1.本发明属于页岩油开发技术领域,尤其涉及一种页岩油产能预测方法、系统、介质、设备及终端。
背景技术:
2.目前,继北美地区的致密砂岩油、致密碳酸盐岩油和页岩凝析油等非常规油气获得重大突破后,我国在鄂尔多斯、准噶尔、渤海湾、四川等盆地的页岩储层中也获重大发现,页岩油开始成为全球非常规油气的新亮点。美国页岩油的迅猛开发使其原油对外依存度由2005年的60%降至2011年的45%。2010年,页岩油资源评价结果显示我国油页岩地质储量为11602亿吨,可回收页岩油资源量为160亿吨。考虑到页岩油的快速发展对美国石油供应格局产生的深远影响,我国在努力控制石油消费需求过快增长的同时,迫切需要高度重视页岩油的勘探开发工作,来缓解我国原油对外依存度高的局面,保障国家能源安全。
3.长水平段快速钻完井、密切割水力压裂、井网井距优化是高效开发页岩油藏的关键技术。受页岩储层特征、流体性质、压裂措施和开发制度等因素的综合影响,页岩油压裂水平井的生产特征差异较大。同一页岩油区块的压裂水平井可能表现出完全不同的生产动态模式,导致油井产能预测面临极大的不确定性,严重制约页岩油藏的开发部署。准确评价页岩油压裂水平井的生产动态模式和产能对页岩油藏的高效开发至关重要,但目前缺少有效的评价手段。因此,亟待建立一套科学的页岩油产能预测方法及系统。
4.通过上述分析,现有技术存在的问题及缺陷为:目前的现有技术中缺少能准确评价页岩油压裂水平井的生产动态模式和产能的评价手段。
5.解决以上问题及缺陷的难度为:现有的产能预测方法众多,例如数值模拟法、解析法、传统拟合公式法。数值模拟法产能预测结果准确,但在现场应用过程中数值模拟法需要全面且大量的地质资料和生产资料,而获取这些资料需投入大量的资金、人力、物力,因此难以用于现场。解析法通常会运用到拉普拉斯变换、参数反演、大型稀疏矩阵等复杂的数学计算。其计算量巨大、且参数众多,因此难以满足现场快捷、简便的要求。传统的公式拟合方法,虽然满足现场应用的要求,但是影响页岩产能的因素众多,难以判断这些影响因素的重要程度。且统计数据多而杂,难以提取出有用的信息。
6.解决以上问题及缺陷的意义为:充分涵盖了影响页岩油产量的可能因素(地质类因素、油藏类因素和工程类因素),针对统计数据规律性不明显的,影响因素不明确等问题,通过运用改进层次分析法,明确产量影响因素。然后通过多元回归分析,判断所选因素与产量之间的相关程度、公式回归和拟合的效果,最后得到准确且实用的拟合公式产能预测公式。
技术实现要素:
7.针对现有技术存在的问题,本发明提供了一种页岩油产能预测方法、系统、介质、设备及终端。
8.本发明是这样实现的,一种页岩油产能预测方法,所述页岩油产能预测方法包括以下步骤:
9.步骤一,根据评价目的确定评价指标体系建立产量影响因素数据库;
10.步骤二,根据现有开发方案数据库将影响产量的因素划分成四个水平值;
11.步骤三,根据产量影响因素数据库构建产量影响因素的平均效果数据库;
12.步骤四,根据产量影响因素平均效果数据库构建产量影响因素极差数据库;
13.步骤五,根据产量影响因素极差数据库构建不同因素之间的对比矩阵;
14.步骤六,计算影响因素权重,并进行一致性检验;
15.步骤七,构建多元回归拟合产量公式。
16.本发明的第一步:是为了明确层次分析法中的目标层(产量)和影响因素。
17.本发明的第二、三、四步:是通过统计学方法得到各影响因素的极差数据库,定量表征各影响因素对产量的影响程度,消除人为经验判断的误差。
18.本发明的第五步:将各因素两两相互比较,采用相对尺度,以尽可能减少性质不同的因素相互比较的困难,以提高准确度。
19.本发明的第六步:因为构建的两两对比矩阵是正互反矩阵,因此我们需要检验矩阵的一致性,判断矩阵是否为一致性矩阵。一致性矩阵的定义为:若n阶正互反矩阵(a
ij
)n×n满足a
ik
·akj
=a
ij
,则称该矩阵为一致性矩阵。所谓一致性就是用来判断一种传递性。在构建两两对比矩阵时。每个元素都是两个因素之间的比值,假设:
20.因素1:因素2=4:1
21.因素2:因素3=1:5
22.因素1:因素3=4:7(正常情况下按照比例的传递性,因素1:因素3=4:5)
23.而就是要判断上述的一致性(比例的传递性)
