1.本发明属于自然语言处理领域,具体涉及一种基于表达式链表树匹配程度的数学主观题评分方法及系统。
背景技术:
2.教育教学过程中,考试测评作为教育教学过程的重要环节,有利于评价教师的教学效果和学习者的学习成效。在传统教学过程中,考试通常是书面形式,主要类型包括客观题和主观题。客观题通常为选择、判断等题型,其答案明确唯一,现有自动评分方法已经可以做到十分精确;而主观题多为简答、论述等题型,现阶段仍以手工评分为主。教师作为阅卷主体,长期承担大量重复阅卷和统计工作。引入计算机技术的主观题自动阅卷系统,其阅卷速度快、准确度高、不会疲劳等特点,不仅能代替教师完成大规模、大批量试题阅卷任务,减轻教师工作量,而且可以即时给出评分结果,减少主观性带来的评分误差,保证评分结果的公平、公正,从而真实客观地反映学生学习成效和教师的教学成果。
技术实现要素:
3.本发明的技术问题是现有技术缺乏对包含公式的数学主观题答题结果进行自动评阅打分的系统。
4.本发明的目的是针对上述问题,提供一种基于表达式链表树匹配程度的数学主观题评分方法,利用神经网络模型识别数学主观题答题结果中的步骤分界点,根据步骤分界点分离出各个答题步骤,将答题结果步骤中的表述式表示成链表树,判断答题结果步骤表述式的链表树与标准答案步骤表达式链表树的相似度并作为第一评阅特征,并计算答题结果的步骤间关系与标准答案的步骤间关系的相似度作为第二评阅特征,根据第一评阅特征和第二评阅特征自动计算得到答题结果的评分;本发明还提供相应的数学主观题评分系统。
5.本发明的技术方案是基于表达式链表树匹配程度的数学主观题评分方法,包括以下步骤:
6.步骤1:获取数学主观题的答题结果;
7.步骤2:对答题结果进行分词处理;
8.步骤3:确定答题步骤的步骤分界点,将答题结果的各个答题步骤分离;
9.步骤4:计算答题步骤中的表达式与标准答案步骤表达式的相似度,作为第一评阅特征;
10.步骤5:计算答题结果与标准答案的结构相似度,作为第二评阅特征;
11.步骤6:根据第一评阅特征、第二评阅特征,计算得到答题结果的评分。
12.步骤1中,所述获取数学主观题答题结果,包括从答题系统中获取文字版的学生答题结果及图片格式或扫描版学生答题结果;采用图像识别技术,将图片格式的学生答题结果转换为文字版学生答题结果。
13.步骤2中,根据数学答案中常见的汉字数据语料库,对答题结果进行分词处理。
14.步骤3中,所述确定答题步骤的步骤分界点,将步骤2中分词处理得到的分词点作为候选分离点,利用步骤分离模型判断候选分离点是否为步骤分界点。
15.优选地,所述步骤分离模型采用支持向量机(support vector machines,svm)分类模型。
16.步骤4包括以下子步骤:
17.步骤4.1:分别将答题步骤中的表达式、标准答案步骤表达式表示为待评链表树、基准链表树;步骤4.2:计算待评链表树与基准链表树的相似度,得到第一类公式相似度;
18.步骤4.3:判断第一类公式相似度是否等于1,若第一类公式相似度等于1,则将答题步骤中的表达式与标准答案步骤表达式的相似度的计算结果设为1,结束步骤4;否则,执行步骤4.4;
19.步骤4.4:计算答题步骤表达式子公式的链表树与标准答案步骤表达式子公式的链表树的相似度,得到第二类公式相似度;
20.步骤4.5:比较第一类公式相似度、第二类公式相似度的大小,取两者中较大值作为答题步骤中的表达式与标准答案表达式的相似度的计算结果。
21.步骤4.2中,所述计算待评链表树与基准链表树的结构相似度,分别对待评链表树、基准链表树进行层次遍历,得到待评链表树的层次遍历序列的数组p={p1,p2,p3,
…
,pn}和基准链表树的层次遍历序列的数组b={b1,b2,b3,
…
,bm},根据数组p和数组b的相似度计算得到待评链表树与基准链表树的相似度,其中pi,i=1,2,3,
…
,n表示数组p的第i个元素即待评链表树的层次遍历序列的第i个遍历节点,bj,j=1,2,3,
…
