使用单核苷酸变异密度验证人类胚胎中拷贝数变异的系统和方法
相关申请的交叉援引
1.本技术要求于2019年6月21日提交的美国临时专利申请62/865,126的优先权,该申请的全部内容通过援引并入本技术。
2.援引加入本文援引的任何专利、专利申请和出版物的公开内容通过援引整体并入本技术。
技术领域
3.本文公开的实施例一般涉及用于识别人类胚胎中拷贝数量变异(cnv)的系统和方法。更具体地说,需要优化系统和方法以在植入母体之前验证对人类胚胎的cnv调用。
背景技术:
4.体外受精(ivf)是一种辅助生殖技术,越来越受高龄妇女、受孕困难的夫妇的欢迎,并作为辅助妊娠的一种手段。受精过程包括提取卵子、取得精子样本,然后在实验室环境中手动结合卵子和精子。然后将胚胎植入宿主子宫以将胚胎带到足月。
5.ivf手术费用昂贵,并且会对患者造成重大的情感/身体伤害,因此在接受ivf手术的患者中,在植入前对胚胎进行基因筛查变得越来越普遍。例如,目前ivf胚胎通常会筛查遗传异常(例如,cnv、snv等)和其他可能影响移植生存能力的条件(即胚胎植入生存能力)。与任何诊断测试一样,最终诊断的准确性至关重要,并且可能受到许多因素的影响,例如所使用的数据采集和分析技术。特别地,由于测序数据中的测序人为假象和噪声,对低覆盖率(~0.1x)的基因组测序数据进行生物信息学分析可能会导致对节段和镶嵌非整倍性和拷贝数量变异(cnv)的错误识别。
6.因此,需要能够独立验证胚胎中识别的遗传异常的系统和方法。
技术实现要素:
7.本说明书描述了各种示例性实施例系统和方法,该系统和方法被优化以在植入母体之前验证对人类胚胎进行的cnv调用。
8.在一方面,公开了一种用于验证胚胎中基因组变异区域的方法。由一个或多个处理器接收胚胎测序数据。由一个或多个处理器将接收到的胚胎测序数据与参考基因组比对(align)。由一个或多个处理器识别比对的胚胎测序数据中的基因组变异区域。由一个或多个处理器计算已识别的基因组变异区域中的多个单核苷酸变异(snv)。通过一个或多个处理器,将所识别的基因组变异区域中的snv的计数数量与对应于所识别的基因组变异区域的参考区域的snv基线计数进行归一化,以生成基因组变异区域的归一化snv密度。如果所识别的基因组变异区域中的归一化snv密度满足公差标准,则由一个或多个处理器验证所识别的基因组变异区域。
9.在另一方面,公开了一种用于验证胚胎中的基因组变异区域的系统。该系统包括
数据存储器、计算设备和显示器。数据存储器用于存储胚胎测序数据。计算设备以通信方式连接到数据存储器并承载比对引擎、基因组变异调用器和验证引擎。
10.比对引擎被配置为接收胚胎测序数据并将其与参考基因组比对。基因组变异调用器被配置为在比对的胚胎测序数据中识别基因组变异区域。验证引擎被配置为:对识别的基因组变异区域中的单核苷酸变异(snv)进行计数,并将所识别的基因组变异区域中的snv的计数与对应于所识别的基因组变异区域的参考区域的snv的基线计数进行归一化,以为已识别的基因组变异区域生成归一化snv密度,以及如果已识别的基因组变异区域中的归一化snv密度满足公差标准,则验证已识别的基因组变异区域。
11.显示器与计算设备通信连接并被配置为显示包含来自验证引擎的基因组变异区域结果的报告。
附图说明
12.为了更完整地理解本文公开的原理及其优点,现结合附图参考以下描述,其中:
13.图1是根据各种实施例的总测序覆盖率归一化密度相关性如何比基于测序覆盖率的人为变化的相关性更好地检测拷贝数量(即,cnv)的真实生物学变化的图形描述。
14.图2是根据各种实施例的来自临床胚胎样本的snv密度与100个正常(不含cnv)胚胎样本的平均snv密度相比较的图解描述。
15.图3是根据各种实施例的如何使用snv密度来确认基于计数的cnv调用的图示。
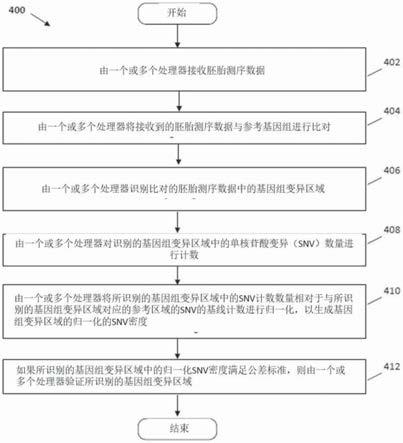
16.图4是显示根据各种实施例的用于验证对胚胎进行的cnv调用的方法的示例性流程图。
17.图5是根据各种实施例的用于验证对胚胎进行的cnv调用的系统的示意图。
18.图6是示出根据各种实施例的用于执行本文提供的方法的计算机系统的框图。
19.应当理解,附图不一定按比例绘制,附图中的对象也不一定按彼此的关系按比例绘制。附图是旨在使本文公开的装置、系统和方法的各种实施例变得清楚和理解的描绘。在可能的情况下,在整个附图中将使用相同的附图标记来指代相同或相似的部件。此外,应当理解,附图不旨在以任何方式限制本教导的范围。
具体实施方式
20.本说明书描述了各种示例性实施例系统和方法,该系统和方法被优化以在植入母体之前验证对人类胚胎进行的cnv调用。
21.然而,本公开不限于这些示例性实施例和应用或者示例性实施例和应用的操作方式或在此描述的方式。
22.此外,附图可能显示简化或局部视图,并且附图中元件的尺寸可能被夸大或以其他方式不成比例。此外,当在本文中使用术语“在之上”、“附着到”、“连接到”、“耦合到”或类似词汇时,一个元件(例如,材料、层、衬底等)可以“在之上”、“附着到”、“连接到”或“耦合到”另一元件,而不管该元件是直接在之上、附着到、连接到或耦合到另一元件还是在一个元件和另一个元件之间存在一个或多个中间元件。此外,当提及元件列表(例如元件a、b、c)时,此类提及旨在包括所列元件中的任何一个元件本身、少于所有所列元件的任何组合,和/或所有列出的元件的组合。说明书中的部分划分只是为了便于审查,并不限制所讨论元
