1.本发明涉及车辆数据处理技术领域,具体涉及一种基于车端数据的道路问题检测方法及可读存储介质。
背景技术:
2.随着智能汽车的发展,行车辅助功能越来越完善并且逐渐普及。用户能够通过行车辅助功能实现车辆的智能驾驶或智能辅助驾驶。
3.同时,随着我国公路运营里程和汽车保有量的飞速增长,道路维护任务日益繁重,道路维护是保证路网功能稳定的重要措施。其中,如何快速的发现道路问题(例如路面损害等影响道路通行质量的问题)是实现道路及时维护的关键之一。
4.现有方法主要依靠人工操作巡检车辆或无人机设备进行巡检,并通过人工识别或图像识别的方式检测问题道路,存在成本高且效率低等问题。为此,公开号为cn112595728b的中国专利公开了《一种道路问题确定方法和相关装置》,其方法通过多种传感器获取车辆惯性数据和路况图像数据,利用计算机视觉技术,根据车辆惯性数据确定对应目标道路的第一道路问题信息,根据路况图像数据确定目标道路的第二道路问题信息;通过第一道路问题信息和第二道路问题信息确定目标道路的道路综合问题数据;根据道路综合问题数据确定目标道路中的道路问题点,结合道路问题点生成高精地图。
5.上述现有方案的道路问题确定方法通过车辆惯性数据和路况图像数据检测道路问题,能够实现较高的检测准确度。但是,现有道路问题确定方法需要通过多种硬件(传感器)来采集相关数据,硬件成本很高,进而导致数据获取的成本高。此外,现有道路问题确定方法需要通过处理和分析图像数据才能确定道路问题,而图像数据的处理过程复杂、难度大,并且处理时间很长,导致道路问题检测的效率很低。因此,如何设计一种能够降低硬件成本并降低数据处理复杂度和难度的道路问题检测方法是亟需解决的技术问题。
技术实现要素:
6.针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种能够降低硬件成本并降低数据处理复杂度和难度的道路问题检测方法,从而提升道路问题检测的效率并降低道路问题检测的成本。
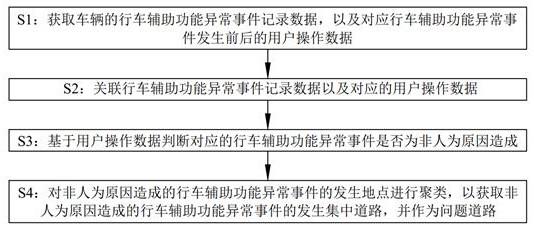
7.为了解决上述技术问题,本发明采用了如下的技术方案:一种基于车端数据的道路问题检测方法,包括以下步骤:s1:获取车辆的行车辅助功能异常事件记录数据,以及对应行车辅助功能异常事件发生前后的用户操作数据;s2:关联行车辅助功能异常事件记录数据以及对应的用户操作数据;s3:基于用户操作数据判断对应的行车辅助功能异常事件是否为非人为原因造成;s4:对非人为原因造成的行车辅助功能异常事件的发生地点进行聚类,以获取非
人为原因造成的行车辅助功能异常事件的发生集中道路,并作为问题道路。
8.优选的,步骤s1中,行车辅助功能异常事件记录数据包括但不限于行车辅助功能异常事件的事件类型、发生时间和发生地点;其中,事件类型包括但不限于退出行车辅助和提示用户接管驾驶。
9.优选的,步骤s1中,用户操作数据包括但不限于刹车踏板深度、油门踏板深度、方向盘手力矩、转向灯状态和辅助驾驶功能按键状态及语音接口状态。
10.优选的,步骤s2中,在行车辅助功能异常事件记录数据和对应用户操作数据间增加事件标识字段以完成关联。
11.优选的,步骤s3中,基于刹车踏板深度变化幅度、油门踏板深度变化幅度、方向盘手力矩最大值、转向灯激活状态和辅助驾驶功能按键使用状态及语音接口使用状态判断行车辅助功能异常事件是否为非人为原因造成。
12.优选的,步骤s4中,通过dbscan聚类模型对非人为原因造成的行车辅助功能异常事件的发生地点进行聚类。
13.优选的,dbscan聚类模型的扫描半径设置为30m至80m,最少点数设置为3至8。
14.优选的,dbscan聚类模型通过欧氏距离算法计算两点之间的距离。
15.优选的,通过dbscan聚类模型完成聚类后,排除噪音点,剩下的每个类别即为一个问题道路本发明还公开了一种可读存储介质,其上存储有计算机管理类程序,所述计算机管理类程序被处理器执行时实现本发明的基于车端数据的道路问题检测方法的步骤。