24.判断正互反矩阵为一致矩阵的充要条件是,最大特征值等于矩阵的阶数,但是在实际应用过程中,satty认为一致性偏差可能是由于随机原因造成的,故允许对比矩阵有一定范围内的不一致。所以他引入了cr指标,当cr《0.1时,虽然有矩阵可能有一致性偏差,但偏差在允许范围内。这样就能够判断对比矩阵的一致性了,此时才能得到合理的权重。
25.进一步,所述步骤一中的根据评价目的确定评价指标体系建立产量影响因素数据库包括:
26.根据页岩油实际区块现有典型生产井日产量数据q以及产量影响因素建立生产井产量影响因素数据库;其中,所述产量影响因素包括地质类因素、油藏类因素和工程类因素;所述地质因素包括osi平均值、i类甜点钻遇率和脆性指数平均值;所述油藏因素包括压裂段长、井距、与主应力夹角;所述工程类因素包括米液量、米砂量和陶粒。
27.进一步,所述步骤二中的根据现有开发方案数据库将影响产量的因素划分成四个水平值包括:
28.计算数据的分位数,对于某一影响因素c,从小到大排列:{c1,c2,c3,
…ci
}。
29.其中,c
min
=c1<c2<c3<
…
<ci=c
max
;
30.设n表示数据的长度,q
25
、q
50
、q
75
分别表示所求的第25分位数、第45分位数、第75分位数,i表示对i值向上取整。
31.计算分位指数:i=n
×
p%;
32.3)若i不是整数,则分位数为
33.4)若i是整数,则则分位数为
34.第零分位数:
35.q0=c
min
;
36.第25分位数:
37.i=n
×
p%=12
×
25%=3;
[0038][0039]
第50分位数:
[0040]
i=n
×
p%=12
×
50%=6;
[0041][0042]
第75分位数:
[0043]
i=n
×
p%=12
×
75%=9;
[0044][0045]
第100分位数:
[0046]q100
=c
max
;
[0047]
若q0≤ci≤q
25
,
[0048]
则ci=1;
[0049]
若q
25
<ci≤q
50
,
[0050]
则ci=2;
[0051]
若q
50
<ci≤q
75
,
[0052]
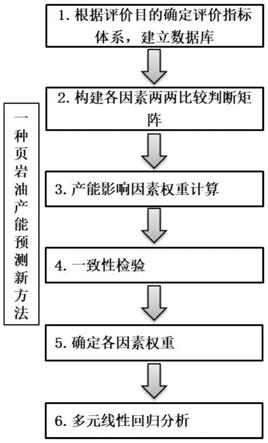
则ci=3;
[0053]
若q
75
<ci≤q
100
,
[0054]
则ci=4;
[0055]
得到油田产量影响因素水平值数据库。
[0056]
进一步,所述步骤五中的根据产量影响因素极差数据库构建不同因素之间的对比矩阵包括:
[0057]
根据层次分析法用两个因素之间极差的比值定量表征两个因素ci和cj对产量的相对重要性程度即结果用矩阵d=(c
ij
)m×n表示,得到判断矩阵。
[0058]
进一步,所述步骤六中的计算影响因素权重包括:
[0059]
计算判断矩阵的最大特征值λ
max
所对应的特征向量a,即:
[0060]
det(ai-d)=0;
[0061]
da=λ
max
a;
[0062]
式中,d为判断矩阵,i为与d同阶的单位矩阵,将求得的特征向量a归一化后即为权重,归一化公式为:
[0063][0064]
所述一致性检验包括:
[0065]
由于产量影响因素权重计算的准确性受含水上升影响较大,对判断矩阵进行一致性检验,所述一致性指标为:
[0066][0067]
式中,n为判断矩阵的阶数,当ci=0,具有有完全一致性;ci接近0,具有满意的一致性;ci越大,一致性越差。为了衡量ci的大小,引入随机一致性指标ri:
[0068][0069]
式中,ri与判断矩阵的阶数n有关,在saaty表格中根据n查找。
[0070]
在检验判断矩阵是否具有满意的一致性时,将ci和随机一致性指标ri进行比较,得出检验系数cr,公式如下:
[0071][0072]
若cr<0.1,则认为判断矩阵通过一致性检验,否则就不具有满意一致性。
[0073]
进一步,所述步骤七中的构建多元回归拟合产量公式包括:
[0074]
选取权重前五的因素进行产量多元回归拟合,由权重得影响因素前五的为:井距x1、压裂段长x2、osi平均值x3、米砂量x4、米液量x5。假设拟合公式为:
[0075]q拟合
=b0 b1x1 b2x2 b3x3 b4x4 b5x5;
