技术特征:
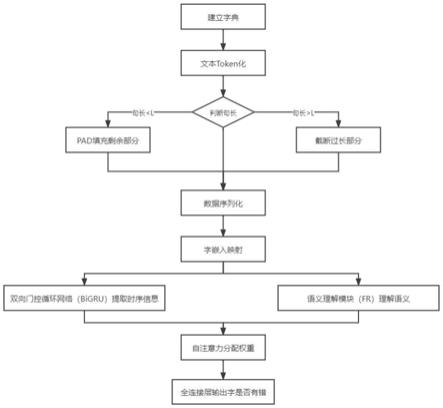
1.一种基于语序与语义联合分析的中文文本检错方法,其特征在于包括以下步骤:步骤1:数据预处理;1-1获取原始文本数据,将原始文本数据中所有文本按字级别划分,构建得到中文字集合d(w);对中文字集合d(w)中插入标识符,然后使用索引对中文字集合d(w)进行标记,每一个字对应一个字典索引,形成字典dic(w,k);1-2对原始文本数据中文本语句token化,并加入标识符,并将其进行固定句长;1-3根据步骤1-1的字典索引对步骤1-2token化后的文本语句序列化;1-4对步骤1-3索引序列化后的数据通过字嵌入embedding技术映射成768维向量;步骤2:通过基于语序与语义联合分析的中文文本检错模型rfra,实现中文文本检错;所述基于语序与语义联合分析的中文文本检错模型包括信息提取模块、自注意力模块self-attention、输出层;所述信息提取模块包括双向门控循环神经网络bigru和语义理解模块fr;所述语义理解模块fr的输入为步骤1预处理后的768维向量,用于提取文本语义信息;其包括多个语义理解单元,每个语义理解单元包括全卷积神经网络fcn;每个语义理解单元采用残差网络resnet连接,并且采用改进的sigmoid函数;每个语义理解单元的输入为前两层单元的输出;所述自注意力模块self-attention的输入为双向门控循环神经网络bigru和语义理解模块fr的叠加输出,用于分配字权重;将输入分化成键矩阵key、问号矩阵query、值矩阵value,其次根据键矩阵与问号矩阵计算相似度矩阵similarity,再对相似度矩阵归一化,最后将相似度矩阵与值矩阵加权得到注意力矩阵attention;所述输出层用于判断输出字是否有错。2.如权利要求1所述的方法,其特征在于步骤1-2所述加入标识符是在句首加入“start”起始符,在句中加入“cls”间隔符,在句末加入“end”终止符。3.如权利要求1所述的方法,其特征在于步骤1-2所述固定句长是将长句截断过长部分,短句使用“pad”符填充至固定句长长度。4.如权利要求1所述的方法,其特征在于所述双向门控循环神经网络bigru的输入为步骤1预处理后的768维向量与自身产出的上一个时刻的隐藏状态,用于提取文本时序信息;具体是:所述的双向门控循环单元模型包括两个门控循环单元gru;gru具有重置门r与更新门z,在t时刻的重置门r
t
与t时刻的更新门z
t
计算如下所示:计算如下所示:其中是来自步骤1在t时刻的映射成的768维向量,h
t-1
是t-1时刻的隐藏状态,w
xr
是重置门输入权重参数,w
xz
是更新门输入权重参数,w
hr
是重置门隐藏状态权重参数,w
hz
是更新门隐藏状态权重参数,b
rr
和b
rz
分别是重置门和更新门的偏置参数;σ是sigmoid函数,控制重置门与更新门的大小范围在0,1之间;重置门用于生成候选隐藏状态计算如下表示:
其中w
xh
是候选隐藏状态输入权重参数,w
hh
是候选隐藏状态关于隐藏状态的权重参数,b
h
是候选隐藏状态偏置参数,tahn是激活函数;更新门用于生成当前时刻的隐藏状态h
t
,计算如下表示:其中表示哈达玛积,是针对元素的相乘;两个门控循环单元gru一个是正向输入,一个是反向输入,其正向隐藏状态和反向隐藏状态计算如下表示:计算如下表示:其中表示顺序使用gru生成隐藏状态,表示逆向使用gru生成隐藏状态,表示t时刻正向隐藏状态,表示t时刻逆向隐藏状态;隐藏状态h的生成具体如下所示:其中表示维度连接操作。5.如权利要求1所述的方法,其特征在于所述残差网络resnet计算公式如下表示:所述改进的sigmoid函数计算公式如下:其中表示resnet在t时刻的输出,表示语义理解单元在t-1时刻的输出,表示语义理解单元在t-2时刻的输出。6.如权利要求1所述的方法,其特征在于所述自注意力模块self-attention具体是:(a)将双向门控循环神经网络(bigru)和语义理解模块(fr)的输出叠加后分化成键矩阵(key),问号矩阵(query),值矩阵(value);具体是具体是具体是具体是其中w
q
是问号矩阵权重参数,w
k
是键矩阵权重参数,w
v
是值矩阵权重参数;表示信息提取模块中的双向循环神经网络bigru与fr语义理解模块在t时刻的输出;(b)根据键矩阵与问号矩阵计算相似度矩阵(similarity):similarity(query,key)=query
×
key(2.14)
(c)对相似度矩阵的每一行归一化其中a
ij
表示在第i行第j列经过归一化的相似度矩阵的值,n表示相似度矩阵每行元素数目;similarity
ij
表示相似度矩阵在第i行第j列的值,表示以e为底similarity
ij
为指数的幂运算;(d)将归一化后相似度矩阵与值矩阵加权得到注意力矩阵(attention)其中attention
ij
表示注意力矩阵attention在第i行第j列的值,value
ij
表示值矩阵在第i行第j列的值,l表示归一化后相似度矩阵的每列元素数目。7.如权利要求1所述的方法,其特征在于所述输出层包括两层全连接层fully connected layer与两个激活函数gelu组成。8.一种基于语序与语义联合分析的中文文本检错系统,其特征在于包括:数据预处理模块,用于将文本数据转化为768维向量;中文文本检错模块,利用基于语序与语义联合分析的中文文本检错模型实现中文文本检错。
技术总结
本发明公开一种基于语序与语义联合分析的中文文本检错方法及系统。针对现有的中文文本检错方法,无法深入理解中文文本语义,自动分配权重,设计了一种把文本视为一维图片,并且使用双向循环神经网络拟合文本与自注意力机制分配权重的中文文本预测错误模型。本发明采用全卷积神经网络(FCN)与残差网络(ResNet)组成的语义理解模块(FR),具有以下两个优点:一是使用全卷积神经网络(FCN)把一维文本数据视为一维图片,理解文本语义,解决了现有技术处理语义手段缺乏问题;二是使用残差网络(ResNet)加深了网络的层数,提高了特征的数量,加深对文本语义的理解程度。加深对文本语义的理解程度。加深对文本语义的理解程度。
技术研发人员:周仁杰 沈佳冰 任永坚 张纪林 万健 曾艳 寇亮 袁俊峰 王星
受保护的技术使用者:杭州电子科技大学
技术研发日:2022.02.25
技术公布日:2022/5/31
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。