1.本发明属于深度学习测试领域,特别是深度学习算子准确性问题测试领域。各类深度学习模型的使用者希望通过某种方法测试其模型依赖的深度学习算子是否会出现准确性问题。
背景技术:
2.随着深度学习技术的逐渐成熟和智能应用的需求涌现,各类深度学习模型被提出并广泛应用于各个领域下的各类场景。然而,人们在研究、使用和测试深度学习模型时,往往倾向于关注模型整体功能或流程的正确性和完整性,而忽略其模型背后依赖的特定算子的正确性。事实上,深度学习算子常常会引发一系列准确性问题,从而对模型造成严重的危害和影响,因此,对于深度学习算子的准确性测试是十分有必要的。
3.不同于传统测试,深度学习算子准确性测试的测试用例生成存在困难,人们无法准确获知有效测试用例的具体特征,因而也无法针对测试用例进行精确设计,只能通过诸如随机采样的方式对于有效的测试用例进行寻找。然而,单纯的均匀随机采样存在许多问题,它往往是极其低效率的,且没有给予一些重要取值区间足够的重视,如:小于1的浮点数。借鉴传统变异测试的思想,对随机生成的测试数据进行变异能够有效提高测试触发准确性问题的概率,但这其中仍然存在无法确定在何时使用何种变异方法的问题。本发明较好地解决了上述问题,不仅提供了较为有效的基本变异方法组并允许其灵活变化,还通过蒙特卡罗方法和带权重采样提出了一种确定如何在何时使用何种变异方法的解决方案。
技术实现要素:
4.本发明要解决的问题是:深度学习算子准确性测试的测试用例生成难以精确设计,生成效率低下的问题。人们无法准确获知有效测试用例的具体特征,因而也无法针对测试用例进行精确设计,只能通过诸如随机采样的方式对于有效的测试用例进行寻找。然而,单纯的均匀随机采样存在许多问题,它往往是极其低效率的,且没有给予一些重要取值区间足够的重视,如:小于1的浮点数。本发明针对上述问题,设计了一系列测试数据变异方法,并通过蒙特卡罗采样对这些方法进行有效性评价,从而挑选合适的变异方法及对应权重进行带权重的变异数据采样,大大提高了深度学习算子准确性测试的测试用例生成效率、有效性和多样性。
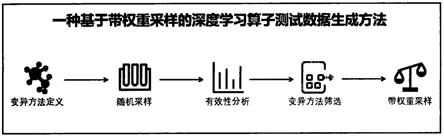
5.本发明的技术方案为:一种基于带权重采样的深度学习算子测试数据生成方法,其特征是将一组被提前设计的数据变异方法视作向不同数据取值域的映射,并在其中进行预先的蒙特卡罗采样,从而获取各变异方法的有效性并以此为权重带权重地进行采样,并最终达到在兼顾数据多样性的条件下更有效地生成深度学习算子测试数据的目的。数据变异方法组合可根据需要灵活地进行增加、删除和修改,本方法提供的基本数据变异方法包括:字节变异、噪声变异和倒转变异。其中,字节变异是指对测试数据的浮点数二进制编码进行字节操作的变异,操作包括二进制编码各字节的增加、删除、取反、移位、随机重置,支
持float32和float16格式编码;噪声变异是指均匀地随机使用高斯噪声或均匀噪声施加于测试数据;倒转变异是指将测试数据作为分母计算其在取值域内的伪倒数的变异。上述变异基于不同的基本思想,如:边界数据更容易引发异常、均匀采样对于小于1的数不利等,兼顾有效性与多样性。该方法分为以下几个步骤:
6.1)变异方法定义:本发明预定义了几种变异方法作为基本变异组,具体变异方法将在1.1中进行陈述,实际使用时可根据需要添加、减少、修改变异方法,定义该次实践专属的变异方法组。
7.1.1)基本变异方法组包括以下变异方法:字节变异、噪声变异和倒转变异。其中,字节变异是指对测试数据的浮点数二进制编码进行字节操作的变异,操作包括二进制编码各字节的增加、删除、取反、移位、随机重置,支持float32和float16格式编码;噪声变异是指均匀地随机使用高斯噪声或均匀噪声施加于测试数据;倒转变异是指将测试数据作为分母计算其在取值域内的伪倒数的变异;
8.2)随机采样,得到每一种变异方法的变异后准确性问题触发成功率;
9.2.1)使用均匀随机采样得到种子随机测试用例;
10.2.2)对该种子随机测试用例分别施加每一种变异方法并测试变异效果,多次迭代后,统计每一种变异方法的变异后准确性问题触发成功率;