[0076]
在excel通过回归得到回归统计表、方差分析表和回归参数表。
[0077]
在回归统计表中:
[0078]
multiple r:为相关系数,用于衡量自变量x与y之间的相关程度的大小;表中r=0.959409,表明他们之间的相关性很高。
[0079]
r square:用于说明自变量解释因变量y变差的程度,以测定因变量y的拟合效果;表中r square=0.920465,说明自变量可以解释因变量变差的92.0465%。
[0080]
adjusted r square:为调整后的r square,值为0.854186,用于表明自变量能说明因变量的85.4186%,因变量y的14.5814由其他因素解释。
[0081]
标准误差:用于衡量拟合程度的大小,该值越小,拟合效果越好;表中的值为2.542898,该值很小,说明拟合效果好。
[0082]
在方差分析表中,通过f检验来判定回归模型的效果:
[0083]
significance f=0.00301,小于显著水平0.05,说明回归效果显著。
[0084]
回归参数表中:
[0085]
第二列为回归方程中的常数和系数,根据该表得到拟合方程为:
[0086]q拟合
=7.406069-0.00166x1 0.015805x
2-0.01726x
3-5.44149x4 0.255153x5;
[0087]
画出拟合值与实测值之间的拟合图,r2=0.9205,说明拟合值与实测值相关性很
强,且成正相关,符合预期。
[0088]
本发明的另一目的在于提供一种应用所述的页岩油产能预测方法的页岩油产能预测系统,所述页岩油产能预测系统包括:
[0089]
产量影响因素数据库构建模块,用于根据评价目的确定评价指标体系,建立产量影响因素水平值数据库;
[0090]
产量影响因素划分模块,用于根据现有开发方案数据库将影响产量的因素划分成四个水平值;
[0091]
平均效果数据库构建模块,用于根据所述产量影响因素水平值数据库构建产量影响因素的平均效果数据库;
[0092]
极差数据库构建模块,用于根据所述产量影响因素的平均效果数据库构建产量影响因素极差数据库;
[0093]
对比矩阵构建模块,用于根据所述产量影响因素极差数据库构建不同因素之间的对比矩阵;
[0094]
影响因素权重计算模块,用于计算影响因素权重,并进行一致性检验;
[0095]
页岩油产能预测模块,用于通过构建多元回归拟合产量公式,进行页岩油产能的预测。
[0096]
本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如下步骤:
[0097]
根据评价目的确定评价指标体系,建立产量影响因素水平值数据库;根据现有开发方案数据库将影响产量的因素划分成四个水平值;根据所述产量影响因素水平值数据库构建产量影响因素的平均效果数据库;根据所述产量影响因素的平均效果数据库构建产量影响因素极差数据库;根据所述产量影响因素极差数据库构建不同因素之间的对比矩阵;计算影响因素权重,并进行一致性检验;构建多元回归拟合产量公式,进行页岩油产能的预测。
[0098]
本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如下步骤:
[0099]
根据评价目的确定评价指标体系,建立产量影响因素水平值数据库;根据现有开发方案数据库将影响产量的因素划分成四个水平值;根据所述产量影响因素水平值数据库构建产量影响因素的平均效果数据库;根据所述产量影响因素的平均效果数据库构建产量影响因素极差数据库;根据所述产量影响因素极差数据库构建不同因素之间的对比矩阵;计算影响因素权重,并进行一致性检验;构建多元回归拟合产量公式,进行页岩油产能的预测。
[0100]
本发明的另一目的在于提供一种信息数据处理终端,所述信息数据处理终端用于实现所述的页岩油产能预测系统。
[0101]
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明提供的页岩油产能预测方法,在非常规油气藏早期开采规律认识不清、产能影响因素无法明确时,既可以定量的评价产能影响主控因素,又可以快速预测页岩油井产能大小,指导油田新井部署,填补了页岩油平台井初期快速预测产能方法的空白,并已经在相关油田进行了应用。本
