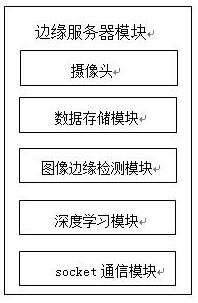
1.本发明属于中文文本处理,文本清洗、文本检错领域,涉及一种基于语序与语义联合分析的中文文本检错方法及系统。
背景技术:
2.随着科技发展,4g,5g普及,整个社会信息化水日益增高,线上办公,远程办公已不再是天方夜谭,无纸化时代已然降临。伴随着无纸化的到来,信息越来越多以电子信息方式存储在存储设备之中。因为文本的特殊性,仅仅是细微差别,可能会带来完全不一样的意义,可能是一个字增多,整句话的意思都变得不一样。这些问题给人们带来了巨大的困扰和损失。像机关公文、学术论文、法律文书、病例文书,这些文本更是无比珍贵的信息,被理解错误,往往会带来不可预估的后果。
3.中文是全世界最复杂最优美的语言,这复杂和优美带来的是语言的多变性,往往相同一字不差句子的语义在不同的上下文都会产生不同含义,伴随有中文文本的错误发生,整一段文本的意义将会有巨大不同。中文文本错误方向有很多,比如很多时候人们往往因为字音的相似,读音的相同,会理解错不同字,有时候人们会因为字形的相似,误写不同含义的字。中国是一个幅员辽阔,地大物博,多民族融合的国家,不同地区的人民使用不同方言,不同方言对表达相同的一个字有不同的读法,对于同一个事物往往有着不同的描述。这些问题也等待被解决。现在对于中文文本的纠错往往还具有缺乏常识知识问题,因此对于真实场景之下检查错误的中文文本,成为当下研究的热点。
4.顺利解决此类问题,可以帮助人们从繁重且机械化的人工检错对比错误中解放出来。如果采用人工来对比不同的错误,首先是成本的上升,其次,对于很多专业错误,需要有专业知识的人来识别错误,这往往会造成人力资源的浪费。提出方法解决这些问题势在必行。
5.纵观文本检错的技术,目前主流的方法例如卷积神经网络与循环神经网络,这些方法已经取得了不错的成效。但是应用在中文文本领域效果显示的并不理想。主要在于中文本的语义复杂,需要模型理解语义,在理解语义的基础上,进行检错。比如,原句是“肖申克有很强的求生欲”与错句“肖申克有很强的求胜欲”,这两句话在字的结构上没有问题,但是根据上下文的内容可知,“求胜欲”才是正确的。而目前主流的技术很难挖掘字的语义问题,从而无法很好的进行检错。并且不同的字之间相互关系是不同的,需要分配不同的权重来表示其相关性,现有的方法,对于权重的分配也并不理想。
技术实现要素:
6.本发明的一个目的是针对上述问题,提出一种基于语序与语义联合分析的中文文本检错方法。该方法能够在拟合文本的情况下同时兼顾语义理解以及字与字权重分配。
7.本发明所采用的技术方案如下:
8.步骤1:数据预处理;
9.1-1获取原始文本数据,将原始文本数据中所有文本按字级别划分,构建得到中文字集合d(w);对中文字集合d(w)中插入标识符,然后使用索引对中文字集合d(w)进行标记,每一个字对应一个字典索引,形成字典dic(w,k);
10.1-2对原始文本数据中文本语句token化,并加入标识符,并将其进行固定句长;
11.作为优选,步骤1-2所述加入标识符是在句首加入“start”起始符,在句中加入“cls”间隔符,在句末加入“end”终止符;
12.作为优选,所述固定句长是将长句截断过长部分,短句使用“pad”符填充至固定句长长度;
13.1-3根据步骤1-1的字典索引对步骤1-2token化后的文本语句序列化;
14.1-4对步骤1-3索引序列化后的数据通过字嵌入(embedding)技术映射成768维向量;
15.步骤2:通过基于语序与语义联合分析的中文文本检错模型rfra,实现中文文本检错;
16.所述基于语序与语义联合分析的中文文本检错模型包括信息提取模块、自注意力模块(self-attention)、输出层;
17.所述信息提取模块包括双向门控循环神经网络(bigru)和语义理解模块(fr);