件的任何组合。
23.除非另有定义,与本文描述的本教导相关使用的科学和技术术语应具有本领域普通技术人员通常理解的含义。此外,除非上下文另有要求,单数术语应包括复数,而复数术语应包括单数。通常,与本文所述的细胞和组织培养、分子生物学、以及蛋白质和寡核苷酸或多核苷酸化学和杂交结合使用的术语和技术是本领域公知的和常用的。标准技术用于例如核酸纯化和制备、化学分析、重组核酸和寡核苷酸合成。酶促反应和纯化技术根据制造商的说明书或如本领域中通常完成的或如本文所述进行的。本文所述的技术和程序通常根据本领域公知的常规方法进行,并且如在本说明书通篇引用和讨论的各种一般性和更具体的参考文献中所述。参见例如sambrook等人,分子克隆:实验室手册(第三版,冷泉港实验室出版社,冷泉港,纽约2000)。结合使用的术语以及本文所述的实验室程序和技术是本领域公知和常用的。
24.dna(脱氧核糖核酸)是由4种核苷酸组成的核苷酸链;a(腺嘌呤)、t(胸腺嘧啶)、c(胞嘧啶)和g(鸟嘌呤),rna(核糖核酸)由4种核苷酸组成;a、u(尿嘧啶)、g和c。某些核苷酸对以互补方式彼此特异性结合(称为互补碱基配对)。也就是说,腺嘌呤(a)与胸腺嘧啶(t)配对(然而,在rna的情况下,腺嘌呤(a)与尿嘧啶(u)配对),胞嘧啶(c)与鸟嘌呤(g)配对。当第一核酸链与由与第一链中的核苷酸互补的核苷酸组成的第二核酸链结合时,两条链结合形成双链。如本文所用,“核酸测序数据”、“核酸测序信息”、“核酸序列”、“基因组序列”、“基因序列”或“片段序列”或“核酸测序读数”表示指示dna或rna分子(例如,全基因组、全转录组、外显子组、寡核苷酸、多核苷酸、片段等)中核苷酸碱基(例如,腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶/尿嘧啶)顺序的任何信息或数据。应当理解,本教导考虑使用所有可用的各种技术、平台或技术获得的序列信息,包括但不限于:毛细管电泳、微阵列、基于连接的系统、基于聚合酶的系统、基于杂交的系统、直接或间接核苷酸识别系统、焦磷酸测序、基于离子或ph的检测系统、基于电子签名的系统等。
[0025]“多核苷酸”、“核酸”或“寡核苷酸”是指通过核苷间键连接的核苷(包括脱氧核糖核苷、核糖核苷或其类似物)的线性聚合物。通常,多核苷酸包含至少三个核苷。通常寡核苷酸的大小范围从几个单体单元,例如3-4,至数百个单体单元。每当多核苷酸(例如寡核苷酸)由字母序列(例如“atgcctg”)表示时,应理解核苷酸从左到右按5'-》3'顺序排列,并且“a”表示脱氧腺苷,“c”表示脱氧胞苷,“g”表示脱氧鸟苷,“t”表示胸苷,除非另有说明。字母a、c、g和t可用于指碱基本身、核苷或包含碱基的核苷酸,如本领域标准。
[0026]
如本文所用,术语“细胞”与术语“生物细胞”可互换使用。生物细胞的非限制性实例包括真核细胞、植物细胞、动物细胞,例如哺乳动物细胞、爬行动物细胞、鸟类细胞、鱼细胞等、原核细胞、细菌细胞、真菌细胞、原生动物细胞等,从组织中分离的细胞,例如肌肉、软骨、脂肪、皮肤、肝脏、肺、神经组织等,免疫细胞,例如t细胞、b细胞、自然杀伤细胞、巨噬细胞等,胚胎(例如,受精卵)、卵母细胞、卵子、精细胞、杂交瘤、培养细胞、来自细胞系的细胞、癌细胞、感染细胞、转染和/或转化细胞、报告细胞等。哺乳动物细胞可以来自例如人、小鼠、大鼠、马、山羊、绵羊、牛、灵长类动物等。
[0027]
基因组是细胞或生物体的遗传物质,包括动物,例如哺乳动物,例如人类。在人类中,基因组包括总dna,例如基因、非编码dna和线粒体dna。人类基因组通常包含23对线性染色体:22对常染色体加上决定性别的x和y染色体。23对染色体包括来自每个亲本的一个副
本。构成染色体的dna被称为染色体dna,存在于人类细胞的细胞核中(核dna)。线粒体dna作为环状染色体位于线粒体中,仅从母本遗传,与位于细胞核中的dna的核基因组相比,通常被称为线粒体基因组。
[0028]
短语“下一代测序”(ngs)是指与传统的基于桑格和毛细管电泳的方法相比具有增加通量的测序技术,例如具有一次产生数十万个相对小的序列读数的能力。下一代测序技术的一些示例包括但不限于合成测序、连接测序和杂交测序。更具体地说,illumina的miseq、hiseq和nextseq系统以及life technologies corp的个人基因组机器(pgm)和solid测序系统提供了对整个或靶向基因组的大规模并行测序。solid系统和相关的工作流程、方案、化学等更详细地描述于国际申请日期为2006年2月1日的pct公开号wo 2006/084132,标题为“reagents,methods,and libraries for bead-based sequencing”,2010年8月31日提交的标题为“low-volume sequencing system and method of use”的序列号为12/873,190的美国专利申请,以及2010年8月31日提交的标题为“fast-indexing filter wheel and method of use”的序列号为12/873,132的美国专利申请中,这些申请中的每一个的全部内容通过援引并入本文。