发明针对统计数据规律性不明显的问题,提出了基于改进层次分析方法的产能主控因素权重分析方法,可定量明确地质、储层、工艺等多因素条件下的产能变化主控因素,进而根据计算出的权重选取权重较大的因素与产量进行多元回归,拟合出较为准确的页岩油产能公式。
[0102]
本发明考虑了地质、油藏、工程等多个因素对页岩油产能的影响,运用改进层次分析法以及多元回归分析建立可靠的页岩油产能预测公式;通过定量计算,判断出影响因素的权重,消除人为判断带来的可能误差,进而根据权重较大的几个影响因素与产能进行多元回归,拟合出较为合理与准确的产能公式。
附图说明
[0103]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
[0104]
图1是本发明实施例提供的页岩油产能预测方法流程图。
[0105]
图2是本发明实施例提供的页岩油产能预测方法原理图。
[0106]
图3是本发明实施例提供的页岩油产能预测系统结构框图;
[0107]
图中:1、产量影响因素数据库构建模块;2、产量影响因素划分模块;3、平均效果数据库构建模块;4、极差数据库构建模块;5、对比矩阵构建模块;6、影响因素权重计算模块;7、页岩油产能预测模块。
[0108]
图4是本发明实施例提供的拟合值与计算值之间的拟合图。
具体实施方式
[0109]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0110]
针对现有技术存在的问题,本发明提供了一种页岩油产能预测方法、系统、介质、设备及终端,下面结合附图对本发明作详细的描述。
[0111]
如图1所示,本发明实施例提供的页岩油产能预测方法包括以下步骤:
[0112]
s101,根据评价目的确定评价指标体系建立产量影响因素数据库;
[0113]
s102,根据现有开发方案数据库将影响产量的因素划分成四个水平值;
[0114]
s103,根据产量影响因素数据库构建产量影响因素的平均效果数据库;
[0115]
s104,根据产量影响因素的平均效果数据库构建产量影响因素极差数据库;
[0116]
s105,根据产量影响因素极差数据库构建不同因素之间的对比矩阵;
[0117]
s106,计算影响因素权重,并进行一致性检验;
[0118]
s107,构建多元回归拟合产量公式。
[0119]
本发明实施例提供的页岩油产能预测方法原理图如图2所示。
[0120]
如图3所示,本发明实施例提供的页岩油产能预测系统包括:
[0121]
产量影响因素数据库构建模块1,用于根据评价目的确定评价指标体系,建立产量
影响因素水平值数据库;
[0122]
产量影响因素划分模块2,用于根据现有开发方案数据库将影响产量的因素划分成四个水平值;
[0123]
平均效果数据库构建模块3,用于根据所述产量影响因素水平值数据库构建产量影响因素的平均效果数据库;
[0124]
极差数据库构建模块4,用于根据所述产量影响因素的平均效果数据库构建产量影响因素极差数据库;
[0125]
对比矩阵构建模块5,用于根据所述产量影响因素极差数据库构建不同因素之间的对比矩阵;
[0126]
影响因素权重计算模块6,用于计算影响因素权重,并进行一致性检验;
[0127]
页岩油产能预测模块7,用于通过构建多元回归拟合产量公式,进行页岩油产能的预测。
[0128]
下面结合具体实施例对本发明的技术方案作进一步描述。
[0129]
实施例1
[0130]
本发明考虑了地质、油藏、工程等多个因素对页岩油产能的影响,运用改进层次分析法以及多元回归分析建立了可靠的页岩油产能预测公式。
[0131]
针对统计数据规律性不明显的问题,本发明提出了基于改进层次分析方法的产能主控因素权重分析方法,可定量明确地质、储层、工艺等多因素条件下的产能变化主控因素,进而根据计算出的权重选取权重较大的因素与产量进行多元回归,拟合出较为准确的页岩油产能公式。
[0132]
本发明中权重分析通过matlab编程实现,多元线性回归分析通过excel实现,技术路线如图2所示。
[0133]
步骤一,根据评价目的确定评价指标体系,建立数据库。
