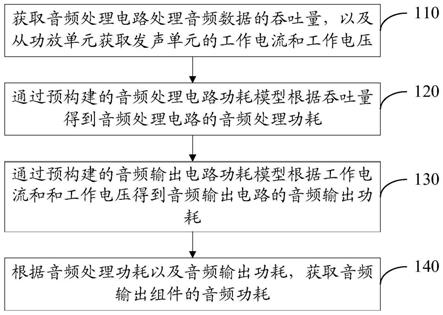
1.本发明属于电力系统的电量预测技术领域,涉及基于互相关熵门控循环单元的短期电量预测方法。
技术背景
2.在电力系统规划角度,用电预测作为在电力系统规划,国民经济运转以及电力调节智能化系统中的依据,同时也作为电力安全运行可靠性供电的必要条件;在电力市场角度,新电力改革下参与电力市场的售电公司交易形式主要包括中长期交易和现货交易,由于当售电公司提前申报企业预计的用户用能量较用户的实际用能量差别巨大的情况下,售电公司需要接受误差考评并向能源交易流程监督管理中心上缴罚金,此外还要在现货市场重面临利润风险,因此售电公司对用户用能量的预估需保证准确来提高核心竞争性,减少售电风险程度。基于此采用合理适当的电量预测方法来提高预测精度,规避其风险有重要工程应用价值。
3.传统的电量预测问题主要针对大区域,历史数据多,而且预测技术已交完善;新电改下的电量预测问题主要是针对多个或单个用户,预测区域小,预测时间间隔小,从而受随机因素影响较大体现出较强的随机性、非线性、时变性、以及数据分布的非高斯性。针对电量预测,国内外学者做了很多研究,其模型主要可分为两类:传统预测模型与机器学习模型。传统预测模型包括ar综合模型、移动平均模型、自回归时间序列模型灰色预测模型等,这些模型的理论基础是线性模型,其对时间序列的平稳性要求高,对数据回归能力弱。机器学习算法因可以很好的处理各种影响因素和非线性数据,在电量预测中得到了广泛的应用。传统机器算法的损失函数为均方根误差,均方根误差仅仅对误差分布的二阶矩进行了分析考虑,对含高斯特性的数据有很高的的预测准确度。然而电量预测的数据和误差往往具有非高斯、非线性特性,因此该算法应用于售电量预测问题时,具有一定的局限性。
技术实现要素:
4.本发明的目的是提出基于互相关熵门控循环单元的短期电量预测方法,解决了现有预测技术对非高斯非线性售电数据预测精度不高,难以满足售电公司进行电力交易时对售电量预测精度需求的问题。
5.本发明采用的技术方案是,基于互相关熵门控循环单元的短期电量预测方法,按照以下步骤实施:
6.步骤1、数据的预处理
7.先对历史小时用电量以及该时所对应的温度的数据进行收集,同时补充其中的缺失数据,对数据进行标准化处理;
8.步骤2、将步骤1标准化后数据中影响用户用电量的特征向量利用mrmr算法进行进一步提取,选出信息冗余小,信息包含量大的特征;
9.步骤3、选用门控循环单元gru模型对小时用电量进行预测,针对售电量预测误差
的非高斯特征,使用互相关熵对应的最大相关熵准则mcc代替门控循环单元中的均方误差准则作为预测模型的代价函数;
10.步骤4、通过k-折交叉验证与网格寻优方法对互相关熵门控循环单元模型的关键参数p、核宽度θ进行优化,利用网格寻优进行参数搜索:根据步骤2中选取的信息冗余小,信息包含量大的特征,给出参数p、θ可能的取值范围,再从参数p、θ的取值范围内取若干取值,并两两组合形成关于参数p、θ的参数对,从而选择令最大相关熵值最大的参数对;利用k-折交叉验证法衡量参数的泛化能力:将已有的数据集分为k个子集,令每个子集分别做一次测试集,其他子集做训练集进行k次验证参数的泛化能力;
11.步骤5、用互相关熵门控循环单元预测模型对小时时间尺度的售电量进行预测,得到预测结果;采用均方根误差rmse和平均绝对百分比误差mape两个指标作为模型的评价指标。
12.本发明的特点还在于,
13.步骤1具体如下:
14.收集数据,并对售电用户历史用电量数据中的缺失数据进行补充,构建训练样本集,以历史小时用电量以及该时所对应的温度作为预测模型的训练样本集,数据标准化,具体过程是:
15.电量预测模型中主要用到的数据有历史小时用电量数据以及该时所对应的温度数据,为了减少两种数据数量级相差较大对预测结果造成的影响,故对两种数据进行标准化处理,标准化公式如式(1):