16.本发明的道路问题检测方法与现有技术相比,具有如下有益效果:本发明通过用户操作数据判断非人为原因造成的行车辅助功能异常事件,并通过对行车辅助功能异常事件的发生地点进行聚类的方式实现问题道路的检测,行车辅助功能异常事件记录数据和用户操作数据均属于车辆状态相关数据,能够通过车辆现有的硬件和数据资源获取,而无需通过额外的硬件来获取,这降低了获取数据的硬件成本,从而能够降低道路问题检测的成本。同时,本发明通过车辆状态相关数据实现问题道路的检测,而不涉及图像数据等复杂数据,降低了数据处理复杂度和难度,从而能够提升道路问题检测的效率。此外,本发明通过海量车辆的车辆状态相关数据实现了大范围路网的覆盖,能够有效的保证道路问题检测的准确性和效果。
附图说明
17.为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:图1为基于车端数据的道路问题检测方法的逻辑框图;图2为某道路经过道路问题检测方法得到的数据可视化示意图。
具体实施方式
18.下面通过具体实施方式进一步详细的说明:实施例一:本实施例中公开了一种基于车端数据的道路问题检测方法。
19.如图1所示,基于车端数据的道路问题检测方法,包括以下步骤:s1:获取车辆的行车辅助功能异常事件记录数据,以及对应行车辅助功能异常事件发生前后的用户操作数据;s2:关联行车辅助功能异常事件记录数据以及对应的用户操作数据;s3:基于用户操作数据判断对应的行车辅助功能异常事件是否为非人为原因造成;s4:对非人为原因造成的行车辅助功能异常事件的发生地点进行聚类,以获取非人为原因造成的行车辅助功能异常事件的发生集中道路,并作为问题道路。
20.具体的,本发明的道路问题检测方法实际上是利用l2级及以上级别辅助驾驶功能车辆现有的硬件资源和数据资源,通过海量车辆的车辆状态相关数据实现大范围路网的覆盖。具体方法可通过程序编程的方式生成相应的软件包,进而能够在云端服务器、计算机或车机系统上运行和实施。
21.具体的,行车辅助功能异常事件记录数据包括但不限于行车辅助功能异常事件的事件类型、发生时间和发生地点;事件类型包括但不限于退出行车辅助和提示用户接管驾驶。获取行车辅助功能异常事件发生时间前后2秒的用户操作数据。用户操作数据包括但不限于刹车踏板深度、油门踏板深度、方向盘手力矩、转向灯状态和辅助驾驶功能按键状态及语音接口状态。为了保护用户的隐私,以上数据均不含用户隐私信息,且无法追踪和定位到具体用户或车辆。
22.具体的,行车辅助功能异常事件记录数据和用户操作数据均需上传至云端,而数据关联操作可在车端完成后上传云端进行,也可以将数据分别上传云端后再进行关联。在行车辅助功能异常事件记录数据和对应用户操作数据间增加事件标识字段(用于数据匹配)以完成关联。为了保护用户的隐私,该事件标识字段不会对用户和车辆进行标识。
23.本发明通过用户操作数据判断非人为原因造成的行车辅助功能异常事件,并通过对行车辅助功能异常事件的发生地点进行聚类的方式实现问题道路的检测,行车辅助功能异常事件记录数据和用户操作数据均属于车辆状态相关数据,能够通过车辆现有的硬件和数据资源获取,而无需通过额外的硬件来获取,这降低了获取数据的硬件成本,从而能够降低道路问题检测的成本。同时,本发明通过车辆状态相关数据实现问题道路的检测,而不涉及图像数据等复杂数据,降低了数据处理复杂度和难度,从而能够提升道路问题检测的效率。此外,本发明通过海量车辆的车辆状态相关数据实现了大范围路网的覆盖,能够有效的保证道路问题检测的准确性和效果。
24.需要说明的是,非人为因素导致的行车辅助功能异常的原因可能有车辆故障、突发事件、道路问题等。由于车辆故障、突发事件的发生的偶然性较高,不会在同一地点集中出现,所以当某一道路集中出现大量行车辅助功能异常事件时,大概率是道路原因导致的。因此,通过对行车辅助功能异常事件的发生地点进行聚类,能够有效的找出事件集中的道路,即可准确的判断出问题道路。