[0134]
表1产量影响因素案数据库
[0135][0136]
步骤二,根据现有开发方案数据库将影响产量的因素划分成四个水平值。首先计算这一组数据的分位数,对于某一影响因素c,将其从小到大排列:{c1,c2,c3,
…ci
}。
[0137]
其中c
min
=c1<c2<c3<
…
<ci=c
max
:
[0138]
这里本发明设n表示数据的长度,q
25
、q
50
、q
75
分别表示所求的第25分位数、第45分位数、第75分位数。表示对i值向上取整。
[0139]
计算分位指数:i=n
×
p%
[0140]
5)若i不是整数,则分位数为
[0141]
6)若i是整数,则则分位数为
[0142]
第零分位数:
[0143]
q0=c
min
[0144]
第25分位数:
[0145]
i=n
×
p%=12
×
25%=3
[0146][0147]
第50分位数:
[0148]
i=n
×
p%=12
×
50%=6
[0149][0150]
第75分位数:
[0151]
i=n
×
p%=12
×
75%=9
[0152][0153]
第100分位数:
[0154]q100
=c
max
[0155]
若q0≤ci≤q
25
[0156]
则ci=1
[0157]
若q
25
<ci≤q
50
[0158]
则ci=2
[0159]
若q
50
<ci≤q
75
[0160]
则ci=3
[0161]
若q
75
<ci≤q
10o
[0162]
则ci=4
[0163]
通过上述方法得到油田产量影响因素水平值数据库(见表2)。
[0164]
表2产量影响因素水平值数据库
[0165][0166]
步骤三:根据产量影响因素水平值数据库构建产量影响因素的平均效果数据库(见表3)。
[0167]
以陶粒(40~70)水平值为1时为例:
[0168][0169]
表3产量影响因素的平均效果数据库
[0170][0171]
若某一水平值不存在就按缺损值处理。
[0172]
步骤四:根据产量影响因素的平均效果数据库构建产量影响因素极差数据库(见表4)。所谓极差数据库,就是同一影响因素下同一水平值最大和最小值之差。
[0173]
表4产量影响因素极差数据库
[0174]
osi平均值i类甜点钻遇率脆性指数平均值压裂段长井距与主应力夹角米液量米砂量陶粒(40-70)13.703710.659268.78888914.3555615.147229.92222210.696312.159263.977778
[0175]
步骤五:根据产量影响因素极差数据库构建不同因素之间的对比矩阵。根据层次分析法用两个因素之间极差的比值定量表征两个因素ci和cj对产量的相对重要性程度即结果用矩阵d=(c
ij
)m×n表示,得到判断矩阵(见表5)。
[0176]
表5判断矩阵
[0177] osi平均值i类甜点钻遇率脆性指数平均值压裂段长井距与主应力夹角米液量米砂量陶粒(40-70)osi平均值11.2856151.5592080.9545920.9047011.3811121.2811631.1270183.445065i类甜点钻遇率0.77783811.2128110.7425180.703711.0742810.9965370.8766372.679702脆性指数平均值0.6413510.82453110.6122290.5802310.8857780.8216760.7228152.209497压裂段长1.0475681.3467691.63337610.9477351.4468091.3421051.1806283.608939井距1.1053381.4210391.7234511.05514711.5265961.4161181.2457363.807961与主应力夹角0.7240540.9308551.1289510.6911760.65505210.9276320.8160222.494413米液量0.7805411.0034751.2170250.7450980.7061561.07801410.8796832.689013米砂量0.8872971.1407231.3834810.8470070.8027391.2254571.13677313.056797陶粒(40-70)0.290270.3731760.4525920.277090.2626080.4008960.3718840.327141
