所有三种筛选中鉴定到的所有候选负调控物的名单可以在表2中找到。
[0293]
表2.三种神经元分化筛选中的所有负命中物
[0294]
[0295]
[0296][0297]
有趣的是,大多数负调控物在sgngn3和sgascl1筛选中共有(图6a)。它们由一组多样化的tf组成,跨越许多tf家族,在胚胎干细胞中具有广范围的基础表达。当使用与neurog3 grna共表达的单种grna进行单独测试时,包括hes和dmrt1在内的几种tf将mcherry阳性细胞的百分率降低到基础水平(图6b)。为了证明这种阻遏不仅仅局限于报告基因,我们还证明了所测试的8种阻遏型因子中的7种将ncam表达降低多达8倍(图6c)。当在h9人类胚胎干细胞中测试这些因子时,我们同样观察到神经元分化的阻遏(图6d)。事实上,在ipsc相比于esc中,这些负调控物的相对影响之间存在引人注目的相关性(图6e),强调了这些影响在多种多能干细胞系中的稳健性。
[0298]
我们推断,在多能干细胞中基础表达的这些鉴定到的负调控物中的一些可能充当神经元转化的障碍,并且它们的抑制可以提高分化效率。来自于不同细菌物种的cas9蛋白可以被编程,用于正交基因调控和表观遗传修饰。因此,我们选择使用基于金黄色葡萄球菌的cas9蛋白的正交dsacas9
krab
(thakore等,nat.commun.2018,9,1674)来靶向在多能干细胞中基础表达的两种负调控物zfp36l1和hes3的启动子(图6f)。使用dsacas9
krab
靶向这些基因的启动子导致zfp36l1和hes3的转录分别被阻遏10倍和4倍(图13a)。
[0299]
将dsacas9
krab
用于靶向基因阻遏能够共表达正交的
vp64
dspcas9
vp64
,同时激活神经源性因子(图6f)。首先将tubb3-2a-mcherry
vp64
dspcas9
vp64
ipsc用共表达zfp36l1、hes3或乱序的金黄色葡萄球菌grna的dsacas9
krab
慢病毒转导。在金黄色葡萄球菌grna转导后9天后,将细胞用编码来自于酿脓链球菌的sgngn3或sgascl1的慢病毒转导,并在该最后的转导后4天进行分析。zfp36l1的敲减将使用sgngn3获得的mcherry阳性细胞的百分率相对于表达乱序金黄色葡萄球菌grna的对照细胞系提高2倍(图13b)。同样,在使用sgascl1获得的分化细胞的ncam阳性群体中,zfp36l1敲减将mcherry报告基因的表达水平提高1.2倍(图13c)。
[0300]
为了鉴定这种基于正交crispr的调控的基因组广度的效果,我们对源自于ngn3激活并伴有zfp36l1或hes3阻遏的神经元进行了mrna测序。尽管相对于接受乱序金黄色葡萄球菌grna的细胞hes3的敲减仅仅引起基因表达的少量细微变化(图14a),但相对于单独的ngn3激活zfp36l1的敲减引起全局基因表达谱的显著变化(图6g和图14b)。在zfp36l1敲减细胞中,我们还观察到neurog3和酿脓链球菌grna的略微增加,其通过grna载体上的gfp转入基因的表达来量化(图14c和图14d)。在具有zfp36l1敲减的神经元细胞中上调的基因富集在与神经元分化和形态发育相关的go条目中(图6h)。相比之下,被zfp36l1敲减下调的基因富集在与细胞周期发育和进展相关的go条目中(图6h)。被zfp36l1敲减上调的基因的实例包括神经元转录因子neurod4、insm1和olig2,以及参与神经元形态发生的基因包括
nefl、ngef和ntn1(图6i)。
[0301]
实施例8
[0302]
讨论
[0303]
正如本文中详述的,我们通过单个和组合crispra筛选系统地剖析了1,496种假定人类转录因子在调控多能干细胞的神经元分化中的作用。这项工作强调了基于crispr的技术以高通量方式改变基因表达的用途,并突出了基于dcas9的基因激活用于研究基因表达在复杂细胞表型中的因果作用的稳健本质。
[0304]
使用早期泛神经元标志物如tubb3作为神经元表型的替代性指标,能够鉴定一组广范围的具有不同神经源性活性的tf。例如,尽管neurog3足以在表达的4天内迅速产生神经元细胞,但atoh7和ascl1需要更长的培养时间才能实现类似的表型(图2d和图2e)。很可能添加辅助因子例如在我们的组合grna筛选中鉴定到的辅助因子可以提高分化的效率和动力学,正如使用其他细胞重编程研究所看到的(pang等,nature 2011,476,220-223)。此外,包括klf7、nr5a1和ovol1在内的几种tf诱导tubb3的表达,但不能产生神经元细胞(图2d)。这些tf可能充当辅助因子或下游调控物,需要其他神经源性因子的共表达才能获得更完全的分化。事实上,许多在单因子筛选中鉴定到的tf在成对grna筛选中也是命中物(表1)。
[0305]
我们发现,包括ascl1和atoh7在内的几种具有明显神经源性活性的tf在cas-tf筛选中仅有单种grna被富集(图8)。由于单种富集的grna可能是脱靶活性或噪声的结果,因此准确分类这些grna可能具有挑战性。每个基因使用更多的grna或下一代基于dcas9的激活物平台可能有助于更准确地定义真正的正效应。事实上,我们的每个基因使用更大数目的grna的子文库筛选揭示出几个另外的候选命中物(图10)。grna设计和筛选分析的进一步改进可能继续使基于crispr的筛选更加稳健,并且可以扩展到更复杂的表型。
[0306]
通过使用成对grna筛选,我们鉴定到一组改进神经元分化效率、成熟和亚型特化的tf。有趣的是,这些tf中的大多数本身不具有神经源性活性,正如在我们的单因子cas-tf筛选中所评估的。这个观察强调了控制细胞分化的协同tf相互作用的重要性,并支持使用无偏倚的方法来鉴定这些tf。我们将e2f7鉴定为可以提高神经元转化效率(图3f和图3g),这可能是由于它在抑制细胞增殖中的已知作用,这是从增殖性多能干细胞向有丝分裂后神经元转变中的重要开关。此外,我们发现runx3独特地诱导亚型特异性受体基因表达(图5c),因此可以作为分化方案的有用补充,以更精确地指导神经元亚型身份。神经元辅助因子lhx8对神经元成熟的标志物具有深远影响,正如从许多突触相关基因的富集和电生理成熟的明显改善中看出的(图5)。功能性突触形成是体外衍生的神经元的必需表型,并且它通常是限速步骤。通过tf编程提高突触成熟可能有助于加快用于疾病建模和药物筛选的有用神经元模型的开发。
[0307]
未来的研究可能会利用先进的筛选平台来进一步表征规定细胞谱系特化因子。神经元tf的更详尽的名单可能通过执行依赖于多个神经元标志物或使用成熟或亚型身份的标志物的筛选来鉴定。或者,这些筛选可以使用单细胞rna测序(scrna-seq)输出而不是对几个离散的标志物进行分析来执行,以更准确地定义使用不同的tf组合获得的神经元表型的多样性,并针对不断增长的来自于人脑样品的scrna-seq数据图谱来衡量这些结果。从本文详述的筛选鉴定到的tf可以充当子文库的主要候选物,以在这些可能在文库尺寸规模方
面更加受限的替代方法中进行测试。
[0308]
所述成对grna筛选还鉴定到神经元分化的负调控物。这些tf之一zfp36l1的敲减足以改进分化,导致基因表达朝向更加分化的神经元表型的全面变化(图6g、图6h、图6i)。尽管在这个实施例中对分化的影响有些轻微,但在不太易于转化的细胞类型例如成年成纤维细胞中可能会看到更剧烈的改进。重要的是,许多在我们的筛选中鉴定到的负调控物在用于重编程研究的其他细胞类型例如成纤维细胞和星形胶质细胞中表达。
[0309]
除了tf之外还靶向表观遗传修饰物或其他基因子集的另外的crispra筛选可能有助于进一步阐明基因激活可以调节神经元细胞命运的程度。用于内源基因表达和染色质状态的可编程调控的合成系统的持续开发,以及这些系统在更复杂的体外和体内模型中的应用,可能使研究能够更全面地定义控制细胞命运决定的基因网络和表观遗传机制。
[0310]
总体而言,如本文中详述的,我们已鉴定了在人类细胞中控制神经元命运特化的一组广泛的转录因子。这个因子的目录可以作为开发用于以高的效率和保真度产生多样化神经元细胞类型的方案的基础,用于再生医学和疾病建模应用。最终,本文中详述的crispra筛选平台可以扩展到其他细胞重编程范例,并促进许多临床相关的细胞类型的体外生产。
[0311]
实施例9
[0312]
鉴定成肌祖细胞命运的新的驱动物的高通量crispr激活筛选
[0313]
骨骼肌再生是由肌肉卫星细胞介导的复杂过程。驱动从肌肉卫星细胞的正确成肌分化的事件级联已被良好地表征;然而,在胚胎发育过程中规定卫星细胞命运的上游事件尚未被完全理解。转录因子pax7在卫星细胞的特化和维持中发挥重要作用,其过表达可以在人类多能干细胞中决定成肌祖细胞的命运。为了研究卫星细胞命运的新的驱动物,我们在人类h9胚胎干细胞中产生了pax7-2a-gfp细胞系。我们使用了靶向所有人类转录因子的启动子处的grna文库,并共同递送了基于crispr/cas9的转录激活物,以系统性地鉴定pax7表达的独立驱动物。然后,通过使用所述grna文库以及靶向pax7启动子的grna,我们进行了第二次筛选以调查pax7的辅助因子。该第二次筛选鉴定到单独的一组转录因子,并且一共鉴定到21种转录因子。个体验证证实了某些命中物诱导pax7表达和成肌细胞命运的采纳。从本研究产生的数据可以在细胞和基因疗法的背景中用于骨骼肌再生的潜在治疗靶点。
[0314]
pax7-2a-gfp细胞系的产生。将人类h9 esc(从wicell stem cell bank获得)用于这些研究,将它们维持在mtesr(stem cell technologies)中,并在包被有es合格基质胶的组织培养处理板(corning)上铺板。将h9 esc用靶向pax7亚型a终止密码子的cas9-grna质粒和具有与pax7亚型a的外显子8和3’utr互补的同源臂的供体质粒共转染。转染使用genepulser xcell(bio-rad),在250v、750μf和无限电阻下,在4mm比色皿中进行。所述供体质粒还含有被loxp位点包围的pgk-puror表达盒,以允许选择性扩增具有供体质粒整合的细胞。在嘌呤霉素选择(1μg/ml)两周后,挑取克隆并通过pcr筛选供体表达盒在正确基因组位点处的整合。将所选的阳性克隆用cre重组酶质粒转染,以除去大的pgk-puror表达盒。将细胞稀疏铺板,挑取克隆并使用在供体模板之外的引物筛选正确的整合。通过sanger测序确认得到的pcr条带。
[0315]
crispr激活-转录因子(cra-tf)grna文库的产生。在以前整理的名单的基础上选择假定的人类转录因子。可用于基因列表的相应的grna从人类子合并crispra文库提取。也
从该文库提取了100种乱序非靶向grna。我们的自定义文库由1496个独特基因的靶向每个转录起始位点的5种grna和100种乱序非靶向grna组成,文库总规模为8,505种grna。将寡核苷酸合并物(custom array)pcr扩增,并使用gibson组装法克隆到单个grna表达质粒中用于单一cra-tf筛选,或克隆到双grna表达质粒中用于使用靶向pax7启动子的grna的成对cra-tf筛选。
[0316]
慢病毒产生。hek293t细胞从美国组织保藏中心(american tissue collection center)(atcc)获得并通过杜克大学癌症中心部门(duke university cancer center facilities)购买,并在增补有10%fbs(sigma)和1%青霉素/链霉素(invitrogen)的dulbecco改良的eagle’s培养基(invitrogen)中,在37℃和5%co2下培养。将大约3.5百万个细胞铺于每个10cm tcps培养皿上。24小时后,使用磷酸钙沉淀法将所述细胞用所述表达质粒、pmd2.g包膜质粒(addgene#12259)和pspax2第二代包装质粒(addgene#12260)转染。在转染后12小时更换培养基,并在这次培养基更换后24和48小时收获病毒上清液。将病毒上清液合并并以500g离心5分钟,通过0.45μm滤器,并使用lenti-x浓缩仪(clontech)按照制造商的方案浓缩至20x。慢病毒grna文库通过流式细胞术来滴定。
[0317]
用于pax7的上游调控物的高通量cra-tf筛选。将稳定表达
vp64
dcas9
vp64
的未分化的h9 pax7-2a-gfp细胞解离,并将22.5x106个细胞用cra-tf慢病毒文库以每个平行样0.2的moi转导(3.1x104个细胞/cm2)。我们的目标是实现每个平行样500倍的文库覆盖率。将细胞用1μg/ml嘌呤霉素选择6天。对于分化来说,将所述hesc用accutase(stem cell technologies)解离成单细胞,并在基质胶包被的培养板上在增补有10μm y27632(stem cell technologies)的mtesr培养基中铺板(3.6x104个细胞/cm2)。第二天,将mtesr培养基更换为增补有10μm chir99021(sigma)的e6培养基,以开始中胚层分化。2天后,除去chir99021并将细胞维持在e6培养基中并每天增补10ng/ml fgf2(sigma)。在分析之前,在第1版筛选中2周和第2版筛选中1周的分化期间细胞未传代。
[0318]
在诱导分化后1或2周时,将细胞用0.2%胶原酶ii(thermofisher)解离,并用中和培养基(含有10%fbs的dmem/f12)清洗。通过离心沉积细胞,并将细胞重悬浮在流动培养基(含有5%fbs的pbs)中。将细胞对阳性mcherry表达进行门选,并在sony sh800流式细胞仪上将gfp表达排名靠前的10%和靠后的10%的细胞分选到独立的管中。将分选的细胞沉积,并使用qiagen dneasy试剂盒提取基因组dna。也留出未分拣的细胞用于基因组dna分离,以充当输入对照。
[0319]
通过pcr从所述基因组dna回收grna序列。测序在illumina miseq上,使用21bp配对末端测序法并使用自定义读出和索引引物来进行。
[0320]
数据处理和富集分析。使用bowtie并使用选项-p 32
‑‑
端对端
‑‑
非常灵敏-3 1
ꢀ‑
i 0-x 200,将fastq文件与自定义索引(从bowtie2-build函数生成)对齐。提取每种grna的计数并用于进一步分析。所有富集分析均使用r进行。对于个体grna富集分析来说,使用deseq2软件包在每个筛选的高和低、未分拣的和低或未分拣的和高条件之间进行比较。
[0321]
个体grna验证。来自于在每个筛选中发现的排名靠前的富集grna的前间区序列作为寡核苷酸从idt订购,并如较早时所述将它们克隆到慢病毒grna表达载体中。将与在合并cra-tf筛选中使用的相同的h9 pax7-2a-gfp细胞系用于个体grna验证。细胞用个体grna转导,并经历与原始筛选中相同但规模较小的嘌呤霉素选择和分化方案。
[0322]
使用rneasy plus rna分离试剂盒(qiagen)分离rna。使用superscript vilo cdna合成试剂盒(invitrogen)合成cdna。使用cfx96实时pcr检测系统(bio-rad)进行使用perfecta sybr green fastmix(quanta biosciences)的实时pcr。结果使用δδc
t
法表示成归一化到gapdh表达的感兴趣基因的表达的提高倍数。
[0323]
