1.本发明属于生物信息技术领域,首次结合残基倾向性分析将经典的深度学习算法textcnn应用到抗血管生成肽(aap,anti-angiogenic peptide)的预测问题上,为aap的挖掘和预测设计出具备优秀性能的分类器aapred-cnn。aapred-cnn基于嵌入技术,不依赖于特征工程,能够通过自适应地方式从纯粹的氨基酸残基序列中提取有用的信息,并用于预测多肽是否具有抗血管生成的功能活性,尤其涉及基于深度卷积神经网络的生物活性肽预测方法。
背景技术:
2.随着后基因组数据的快速增长,肽序列广泛存在于各种数据库中,促进了治疗性肽的研究。例如,抗血管生成肽(aap)已被证明对癌症、失明、类风湿性关节炎和银屑病等疾病的治疗有效。众所周知,单克隆抗血管内皮生长因子抗体(anti-vegf antibody,avastin或bevacizumab)是第一种能够抑制肿瘤血管生长并提高癌症患者生存率的抗血管生成药物。肽的显著特性,如显著的效力、高选择性和低毒性,吸引了许多研究人员开发新型靶向药物。然而,全球市场上现有的肽类药物只有不到一百种,因为用于识别和开发肽类药物的传统实验技术非常缓慢,包括aap。因此,基于计算模型识别潜在aap是非常可取的,因为它们具有节省时间和金钱的优势。
3.但是,迄今为止,很少有人致力于开发准确预测aap的方法。所有现有的计算方法都基于传统的机器学习,如svm(支持向量机)和rf(随机森林)。2015年,ramaprasad等人提出了anti angiopred,这是第一个基于svm和特征工程的aap识别计算模型,准确率约为75%。最近,blanco等人在2018年基于三个基本序列描述符氨基酸(aac)、二肽(dc)和三肽成分(tc)开发了一个广义线性模型,并获得了性能改进。之后,zahiri等人在2019年选择了2000多个信息特征并评估了227个机器学习模型,建立了一个名为antangiocool的r软件包。他们还揭示了dc在k-聚体组成特征中对抗血管生成肽预测的贡献最大。最近,laengsri等人利用随机森林和不同类别的肽特征构建了目前最先进的分类器targetantiangio,在独立验证测试中获得了约77%的最高准确率。
技术实现要素:
4.我们可以看到,现有的方法都是基于传统的机器学习模型,并且受到特征工程的影响,这需要研究人员的先验知识来设计合适的描述符来训练一个好的模型。这些缺点是限制aap预测性能进一步提高的重要原因。此外,最近在相关治疗性肽预测任务中出现了一些最先进的预测因子,如acp(抗癌肽)的acpred-laf、afp(抗真菌肽)的deep-antifp、bp(苦味肽)的bert4bitter已经证明,基于深度学习的模型优于现有的传统机器学习方法。
5.在本发明中,作为一项尝试性工作,我们基于深度学习模型和嵌入技术来预测aap,并结合残基倾向性分析提出了第一个基于深度卷积神经网络的aap分类新预测器(aapred-cnn)。aapred-cnn源自textcnn(文本卷积神经网络),采用多个卷积通道来提取输
入序列的局部特征。实验结果表明,aapred-cnn在所有评估指标上都优于最先进的方法,取得了显著的进步。值得注意的是,即使只提供数百个训练样本,aapred-cnn也能很好的工作。我们还解释了超参数和训练样本对深度学习模型性能的影响,以帮助理解模型是如何工作的。此外,我们还通过降维将学习到的嵌入可视化,以增加模型的可解释性,并通过对不同残基的卷积特征的统计来揭示aap的残基倾向。综上所述,本工作展示了aapred-cnn对aap预测的强大表示能力,进一步提高了aap的预测精度。本发明的目的是通过下述技术方案予以实现的。
6.一种基于深度卷积模型的用于预测抗血管生成肽的判别方法,包括以下步骤:
7.步骤1,基准数据集构造
8.为了评估我们的模型并对现有方法进行公平比较,我们采用了ramaprasad等人和laengsri等人工作中使用的基准数据集。最初,基准的所有阳性样本(经实验验证的aap)均来自文献。序列相似性大于70%的肽和含有非标准残基的序列通过cd-hit过滤掉,以避免冗余,产生135个aap肽(表示为)。由于没有经实验证明的非抗血管生成的来源,所以从swiss-prot下载的蛋白质随机肽区作为非aap(表示为),其数量与正例样本相同。负数集的长度分布与正数集的长度分布相同,以避免偏差。在形式上,本研究中使用的主要数据集(表示为s