[0178]
步骤6:计算影响因素权重
[0179]
计算判断矩阵的最大特征值λ
max
所对应的特征向量a
[0180]
即:
[0181]
det(ai-d)=0
[0182]
da=λ
maxa[0183]
上式中d为判断矩阵,i为与d同阶的单位矩阵,将求得的特征向量a归一化后即为权重(见表6),归一化公式为:
[0184][0185]
表6各影响因素权重
[0186]
osi平均值i类甜点钻遇率脆性指数平均值压裂段长井距与主应力夹角米液量米砂量陶粒(40-70)0.137850.1072250.088410.1444070.1523710.0998110.1075980.1223140.040014
[0187]
步骤7:一致性检验
[0188]
由于产量影响因素权重计算的准确性受含水上升影响较大,需要对判断矩阵进行一致性检验,一致性指标为:
[0189][0190]
其中n为判断矩阵的阶数,当ci=0,具有有完全一致性;ci接近0,具有满意的一致性;ci越大,一致性越差。为了衡量ci的大小,引入随机一致性指标ri:
[0191][0192]
其中ri与判断矩阵的阶数n有关,可再saaty表格中根据n查找。
[0193]
表7 saaty表格
[0194]
n123456789101112ri000.580.91.121.241.321.411.451.491.511.54
[0195]
考虑到一致性的偏离可能是由于随机原因造成的,因此在检验判断矩阵是否具有满意的一致性时,还需将ci和随机一致性指标ri进行比较,得出检验系数cr,公式如下:
[0196][0197]
若cr<0.1,则认为判断矩阵通过一致性检验,否则就不具有满意一致性。
[0198]
步骤:8多元回归拟合产量公式
[0199]
选取权重前五的因素进行产量多元回归拟合,由权重可知影响因素前五的为:井距(x1)、压裂段长(x2)、osi平均值(x3)、米砂量(x4)、米液量(x5)。假设拟合公式为:
[0200]q拟合
=b0 b1x1 b2x2 b3x3 b4x4 b5x5[0201]
在excel通过回归得到了3张表格:回归统计表(见表8)、方差分析表(见表9)、回归参数表(见表10)。
[0202]
表8回归统计表
[0203][0204]
表9方差分析表
[0205]
方差分析
ꢀꢀꢀꢀꢀꢀ
dfssmsfsignificance f回归分析5449.013889.8027713.887750.003011042残差638.797986.466329
ꢀꢀ
总计11487.8118
ꢀꢀꢀ
[0206]
表10回归参数表
[0207] coefficients标准误差t statp-valuelower 95%upper 95%下限95.0%上限95.0%
intercept7.4060693836.8925931.0744970.3239-9.45949897124.27164-9.459524.27164x variable 1-0.0016641420.023186-0.071770.945114-0.0583974970.055069-0.05840.055069x variable 20.015804940.0065062.4292680.051213-0.000114790.031725-0.000110.031725x variable 3-0.017257110.011897-1.450590.197085-0.0463670980.011853-0.046370.011853x variable 4-5.4414874281.53211-3.551630.012048-9.190424767-1.69255-9.19042-1.69255x variable 50.2551529590.1925661.3250170.233389-0.2160385620.726344-0.216040.726344
[0208]
在回归统计表中:
[0209]