培养的细胞的免疫荧光染色。对于分化来说,将细胞生长至合生并在基质胶包被的24孔组织培养板上分化,并在孔中直接进行免疫荧光染色。将细胞用4%pfa固定15min,并在阻断缓冲液(增补有3%bsa和0.2%triton x-100的pbs)中在室温通透化1hr。将样品与pax7(1:20,developmental studies hybridoma bank)和肌球蛋白重链mf20(1:200,dshb)在4℃温育过夜。将样品用pbs清洗15min,并与1:500稀释的来自于invitrogen的相容的第二抗体和dapi在室温温育1hr。将样品用pbs清洗3次,每次15min,并将孔保持在pbs中并使用常规荧光显微镜成像。
[0324]
结果:人类esc中pax7报告细胞系的产生。pax7对卫星细胞特化、功能和维持来说可能是关键的。由于成体卫星细胞也通过它们独特的pax7表达来鉴定,因此我们决定使用这个基因来产生卫星细胞报告细胞系。我们在h9 esc中测试了三种被设计用于在pax7的终止密码子附近切割的grna,并通过surveyor分析发现grna 1具有最高的切割活性。我们设计了一种供体模板,其含有同源臂和插入到pax7的最后一个外显子下游的p2a-egfp序列(图15a)。将h9 esc用crispr/cas9质粒和供体载体共转染,所述供体载体含有两侧带有loxp的pgk-puror表达盒,以允许选择重组事件。抗性克隆经过分子验证,并通过cre重组切除所述选择盒。使用被设计在同源臂外部的引物,通过pcr进一步验证得到的克隆(图15b)。多个克隆的较大整合条带通过sanger测序来验证,以确保报告物表达盒的框内定位(图15c)。较小的野生型条带也被测序,以确保在非报告基因等位基因上不产生插入缺失。选择一个克隆并用于后续研究。
[0325]
通过用编码
vp64
dcas9
vp64
的慢病毒载体和靶向pax7启动子处的grna转导细胞以激活内源基因表达,来验证报告基因的活性。流式细胞术分析显示,与未转导的细胞相比,克隆群体中的gfp表达明显改变(图15d)。分拣排名前15%和后15%的表达gfp的细胞,并提取rna用于qrt-pcr,其证实了gfp与pax7表达的正相关性(图15e)。
[0326]
cra-tf筛选以鉴定pax7表达的新的调控物。为了系统性地鉴定作用于pax7上游的tf,我们在以前精选的名单的基础上产生了靶向所有假定tf的启动子的grna文库。可用于基因列表的相应的grna从以前产生的人类子合并crispra文库提取。为我们的研究产生的自定义crispra-tf(cra-tf)文库包括1496种独特基因的靶向每个转录起始位点的5种grna和100种乱序非靶向grna,文库总规模为8,505种grna。
[0327]
由于在胚胎发育期间pax7在外胚层衍生的神经嵴中表达,因此我们将我们的筛选与中胚层分化方案配对,以促进成肌谱系特化。hpsc向中胚层细胞的分化可以通过添加小分子chir99021这种gsk3抑制剂来启动。在分化之前,我们转导我们的细胞系以稳定表达
vp64
dcas9
vp64
。接下来,我们以0.2的moi转导了我们的cra-tf文库,进行选择,并允许细胞在无血清培养基条件下在fgf2存在下分化2周(图16a)。我们以前以确定,单独的2周中胚层分化不足以诱导gfp表达。
[0328]
使用cra-tf文库和分化,出现了可鉴别的gfp 细胞群体,并且我们通过facs分拣了前10%和后10%的表达gfp的细胞(图16b)。我们进行了下一代测序(ngs)以鉴定在任一
组中富集的grna。当我们将gfp低表达细胞与未分拣的细胞进行比较时,没有出现命中物,表明该细胞群体完全缺乏pax7表达。当我们将gfp高表达细胞与未分拣的细胞进行比较时,出现了10个独特的基因(不包括pax7 grna)作为显著命中物(图16c)。将这些grna单独地克隆到慢病毒载体中,并使用2周分化方案在同一细胞系中进行验证(图16d)。我们还将等效的cdna克隆到慢病毒构建物中,并确定了蛋白质递送也可以导致pax7的激活,尽管程度不同(图16e)。
[0329]
组合cra-tf筛选以鉴定与pax7协同的tf。尽管已显示使用小分子进行中胚层分化会产生成肌细胞,但它也导致包括神经元在内的非均一细胞类型的分化。使用chir99021进行的中胚层分化也用于将多能细胞分化成心脏和肾脏谱系。以前已证明,在分化时间过程中pax7 cdna的表达可以影响细胞采纳成肌细胞命运超过可选谱系。
[0330]
通过在慢病毒cra-tf文库中添加靶向mu6-pax7启动子的grna表达盒,我们进行了第二个筛选(图17a)。这个筛选也具有鉴定与pax7协同工作以增强成肌祖细胞特化的tf的潜力。我们如较早时所述进行了所述筛选,区别在于我们将分化减少到1周而不是2周,因为我们预期pax7会快速上调。在分化1周后,我们看到gfp群体中发生明显变化,并分拣出前10%和后10%的gfp表达细胞(图17b)。该第二个筛选发现了13种tf,它们在与pax7共表达时对pax7表达产生累加效应。总的来说,两个筛选产生了在中胚层分化的背景中上调pax7的21种tf的名单(图17c)。
[0331]
促进成肌分化的命中tf的验证。接下来,我们希望确定tf是否不仅可以上调pax7表达,而且可以产生成肌细胞。我们将21种tf grna命中物各自克隆到表达rtta3的慢病毒载体中,并使用四环素诱导型启动子来驱动
vp64
dcas9
vp64
的表达。我们将两种构建体转导到h9pax7-2a-gfp细胞系中,并在强力霉素(dox)存在下将细胞分化28天,并在第14天进行传代步骤。我们在28天后撤除dox以允许下调pax7,这允许下游成肌基因上调,以诱导成肌祖细胞终末分化成肌细胞(图18a)。qrt-pcr分析显示,与乱序grna对照相比,在许多条件下在终末分化2周后pax7表达略微上调。令人吃惊的是,当与表达pax7 grna的对照相比时,myod、dmrt1和pax3这三种tf表现出更高的pax7表达(图18b)。我们还检查了下游成肌标志物myog的表达,并发现它在21种新的tf grna命中物中的8种中高表达(图18c)。最后,我们对固定的分化细胞进行了免疫荧光染色,以检测肌球蛋白重链(mhc)阳性肌纤维的存在(图18d)。我们还对pax7进行了染色,以确定是否有任何新的命中物可以产生可维持pax7 卫星细胞表型的细胞类型。许多表达myog的假定命中物也表现出mhc 肌纤维的存在。dmrt1显示出最高数量的pax7 细胞核,并且最稳健地产生肌纤维。
[0332]
讨论。在本研究中,我们使用无偏倚的系统性方法来筛选所有tf,以获得成肌祖细胞命运特化。使用pax7表达作为卫星细胞特化的替代性指标,我们产生了pax7-2a-gfp人类胚胎干细胞系,以在成肌分化过程中发现新的pax7上游调控物。使用个体和组合crispra筛选,我们产生了一个21种表现出pax7激活的假定tf的名单。这些tf中的一部分也表现出将esc分化成肌纤维的能力。诸如twist1和pax3的命中物并不令人吃惊,因为以前已表征过它们对近轴中胚层发育是重要的。具体来说,pax3是pax7的旁系同源物,它们具有作为肌生成的上游调控物的重叠功能。myod和myog是有趣的命中物,因为它们被认为在肌生成过程中位于pax7表达的下游。一个可能的解释是,这些成肌因子的过表达将胚胎干细胞推向成肌程序,以产生肌节的初级肌纤维,这然后可以形成一个正反馈回路,以产生更多pax7衍生的
胚胎成肌细胞。在本研究中进行的两个版本的crispra筛选中,sox9和sox10是在两者中都作为命中物出现的仅有的tf。sox9和sox10两者都是在发育过程中重要的tf,并且sox因子总的来说参与细胞命运的决定。sox9的影响跨越从软骨形成到中枢神经系统发育,并且还已显示它增强esc向所有3个胚层的祖细胞的分化。与sox9和pax7一样,sox10在神经嵴发育中也发挥重要作用。与pax7不同,sox10不在中胚层中表达;然而,sox10缺陷胚胎表现出pax7 肌肉祖细胞的显著减少和肌节形成的减少。将sox9和sox10与分化和正确的肌生成联系起来的以前的研究与这些tf在我们的cra-tf筛选中的出现的组合,巩固了它们在成肌祖细胞特化中的重要性。
[0333]
在所有被分析的命中物中,一种tf,具体来说是dmrt1,显示出在体外在丰富的肌纤维中产生大量pax7 细胞的激动人心的能力。dmrt1是一种特别出人意料的命中物,因为它主要被认为是一个性别决定基因。这个基因主要表达在支持细胞中,是睾丸成熟所必需的。有趣的是,pax7最近被鉴定为是小鼠中具有干细胞样性质的罕见精原细胞亚群的标志物。尽管在精子发生或肌发生的背景中dmrt1与pax7之间没有明确的联系,但我们的结果表明,dmrt1能够在pax7上游发挥作用并激活它的表达,以赋予细胞以干细胞表型。在我们的筛选中使用的中胚层分化的背景中,这会导致成肌祖细胞和肌纤维生成。尽管这个过程可能不是自然发生的现象,但dmrt1过表达可能被用于产生稳健的用于细胞治疗的成肌祖细胞。
[0334]
总之,我们对所有人类tf进行了强有力的crispra筛选,发现了作为预期、有趣和令人惊讶的组合的命中物。这些结果阐明了我们对卫星细胞发育和pax7的上游调控物的理解,并且可用于工程化改造成肌祖细胞。本研究中开发的方法对于发现新的tf以加强其他细胞谱系的工程化改造具有广泛的用途。
[0335]
实施例10
[0336]
调控软骨形成的转录因子的鉴定
[0337]
使用与实施例9中详述的相似的高通量crispr激活筛选来鉴定软骨细胞特异性基因表达的新的驱动物。使用在胶原中特异性表达的基因作为软骨细胞特异性标志物。鉴定了软骨细胞特异性转录因子。
[0338]
tf靶向crispr激活文库的产生。如前面的实施例中所述从文库提取靶向被注释的tf的grna,产生一个包含8,435种grna(每种tf大约5种grna)的文库。将所述文库扩增,并使用gibson组装法克隆到含有mcherry-2a-puror表达盒的改良的lenti-crispr构建物中。
[0339]
慢病毒生产和滴定。grna文库和vp64-dcas9-vp64表达载体的慢病毒包装,通过使用磷酸钙沉淀法将合并的grna文库质粒或vp64-dcas9-vp64质粒(20μg)、pmd2.g(addgene,12259,6μg)和pspax2(addgene,12260,15μg)转染到3e6 hek 293t中来进行。16小时后更换培养基。在24和48小时后收集病毒上清液,并使用lenti-x浓缩系统(clonetech)按照制造商的说明书进行浓缩。
[0340]
含有grna文库的慢病毒的滴定,通过在铺板后8小时转导24孔板中密度为60k细胞/cm2的col2a1-2a-gfp;vp64-dcas9-vp64 hipsc来进行。向培养基添加浓缩慢病毒的10倍连续稀释液,范围从5e-5至5μl。在转导后16小时更换培养基,并在d3使用bd accuri c6细胞仪测量mcherry荧光,以确定转导效率。
[0341]
crispr激活物hipsc细胞系的产生的验证。如前所述将col2a1-2a-gfp报告hipsc0ꢀ‑
x 200,将通过miseq测序生成的fastq文件与自定义索引对齐。然后我们生成了每个被测序群体中每种grna的读出数目的计数表。使用r中的deseq2软件包评估每种grna的显著富集。我们将未分拣与gfp
高
、未分拣与gfp
低
和gfp
高
与gfp
低
进行了比较;在这里我们仅示出了gfp
高
与gfp
低
比较的数据。
[0355]
候选tf的验证。如4.4.3中所述将报告hipsc用含有sox9 cdna的慢病毒转导,同时制备了未转导的对照。在恢复两天后,将细胞按照2.4.2中描述的成软骨方案进行分化,但在生骨节阶段(d6)收获。在这个时间点,使用accuri c6细胞仪通过流式细胞术来评估成软骨分化。
[0356]
hipsc软骨形成的候选调控物的鉴定。为了评估激活的tf对成软骨分化的影响,我们在col2a1-2a-gfp背景中产生了稳定表达在n-和c-端两端均融合到vp64反式激活结构域的dcas9(vp64-dcas9-vp64)的细胞系(图19a)。对转导的细胞进行选择,以产生多克隆激活细胞系。该多克隆细胞系在转导靶向ngn2的启动子的grna后,稳健地激活内源neurogenin 2(ngn2)(图19b)。
[0357]
为了产生tf靶向crispr激活文库,与实施例9中详述的相似,我们从以前描述的可公开获得的基因组尺度的激活文库提取了靶向tf的grna。将所述grna文库克隆到带有mcherry-2a-puror表达盒的lenti-crispr构建物中,以允许选择转导的细胞系(图20a)。将lenti-crispr文库以低感染复数(moi)转染到我们的激活/报告细胞系中,以确保每个细胞一种grna,并维持足够的文库覆盖率(》500x)。然后将转导的细胞分化(图20a)。grna文库的转导在第21天似乎消除了gfp的双峰分布;然而,分拣到gfp
高/低
群体(图20b)。我们观察到36种grna的显著的(调整后的p-值《0.05)差异富集(图20c)。
[0358]
值得注意的是,靶向sox9的两种grna在gfp
高
群体中显著富集。我们还观察到靶向已知参与肢芽软骨形成的另一种转录因子sox10的两种grna的强烈富集。sox15和tbr1的作用仍然有待验证和确定。有趣的是,在gfp
低
群体中富集了另外几种grna。正如预期,靶向在多能状态下强烈表达的tf例如prdm14和nr5a2的grna在该群体中富集。然而,其他常常引用的多能性tf例如nanog和oct4没有在该群体中富集。令人吃惊的是,靶向在软骨形成期间诱导的tf例如pitx1、hes1、id4、sp9和six6的grna在gfp
低
群体中富集。在任一群体中富集超过3倍但不满足显著性标准的grna用蓝色着色(图20c)。
[0359]
通过sox9过表达初步验证筛选结果。尽管sox9是一种直接结合到编码软骨基质蛋白的基因的启动子和增强子元件的已知成软骨转录因子,但尚不清楚在我们的分阶段分化的背景中sox9激活将具有何种影响。来自于时间过程实验的基因表达数据表明sox9激活发生在该分化方案的d12。为了确定在我们的分化计划的背景中sox9过表达对软骨形成的影响,我们将编码sox9 cdna的慢病毒转导到报告hipsc,并在分化6天后评估了报告物荧光(图21a)。在这个阶段,细胞尚未暴露于成软骨生长因子bmp-4,并且建立绕过对单层细胞中漫长(6-15天)的成软骨前分化的需要的方案将是有价值的。事实上,我们在我们的成软骨分化方案中观察到的许多变动发生在这个分化阶段。
[0360]
在使用sox9过表达的分化6天后并在任何bmp-4处理之前,我们观察到占总群体的大约2-3%的gfp
高
群体(图21b)。sox9转导似乎也将报告物荧光的分布向左侧拓宽。在分化的第21天,通过sox9过表达产生的这个群体的荧光强度与报告细胞的荧光强度相当,尽管这些细胞的比例低得多(图21c)。
[0361]
讨论。在这里,我们显示了对所有tf的调控软骨形成的能力进行的高通量筛选。被我们预计将在gfp
高
群体中富集的sox9充当内部对照。已知参与软骨形成的其他因子例如sox10也在gfp
高
群体中富集。已显示sox10参与肢芽软骨形成并与sox9和sox8一起协调成软骨程序,并且可能参与促进软骨细胞的肥大性分化。tbr1和sox15对软骨形成的潜在作用可能不太清楚;sox15可能与肌肉再生有关,并且tbr1已知在谷氨酸能神经元中表达。
