1.本发明涉及计算机技术领域,尤其是涉及一种基于融合模型的销售预测方法、系统、设备及存储介质。
背景技术:
2.当前,随着线上电商的兴起,线下新零售的运营变得愈加困难,面对日益严峻的新形势,为了降低成本增加效益,提升企业的营业额,零售商经常使用的两个需求场景:一、在年度企划之前,根据以往年份的销售数据确定较为准确的订货计划;二、在商品当季上市销售之后,随着销售事件的发生,通过销售情况确定针对哪些商品进行提前向工厂发订单补货。零售商针对场景一需要根据历史的销售数据由经验丰富的买手进行判断提前备货,然而线上电商的冲击,导致线下的提前订货与实际销售误差过大,订货过多导致商品难以卖出从而需要亏本折扣甩卖,订货较少无法满足市场需求,影响品牌形象,对企业造成的损失难以预估。场景二由于工厂生产过程存在一定周期,因此需要预测具体的商品销售情况,提前做好补货准备。所以准确有效的商品销售预测对于零售企业在年度企划之前订货和销售后期补货具有重要的参考价值。
3.然而,零售商品的销售预测所受影响因素较多。无论是客流量、商品折扣、商品属性,还是当日天气都是影响商品销量的制约因素。现有预测算法在面临主要影响因素无法获取的情况下,往往通过对数据的分析挖掘出有用的深层信息来预测未来销量,常用的方法主要包括深度学习预测和时间序列预测两类:深度学习方法主要采用特殊的循环神经网络lstm(长短时记忆网络)的方法,通过新增遗忘门,可以决定预测序列中的有用信息程度,从而更好的预测未来的序列值;时间序列预测主要包含es(指数平滑法)、ar(自回归模型)和arima(差分自回归移动平均模型)方法等。
4.在相关技术中,通过对零售商的销售数据分析发现,一般具备周期特性的商品类型均可以采用时序算法进行预测,但是线下零售受外界因素影响较多,单一算法的预测无法满足线下预测的需要。时序预测算法主要根据历史和当前的门店销售数据预测未来一段时间内的销售情况,但其只考虑了数据的时间序列相关性,并没有考虑天气和商场客流等外界因素对预测对象的影响,故当有节假日等特殊时段时,导致其预测结果偏差可能较大。
技术实现要素:
5.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于融合模型的销售预测方法、系统、设备及存储介质,能够通过对历史销售数据进行处理,构建出融合模型然后根据融合模型确定出目标预测销售结果,从而提高了预测的精确度。
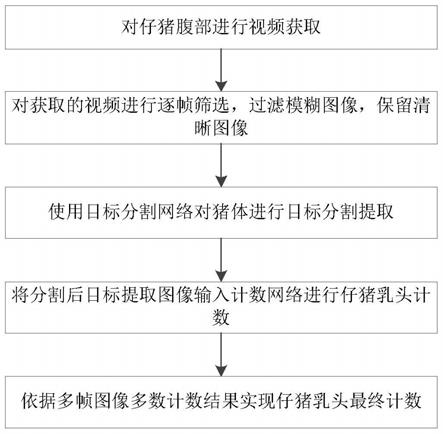
6.为实现上述目的,本公开实施例的第一方面提出了一种基于融合模型的销售预测方法,包括:
7.获取预设时期的历史销售数据;
8.对历史销售数据进行预处理,生成目标训练数据和目标测试数据,其中目标训练
数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据;
9.将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果;
10.根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型;
11.将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果;
12.根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络;
13.根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。
14.在一些实施例,预设的操作函数至少包括以下之一:对数函数、归一化特征函数,对历史销售数据进行预处理,生成目标训练数据和目标测试数据,包括:
15.根据预设的清洗规则对历史销售数据进行清洗处理,得到目标销售数据;
16.对目标销售数据进行聚合处理,得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据;
17.根据对数函数和归一化特征函数分别对销量信息维度数据进行计算处理,分别得到对应的对数数据和归一数据;
18.根据预设的时间划分规则分别对对数数据和归一数据进行分类处理,生成目标训练数据和目标测试数据。
19.在一些实施例,历史销售数据至少包括以下之一:商品属性数据、商品销售数据、上柜信息数据,根据预设的清洗规则对历史销售数据进行清洗处理,得到目标销售数据,包括:
20.根据预设的数据分析库代码对不同历史时期的历史销售数据进行合并处理,得到第一合并信息;
21.基于第一合并信息,将商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据;
22.根据清洗规则对第一组合数据进行第一清洗处理,得到第一清洗数据;
23.将第一清洗数据与商品属性数据进行第二组合处理,得到第二组合数据;
24.根据清洗规则对第二组合数据进行第二清洗处理,得到目标销售数据。
25.在一些实施例,将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果,包括:
26.设置影响销量的节假日节点数据和与节假日节点数据所对应的影响因子数据;
27.根据影响因子数据和初始时间序列预测模型的参数取值数据组合成参数空间组合数据;
28.将参数空间组合数据和第一训练数据进行组合处理,得到第一参数数据;
29.将第一参数数据输入初始时间序列预测模型进行第一训练,输出第一预测结果。
30.在一些实施例,根据第一预测结果和第一测试数据,确定出第一目标参数,用以根
据第一目标参数确定出目标时间序列预测模型,包括:
31.定义预设的评价函数作为预测评价指标,评价函数至少包括以下之一:均方误差函数和均方根误差函数;
32.将第一预测结果和第一测试数据分别输入均方误差函数和均方根误差函数,分别得到对应的第一均方误差函数值和第一均方根误差函数值;