main
)可以使用集合论总结如下:
[0009][0010]
由于抗血管生成素和靶向抗血管生成素也使用了nt15数据集进行开发,该数据集包括主数据集中序列肽序列n端区域的前15个残基,因此我们也在该子集中评估我们的模型以进行比较研究。与s
main
类似,nt15dataset(表示为s
nt15
)的格式如下:
[0011][0012]
其中,是包含99个aap的正集,而是包含101个非aap的负集。
[0013]
最后,将main数据集和nt15数据集按80%和20%的比例随机分为训练集(用于训练模型)和测试集(用于独立测试)。图1总结了这两个数据集的统计信息。具体选择依据详见实例3。
[0014]
步骤2,aapred-cnn模型的构建
[0015]
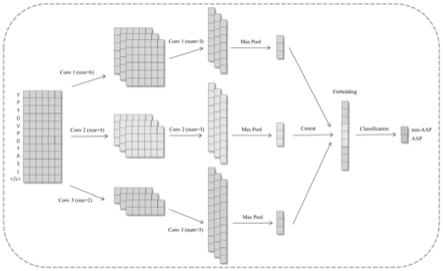
模型框架。aapred-cnn的整体框架如图2所示。模型由嵌入层,卷积层,池化层,特征融合,以及最后全连接的二元分类所组成。
[0016]
嵌入层。每种残基在初始时都被赋予一个随机的向量作为表征。向量的维度根据残基的种类设定为d。假设最长的肽序列的长度为l,那么嵌入层就是一个l
×
d的二维矩阵。在嵌入层中,每个肽序列都被嵌入为l
×
d的二维矩阵。如果肽序列的长度小于l,多余的部分用0填充。在训练的过程中,每个残基的表征向量会通过反向传播被不断更新。如图2中,l为12,d为6。
[0017]
卷积层。卷积层利用不同尺寸的过滤器获取不同局部区域的序列特征;同时,每种尺寸都设置了多个过滤器,以确保模型即使在特定的局部区域也能从不同的角度学习更多不同的特征,从而增强了表示能力。图2示意图中描述了3种不同尺寸的过滤器,长度l分别为6,4,2,但每种过滤器的宽度与残基向量的维度一致,都为d=6。而且,每种尺寸都有3个不同的过滤器。每个过滤器的移动步长为1,所以卷积操作之后我们都得到一个(l-l 1)*1
的特征图(feature map),在图例中长度分别为7,9,11。
[0018]
池化层。由于每个过滤器都学习到相应的特征图,因此对每个特征图采用最大池操作以减少参数数量并进一步提取最突出的特征。图2中卷积后的特征图有3*3个,参数数量从3*(7 9 11)个减少到3*3个。
[0019]
特征融合与二元分类。上一步得到的不同特征图的最具代表性的特征通过级联进行融合,得到新的特征图(图2所示,一个9*1的特征图)。将这个特征图作为aapred-cnn学习到的嵌入,并输入到全连接的神经网络进行二元分类,从而预测输入肽属于非aap或aap的概率。
[0020]
超参数设置。值得注意的是,残基的嵌入维数、过滤器的尺寸以及每种尺寸的过滤器数量都是超参数。具体来说,我们为aapred-cnn设计了8种不同尺寸的过滤器,并设定每一个卷积核的移动步长都为1。通过分析数据集,我们得知所有序列的最大长度为68,因此我们设定这8种过滤器的大小分别为1,2,4,8,16,32,48,64。这样的设置可以保证在参数不太大的前提下,尽可能地覆盖序列中不同大小的局部区域,使模型能够更容易地学习区分特征。对于其他超参数,我们通过网格搜索选择最佳参数,以获得最优异的性能。具体地,我们根据经验,将学习率的选择范围设定为0.0005到0.0030,批大小的范围设定为16到128,过滤器数量和嵌入维度的范围都设定为16到512,然后在这些范围内按照一定的间隔来尝试不同的超参数组合,这一部分的具体分析请见实施例2。
[0021]
步骤3,确定评估指标
[0022]
我们使用常用的分类指标来评估aapred-cnn的性能,包括准确度(acc)、平衡准确度(bacc)、敏感性(se)、特异性(sp)和马修相关系数(mcc)。这些指标的公式描述如下:
[0023][0024]