[0362]
我们的筛选产生了在gfp
低
群体中富集的远远更多的命中物。大多数tf的强烈激活可能在分化的不同阶段阻碍成软骨特化。在该群体中最显著富集的grna靶向prdm14这种天生多能性的调控物。靶向也在多能性中高表达的nr5a2的grna,也在该群体中富集。值得注意的是,靶向参与软骨形成并在软骨形成期间激活的tf例如pitx1的grna,也在gfp
低
中富集。
[0363]
在我们的在分化的背景中测试sox9过表达的验证实验中,我们在分化6天后在添加bmp-4之前观察到gfp
高
群体的出现,表明tf的外源递送可以绕过分化的成软骨前阶段。似乎hipsc衍生的生骨节已被适合地准备,以对sox9做出响应激活col2a1。对图21b中示出的柱状图的仔细分析揭示出sox9的过表达除了产生gfp
高
之外,似乎还提高柱状图左侧尾部的高度,这表明sox9的过表达可能也在一部分细胞中抑制成软骨分化。
[0364]
总之,通过使用col2a1敲入报告基因来筛选促软骨形成tf,我们证实了高通量hipsc软骨形成平台的用途。所述筛选成功地富集了靶向已知成软骨tf sox9的grna,并产生了几个其他的有趣命中物。本文中发现的tf可以改进技术以产生hipsc衍生的软骨或规定各种不同的软骨细胞亚型(例如关节板相比于生长板)。
[0365]
上面对特定方面的描述如此充分地揭示出本发明的总体性质,使得其他人通过应用本领域技术内的知识,无需过多实验即可容易地修改和/或改编这些特定方面以适应于各种不同的应用,而不背离本公开的总体概念。因此,基于本文中呈现的教导和指导,此类改编和修改旨在落于所公开的方面的含义和等同性范围之内。应该理解,本文中的短语或术语是出于描述而不是限制的目的,使得本说明书的术语或短语应该由专业技术人员根据所述教导和指导来解释。
[0366]
本公开的广度和范围不应受任何上述示例性方面的限制,而是应该仅根据下面的权利要求书及其等同物来定义。
[0367]
本技术中引用的所有出版物、专利、专利申请和/或其他文献为所有目的整体通过参考并入本文,其程度如同每个单独的出版物、专利、专利申请和/或其他文献被单独地指明为所有目的通过参考并入本文。
[0368]
为完整起见,本发明的各个不同方面被阐述在下述编号的条款中:
[0369]
条款1.一种多核苷酸,其编码(1)选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子;或(2)选自ngn3和ascl1或其组合的第一神经元特异性转录因子;和选自下述的第二神经元特异性转录因子:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、
prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l、e2f7;(iv)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(v)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(vi)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
[0370]
条款2.一种用于提高神经元特异性基因的表达的系统,所述系统包含:(a)选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子;或(b)靶向选自ngn3和ascl1或其组合的第一神经元特异性转录因子的第一grna;和靶向选自下述的第二神经元特异性转录因子的第二grna:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l、e2f7;(iv)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(v)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、
znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(vi)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx;和cas蛋白或融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、锌指蛋白或tale蛋白,并且第二多肽结构域具有选自转录激活活性、转录阻遏活性、转录释放因子活性、组蛋白修饰活性、核酸酶活性、核酸结合活性、甲基化酶活性和脱甲基化酶活性的活性。
[0371]
条款3.条款1所述的多核苷酸或条款2所述的系统,其中所述第二神经元特异性转录因子选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2、nkx2-2、hes3和zfp36l1。
[0372]
条款4.条款3所述的多核苷酸或系统,其中所述第二神经元特异性转录因子选自lhx8、lhx6、e2f7、runx3、foxh1、sox2、hmx2和nkx2-2。
[0373]
条款5.条款3所述的多核苷酸或系统,其中所述第二神经元特异性转录因子选自hes3和zfp36l1。
[0374]
条款6.条款2所述的系统,其中所述第二神经元特异性转录因子选自:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7,并且其中所述第二多肽结构域具有转录激活活性。
[0375]
条款7.条款6所述的系统,其中所述融合蛋白包含
vp64
dcas9
vp64
或dcas9-p300。
[0376]
条款8.条款2所述的系统,其中所述第二神经元特异性转录因子选自:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、
glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx,并且其中所述第二多肽结构域具有转录阻遏活性。
[0377]
条款9.条款8所述的系统,其中所述融合蛋白包含dcas9-krab。
[0378]
条款10.条款2-9中的任一项所述的系统,其中所述第一grna和所述第二grna各自单独地包含12-22个碱基对的靶dna序列的互补多核苷酸序列,随后是前间区序列邻近基序,并且任选地其中所述grna结合并靶向和/或包含含有选自seq id no:38-87的序列的多核苷酸,并且任选地其中所述第一grna和/或第二grna包含crrna、tracrrna或其组合。
[0379]
条款11.一种分离的多核苷酸,其编码条款2-10中的任一项所述的系统。
[0380]
条款12.一种载体,其包含条款11所述的分离的多核苷酸。
[0381]
条款13.一种细胞,其包含条款11所述的分离的多核苷酸或条款12所述的载体。
[0382]
条款14.一种提高干细胞衍生的神经元的成熟的方法,所述方法包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
[0383]
条款15.一种提高干细胞衍生的神经元的成熟的方法,所述方法包括:提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、
ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
[0384]
条款16.一种提高干细胞向神经元的转化的方法,所述方法包括:(a)提高所述干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
[0385]
条款17.一种提高干细胞向神经元的转化的方法,所述方法包括:提高所述干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
[0386]
条款18.一种治疗有需要的对象的方法,所述方法包括:(a)提高所述对象中的干细胞中选自neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2的第一神经元特异性转录因子的水平,或(b)提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并提高所述
对象中的干细胞中选自下述的第二神经元特异性转录因子的水平:(i)neurog3、sox4、sox9、klf4、nr5a1、neurod1、sox17、smad1、atoh1、insm1、neurog1、sox18、rfx4、klf7、sp8、ovol1、neurog2、erf、prdm1、olig3、hic1、sox3、foxj1、sox10、klf6、ascl1和plagl2;(ii)prdm1、lhx6、neurog3、pax8、sox3、klf4、fli1、foxh1、fev、sox17、fos、insm1、sox2、wt1、sox18、znf670、lhx8、ovol1、e2f7、aff1、hmx2、maz、rara、prop1、fosl1、pax5、klf3;(iii)runx3、prdm1、klf6、pax2、rfx3、sox10、gata1、klf5、klf1、erf、lhx6、phox2b、nanog、nr5a2、etv3、neurog3、sox4、sox9、pax8、irf5、cdx4、rara、bhlhe40、sox3、klf4、nr5a1、irf4、ascl1、gata6、spib、thrb、foxh1、neurod1、sox17、cdx2、zeb2、rarg、insm1、fosl1、neurog1、sox1、wt1、pax5、sox18、pou5f1、rfx4、klf7、nkx2-2、ovol2、foxj1、prdm14、ventx、lhx8、gfi1、klf17、ovol1、olig3、hmx3、znf521、onecut3、ovol3、znf362、aff1、hmx2、znf786、gata5、tbx3、znf385a、atoh1、prop1、sox11、jun、foxe3、ferd3l和e2f7。
[0387]
条款19.一种治疗有需要的对象的方法,所述方法包括:提高所述对象中的干细胞中选自ngn3和ascl1或其组合的第一神经元特异性转录因子的水平;并降低所述对象中的干细胞中选自下述的第二神经元特异性转录因子的水平:(i)zic2、spi1、grhl2、tfap2c、klf8、myb、tcf21、klf12、twist1、snai1、rreb1、gcm2、grhl1、ets1、barhl2、grhl3、elf3、ptf1a、gsx1、pbx2、noto、klf3、znf311、elmsan1、znf296、plek、kmt2a、hes3;(ii)hes2、srebf1、cic、whsc1、vdr、hes1、id2、tcf21、snai1、rreb1、gcm2、irf3、foxa1、gata5、grhl1、sox5、dmrt1、gcm1、barhl2、sox13、zeb1、pitx2、ptf1a、znf282、npas2、znf160、hes7、zbed4、sall4、glis3、tbx22、znf331、egr4、zic5、znf710、znf697、zfp36l2、elmsan1、znf296、znf318、znf570、znf683、zfp36l1、hes4、znf777、hes5、zim2、znf579、bmp2、cramp1l、tox3、fezf2、hes3、znf791;(iii)etv1、zic2、gsc2、cic、grhl2、rest、tfap2c、sall1、nfkb1、elf2、hes1、myb、klf12、vsx2、nfe2、snai1、trerf1、rreb1、irf1、irf3、klf2、myod1、sox15、barx1、grhl1、sox5、ets1、skil、barhl2、sox13、erg、grhl3、znf281、elf3、hesx1、klf15、pitx2、ptf1a、gsx1、znf160、etv5、mybl1、noto、dpf1、mecom、glis3、klf3、tbx22、esx1、znf337、zfp36l2、elmsan1、znf618、znf296、znf318、znf570、znf497、zfp36l1、hes5、bmp2、cramp1l、znf821、kmt2a、hes3和bsx。
[0388]
条款20.条款14-19中的任一项所述的方法,其中提高所述第一神经元特异性转录因子的水平包括下述至少一者:(a)向所述干细胞给药编码所述第一神经元特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述第一神经元特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第一神经元特异性转录因子的锌指蛋白或靶向所述第一神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第一神经元特异性转录因子的grna。
[0389]
条款21.条款14、16和18中的任一项所述的方法,其中提高所述第二神经元特异性转录因子的水平包括下述至少一者:(a)向所述干细胞给药编码所述第二神经元特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述第二神经元特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第二神经元特异性转录因子的锌指蛋白或靶向所述第二
神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第二神经元特异性转录因子的grna。
[0390]
条款22.条款15、17和19中的任一项所述的方法,其中降低所述第二神经元特异性转录因子的水平包括向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述第二神经元特异性转录因子的锌指蛋白或靶向所述第二神经元特异性转录因子的tale蛋白,并且第二多肽结构域具有转录阻遏活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外向所述干细胞给药靶向所述第二神经元特异性转录因子的grna。
[0391]
条款23.条款14-22中的任一项所述的方法,其中所述干细胞不经历多能阶段直接转化成神经元。
[0392]
条款24.条款13所述的细胞或条款14-23中的任一项所述的方法,其中所述干细胞是多能干细胞、诱导多能干细胞或胚胎干细胞。
[0393]
条款25.一种用于选择具有作为细胞类型特异性转录因子的活性的多核苷酸的系统,所述系统包含:编码报告蛋白和细胞类型标志物的多核苷酸;融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白,并且第二多肽结构域具有转录激活活性;和指导rna(grna)的文库,每种grna靶向不同的假定细胞类型特异性转录因子。
[0394]
条款26.条款25所述的系统,其中所述细胞类型特异性转录因子是神经元特异性转录因子,其中所述细胞类型标志物是神经元标志物,并且其中所述神经元标志物包括tubb3。
[0395]