33.根据第一均方误差函数值和第一均方根误差函数值,确定出第一目标参数,第一目标参数用于确定出目标时间序列预测模型。
34.在一些实施例,将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果,包括:
35.将参数空间组合数据和第二训练数据进行组合处理,得到第二参数数据;
36.将第二参数数据输入初始长短期记忆网络进行第二训练,输出第二预测结果。
37.在一些实施例,根据融合模型函数以确定出目标预测销售结果,包括:
38.根据融合模型函数的目标函数值与对应相同时期的历史销售值,确定出用以得到目标函数值的目标参数组;
39.将目标参数组输入融合模型函数进行计算处理,得到目标预测销售结果。
40.为实现上述目的,本公开实施例的第二方面提出了一种基于融合模型的销售预测系统,包括:
41.获取模块,用于获取预设时期的历史销售数据;
42.预处理模块,用于对历史销售数据进行预处理,生成目标训练数据和目标测试数据,其中目标训练数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据;
43.第一训练模块,用于将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果;
44.第一确定模块,用于根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型;
45.第二训练模块,用于将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果;
46.第二确定模块,用于根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络;
47.预测模块,用于根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。
48.为实现上述目的,本公开实施例的第三方面提出了一种基于融合模型的销售预测设备,包括:
49.至少一个存储器;
50.至少一个处理器;
51.至少一个程序;
52.所述程序被存储在存储器中,处理器执行所述至少一个程序以实现:
53.如上述第一方面所述的一种基于融合模型的销售预测方法。
54.为实现上述目的,本公开实施例的第四方面提出了一种存储介质,该存储介质是
计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行:
55.如上述第一方面所述的一种基于融合模型的销售预测方法。
56.根据本发明实施例提供的一种基于融合模型的销售预测方法、系统、设备及存储介质,至少具有如下有益效果:
57.本公开实施例提出的一种基于融合模型的销售预测方法、系统、设备及存储介质,首先通过获取预设时期的历史销售数据;对历史销售数据进行预处理,生成目标训练数据和目标测试数据,其中目标训练数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据;将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果;根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型;将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果;根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络;根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。通过本公开实施例能够通过对历史销售数据进行处理,构建出融合模型然后根据融合模型确定出目标预测销售结果,从而提高了预测的精确度。
58.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
59.下面结合附图和实施例对本发明做进一步的说明,其中:
60.图1为本发明提供的一种基于融合模型的销售预测方法的一具体流程示意图;
61.图2为图1中步骤s200的一具体流程示意图;
62.图3为图2中步骤s210的一具体流程示意图;
63.图4为图1中步骤s300的一具体流程示意图;
64.图5为图1中步骤s400的一具体流程示意图;
65.图6为图1中步骤s500的一具体流程示意图;
66.图7为图1中步骤s700的一具体流程示意图;
67.图8是本发明提供的预设时期的历史销售数据的可视化图;
68.图9是本发明提供的初始时间序列预测模型某品类拟合的销售预测曲线;
69.图10是本发明提供的初始长短期记忆网络模型的单元内部数据流向及门处理图;
70.图11是本发明提供的初始长短期记忆网络模型的某品类预测值和实际值的对比图;
71.图12是本发明提供的融合模型的某品类按周合并的实际值和预测值对比图。
具体实施方式
72.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
73.在本发明的描述中,需要理解的是,涉及到方位描述,例如上、下、前、后、左、右等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
74.在本发明的描述中,若干的含义是一个以上,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
75.本发明的描述中,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
76.本发明的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
77.首先,对本技术中涉及的若干名词进行解析:
78.初始时间序列预测模型:也称作为prophet时序预测模型,是facebook开源一款基于python和r语言的数据预测工具。首先,输入已知的时间序列和对应的值(prophet是单特征模型,输入只有两列,日期列必须被称为“ds”,数值列被称为“y”);再输入需要预测的时间序列的长度,比如periods设置365,就表示预测365个新值;使用已经有的时间序列和对应值训练模型,并输出结果,输出结果包括目标值,上界和下界等,还可以画出趋势曲线。
79.初始长短期记忆网络(lstm,long short-term memory):是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。在标准rnn中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。
80.在相关技术中,通过对零售商的销售数据分析发现,一般具备周期特性的商品类型均可以采用时序算法进行预测,但是线下零售受外界因素影响较多,单一算法的预测无法满足线下预测的需要。时序预测算法主要根据历史和当前的门店销售数据预测未来一段时间内的销售情况,但其只考虑了数据的时间序列相关性,并没有考虑天气和商场客流等外界因素对预测对象的影响,故当有节假日等特殊时段时,导致其预测结果偏差可能较大。
81.基于此,本公开实施例提供一种基于融合模型的销售预测方法、系统、设备及存储介质。针对历史年份的销售数据、日期信息、天气信息等信息,分别构建prophet和lstm预测方法,并基于权重系数法将prophet和lstm结合,引入均方误差(mse)和均方根误差(rmse)对模型进行优化,得到最终的prophet-lstm融合模型。根据本公开实施例中的基于融合模型的销售预测方法对某行业零售商的实际销售数据进行验证,结果表明,prophet-lstm融合模型相比prophet模型和lstm模型拥有更高的预测精度。
82.其具体通过如下实施例进行说明,首先描述本公开实施例中的基于融合模型的销售预测方法。
83.如图1所示,其为本技术实施例提供的一种基于融合模型的销售预测方法的实施流程示意图,基于融合模型的销售预测方法可以包括但不限于步骤s100至s700。
84.s100,获取预设时期的历史销售数据;
85.s200,对历史销售数据进行预处理,生成目标训练数据和目标测试数据,其中目标训练数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据;
86.s300,将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果;
87.s400,根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型;
88.s500,将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果;
89.s600,根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络;
90.s700,根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。
91.在一些实施例的步骤s100中,获取预设时期的历史销售数据。可以理解的是,通过计算机程序从数据库中选取某零售商品,再获取到某零上商品在预设时期的线下历史销售数据。
92.可选的,历史销售数据至少包括以下之一:商品属性数据、商品销售数据、上柜信息数据。
93.可选的,预设时期为根据实际需求选取的某个时期,在本技术的实施例中可以选取2018年1月至2021年8月这个时间段为预设时期。
94.在一些实施例的步骤s200中,对历史销售数据进行预处理,生成目标训练数据和目标测试数据。可以理解的是,其具体执行步骤可以为:首先根据预设的数据分析库代码对不同历史时期的历史销售数据进行合并处理,得到第一合并信息,基于第一合并信息,将商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据,根据清洗规则对第一组合数据进行第一清洗处理,得到第一清洗数据,将第一清洗数据与商品属性数据进行第二组合处理,得到第二组合数据,根据清洗规则对第二组合数据进行第二清洗处理,得到目标销售数据,对目标销售数据进行聚合处理,得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据,根据对数函数和归一化特征函数分别对销量信息维度数据进行计算处理,分别得到对应的对数数据和归一数据,根据预设的时间划分规则分别对对数数据和归一数据进行分类处理,生成目标训练数据和目标测试数据。
95.需要说明的是,目标训练数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据
96.在一些实施例的步骤s300中,将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果。可以理解的是,其具体执行步骤可以为:首先设置影响销量的节假日节点数据和与节假日节点数据所对应的影响因子数据,根据影响因子数据和初始时间序列预测模型的参数取值数据组合成参数空间组合数据,将参数空间组合数据和
第一训练数据进行组合处理,得到第一参数数据,将第一参数数据输入初始时间序列预测模型进行第一训练,输出第一预测结果。
97.需要说明的是,初始时间序列预测模型:也称作为prophet时序预测模型,是facebook开源一款基于python和r语言的数据预测工具。首先,输入已知的时间序列和对应的值(prophet是单特征模型,输入只有两列,日期列必须被称为“ds”,数值列被称为“y”);再输入需要预测的时间序列的长度,比如periods设置365,就表示预测365个新值;使用已经有的时间序列和对应值训练模型,并输出结果,输出结果包括目标值,上界和下界等,还可以画出趋势曲线。
