1.本发明属于飞行器技术领域,具体涉及一种基于模态预测的飞行车辆路径规划方法。
背景技术:
2.飞行车辆具有两种运动模态,分别是地面行驶模态与飞行模态。通过两种模态的切换,其既可以在地面行驶又可以在空中飞行。面对地面行驶车辆难以翻越的障碍物,飞行车辆可以切换至飞行模态翻越障碍。并且与飞行器相比,飞行车辆不需要长期保持飞行状态,只需在必要时起飞,有效提高了能源利用率。
3.现有路径规划方案大多是无人地面车辆或者无人飞行器等的单一运动模态的规划。缺乏一种针对飞行车辆,考虑空地模态切换的规划策略。进一步地,考虑突变环境的模态预测的飞行车辆路径规划策略更具有挑战性,研究更少。
4.复杂突变环境的模态预测规划存在着很大的研究价值,例如地震灾情过后,房屋倒塌,现有的地图信息完全失效,该复杂突变环境要求飞行车辆能够根据感知到的局部障碍物信息预测应切换的空地模态,自主规划多模态避障路径,完成救援等一系列任务。
5.目前路径规划方案的研究主要集中在无人车辆以及无人飞行器等单一模态的研究,缺乏针对飞行车辆,考虑空地模态切换的规划策略。
6.尤其复杂突变环境下,地图先验信息已经失效,空地模态的切换决策缺乏完整障碍物信息的指导,需要根据静态环境中的障碍物数据训练结果来预测当前复杂突变环境中的切换动作,然而基于模态预测的飞行车辆路径规划策略具有更大的挑战性,相关研究更少。
7.并且目前,飞行车辆并没有现成的静态环境训练数据,需要相关数据的采集方案设计。
技术实现要素:
8.本发明提出了一种基于模态预测的飞行车辆路径规划方法,包括静态环境全局多模态路径规划与突变环境局部多模态路径规划分层架构的全局-局部混合路径规划。着重解决以下三点问题:静态环境模态切换训练数据采集与处理,复杂突变环境空地模态切换预测和飞行车辆多模态路径生成。具体方法如下:
9.基于模态预测的飞行车辆路径规划方法,包括两层架构,第一层为静态环境全局路径规划层,第二层为复杂突变环境局部规划层;
10.第一层主要用于解决静态环境中模态训练数据的采集与处理问题。在第一层中,车辆采取博弈学习的框架完成全局规划,同时采集模态切换训练数据,该数据包括车辆与障碍物的相对位置信息、障碍物属性信息以及空地模态的切换动作。相对位置信息与障碍物属性信息是后续模态预测网络的输入,空地模态的切换动作是模态预测网络的输出。
11.第二层则解决了复杂突变环境中的空地模态切换预测和飞行车辆多模态路径规
划难题。用第一层采集的训练数据训练模态预测网络,在突变环境中,根据传感器采集的相对位置信息、障碍物属性信息预测切换模态,最终将预测的模态值回送到第一层的学习框架,获取局部规划路径。
12.第一层具体包括以下四步:
13.step1:获取静态环境的地图信息以及车辆的绝对位置信息用于后续全局路径规划。
14.step2:充分考虑飞行车辆的多域运动能力,为空地模态的切换动作以及切换后向不同方向的运动设置相应奖励函数值。凭借空地模态的切换对障碍物的飞跃,飞行车辆通行区域得到极大的拓宽,相应地,向可飞跃区域方向的运动将不受障碍物的惩罚。在所设置奖励函数的基础上,利用追逐博弈获取恰当的时机与位置的空地模态切换决策。在该博弈中,构建飞行车辆的追逐目标车辆,飞行车辆与目标车辆对间隔距离的博弈需求不同,飞行车辆希望尽可能的缩短两车间隔距离以追捕目标车辆,而目标车辆希望最大化间隔距离以逃离追捕。面对障碍物,两车均有不同的模态切换动作选项,选择的切换动作应最大程度地满足各自的博弈需求,这就是模态切换纳什均衡解。最终通过两车的行为博弈对均衡解的求解,飞行车辆可获取恰当的空地模态切换决策。