[0029]
短语“测序运行”是指为确定与至少一种生物分子(例如,核酸分子)有关的一些信息而进行的测序实验的任何步骤或部分。
[0030]
关于核酸测序的术语“读数”是指针对已进行测序的核酸片段例如ngs确定的核苷酸序列。读数可以是定义读数长度的任意数量核苷酸的任何序列。
[0031]
短语“测序覆盖率”或“序列覆盖率”在本文中可互换使用,通常是指序列读数和参考之间的关系,例如细胞或生物体的全基因组、基因组中的一个基因座或一个核苷酸在基因组中的位置。覆盖可以用多种形式描述(参见,例如sims等人(2014)自然评论遗传学15:121-132)。例如,覆盖可以指基因组有多少在碱基对水平上被测序,可以计算为nl/g,其中n是读取数,l是平均读取长度,g是长度,或基因组(参考)的碱基数。例如,如果参考基因组为1000mbp,并且对平均长度为100bp的1亿个读数进行测序,则覆盖的冗余将为10x。此类覆盖可以表示为“倍数”,例如1x、2x、3x等(或1、2、3等倍数覆盖)。覆盖还可以指测序相对于参考核酸的冗余,以描述参考序列被读数覆盖的频率,例如,在测序期间读取任何给定基因座的单个碱基的次数。因此,可能存在一些未被覆盖且深度为0的底数和一些被覆盖且深度介于1和50之间的任何底数。覆盖冗余提供了序列数据可靠性的指示,也称为覆盖深度。覆盖的冗余可以针对尚未与参考或比对(例如,定位(mapping))读数比对的“原始”读数进行描述。也可以根据读数覆盖的参考(例如基因组)的百分比来考虑覆盖率。例如,如果参考基因组为10mbp,并且序列读取数据定位到参考的8mbp,则覆盖百分比将为80%。序列覆盖度也可以用覆盖广度来描述,覆盖广度是指在某特定深度以给定次数进行测序的参考碱基的百分比。
[0032]
如本文所用,关于核酸测序的短语“低覆盖率”是指小于约10x、或约0.001x至约10x、或约0.002x至约0.2x、或约0.01x的到约0.05x的测序覆盖率。
[0033]
如本文所用,关于核酸测序的短语“低深度”是指小于约10x、或约0.1x至约10x、或约0.2x至约5x、或约0.5x至约2x的测序深度。
[0034]
关于基因组序列核酸序列的术语“分辨率”是指通过细胞(例如胚胎或生物体)的核酸测序获得的基因组核酸序列(例如,整个基因组的序列或基因组的特定区域或基因座)
的质量或准确性和范围。基因组核酸序列的分辨率主要由测序过程覆盖的深度和广度决定,并涉及对测序过程中读取的独特碱基数量和测序过程中读取任何一个碱基的次数的考虑。短语“低分辨率序列”或“低分辨率序列数据”或“稀疏序列数据”在本文中可互换使用,关于细胞(例如胚胎或生物体)的基因组核酸序列,是指对通过低覆盖、低广度测序方法获得的基因组核酸的核苷酸碱基序列信息。
[0035]
如本文所用,短语“基因组特征”可以指具有一些注释功能的基因组区域(例如,基因、蛋白质编码序列、mrna、trna、rrna、重复序列、反向重复序列、mirna、sirna等)或遗传/基因组变异(例如,单核苷酸多态性/变异、插入/缺失序列、拷贝数变异(cnv)、倒位等),其表示单个或一组基因(在dna或rna中)由于突变、重组/交叉或遗传漂变,已经历了针对特定物种或特定物种内的亚群的变化。
[0036]
可以使用多种技术来识别基因组变异,包括但不限于:基于阵列的方法(例如dna微阵列等)、实时/数字/定量pcr仪器方法和完整或靶向核酸测序系统(例如,ngs系统、毛细管电泳系统等)。通过核酸测序,可以在单碱基分辨率下获得覆盖数据。
[0037]
短语“镶嵌胚胎”表示包含两种或更多种细胞遗传学上不同的细胞系的胚胎。例如,镶嵌胚胎可以包含具有不同类型的非整倍性的细胞系或整倍体和遗传异常细胞的混合物,这些细胞包含具有遗传变异的dna,这些变异可能对胚胎在怀孕期间的生存能力有害。
[0038]
基因座的短语“snv密度”,其中基因座是指染色体内的感兴趣的动态区域,是指从基因座内识别的snv数量除以样本的相同基因座中识别的序列计数总数得出的值。核酸序列数据生成
[0039]
本文提供的用于分析基因组核酸和对基因组特征进行分类的方法和系统的一些实施例包括分析细胞和/或生物体的基因组的核苷酸序列。可以使用本文描述的和/或本领域已知的多种方法获得核酸序列数据。在一个示例中,细胞(例如胚胎细胞)的基因组核酸序列可以从细胞中提取的dna样本的下一代测序(ngs)中获得。ngs,也称为第二代测序,基于高通量、大规模并行测序技术,涉及对dna样本(例如,从胚胎中提取的)的核酸扩增所产生的数百万个核苷酸进行并行测序(参见,例如,kulski(2016)“next-generation sequencing-an overview of the history,tools and
‘
omic’applications,”记载于下一代测序-进展、应用和挑战,j.kulski编辑,london:intech open,第3-60页)。
[0040]