98.在一些实施例的步骤s400中,根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型。可以理解的是,其具体执行步骤可以为:首先定义预设的评价函数作为预测评价指标,评价函数至少包括以下之一:均方误差函数和均方根误差函数,将第一预测结果和第一测试数据分别输入均方误差函数和均方根误差函数,分别得到对应的第一均方误差函数值和第一均方根误差函数值,根据第一均方误差函数值和第一均方根误差函数值,确定出第一目标参数,第一目标参数用于确定出目标时间序列预测模型。
99.在一些实施例的步骤s500中,将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果。可以理解的是,其具体执行步骤可以为:首先将参数空间组合数据和第二训练数据进行组合处理,得到第二参数数据,再将第二参数数据输入初始长短期记忆网络进行第二训练,输出第二预测结果。
100.需要说明的是,初始长短期记忆网络(lstm,long short-term memory):是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。在标准rnn中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。
101.在一些实施例的步骤s600中,根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络。可以理解的是,其具体执行步骤可以为:首先将第二预测结果和第二测试数据分别输入均方误差函数和均方根误差函数,分别得到对应的第二均方误差函数值和第二均方根误差函数值,根据第二均方误差函数值和第二均方根误差函数值,确定出第二目标参数,第二目标参数用于确定出目标长短期记忆网络。
102.在一些实施例的步骤s700中,根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。可以理解的是,其具体执行步骤可以为:首先根据融合模型函数的目标函数值与对应相同时期的历史销售值,确定出用以得到目标函数值的目标参数组,将目标参数组输入融合模型函数进行计算处理,得到目标预测销售结果。
103.在一些实施例中,参考图2所示,步骤s200还可以包括但不限于步骤s210至s240。
104.s210,根据预设的清洗规则对历史销售数据进行清洗处理,得到目标销售数据;
105.s220,对目标销售数据进行聚合处理,得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据;
106.s230,根据对数函数和归一化特征函数分别对销量信息维度数据进行计算处理,
分别得到对应的对数数据和归一数据;
107.s240,根据预设的时间划分规则分别对对数数据和归一数据进行分类处理,生成目标训练数据和目标测试数据。
108.在一些实施例的步骤s210中,根据预设的清洗规则对历史销售数据进行清洗处理,得到目标销售数据。可以理解的是,其具体执行步骤可以为:首先根据预设的数据分析库代码对不同历史时期的历史销售数据进行合并处理,得到第一合并信息,基于第一合并信息,将商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据,根据清洗规则对第一组合数据进行第一清洗处理,得到第一清洗数据,将第一清洗数据与商品属性数据进行第二组合处理,得到第二组合数据,根据清洗规则对第二组合数据进行第二清洗处理,得到目标销售数据。
109.需要说明的是,在本技术的实施例中,目标销售数据也为商品销售信息全表所记录的数据。
110.在一些实施例的步骤s220中,对目标销售数据进行聚合处理,得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据。可以理解的是,可以先根据需求定义一个品类根据品类对目标销售数据进行聚合处理,从而得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据。
111.可选的,在本技术的实施例中的品类可以至少包括:风格细类和季节和性别。
112.在一些实施例中,将“风格细类和季节和性别”组成的方式定义为一个品类,并从目标销售数据所对应的商品销售信息全表中将对应的品类按照年份进行聚合,得到销售时间维度数据和与销售时间维度数据所对应的销量信息维度数据,其中分别为按天为步距的销售时间维度数据t,和对应的销量信息维度数据y(t)。
113.在一些实施例的步骤s230中,根据对数函数和归一化特征函数分别对销量信息维度数据进行计算处理,分别得到对应的对数数据和归一数据。可以理解的是,根据对数函数对销量信息维度数据y(t)进行对数变换操作处理,得到对数数据,由于实际销售数据分部在0~300之间,为了在训练prophet模型时使数据更加服从高斯分布,需要采用log1p函数对原数据进行对数转换,输出结果再使用expm1函数进行还原,得到对数数据的具体计算公式如下:
114.log1p:=ln(x 1)
ꢀꢀꢀꢀꢀꢀꢀ
(1)
115.expm1:=exp(x)-1
ꢀꢀꢀꢀꢀꢀ
(2)
116.根据归一化特征函数对销量信息维度数据y(t)进行归一化操作处理,得到归一数据,由于lstm模型中包含sigmoid函数和tanh函数,因此需要采用minmaxscaler函数对原始数据归一化,以及预测输出时采用inverse_transform函数进行数据还原,得到归一数据的具体计算公式如下:
[0117][0118]
x(t)=x
′
(t)(x
max-x
min
) x
min
ꢀꢀ
(4)
[0119]
其中x(t)为某一天的销售数据,x’(t)为转换后的数据也即归一数据。
[0120]
在一些实施例的步骤s240中,根据预设的时间划分规则分别对对数数据和归一数据进行分类处理,生成目标训练数据和目标测试数据。可以理解的是,预设时间规则可以为