,m表示数组b的第j个元素即基准链表树的层次遍历序列的第j个遍历节点,n、m分别表示待评链表树、基准链表树的节点数量;
22.待评链表树与基准链表树的相似度的计算式如下
[0023][0024]
式中f
sim1
表示待评链表树与基准链表树的第一类公式相似度,common(p,b)表示数组p和数组b的相似度计算函数,min(n,m)表示取变量n、m的较小值。
[0025]
步骤4.4中,所述计算待评链表树与基准链表树的子结构相似度,具体包括:
[0026]
1)获取待评链表树原子节点集合和基准链表树的原子节点集合;
[0027]
2)比较确定待评链表树和基准链表树原子节点集合中原子节点匹配数量;
[0028]
3)计算待评链表树和基准链表树互相匹配的原子节点之间的语义相似度;
[0029]
4)获取待测链表树的边集合和基准链表树的边集合;
[0030]
5)计算待测链表树边集合与基准链表树边集合中边的匹配数量;
[0031]
6)计算相似度,相似度计算式如下
[0032][0033]
其中f
sim2
表示待评链表树与基准链表树的第二类公式相似度,n
base
表示基准链表
树原子节点集合的原子节点总数量,n
match
表示待评链表树和基准链表树的原子节点匹配数量,e
match
表示待评链表树和基准链表树中边的匹配数量,e
base
表示基准链表树中边的总数量,σi表示待评链表树和基准链表树中第i个互相匹配的原子节点的语义相似度。
[0034]
步骤3)中,所述计算待评链表树和基准链表树互相匹配的原子节点之间的语义相似度,将原子节点的类型分为数字、变量以及运算符,语义相似度的计算规则包括:
[0035]
a)若待评链表树的原子节点与匹配的基准链表树的原子节点的类型不同,则此待评链表树原子节点的语义相似度为0;
[0036]
b)若待评链表树的原子节点与匹配的基准链表树的原子节点均为数字且两者相等,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为数字且两者不相等,则此待评链表树原子节点的语义相似度为0;
[0037]
c)若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者相同,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者不相同,则此待评链表树原子节点的语义相似度为0;
[0038]
d)若待评链表树的原子节点与匹配的基准链表树的原子节点均为运算符且两者相同或相近,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者既不相同也不相近,则此待评链表树原子节点的语义相似度为0。
[0039]
步骤4.4中,所述计算答题步骤表达式子公式的链表树与标准答案步骤表达式子公式的链表树的相似度,利用式(2)计算得到第二类公式相似度。
[0040]
优选地,第二评阅特征包括答题结果的步骤数量和答题步骤的结构关系是否分别与标准答案的步骤数量、步骤结构关系一致。
[0041]
步骤5利用步骤关系分析模型确定答题步骤的步骤间关系,所述步骤关系分析模型包括输入层、隐藏层、分类层和输出层,输入层的输入为答题步骤向量,隐藏层为多层,隐藏层的输出为步骤特征向量,分类层的输入为步骤特征向量和答题步骤向量统计特征,输出层的输出为步骤间关系判断结果。
[0042]
上述的数学主观题评分方法的系统包括以下模块:
[0043]
答题结果获取模块:获取数学主观题的答题结果;
[0044]
答题步骤分离模块:从获取的答题结果中识别判断出步骤分界点,根据步骤分界点将答题结果分离成多个答题步骤,得到答题步骤向量;
[0045]
表达式相似度计算模块:计算待评答题步骤与标准答案步骤的表达式相似度,作为第一评阅特征;
[0046]
答题结构相似度计算模块:计算待评答题结果与标准答案的结构相似度,作为第二评阅特征;评阅模块:根据第一评阅特征、第二评阅特征,计算得到答题结果的评分。
[0047]
所述表达式相似度计算模块包括以下单元:
[0048]
处理单元:将待评数学公式与基准数学公式分别表示为待评链表树和基准链表树;
[0049]
计算单元:计算第一类公式相似度和第二类公式相似度,得到第一评阅特征;
[0050]
比较单元:判断第一类公式相似度是否小于1,并比较第一类公式相似度与第二类公式相似度的大小。
[0051]
相比现有技术,本发明的有益效果包括:
[0052]
1)本发明的评分方法计算答题结果步骤表述式的链表树与标准答案步骤表达式链表树的相似度并作为第一评阅特征,并计算答题结果的步骤间关系与标准答案的步骤间关系的相似度作为第二评阅特征,根据第一评阅特征和第二评阅特征计算得到答题结果的评分,提高了评分计算结果的客观性和合理性,且便于计算机执行,代替人工,省时省力;
[0053]
2)本发明的评分方法判断确定第一类公式相似度不等于1即答题结果步骤的表达式与标准答案步骤表达式不完全相等时,计算第二类公式相似度即答题结果步骤表达式的子公式与标准答案步骤表达式子公式的相似度,并比较第一类公式相似度、第二类公式相似度的大小,取两者中较大值作为答题步骤中的表达式与标准答案表达式的相似度的计算结果,进一步地提高了数学主观题评分计算结果的客观性和合理性;
[0054]
3)本发明的评分方法将答题结果步骤中的表述式表示成链表树,判断链表树的边、原子节点分别与标准答案步骤表达式链表树的边、原子节点是否互相匹配,并计算匹配的原子节点的语义相似度,进而计算得到答题结果步骤中的表述式与标准答案步骤表达式的相似度,便于计算机执行,且在保证相似度计算结果合理性的前提下,提高了数学主观题表达式与标准答案表达式的相似度的计算效率;
[0055]
4)本发明的评分系统实现了数学主观题答题结果的自动评阅、打分,代替人工阅卷,可用于数学主观题的批量阅卷,大大缩短数学主观题的阅卷评分时间,且避免阅卷打分中的人为主观性导致的评分不合理,使阅卷评分结果更公平、公正。
附图说明
[0056]
下面结合附图和实施例对本发明作进一步说明。
[0057]
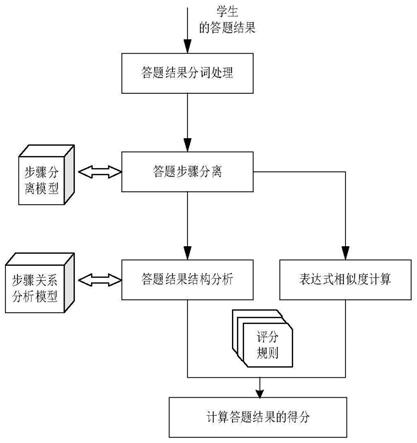
图1为本发明实施例的数学主观题评分方法的流程示意图。
[0058]
图2为本发明实施例的计算第一评阅特征的流程示意图。
[0059]
图3a为本发明实施例的待评答题步骤表达式链表树的示意图。
[0060]
图3b为本发明实施例的标准答案表达式链表树的示意图。
[0061]
图4为本发明实施例的步骤关系分析模型的示意图。
[0062]
图5为本发明实施例的数学主观题评分系统的模块结构示意图。
具体实施方式
[0063]
如图1和图2所示,基于表达式链表树匹配程度的数学主观题评分方法,包括以下步骤,步骤1:获取数学主观题的答题结果的图像,对答题结果图像中的数学实体、文本进行识别,得到答题结果;
[0064]
步骤2:对答题结果进行分词处理,并从分词结果中识别出表明答题结构关系的关键字即结构关键词或数学推理符号以及步骤关联词;对于关键词和数学公式混合的数学答案文本,由于汉字与构成数学公式的数字、字母有较大区别,所以在实施例中采用数学模板匹配方式,由标准答案中的答案关键词来匹配得到汉字关键词,并对其做出相应标注。
[0065]
实施例使用编码器-解码器模型识别数学公式,并且使用lstm网络作为解码器,lstm网络可有效捕捉长期依赖性和促进反向传播梯度。实施例的lstm网络为现有技术的lstm。步骤3:将步骤2中分词处理得到的分词点作为候选分离点,利用步骤分离模型判断候
选分离点是否为步骤分界点。确定答题步骤的步骤分界点后,将答题结果的各个答题步骤分离;步骤分离模型采用svm分类模型,输入为步骤2中分词得到的候选答案步骤分离点,根据已有的标准答案构建并训练svm分类模型及标签,预测得到分词点是否为步骤分界点。
[0066]
实施例的svm分类模型为现有技术的svm分类模型。
[0067]
步骤4:计算答题步骤中的表达式与标准答案步骤表达式的相似度;
[0068]