25.具体实施过程中,基于刹车踏板深度变化幅度、油门踏板深度变化幅度、方向盘手力矩最大值、转向灯激活状态和辅助驾驶功能按键使用状态及语音接口使用状态判断行车辅助功能异常事件是否为非人为原因造成。
26.具体的,当用户操作数据满足如下所有条件时,判断行车辅助功能异常事件为非
人为原因造成,否则,判断为人为原因造成:刹车踏板深度变化幅度《5%;油门踏板深度变化幅度《5%;方向盘手力矩最大值《0.5n*m;左转向灯激活状态:始终为未激活;右转向灯激活状态:始终为未激活;行车辅助功能硬按键使用状态:未使用;行车辅助功能软按键使用状态:未使用;行车辅助功能语音接口使用状态:未使用。
27.具体实施过程中,聚类算法有多种模型,在进行选择时需要考虑问题道路识别场景的特殊性。首先道路的形状多样,可能有岔路口、直路、弯道等,其次道路可能有长有短。聚类时我们需要将这些道路完整的识别出来,最好是将相近的失效点归为一类,最后得到整个完整的失效道路。申请人经过研究发现,dbscan聚类模型具有很好的聚类效果,因此本发明通过dbscan聚类模型对非人为原因造成的行车辅助功能异常事件的发生地点进行聚类。
28.具体的,dbscan(density-based spatial clustering of applications with noise)是一种现有的基于密度的聚类算法,其于1996年由martin ester, hans-peter kriegel, j
ö
rg sander及xiaowei xu等人提出。dbscan聚类算法以密度为本:给定某空间里的一个点集合,其能够把附近的点分成一组(有很多相邻点的点),并标记出位于低密度区域的局外点(最接近它的点也十分远)。
29.dbscan聚类模型需要两个参数:扫描半径ε(eps)和形成高密度区域所需要的最少点数(minpts),它由一个任意未被访问的点开始,然后探索这个点的ε-邻域,如果ε-邻域里有足够的点,则建立一个新的聚类,否则这个点被标签为噪音点(杂音)。注意这个点之后可能被发现在其它点的ε-邻域里,而该ε-邻域可能有足够的点,届时这个点会被加入该聚类中。如果一个点位于一个聚类的密集区域里,它的ε-邻域里的点也属于该聚类,当这些新的点被加进聚类后,如果它(们)也在密集区域里,它(们)的ε-邻域里的点也会被加进聚类里。这个过程将一直重复,直至不能再加进更多的点为止,这样,一个密度连结的聚类被完整地找出来。然后,一个未曾被访问的点将被探索,从而发现一个新的聚类或噪音点。
30.具体实施过程中,通过dbscan聚类模型完成聚类后,排出噪音点,剩下的每个类别即为一个问题道路。
31.本实施例中,dbscan聚类模型的参数设计如下:扫描半径ε(eps)设置为30 m至80m(优选50m,具体根据定位精度确定大小);最少点数(minpts)设置为3至8(优选5,具体根据样本量多少确定大小);计算两点之间距离时,使用欧式距离计算方法。
32.本发明通过dbscan聚类模型对非人为原因造成的行车辅助功能异常事件的发生地点进行聚类,使得能够有效的识别岔路口、直路、弯道等道路,能够很好的将相近的失效点归为一类(如图2所示),从而能够提升道路问题检测的准确性。
33.实施例二:本实施例中公开了一种可读存储介质,其上存储有计算机管理类程序,所述计算
机管理类程序被处理器执行时实现本发明的基于车端数据的道路问题检测方法的步骤。
34.需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过参照本发明的优选实施例已经对本发明进行了描述,但本领域的普通技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离所附权利要求书所限定的本发明的精神和范围。同时,实施例中公知的具体结构及特性等常识在此未作过多描述。最后,本发明要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。