15.step3:将获得的模态切换动作用于多模态路径规划,在车辆对环境的探索学习过程中,博弈学习追求最大化的学习奖励,进而获得满足规划目标的全局多模态路径。
16.step4:在规划过程中,车辆记录与障碍物的相对位置信息,障碍物属性信息,以及相应的模态切换信息,存储后用于后续训练。
17.第二层具体包括以下四步:
18.step5:在复杂突变环境中,传感器获取障碍物的局部感知信息,包括车辆与障碍物的相对位置信息以及障碍物属性信息,作为已训练的模态预测网络的输入量。
19.step6:模态预测网络用静态环境中采集的训练数据进行网络训练,完成后,根据复杂突变环境中的障碍物局部感知信息预测切换模态。预测的模态动作用于后续局部路径的规划。
20.step7:预测的模态动作回送到第一层的学习框架中,当前障碍物的切换动作已知,只需寻找出最大化学习奖励的运动轨迹即可,最终可规划出飞行车辆在复杂突变环境中的局部多模态路径。
21.本发明具有以下技术效果:
22.(1)提出了一种基于模态预测的飞行车辆路径规划方法,解决了飞行车辆复杂突变环境中空地模态切换决策以及多模态路径规划的难题。
23.(2)利用博弈学习框架既为飞行车辆规划了一条静态环境的全局多模态路径,又解决了复杂突变环境模态预测网络训练数据的采集处理问题。
24.(3)为飞行车辆设计了一套从训练数据采集,到模态预测训练,再到最终复杂突变环境多模态路径生成的全方面路径规划方案。
附图说明
25.图1a为实施例的飞行车辆空中飞行状态构型;
26.图1b为实施例的飞行车辆地面行驶状态构型;
27.图2为本发明的博弈学习流程示意图;
28.图3为本发明的整体流程示意图。
具体实施方式
29.结合实施例说明本发明的具体技术方案。
30.图1a和图1b为飞行车辆构型,其存在空中飞行与地面行驶两种模态。其特征在于包括飞控系统,底盘系统与动力系统。飞控系统采用八旋翼共轴双桨设计,每个螺旋桨都配有单独的旋翼电机,通过调节各个旋翼电机的转速进行飞行车辆飞行过程中高自由度的姿态变化与运动控制。底盘系统采用分布式四轮独立驱动系统,轮毂电机将驱动部件、传动部件和制动装置集成到车轮轮毂内,车辆直接由集成到车轮轮毂内的四个轮毂电机总成驱动行驶。动力系统由发动机电机组、电池组、电调等组成,采用串联式混合动力形式。旋翼电机和轮毂电机由同一动力系统完成能源供应。
31.基于模态预测的飞行车辆路径规划方法,包括两层架构,第一层为静态环境全局路径规划层,第二层为复杂突变环境局部规划层;
32.第一层主要用于解决静态环境中模态训练数据的采集与处理问题。在第一层中,车辆采取博弈学习的框架完成全局规划,同时采集模态切换训练数据,该数据包括车辆与障碍物的相对位置信息、障碍物属性信息(高度与宽度)以及空地模态的切换动作。相对位置信息与障碍物属性信息是后续模态预测网络的输入,空地模态的切换动作是模态预测网络的输出。第一层中的博弈学习框架如图2所示。
33.其中静态环境的博弈学习框架包括以下四步:
34.step1:获取静态环境的地图信息以及车辆的绝对位置信息用于后续全局路径规划。