步骤4.1:分别将答题步骤中的表达式、标准答案步骤表达式表示为待评链表树、基准链表树;步骤4.2:计算待评链表树与基准链表树的相似度,得到第一类公式相似度。
[0069]
分别对待评链表树、基准链表树进行层次遍历,得到待评链表树的层次遍历序列的数组p={p1,p2,p3,
…
,pn}和基准链表树的层次遍历序列的数组b={b1,b2,b3,
…
,bm},使用最长公共子序列算法计算得到待评链表树与基准链表树的相似度,其中pi,i=1,2,3,
…
,n表示数组p的第i个元素即待评链表树的层次遍历序列的第i个遍历节点,bj,j=1,2,3,
…
,m表示数组b的第j个元素即基准链表树的层次遍历序列的第j个遍历节点,n、m分别表示待评链表树、基准链表树的节点数量;
[0070]
待评链表树与基准链表树的相似度的计算式如下
[0071][0072]
式中f
sim1
表示待评链表树与基准链表树的第一类公式相似度,common(p,b)表示数组p和数组b的相似度计算函数,min(n,m)表示取变量n、m的较小值。
[0073]
步骤4.3:计算待评链表树与基准链表树的子结构相似度,得到第二类公式相似度,计算过程如下:
[0074]
1)获取待评链表树原子节点集合和基准链表树的原子节点集合;
[0075]
2)比较确定待评链表树和基准链表树原子节点集合中原子节点匹配数量;
[0076]
3)计算待评链表树和基准链表树互相匹配的原子节点之间的语义相似度,将原子节点的类型分为数字、变量以及运算符,语义相似度的计算规则包括:
[0077]
(a)若待评链表树的原子节点与匹配的基准链表树的原子节点的类型不同,则此待评链表树原子节点的语义相似度为0;
[0078]
(b)若待评链表树的原子节点与匹配的基准链表树的原子节点均为数字且两者相等,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为数字且两者不相等,则此待评链表树原子节点的语义相似度为0;
[0079]
(c)若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者相同,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者不相同,则此待评链表树原子节点的语义相似度为0;
[0080]
(d)若待评链表树的原子节点与匹配的基准链表树的原子节点均为运算符且两者相同或相近,则此待评链表树原子节点的语义相似度为1;若待评链表树的原子节点与匹配的基准链表树的原子节点均为变量且两者既不相同也不相近,则此待评链表树原子节点的语义相似度为0;
[0081]
4)获取待测链表树的边集合和基准链表树的边集合;
[0082]
5)计算待测链表树边集合与基准链表树边集合中边的匹配数量;
[0083]
6)计算相似度,相似度计算式如下
[0084][0085]
其中f
sim2
表示待评链表树与基准链表树的第二类公式相似度,n
base
表示基准链表树原子节点集合的原子节点总数量,n
match
表示待评链表树和基准链表树的原子节点匹配数量,e
match
表示待评链表树和基准链表树中边的匹配数量,e
base
表示基准链表树中边的总数量,σi表示待评链表树和基准链表树中第i个互相匹配的原子节点的语义相似度。
[0086]
步骤4.3:判断第一类公式相似度是否等于1,若第一类公式相似度等于1,则将答题步骤中的表达式与标准答案步骤表达式的相似度的计算结果设为1,结束步骤4;否则,执行步骤4.4;
[0087]
步骤4.4:利用式(2)计算答题步骤表达式子公式的链表树与标准答案步骤表达式子公式的链表树的相似度,得到第二类公式相似度;
[0088]
步骤4.5:比较第一类公式相似度、第二类公式相似度的大小,取两者中较大值作为答题步骤中的表达式与标准答案表达式的相似度的计算结果。
[0089]
步骤5:计算答题结果与标准答案的结构相似度,作为第二评阅特征,第二评阅特征包括答题结果的步骤数量和答题步骤的结构关系是否分别与标准答案的步骤数量、步骤结构关系一致,利用步骤关系分析模型得到答题步骤的步骤关系;