18.所述双向门控循环神经网络(bigru)的输入为步骤1预处理后的768维向量与自身产出的上一个时刻的隐藏状态,用于提取文本时序信息;具体是:
19.所述的双向门控循环单元模型包括两个门控循环单元(gru);
20.gru具有重置门r与更新门z,在t时刻的重置门r
t
与t时刻的更新门z
t
计算如下所示:
[0021][0022][0023]
其中是来自步骤1在t时刻的映射成的768维向量,h
t-1
是t-1时刻的隐藏状态,w
xr
是重置门输入权重参数,w
xz
是更新门输入权重参数,w
hr
是重置门隐藏状态权重参数,w
hz
是更新门隐藏状态权重参数,b
rr
和b
rz
分别是重置门和更新门的偏置参数;σ是sigmoid函数,控制重置门与更新门的大小范围在0,1之间;
[0024]
重置门用于生成候选隐藏状态计算如下表示:
[0025][0026]
其中w
xh
是候选隐藏状态输入权重参数,w
hh
是候选隐藏状态关于隐藏状态的权重参数,bh是候选隐藏状态偏置参数,tahn是激活函数;
[0027]
更新门用于生成当前时刻的隐藏状态h
t
,计算如下表示:
[0028][0029]
其中表示哈达玛积,是针对元素的相乘;
[0030]
两个门控循环单元(gru)一个是正向输入,一个是反向输入,其正向隐藏状态和反向隐藏状态计算如下表示:
[0031][0032][0033]
其中表示顺序使用gru生成隐藏状态,表示逆向使用gru生成隐藏状态,表示t时刻正向隐藏状态,表示t时刻逆向隐藏状态;
[0034]
隐藏状态h的生成不是简单的相加而是拼接,具体如下所示:
[0035][0036]
其中表示哈达玛积,是针对元素的相乘;
[0037]
所述语义理解模块(fr)的输入为步骤1预处理后的768维向量,用于提取文本语义信息;其包括多个语义理解单元,每个语义理解单元包括全卷积神经网络(fcn);每个语义理解单元采用残差网络(resnet)连接,并且采用了改进的sigmoid函数;每个语义理解单元的输入为前两层单元的输出;
[0038]
所述残差网络resnet与改进的sigmoid激活函数计算公式如下表示:
[0039][0040][0041]
其中表示resnet在t时刻的输出,表示语义理解单元在t-1时刻的输出,表示语义理解单元在t-2时刻的输出;
[0042]
所述自注意力模块(self-attention)的输入为双向门控循环神经网络(bigru)和语义理解模块(fr)的叠加输出,用于分配字权重;将输入分化成键矩阵(key)、问号矩阵(query)、值矩阵(value),其次根据键矩阵与问号矩阵计算相似度矩阵(similarity),再对相似度矩阵归一化,最后将相似度矩阵与值矩阵加权得到注意力矩阵(attention);具体是:
[0043]
(a)将双向门控循环神经网络(bigru)和语义理解模块(fr)的输出叠加后分化成键矩阵(key),问号矩阵(query),值矩阵(value);具体是
[0044][0045][0046][0047][0048]
其中wq是问号矩阵权重参数,wk是键矩阵权重参数,wv是值矩阵权重参数;表示信息提取模块中的双向循环神经网络bigru与fr语义理解模块在t时刻的输出;
[0049]
(b)根据键矩阵与问号矩阵计算相似度矩阵(similarity):
[0050]
similarity(query,key)=query
×
key(2.14)
[0051]
(c)对相似度矩阵的每一行归一化
[0052][0053]
其中a
ij
表示在第i行第j列经过归一化的相似度矩阵的值,n表示相似度矩阵每行元素数目;similarity
ij
表示相似度矩阵在第i行第j列的值,表示以e为底similarity
ij
为指数的幂运算;
[0054]
(d)将归一化后相似度矩阵与值矩阵加权得到注意力矩阵(attention)