在一个时间段中划分一个时间节点,可以规定在时间节点之前为训练数据,在时间节点之后的数据为测试数据,因此,在本技术的实施例中,可以以2020年12月31日为一个时间节点,并以此节点为依据对对数数据和归一数据进行分类处理,即该时间节点前的对数数据p’(t)和归一数据l’(t)为目标训练数据,该节点后的对数数据p”(t)和归一数据l”(t)为目标测试数据。
[0121]
进一步地,目标训练数据至少包括以下之一:第一训练数据p’(t)、第二训练数据l’(t);目标测试数据至少包括以下之一:第一测试数据p”(t)、第二测试数据l”(t)。
[0122]
在一些实施例中,参考图3所示,步骤s210还可以包括但不限于步骤s211至s215。
[0123]
s211,根据预设的数据分析库代码对不同历史时期的历史销售数据进行合并处理,得到第一合并信息;
[0124]
s212,基于第一合并信息,将商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据;
[0125]
s213,根据清洗规则对第一组合数据进行第一清洗处理,得到第一清洗数据;
[0126]
s214,将第一清洗数据与商品属性数据进行第二组合处理,得到第二组合数据;
[0127]
s215,根据清洗规则对第二组合数据进行第二清洗处理,得到目标销售数据。
[0128]
在一些实施例的步骤s211中,根据预设的数据分析库代码对不同历史时期的历史销售数据进行合并处理,得到第一合并信息。可以理解的是,可以使用程序代码,比如调用pandas库将历年的历史销售数据进行合并处理,得到第一合并信息以及得到第一合并数据。
[0129]
在一些实施例中,在得到第一合并信息之后,删除商品销售数据中折扣为零的销售记录数据,该数据包含赠品或购物袋等非商品销售信息。
[0130]
可选的,历史销售数据至少包括以下之一:商品属性数据、商品销售数据、上柜信息数据。
[0131]
在一些实施例的步骤s212中,基于第一合并信息,将商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据。可以理解的是,在执行完步骤s211对历史销售数据进行初步合并之后,将历史销售数据中的商品销售数据和上柜信息数据进行第一组合处理,得到第一组合数据,用于清洗数据以去除无效数据。
[0132]
在一些实施例的步骤s213中,根据清洗规则对第一组合数据进行第一清洗处理,得到第一清洗数据。可以理解的是,在商品销售数据和上柜信息数据进行第一组合处理得到第一组合数据之后,在根据预设的清洗规则清洗第一组合数据,从而去除无效数据,得到第一清洗数据。
[0133]
在一些实施例的步骤s214中,将第一清洗数据与商品属性数据进行第二组合处理,得到第二组合数据。可以理解的是,将第一清洗数据与历史销售数据中的商品属性数据进行第二组合处理得到第二组合数据,用于再次清洗数据以去除无效数据。
[0134]
在一些实施例的步骤s215中,根据清洗规则对第二组合数据进行第二清洗处理,得到目标销售数据。可以理解的是,在将第一清洗数据与商品属性数据进行第二组合处理得到第二组合数据之后,在根据预设的清洗规则清洗第二组合数据,从而去除无效数据,得到目标销售数据。
[0135]
在一些实施例中,参考图4所示,步骤s300还可以包括但不限于步骤s310至s340。
[0136]
s310,设置影响销量的节假日节点数据和与节假日节点数据所对应的影响因子数据;
[0137]
s320,根据影响因子数据和初始时间序列预测模型的参数取值数据组合成参数空间组合数据;
[0138]
s330,将参数空间组合数据和第一训练数据进行组合处理,得到第一参数数据;
[0139]
s340,将第一参数数据输入初始时间序列预测模型进行第一训练,输出第一预测结果。
[0140]
在一些实施例的步骤s310中,设置影响销量的节假日节点数据和与节假日节点数据所对应的影响因子数据。可以理解的是,在本技术的一些实施例中,节假日节点数据至少可以包括以下之一:2018~2021年间中国的法定节假日数据,具备零售行业领域的节假日,例如“618”、“双11”和“双12”等,此外,还新增了教师节的节假日数据,以及设置对应的影响因子数据。
[0141]
在一些实施例的步骤s320中,根据影响因子数据和初始时间序列预测模型的参数取值数据组合成参数空间组合数据。可以理解的是,将步骤s340得到的影响因子数据和初始时间序列预测模型的参数取值数据进行组合处理,共同组合成参数空间组合数据。
[0142]
可选的,初始时间序列预测模型的参数取值数据至少包括以下之一:yearly_seasonality、weekly_seasonality、changepoints、daily_seasonality、seasonality_prior_scale、changepoint_prior_scale、holidays_prior_scale、n_changepoints。
[0143]
进一步地,增长趋势(growth)、季节趋势(seasonality)和节假日效应(holidays),yearly_seasonality,用以拟合每年的季节趋势。;weekly_seasonality,用以拟合每周的季节趋势。;daily_seasonality,用以拟合每天的季节趋势;holidays,包含假期名称和时间的输入数据帧。;seasonality_prior_scale,用来改变seasonality模型强度的参数;holiday_prior_scale,用来改变holiday模型强度的参数;changepoints,变点。
[0144]
在一些实施例的步骤s330中,将参数空间组合数据和第一训练数据进行组合处理,得到第一参数数据。可以理解的是,将通过步骤s320得到的参数空间组合数据与通过步骤s240得到的第一训练数据p’(t)进行组合处理,得到第一参数数据,用于输入初始时间序列预测模型进行训练。