需要通过ngs测序的核酸样本可以通过多种方式获得,具体取决于样本的来源。例如,人类核酸可以经由颊刷拭子很容易地获得,以收集细胞,然后从中提取核酸。为了从胚胎中获得用于测序的最佳dna量(例如,用于植入前遗传筛选),通常在囊胚阶段通过滋养外胚层活检收集细胞(例如5-7个细胞)。在经由ngs测序之前,dna样本需要进行处理,包括例如片段化、扩增和接头连接。在此类处理中对核酸的操作可能会在扩增序列中引入人为假象(例如,与聚合酶链反应(pcr)扩增相关的gc偏差)并限制序列读数的大小。因此,ngs方法和系统与系统之间可能不同的错误率相关联。
[0041]
此外,与识别序列读数中的碱基(例如,碱基调用)结合使用的软件会影响来自ngs测序的序列数据的准确性。此类人为假象和限制可能使对基因组的长重复区域进行测序和定位以及识别基因组中的多态等位基因和非整倍性变得困难。例如,因为大约40%的人类基因组由重复的dna元件组成,与参考基因组中的重复元件比对的相同序列的较短单读数通常无法准确定位到基因组的特定区域。解决并可能减少序列确定中错误和/或不完整性
的一些影响的一种方法是增加测序覆盖率或深度。然而,测序覆盖率的增加与测序时间和成本的增加有关。还可以使用双端测序,这在将序列定位到基因组或参考组时提高了序列读数放置的准确性,例如在长重复区域中,并提高了结构重排(例如基因缺失、插入和倒位)的分辨率。例如,在本文提供的方法的一些实施例中,使用从来自胚胎的核酸的双端ngs获得的数据将读数定位增加了平均15%。双端测序方法是本领域已知的和/或本文描述的,并且涉及确定核酸片段在两个方向上的序列(即,从片段的一端读取一次,从片段的另一端读取第二次)。双端测序还通过将读取数量加倍,有效地增加了测序覆盖率冗余,特别是增加了困难基因组区域的覆盖率,。核酸序列分析
[0042]
在本文提供的用于分析基因组核酸和对基因组特征进行分类的方法和系统的一些实施例中,从细胞(例如胚胎细胞或生物体)获得的核酸序列用于使用基因组定位方法重建细胞/生物体的基因组(或其部分)。通常,基因组定位涉及在称为比对的过程中将序列与参考基因组(例如,人类基因组)匹配。可用于定位过程的人类参考基因组的示例包括基因组参考联盟的发布,例如2009年发布的grch37(hg19)和2013年发布的grch38(hg38)(例如参见,https://genome.ucsc.edu/cgi-bin/hggateway?db=hg19https://www.ncbi.nlm.nih.gov/assembly/gcf_000001405.39)。通过比对,通常使用计算机程序将序列读数分配给基因组基因座以进行序列匹配。许多比对程序是公开可用的,包括bowtie(例如参见,http://bowtie-bio.sourceforge.net/manual.shtml)以及bwa(例如参见,http://bio-bwa.sourceforge.net/)。已处理(例如去除pcr重复和低质量序列)并与基因座匹配的序列通常称为比对序列或比对读数。
[0043]
在将序列读数定位到基因组参考时,可以识别序列核苷酸变异(snv)或单核苷酸多态性(snp)。还应当注意,根据各种实施例使用术语snv和snp。尽管这两个术语对于本领域普通技术人员来说可能是可区分的,但是根据本文的各种实施例,这些术语可以互换使用。因此,其中一个术语的使用都应包括这两个术语,因为它适用于分析接收到的测序数据的过程。单核苷酸变异/多态性是基因组中单核苷酸位置变异的结果。用于snv检测的几种不同的ngs分析程序是公开可用的、本领域已知的和/或本文描述的。该方法利用bcftools(开源)来消化比对的测序数据并生成用于下游过程的snv/基因型调用。通过对来自细胞或生物体样本核酸的序列进行基因组定位来检测和鉴定基因组特征,例如染色体异常,例如非整倍性、cnv,具有特殊的挑战,特别是当序列数据是从低覆盖率和低深度测序方法中获得时因为整个基因组没有被询问,并且在基因组中被询问的位置特别容易受到偏差和错误的影响,因为用于生成测序数据的方法包括但不限于:全基因组扩增、文库制备和选择下一代测序系统和方法。计算机程序和系统是本领域已知的和/或本文中描述的用于在鉴定某些基因组特征时增加序列数据解释的简便性和/或准确性。例如,在美国专利申请公开号2020/0111573中描述了用于自动检测染色体异常的系统和方法,包括节段重复/缺失、镶嵌特征、非整倍性和一些形式的多倍性,其通过援引并入本文。此类方法包括去噪/归一化(对原始序列读数进行去噪和归一化基因组序列信息以校正基因座效应)以及机器学习和将位点分数解释(或解码)为核型图的机器学习和人工智能。例如,测序完成后,原始序列数据被解复用(归因于给定样本),读数与参考基因组(例如hg19)比对,以及每100万个碱基对位(base pair bin)中的读数总数被计算在内。该数据根据gc含量和深度进行归一化,并根据
已知结果的样本生成的基线进行测试。然后将与2拷贝数量的统计偏差(如果存在,如果不存在=整倍体)报告为非整倍性。使用这种方法,减数分裂非整倍体和有丝分裂非整倍性可以基于cnv度量相互区分。基于与正常的偏差,生成具有存在的染色体总数、存在的任何非整倍性以及这些非整倍性的镶嵌水平(如果适用)的核型。
[0044]
在ngs中可能发生的人为假象、覆盖范围的变化和错误也给使用低覆盖率测序数据准确识别基因组变异带来了挑战。因此,需要可以验证从低覆盖率测序数据中识别出的基因组变异是否实际上是真正的基因组变异的方法,以确保它们被正确调用。
[0045]