[0055][0056]
其中attention
ij
表示注意力矩阵attention在第i行第j列的值,value
ij
表示值矩阵在第i行第j列的值,l表示归一化后相似度矩阵的每列元素数目;
[0057]
所述输出层包括全连接层(fully connectedlayer)与激活函数sigmoid,用于判断输出字是否有错。
[0058]
本发明的另一个目的是提供一种基于语序与语义联合分析的中文文本检错系统,包括:
[0059]
数据预处理模块,用于将文本数据转化为768维向量;
[0060]
中文文本检错模块,利用基于语序与语义联合分析的中文文本检错模型实现中文文本检错。
[0061]
本发明提供的技术方案将产生以下有益效果:
[0062]
(1)本发明采用全卷积神经网络(fcn)与残差网络(resnet)组成的语义理解模块(fr),具有以下两个优点:一是使用全卷积神经网络(fcn)把一维文本数据视为一维图片,理解文本语义,解决了现有技术处理语义手段缺乏问题;二是使用残差网络(resnet)加深了网络的层数,提高了特征的数量,加深对文本语义的理解程度。
[0063]
(2)本发明使用双向门控循环神经网络(bigru)拟合文本数据,具有以下两个优点:一是门控循环神经网络(gru)可以避免普通循环神经网络(rnn)无法拟合长句子的缺点;二是同时使用来自过去和未来的文本信息用更多特征信息来拟合当前文本。
[0064]
(3)本发明叠加语义理解模块(fr)输出与双向门控循环网络(bigru)输出,避免了时序信息通过全卷积神经网络的池化层,填充层时的丢失问题。
[0065]
(4)本发明采用自注意力机制(self-attention),具有以下两个优点:一是注意力机制(attention)自动分配权重的能力,对于关系较近的字分配更大的权重,表示其相关性程度更高;二是自注意力机制(self-attention)具有抗干扰能力,有效避免错字来带语义的问题。
附图说明
[0066]
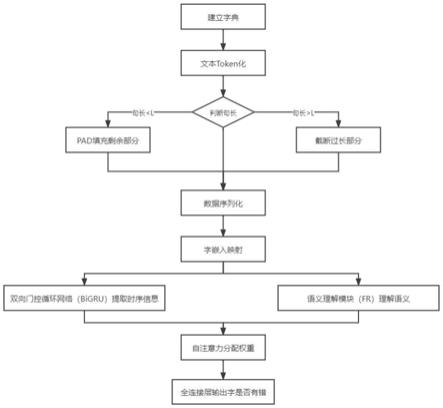
图1为本发明所涉及的流程图;
[0067]
图2为语义理解模块结构图(图中虚线为残差网络连接);
[0068]
图3为双向门控循环网络结构图
[0069]
图4为残差网络结构图
[0070]
图5为模型结构图;
具体实施方式
[0071]
下面结合附图,对本发明的具体实施方案作进一步详细描述。其具体流程描述如图1所示,其中:
[0072]
步骤1:预处理模型获取的输入数据。
[0073]
预处理的过程分为以下四步:
[0074]
1-1创建字典。对所有文本句子分字处理,构建候选中文字集合根据集合统计每一个字出现的频率,频率低于3的字过滤,过滤后的集合去重,形成中文字集合d(w)。在中文字集合d(w)中插入一些特殊的符号例如“start”起始符,“end”终止符,“cls”间隔符,“unknow”未知符,“pad”填充符等。这些符号帮助计算机更好的去拟合文本。然后使用索引标记中文字集合d(w)中的每一个字,每一个字都有唯一映射,形成字典dic(w,k)。
[0075]
1-2数据token化。数据以句的形式存在,每一句话的开头都要加入“start”起始符,在句中加入“cls”间隔符,在句末加入“end”终止符,遇到字典中没有出现的字,使用“unknow”未知符代替。判断剧场,句子并不是固定长度,对于句子的长度需要处理。长句截断过长部分,短句需要使用“pad”填充符填充剩余部分。
[0076]
1-3数据序列化:使用步骤1-1得到的字典dic(w,k),将token化后的文本中的每一个字转换成字典索引。
[0077]
1-4字嵌入映射。字典中中字数过多,使用one-hot编码带来稀疏矩阵,会浪费存储空间和减慢运行速度。采用字嵌入(embedding)的技术把序列化后每一个字的索引映射成768维的向量。