[0145]
在一些实施例的步骤s340中,将第一参数数据输入初始时间序列预测模型进行第一训练,输出第一预测结果。可以理解的是,将通过步骤s330得到的第一参数数据输入至初始时间序列预测模型进行训练得到第一预测结果。
[0146]
需要说明的是,将输出的第一预测结果采用expm1函数进行还原然后将目标销售数据的每天销售数据聚合成周销售预测数据,取前n周的销售预测数据
[0147]
在一些实施例中,参考图5所示,步骤s400还可以包括但不限于步骤s410至s430。
[0148]
s410,定义预设的评价函数作为预测评价指标,评价函数至少包括以下之一:均方误差函数和均方根误差函数;
[0149]
s420,将第一预测结果和第一测试数据分别输入均方误差函数和均方根误差函数,分别得到对应的第一均方误差函数值和第一均方根误差函数值;
[0150]
s430,根据第一均方误差函数值和第一均方根误差函数值,确定出第一目标参数,第一目标参数用于确定出目标时间序列预测模型。
[0151]
在一些实施例的步骤s410中,定义预设的评价函数作为预测评价指标。可以理解的是,引用现有的评价函数对第一预测结果和第二预测结果进行评价,并以此为评价指标。
[0152]
可选的,评价函数至少包括以下之一:均方误差函数(mse)和均方根误差函数(rmse)。
[0153]
评价函数的具体公式如下:
[0154][0155][0156]
其中y
t
为真实销售值,为销售预测值,n为预测未来的周数,一般来说,零售商取28周为品类销售的生命周期,该周期适用常规的促销、补货等销售手段。
[0157]
在一些实施例的步骤s420中,将第一预测结果和第一测试数据分别输入均方误差函数和均方根误差函数,分别得到对应的第一均方误差函数值和第一均方根误差函数值。可以理解的是,将通过步骤s340得到的第一预测结果和通过步骤s240得到的第一测试数据p”(t)输入步骤s410的评价函数中进行计算,分别得到对应的第一均方误差函数值和第一均方根误差函数值。
[0158]
在一些实施例的步骤s430中,根据第一均方误差函数值和第一均方根误差函数值,确定出第一目标参数,第一目标参数用于确定出目标时间序列预测模型。可以理解的是,根据通过步骤s420进行评价计算得到的第一均方误差函数值和第一均方根误差函数值,取第一均方误差函数值和第一均方根误差函数值最低的参数组合作为第一目标参数,并将该第一目标参数所对应的时间序列预测模型作为目标时间序列预测模型。
[0159]
在一些实施例中,参考图6所示,步骤s500还可以包括但不限于步骤s510至s520。
[0160]
s510,将参数空间组合数据和第二训练数据进行组合处理,得到第二参数数据;
[0161]
s520,将第二参数数据输入初始长短期记忆网络进行第二训练,输出第二预测结果。
[0162]
在一些实施例的步骤s510中,将参数空间组合数据和第二训练数据进行组合处理,得到第二参数数据。可以理解的是,将通过步骤s320得到的参数空间组合数据与通过步骤s240得到的第二训练数据p”(t)进行组合处理,得到第二参数数据,用于输入初始长短期记忆网络进行训练。
[0163]
在一些实施例的步骤s520中,将第二参数数据输入初始长短期记忆网络进行第二训练,输出第二预测结果。可以理解的是,将通过步骤s510得到的第二参数数据输入至初始长短期记忆网络进行训练得到第二预测结果。
[0164]
需要说明的是,将输出结果采用inverse_transform函数进行还原然后将目标销售数据的每天销售数据聚合成周销售预测数据,取前n周的销售预测数据
[0165]
在一些实施例中,参考图7所示,步骤s700还可以包括但不限于步骤s710至s720。
[0166]
s710,根据融合模型函数的目标函数值与对应相同时期的历史销售值,确定出用以得到目标函数值的目标参数组;
[0167]
s720,将目标参数组输入融合模型函数进行计算处理,得到目标预测销售结果。
[0168]
在一些实施例的步骤s710中,根据融合模型函数的目标函数值与对应相同时期的
历史销售值,确定出用以得到目标函数值的目标参数组。可以理解的是,根据通过步骤s400得到的第一目标参数和通过步骤s600得到的第二目标参数构建出融合模型函数,并根据融合模型函数的目标函数值与对应相同时期的历史销售值,确定出用以得到目标函数值的目标参数组。
[0169]
设定第一目标参数为ω
1t
和第二目标参数为ω
2t
,共同构成两组参数空间集合,其中t∈[1,n],ω
1t
,ω
2t
∈[0,1],即取n周的参数组。
[0170]
融合模型函数:
[0171][0172]
当目标函数值与实际销售值y(t)基于mse和rmse的评价值最小时,该参数组ω
1t
和ω
2t
即为目标参数组。
[0173]
在一些实施例的步骤s720中,将目标参数组输入融合模型函数进行计算处理,得到目标预测销售结果。可以理解的是,将目标参数组输入构建的融合模型函数中进行计算处理,即可得到目标预测销售结果,以根据该目标预测销售结果对零售商品进行合理的规划。
[0174]
进一步地,通过实验可知,通过对比prophet、lstm和prophet-lstm(融合模型)三种模型的mse和rmse值发现,本公开实施例的技术方案所公开的算法模型可以很好的缓解prophet单一时序算法的预测平缓性,也弥补了lstm的较短周期且单一预测输出的劣势,并且该融合模型可以适用于其他时序特征的预测场景。
[0175]
另外,对应于本发明申请公开的一种基于融合模型的销售预测方法还公开了一具体实施例:
[0176]
在一些实施例中,首先选取某零售商2018年至2021年8月的线下历史销售数据,数据包含商品属性数据、商品销售数据、上柜信息数据,然后进行数据清洗,剔除非预测项的干扰数据和重复的销售数据,根据本发明的融合模型选取时间和销量两个维度构建特征工程,分别输入到prophet和lstm模型进行训练和预测,最终将通过平衡参数的网格搜索,得到最优的参数组合作为融合模型的预测结果。