11.3)有效性分析:根据蒙特卡罗采样方法的基本思想,将每一种变异方法的变异后准确性问题触发成功率视为其在该算子下的有效性,并对其进行归一化得到采样权重矩阵;
12.4)变异方法筛选:根据需要对变异方法组中的变异方法进行筛选;
13.4.1)变异方法剔除:对于一些特殊情况,如:存在0成功率或反而将成功率大幅降低的变异方法、存在大量成功率与随机方法相差无几的变异方法、应用场景不要求多样性而急需以高成功率进行大量采样等,需要对变异方法组进行进一步筛选;
14.4.2)筛选、剔除操作主要包括:筛选出变异组中前k高有效性的变异方法形成新的变异组和剔除变异组中前k低有效性的变异方法形成新的变异组,如有必要,可重新定义变异组并重新进行全套过程
15.4.3)矩阵修改:根据变异方法组筛选、剔除或修改的结果,修改有效性矩阵,并重新生成用于带权重采样的权重矩阵;
16.5)带权重采样:根据4.2得到的权重矩阵,进行带权重采样并检查是否成功触发准确性问题;
17.5.1)对权重矩阵从大到小进行排序,同时记录每种变异方法对于的索引,然后在0到其权重总和的区间内进行均匀采样,并找到对应的变异方法,该方法及其前面的变异方法的权重和大于或等于该随机值,且其前面的变异方法的权重和小于该随机值;
18.5.2)随机采样得到种子测试数据,将采样得到的变异方法施加于该数据得到最终测试数据并将其输入算子检查是否成功触发准确性问题;
19.本发明的特点在于:
20.1.提出了一种新颖的方法,通过对随机生成的种子测试用例施加各类变异方法,并分别评估它们的有效性,实现兼顾数据生成效率、有效性和多样性的深度学习算子测试数据生成方法;
21.2.提供了一个经过大量实验被证明有效的基本变异方法组及其有效性参考,并允许方法使用者根据需要灵活添加、删减、修改变异方法;
22.3.将蒙特卡罗采样得到的变异后准确性问题触发成功率视为变异方法的有效性度量,提供了一种新颖且具有理论依据的变异方法评价方法;
23.基于以上三点,本发明可以有效解决深度学习算子准确性测试的测试用例生成效率低下的问题,显著地提高了深度学习算子准确性测试的测试用例生成效率、有效性和多样性,较好地为后续深度学习算子准确性测试提供了支持。
附图说明
24.图1为本发明总体架构图
25.图2为本发明变异方法定义子过程架构图
26.图3为本发明蒙特卡罗随机采样子过程架构图
27.图4为本发明有效性分析子过程架构图
28.图5为本发明变异方法筛选子过程架构图
29.图6为本发明带权重采样子过程架构图
具体实施方式
30.本发明涉及的关键技术是利用一些已有的深度学习算子来基于带权重变异方法采样生成测试数据,并进行准确性问题检测,随机张量的生成及变异主要通过numpy进行实现,准确性问题检测及深度学习算子主要涉及tensorflow、pytorch、mnn框架以及mre/mare算法。
31.1、张量生成与变异
32.本发明中,主要通过numpy库进行随机张量的生产及变异,numpy是python语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,包括线性代数、随机数生成等功能。
33.2、深度学习算子
34.本发明中,涉及三种框架下的算子,这三种框架分别是:tensorflow、pytorch和mnn。tensorflow是一个由谷歌人工智能团队谷歌大脑(google brain)开发和维护的基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现,其前身是谷歌的神经网络算法库distbelief。pytorch是一个由facebook人工智能研究院(fair)推出的开源的python机器学习库,基于torch,常用于自然语言处理等各类机器学习应用程序。mnn是一个由阿里开发的高效、轻量的深度学习框架,它支持深度模型推理与训练,尤其在端侧的推理与训练性能在业界处于领先地位。目前,mnn已被广泛应用于阿里巴巴的于机淘宝、手机天猫、优酷等20多个app。
35.本发明涉及的深度学习算子在三种框架下的具体实现分别为:
36.(1)tensorflow:tf.nn.bias_add、tf.nn.avg_pool、tf.nn.max_pool、tf.nn.softmax、tf.nn.sigmoid、tf.nn.tanh、tf.nn.relu、tf.nn.conv2d、tf.nn.reduce_mean、tf.matmul、tf.nn.reduce_max、tf.keras.layers.batchnormalization。
37.(2)pytorch:torch.add、f.avg_pool2d、f.max_pool2d、f.softmax、
torch.sigmoid、torch.tanh、torch.nn.functional.relu、torch.nn.conv2d、torch.mean、torch.matmul、torch.max、torch.nn.batchnorm2d。
38.(3)mnn:mnn.expr.bias_add、mnn.expr.avg_pool、mnn.expr.max_pool、mnn.expr.softmax、mnn.expr.sigmoid、mnn.expr.tanh、mnn.expr.relu、mnn.nn.conv、mnn.expr.reduce_mean、mnn.expr.matmul、mnn.expr.reduce_max、mnn.nn.batch_norm。
39.3、准确性问题检测
40.本发明进行准确性问题检测的算法主要包括mre和mare算法。mre及mare算法的定义如下:
41.假设对于给定的算子和给定的输入,tensorflow,、pytorch和mnn的计算结果分别为f
t
,f
p
,fm,这些结果之间的方差分别是var
tm
(tensorflow和mnn)、var
tp
(tensorflow和pytorch)以及var
mp
(mnn和pytorch),则算子计算的benchmark结果fb的计算方式为:if min(var
tp
,var
tm
,var
mp
)=var
tp
,then fb=(f
t
f
p
)/2;min(var
tp
,var
tm
,var
mp
)=var
tm
,then fb=(f
t
fm)/2;if(var
tp
,var
tm
,var
mp
)=var
mp
,thenfb=(fm f
p
)/2。
42.mre和mare基于实际计算结果与benchmark结果之问的误差,分别定义为:
[0043][0044][0045]
实际使用中,通过比较mre和mare的实际计算值和预设阈值来检测准确性问题是否发生。
[0046]
4、示例
[0047]
下面使用具体示例来说明本发明的步骤,并展示结果。
[0048]
实验环境为:tensorflow 2.0、pytorch 1.8.1、mnn 1.1.4,显卡为geforce gtx 1080ti。
[0049]
本发明的整体流程如图1所示,具体实施步骤如下:
[0050]
1)定义变异方法组,实验直接使用基础变异方法组,该方法组包含了3种类型的变异方法共34个,设定随机采样迭代次数为20000次,带权重采样次数为15000次;
[0051]
2)分别使用3种框架下的36个算子在mre和mare下进行实验,为这些算子分别预设两组不同的mre和mare算法阈值β、γ,分别保证随机采样的准确性问题触发率在15%以下及在30%-50%之间。本阶段获得所有算子在不同情况下的准确性问题触发率;
[0052]
3)将上述准确性问题触发率视为变异方法的有效性,将其转化为归一化的权重矩阵并进行适当筛选和修改后,根据这些权重矩阵进行带权重采样,并在每次采样后进行测试,检测生成数据是否成功触发算子的准确性问题。
[0053]
4)各框架下算子测试数据生成的实验结果如表格1所示。各项数据通过mre、mare的两种不同阈值取值共4种情况的结果取平均得到,可以发现使用本发明进行的采样在各框架的各类算子下成功率均明显高于随机采样算法。
[0054]
表格1各框架下算子测试数据生成实验结果
[0055]
[0056]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。