[0078]
步骤2:通过基于语序与语义联合分析的中文文本检错模型rfra,实现中文文本检错;
[0079]
所述基于语序与语义联合分析的中文文本检错模型包括信息提取模块、自注意力模块(self-attention)、输出层;
[0080]
所述信息提取模块包括双向门控循环神经网络(bigru)和语义理解模块(fr);
[0081]
采用语义理解模块具有以下两个优点:一是使用全卷积神经网络(fcn)把一维文本数据视为一维图片,理解文本语义,解决了现有技术处理语义手段缺乏问题;二是使用残差网络(resnet)加深了网络的层数,提高了特征的数量,加深对文本语义的理解程度;采用双向门控循环网络具有两个优点:一是门控循环神经网络(gru)可以避免普通循环神经网络(rnn)无法拟合长句子的缺点;二是同时使用来自过去和未来的文本信息用更多特征信息来拟合当前文本;
[0082]
叠加语义理解模块输出与双向门控循环网络输出,避免了时序信息通过全卷积神经网络的池化层,填充层时的丢失问题;
[0083]
所述双向门控循环神经网络(bigru)的输入为步骤1预处理后的768维向量与上一个时刻的隐藏状态,用于提取文本时序信息;具体是:
[0084]
所述的双向门控循环单元模型包括两个门控循环单元(gru);
[0085]
gru具有重置门r与更新门z,在t时刻的重置门r
t
与t时刻的更新门z
t
计算如下所示:
[0086]
[0087][0088]
其中是来自步骤1在t时刻的映射成的768维向量,h
t-1
是t-1时刻的隐藏状态,w
xr
是重置门输入权重参数,w
xz
是更新门输入权重参数,w
hr
是重置门隐藏状态权重参数,w
hz
是更新门隐藏状态权重参数,b
rr
和b
rz
分别是重置门和更新门的偏置参数。σ是sigmoid函数,控制重置门与更新门的大小范围在0,1之间。
[0089]
重置门可以用于生成候选隐藏状态计算如下表示:
[0090][0091]
其中w
xh
是候选隐藏状态输入权重参数,w
hh
是候选隐藏状态关于隐藏状态的权重参数,bh是候选隐藏状态偏置参数,tahn是激活函数。
[0092]
更新门可以生成当前时刻的隐藏状态h
t
计算如下表示:
[0093][0094]
其中是哈达玛积,是针对元素的相乘。
[0095]
两个门控循环单元(gru)一个是正向输入,一个是反向输入,其正向隐藏状态和反向隐藏状态计算如下表示:
[0096][0097][0098]
其中表示顺序使用gru生成正向隐藏状态,表示逆序使用gru生成隐藏状态。隐藏状态h的生成不是简单的相加而是拼接,具体如下所示:
[0099][0100]
其中是维度连接操作。
[0101]
所述语义理解模块(fr)的输入为步骤1预处理后的768维向量,用于提取文本语义信息;其包括3个单元,第一单元的输入为步骤1预处理后的768维向量,第二单元的输入为步骤1预处理后的768维向量和第一单元的输出,第二单元的输入为第一、二单元的输出;
[0102]
每个单元包括全卷积神经网络(fcn),所述全卷积神经网络包括一个卷积层、一个relu激活函数、一个平均池化层、一个反卷积层、一个改进的sigmoid激活函数;每个单元采用残差网络(resnet)连接;
[0103]
所述残差网络resnet计算公式与改进sigmoid激活函数如下表示:
[0104][0105][0106]
其中表示resnet在t时刻的输出,表示resnet在t-1时刻的输出,表示resnet在t-2时刻的输出。
[0107]
所述自注意力模块(self-attention)的输入为双向门控循环神经网络(bigru)和语义理解模块(fr)的叠加输出,用于分配字权重;将输入分化成键矩阵(key),问号矩阵(query),值矩阵(value),其次根据键矩阵与问号矩阵计算相似度矩阵(similarity),再对