[0177]
进一步地,图8展示了某零售商的线下销售数据按照“风格细类 季节 性别”的规则构建一个品类,以及其中一个品类的历年实际销售曲线图,从该曲线图中可以明显的观察到销售曲线存在的历史周期性以及节假日导致的销售量影响。
[0178]
可选的,根据模型的输入要求构建特征工程,首先按照2018~2020年的销售数据预测2021年的销售数据为目的,以“2020-12-31”为日期节点,将数据分为图8中2021年1月之前曲线的训练集和2021年1月之后红色曲线的测试集,在此日期前的为训练集,在此日期之后的为测试集。然后将训练集分别输入到prophet和lstm模型中,具体的实现方式如下:
[0179]
可选的,由于实际销售数据分布在0~300之间,为了在训练prophet模型时使数据更加服从高斯分布,需要采用log1p函数对原数据进行对数转换,输出结果再使用expm1函数进行还原,具体运算如下:
[0180]
log1p:=ln(x 1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0181]
expm1:=exp(x)-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0182]
可选的,由于lstm模型中包含sigmoid函数和tanh函数,因此需要采用
minmaxscaler函数对原始数据归一化,以及预测输出时采用inverse_transform函数进行数据还原,具体运算如下:
[0183][0184]
x(t)=x
′
(t)(x
max-x
min
) x
min
ꢀꢀ
(4)
[0185]
其中x(t)为某一天的销售数据,x’(t)为转换后的数据。
[0186]
可选的,将原始数据进行转换之后,需要分别输入到prophet和lstm模型进行训练,prophet为时间序列预测模型,适应不同的季节性趋势和节假日分布,模型可以分解为三个部分:趋势项、季节项和节假日项,表达式如下:
[0187][0188]
其中g(t)为趋势项,s(t)为季节项,h(t)为节假日项,ε
t
为误差项。
[0189]
可选的,趋势项可以调节模型的光滑程度以及根据数据的变点改变模型的拟合趋势走向,本发明采用logistic饱和增长模型,基本公式如下:
[0190][0191]
其中c为模型的容量,k为增长率,m为偏移量。
[0192]
可选的,季节项代表周期的规律性变化,为了拟合销量数据的年、月、周、日等周期性变化,prophet采用基于傅里叶级数的季节模型:
[0193][0194]
在一些实施例中,通过调节周期总数n、固定的周期p以及2n个周期个数,来调节拟合曲线的走势。本发明实施例根据图8的特征可视化分析,将周期性特征yearly_seasonality、weekly_seasonality,day_seasonality均设置为true状态,设置seasonality_prior_scale参数空间范围在(1,15)之间且间隔为0.5。
[0195]
可选的,节假日项根据预定的节假日事件建立独立的模型,并根据以下公式进行估算:
[0196][0197]
其中l为节假日的集合,i为第几个节假日,ki为对应的节假日影响因子,di为窗口期中包含的时间t。本发明在节假日的设置上除2018~2021年间中国的法定节假日外,尤其新增了具备零售行业领域的节假日,例如“618”、“双11”和“双12”等,此外,也新增了教师节的影响因素。通过以上节假日和影响因子的设定,完成节假日模型的建模,设定holidays_prior_scale参数空间范围在(1,15)之间且间隔0.5。
[0198]
可选的,除了以上超参数需要设定之外,prophet仍然需要设定改变点(changepoints),一般根据自动检测或者人为根据业务输入获取,从而更改变化的趋势,一般改变点的个数(n_changepoints)设置为25,并设置changepoint_range的范围为(0.1,1.5),间隔为0.1,changepoint_prior_scale的参数设置范围为(0.01,0.1),间隔为0.05。
[0199]
进一步地,按照以上详细步骤的参数设定范围,然后进行网格化参数搜索训练,每一组参数的预测结果与实际销量的结果进行如下均方误差(mse)和均方根误差(rmse)的对比,取mse和rmse最小值的参数组合作为最后prophet模型的参数,拟合曲线如图9所示,黑
点为经过归一化后的天销量数据,灰色曲线为prophet算法拟合的曲线。
[0200][0201][0202]
可选的,lstm是一种特殊的循环神经网络(rnn),它由一组具有特征的单元集合组成,利用这些特征来记忆数据序列,集合中的单元用于捕获并存储数据流,适合用于处理和预测时间序列中间隔和延迟非常长的重要事件。此外,集合中的单元构成先前的模块与当前的模块的内部互连,从而将来自多个过去时间瞬间的信息传送给当前的模块。
[0203]
进一步地,如图10所示lstm每个单元中会使用到遗忘门、输入门和输出门,分别为下一个单元处理、过滤或添加单元中的数据,其中输入h
t-1
为上一刻的隐藏层状态,x
t
为当前时刻输入值,h
t
为当前时刻的隐藏层状态,c
t-1
为上一刻的隐藏层状态,c
t
为当前时刻的单元状态。
[0204]
可选的,遗忘门对于输入的x
t
和h
t-1
,经过sigmoid激活函数之后输出一个介于0到1之间的数字,这个数字为每个单元中应该通过的数据数量,其中1表示“完全保留此值”;而0则意味着“完全忽略此值”。
[0205][0206]
可选的,输入门决定选择哪些数据通过sigmoid层和tanh层后需要存储到数据单元中。初始sigmoid层,称为“输入门层”,决定需要对哪些数值进行修改,随后,由tanh层生成可以添加到状态的新候选值的向量。