其中,tp是真阳性样本数(aap预测为aap),fp是假阳性样本数(非aap预测为aap),tn是真阴性样本数(非aap预测为非aap),fn是假阴性样本数(aap预测为非aap)。此外,我们使用接收器工作特性曲线下面积(auc)的度量进行更全面的评估,其中auc值1.0表示完美预测,0表示随机预测模型。
[0025]
步骤4,进行实验评估
[0026]
首先,我们比较了aapred-cnn和现有最优的方法在相应基准数据集上的独立测试性能,从整体上证明了该方法在预测aap任务上的泛化优越性。实验结果表明,在两个基准数据集中,该模型整体性能优于现有模型。详见实例1。其次,我们针对模型对超参数的敏感性进行了详细的研究,分析不同超参数对模型性能的影响。详见实例2。最后,我们对aapred-cnn的可解释性进行了分析,结合pca和t-sne等降维算法可视化模型学习到的嵌入以及残基倾向性分析,帮助用户更好地理解模型的原理,并为日后相关的工作提供启发。详
见实例4。
附图说明
[0027]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0028]
图1为benchmark数据集的统计信息图;
[0029]
图2为aapred-cnn的模型框架图;
[0030]
图3为main数据集和nt15数据集上独立测试性能的比较;
[0031]
图4为模型在main数据集上随着超参数变化的性能变化趋势。(a)不同学习率和批大小对acc的影响。(b)不同过滤器数目和嵌入维数对acc的影响;
[0032]
图5为模型在nt15数据集上随着超参数变化的性能变化趋势。(a)不同学习率和批大小对acc的影响。(b)不同过滤器数目和嵌入维数对acc的影响;
[0033]
图6为在main数据集上使用不同比例的训练集时aapred-cnn的性能;
[0034]
图7为在nt15数据集上使用不同比例的训练集时aapred-cnn的性能;
[0035]
图8为main数据集上残基倾向的热图。每个单元格的值表示特定子集中相应的残基得分。每行中的分数都已标准化;
[0036]
图9为main数据集上模型学习到的嵌入的可视化。(a)不同类别的t-sne可视化。(b)混淆矩阵上的t-sne可视化。(c)不同类别的pca可视化。(d)
[0037]
基于混淆矩阵的pca可视化;
[0038]
图10为main数据集上的错误预测序列。
具体实施方式
[0039]
下面详细叙述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
[0040]
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。
[0041]
还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
[0042]
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件和/或它们的组。
[0043]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。而且,描述的具体特征、结构、材料或者特点
可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0044]
为便于理解本发明,下面结合附图以具体实施例对本发明作进一步解释说明,且具体实施例并不构成对本发明实施例的限定。
[0045]
本领域技术人员应该理解,附图只是实施例的示意图,附图中的部件并不一定是实施本发明所必须的。
[0046]
实施例1
[0047]
一、aapred-cnn与现有预测方法的基准比较
[0048]
实验设置。为了评估aapred-cnn的有效性,在监督训练后对基准数据集(包括s
main
和s
nt15
)进行独立测试。请注意,当给定非可见(新)样本时,独立测试可以评估模型的泛化,这足以进行模型比较。我们报告了aapred-cnn与当前最优模型的性能比较和分析。图3总结了实验结果。
[0049]