条款27.条款25所述的系统,其中所述细胞类型特异性转录因子是肌肉特异性转录因子,其中所述细胞类型标志物是成肌标志物,并且其中所述成肌标志物包括pax7。
[0396]
条款28.条款25所述的系统,其中所述细胞类型特异性转录因子是软骨细胞特异性转录因子,其中所述细胞类型标志物是胶原标志物,并且其中所述胶原标志物包括col2a1。
[0397]
条款29.条款25-28中的任一项所述的系统,其中所述报告蛋白包括mcherry。
[0398]
条款30.一种分离的多核苷酸序列,其编码条款25-29中的任一项所述的系统。
[0399]
条款31.一种载体,其包含条款30所述的分离的多核苷酸序列。
[0400]
条款32.一种细胞,其包含条款25-29中的任一项所述的系统、条款30所述的分离的多核苷酸序列或条款31所述的载体或其组合。
[0401]
条款33.一种筛选细胞类型特异性转录因子的方法,所述方法包括:用条款25-29中的任一项所述的系统以约0.2的感染复数(moi)转导细胞群体,使得大多数细胞各自独立地包括一种grna并靶向一种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中所述grna的水平,其中所述报告蛋白的高表达被定义为在所述细胞群体内的前5%中;并且当所述假定转录因子对应于在具有所述报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述假定转录因子作为细胞类型特异性转录因子。
[0402]
条款34.一种筛选一对细胞类型特异性转录因子的方法,所述方法包括:用条款
25-29中的任一项所述的系统以约0.2的感染复数(moi)转导细胞群体,使得大多数细胞各自独立地包括两种grna并靶向两种假定转录因子;确定每个细胞中所述报告蛋白的表达水平;确定每个具有所述报告蛋白的高表达的细胞中所述两种grna的水平,其中所述报告蛋白的高表达被定义为在所述细胞群体内的前5%中;并且当所述假定转录因子对应于在具有所述报告蛋白的高表达的细胞中富集的至少两种grna时,选择所述两种假定转录因子作为一对细胞类型特异性转录因子。
[0403]
条款35.条款33或34所述的方法,其中每个细胞中所述报告蛋白的表达水平在从转导起约4天后确定。
[0404]
条款36.条款33-35中的任一项所述的方法,其中每个细胞中所述报告蛋白的表达水平通过流式细胞术来确定。
[0405]
条款37.条款33-36中的任一项所述的方法,其中每个具有所述报告蛋白的高表达的细胞中所述grna的水平通过深度测序来确定。
[0406]
条款38.条款33-37中的任一项所述的方法,其中相对于非靶向grna,所述grna将所述细胞中所述报告蛋白的表达提高约2-50%。
[0407]
条款39.一种多核苷酸,其编码选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子。
[0408]
条款40.一种用于提高肌肉特异性基因的表达的系统,所述系统包含:(a)选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子;或(b)融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的锌指蛋白或靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的tale蛋白,其中第二多肽结构域具有选自转录激活活性、转录释放因子活性、组蛋白修饰活性、核酸结合活性、甲基化酶活性和脱甲基化酶活性的活性,并且其中当所述第一多肽结构域包含cas蛋白时,所述系统还包括靶向选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的grna。
[0409]
条款41.条款40所述的系统,其中所述融合蛋白包含
vp64
dcas9
vp64
或dcas9-p300。
[0410]
条款42.一种分离的多核苷酸,其编码条款40-41中的任一项所述的系统。
[0411]
条款43.一种载体,其包含条款42所述的分离的多核苷酸。
[0412]
条款44.一种细胞,其包含条款42所述的分离的多核苷酸或条款43所述的载体。
[0413]
条款45.一种提高干细胞向成肌细胞的分化的方法,所述方法包括:提高所述干细胞中选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的水平。
[0414]
条款46.一种治疗有需要的对象的方法,所述方法包括:提高来自于所述对象的干细胞中选自twist1、pax3、myod、myog、sox9、sox10和dmrt1的肌肉特异性转录因子的水平。
[0415]
条款47.条款45或46所述的方法,其中提高所述肌肉特异性转录因子的水平包括下述至少一者:(a)向所述干细胞给药编码所述肌肉特异性转录因子的多核苷酸;(b)向所述干细胞给药包含所述肌肉特异性转录因子的多肽;和(c)向所述干细胞给药融合蛋白,其中所述融合蛋白包含两个异源多肽结构域,其中第一多肽结构域包含cas蛋白、靶向所述肌肉特异性转录因子的锌指蛋白或靶向所述肌肉特异性转录因子的tale蛋白,其中第二多肽结构域具有转录激活活性,并且其中当所述第一多肽结构域包含cas蛋白时,另外给药靶向
所述肌肉特异性转录因子的grna。
[0416]
序列
[0417]
seq id no:1
[0418]
ngg(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0419]
seq id no:2
[0420]
nga(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0421]
seq id no:3
[0422]
ngan(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0423]
seq id no:4
[0424]
ngng(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0425]
seq id no:5
[0426]
nggng(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0427]
seq id no:6
[0428]
nnagaaw(w=a或t;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0429]
seq id no:7
[0430]
naar(r=a或g;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0431]
seq id no:8
[0432]
nngrr(r=a或g;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0433]
seq id no:9
[0434]
nngrrn(r=a或g;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0435]
seq id no:10
[0436]
nngrrt(r=a或g;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0437]
seq id no:11
[0438]
nngrrv(r=a或g;n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0439]
seq id no:12
[0440]
nnnngatt(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0441]
seq id no:13
[0442]
nnnngnnn(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0443]
seq id no:14
[0444]
编码酿脓链球菌cas9的密码子优化的多核苷酸
[0445]
[0446]
[0447][0448]
seq id no:15
[0449]
编码酿脓链球菌cas9的密码子优化的多核苷酸的氨基酸序列
[0450]
mdkkysigldigtnsvgwavitdeykvpskkfkvlgntdrhsikknligallfdsgetaeatrlkrtarrrytrrknricylqeifsnemakvddsffhrleesflveedkkherhpifgnivdevayhekyptiyhlrkklvdstdkadlrliylalahmikfrghfliegdlnpdnsdvdklfiqlvqtynqlfeenpinasgvdakailsarlsksrrlenliaqlpgekknglfgnlialslgltpnfksnfdlaedaklqlskdtydddldnllaqigdqyadlflaaknlsdaillsdilrvnteitkaplsasmikrydehhqdltllkalvrqqlpekykeiffdqskngyagyidggasqeefykfikpilekmdgteellvklnredllrkqrtfdngsiphqihlgelhailrrqedfypflkdnrekiekiltfripyyvgplargnsrfawmtrkseetitpwnfeevvdkgasaqsfiermtnfdknlpnekvlpkhsllyeyftvyneltkvkyvtegmrkpaflsgeqkkaivdllfktnrkvtvkqlkedyfkkiecfdsveisgvedrfnaslgtyhdllkiikdkdfldneenediledivltltlfedremieerlktyahlfddkvmkqlkrrrytgwgrlsrklingirdkqsgktildflksdgfanrnfmqlihddsltfkediqkaqvsgqgdslhehianlagspaikkgilqtvkvvdelvkvmgrhkpeniviemarenqttqkgqknsrermkrieegikelgsqilkehpventqlqneklylyylqngrdmyvdqeldinrlsdydvdhivpqsflkddsidnkvltrsdknrgksdnvpseevvkkmknywrqllnaklitqrkfdnltkaergglseldkagfikrqlvetrqitkhvaqildsrmntkydendklirevkvitlksklvsdfrkdfqfykvreinnyhhahdaylnavvgtalikkypklesefvygdykvydvrkmiakseqeigkatakyffysnimnffkteitlangeirkrplietngetgeivwdkgrdfatvrkvlsmpqvnivkktevqtggfskesilpkrnsdkliarkkdwdpkkyggfdsptvaysvlvvakvekgkskklksvkellgitimerssfeknpidfleakgykevkkdliiklpkyslfelengrkrmlasagelqkgnelalpskyvnflylashyeklkgspedneqkqlfveqhkhyldeiieqisefskrviladanldkvlsaynkhrdkpireqaeniihlftltnlgapaafkyfdttidrkrytstkevldatlihqsitglyetridlsqlggd
[0451]
seq id no:16
[0452]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0453]
[0454]
[0455][0456]
seq id no:17
[0457]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0458]
[0459]
[0460][0461]
seq id no:18
[0462]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0463]
[0464][0465]
seq id no:19
[0466]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0467]
atggccccaaagaagaagcggaaggtcggtatccacggagtcccagcagccaagcggaactacatcctgggcctggacatcggcatcaccagcgtgggctacggcatcatcgactacgagacacgggacgtgatcgatgccggcgtgcggctgttcaaagaggccaacgtggaaaacaacgagggcaggcggagcaagagaggcgccagaaggctgaagcggcggaggcggcatagaatccagagagtgaagaagctgctgttcgactacaacctgctgaccgaccacagcgagctgagcggcatcaacccctacgaggccagagtgaagggcctgagccagaagctgagcgaggaagagttctctgccgccctgctgcacctggccaagagaagaggcgtgcacaacgtgaacgaggtggaagaggacaccggcaacgagctgtccaccagagagcagatcagccggaacagcaaggccctggaagagaaatacgtggccgaactgcagctggaacggctgaagaaagacggcgaagtgcggggcagcatcaacagattcaagaccagcgactacgtgaaagaagccaaacagctgctgaaggtgcagaaggcctaccaccagctggaccagagcttcatcgacacctacatcgacctgctggaaacccggcggacctactatgagggacctggcgagggcagccccttcggctggaaggacatcaaagaatggtacgagatgctgatgggccactgcacctacttccccgaggaactgcggagcgtgaagtacgcctacaacgccgacctgtacaacgccctgaacgacctgaacaatctcgtgatcaccagggacgagaacgagaagctggaatattacgagaagttccagatcatcgagaacgtgttcaagcagaagaagaagcccaccctgaagcagatcgccaaagaaatcctcgtgaacgaagaggatattaagggctacagagtgaccagcaccggcaagcccgagttcaccaacctgaaggtgtaccacgacatcaaggacattaccgcccggaaagagattattgagaacgccgagctgctggatcagattgccaagatcctgaccatctaccagagcagcgaggacatccaggaagaactgaccaatctgaactccgagctgacccaggaagagatcgagcagatctctaatctgaagggctataccggcacccacaacctgagcctgaaggccatcaacctgatcctggacgagctgtggcacaccaacgacaaccagatcgctatcttcaaccggctgaagctggtgcccaagaaggtggacctgtcccagcagaaagagatccccaccaccctggtggacgacttcatcctgagccccgtcgtgaagagaagcttcatccagagcatcaaagtgatcaacgccatcatcaagaagtacggcctgcccaacgacatcattatcgagctggcccgcgagaagaactccaaggacgcccagaaaatgatcaacgagatgcagaagcggaaccggcagaccaacgagcggatcgaggaaatcatccggaccaccggcaaagagaacgccaagtacctgatcgagaagatcaagctgcacgacatgcaggaaggcaagtgcctgtacagcctggaagccatccctctggaagatctgctgaacaaccccttcaactatgaggtggaccacatcatccccagaagcgtgtccttcgacaacagcttcaacaacaaggtgctcgtgaagcaggaagaaaacagcaagaagggcaaccggaccccattccagtacctgagcagcagcgacagcaagatcagctacgaaaccttcaagaagcacatcctgaatctggccaagggcaagggcagaatcagcaagaccaagaaagagtatctgctggaagaacgggacatcaacaggttctccgtgcagaaagacttcatcaaccggaacctggtggataccagatacgccaccagaggcctgatgaacctgctgcggagctacttcagagtgaacaacctggacgtgaaagtgaagtccatcaatggcggcttcaccagctttctgcggcggaagtggaagtttaagaaagagcggaacaaggggtacaagcaccacgccgaggacgccctgatcattgccaacgccgatttcatcttcaaagagtggaagaaactggacaaggccaaaaaagtgatggaaaaccagatgttcgaggaaaggcaggccgagagcatgcccgagatcgaaaccgagcaggagtacaaagagatcttcatcaccccccaccagatcaagcacattaaggacttcaaggactacaagtacagccaccgggtggacaagaagcctaatagagagctgattaacgacaccctgtactccacccggaaggacgacaagggcaacaccctgatcgtgaacaatctgaacggcctgtacgacaaggacaatgacaagctgaaaaagctgatcaacaagagccccgaaaagctgctgatgtaccaccacgacccccagacctaccagaaactgaagctgattatggaacagtacggcgacgagaagaatcccctgtacaagtactacgaggaaaccgggaactacctgaccaagtactccaaaaaggacaacggccccgtgatcaagaagattaagtattacggcaacaaactgaacgcccatctggacatcaccgacgactaccccaacagcagaaacaaggtcgtgaagctgtccctgaagccctacagattcgacgtgtacctggacaatggcgtgtacaagttcgtgaccgtgaagaatctggatgtgatcaaaaaagaaaactactacgaagtgaatagcaagtgctatgaggaagctaagaagctgaagaagatcagcaaccaggccgagtttatcgcctccttctacaacaacg
atctgatcaagatcaacggcgagctgtatagagtgatcggcgtgaacaacgacctgctgaaccggatcgaagtgaacatgatcgacatcacctaccgcgagtacctggaaaacatgaacgacaagaggccccccaggatcattaagacaatcgcctccaagacccagagcattaagaagtacagcacagacattctgggcaacctgtatgaagtgaaatctaagaagcaccctcagatcatcaaaaagggcaaaaggccggcggccacgaaaaaggccggccaggcaaaaaagaaaaag
[0468]
seq id no:20
[0469]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0470]
[0471]
[0472][0473]
seq id no:21
[0474]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列的氨基酸序列
[0475]
mkrnyilgldigitsvgygiidyetrdvidagvrlfkeanvennegrrskrgarrlkrrrrhriqrvkkllfdynlltdhselsginpyearvkglsqklseeefsaallhlakrrgvhnvneveedtgnelstkeqisrnskaleekyvaelqlerlkkdgevrgsinrfktsdyvkeakqllkvqkayhqldqsfidtyidlletrrtyyegpgegspfgwkdikewyemlmghctyfpeelrsvkyaynadlynalndlnnlvitrdenekleyyekfqiienvfkqkkkptlkqiakeilvneedikgyrvtstgkpeftnlkvyhdikditarkeiienaelldqiakiltiyqssediqeeltnlnseltqeeieqisnlkgytgthnlslkainlildelwhtndnqiaifnrlklvpkkvdlsqqkeipttlvddfilspvvkrsfiqsikvinaiikkyglpndiiielareknskdaqkminemqkrnrqtnerieeiirttgkenakyliekiklhdmqegkclysleaipledllnnpfnyevdhiiprsvsfdnsfnnkvlvkqeenskkgnrtpfqylsssdskisyetfkkhilnlakgkgrisktkkeylleerdinrfsvqkdfinrnlvdtryatrglmnllrsyfrvnnldvkvksinggftsflrrkwkfkkernkgykhhaedaliianadfifkewkkldkakkvmenqmfeekqaesmpeieteqeykeifitphqikhikdfkdykyshrvdkkpnrelindtlystrkddkgntlivnnlnglydkdndklkklinkspekllmyhhdpqtyqklklimeqygdeknplykyyeetgnyltkyskkdngpvikkikyygnklnahlditddypnsrnkvvklslkpyrfdvyldngvykfvtvknldvikkenyyevnskcyeeakklkkisnqaefiasfynndlikingelyrvigvnndllnrievnmidityreylenmndkrppriiktiasktqsikkystdilgnlyevkskkhpqiikkg
[0476]
seq id no:22
[0477]
金黄色葡萄球菌cas9的d10a突变体的多核苷酸序列
[0478]
[0479]
[0480][0481]
seq id no:23
[0482]
金黄色葡萄球菌cas9的n580a突变体的多核苷酸序列
[0483]
[0484]
[0485][0486]
seq id no:24
[0487]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0488]
atggccccaaagaagaagcggaaggtcggtatccacggagtcccagcagccaagcggaactacatcctgggcctggacatcggcatcaccagcgtgggctacggcatcatcgactacgagacacgggacgtgatcgatgccggcgtgcggctgttcaaagaggccaacgtggaaaacaacgagggcaggcggagcaagagaggcgccagaaggctgaagcggcggaggcggcatagaatccagagagtgaagaagctgctgttcgactacaacctgctgaccgaccacagcgagctgagcggcatcaacccctacgaggccagagtgaagggcctgagccagaagctgagcgaggaagagttctctgccgccctgctgcacctggccaagagaagaggcgtgcacaacgtgaacgaggtggaagaggacaccggcaacgagctgtccaccaaagagcagatcagccggaacagcaaggccctggaagagaaatacgtggccgaactgcagctggaacggctgaagaaagacggcgaagtgcggggcagcatcaacagattcaagaccagcgactacgtgaaagaagccaaacagctgctgaaggtgcagaaggcctaccaccagctggaccagagcttcatcgacacctacatcgacctgctggaaacccggcggacctactatgagggacctggcgagggcagccccttcggctggaaggacatcaaagaatggtacgagatgctgatgggccactgcacctacttccccgaggaactgcggagcgtgaagtacgcctacaacgccgacctgtacaacgccctgaacgacctgaacaatctcgtgatcaccagggacgagaacgagaagctggaatattacgagaagttccagatcatcgagaacgtgttcaagcagaagaagaagcccaccctgaagcagatcgccaaagaaatcctcgtgaacgaagaggatattaagggctacagagtgaccagcaccggcaagcccgagttcaccaacctgaaggtgtaccacgacatcaaggacattaccgcccggaaagagattattgagaacgccgagctgctggatcagattgccaagatcctgaccatctaccagagcagcgaggacatccaggaagaactgaccaatctgaactccgagctgacccaggaagagatcgagcagatctctaatctgaagggctataccggcacccacaacctgagcctgaaggccatcaacctgatcctggacgagctgtggcacaccaacgacaaccagatcgctatcttcaaccggctgaagctggtgcccaagaaggtggacctgtcccagcagaaagagatccccaccaccctggtggacgacttcatcctgagccccgtcgtgaagagaagcttcatccagagcatcaaagtgatcaacgccatcatcaagaagtacggcctgcccaacgacatcattatcgagctggcccgcgagaagaactccaaggacgcccagaaaatgatcaacgagatgcagaagcggaaccggcagaccaacgagcggatcgaggaaatcatccggaccaccggcaaagagaacgccaagtacctgatcgagaagatcaagctgcacgacatgcaggaaggcaagtgcctgtacagcctggaagccatccctctggaagatctgctgaacaaccccttcaactatgaggtggaccacatcatccccagaagcgtgtccttcgacaacagcttcaacaacaaggtgctcgtgaagcaggaagaaaacagcaagaagggcaaccggaccccattccagtacctgagcagcagcgacagcaagatcagctacgaaaccttcaagaagcacatcctgaatctggccaagggcaagggcagaatcagcaagaccaagaaagagtatctgctggaagaacgggacatcaacaggttctccgtgcagaaagacttcatcaaccggaacctggtggataccagatacgccaccagaggcctgatgaacctgctgcggagctacttcagagtgaacaacctggacgtgaaagtgaagtccatcaatggcggcttcaccagctttctgcggcggaagtggaagtttaagaaagagcggaacaaggggtacaagcaccacgccgaggacgccctgatcattgccaacgccgatttcatcttcaaa
gagtggaagaaactggacaaggccaaaaaagtgatggaaaaccagatgttcgaggaaaagcaggccgagagcatgcccgagatcgaaaccgagcaggagtacaaagagatcttcatcaccccccaccagatcaagcacattaaggacttcaaggactacaagtacagccaccgggtggacaagaagcctaatagagagctgattaacgacaccctgtactccacccggaaggacgacaagggcaacaccctgatcgtgaacaatctgaacggcctgtacgacaaggacaatgacaagctgaaaaagctgatcaacaagagccccgaaaagctgctgatgtaccaccacgacccccagacctaccagaaactgaagctgattatggaacagtacggcgacgagaagaatcccctgtacaagtactacgaggaaaccgggaactacctgaccaagtactccaaaaaggacaacggccccgtgatcaagaagattaagtattacggcaacaaactgaacgcccatctggacatcaccgacgactaccccaacagcagaaacaaggtcgtgaagctgtccctgaagccctacagattcgacgtgtacctggacaatggcgtgtacaagttcgtgaccgtgaagaatctggatgtgatcaaaaaagaaaactactacgaagtgaatagcaagtgctatgaggaagctaagaagctgaagaagatcagcaaccaggccgagtttatcgcctccttctacaacaacgatctgatcaagatcaacggcgagctgtatagagtgatcggcgtgaacaacgacctgctgaaccggatcgaagtgaacatgatcgacatcacctaccgcgagtacctggaaaacatgaacgacaagaggccccccaggatcattaagacaatcgcctccaagacccagagcattaagaagtacagcacagacattctgggcaacctgtatgaagtgaaatctaagaagcaccctcagatcatcaaaaagggcaaaaggccggcggccacgaaaaaggccggccaggcaaaaaagaaaaag