[0207][0208]
可选的,输出门决定每个单元输出的内容,根据数据过滤及新增数据后数据单元的状态,输出门会输出一个数据值。
[0209]
在一些实施例中,在超参的选择上,本发明使用50~130个隐藏层节点,间隔为10,移动窗口为7~28,间隔为7作为未来销售的预测的观测期,并且采用网格搜索的方式对每个品类单独进行最优超参搜索,经过100~500个epochs的训练之后,如图11所示为lstm算法的预测结果和实际值的对比,根据mse和rmse的最小值得到的参数组合完成最优的lstm预测模型生成。
[0210]
进一步地,完成最优的prophet模型和lstm模型训练之后,需要对两者进行融合预测,避免单一模型所带来的的缺陷,本发明按照以下方式进行融合预测:
[0211][0212]
其中t∈[1,n],ω
1t
,ω
2t
∈[0,1],即取n周的参数组,为融合预测值,为prophet的预测值,ω
1t
为t时刻prophet预测值的权重参数,为lstm的预测值,ω
2t
为t时刻lstm预测值的权重参数。
[0213]
可选的,为了确定ω
1t
和ω
2t
的具体值,本发明采用投票法和权重法,当预测结果均单侧偏离真实值时,采用投票法选择偏离更小的结果,当预测结果在真实值两侧时,采用权重法由偏离更小的得到更大的权重,具体计算方式如下:
[0214][0215][0216]
其中ε
p
和ε
l
分别为prophet和lstm的预测误差,计算方式如下:
[0217][0218][0219]
在一些实施例中,参考图12所示,本发明公开实施例根据一种基于融合模型的销售预测方法实施的技术方案,预测结果相比单一模型存在更优的预测结果,能够避免单一模型带来的欠拟合问题,并有效提升了预测精度。
[0220]
另外,本公开实施例还提供一种基于融合模型的销售预测系统,可以实现上述基于融合模型的销售预测方法,该系统包括:
[0221]
获取模块,用于获取预设时期的历史销售数据;
[0222]
预处理模块,用于对历史销售数据进行预处理,生成目标训练数据和目标测试数据,其中目标训练数据至少包括以下之一:第一训练数据、第二训练数据,目标测试数据至少包括以下之一:第一测试数据、第二测试数据;
[0223]
第一训练模块,用于将第一训练数据输入预设的初始时间序列预测模型进行第一训练,输出第一预测结果;
[0224]
第一确定模块,用于根据第一预测结果和第一测试数据,确定出第一目标参数,用以根据第一目标参数确定出目标时间序列预测模型;
[0225]
第二训练模块,用于将第二训练数据输入预设的初始长短期记忆网络进行第二训练,输出第二预测结果;
[0226]
第二确定模块,用于根据第二预测结果和第二测试数据,确定出第二目标参数,用以根据第二目标参数确定出目标长短期记忆网络;
[0227]
预测模块,用于根据第一目标参数和第二目标参数构建出融合模型函数,并根据融合模型函数以确定出目标预测销售结果。
[0228]
本公开实施例提出的一种基于融合模型的销售预测系统,通过实现上述一种基于融合模型的销售预测方法,能够通过获取模块、预处理模块、第一训练模块、第一确定模块、第二训练模块、第二确定模块和预测模块,能够通过对历史销售数据进行处理,构建出融合模型然后根据融合模型确定出目标预测销售结果,从而提高了预测的精确度。
[0229]
另外,本公开实施例还提供一种基于融合模型的销售预测设备,该设备包括:
[0230]
至少一个存储器;
[0231]
至少一个处理器;
[0232]
至少一个程序;
[0233]
所述程序被存储在存储器中,处理器执行所述至少一个程序以实现:
[0234]
如本公开实施例第一方面提供的一种基于融合模型的销售预测方法。
[0235]
另外,本公开实施例还提供一种存储介质存储有可执行指令,可执行指令能被计算机执行,使计算机执行如本公开实施例第一方面提供的一种基于融合模型的销售预测方法。
[0236]
存储器作为一种非暂态存储介质,可用于存储非暂态软件程序以及非暂态性计算机可执行程序。此外,存储器可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施方式中,存储器可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至该处理器。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0237]
本公开实施例描述的实施例是为了更加清楚的说明本公开实施例的技术方案,并不构成对于本公开实施例提供的技术方案的限定,本领域技术人员可知,随着技术的演变和新应用场景的出现,本公开实施例提供的技术方案对于类似的技术问题,同样适用。
[0238]
在本技术所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0239]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0240]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0241]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括多指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,简称rom)、随机存取存储器(randomaccess memory,简称ram)、磁碟或者光盘等各种可以存储程序的介质。
[0242]
以上参照附图说明了本公开实施例的优选实施例,并非因此局限本公开实施例的权利范围。本领域技术人员不脱离本公开实施例的范围和实质内所作的任何修改、等同替换和改进,均应在本公开实施例的权利范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。