aapred-cnn优于当前最优的模型。如图3所示,在main数据集中,aapred-cnn在acc、bacc、sp和mcc方面的表现分别比targetantiangio高2.58%、2.75%、9.06%、5.77%。同样,在nt15数据集中,aapred-cnn在acc、bacc、sp和mcc上分别超过antiangiopred方法5.00%、5.68%、36.84%和13.69%。两个对比结果都表明了所提出的深度模型在aap预测中的综合优势。与targetantiangio和antiangiopred相比,aapred-cnn的baac和mcc性能明显优于传统机器学习。从另一个角度来看,aapred cnn在识别阴性样本方面表现出色,而在识别阳性样本方面表现较弱,而targetantiangio恰恰相反。我们推测,aapred-cnn的这一缺陷是由于训练样本较少,而这个问题会将随着生物实验验证的aap的增加而缓解。
[0050]
实施例2
[0051]
二、aapred-cnn超参数对性能影响的研究
[0052]
实验设置。为了研究哪些因素在aapred-cnn中起着重要作用,我们选择了学习率、批大小、嵌入维数等超参数来研究对aapred-cnn性能的影响。为方便起见,我们仅选择常用的候选超参数进行研究。具体来说,学习率的选择范围为0.0005到0.0030,批大小的选择范围为16到128。过滤器数量和嵌入维度的范围都是从16到512。比较结果如图4-5所示。
[0053]
对于两个评估数据集,当超参数在一定范围内时,aapred-cnn的性能相对稳定。从图4-5可以看出,当学习率约为0.0001,批大小约为32,过滤器数量约为128,嵌入维数约为128时,模型能够达到最佳性能,且相对稳定。总体而言,较高的学习率和较大的批大小、较低的过滤器数目和嵌入维数不利于模型性能的提高。具体地说,该模型对批大小和嵌入维数比学习率和过滤器数量更敏感,这表明隐藏在肽序列中的高维信息是更重要、更有助于区分的,并且深度模型具有捕获它的能力。综上所述,尽管当超参数在特定范围内时,模型性能可以保持稳定,但不同超参数对应的模型性能可能会有很大差异。
[0054]
实施例3
[0055]
三、训练数据量对模型性能影响的研究
[0056]
实验设置。如上所述,尽管只给出了几个训练样本,但深度学习模型仍然取得了优异的性能,这是违反直觉的。因此,有必要研究深度学习模型的性能在多大程度上取决于数据量,以便进一步讨论为什么深度学习模型可以在这样几个示例场景中很好地工作。对于smain
和s
nt15
。我们保持测试集不变,并使用不同比例的训练集来构建评估模型。具体来说,从0到100%,每10%被选为一个区间,以随机选择相应比例的训练集。对比实验的结果如图6-7所示。
[0057]
训练样本比例越大,模型性能越好。图6-7中的比较结果表明,aapred-cnn在两个数据集上给出的训练序列较少时的综合性能较低。但当main数据集中有80%的训练序列和nt15数据集中有90%的训练序列时,该模型性能表现较好。此外,一些指标比如se,不会随着main数据集中样本的减少而下降,而是上升。这些结果表明,深度学习模型能否表现良好,不仅取决于训练集的数量,还与样本在数据集中的分布以及区分不同类别样本的难度有关。如果训练集中标记样本的质量很好,并且样本在相应的类中具有很好的代表性,那么即使数据量不足,我们也可以得到一个具有良好泛化能力的预测器。通过这一部分的研究,我们可以推测,深度学习模型适用于只有少量标记数据的任务。
[0058]
实施例4
[0059]
四、模型的可解释性研究
[0060]
实验设置。由于深度学习模型总是被视为黑匣子,因此有必要提供aapred-cnn的一些可解释性。通过反向推断原始输入序列与每个通道和最大池的所有过滤器卷积后提取的特征相对应的位置,我们可以解释模型关注的区域。通过对整个数据集上这些区域中包含的各种残基的数量进行统计,我们可以分别得到aap和非aap的残基倾向。我们在main数据集上进行了上述实验,结果如图8所示。此外,为了更好地分析aap和非aap的分类,我们通过pca和t-sne等降维算法可视化了模型学习到的嵌入。此外,我们还列出了错误的预测序列,以帮助相关研究人员更好地研究未区分aap和非aap之间的关系。结果如图9-10。