[0016][0017]
其中,x
min
为该类数据的最小值,x
max
为该类数据的最大值,xi为数据真实值。
[0018]
步骤2具体如下:
[0019]
特征的选择是通过特征和类变量之间的相关性最大化和特征之间冗余度最小化来实现的:
[0020]
最大相关
[0021]
式中,xi为第i个特征,i的范围[i1~ip],c={c1,c2,
…
,c
l
}为类变量,l为类别总个数,s为特征子集;
[0022]
最小冗余
[0023]
从信息的角度来看,特征选择是选择输出变量尽可能多、维数最小的特征子集,即需要同时经过式(2)与式(3)进行检验,满足其要求:
[0024]
信息差maxφ(d,r),φ=d-r
ꢀꢀ
(4)
[0025]
信息熵
[0026]
步骤3具体如下:
[0027]
选用门控循环单元gru模型对小时用电量进行预测,针对售电量预测误差的非高
斯特征,使用互相关熵对应的最大相关熵准则mcc代替门控循环单元中的均方误差准则作为预测模型的代价函数:
[0028]
最大相关熵对应的最大相关熵准则的表达式见(6):
[0029][0030]
其中,k
θ
是核函数,n是样本个数;
[0031]
gru网络是一种深度学习模型,其网络前馈过程如下:
[0032][0033]
其中,x
t
为t时刻的输入;w,u为对应的权重;σ为sigmoid激活函数;z
t
,r
t
分别为更新门和复位门的输出;wz,uz为更新门对应的权重;wr,ur为复位门对应的权重;分别表示更新门,复位们以及预测输出的各权重,h
t
为t时刻网络隐含状态,也是t 1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出;
[0034]
从而得到门控循环单元网络中各权重参数的更新公式:
[0035]
[0036]
其中,c是惩罚系数,θ是核宽度,t
t
为时间步、d
t
是模型实际值,w,u为对应的权重;σ为sigmoid激活函数;z
t
,r
t
分别为更新门和复位门的输出;h
t
为t时刻网络隐含状态,也是t 1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出;
[0037]
利用公式(8)表示出来的权重参数,从而得出网络各权重的更新公式:
[0038][0039]
其中,x
t
为t时刻的输入;w,u为对应的权重;h
t
为t时刻网络隐含状态,也是t 1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出。
[0040]
步骤5具体如下:
[0041]
用互相关熵门控循环单元预测模型对小时时间尺度的售电量进行预测,得到预测结果;采用均方根误差rmse和平均绝对百分比误差mape两个指标作为模型的评价指标,这两个指标定义如下:
[0042][0043][0044]
本发明的有益效果是,针对电量预测本身预测范围小,随机性强,具有时序性等特点,选用门控循环单元模型对用户电量进行预测。门控循环单元的代价函数为均方根误差,均方根误差是一种全局性度量准则,只考虑预测误差分布的二阶距,对具有高斯特性的平稳数据预测有效性较高,而售电量数据往往为非高斯分布,经典门控循环单元预测模型在电量预测的问题上具有一定的局限性。互相关熵对应的最大相关熵准则是一种局部相似性度量准则,它对售电数据中的离群值与噪声均不敏感,对非高斯分布的数据预测有效性页较高,针对以上问题,采用最大相关熵准则替代了经典门控循环单元的代价函数均方根误差准则,建立基于互相关熵门控循环单元的预测模型,提高对售电量预测的有效性。该方法首次应用于电力系统售电量预测,并且可以有效对用户售电量进行预测,具有关键的理论
意义与实际工程价值。
附图说明