multiple r:为相关系数,用来衡量自变量x与y之间的相关程度的大小。表中r=0.959409,表明他们之间的相关性很高。
[0210]
r square:用来说明自变量解释因变量y变差的程度,以测定因变量y的拟合效果。表中r square=0.920465,说明自变量可以解释因变量变差的92.0465%。
[0211]
adjusted r square:为调整后的r square,其值为0.854186,表明自变量能说明因变量的85.4186%,因变量y的14.5814由其他因素解释。
[0212]
标准误差:用来衡量拟合程度的大小,该值越小,拟合效果越好。表中的值为2.542898,该值很小,说明拟合效果好。
[0213]
在方差分析(作用是通过f检验来判定回归模型的效果)表中:
[0214]
significance f=0.00301,小于显著水平0.05,说明回归效果显著。
[0215]
回归参数表中:
[0216]
第二列为回归方程中的常数和系数,根据该表可以得到拟合方程为:
[0217]q拟合
=7.406069-0.00166x1 0.015805x
2-0.01726x
3-5.44149x4 0.255153x5[0218]
画出拟合值与实测值之间的拟合图(见图4),r2=0.9205,说明拟合值与实测值相关性很强,且成正相关,符合预期。
[0219]
实施例2
[0220]
本发明涉及页岩油开发领域。针对统计数据规律性不明显的问题,提出了基于改进层次分析方法的产能主控因素权重分析方法,可定量明确地质、储层、工艺等多因素条件下的产能变化主控因素。进而根据计算出的权重选取权重较大的因素与产量进行多元回归,拟合出较为准确的页岩油产能公式。
[0221]
本发明的目的是通过定量计算,判断出影响因素的权重,消除人为判断带来的可能误差。进而根据权重较大的几个影响因素与产能进行多元回归,拟合出较为合理与准确的产能公式。
[0222]
本发明通过以下步骤实现:
[0223]
步骤一:根据页岩油实际区块现有典型生产井日产量数据q以及产量影响因素建立生产井产量影响因素,所述产量影响因素包括地质类因素、油藏类因素、工程类因素。地质因素包括osi平均值、i类甜点钻遇率、脆性指数平均值;油藏因素包括压裂段长、井距、与主应力夹角;工程类因素包括米液量、米砂量、陶粒(40~70)。
[0224]
步骤二,根据现有开发方案数据库将影响产量的因素划分成四个水平值。首先计算这一组数据的分位数,对于某一影响因素c,将其从小到大排列:{c1,c2,c3,
…ci
}。
[0225]
其中c
min
=c1<c2<c3<
…
<ci=c
max
:
[0226]
这里本发明设n表示数据的长度,q
25
、q
50
、q
75
分别表示所求的第25分位数、第45分位数、第75分位数。i表示对i值向上取整。
[0227]
计算分位指数:i=n
×
p%
[0228]
7)若i不是整数,则分位数为
[0229]
8)若i是整数,则则分位数为
[0230]
以陶粒(40~70)数据为例:
[0231]
先将陶粒(40~70)数据从小到大排列:300.08304.08351.56415.86754.46782.29801.45832.69915.19955.18965.571101。
[0232]
第零分位数:
[0233]
q0=c
min
=c1=300.08
[0234]
第25分位数:
[0235]
i=n
×
p%=12
×
25%=3
[0236][0237]
第50分位数:
[0238]
i=n
×
p%=12
×
50%=6
[0239][0240]
第75分位数:
[0241]
i=n
×
p%=12
×
75%=9
[0242][0243]
第100分位数:
[0244]q100
=c
max
=c
12
=1101
[0245]
若q0≤ci≤q
25
[0246]
则ci=1
[0247]
若q
25
<ci≤q
50
[0248]
则ci=2
[0249]
若q
50
<ci≤q
75
[0250]
则ci=3
[0251]
若q
75
<ci≤q
100
[0252]
则ci=4
[0253]