[0061]
aap更多地依赖于残基“g”、“s”、“r”,而非aap更多地依赖于残基“a”、“l”、“v”。图8描述了残基分数越高(颜色越深),模型认为这些残基在相应子集中提供的信息越重要。首先,我们可以看到预测阳性或预测阴性子集的残基倾向与真阳性或真阴性子集的残基倾向高度一致,这表明模型捕获的特征与现实中aap或非aap中的隐藏残基倾向是一致的,该模型预测效果良好。其次,残基“g”、“s”、“r”似乎为模型识别aap提供了最重要的信息,而非aap更依赖于残基“a”、“l”、“v”。这可以启发相关研究人员和用户更好地理解aap的组成特征。
[0062]
以上对本发明做了示例性的描述,应该说明的是,在不脱离本发明的核心的情况下,任何简单的变形、修改或者其他本领域技术人员能够不花费创造性劳动的等同替换均落入本发明的保护范围。
[0063]
综上所述,抗血管生成肽在癌症、失明、类风湿性关节炎和银屑病等疾病中起着重要作用。为了促进aap药物的发现和发展,已经建立了一些针对抗血管生成肽的计算预测器。然而,aap的预测性能仍然存在局限性,并且没有深入的学习技术应用于该领域。在这项研究中,我们提出了第一个基于深度学习的抗血管生成肽分类器aapred-cnn。该深度模型采用嵌入技术提取aap的自适应学习特征,而不是采用传统的特征工程。独立测试的实验结果表明,aapred-cnn优于当前最优的方法,具有显著的优势。为了了解超参数和训练样本量对该模型的影响,我们进行了控制实验。对于模型的可解释性,我们还利用热图、pca、t-sne可视化残基倾向和学习到的嵌入,揭示aap的潜在特征。总之,这是将深度学习技术应用于aap预测任务的尝试性工作,我们相信这些强大的技术将进一步促进aap预测的发展,并帮
助研究人员理解aap的原理。
[0064]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0065]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0066]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0067]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0068]
属于生物信息处理技术领域,通过将首次将经典的深度学习算法textcnn结合嵌入技术、残基倾向性分析等应用到抗血管生成肽(aap,anti-angiogenic peptide)的预测问题上,为aap的挖掘和预测设计出具备优秀性能分类器aapred-cnn。aapred-cnn基于嵌入技术,不依赖于特征工程,能够通过自适应地方式从纯粹的氨基酸残基序列中提取有用的信息并用于预测多肽是否具有抗血管生成的功能活性。总结来说本发明是一种基于深度卷积模型的用于预测抗血管生成肽的判别方法。总的来说,抗血管生成肽在癌症、失明、类风湿性关节炎和银屑病等疾病中起着重要作用,为了促进aap药物的发现和发展,已经建立了一些针对抗血管生成肽的计算预测器。然而,当前aap的预测性能仍然存在局限性。在这项研究中,我们提出了第一个基于深度学习的抗血管生成肽分类器aapred-cnn。该深度模型采用嵌入技术提取aap的自适应学习特征,而不是采用传统的特征工程。独立测试的实验结果表明,aapred-cnn优于当前最优的方法,具有显著的优势。为了了解超参数和训练样本量对该模型的影响,我们进行了控制实验。对于模型的可解释性,我们还利用热图、pca、t-sne可视化残基倾向和学习到的嵌入,揭示aap的潜在特征。总之,这是将深度学习技术应用于aap预测任务的尝试性工作,我们相信这些强大的技术将进一步促进aap预测的发展,并帮助研究人员理解aap的原理。
[0069]
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明公开的技术方案的基础上,本领域技术人员在不需要付出创造性劳动即可做出的各种修改或变形,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