[0489]
seq id no:25
[0490]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列
[0491]
aagcggaactacatcctgggcctggacatcggcatcaccagcgtgggctacggcatcatcgactacgagacacgggacgtgatcgatgccggcgtgcggctgttcaaagaggccaacgtggaaaacaacgagggcaggcggagcaagagaggcgccagaaggctgaagcggcggaggcggcatagaatccagagagtgaagaagctgctgttcgactacaacctgctgaccgaccacagcgagctgagcggcatcaacccctacgaggccagagtgaagggcctgagccagaagctgagcgaggaagagttctctgccgccctgctgcacctggccaagagaagaggcgtgcacaacgtgaacgaggtggaagaggacaccggcaacgagctgtccaccaaagagcagatcagccggaacagcaaggccctggaagagaaatacgtggccgaactgcagctggaacggctgaagaaagacggcgaagtgcggggcagcatcaacagattcaagaccagcgactacgtgaaagaagccaaacagctgctgaaggtgcagaaggcctaccaccagctggaccagagcttcatcgacacctacatcgacctgctggaaacccggcggacctactatgagggacctggcgagggcagccccttcggctggaaggacatcaaagaatggtacgagatgctgatgggccactgcacctacttccccgaggaactgcggagcgtgaagtacgcctacaacgccgacctgtacaacgccctgaacgacctgaacaatctcgtgatcaccagggacgagaacgagaagctggaatattacgagaagttccagatcatcgagaacgtgttcaagcagaagaagaagcccaccctgaagcagatcgccaaagaaatcctcgtgaacgaagaggatattaagggctacagagtgaccagcaccggcaagcccgagttcaccaacctgaaggtgtaccacgacatcaaggacattaccgcccggaaagagattattgagaacgccgagctgctggatcagattgccaagatcctgaccatctaccagagcagcgaggacatccaggaagaactgaccaatctgaactccgagctgacccaggaagagatcgagcagatctctaatctgaagggctataccggcacccacaacctgagcctgaaggccatcaacctgatcctggacgagctgtggcacaccaacgacaaccagatcgctatcttcaaccggctgaagctggtgcccaagaaggtggacctgtcccagcagaaagagatccccaccaccctggtggacgacttcatcctgagccccgtcgtgaagagaagcttcatccagagcatcaaagtgatcaacgccatcatcaagaagtacggcctgcccaacgacatcattatcgagctggcccgcgagaagaactccaaggacgcccagaaaatgatcaacgagatgcagaagcggaaccggcagaccaacgagcggatcgaggaaatcatccggaccaccggcaaagagaacgccaagtacctgatcgagaagatcaagctgcacgacatgcaggaaggcaagtgcctgtacagcctggaagccatccctctggaagatctgctgaacaaccccttcaactatgaggtggaccacatcatccccagaagcgtgtccttcgacaacagcttcaacaacaaggtgctcgtgaagcaggaagaaaacagc
aagaagggcaaccggaccccattccagtacctgagcagcagcgacagcaagatcagctacgaaaccttcaagaagcacatcctgaatctggccaagggcaagggcagaatcagcaagaccaagaaagagtatctgctggaagaacgggacatcaacaggttctccgtgcagaaagacttcatcaaccggaacctggtggataccagatacgccaccagaggcctgatgaacctgctgcggagctacttcagagtgaacaacctggacgtgaaagtgaagtccatcaatggcggcttcaccagctttctgcggcggaagtggaagtttaagaaagagcggaacaaggggtacaagcaccacgccgaggacgccctgatcattgccaacgccgatttcatcttcaaagagtggaagaaactggacaaggccaaaaaagtgatggaaaaccagatgttcgaggaaaagcaggccgagagcatgcccgagatcgaaaccgagcaggagtacaaagagatcttcatcaccccccaccagatcaagcacattaaggacttcaaggactacaagtacagccaccgggtggacaagaagcctaatagagagctgattaacgacaccctgtactccacccggaaggacgacaagggcaacaccctgatcgtgaacaatctgaacggcctgtacgacaaggacaatgacaagctgaaaaagctgatcaacaagagccccgaaaagctgctgatgtaccaccacgacccccagacctaccagaaactgaagctgattatggaacagtacggcgacgagaagaatcccctgtacaagtactacgaggaaaccgggaactacctgaccaagtactccaaaaaggacaacggccccgtgatcaagaagattaagtattacggcaacaaactgaacgcccatctggacatcaccgacgactaccccaacagcagaaacaaggtcgtgaagctgtccctgaagccctacagattcgacgtgtacctggacaatggcgtgtacaagttcgtgaccgtgaagaatctggatgtgatcaaaaaagaaaactactacgaagtgaatagcaagtgctatgaggaagctaagaagctgaagaagatcagcaaccaggccgagtttatcgcctccttctacaacaacgatctgatcaagatcaacggcgagctgtatagagtgatcggcgtgaacaacgacctgctgaaccggatcgaagtgaacatgatcgacatcacctaccgcgagtacctggaaaacatgaacgacaagaggccccccaggatcattaagacaatcgcctccaagacccagagcattaagaagtacagcacagacattctgggcaacctgtatgaagtgaaatctaagaagcaccctcagatcatcaaaaagggc
[0492]
seq id no:26
[0493]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列的氨基酸序列
[0494]
krnyilgldigitsvgygiidyetrdvidagvrlfkeanvennegrrskrgarrlkrrrrhriqrvkkllfdynlltdhselsginpyearvkglsqklseeefsaallhlakrrgvhnvneveedtgnelstkeqisrnskaleekyvaelqlerlkkdgevrgsinrfktsdyvkeakqllkvqkayhqldqsfidtyidlletrrtyyegpgegspfgwkdikewyemlmghctyfpeelrsvkyaynadlynalndlnnlvitrdenekleyyekfqiienvfkqkkkptlkqiakeilvneedikgyrvtstgkpeftnlkvyhdikditarkeiienaelldqiakiltiyqssediqeeltnlnseltqeeieqisnlkgytgthnlslkainlildelwhtndnqiaifnrlklvpkkvdlsqqkeipttlvddfilspvvkrsfiqsikvinaiikkyglpndiiielareknskdaqkminemqkrnrqtnerieeiirttgkenakyliekiklhdmqegkclysleaipledllnnpfnyevdhiiprsvsfdnsfnnkvlvkqeenskkgnrtpfqylsssdskisyetfkkhilnlakgkgrisktkkeylleerdinrfsvqkdfinrnlvdtryatrglmnllrsyfrvnnldvkvksinggftsflrrkwkfkkernkgykhhaedaliianadfifkewkkldkakkvmenqmfeekqaesmpeieteqeykeifitphqikhikdfkdykyshrvdkkpnrelindtlystrkddkgntlivnnlnglydkdndklkklinkspekllmyhhdpqtyqklklimeqygdeknplykyyeetgnyltkyskkdngpvikkikyygnklnahlditddypnsrnkvvklslkpyrfdvyldngvykfvtvknldvikkenyyevnskcyeeakklkkisnqaefiasfynndlikingelyrvigvnndllnrievnmidityreylenmndkrppriiktiasktqsikkystdilgnlyevkskkhpqiikkg
[0495]
seq id no:27
[0496]
编码金黄色葡萄球菌cas9的密码子优化的核酸序列的编码载体(pdo242)
[0497]
ctaaattgtaagcgttaatattttgttaaaattcgcgttaaatttttgttaaatcagctcattttttaaccaataggccgaaatcggcaaaatcccttataaatcaaaagaatagaccgagatagggttgagtgttgttccagt
ttggaacaagagtccactattaaagaacgtggactccaacgtcaaagggcgaaaaaccgtctatcagggcgatggcccactacgtgaaccatcaccctaatcaagttttttggggtcgaggtgccgtaaagcactaaatcggaaccctaaagggagcccccgatttagagcttgacggggaaagccggcgaacgtggcgagaaaggaagggaagaaagcgaaaggagcgggcgctagggcgctggcaagtgtagcggtcacgctgcgcgtaaccaccacacccgccgcgcttaatgcgccgctacagggcgcgtcccattcgccattcaggctgcgcaactgttgggaagggcgatcggtgcgggcctcttcgctattacgccagctggcgaaagggggatgtgctgcaaggcgattaagttgggtaacgccagggttttcccagtcacgacgttgtaaaacgacggccagtgagcgcgcgtaatacgactcactatagggcgaattgggtacctttaattctagtactatgcatgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactaccggtgccaccatgaaaaggaactacattctggggctggacatcgggattacaagcgtggggtatgggattattgactatgaaacaagggacgtgatcgacgcaggcgtcagactgttcaaggaggccaacgtggaaaacaatgagggacggagaagcaagaggggagccaggcgcctgaaacgacggagaaggcacagaatccagagggtgaagaaactgctgttcgattacaacctgctgaccgaccattctgagctgagtggaattaatccttatgaagccagggtgaaaggcctgagtcagaagctgtcagaggaagagttttccgcagctctgctgcacctggctaagcgccgaggagtgcataacgtcaatgaggtggaagaggacaccggcaacgagctgtctacaaaggaacagatctcacgcaatagcaaagctctggaagagaagtatgtcgcagagctgcagctggaacggctgaagaaagatggcgaggtgagagggtcaattaataggttcaagacaagcgactacgtcaaagaagccaagcagctgctgaaagtgcagaaggcttaccaccagctggatcagagcttcatcgatacttatatcgacctgctggagactcggagaacctactatgagggaccaggagaagggagccccttcggatggaaagacatcaaggaatggtacgagatgctgatgggacattgcacctattttccagaagagctgagaagcgtcaagtacgcttataacgcagatctgtacaacgccctgaatgacctgaacaacctggtcatcaccagggatgaaaacgagaaactggaatactatgagaagttccagatcatcgaaaacgtgtttaagcagaagaaaaagcctacactgaaacagattgctaaggagatcctggtcaacgaagaggacatcaagggctaccgggtgacaagcactggaaaaccagagttcaccaatctgaaagtgtatcacgatattaaggacatcacagcacggaaagaaatcattgagaacgccgaactgctggatcagattgctaagatcctgactatctaccagagctccgaggacatccaggaagagctgactaacctgaacagcgagctgacccaggaagagatcgaacagattagtaatctgaaggggtacaccggaacacacaacctgtccctgaaagctatcaatctgattctggatgagctgtggcatacaaacgacaatcagattgcaatctttaaccggctgaagctggtcccaaaaaaggtggacctgagtcagcagaaagagatcccaaccacactggtggacgatttcattctgtcacccgtggtcaagcggagcttcatccagagcatcaaagtgatcaacgccatcatcaagaagtacggcctgcccaatgatatcattatcgagctggctagggagaagaacagcaaggacgcacagaagatgatcaatgagatgcagaaacgaaaccggcagaccaatgaacgcattgaagagattatccgaactaccgggaaagagaacgcaaagtacctgattgaaaaaatcaagctgcacgatatgcaggagggaaagtgtctgtattctctggaggccatccccctggaggacctgctgaacaatccattcaactacgaggtcgatcatattatccccagaagcgtgtccttcgacaattcctttaacaacaaggtgctggtcaagcaggaagagaactctaaaaagggcaataggactcctttccagtacctgtctagttcagattccaagatctcttacgaaacctttaaaa