[0045]
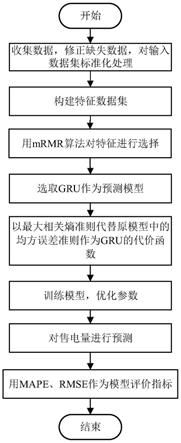
图1是本发明预测方法的总流程示意图;
[0046]
图2是本发明预测方法实施例的结果示意图。
具体实施方式
[0047]
参照图1,本发明的电量预测方法,按照以下步骤实施:
[0048]
步骤1、数据的预处理
[0049]
先对历史小时用电量以及该时所对应的温度的数据进行收集,同时补充其中的缺失数据。收集的数据主要用于电量预测模型中,为了减少两种数据数量级相差较大对预测结果造成的影响,故对两种数据进行标准化处理。
[0050][0051]
其中,x
min
为该类数据的最小值,x
max
为该类数据的最大值,xi为数据真实值。
[0052]
步骤2、特征的选择采用最大相关最小冗余(max-relevance and min-redundancy,mrmr)算法进行判断。最大相关最小冗余是一种基于互信息度量特征之间冗余以及特征与类变量之间相关性的特征选择方法。特征的选择是通过特征和类变量之间的相关性最大化和特征之间冗余度最小化来实现的。
[0053][0054]
式中,xi为第i个特征,i=1,2,...,p,c={c1,c2,
…
,c
l
}为类别变量,l为类别总个数,s为特征子集。
[0055][0056]
挖掘影响因素与耗电量映射规则的难度取决于特征空间的维数和冗余度,这些维数和冗余度与模型的训练难度和计算复杂度成正比。从信息的角度来看,特征选择是选择输出变量尽可能多、维数最小的特征子集。即需要同时经过式(2)与式(3)进行检验,满足其要求。
[0057]
信息差maxφ(d,r),φ=d-r
ꢀꢀ
(4)
[0058]
信息熵
[0059]
步骤3、针对小时时间尺度的短期电量预测,预测范围小,非线性随机性强,具有时序性等特点,选用门控循环单元(gated recurrent unit,gru)模型对小时用电量进行预测。针对售电量预测误差的非高斯特征,使用互相关熵对应的最大相关熵准则(maximum correntropy criterion,mcc)代替门控循环单元中的均方误差准则作为预测模型的代价函数。
[0060]
最大相关熵对应的最大相关熵准则的表达式见(6):
[0061][0062]
其中,k
θ
是核函数,n是样本个数。
[0063]
gru网络是一种深度学习模型,其网络前馈过程如下:
[0064][0065]
其中,x
t
为t时刻的输入;w,u为对应的权重;σ为sigmoid激活函数;z
t
,r
t
分别为更新门和复位门的输出;wz,uz为更新门对应的权重;wr,ur为复位门对应的权重;分别表示更新门,复位们以及预测输出的各权重,h
t
为t时刻网络隐含状态,也是t 1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出。
[0066]
从而可得到门控循环单元网络中各权重参数的更新公式:
[0067][0068]
其中,c是惩罚系数,θ是核宽度,t
t
为时间步、d
t
是模型实际值,w,u为对应的权重;σ为sigmoid激活函数;z
t
,r
t
分别为更新门和复位门的输出;h
t
为t时刻网络隐含状态,也是t
1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出。
[0069]
利用公式8表示出来的权重参数,从而得出网络各权重的更新公式:
[0070][0071]
其中,x
t
为t时刻的输入;w,u为对应的权重;h
t
为t时刻网络隐含状态,也是t 1时刻的输入,具有短期记忆功能;分别为细胞状态,具有长期记忆功能;y
t
为t时刻预测输出。
[0072]