本文提供了用于验证使用低覆盖率测序数据进行的基因组变异调用(特别是cnv调用)的改进的、有效的、快速的和具有成本效益的方法和系统。使用snv密度验证cnv调用
[0046]
本文公开的系统和方法涉及使用总测序覆盖率归一化密度相关性比基于测序覆盖率的人为变化的相关性更好地检测拷贝数量(即,cnv)的真实生物学变化的确定。从历史上看,snv密度数据以前并未用于在低于15x的测序覆盖率水平下验证cnv调用。在原始形式中,不同基因座之间的snv密度变异通常大于由于拷贝数量变化引起的变异。通过纳入归一化步骤来消除不同基因座之间的snv密度变异,从而使snv密度可用于验证使用低覆盖率的基因组测序数据进行的cnv调用,从而解决了这一缺点。这是对传统方法(要求数据的测序覆盖率水平为15x或更高)的重大改进,因为所需的测序覆盖率水平越高,分析的成本和耗时(低通量)就越高。
[0047]
图1是根据各种实施例,总测序覆盖率归一化密度相关性如何比基于测序覆盖率的人为变化的相关性更好地检测拷贝数量(即,cnv)的真实生物学变化的图形描述。
[0048]
如图1所示,读数圈102表示当胚胎中存在真正的生物学变异时总测序覆盖率归一化密度之间的相关关系(也在cnv配置文件中观察到-参见指向cnv配置文件104的红色箭头)。与cnv位所指示的信号是人为假象或噪声的情况相比,由线106表示的准线性关系所示的那些单个位的归一化cnv位得分(y轴)和snv密度得分(x轴)的相关性高于存在真实生物变化时的相关性,以及它们与圆108中发现的snv密度和随后的斜率减小的趋势线110的相关性。因此,当确定在cnv方法中识别的变化是否通过本公开中描述的方法验证时,该方法利用了cnv位得分和snv得分之间的这些相关值。
[0049]
图2是根据各种实施例的来自临床胚胎样本204的snv密度与100个正常(不含cnv的)胚胎样本202的平均snv密度相比较的图解描述。
[0050]
本文公开的归一化操作利用了以下事实:没有cnv调用的样本中的snv密度遵循可用于归一化snv密度的一致模式。因此,如图2所示,snv密度的归一化可以涉及将基因座的snv密度204(来自临床胚胎样本)除以正常样本基线组(即,100个正常女性胚胎)中的平均snv密度202。该归一化函数如公式1所示。公式1:d
norm
(locus,baseline sample)=(sample snv density at locus)/(average baseline snv density at locus)
[0051]
然后可以使用所得归一化的snv密度来确认基于计数的cnv调用。
[0052]
图3是根据各种实施例的如何使用snv密度来确认基于计数的cnv调用的图示。
[0053]
如图3所示,使用基于计数的方法对1号染色体(缺失)302、7号染色体(重复)304、
14号染色体(重复)306和21号染色体(重复)308进行了潜在的cnv调用。这些cnv调用是根据归一化的snv密度图进行验证的,其中包括用于验证潜在cnv调用实际上是否真实的预设置信区间。在这种情况下,所有四个cnv调用都被验证为真正的cnv调用,因为图表显示cnv调用的染色体位置中的snv密度落在预设的置信区间之外。
[0054]
图4是一个示例性流程图,显示了根据各种实施例的用于验证对胚胎进行的cnv调用的方法。
[0055]
在步骤402中,胚胎测序数据由一个或多个处理器接收。在各种实施例中,胚胎可以是人胚胎。在各种实施例中,胚胎是非人类胚胎。
[0056]
在步骤404中,接收的胚胎测序数据由一个或多个处理器与参考基因组比对。在各种实施例中,参考基因组可以是从单个个体获得的全基因组。在各种实施例中,参考基因组可以是来自多个个体的复合全基因组。可用于比对过程的参考基因组的示例包括但不限于从基因组参考联盟发布的基因组,例如2009年发布的grch37(hg19)和2013年发布的grch38(hg38)(参见,例如,https://genome.ucsc.edu/cgi-bin/hggateway?db=hg19https://www.ncbi.nlm.nih.gov/assembly/gcf_000001405.39)。
[0057]
在步骤406中,比对的胚胎测序数据中的基因组变异区域由一个或多个处理器识别。在各种实施例中,基因组变异区域是使用基于计数的cnv调用方法识别的cnv区域。在各种实施例中,基因组变异区域是非整倍性区域。在各种实施例中,基因组变异区域是多倍性区域。在各种实施例中,基因组变异区域包括代表整个染色体的序列区段。在各种实施例中,基因组变异区域包括仅代表染色体的一部分的序列区段。
[0058]
在步骤408中,snv识别的基因组变异区域中的snv数量由一个或多个处理器进行计数。
[0059]
在步骤410中,所识别的基因组变异区域中的snv的计数数量针对对应于所识别的基因组变异区域的参考区域的snv的基线计数进行归一化,以通过一个或多个处理器生成基因组变异区域的归一化的snv密度。在各种实施例中,snv的基线计数从源自一个或多个正常(非cnv)样本的测序数据中获得。在各种实施例中,经识别的变异区域和参考区域覆盖相同的对应基因组区段(或基因组位置)。在各种实施例中,经识别的基因组变异区域和参考区域包括代表整个染色体的序列区段。在各种实施例中,经识别的基因组变异区域和参考区域包括仅代表染色体的一部分的序列区段。