agcacattctgaatctggccaaaggaaagggccgcatcagcaagaccaaaaaggagtacctgctggaagagcgggacatcaacagattctccgtccagaaggattttattaaccggaatctggtggacacaagatacgctactcgcggcctgatgaatctgctgcgatcctatttccgggtgaacaatctggatgtgaaagtcaagtccatcaacggcgggttcacatcttttctgaggcgcaaatggaagtttaaaaaggagcgcaacaaagggtacaagcaccatgccgaagatgctctgattatcgcaaatgccgacttcatctttaaggagtggaaaaagctggacaaagccaagaaagtgatggagaaccagatgttcgaagagaagcaggccgaatctatgcccgaaatcgagacagaacaggagtacaaggagattttcatcactcctcaccagatcaagcatatcaaggatttcaaggactacaagtactctcaccgggtggataaaaagcccaacagagagctgatcaatgacaccctgtatagtacaagaaaagacgataaggggaataccctgattgtgaacaatctgaacggactgtacgacaaagataatgacaagctgaaaaagctgatcaacaaaagtcccgagaagctgctgatgtaccaccatgatcctcagacatatcagaaactgaagctgattatggagcagtacggcgacgagaagaacccactgtataagtactatgaagagactgggaactacctgaccaagtatagcaaaaaggataatggccccgtgatcaagaagatcaagtactatgggaacaagctgaatgcccatctggacatcacagacgattaccctaacagtcgcaacaaggtggtcaagctgtcactgaagccatacagattcgatgtctatctggacaacggcgtgtataaatttgtgactgtcaagaatctggatgtcatcaaaaaggagaactactatgaagtgaatagcaagtgctacgaagaggctaaaaagctgaaaaagattagcaaccaggcagagttcatcgcctccttttacaacaacgacctgattaagatcaatggcgaactgtatagggtcatcggggtgaacaatgatctgctgaaccgcattgaagtgaatatgattgacatcacttaccgagagtatctggaaaacatgaatgataagcgcccccctcgaattatcaaaacaattgcctctaagactcagagtatcaaaaagtactcaaccgacattctgggaaacctgtatgaggtgaagagcaaaaagcaccctcagattatcaaaaagggcagcggaggcaagcgtcctgctgctactaagaaagctggtcaagctaagaaaaagaaaggatcctacccatacgatgttccagattacgcttaagaattcctagagctcgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagagaatagcaggcatgctggggaggtagcggccgcccgcggtggagctccagcttttgttccctttagtgagggttaattgcgcgcttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaaggacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgt
tcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccac
[0498]
seq id no:28
[0499]
mcherry多肽
[0500]
mvskgeednmaiikefmrfkvhmegsvnghefeiegegegrpyegtqtaklkvtkggplpfawdilspqfmygskayvkhpadipdylklsfpegfkwervmnfedggvvtvtqdsslqdgefiykvklrgtnfpsdgpvmqkktmgweassermypedgalkgeikqrlklkdgghydaevkttykakkpvqlpgaynvniklditshnedytiveqyeraegrhstggmdelykpkkkrkvggpkkkrkv
[0501]
seq id no:29
[0502]
mcherry多核苷酸
[0503]
atggtgagcaagggcgaggaggataacatggccatcatcaaggagttcatgcgcttcaaggtgcacatggagggctccgtgaacggccacgagttcgagatcgagggcgagggcgagggccgcccctacgagggcacccagaccgccaagctgaaggtgaccaagggtggccccctgcccttcgcctgggacatcctgtcccctcagttcatgtacggctccaaggcctacgtgaagcaccccgccgacatccccgactacttgaagctgtccttccccgagggcttcaagtgggagcgcgtgatgaacttcgaggacggcggcgtggtgaccgtgacccaggactcctccctgcaggacggcgagttcatctacaaggtgaagctgcgcggcaccaacttcccctccgacggccccgtaatgcagaagaagaccatgggctgggaggcctcctccgagcggatgtaccccgaggacggcgccctgaagggcgagatcaagcagaggctgaagctgaaggacggcggccactacgacgctgaggtcaagaccacctacaaggccaagaagcccgtgcagctgcccggcgcctacaacgtcaacatcaagttggacatcacctcccacaacgaggactacaccatcgtggaacagtacgaacgcgccgagggccgccactccaccggcggcatggacgagctgtacaagcccaagaagaagaggaaggtgggtggccctaagaaaaagagaaaggtgtga
[0504]
seq id no:30
[0505]
fwd:5
′‑
aatgatacggcgaccaccgagatctacacaatttcttgggtagtttgcagtt
[0506]
seq id no:31
[0507]
rev:5
′‑
caagcagaagacggcatacgagat-(6-bp索引序列)-gactcggtgccactttttcaa
[0508]
seq id no:32
[0509]
读出1:5
′‑
gatttcttggctttatatatcttgtggaaaggacgaaacaccg
[0510]
seq id no:33
[0511]
索引:5
′‑
gctagtccgttatcaacttgaaaaagtggcaccgagtc
[0512]
seq id no:34
[0513]
读出2:5
′‑
gttgataacggactagccttatttaaacttgctatgctgtttccagcatagctcttaaac
[0514]
seq id no:35
[0515]
tttn(n可以是任何核苷酸残基,例如a、g、c或t中的任一者)
[0516]
seq id no:36
[0517]
vp64-dcas9-vp64蛋白
[0518]
radalddfdldmlgsdalddfdldmlgsdalddfdldmlgsdalddfdldmvnpkkkrkvgrgmdkkysiglaigtnsvgwavitdeykvpskkfkvlgntdrhsikknligallfdsgetaeatrlkrtarrrytrrknricylqeifsnemakvddsffhrleesflveedkkherhpifgnivdevayhekyptiyhlrkklvdstdkadlrliylalahmikfrghfliegdlnpdnsdvdklfiqlvqtynqlfeenpinasgvdakailsarlsksrrlenliaqlpgekknglfgnlialslgltpnfksnfdlaedaklqlskdtydddldnllaqigdqyadlflaaknlsdaillsdilrvnteitkaplsasmikrydehhqdltllkalvrqqlpekykeiffdqskngyagyidggasqeefykfikpilekmdgteellvklnredllrkqrtfdngsiphqihlgelhailrrqedfypflkdnrekiekiltfripyyvgplargnsrfawmtrkseetitpwnfeevvdkgasaqsfiermtnfdknlpnekvlpkhsllyeyftvyneltkvkyvtegmrkpaflsgeqkkaivdllfktnrkvtvkqlkedyfkkiecfdsveisgvedrfnaslgtyhdllkiikdkdfldneenediledivltltlfedremieerlktyahlfddkvmkqlkrrrytgwgrlsrklingirdkqsgktildflksdgfanrnfmqlihddsltfkediqkaqvsgqgdslhehianlagspaikkgilqtvkvvdelvkvmgrhkpeniviemarenqttqkgqknsrermkrieegikelgsqilkehpventqlqneklylyylqngrdmyvdqeldinrlsdydvdaivpqsflkddsidnkvltrsdknrgksdnvpseevvkkmknywrqllnaklitqrkfdnltkaergglseldkagfikrqlvetrqitkhvaqildsrmntkydendklirevkvitlksklvsdfrkdfqfykvreinnyhhahdaylnavvgtalikkypklesefvygdykvydvrkmiakseqeigkatakyffysnimnffkteitlangeirkrplietngetgeivwdkgrdfatvrkvlsmpqvnivkktevqtggfskesilpkrnsdkliarkkdwdpkkyggfdsptvaysvlvvakvekgkskklksvkellgitimerssfeknpidfleakgykevkkdliiklpkyslfelengrkrmlasagelqkgnelalpskyvnflylashyeklkgspedneqkqlfveqhkhyldeiieqisefskrviladanldkvlsaynkhrdkpireqaeniihlftltnlgapaafkyfdttidrkrytstkevldatlihqsitglyetridlsqlggdsradpkkkrkvasradalddfdldmlgsdalddfdldmlgsdalddfdldmlgsdalddfdldmli
[0519]
seq id no:37
[0520]
vp64-dcas9-vp64 dna
[0521]
cgggctgacgcattggacgattttgatctggatatgctgggaagtgacgccctcgatgattttgaccttgacatgcttggttcggatgcccttgatgactttgacctcgacatgctcggcagtgacgcccttgatgatttcgacctggacatggttaaccccaagaagaagaggaaggtgggccgcggaatggacaagaagtactccattgggctcgccatcggcacaaacagcgtcggctgggccgtcattacggacgagtacaaggtgccgagcaaaaaattcaaagttctgggcaataccgatcgccacagcataaagaagaacctcattggcgccctcctgttcgactccggggaaaccgccgaagccacgcggctcaaaagaacagcacggcgcagatatacccgcagaaagaatcggatctgctacctgcaggagatctttagtaatgagatggctaaggtggatgactctttcttccataggctggaggagtcctttttggtggaggaggataaaaagcacgagcgccacccaatctttggcaatatcgtggacgaggtggcgtaccatgaaaagtacccaaccatatatcatctgaggaagaagcttgtagacagtactgataaggctgacttgcggttgatctatctcgcgctggcgcatatgatcaaatttcggggacacttcctcatcgagggggacctgaacccagacaacagcgatgtcgacaaactctttatccaact