步骤4、通过k-折交叉验证与网格寻优方法对互相关熵门控循环单元模型的关键参数p、核宽度θ进行优化。利用网格寻优进行参数搜索:根据样本给出参数p、θ可能的取值范围,再在每个参数的取值范围内取若干取值,并两两组合形成关于参数p、θ的参数对,从而选择令最大相关熵值最大的参数对。利用k-折交叉验证法衡量参数的泛化能力:将已有的数据集分为k个子集,令每个子集分别做一次测试集,其他子集做训练集进行k次验证参数的泛化能力。
[0073]
步骤5、用互相关熵门控循环单元预测模型对小时时间尺度的售电量进行预测,得到预测结果,为了从多个角度评价预测方法的有效性和准确性,本专利采用均方根误差(rmse)和平均绝对百分比误差(mape)两个指标作为模型的评价指标。
[0074]
这两个指标定义如下:
[0075][0076][0077]
由于不同的样本数据对应的波动范围不同,精度也不完全一样,因此评价指标是用于和已有的方法进行比较来突出本专利方法更为有效。
[0078]
实施例
[0079]
步骤1、数据预处理。收集某售电公司某用户2020年5月1日-2020年6月19日历史小时用电数据,并对售电用户历史用电量数据中的缺失数据进行补充。对于缺失数据进行修正。电量预测模型中主要用到的数据为收集到的数据,即包括有历史小时用电量数据以及该时所对应的温度数据,为了减少两种数据数量级相差较大对预测结果造成的影响,故对两种数据进行标准化处理,对历史售电量数据、温度数据进行归一化处理。
[0080]
步骤2、构建以2020年5月1日-2020年6月18日小时用电量以及该时所对应的温度作为预测模型的训练样本集,并将预测小时前24小时的用电量、以及预测小时对应的温度为特征输入,采用mrmr算法对该特征进行进一步选择得到预测模型的输入集。
[0081]
步骤3、针对小时时间尺度的短期电量预测,预测范围小,非线性随机性强,具有时序性等特点,选用门控循环单元(gated recurrent unit,gru)模型对小时用电量进行预测。针对售电量预测误差的非高斯特征,使用互相关熵对应的最大相关熵准则(maximum correntropy criterion,mcc)代替门控循环单元中的均方误差准则作为预测模型的代价函数。并用公式(6)对网络权重进行计算。
[0082]
步骤4、通过k-折交叉验证与网格寻优方法对互相关熵门控循环单元模型的关键参数p、核宽度θ进行优化。
[0083]
步骤5、测试训练好的模型对测试集的数据的有效性和准确性。利用已确定的参数以及更新的网络权值,预测2020年6月19日的24小时售电量,并用指标rmse与mape评价预测模型的有效性和准确性。
[0084]
表1 mrmr-mcc-gru6.19日小时电量预测误差
[0085][0086]
由表1可见,本发明方法(即互相关熵门控循环单元方法)的预测精度更高,方法更有效,且预测准确率可满足实际需求。
[0087]
本发明基于互相关熵门控循环单元的短期电量预测方法进行售电量预测,针对电量预测本身预测范围小,随机性强,具有时序性等特点,选用门控循环单元模型对用户电量进行预测。门控循环单元的代价函数为均方根误差,均方根误差是一种全局性度量准则,只考虑预测误差分布的二阶距,对具有高斯特性的平稳数据预测有效性较高,而售电量数据往往为非高斯分布,经典门控循环单元预测模型在电量预测的问题上具有一定的局限性。互相关熵对应的最大相关熵准则是一种局部相似性度量准则,它对售电数据中的离群值与噪声均不敏感,对非高斯分布的数据预测有效性页较高,针对以上问题,采用最大相关熵准则替代了经典门控循环单元的代价函数均方根误差准则,建立基于互相关熵门控循环单元的预测模型,提高对售电量预测的有效性。该方法首次应用于电力系统售电量预测,并且可以有效对用户售电量进行预测,具有关键的理论意义与实际工程价值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。