[0060]
在步骤412中,如果所识别的基因组变异区域中的归一化snv密度得分满足公差标准,则由一个或多个处理器验证所识别的基因组变异区域。在各种实施例中,如果所识别的基因组变异区域的snv密度在零假设(null hypothesis)下的平均snv密度的预设置信区间之外,则不存在真正的拷贝数量变异。在各种实施例中,预设置信区间为约90%。在各种实施例中,预设置信区间为约95%。在各种实施例中,预设置信区间为约96%、约97%、约98%和约99%。
[0061]
如果snv密度高于预设置信上限,则验证重复,如果snv密度低于预设置信下限,则验证删除。预设置信区间是根据正态性假设定义的(c
±
z sigma/sqrt(n)),其中c是零假设下平均snv密度的中心或期望值,n是与已识别基因组变异区域重叠的窗口数,sigma是所有常染色体上归一化snv密度的全局标准偏差,z是标准正态分布的第x个百分位数。“ ”号表示数值为置信区间的上限相加,
“–”
号表示数值为置信区间的下限相减。
[0062]
在各种实施例中,公差标准是来自镶嵌胚胎的参考区域的预期snv密度。
[0063]
在各种实施例中,如果其snv密度高于镶嵌胚胎替代假设的预设置信区间的下限(对于重复)或低于上限(对于缺失),则验证所识别的基因组变异区域(包含镶嵌水平百分比m的真实拷贝数量变异)。在各种实施例中,预设置信区间为约90%。在各种实施例中,预设置信区间为约95%。在各种实施例中,预设置信区间为约96%、约97%、约98%和约99%。
[0064]
替代假设的预设置信区间是根据正态性假设(c
±
z sigma/sqrt(n))定义的,其中c是替代假设下平均snv密度的中心或预期值,c=e(snv density|m)=1.0
±
0.5*m/100,并且n是重叠已识别基因组变异区域的窗口数,sigma是所有常染色体上归一化snv密度的全局标准偏差,z是标准正态分布的第x个百分位数。“ ”号表示数值为置信区间的上限相加,
“‑”
号表示数值为置信区间的下限相减。
[0065]
在各种实施例中,如果所识别的基因组变异区域包括的snv数量超过了高于或低于参考区域的snv基线计数的snv的预设方差数量(variance number),则验证所识别的基因组变异区域。
[0066]
图5是根据各种实施例的用于验证对胚胎进行的cnv调用的系统的示意图。
[0067]
系统500包括基因组测序仪502、数据存储器504、计算设备/分析服务器506和显示器514。
[0068]
基因组序列分析器502可以通过串行总线(如果两者形成集成仪器平台)或通过网络连接(如果两者都是分布式/分离设备)可通信地连接到数据存储单元504。基因组序列分析器502可以被配置为处理和分析从胚胎样本获得的一个或多个基因组序列数据集,其包括多个片段序列读数。在各种实施例中,基因组序列分析器902可以处理和分析由下一代测序平台和测序仪例如测序仪,miseq
tm
,nextseq
tm 500/550(高输出),hiseq 2500
tm
(快速运行),hiseq
tm 3000/4000以及novaseq生成的一个或多个基因组序列数据集。
[0069]
在各种实施例中,处理和分析的基因组序列数据集然后可以存储在数据存储单元504中用于后续处理。在各种实施例中,一个或多个原始基因组序列数据集也可以在处理和分析之前存储在数据存储单元504中。因此,在各种实施例中,数据存储单元504被配置为存储一个或多个基因组序列数据集。在各种实施例中,处理和分析的基因组序列数据集可以实时馈送到计算设备/分析服务器506以用于进一步的下游分析。
[0070]
在各种实施例中,数据存储单元504通信连接到计算设备/分析服务器506。在各种实施例中,数据存储单元904和计算设备/分析服务器506可以是集成装置的一部分。在各种实施例中,数据存储单元504可以由与计算设备/分析服务器506不同的设备承载。在各种实施例中,数据存储单元904和计算设备/分析服务器506可以是分布式网络系统的一部分。在各种实施例中,计算设备/分析服务器506可以经由网络连接通信连接到数据存储单元504,该网络连接可以是“硬连线”物理网络连接(例如,互联网、lan、wan、vpn等)或无线网络连接(例如wi-fi、wlan等)。在各种实施例中,计算设备/分析服务器506可以是工作站、大型计算机、分布式计算节点(“云计算”或分布式网络系统的一部分)、个人计算机、移动设备等。
[0071]
在各种实施例中,计算设备/分析服务器506可以被配置为承载比对引擎508、基因组变异调用器510和验证引擎512。
[0072]
比对引擎508可以被配置为接收胚胎测序数据并将其与参考基因组比对。在各种实施例中,参考基因组可以是从单个个体获得的全基因组。在各种实施例中,参考基因组可
以是来自多个个体的复合全基因组。可用于比对过程的参考基因组的示例包括但不限于从基因组参考联盟发布的基因组,例如2009年发布的grch37(hg19)和2013年发布的grch38(hg38)(例如,参见,https://genome.ucsc.edu/cgi-bin/hggateway?db=hg19https://www.ncbi.nlm.nih.gov/assembly/gcf_000001405.39)。