[0090]
如图4所示,步骤关系分析模型包括依次连接的输入层、隐藏层、分类层和输出层;输入层的输入为答题步骤向量x1,x2,x3,..,xn;隐藏层为多层,隐藏层的输出为步骤特征向量;分类层的输入为步骤特征向量和答题步骤向量统计特征,输出层的输出为步骤关系判断结果y1,y2。答题步骤向量统计特征包括步骤数量以及步骤2识别出的结构关键词、数学推理符号、步骤关联词。步骤关联词包括“因为”、
‘“
所以”等。
[0091]
步骤6:根据第一评阅特征、第二评阅特征,计算得到答题结果的评分
[0092]
实施例中,获取两份的学生答题步骤的表达式为
[0093][0094][0095]
学生答题步骤的表达式的latex格式为
[0096]
(\sinb\cosc \sin c\cosb)\sinb=-\sqrt 3\sin b\cosa
ꢀꢀ
(5)
[0097]
(\sinb\cosc \sin c\cosb)\sinb=-\sqrt 3\sin b\sina
ꢀꢀꢀꢀꢀ
(6)
[0098]
对应的标准答案表达式为
[0099][0100]
标准答案表达式的latex格式为
[0101]
(b\cosc c\cosb)\sinb=-\sqrt 3 b\cosa
ꢀꢀꢀꢀꢀ
(8)
[0102]
实施例中,将latex格式的答题步骤表达式即式(3)表示成待评链表树,如图3a所示;将latex格式的标准答案表达式即式(8)表示成基准链表树,如图3b所示。从待评链表树的根节点出发,按照树的先序遍历原则,即“先遍历父节点,再遍历左子树节点,然后遍历右子树节点”的顺序,完成对待评链表树的遍历,得到待评链表树的原子节点集合,原子节点
集合中原子节点按遍历的前后顺序依次编号。同理,对基准链表树进行遍历,得到具有顺序关系的基准链表树原子节点集合。依次比较待评链表树的原子节点集合中的原子节点与基准链表树的原子节点集合中的原子节点,判断其是否一一匹配,若待评链表树的原子节点的遍历路径与基准链表树的原子节点的遍历路径相同,则判断为匹配并进一步计算匹配的原子节点的相似度;同理,判断待评链表树的边与基准链表树的边是否一一匹配。
[0103]
如图3b所示,待评链表树与基准链表树最长公共子序列节点个数为9,树的总节点最小个数为18,根据式(1)计算得到待评链表树与基准链表树的相似度为0.5,即第一类公式相似度为0.5。基准链表树的原子节点总数量n
base
=17,基准链表树的边的总数量e
base
=16。经比较判断得到的待评链表树和基准链表树的原子节点匹配数量n
match
=14,边的匹配数量e
match
=16。利用式(2)计算得到的第二类公式相似度结果为0.515。通过比较得出,第一评阅特征相似度为0.515。
[0104]
上述的数学主观题评分方法的系统如图5所示,包括以下模块:
[0105]
答题结果获取模块:获取数学主观题的答题结果;
[0106]
答题步骤分离模块:从获取的答题结果中识别判断出步骤分界点,根据步骤分界点将答题结果分离成多个答题步骤,得到答题步骤向量;
[0107]
表达式相似度计算模块:计算待评答题步骤与标准答案步骤的表达式相似度,作为第一评阅特征;
[0108]
答题结构相似度计算模块:计算待评答题结果与标准答案的结构相似度,作为第二评阅特征;评阅模块:根据第一评阅特征、第二评阅特征,计算得到答题结果的评分。
[0109]
表达式相似度计算模块包括以下单元:
[0110]
处理单元:将待评数学公式与基准数学公式分别表示为待评链表树和基准链表树;
[0111]
计算单元:计算第一类公式相似度和第二类公式相似度,得到第一评阅特征;
[0112]
比较单元:判断第一类公式相似度是否小于1,并比较第一类公式相似度与第二类公式相似度的大小。
[0113]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。