相似度矩阵归一化,最后将相似度矩阵与值矩阵加权得到注意力矩阵(attention);具体是:
[0108]
(a)将双向门控循环神经网络(bigru)和语义理解模块(fr)的输出叠加后分化成键矩阵(key),问号矩阵(query),值矩阵(value);具体是
[0109][0110][0111][0112][0113]
其中wq是问号矩阵权重参数,wk是键矩阵权重参数,wv是值矩阵权重参数。
[0114]
(b)根据键矩阵与问号矩阵计算相似度矩阵(similarity):
[0115]
similarity(query,key)=query
×
key(2.14)
[0116]
(c)对相似度矩阵的每一行归一化
[0117][0118]
其中a
ij
表示在第i行第j列经过归一化的相似度矩阵的值,n表示一行有几个元素。
[0119]
(d)将相似度矩阵与值矩阵加权得到注意力矩阵(attention)
[0120][0121]
其中attention
ij
表示注意力矩阵(attention)在第i行第j列的值,value
ij
表示值矩阵在第i行第j列的值,l表示有几行元素。
[0122]
所述输出层包括全连接层(fullyconnectedlayer)与激活函数sigmoid。输出层的输入来自于是注意力矩阵(attention),经过全连接层与激活函数,输出字错误的概率,若错误的概率大于0.5则判定是错别字。
[0123]
采用自注意力机制(self-attention),具有以下两个优点:一是注意力机制(attention)自动分配权重的能力,对于关系较近的字分配更大的权重,表示其相关性程度更高;二是自注意力机制(self-attention)具有抗干扰能力,有效避免错字来带语义的问题。
[0124]
本发明训练采用自身采集的数据集merge进行训练,性能评估采用sighan15公开中文拼写数据集进行评估。模型在这个数据集上进行了预测错别字的实验,并且统计了各项指标以供对比。下表为merge与sighan15数据集数据量的情况。
[0125] mergesighan15段落数23901100错误数37401602
[0126]
本发明采用的性能评价指标是precesion、recall、f1、f
0.5
。
[0127] 真实值1真实值-1预测值1tp(truepositive)fp(falsenegative)预测值-1fn(falsenegative)tn(truenegative)
[0128]
precision:针对预测结果而言,在所有被预测为正的样本中,实际为正的样本的概率。
[0129][0130]
recall:针对原样本而言,在实际为正的样本中被预测为正样本的概率
[0131][0132]
f1与f
0.5
是在两者之间找到一个平衡点,参考了精确率和召回率,综合全面的反应模型质量的衡量标准。
[0133][0134][0135]
下表为本发明在sighan15数据集上性别预测实验结果:
[0136] precision(%)recall(%)f1(%)f
0.5
(%)lstm56.1647.0351.1954.06gru70..1746.1855.7063.57bigru-cnn81.9489.3885.5083.33bigru-attention64.4599.0678.0969.29rfra84.6098.0190.8187.00
[0137]
上述中文文本检错实验结果表中,lstm与gru为传统的循环神经网络检测器,bigru-cnn是循环神经网络和卷积神经网络的结合,bigru-attention是循环神经网络和注意力机制的结合。rfra即为本发明中的基于语序与语义联合分析的中文文本检错模型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。