[0073]
基因组变异调用器510可以被配置为在比对的胚胎测序数据中识别基因组变异区域。在各种实施例中,基因组变异区域是使用基于计数的cnv调用方法鉴定的cnv区域。在各种实施例中,基因组变异区域是非整倍性区域。在各种实施例中,基因组变异区域是多倍性区域。在各种实施例中,基因组变异区域包括代表整个染色体的序列区段。在各种实施例中,基因组变异区包括仅代表染色体的一部分的序列区段。
[0074]
验证引擎512可以被配置为对所识别的基因组变异区域中的单核苷酸变异(snv)的数量进行计数,并且针对对应于所识别的基因组变异区域的参考区域的snv的基线计数将snv计数进行归一化,以为已识别的基因组变异区域生成归一化的snv密度,如果已识别的基因组变异区域中的snv密度满足公差标准,则验证已识别的基因组变异区域。
[0075]
在各种实施例中,snv的基线计数从源自一个或多个正常(非cnv)样本的测序数据中获得。在各种实施例中,经识别的变异区和参考区域覆盖相同的对应基因组区段(或基因组位置)。在各种实施例中,经识别的基因组变异区域和参考区包括代表整个染色体的序列区段。在各种实施例中,经识别的基因组变异区域和参考区域包括仅代表染色体的一部分的序列区段。
[0076]
在各种实施例中,如果所识别的基因组变异区域的snv密度在零假设下平均snv密度的预设置信区间之外,则不存在真正的拷贝数量变异。在各种实施例中,预设置信区间为约90%。在各种实施例中,预设置信区间为约95%。在各种实施例中,预设置信区间为约96%、约97%、约98%和约99%。
[0077]
如果snv密度大于预设置信度上限,则验证重复,如果snv密度低于预设置信度下限,则验证删除。预设置信区间是根据正态性假设定义的(c
±
z sigma/sqrt(n)),其中c是零假设下平均snv密度的中心或期望值,n是与识别的基因组变异区域重叠的窗口数,sigma是所有常染色体上归一化snv密度的全局标准偏差,z是标准正态分布的第x个百分位数。“ ”号表示数值为置信区间的上限相加,
“–”
号表示数值为置信区间的下限相减。
[0078]
在各种实施例中,公差标准源自镶嵌胚胎的参考区域的预期snv密度。
[0079]
在各种实施例中,如果其snv密度高于镶嵌胚胎替代假设的预设置信区间的下限(对于重复)或低于上限(对于缺失),则验证所识别的基因组变异区域(包含镶嵌水平百分比m的真实拷贝数量变异)。在各种实施例中,预设置信区间为约90%。在各种实施例中,预设置信区间为约95%。在各种实施例中,预设置信区间为约96%、约97%、约98%和约99%。
[0080]
替代假设的预设置信区间是根据正态性假设(c
±
z sigma/sqrt(n))定义的,其中c是替代假设下平均snv密度的中心或期望值,c=e(snv density|m)=1.0
±
0.5*m/100,并且n是与识别的基因组变异区域重叠的窗口数,sigma是所有常染色体上归一化snv密度的全局标准偏差,z是标准正态分布的第x个百分位数。“ ”号表示数值为置信区间的上限相加,
“‑”
号表示数值为置信区间的下限相减。
[0081]
在各种实施例中,如果识别的基因组变异区域包括的snv的数量超过参考区域的snv基线计数之上或之下的snv的预设方差数量,则验证识别的基因组变异区域。
[0082]
在已执行识别的基因组变异区域验证之后,结果可作为结果或摘要显示在显示器或客户端514上,该显示器或客户端514可通信地连接到计算设备/分析服务器506。在各种实施例中,显示器或客户端514可以是瘦客户端(thin client)计算设备。在各种实施例中,显示器或客户端514可以是具有可用于控制基因组序列分析器502的操作的网络浏览器(例如,internet explorer
tm
,firefox
tm
,safari
tm
等)的个人计算设备,其可用于控制基因组序列分析器502、数据存储器504、比对引擎508、基因组变异调用器510和验证引擎512的操作。实验结果表1 真阳性真阴性假阳性假阴性总数513381119
[0083]
如上表1所示,通过本文公开的方法询问了具有已知事实(snp阵列)的总共70个三倍体样本和349个二倍体样本是否存在雌性三倍性。结果如上所述,其中“真阳性”定义为成功称为疾病状态(多倍体),“真阴性”定义为成功称为“整倍体”状态,“假阳性”定义为整倍体胚胎中错误地称为疾病状态以及“假阴性”被定义为在疾病状态胚胎中被错误地称为整倍体。
[0084]
该表清楚地显示了所公开的方法在验证胚胎中真实cnv的存在方面的高准确度。计算机实现的系统
[0085]
在各种实施例中,使用snv密度验证胚胎中的cnv的方法可以经由计算机软件或硬件实施。即,如图5所示,本文公开的方法可以在包括比对引擎508、数据存储器504、基因组变异调用器510和验证引擎512的计算设备/分析服务器506上实施。在各种实施例中,计算设备/分析服务器506可以经由直接连接或通过互联网连接通信地连接到显示设备514。
[0086]
应当理解,根据特定应用或系统架构的要求,图5中描绘的各种引擎可以组合或折叠成单个引擎、组件或模块。此外,在各种实施例中,比对引擎508、数据存储器504、基因组变异调用器510和验证引擎512可以包括特定应用程序或系统架构需要的附加引擎或组件。