ggttcagacttacaatcagcttttcgaagagaacccgatcaacgcatccggagttgacgccaaagcaatcctgagcgctaggctgtccaaatcccggcggctcgaaaacctcatcgcacagctccctggggagaagaagaacggcctgtttggtaatcttatcgccctgtcactcgggctgacccccaactttaaatctaacttcgacctggccgaagatgccaagcttcaactgagcaaagacacctacgatgatgatctcgacaatctgctggcccagatcggcgaccagtacgcagacctttttttggcggcaaagaacctgtcagacgccattctgctgagtgatattctgcgagtgaacacggagatcaccaaagctccgctgagcgctagtatgatcaagcgctatgatgagcaccaccaagacttgactttgctgaaggcccttgtcagacagcaactgcctgagaagtacaaggaaattttcttcgatcagtctaaaaatggctacgccggatacattgacggcggagcaagccaggaggaattttacaaatttattaagcccatcttggaaaaaatggacggcaccgaggagctgctggtaaagcttaacagagaagatctgttgcgcaaacagcgcactttcgacaatggaagcatcccccaccagattcacctgggcgaactgcacgctatcctcaggcggcaagaggatttctacccctttttgaaagataacagggaaaagattgagaaaatcctcacatttcggataccctactatgtaggccccctcgcccggggaaattccagattcgcgtggatgactcgcaaatcagaagagaccatcactccctggaacttcgaggaagtcgtggataagggggcctctgcccagtccttcatcgaaaggatgactaactttgataaaaatctgcctaacgaaaaggtgcttcctaaacactctctgctgtacgagtacttcacagtttataacgagctcaccaaggtcaaatacgtcacagaagggatgagaaagccagcattcctgtctggagagcagaagaaagctatcgtggacctcctcttcaagacgaaccggaaagttaccgtgaaacagctcaaagaagactatttcaaaaagattgaatgtttcgactctgttgaaatcagcggagtggaggatcgcttcaacgcatccctgggaacgtatcacgatctcctgaaaatcattaaagacaaggacttcctggacaatgaggagaacgaggacattcttgaggacattgtcctcacccttacgttgtttgaagatagggagatgattgaagaacgcttgaaaacttacgctcatctcttcgacgacaaagtcatgaaacagctcaagaggcgccgatatacaggatgggggcggctgtcaagaaaactgatcaatgggatccgagacaagcagagtggaaagacaatcctggattttcttaagtccgatggatttgccaaccggaacttcatgcagttgatccatgatgactctctcacctttaaggaggacatccagaaagcacaagtttctggccagggggacagtcttcacgagcacatcgctaatcttgcaggtagcccagctatcaaaaagggaatactgcagaccgttaaggtcgtggatgaactcgtcaaagtaatgggaaggcataagcccgagaatatcgttatcgagatggcccgagagaaccaaactacccagaagggacagaagaacagtagggaaaggatgaagaggattgaagagggtataaaagaactggggtcccaaatccttaaggaacacccagttgaaaacacccagcttcagaatgagaagctctacctgtactacctgcagaacggcagggacatgtacgtggatcaggaactggacatcaatcggctctccgactacgacgtggatgccatcgtgccccagtcttttctcaaagatgattctattgataataaagtgttgacaagatccgataaaaatagagggaagagtgataacgtcccctcagaagaagttgtcaagaaaatgaaaaattattggcggcagctgctgaacgccaaactgatcacacaacggaagttcgataatctgactaaggctgaacgaggtggcctgtctgagttggataaagccggcttcatcaaaaggcagcttgttgagacacgccagatcaccaagcacgtggcccaaattctcgattcacgcatgaacaccaagtacgatgaaaatgacaaactgattcgagaggtgaaagttattactctgaagtctaagctggtctcagatttcagaaaggactttcagttttataaggtgagagagatcaacaattaccaccatgcgcatgatgcctacctgaatgcagtggtaggcactgcacttatcaaaaaatatcccaagcttgaatctgaatttgtttacggagactataaagtgtacgatgttaggaaaatgatcgcaaagtctgagcaggaaataggcaaggccaccgctaagtacttcttttacagcaatattatgaattttttcaagaccgagattacactggccaatggagagattcggaagcgaccacttatcgaaacaaacggagaaacaggagaaatcgtgtgggacaagggtagggatttcgcgacagtccggaaggtcctgtccatgccgcaggtgaacatcgttaaaaagaccgaagtacagaccggaggcttctccaaggaaagtatcctcccgaaaaggaacagcgacaagctgatcgcacgcaaaaaagattgggaccccaagaaatacggcggattcgattctcctacagtcgcttacagtgtactggttgtggccaaagtggagaaagggaagtctaaaaaactcaaaagcgtcaaggaactgctgggcatcacaatcatggagcgatcaagcttcgaaaa
aaaccccatcgactttctcgaggcgaaaggatataaagaggtcaaaaaagacctcatcattaagcttcccaagtactctctctttgagcttgaaaacggccggaaacgaatgctcgctagtgcgggcgagctgcagaaaggtaacgagctggcactgccctctaaatacgttaatttcttgtatctggccagccactatgaaaagctcaaagggtctcccgaagataatgagcagaagcagctgttcgtggaacaacacaaacactaccttgatgagatcatcgagcaaataagcgaattctccaaaagagtgatcctcgccgacgctaacctcgataaggtgctttctgcttacaataagcacagggataagcccatcagggagcaggcagaaaacattatccacttgtttactctgaccaacttgggcgcgcctgcagccttcaagtacttcgacaccaccatagacagaaagcggtacacctctacaaaggaggtcctggacgccacactgattcatcagtcaattacggggctctatgaaacaagaatcgacctctctcagctcggtggagacagcagggctgaccccaagaagaagaggaaggtggctagccgcgccgacgcgctggacgatttcgatctcgacatgctgggttctgatgccctcgatgactttgacctggatatgttgggaagcgacgcattggatgactttgatctggacatgctcggctccgatgctctggacgatttcgatctcgatatgttaatc
[0522]
seq id no:159
[0523]
人类p300(带有l553m突变)蛋白
[0524]
maenvvepgppsakrpklsspalsasasdgtdfgslfdlehdlpdelinstelgltnggdinqlqtslgmvqdaaskhkqlsellrsgsspnlnmgvggpgqvmasqaqqsspglglinsmvkspmtqagltspnmgmgtsgpnqgptqstgmmnspvnqpamgmntgmnagmnpgmlaagngqgimpnqvmngsigagrgrqnmqypnpgmgsagnllteplqqgspqmggqtglrgpqplkmgmmnnpnpygspytqnpgqqigasglglqiqtktvlsnnlspfamdkkavpgggmpnmgqqpapqvqqpglvtpvaqgmgsgahtadpekrkliqqqlvlllhahkcqrreqangevrqcnlphcrtmknvlnhmthcqsgkscqvahcassrqiishwknctrhdcpvclplknagdkrnqqpiltgapvglgnpsslgvgqqsapnlstvsqidpssierayaalglpyqvnqmptqpqvqaknqqnqqpgqspqgmrpmsnmsaspmgvnggvgvqtpsllsdsmlhsainsqnpmmsenasvpsmgpmptaaqpsttgirkqwheditqdlrnhlvhklvqaifptpdpaalkdrrmenlvayarkvegdmyesannraeyyhllaekiykiqkeleekrrtrlqkqnmlpnaagmvpvsmnpgpnmgqpqpgmtsngplpdpsmirgsvpnqmmpritpqsglnqfgqmsmaqppivprqtpplqhhgqlaqpgalnppmgygprmqqpsnqgqflpqtqfpsqgmnvtniplapssgqapvsqaqmsssscpvnspimppgsqgshihcpqlpqpalhqnspspvpsrtptphhtppsigaqqppattipapvptppamppgpqsqalhppprqtptppttqlpqqvqpslpaapsadqpqqqprsqqstaasvptptapllppqpatplsqpavsiegqvsnppstsstevnsqaiaekqpsqevkmeakmevdqpepadtqpediseskvedckmesteteerstelkteikeeedqpstsatqsspapgqskkkifkpeelrqalmptlealyrqdpeslpfrqpvdpqllgipdyfdivkspmdlstikrkldtgqyqepwqyvddiwlmfnnawlynrktsrvykycsklsevfeqeidpvmqslgyccgrklefspqtlccygkqlctiprdatyysyqnryhfcekcfneiqgesvslgddpsqpqttinkeqfskrkndtldpelfvectecgrkmhqicvlhheiiwpagfvcdgclkksartrkenkfsakrlpstrlgtflenrvndflrrqnhpesgevtvrvvhasdktvevkpgmkarfvdsgemaesfpyrtkalfafeeidgvdlcffgmhvqeygsdcpppnqrrvyisyldsvhffrpkclrtavyheiligyleyvkklgyttghiwacppsegddyifhchppdqkipkpkrlqewykkmldkavserivhdykdifkqatedrltsakelpyfegdfwpnvleesikeleqeeeerkreentsnestdvtkgdsknakkknnkktsknksslsrgnkkkpgmpnvsndlsqklyatmekhkevffvirliagpaanslppivdpdplipcdlmdgrdafltlardkhlefsslrraqwstmcmlvelhtqsqdrfvytcneckhhvetrwhctvcedydlcitcyntknhdhkmeklglglddesnnqqaaatqspgdsrrlsiqrciqslvhacqcrnancslpscqkmkrvvqhtkgckrktnggcpickqlialccyhakhcqenkcpvpfclnikqklrqqqlqhrlqqaqmlrrrmasmqrtgvvgqqqglpsptpatpttptgqqpttpqtpqptsqpqptppnsmppylprtqaagpvsqgkaagqvtpptppqtaqpplpgpppaavemamqiqraaetqrqmahvqifqrpiqhqmppmtpmapmgmnpppmtrgpsghlepgmgptgmqqqpp
wsqgglpqpqqlqsgmprpammsvaqhgqplnmapqpglgqvgisplkpgtvsqqalqnllrtlrspssplqqqqvlsilhanpqllaafikqraakyansnpqpipgqpgmpqgqpglqpptmpgqqgvhsnpamqnmnpmqagvqraglpqqqpqqqlqppmggmspqaqqmnmnhntmpsqfrdilrrqqmmqqqqqqgagpgigpgmanhnqfqqpqgvgyppqqqqrmqhhmqqmqqgnmgqigqlpqalgaeagaslqayqqrllqqqmgspvqpnpmspqqhmlpnqaqsphlqgqqipnslsnqvrspqpvpsprpqsqpphsspsprmqpqpsphhvspqtssphpglvaaqanpmeqghfaspdqnsmlsqlasnpgmanlhgasatdlglstdnsdlnsnlsqstldih
[0525]
seq id no:160
[0526]
人类p300核心效应物蛋白(seq id no:134的aa 1048-1664)
[0527]
ifkpeelrqalmptlealyrqdpeslpfrqpvdpqllgipdyfdivkspmdlstikrkldtgqyqepwqyvddiwlmfnnawlynrktsrvykycsklsevfeqeidpvmqslgyccgrklefspqtlccygkqlctiprdatyysyqnryhfcekcfneiqgesvslgddpsqpqttinkeqfskrkndtldpelfvectecgrkmhqicvlhheiiwpagfvcdgclkksartrkenkfsakrlpstrlgtflenrvndflrrqnhpesgevtvrvvhasdktvevkpgmkarfvdsgemaesfpyrtkalfafeeidgvdlcffgmhvqeygsdcpppnqrrvyisyldsvhffrpkclrtavyheiligyleyvkklgyttghiwacppsegddyifhchppdqkipkpkrlqewykkmldkavserivhdykdifkqatedrltsakelpyfegdfwpnvleesikeleqeeeerkreentsnestdvtkgdsknakkknnkktsknksslsrgnkkkpgmpnvsndlsqklyatmekhkevffvirliagpaanslppivdpdplipcdlmdgrdafltlardkhlefsslrraqwstmcmlvelhtqsqd
[0528]
seq id no:158
[0529]
grna支架的多核苷酸序列
[0530]
gttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcttttttt
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。