通过上述方法得到油田产量影响因素水平值数据库。
[0254]
步骤三:根据产量影响因素水平值数据库构建产量影响因素的平均效果数据库。
[0255]
以陶粒(40~70)水平值为1时为例:
[0256][0257]
若某一水平值不存在就按缺损值处理。
[0258]
步骤四:根据产量影响因素的平均效果数据库构建产量影响因素极差数据库。所
谓极差数据库,就是同一影响因素下同一水平值最大和最小值之差。
[0259]
步骤五:根据产量影响因素极差数据库构建不同因素之间的对比矩阵。根据层次分析法用两个因素之间极差的比值定量表征两个因素ci和cj对产量的相对重要性程度即结果用矩阵d=(c
ij
)m×n表示,得到判断矩阵。
[0260]
步骤6:计算影响因素权重
[0261]
计算判断矩阵的最大特征值λ
max
所对应的特征向量a
[0262]
即:
[0263]
det(ai-d)=0
[0264]
da=λ
maxa[0265]
上式中d为判断矩阵,i为与d同阶的单位矩阵,将求得的特征向量a归一化后即为权重,归一化公式为:
[0266][0267]
步骤7:一致性检验
[0268]
由于产量影响因素权重计算的准确性受含水上升影响较大,需要对判断矩阵进行一致性检验,一致性指标为:
[0269][0270]
其中n为判断矩阵的阶数,当ci=0,具有有完全一致性;ci接近0,具有满意的一致性;ci越大,一致性越差。为了衡量ci的大小,引入随机一致性指标ri:
[0271][0272]
其中ri与判断矩阵的阶数n有关,可在saaty表格中根据n查找。
[0273]
考虑到一致性的偏离可能是由于随机原因造成的,因此在检验判断矩阵是否具有满意的一致性时,还需将ci和随机一致性指标ri进行比较,得出检验系数cr,公式如下:
[0274][0275]
若cr<0.1,则认为判断矩阵通过一致性检验,否则就不具有满意一致性。
[0276]
步骤:8多元回归拟合产量公式
[0277]
选取权重前五的因素进行产量多元回归拟合,由权重可知影响因素前五的为:井距(x1)、压裂段长(x2)、osi平均值(x3)、米砂量(x4)、米液量(x5)。假设拟合公式为:
[0278]q拟合
=b0 b1x1 b2x2 b3x3 b4x4 b5x5[0279]
在excel通过回归得到了3张表格:回归统计表、方差分析表、回归参数表。
[0280]
在回归统计表中:
[0281]
multiple r:为相关系数,用来衡量自变量x与y之间的相关程度的大小。表中r=0959409,表明他们之间的相关性很高。
[0282]
r square:用来说明自变量解释因变量y变差的程度,以测定因变量y的拟合效果。
表中r square=0.920465,说明自变量可以解释因变量变差的92.0465%。
[0283]
adjusted r square:为调整后的r square,其值为0.854186,表明自变量能说明因变量的85.4186%,因变量y的14.5814由其他因素解释。
[0284]
标准误差:用来衡量拟合程度的大小,该值越小,拟合效果越好。表中的值为2.542898,该值很小,说明拟合效果好。
[0285]
在方差分析(作用是通过f检验来判定回归模型的效果)表中:
[0286]
significance f=0.00301,小于显著水平0.05,说明回归效果显著。
[0287]
回归参数表中:
[0288]
第二列为回归方程中的常数和系数,根据该表可以得到拟合方程为:
[0289]q拟合
=7.406069-0.00166x1 0.015805x
2-0.01726x
3-5.44149x4 0.255153x5[0290]
画出拟合值与实测值之间的拟合图(见图4),r2=0.9205,说明拟合值与实测值相关性很强,且成正相关,符合预期。
[0291]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如软盘、硬盘、磁带)、光介质(例如dvd)、或者半导体介质(例如固态硬盘solid state disk(ssd))等。
[0292]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