35.step2:充分考虑飞行车辆的多域运动能力,为空地模态的切换动作以及切换后向不同方向的运动设置相应奖励函数值。凭借空地模态的切换对障碍物的飞跃,飞行车辆可通行区域得到极大的拓宽,相应地,向可飞跃区域方向的运动将不受障碍物的惩罚。在所设置奖励函数的基础上,利用追逐博弈获取恰当的时机与位置的空地模态切换决策。在该博弈中,构建飞行车辆的追逐目标车辆,飞行车辆与目标车辆对间隔距离的博弈需求不同,飞行车辆希望尽可能的缩短两车间隔距离以追捕目标车辆,而目标车辆希望最大化间隔距离以逃离追捕。面对障碍物,两车均有不同的模态切换动作选项,选择的切换动作应最大程度地满足各自的博弈需求,这就是模态切换纳什均衡解。最终通过两车的行为博弈对均衡解的求解,飞行车辆可获取恰当的空地模态切换决策。
36.step3:将获得的模态切换动作用于多模态路径规划,在车辆对环境的探索学习过程中,博弈学习追求最大化的学习奖励,进而获得满足规划目标的全局多模态路径。
37.step4:博弈学习框架不仅仅起到全局规划的作用,更提供了后续模态预测的训练数据。在规划过程中,车辆记录与障碍物的相对位置信息,障碍物属性信息,以及相应的模态切换信息,存储后用于后续训练。
38.第二层则解决了复杂突变环境中的空地模态切换预测和飞行车辆多模态路径规划难题。用第一层采集的训练数据训练模态预测网络,在突变环境中,根据传感器采集的障碍物局部感知信息(相对位置信息、障碍物属性信息)预测切换模态,最终将预测的模态值
回送到第一层的学习框架,获取局部规划路径。
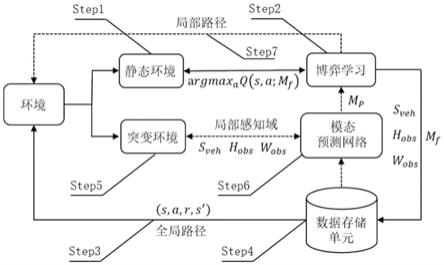
39.综上,所述基于模态预测的飞行车辆路径规划方法的整体流程如图3所示。
40.图中实线标注的静态环境的全局路径获取流程为第一层架构,虚线标注的复杂突变环境的局部路径获取流程为第二层架构。s
veh
是车辆与障碍物的相对位置信息,h
obs
是障碍物的高度信息,w
obs
是障碍物的宽度信息,mf是博弈学习框架获取的静态环境空地模态切换动作,m
p
是模态预测网络获取的突变环境空地模态预测动作,s是当前飞行车辆的位置状态,s
′
为下一位置状态,a是飞行车辆所采取的动作策略,r是动作策略反馈的奖励值。
41.所述基于模态预测的飞行车辆路径规划方法,包括以下步骤。
42.首先是第一层架构工作流程:
43.step1:获取静态环境中的车辆绝对位置信息与地图信息。同上述博弈学习框架step1。
44.step2:设置飞行车辆不同模态动作以及运动方向的奖励函数,利用追逐博弈获取恰当时机与位置的空地模态切换决策。具体同上述博弈学习框架step2。
45.step3:规划静态环境中的多模态全局路径。具体同上述博弈学习框架step3。
46.step4:采集静态环境全局规划过程中的障碍物以及模态切换动作数据,并存储到数据存储单元,用于后续模态预测网络的训练。具体同博弈学习框架step4。
47.以下是第二层架构工作流程:
48.step5:在复杂突变环境中,传感器获取障碍物的局部感知信息,包括车辆与障碍物的相对位置信息以及障碍物属性信息,作为已训练的模态预测网络的输入量。
49.step6:模态预测网络用静态环境中采集的训练数据进行网络训练,完成后,根据复杂突变环境中的障碍物局部感知信息预测切换模态。预测的模态动作用于后续局部路径的规划。
50.step7:预测的模态动作回送到第一层的学习框架中,当前障碍物的切换动作已知,只需寻找出最大化学习奖励的运动轨迹即可,最终可规划出飞行车辆在复杂突变环境中的局部多模态路径。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