[0087]
图6是示出根据各种实施例的计算机系统的框图。在本教导的各种实施例中,计算机系统600可以包括用于传送信息的总线602或其他通信机制,以及与总线602耦合用于处理信息的处理器604。在各种实施例中,计算机系统600还可以包括存储器,其可以是随机存取存储器(ram)606或其他动态存储设备,耦合到总线602用于确定将由处理器604执行的指令。存储器还可以用于在要由处理器604执行的指令的执行期间存储临时变量或其他中间信息。在各种实施例中,计算机系统600还可以包括耦合到总线602的只读存储器(rom)608或其他静态存储设备,用于为处理器604存储静态信息和指令。存储设备610,例如磁盘或光盘,可以提供并耦合到总线602以用于存储信息和指令。
[0088]
在各种实施例中,计算机系统600可以经由总线602耦合到显示器612,例如阴极射线管(crt)或液晶显示器(lcd),用于向计算机用户显示信息。包括字母数字键和其他键的输入设备614可以耦合到总线602以将信息和命令选择传送到处理器604。另一种类型的用户输入设备是光标控件616,例如鼠标、轨迹球或光标方向键,用于将方向信息和命令选择传送到处理器604并用于控制显示器612上的光标移动。该输入设备614通常在两个轴上具有两个自由度,第一轴(即,x)和第二轴(即,y),这允许设备指定平面中的位置。然而,应当理解,这里还考虑允许3维(x、y和z)光标移动的输入设备614。
[0089]
与本教导的某些实施方式一致,响应于处理器604执行包含在存储器606中的一个或多个指令的一个或多个序列,可由计算机系统600提供结果。此类指令可从另一计算机可读介质或计算机可读存储介质(例如存储设备610)读入存储器606。包含在存储器606中的指令序列的执行可使处理器604执行本文所述的过程。或者,可以使用硬连线电路代替软件指令或与软件指令结合使用以实现本教导。因此,本教导的实现不限于硬件电路和软件的任何特定组合。
[0090]
本文使用的术语“计算机可读介质”(例如,数据存储器、数据存储等)或“计算机可读存储介质”是指参与向处理器604提供指令以供执行的任何介质。这种介质可以采用多种形式,包括但不限于非易失性介质、易失性介质和传输介质。非易失性介质的示例可以包括但不限于光学、固态、磁盘,例如存储设备610。易失性介质的示例可以包括但不限于动态存储器,例如存储器606。传输介质的示例可以包括但不限于同轴电缆、铜线和光纤,包括构成总线602的电线。
[0091]
计算机可读介质的常见形式包括例如软盘、软盘、硬盘、磁带或任何其他磁介质、cd-rom、任何其他光学介质、穿孔卡、纸带、具有孔洞图案的任何其他物理介质、ram、prom和eprom、flash-eprom、任何其他存储芯片或盒式磁带,或任何其他计算机可以读取的有形介质。
[0092]
除了计算机可读介质之外,指令或数据可以被提供为通信装置或系统中包括的传输介质上的信号,以将一个或多个指令的序列提供给计算机系统600的处理器604以供执行。例如,通信装置可以包括具有指示指令和数据的信号的收发器。指令和数据被配置为使一个或多个处理器实现本文公开中概述的功能。数据通信传输连接的代表性示例可以包括但不限于电话调制解调器连接、广域网(wan)、局域网(lan)、红外数据连接、nfc连接等。
[0093]
应当理解,可以使用作为独立设备的计算机系统600或在诸如云计算网络的共享计算机处理资源的分布式网络上来实现这里描述的流程图、图表和所附公开的方法。
[0094]
这里描述的方法可以根据应用通过各种方式来实现。例如,这些方法可以在硬件、固件、软件或其任何组合中实现。对于硬件实现,处理单元可以在一个或多个专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑设备(pld)、现场可编程逻辑门阵列(fpga)、处理器、控制器、微控制器、微处理器、电子设备、其他旨在执行本文所述功能的电子单元,或其组合内实现。
[0095]
在各种实施例中,本教导的方法可以被实现为固件和/或以诸如c、c 、python等常规编程语言编写的软件程序和应用程序。如果被实现为固件和/或软件,这里描述的实施例可以在非暂时性计算机可读介质上实现,其中存储了用于使计算机执行上述方法的程序。应当理解,这里描述的各种引擎可以被提供在计算机系统上,例如计算机系统600,由此处理器604将执行由这些引擎提供的分析和确定,受制于由存储器组件606/608/610和经由输入设备614提供的用户输入中的任何一个或其组合提供的指令。
[0096]
虽然结合各种实施例描述了本教导,但本教导并不旨在限于这些实施例。相反,如本领域技术人员将理解的,本教导包含各种替代、修改和等效物。
[0097]
在描述各种实施例时,说明书可能已经将方法和/或过程呈现为特定的步骤序列。然而,就该方法或过程不依赖于本文所述的特定步骤顺序而言,该方法或过程不应限于所描述的特定步骤顺序,并且本领域技术人员可以容易地理解该顺序可以改变并且仍然保持
在各种实施例的精神和范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。